1 Synchronization Clock Synchronization and algorithm

1 Synchronization Clock Synchronization and algorithm.
Dec 21, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Synchronization
Clock Synchronization and algorithm

2
Synchronization Concentrate on how process can synchronize
– Not simultaneously access a shared resources.– Multiple process can agree on the ordering of event/access the shared resources;
• E.g: process p1 should send message m1 prior to pcs p2 and message m2
Synchronization in DS is much more difficult rather that in uniprocessor/multiprocessor system

3
Use of time in distributed systems:

4

5
Clock Synchronizationmake example
When each machine has its own clock, an event that occurred after another event may nevertheless be assigned an earlier time.

6
Clock Synchronization Algorithms Centralized Algorithms
Cristian’s Algorithm (1989)Berkeley Algorithm (1989)
Decentralized AlgorithmsAveraging Algorithms (e.g. NTP)Multiple External Time Sources

7
Cristian’s Algorithm Assume one machine (the time server) has
a WWV receiver and all other machines areto stay synchronized with it.
Every specificseconds, each machine sends a message to the time server asking for the current time.
Time server responds with message containing current time, CUTC.

8
Cristian's Algorithm Getting the current time from a time server.

9
Cristian's AlgorithmA major problem – the sender clock/client is fast arriving value of CUTC from the time server will be smaller than client’s current time, C.
What to do?One needs to gradually slow down client clock by adding less time per tick.
Normally each interrupt add 10msec => 9msec per tick.
or add 11 msec per tick to advance the time

10
Cristian’s Algorithm Minor problem
– the one-way delay from the server to client is “significant” and may vary considerably.
What to do? Measure this delay and add it to CUTC.
The best estimate of delay is (T1 – T0)/2 for the message propagation time.
Can subtract off I (the server interrupt handling time). one way propagation time = (T1 – T0-I)/2
11
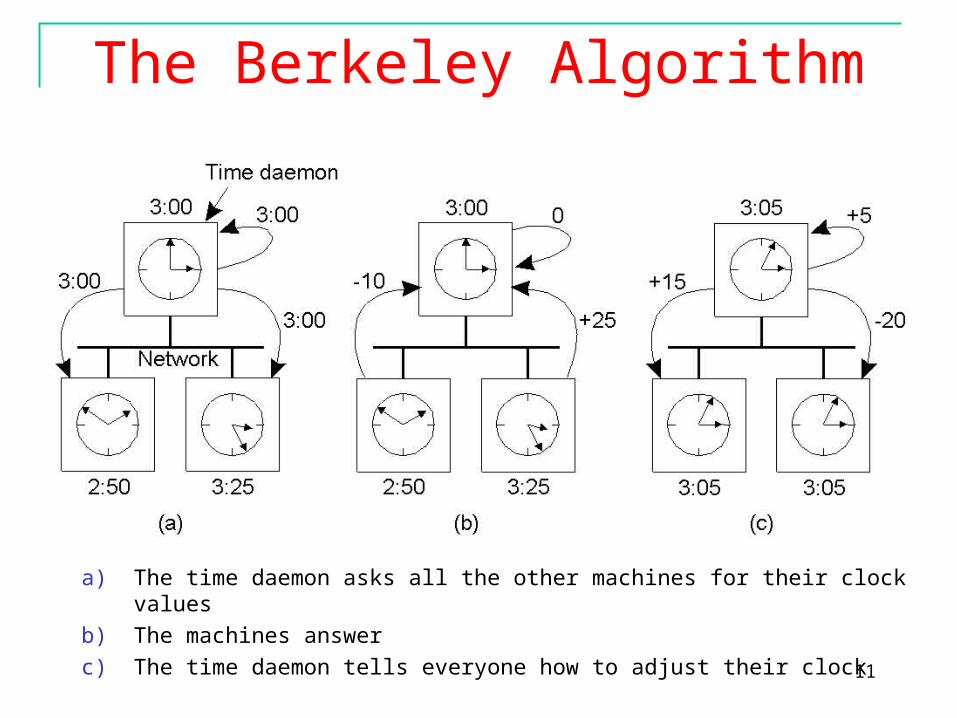
The Berkeley Algorithm
a) The time daemon asks all the other machines for their clock values
b) The machines answer
c) The time daemon tells everyone how to adjust their clock
12
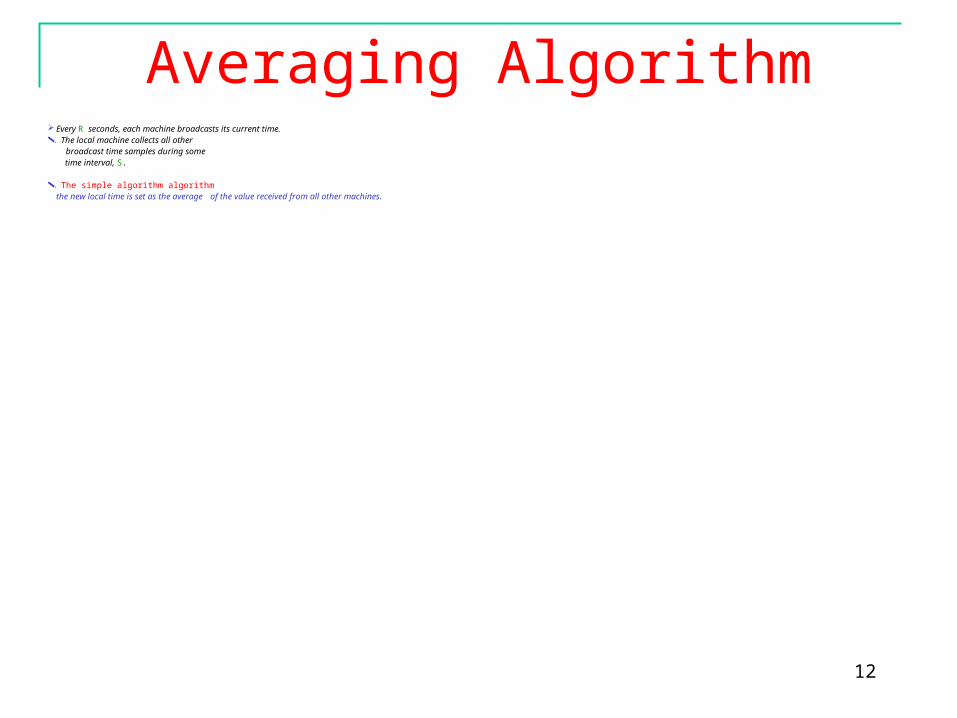
Averaging Algorithm Every R seconds, each machine broadcasts its current time.The local machine collects all other broadcast time samples during some
time interval, S.
The simple algorithm algorithmthe new local time is set as the average of the value received from all other machines.

13
Averaging Algorithms
A slightly more sophisticated algorithm :: Discardthe m highest and m lowest to reduce the effect of aset of faulty clocks. – Average the rest.
Another improved algorithm :: Correct eachmessage by adding to the received time an estimateof the propagation time from the source.
One of the most widely used algorithms in theInternet is the Network Time Protocol (NTP).

