© 2005 Andreas Haeberlen, Rice University 1 Glacier: Highly durable, decentralized storage despite massive correlated failures Andreas Haeberlen Alan Mislove Peter Druschel Rice University Houston, TX 2nd Symposium on Networked Systems Design & Implementation (NSDI) Boston, MA May 2-4, 2005

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

© 2005 Andreas Haeberlen, Rice University1
Glacier: Highly durable, decentralized storage despite massive correlated failures
Andreas Haeberlen
Alan Mislove
Peter Druschel
Rice UniversityHouston, TX
2nd Symposium on Networked Systems Design & Implementation (NSDI)
Boston, MAMay 2-4, 2005

2© 2005 Andreas Haeberlen, Rice University
Introduction
Many distributed applications require storage
Cooperative storage: Aggregate storage on participating nodes
Advantages: Resilient Highly scalable
Examples: Farsite, PAST, OceanStore
Structuredoverlaynetwork

3© 2005 Andreas Haeberlen, Rice University
Motivation Common assumption:
High node diversity Failure independence
Unrealistic! Node population may have low diversity (e.g. OS)
Worms can cause large-scale correlated Byzantine failures
Reactive systems are too slow to prevent data loss

4© 2005 Andreas Haeberlen, Rice University
Related Work Phoenix, OceanStore use
introspection: Build failure model Store data on nodes
with low correlation Limitations:
Model must reflect all possible correlations
Even small inaccuracies may lead to data loss
Users have an incentive to report incorrect data

5© 2005 Andreas Haeberlen, Rice University
Our Approach: Glacier
Create massive redundancy to ensure that data survives any correlated failure with high probability
Assumption: Magnitude of the failure can be bounded by fraction fmax
Challenges: Minimize storage
and bandwidth requirements
Withstand attacks, Byzantine failures

6© 2005 Andreas Haeberlen, Rice University
6543 2 1
Glacier: Insertion When a new object is
inserted:1. Apply erasure code2. Attach manifest
with hashes of fragments
3. Send each fragment to a different node
No remote delete operation, but lifetime of objects can be limited
Storage is lease-based; reclaims unused storage
1 2 3 4 5 6
X

7© 2005 Andreas Haeberlen, Rice University
Glacier: Maintenance
Nodes with distance store similar fragments
Periodic maintenance: Ask a peer node
for its list of fragments
Compare with local list, recover any missing fragments
Fragments remain on their nodes during offline periods
3
2 1
6
54
Xk ?
X

8© 2005 Andreas Haeberlen, Rice University
Glacier: Recovery
During a failure, some fragments are damaged or lost Communication may not be possible Unaffected nodes do not take any special action:
Failed nodes are eventually repaired Maintenance gradually restores lost fragments
1
2
3
4
5
6
Time
Insert Correlated failure
Tfail
Offline period

9© 2005 Andreas Haeberlen, Rice University
Glacier: Durability
Example configuration: 48 fragments, any 5 sufficient for recovery Bad news: Storage overhead 9.6x Good news: Survives 60% correlated failure
with P=0.999999 (single object)
fmax Durability
Code Fragments Storage
0.30 0.9999 3 13 4.33
0.50 0.99999 4 29 7.25
0.60 0.999999
5 48 9.60
0.70 0.999999
5 68 13.60
0.85 0.999999
5 149 29.80
More
stora
ge
Hig
her d
ura
bility

10© 2005 Andreas Haeberlen, Rice University
Aggregation If objects are small:
Huge number of fragments
High overhead for storage, management
Solution: Aggregate objects before storing them in Glacier
Challenges: Untrusted
environment Aggregates must be
self-authenticating
App
Glacier
App
Aggreg.
Glacier

11© 2005 Andreas Haeberlen, Rice University
Aggregation: Links Mapping from objects to
aggregates is crucial! Need durability Need authentication
Solution: Link aggregates Result: DAG Can recover mapping
by traversing the DAG DAG forms a hash
tree; easy to authenticate
Top-level pointer is kept in Glacier itself

