Proceedings of the 3rd Clinical Natural Language Processing Workshop, pages 178–193 November 19, 2020. c 2020 Association for Computational Linguistics 178 Weakly Supervised Medication Regimen Extraction from Medical Conversations Dhruvesh Patel * College of Information and Computer Sciences University of Massachusetts Amherst [email protected] Sandeep Konam Abridge AI Inc. [email protected] Sai P. Selvaraj Abridge AI Inc. [email protected] Abstract Automated Medication Regimen (MR) extraction from medical conversations can not only improve recall and help patients follow through with their care plan, but also reduce the documentation bur- den for doctors. In this paper, we focus on extract- ing spans for frequency, route and change, corre- sponding to medications discussed in the conver- sation. We first describe a unique dataset of anno- tated doctor-patient conversations and then present a weakly supervised model architecture that can perform span extraction using noisy classification data. The model utilizes an attention bottleneck inside a classification model to perform the ex- traction. We experiment with several variants of attention scoring and projection functions and pro- pose a novel transformer-based attention scoring function (TAScore). The proposed combination of TAScore and Fusedmax projection achieves a 10 point increase in Longest Common Substring F1 compared to the baseline of additive scoring plus softmax projection. 1 Introduction Patients forget 40-80% of the medical information provided by healthcare practitioners immediately (Mcguire, 1996) and misconstrue 48% of what they think they remembered (Anderson et al., 1979), and this adversely affects patient adherence. Automat- ically extracting information from doctor-patient conversations can help patients correctly recall doc- tor’s instructions and improve compliance with the care plan (Tsulukidze et al., 2014). On the other hand, clinicians spend up to 49.2% of their overall time on EHR and desk work, and only 27.0% of their total time on direct clinical face time with * Work done as an intern at Abridge AI Inc. DR: Limiting your alcohol consumption is important, so, and, um, so, you know, I would recommend vitamin D 1 to be taken 1 . Have you had Fosamax 2 before? PT: I think my mum did. DR: Okay, Fosamax 2 , you take 2 one pill 2 on Monday and one on Thursday 2 . DR: Do you use much caffine? PT: No, none. DR: Okay, this is 3 Actonel 3 and it’s one tablet 3 once a month 3 . DR: Do you get a one month or a three months supply in your prescriptions? Figure 1: An example excerpt from a doctor- patient conversation transcript. Here, there are three medications mentioned indicated by the superscript. The extracted attributes, change , route and frequency, for each medications are also shown. patients (Sinsky et al., 2016). Increased data man- agement work is also correlated with increased doc- tor burnout (Kumar, 2016). Information extracted from medical conversations can also aid doctors in their documentation work (Rajkomar et al., 2019; Schloss and Konam, 2020), allow them to spend more face time with the patients, and build better relationships. In this work, we focus on extracting Medication Regimen (MR) information (Du et al., 2019; Sel- varaj and Konam, 2019) from the doctor-patient conversations. Specifically, we extract three at- tributes, i.e., frequency, route and change, corre- sponding to medications discussed in the conversa- tion (Figure 1). Medication Regimen information can help doctors with medication orders cum re- newals, medication reconciliation, verification of

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Proceedings of the 3rd Clinical Natural Language Processing Workshop, pages 178–193November 19, 2020. c©2020 Association for Computational Linguistics
178
Weakly Supervised Medication Regimen Extractionfrom Medical Conversations
Dhruvesh Patel∗College of Information and Computer Sciences
University of Massachusetts [email protected]
Sandeep KonamAbridge AI Inc.
Sai P. SelvarajAbridge AI Inc.
Abstract
Automated Medication Regimen (MR) extractionfrom medical conversations can not only improverecall and help patients follow through with theircare plan, but also reduce the documentation bur-den for doctors. In this paper, we focus on extract-ing spans for frequency, route and change, corre-sponding to medications discussed in the conver-sation. We first describe a unique dataset of anno-tated doctor-patient conversations and then presenta weakly supervised model architecture that canperform span extraction using noisy classificationdata. The model utilizes an attention bottleneckinside a classification model to perform the ex-traction. We experiment with several variants ofattention scoring and projection functions and pro-pose a novel transformer-based attention scoringfunction (TAScore). The proposed combination ofTAScore and Fusedmax projection achieves a 10point increase in Longest Common Substring F1compared to the baseline of additive scoring plussoftmax projection.
1 Introduction
Patients forget 40-80% of the medical informationprovided by healthcare practitioners immediately(Mcguire, 1996) and misconstrue 48% of what theythink they remembered (Anderson et al., 1979), andthis adversely affects patient adherence. Automat-ically extracting information from doctor-patientconversations can help patients correctly recall doc-tor’s instructions and improve compliance with thecare plan (Tsulukidze et al., 2014). On the otherhand, clinicians spend up to 49.2% of their overalltime on EHR and desk work, and only 27.0% oftheir total time on direct clinical face time with
∗Work done as an intern at Abridge AI Inc.
DR: Limiting your alcohol consumptionis important, so, and, um, so, youknow, I would recommend vitamin D1
to be taken1 . Have you had Fosamax2
before?PT: I think my mum did.DR: Okay, Fosamax2 , you take2
one pill2 on Monday and one on Thursday2 .DR: Do you use much caffine?PT: No, none.DR: Okay, this is3 Actonel3 and it’s
one tablet3 once a month3 .DR: Do you get a one month or a three
months supply in your prescriptions?
Figure 1: An example excerpt from a doctor-patient conversation transcript. Here, there are threemedications mentioned indicated by the superscript.The extracted attributes, change, route and frequency,for each medications are also shown.
patients (Sinsky et al., 2016). Increased data man-agement work is also correlated with increased doc-tor burnout (Kumar, 2016). Information extractedfrom medical conversations can also aid doctors intheir documentation work (Rajkomar et al., 2019;Schloss and Konam, 2020), allow them to spendmore face time with the patients, and build betterrelationships.
In this work, we focus on extracting MedicationRegimen (MR) information (Du et al., 2019; Sel-varaj and Konam, 2019) from the doctor-patientconversations. Specifically, we extract three at-tributes, i.e., frequency, route and change, corre-sponding to medications discussed in the conversa-tion (Figure 1). Medication Regimen informationcan help doctors with medication orders cum re-newals, medication reconciliation, verification of

179
reconciliations for errors, and other medication-centered EHR documentation tasks. It can alsoimprove patient engagement, transparency and bet-ter compliance with the care plan (Tsulukidze et al.,2014; Grande et al., 2017).
MR attribute information present in a conversa-tion can be obtained as spans in text (Figure 1) orcan be categorized into classification labels (Table2). While the classification labels are easy to obtainat scale in an automated manner – for instance, bypairing conversations with billing codes or medi-cation orders – they can be noisy and can resultin a prohibitively large number of classes. Classi-fication labels go through normalization and dis-ambiguation, often resulting in label names whichare very different from the phrases used in the con-versation. This process leads to a loss of granularinformation present in the text (see, for example,row 2 in Table 2). Span extraction, on the otherhand, alleviates this issue as the outputs are actualspans in the conversation. However, span extrac-tion annotations are relatively hard to come by andare time-consuming to annotate manually. Hence,in this work, we look at the task of MR attributespan extraction from doctor-patient conversationusing weak supervision provided by the noisy clas-sification labels.
