1 CS/INFO 430 Information Retrieval Lecture 16 Metadata 3

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
CS/INFO 430Information Retrieval
Lecture 16
Metadata 3

2
Course Administration
Assignment 2 and Midterm Examinations
Grades were sent out by email yesterday.
Assignment 3
Will be posted tomorrow.

3
Theoretical Problems in Metadata: What to Catalog
The IFLA Model
Work A work is the underlying abstraction, e.g.,
• The Iliad
• The Computer Science departmental web site
• Beethoven's Fifth Symphony
• Unix operating system
• The 1996 U.S. census
This is roughly equivalent to the concept of "literary work" used in copyright law.

4
IFLA Model
Expression. A work is realized through an expression, e.g.,
• The Illiad has oral expressions and written expressions
• A musical work has score and performance(s).
• Software has source code and machine code
Many works have only a single expression, e.g. a Web page, or a book.

5
IFLA Model
Manifestation. A expression is given form in one or more manifestations, e.g.,
• The text of The Iliad has been manifest in numerous manuscripts and printed books.
• A musical performance can be distributed on CD, or broadcast on television.
• Software is manifest as files, which may be stored or transmitted in any digital medium.

6
IFLA Model
Item. When many copies are made of a manifestation, each is a separate item, e.g.,
• a specific copy of a book
• computer file
[Works, expressions, manifestations and items are explored in CS 431, Architecture of Web Information Systems.]

7
Theoretical Problems in Metadata: : Events
Version 1
New material
Version 2
Should Version 2 have its own record or should extra information be added to the Version 2 record?
How are these represented in Dublin Core or MARC?

8
Theoretical Problems in Metadata: : Complex Objects
Complex objects
• Article within a journal• Page within a Web site• A thumbnail of another image• The March 28 final edition of a newspaper
Complete object
Sub-objects
Metadata records

9
Theoretical Problems in Metadata: Packaging Rules
When an object consists of various parts, how should their interaction be described?
Example: An object on the Web may consist of several html pages with images, applets, etc.
Metadata Object Description Schema (MODS)http://www.loc.gov/standards/mods/
MPEG 21http://www.chiariglione.org/mpeg/standards/mpeg-21/mpeg-21.htm

10
MPEG 21

11
Theoretical Problems in Metadata: Flat v. linked records
Flat record
All information about an item is held in a single record (e.g., a Dublin Core record), including information about related items
convenient for access and preservation
information is repeated -- maintenance problem
Linked record
Related information is held in separate records with a link from the item record
less convenient for access and preservation
information is stored once
Compare with normal forms in relational databases
12

13
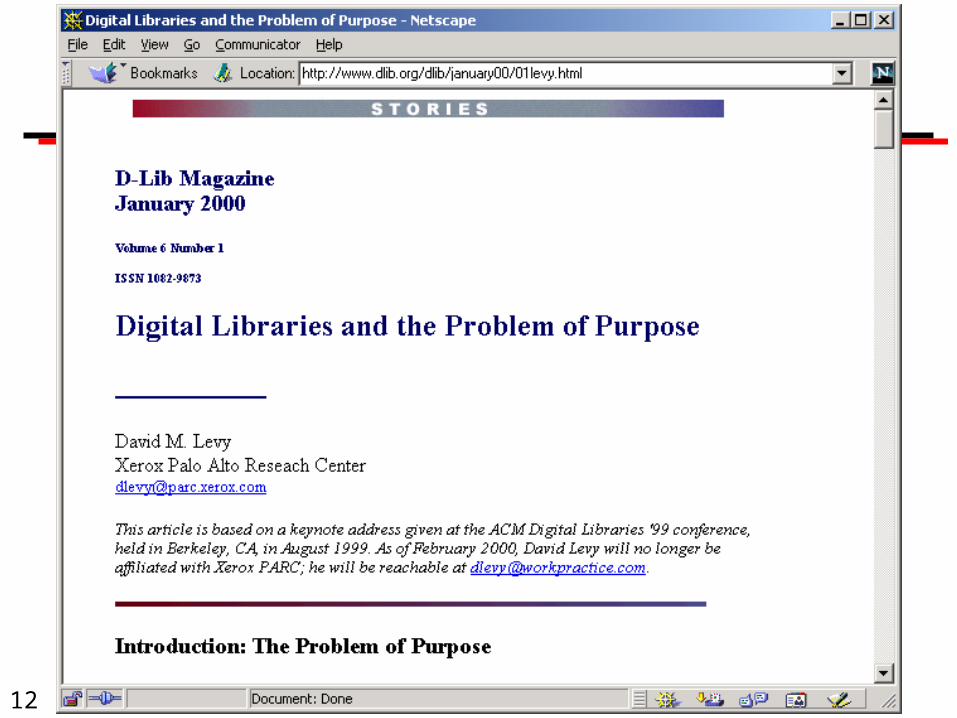
Representations of Dublin Core: XML (with qualifiers)
<title>Digital Libraries and the Problem of Purpose</title>
<creator>David M. Levy</creator>
<publisher>Corporation for National Research Initiatives</publisher>
<date date-type = "publication">January 2000</date>
<type resource-type = "work">article</type>
<identifier uri-type = "DOI">10.1045/january2000-levy</identifier>
<identifier uri-type = "URL">http://www.dlib.org/dlib/january00/01levy.html</identifier>
<language>English</language>
<rights>Copyright (c) David M. Levy</rights>to be continued

