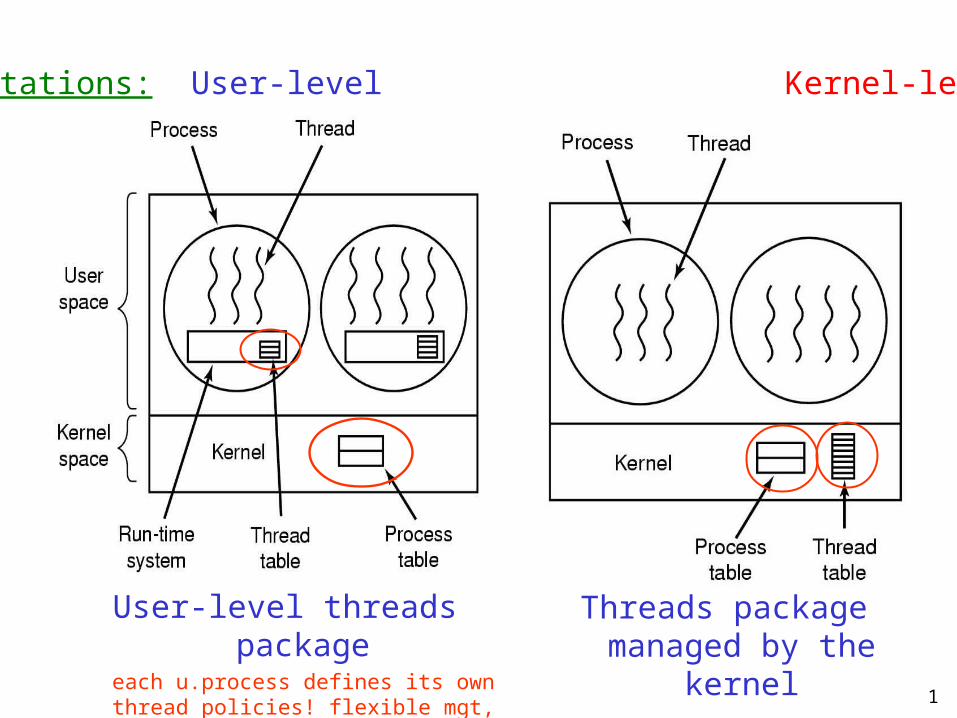
1 tations: User-level Kernel-lev User-level threads package each u.process defines its own thread policies! flexible mgt, Threads package managed by the kernel

1 Implementations: User-level Kernel-level User-level threads package each u.process defines its own thread policies! flexible mgt, scheduling etc…kernel.
Dec 22, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript
1
Implementations: User-level Kernel-level
User-level threads packageeach u.process defines its own thread policies!
flexible mgt, scheduling etc…kernel has NO knowledge no support for any problems
Threads package managed by the kernel

2
Resource Control: Processes Threads ?
• # of resources in a system: finite
• Traditional Unix (life was easy!)– single thread of control
– multiprogramming: 1 process actually executing
– non-preemptive processes
• Multi-threading, kernel/user spaces, networked systems…
How do we handle issues of resource constraints, ordering of processes/threads, precedence relations, access control for global parameters, shared memory and IPC such that the solutions are: fair, efficient, deadlock/race-free

Today: Critical Section (CS) aspects
• Race conditions• Mutual Exclusion (ME)
– Conditions to provide for ME– Solutions to the ME problem
• interrupts• locks• busy-waiting• TSL• semaphores

4
CS: Race Conditions, Mutual Exclusion
The code-segement where a shared resource is accessed (changing global variables, writing files etc) is called the Critical Section (CS)
1. If several processes access and modify shared data concurrently, the outcome can depend solely on the order of accesses (without pre-ordered control): Race Condition
2. [Generalization of the Race Conditions] In a situation involving shared memory, shared files, shared address spaces and IPC, how do we find ways of prohibiting more than 1 process from accessing shared data at the same time and providing ordered access? Mutual Exclusion (ME)

