1

1. 2 3 Example of a Decision Tree categorical continuous class Refund MarSt TaxInc YES NO YesNo Married Single, Divorced < 80K> 80K Splitting Attributes.
Dec 21, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1

2
3
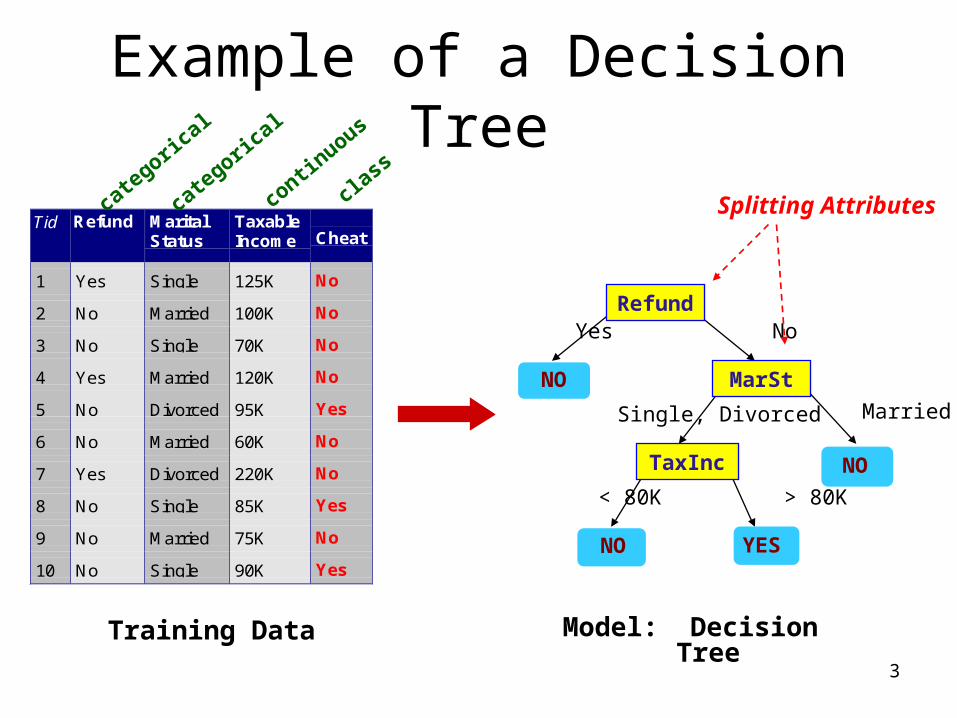
Example of a Decision Tree
Tid Refund MaritalStatus
TaxableIncome Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes10
categoric
al
categoric
al
continuous
class
Refund
MarSt
TaxInc
YESNO
NO
NO
Yes No
Married Single, Divorced
< 80K > 80K
Splitting Attributes
Training Data Model: Decision Tree
4
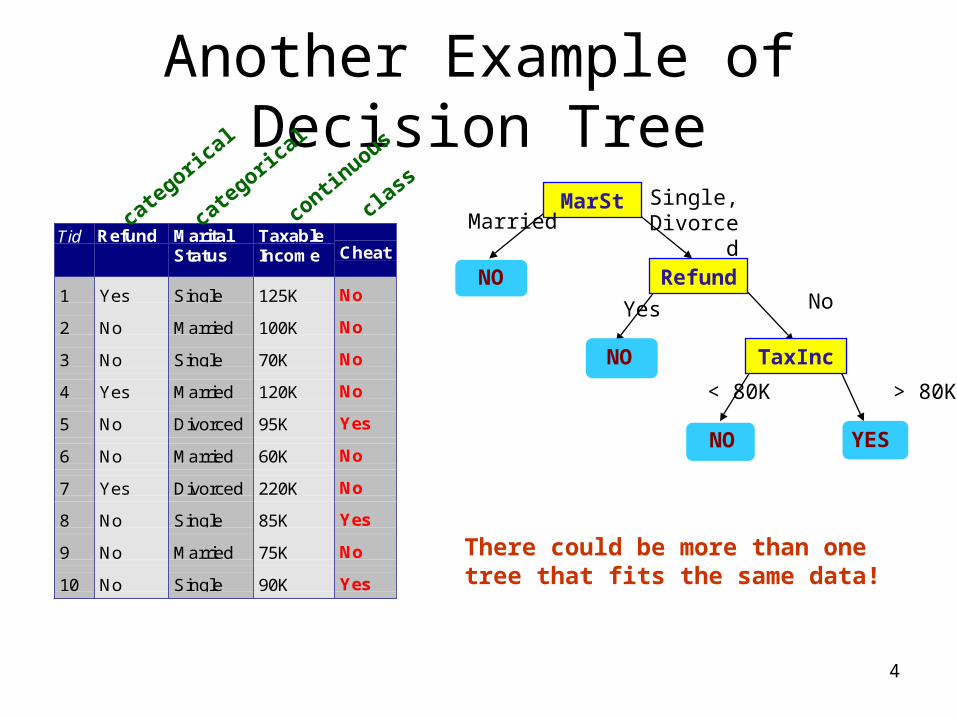
Another Example of Decision Tree
Tid Refund MaritalStatus
TaxableIncome Cheat
1 Yes Single 125K No
2 No Married 100K No
3 No Single 70K No
4 Yes Married 120K No
5 No Divorced 95K Yes
6 No Married 60K No
