
© 2008 OSIsoft, Inc. | Company Confidential High Availability Michael Jakob Colin Breck Colin Breck Michael Jakob Colin Breck Colin Breck.
Dec 29, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript


© 2008 OSIsoft, Inc. | Company Confidential
High AvailabilityHigh AvailabilityHigh AvailabilityHigh Availability
Michael JakobMichael Jakob Colin BreckColin Breck
Michael JakobMichael Jakob Colin BreckColin Breck

3© 2008 OSIsoft, Inc. | Company Confidential
IntroductionIntroduction
PI High Availability (HA) has been available for approximately two years– Adoption has been rapid– HA has greatly enhanced the PI Infrastructure
Outline– Review HA Infrastructure– Highlight HA adoption and deployment– Answer common questions– Future development directions

4© 2008 OSIsoft, Inc. | Company Confidential
SecondaryMetadata
Replication
SecondaryMetadata
Replication
PI Server Collective
Time-SeriesData
PI Server
PI Interface
Time-SeriesData
Data Collection & Buffering
PI SDKSystem
Management Tools
PI High Availability: InfrastructurePI High Availability: Infrastructure
ProcessBook, DataLink, RtWebParts,Notifications, ACE, etc.
Primary

5© 2008 OSIsoft, Inc. | Company Confidential
