13 th September 2007 UK e-Science All Hands Meeting Text Mining Services to Support e-Research Brian Rea and Sophia Ananiadou National Centre for Text Mining www.nactem.ac.uk University of Manchester

13 th September 2007 UK e-Science All Hands Meeting Text Mining Services to Support e-Research Brian Rea and Sophia Ananiadou National Centre for Text.
Dec 16, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

13th September 2007 UK e-Science All Hands Meeting
Text Mining Servicesto Support e-Research
Brian Rea and Sophia AnaniadouNational Centre for Text Mining
www.nactem.ac.uk University of Manchester

Outline
•Recent History•Document Enrichment•Information Retrieval and Text Mining•Text Mining Applications•Case Study: ASSERT Project•Case Study: BBC Online News Feeds•Future Opportunities

What is Text Mining
•Text mining discovers and extracts information hidden in unstructured texts.
•It aids the construction of hypotheses based upon associations between the extracted information
•Due to this it can often discover things overlooked by human readers

What Text Mining is not
•Text mining is not based upon an understanding of document content.
• Instead it predicts the most likely meaning of a fragment of text based upon models of language.
•Text mining will generally not pick up on sarcasm, irony or other subtleties of language usage.
•Text mining tools must be tuned before use on different text types, styles or languages.

13th September 2007 UK e-Science All Hands Meeting 5
Recent History
1,418,949,650Number of words
3.2GBCompressed data size
10GBUncompressed data size
70,815,480Number of sentences
7,434,879Number of abstracts
14,792,890Number of MEDLINE references
Suppose, for example, that it
takes one second to analyse one sentence….70 million
seconds, that is more than
2 years

13th September 2007 UK e-Science All Hands Meeting
• Rapid increase in the amount of literature means it is becoming impractical to read everything in many disciplines.
• Text mining systems can begin to address this by automating some of the process.
• Without any inherent understanding of language the system must use different methods to that of a human.
• As such it can often discover facts or patterns that a human may easily miss.

13th September 2007 UK e-Science All Hands Meeting
Document Enhancement
• How do we approximate an understanding of natural language?
• Levels of annotation are built up in stages.• Tokenisation gives us words and boundaries.• Part-Of-Speech (POS) Tagging gives us a
basic model with nouns, verbs, etc.– There are many methods for predicting POS– Training on hand coded documents is necessary to
improve accuracy– Errors at this early stage can grow exponentially
through the system

13th September 2007 UK e-Science All Hands Meeting
Document Enhancement
• How do we fit these words together?• Grammars provide simple syntax rules for
building up complex sentences based upon POS tag information.
• Shallow Parsing – gives information about noun and verb phrases
• Deep Parsing – generates complex representations of the underlying relationships between phrases

