Опыт использования spark Основано на реальных событиях

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Опыт использования spark
Основано на реальных событиях

Чтение бинарных логов• задача - по логам найти тех, кто подбирает пароли• одна запись лога раскидана на несколько бинарных файлов• часть бинарных файлов = справочники• остальные файлы читаются последовательно• такую задачу можно решать на hadoop• также можно решать переводом бинарных данных в текстовый формат, но это потери
времени и ресурсов кластера

Чтение в hadoop
InputFormat
split
split
split
RecordReader
RecordReader
RecordReader
Record
Record
Record

Использование в спарк• этапы решения
• работа с бинарными файлами в одном потоке• упаковка логики в inputformat, record reader• написание mr джоба
• как это всё засунуть в спаркval fileRDDs = filesToProcess.toArray.map{ file => sc.newAPIHadoopFile[IntWritable, Text, BWLogsInputFormat[IntWritable, Text]](file)}val rdd = new UnionRDD(sc, fileRDDs)

Оптимизация ETL
конвертировать бинлоги в текстовое представление,не всегда это можно сделать даже используя fuseи это приведёт к потери времени и ресурсов кластера
бинарные данные
текстовые данные
обработка

Запись с группировкой по директориям
• проблема: rdd.saveAsTextFile(“/var/blob/result”) сохраняет всё в директорию path/var/blob/result/part-00000/var/blob/result/part-00001
• чего хотелось бы: разбить данные по директориям - партицировать по значениям полей
/var/blob/result/type1/part-00000/var/blob/result/type1/part-00001/var/blob/result/type2/part-00000/var/blob/result/type2/part-00001/var/blob/result/type3/part-00000/var/blob/result/type3/part-00001/var/blob/result/type4/part-00000/var/blob/result/type4/part-00001

N+1 чтение resultRdd.map {
x => x._1 //partition value }.distinct().collect()/* first read*/.foreach {
part => resultRdd.filter(part.equals(_._1))/* N reads*/.saveAsTextFile("path/" + part) }

1 чтение и много кода resultRdd.foreachPartition {
p =>
val hdfs = HdfsUtils.setupHdfs(hdfsConf)
val pathToOut = collection.mutable.Map[String, FSDataOutputStream]()
try {
//save to dirs by value
p.foreach(csv => {
val fileName = "%1$s/%2$s/%3$s".format(sortByDateDir, dateValue, exeDirName)
val output = getFileOutput(fileName, pathToOut, hdfs)
output.write(csv._2.toString.getBytes("utf8"))
output.writeBytes(CSV_DELIMITER)
})
} catch {
case t: Throwable => {
log.error("" + t, t)
}
}
pathToOut.foreach(out => {
tryToCloseNTimes(out._2, 5, 2000)
})
}
def getFileOutput(fileName: String, files: collection.mutable.Map[String, FSDataOutputStream], fs: FileSystem): FSDataOutputStream = {
//20 lines of code
}

1 чтение + мало кодироватьclass KeyPartitionedMultipleTextOutputFormat extends MultipleTextOutputFormat[NullWritable, String] { override def generateFileNameForKeyValue(key: NullWritable, value: String, name: String): String = {
val elements = value.toString.split(",")"key%1$s/%2$s".format(elements(1), name)
}}
val pairRdd = new PairRDDFunctions[NullWritable, String](pairBlob)pairRdd.saveAsHadoopFile(fs.getUri + config.dstDir, classOf[NullWritable], classOf[String], classOf[KeyPartitionedMultipleTextOutputFormat], conf = new JobConf(appConf))

Скорость и надёжность кафки• чем хороша кафка
• легко масштабировать• хорошая скорость чтения записи
• недостатки• для предсказуемого поведения с оффсетами и равномерностью чтения партиций
лучше использовать низкоуровневый simpleconsumer• документация - лучше сразу смотреть исходники
• важно не путать её с jms очередями
топик
партиция 1
партиция 2
партиция 3
реплика 1
реплика 2

