XSEarch: A Semantic Search Engine for XML Sara Cohen Jonathan Mamou Yaron Kanza Yehoshua Sagiv Presented at VLDB 2003, Germany

XSEarch: A Semantic Search Engine for XML Sara Cohen Jonathan Mamou Yaron Kanza Yehoshua Sagiv Presented at VLDB 2003, Germany.
Dec 21, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

XSEarch: A Semantic Search Engine for XML
Sara Cohen
Jonathan Mamou
Yaron Kanza
Yehoshua Sagiv
Presented at VLDB 2003, Germany

XSEarch an XML Search Engine
XSEarch an XML Search Engine
Our Goal:
Find the “relevant” XML fragments,
given tag names and keywords
Our Goal:
Find the “relevant” XML fragments,
given tag names and keywords

Excerpt from the XML Version of DBLP
<proceedings>
<inproceedings>
<author>Moshe Y. Vardi</author>
<title>Querying Logical Databases</title>
</inproceedings>
<inproceedings>
<author>Victor Vianu</author>
<title>A Web Odyssey: From Codd to XML</title>
</inproceedings>
</proceedings>

A Search Example
Find papers by Vianu on the topic of “logical databases”
How can we find such papers?
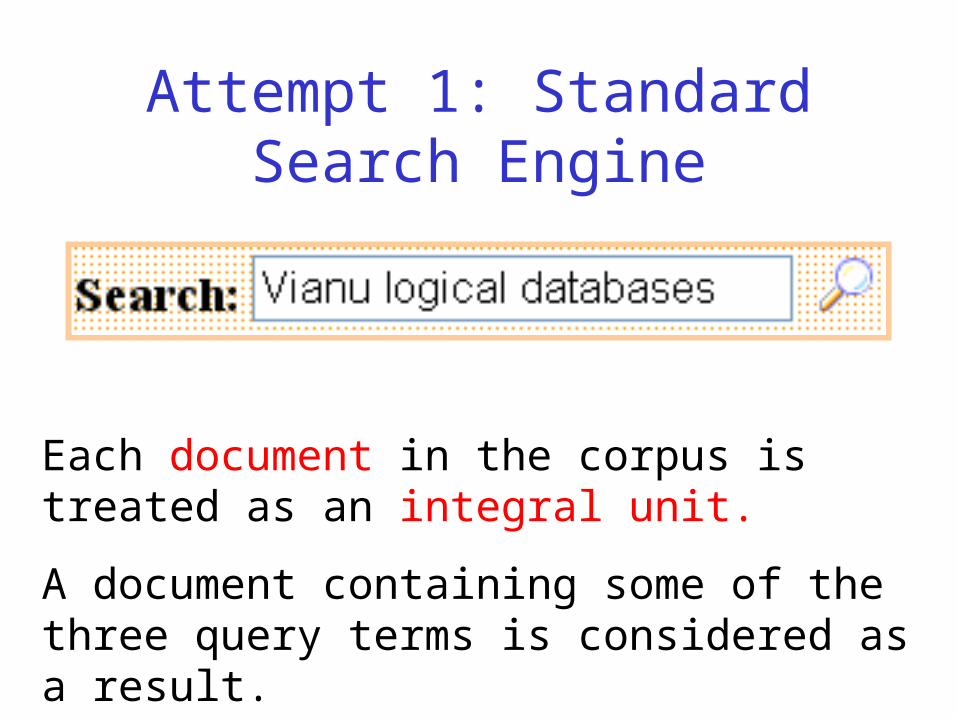
Attempt 1: Standard Search Engine
Each document in the corpus is treated as an integral unit.
A document containing some of the three query terms is considered as a result.

The document is not relevant to the query.
This does not work!!!
The document is returned BUT it does not
contain any paper on “logical databases” by VianuThis fragment does not represent
a paper by Vianu
This fragment does not represent a paper about logical databases
<proceedings> <inproceedings> <author>Moshe Y. Vardi</author> <title>Querying Logical Databases</title> </inproceedings> <inproceedings> <author>Victor Vianu</author> <title>A Web Odyssey: From Codd to XML</title> </inproceedings></proceedings>
The document contains the three query terms. Hence, it is returned by a standard search engine. BUT

Attempt 2: XML Query Language
FOR $i IN document(“bib.xml”)//inproceedingsWHERE $i/author contains ‘Vianu’
AND $i/title contains ‘Logical’ AND $i/title contains ‘Databases’
RETURN <result> <author> $i/author </author>
<title> $i/title </title> </result>
FOR $i IN document(“bib.xml”)//inproceedingsWHERE $i/author contains ‘Vianu’
AND $i/title contains ‘Logical’ AND $i/title contains ‘Databases’
RETURN <result> <author> $i/author </author>
<title> $i/title </title> </result>
• Complicated syntax• Extensive knowledge of the document structure required to
write the query• No mechanism for ranking results
This does work, BUT

