1 On the Probabilistic Foundations of Probabilistic Roadmaps Jean-Claude Latombe Stanford University joint work with David Hsu and Hanna Kurniawati National University of Singapore D. Hsu, J.C. Latombe, H. Kurniawati. On the Probabilistic Foundations of Probabilistic Roadmap Planning. IJRR, 25(7):627-643, 2006.

1 On the Probabilistic Foundations of Probabilistic Roadmaps Jean-Claude Latombe Stanford University joint work with David Hsu and Hanna Kurniawati National.
Dec 19, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
On the Probabilistic Foundations of Probabilistic
Roadmaps
Jean-Claude LatombeStanford University
joint work with David Hsu and Hanna Kurniawati
National University of Singapore
D. Hsu, J.C. Latombe, H. Kurniawati. On the Probabilistic Foundations of Probabilistic Roadmap Planning. IJRR, 25(7):627-
643, 2006.

2
Rationale of PRM Planners
The cost of computing an exact representation of a robot’s free space F is often prohibitive
Fast algorithms exist to check if a given configuration or path is collision-free
A PRM planner computes an extremely simplified representation of F in the form of a network of “local” paths connecting configurations sampled at random in F according to some probability measure

3This answer may occasionally be incorrect
Connection strategy
Sampling strategy
Procedure BasicPRM(s,g,N)
1. Initialize the roadmap R with two nodes, s and g2. Repeat:
a. Sample a configuration q from C with probability measure
b. If q F then add q as a new node of Rc. For every node v in R such that v q do
If path(q,v) F then add (q,v) as a new edge of R
until s and g are in the same connected component of R or R contains N+2 nodes
3. If s and g are in the same connected component of R then
Return a path between them
4. ElseReturn NoPath

4

5

6

7
PRM planners work well in practice. Why?
Why are they probabilistic?
What does their success tell us?
How important is the probabilistic sampling measure ?
How important is the randomness of the sampling source?

8
Why is PRM planning probabilistic?
A PRM planner ignores the exact shape of F. So, it acts like a robot building a map of an unknown environment with limited sensors
At any moment, there exists an implicit distribution (H,), where • H is the set of all consistent hypotheses over the shapes of F • For every x H, (x) is the probability that x is correct
The probabilistic sampling measure used by the planner reflects this uncertainty. The goal is to minimize the expected number of iterations to connect s and g, whenever they lie in the same component of F

9
Why is PRM planning probabilistic?
A PRM planner ignores the exact shape of F. So, it acts like a robot building a map of an unknown environment with limited sensors
At any moment, there exists an implicit distribution (H,), where • H is the set of all consistent hypotheses over the shapes of F
• For every x H, (x) is the probability that x is correct
The probabilistic sampling measure reflects this uncertainty. The goal is to minimize the expected number of remaining iterations to connect s and g, whenever they lie in the same component of F

10
So ...
PRM planning trades the cost of computing F exactly against the cost of dealing with uncertainty
This choice is beneficial only if a small roadmap has high probability to represent F well enough to answer planning queries correctly[Note the analogy with PAC learning]
Under which conditions is this the case?

11
Relation to Monte Carlo Integration
x
f(x)
2
1
x
x
I = f (x)dx
a
bA = a × b
x1 x2
(xi,yi)
Ablack#red#
red#I
But a PRM planner must construct a path
The connectivity of F may depend on small regions
Insufficient sampling of such regions may lead the planner to failure
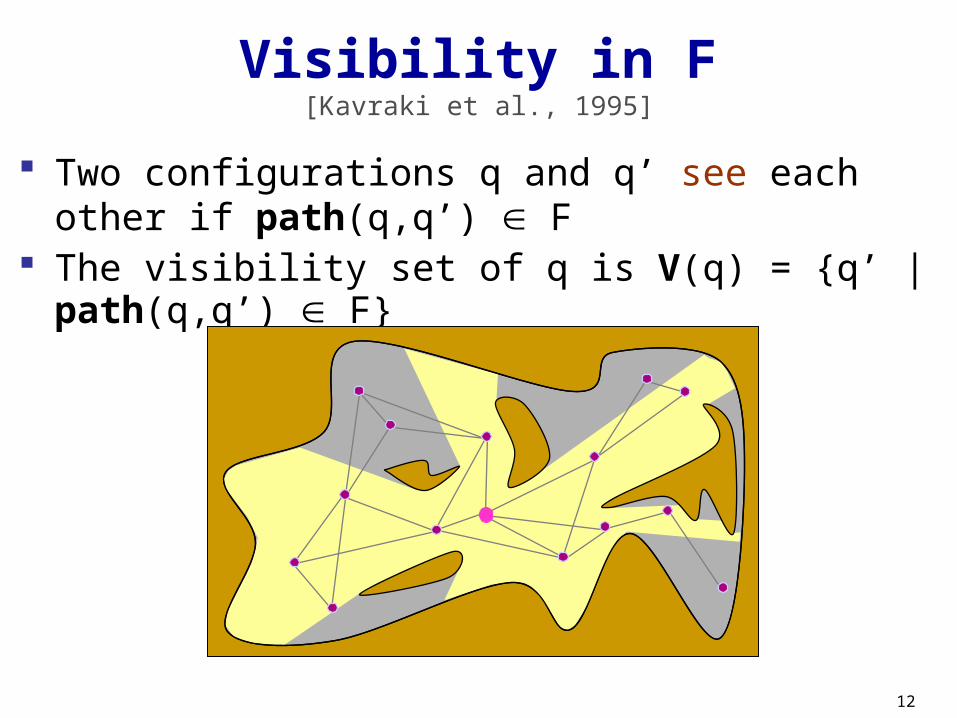
12
Two configurations q and q’ see each other if path(q,q’) F
The visibility set of q is V(q) = {q’ | path(q,q’) F}
Visibility in F[Kavraki et al., 1995]

