1 Association Rules & Correlations Basic concepts Efficient and scalable frequent itemset mining methods: Apriori, and improvements FP-growth Rule postmining: visualization and validation Interesting association rules.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Association Rules & Correlations
Basic concepts Efficient and scalable frequent itemset mining
methods: Apriori, and improvements FP-growth
Rule postmining: visualization and validation Interesting association rules.

2
Rule Validations
Only a small subset of derived rules might be meaningful/useful Domain expert must validate the rules
Useful tools: Visualization Correlation analysis
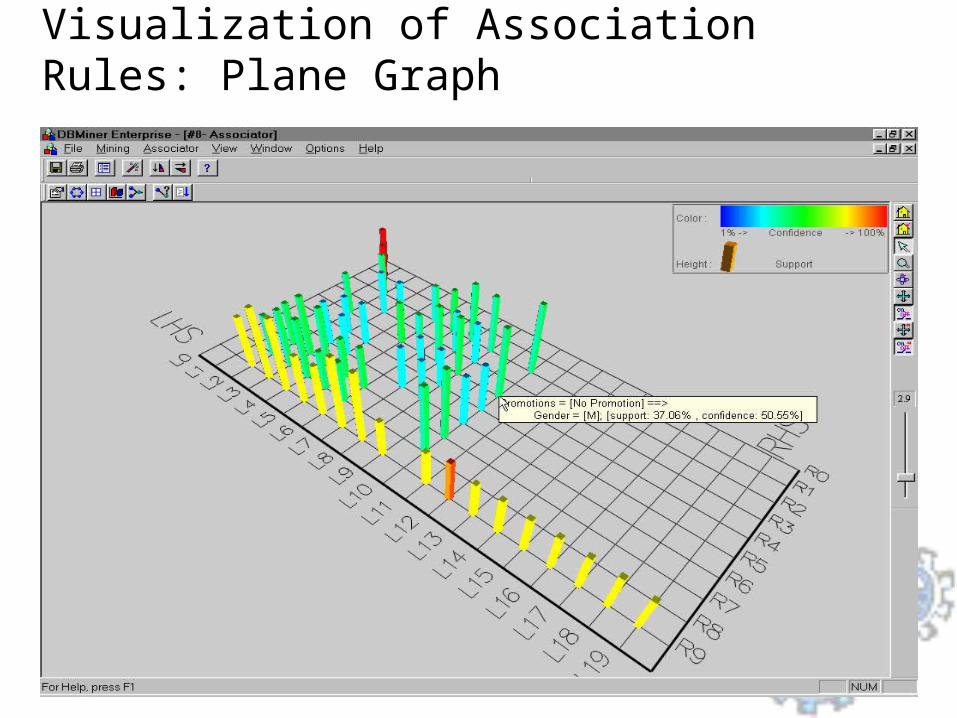
3
Visualization of Association Rules: Plane Graph