14
Logical Clocks
All machine must agree with one time/clock. Logical clock: no matter its not the same to the real time. Lamport “ all process must agree with the sequence of event occurs” Either input.c is older or newer then input.o

15
Logical Clock and Lamport Timestamp Logical clocks
– Order of events matters more than absolute time– E.g. UNIX make: input.c input.o
Lamport timestamp– Synchronize logical clocks
Happens-before relation– A -> B : A happens before B– Two cases which determine “happens-before”1. A and B are in same process, and A occurs before B: a -> b2. A is send-event of message M, and B is receive-event of same message M
Transitive relation– If A -> B and B -> C, then A-> C
Concurrent events– Neither A -> B nor B -> A is true

16
Lamport Algorithm Assign time value C(A) such that
1. If a happens before b in the same process, C(a) < C(b)
2. If a and b represent the sending and receiving of a message, C(a) < C(b)
Lamport Algorithm– Each process increments local clock between any two successive events
– Message contains a timestamp
– Upon receiving a message, if received timestamp is ahead, receiver fast forward it clock to be one more than sending time
Extension for total ordering– Requirement: For all distinctive events a and b, C(a) C(b)
– Solution: Break tie between concurrent events using process number
17
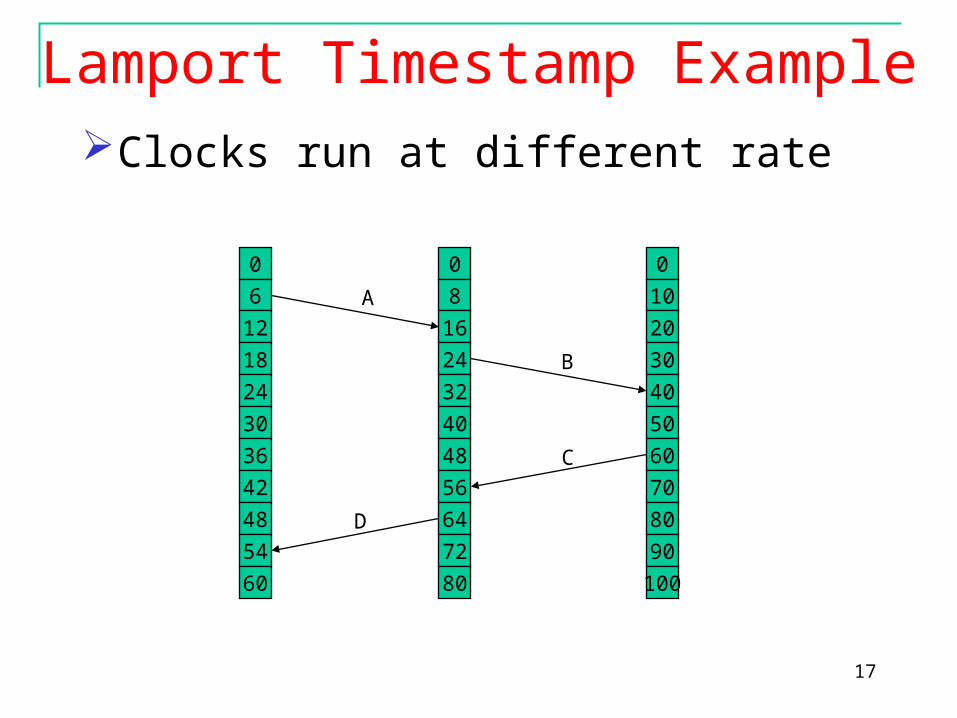
Lamport Timestamp ExampleClocks run at different rate
0
6
12
18
24
30
36
42
48
54
60
0
8
16
24
32
40
48
56
64
72
80
0
10
20
30
40
50
60
70
80
90
100
A
B
C
D
18
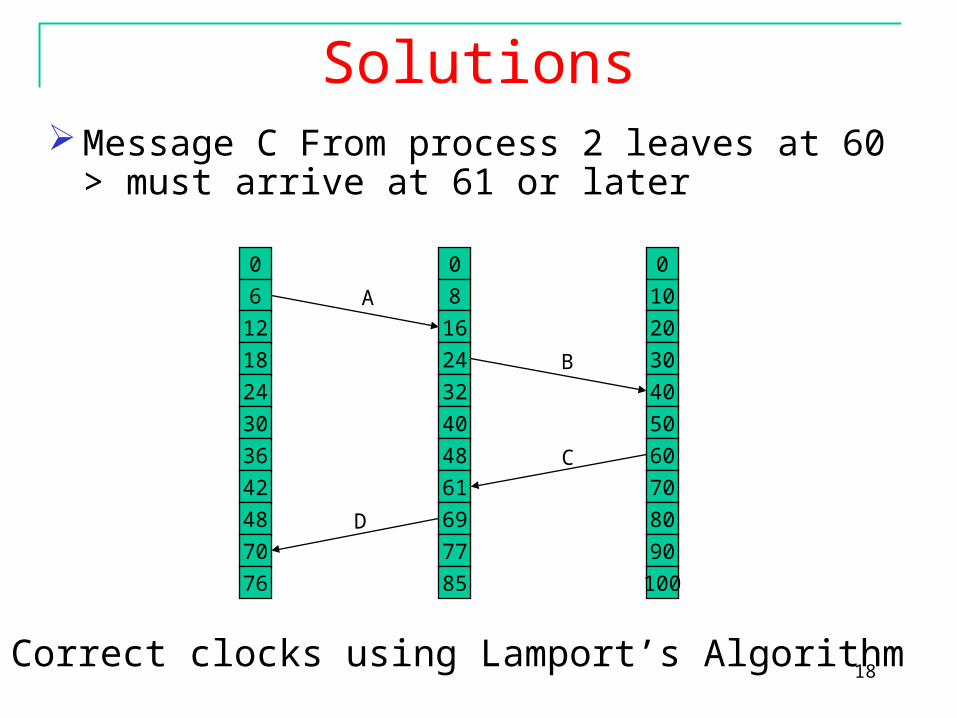
Solutions Message C From process 2 leaves at 60 > must arrive at
61 or later
0
6
12
18
24
30
36
42
48
70
76
0
8
16
24
32
40
48
61
69
77
85
0
10
20
30
40
50
60
70
80
90
100
A
B
C
D
Correct clocks using Lamport’s Algorithm

19
Application of Lamport timestampsScenario
– Replicated accounts in New York(NY) and San Francisco(SF)
– Two transactions occur at the same time and multicast
• Current balance: $1,000• Add $100 at SF• Add interest of 1% at NY
– Possible results ??•
Example: Totally-Ordered Multicast
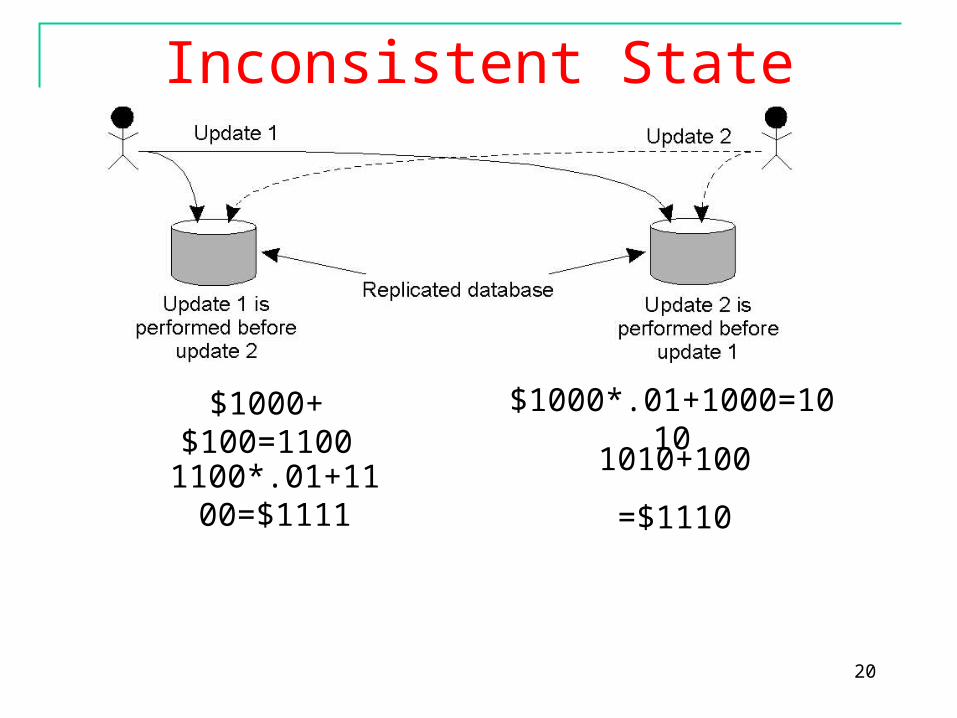
20
$1000+$100=1100 $1000*.01+1000=1010
1100*.01+1100=$1111
1010+100
=$1110
Inconsistent State