13th September 2007 UK e-Science All Hands Meeting
Document Enhancement
Example:
“The MPs discussed the policy with the ambassador”
• This is a relatively simple example but many ways of interpreting it.• Parsing techniques choose the most likely meaning based upon
complex internal models.• Complex sentences can take longer to process as many
possibilities are available and need to be ruled out.
13th September 2007 UK e-Science All Hands Meeting
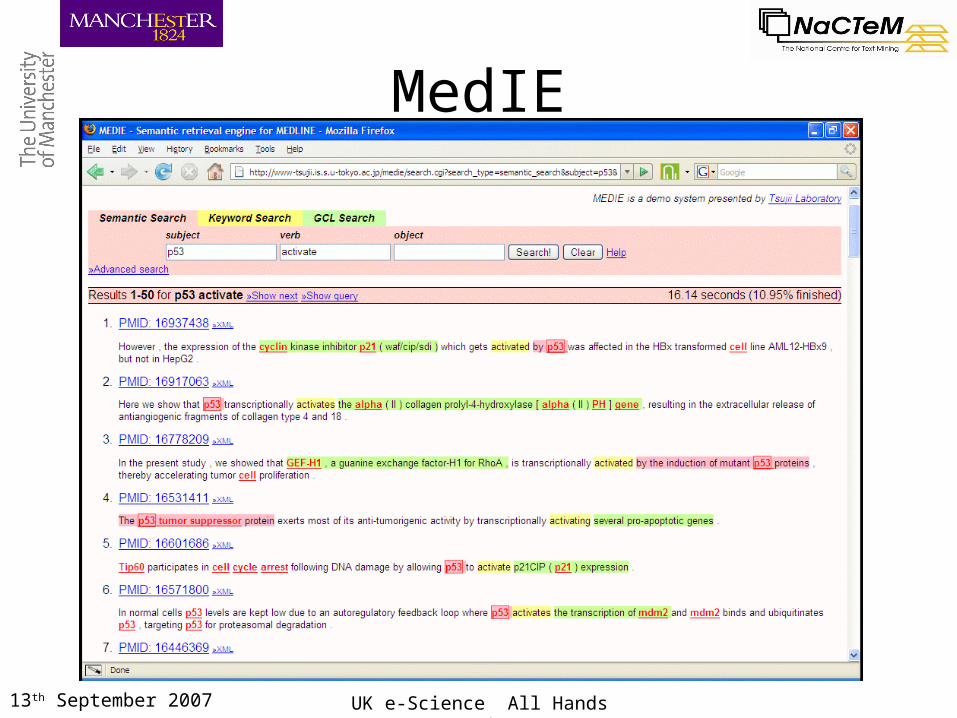
MedIE

13th September 2007 UK e-Science All Hands Meeting
Term Discovery
• Keywords are often used when searching within documents. This reduces the noise created by common words that carry little information.
• Text mining can take this a stage further and identify significant terms (multi-word units).
• Terms can be used to:– Gain an overview of the document contents– Assist searching by allowing query expansion and browsing
– Identify important concepts for generating ontologies
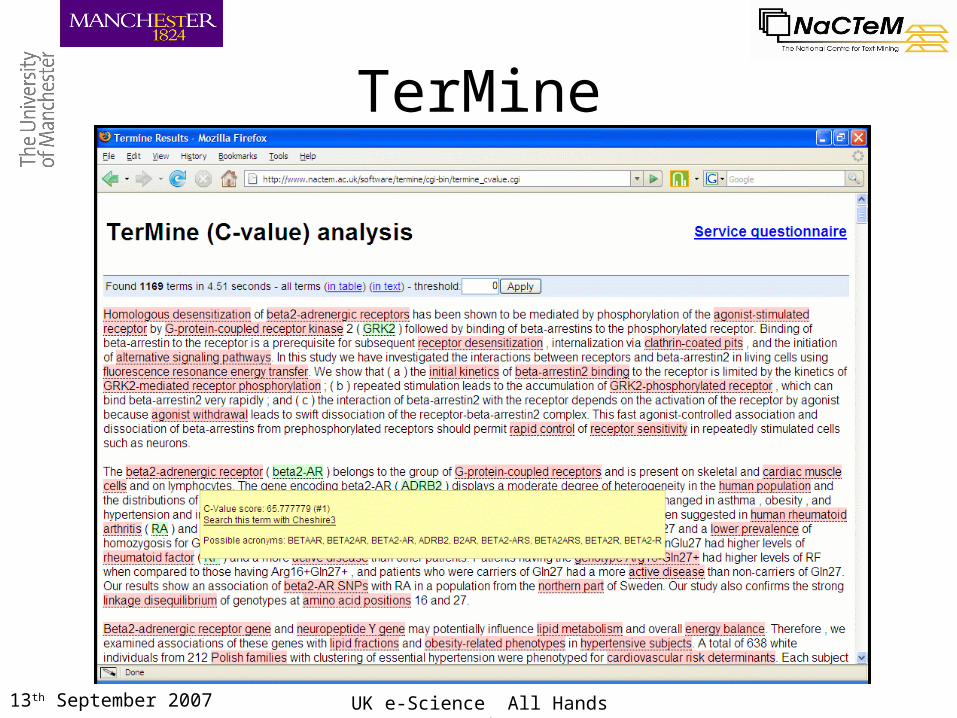
13th September 2007 UK e-Science All Hands Meeting
TerMine

