1 Crawling the Web Crawling the Web Discovery and Maintenance Discovery and Maintenance of of Large-Scale Web Data Large-Scale Web Data Junghoo Cho Junghoo Cho Stanford University Stanford University

1 Crawling the Web Discovery and Maintenance of Large-Scale Web Data Junghoo Cho Stanford University.
Dec 22, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Crawling the WebCrawling the Web
Discovery and Maintenance of Discovery and Maintenance of
Large-Scale Web DataLarge-Scale Web Data
Junghoo ChoJunghoo Cho
Stanford UniversityStanford University

2
What is a Crawler?What is a Crawler?
web
init
get next url
get page
extract urls
initial urls
to visit urls
visited urls
web pages

3
ApplicationsApplications
Internet Search EnginesInternet Search Engines– Google, AltaVistaGoogle, AltaVista
Comparison Shopping ServicesComparison Shopping Services– My Simon, BizRateMy Simon, BizRate
Data miningData mining– Stanford Web Base, IBM Web FountainStanford Web Base, IBM Web Fountain

4
WebBase CrawlerWebBase Crawler
Web Base ProjectWeb Base Project BackRub Crawler, PageRankBackRub Crawler, PageRank GoogleGoogle New Web Base CrawlerNew Web Base Crawler
– 20,000 lines in C/C++20,000 lines in C/C++– 130M pages collected130M pages collected

5
Crawling Issues (1)Crawling Issues (1)
Load at visited web sitesLoad at visited web sites– Space out requests to a siteSpace out requests to a site– Limit number of requests to a site per dayLimit number of requests to a site per day– Limit depth of crawlLimit depth of crawl
6
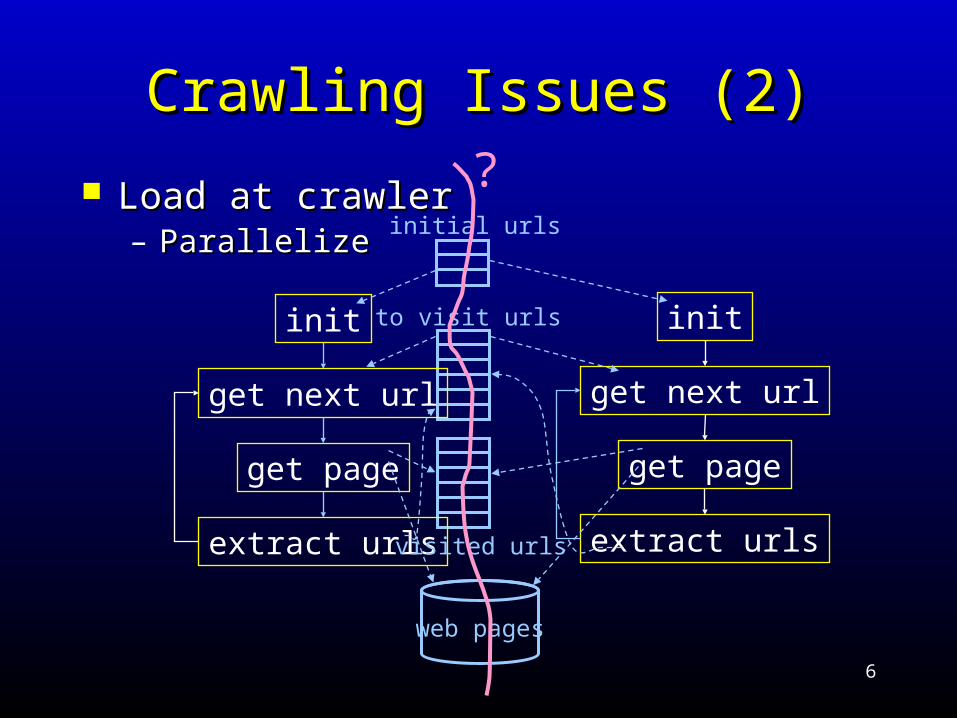
Crawling Issues (2)Crawling Issues (2)
Load at crawlerLoad at crawler– ParallelizeParallelize
init
get next url
get page
extract urls
initial urls
to visit urls
visited urls
web pages
init
get next url
get page
extract urls
?