Актуальный сценарий интеграции
серверное приложение (C++ python)
логика отправки данных в кафку кафка
спарк batch & streaming
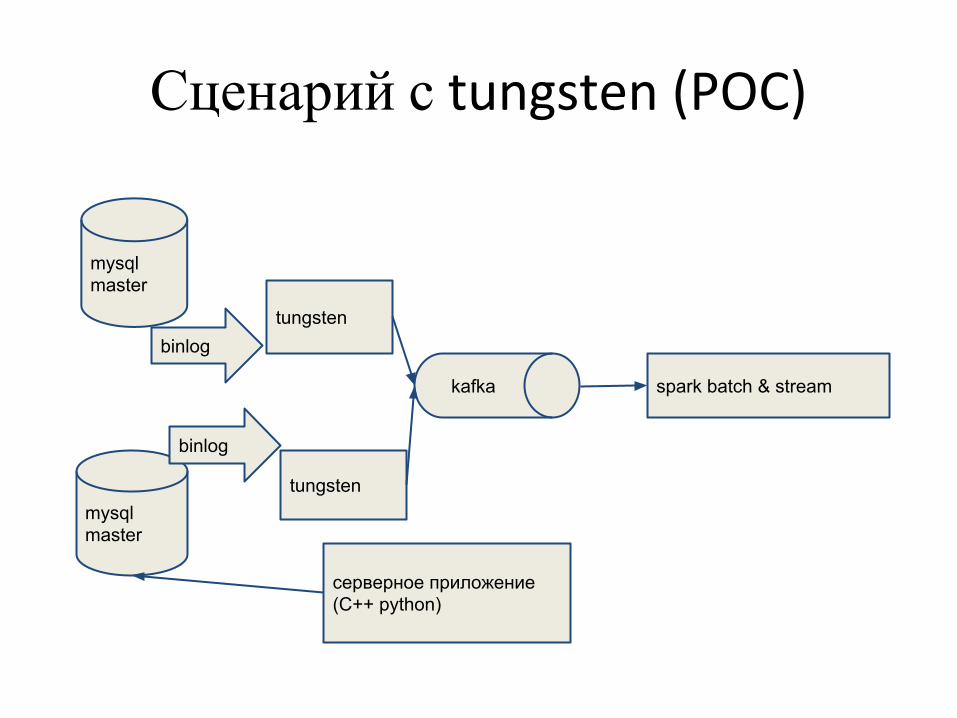
Сценарий с tungsten (POC)
mysql master
tungsten
spark batch & streamkafka
mysql master
tungsten
binlog
binlog
серверное приложение (С++ python)

Типичный ETL сценарий
mysql
dump csv + tgz HDFS spark
тут напрягаем периодически mysql сервер дампами, невозможно сделать журнал
тут скорость будет хуже чем у кафка,удобнее писать читать кафку чем hdfs

Чтение из Кафки
• создан inputformat для чтение топиков из кафки (по мотивам camus)• алгоритм работы
• для каждого осчетания топик+партиция создать сплит• в рамках обработки сплита посмотреть текущие оффсеты записи и поднять
последние оффсеты чтения с hdfs• выполнить чтение и сохранить новые оффсеты чтения на hdfs
• недостатки• хранение оффсетов чтения на hdfs• неравномерная загрузка кластера в случае малого числа партиций или
неравномерной загрузки партиций• проблема отсутствия лидера партиции на момент старта выгрузки

Спарк Стриминг• приницип работы - создавать рдд на основе принятых данных и обрабатывать их• позволяет партицировать поток (получать данные на нескольких нодах одновременно)
val allInputs = (0 to numberOfNodes - 1).map {x =>SparkUtils.createStreamPartition(ssc, ...)}
• позволяет работать с окнами = запоминает набор рдд для окна• для отказоустойчивости есть механизм сохранения снимков рдд• позволяет сделать ограничитель скорости приёма данных

Недостатки Стриминга• трудно организовать обработку данных без потерь (но для стриминга это не всегда нужно)
• проблема в блок генераторе• получили данные из потока• закинули данные в блок генератор на создание рдд• данные попадают в буффер (для асинхронности и скорости)• с задержкой по времени данные попадают в рдд
• т.е. при падении есть вероятность потерять содержимое буфера• есть возможности это обойти при условии возможности перечитать данные из потока
• надо играть настройками генератора рдд чтобы избежать OOMspark.streaming.blockInterval=100 (в миллисекундах)
канал сообщений
Генератор РДДОкно РДД (память + диск)
РДД РДД РДДБуфер

Работа с потоком из кафки• в поставке спарка есть реализация кафка стрима, но она не устроила
• основана на высокоуровневом апи кафка ридера с его проблемами сохранения офсетов и равномерностью нагрузки на чтение
• задача где используется• вычислять качество соединения в 5ти минутных окнах и отображать на карте мира

Своя реализация стримера• оффсеты сохраняются после каждого чтения в hbase• чтение партиций равномерное в рамках пула потоков• поддержка партицирования чтения потока• поддержка механизма метрик в спарке (основан на codahale metrics)
• скорость приёма данных• отставание

Недостатки реализации• завязан на hbase - надо вынести на уровень апи возможность подсунуть свою реализацию
хранилища• не реализовано восстановление после падения с учётом потери буфера генератора рдд -
нет необходимости это делать, но возможность есть

Проблемы внедрения• как и во что собрать? как запускать?
• 3 опции• uberjar + java -jar• spark-submit --deploy-mode client• spark-submit --deploy-mode cluster
• как передать конфиги?• актуально для spark-submit --deploy-mode cluster• решается через --files /path/to/config.xml
• что делать с ошибками сериализации?• понять как работает спарк приложение + рефакторинг кода
val rdd = sc.textFile("") val a = ... val resultRdd = rdd.map {
x => (x, a) }

Всё
Related Documents