21
Totally Ordered Multicast Use Lamport timestamps Algorithm
– Message is time stamped with sender’s logical time
– Message is multicast (including sender itself)
– When message is received• It is put into local queue
• Ordered according to timestamp
• Multicast acknowledgement
– Message is delivered to applications only when• It is at head of queue
• It has been acknowledged by all involved processes
– Lamport algorithm (extended) ensures total ordering of events– All processes will eventually have the same copy
– of the local queue consistent global ordering.
22
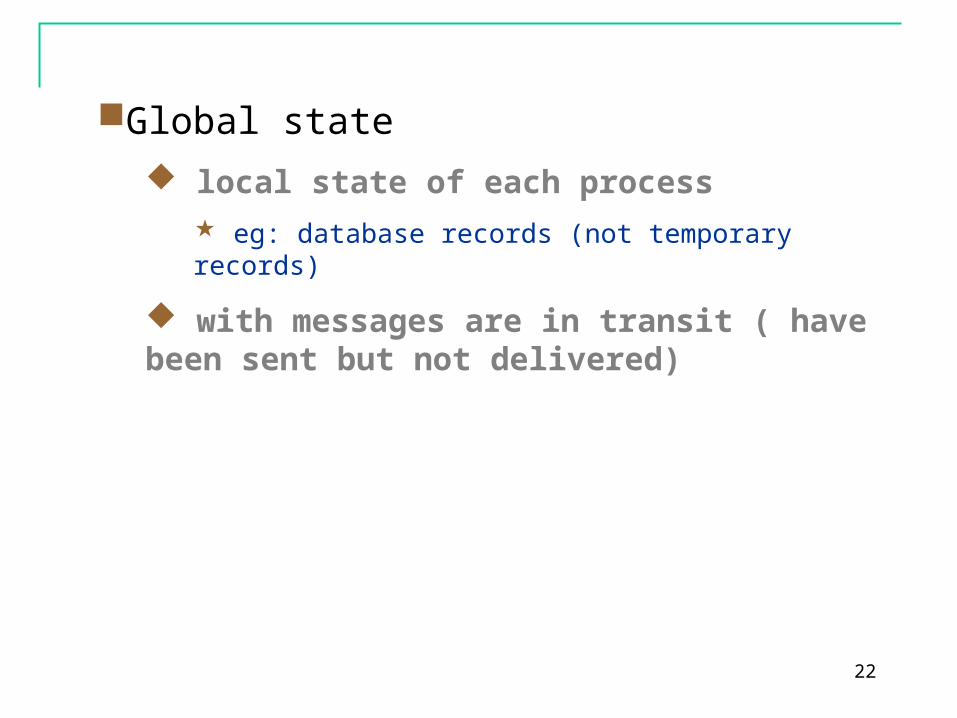
Global state
local state of each process
eg: database records (not temporary records)
with messages are in transit ( have been sent but not delivered)

23
Distributed Snapshot: Intro
Reflects the state in which a system might have been– Chandy and Lamport (1985)
If it is recorded that Q recd a msg from P– then it should also be recorded that P sent it
However, If P’s sending is recorded, but not that of Q receiving it, that’s allowed
Assumption: processes are connected to each other via uni-directional point-to-point channels
Any process can initiate the algorithm – Use a marker with the message to initiate communication
24
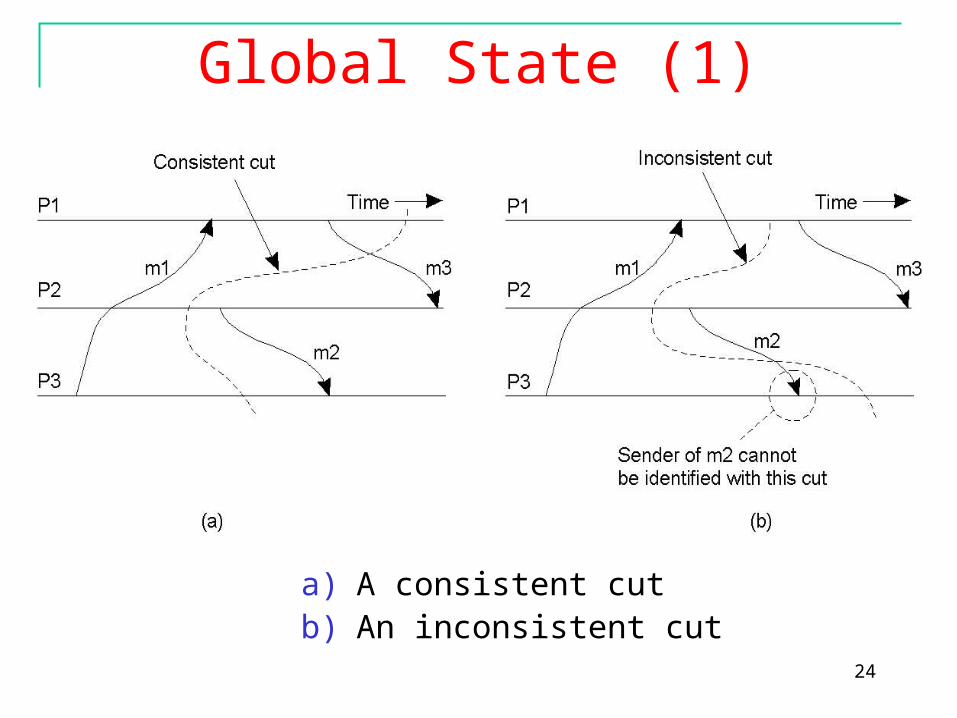
Global State (1)
a) A consistent cutb) An inconsistent cut

25
Global State (2)
a) Organization of a process and channels for a distributed snapshot

26
1. Any process can initiate the algorithm.
2. Initiating process P starts by recording its own local state. Then it sends a marker
along each of its outgoing channels.
3. When a process Q receives a marker through an incoming channel C:
• If Q hasn’t already saved its local state,
Q first records its local state and then sends a marker along each of its own outgoing channels.
• If Q has already recorded its state earlier, the marker on channel C is an indicator that Q
should record the state of the channel.
4. A process is done when it has received a marker on each of its coming channels. The
local state of the process and the state of each of its incoming channels are sent to the
initiating process.
ALGORITHM

27
Global State (3)
b) Process Q receives a marker for the first time and records its local state
c) Q records all incoming messaged) Q receives a marker for its incoming channel and finishes recording
the state of the incoming channel

28
When Q finishes its role in the snapshot it can send one of the two messages to it predecessor
DONE or CONTINUE
A DONE message is sent if All of Q’s successors have returned a “DONE”
Q has not received any message
ElSE
CONTINUE message will sent to its predecessor

29
Election Algorithms
Need to find one process that is the coordinator Assume
– Each process has a unique identifier• network address for example
– One process per machine
– Every process knows the process number of every other process
– Processes don’t know which processes are down and which ones are still running
End result of the algorithm: all processes agree on who is the new coordinator/leader
Bully algorithm & Ring Algorithm

30
Bully Algorithm (Garcia-Molina) A process notices that coordinator is not responding
– it starts an election (any process can start one) Election algorithm
– P sends an ELECTION message to processes with higher numbers
– If no one responds, P wins the election– If some process with higher process number responds
• P’s job is done, that process takes over • the receiver sends an OK message to P• receiver starts an election process
Eventually all processes give up, except one This process sends out a message saying that it is the new
“COORDINATOR” A process that was down, when it comes back up starts a new
election of its own