5
Race Condition: concurrent accesses to shared memory
next_file_to_print
next_free_slot
next print request
• A & B generate print jobs• To print a file, both A and B enter f.n to spooler directory
A (next_free_slot) 7 (reads “in”)A interrupted; B switches in (and then A comes back)
B reads in (7) A next_free_slot (7)B f.n slot 7 A f.n slot 7in = 7+1 = 8 in = 7+1 = 8
A prints, B stuck
6
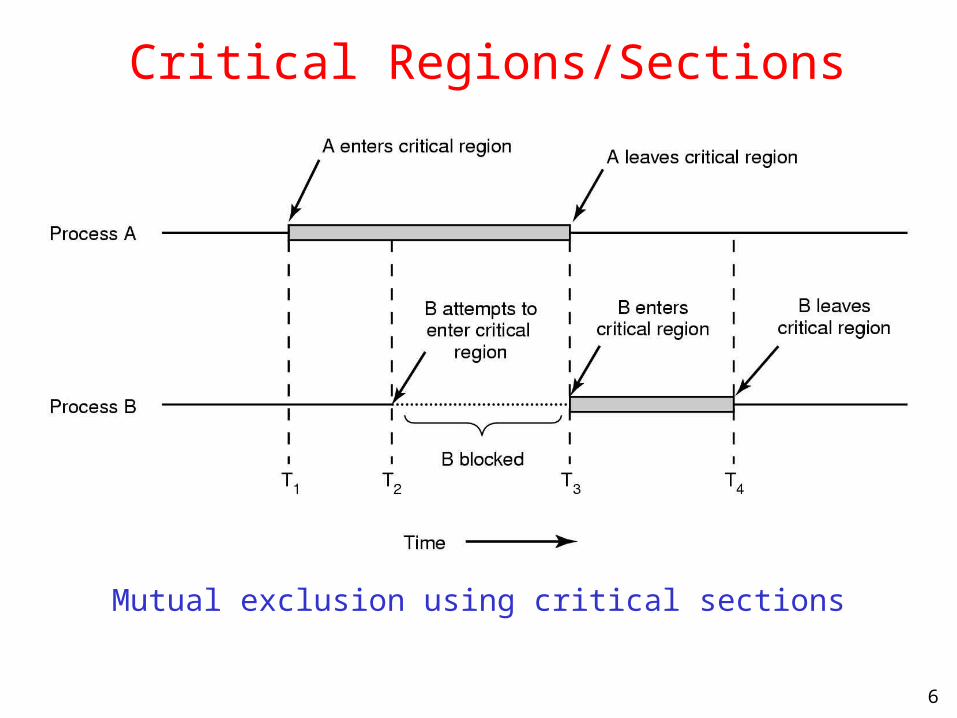
Critical Regions/Sections
Mutual exclusion using critical sections

7
Critical Sections & Mutual Exclusion
Four conditions need to hold to provide mutual exclusion
1. Unity: No two processes are simultaneously in the CS
2. Fairness: No assumptions can be made about speeds or numbers of CPUs except that each process executes at non-zero speed
3. Progress: No process running outside its CS may block another process (from accessing the CS)
4. Bounded Waiting: No process must wait forever to enter its CS

8
Potential ME Solutions: Interrupts• Interrupt Masking (Disable Interrupts)
– each interrupt has an “interrupt priority level” (ipl)
– for each executing process, kernel maintains “current ipl”
– incoming_interrupt > current_ipl handle interrupt, else wait
• For MEEnter CS
Current_ipl max_ipl ; disable interrupts
CS
Restore_ipl
Exit CS
Restore_ipl lost? Process hangs other processes blocked? - segregated kernel_ipl and user_ipl levels…
Multiprocessors: 1 CPU disabled, process from CPU 2 can come in… so how do we realize “ipl” across processors?

9
ME Using Locks for Access?
unlocked? acquire lock
enter CS
done release lock
do non-CS

10
ME: Lock Variables
• flag(lock) as global variable for access to shared section lock = 0 ; resource_free lock = 1 ; resource_in_use Unix flags: locked (0,1); wanted
• Check lock; if free (0); set lock to 1 and then access CS A reads lock(0); initiates set_to_1 B comes in before lock(1) finished; sees lock(0), sets lock(1) Both A and B have access rights race condition Happening as “locking” (the global var.) is not an atomic action

11
Process Alternation: ME with Busy Waiting
A sees turn=0; enters CS B sees turn=0; busy_waits (CPU waste)A exits CS, sets turn =1 B sees turn=1; enters CS
B finishes CS; sets turn=0; A enters CS; finishes CS quickly; sets turn=1; B in non-CS, A in non-CS; A finishes non-CS & wants CS; BUT turn=1 A waits (Condition 3 of ME? Process seeking CS should not be blocked by a process not using CS! But, no race condition given the strict alternation!)
Turn 0 Turn 1

12
Peterson’s Busy Waiting Sans Strict Alternation
Process 0: other = 1; interested[0] = TRUE; turn = 0; interested[1] = FALSE; P0 exits call and gets CSProcess 1: other = 0; interested[1] = TRUE; turn = 1; interested[0] = TRUE; loops
Step 1:
Step 2:
turn is “global”var; written by last requester
if both accesses come ~simultaneously?
shared var

13
Petersons ME (Alternate implementation)
• int turn; “turn” to enter CS
• boolean flag[2]; TRUE indicates ready (access) to enter CS
do {
flag[i] = TRUE;
turn = j ; set access for next_CS access
while (flag[j] && turn = = j); CS only if flag[j]=FALSE or turn = i
CS
flag[i] = FALSE;
non-CS
} while(TRUE);* Check that conditions of ME, Fairness, Progress, Bounded-Waiting hold!