13
ε-Goodness of F[Kavraki et al., 1995]
Let μ(X) stand for the volume of X F
Given ε (0,1], q F is ε-good if it sees at least an ε-fraction of F, i.e., if μ(V(q)) εμ(F)
F is -good if every q in F is -good
Intuition: If F is ε-good, then with high probability a small set of configurations sampled at random will see most of F

14
F1 F2
Connectivity Issue

15
F1 F2
Connectivity Issue
Lookout of F1
The β-lookout of a subset X of F is the set of all configurations in X that see a β-fraction of F\X
β-lookout(X) {q X | μ(V(q)\X) βμ(F\X)}

16
F1 F2
(ε,,β)-Expansiveness of F
Lookout of F1
F is (ε)-expansive if it is ε-good and each one of its subsets X has a β-lookout whose volume is at least μ(X)
The β-lookout of a subset X of F is the set of all configurations in X that see a β-fraction of F\X
β-lookout(X) {q X | μ(V(q)\X) βμ(F\X)}
[Hsu et al., 1997]

17
Expansiveness only depends on volumetric ratios
It is not directly related to the dimensionality of the configuration space
In 2-D the expansiveness of the free space can be made arbitrarily poor
In n-D the passage can be made narrow in 1, 2, ..., n-1 dimensions
Comments
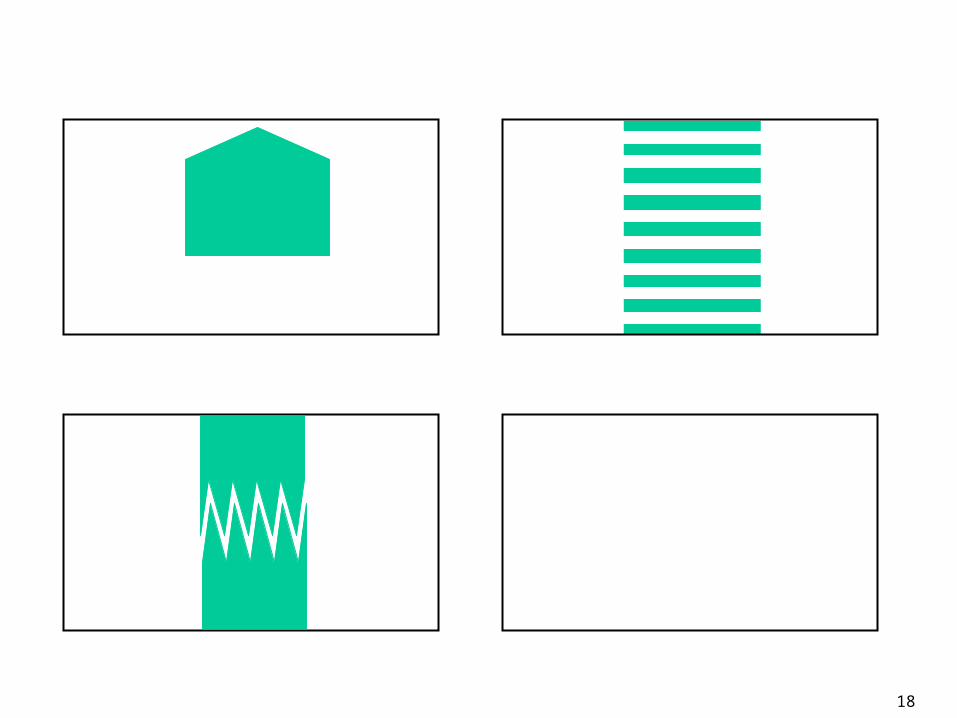
18