12© 2005 Andreas Haeberlen, Rice University
Evaluation Two sets of experiments:
Trace-driven simulations (scalability, churn, ...) Actual deployment: ePOST
ePOST: A cooperative, serverless e-mail system In production use: Initially 17 users, 20 nodes Based on FreePastry, PAST, Scribe, POST Added Glacier for durability
Glacier configuration in ePOST: 48 fragments, 0.2 encoding fmax=0.6, P=0.999999
140 days of practical experience (incl. some failures)

13© 2005 Andreas Haeberlen, Rice University
Evaluation: Storage
Inherent storage overhead: 48/5=9.6 17 GB of on-disk storage for 1.3GB of data Actual storage overhead on disk: About 12.6
14© 2005 Andreas Haeberlen, Rice University
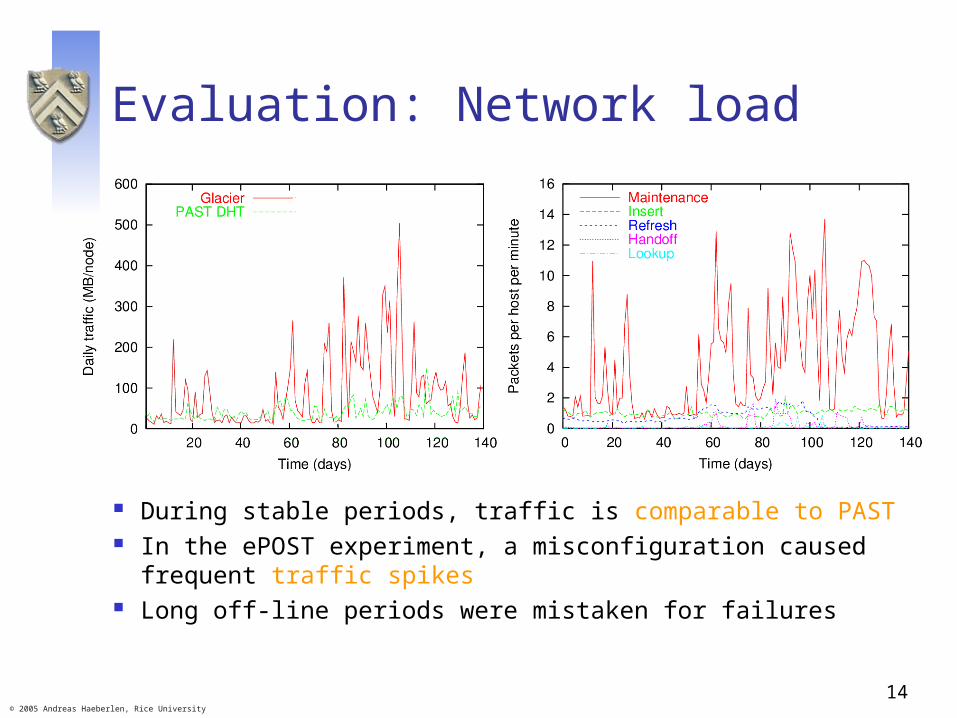
Evaluation: Network load
During stable periods, traffic is comparable to PAST In the ePOST experiment, a misconfiguration caused
frequent traffic spikes Long off-line periods were mistaken for failures

15© 2005 Andreas Haeberlen, Rice University
Evaluation: Recovery
Experiment: Created a 'clone' of the ePOST ring with only 13 of the 31 nodes (a 58% failure!)
Started recovery process on a freshly installed node: User entered e-mail address and date of last use Glacier located head of aggregate tree, recovered it System was again ready for use; no data loss

16© 2005 Andreas Haeberlen, Rice University
Conclusions
Large-scale correlated failures are a realistic threat to distributed storage systems
Glacier provides hard durability guarantees with minimal assumptions about the failure model
Glacier transforms abundant but unreliable disk space into reliable storage
Bandwidth cost is low
Thank you!

17© 2005 Andreas Haeberlen, Rice University
Glacier is available!
Download: www.epostmail.org
• Serverless, secure e-mail• Easy to set up• Uses Glacier for durability
Related Documents