The main contributions of this work are as fol-lows. We present a way of setting up an MRattribute extraction task from noisy classificationdata (Section 2). We propose a weakly supervisedmodel architecture which utilizes attention bottle-neck inside a classification model to perform spanextraction (Section 3 & 4). In order to favor sparseand contiguous extractions, we experiment withtwo variants of attention projection functions (Sec-tion 3.1.2), namely, softmax and Fusedmax (Nicu-lae and Blondel, 2017). Further, we propose a noveltransformer-based attention scoring function TAS-core (Section 3.1.1). The combination of TAScoreand Fusedmax achieves significant improvementsin extraction performance over a phrase-based (22LCSF1 points) and additive softmax attention (10LCSF1 points) baselines.
2 Medication Regimen (MR) using WeakSupervision
Medication Regimen (MR) consists of informationabout a prescribed medication akin to attributes ofan entity. In this work, we specifically focus on fre-quency, route of the medication and any change in
Attribute Normalized Classes
frequency
Daily | Every morning | At Bedtime |Twice a day | Three times a day | Every six hours |Every week | Twice a week | Three times a week |Every month | Other | None
routePill | Injection | Topical cream | Nasal spray |Medicated patch | Ophthalmic solution | Inhaler |Oral solution | Other | None
change Take | Stop | Increase | Decrease | None | Other
Table 1: The normalized labels in the classificationdata.
the medication’s dosage or frequency as shownin Figure 1. For example, given the conversationexcerpt and the medication “Fosamax” as shownin Figure 1, the model needs to extract the spans“one pill on Monday and one on Thursday”, “pill”and “you take” for attributes frequency, route andchange, respectively. The major challenge, how-ever, is to perform the attribute span extraction us-ing noisy classification labels with very few or nospan-level labels. The rest of this section describesthe dataset used for this task.
2.1 Data
The data used in this paper comes from a collectionof human transcriptions of 63000 fully-consentedand de-identified doctor-patient conversations. Atotal of 57000 conversations were randomly se-lected to construct the training (and dev) conver-sation pool and the remaining 6000 conversationswere reserved as the test pool.
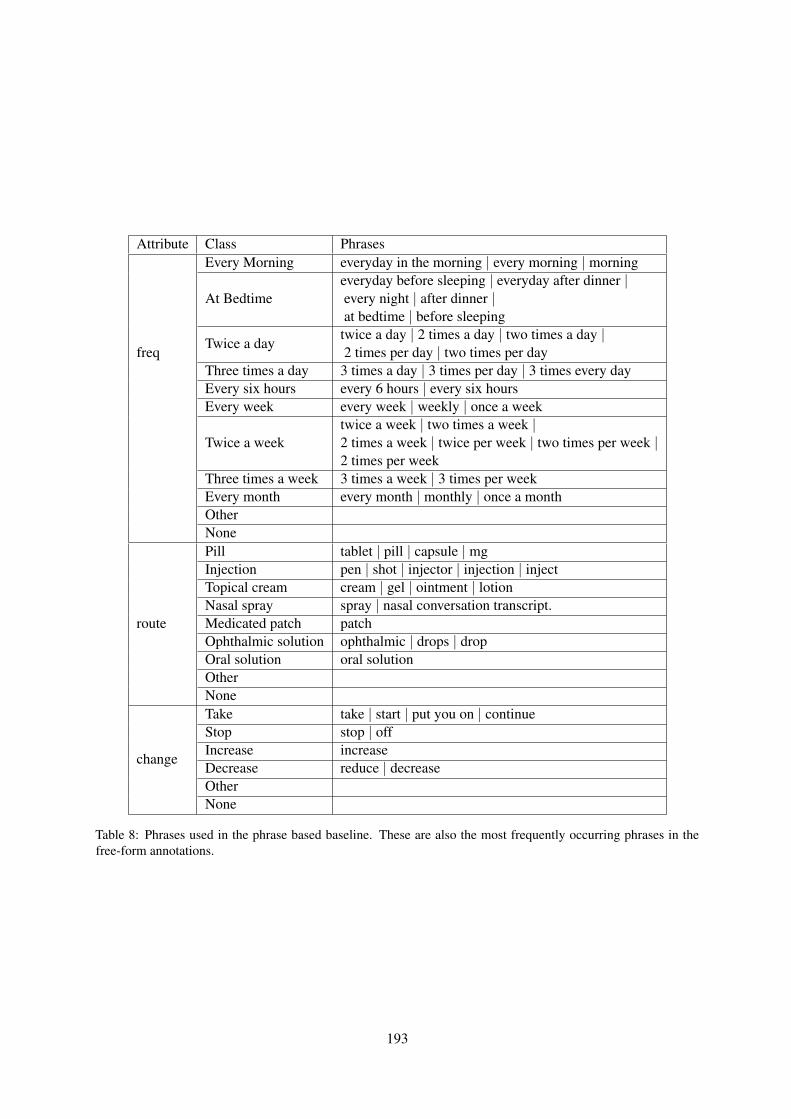
The classification dataset: All the conversationsare annotated with MR tags by expert human an-notators. Each set of MR tags consists of the med-ication name and its corresponding attributes fre-quency, route and change, which are normalizedfree-form instructions in natural language phrasescorresponding to each of the three attributes (seeTable 8 in A.4). Each set of MR tags is grounded toa contiguous window of utterances’ text,1 around amedication mention as evidence for that set. Hence,each set of grounded MR tags can be writtenas <medication, text, frequency, route, change>,where the last three entries correspond to the threeMR attributes.
The free-form instructions for each attribute inthe MR tags are normalized and categorized intomanageable number of classification labels to avoidlong tail and overlapping classes. This process re-
1The text includes both the spoken words and the speakerinformation.

180
text medicationClassification labels
frequency route change
. . . I would recommend vitamin D to be taken.Have you had Fosamax before?. . . vitamin D none none take
. . . I think my mum did. Okay, Fosamax, you take one pill on Mondayand one on Thursday. Do you have much caffine? No, none. . . Fosamax Twice a week pill take
Do you have much caffine? No, none. Okay, this is Actonel and it’s,one tablet once a month.. . . Actonel Once a month pill take
Table 2: Classification examples resulting from the conversation shown in Figure 1.
sults in classes shown in Table 1.2 As an illustra-tion, this annotation process when applied to theconversation piece shown in Figure 1 would resultin the three data points shown in Table 2. Usingthis procedure on both the training and test con-versation pools, we obtain 45,059 training, 11,212validation and 5,458 test classification data points.3
The extraction dataset: Since the goal is to ex-tract spans related to MR attributes, we would ide-ally need a dataset with span annotations to performthis task in a fully supervised manner. However,span annotation is laborious and expensive. Hence,we re-purpose the classification dataset (along withits classification labels) to perform the task of spanextraction using weak supervision. We also man-ually annotate a small fraction of the train, vali-dation and test sets (150, 150 and 500 data-pointsrespectively) for attribute spans to see the effect ofsupplying a small number of strongly supervisedinstances on the performance of the model. In or-der to have a good representation of all the classesin the test set, we increase the sampling weight ofdata-points which have rare classes. Hence, our testset is relatively more difficult compared to a ran-dom sample of 500 data-points. All the results arereported on our test set of 500 difficult data-pointsannotated for attribute spans.
For annotating attribute spans, the annotatorswere given instructions to mark spans which pro-vide minimally sufficient and natural evidence forthe already annotated attribute class as describedbelow.