Our Requirements from the Search Tool
• A simple syntax that can be used by naive users• Search results should include XML fragments and
not necessarily full documents• The XML fragments in an answer, should be
semantically related– For example, a paper and an author should be in an
answer only if the paper was written by this author
• Search results should be ranked• Search results should be returned in “reasonable”
time
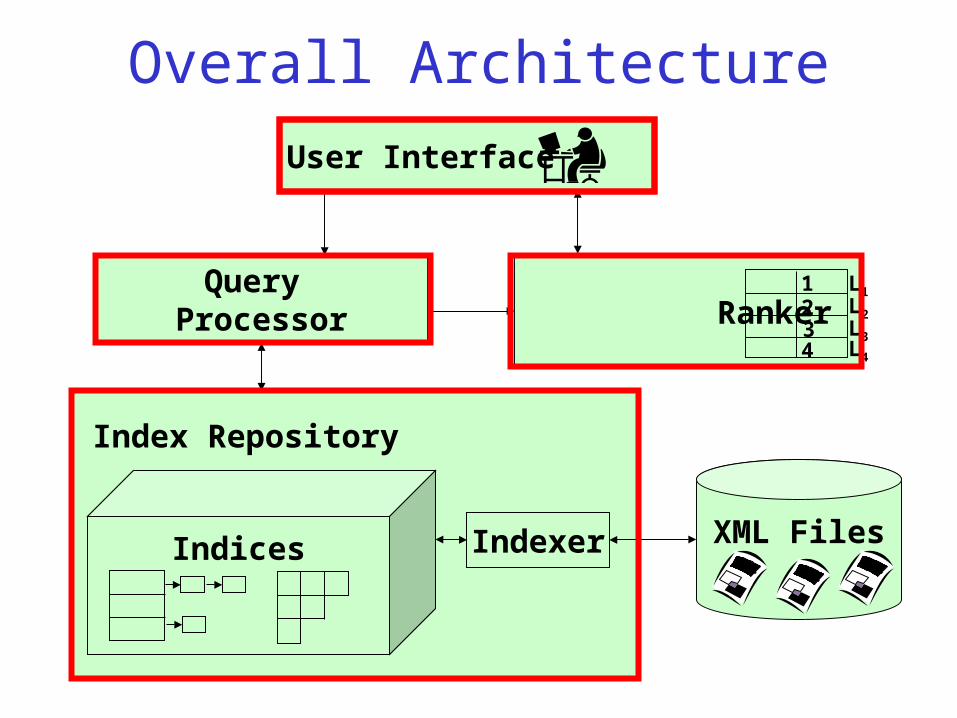
Overall Architecture
User Interface
Query Processor Ranker
XML Files
1 2 3 4
L1 L2 L3 L4
IndexerIndices
Index Repository
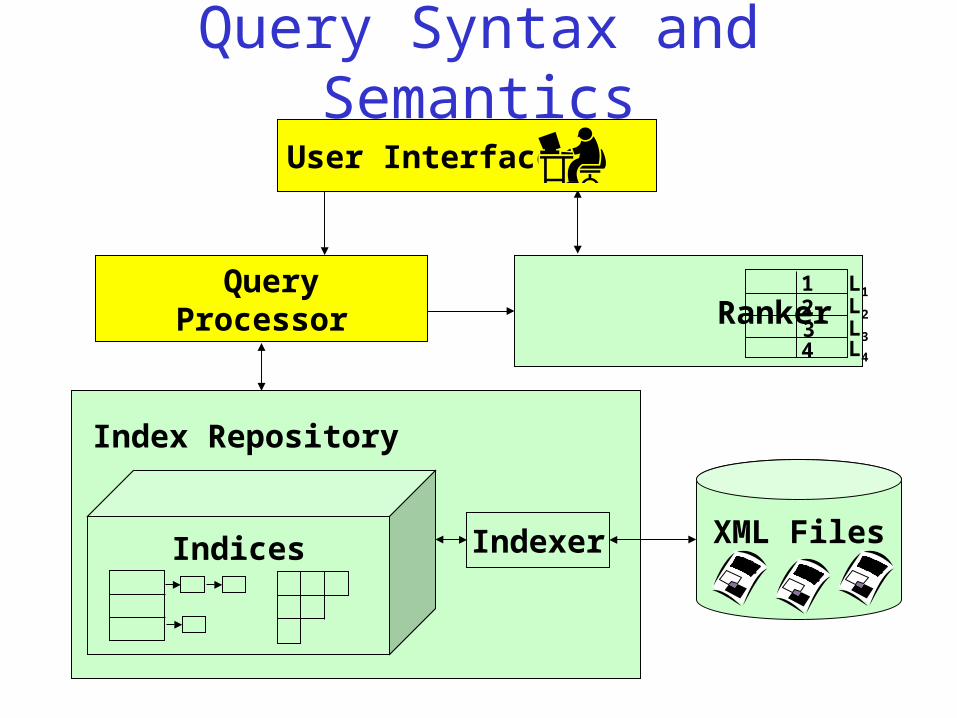
Query Syntax and Semantics
User Interface
Query Processor Ranker
XML Files
1 2 3 4
L1 L2 L3 L4
IndexerIndices
Index Repository
User Interface
Query Processor

XSEarch Query Syntax
• A query is a list of query terms
• A query term can be a – Keyword, e.g., database
– Tag, e.g., inproceedings: – Tag-keyword combination, e.g., author:Vianu
• Optionally preceded by a ‘+’

Appearance of logical in thefragment increases the rank ofthis fragment
Note that the different document fragments matching these query terms must be “semantically related”
Example
• Find papers by Vianu on the topic of “logical databases”
logical +database inproceedings: author:Vianulogical +database inproceedings: author:Vianu
Appearance of the tag inproceedings, in the fragment, increases the rank of this fragment
Appearance of Vianu under the tag author, in the fragment, increases the rank of this fragment
The keyword databasemust appear in the fragment

Semantic Relation: The Intuition
Semantic Relation: The Intuition
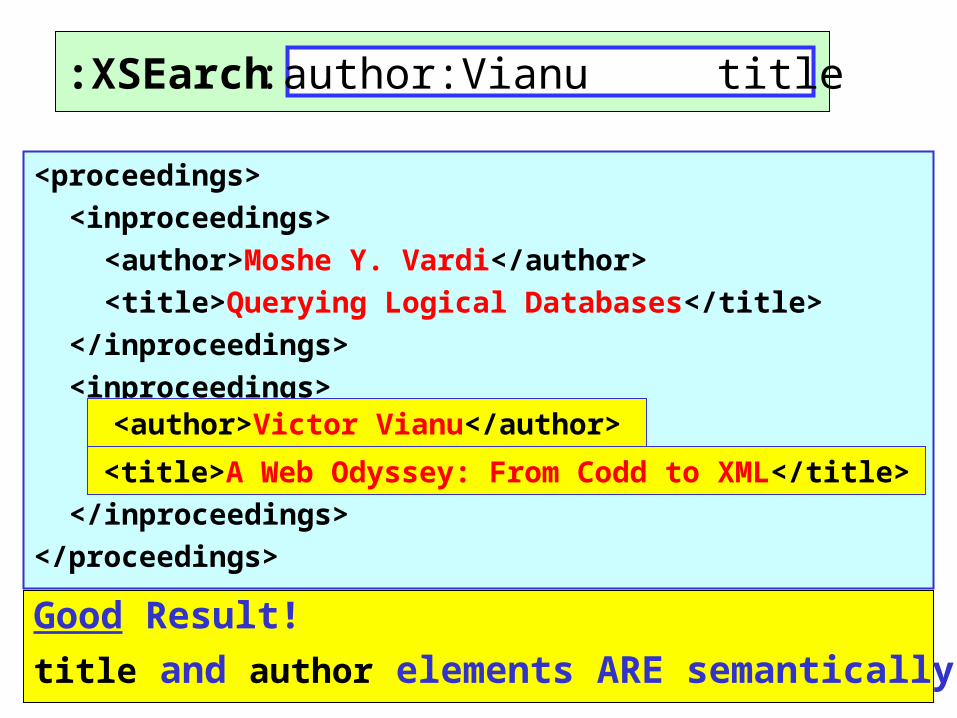
XSEarch:
<proceedings>
<inproceedings>
<author>Moshe Y. Vardi</author>
<title>Querying Logical Databases</title>
</inproceedings>
<inproceedings>
<author>Victor Vianu</author>
<title>A Web Odyssey: From Codd to XML</title>
</inproceedings>
</proceedings>
>title>A Web Odyssey: From Codd to XML</title<
>author>Victor Vianu</author<
Good Result!
title and author elements ARE semantically related
author:Vianu title:
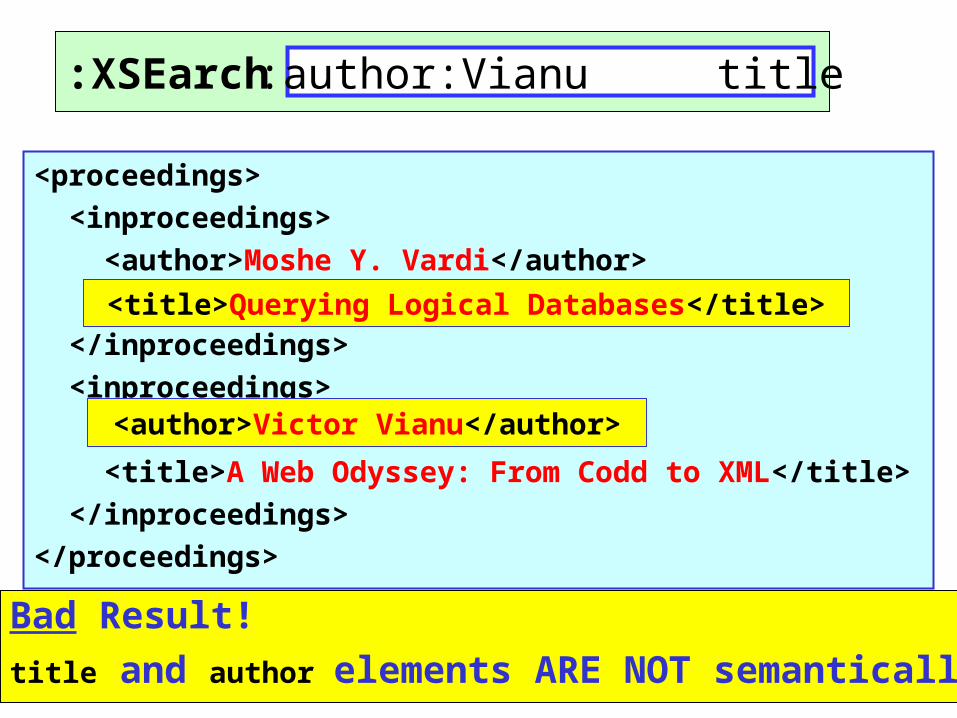
<proceedings>
<inproceedings>
<author>Moshe Y. Vardi</author>
<title>Querying Logical Databases</title>
</inproceedings>
<inproceedings>
<author>Victor Vianu</author>
<title>A Web Odyssey: From Codd to XML</title>
</inproceedings>
</proceedings>
<title>Querying Logical Databases</title>
>author>Victor Vianu</author<
Bad Result!
title and author elements ARE NOT semantically related
XSEarch: author:Vianu title:

