1 2016-06-30 ●シンプルでシステマチックな Linux 性能分析方法 日本オラクル株式会社 テクノロジーコンサルティング統括本部 畔勝洋平(あぜかつ ようへい) ※この発表の内容は私自身の個人的な見解で、所属する組織とは関係ありません UEK(Unbreakable Enterprise Kernel) なら DTrace が使える!

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
2016-06-30 ●シンプルでシステマチックな Linux 性能分析方法
日本オラクル株式会社
テクノロジーコンサルティング統括本部
畔勝洋平(あぜかつ ようへい)
※この発表の内容は私自身の個人的な見解で、所属する組織とは関係ありません
UEK(Unbreakable Enterprise Kernel) なら DTrace が使える!

Twitter: @yoheia
Blog: http://d.hatena.ne.jp/yohei-a
著書(共著):絵で見てわかるITインフラの仕組み
JPOUG(Japan Oracle User Group)の運営に関わってます
略歴:
• 大阪生まれ和歌山育ち
• Webデザイナー&プログラマなど@大阪
• フリーランスエンジニア@東京
• ドワンゴ(明治座の頃)
• 日本オラクル ← イマココ
自己紹介
2
カバーを裏返すとシステムの全貌がわかる解剖図
2013年ジュンク堂池袋本店コンピュータ書
売上冊数ランキング第5位
http://compbook.g.hatena.ne.jp/compbook/20140107/p1

3
Brendan D. Gregg http://www.brendangregg.com
LinuxCon
BSD conference
Oaktable
など幅広く活動
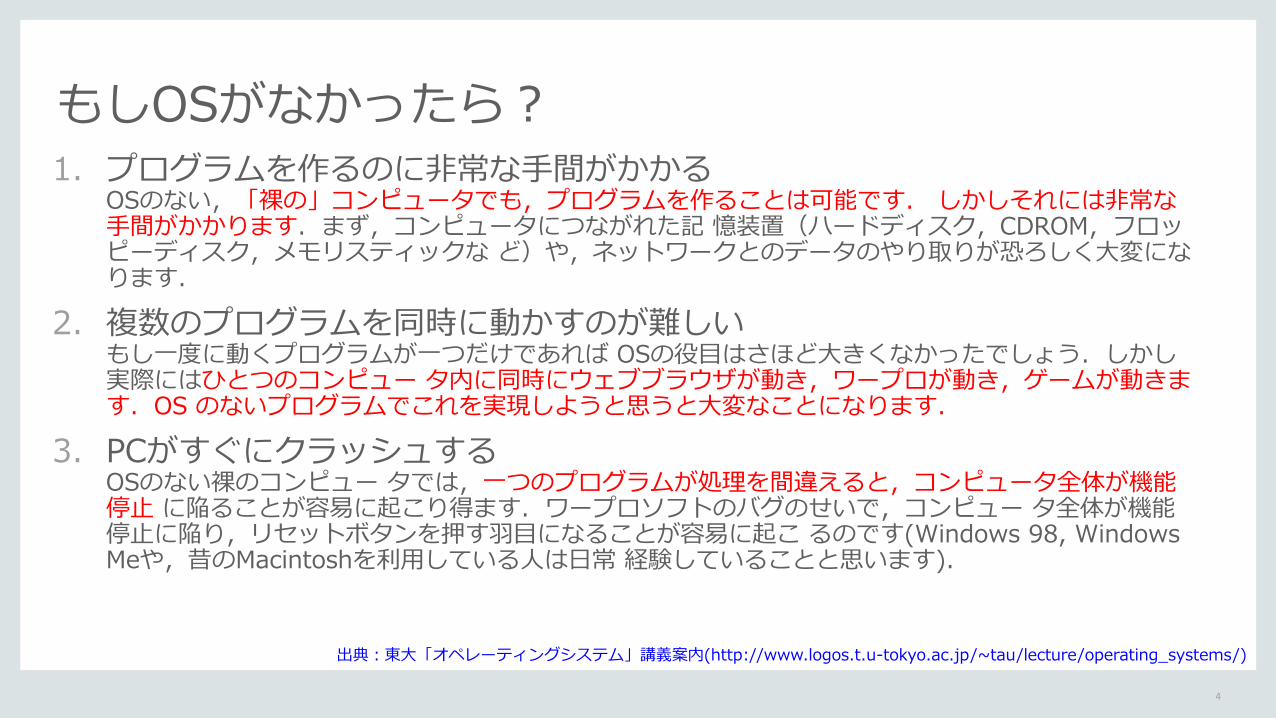
1. プログラムを作るのに非常な手間がかかる OSのない,「裸の」コンピュータでも,プログラムを作ることは可能です. しかしそれには非常な手間がかかります.まず,コンピュータにつながれた記 憶装置(ハードディスク,CDROM,フロッピーディスク,メモリスティックな ど)や,ネットワークとのデータのやり取りが恐ろしく大変になります.
2. 複数のプログラムを同時に動かすのが難しい もし一度に動くプログラムが一つだけであれば OSの役目はさほど大きくなかったでしょう.しかし実際にはひとつのコンピュー タ内に同時にウェブブラウザが動き,ワープロが動き,ゲームが動きます.OS のないプログラムでこれを実現しようと思うと大変なことになります.
3. PCがすぐにクラッシュする OSのない裸のコンピュー タでは,一つのプログラムが処理を間違えると,コンピュータ全体が機能停止 に陥ることが容易に起こり得ます.ワープロソフトのバグのせいで,コンピュー タ全体が機能停止に陥り,リセットボタンを押す羽目になることが容易に起こ るのです(Windows 98, Windows Meや,昔のMacintoshを利用している人は日常 経験していることと思います).
もしOSがなかったら?
4
出典:東大「オペレーティングシステム」講義案内(http://www.logos.t.u-tokyo.ac.jp/~tau/lecture/operating_systems/)