Sufficiency: Given only the annotated span for aparticular attribute, one should be able to predictthe correct classification label. This aims to encour-age the attribute spans to cover all distinguishinginformation for that attribute.
2The detailed explanation for each of the classes can befound in Table 7 in Appendix A.1.
3The dataset statistics are given in Appendix A.1.
Minimality: Peripheral words which can be re-placed with other words without changing the at-tribute’s classification label should not be includedin the extracted span. This aims to discourage mark-ing entire utterances as attribute spans.Naturalness: The marked span(s) if presented to ahuman should sound like complete English phrases(if it has multiple tokens) or a meaningful word if ithas only a single token. In essence, this means thatthe extractions should not drop stop words fromwithin phrases. This requirement aims to reduce thecognitive load on the human who uses the model’sextraction output.
2.2 Challenges
Using medical conversations for information ex-traction is more challenging compared to writtendoctor notes because the spontaneity of conver-sation gives rise to a variety of speech patternswith disfluencies and interruptions. Moreover, thevocabulary can range from colloquial to medicaljargon.
In addition, we also have noise in our classifica-tion dataset with its main source being annotators’use of information outside the grounded text win-dow to produce the free-form tags. This happensin two ways. First, when the free-form MR instruc-tions are written using evidence that was discussedelsewhere in the conversation but is not present inthe grounded text window. Second, when the anno-tator uses their domain knowledge instead of usingjust the information in the grounded text window– for instance, when the route of a medication isnot explicitly mentioned, the annotator might usethe medication‘s common route in their free-forminstructions. Using manual analysis of the 800 data-points across the train, dev and test sets, we findthat 22% of frequency, 36% of route and 15% ofchange classification labels, have this noise.
In this work, our approach to extraction depends

181
on the size of the auxiliary task’s (classification)dataset to overcome above mentioned challenges.
3 Background
There have been several successful attempts to useneural attention (Bahdanau et al., 2015) to extractinformation from text in an unsupervised manner(He et al., 2017; Lin et al., 2016; Yu et al., 2019).Attention scores provide a good proxy for impor-tance of a particular token in a model. However,when there are multiple layers of attention, or if theencoder is too complex and trainable, the model nolonger provides a way to produce reliable and faith-ful importance scores (Jain and Wallace, 2019).
We argue that, in order to bring in the faithful-ness, we need to create an attention bottleneck inour classification + extraction model. The attentionbottleneck is achieved by employing an attentionfunction which generates a set of attention weightsover the encoded input tokens. Attention bottle-neck forces the classifier to only see the portionsof input that pass through it, thereby enabling us totrade the classification performance for extractionperformance and getting span extraction with weaksupervision from classification labels.
In the rest of this section, we provide generalbackground on neural attention and present its vari-ants employed in this work. This is followed by thepresentation of our complete model architecture inthe subsequent sections.
3.1 Neural AttentionGiven a query q ∈ Rm and keys K ∈ Rl×n,the attention function α : Rm × Rl×n → ∆l iscomposed of two functions: a scoring functionS : Rm × Rl×n → Rl which produces unnormal-ized importance scores, and a projection functionΠ: Rl → ∆l which normalizes these scores by pro-jecting them to an (l − 1)-dimensional probabilitysimplex.4
3.1.1 Scoring FunctionThe purpose of the scoring function is to produceimportance scores for each entry in the key K w.r.tthe query q for the task at hand, which in our caseis classification. We experiment with two scoringfunctions: additive and transformer-based.Additive: This is same as the scoring functionused in Bahdanau et al. (2015), where the scores
4Throughout this work l represents the sequence lengthdimension and ∆l = x ∈ Rl | x > 0, ‖x‖1 = 1 representsa probability simplex.
Multi-layer Transformer
Linear
Linear + PositionalEmbeddingsSeparator
Emb.
Feedforward
Figure 2: Architecture of TAScore. q and K are in-put query and keys, respectively, and s are the outputscores.
are produced as follows:
sj = vT tanh(Wq q + Wk kj) ,
where, v ∈ Rm, Wq ∈ Rm×m and Wk ∈ Rm×nare trainable weights.
Transformer-based Attention Score (TAScore):While the additive scoring function is simple andeasy to train, it suffers from one major drawbackin our setting: since we freeze the weights of ourembedder and do not use multiple layers of train-able attention (Section 4.4), the additive attentioncan struggle to resolve references – finding thecorrect attribute when there are multiple entitiesof interest, especially when there are multiple dis-tinct medications (Section 6.4). For this reason,we propose a novel multi-layer transformer-basedattention scoring function (TAScore) which canperform this reference resolution while also pre-serving the attention bottleneck. Figure 2 showsthe architecture of TAScore. The query and keyvectors are projected to the same space using twoseparate linear layers while also adding sinusoidalpositional embeddings to the key vectors. A spe-cial trainable separator vector is added between thequery and key vectors and the entire sequence ispassed through a multi-layer transformer (Vaswaniet al., 2017). Finally, scalar scores (one correspond-ing to each vector in the key) are produced from theoutputs of the transformer by passing them througha feed-forward layer with dropout.
3.1.2 Projection FunctionA projection function Π: Rl → ∆l in the contextof attention distribution, normalizes the real valuedimportance scores by projecting them to an (l −

182
1)-dimensional probability simplex ∆l. Niculaeand Blondel (2017) provide a unified view of theprojection function as follows:
ΠΩ(s) = arg maxa∈∆l
aT s− γΩ(a) .
Here, a ∈ ∆l, γ is a hyperparameter and Ω is aregularization penalty which allows us to introduceproblem specific inductive bias into our attentiondistribution. When Ω is strongly convex, we havea closed form solution to the projection operationas well as its gradient (Niculae and Blondel, 2017;Blondel et al., 2020). Since we use the attentiondistribution to perform extraction, we experimentwith the following instances of projection functionsin this work.
Softmax: Ω(a) =∑l
i=1 ai log aiUsing the negative entropy as the regularizer, re-sults in the usual softmax projection operatorΠΩ(s) = exp(s/γ)∑l
i=1 exp(si/γ).
Fusedmax: Ω(a) = 12‖a‖
22 +
∑li=1 |ai+1 − ai|
Using squared loss with fused-lasso penalty (Nic-ulae and Blondel, 2017), results in a projectionoperator which produces sparse as well as con-tiguous attention weights5. The fusedmax pro-jection operator can be written as ΠΩ(s) =P∆l (PTV (s)) , where
PTV (s) = arg miny∈Rl
‖y − s‖22 +l−1∑d=1
|yd+1 − yd|
is the proximal operator for 1d Total Variation De-noising problem, and P∆l is the euclidean projec-tion operator. Both these operators can be com-puted non-iteratively as described in Condat (2013)and Duchi et al. (2008), respectively. The gradientof Fusedmax operator can be efficiently computedas described in Niculae and Blondel (2017).6
Fusedmax*: We observe that while softmax learnsto focus on the right region of text, it tends toassign very low attention weights to some to-kens of phrases resulting in multiple discontinuousspans per attribute, while Fusedmax on the otherhand, almost always generates contiguous attentionweights. However, Fusedmax makes more mis-takes in identifying the overall region that contains
5Some example outputs of softmax and fusedmax on ran-dom inputs are shown in Appendix A.3
6The pytorch implementation to compute fusedmax usedin this work is available at https://github.com/dhruvdcoder/sparse-structured-attention.