7
Crawling Issues (3)Crawling Issues (3)
Scope of crawlScope of crawl– Not enough space for “all” pagesNot enough space for “all” pages– Not enough time to visit “all” pagesNot enough time to visit “all” pages
Solution: Visit “important” pages
visitedpages
Intel
Intel

8
Crawling Issues (4)Crawling Issues (4)
ReplicationReplication– Pages mirrored at multiple locationsPages mirrored at multiple locations

9
Crawling Issues (5)Crawling Issues (5)
Incremental crawlingIncremental crawling– How do we avoid crawling from scratch?How do we avoid crawling from scratch?– How do we keep pages “fresh”?How do we keep pages “fresh”?

10
Summary of My ResearchSummary of My Research
Load on sites [PAWS00]Load on sites [PAWS00] Parallel crawler [Tech Report 01]Parallel crawler [Tech Report 01] Page selection [WWW7]Page selection [WWW7] Replicated page detection [SIGMOD00]Replicated page detection [SIGMOD00] Page freshness [SIGMOD00]Page freshness [SIGMOD00] Crawler architecture [VLDB00]Crawler architecture [VLDB00]

11
Outline of This TalkOutline of This Talk
How can we maintain pages fresh?How can we maintain pages fresh? How does the Web change?How does the Web change? What do we mean by “fresh” pages?What do we mean by “fresh” pages? How should we refresh pages?How should we refresh pages?

12
Web Evolution ExperimentWeb Evolution Experiment
How often does a Web page change?How often does a Web page change? How long does a page stay on the Web?How long does a page stay on the Web? How long does it take for 50% of the Web How long does it take for 50% of the Web
to change?to change? How do we model Web changes?How do we model Web changes?

13
Experimental SetupExperimental Setup
February 17 to June 24, 1999February 17 to June 24, 1999 270 sites visited (with permission)270 sites visited (with permission)
– identified 400 sites with highest “PageRank”identified 400 sites with highest “PageRank”– contacted administratorscontacted administrators
720,000 pages collected720,000 pages collected– 3,000 pages from each site daily3,000 pages from each site daily– start at root, visit breadth first (get new & old pages)start at root, visit breadth first (get new & old pages)– ran only 9pm - 6am, 10 seconds between site requestsran only 9pm - 6am, 10 seconds between site requests

14
Average Change IntervalAverage Change Intervalfr
actio
n of
pag
es
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
1day 1day- 1week
1week-1month
1month-4months
4months
average change interval

15
Change Interval – By DomainChange Interval – By Domainfr
actio
n of
pag
es
0
0.1
0.2
0.3
0.4
0.5
0.6
1day 1day- 1week
1week-1month
1month-4months
4months
com
netorg
edu
gov
average change interval

16
Modeling Web EvolutionModeling Web Evolution
Poisson process with rate Poisson process with rate T is time to next eventT is time to next event ffTT ((tt) = ) = ee--
tt ( (tt > 0) > 0)

17
Change Interval of PagesChange Interval of Pagesfor pages thatchange every
10 days on average
interval in days
frac
tion
of c
hang
esw
ith g
iven
inte
rval
Poisson model

18
Change MetricsChange Metrics
FreshnessFreshness– Freshness of element Freshness of element eeii at time at time tt is is
F F ( ( eeii ; ; tt ) = 1 if ) = 1 if eeii is up-to-date at time is up-to-date at time tt 0 otherwise 0 otherwise
eiei
......
web databaseFreshness of the database S at time t is
F( S ; t ) = F( ei ; t )
(Assume “equal importance” of pages)
N
1 N
i=1

