第第第 第第第第第第 第第第第第第: • 第第第第第第第 • 第第第第 • 第第第第 第第第第第第 • Replication ( 第第第 ) • Randomization ( 第第第 ) • Blocking ( 第第第 )

第六章 完全隨機設計
Dec 30, 2015
第六章 完全隨機設計. 實設基本原則 Replication ( 重複性) Randomization ( 隨機性) Blocking ( 分區性). 試驗客觀因素: 試驗材料之性質 試驗環境 試驗時間. 完全隨機設計 Completely Randomized Design ( CRD ) 試驗材料同質,或隨機分配 試驗環境相同 試驗順序隨機排列. 【例6.1 】 Subject : 研究A、B、C三營養食品 的影響 因 素 : 營養食品 測量值 : 增重 - PowerPoint PPT Presentation
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

第六章 完全隨機設計
試驗客觀因素:• 試驗材料之性質• 試驗環境• 試驗時間
實設基本原則• Replication ( 重複性 )
• Randomization ( 隨機性 )• Blocking ( 分區性 )

【例 6.1 】 Subject : 研究 A 、 B 、 C 三營養食品的影響 因素 :營養食品 測量值 : 增重 3 處理: A 、 B 、 C 每處理重複 4 次
(A) 設計: 12 隻老鼠隨機安排食用營養品
完全隨機設計 Completely Randomized Design (CRD)
• 試驗材料同質,或隨機分配• 試驗環境相同• 試驗順序隨機排列
(1) B (2) C (3) A (4) B
(8) A (7) A (6) B (5) C
(9) C (10) B (11) C (12) A
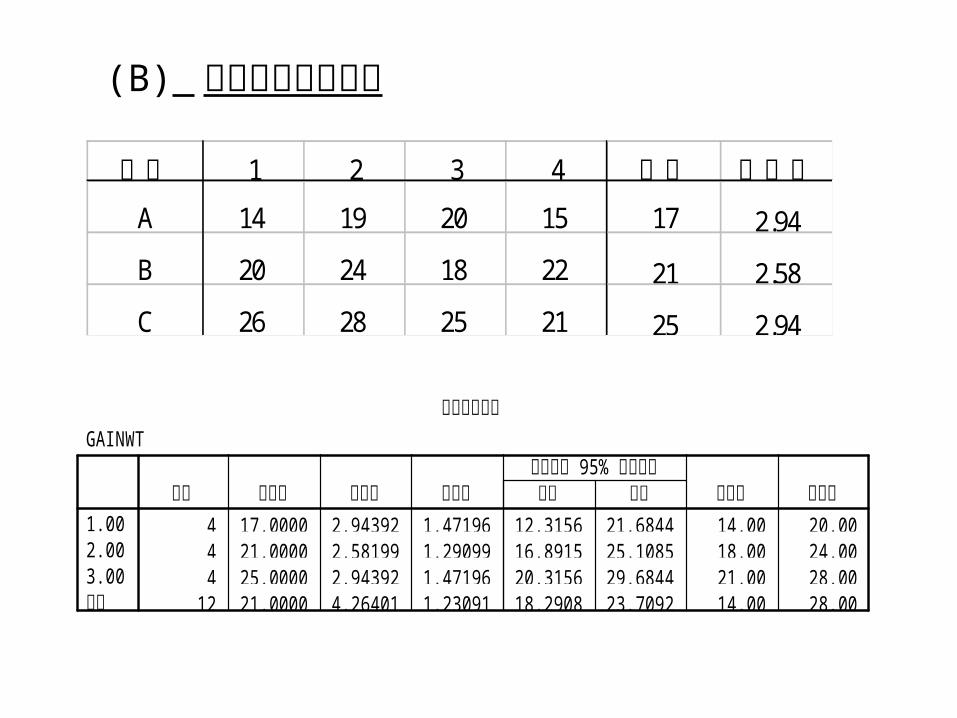
(B) 資料均值及標準差
處理 1 2 3 4 均值 標準差
A 14 19 20 15 17 2.94
B 20 24 18 22 21 2.58
C 26 28 25 21 25 2.94
描述性統計量
GAINWT
4 17.0000 2.94392 1.47196 12.3156 21.6844 14.00 20.004 21.0000 2.58199 1.29099 16.8915 25.1085 18.00 24.004 25.0000 2.94392 1.47196 20.3156 29.6844 21.00 28.00
12 21.0000 4.26401 1.23091 18.2908 23.7092 14.00 28.00
1.002.003.00總和
個數 平均數 標準差 標準誤 下界 上界 95% 平均數的 信賴區間
最小值 最大值