Evidence ScorerEvidence Scorer
Embedder
Conversation
Embedder
Medication
Weighted pooler
ClassifieriClassification
Labels
SpeakerEmbedder
Speaker
Concat
Attention functions
ClassifieriClassifiers
)
SpanLabels
Extractor
Pooler
Iden
tifyCl
assif
y
Extract
Figure 3: Complete model for weakly supervised MRattribute extraction.
the target span (Section 6.3). In order to combinethe advantages of softmax and Fusedmax, we firsttrain a model using softmax as the projector andthen swap the softmax with Fusedmax in the finalfew epochs. We call this approach Fusedmax*.
4 Model
Our classification + extraction model uses MRattributes classification labels to extract MR at-tributes. The model can be divided into threephases: identify, classify and extract (Figure 3).The identify phases encodes the input text and med-ication name and uses the attention bottleneck toproduce attention over the text. Classify phase com-putes the context vector using the attention from theidentify phases and classifies the context vectors.Finally, the extract phase uses the attention fromthe identify phase to extract spans correspondingto MR attributes.
Notation: Let the dataset D be(x(1),y(1)), . . . (x(N),y(N)). Each x con-sists of a medication m and conversation text t,and each y consists of classification labels forfrequency, route and change, i.e, y = (fy,r y,c y),respectively. The number of classes for eachattribute is denoted by (·)n. As seen from Table1, fn = 12, rn = 10 and cn = 8. The length of atext excerpt is denoted by l. The extracted span forattribute k ∈ f, r, c is denoted by a binary vectorke of length l, such that kej = 1, if jth token is inthe extracted span for attribute k.

183
4.1 Identify
As shown in the Figure 3, the identify phase findsthe most relevant parts of the text w.r.t each ofthe three attributes. For this, we first encode thetext as well as the given medication using a con-textualized token embedder E . In our case, thisis 1024 dimensional BERT (Devlin et al., 2019)7.Since BERT uses WordPiece representations (Wuet al., 2016), we average these wordpiece repre-sentations to form the word embeddings. In orderto supply the speaker information, we concatenatea 2-dimensional fixed vocabulary speaker embed-ding to every token embedding in the text to obtainspeaker-aware word representations.
We then perform average pooling of the med-ication representations to get a single vector rep-resentation for the medication8. Finally, with thegiven medication representation as the query andthe speaker-aware token representations as the key,we use three separate attention functions (attentionbottleneck), one for each attribute (no weight shar-ing), to produce three sets of normalized attentiondistributions f a, ra and ca over the tokens of thetext. The identify phase can be succinctly describedas follows:
ka = kα(E(m), E(t)) , where k ∈ f, r, c
Here, each ka is an element of the probability sim-plex ∆l and is used to perform attribute extraction(Section 4.3).
4.2 Classify
We obtain the attribute-wise context vectors kc, asthe weighted sum of the encoded tokens (K in Fig-ure 3) where the weights are given by the attribute-wise attention distributions ka. To perform theclassification for each attribute, the attribute-wisecontext vectors are used as input to feed-forwardneural networks Fk (one per attribute), as shownbelow:9
kp = softmax(Fk(kc)
)ky = arg max
j∈1,2,...,kn
kpj , where k ∈ f, r, c.
7The pre-trained weight for BERT is from the Hugging-Face library(Wolf et al., 2019)
8Most medication names are single word, however a fewmedicines have names which are upto 4-5 words.
9Complete set of hyperparameters used is given in Ap-pendix A.2
4.3 Extract
The spans are extracted from the attention distri-bution using a fixed extraction function X : ∆l →0, 1l, defined as:
kej = Xk(ka)j =
1 if kaj > kγ
0 if kaj ≤ kγ ,
where kγ is the extraction threshold for attributek. For softmax projection function, it is importantto tune the attribute-wise extraction thresholds γ.We tune these using extraction performance on theextraction validation set. For fusedmax projectionfunction which produces spare weights, the thresh-olds need not be tuned, and hence are set to 0.
4.4 Training
We train the model end-to-end using gradient de-scent, except the extract module (Figure 3), whichdoes not have any trainable weights, and the em-bedder E . Freezing the embedder is vital for theperformance, since not doing so results in exces-sive dispersion of token information to other nearbytokens, resulting in poor extractions.
The total loss for the training is divided into twoparts as described below.(1) Classification Loss Lc: In order to performclassification with highly class imbalanced data(see Table 1), we use weighted cross-entropy:
Lc =∑
k∈f,r,c
− kwky log(kpky
),
where the class weights kwky are obtained by in-verting each class’ relative proportion.
(2) Identification Loss Li: If span labels e arepresent for some subset A of training examples,we first normalize these into ground truth attentionprobabilities a:
kaj =kej∑lj=1
kejfor k ∈ f, r, c
We then use KL-Divergence between the groundtruth attention probabilities and the ones generatedby the model (a) to compute identification lossLi =
∑k∈f,r,c KL
(ka∥∥∥ka). Note that Li is
zero for data-points that do not have span labels.Using these two loss functions, the overall lossL = Lc + λLi.
184
Model Spanlabels
Token-wise extraction F1 LCSF1 Classification F1
Encoder Scorer Projector freq. route change Avg. freq. route change Avg. freq. route change Avg.
Phrase-based baseline - 41.03 48.57 10.75 33.45 36.26 50.41 11.54 32.73 - - - -
BERT Additive Softmax 0 51.22 46.27 22.81 40.10 39.87 46.40 18.92 35.06 51.51 54.06 51.65 52.40BERT Additive Fusedmax 0 47.55 51.31 5.10 34.65 46.39 59.10 4.82 36.77 43.54 42.91 9.19 31.88BERT TAScore Softmax 0 66.53 48.96 27.61 47.70 61.49 47.34 22.49 43.77 44.93 51.34 46.49 47.58BERT TAScore Fusedmax 0 56.35 44.04 22.07 40.82 61.96 50.27 25.25 45.82 51.95 48.37 43.00 47.77
BERT Additive Softmax 150 61.56 45.08 33.54 46.73 57.90 48.14 28.28 44.77 55.62 52.42 50.40 52.81BERT Additive Fusedmax 150 47.05 52.49 27.69 42.41 42.37 57.50 30.63 43.50 54.04 48.40 52.28 51.57BERT Additive Fusedmax* 150 65.90 47.30 34.77 49.32 67.15 51.12 36.04 51.30 56.46 42.63 50.68 49.93BERT TAScore Softmax 150 66.53 54.35 34.27 51.72 62.90 53.05 28.33 48.09 50.13 45.86 47.16 47.72BERT TAScore Fusedmax 150 58.24 58.09 25.09 47.32 57.93 64.05 26.70 49.56 51.61 53.95 43.51 49.69BERT TAScore Fusedmax* 150 66.90 54.85 33.28 51.67 70.10 60.05 35.92 55.36 64.26 44.50 51.21 53.32
Table 3: Attribute extraction performance for various combinations of scoring and projection functions. The avg.columns represent the macro average of the corresponding metric across the attributes.
Training Type ModelTokenwise Extraction F1 Classification F1
freq. route change avg. freq. route change avg.