OSの歴史
Oracle Confidential – Internal/Restricted/Highl
5
出典:Wikipedia と http://danjo.city.kashiwa.lg.jp/gakushuu/pcschool/pc_history/comp_history09.htm
現在のOSの概念や基本部分(カーネル)の技術の大半は、この1960年代に完成された。それらの技術は今もあなたが使っている Windows 7、Linux、OS X、iPhone、Android に引継がれている。”ls “コマンドのルーツは Multics の “list segments” に遡る。
デヴィッド・カトラー DECでVMS、MSでWindows NT を開発。NT-2000-XP-Vista-7-8は全てNTの子孫。
ケン・トンプソン ベル研究所でMulticsの開発に参加後、UNIX、C言語、正規表現などを開発。現在はGoogleでGo言語の開発などに携わっている ビル・ジョイ カリフォルニア大学バークレー校でBSD UNIX、vi、csh などを開発。Sunでは、NFS、SPARC プロセッサ、Java の開発などで大きな役割を果たした。 。BSD UNIX からSunOS/Solaris などが生まれ、Mac OS XもBSDをベース。
リーナス・トーバルズ アンドリュー・タネンバウムのMinixに刺激を受け、Linuxカーネルを開発した。
基本原理は変わらない。本質を理解していると新しい技術にもすぐキャッチアップできる(物理法則は変わらない!)

もくじ
1
2
3
4
5
性能問題は交通渋滞と同じ
渋滞を見つけて原因を特定する方法
CPU編
メモリ編
ディスク編
参考情報
お願い
6
6
7

7
性能問題は交通渋滞と同じ 現実世界で使っている考え方をコンピュータ世界に当てはめるだけ!(実はカンタン)

交通渋滞の原因は2つ
1. 交通量が多い(性能限界)
単純に交通量が多くて渋滞している
例)年末年始やお盆の帰省ラッシュやUターンラッシュ
⇒ 対処方法:車線を増やす(CPU増設、サーバ追加)
2. 途中の経路が詰まっている(ボトルネック)
車線減少や通行止めなどで渋滞している
例)年度末の工事による車線減少、交通事故による通行止め
⇒ 対処方法:レッカー車で事故車を移動
性能問題は交通渋滞と同じ
8
性能問題のほとんどはボトルネックの発生によるもの

詰まっている原因を見つけて、原因を取り除く
1. 車線が減少している場所を見つける
2. 車線が減少している原因を見つける
3. 車線数を元に戻す
途中の経路が詰まっている場合
9
1. 車線減少で交通渋滞
交通渋滞
2. 事故車が原因 3. 事故車を撤去
ここがボトルネック(瓶の首のように細く
詰まる所)

ボトルネックを見つけて原因を特定する
1. ボトルネックを見つける
2. ドリルダウンして原因を特定する
3. 原因を取り除く(チューニングなど)
コンピュータの世界では
10
メモリ CPU
Disk NIC
usr
sys
wa
idle
1. ボトルネックを見つける
プロセ
ス1
プロセ
ス2
2.ドリルダウンして原因特定
3. 原因を取り除く
I/Oスケジューラ
プロセススケジューラ
メモリ管理

渋滞を見つけて原因を特定する方法 長蛇の列ができている箇所を見つけたら、ドリルダウンして原因を特定する
11

USE Method by Brendan Gregg
12
1. Utilization(使用率)
2. Saturation(サチり度、どれくらい行列待ちしてるか)
3. Errors(エラー)
出典: Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098] http://www.brendangregg.com/usemethod.html
使用率(Utilization)が100%を超えると行例ができる。実際には100%より低い使用率でも行例待ちが
増えることもある。
Errors

USEでボトルネックを見つける(1/2)
13
CPU、メモリ、ディスクなどのH/WリソースをUtilization、Saturation、Errorsの3つでチェックしてボトルネックを見つける
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]

USEでボトルネックを見つける(2/2)
14
具体的にはどんなコマンドでチェックすれば良いのか?
出典: http://www.brendangregg.com/USEmethod/use-linux.html http://www.atmarkit.co.jp/ait/articles/0803/18/news147_2.html
例えば、CPU使用率は vmstat の us + sys などで見ることができる ※ st(eal)列にはゲストOSがリソース要求を行ったにもかかわらずCPUリソースを割り当ててもらえなかった時間の割合

USE でボトルネックを発見したらドリルダウン
15
ボトルネックを発見したらドリルダウンして原因を特定
usr
sys
wa
idle
ボトルネックを見つけたらドリルダウン
する
適切なコマンドを使って調査する
様々なコマンドがあるが /proc などカーネルのメモリにアクセス
していることが多い
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098] http://www.brendangregg.com/linuxperf.html

CPU編 • アーキテクチャ – ハードウェア編 • アーキテクチャ – ソフトウェア編 • 分析方法 - USE Method • 分析方法 - ドリルダウン • 分析例
16

CPU編 アーキテクチャ – ハードウェア編
17

CPU - アーキテクチャ(1/3)
18
ハードウェア OSから見えるCPU
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
論理CPU
UMA(Uniform Memory Access)
NUMA(Non-Uniform Memory Access)
ハードウェア スレッド
コア

CPU - アーキテクチャ – H/W編(2/3)
19
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
Zoom up
下の階層に行くほど遅い

CPU - アーキテクチャ – H/W編(3/3)
20
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
仮にCPUの1サイクルを1秒とすると、ハードディスクへのアクセスは1ヶ月~1年にもなる!