19
Theoretical Convergence of PRM Planning
Theorem 1 [Hsu, Latombe, Motwani, 1997]
Let F be (ε,,β)-expansive, and s and g be two configurations in the same component of F. BasicPRM(s,g,N) with uniform sampling returns a path between s and g with probability converging to 1 at an exponential rate as N increases
s g
Linking sequence

20
Theoretical Convergence of PRM Planning
Theorem 1 [Hsu, Latombe, Motwani, 1997]
Let F be (ε,,β)-expansive, and s and g be two configurations in the same component of F. BasicPRM(s,g,N) with uniform sampling returns a path between s and g with probability converging to 1 at an exponential rate as N increases
= Pr(Failure)
Experimental convergence

21
Theoretical Convergence of PRM Planning
Theorem 1 [Hsu, Latombe, Motwani, 1997]
Let F be (ε,,)-expansive, and s and g be two configurations in the same component of F. BasicPRM(s,g,N) with uniform sampling returns a path between s and g with probability converging to 1 at an exponential rate as N increases
Theorem 2 [Hsu, Latombe, Kurniawati, 2006]
For any ε 0, any N 0, and any in (0,1], there exists o and o such that if F is not (ε,,)-expansive for 0 and 0, then there exists s and g in the same component of F such that BasicPRM(s,g,N) fails to return a path with probability greater than .

22
What does the empirical success of PRM planning
tell us? It tells us that F is often favorably
expansive despite its overwhelming algebraic/geometric complexity
Revealing this property might well be the most important contribution of PRM planning

23
In retrospect, is this property surprising?
Not really! Narrow passages are unstable features under small random perturbations of the robot/workspace geometry

24
In retrospect, is this property surprising?
Not really! Narrow passages are unstable features under small random perturbations of the robot/workspace geometry
[Chaudhuri and Koltun, 2006] PRM planning with uniform sampling has polynomial smoothed running time in spaces of fixed dimensions (Recall that the worst-case running time of PRM planning is unbounded as a function of the input’s combinatorial complexity)
Poorly expansive space are unlikely to occur by accident

25
Most narrow passages in F are intentional …
… but it is not easy to intentionally create complex narrow passages in F
Alpha puzzle

26
PRM planners work well in practice. Why?
Why are they probabilistic?
What does their success tell us?
How important is the probabilistic sampling measure ?
How important is the randomness of the sampling source?
27
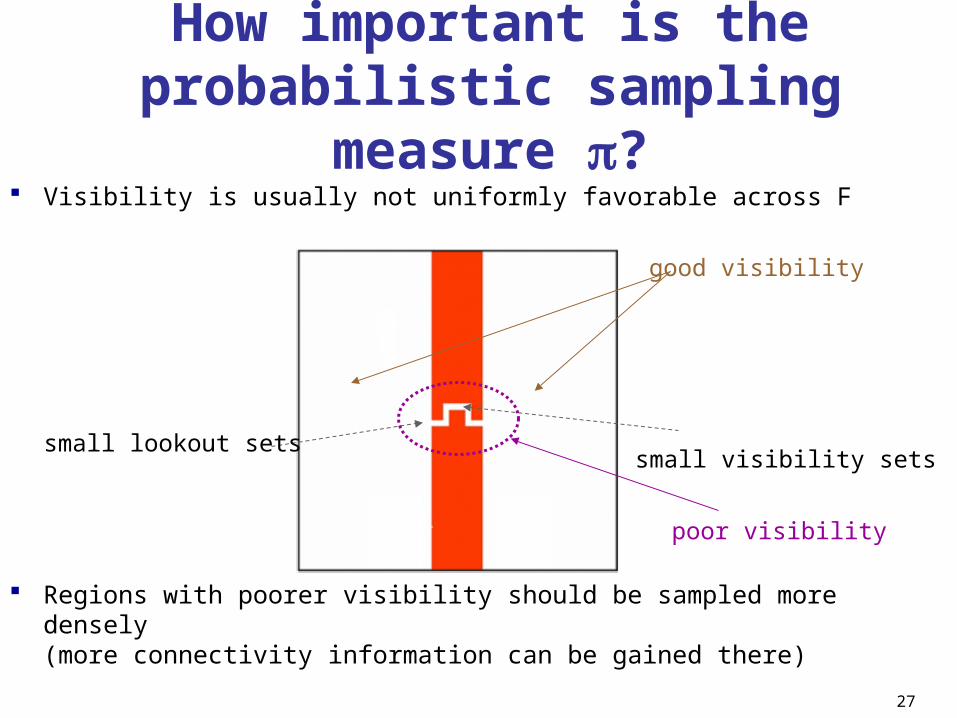
How important is the probabilistic sampling
measure ? Visibility is usually not uniformly favorable across F
Regions with poorer visibility should be sampled more densely(more connectivity information can be gained there)
small visibility setssmall lookout sets
good visibility
poor visibility