Semantic Relation: Formalization
Semantic Relation: Formalization
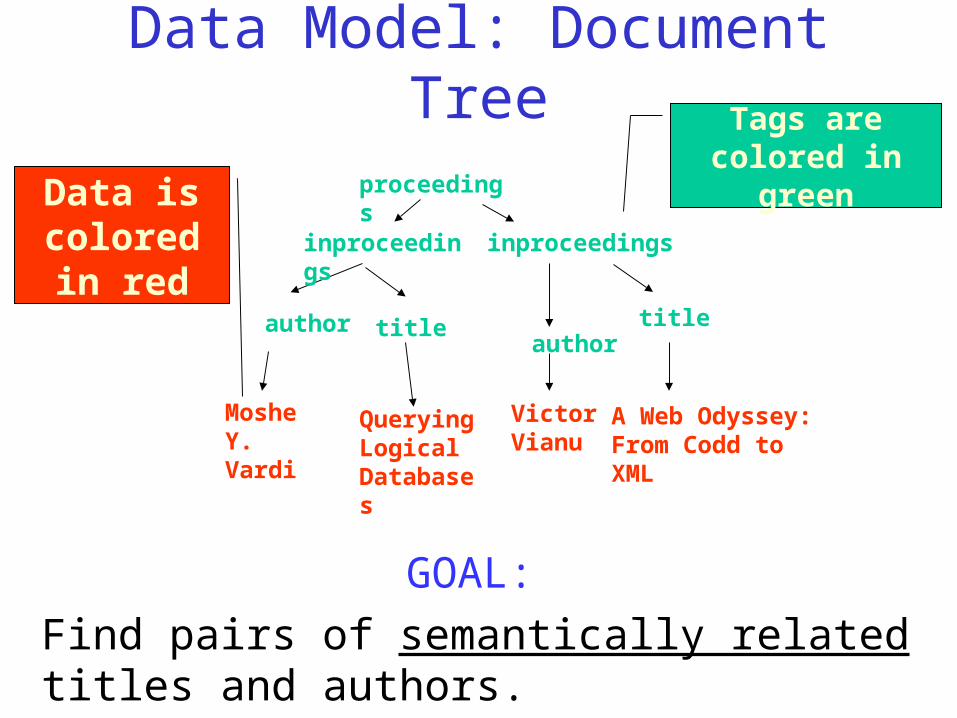
Data Model: Document TreeTags are colored
in greenData is colored in
red
proceedings
Moshe Y. Vardi
inproceedings
author title
Querying Logical Databases
authortitle
Victor Vianu
A Web Odyssey: From Codd to XML
inproceedings
GOAL:
Find pairs of semantically related titles and authors.
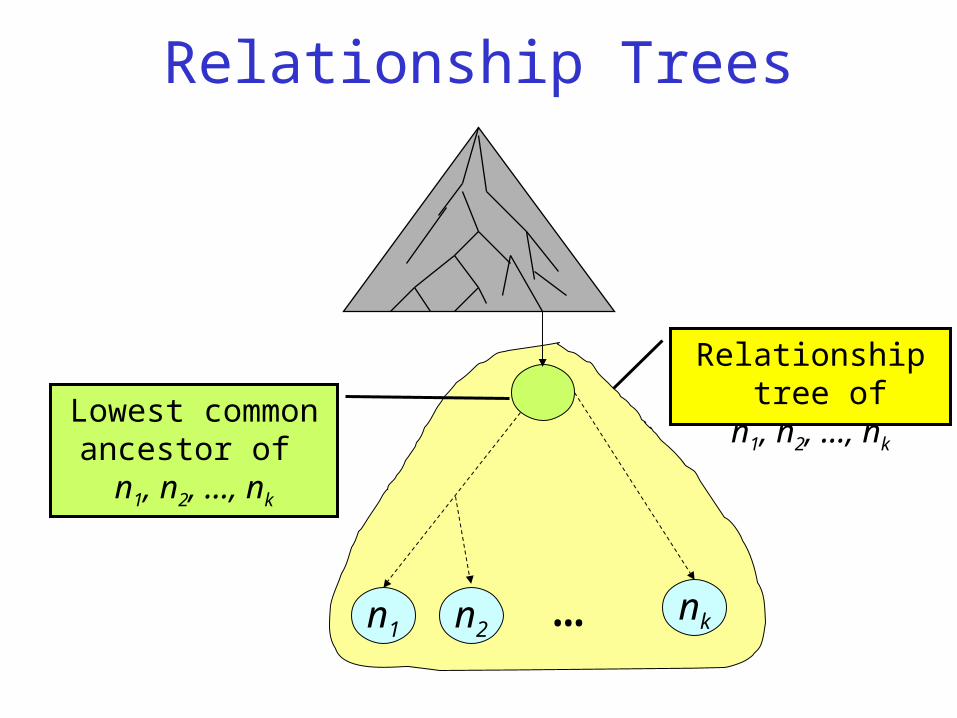
Relationship Trees
Relationship tree of n1, n2, …, nk
n1 n2nk…
Lowest common ancestor of n1, n2, …, nk