14
Dublin Core with flat record extension
Continuation of D-Lib Magazine record
<relation rel-type = "InSerial">
<serial-name>D-Lib Magazine</serial-name>
<issn>1082-9873</issn>
<volume>6</volume>
<issue>1</issue>
</relation>

15
Theoretical Problems in Metadata: Many Languages
See:
Thomas Baker, Languages for Dublin Core, D-Lib MagazineDecember 1998, http://www.dlib.org/dlib/december98/12baker.html

16
Automatic extraction of catalog data
Strategies
• Manual by trained cataloguers - high quality records, but expensive and time consuming
• Entirely automatic - fast, almost zero cost, but poor quality
• Automatic followed by human editing - cost and quality depend on the amount of editing
• Manual collection level record, automatic item level record - moderate quality, moderate cost

17
DC-dot
DC-dot is a Dublin Core metadata editor for Web pages, created by Andy Powell at UKOLN
http://www.ukoln.ac.uk/metadata/dcdot/
DC-dot has two parts:
(a) A skeleton Dublin Core record is created automatically from clues in the web page
(b) A user interface is provided for cataloguers to edit the record

18

19
Automatic record for CS 430 home page
DC-dot applied to http://www.cs.cornell.edu/courses/cs430/2001sp/
<link rel="schema.DC" href="http://purl.org/dc">
<meta name="DC.Title" content="CS 430: Information Discovery">
<meta name="DC.Subject" content="[email protected]; Course Structure; Readings and references; Slides; Basic Information; William Y. Arms; Information Retrieval Data Structures and Algorithms; [email protected]; Assignments; Syllabus; Text Book; Laptop computers; Assumed Background; Nomadic Computing Experiment; Notices; Course Description; Code of practice; Assignments and Grading; Last changed: February 6, 2001">
continued on next slide

20
Automatic record for CS 430 home page (continued)
DC-dot applied to http://www.cs.cornell.edu/courses/cs430/2001sp/
<meta name="DC.Publisher" content="Cornell University">
<meta name="DC.Date" scheme="W3CDTF" content="2001-02-07">
<meta name="DC.Type" scheme="DCMIType" content="Text">
<meta name="DC.Format" content="text/html">
<meta name="DC.Format" content="5781 bytes">
<meta name="DC.Identifier" content="http://www.cs.cornell.edu/courses/cs430/2001sp/">

21
Observations on DC-dot applied to CS430 home page
DC.Title is a copy of the html <title> field
DC.Publisher is the owner of the IP address where the page was stored
DC.Subject is a list of headings and noun phrases presented for editing
DC.Date is taken from the Last-Modified field in the http header
DC.Type and DC.Format are taken from the MIME type of the http response
DC.Identifier was supplied by the user as input

