Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching 1 Advanced databases – Core ideas of federated databases; Schema and ontology matching Bettina Berendt Katholieke Universiteit Leuven, Department of Computer Science http://www.cs.kuleuven.ac.be/~berendt/teaching/2011-12- 1stsemester/adb/ ast update: 18 October 2011

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
1
Advanced databases –
Core ideas of federated databases; Schema and ontology matching
Bettina Berendt
Katholieke Universiteit Leuven, Department of Computer Science
http://www.cs.kuleuven.ac.be/~berendt/teaching/2011-12-1stsemester/adb/
Last update: 18 October 2011

2Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
2
Until now ...
... we have looked into modelling
... we have seen how the languages RDF and OWL allow us to combine different schemas and data
... we have seen how Linked Data on the Web uses HTTP as a connecting protocol/architecture
... we have assumed that such combinations can be done effortlessly (unique names etc.)
... we have looked at some interpretation problems associated with these procedures
Now we need to ask: What are (further) challenges of such combinations?
What are approaches proposed to solve it?
– from the databases & the Semantic Web / ontologies fields
– from architectural and logical points of view
3Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
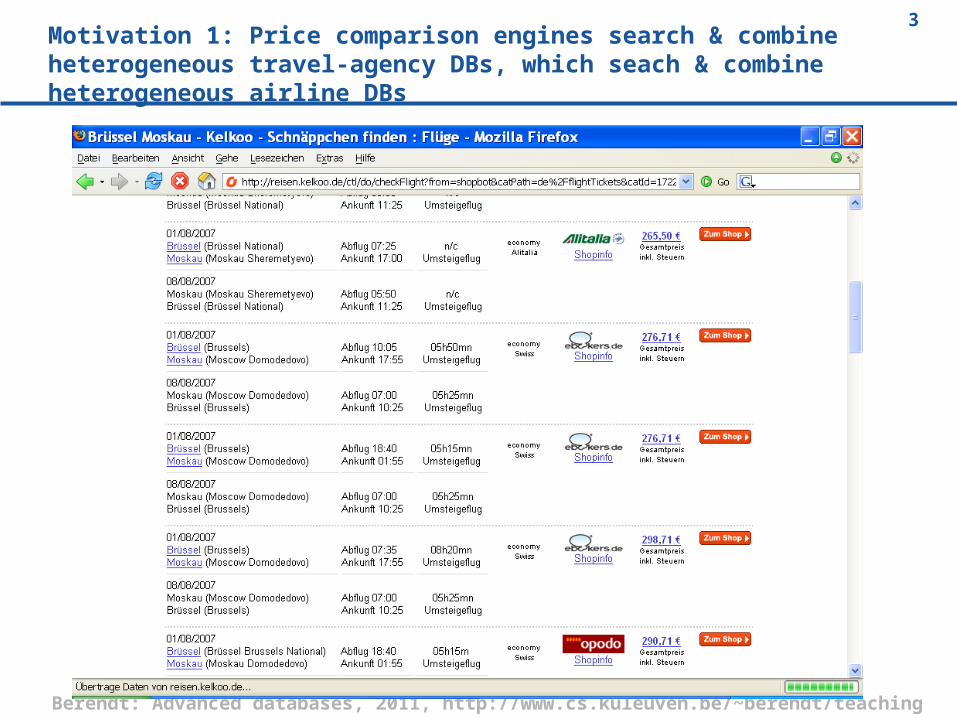
3Motivation 1: Price comparison engines search & combine heterogeneous travel-agency DBs, which seach & combine heterogeneous airline DBs

4Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
4
Motivation 2: Schemas coming from different languages
A river is a natural stream of water, usually freshwater, flowing toward an ocean, a lake, or another stream. In some cases a river flows into the ground or dries up completely before reaching another body of water. Usually larger streams are called rivers while smaller streams are called creeks, brooks, rivulets, rills, and many other terms, but there is no general rule that defines what can be called a river. Sometimes a river is said to be larger than a creek,[1] but this is not always the case.[2]
Une rivière est un cours d'eau qui s'écoule sous l'effet de la gravité et qui se jette dans une autre rivière ou dans un fleuve, contrairement au fleuve qui se jette, lui, dans la mer ou dans l'océan.
Een rivier is een min of meer natuurlijke waterstroom. We onderscheiden oceanische rivieren (in België ook wel stroom genoemd) die in een zee of oceaan uitmonden, en continentale rivieren die in een meer, een moeras of woestijn uitmonden. Een beek is de aanduiding voor een kleine rivier. Tussen beek en rivier ligt meestal een bijrivier.
5Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
5
Motivation 3 (a): Are these the same entity?
6Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
6
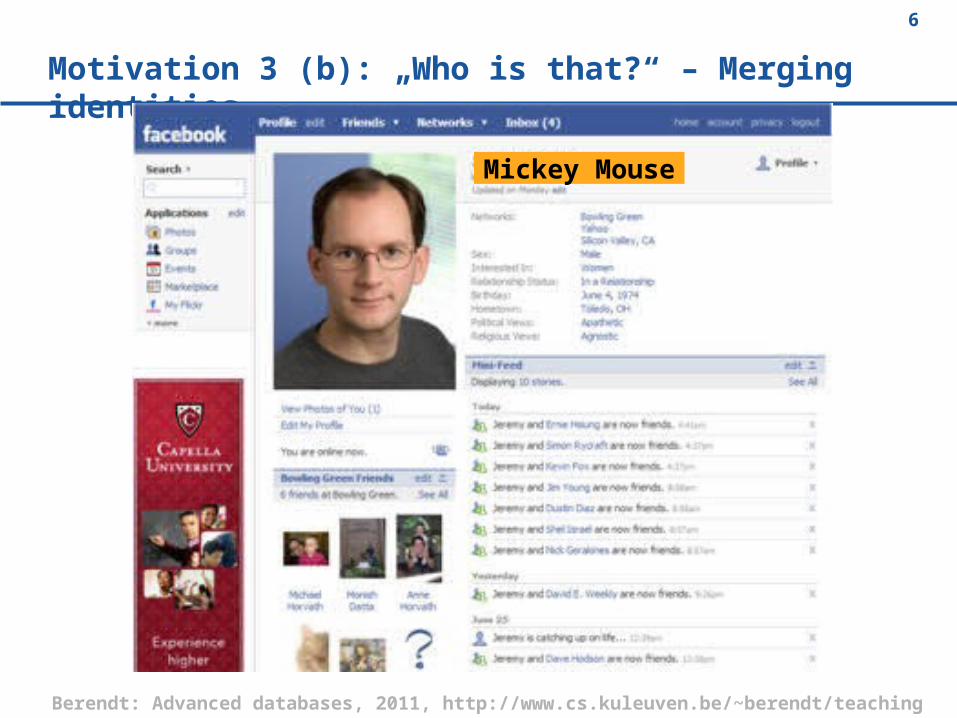
Motivation 3 (b): „Who is that?“ – Merging identities
Mickey Mouse
7Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
7
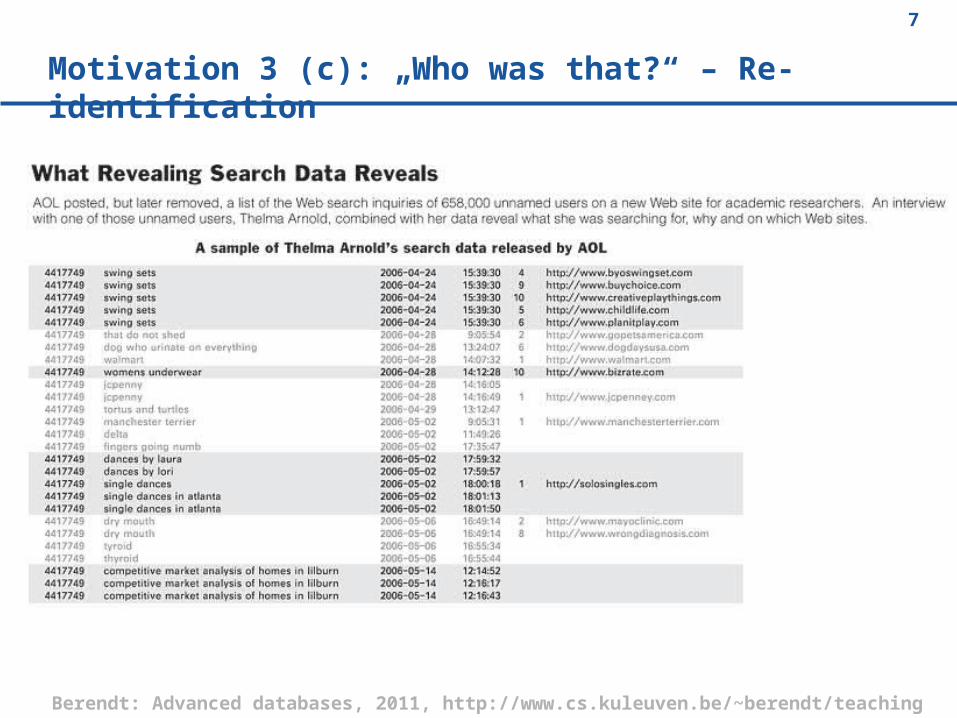
Motivation 3 (c): „Who was that?“ – Re-identification

8Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
8
High-level overview: Goals and approaches in data integration
Basic goal: Combine data/knowledge from different sources
Goal / emphasis can lie on finding correspondences between
the models schema matching, ontology matching
the instances record linkage
Techniques can leverage similarities between
schema/ontology-level information
instance information
most of today
An established problem in DB; a focus and challenge for LOD (“owl:sameAs“)
9Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
9
Agenda
The match problem & what info to use for matching
(Semi-)automated matching: Example CUPID
(Semi-)automated matching: Example iMAP
Ontology matching
Evaluating matching
Core ideas of federated databases
Involving the user: Explanations; mass collaboration

10Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
10
Overview
goal: interoperability through data integration:
combining heterogeneous data sources under a single query interface
A federated database system is a type of meta-database management system (DBMS) which transparently integrates multiple autonomous database systems into a single federated database.
The constituent databases are interconnected via a computer network, and may be geographically decentralized.
Since the constituent database systems remain autonomous, a federated database system is a contrastable alternative to the (sometimes daunting) task of merging together several disparate databases.
A federated database (or virtual database) is the fully-integrated, logical composite of all constituent databases in a federated database system.

11Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
11
Issues in federating data sources
Interconnection and cooperation of autonomous and heterogeneous databases must address
Distribution
Autonomy
Heterogeneity
12Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
12
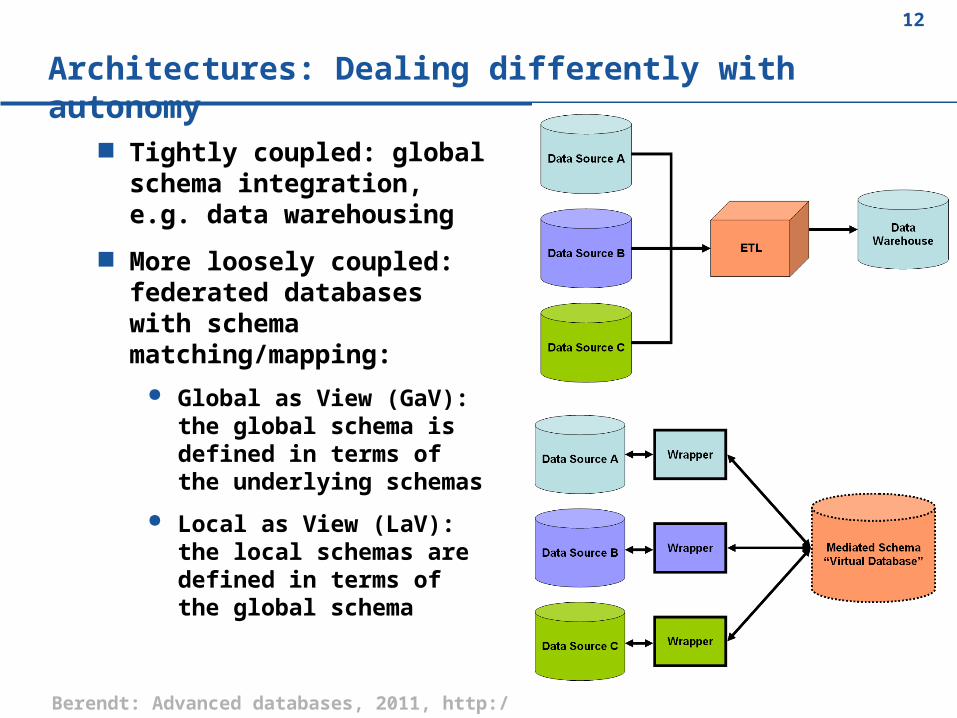
Architectures: Dealing differently with autonomy
Tightly coupled: global schema integration, e.g. data warehousing
More loosely coupled: federated databases with schema matching/mapping:
Global as View (GaV): the global schema is defined in terms of the underlying schemas
Local as View (LaV): the local schemas are defined in terms of the global schema

13Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
13
Issues in query processing
In both GaV and LaV systems, a user poses conjunctive queries over a virtual schema represented by a set of views, or "materialized" conjunctive queries.
Integration seeks to rewrite the queries represented by the views to make their results equivalent or maximally contained by our user's query.
This corresponds to the problem of answering queries using views.

14Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
14
An example developed in-house: SQI - PLQL
Purpose: For federated search in learning-object repositories
An approach with conceptual-level abstraction from data sources
Integratable data source types:
Relational, XML, IR systems, (search engine) Web services, search APIs
Full abstraction of user from data sources:
Yes
User-specific data souce selection for integration:
Depends on application
User-specific data modeling for integration:
No
Explicit, queryable semantics:
(delegated to the sources: LOM etc.)

15Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
15
Heterogeneity
Heterogeneity is independent of location of data
When is an information system homogeneous?
Software that creates and manipulates data is the same
All data follows same structure and data model and is part of a single universe of discourse
Different levels of heterogeneity Different languages to write applications Different query languages Different models Different DBMSs Different file systems Semantic heterogeneity etc.
16Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
16
Agenda
The match problem & what info to use for matching
(Semi-)automated matching: Example CUPID
(Semi-)automated matching: Example iMAP
Ontology matching
Evaluating matching
Core ideas of federated databases
Involving the user: Explanations; mass collaboration
17Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
17
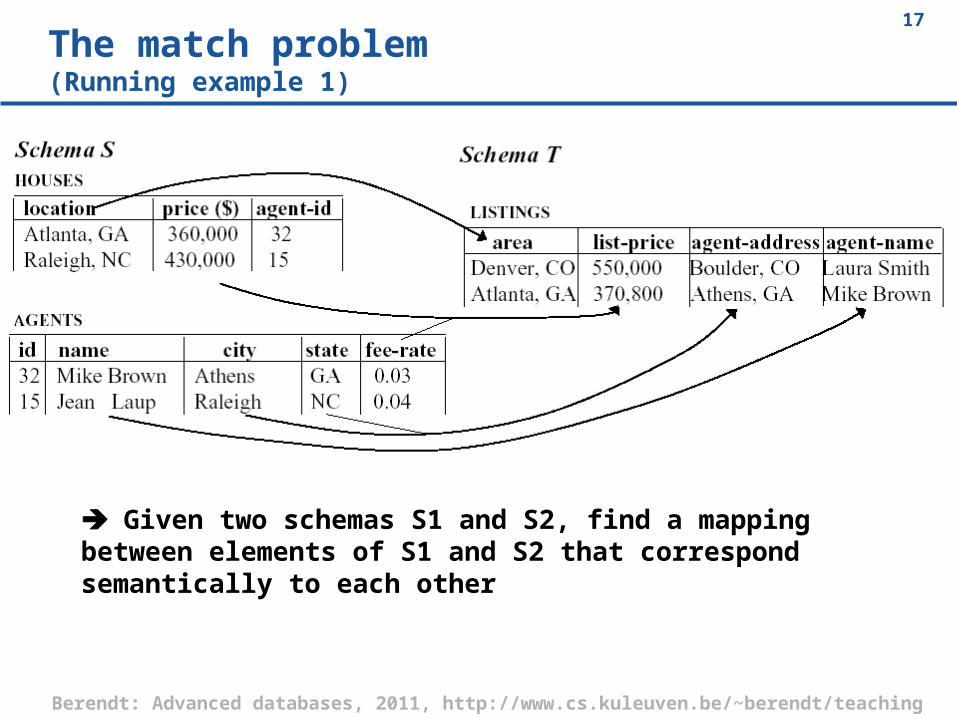
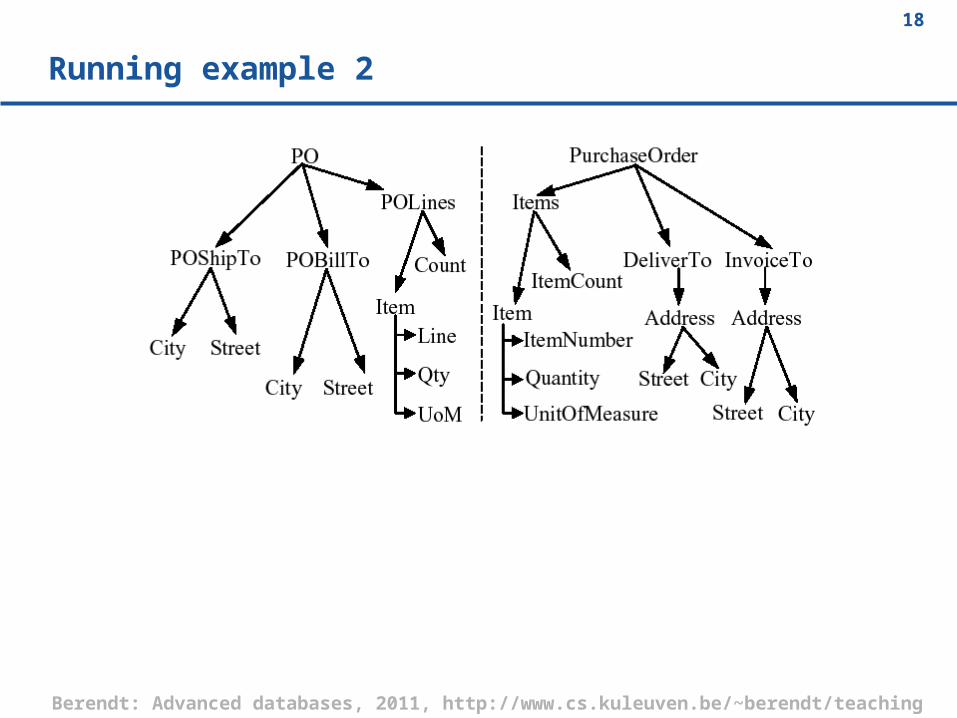
The match problem(Running example 1)
Given two schemas S1 and S2, find a mapping between elements of S1 and S2 that correspond semantically to each other
18Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
18
Running example 2

19Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
19
Motivation: application areas
Schema integration in multi-database systems
Data integration systems on the Web
Translating data (e.g., for data warehousing)
E-commerce message translation
P2P data management
Model management (tools for easily manipulating models of data)

20Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
20
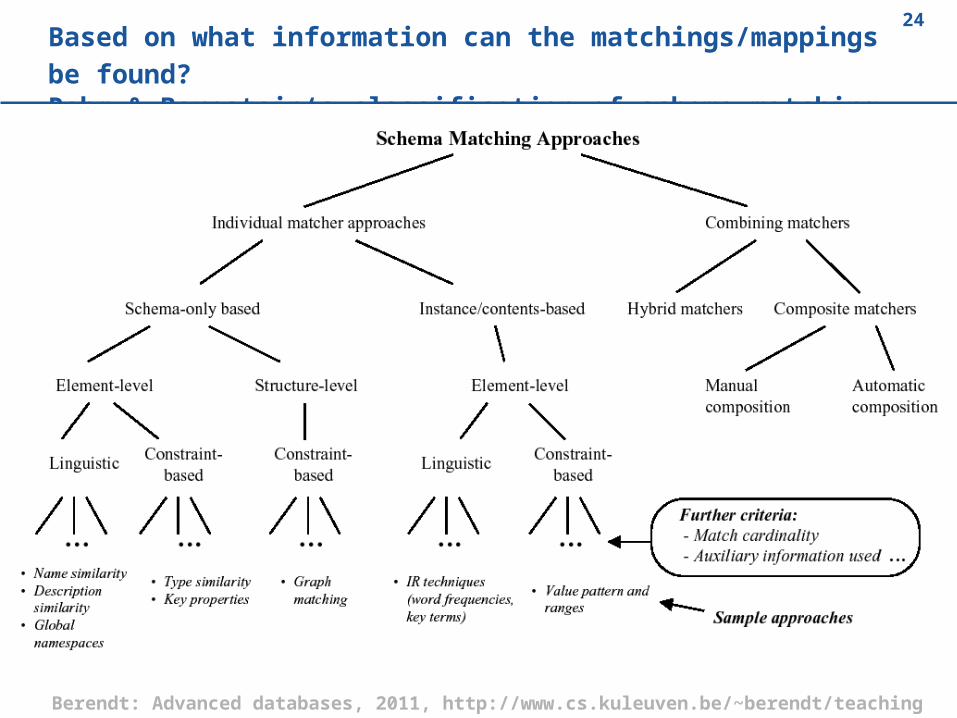
Based on what information can the matchings/mappings be found?
(work on the two running examples)

21Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
21
The match operator
Match operator: f(S1,S2) = mapping between S1 and S2
for schemas S1, S2
Mapping
a set of mapping elements
Mapping elements
elements of S1, elements of S2, mapping expression
Mapping expression
different functions and relationships
22Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
22
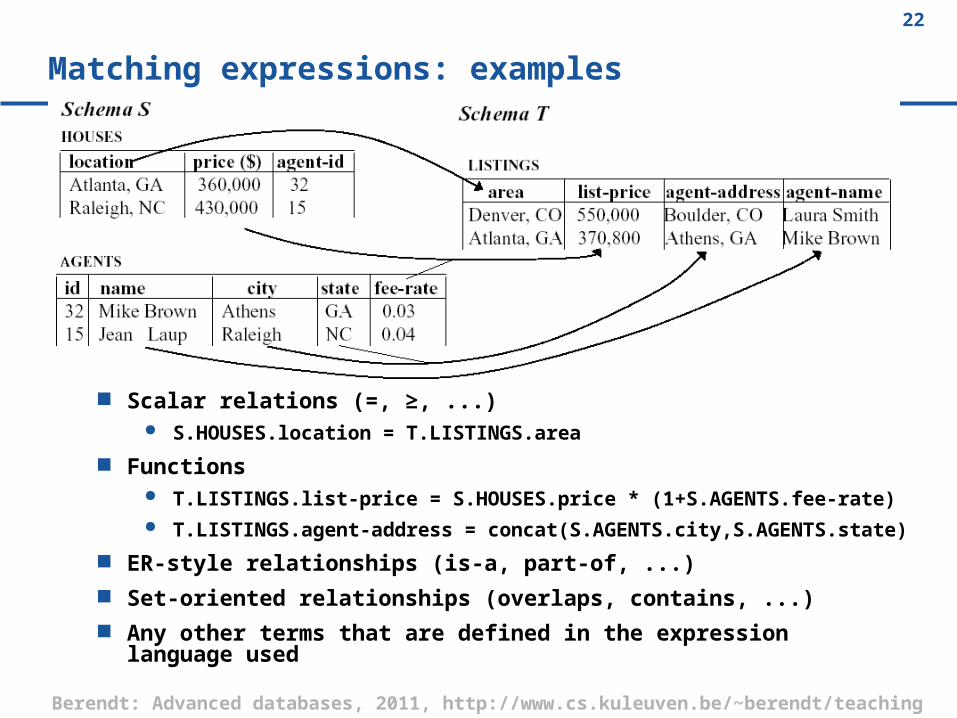
Matching expressions: examples
Scalar relations (=, ≥, ...) S.HOUSES.location = T.LISTINGS.area
Functions T.LISTINGS.list-price = S.HOUSES.price * (1+S.AGENTS.fee-rate) T.LISTINGS.agent-address = concat(S.AGENTS.city,S.AGENTS.state)
ER-style relationships (is-a, part-of, ...) Set-oriented relationships (overlaps, contains, ...) Any other terms that are defined in the expression language used

23Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
23
Matching and mapping
1. Find the schema match („declarative“)
2. Create a procedure (e.g., a query expression) to enable automated data translation or exchange (mapping, „procedural“)
Example of result of step 2: To create T.LISTINGS from S (simplified notation):
area = SELECT location FROM HOUSES
agent-name = SELECT name FROM AGENTS
agent-address = SELECT concat(city,state) FROM AGENTS
list-price = SELECT price * (1+fee-rate)
FROM HOUSES, AGENTS
WHERE agent-id = id
24Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
24Based on what information can the matchings/mappings be found?
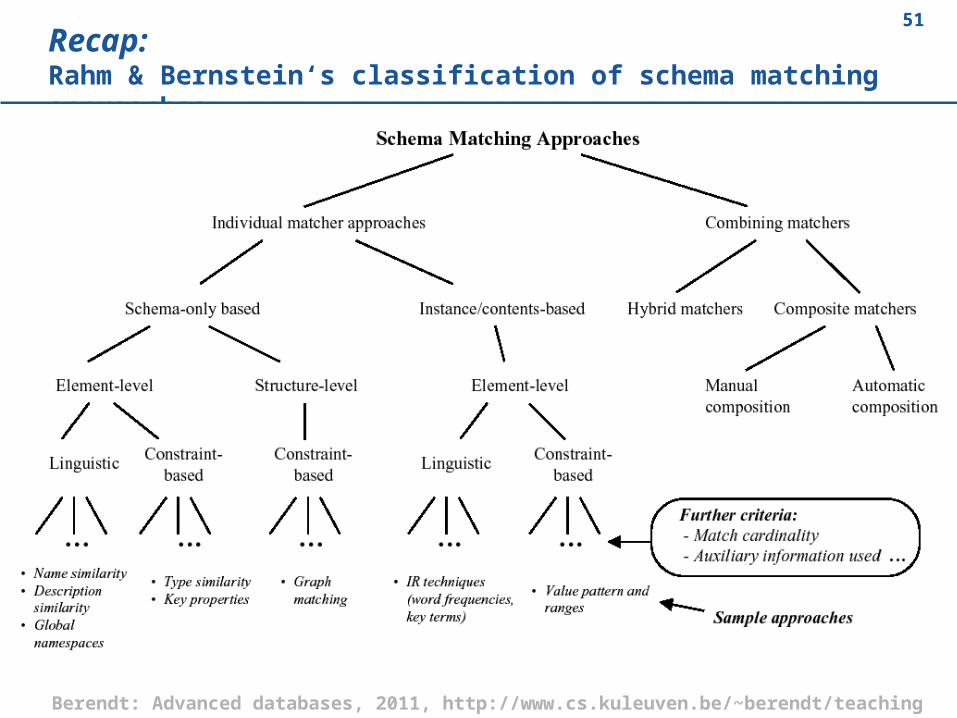
Rahm & Bernstein‘s classification of schema matching approaches

25Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
25
Challenges
Semantics of the involved elements often need to be inferred
Often need to base (heuristic) solutions on cues in schema and data, which are unreliable
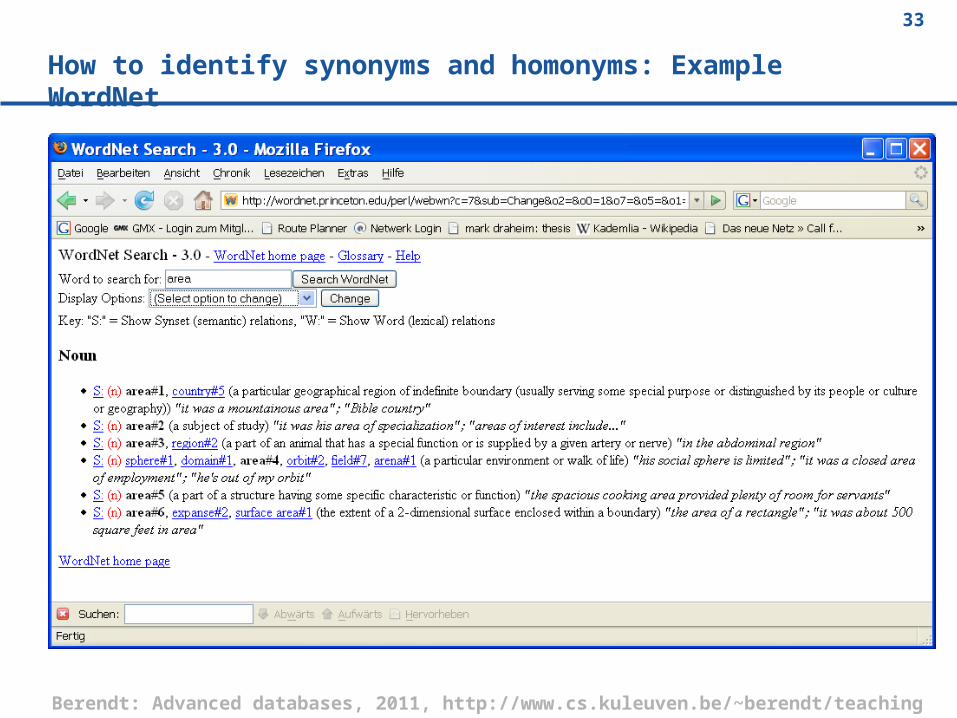
e.g., homonyms (area), synonyms (area, location)
Schema and data clues are often incomplete e.g., date: date of what?
Global nature of matching: to choose one matching possibility, must typically exclude all others as worse
Matching is often subjective and/or context-dependent e.g., does house-style match house-description or not?
Extremely laborious and error-prone process e.g., Li & Clifton 200: project at GTE telecommunications:
40 databases, 27K elements, no access to the original developers of the DB estimated time for just finding and documenting the matches: 12 person years

26Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
26
Semi-automated schema matching (1)
Rule-based solutions
Hand-crafted rules
Exploit schema information
+ relatively inexpensive
+ do not require training
+ fast (operate only on schema, not data)
+ can work very well in certain types of applications & domains
+ rules can provide a quick & concise method of capturing user knowledge about the domain
– cannot exploit data instances effectively
– cannot exploit previous matching efforts
(other than by re-use)

27Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
27
Semi-automated schema matching (2)
Learning-based solutions
Rules/mappings learned from attribute specifications and statistics of data content (Rahm&Bernstein: „instance-level matching“)
Exploit schema information and data
Some approaches: external evidence Past matches
Corpus of schemas and matches („matchings in real-estate applications will tend to be alike“)
Corpus of users (more details later in this slide set)
+ can exploit data instances effectively
+ can exploit previous matching efforts
– relatively expensive
– require training
– slower (operate data)
– results may be opaque (e.g., neural network output) explanation components! (more details later)
28Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
28
Agenda
The match problem & what info to use for matching
(Semi-)automated matching: Example CUPID
(Semi-)automated matching: Example iMAP
Ontology matching
Evaluating matching
Core ideas of federated databases
Involving the user: Explanations; mass collaboration

29Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
29
Overview (1)
Rule-based approach
Schema types:
Relational, XML
Metadata representation:
Extended ER
Match granularity:
Element, structure
Match cardinality:
1:1, n:1

30Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
30
Overview (2)
Schema-level match:
Name-based: name equality, synonyms, hypernyms, homonyms, abbreviations
Constraint-based: data type and domain compatibility, referential constraints
Structure matching: matching subtrees, weighted by leaves
Re-use, auxiliary information used:
Thesauri, glossaries
Combination of matchers:
Hybrid
Manual work / user input:
User can adjust threshold weights
31Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
31
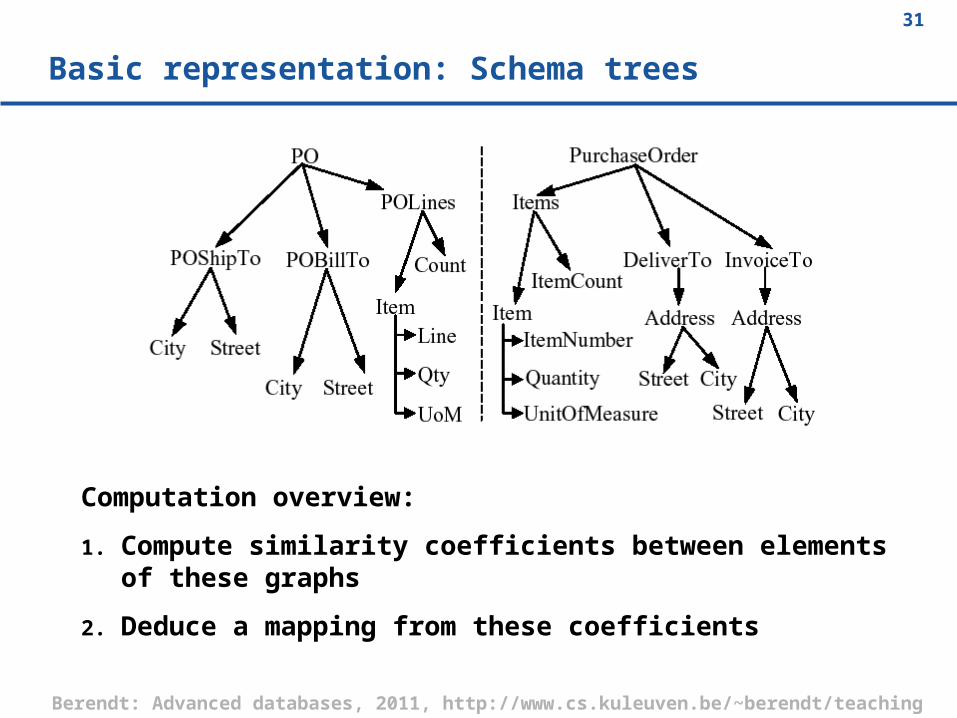
Basic representation: Schema trees
Computation overview:
1. Compute similarity coefficients between elements of these graphs
2. Deduce a mapping from these coefficients

32Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
32
Computing similarity coefficients (1): Linguistic matching
Operates on schema element names (= nodes in schema tree)
1. Normalization Tokenization (parse names into tokens based on punctuation, case,
etc.)
e.g., Product_ID {Product, ID}
Expansion (of abbreviations and acronyms)
Elimination (of prepositions, articles, etc.)
2. Categorization / clustering Based on data types, schema hierarchy, linguistic content of names
e.g., „real-valued elements“, „money-related elements“
3. Comparison (within the categories) Compute linguistic similarity coefficients (lsim) based on thesarus
(synonmy, hypernymy)
Output: Table of lsim coefficients (in [0,1]) between schema elements
33Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
33
How to identify synonyms and homonyms: Example WordNet
34Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
34
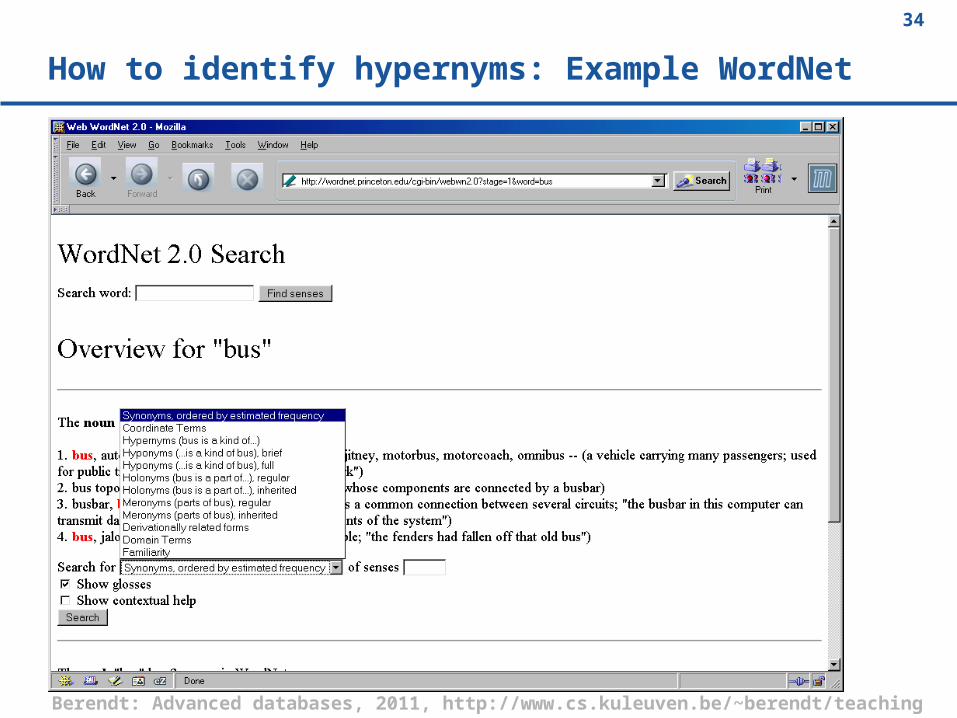
How to identify hypernyms: Example WordNet

35Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
35
Computing similarity coefficients (2): Structure matching
Intuitions:
Leaves are similar if they are linguistic & data-type similar, and if they have similar neighbourhoods
Non-leaf elements are similar if linguistically similar & have similar subtrees (where leaf sets are most important)
Procedure:
1. Initialize structural similarity of leaves based on data types
Identical data types: compat. = 0.5; otherwise in [0,0.5]
2. Process the tree in post-order
3. Stronglink(leaf1, leaf2) iff their weighted sim. ≥ threshold
4. .

36Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
36
The structure matching algorithm
Output: an 1:n mapping for leaves
To generate non-leaf mappings: 2nd post-order traversal
37Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
37
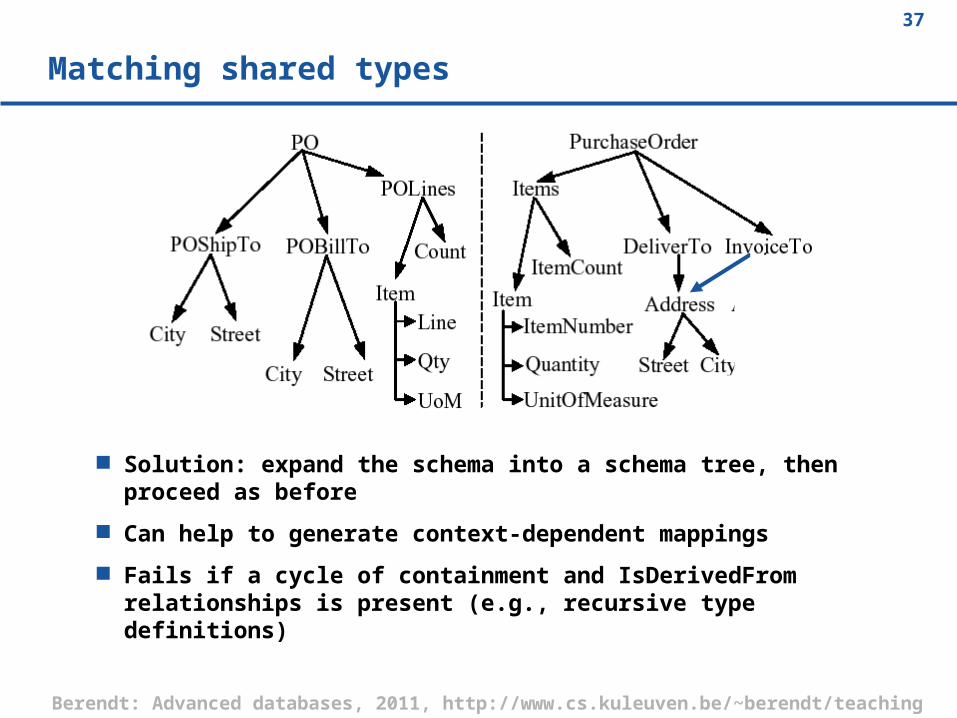
Matching shared types
Solution: expand the schema into a schema tree, then proceed as before
Can help to generate context-dependent mappings
Fails if a cycle of containment and IsDerivedFrom relationships is present (e.g., recursive type definitions)
38Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
38
Agenda
The match problem & what info to use for matching
(Semi-)automated matching: Example CUPID
(Semi-)automated matching: Example iMAP
Ontology matching
Evaluating matching
Core ideas of federated databases
Involving the user: Explanations; mass collaboration

39Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
39
Main ideas
A learning-based approach
Main goal: discover complex matches
In particular: functions such as
T.LISTINGS.list-price = S.HOUSES.price * (1+S.AGENTS.fee-rate)
T.LISTINGS.agent-address = concat(S.AGENTS.city,S.AGENTS.state)
Works on relational schemas
Basic idea: reformulate schema matching as search
40Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
40
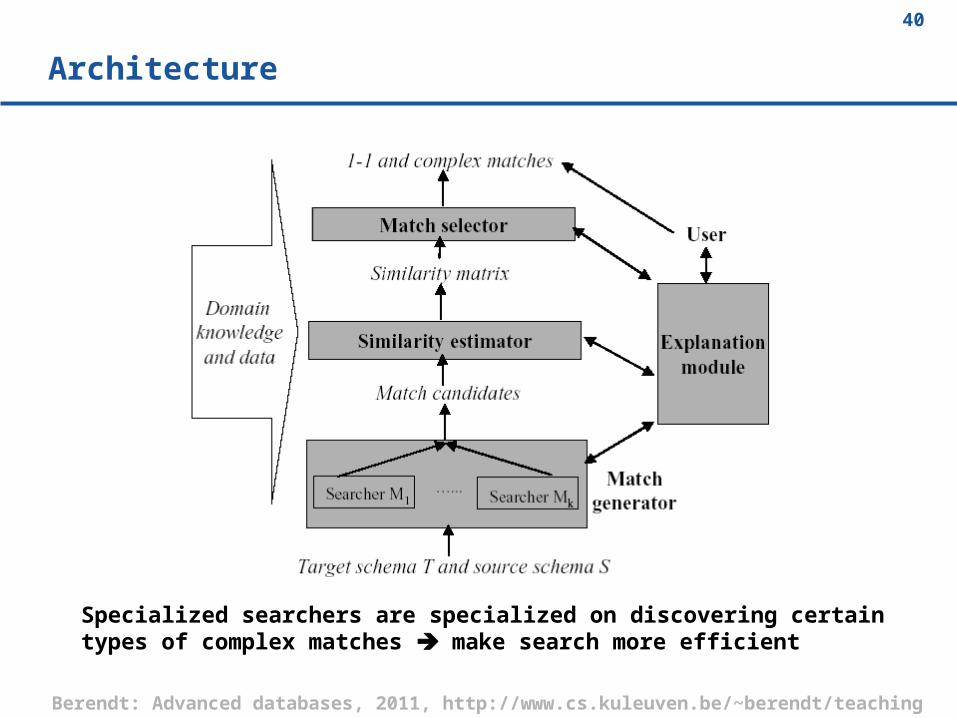
Architecture
Specialized searchers are specialized on discovering certain types of complex matches make search more efficient
41Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
41
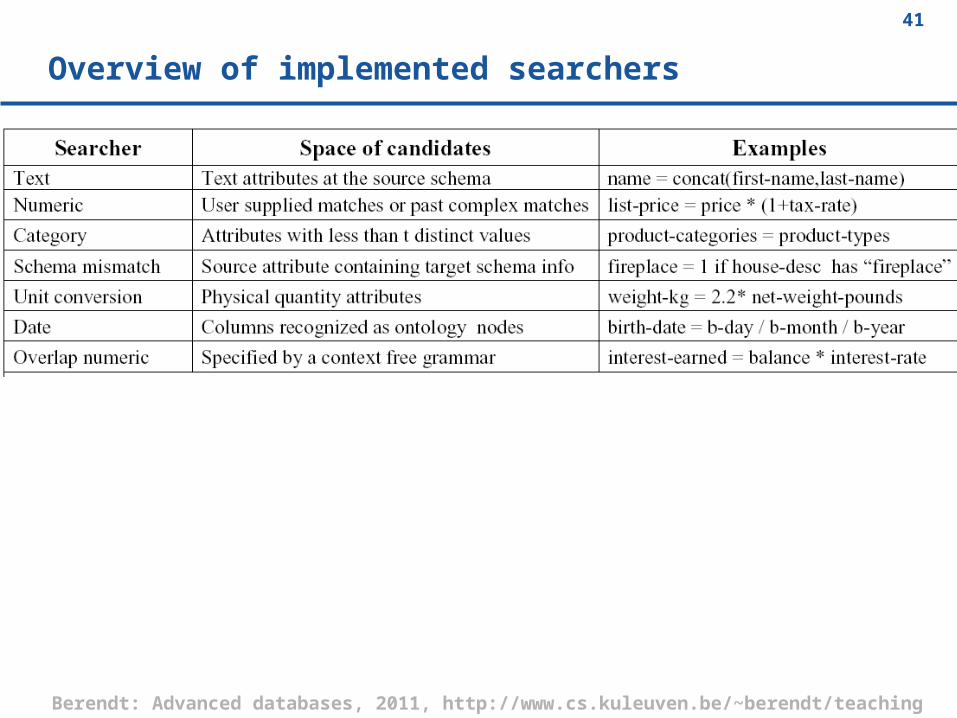
Overview of implemented searchers
42Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
42
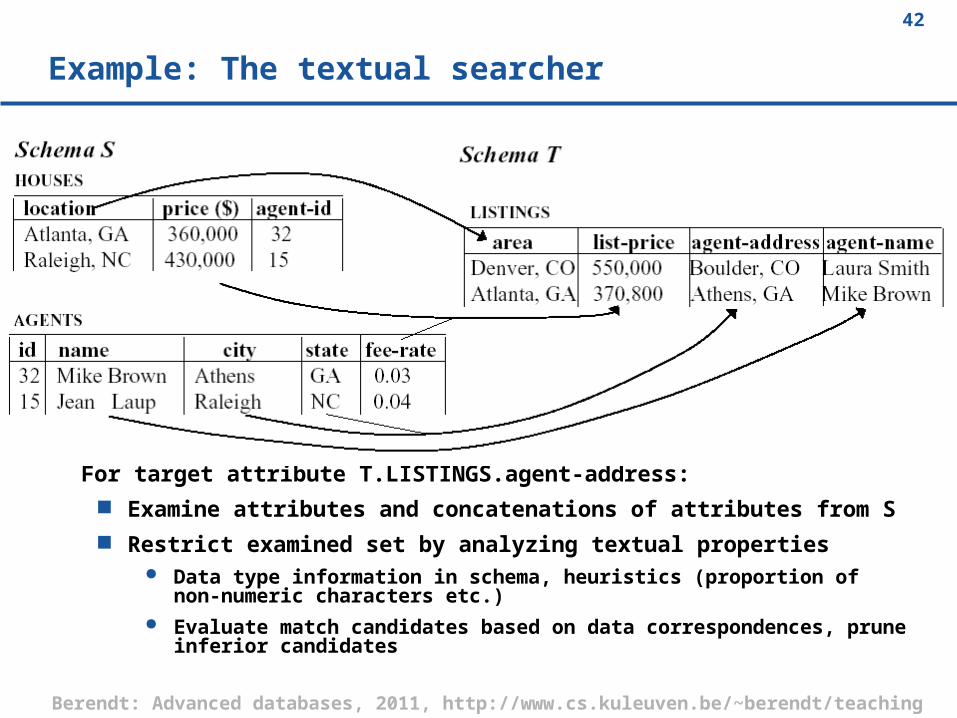
Example: The textual searcher
For target attribute T.LISTINGS.agent-address: Examine attributes and concatenations of attributes from S Restrict examined set by analyzing textual properties
Data type information in schema, heuristics (proportion of non-numeric characters etc.)
Evaluate match candidates based on data correspondences, prune inferior candidates
43Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
43
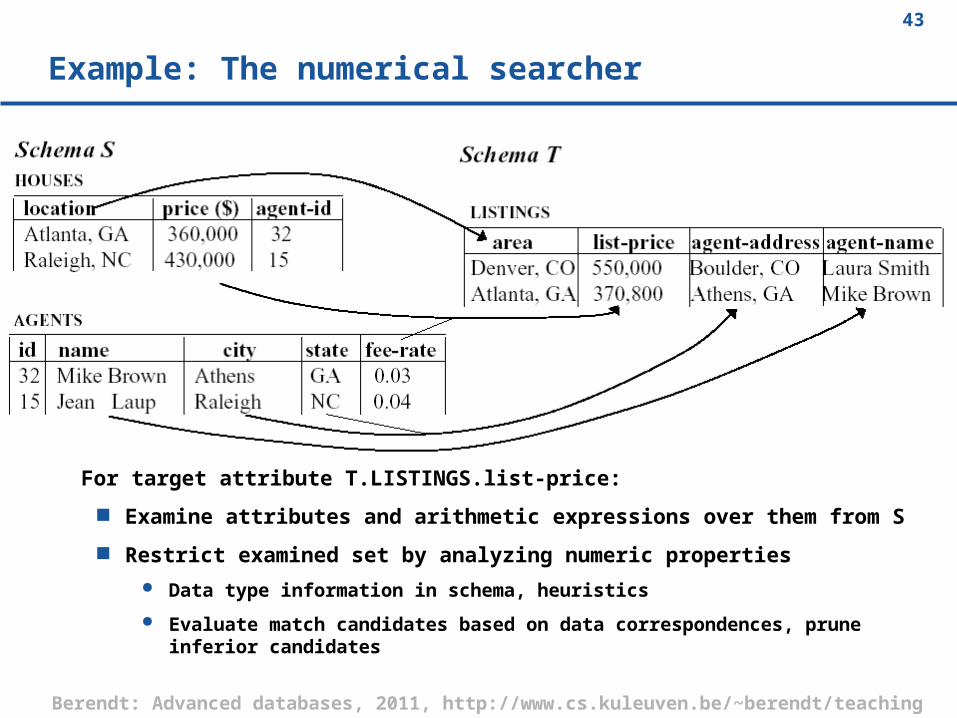
Example: The numerical searcher
For target attribute T.LISTINGS.list-price:
Examine attributes and arithmetic expressions over them from S
Restrict examined set by analyzing numeric properties
Data type information in schema, heuristics
Evaluate match candidates based on data correspondences, prune inferior candidates
44Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
44
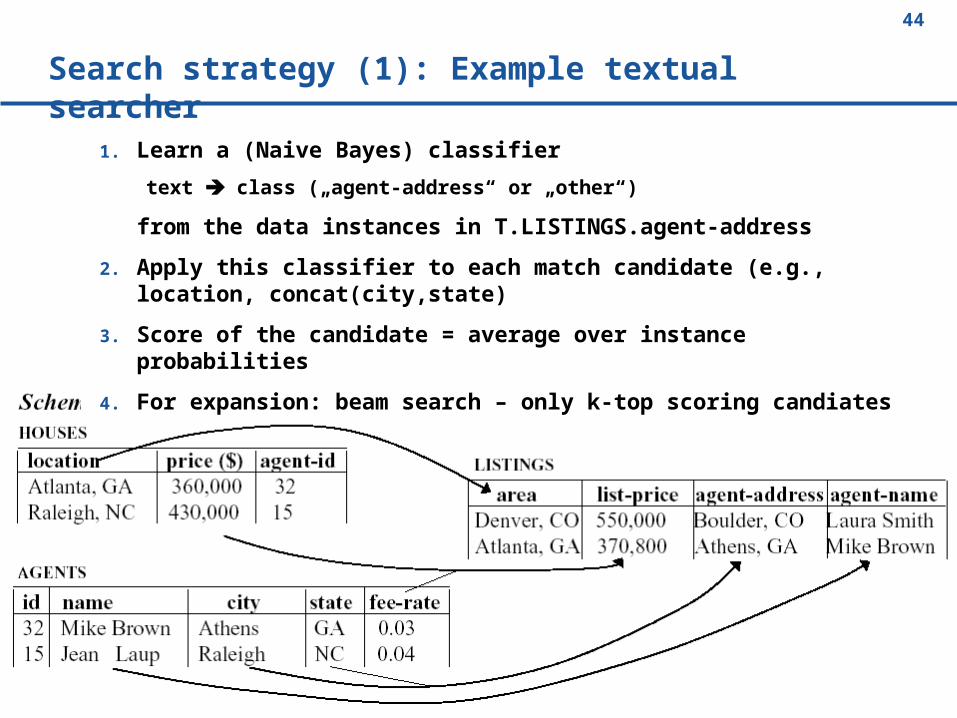
Search strategy (1): Example textual searcher
1. Learn a (Naive Bayes) classifier
text class („agent-address“ or „other“)
from the data instances in T.LISTINGS.agent-address
2. Apply this classifier to each match candidate (e.g., location, concat(city,state)
3. Score of the candidate = average over instance probabilities
4. For expansion: beam search – only k-top scoring candiates
45Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
45
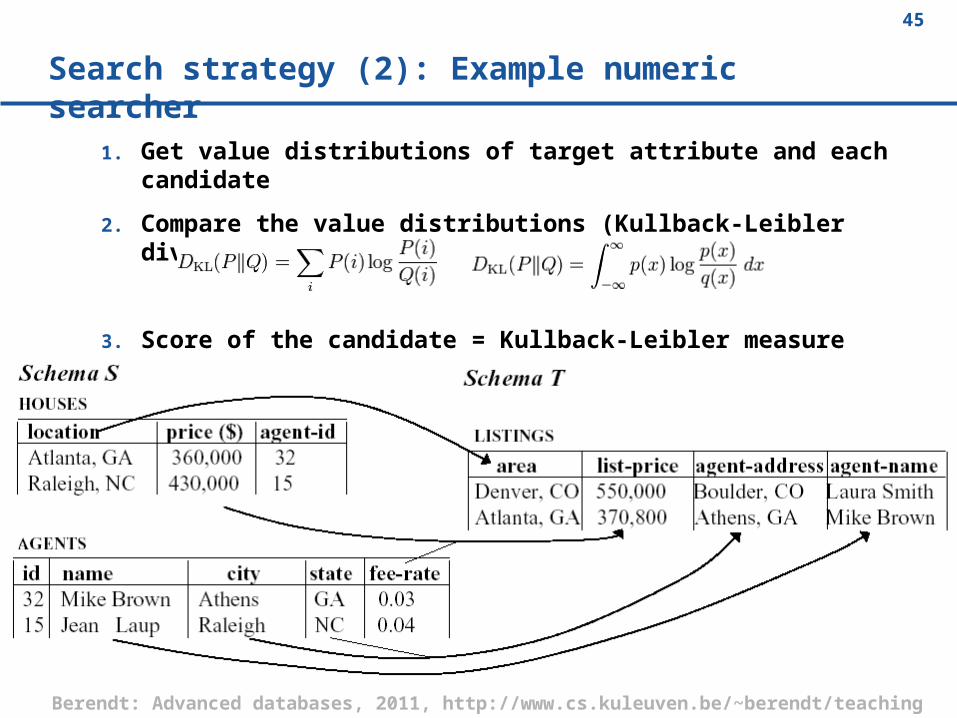
Search strategy (2): Example numeric searcher
1. Get value distributions of target attribute and each candidate
2. Compare the value distributions (Kullback-Leibler divergence measure)
3. Score of the candidate = Kullback-Leibler measure
46Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
46
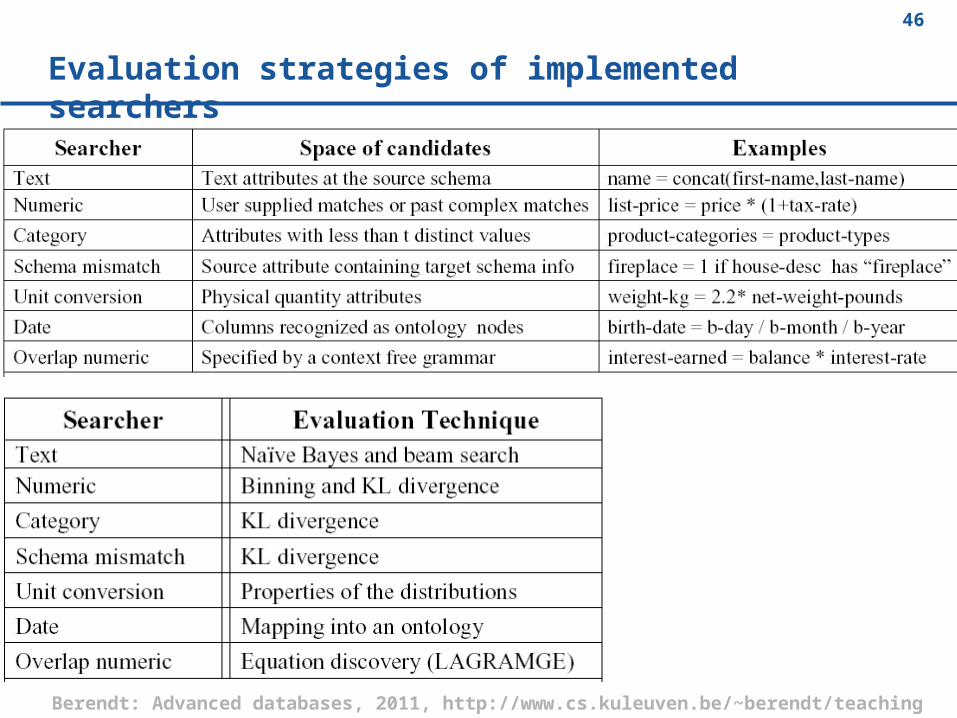
Evaluation strategies of implemented searchers

47Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
47
Pruning by domain constraints
Multiple attributes of S: „attributes name and beds are unrelated“ do not generate match candidates with these 2 attributes
Properties of a single attribute of T: „the average value of num-rooms does not exceed 10“ use in evaluation of candidates
Properties of multiple attributes of T: „lot-area and num-baths are unrelated“ at match selector level, „clean up“:
Example
– T.num_baths S.baths
– ? T.lot-area (S.lot-sq-feet/43560)+1.3e-15 * S.baths
Based on the domain constraint, drop the term involving S.baths

48Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
48
Pruning by using knowledge from overlap data
When S and T share the same data
Consider fraction of data for which mapping is correct
e.g., house locations:
S.HOUSES.location overlaps more with T.LISTINGS.area than with T.LISTINGS.agent-address
Discard the candidate T.LISTINGS.agent-address = S.HOUSES.location,
keep only T.LISTINGS.agent-address = concat(S.AGENTS.city,S.AGENTS,state)
49Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
49
Agenda
The match problem & what info to use for matching
(Semi-)automated matching: Example CUPID
(Semi-)automated matching: Example iMAP
Ontology matching
Evaluating matching
Core ideas of federated databases
Involving the user: Explanations; mass collaboration

50Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
50
What is ontology matching (relative to schema matching)?
same basic idea
but works on ontologies that are conceptual models (not on logical schemas such as relational tables or XML trees)
emphasizes that concepts and relations need to be matched and mapped, and may treat these differently
(Note: in the schema matching literature, it is not always clearly laid out whether the matched items come from a conceptual or a logical model; the toy examples above in particular are also conceptual)
In practice, some ontology matching tasks in fact work on such simple models (or simple subparts of models) that they do not differ at all from what we have seen so far
example: Anatomy task, see below in evaluation
Terminology: Also known as ontology alignment See (Shvaiko & Euzenat, 2005) for more details
51Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
51Recap: Rahm & Bernstein‘s classification of schema matching approaches
52Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
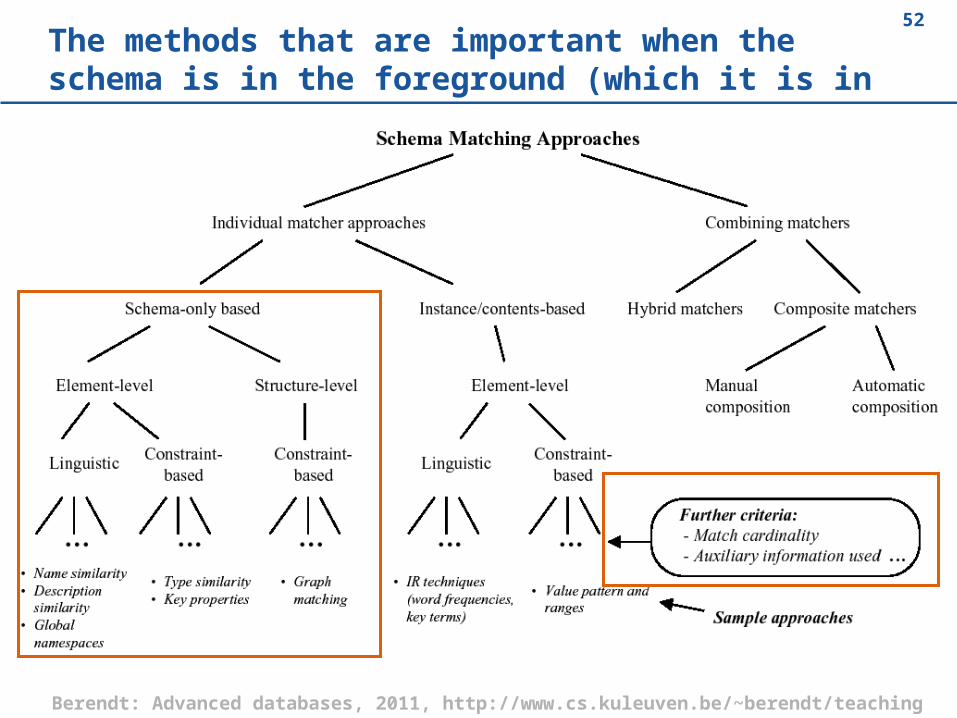
52The methods that are important when the schema is in the foreground (which it is in ontologies!)

53Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
53
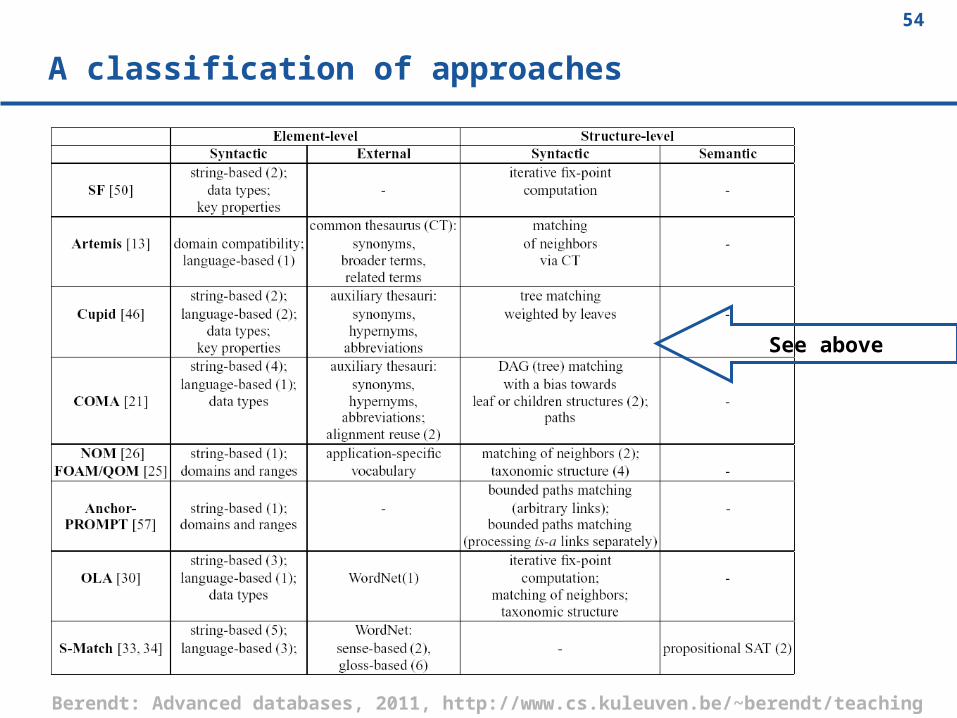
The extension by Shvaiko & Euzenat (2005) [Partial view]
54Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
54
A classification of approaches
See above

55Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
55One area in which ontology alignment becomes particularly interesting: Natural language and cross-lingual integration
(because this shows very nicely how concepts are not always aligned nicely)
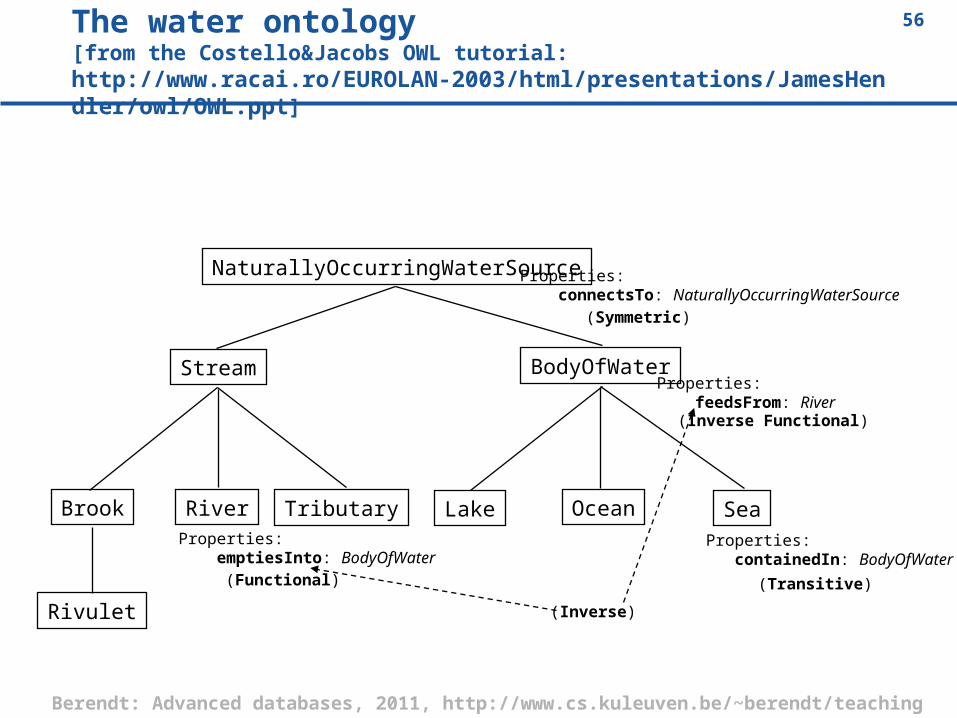
56Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
56
OceanLake
BodyOfWater
River
Stream
Sea
NaturallyOccurringWaterSource
The water ontology [from the Costello&Jacobs OWL tutorial: http://www.racai.ro/EUROLAN-2003/html/presentations/JamesHendler/owl/OWL.ppt]
TributaryBrook
Rivulet
Properties: feedsFrom: River
Properties: emptiesInto: BodyOfWater
(Functional)
(Inverse Functional)
(Inverse)
Properties: containedIn: BodyOfWater
(Transitive)
Properties: connectsTo: NaturallyOccurringWaterSource
(Symmetric)

57Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
57
How could this give rise to a mapping/matching problem?
A river is a natural stream of water, usually freshwater, flowing toward an ocean, a lake, or another stream. In some cases a river flows into the ground or dries up completely before reaching another body of water. Usually larger streams are called rivers while smaller streams are called creeks, brooks, rivulets, rills, and many other terms, but there is no general rule that defines what can be called a river. Sometimes a river is said to be larger than a creek,[1] but this is not always the case.[2]
Une rivière est un cours d'eau qui s'écoule sous l'effet de la gravité et qui se jette dans une autre rivière ou dans un fleuve, contrairement au fleuve qui se jette, lui, dans la mer ou dans l'océan.
Een rivier is een min of meer natuurlijke waterstroom. We onderscheiden oceanische rivieren (in België ook wel stroom genoemd) die in een zee of oceaan uitmonden, en continentale rivieren die in een meer, een moeras of woestijn uitmonden. Een beek is de aanduiding voor een kleine rivier. Tussen beek en rivier ligt meestal een bijrivier.
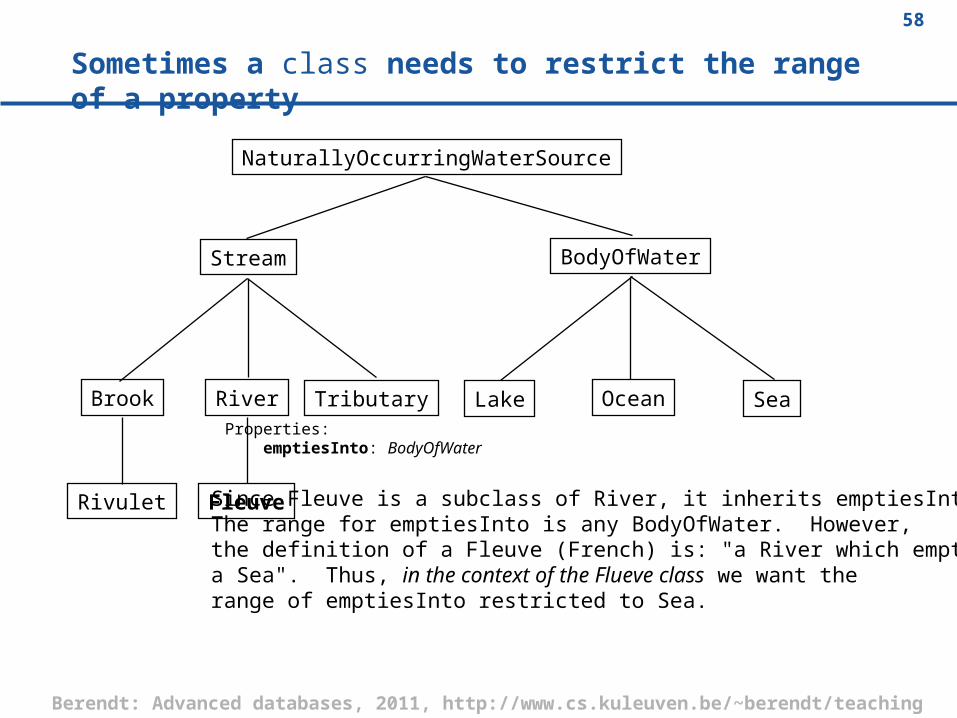
58Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
58
Sometimes a class needs to restrict the range of a property
OceanLake
BodyOfWater
River
Stream
Sea
NaturallyOccurringWaterSource
TributaryBrook
Rivulet Fleuve
Properties: emptiesInto: BodyOfWater
Since Fleuve is a subclass of River, it inherits emptiesInto.The range for emptiesInto is any BodyOfWater. However,the definition of a Fleuve (French) is: "a River which emptiesIntoa Sea". Thus, in the context of the Flueve class we want therange of emptiesInto restricted to Sea.

59Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
59
Pretty standard: A class and an object property in OWL
<owl:ObjectProperty rdf:ID="emptiesInto"> <rdfs:domain rdf:resource="#River"/> <rdfs:range rdf:resource="#BodyOfWater"/></owl:ObjectProperty>
<owl:Class rdf:ID="River"> <rdfs:subClassOf rdf:resource="#Stream"/></owl:Class>
Note for nerds: Why does this use „rdf:ID“ and not „rdf:about“ (as FOAF does)?
“As for choosing between rdf:ID and rdf:about, you will most likely want to use the former if you are describing a resource that doesn't really have a meaningful location outside the RDF file that describes it. Perhaps it is a local or convenience record, or even a proxy for an abstraction or real-world object (although I recommend you take great care describing such things in RDF as it leads to all sorts of metaphysical confusion; I have a practice of only using RDF to describe records that are meaningful to a computer). rdf:about is usually the way to go when you are referring to a resource with a globally well-known identifier or location.“ (http://www.ibm.com/developerworks/xml/library/x-tiprdfai.html)

60Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
60
Global vs Local Properties
rdfs:range imposes a global restriction on the emptiesInto property, i.e., the rdfs:range value applies to River and all subclasses of River.
As we have seen, in the context of the Fleuve class, we would like the emptiesInto property to have its range restricted to just the Sea class. Thus, for the Fleuve class we want a local definition of emptiesInto.

61Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
61
Defining emptiesInto (when used in Fleuve) to have allValuesFrom the Sea class
<?xml version="1.0"?><rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:owl="http://www.w3.org/2002/07/owl#" xml:base="http://www.geodesy.org/water/naturally-occurring">
<owl:Class rdf:ID="Fleuve"> <rdfs:subClassOf rdf:resource="#River"/> <rdfs:subClassOf> <owl:Restriction> <owl:onProperty rdf:resource="#emptiesInto"/> <owl:allValuesFrom rdf:resource="#Sea"/> </owl:Restriction> </rdfs:subClassOf> </owl:Class>
...
</rdf:RDF>
naturally-occurring.owl (snippet)
One way of specifying matching
expressions in OWL ... here: by
model extension
62Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
62
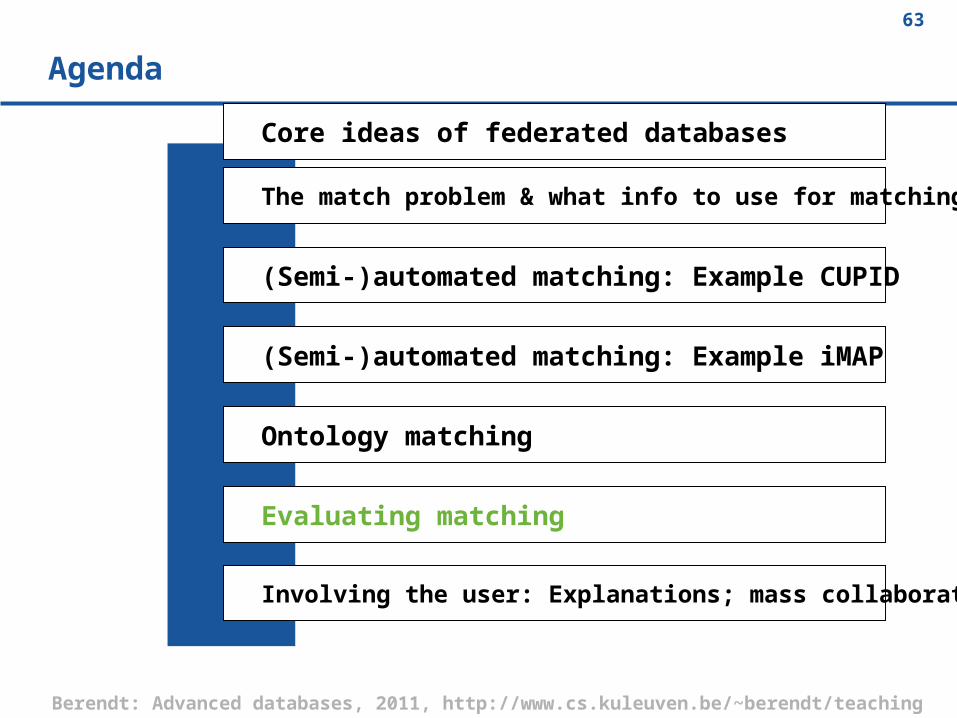
Older brother
Younger brother
Older sister
Younger sister
What about this?Different languages have different (lexicalized) concept boundaries
63Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
63
Agenda
The match problem & what info to use for matching
(Semi-)automated matching: Example CUPID
(Semi-)automated matching: Example iMAP
Ontology matching
Evaluating matching
Core ideas of federated databases
Involving the user: Explanations; mass collaboration

64Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
64
How to compare?
Input: What kind of input data? (What languages? Only toy examples? What external information?)
Output: mapping between attributes or tables, nodes or paths? How much information does the system report?
Quality measures: metrics for accuracy and completeness?
Effort: how much savings of manual effort, how quantified?
Pre-match effort (training of learners, dictionary preparation, ...)
Post-match effort (correction and improvement of the match output)
How are these measured?
65Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
65
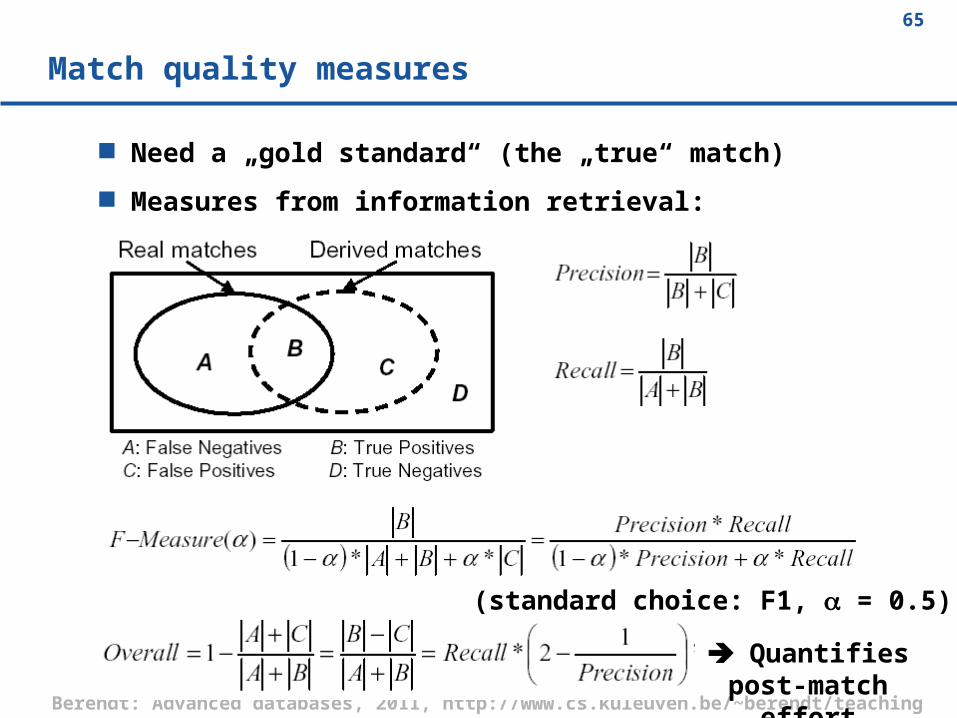
Match quality measures
Need a „gold standard“ (the „true“ match)
Measures from information retrieval:
(standard choice: F1, = 0.5)
Quantifies post-match effort

66Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
66
Benchmarking
Do, Melnik, and Rahm (2003) found that evaluation studies were not comparable
Need more standardized conditions (benchmarks)
Now a tradition of competitions in ontology matching (more in the next session):
Test cases and contests at http://www.ontologymatching.org/evaluation.html

67Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
67Example: Tasks 2009 (various are re-used; 2011 is currently running)(excerpt; from http://oaei.ontologymatching.org/2009/)
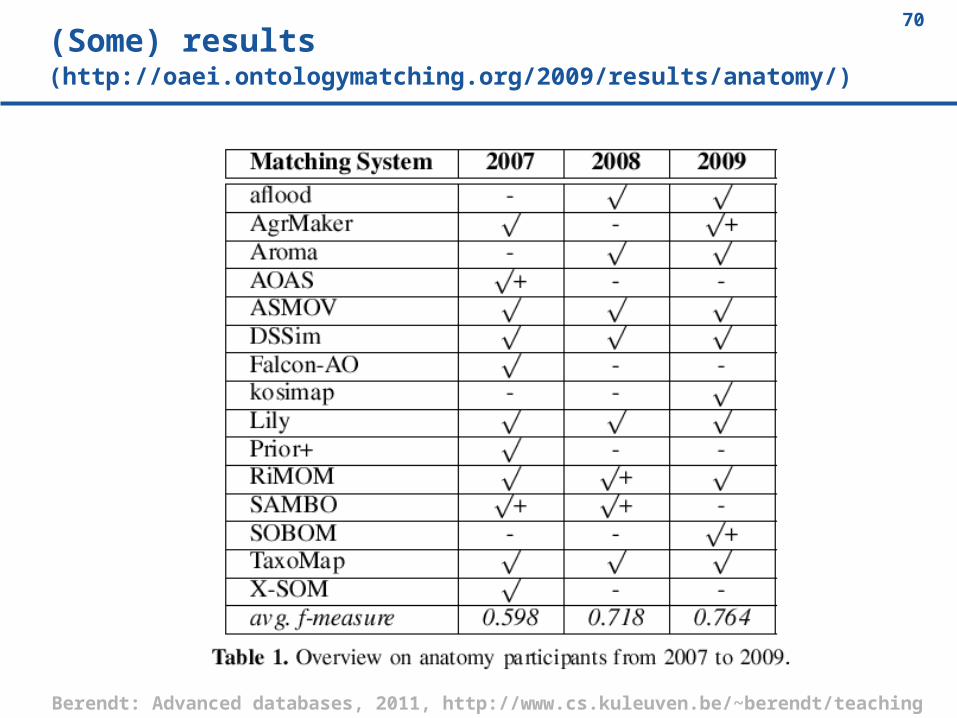
Expressive ontologies anatomy
The anatomy real world case is about matching the Adult Mouse Anatomy (2744 classes) and the NCI Thesaurus (3304 classes) describing the human anatomy.
conference Participants will be asked to find all correct correspondences (equivalence and/or
subsumption correspondences) and/or 'interesting correspondences' within a collection of ontologies describing the domain of organising conferences (the domain being well understandable for every researcher). Results will be evaluated a posteriori in part manually and in part by data-mining techniques and logical reasoning techniques. There will also be evaluation against reference mapping based on subset of the whole collection.
Directories and thesauri fishery gears
features four different classification schemes, expressed in OWL, adopted by different fishery information systems in FIM division of FAO. An alignment performed on this 4 schemes should be able to spot out equivalence, or a degree of similarity between the fishing gear types and the groups of gears, such to enable a future exercise of data aggregation cross systems.
Oriented matching This track focuses on the evaluation of alignments that contain other mapping
relations than equivalences.
Instance matching very large crosslingual resources
The purpose of this task (vlcr) is to match the Thesaurus of the Netherlands Institute for Sound and Vision (called GTAA, see below for more information) to two other resources: the English WordNet from Princeton University and DBpedia.

68Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
68
Mice and humans
The anatomy real world case is about matching the Adult Mouse Anatomy (2744 classes) and the NCI Thesaurus (3304 classes) describing the human anatomy.
(http://oaei.ontologymatching.org/2008/anatomy/)

69Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
69Matching task and evaluation approach(http://oaei.ontologymatching.org/2007/anatomy/)
We would like to gratefully thank Martin Ringwald and Terry Hayamizu (Mouse Genome Informatics - http://www.informatics.jax.org/), who provided us with a reference mapping for these ontologies.
The reference mapping contains only equivalence correspondences between concepts of the ontologies. No correspondences between properties (roles) are specified.
If your system also creates correspondences between properties or correspondences that describe subsumption relations, these results will not influence the evaluation (but can nevertheless be part of your submitted results).
The results of your matching system will be compared to this reference alignment. Therefore, all of the the results have to be delivered in the format specified here.
70Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
70(Some) results(http://oaei.ontologymatching.org/2009/results/anatomy/)
71Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
71
Agenda
The match problem & what info to use for matching
(Semi-)automated matching: Example CUPID
(Semi-)automated matching: Example iMAP
Ontology matching
Evaluating matching
Core ideas of federated databases
Involving the user: Explanations; mass collaboration

72Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
72
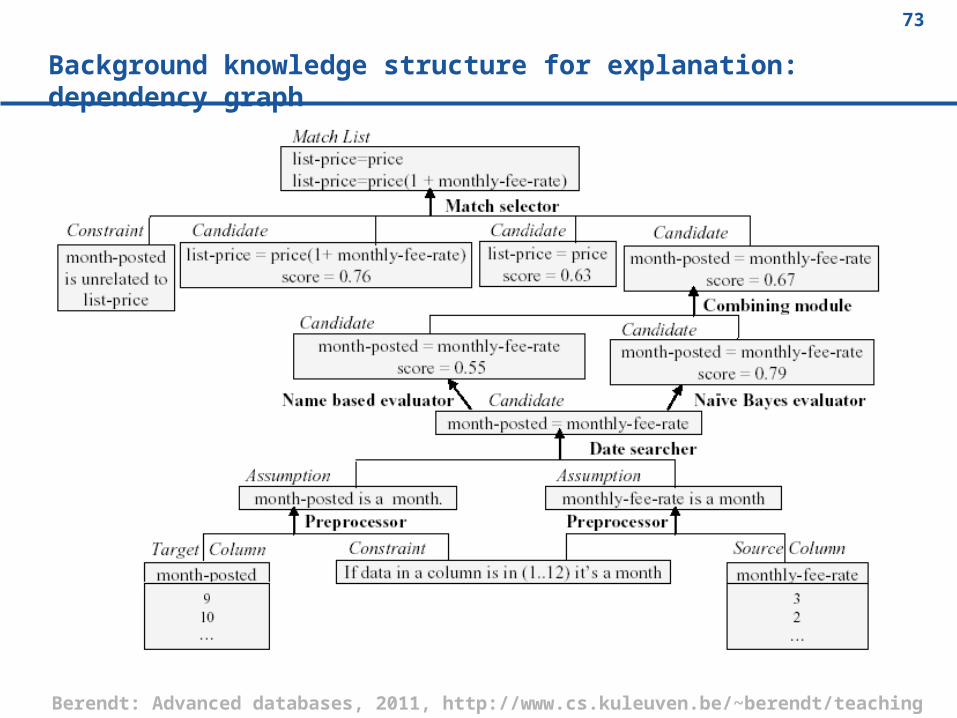
Example in iMAP
User sees ranked candidates:
1. List-price = price
2. List-price = price * (1 + fee-rate)
Explanation:
a) Both generated from numeric searcher, 2 ranked higher than 1
b) But:
c) Match month-posted = fee-rate
d) domain constraint: matches for month-posted and price do not share attributes
)e cannot match list-price to anything to do with fee-rate
f) Why c)?
g) Data instances of fee-rate were classified as of type date
User corrects this wrong step f), the rest is repaired accordingly
73Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
73
Background knowledge structure for explanation: dependency graph
74Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
74
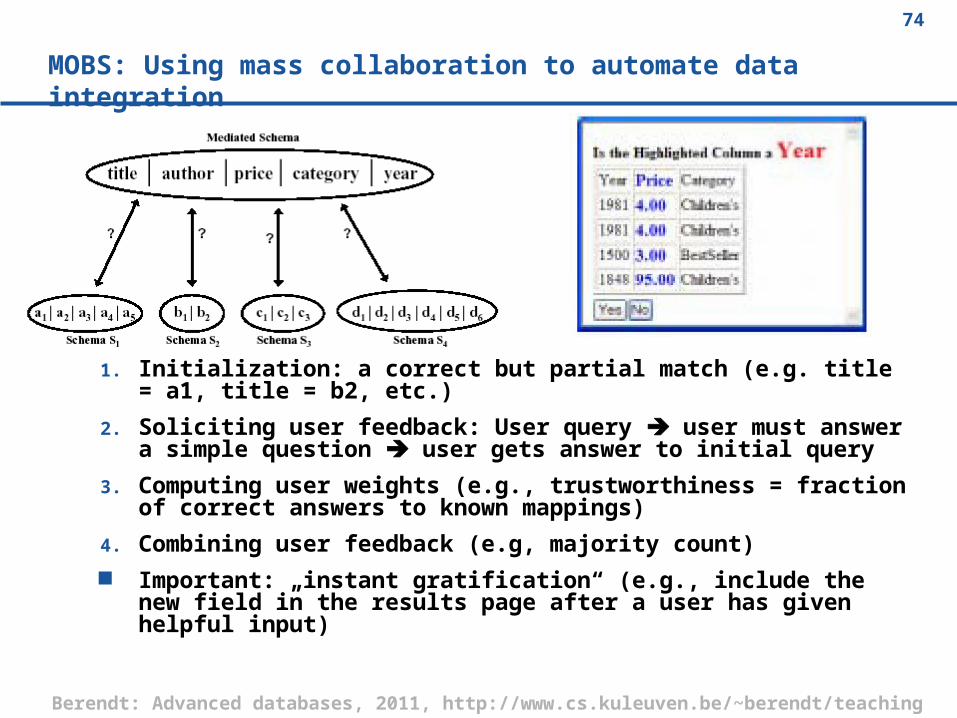
MOBS: Using mass collaboration to automate data integration
1. Initialization: a correct but partial match (e.g. title = a1, title = b2, etc.)
2. Soliciting user feedback: User query user must answer a simple question user gets answer to initial query
3. Computing user weights (e.g., trustworthiness = fraction of correct answers to known mappings)
4. Combining user feedback (e.g, majority count) Important: „instant gratification“ (e.g., include the new field in the
results page after a user has given helpful input)

75Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
75
Some issues of matching – (not only) when it comes to individuals
“Is this the same entity?“:
What does “the same“ mean anyway?
(When) do we want these inferences?
76Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
76
Outlook
The match problem & what info to use for matching
(Semi-)automated matching: Example CUPID
(Semi-)automated matching: Example iMAP
Ontology matching
Evaluating matching
Core ideas of federated databases
Involving the user: Explanations; mass collaboration
KDD (1): Visualizations for exploratory data analysis

77Berendt: Advanced databases, 2011, http://www.cs.kuleuven.be/~berendt/teaching
77
References / background reading; acknowledgements
Rahm, E. & Bernstein, P.A. (2001). A survey of approaches to automatic schema matching. The VLBD Journal, 10, 334-350.
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.16.700
Doan, A. & Halevy, A.Y. (2004). Semantic Integration Research in the Database Community: A brief survey. AI Magazine.
http://dit.unitn.it/~p2p/RelatedWork/Matching/si-survey-db-community.pdf
Madhavan, J., Bernstein, P.A., Rahm, E. (2001). Generic Schema Matching with Cupid. In Proc. Of the 27th VLDB Conference.
http://dbs.uni-leipzig.de/de/publication/title/generic_schema_matching_with_cupid
Dhamankar, R., Lee, Y., Doan, A., Halevy, A., & Domingos, P. (2004). iMAP: Discovering complex semantic matches between database schemas. In Proc. Of SIGMOD 2004.
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.5.4117
P. Shvaiko, J. Euzenat: A Survey of Schema-based Matching Approaches. Journal on Data Semantics, 2005.
http://www.dit.unitn.it/~p2p/RelatedWork/Matching/JoDS-IV-2005_SurveyMatching-SE.pdf
also interesting: N. Noy: Semantic Integration: A Survey of Ontology-based Approaches. SIGMOD Record, 33(3), 2004. http://www.dit.unitn.it/~p2p/RelatedWork/Matching/13.natasha-10.pdf
Do, H.-H., Melnik, S., & Rahm, E. (2003). Comparison of schema matching evaluations. In Web, Web-Services, and Database Systems: NODe 2002, Web- and Database-Related Workshops, Erfurt, Germany, October 7-10, 2002. Revised Papers (pp. 221-237). Springer.
http://dit.unitn.it/~p2p/RelatedWork/Comparison%20of%20Schema%20Matching%20Evaluations.pdf
McCann, R., Doan, A., Varadarajan, V., & Kramnik, A. (2003). Building data integration systems via mass collaboration. In Proc. International Workshop on the Web and Databases (WebDB).
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.4.9964
Please see the Powerpoint slide-specific „notes“ for URLs of used pictures and formulae
Related Documents