19
Change MetricsChange Metrics
AgeAge– Age of element Age of element eeii at time at time tt is is
A A( ( eeii ; ; tt ) = 0 if ) = 0 if eeii is up-to-date at time is up-to-date at time tt tt - (modification - (modification eei i time) otherwisetime) otherwise
eiei
......
web databaseAge of the database S at time t is
A( S ; t ) = A( ei ; t )
(Assume “equal importance” of pages)
N
1 N
i=1
20
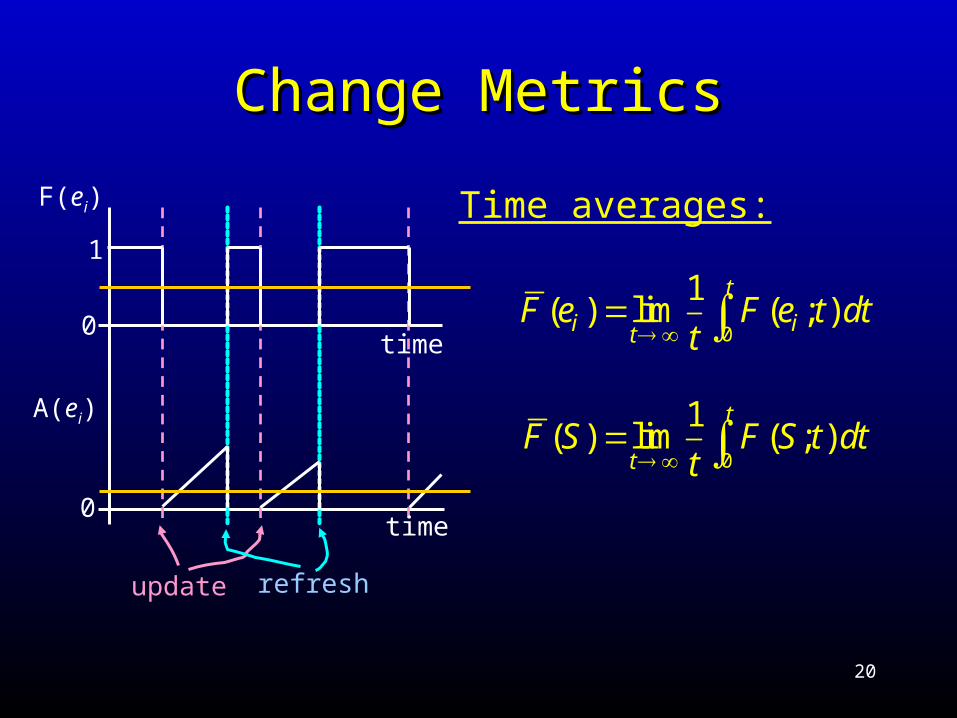
Change MetricsChange Metrics
F(ei)
A(ei)
0
0
1
time
time
update refresh
Time averages:
0
1( ) lim ( ; )
t
i itF e F e t dt
t
0
1( ) lim ( ; )
t
tF S F S t dt
t

21
Refresh OrderRefresh Order
Fixed orderFixed order– Explicit list of URLs to visitExplicit list of URLs to visit
Random orderRandom order– Start from seed URLs & follow linksStart from seed URLs & follow links
Purely randomPurely random– Refresh pages on demand, Refresh pages on demand, as requested by useras requested by user
eiei
......
webdatabase

22
Freshness vs. Revisit FrequencyFreshness vs. Revisit Frequency
r = / f = average change frequency / average visit frequency

23
Age vs. Revisit FrequencyAge vs. Revisit Frequency
r = / f = average change frequency / average visit frequency
= Age / time to refresh all N elements

24
Trick QuestionTrick Question
Two page databaseTwo page database e1 changes dailychanges daily e2 changes once a weekchanges once a week Can visit one page per weekCan visit one page per week How should we visit pages?How should we visit pages?
– e1 e2 e1 e2 e1 e2 e1 e2... ... [uniform] [uniform]
– e1 e1 e1 e1 e1 e1 e1 e2 e1 e1 … … [proportional][proportional]
– e1 e1 e1 e1 e1 e1 ... ...
– e2 e2 e2 e2 e2 e2 ... ...
– ??
e1
e2
e1
e2
webdatabase

25
Proportional Often Not Good!Proportional Often Not Good!
Visit fast changing Visit fast changing e1
get 1/2 day of freshnessget 1/2 day of freshness
Visit slow changing Visit slow changing e2
get 1/2 week of freshnessget 1/2 week of freshness
Visiting Visiting e2 is a better deal!is a better deal!

26
Optimal Refresh FrequencyOptimal Refresh Frequency
ProblemProblem
Given and Given and f ,f ,
findfind
that maximizethat maximize
1 2, , ..., N
1 21
, ,... , /N
N
ii
f f f f f N
1
1( ) ( )
N
ii
F S F eN

27
SolutionSolution
Compute Compute
Lagrange multiplier methodLagrange multiplier method
AllAll
( )iF e
1 /
0
1
0
1 1( ) ( ; )lim
/
ii ff
n
i in j i i
j eF e f F e t dt
n f f
/ /( , )( ) 1i i i if fi i
i i i i
F fF S e e
f f f
/ /1
( , ) pairs should satisfy f f
i ie e
ff

28
Optimal Refresh FrequencyOptimal Refresh Frequency
• Shape of curve is the same in all cases• Holds for any change frequency distribution

29
Optimal Refresh for AgeOptimal Refresh for Age
• Shape of curve is the same in all cases• Holds for any change frequency distribution