Our “Semantic Relation”: Interconnection
• n1,..., nk are strongly interconnected if the relationship tree of n1,..., nk does not contain two nodes with the same label
• n1,..., nk are interconnected if either
– they are strongly interconnected, or– the only nodes with the same label in the
relationship tree of n1,..., nk, are among n1,..., nk
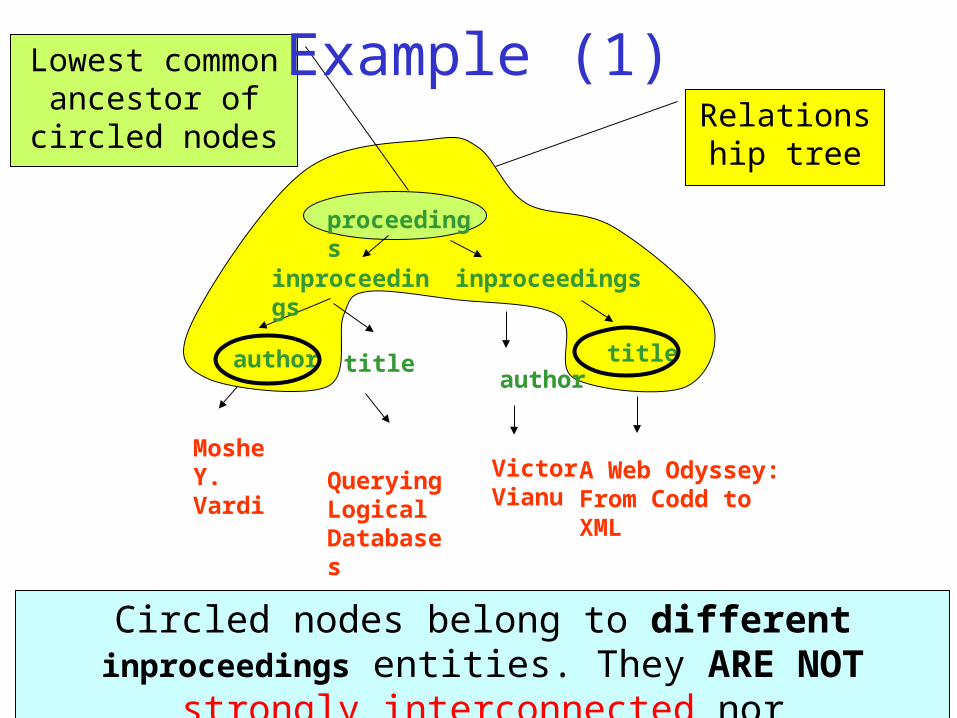
proceedings
Moshe Y. Vardi
inproceedings
author title
Querying Logical Databases
authortitle
Victor Vianu
A Web Odyssey: From Codd to XML
inproceedings
Circled nodes belong to different inproceedings entities. They ARE NOT strongly interconnected nor interconnected!
Relationship tree
Lowest common ancestor of circled
nodes
Example (1)
proceedings
Moshe Y. Vardi
inproceedings
author title
Querying Logical Databases
authortitle
Victor Vianu
A Web Odyssey: From Codd to XML
inproceedings
Circled nodes belong to the same inproceedings entity. They ARE strongly interconnected, thus, interconnected!
Relationship tree
Lowest common ancestor of circled
nodes
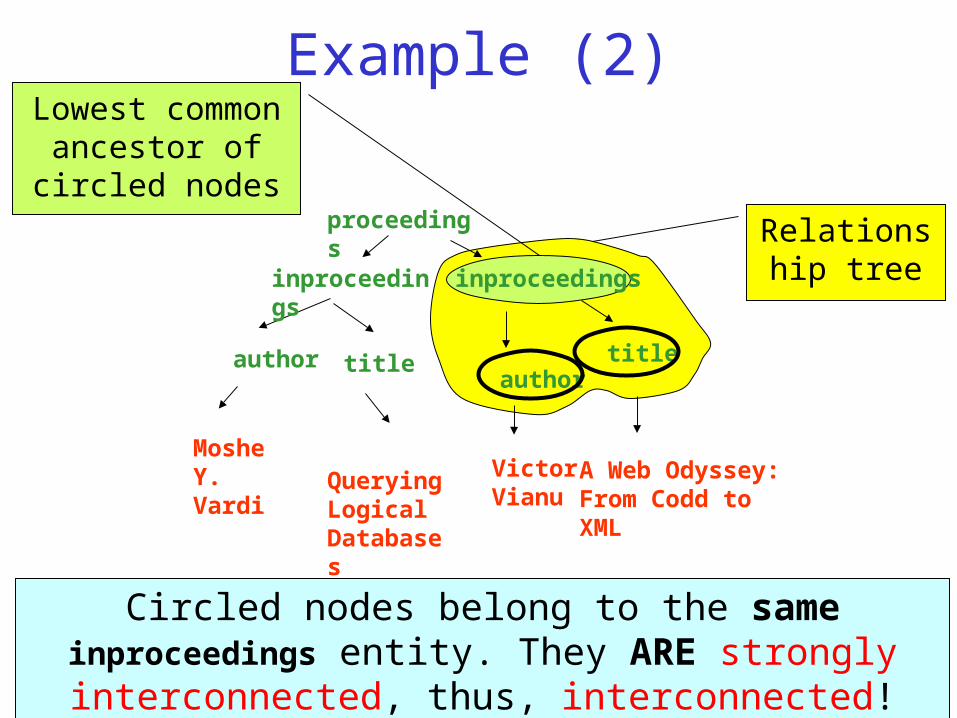
Example (2)
proceedings
Moshe Y. Vardi
inproceedings
author title
Querying Logical Databases
authortitle
Victor Vianu
Queries and Computation on the Web
inproceedings
Circled nodes belong to the same inproceedings entity, but are labeled with the same tag.
They ARE interconnected, BUT NOT strongly interconnected!
Relationship tree
Lowest common ancestor of circled
nodes
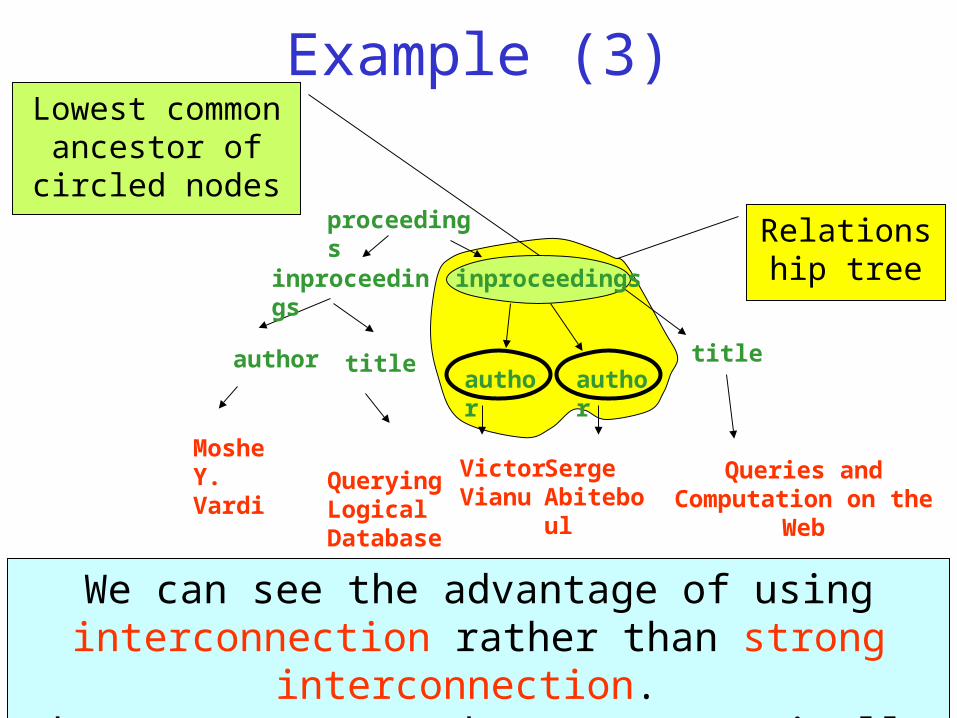
Example (3)
author
Serge Abiteboul
We can see the advantage of using interconnection rather than strong interconnection.
These two author nodes ARE semantically related.