4
Visualization of Association Rules
(SGI/MineSet 3.0)

5
Pattern Evaluation
Association rule algorithms tend to produce too many rules many of them are uninteresting or redundant confidence(A B) = p(B|A) = p(A & B)/p(A) Confidence is not discriminative enough
criterion Beyond original support & confidence Interestingness measures can be used to
prune/rank the derived patterns
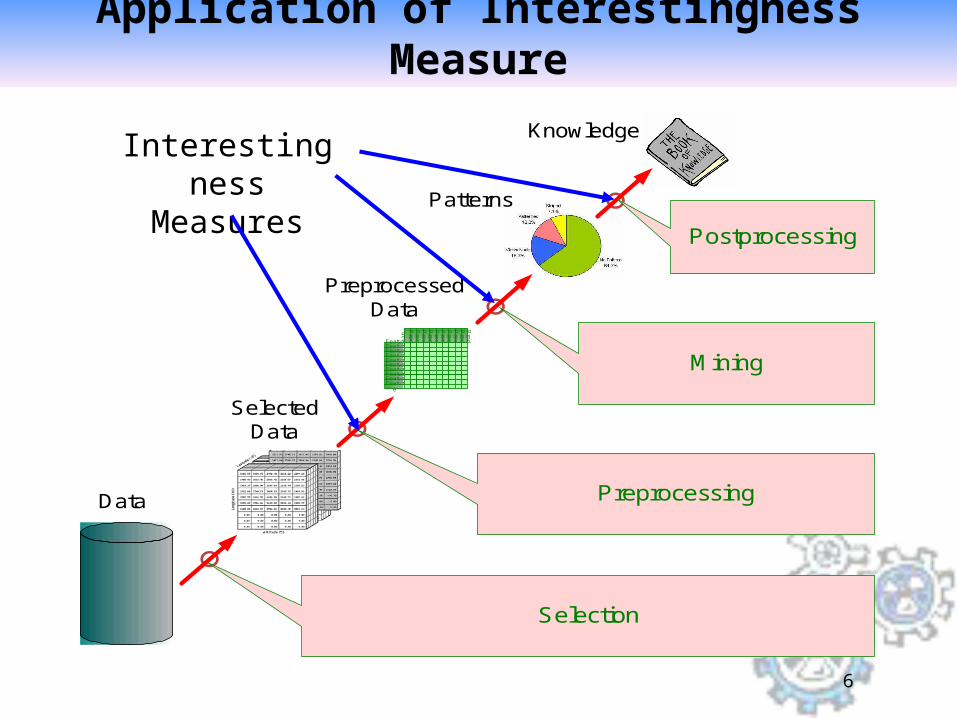
6
Application of Interestingness Measure
Feature
Pro
du
ct
Pro
du
ct
Pro
du
ct
Pro
du
ct
Pro
du
ct
Pro
du
ct
Pro
du
ct
Pro
du
ct
Pro
du
ct
Pro
du
ct
FeatureFeatureFeatureFeatureFeatureFeatureFeatureFeatureFeature
Selection
Preprocessing
Mining
Postprocessing
Data
SelectedData
PreprocessedData
Patterns
KnowledgeInterestingness
Measures

7
Computing Interestingness Measure
Given a rule X Y, information needed to compute rule interestingness can be obtained from a contingency table
Y Y
X f11 f10 f1+
X f01 f00 fo+
f+1 f+0 |T|
Contingency table for X Y
f11: support of X and Yf10: support of X and Yf01: support of X and Yf00: support of X and Y
Used to define various measures
support, confidence, lift, Gini, J-measure, etc.

8
Drawback of Confidence
Coffee
Coffee
Tea 15 5 20
Tea 75 5 80
90 10 100 Association Rule: Tea Coffee
Confidence= P(Coffee|Tea) = 0.75
but P(Coffee) = 0.9 … >0.75
Although confidence is high, rule is misleading
P(Coffee|Tea) = 0.9375 …>>0.75

9
Statistical-Based Measures
Measures that take into account statistical dependence
)()(),(
)()(),(
)()|(
YPXPYXPPS
YPXPYXP
Interest
YPXYP
Lift
Does X lift the probability of Y? i.e. probability of Y given X over probability of Y.
This is the same as interest factor I =1 independence,
I> 1 positive association (<1 negative)
Many other measures
PS: Piatesky-Shapiro

10
Example: Lift/Interest
Coffee Coffee
Tea 15 5 20
Tea 75 5 80
90 10 100
Association Rule: Tea Coffee
Confidence= P(Coffee|Tea) = 0.75
but P(Coffee) = 0.9
Lift = 0.75/0.9= 0.8333 (< 1, therefore is negatively associated)

11
Drawback of Lift & Interest
Y Y
X 10 0 10
X 0 90 90
10 90 100
Y Y
X 90 0 90
X 0 10 10
90 10 100
10)1.0)(1.0(
1.0 Lift 11.1)9.0)(9.0(
9.0 Lift
Statistical independence:If P(X,Y)=P(X)P(Y) => Lift = 1
Lift favors infrequent items
Other criteria proposed Gini, J-measure, etc.

12
There are lots of measures proposed in the literature
Some measures are good for certain applications, but not for others
What criteria should we use to determine whether a measure is good or bad?
What about Apriori-style support based pruning? How does it affect these measures?

