1.4 Hadoop Architecture - HDFS Leons Petrazickis Bradley Steinfeld Marius Butuc

125424653 Hadoop Architecture
Oct 22, 2015
a
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1.4 Hadoop Architecture - HDFS
Leons Petrazickis
Bradley Steinfeld
Marius Butuc

Disclaimer © Copyright IBM Corporation 2012. All rights reserved.
U.S. Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp.
THE INFORMATION CONTAINED IN THIS PRESENTATION IS PROVIDED FOR INFORMATIONAL PURPOSES ONLY. WHILE EFFORTS WERE MADE TO VERIFY THE COMPLETENESS AND ACCURACY OF THE INFORMATION CONTAINED IN THIS PRESENTATION, IT IS PROVIDED “AS IS” WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. IN ADDITION, THIS INFORMATION IS BASED ON IBM’S CURRENT PRODUCT PLANS AND STRATEGY, WHICH ARE SUBJECT TO CHANGE BY IBM WITHOUT NOTICE. IBM SHALL NOT BE RESPONSIBLE FOR ANY DAMAGES ARISING OUT OF THE USE OF, OR OTHERWISE RELATED TO, THIS PRESENTATION OR ANY OTHER DOCUMENTATION. NOTHING CONTAINED IN THIS PRESENTATION IS INTENDED TO, NOR SHALL HAVE THE EFFECT OF, CREATING ANY WARRANTIES OR REPRESENTATIONS FROM IBM (OR ITS SUPPLIERS OR LICENSORS), OR ALTERING THE TERMS AND CONDITIONS OF ANY AGREEMENT OR LICENSE GOVERNING THE USE OF IBM PRODUCTS AND/OR SOFTWARE.
IBM, the IBM logo, ibm.com, and DB2 are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. If these and other IBM trademarked terms are marked on their first occurrence in this information with a trademark symbol (® or ™), these symbols indicate U.S. registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered or common law trademarks in other countries. A current list of IBM trademarks is available on the Web at “Copyright and trademark information” at http://www.ibm.com/legal/copytrade.shtml
Other company, product, or service names may be trademarks or service marks of others.
2

Agenda
• Terminology review
• HDFS
• MapReduce
• Type of nodes
• Topology awareness
• Configuring Hadoop
3

InfoSphere BigInsights – A Full Hadoop Stack
HDFS
Storage HBase
GPFS-SNC
Application
AdaptiveMR
Zo
okeep
er
Av
ro Pig Hive Jaql
MapReduce
Flume
Data Sources/ Connectors
Informix
DB2 LUW Netezza
DB2 z
Streams
Oracle
Oozie
User Interface Development Tooling (ODS)
Analytics Visualization
Management Console
Analytics
ML Analytics
Text Analytics
Lucene
R
Teradata Data Stage

InfoSphere BigInsights – A Full Hadoop Stack
HDFS
Storage HBase
GPFS-SNC
Application
AdaptiveMR
Zo
okeep
er
Av
ro Pig Hive Jaql
MapReduce
Flume
Data Sources/ Connectors
Informix
DB2 LUW Netezza
DB2 z
Streams
Oracle
Oozie
User Interface Development Tooling (ODS)
Analytics Visualization
Management Console
Analytics
ML Analytics
Text Analytics
Lucene
R
Teradata Data Stage

Agenda
• Terminology review
• HDFS
• MapReduce
• Type of nodes
• Topology awareness
• Configuring Hadoop
6

7
Node 1
Terminology review

8
Node 2
Node 1
Terminology review

9
Node 2
Node n
…
Node 1
Terminology review

10
Rack 1
Node 2
Node n
…
Node 1
Terminology review

11
Rack 1
Node 2
Node n
…
Node 1
Node 2
Node n
…
Rack 2
Node 1
Terminology review

12
Rack 1
Node 2
Node n
…
Node 1
Node 2
Node n
…
Rack 2
Node 1
Node 2
Node n
…
Rack n
Node 1
…
Terminology review

13
Hadoop cluster
Rack 1
Node 2
Node n
…
Node 1
Node 2
Node n
…
Rack 2
Node 1
Node 2
Node n
…
Rack n
Node 1
…
Terminology review

Hadoop architecture
• Two main components:
– Hadoop Distributed File System (HDFS)
14
– MapReduce Engine