Interconnection
• Based on theoretical results of “Generating relations from XML documents”, S. Cohen, Y.Kanza, Y. Sagiv, ICDT 2003.– Three types of interconnection
• We have implemented two types of interconnection• XSEarch can easily accommodate different types
of interconnection, or other semantic relations between nodes

Checking Whether Two Nodes Are Interconnected
• Given a document T, it is possible to check whether nodes n and n’ are interconnected in O(|T|) time
• Too expensive to do it during query processing!
• During query processing, we need to check whether pairs of nodes are interconnected

Interconnection Index
• Is built offline• Allows for checking interconnection
between two nodes, during query processing, in O(1) time
• We have two implementations – as a hash table– as a symmetric matrix
• The Indexer is responsible for building the Interconnection Index
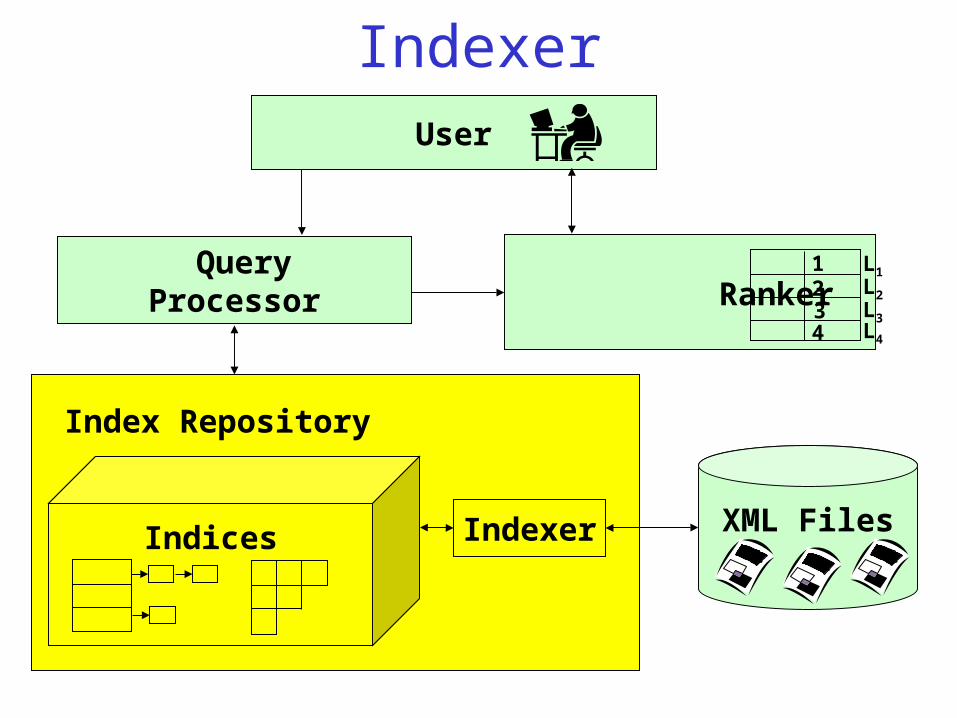
IndexerUser
Query Processor Ranker
XML Files
1 2 3 4
L1 L2 L3 L4
IndexerIndices
Index Repository

• For each pair of nodes, check whether this pair is interconnected– There are O(|T|2) pairs– Checking interconnection is in O(|T|) time
• As a result, checking for interconnection of all pairs of nodes in T is in O(|T|3) time
Too expensive also if it is done offline!!!
Building the Interconnection Index: Naïve Approach

• Idea: Checking whether two nodes are interconnected can be done by checking interconnection between their parents/children
• There are two characterizations of nodes interconnection– For child-ancestor nodes– For non child-ancestor nodes
Building the Interconnection Index: Dynamic Programming Approach

Interconnection Characterization: n is an ancestor of n’
n and n’ are interconnected
if and only if:– the parent of n’ is strongly
interconnected with n – the child of n on the path to n’
is strongly interconnected with n’ parent of n’
child of n
…
n
n’
– the parent of n’ is strongly
interconnected with n
parent of n’
n
child of n
n’
– the child of n on the path to n’
is strongly interconnected with n’
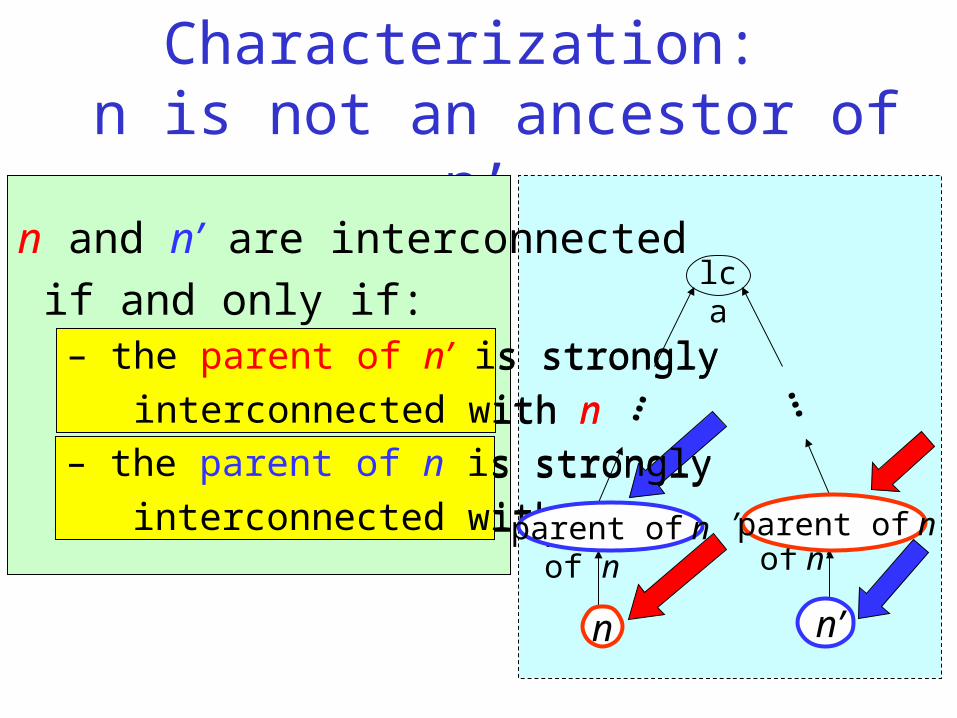
Interconnection Characterization: n is not an ancestor of n’
n and n’ are interconnected
if and only if:– the parent of n’ is strongly
interconnected with n – the parent of n is strongly
interconnected with n’
n’n
parent of n’parent of n
…
lca
…
– the parent of n is strongly
interconnected with n’
n’
parent of n
– the parent of n’ is strongly
interconnected with n
n
parent of n’