31
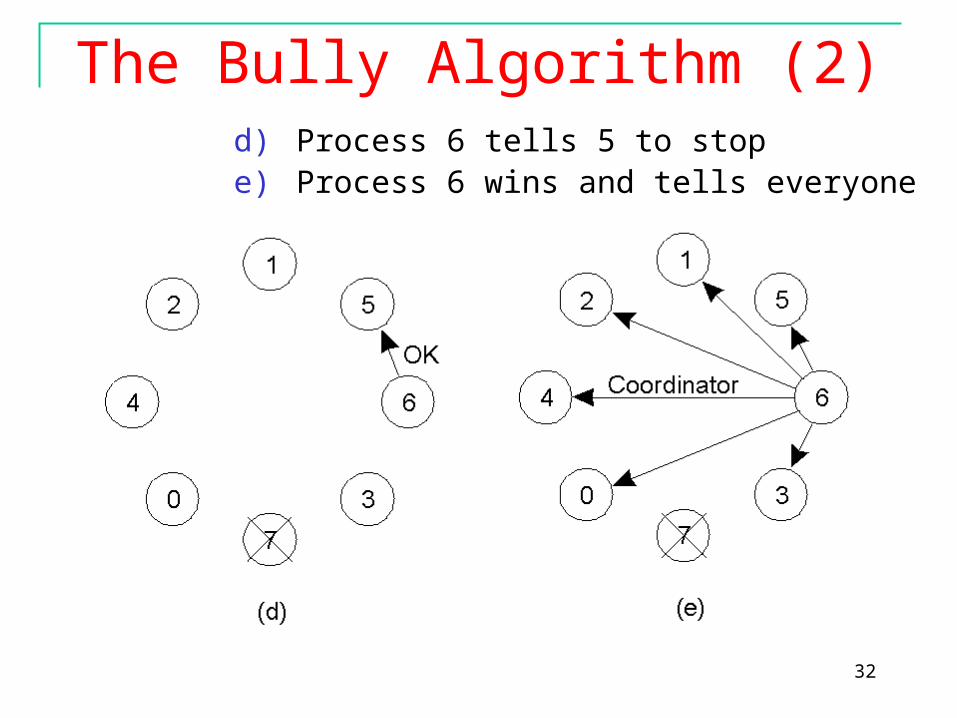
The Bully Algorithm (1)
The bully election algorithm; pcs 7 as coordinator=> crashed(a) Process 4 is the first on noticed the crashed >> send
ELECTION process to 5, 6 and 7 (higher pcs)(b) Process 5 and 6 respond, telling 4 to stop(c) Now 5 and 6 each hold an election
32
The Bully Algorithm (2)d) Process 6 tells 5 to stope) Process 6 wins and tells everyone

33
Ring Algorithm (1)
Does NOT use a token Assume
– processes are ordered– each process knows its successor
• and the successor’s successor, and so on (needed in case of failures)
Process P detects that the coordinator is dead– sends an ELECTION message to its successor– includes its process number in the message– each process that receives it
• adds its own process number and then forwards it to its successor
– eventually it gets back that message• now what does it do?

34
Ring Algorithm (2)
The process that initiated it, then sends out a message saying “COORDINATOR”– the process with highest number in list is the leader– when this comes back, then process P deletes it
35
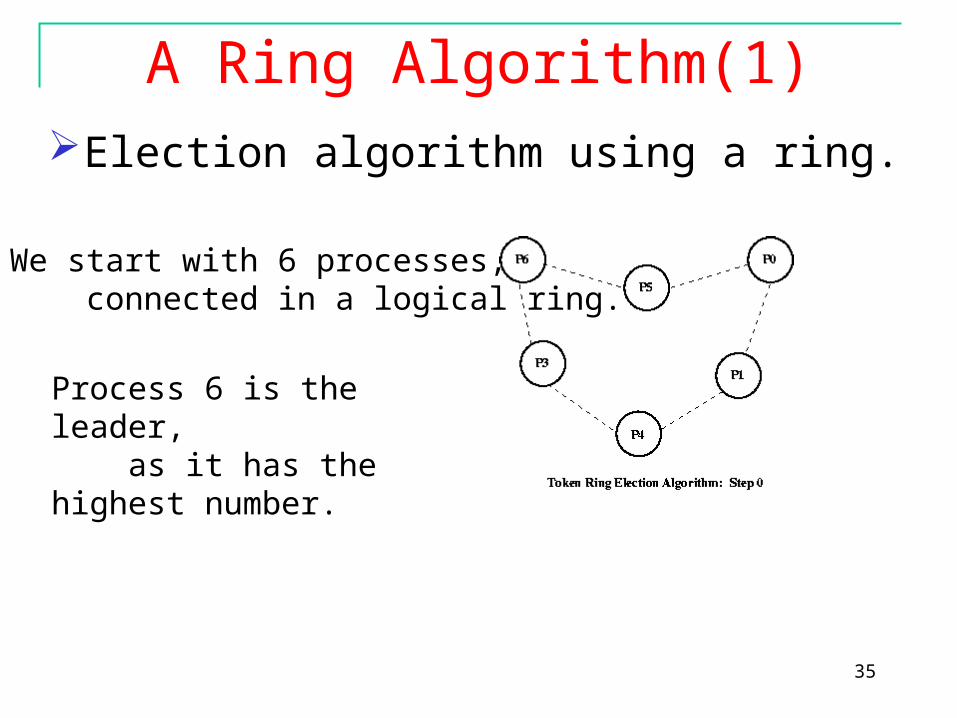
A Ring Algorithm(1)Election algorithm using a ring.
We start with 6 processes, connected in a logical ring.
Process 6 is the leader, as it has the highest number.