13th September 2007 UK e-Science All Hands Meeting
Named Entity Recognition
• Uses techniques to find common forms or patterns in text to identify items belonging to particular semantic categories.
• Different methods can be used including rule-based, template driven or machine learning.
• Some examples include: names, addresses, organisations, dates, times, quantities…
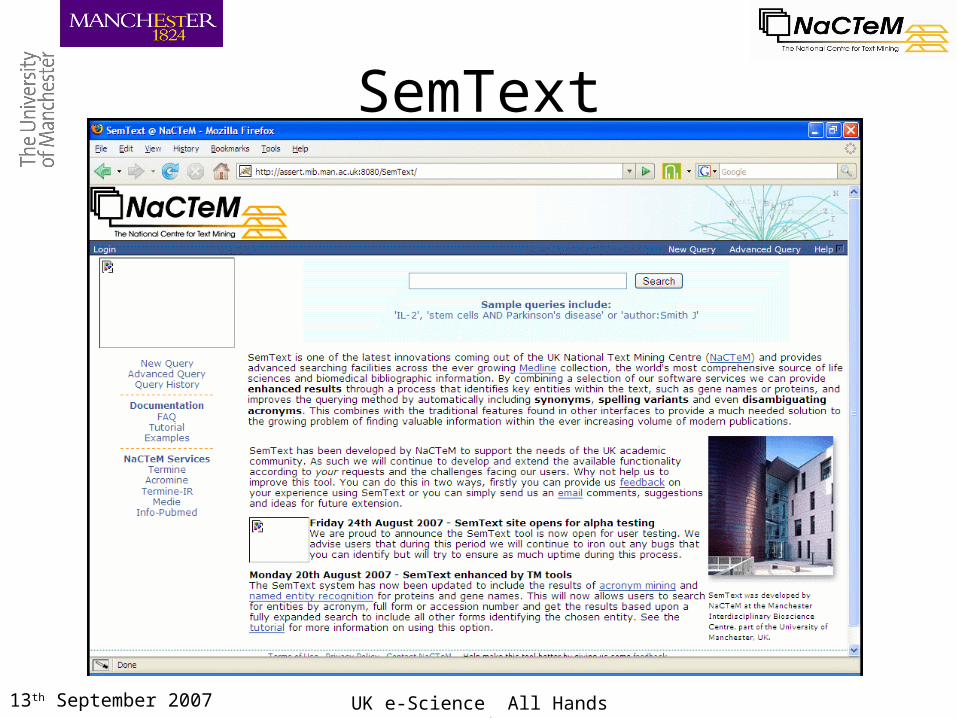
13th September 2007 UK e-Science All Hands Meeting
SemText

13th September 2007 UK e-Science All Hands Meeting
Document Similarity
• One of the most common models of document similarity is the Vector Space model.
• Each document is represented in a multi-dimensional space where each term acts as a dimension.
• The distance in that dimension is represented by the contribution or strength of that term in the given document.
• Similarity can be calculated using the cosine of the angle between the two vectors.

13th September 2007 UK e-Science All Hands Meeting
Dimensionality Reduction
• Due to computation limitations it is impractical to search the entire document space.
• Where possible we can reduce the space by mapping all synonyms of a term to a single label.
• For larger scale reduction we can use Latent Semantic Indexing which merges terms that regularly co-occur together with remarkably good results.
• Benefits of this include noise reduction and removal of redundant terms.
• Drawbacks include the expensive matrix operations involved to generate the mapping rules

13th September 2007 UK e-Science All Hands Meeting
Online or Offline Processing
• Many of the techniques introduced so far can be processed at any time, not just at run time.
• This allows us to handle the major bulk of processing well in advance of our services becoming available.
• For larger document collections the scale of this processing makes it impractical for a single machine.
• We are currently in the process of preparing our tools to allow use on the national computing resources i.e. HPC and Grid