Classification only BERT Classifiers - - - - 74.72 40.82 55.76 58.48Classification only BERT+TAScore+Fusedmax* 58.55 45.00 24.43 42.66 52.45 46.37 43.00 47.27Extraction only BERT+TAScore+Fusedmax* 53.79 44.44 14.32 37.18 - - - -Classification +Extraction BERT+TAScore+Fusedmax* 66.90 54.85 33.28 51.67 64.26 44.50 51.21 53.32
Table 4: Effect of performing extraction+classification jointly in our proposed model. While the Extraction Onlytraining only uses the 150 examples which are explicitly annotated with span labels, the Classification only traininguses the complete training dataset with classification labels.
5 Metrics
Token-wise F1 (TF1): Each token in text is eitherpart of the extracted span (positive class) for an at-tribute or not (negative class). Token-wise F1 scoreis the F1 score of the positive class obtained byconsidering all the tokens in the dataset as separatebinary classification data points. TF1 is calculatedseparately for each attribute.
Longest Common Substring F1 (LCSF1):LCSF1 measures if the extracted spans, along withbeing part of the gold spans, are contiguous or not.Longest Common Substring (LCS) is the longestoverlapping contiguous span of tokens between thepredicted and gold spans. LCSF1 is defined as theharmonic mean of LCS-Recall and LCS-Precisionwhich are defined per extraction as:
LCS-Recall =#tokens in LCS
#tokens in gold span
LCS-Precision =#tokens in LCS
#tokens in predicted span
6 Results and Analysis
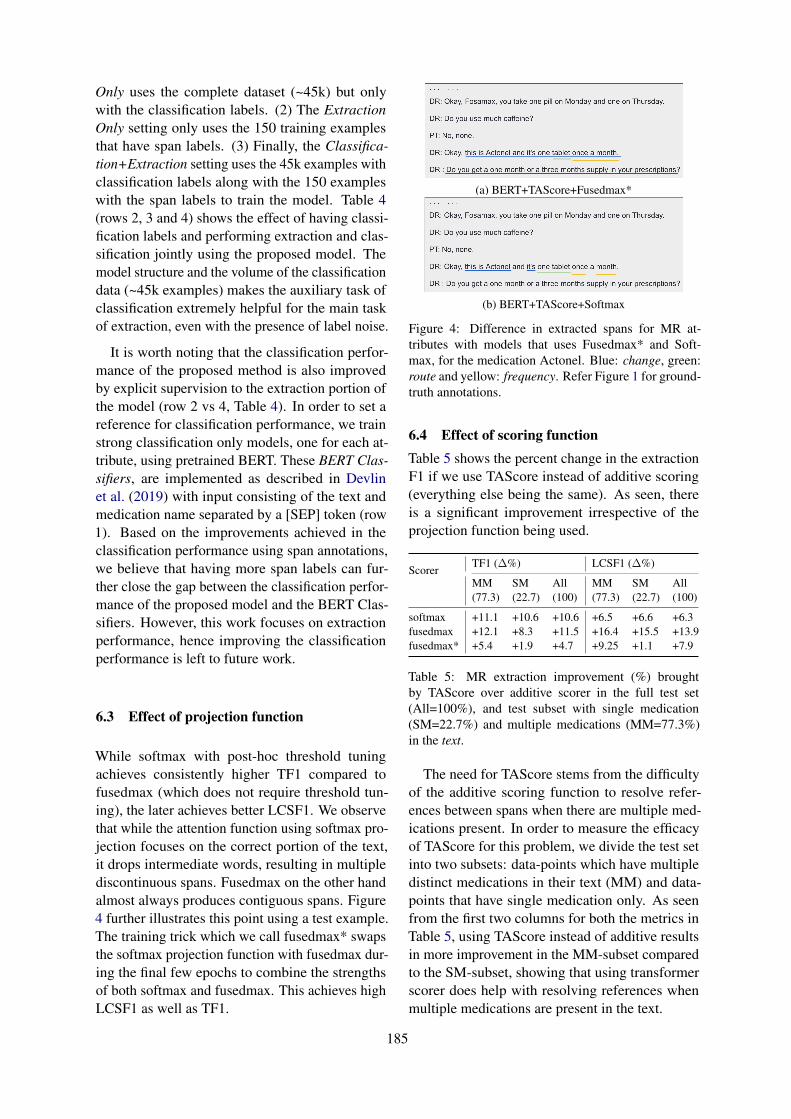
Table 3 shows the results obtained by various com-binations of attention scoring and projection func-tions on the task of MR attribute extraction in termsof the metrics defined in Section 5. It also shows
the classification F1 score to emphasize how theattention bottleneck affects classification perfor-mance. The first row shows how a simple phrasebased extraction system would perform on thetask.10
6.1 Effect of Span labels
In order to see if having a small number of extrac-tion training data-points (containing explicit spanlabels) helps the extraction performance, we anno-tate 150 (see Section 2 for how we sampled thedatapoints) of the training data-points with spanlabels. As seen from Table 3, even a small numberof examples with span labels (≈ 0.3%) help a lotwith the extraction performance for all models. Wethink this trend might continue if we add more train-ing span labels. We leave the finding of the rightbalance between annotation effort and extractionperformance as a future direction to explore.
6.2 Effect of classification labels
In order to quantify the effect of performing theauxiliary task of classification along with the maintask of extraction, we train the proposed modelin three different settings. (1) The Classification
10The details about the phrase based baseline are presentedin Appendix A.4
185
Only uses the complete dataset (~45k) but onlywith the classification labels. (2) The ExtractionOnly setting only uses the 150 training examplesthat have span labels. (3) Finally, the Classifica-tion+Extraction setting uses the 45k examples withclassification labels along with the 150 exampleswith the span labels to train the model. Table 4(rows 2, 3 and 4) shows the effect of having classi-fication labels and performing extraction and clas-sification jointly using the proposed model. Themodel structure and the volume of the classificationdata (~45k examples) makes the auxiliary task ofclassification extremely helpful for the main taskof extraction, even with the presence of label noise.
It is worth noting that the classification perfor-mance of the proposed method is also improvedby explicit supervision to the extraction portion ofthe model (row 2 vs 4, Table 4). In order to set areference for classification performance, we trainstrong classification only models, one for each at-tribute, using pretrained BERT. These BERT Clas-sifiers, are implemented as described in Devlinet al. (2019) with input consisting of the text andmedication name separated by a [SEP] token (row1). Based on the improvements achieved in theclassification performance using span annotations,we believe that having more span labels can fur-ther close the gap between the classification perfor-mance of the proposed model and the BERT Clas-sifiers. However, this work focuses on extractionperformance, hence improving the classificationperformance is left to future work.