Agenda
• Terminology review
• HDFS
• MapReduce
• Type of nodes
• Topology awareness
• Configuring Hadoop
15

Hadoop distributed file system (HDFS)
16
• Hadoop file system that runs on top of existing file system
• Designed to handle very large files with streaming data access patterns
• Uses blocks to store a file or parts of a file
• Can create, delete, copy, but NOT update

HDFS - Blocks
17
• File Blocks – 64MB (default), 128MB (recommended) – compare to
4KB in UNIX – Behind the scenes, 1 HDFS block is supported by
multiple operating system (OS) blocks
128 MB
OS Blocks
HDFS Block
. . .

HDFS - Blocks
18
• Fits well with replication to provide fault tolerance and availability
• Advantages of blocks:
– Fixed size – easy to calculate how many fit on a disk – A file can be larger than any single disk in the network – If a file or a chunk of the file is smaller than the block size, only
needed space is used. Eg: 420MB file is split as:
128 MB 128 MB 128 MB 36 MB

HDFS - Replication
• Blocks with data are replicated to multiple nodes
• Allows for node failure without data loss
19
Node 1
Node 2
Node 3

Writing a file to HDFS
20

Writing a file to HDFS
21
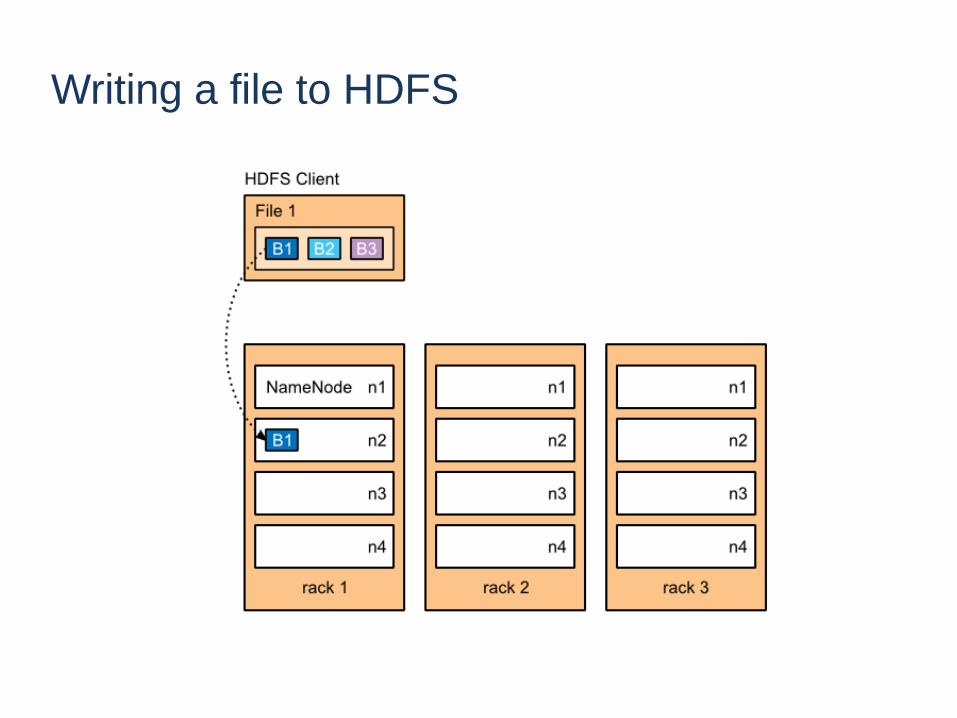
Writing a file to HDFS
22

Writing a file to HDFS
23

Writing a file to HDFS
24

Writing a file to HDFS
25

Writing a file to HDFS
26

Writing a file to HDFS
27

Writing a file to HDFS
28

Writing a file to HDFS
29

Writing a file to HDFS
30

HDFS Command line interface
31
Type “hadoop” from the Linux shell to get different options

namenode -format
32
hadoop namenode -format
• Before it can be used, a new HDFS installation needs to be formatted
• May need to stop Hadoop first using stop.sh hadoop

namenode -format
33

fsck – file system check
34
hadoop fsck -delete
•Eg: To delete corrupted files use:

fs – file system shell
35
• File System Shell (fs)
• Invoked as follows:
hadoop fs <args>
• Example:
• Listing the current directory in hdfs
hadoop fs –ls .