13th September 2007 UK e-Science All Hands Meeting
Associative Search
• Relies upon the vector space similarity to identify a set of documents with related content to a target collection.
• Single document targets are treated like a normal query.
• Multiple document targets involve extra effort to identify the related set of terms that best represents the collection.
• This process not only identifies similar documents but may also recognise previously unknown yet related areas.
13th September 2007 UK e-Science All Hands Meeting
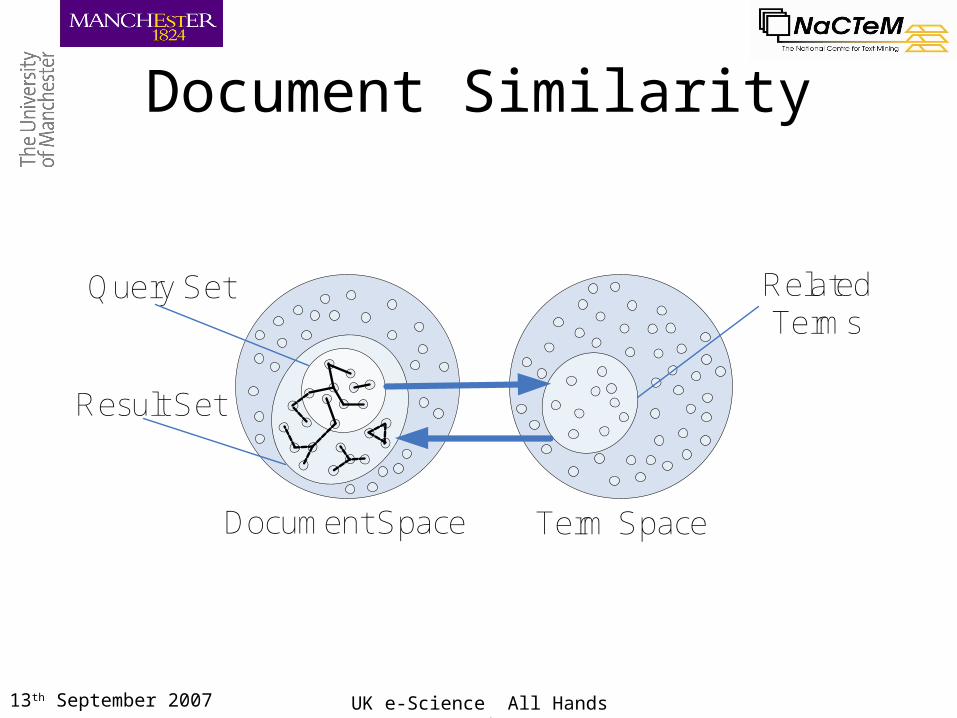
Document Similarity
Document Space Term Space
Query Set
Result Set
Related Terms