CPU編 アーキテクチャ – ソフトウェア編
21

22
論理CPU
Linux では On-CPU も Ready to run もランキューにカウントされる
マルチプロセス Oracle Database on Linux
マルチスレッド Oracle Database on Windows、JVM
割当てられたCPU時間(タイムスライス)を使いきると待ち行列の最後尾に戻される(タイムシェアリン
グ)
RACのLMSプロセスはリアルタイムクラスで動作するためCPUを占有することがある(KROWN#120958)
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
CPU - アーキテクチャ - S/W編

CPU編 分析方法 - USE Method
23

CPU - USE - Utilization
24
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098] http://www.brendangregg.com/USEmethod/use-linux.html
vmstat: us + sy + st sar -u: 100% - (%idle + %iowait)
mpstat -P ALL 1: 100% - (%idle + %iowait) sar -P ALL: 100% - (%idle + %iowait)
システム全体のCPU使用率は低くても、CPU別に見ると特定のCPUだけ使用率が高い場合がある。例えば、2CPUのマシンでシステム全体のCPU使用率が50%の場合、CPU別に見ると、1CPUは100%で張り付いていることがある。 ※CPU:論理CPU

CPU - USE - Saturation
25 25
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098] http://www.brendangregg.com/USEmethod/use-linux.html
vmstat : r sar -q: runq-sz
Linux のランキュー数には On-CPU と Ready to run の両方が含まれる。例えば、2CPUでランキューが4の場合、2プロセスは On-CPU、残り2プロセスはCPU待ちとなる(Systems Performance: Enterprise and the Cloud - 6.6.2. vmstat “On Linux, the r column is the total number of tasks waiting plus those running")。 ランキューの数 > 論理CPU数 の場合、サチっていると言える。常に「ランキュー数 > 論理CPU数」の状態では、CPU使用率は100%になり、常にランキューでCPU待ちになっているプロセスが存在することになる。

CPU - USE - Errors
26 26 26
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098] http://www.brendangregg.com/USEmethod/use-linux.html
perf perf コマンドでエラーをチェックできるらしい “perf (LPE) if processor specific error events (CPC) are available; eg, AMD64's "04Ah Single-bit ECC Errors Recorded by Scrubber" [4]” http://www.brendangregg.com/USEmethod/use-linux.html

CPU編 分析方法 -ドリルダウン
27

カーネル
ユーザープロセス
CPU - ドリルダウン(1/2)
28
ユーザーモード vmstat.us
カーネルモード vmstat.sy
I/O待ち %iowait
システムコール(%sys)
ひま
%idle
割込み(%irq + %soft)
カーネルスレッド(%sys)
処理量が多い
特定のプロセスが消費
ドリルダウン
CPU使用率の内訳
vmstat(合計) mpstat(CPU別) sar(事例列推移)
システムコール
割込み
デバイスドライバ

29
出典:Linux Kernel Development, Third Edition - Table 11.1. Frequency of the Timer Interrupt [ISBN-10: 0672329468] http://shallahamer-orapub.blogspot.com/2014/04/where-does-vosstat-get-its-data.html
KROWN#162332
[参考]CPU使用率はどのように算出されるか
10ms 10ms 10ms 10ms 10ms 10ms 10ms
10msごとに割込んで誰がどのモードでCPUを使っているかチェックしている
user kernel kernel user CPUの時間
これ以降誰もCPUを使っていない
%usr %sys %iowait %idle
メモリにCPU使用率が累積方式で加算される(おそらく、プロセス別とCPU別に
記録される) /proc OSコマンド
MMON V$OSSTAT
AWR レポート
ps vmstat top mpstat など
Oracle Database もvmstat、topなどのコマンドも /proc を参照しているものが多い。/proc の実体はメモリにあるデータ。 /proc は累積値なので、例えば「vmstat 5」とすると、5秒間隔で/proc を参照して差分を計算して表示している(だから最初の1行目は無視する)。
V$ WRH$_OSSTAT
I/Oを発行してSleep(%iowaitはCPUは暇な状態)
カーネル空間のデータ

デモ
30
strace -e open ps -elf
strace –e open vmstat 1
strace -e open top -b > /dev/null
strace –e open iostat
strace -e open dstat 10 1

CPU -ドリルダウン(2/2)
31
ドリルダウン
CPU負荷が高い
ユーザー プログラム
カーネルモードの処理
システムコール
割込み
プロセス CPUを消費してい
る処理を特定
システムコールの種類特定する
割込みの種類を特定する
vmstat の us mpstat の %usr sar の %user
vmstat の sy mpstat の %sys sar の %system
top の %CPU
vmstat の in mpstat の %irq、%soft
vmstat の cs(参考レベル)
Perf SystemTap Dtrace(UEK)
具体的にCPU使用率の内訳をどのようなコマンドでドリルダウンするか
pstack perf oprofile SystemTap Dtrace(UEK)
strace perf
カーネルスレッド
top の %CPU
CPUを消費している処理を特定
pstack perf oprofile SystemTap Dtrace(UEK)

脱線 今朝、公開された Brendan Gregg が AWS re:Invent 2014 で発表したスライドからちょっと紹介
32

33
Utilization Saturation
ErrorsPer device
Breakdowns

34

CPU - 分析例(1/5)
35
4CPUでランキューは1~2なのでサチっていない
CPU使用率は30%程度だが、sys が24%程度で横ばい
システム全体の Utilization と Saturation をチェック
$ dstat -tv 5 (vmstat 5 の代り、今回は見やすいのでdstatにしました)
参考:http://d.hatena.ne.jp/yohei-a/20131208/1386485282

[参考]現実世界に例えよう!知ってる事ばかりだ!
36
参考:http://d.hatena.ne.jp/yohei-a/20101206/1291668680
注文待ちの行列
注文後の商品待ちの行列
注文待ちの行列
注文後の商品待ちの行列
vmstat や dstat をハンバーガーショップに例えてみます。r(run)列はレジで注文待ちの行列、b(blk)は注文後の商品待ちの行列、CPU使用率(usr + sys)はレジ担当者の稼働率と考えます。あなたがお客さんだとして混んでるかどうかはどのように判断していますか?

