1 CS 430: Information Discovery Lecture 6 Data Structures for Information Retrieval

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
CS 430: Information Discovery
Lecture 6
Data Structures for Information Retrieval

2
Course Administration
• Course news group
cornell.courses.cs430
• Sending messages to [email protected]
The Teaching Assistants should not do your work for you.
Before sending them a question, check the slides and the text book.
The assignments leave several decisions to your judgment. Make your own decisions and record them in your report.
3
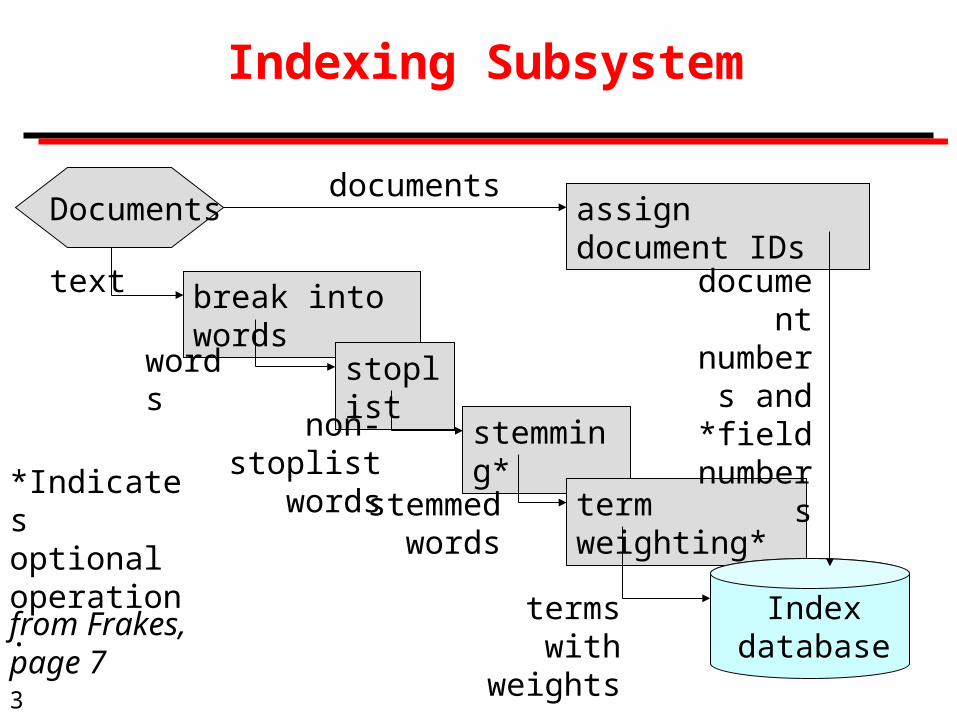
Indexing Subsystem
Documents
break into words
stoplist
stemming*
term weighting*
Index database
text
non-stoplist words
words
stemmed words
terms with weights
*Indicates optional operation.
from Frakes, page 7
assign document IDsdocuments
document numbers
and *field numbers

4
Organization of Inverted Files
Term Pointer topostings
ant
bee
cat
dog
elk
fox
gnu
hog
Inverted lists
Index file Postings file Documents file

5
Documents File for Web Search System
Indexes are built using a web crawler, which retrieves each page on the web (or a subset). After indexing each page is discarded, unless stored in a cache. In addition to the usual index file (word list) and postings files the indexing system stores:
1. List of URLs of pages indexed.
This list is used instead of the documents file.
2. Short abstract of each page (optional).
Used to describe the page when lists of hits returned to user.
3. For each page, list of URLs of pages it links to.
This data structure is used for reference pattern ranking, either static (e.g., PageRank), or dynamic.

6
Index File Structures: Linear Index
Advantages
Can be searched quickly, e.g., by binary search, O(log n)
Good for sequential processing, e.g., comp*
Convenient for batch updating
Economical use of storage
Disadvantages
Index must be rebuilt if an extra term is added

7
Index File Structures: Binary Tree
elk
bee hog
cat
dog
foxant
gnu
Input: elk, hog, bee, fox, cat, gnu, ant, dog

8
Binary Tree
Advantages
Can be searched quickly
Convenient for batch updating
Easy to add an extra term
Economical use of storage
Disadvantages
Poor for sequential processing, e.g., comp*
Tree tends to become unbalanced
If the index is held on disk, important to optimize the number of disk accesses

9
Binary Tree
Calculation of maximum depth of tree.
Illustrates importance of balanced trees.
Worst case: depth = n
O(n)
Ideal case: depth = log(n + 1)/log 2
O(log n)