36
A Ring Algorithm(2)
Process 6 fails.

37
A Ring Algorithm(3)
Process 3 notices that Process 6 does not respond
So it starts an election, sending a message containing its id to the next node in the ring.
38
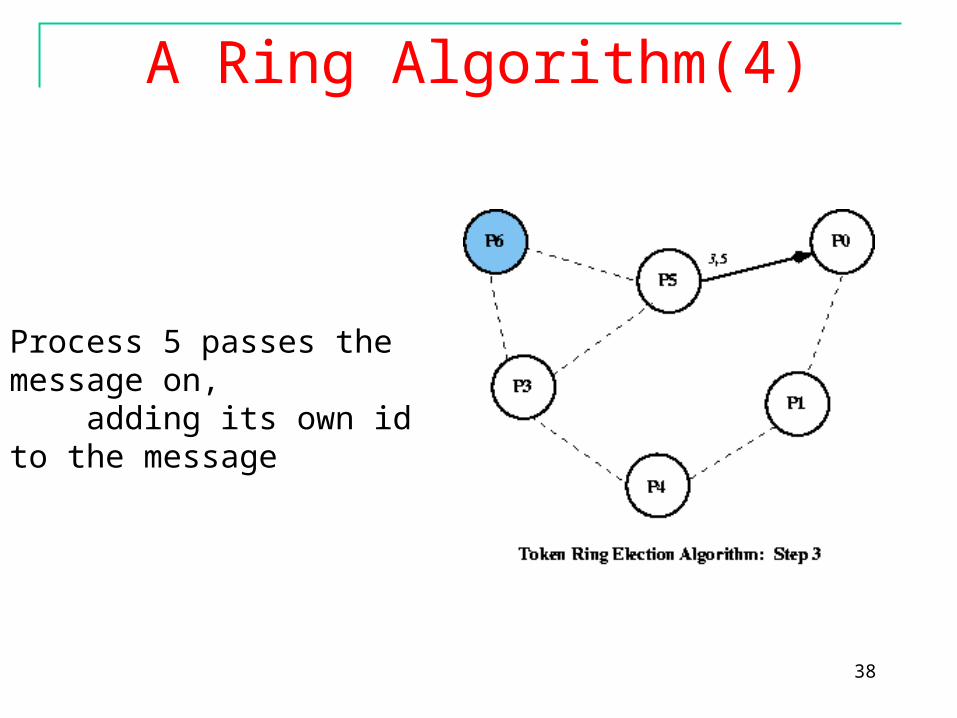
A Ring Algorithm(4)
Process 5 passes the message on, adding its own id to the message
39
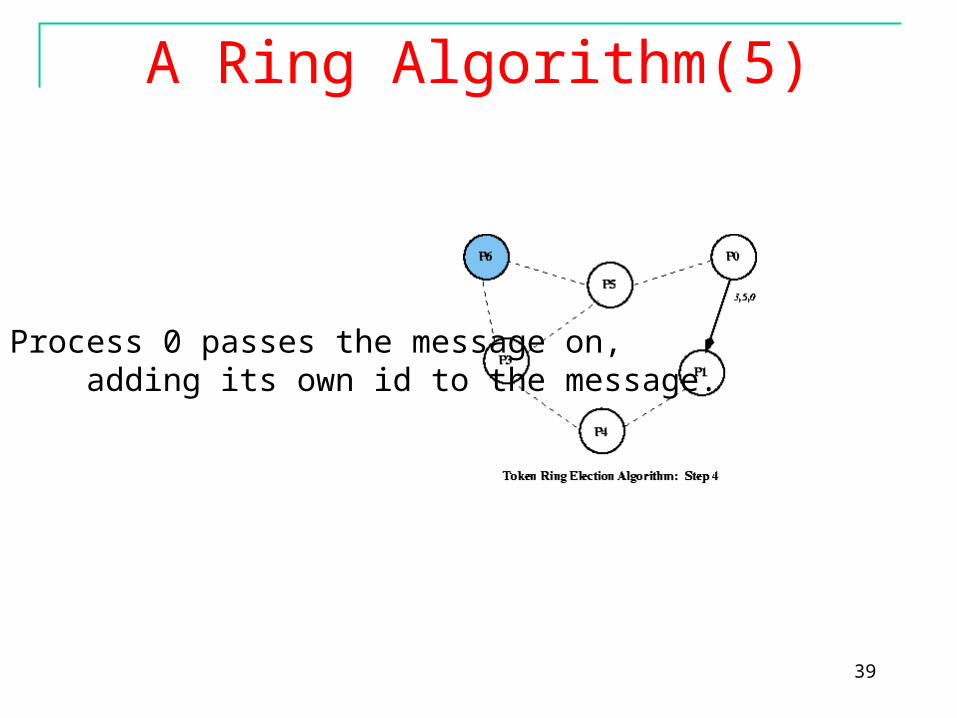
A Ring Algorithm(5)
Process 0 passes the message on, adding its own id to the message.

40
A Ring Algorithm(6)
Process 1 passes the message on, adding its own id to the message.

41
A Ring Algorithm(7)
Process 4 passes the message on, adding its own id to the message

42
A Ring Algorithm(8)
When Process 3 receives the message back, it knows the message has gone around the ring, as its own id is in the list.
Picking the highest id in the list, it starts the coordinator message "5 is the leader" around the ring

43
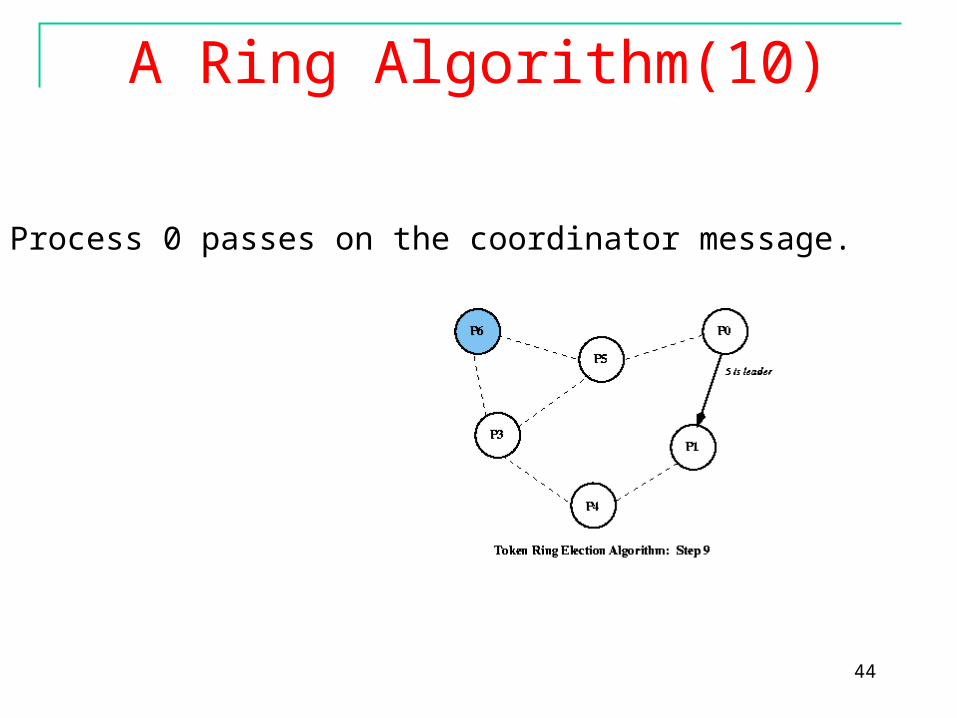
A Ring Algorithm(9)
Process 5 passes on the coordinator message
44
A Ring Algorithm(10)
Process 0 passes on the coordinator message.

45
A Ring Algorithm(11)
Process 1 passes on the coordinator message.
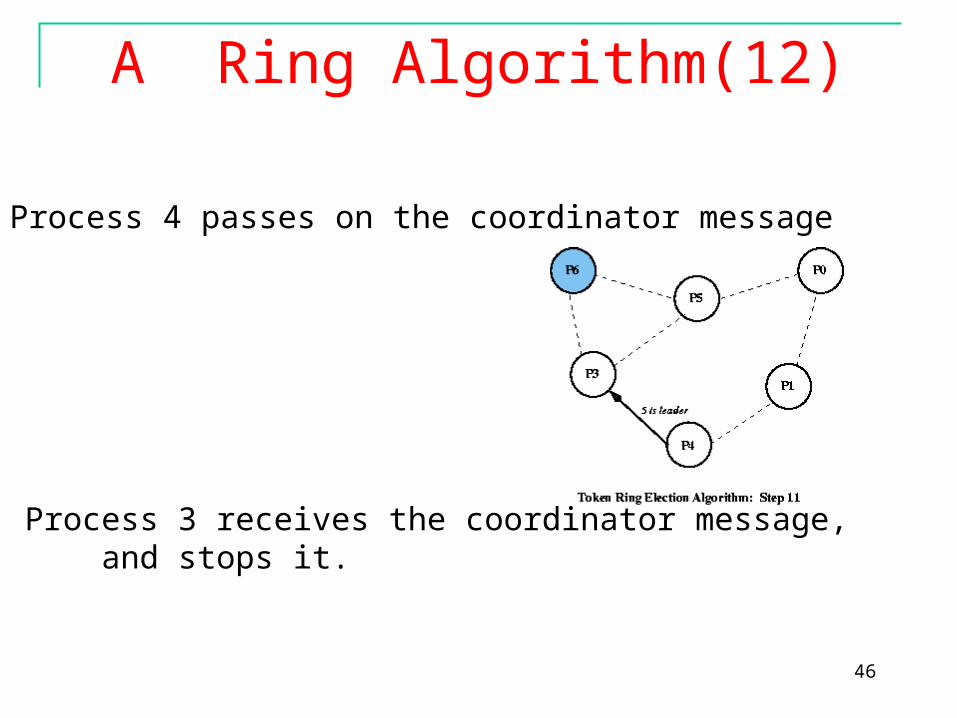
46
A Ring Algorithm(12)
Process 4 passes on the coordinator message
Process 3 receives the coordinator message, and stops it.