13th September 2007 UK e-Science All Hands Meeting
Information Extraction
• IE brings together term discovery, pattern matching and named entity recognition to identify and extract facts.
• We define the form of the information we are interested in as fact templates.
• Each template has attribute slots that can be filled by named entities or other facts.
• Example: Person_X is a programme manager for Programme_Y with JISC.
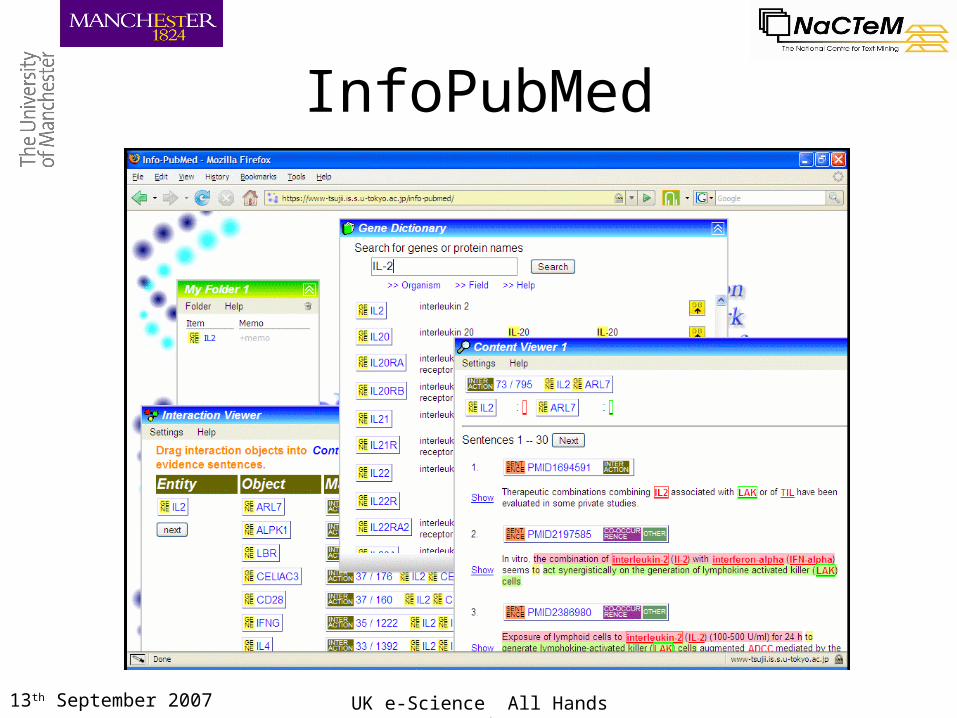
13th September 2007 UK e-Science All Hands Meeting
InfoPubMed

13th September 2007 UK e-Science All Hands Meeting
Document Summarisation
• Two main methods of manual summarisation:– Abstractive – relies upon an understanding of the
content to rewrite a new version in a shorter form– Extractive – draws upon key sections to form a
readable shorter form
• Preserve the important informative content• Reduce redundancy through knowledge of
terms and synonyms• It is much harder across multiple documents• Potentially important to link back to key
evidence

13th September 2007 UK e-Science All Hands Meeting
Case Study: ASSERT
Multi-DocumentSummarisation
DocumentClassification
DocumentClustering
SynthesizeScreen
DocumentSectioning
TermExtraction
Search
QueryExpansion
SentenceExtraction
DocumentCollections
Automatic Summarisation forSystematic Reviews using Text Mining

13th September 2007 UK e-Science All Hands Meeting 24
Case Study: BBC News Feeds• Analyse, structure and visualise BBC news online,
according to a user’s query using advanced text mining techniques
• Concept discovery and retrieval – interface allows a user to enter a query across the document
collection and automatically calculate a list of concepts specific to the query and ranked by perceived importance.
• Creation of user oriented knowledge maps– Based on clusters of articles and their automatic concept
categorisation.

13th September 2007 UK e-Science All Hands Meeting
Future Developments
• Ongoing development of key text mining services to support the UK academic community
• Further application of HPC and Grid technology– processing for document enhancement– handling data and processing for intermediary results– responsive and efficient service implementations
• Transformation of components to web services and integration with work flow solutions
• Investigation into interoperability issues between components and intermediary formats

13th September 2007 UK e-Science All Hands Meeting
Conclusions
• NaCTeM has made strong progress in– Provision of core text mining services and support– Leveraging strengths in BioSciences out to social sciences,
arts and humanities
• Text Mining is integral to UK infrastructure for eResearch, but requires closer integration into existing research methodology and practice
• Links with infrastructure are essential to support scalable solutions for future challenges
• Interoperability between tools and formats is necessary for true flexibility between text mining components
• IPR issues and policy require further investigation

13th September 2007 UK e-Science All Hands Meeting 27
How to contact us
Visit the Text Mining Centre Website at
http://www.nactem.ac.uk
Related Documents