10
Right Threaded Binary Tree
Threaded tree:
A binary search tree in which each node uses an otherwise-empty left child link to refer to the node's in-order predecessor and an empty right child link to refer to its in-order successor.
Right-threaded tree:
A variant of a threaded tree in which only the right thread, i.e. link to the successor, of each node is maintained.
Knuth vol 1, 2.3.1, page 325.
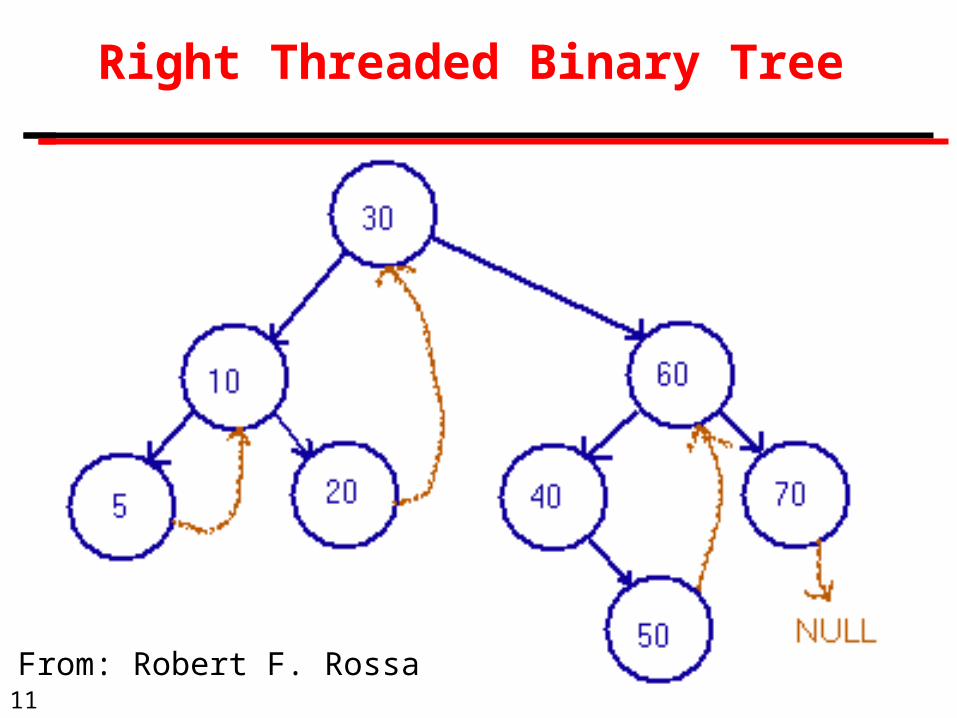
11
Right Threaded Binary Tree
From: Robert F. Rossa

12
B-trees
B-tree of order m:
A balanced, multiway search tree:
• Each node stores many keys
• Root has between 2 and 2m keys. All other internal nodes have between m and 2m keys.
• If ki is the ith key in a given internal node
-> all keys in the (i-1)th child are smaller than ki
-> all keys in the ith child are bigger than ki
• All leaves are at the same depth

13
B-trees
B-tree example (order 2)
50 65
10 19 35 55 59 70 90 98
1 5 8 9
12 14 18
36 47 66 68
72 73
91 95 97
Every arrow points to a node containing between 2 and 4 keys.A node with k keys has k + 1 pointers.
21 24 28
14
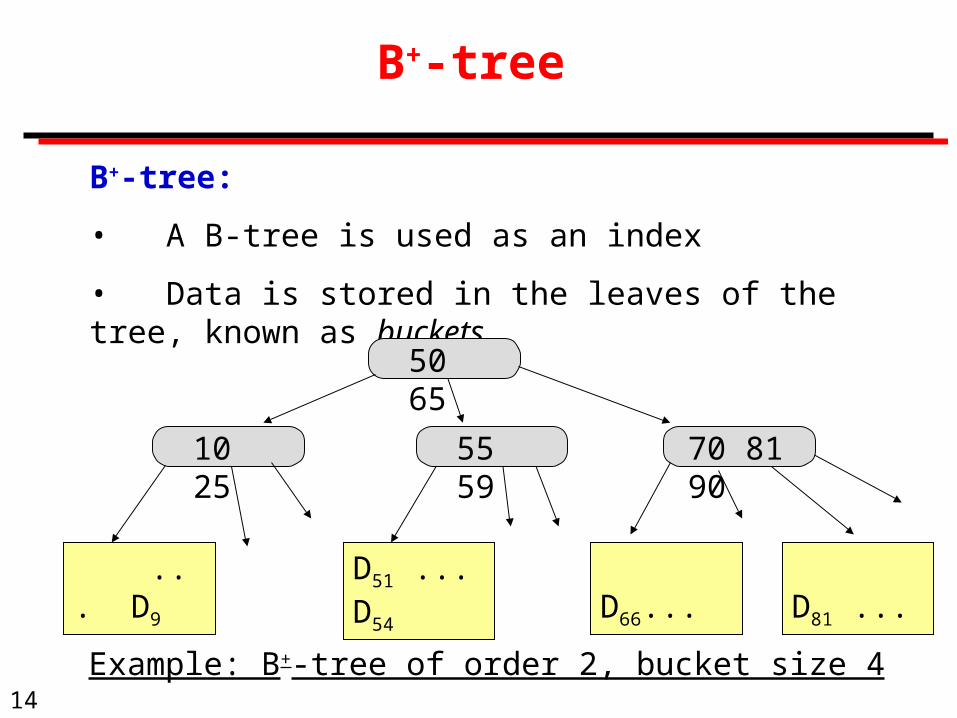
B+-tree
B+-tree:
• A B-tree is used as an index
• Data is stored in the leaves of the tree, known as buckets
50 65
10 25 55 59 70 81 90
... D9 D51 ... D54 D66... D81 ...
Example: B+-tree of order 2, bucket size 4