6.3 Effect of projection function
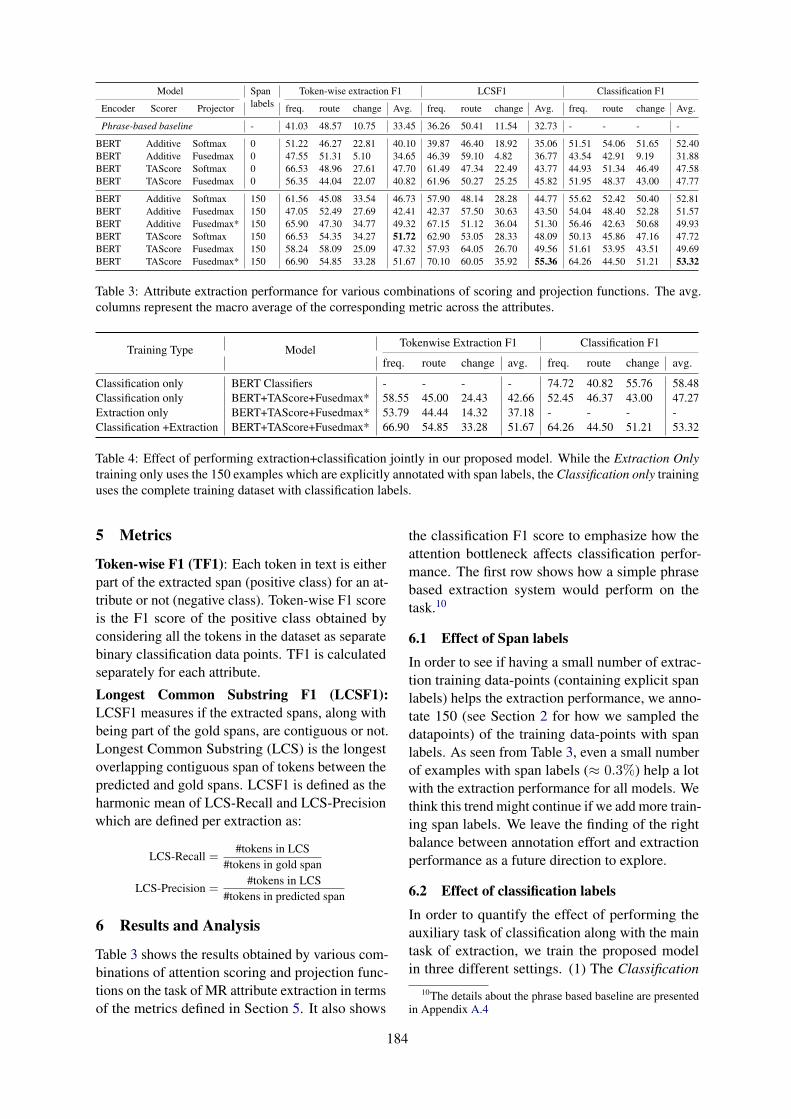
While softmax with post-hoc threshold tuningachieves consistently higher TF1 compared tofusedmax (which does not require threshold tun-ing), the later achieves better LCSF1. We observethat while the attention function using softmax pro-jection focuses on the correct portion of the text,it drops intermediate words, resulting in multiplediscontinuous spans. Fusedmax on the other handalmost always produces contiguous spans. Figure4 further illustrates this point using a test example.The training trick which we call fusedmax* swapsthe softmax projection function with fusedmax dur-ing the final few epochs to combine the strengthsof both softmax and fusedmax. This achieves highLCSF1 as well as TF1.
(a) BERT+TAScore+Fusedmax*
(b) BERT+TAScore+Softmax
Figure 4: Difference in extracted spans for MR at-tributes with models that uses Fusedmax* and Soft-max, for the medication Actonel. Blue: change, green:route and yellow: frequency. Refer Figure 1 for ground-truth annotations.
6.4 Effect of scoring functionTable 5 shows the percent change in the extractionF1 if we use TAScore instead of additive scoring(everything else being the same). As seen, thereis a significant improvement irrespective of theprojection function being used.
ScorerTF1 (∆%) LCSF1 (∆%)
MM(77.3)
SM(22.7)
All(100)
MM(77.3)
SM(22.7)
All(100)
softmax +11.1 +10.6 +10.6 +6.5 +6.6 +6.3fusedmax +12.1 +8.3 +11.5 +16.4 +15.5 +13.9fusedmax* +5.4 +1.9 +4.7 +9.25 +1.1 +7.9
Table 5: MR extraction improvement (%) broughtby TAScore over additive scorer in the full test set(All=100%), and test subset with single medication(SM=22.7%) and multiple medications (MM=77.3%)in the text.
The need for TAScore stems from the difficultyof the additive scoring function to resolve refer-ences between spans when there are multiple med-ications present. In order to measure the efficacyof TAScore for this problem, we divide the test setinto two subsets: data-points which have multipledistinct medications in their text (MM) and data-points that have single medication only. As seenfrom the first two columns for both the metrics inTable 5, using TAScore instead of additive resultsin more improvement in the MM-subset comparedto the SM-subset, showing that using transformerscorer does help with resolving references whenmultiple medications are present in the text.

186
Figure 5: Distribution of the Avg. LCSF1 for the bestperforming model (BERT+TAScore+Fusedmax*). Asignificant number (≈ 10%) of datapoints with multi-ple medication in their text get LCSF1 of zero (1st bar).
Figure 5 shows the distribution of Avg. LCSF1(average across all three attributes). It can be seenthat there are a significant number of datapoints inthe MM subset which get LCSF1 of zero, show-ing that even when the transformer scorer achievesimprovement on MM subset, it gets quite a lot ofthese data-points completely wrong. This showsthat the there is still room for improvement.
6.5 DiscussionIn summary, our analysis reveals that Fused-max/Fusedmax* favors contiguous extractionspans which is a necessity for our task. Irrespectiveof the projection function used, the proposed scor-ing function TAScore improves the extraction per-formance when compared to the popular additivescoring function. The proposed model architectureis able to establish a synergy between the classifica-tion and span extraction tasks where one improvesthe performance of the other. Overall, the proposedcombination of TAScore and Fusedmax* achievesa 22 LCSF1 points improvement over the phrase-based baseline and 10 LCSF1 points improvementover the naive additive and softmax combination.
7 Related Work
Existing literature directly related to our work canbe bucketed into two categories – related methodsand related tasks.
Methods: The recent work on generating ratio-nales/explanations for deep neural network basedclassification models (Lei et al., 2016; Bastingset al., 2020; Paranjape et al., 2020) is closely relatedto ours in terms of the methods used. Most of theseworks use binary latent variables to perform extrac-tion as an intermediate step before classification.Our work is closely related to (Jain et al., 2020;Zhong et al., 2019), who use attention scores to
generate rationales for classification models. Theseworks, however, focus on generating faithful andplausible explanation for classification as opposedto extracting the spans for attributes of an entity,which is the focus of our work. Moreover, ourmethod can be generalized to any number of at-tributes while all these methods would require aseparate model for each attribute.
Tasks: Understanding doctor-patient conversationsis starting to receive attention recently (Rajkomaret al., 2019; Schloss and Konam, 2020). Selvarajand Konam (2019) performs MR extraction byframing the problem as a generative question an-swering task. This approach is not efficient at infer-ence time – it requires one forward pass for eachattribute. Moreover, unlike a span extraction model,the generative model might produce hallucinatedfacts. Du et al. (2019) obtain MR attributes asspans in text; however, they use a fully supervisedapproach which requires a large dataset with span-level labels.
8 Conclusion and Future work
We provide a framework to perform MR attributeextraction from medical conversations with weaksupervision using noisy classification labels. Thisis done by creating an attention bottleneck in theclassification model and performing extraction us-ing the attention weights. After experimenting withseveral variants of attention scoring and projectionfunctions, we show that the combination of ourtransformer-based attention scoring function (TAS-core) combined with Fusedmax* achieves signif-icantly higher extraction performance comparedto the other attention variants and a phrase-basedbaseline.