7 Yes Divorced 220K No
8 No Single 85K Yes
9 No Married 75K No
10 No Single 90K Yes10
categoric
al
categoric
al
continuous
classMarSt
Refund
TaxInc
YESNO
NO
NO
Yes No
Married Single,
Divorced
< 80K > 80K
There could be more than one tree that fits the same data!
5
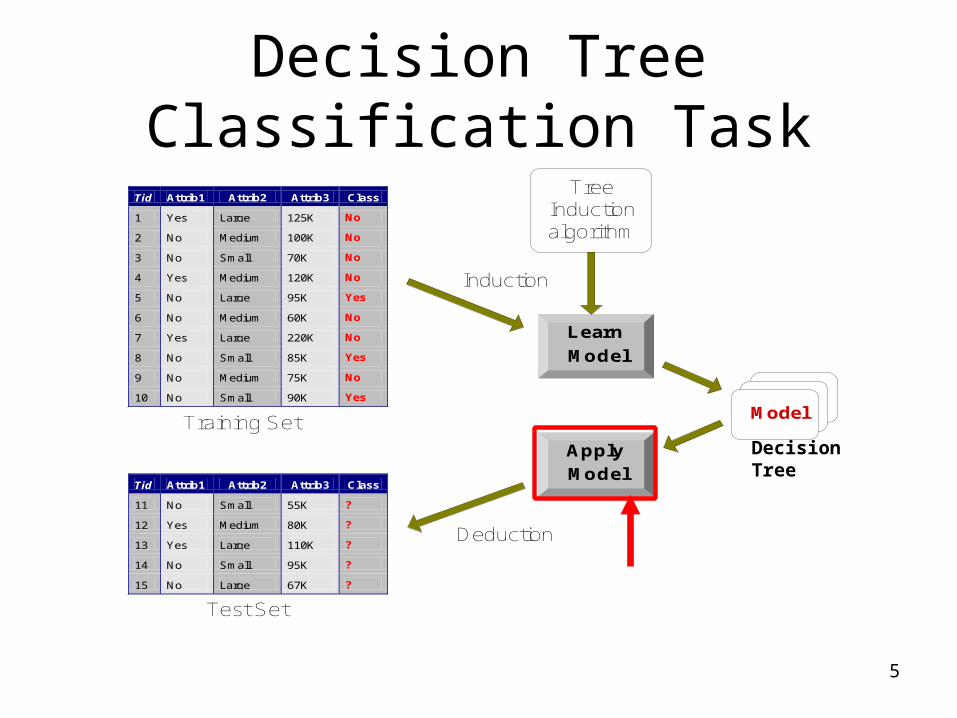
Decision Tree Classification Task
Apply
Model
Induction
Deduction
Learn
Model
Model
Tid Attrib1 Attrib2 Attrib3 Class
1 Yes Large 125K No
2 No Medium 100K No
3 No Small 70K No
4 Yes Medium 120K No
5 No Large 95K Yes
6 No Medium 60K No
7 Yes Large 220K No
8 No Small 85K Yes
9 No Medium 75K No
10 No Small 90K Yes 10
Tid Attrib1 Attrib2 Attrib3 Class
11 No Small 55K ?
12 Yes Medium 80K ?
13 Yes Large 110K ?
14 No Small 95K ?
15 No Large 67K ? 10
Test Set
TreeInductionalgorithm
Training SetDecision Tree