14
Refresh: Race Conditions using Lock Variables
• flag(lock) as global variable for access to shared section lock = 0 ; resource_free lock = 1 ; resource_in_use Unix flags: locked (0,1); wanted
• Check lock; if free; set lock to 1 and then access CS A reads lock(0); initiates set_to_1 B comes in before lock(1) finished; sees lock(0), sets lock(1) Both A and B have access rights race condition Happening as “locking” (the global var.) is not an atomic action

15
• Is finer granularity & speed possible at the HW level? Provide “concurrency control” or “synchronizer” instructions Make “test & set lock” as an atomic (“uninterruptible op”)

16
ME with Busy Waiting: Atomic TSL
Entering and leaving CS using TSL (HW based – fast!!)
Works for multiple processors as well (unlike ipl)
< indivisible/atomic op >
global variable!
0 =‘s unlocked

17
• Busy Waiting Wasted CPU cycles (Busy-waiting locks Spin locks)
• Some spin lock problems: “The Priority Inversion Case”– 2 threads: H (high priority); L (low priority)…L not scheduled if H is there!
– H runs whenever “ready”
– L in CS; H gets “ready”; H busy-waits (~ running state for H)
– BUT: L is not scheduled anytime H is running; so L is stuck in CS (cannot exit) while H loops forever (waiting for L to get out).
– So does H really have high priority or is L over-riding it? Is ME condition 4: Bounded Waiting holding?
• Can we use “block” or “sleep” state than busy-waiting?

18
Sleep and Wakeup (Bounded Buffer PC, IPC)
… but can have a fatal race condition!!!
Shared fixed-size buffer- Producer puts info IN- Consumer takes info OUT
buffer_size = 1full = in_CSnull = non_CS- use wakeup callsto notify on CS state
P
C
full? sleep
1? wakeup call to C
0? sleep
N-1? wakeup call to P
19
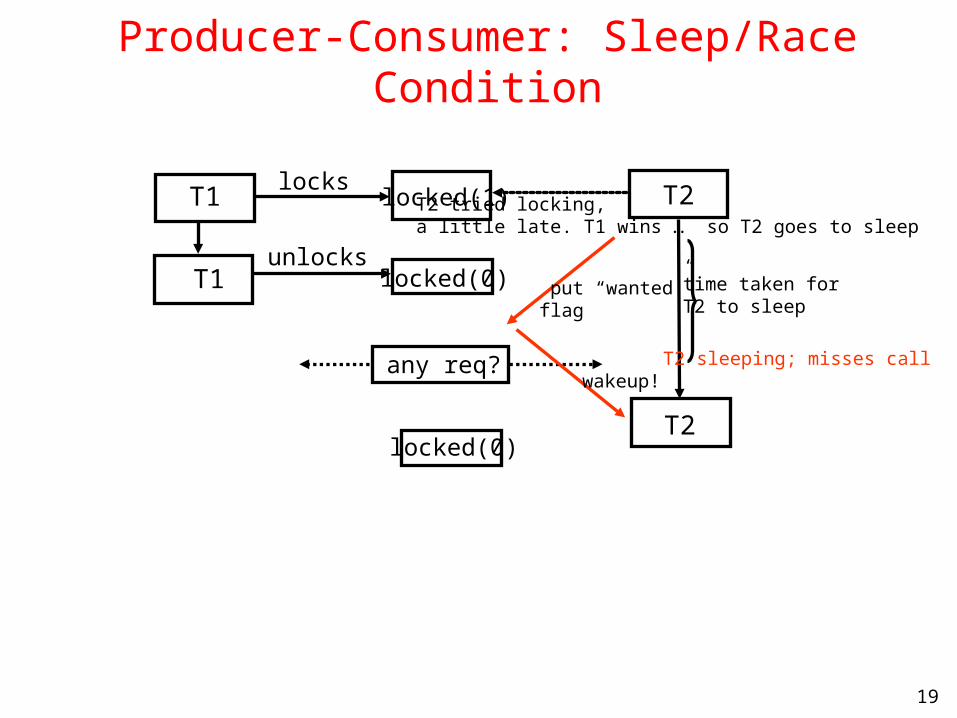
Producer-Consumer: Sleep/Race Condition
T1
T1
T2
T2
lockslocked(1)
unlockslocked(0)
any req?
locked(0)
T2 tried locking,a little late. T1 wins … so T2 goes to sleep
time taken forT2 to sleep
T2 sleeping; misses call
put “wanted”flag
wakeup!

20
Do Semaphores help?
• Do SW mechanisms exist for synchronization than HW TSL?• Semaphores (S): Integer Variables [System Calls]
– Accessible only through 2 standard atomic operations (i.e., operation must execute indivisibly) of:
• wait()• signal()
Wait(S) { ; sleep while S 0 ; // no-op S--; } Signal(S) { ; wakeup S++; }
S can be an integer resource counter;If S is binary, it is called a “mutex”
wait(0) block if 0wait(1) decrement & progress (DOWN)signal(0) increment and unblock (UP)

21
ME using Semaphores
do {
wait (mutex); ”mutex” variable initialized to 1
// critical section
signal (mutex);
// non critical section
} while (TRUE);
wait(0) block if 0wait(1) decrement & progress (DOWN)signal(0) increment and unblock (UP)
Related Documents