While our proposed method achieves good per-formance, there is still room for improvement, es-pecially for text with multiple medications. Dataaugmentation by swapping or masking medicationnames is worth exploring. An alternate directionof future work involves improving the naturalnessof extracted spans. Auxiliary supervision using alanguage modeling objective would be a promisingapproach for this.
Acknowledgments
We thank University of Pittsburgh Medical Center(UPMC) and Abridge AI Inc. for providing accessto the de-identified data corpus.

187
ReferencesJ. L. Anderson, Sally Dodman, M. Kopelman, and
A. Fleming. 1979. Patient Information Recall in aRheumatology Clinic. Rheumatology, 18:18–22.
Dzmitry Bahdanau, Kyunghyun Cho, and YoshuaBengio. 2015. Neural machine translation byjointly learning to align and translate. CoRR,abs/1409.0473.
Joost Bastings, Wilker Aziz, and Ivan Titov. 2020. In-terpretable neural predictions with differentiable bi-nary variables. In ACL 2019 - 57th Annual Meet-ing of the Association for Computational Linguistics,Proceedings of the Conference, pages 2963–2977.Association for Computational Linguistics.
Lukas Biewald. 2020. Experiment tracking withweights and biases. Software available fromwandb.com.
Mathieu Blondel, Andre F.T. Martins, and Vlad Nic-ulae. 2020. Learning with fenchel-young losses.Journal of Machine Learning Research, 21(35):1–69.
Laurent Condat. 2013. A direct algorithm for 1-D totalvariation denoising. IEEE Signal Processing Letters,20(11):1054–1057.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. 2019. BERT: Pre-training ofdeep bidirectional transformers for language under-standing. In Proceedings of the 2019 Conferenceof the North American Chapter of the Associationfor Computational Linguistics: Human LanguageTechnologies, Volume 1 (Long and Short Papers),pages 4171–4186, Minneapolis, Minnesota. Associ-ation for Computational Linguistics.
Nan Du, Mingqiu Wang, Linh Tran, Gang Li, and IzhakShafran. 2019. Learning to infer entities, proper-ties and their relations from clinical conversations.arXiv preprint arXiv:1908.11536.
John Duchi, Shai Shalev-Shwartz, Yoram Singer, andTushar Chandra. 2008. Efficient projections ontothe l1-ball for learning in high dimensions. In Pro-ceedings of the 25th International Conference onMachine Learning, ICML ’08, page 272–279, NewYork, NY, USA. Association for Computing Machin-ery.
Matt Gardner, Joel Grus, Mark Neumann, OyvindTafjord, Pradeep Dasigi, Nelson F. Liu, MatthewPeters, Michael Schmitz, and Luke S. Zettlemoyer.2017. Allennlp: A deep semantic natural languageprocessing platform.
Stuart W Grande, Mary Ganger Castaldo, ElizabethCarpenter-Song, Ida Griesemer, and Glyn Elwyn.2017. A digital advocate? reactions of rural peo-ple who experience homelessness to the idea ofrecording clinical encounters. Health Expectations,20(4):618–625.
Ruidan He, Wee Sun Lee, Hwee Tou Ng, and DanielDahlmeier. 2017. An unsupervised neural attentionmodel for aspect extraction. In Proceedings of the55th Annual Meeting of the Association for Compu-tational Linguistics (Volume 1: Long Papers), pages388–397, Vancouver, Canada. Association for Com-putational Linguistics.
Sarthak Jain and Byron C. Wallace. 2019. Attention isnot explanation. In NAACL-HLT.
Sarthak Jain, Sarah Wiegreffe, Yuval Pinter, and By-ron C Wallace. 2020. Learning to Faithfully Ratio-nalize by Construction.
Shailesh Kumar. 2016. Burnout and doctors: preva-lence, prevention and intervention. In Healthcare,volume 4, page 37. Multidisciplinary Digital Pub-lishing Institute.
Tao Lei, Regina Barzilay, and Tommi Jaakkola. 2016.Rationalizing neural predictions. In EMNLP 2016- Conference on Empirical Methods in Natural Lan-guage Processing, Proceedings, pages 107–117.
Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan,and Maosong Sun. 2016. Neural relation extractionwith selective attention over instances. In Proceed-ings of the 54th Annual Meeting of the Associationfor Computational Linguistics (Volume 1: Long Pa-pers), pages 2124–2133, Berlin, Germany. Associa-tion for Computational Linguistics.
Lisa C. Mcguire. 1996. Remembering what the doctorsaid: Organization and adults’ memory for medicalinformation. Experimental Aging Research, 22:403–428.
Vlad Niculae and Mathieu Blondel. 2017. A regular-ized framework for sparse and structured neural at-tention. In Advances in neural information process-ing systems, pages 3338–3348.
Bhargavi Paranjape, Mandar Joshi, John Thickstun,Hannaneh Hajishirzi, and Luke Zettlemoyer. 2020.An Information Bottleneck Approach for Control-ling Conciseness in Rationale Extraction. Technicalreport.
Alvin Rajkomar, Anjuli Kannan, Kai Chen, Laura Var-doulakis, Katherine Chou, Claire Cui, and JeffreyDean. 2019. Automatically charting symptoms frompatient-physician conversations using machine learn-ing. JAMA internal medicine, 179(6):836–838.
Benjamin Schloss and Sandeep Konam. 2020. To-wards an automated soap note: Classifying utter-ances from medical conversations. Machine Learn-ing for Health Care, 2020, arXiv:2007.08749. Ver-sion 3.
Sai P Selvaraj and Sandeep Konam. 2019. Medica-tion regimen extraction from clinical conversations.arXiv preprint arXiv:1912.04961.

188
Christine Sinsky, Lacey Colligan, Ling Li, MirelaPrgomet, Sam Reynolds, Lindsey Goeders, JohannaWestbrook, Michael Tutty, and George Blike. 2016.Allocation of physician time in ambulatory practice:a time and motion study in 4 specialties. Annals ofinternal medicine, 165(11):753–760.
Maka Tsulukidze, Marie-Anne Durand, Paul J Barr,Thomas Mead, and Glyn Elwyn. 2014. Provid-ing recording of clinical consultation to patients–a highly valued but underutilized intervention: ascoping review. Patient Education and Counseling,95(3):297–304.
Ashish Vaswani, Noam Shazeer, Niki Parmar, JakobUszkoreit, Llion Jones, Aidan N Gomez, Ł ukaszKaiser, and Illia Polosukhin. 2017. Attention is allyou need. In I. Guyon, U. V. Luxburg, S. Bengio,H. Wallach, R. Fergus, S. Vishwanathan, and R. Gar-nett, editors, Advances in Neural Information Pro-cessing Systems 30, pages 5998–6008. Curran Asso-ciates, Inc.
Thomas Wolf, Lysandre Debut, Victor Sanh, JulienChaumond, Clement Delangue, Anthony Moi, Pier-ric Cistac, Tim Rault, R’emi Louf, Morgan Funtow-icz, and Jamie Brew. 2019. Huggingface’s trans-formers: State-of-the-art natural language process-ing. ArXiv, abs/1910.03771.
Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V.Le, Mohammad Norouzi, Wolfgang Macherey,Maxim Krikun, Yuan Cao, Qin Gao, KlausMacherey, Jeff Klingner, Apurva Shah, Melvin John-son, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws,Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, KeithStevens, George Kurian, Nishant Patil, Wei Wang,Cliff Young, Jason Smith, Jason Riesa, Alex Rud-nick, Oriol Vinyals, Greg Corrado, Macduff Hughes,and Jeffrey Dean. 2016. Google’s neural machinetranslation system: Bridging the gap between humanand machine translation.