CPU - 分析例(2/5)
37
4CPUのうちの1つが100%近く、sys が80%程度となっている
CPU別の Utilization をチェック
$ dstat -taf 5 (mpstat -P –ALL 5 の代り、今回は見やすいのでdstatにしました)
参考:http://d.hatena.ne.jp/yohei-a/20131208/1386485282

CPU - 分析例(3/5)
38
CPUを消費しているプロセスを特定する
PID 5265 のプロセスが4CPUのうちの1つを使い切り、100%になっている
$ top -c
参考:http://d.hatena.ne.jp/yohei-a/20131208/1386485282

CPU - 分析例(4/5)
39
CPUを消費しているシステムコールを特定する
sysの割合が高いのはwriteシステムコールが大量に発行されていることが原因らしきことがわかる
$ strace -c -p [PID]
参考:http://d.hatena.ne.jp/yohei-a/20131208/1386485282

CPU - 分析例(5/5)
40
CPUを消費している関数を特定する
ユーザー空間、カーネル空間の両方の関数をCPU使用率が高い順に表示。システムコールより先のカーネル内の関数まで調べることができるので便利
# perf top -C [CPU Number]
参考:http://d.hatena.ne.jp/yohei-a/20131208/1386485282

CPU - 分析例(top をグラフ化する)
41
CPUを消費しているプロセスを見える化する $ top -bc -d 1 top - 12:08:54 up 20 days, 1:12, 10 users, load average: 4.62, 6.17, 6.16 Tasks: 351 total, 7 running, 344 sleeping, 0 stopped, 0 zombie Cpu(s): 51.7%us, 45.5%sy, 0.0%ni, 0.3%id, 0.2%wa, 0.0%hi, 1.7%si, 0.6%st Mem: 4104972k total, 3076880k used, 1028092k free, 9240k buffers Swap: 8385532k total, 1598312k used, 6787220k free, 1163316k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 14987 oracle 20 0 1476m 21m 20m R 27.1 0.5 4622:02 ora_qmnc_sharedb1 30079 oracle 20 0 1458m 95m 94m S 23.2 2.4 3869:49 ora_q003_sharedb1 9282 oracle 20 0 1456m 64m 64m S 3.9 1.6 471:45.36 ora_q01c_sharedb1 20642 oracle 20 0 1455m 63m 63m S 3.9 1.6 469:14.05 ora_q01b_sharedb1 24555 oracle 20 0 1455m 60m 60m S 3.9 1.5 539:35.26 ora_q000_sharedb1 24599 oracle 20 0 1456m 67m 66m R 3.9 1.7 467:57.12 ora_q004_sharedb1 24668 oracle 20 0 1459m 72m 68m S 3.9 1.8 528:19.15 ora_q009_sharedb1 24801 oracle 20 0 1457m 71m 68m S 3.9 1.8 469:24.25 ora_q00d_sharedb1 24972 oracle 20 0 1456m 69m 68m S 3.9 1.7 536:16.71 ora_q00h_sharedb1 24986 oracle 20 0 1455m 60m 59m S 3.9 1.5 531:50.28 ora_q00i_sharedb1 25105 oracle 20 0 1455m 62m 62m S 3.9 1.6 469:50.96 ora_q00l_sharedb1 25129 oracle 20 0 1456m 65m 64m S 3.9 1.6 470:35.82 ora_q00m_sharedb1 25278 oracle 20 0 1457m 68m 67m S 3.9 1.7 470:20.44 ora_q00q_sharedb1 25328 oracle 20 0 1455m 59m 59m S 3.9 1.5 543:32.96 ora_q00s_sharedb1 25371 oracle 20 0 1456m 61m 61m S 3.9 1.5 531:16.63 ora_q00t_sharedb1 25476 oracle 20 0 1457m 65m 65m S 3.9 1.6 528:18.89 ora_q00u_sharedb1 25660 oracle 20 0 1455m 63m 62m S 3.9 1.6 467:17.30 ora_q00w_sharedb1 27611 oracle 20 0 1455m 63m 62m S 3.9 1.6 466:30.37 ora_q010_sharedb1 28456 oracle 20 0 1456m 66m 63m S 3.9 1.7 466:30.15 ora_q014_sharedb1 29878 oracle 20 0 1455m 60m 59m S 3.9 1.5 540:15.48 ora_q005_sharedb1 1984 root 20 0 1146m 24m 14m S 1.9 0.6 103:23.97 /u01/app/11.2.0.4/grid/bin/ohasd.bin reboot 2549 root RT -5 887m 158m 62m S 1.9 4.0 388:37.52 /u01/app/11.2.0.4/grid/bin/ologgerd -M -d /u01/app/11.2.0.4/grid/crf/db/consdb112n1 5825 grid -2 0 1306m 4296 4164 S 1.9 0.1 336:10.59 asm_vktm_+ASM1 5843 grid 20 0 1315m 8656 7736 S 1.9 0.2 38:57.81 asm_lmon_+ASM1 6166 root 20 0 1181m 36m 18m S 1.9 0.9 165:44.51 /u01/app/11.2.0.4/grid/bin/crsd.bin reboot 6305 oracle 20 0 1456m 63m 63m S 1.9 1.6 475:39.25 ora_q016_sharedb1 6335 oracle 20 0 1455m 63m 62m S 1.9 1.6 469:22.68 ora_q017_sharedb1 7857 oracle 20 0 1456m 60m 60m S 1.9 1.5 541:25.79 ora_q01a_sharedb1 10910 oracle 20 0 1455m 63m 62m S 1.9 1.6 474:27.15 ora_q01d_sharedb1 21311 oracle 20 0 15208 1316 848 R 1.9 0.0 0:00.02 top -bc -d 1 24482 oracle 20 0 1459m 71m 70m R 1.9 1.8 468:10.14 ora_q006_sharedb1 24514 oracle 20 0 1456m 64m 64m S 1.9 1.6 466:55.69 ora_q001_sharedb1 24534 oracle 20 0 1455m 60m 60m S 1.9 1.5 538:40.52 ora_q007_sharedb1 24704 oracle 20 0 1456m 60m 60m S 1.9 1.5 523:07.36 ora_q00b_sharedb1 24733 oracle 20 0 1456m 66m 65m S 1.9 1.7 467:46.55 ora_q00c_sharedb1 24871 oracle 20 0 1456m 64m 63m S 1.9 1.6 466:18.69 ora_q00e_sharedb1 24890 oracle 20 0 1455m 60m 59m S 1.9 1.5 536:55.73 ora_q00f_sharedb1 24950 oracle 20 0 1456m 63m 63m S 1.9 1.6 467:32.91 ora_q00g_sharedb1 25063 oracle 20 0 1455m 63m 62m S 1.9 1.6 469:04.99 ora_q00j_sharedb1 25090 oracle 20 0 1454m 61m 60m S 1.9 1.5 467:56.07 ora_q00k_sharedb1 25155 oracle 20 0 1455m 65m 64m S 1.9 1.6 466:29.63 ora_q00n_sharedb1 25210 oracle 20 0 1455m 63m 62m S 1.9 1.6 467:35.19 ora_q00o_sharedb1 25255 oracle 20 0 1457m 70m 68m S 1.9 1.8 472:34.51 ora_q00p_sharedb1 25292 oracle 20 0 1457m 76m 76m S 1.9 1.9 468:52.91 ora_q00r_sharedb1 25734 oracle 20 0 1455m 60m 60m S 1.9 1.5 536:39.85 ora_q00x_sharedb1 27589 oracle 20 