(2) 變方同質性檢定 Levere 檢定得到 p-value=.822, 可假設資料滿足同質性。
(C) 分析
變異數同質性檢定
GAINWT
.200 2 9 .822Levene 統計量 分子自由度 分母自由度 顯著性
(1) ANOVA
F 檢定得到 p-value=.0.10 , 三營養品之差異顯著。
ANOVA
GAINWT
128.000 2 64.000 8.000 .01072.000 9 8.000
200.000 11
組間組內總和
平方和 自由度 平均平方和 F 檢定 顯著性
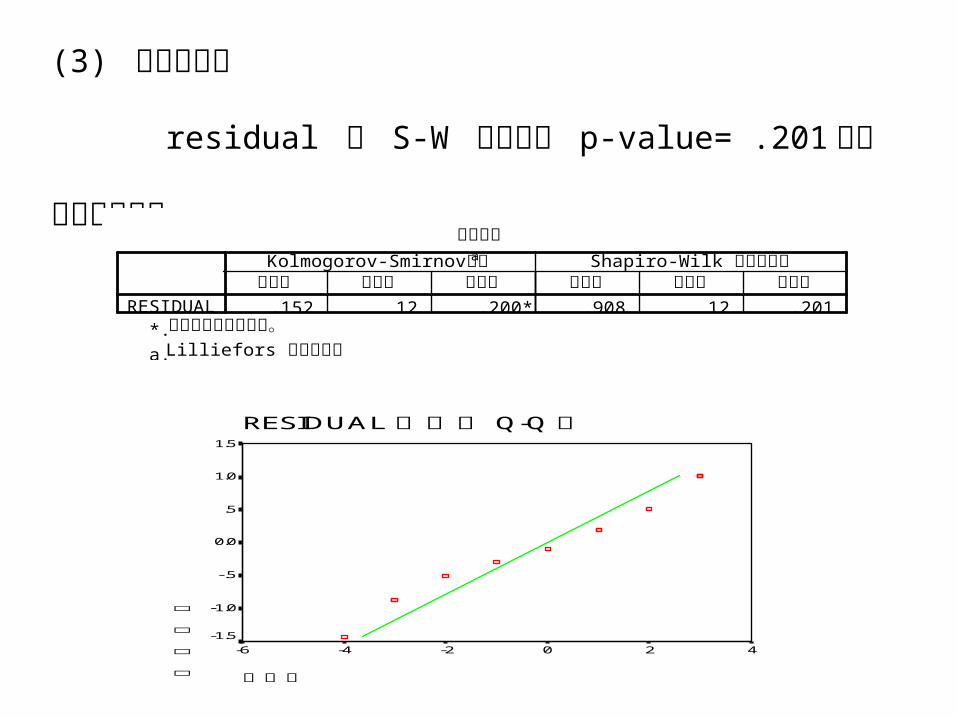
(3) 常態性檢定
residual 經 S-W 檢定得到 p-value= .201 ,常態機
率圖顯示 資料滿足常態性。
常態檢定
.152 12 .200* .908 12 .201RESIDUAL統計量 自由度 顯著性 統計量 自由度 顯著性
Kolmogorov-Smirnov檢定a Shapiro-Wilk 常態性檢定
此為真顯著性的下限。*. Lilliefors 顯著性校正a.
RESIDUAL Q-Q 的常態 圖
觀察值
420-2-4-6
期望次數常態
1.5
1.0
.5
0.0
-.5
-1.0
-1.5

(4) 對對比較 由 Tukey HSD 法得到在 α=0.05水準下,營養品 A與 C 間差異顯著,其他則無顯著差異。
GAINWT
4 17.00004 21.0000 21.00004 25.0000
.168 .168
VITAMIN1.002.003.00顯著性
Tukey HSDa個數 1 2
alpha = .05 的子集
顯示的是同質子集中組別的平均數。 = 4.000使用調和平均數樣本大小 。a.