47
Mutual Exclusion
What is mutual exclusion?– Make sure that no other will use the shared data structure at the same time.
Single processor systems– use semaphores and monitors
Three different algorithms– Centralized Algorithm– Distributed Algorithm– Token Ring Algorithm

48
Mutual Exclusion:Centralized Algo(1) One process is elected as coordinator Other processes send it a message asking for permission
– coordinator grants permission– or says no-permission (or doesn’t reply at all)
• queues the request
When the critical region is free– it sends a message to the first one in the queue
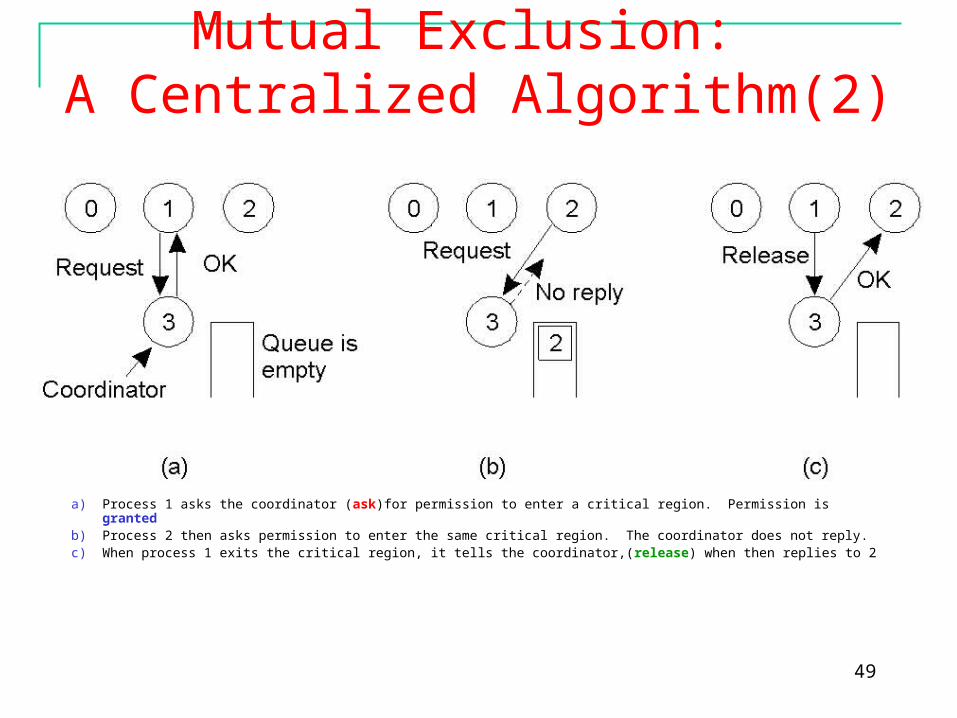
49
Mutual Exclusion: A Centralized Algorithm(2)
a) Process 1 asks the coordinator (ask)for permission to enter a critical region. Permission is grantedb) Process 2 then asks permission to enter the same critical region. The coordinator does not reply.c) When process 1 exits the critical region, it tells the coordinator,(release) when then replies to 2

50
Mutual Exclusion: A Centralized Algorithm(3)Coordinator only let one process to enter the critical region.
The request is granted in the order: no process ever waits forever ( no starvation).Three messages is use in accessing the critical region/shared resources:
RequestGrantRelease
Drawback:coordinator is single point failureIf process blocked after making a request- it is cannot distinguish either the coordinator is dead or resource not available.Performance bottleneck in a large system.

51
Mutual Exclusion:A Distributed Algo(1) There are total ordering of all event in the system Provide timestamps by using Lamport Algorithm Algorithm: A process wanting to enter the Critical Section (CS)
– Build a msg :- • forms <cs-name, its process id, current-time>
– sends to all processes including itself.– assume that sending is reliable; every msg is acknowledge

52
Mutual Exclusion: A Distributed Algorithm(2)
Every receiving process sends an OK, if it is not interested in the CS if it is already in the CS, just queues the message if it itself has sent out a message for the CS
compares the time stamps
if an incoming message has lower timestamp it sends out an OK
else it just queues it Once it receives an OK from everyone
it enters the CS once its done, its sends an OK to everyone in its queue

53
Mutual Exclusion: A Distributed Algo(3)
a) Two processes(0&2) want to enter the same critical region at the same moment. b) Process 1 not interested for CS-> send OK to 0 and 2.
0 & 1 compare the timestamps=> Process 0 has the lowest timestamp, so it wins.c) When process 0 is done, it sends an OK also, so 2 can now enter the critical region.
8
12

54
A Token Ring Algorithm(1) Create a logical ring (in software)
– each process knows who is next When a process have the token, it can enter the CS Finished, release the token and pass to the next guy The token circulate at high speed around the ring if no process wants to enter the CS. No starvation
– at worst wait for each other process to complete Detecting that a token has been lost is hard What if a process crashes?
– recovery depends on the processes being able to skip this process while passing on the ring

55
A Token Ring Algorithm(2)
a) An unordered group of processes on a network. b) A logical ring constructed in software.
Process must have token to enter.– If don’t want to enter, pass token along.– If token lost (detection is hard), regenerate token. – If host down, recover ring.
Token
K+1%8
6+1%8=7

56
ComparisonA comparison of three mutual exclusion algorithms.
AlgorithmMessages per entry/exit
Delay before entry (in message times)
Problems
Centralized 3 2 Coordinator crash
Distributed 2 ( n – 1 ) 2 ( n – 1 )Crash of any process
Token ring 1 to 0 to n – 1Lost token, process crash
Centralized most efficientToken ring efficient when many want to use
critical region

57
The Transaction Model(1)
A transaction is a unit of program execution that accesses and possibly updates various data items.
A transaction must see a consistent database. During transaction execution the database may be
inconsistent. When the transaction is committed, the database must
be consistent. Two main issues to deal with:
– Failures of various kinds, such as hardware failures and system crashes
– Concurrent execution of multiple transactions

58
The Transaction Model (3)Examples of primitives for transactions.
Primitive Description
BEGIN_TRANSACTION Make the start of a transaction
END_TRANSACTION Terminate the transaction and try to commit
ABORT_TRANSACTION Kill the transaction and restore the old values
READ Read data from a file, a table, or otherwise
WRITE Write data to a file, a table, or otherwise
Above may be system calls, libraries or statements in a language (Sequential Query Language or SQL)

59
The Transaction Model (4)
a) Transaction to reserve three flights commitsb) Transaction aborts when third flight is unavailable
BEGIN_TRANSACTION reserve WP -> JFK; reserve JFK -> Nairobi; reserve Nairobi -> Malindi;END_TRANSACTION
(a)
BEGIN_TRANSACTION reserve WP -> JFK; reserve JFK -> Nairobi; reserve Nairobi -> Malindi full =>ABORT_TRANSACTION (b)
Reserving Flight from White Plains to Malindi

60
Characteristics of Transaction(5) Atomic
– Completely happened or nothing Consistent
– The system not violate system invariant-one state to another– Ex: no money lost after operations
Isolated– Operations can happen in parallel but as if were done serially
Durable– The result become permanent when its finish/commit
– ACID- FLAT TRANSACTION

61
Example: Funds Transfer
Transaction to transfer $50 from account A to account B:
1. read(A)2. A := A – 503. write(A)
4. read(B)5. B := B + 506. write(B)
Consistency requirement – the sum of A and B is unchanged by the execution of the transaction.
Atomicity requirement — if the transaction fails after step 3 and before step 6, the system ensures that its updates are not reflected in the database.