28
Impact
s g
Gaussian[Boor, Overmars,
van der Stappen, 1999]Connectivity expansion[Kavraki, 1994]

29
But how to identify poor visibility regions?
• What is the source of information? Robot and workspace geometry
• How to exploit it? Workspace-guided strategies Filtering strategies Adaptive strategies Deformation strategies

30
Workspace-Guided Strategies Main idea:
• Most narrow passages in configuration space derive from narrow passages in the workspace
Methods: • Detect narrow passages in the workspace • Sample more densely configurations that place
selected robot points in workspace’s narrow passages
Uniform sampling
Workspace-guided sampling[Kurniawati and Hsu, 2004]

31
??

32
Filtering Strategies Main Idea:
• Sample several configurations in the same region • If a “pattern” is detected, then retain one of the
configurations as a roadmap node(~ a more sophisticated probe) More sampling work, but better distribution of nodes Less time is wasted in connecting nodes
Methods:• Gaussian sampling• Bridge Test• Visibility PRM

33
Adaptive Strategies
Main idea:• Use previous sampling results to identify which
regions to sample next Time-varying sampling measure
Methods:• Connectivity expansion• Diffusion (EST, RRT, SRT)• Active learning
34
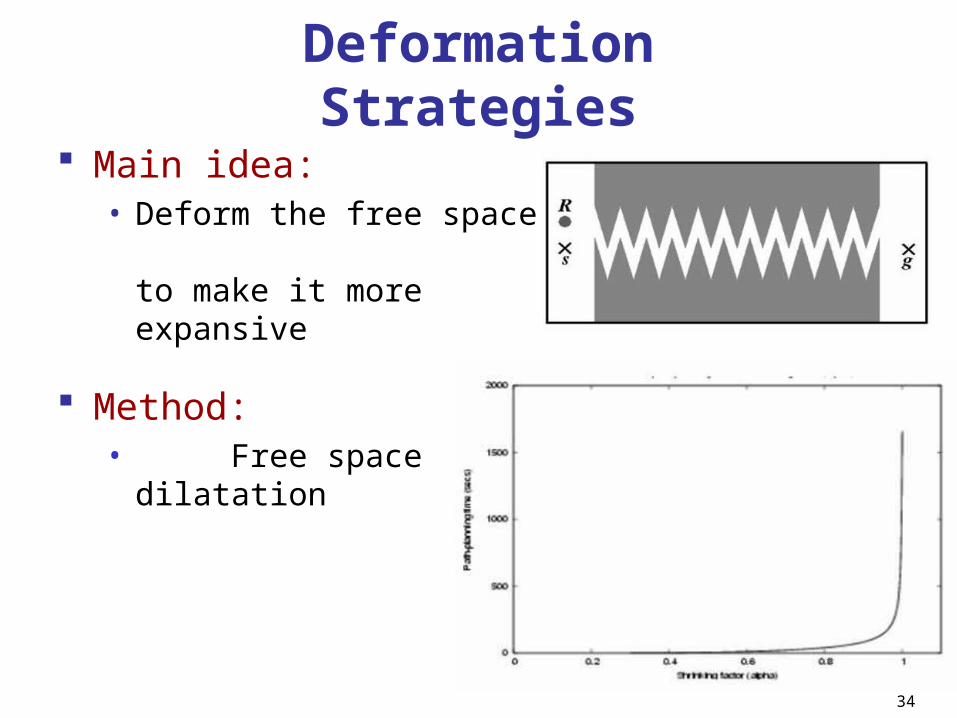
Deformation Strategies
Main idea:• Deform the free space
to make it more expansive
Method:• Free space
dilatation

35
Deformation Strategies
Main idea:• Deform the free space
to make it more expansive
Method:• Free space
dilatation
dilated free space
[Saha et al, 2004]
Relation with Gaussian sampling

36
How important is the randomness of the sampling
source?
Sampler = Uniform source S + Measure
Random Pseudo-random Deterministic [LaValle, Branicky, and Lindemann,
2004]