fs – file system shell
36
• FS shell commands take URIs as argument
• URI format:
scheme://authority/path
• Scheme:
• For the local filesystem, the scheme is file
• For HDFS, the scheme is hdfs
hadoop fs –copyFromLocal file://myfile.txt hdfs://localhost:9000/user/keith/myfile.txt
• Scheme and authority are optional
• Defaults are taken from configuration file core-site.xml
• Authority is the hostname and port of the NameNode

fs – file system shell
37
• Many POSIX-like commands
• cat, chgrp, chmod, chown, cp, du, ls, mkdir, mv, rm, stat, tail
• Some HDFS-specific commands
• copyFromLocal, put, copyToLocal, get, getmerge, setrep

HDFS – FS shell commands
38
• copyFromLocal / put
• Copy files from the local file system into fs
hadoop fs -copyFromLocal <localsrc> .. <dst>
hadoop fs -put <localsrc> .. <dst>
Or

39
• copyToLocal / get
• Copy files from fs into the local file system
hadoop fs -copyToLocal [-ignorecrc] [-crc] <src> <localdst>
hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>
Or
HDFS – FS shell commands

40
• getMerge
• Get all the files in the directories that match the source file pattern
• Merge and sort them to only one file on local fs
• <src> is kept
hadoop fs -getmerge <src> <localdst>
HDFS – FS shell commands

41
• setRep
• Set the replication level of a file.
• The -R flag requests a recursive change of replication level for an entire tree.
• If -w is specified, waits until new replication level is achieved.
hadoop fs -setrep [-R] [-w] <rep> <path/file>
HDFS – FS shell commands

HDFS – FS shell commands • cat
– Usage: hadoop fs -cat URI [URI …]
• Copies source paths to stdout.
• Example:
– hadoop fs -cat hdfs:/mydir/test_file1 hdfs:/mydir/test_file2
– hadoop fs -cat file:///file3 /user/hadoop/file4
• chgrp – Usage: hadoop fs -chgrp [-R] GROUP URI [URI …]
• Change the permissions of files.
• With -R, make the change recursively through the directory structure.
• chmod – Usage: hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI …]
• Change group association of files
• With -R, make the change recursively through the directory structure.

HDFS – FS shell commands
• chown – Usage: hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
• Change the owner of files.
• With -R, make the change recursively through the directory structure.
• count – Usage: hadoop fs -count [-q] <paths>
• Count the number of directories, files and bytes under the paths that match the specified file pattern.
• The output columns are: DIR_COUNT, FILE_COUNT, CONTENT_SIZE FILE_NAME.
• The output columns with -q are: QUOTA, REMAINING_QUATA, SPACE_QUOTA, REMAINING_SPACE_QUOTA, DIR_COUNT, FILE_COUNT, CONTENT_SIZE, FILE_NAME.
– Example: • hadoop fs -count hdfs:/mydir/test_file1 hdfs:/mydir/test_file2
• hadoop fs -count -q hdfs:/mydir/test_file1

HDFS – FS shell commands
• cp
– Usage: hadoop fs -cp URI [URI …] <dest>
• Copy files from source to destination.
• This command allows multiple sources as well in which case the destination must be a directory.
• Example: – hadoop fs -cp hdfs:/mydir/test_file
file:///home/hdpadmin/foo
– hadoop fs -cp file:///home/hdpadmin/foo file:///home/hdpadmin/boo hdfs:/mydir
• du
– Usage: hadoop fs -du URI [URI …]
• Displays aggregate length of files contained in the directory or the length of a file in case its just a file.