Building the Interconnection Index Using Dynamic Programming
• Theorem: Let T be a document. Then it is possible to determine interconnection of all pairs of nodes in T in O(|T|2) time
• Proof hint: – Derive nodes numbers in T by a depth-first
traversal of T– Compute the index using dynamic
programming, based on the characterizations

Query Processing
• Document fragments are extracted using the interconnection index and other indices
• Extracted fragments are returned ranked by the estimated relevance
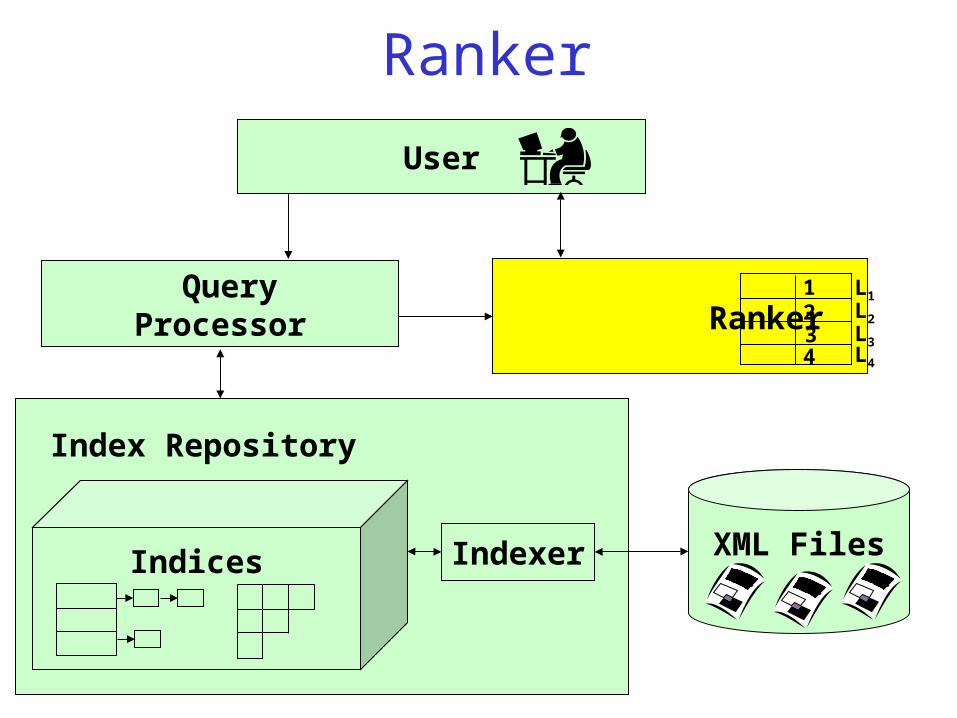
Ranker
User
Query Processor Ranker
XML FilesIndexerIndices
Index Repository
1 2 3 4
L1 L2 L3 L4

Ranking Factors
Several factors increase the rank of a result
• Similarity between query and result
• Weight of labels appearing in the result
• Characteristics of result tree

Query and Result Similarity
TFILF– Extension of TFIDF, classical in IR
– Term Frequency: number of occurrences of a query term in a fragment
– Inverse Leaf Frequency: number of leaves containing a query term divided by number of leaves in the corpus

TFILF• Term frequency of keyword k in a leaf node nl
• Inverse leaf frequency
TFILF is the product between tf and ilf

Weight of Labels
• Some labels are considered more important than others– Text under an element labeled with title is
more “important” than text under element labeled with section
• Label weights can be– system generated– user defined
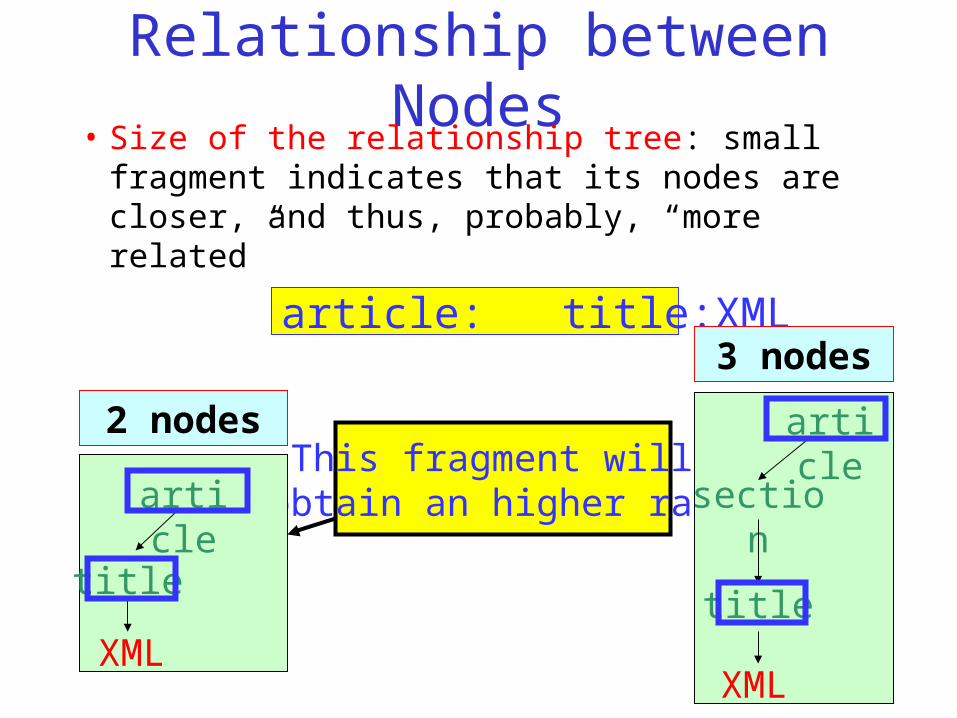
Relationship between Nodes• Size of the relationship tree: small fragment
indicates that its nodes are closer, and thus, probably, “more related”
article: title:XML
2 nodes
3 nodes
This fragment will obtain an higher rankarticle
title
XML
article
section
title
XML
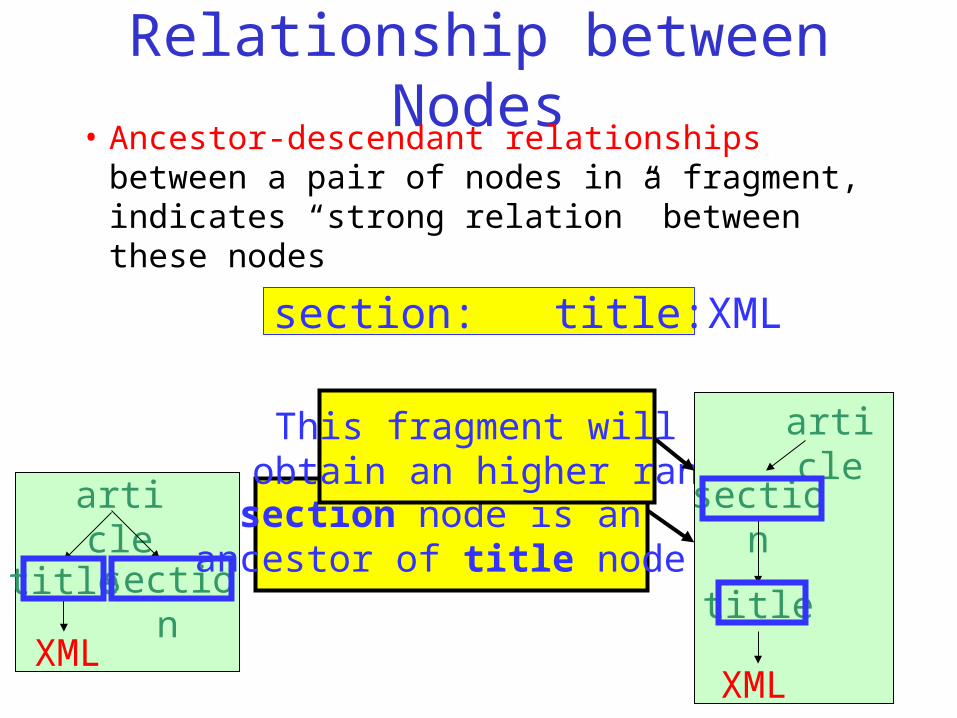
Relationship between Nodes• Ancestor-descendant relationships between
a pair of nodes in a fragment, indicates “strong relation” between these nodes
section: title:XML
article
title
XML
section
section node is an ancestor of title node
This fragment will obtain an higher rank
section
title
article
XML