30
Comparing PoliciesComparing Policies
Freshness AgeProportional 0.12 400 days
Uniform 0.57 5.6 daysOptimal 0.62 4.3 days
Based on Statistics from experimentand revisit frequency of every month

31
Topics to FollowTopics to Follow
Weighted FreshnessWeighted Freshness Non-Poisson ModelNon-Poisson Model Change Frequency EstimationChange Frequency Estimation

32
Not Every Page is Equal!Not Every Page is Equal!
1 211
( ) ( ) (2 )3
F S F e F e
In general,1 1
( ) ( )N N
i i ii i
F S w F e w
e1
e2 Accessed by users 20 times/day
Accessed by users 10 times/day
Some pages are “more important”Some pages are “more important”

33
Weighted FreshnessWeighted Freshness
w = 1
w = 2
f

34
Non-Poisson ModelNon-Poisson Model
interval in days
frac
tion
of c
hang
esw
ith g
iven
inte
rval
Poisson model
Heavy-tail distribution 2(1 )t

35
Optimal Revisit FrequencyOptimal Revisit Frequencyfor Heavy-Tail Distributionfor Heavy-Tail Distribution f

36
Principle of Diminishing ReturnPrinciple of Diminishing Return
TT: time to next change: time to next change : continuous, differentiable: continuous, differentiable Every page changesEvery page changes
Definition of change rate Definition of change rate
Pr( | )T t
Pr( 0 | ) 1 and Pr( | ) 0limt
T T t
Pr( | ) Pr( | )T t k T kt
0lim f

37
Change Frequency EstimationChange Frequency Estimation
How to estimate change frequency?How to estimate change frequency?– Naïve Estimator: Naïve Estimator: XX//TT
– XX: number of detected changes: number of detected changes
– TT: monitoring period: monitoring period
– 2 changes in 10 days: 0.2 times/day2 changes in 10 days: 0.2 times/day
Change detected1 day
Page visitedPage changed
Incomplete change historyIncomplete change history

38
Improved EstimatorImproved Estimator
Based on the Poisson modelBased on the Poisson model
– XX: number of detected changes: number of detected changes– NN: number of accesses: number of accesses– f f : access frequency: access frequency
2log
1
Nf
N X
3 changes in 10 days: 0.36 times/day Accounts for “missed” changes

39
Improved EstimatorImproved Estimator
BiasBias
EfficiencyEfficiency
ConsistencyConsistency
0
2ˆ[ ] log 1
1
N iN ir r
i
NNE r e e
iN i
0
22
ˆ[ ] log 11
N iN ir r
i
NNVar r e e
iN i
0
22
log 11
N iN ir r
i
NNe e
iN i
ˆ ˆE[ ] Var[ ] 0lim limn n
r r r

40
Improvement Significant?Improvement Significant?
Application to a Web crawlerApplication to a Web crawler– Visit pages once every week for 5 weeksVisit pages once every week for 5 weeks– Estimate change frequency Estimate change frequency – Adjust revisit frequency based on the estimateAdjust revisit frequency based on the estimate
» Uniform: do not adjustUniform: do not adjust
» Naïve: based on the naïve estimatorNaïve: based on the naïve estimator
» Ours: based on our improved estimatorOurs: based on our improved estimator

41
Improvement from Our EstimatorImprovement from Our Estimator
Detected changesDetected changes Ratio to uniformRatio to uniform
UniformUniform 2,147,5892,147,589 100%100%
NaïveNaïve 4,145,5824,145,582 193%193%
OursOurs 4,892,1164,892,116 228%228%
(9,200,000 visits in total)

42
Other EstimatorsOther Estimators
Irregular access intervalIrregular access interval Last-modified dateLast-modified date CategorizationCategorization

43
SummarySummary
Web evolution experimentWeb evolution experiment Change metricChange metric Refresh policyRefresh policy Frequency estimatorFrequency estimator

44
ContributionContribution
Freshness [SIGMOD00]Freshness [SIGMOD00] Page selection [WWW7]Page selection [WWW7] Replicated page detection [SIGMOD00]Replicated page detection [SIGMOD00] Load on sites [PAWS00]Load on sites [PAWS00] Parallel crawler [Tech Report 01]Parallel crawler [Tech Report 01] Crawler architecture [VLDB00]Crawler architecture [VLDB00]

45
The EndThe End
Thank you for your attentionThank you for your attention For more information visitFor more information visit
http://www-db.stanford.edu/~cho/http://www-db.stanford.edu/~cho/
Related Documents