6
7
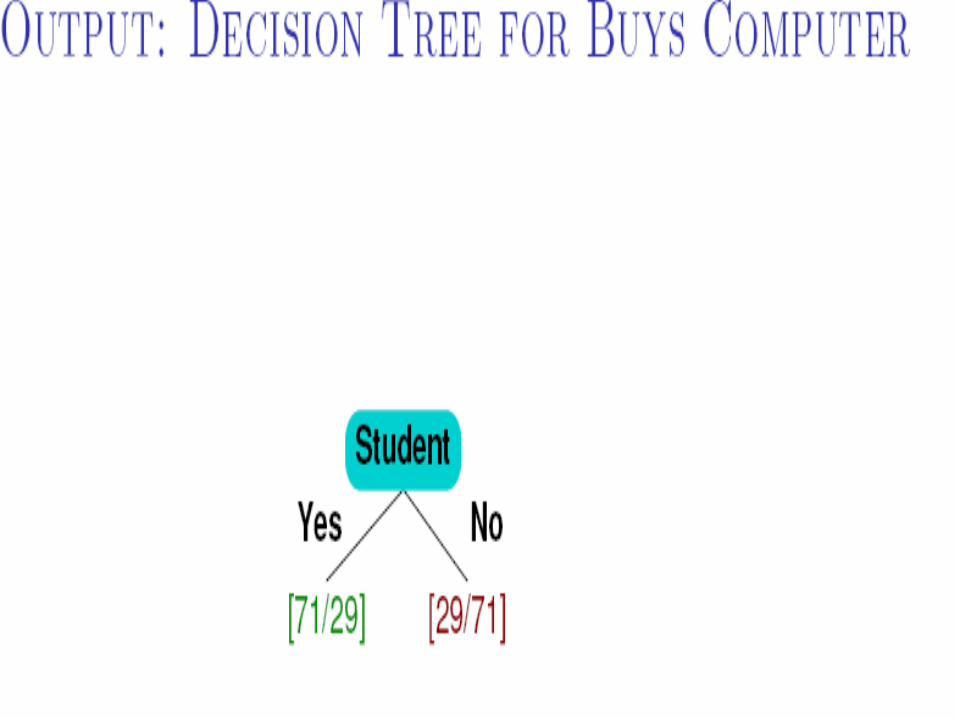
8
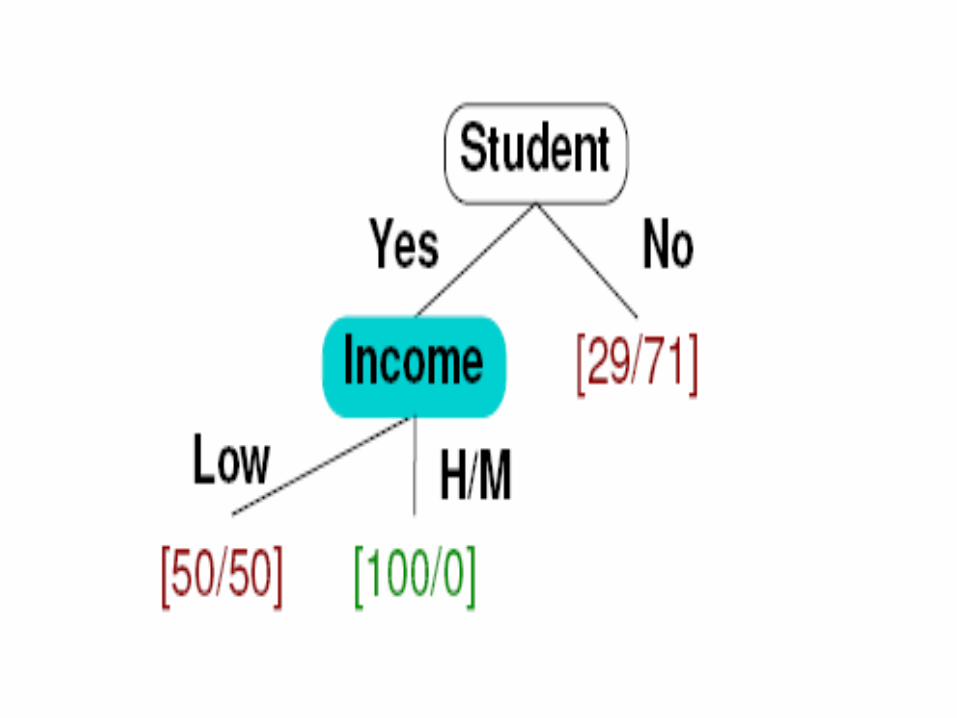
9
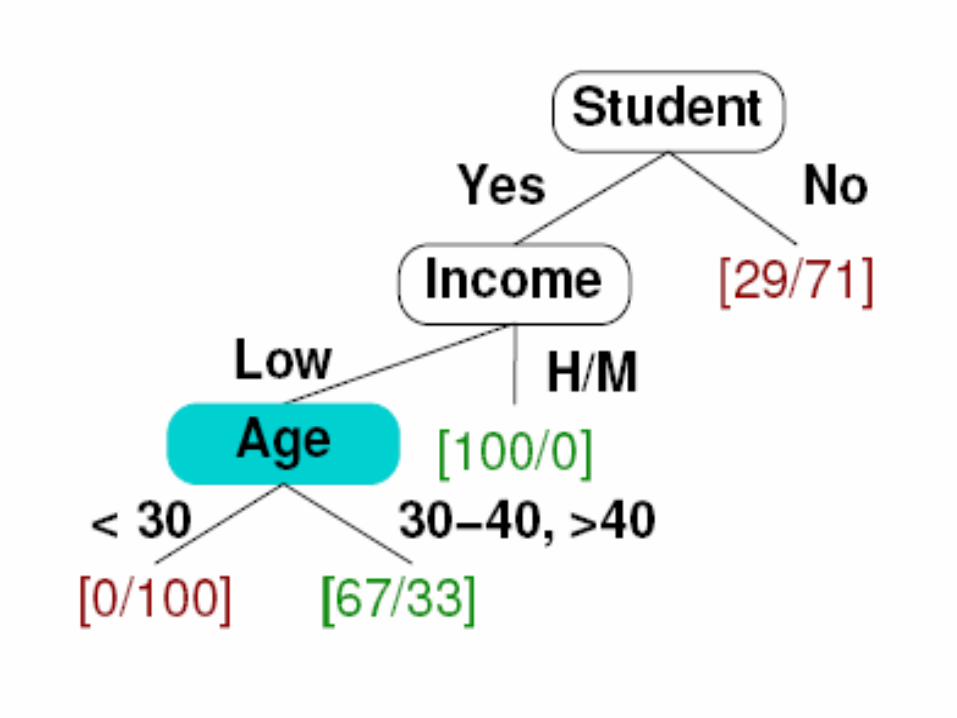
10