Experimental ResultsExperimental Results

Hardware and Software Used
• Language: Java
• Processor: 1.6 GHZ Pentium 4
• RAM: 2 GB (limited to 1.46 GB by JVM)
• OS: Windows XP

Choosing the Implementation for the Interconnection Index
• We have experimented the two implementations of the interconnection index1. IIH: the index is an hash table2. IIM: the index is a symmetric matrix
• We compare the two implementations – Cost of building the index– Cost of query processing, i.e., using the index

• IIM is better than IIH, because of the additional overhead of hashing
Time For Building Indices
XML corpus
Size (KB)
Number of nodes
IIM time (ms)
IIH time (ms)
Dream1463,3602936
Hamlet2816,635114185
Sigmod70421,2461,5521,729
Mondial1,19849,4226,2317,837
• Both implementations are reasonable

On the Fly Indexing (OFI)
• Fully building the indices as a preprocess of querying is expensive in memory for “huge” corpuses!– Also expensive in time because of the additional
overhead of using virtual memory
• Instead, compute interconnection index incrementally on-the-fly during query processing for each pair that must be checked– By how much will query processing be slowed
down?
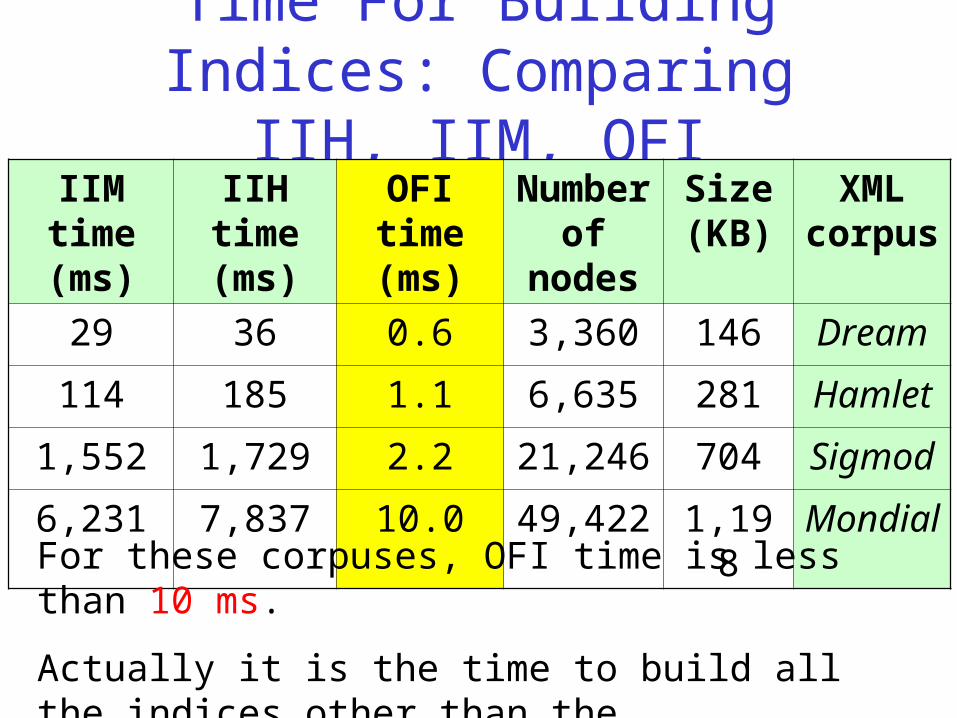
Time For Building Indices: Comparing IIH, IIM, OFI
XML corpus
Size (KB)
Number of nodes
OFI time (ms)
IIH time (ms)
IIM time (ms)
Dream1463,3600.63629
Hamlet2816,6351.1185114
Sigmod70421,2462.21,7291,552
Mondial1,19849,42210.07,8376,231
For these corpuses, OFI time is less than 10 ms.
Actually it is the time to build all the indices other than the interconnection index.