PI High Availability: ReleasesPI High Availability: Releases
PI Server PR1 and Buffer Subsystem PR1 (3.4.375.38)– December, 2006
PI Server PR1 SP1a (3.4.375.80)– May, 2008
Buffer Subsystem SP1 (3.4.375.84)– September, 2008

6© 2008 OSIsoft, Inc. | Company Confidential
PI High Availability: AdoptionPI High Availability: Adoption
Hard to provide accurate numbers…but we can provide minimum numbers
Independent customer downloads– PI Server PR1 1000+– PI Server PR1 SP1 1000+– Buffer Subsystem PR1 500+– Buffer Subsystem PR1 SP1 200+
Licenses for PI Server Collectives– 1 secondary 250+– 2 secondary 15+– 3+ secondary 5+
7© 2008 OSIsoft, Inc. | Company Confidential
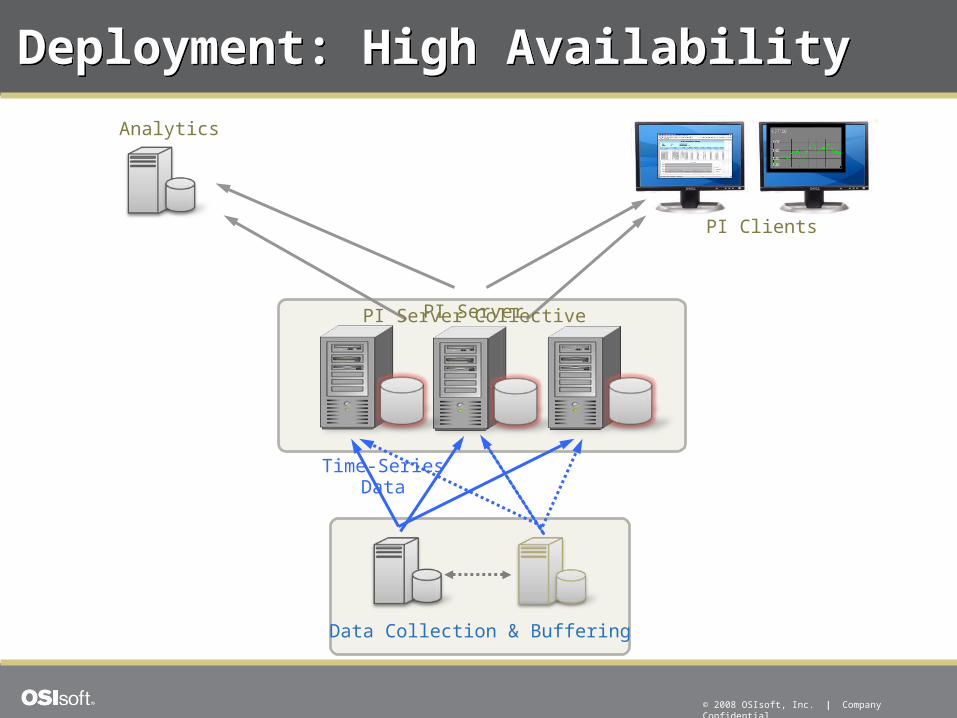
Deployment: High AvailabilityDeployment: High Availability
PI Server
Time-SeriesData
Data Collection & Buffering
PI Clients
Analytics
PI Server Collective
8© 2008 OSIsoft, Inc. | Company Confidential
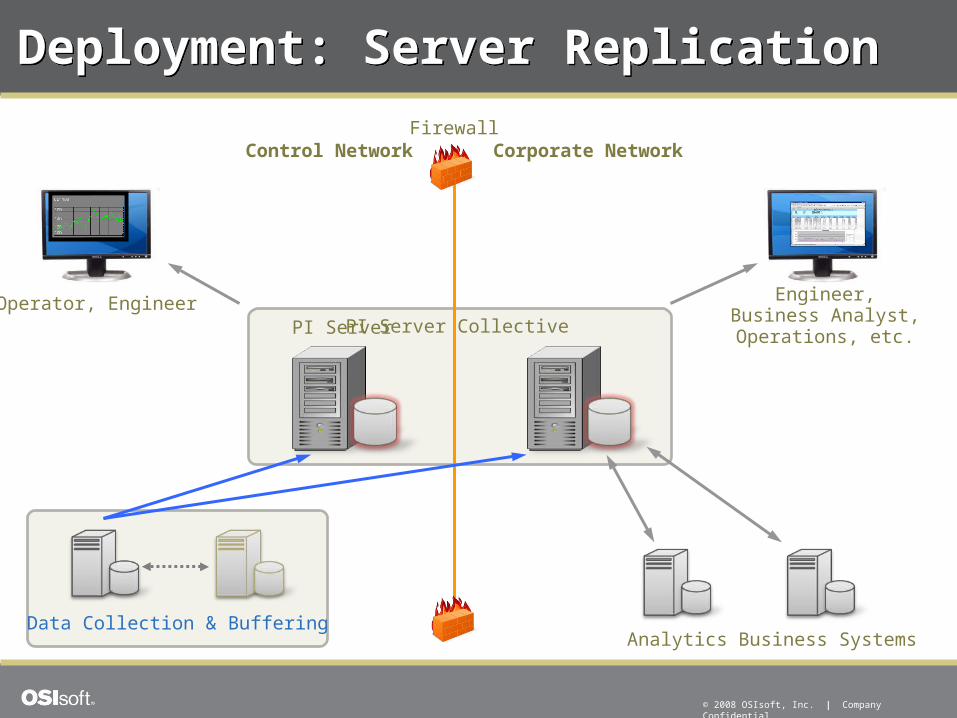
Deployment: Server ReplicationDeployment: Server Replication
PI ServerPI Server Collective
Data Collection & Buffering
Control Network Corporate NetworkFirewall
Analytics
Operator, Engineer Engineer,Business Analyst,Operations, etc.
Business Systems