11

12

13
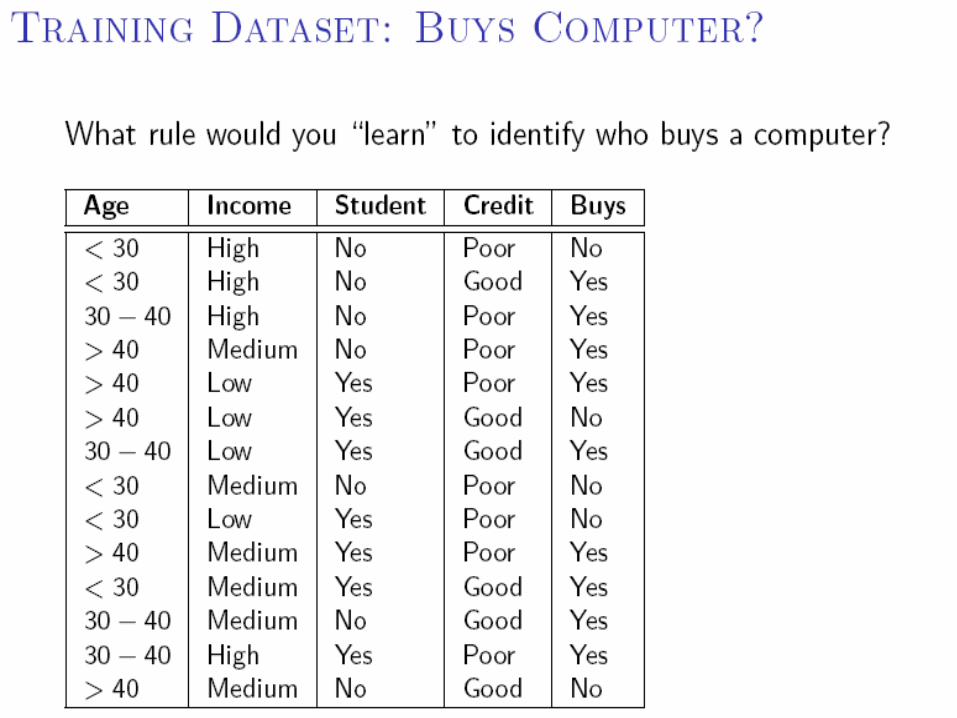
Decision Tree Induction is often based on Information Theory
14
Information