0 1457m 66m 64m S 1.9 1.7 466:57.24 ora_q00y_sharedb1 27600 oracle 20 0 1455m 60m 60m S 1.9 1.5 524:24.46 ora_q00z_sharedb1 27635 oracle 20 0 1457m 66m 65m S 1.9 1.7 470:39.90 ora_q019_sharedb1 27641 oracle 20 0 1456m 70m 69m S 1.9 1.8 467:07.28 ora_q011_sharedb1 27924 oracle 20 0 1456m 64m 64m R 1.9 1.6 467:15.43 ora_q012_sharedb1 27969 oracle 20 0 1457m 68m 68m R 1.9 1.7 466:36.72 ora_q013_sharedb1 1 root 20 0 19396 1052 868 S 0.0 0.0 0:05.77 /sbin/init 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kthreadd] 3 root 20 0 0 0 0 S 0.0 0.0 4:12.11 [ksoftirqd/0] 4 root 20 0 0 0 0 S 0.0 0.0 0:15.73 [kworker/0:0] 6 root RT 0 0 0 0 S 0.0 0.0 20943:14 [migration/0] 7 root RT 0 0 0 0 S 0.0 0.0 0:09.43 [watchdog/0] 8 root RT 0 0 0 0 S 0.0 0.0 6399:26 [migration/1] 9 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kworker/1:0] 10 root 20 0 0 0 0 S 0.0 0.0 4:09.11 [ksoftirqd/1] 11 root RT 0 0 0 0 S 0.0 0.0 0:09.11 [watchdog/1] 12 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [cpuset] 13 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [khelper] 14 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [netns] 15 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [xenwatch] 16 root 20 0 0 0 0 S 0.0 0.0 0:00.01 [xenbus] 17 root 20 0 0 0 0 S 0.0 0.0 0:02.62 [sync_supers] 18 root 20 0 0 0 0 S 0.0 0.0 0:00.07 [bdi-default] 19 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kintegrityd] 20 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kblockd] 21 root 20 0 0 0 0 S 0.0 0.0 0:56.26 [kworker/0:1] 22 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [ata_sff] 23 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [khubd] 24 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [md] 25 root 20 0 0 0 0 S 0.0 0.0 1:09.75 [kworker/1:1] 26 root 20 0 0 0 0 S 0.0 0.0 0:01.64 [khungtaskd] 27 root 20 0 0 0 0 S 0.0 0.0 2:26.39 [kswapd0] 28 root 25 5 0 0 0 S 0.0 0.0 0:00.00 [ksmd] 29 root 20 0 0 0 0 S 0.0 0.0 0:00.46 [fsnotify_mark] 30 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [crypto] 35 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kthrotld] 36 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kworker/u:1] 37 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [khvcd] 38 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kpsmoused] 349 root 20 0 0 0 0 S 0.0 0.0 1:32.56 [kjournald] 394 root 20 0 0 0 0 S 0.0 0.0 1:44.37 [flush-202:0] 440 root 16 -4 10888 624 312 S 0.0 0.0 0:16.76 /sbin/udevd -d 947 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kjournald] 1051 root 20 0 0 0 0 S 0.0 0.0 0:00.19 [kauditd] 1054 root 20 0 12280 2020 1060 S 0.0 0.0 4:52.25 /bin/sh /etc/init.d/init.tfa run 1055 root 20 0 11380 992 988 S 0.0 0.0 0:00.00 /bin/sh /etc/init.d/init.ohasd run 1376 root 16 -4 91196 688 548 S 0.0 0.0 0:01.36 auditd 1401 root 20 0 237m 1372 688 S 0.0 0.0 0:00.55 /sbin/rsyslogd -i /var/run/syslogd.pid -c 5 1438 rpc 20 0 19020 572 512 S 0.0 0.0 0:01.21 rpcbind 1454 dbus 20 0 22168 1116 504 S 0.0 0.0 0:01.58 dbus-daemon --system 1464 root 20 0 81836 2508 1320 S 0.0 0.1 0:02.92 NetworkManager --pid-file=/var/run/NetworkManager/NetworkManager.pid 1467 root 20 0 55884 1016 808 S 0.0 0.0 0:00.05 /usr/sbin/modem-manager 1483 rpcuser 20 0 23392 736 732 S 0.0 0.0 0:00.00 rpc.statd 1517 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [rpciod] 1524 root 20 0 23136 140 140 S 0.0 0.0 0:00.00 rpc.idmapd 1574 root 20 0 44668 32 28 S 0.0 0.0 0:00.00 /usr/sbin/wpa_supplicant -c /etc/wpa_supplicant/wpa_supplicant.conf -B -u -f /var/log/wpa_supplican 1575 root 20 0 184m 644 644 S 0.0 0.0 0:00.00 cupsd -C /etc/cups/cupsd.conf 1615 haldaemo 20 0 26544 1604 988 S 0.0 0.0 0:02.65 hald 1616 root 20 0 18152 624 620 S 0.0 0.0 0:00.01 hald-runner 1697 root 20 0 20268 404 404 S 0.0 0.0 0:00.00 hald-addon-i
0
10
20
30
40
50
60
70
80
90
100
12
:08
:54
12
:08
:59
12
:09
:05
12
:09
:10
12
:09
:15
12
:09
:21
12
:09
:26
12
:09
:31
12
:09
:37
12
:09
:43
12
:09
:48
12
:09
:53
12
:09
:59
12
:10
:04
12
:10
:09
12
:10
:15
12
:10
:20
12
:10
:27
12
:10
:37
12
:10
:45
12
:11
:00
12
:11
:05
12
:11
:14
12
:11
:20
12
:11
:25
12
:11
:30
12
:11
:35
oraclesharedb1
ora_qmnc_sharedb1
ora_q003_sharedb1
/usr/bin/perl
/u01/app/11.2.0.4/grid/jdk/jre/bin/java
ora_q00i_sharedb1
ora_q009_sharedb1
ora_q005_sharedb1
ora_q00u_sharedb1
ora_q000_sharedb1
perl -ne '/^top - (¥d¥d:¥d¥d:¥d¥d)/ and $t=$1;print qq/$t $_/' top.log