13
Association Rules & Correlations
Basic concepts Efficient and scalable frequent itemset mining
methods: Apriori, and improvements FP-growth
Rule derivation, visualization and validation Multi-level Associations
Summary

14
Multiple-Level Association Rules
Items often form hierarchy. Items at the lower level are
expected to have lower support.
Rules regarding itemsets at appropriate levels could be
quite useful. Transaction database can
be encoded based on dimensions and levels
We can explore shared multi-level mining
Food
breadmilk
skim
SunsetFraser
2% whitewheat
TID ItemsT1 {111, 121, 211, 221}T2 {111, 211, 222, 323}T3 {112, 122, 221, 411}T4 {111, 121}T5 {111, 122, 211, 221, 413}

15
Mining Multi-Level Associations
A top_down, progressive deepening approach: First find high-level strong rules:
milk bread [20%, 60%]. Then find their lower-level “weaker” rules:
2% milk wheat bread [6%, 50%].
Variations at mining multiple-level association rules. Level-crossed association rules:
2% milk Wonder wheat bread Association rules with multiple, alternative
hierarchies:
2% milk Wonder bread

16
Multi-level Association: Uniform Support vs. Reduced Support
Uniform Support: the same minimum support for all levels + One minimum support threshold. No need to examine
itemsets containing any item whose ancestors do not have minimum support.
– Lower level items do not occur as frequently. If support threshold
too high miss low level associations too low generate too many high level associations
Reduced Support: reduced minimum support at lower levels There are 4 search strategies:
Level-by-level independent Level-cross filtering by k-itemset Level-cross filtering by single item Controlled level-cross filtering by single item

17
Uniform Support
Multi-level mining with uniform support
Milk
[support = 10%]
2% Milk
[support = 6%]
Skim Milk
[support = 4%]
Level 1min_sup = 5%
Level 2min_sup = 5%
Back

18
Reduced Support
Multi-level mining with reduced support
2% Milk
[support = 6%]
Skim Milk
[support = 4%]
Level 1min_sup = 5%
Level 2min_sup = 3%
Back
Milk
[support = 10%]

19
Multi-level Association: Redundancy Filtering
Some rules may be redundant due to “ancestor” relationships between Example milk wheat bread [support = 8%, confidence =
70%] Say that 2%Milk is 25% of milk sales, then: 2% milk wheat bread [support = 2%, confidence =
72%]
We say the first rule is an ancestor of the second rule.
A rule is redundant if its support is close to the “expected” value, based on the rule’s ancestor.

20
Multi-Level Mining: Progressive Deepening
A top-down, progressive deepening approach: First mine high-level frequent items:
milk (15%), bread (10%) Then mine their lower-level “weaker” frequent itemsets:
2% milk (5%), wheat bread (4%) Different min_support threshold across multi-
levels lead to different algorithms: If adopting the same min_support across multi-levels
then toss t if any of t’s ancestors is infrequent. If adopting reduced min_support at lower levels
then examine only those descendents whose ancestor’s support is frequent/non-negligible.

21
Association Rules & Correlations
Basic concepts Efficient and scalable frequent itemset mining
methods: Apriori, and improvements FP-growth
Rule derivation, visualization and validation Multi-level Associations Temporal associations and frequent sequences Other association mining methods Summary Temporal associations and frequent sequences [later]

22
Other Association Mining Methods
CHARM: Mining frequent itemsets by a Vertical Data Format
Mining Frequent Closed Patterns Mining Max-patterns Mining Quantitative Associations [e.g., what is the
implication between age and income?] Constraint-base association mining Frequent Patterns in Data Streams: very difficult problem.
Performance is a real issue Constraint-based (Query-Directed) Mining Mining sequential and structured patterns

23
Summary
Association rule mining probably the most significant contribution
from the database community in KDD
New interesting research directions Association analysis in other types of
data: spatial data, multimedia data, time series data,
Association Rule Mining for Data Streams: a very difficult challenge.

24
Statistical Independence
Population of 1000 students 600 students know how to swim (S) 700 students know how to bike (B) 420 students know how to swim and bike (S,B)
P(SB) = 420/1000 = 0.42 P(S) P(B) = 0.6 0.7 = 0.42
P(SB) = P(S) P(B) => Statistical independence P(SB) > P(S) P(B) => Positively correlated P(SB) < P(S) P(B) => Negatively correlated
Related Documents