37
Choice of the Source S
Adversary argument in theoretical proof
Efficiency (or lack of) Robustness (or lack of) Practical convenience (or lack of)

38
Efficiency
s g
corridor width

39
Robustness

40
Practical Convenience
Think about implementing the Gaussian strategy with deterministic sampling

41
Conclusion In PRM, the word probabilistic matters.
The success of PRM planning depends mainly and critically on favorable visibility in F
The probability measure used for sampling F derives from the uncertainty on the shape of F
By exploiting the fact that visibility is not uniformly favorable across F, sampling measures have major impact on the efficiency of PRM planning
In contrast, the impact of the sampling source – random or deterministic – is small

42
How to improve PRM planning?
By improving the sampling strategy!
How? By answering :What is the right granularity of a PRM collision-checking probe?
Build roadmaps where nodes and edges are not fully tested and labeled by probabilities(e.g., lazy collision checking strategies)
Adapt the granularity of the probe (e.g., to get more information on the local shape of F)

43
Open Problems for PRM Planners
Free space made of multiple subspaces of different dimensionalities, like in legged locomotion on rough terrain or arm manipulation
[Bretl and Hauser]

44
Open Problems for PRM Planners
Motion spaces of linkages with huge number of degrees of freedom
[Redon, 2004]
Millipede-like robot with 13,000 joints
[Amato et al., Apaydin et al., Singhal et al., Cortes et al.]

45

46

47
Connection Strategies
Which nodes to connect? Which shapes of local paths to use?
Limit the number of connections:• Nearest-neighbor strategy • Connected component strategy Large impact
Increase expansiveness:• Multiple fixed shapes of local path [Amato 98]
small impact• Local search strategy [Geraerts and Overmars, 2005, Isto 04]
uneven impact

48
Poor expansiveness is caused by narrow passages
But narrow passages do not necessarily imply poor expansiveness
Comments

49
Many narrow passages can lead to a more expansive F than a single one
Comments
50
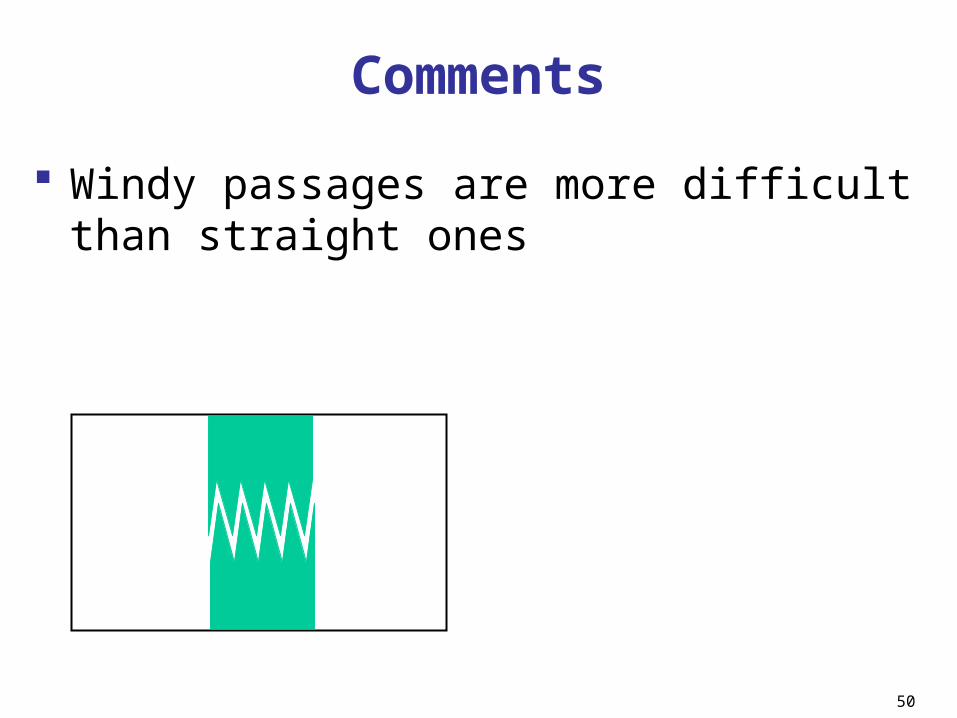
Windy passages are more difficult than straight ones
Comments

51
A convex free space is (1,1,1)-expansive
Comments

52
SBL SBL*
(a) 12295 9.4
(b) 5955 32
(c) 41 2.1
(d) 863 492
(e) 631 65
(f) >100000
13588
(a) (b) (c)
(d) (e)(f)
Alpha 1.0
Experimental Results with Free Space Dilatation
Time (s) [not including robot thinning]
Related Documents