62
Example: Funds Transfer continued
Durability requirement — once the user has been notified that the transaction has completed (i.e., the transfer of the $50 has taken place), the updates to the DB must persist despite failures.
Isolation requirement — if between steps 3 and 6, another transaction is allowed to access the partially updated database, it will see an inconsistent database (the sum A + B will be less than it should be).Can be ensured by running transactions serially.

63
Flat Transaction Simplest type of transaction; all sub transaction were group into a single transaction. Limitation
– what if want to keep first part of flight reservation? If abort and then restart, those might be gone.
1. Does not allowed partial result to be – committed or • Aborted
Solve by using nested transaction

64
Nested Transaction Constructed from a number of sub-transaction Top-level transaction may fork children run in parallel in different machine The children itself may fork another child or subs transaction When one transaction is commit- it will make visible to their parent
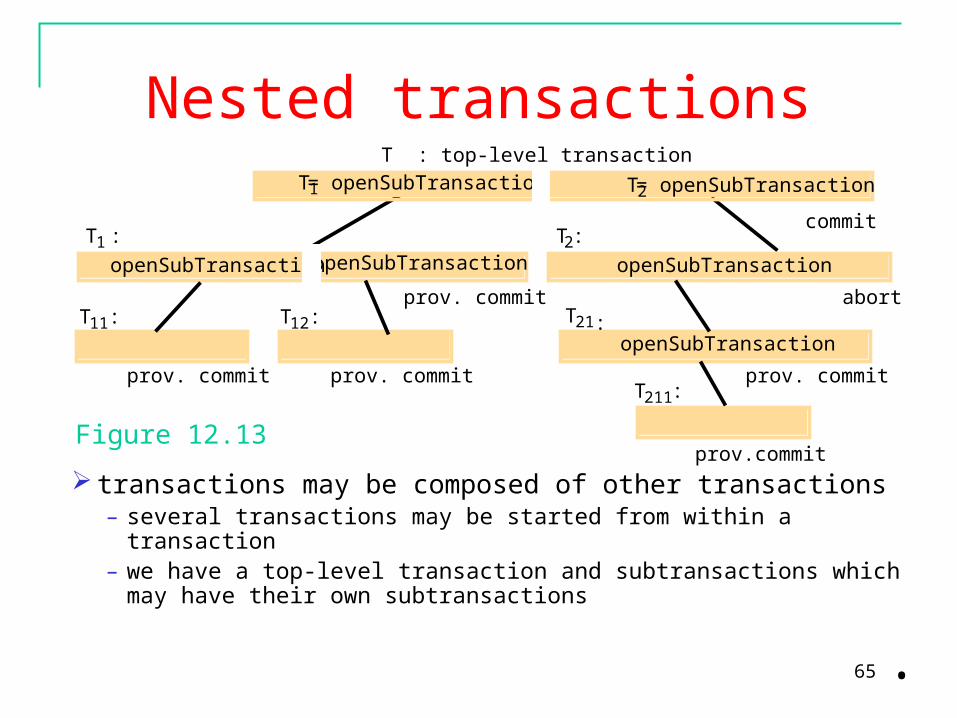
65
Nested transactions
transactions may be composed of other transactions– several transactions may be started from within a transaction– we have a top-level transaction and subtransactions which
may have their own subtransactions
•
T : top-level transactionT1 = openSubTransaction T2 = openSubTransaction
openSubTransaction openSubTransactionopenSubTransaction
openSubTransaction
T1 : T2 :
T11 : T12 :
T211 :
T21 :
prov.commit
prov. commit
abort
prov. commitprov. commit
prov. commit
commit
Figure 12.13

66
Nested transactions (12.3) To a parent, a subtransaction is atomic with respect to failures and concurrent access transactions at the same level (e.g. T1 and T2) can run concurrently but access to common objects is serialised a subtransaction can fail independently of its parent and other subtransactions
– when it aborts, its parent decides what to do, e.g. start another subtransaction or give up
•
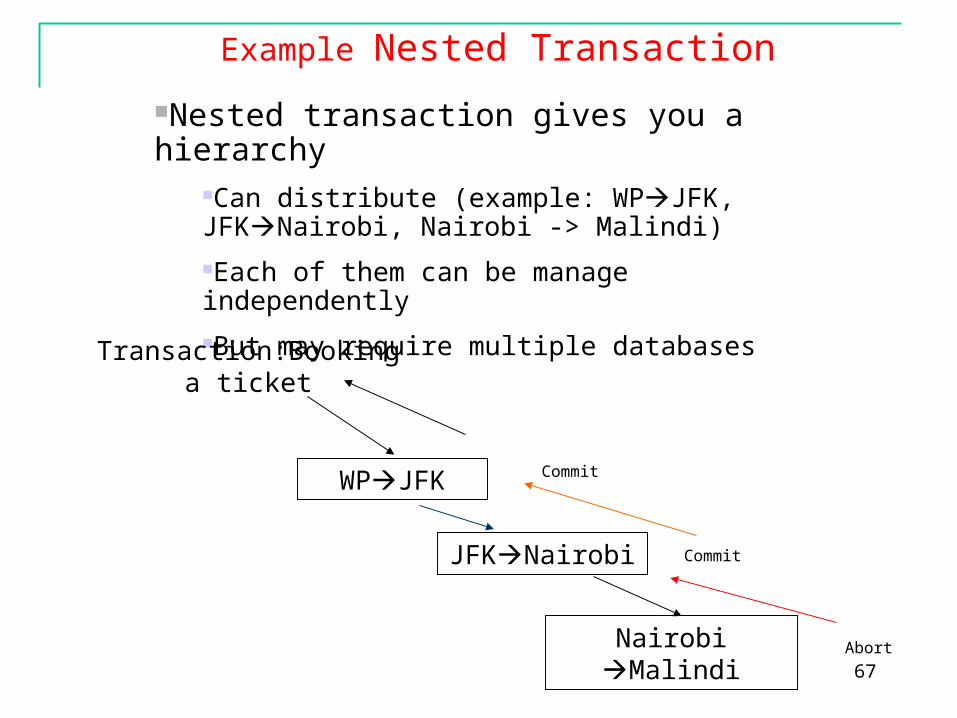
67
Example Nested Transaction
Nested transaction gives you a hierarchy
Can distribute (example: WPJFK, JFKNairobi, Nairobi -> Malindi)Each of them can be manage independentlyBut may require multiple databases
WPJFK
JFKNairobi
Nairobi Malindi
Commit
Abort
Transaction:Booking a ticket
Commit

68
Distributed transaction1. A distributed transaction is composed of several sub-
transactions each running on a different site.
2. Separate algorithms are needed to handle the locking of data and committing the entire transaction.
Differences between nested transaction and distributed transaction