15
B-tree Discussion
For a discussion of B-trees, see Frake, Section 2.3.1, pages 18-20.
• B-trees combine fast retrieval with moderately efficient updating.
• Bottom-up updating is usual fast, but may require recursive tree climbing to the root.
• The main weakness is poor storage utilization; typically buckets are only 0.69 full.
• Various algorithmic improvements increase storage utilization at the expense of updating performance.

16
Signature Files: Sequential Search without Inverted File
Inexact filter: A quick test which discards many of the non-qualifying items.
Advantages
• Much faster than full text scanning -- 1 or 2 orders of magnitude• Modest space overhead -- 10% to 15% of file• Insertion is straightforward
Disadvantages
• Sequential searching no good for very large files• Some hits are false hits

17
Signature Files
Signature size. Number of bits in a signature, F.
Word signature. A bit pattern of size F with m bits set to 1 and the others 0.
The word signature is calculated by a hash function.
Block. A sequence of text that contains D distinct words.
Block signature. The logical OR of all the word signatures in a block of text.

18
Signature Files
Example
Word Signature
free 001 000 110 010text 000 010 101 001
block signature 001 010 111 011
F = 12 bits in a signature
m = 4 bits per word
D = 2 words per block

19
Signature Files
A query term is processed by matching its signature against the block signature.
(a) If the term is in the block, its word signature will always match the block signature.
(b) A word signature may match the block signature, but the word is not in the block. This is a false hit.
The design challenge is to minimize the false drop probability, Fd .
Frake, Section 4.2, page 47 discussed how to minimize Fd. The rest of this chapter discusses enhancements to the basic algorithm.

20
Search for Substring
In some information retrieval applications, any substring can be a search term.
Tries, implemented using suffix trees, provide lexicographical indexes for all the substrings in a document or set of documents.

21
Tries: Search for Substring
Basic concept
The text is divided into unique semi-infinite strings, or sistrings. Each sistring has a starting position in the text, and continues to the right until it is unique.
The sistrings are stored in (the leaves of) a tree, the suffix tree. Common parts are stored only once.
Each sistring can be associated with a location within a document where the sistring occurs. Subtrees below a certain node represent all occurrences of the substring represented by that node.
Suffix trees have a size of the same order of magnitude as the input documents.

22
Tries: Suffix Tree
Example: suffix tree for the following words:
begin beginning between bread break
b
e rea
gin tween d k
_ ning

23
Tries: Sistrings
A binary example
String: 01 100 100 010 111
Sistrings: 1 01 100 100 010 1112 11 001 000 101 113 10 010 001 011 14 00 100 010 1115 01 000 101 11
6 10 001 011 17 00 010 1118 00 101 11