15
DT Induction
• When all the marbles in the bowl are mixed up, little information is given.
• When the marbles in the bowl are all from one class and those in the other two classes are on either side, more information is given.
Use this approach with DT Induction !

16

17
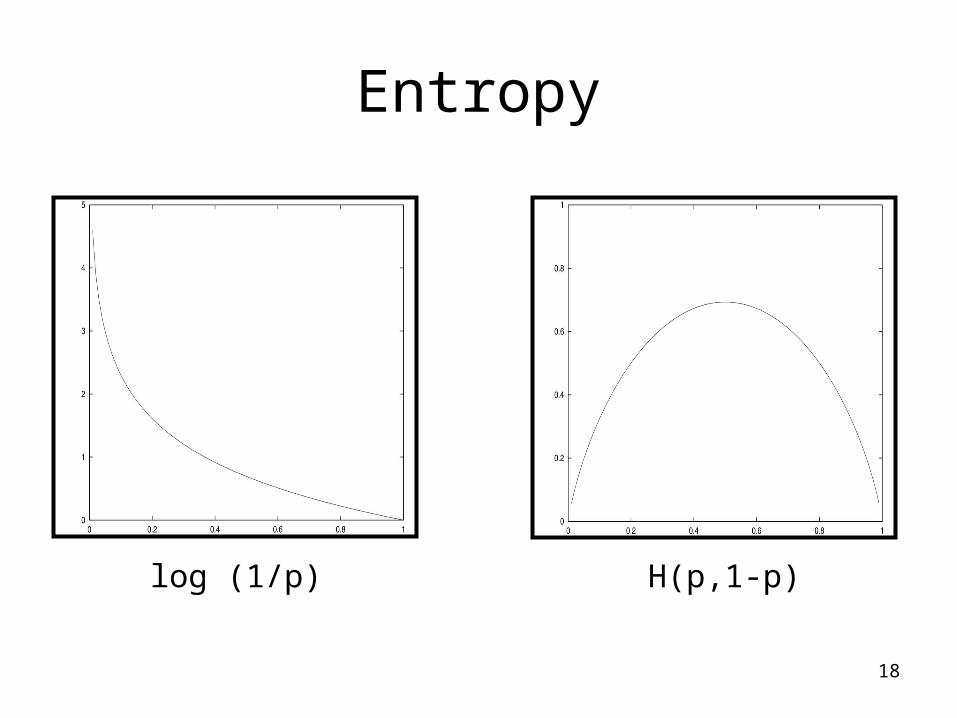
Information/Entropy• Given probabilitites p1, p2, .., ps whose sum is
1, Entropy is defined as:
• Entropy measures the amount of randomness or surprise or uncertainty.
• Goal in classification– no surprise– entropy = 0
18
Entropy
log (1/p) H(p,1-p)

19

20
ID3• Creates tree using information theory
concepts and tries to reduce expected number of comparison..
• ID3 chooses split attribute with the highest information gain:

21
C4.5• ID3 favors attributes with large number of
divisions
• Improved version of ID3:– Missing Data– Continuous Data– Pruning– Rules– GainRatio:

22
CART
• Create Binary Tree• Uses entropy• Formula to choose split point, s, for node t:
• PL,PR : probability that a tuple in the training set will be on the left or right side of the tree.