22

23
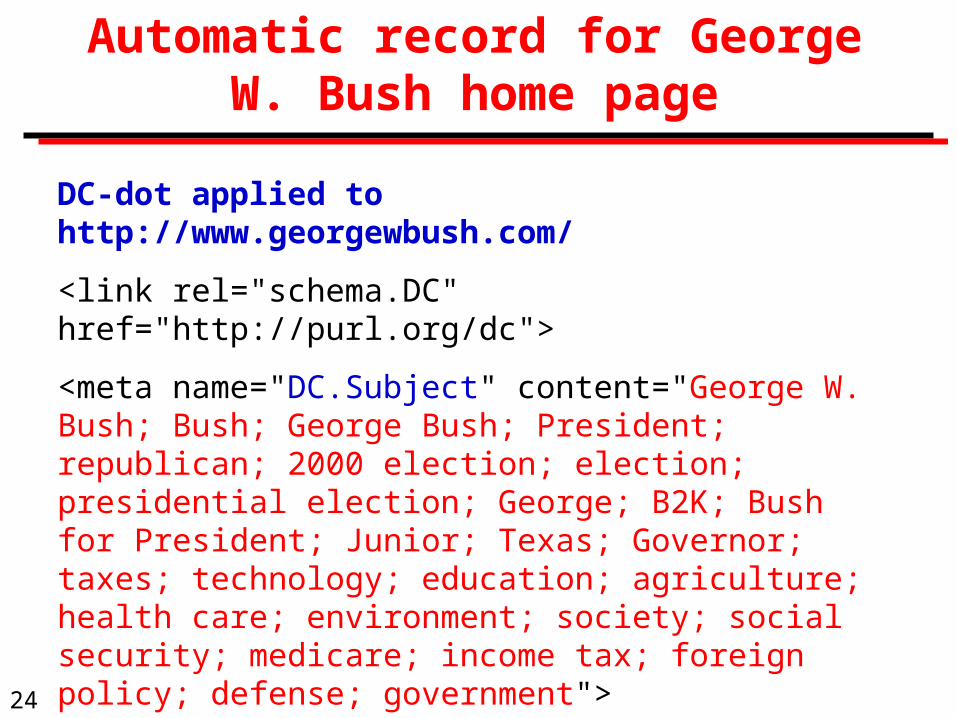
Observations on DC-dot applied to George W. Bush home page
The home page has several meta tags:
<META NAME="TITLE" CONTENT="George W. Bush for President"> [The page has no html <title>]
<META NAME="CONTACT" CONTENT="George W Bush Campaign, P. O. Box 1902, Austin, TX 78767, Phone: (512) 637-2000">
<META NAME="DESCRIPTION" CONTENT="George W. Bush is running for President of the United States to keep the country prosperous.">
<META NAME="KEYWORDS" CONTENT="George W. Bush, Bush, George Bush, President, republican, 2000 election and more
24
DC-dot applied to http://www.georgewbush.com/
<link rel="schema.DC" href="http://purl.org/dc">
<meta name="DC.Subject" content="George W. Bush; Bush; George Bush; President; republican; 2000 election; election; presidential election; George; B2K; Bush for President; Junior; Texas; Governor; taxes; technology; education; agriculture; health care; environment; society; social security; medicare; income tax; foreign policy; defense; government">
<meta name="DC.Description" content="George W. Bush is running for President of the United States to keep the country prosperous.">
continued on next slide
Automatic record for George W. Bush home page

25
DC-dot applied to http://www.georgewbush.com/
<meta name="DC.Publisher" content="Concentric Network Corporation">
<meta name="DC.Date" scheme="W3CDTF" content="2001-01-12">
<meta name="DC.Type" scheme="DCMIType" content="Text">
<meta name="DC.Format" content="text/html">
<meta name="DC.Format" content="12223 bytes">
<meta name="DC.Identifier" content="http://www.georgewbush.com/">
Automatic record for George W. Bush home page (continued)

26
Collection-level metadata
Several of the most difficult fields to extract automatically are the same across all pages in a web site.
Therefore create a collection record manually and combine it with automatic extraction of other fields at item level.
See: Jenkins and Inman

27
Collection-level metadata
Compare:
(a) Metadata extracted automatically by DC-dot
(b) Collection-level record
(c) Combined item-level record (DC-dot plus collection-level)
(d) Manual record

28

29
Metadata extracted automatically by DC-dot
D.C. Field Qualifier Content
title Digital Libraries and the Problem of Purpose
subject not included in this slide
publisher Corporation for National Research Initiatives
date W3CDTF 2000-05-11
type DCMIType Text
format text/html
format 27718 bytes
identifier http://www.dlib.org/dlib/january00/01levy.html

30
Collection-level record
D.C. Field Qualifier Content
publisher Corporation for National Research Initiatives
type article
type resource work
relation rel-type InSerial
relation serial-name D-Lib Magazine
relation issn 1082-9873
language English
rights Permission is hereby given for the material in D-Lib Magazine to be used for ...