24
Tries: Lexical Ordering
7 00 010 1114 00 100 010 1118 00 101 115 01 000 101 111 01 100 100 010 111
6 10 001 011 13 10 010 001 011 12 11 001 000 101 11
Unique string indicated in blue
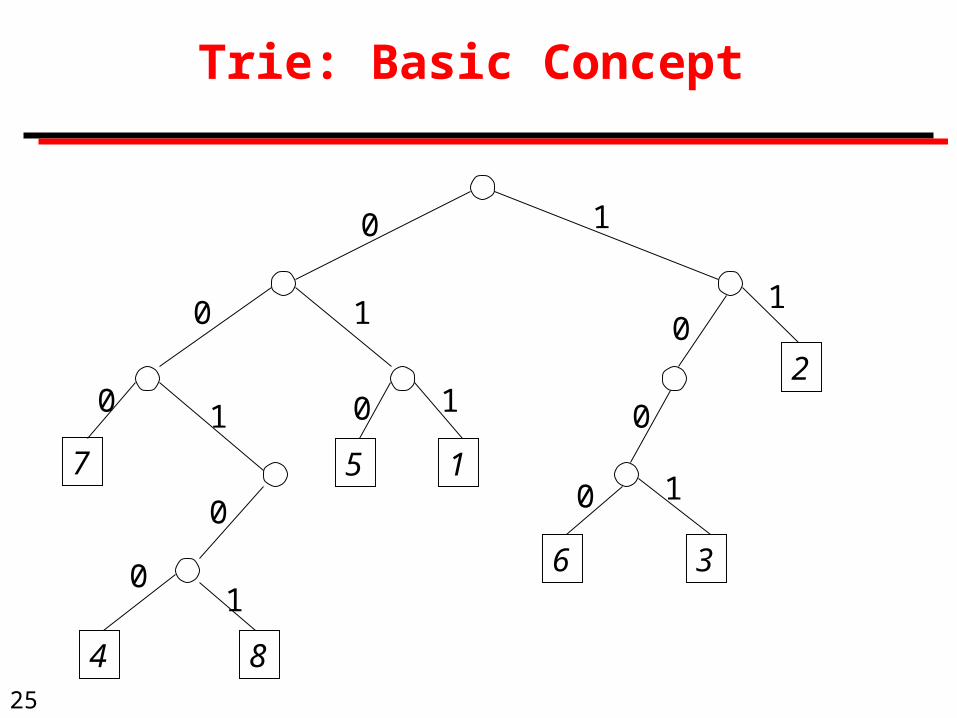
25
Trie: Basic Concept
7
4 8
5 1
2
6 3
0
0
0
0
0
0
0
0
0
1
1
1
11
1
1
26
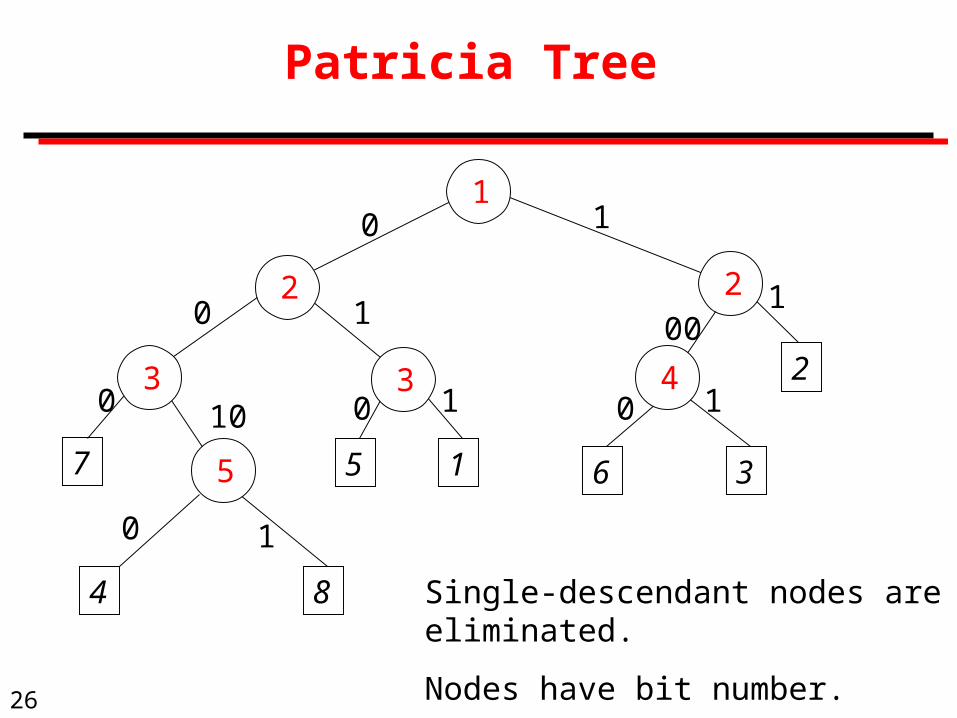
Patricia Tree
7
4 8
5 1
2
6 3
0
0
0
00
0
0
0
1
1
1
110 1
1
1
2 2
3 3 4
5
Single-descendant nodes are eliminated.
Nodes have bit number.

27
Oxford English Dictionary
Related Documents