23
Measure of Impurity: GINI
• Gini Index for a given node t :
(NOTE: p( j | t) is the relative frequency of class j at node t).
– Maximum (1 - 1/nc) when records are equally distributed among all classes, implying least interesting information
– Minimum (0.0) when all records belong to one class, implying most interesting information
j
tjptGINI 2)]|([1)(
C1 0C2 6
Gini=0.000
C1 2C2 4
Gini=0.444
C1 3C2 3
Gini=0.500
C1 1C2 5
Gini=0.278

24
Examples for computing GINI
C1 0 C2 6
C1 2 C2 4
C1 1 C2 5
P(C1) = 0/6 = 0 P(C2) = 6/6 = 1
Gini = 1 – P(C1)2 – P(C2)2 = 1 – 0 – 1 = 0
j
tjptGINI 2)]|([1)(
P(C1) = 1/6 P(C2) = 5/6
Gini = 1 – (1/6)2 – (5/6)2 = 0.278
P(C1) = 2/6 P(C2) = 4/6
Gini = 1 – (2/6)2 – (4/6)2 = 0.444

25
Splitting Based on GINI• Used in CART, SLIQ, SPRINT.• When a node p is split into k partitions (children),
the quality of split is computed as,
where, ni = number of records at child i,
n = number of records at node p.
k
i
isplit iGINI
n
nGINI
1
)(

26
Stopping Criteria for Tree Induction
• Stop expanding a node when all the records belong to the same class
• Stop expanding a node when all the records have similar attribute values
• Early termination

27
Notes on Overfitting
• Overfitting results in decision trees that are more complex than necessary
• Training error no longer provides a good estimate of how well the tree will perform on previously unseen records
• Need new ways for estimating errors

28
Estimating Generalization Errors
• Re-substitution errors: error on training ( e(t) )• Generalization errors: error on testing ( e’(t))
• Methods for estimating generalization errors:– Optimistic approach: e’(t) = e(t)– Pessimistic approach:
• For each leaf node: e’(t) = (e(t)+0.5) • Total errors: e’(T) = e(T) + N 0.5 (N: number of leaf nodes)• For a tree with 30 leaf nodes and 10 errors on training
(out of 1000 instances): Training error = 10/1000 = 1%
Generalization error = (10 + 300.5)/1000 = 2.5%– Reduced error pruning (REP):
• uses validation data set to estimate generalization error
29
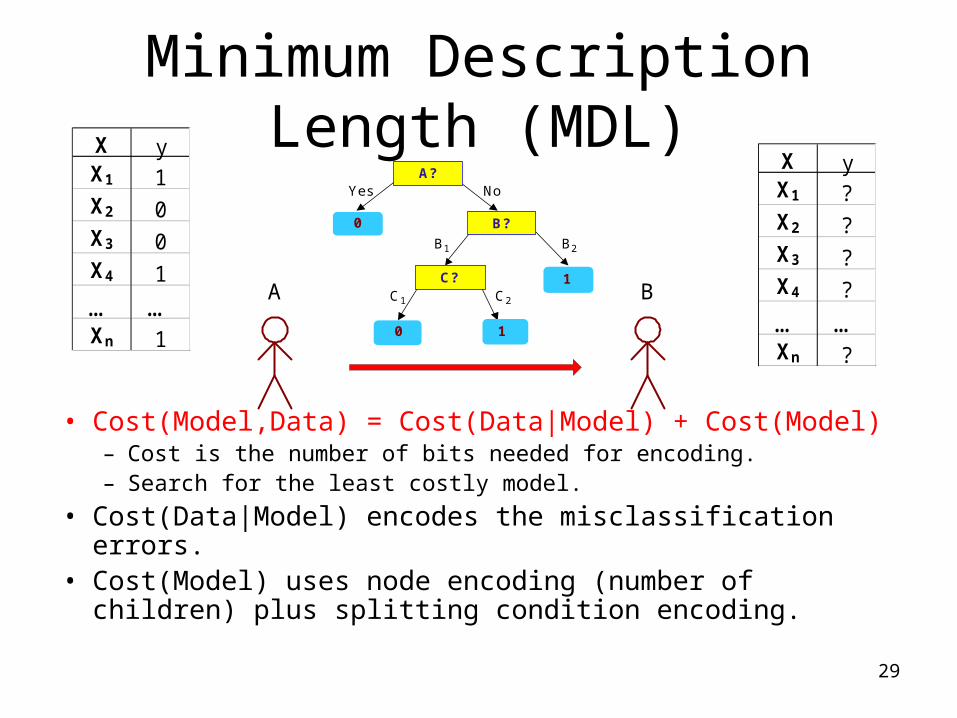
Minimum Description Length (MDL)
• Cost(Model,Data) = Cost(Data|Model) + Cost(Model)– Cost is the number of bits needed for encoding.– Search for the least costly model.
• Cost(Data|Model) encodes the misclassification errors.• Cost(Model) uses node encoding (number of children)
plus splitting condition encoding.
A B
A?
B?
C?
10
0
1
Yes No
B1 B2
C1 C2
X yX1 1X2 0X3 0X4 1
… …Xn 1
X yX1 ?X2 ?X3 ?X4 ?
… …Xn ?