9© 2008 OSIsoft, Inc. | Company Confidential
Deployment: Backup/Disaster RecoveryDeployment: Backup/Disaster Recovery
WAN
PI Server PI Server Collective
Primary Control Center Backup Control Center
Data Collection & Buffering Data Collection & BufferingData Collection & BufferingData Collection & Buffering
10© 2008 OSIsoft, Inc. | Company Confidential
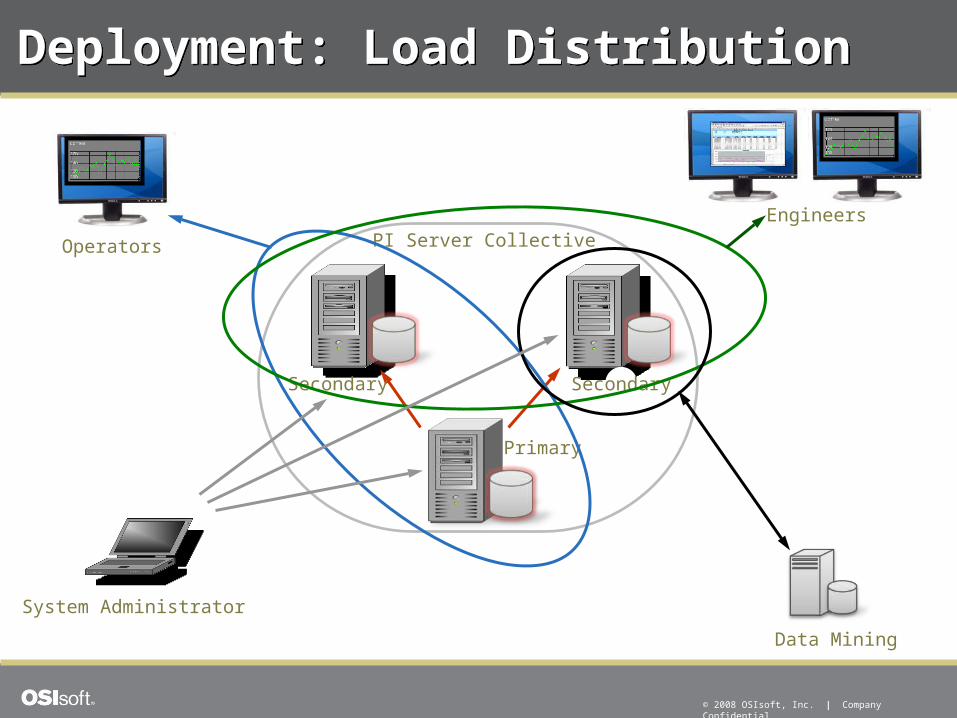
Deployment: Load DistributionDeployment: Load Distribution
Secondary Secondary
Primary
PI Server Collective
System Administrator
Engineers
Data Mining
Operators
11© 2008 OSIsoft, Inc. | Company Confidential
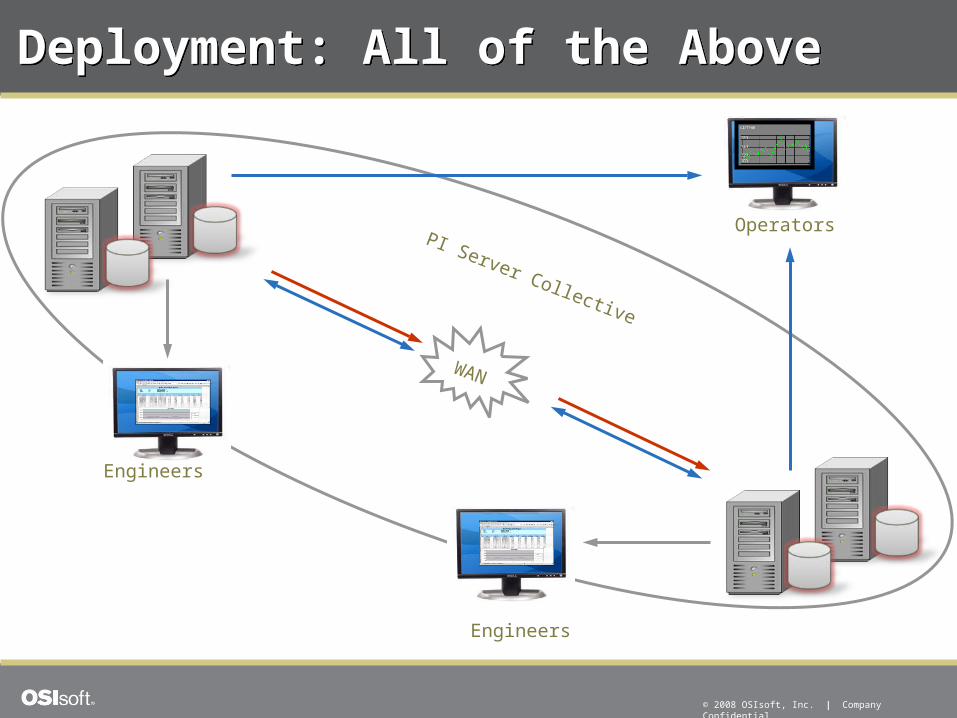
Deployment: All of the AboveDeployment: All of the Above
WAN
PI Server Collective
Operators
Engineers
Engineers