42
[参考]fulltime.sh by Craig Shallahamer
参考:http://resources.orapub.com/Fulltime_sh_Report_Oracle_Wait_and_CPU_Details_p/fulltime-sh.htm

メモリ編 • アーキテクチャ – ハードウェア編 • アーキテクチャ – ソフトウェア編 • 分析方法 - USE Method • 分析方法 - ドリルダウン • 分析例
43

メモリ編 アーキテクチャ – ハードウェア編
44

メモリ - アーキテクチャ(1/3)
45
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
仮想記憶により、物理アドレスを意識しないプログラミング、マルチタスク、物理メモリを超えるメモリ領域の使用が実現されている
プロセス毎に独立したアドレス空間
物理メモリ
スワップ領域にはAnonymousページがメモリから退避される
ページテーブル
ページテーブル をキャッシュ

メモリ - アーキテクチャ(2/3)
46
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
仮想メモリ
ページ
ページング
ps の RSS 列 ps の VSZ 列

メモリ - アーキテクチャ(3/3)
47
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
UMA(Uniform Memory Access) NUMA(Non-Uniform Memory Access)

(参考)メモリアクセスレイテンシ
48
出典:http://www.slideshare.net/hayamiz/ss-31934105 Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
東大喜連川研究室早水さんの発表「性能測定道(実践編)」より http://www.slideshare.net/hayamiz/ss-31934105
Lenovo X230 COREi5(2コア×2スレッド) での計測結果 http://d.hatena.ne.jp/yohei-a/20141219/1418999594

メモリ編 分析方法 - USE Method
49

メモリ - USE - Utilization
50
使用中
cached
空き buffer
free
used -/+ buffers/cache
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
システム全体のメモリ使用率をチェック
$ free (またはvmstat) → メモリ使用率 = used(-/+ buffers/cache) / 物理メモリサイズ
Linux kernel 2.4 以降、Buffer Cache は Page Cache に格納される cached、buffer のうち
ダーティーなページはディスクに書き出すまで解放できない

メモリ - USE - Saturation
51 51
ページイン/ページアウトの頻度をチェック
vmstat の si、so 列
使用中
cached
空き buffer
free
used -/+ buffers/cache
cached、buffer はディスクのデータをキャッシュしているので、スワップする必要なく、解放するだけでよい。ただし、データが更新されている場合はディスクに書き出してから解放する。
プロセスが使っているAnonymousページは解放するとデータを失うため、スワップ領域に退避し、必要な時にメモリに読み込む。
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
それでも足りない場合は、カーネルのスラブキャッシュが解放される

メモリ - USE - Errors
52 52 52
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
使用中
cached
空き buffer
free
used -/+ buffers/cache
$ dmesg | grep killed
ページキャッシュの解放やAnonymousページをページアウトしてもメモリが空かない場合は、OOM Killer がメモリ使用量が多いプロセスをkillする
プロセス
空き
kill
ORA-4030、OOM Killer にプロセスが kill されていないか

メモリ -ドリルダウン(1/2)
53
メモリ使用量の多いプロセスを探す
カーネル(OS本体部分)用メモリ領域
データ(ファイル)のキャッシュ領域
プロセスA用 メモリ領域
複数プロセス共有のメモリ領域
純粋な未使用領域
・・・
PGA
プロセスB用 メモリ領域
PGA
プロセスC用 メモリ領域
PGA
SGA
ps aux top
ps や top の RSS で物理メモリ使用量を確認できるが、共有メモリなど共有している領域も含むサイズが表示されるので、メモリ使用量が大きそうなプロセスに当たりをつける程度に使う
共有メモリ
stack
pmap –x [PID] メモリ使用量が大きそうなプロセスに当たりをつけたら、pmap コマンドで内訳を確認し、共有メモリなど共有している領域を除いてそのプロセスがプライベートに使用しているサイズが大きいか確認する(KROWN#41964参照)
参考:KROWN#41964 Unix 環境におけるデータベースに接続しているサーバープロセスおよびバックグラウンドプロセスのメモリ使用量の確認方法
… …
anon
カーネル空間
ユーザー空間