30
How to Address Overfitting• Pre-Pruning (Early Stopping Rule)
– Stop the algorithm before it becomes a fully-grown tree– Typical stopping conditions for a node:
• Stop if all instances belong to the same class• Stop if all the attribute values are the same
– More restrictive conditions:• Stop if number of instances is less than some user-specified threshold• Stop if expanding the current node does not improve impurity measures (e.g., Gini or information gain)•…

31
How to Address Overfitting…
• Post-pruning– Grow decision tree to its entirety– Trim the nodes of the decision tree in a
bottom-up fashion– If generalization error improves after trimming,
replace sub-tree by a leaf node.– Class label of leaf node is determined from
majority class of instances in the sub-tree– Can use MDL for post-pruning

32
Example of Post-Pruning
A?
A1
A2 A3
A4
Class = Yes 20
Class = No 10
Error = 10/30
Training Error (Before splitting) = 10/30
Pessimistic error = (10 + 0.5)/30 = 10.5/30
Training Error (After splitting) = 9/30
Pessimistic error (After splitting)
= (9 + 4 0.5)/30 = 11/30
PRUNE!
Class = Yes
8
Class = No
4
Class = Yes
3
Class = No
4
Class = Yes
4
Class = No
1
Class = Yes
5
Class = No
1
33
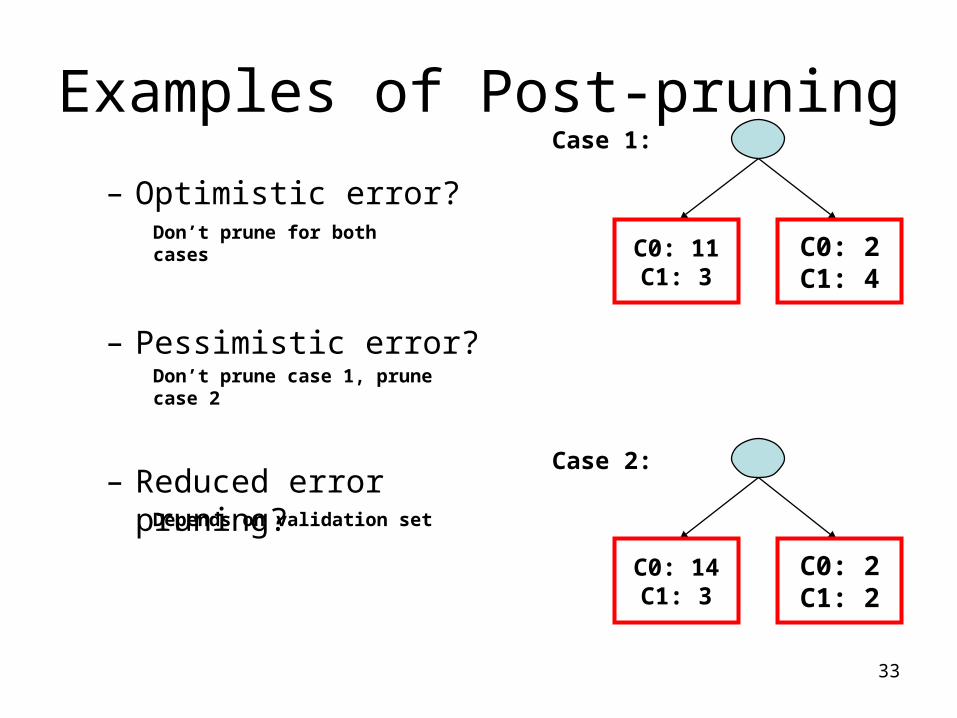
– Optimistic error?
– Pessimistic error?
– Reduced error pruning?
Examples of Post-pruning
C0: 11C1: 3
C0: 2C1: 4
C0: 14C1: 3
C0: 2C1: 2
Don’t prune for both cases
Don’t prune case 1, prune case 2
Case 1:
Case 2:
Depends on validation set

34

35
Related Documents