總結 此為一完全隨機設計的試驗,測得的資料符合同質性及常態性,故可用 ANOVA分析;經 ANOVA及
TukeyHSD的比較法得到營養品 A 與營養品 C 對老鼠的增重有差異顯著, A 與 B ,或 B 與 C 間則無明顯差異。營養品 C 對老鼠效果最佳,但營養品 B 與 C 間則無顯著差異。 B 與 C 應都是考慮使用的對象。
營養品 C B Amean ± SEM 25±1.47a 21±1.29 ab 17±.1.47 b
α =0. 05註:上標字母不同之各組間在 的水準下均值有顯著差異。

試驗處理重複次數之決定可分為兩種方式決定,一是考慮平均差的精確值,一是考慮能以檢定分出差異的能力。
) )1( (
,2 22
22
nk
) (t net eσ
:να/n:να/
Q :試驗要重複幾次?
(1) 考慮平均差的精確值 ( 只限制 α值 )
(1-α)x100% 的信賴區間為 差 ± t α/2 (SE mean)
設定 t α/2 (SE mean) = 特定值 即可求得 n 。
註:上式的 值可以經驗值或先測值代入

(2) 考慮能以檢定分出差異的能力。 限制型 I 及型 II 錯誤機率值 (α & β)
)t(/x)2( 221
2 tn
要求在差異達到 x 時,能檢測出差異的機會至少為 p , β=1-p ,查表得 t1 = tα/2, t2 = tβ/2
同理,要求在差異達到 d% 時,能檢測出差異的機會至少為 p ,則
t(cv/d)td
n 221
2221
2 )t(2 )t()100
2(
【例 6.2】 α=0.05, 至少有 80% 機會檢測出 10% 差異 , 設 CV=5%

第七章 隨機完全區集設計
Treatment Factor : 一般指研究對象之因子。Nuisance factor ( 混淆因子 ) :對觀察值可能產生影響,但並 非研究對象之因子。
未知且無法控制:以 randomization 的設計技巧 來降低其影響。知道但可以控制:通常為實驗使用的媒介 (experiment unit) ,則用 blocking
之設計降低其影響。知道,可以測量:以共變量設計 (covariate design)
降低其影響。 (Chapter 19)
混淆因子
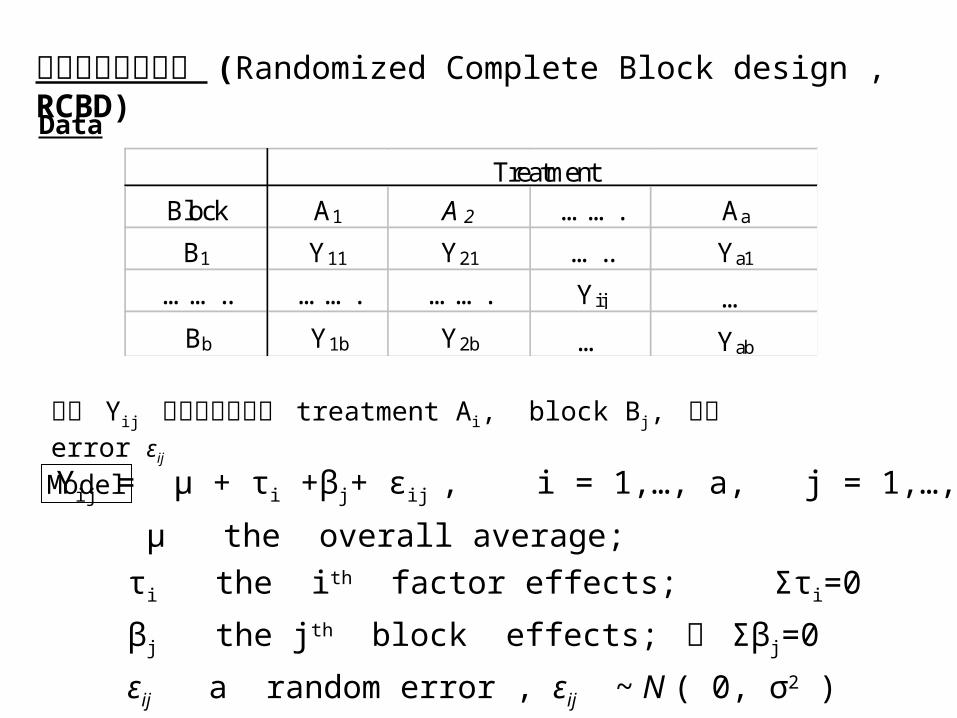
隨機完全區集設計 (Randomized Complete Block design , RCBD) Data
μ the overall average;
τi the ith factor effects; Στi=0
βj the jth block effects; , Σβj=0
εij a random error , εij ~ N ( 0, σ2 )
Model
Block A1 A 2 ……. Aa
B1 Y11 Y21 ….. Ya1
…….. ……. ……. Yij …
Bb Y1b Y2b … Yab
Treatment
影響 Yij 值的因素有來自 treatment Ai, block Bj, 以及 error εij
Yij = μ + τi +βj+ εij , i = 1,…, a, j = 1,…,b ,