12© 2008 OSIsoft, Inc. | Company Confidential
Common QuestionsCommon Questions
Bufserv or Buffer Subsystem?– Two options for interface buffering: Bufserv and Buffer Subsystem – Buffer Subsystem is OSIsoft’s flagship data buffering technology– Use Bufserv when:
• Operating System is UNIX, Linux, Windows NT4• PI Server is pre-PR1 (3.4.375)• Buffering to multiple, non-HA PI Servers

13© 2008 OSIsoft, Inc. | Company Confidential
Common QuestionsCommon Questions
Buffer Subsystem Advantages– Compression is performed on the data collection node,
guaranteeing identical data among collective servers– Buffering capacity is limited only by disk space– PI3 protocol between data collection node and PI server– Automatic HA configuration– Higher data throughput (~10 times)– Performance Counters– Tools for examining/recovering buffer files

14© 2008 OSIsoft, Inc. | Company Confidential
Common QuestionsCommon Questions
Do I still need PI backups?– HA expands the options for backup and recovery
Backups remain important– Disaster recovery (e.g., delete tags or data)– Local backups when PI Collective is geographically distributed– Virtual machine snapshots are not sufficient

15© 2008 OSIsoft, Inc. | Company Confidential
Common QuestionsCommon Questions
How do I size the hardware for HA servers?What is the network bandwidth required for HA?
– Size each server as you would today– Use an existing installation to provide sizing estimates
PI Server
PI Interface & Buffering
PI Server Secondary
Metadata Change(e.g., tag edit)
MetadataReplication
16© 2008 OSIsoft, Inc. | Company Confidential
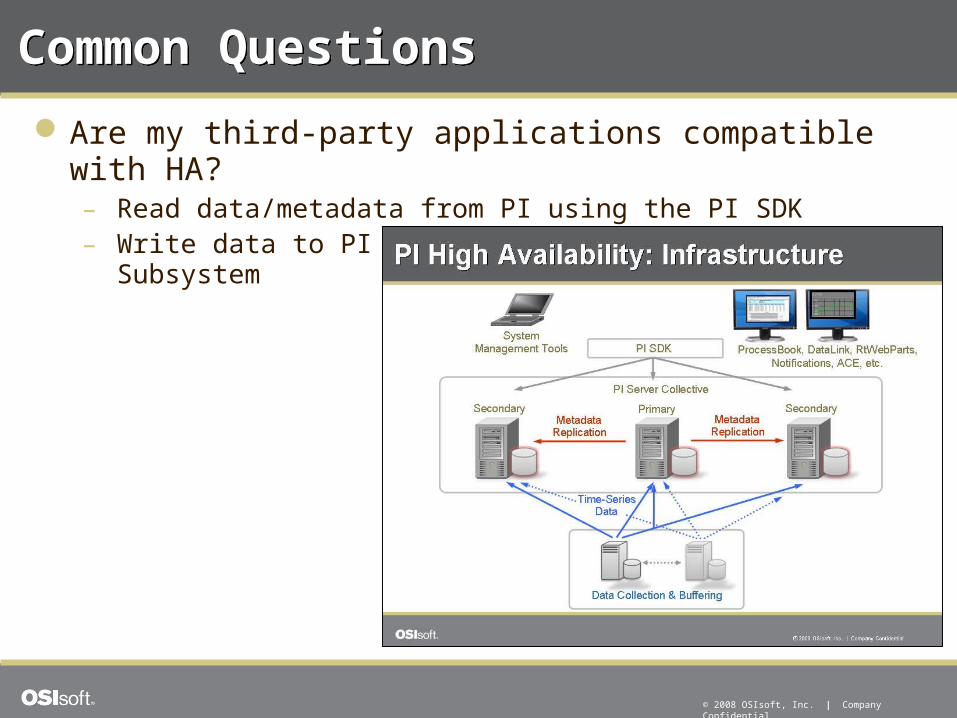
Common QuestionsCommon Questions
Are my third-party applications compatible with HA?– Read data/metadata from PI using the PI SDK– Write data to PI using the PI API and the Buffer Subsystem
17© 2008 OSIsoft, Inc. | Company Confidential
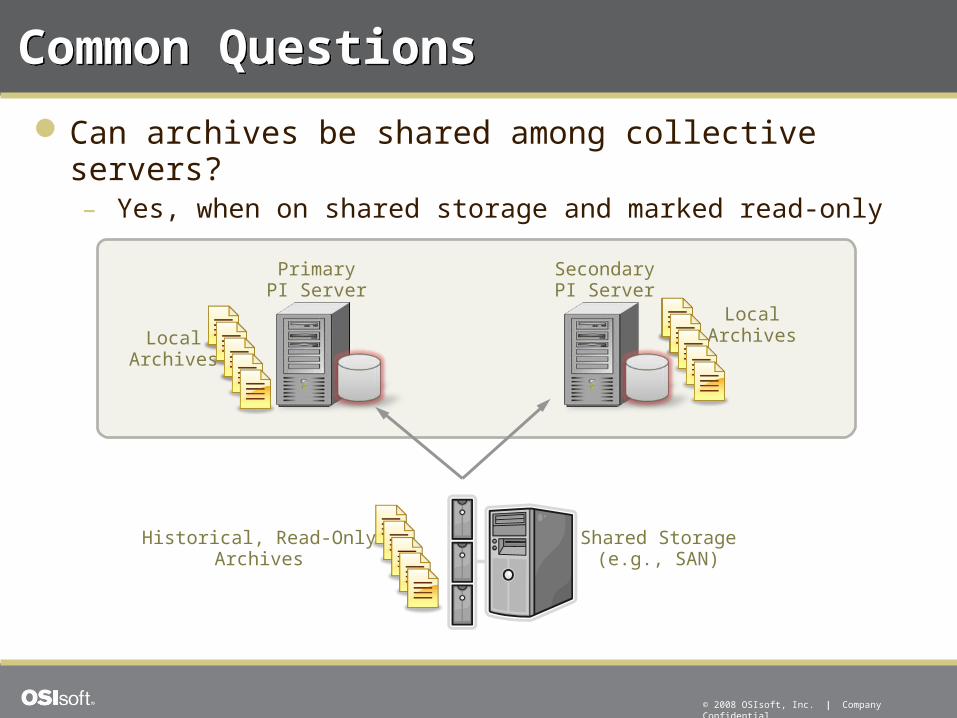
Common QuestionsCommon Questions
Can archives be shared among collective servers?– Yes, when on shared storage and marked read-only
SecondaryPI Server
PrimaryPI Server
LocalArchives
LocalArchives
Historical, Read-OnlyArchives
Shared Storage(e.g., SAN)