31
Combined item-level record (DC-dot plus collection-level)
D.C. Field Qualifier Content
title Digital Libraries and the Problem of Purpose
publisher (*) Corporation for National Research Initiatives
date W3CDTF 2000-05-11
type (*) article
type resource (*) work
type DCMIType Text
format text/html
format 27718 bytes
(*) indicates collection-level metadata
continued on next slide

32
Combined item-level record (DC-dot plus collection-level)
D.C. Field Qualifier Content
relation rel-type (*) InSerial
relation serial-name (*) D-Lib Magazine
relation issn (*) 1082-9873
language (*) English
rights (*) Permission is hereby given for the material in D-Lib Magazine to be used for ...
identifier http://www.dlib.org/dlib/january00/01levy.html
(*) indicates collection-level metadata

33
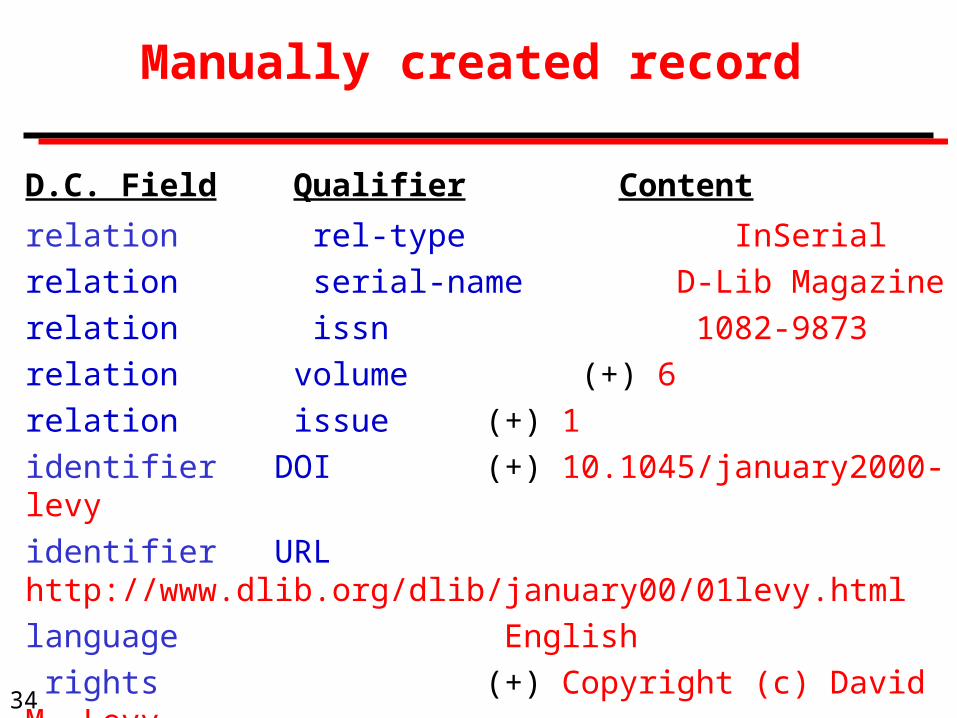
Manually created record
D.C. Field Qualifier Content
title Digital Libraries and the Problem of Purpose
creator (+) David M. Levy
publisher Corporation for National Research Initiatives
date publication January 2000
type article
type resource work
(+) entry that is not in the automatically generated records
continued on next slide
34
Manually created record
D.C. Field Qualifier Content
relation rel-type InSerial
relation serial-name D-Lib Magazine
relation issn 1082-9873
relation volume (+) 6
relation issue (+) 1
identifier DOI (+) 10.1045/january2000-levy
identifier URL http://www.dlib.org/dlib/january00/01levy.html
language English
rights (+) Copyright (c) David M. Levy
(+) entry that is not in the automatically generated records

35
Search Engine Spam
D-Lib Magazine
Web pages created for user, with good quality control and no attempt to impress search engines. (The editor originally trained as a librarian.)
The site lends itself to automatic indexing.
Political Web Sites (Bush and Gore)
Web pages created for marketing, with little consistency, designed to impress search engines. (The editors are specialists in public relations.)
The sites are difficult to index automatically.

36
Metatest
Metatest is a research project led by Liz Liddy at Syracuse with participation from the Human Computer Interaction group at Cornell.
The aim is to compare the effectiveness as perceived by the user of indexing based on:
(a) Manually created Dublin Core
(b) Automatically created Dublin Core (higher quality than DC-dot)
(c) Full text indexing
Preliminary results suggest remarkably little difference in effectiveness.
37
Why is Dublin Core not used to Index and Search the Web?
Technology: The methods used in early Infoseek, Lycos and Altavista have been greatly enhanced.
(Note that these methods provide quite good precision at the expense of low recall.)
Users: The typical user who searches the Web has limited training and does not understand catalogs.
Economics: The size of the Web makes human indexing of every important site impossible. The rate of change requires frequent re-indexing.

38
Why is Dublin Core not used to Index and Search the Web?
For Web pages, information retrieval by automatic indexing works of full text works at least as well as metadata based methods, and is much, much cheaper.
However, we will see later an effective example of automated extraction of metadata from video sequences (Informedia).
Related Documents