SST = SSTr + SSBk +SSE
SSTr : sum of squares due to treatments
SSBk : sum of squares due to blocks
SSE : sum of squares due to error
oneleast at for 0:
0...:Test
1
210
iH
H
i
a
將 total 平方和分解為三項:
d.f. of treatment = a-1, d.f. of block = b-1,
d.f. of error = (a-1)(b-1)

Source SS df MS F-value p-valueTreatment SSTr a-1 MSTr f =MSTr/MSE P(F>f)
Block SSBk b-1 MSBk
Error SSE (a-1 )(b-1 ) MSE
Total SST ab-1
ANOVA Table for Randomized Complete Block Model
檢定 :
f > Fα;a-1,(a-1)(b-1) 時拒絕 H0, (p-value < 0.05)
結論是在 α=0.05 的水準下,主因子對反應變數有顯著影響 ,或,在 α=0.05 的水準下,各組平均數的差異是顯著的。

Exp 7-1
比較 A、 B、 C、 D 四種飼料品質,小豬的天生體質是一可控制的干擾因素,可取胎別為區集。 主因子 : 飼料, 區集因子:胎別 反應變數:增重,
I C 14 A 10 B 16 D 12II A 15 D 16 B 20 C 18III B 25 C 20 A 16 D 18IV D 15 A 15 C 16 B 22
隨機飼養 4 種飼料,試驗排列圖及二個月後之增重 ( 公斤 ) 如下圖。
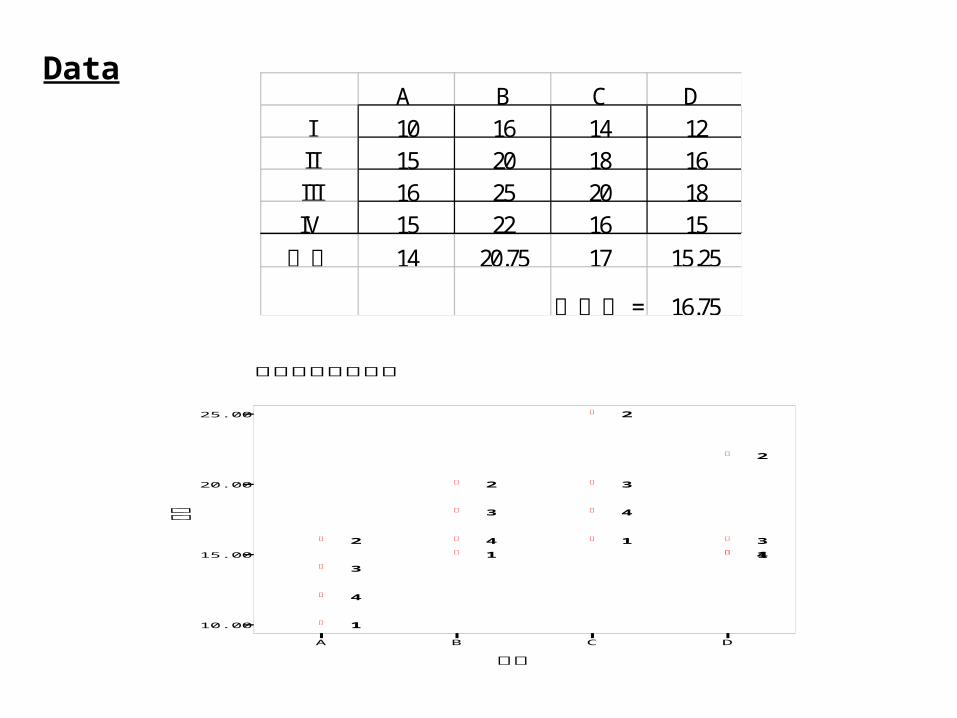
Data A B C D
I 10 16 14 12II 15 20 18 16III 16 25 20 18IV 15 22 16 15均值 14 20.75 17 15.25
=總平均 16.75
A B C D
飼料
10.00
15.00
20.00
25.00
1
2
3
4
1
2
3
4 1
2
3
4
1
2
3
4
飼料對小豬增重圖