HDFS – FS shell commands
• dus – Usage: hadoop fs -dus <args>
• Displays a summary of file lengths.
• expunge – Usage: hadoop fs -expunge
• Empty the Trash
– When a file is deleted by a user or an application, it is not immediately removed from HDFS. Instead, HDFS first renames it to a file in the /trash directory. The file can be restored quickly as long as it remains in /trash. A file remains in /trash for a configurable amount of time

HDFS – FS shell commands
• ls – Usage: hadoop fs -ls <args>
• For a file returns stat on the file with the following format: – permissions number_of_replicas userid groupid filesize
modification_date modification_time filename
– For a directory it returns list of its direct children as in unix.A directory is listed as:
– permissions userid groupid modification_date modification_time dirname
• Example: – hadoop fs -ls hdfs:/mydir/test_file
• lsr – Usage: hadoop fs -lsr <args>
• Recursive version of ls. Similar to Unix ls -R.
• Example: – hadoop fs -lsr hdfs:/mydir

HDFS – FS shell commands
• mkdir
– Usage: hadoop fs -mkdir <paths>
• Takes path uri's as argument and creates directories. The behavior is much like unix mkdir -p creating parent directories along the path.
– Example:
• hadoop fs -mkdir hdfs:/mydir/foodir hdfs:/mydir/boodir

HDFS – FS shell commands
• mv
– Usage: hadoop fs -mv URI [URI …] <dest>
• Moves files from source to destination. This command allows multiple sources as well in which case the destination needs to be a directory.
• Moving files across filesystems is not permitted.
• Example: – hadoop fs -mv file:///home/hdpadmin/test_file
file:///home/hdpadmin/test_file1
– hadoop fs –mv hdfs:/mydir/file1 hdfs:/mydir/file2 hdfs:/mydir2

HDFS – FS shell commands
• rm
– Usage: hadoop fs -rm [-skipTrash] URI [URI …]
• Delete files specified as args.
• Only deletes non empty directory and files.
• If the -skipTrash option is specified, the trash, if enabled, will be bypassed and the specified file(s) deleted immediately. This can be useful when it is necessary to delete files from an over-quota directory.
• Refer to rmr for recursive deletes.
• Example: – hadoop fs -rm hdfs:/home/hdpadmin/test_file
file:///home/hdpadmin/test_file

HDFS – FS shell commands
• rmr
– Usage: hadoop fs -rmr [-skipTrash] URI [URI …]
• Recursive version of delete.
• If the -skipTrash option is specified, the trash, if enabled, will be bypassed and the specified file(s) deleted immediately.
• Example: – hadoop fs -rmr file:///home/hdpadmin/mydir
– hadoop fs -rmr –skipTrash hdfs:/mydir

HDFS – FS shell commands
• stat – Usage: hadoop fs -stat URI [URI …]
• Returns the stat information on the path.
• Example:
– hadoop fs –stat hdfs:/mydir/test_file
• tail – Usage: hadoop fs -tail [-f] URI
• Displays last kilobyte of the file to stdout. -f option can be used as in UNIX.
• Example:
– hadoop fs -tail hdfs:/mydir/test_file

HDFS – FS shell commands
• test
– Usage: hadoop fs -test -[ezd] URI • Options:
-e check to see if the file exists. Return 0 if true. -z check to see if the file is zero length. Return 0 if true. -d check to see if the path is directory. Return 0 if true.
• Example: – hadoop fs -test –e hdfs:/mydir/test_file

Agenda
• Terminology review
• HDFS
• MapReduce
• Type of nodes
• Topology awareness
• Configuring Hadoop
53

MapReduce engine
54
• Technology from Google
• A MapReduce program consists of map and reduce
functions
• A MapReduce job is broken into tasks that run in
parallel

Agenda
• Terminology review
• HDFS
• MapReduce
• Type of nodes
• Topology awareness
• Configuring Hadoop
55