メモリ -ドリルダウン(2/2)
54
/proc/meminfo からメモリを消費している領域を探す
$ cat /proc/meminfo MemTotal: 16158544 kB MemFree: 4016844 kB Buffers: 81960 kB Cached: 6958820 kB SwapCached: 0 kB Active: 1723740 kB Inactive: 5692092 kB Active(anon): 375364 kB Inactive(anon): 126552 kB Active(file): 1348376 kB Inactive(file): 5565540 kB Unevictable: 0 kB Mlocked: 0 kB SwapTotal: 8085500 kB SwapFree: 8085500 kB
Dirty: 3012 kB Writeback: 0 kB AnonPages: 375044 kB Mapped: 4404728 kB Shmem: 126872 kB Slab: 234168 kB SReclaimable: 152964 kB SUnreclaim: 81204 kB KernelStack: 3072 kB PageTables: 42728 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 16164772 kB Committed_AS: 5724604 kB VmallocTotal: 34359738367 kB
VmallocUsed: 384176 kB VmallocChunk: 34359347096 kB HardwareCorrupted: 0 kB AnonHugePages: 0 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB DirectMap4k: 8388 kB DirectMap2M: 16459776 kB
参考:プロのための Linuxシステム・10年効く技術 [ISBN-10: 4774151432] http://d.hatena.ne.jp/enakai00/20110906/1315315488
ページテーブル
Huge Page
共有メモリ

(参考)free と /proc/meminfo を図で表現
55
空き領域(free)
カーネル空間(Slab、KernelStack、PageTablesなど)
総メモリ容量 (/proc/meminfo のMemTotal)
buffer
cached
AnonPages
anon
file
active
inactive
active
inactive 共有メモリ Shmem
スワップされる(空けるとなくなるためディスクに保存する必要がある)
ユーザ空間
①swapping
①ページキャッシュ解放
②Reaping
③OOM Killer
swappiness
共有メモリはファイルシステム(tmpfs)として実装されているため、cached に計上されるが、バッキング・ストアがないため、ページ回収の際はスワップする必要があるため、anon のリストで管理される。
メモリが枯渇するとスラブキャッシュは放される
①ページキャッシュ解放
メモリが枯渇すると解放される。ダーティバッファはディスクに書き出してから解放される。
参考:プロのための Linuxシステム・10年効く技術 [ISBN-10: 4774151432] http://d.hatena.ne.jp/enakai00/20110906/1315315488

メモリ - 付録
56
Oracle Database on Linux でメモリ使用率をどのように見るか
カーネル
buffer
cached
Page Cache
共有メモリ(System V IPC)
共有メモリ(/dev/shm)
Anonymous Pages
free (-/+ buffers/cache)
①/proc/meminfo の MemTotal
②vmstat の used free の used(-/+ buffers/cache)
③ipcs -um → pagesresident × 4KB
④df -k → tmpfs の Used
メモリ使用率(%) = (メモリ使用量(KB) / ①MemTotal(KB)) × 100 メモリ使用量(KB) = ②物理メモリ使用量(ページキャッシュ除く)(KB) + ③共有メモリ使用容量(ページ数×ページサイズ) + ④tmpfs/ramfs使用容量(KB)
Huge Page は使用前はここに含まれる
Huge Page はSGAとして使われている時はここに含まれる

57
RHEL/Oracle Linux 6、7 では
空きメモリサイズ = /proc/meminfo の MemFree + Active(file) + Inactive(file) メモリ使用率 = 100 – 空きメモリサイズ ÷ /proc/meminfo の MemTotal
空き領域(free)
カーネル空間(Slab、KernelStack、PageTablesなど)
総メモリ容量 (/proc/meminfo のMemTotal)
buffer
cached
AnonPages
anon
file
active
inactive
active
inactive 共有メモリ Shmem
スワップされる(空けるとなくなるためディスクに保存する必要がある)
ユーザ空間
共有メモリはファイルシステム(tmpfs)として実装されているため、cached に計上されるが、バッキング・ストアがないため、ページ回収の際はスワップする必要があるため、anon のリストで管理される。
参考:プロのための Linuxシステム・10年効く技術 [ISBN-10: 4774151432] http://d.hatena.ne.jp/enakai00/20110906/1315315488

メモリ - 分析例(1/4)
58
システム全体の Utilization と Saturation をチェック
$ dstat -tv 5 (※ vmstat 5 の代り)
メモリ使用量が5GBから15GBまで増加 (物理メモリサイズは16GB)
ページアウトが発生
メモリ使用率が高くなり、buffer が解放されている

メモリ - 分析例(2/4)
59
メモリを消費しているプロセスを特定する
$ top -c (F, n, Enter キーでMEM%で降順ソート)
Perl のプロセスが8GBもメモリを消費している
Top 実行中に h (help) を押すと、ヘルプが表示され、ソートの仕方などを参照できます

<Mode 列の見方> r-x--: テキストセグメント(命令部分) → プロセス間で共有している領域 rwx--: データセグメントまたはスタックセグメント(データ領域) → プロセス間で共有していない領域 rwxs-: 共用メモリ → SGA
メモリ - 分析例(3/4)
60
プロセスが使用しているメモリ領域の内訳を調べる
$ pmap -x [PID]
Anonymous Page に 8GB 使用
参考:http://d.hatena.ne.jp/yohei-a/20100404/1270400493

メモリ - 分析例(4/4)
61
[参考]/proc/meminfo を見てみる
$ cat /proc/meminfo
Anonymous Page に 8GB 使用

ディスク編
62
• アーキテクチャ – ハードウェア編 • アーキテクチャ – ソフトウェア編 • 分析方法 - USE Method • 分析方法 - ドリルダウン • 分析例

ディスク編 アーキテクチャ – ハードウェア編
63

ディスク – H/Wアーキテクチャ
64
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
ページキャッシュに乗っている場合

ディスク編 アーキテクチャ – ソフトウェア編
65

ディスク - アーキテクチャ(2/2)
66
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]