18© 2008 OSIsoft, Inc. | Company Confidential
Common QuestionsCommon Questions
How does HA change technical support?– Affords time to investigate issues thoroughly– Provides a system of reference– Expands the options for recovery
(e.g., repair vs. server re-initialization)

19© 2008 OSIsoft, Inc. | Company Confidential
Common QuestionsCommon Questions
What about manual data entry?– Use PI-to-PI Interface– Write data to all servers– A number of limitations
What about PI Batch data?– PR1 does not support HA for PI Batch
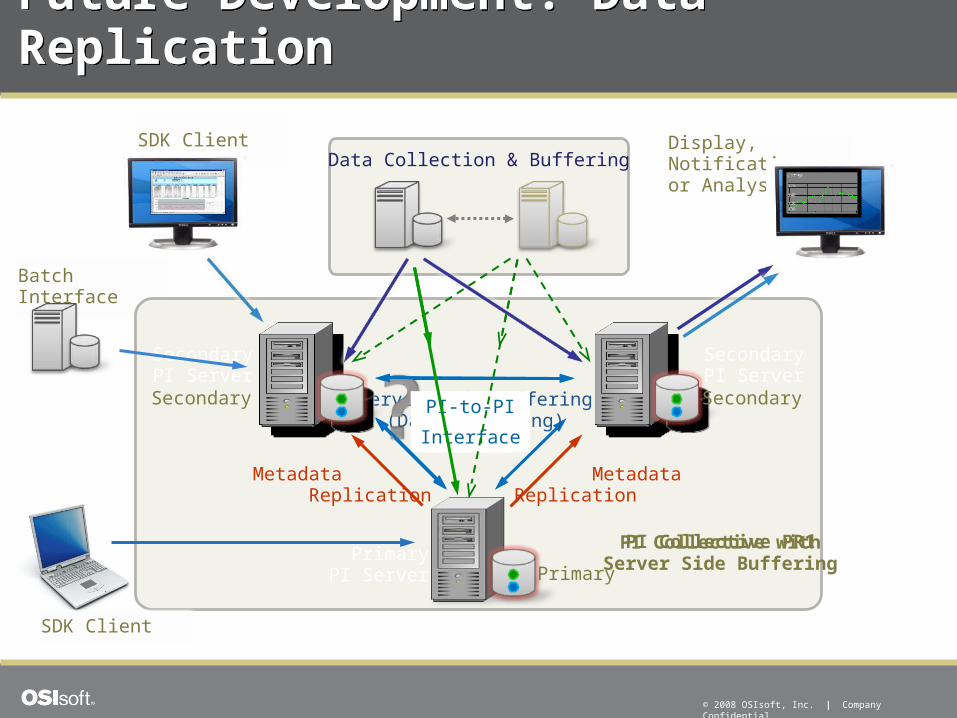
Future developments…
20© 2008 OSIsoft, Inc. | Company Confidential
Batch Interface
Future Development: Data ReplicationFuture Development: Data Replication
Server Side Buffering(Data Mirroring)
Data Collection & Buffering
PrimaryPI Server
SecondaryPI Server
SecondaryPI Server
MetadataReplication
Metadata Replication
SDK Client Display, Notificationor Analysis
Primary
Secondary SecondaryPI-to-PI
Interface
PI Collective PR1PI Collective withServer Side Buffering
SDK Client

21© 2008 OSIsoft, Inc. | Company Confidential
SummarySummary
Adoption of HA has been strongHA has greatly enhanced the PI Infrastructure

22© 2008 OSIsoft, Inc. | Company Confidential
Related Documents