Types of nodes - Overview
56
• HDFS nodes
– NameNode (Master)
– DataNode (Slaves)
– Checkpoint Node
– Secondary NameNode (deprecated)
– Backup Node
• MapReduce nodes
– JobTracker (Master)
– TaskTracker (Slaves)
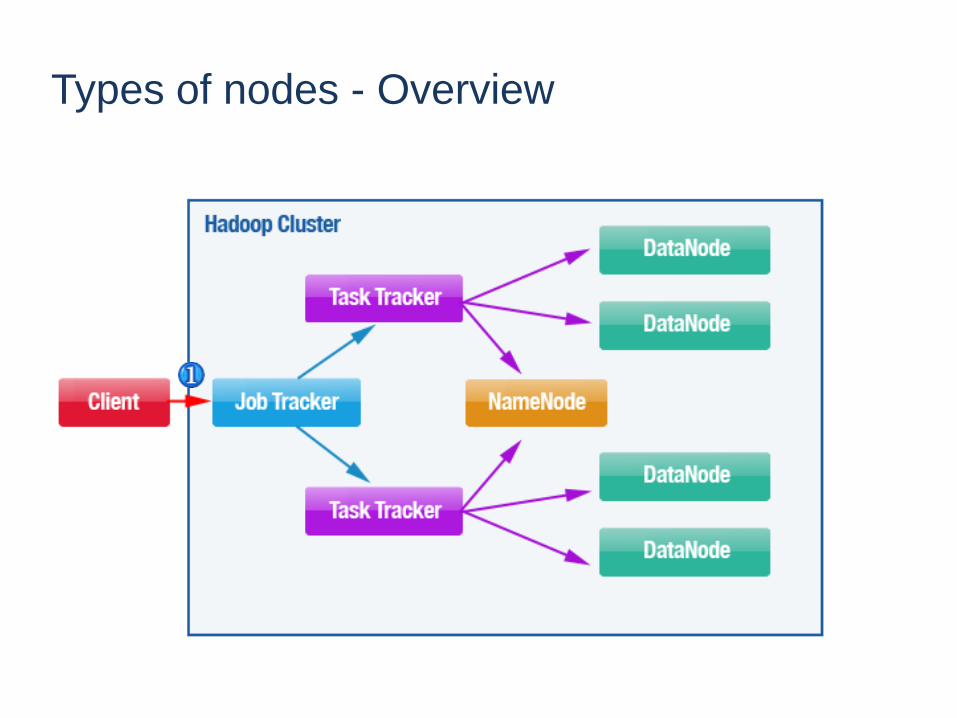
Types of nodes - Overview
57

Types of nodes - Overview
58

Types of nodes - Overview
59

Types of nodes - Overview
60

Types of nodes - NameNode
61
• Manages the filesystem namespace and metadata
• No data goes through the NameNode
• Only one per Hadoop cluster
• Single point of failure
• Mitigated by writing state to multiple filesystems
• Don’t use inexpensive commodity hardware for this node,
large memory requirements

Types of nodes - NameNode
62
• Entire metadata is kept in RAM
• Ensure enough RAM in NameNode
• If run out of RAM, NameNode will crash
• NameNode mainly consists of:
• fsimage: Contains the metadata on disk (not exact
copy of what is in RAM, but a checkpoint copy)
• edit logs: Records all write operations, synchronizes
with metadata in RAM after each write
• In case of ‘power failure’ on NameNode
• Can recover using fsimage + edit logs
• Need to format NameNode to use it:
• hadoop namenode -format

Types of nodes – Checkpoint Node
63
• Use to reduce the size of edit logs
• Periodically creates checkpoints of NameNode
filesystem namespace
• The Checkpoint node should run on a different
machine than the NameNode
• Should have same storage requirements as
NameNode
• There can be many Checkpoint nodes per cluster

Types of nodes – Checkpoint Node
64

Types of nodes – Secondary NameNode
65
• Like Checkpoint Node but it doesn’t copy “new fs
image” back to NameNode
• Edit logs on Secondary NameNode under control, but
not on NameNode
• If there’s a problem in NameNode, it can read
from the Secondary NameNode.
• Should have same storage requirements as
NameNode

Types of nodes – Backup Node
66
• Use to reduce the size of edit logs (like
Checkpoint node)
• Difference with Checkpoint node is that it also
keeps and up-to-date copy of metadata in RAM
• Same RAM requirements as NameNode
• Can only have one Backup node per cluster
• If a Backup node is used, there cannot be
Checkpoint nodes running at the same time

Types of nodes - DataNode
67
• Many per Hadoop cluster
• Manages blocks with data and
serves them to clients
• Periodically reports to
NameNode the list of blocks it
stores
• Use inexpensive commodity
hardware for this node

Types of nodes - JobTracker
68
• One per Hadoop cluster
• Receives job requests submitted by client
• Schedules and monitors MapReduce jobs on task
trackers

Types of nodes - TaskTracker
69
• Many per Hadoop cluster
• Executes MapReduce operations
• Reads blocks from DataNodes

Agenda
• Terminology review
• HDFS
• MapReduce
• Type of nodes
• Topology awareness
• Configuring Hadoop
70

Topology awareness (or Rack awareness)
71
Bandwidth becomes progressively smaller in the following scenarios:

Topology awareness
72
Bandwidth becomes progressively smaller in the following scenarios:
1.Process on the same node.