ディスク編 分析方法 - USE Method
67

ディスク - USE - Utilization
68
システム全体のディスクのビジー率をチェック
$ iostat -xz 1 の %util
使用率(%util)はその期間中、どれだけの割合でディスクが使用されていたか
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098] http://www.brendangregg.com/USEmethod/use-linux.html
素のディスクではなくストレージの場合は非同期で並列にI/Oリクエストをさばくことが可能で、使用率(%util) が100%になってもまだ余力があり、100%の状態からさらにIOリクエストを増やすとI/Oレスポンス(await)は変わらずにIOPSが延びることがある。 従って、使用率が100%であれば性能限界と言えない。

ディスク - USE - Saturation
69 69
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098] http://www.brendangregg.com/USEmethod/use-linux.html
$ iostat -xz 1 の avgqu-sz、await
avgqu-sz
await
svctm
ページキャッシュに乗っていた場合はカーネルのブロックレイヤーに到達しないため、iostat には現われない

ディスク - USE - Errors
70 70 70
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
アプリケーション側でI/Oがタイムアウトしていないか
アプリケーションのレイヤーでI/Oエラーが発生していないか。Oracle Database の場合、アラートログに「WARNING: aiowait timed out 1 times」が出力されていないかなど(KROWN#13964参照)。

ディスク編 分析方法 -ドリルダウン
71

ドリルダウン
ディスク -ドリルダウン(1/2)
72
I/O負荷が高い I/Oの量が多い
1回のI/Oが遅い 1回のI/Oが遅い原因を
調査する
スワップ発生 メモリを消費しているプ
ロセスを確認する
I/O量が増加した原因を調査する
vmstat の si、so
vmstat の bi、bo iostat の r/s、w/s、avgqu-sz、svctm など
iostat の r/s、w/s、avgqu-sz、svctm など
top の %MEM pmap
top iotop
ストレージベンダーに調査依頼するなど(ストレージのキャッシュが切れてないか、ディスク間欠障害などが発生していないか)
具体的にどのコマンドでI/Oボトルネックの原因をでドリルダウンするか

ディスク -ドリルダウン(2/2)
73
I/O ボトルネックが発生しているレイヤーを見つける
Log file parallel write に数十ミリ秒要している
iotstat の svctm は数ミリ秒と速いが、IOPS は延びていない
ファイルシステムのレイヤーで処理が直列化してボトルネックが発生していないか?
非同期I/Oのカーネルのキューが一杯になり遅延していないか?
出典:Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]

ディスク - 分析例(1/4)
74
システム全体の Utilization と Saturation をチェック
$ iostat -x 5
使用率は100%
1回のIO処理は0.07ms程度
I/Oレスポンスは0.6ms程度
キューは9程度
IOPSは1万4千程度

ディスク - 分析例(2/4)
75
I/Oを大量に発行しているプロセスを特定する
$ top -c (F, w, Enter, R キーでStatusで昇順ソート)
カーネルスレッドがI/Oを処理している模様。I/Oが速いのでDにはなっていない。
Top 実行中に h (help) を押すと、ヘルプが表示され、ソートの仕方などを参照できます

ディスク – 分析例(ファイルシステムでの)
76
I/Oを大量に発行しているプロセスを特定する
# iotop -o -d 5
I/Oベンチマークツールが大量にI/Oを発行している

77
ディスク – 分析例(カーネル内に DeepDive) db file sequential read の1回の待機時間が長いが、ストレージのI/O(iostatのawait、svctm)は速い、カーネル内のどこで詰まっているのか? → funcgraph でI/Oシステムコールの遅延理由を特定する
funcgraph で Linux カーネル内のボトルネックをミクロに追跡する http://d.hatena.ne.jp/yohei-a/20150708/1436312890
# ./funcgraph -Htp 4511 vfs_write Tracing "vfs_write" for PID 4511... Ctrl-C to end. # tracer: function_graph # # TIME CPU DURATION FUNCTION CALLS # | | | | | | | | 935.579600 | 3) | vfs_write() { 935.579602 | 3) | rw_verify_area() { 935.579602 | 3) | security_file_permission() { 935.579602 | 3) 0.085 us | cap_file_permission(); 935.579603 | 3) 0.810 us | } 935.579603 | 3) 1.367 us | } 935.579604 | 3) | do_sync_write() { 935.579604 | 3) | pipe_write() { 935.579604 | 3) | mutex_lock() { 935.579604 | 3) 0.044 us | _cond_resched(); 935.579605 | 3) 0.434 us | } 935.579605 | 3) 0.159 us | pipe_iov_copy_from_user(); 935.579606 | 3) 0.097 us | mutex_unlock(); 935.579606 | 3) | __wake_up_sync_key() { 935.579606 | 3) 0.096 us | _raw_spin_lock_irqsave(); 935.579607 | 3) 0.062 us | __wake_up_common();
この区間で1.3マイクロ秒
こういうケースでどう調べるか?

[参考]情報ソース
78
• Systems Performance: Enterprise and the Cloud [ISBN-10: 0133390098]
• 絵で見てわかるOS/ストレージ/ネットワーク データベースはこう使っている [ISBN-10: 479811703X]
• プロのための Linuxシステム・10年効く技術 [ISBN-10: 4774151432]
• [24時間365日] サーバ/インフラを支える技術 [ISBN-10: 4774135666]
• http://www.brendangregg.com/linuxperf.html
• http://www.brendangregg.com/USEmethod/use-linux.html
Related Documents




![最もシンプルで分かりやすい PubMed 検索法 最も …spell.umin.jp/PubMedSearchingMethod2.2.pdf最もシンプルで分かりやすいPubMed 検索法 3 "Hypertension”[Mesh]のPubMed](https://static.cupdf.com/doc/110x72/5e967654df25ad1fdf646b24/oefff-pubmed-oec-oe-spelluminjppubmedsearchingmethod22pdf.jpg)