69
Transaction:Implementation Two methods are used
– Private Workspace– Writeahead Log
– Consideration on a file system

70
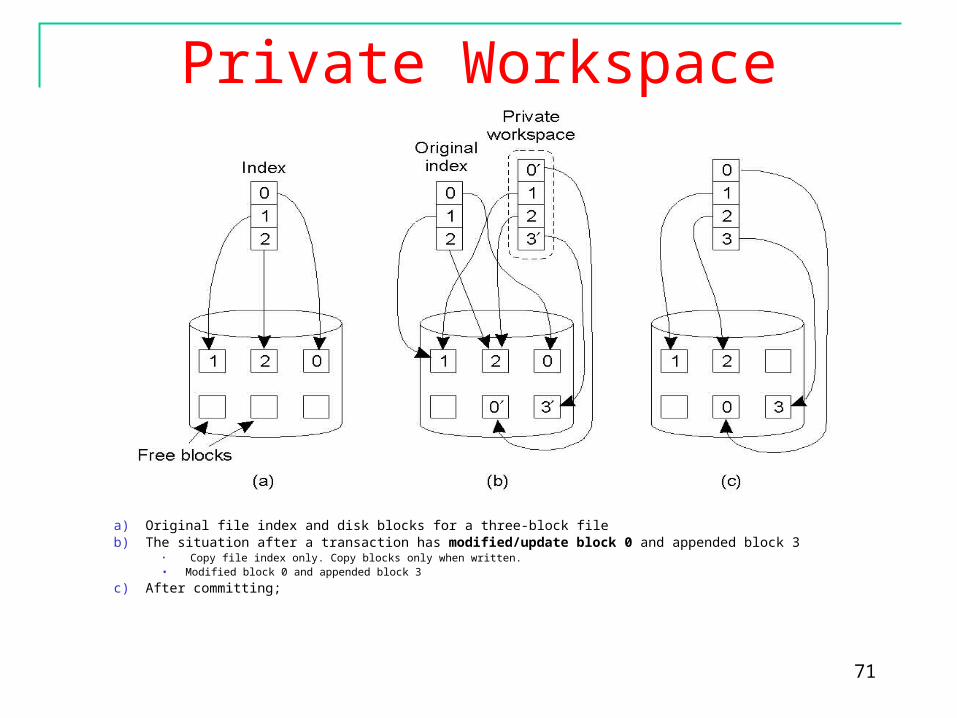
Private WorkspaceConceptually, when a process starts a transaction, it is
given a private workspace (copies) containing all the files and data objects to which it has access.
When it commits, the private workspace replaces the corresponding data items in the permanent workspace. If the transaction aborts, the private workspace can simply be discarded.
This type of implementation leads to many private workspaces and thus consumes a lot of space.
Optimization: (as cost of copying is very expensive) No need for a private copy when a process reads a file. For writing a file, only the file’s index is copied.
71
Private Workspace
a) Original file index and disk blocks for a three-block fileb) The situation after a transaction has modified/update block 0 and appended block 3
• Copy file index only. Copy blocks only when written.• Modified block 0 and appended block 3
c) After committing;

72
More Efficient Implementation/Write ahead log Files are actually modified, but before changes are made,
a record <Ti,Oid,OldValue,NewValue> is written to the writeahead log on the stable storage. Only after the log has been written successfully is the change made to the file.
If the transaction succeeds and is committed, a record is written to the log, but the data objects do not have to be changed, as they have already been updated.
If the transaction aborts, the log can be used to back up to the original state (rollback).
The log can also be used for recovering from crash.

73
Writeahead Log
a) A transaction b) – d) The log before each statement is executed
• If transaction commits, nothing to do• If transaction is aborted, use log to rollback
x = 0;
y = 0;
BEGIN_TRANSACTION;
x = x + 1;
y = y + 2
x = y * y;
END_TRANSACTION;
(a)
Log
[x = 0 / 1]
(b)
Log
[x = 0 / 1]
[y = 0/2]
(c)
Log
[x = 0 / 1]
[y = 0/2]
[x = 1/4]
(d)
Don’t make copies. Instead, record action plus old and new values
Old value
New value

74
Concurrency Control (1)
General organization of managers for handling transactions.
The goal of concurrency control is to allow several transactions to be executed simultaneously, but the collection of data item is remains in a consistent state.
The consistency can be achieved by giving access to the items in a specific order
75
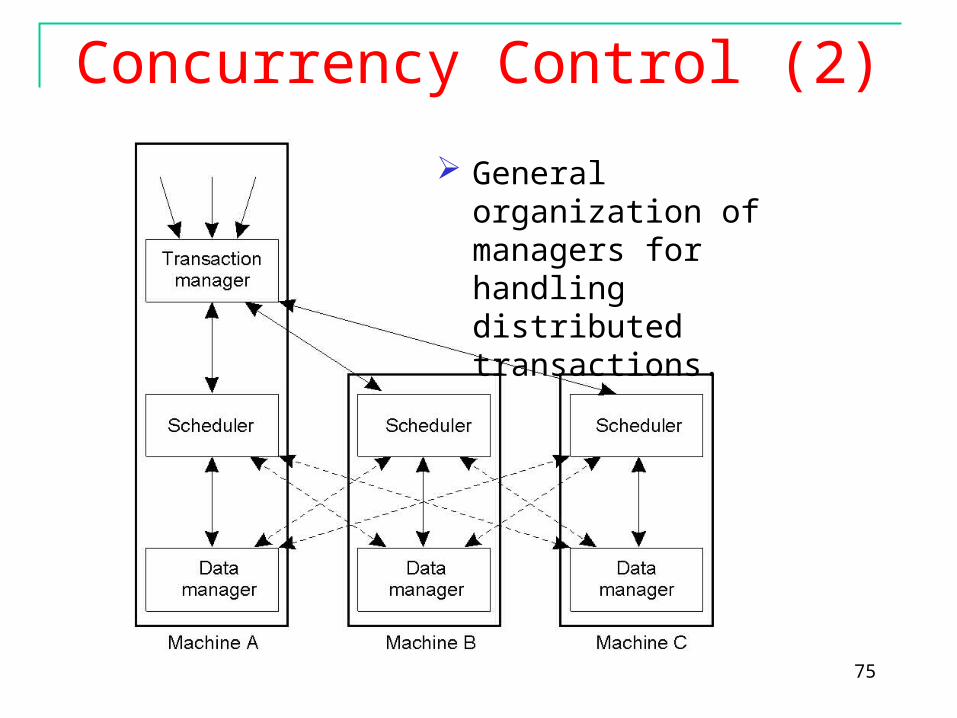
Concurrency Control (2)
General organization of managers for handling distributed transactions.

76
Serializability
a) – c) Three transactions T1, T2, and T3
d) Possible schedules
BEGIN_TRANSACTION x = 0; x = x + 1;END_TRANSACTION
(a)
BEGIN_TRANSACTION x = 0; x = x + 2;END_TRANSACTION
(b)
BEGIN_TRANSACTION x = 0; x = x + 3;END_TRANSACTION
(c)
Schedule 1 x = 0; x = x + 1; x = 0; x = x + 2; x = 0; x = x + 3 Legal
Schedule 2 x = 0; x = 0; x = x + 1; x = x + 2; x = 0; x = x + 3; Legal
Schedule 3 x = 0; x = 0; x = x + 1; x = 0; x = x + 2; x = x + 3; Illegal
(d)

77
Locking Locking is the oldest, and still most widely used, form of concurrency control When a process needs access to a data item, it tries to acquire a lock on it - when it no longer
needs the item, it releases the lock The scheduler’s job is to grant and release locks in a way that guarantees valid schedules

78
In 2PL, the scheduler grants all the locks during a growing phase, and releases them during a shrinking phase
In describing the set of rules that govern the scheduler,
we will refer to an operation on data item x by transaction T as oper(T,x)

79
Two-Phase Locking Rules (Part 1)
When the scheduler receives an operation oper(T,x), ittests whether that operation conflicts with any operationon x for which it has already granted a lock
If it conflicts, the operation is delayedIf not, the scheduler grants a lock for x and passes the operation
to the data manager
The scheduler will never release a lock for x until thedata manager acknowledges that it has performed theoperation on x

80
Two-Phase Locking Rules (Part 2)
Once the scheduler has released any lock on behalf oftransaction T, it will never grant another lock on behalf ofT, regardless of the data item T is requesting the lock for
An attempt by T to acquire another lock after havingreleased any lock is considered a programming error,and causes T to abort

81
Two-Phase Locking (1)Two-phase locking.
Related Documents

![Clock Synchronization in WSN: from Traditional Estimation ...ycwu/Clock Synchronization in WSN_overvi… · Pairwise Synchronization: Gaussian case [1] • Synchronize node j to node](https://static.cupdf.com/doc/110x72/5f8929217e699f4e040a8be7/clock-synchronization-in-wsn-from-traditional-estimation-ycwuclock-synchronization.jpg)