Bandwidth becomes progressively smaller in the following scenarios:
1.Process on the same node
2.Different nodes on the same rack
Topology awareness
73

Bandwidth becomes progressively smaller in the following scenarios:
1.Process on the same node
2.Different nodes on the same rack
3.Nodes on different racks in the same data center
Topology awareness
74

Bandwidth becomes progressively smaller in the following scenarios:
1.Process on the same node
2.Different nodes on the same rack
3.Nodes on different racks in the same data center
4.Nodes in different data centers
Topology awareness
75

Agenda
• Terminology review
• HDFS
• MapReduce
• Type of nodes
• Topology awareness
• Configuring Hadoop
76

Configuration modes
• Standalone (local) mode
– Single machine
– No daemons are running
– Everything runs in single JVM
– Standard OS storage
– Good for development and test with small data, but will not catch all errors

Configuration modes
• Pseudo-distributed mode – Single machine but cluster is simulated – Daemons run – Separate JVMs – Good for development and debugging
• Fully-distributed mode – Run Hadoop on cluster of machines – Daemons run – Production environment

Configuration files
• hadoop-env.sh Environment variables that are used in the scripts to run Hadoop.
• core-site.xml Configuration settings for Hadoop Core, such as I/O settings that are common to HDFS and MapReduce
• hdfs-site.xml Configuration settings for HDFS daemons: the name node, secondary name node, and the data nodes.
• mapred-site.xml Configuration settings for MapReduce daemons and jobtracker, and tasktrackers.
• masters A list of machines (one per line) that each run secondary NameNode.
• slaves A list of machines (one per line) that each run data node and tasktracker.
• hadoop-metrix.properties Properties for controlling how metrics are published in Hadoop.
• log4j.properties Properties for system logfiles, the NameNode audit log, and the task log for the tasktracker child process
BigInsights Configuration Directory: /opt/ibm/biginsights/hadoop-conf

hadoop-env.sh settings • Most variables are default and not set
• Only export JAVA_HOME is required and should be set to java JDK
• HADOOP_HEAPSIZE – heap size used by JVM of each daemon
– Can be overwritten for each daemon:
• NameNode - HADOOP_NAMENODE_OPTS
• DataNode - HADOOP_DATANODE_OPTS
• Secondary NameNode - HADOOP_SECONDARYNAMENODE_OPTS
• JobTracker - HADOOP_JOBTRACKER_OPTS
• TaskTracker - HADOOP_TASKTRACKER_OPTS
• BIGINSIGHTS_HOME – Point to code & config /opt/ibm/biginsights
• BIGINSIGHTS_VAR – Keeps logs /var/ibm/biginsights
• Other environment variables: HADOOP_CLASSPATH, HADOOP_PID_DIR, JAQL_HOME

core-site.xml settings fs.default.name
The name of the default file system. A URI whose scheme
and authority determine the FileSystem implementation.
The uri's scheme determines the config property
(fs.SCHEME.impl) naming the FileSystem implementation
class. The uri's authority is used to determine the host,
port, etc. for a filesystem. Default: file:///
hadoop.tmp.dir A base for other temporary directories.
Default: /tmp/hadoop-${user.name}
fs.trash.interval
Number of minutes between trash checkpoints. If zero, the
trash feature is disabled (default). When greater than zero
erased files will be inserted in .trash in user’s home
directory.
io.file.buffer.size The size of buffer for use in sequence files. The size of this
buffer should be a multiple of hardware page size (4096 on
Intel x86), and it determines how much data is buffered
during read and write operations.

core-site.xml settings (continue) hadoop.rpc.socket.factory.class.default Default SocketFactory to use. This
parameter is expected to be formatted
as package.FactoryClassName".
hadoop.rpc.socket.factory.class.ClientP
rotocol
SocketFactory to use to connect to a
DFS. If null or empty, use
hadoop.rpc.socket.class.default. This
socket factory is also used by
DFSClient to create sockets to
DataNodes.
hadoop.rpc.socket.factory.class.JobSub
missionProtocol
SocketFactory to use to connect to the
JobTracker. If null or empty, uses
hadoop.rpc.socket.class.default.
Recommendation:
Leave all three above parameters empty and mark them as FINAL

hdfs-site.xml settings
dfs.data.dir List of directories where the DataNode stores
its persistent metadata
dfs.name.dir List of directories where the NameNode stores
its persistent metadata.
Recommendation: Remote mount NFS disk to
backup metadata on NameNode (soft mount).
dfs.block.size HDFS block size. Default is 64MB.
Recommendation: Set block size to 128MB or as
appropriate for your data.