Source DF Type III SS Mean Square F Value Pr > F
Feed 3 103.5000000 34.5000000 31.05 <.0001
Mother 3 93.5000000 31.1666667 28.05 <.0001
SAS 報表節錄
主因素與區集因皆顯著
Means with the same letter are not significantly different.
t Grouping Mean N Feed
A 20.7500 4 B
B 17.0000 4 C
C 15.2500 4 D
C 14.0000 4 A
只有 Feed A 與 D 無顯著差異

Tests for Normality
Test Statistic p Value
Shapiro-Wilk W 0.932915 Pr < W 0.2710
Kolmogorov-Smirnov D 0.167354 Pr > D >0.1500
Cramer-von Mises W-Sq 0.059479 Pr > W-Sq >0.2500
Anderson-Darling A-Sq 0.399684 Pr > A-Sq >0.2500
資料符合常態性假設

Level ofFeed
N gainwt
Mean Std Dev
A 4 14.0000000 2.70801280
B 4 20.7500000 3.77491722
C 4 17.0000000 2.58198890
D 4 15.2500000 2.50000000

總結 此為一隨機完全區集設計的試驗,測得的資料符合常態性;經 ANOVA及 TukeyHSD的比較法得到飼料 D 與飼料 A 對增加體重無顯著差異,二者是最低的。餵食飼料 B的小豬體重增加量明顯比其它高,飼料 C 次之。均值估計如下表。
飼料 B C D Amean ± SEM 20.75±3.77a 17±2.58 b 15.25±2.5 c 14±.2.71 c
α =0. 05註:上標字母不同之各組間在 的水準下均值有顯著差異。
註:完全區集設計選 Arithmetic 不完全區集設計選 Least Squares
SASSAS guide guide
1 、輸入資料: 因子佔一行,各區集各佔一行,測值或反應值資料佔一行。 2、 Analysis → ANOVA → Linear Models
Columns :指定 反應變數為 Dependent variable
因子及區集為 Classification variable
Model Builder : 選擇所有因子及區集因子 Model Options : type 3
Post-Hoc tests :
使用 Linear model, 無法檢定同質性

Plots : Means → Dependent means
Predictions: Data to predict ˇoriginal sample
Additional Statistics ˇResiduals
Save output data
─ Effects 選欲比較的效應項─ Comparisons 選擇方法 ─ Means option 選擇欲列印的均值─ Confidence interval
3 、 檢測常態性: Analysis → Descriptive → Dist analysis
選擇儲存的殘差為分析變數,並加 test for normality
Arithmetic ( 算術平均數 ) → Add Effect 加入因子

1 、輸入資料:定義及輸入 : 各因子佔一行,資料佔一行
2 、分析 → 一般線性模式 → 單變量
指定:測量變數→ 依變數,各因子→ 固定因子
自訂 ( 輸入各因子 )
指定主因子,選一方法
儲存 student 化殘差
ˇ 效果項估計
3 、 常態性檢定:分析 → 描述性統計 → 預檢資料
統計圖 ˇ 常態機率圖附檢定
SPSSSPSS guide guide
Post Hoc 檢定
選項
儲存
模式

p-value = .0346 ,與區集設計的分析結果有相當大的差異 .
不考慮 block 之分析結果
區集效率, F :
E
EB
E
EB
MS
abSSSS
)MSab
)MS(ab)MS(bF
)1(/)(
1(
1)1(1
Q :是否有必要作區集設計?
Source DF Type III SS Mean Square F Value Pr > F
Feed 3 103.5000000 34.5000000 4.00 0.0346
F>1 時,區集有效, F 值愈大,區集效應愈佳;例 7-1 的區集效率 = 7.75 。

1. Approximate analysis
原理 : 以一使 SSE 達到最小的值,估計此缺失資料。2. Exact analysis
以最小平方法得解,代入 SSE 做檢定。
區集設計分析之每組個數一定相同,若某組缺失了資料,是否仍可分析?
缺失資料處理

1. 近似法– 估計缺失值 (p114)
原理 : 以一使 SSE 達到最小的值,估計此缺失資料,方法如下。
)1)(1( 0
)()()(
)(
'..
'.
'.
2'..
1'.
1'.
12
2....
ba
ybyayx
x
SS
Rxyxy-xyx
yyyySS
jiE
abjaib
jiijE
組之和為其餘資料第組之和,為其餘資料第
為其餘資料之和,,設有一缺失資料為
i i
'.j
'i.
'..
yy
yx
將 x 代入缺失處,再做分析。 (Table 7-8)
注意: SSE 之自由度降 1 。
Related Documents