Query Execution Time
• We generated 1000 random queries for the Sigmod Record corpus
• Each query had:– At most 3 optional search terms– At most 3 required search terms
• We checked time with IIH, IIM and OFI
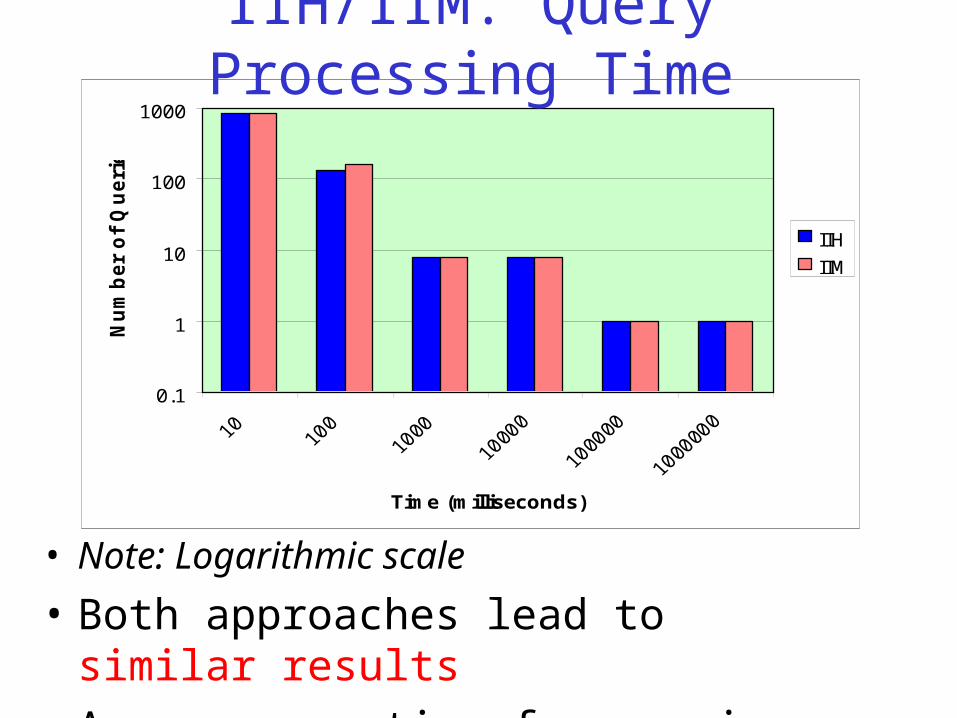
0.1
1
10
100
1000
Time (milliseconds)
Nu
mb
er
of
Qu
eri
es
IIH
IIM
IIH/IIM: Query Processing Time
• Note: Logarithmic scale
• Both approaches lead to similar results
• Average run time for queries: 35 ms
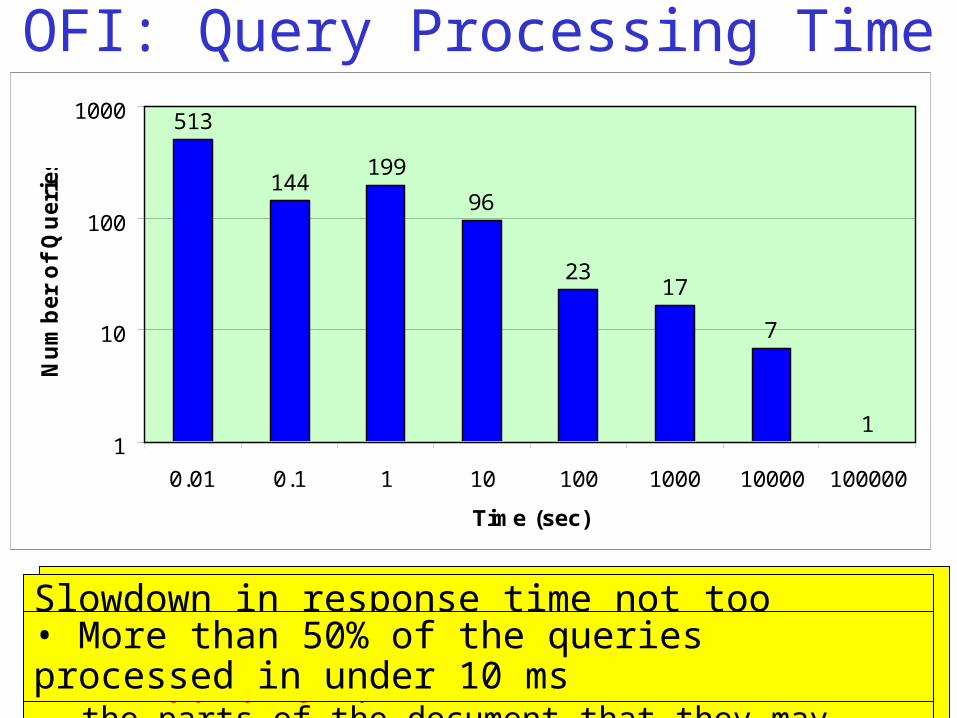
• After processing the 1000 queries, 0.75% of all pairs of nodes were checked for interconnection.•Space saved in main memory
Slowdown in response time not too large!Locality property: queries tend to be similar in the parts of the document that they may access
• More than 50% of the queries processed in under 10 ms
513
144199
96
2317
7
11
10
100
1000
0.01 0.1 1 10 100 1000 10000 100000
Time (sec)
Nu
mb
er
of
Qu
eri
es
OFI: Query Processing Time

How Good are the Results?
• We measured recall & precision for the query:– Find papers written by Buneman that contain the
keyword database in the title
• We tried two different queries that reflect different amounts of user knowledge– Kw: +Buneman +database (classical search
engine query)– Tag-kw: +author:Buneman +title:database
• Corpus: Sigmod, DBLP

• We computed the "correct answers" using XQuery
• Recall
Perfect recall, i.e., XSEarch returns all the correct answers
• Precision at n
Precision and Recall
correct returned answers
correct answers
correct answers in the first n returned answers
n
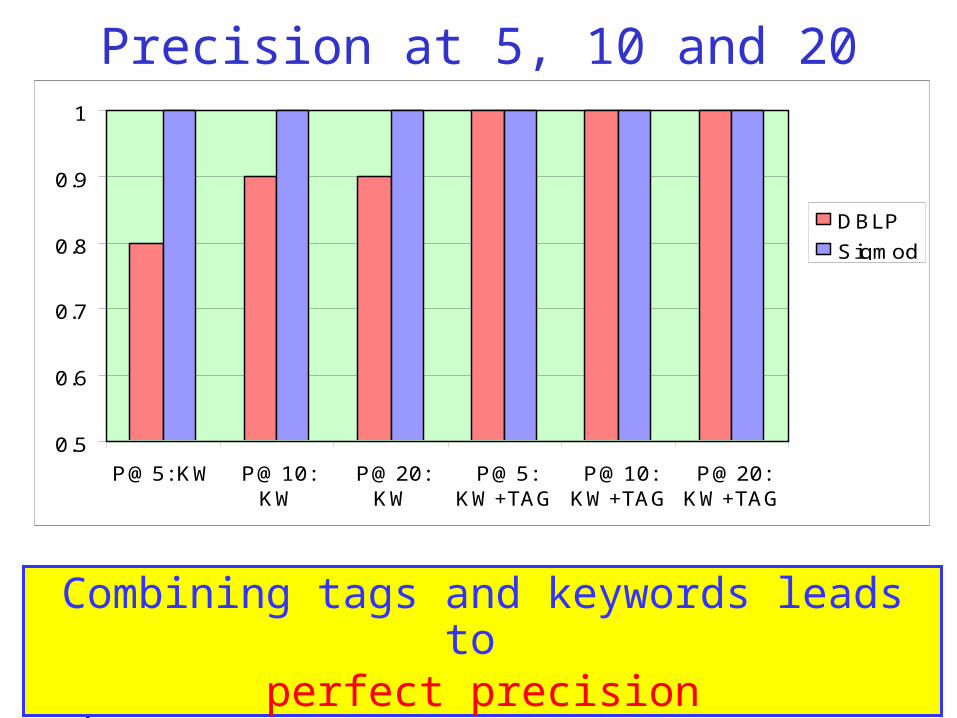
Precision at 5, 10 and 20
0.5
0.6
0.7
0.8
0.9
1
P@5: KW P@10:KW
P@20:KW
P@5:KW+TAG
P@10:KW+TAG
P@20:KW+TAG
DBLP
Sigmod
Sigmod: Perfect precision
DBLP: 0.8/0.9 for query containing only keywords
Combining tags and keywords leads to perfect precision

Conclusions
• Paradigm for querying XML combining IR and database techniques
• Returns semantically related fragments, ranked by estimated relevance
• Combining tags and keywords in the query leads to good results

Conclusions
• Efficient index structures– IIM/IIH for “small” documents– OFI for “big” documents
• Efficient evaluation algorithms– Dynamic algorithm for computing
interconnection
• Extensible implementation– The system can easily accommodate different
types of semantic relations between nodes, other than interconnection

Thank You.
Questions?
Related Documents