hdfs-site.xml settings (continue) dfs.namenode.handler.count Number of threads the NameNode node will use
to handle requests. Default: 10
Recommendation: Increase for larger cluster
dfs.replication The number of time the file block should be
replicated in HDFS. Default: 3
Recommendation: Set it to 1 when not on the
cluster
dfs.hosts Name of a file containing an approved list of
hostnames to access the NameNode.
dfs.hosts.exclude Name of a file containing a list of hostnames not
allowed to access the NameNode
dfs.permissions Enables/Disables unix-like permissions on
HDFS. Enabling the permissions does usually
make things harder to work with while its
bringing limited advantages (its not so much for
securing things but for prohibiting users to
mistakenly mess up others user's data )

mapred-site configuration mapred.hosts Names a file that contains the list of nodes that
may connect to the jobtracker. If the value is
empty, all hosts are permitted.
mapred.hosts.exclude Names a file that contains the list of hosts that
should be excluded by the jobtracker. If the
value is empty, no hosts are excluded.
mapred.max.tracker.failur
es
The number of task-failures on a tasktracker of a
given job after which new tasks of that job aren't
assigned to it. Default is 4
mapred.max.tracker.black
lists
The number of blacklists for a taskTracker by
various jobs after which the task tracker could
be blacklisted across all jobs. The tracker will be
given a tasks later (after a day). The tracker will
become a healthy tracker after a restart. Default
is 4.

mapred-site configuration (continue)
mapred.reduce.tasks The default number of reduce tasks per job. Typically set to
99% of the cluster's reduce capacity, so that if a node fails
the reduces can still be executed in a single wave. Ignored
when mapred.job.tracker is "local". Default: 1.
Recommendation: set it to 90%
mapred.map.tasks.spec
ulative.execution
If true, then multiple instances of some map tasks may be
executed in parallel. Default: true.
mapred.reduce.tasks.sp
eculative.execution
If true, then multiple instances of some reduce tasks may be
executed in parallel. Default: true. Recommended: false.
mapred.tasktracker.map
.tasks.maximum
The maximum number of map tasks that will be run
simultaneously by a task tracker. Default: 2.
Recommendations: set relevant to number of CPUs and
amount of memory on each data node.
mapred.tasktracker.red
uce.tasks.maximum
The maximum number of reduce tasks that will be run
simultaneously by a task tracker. Default: 2.
Recommendations: set relevant to number of CPUs and
amount of memory on each data node.

mapred-site configuration (continue)
mapred.jobtracker.task
Scheduler
The class responsible for scheduling the tasks. Default
points to FIFO scheduler. Recommendation: Use Fair
scheduler - org.apache.hadoop.mapred.FairScheduler
mapred.jobtracker.resta
rt.recover
Recover failed job when JobTracker restarts. For production
clusters recommended to be set to TRUE
mapred.local.dir The local directory where MapReduce stores
intermediate data files. May be a comma-separated
list of directories on different devices in order to
spread disk i/o. Directories that do not exist are
ignored.
Default: ${hadoop.tmp.dir}/mapred/local

Setting Rack Topology (Rack Awareness)
• Can be defined by script which specifies which node is on which rack.
• Script is referenced in topology.script.property.file in core-site.xml.
– Example of property:
<property> <name>topology.script.file.name</name>
<value>/opt/ibm/biginsights/hadoop-conf/rack-aware.sh</value>
</property>
• The network topology script (topology.script.file.name in the above example) receives as arguments one or more IP addresses of nodes in the cluster. It returns on stdout a list of rack names, one for each input. The input and output order must be consistent.

Hadoop core lab – Part1

Thank you!
http://bit.ly/cascon2012
@leonsp, @bsteinfe, @mariusbutuc
Related Documents