Bowen Yu, Zhenyu Zhang, Tingwen Liu, Bin Wang,Sujian Li, and Quangang Li. 2019. Beyond wordattention: Using segment attention in neural relationextraction. In IJCAI, pages 5401–5407.
Ruiqi Zhong, Steven Shao, and Kathleen McKeown.2019. Fine-grained sentiment analysis with faithfulattention.

189
A Appendices
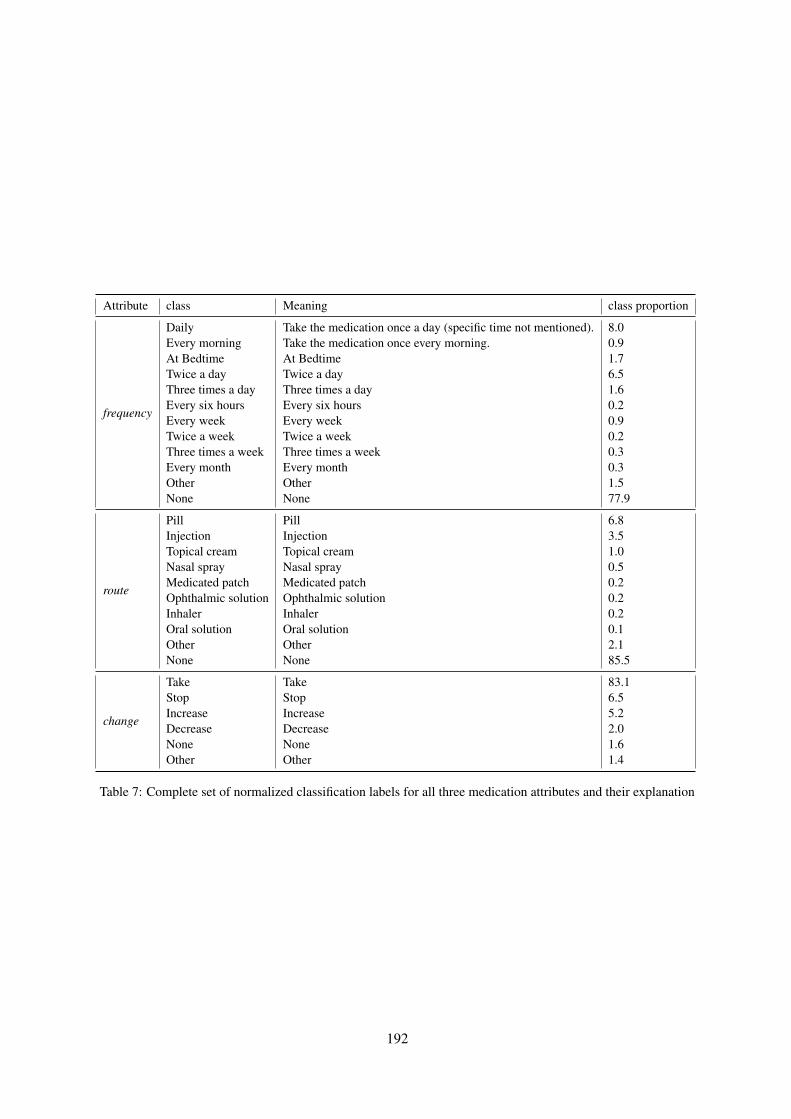
A.1 DataThe complete set of normalized classification labelsfor all three medication attributes and their meaningis shown in Table 7.
Average statistics about the dataset are shown inTable 6.
min max mean σ
#utterances in text 3 20 7.8 2.3#words in text 12 565 80.8 41.0#words in freq span 1 21 4.4 2.6#words in route span 1 9 1.5 1.0#words in change span 1 34 6.8 4.9
Table 6: Statistics of extraction labels (#words) and thecorresponding text
A.2 HyperparametersWe use AllenNLP (Gardner et al., 2017) to imple-ment our models and Weights&Biases (Biewald,2020) to manage our experiments. Following is thelist of hyperparameters used in our experiments:
1. Contextualized Token Embedder:We use 1024-dimensional 24-layerbert-large-cased obtained as apre-trained model from HuggingFace11. Wefreeze the weights of the embedder in ourtraining. The max sequence length is set to256.
2. Speaker embedding: 2-dimensional train-able embedding with vocabulary size of 4 aswe only have 4 unique speakers in our dataset:doctor, patient, caregiver and nurse.
3. Softmax and Fusedmax: The temperaturesof softmax and fusedmax are set to a defaultvalue of 1. The sparsity weight of fusedmaxis also set to its default value of 1 for all at-tributes.
4. TAScore: The transformer used in TAS-core is a 2-layer transformer encoder whereeach layer is implemented as in Vaswani et al.(2017). Both the hidden dimensions inside thetransformer (self-attention and feedforward)are set to 32 and all the dropout probabilities
11https://huggingface.co/bert-large-cased
are set to 0.2. The linear layer for the queryhas input and output dimensions of 1024 and32, respectively. Due to the concatenationof speaker embedding, the linear layer forkeys has input and output dimensions of 1026and 32, respectively. The feedforward layer(which generates scalar scores for each token)on top of the transformer is 2-layered withrelu activations and hidden sizes (16, 1).
5. Classifiers: The final classifier for each at-tribute is a 2-layer feedforward network withhidden sizes (512, “number of classes for theattribute”) and dropout probability of 0.2.
A.3 Examples: Projection FunctionsFigures 6 and 7 show examples of outputs of pro-jection functions softmax and fusedmax on randominput scores.
A.4 Phrase based extraction baselineWe implement a phrase based extraction systemto provide a baseline for the extraction task. Alexicon of relevant phrases is created for each classfor each attribute as shown in Table 8. We thenlook for string matches within these phrases andthe text for the data-point. If there are matches thenthe longest match is considered as an extractionspan for that attribute.
190
(a) Positive and negative scores
(b) Positive scores only
(c) More uniformly distributed positive scores
Figure 6: Sample outputs (right column) of softmax function on random input scores (left column).
191
(a) Positive and negative scores
(b) Positive scores only
(c) More uniformly distributed positive scores
Figure 7: Sample outputs (right column) of fusedmax function on random input scores (left column).
192
Attribute class Meaning class proportion
frequency
DailyEvery morningAt BedtimeTwice a dayThree times a dayEvery six hoursEvery weekTwice a weekThree times a weekEvery monthOtherNone
Take the medication once a day (specific time not mentioned).Take the medication once every morning.At BedtimeTwice a dayThree times a dayEvery six hoursEvery weekTwice a weekThree times a weekEvery monthOtherNone
8.00.91.76.51.60.20.90.20.30.31.577.9
route
PillInjectionTopical creamNasal sprayMedicated patchOphthalmic solutionInhalerOral solutionOtherNone
PillInjectionTopical creamNasal sprayMedicated patchOphthalmic solutionInhalerOral solutionOtherNone
6.83.51.00.50.20.20.20.12.185.5
change
TakeStopIncreaseDecreaseNoneOther
TakeStopIncreaseDecreaseNoneOther
83.16.55.22.01.61.4
Table 7: Complete set of normalized classification labels for all three medication attributes and their explanation
193
Attribute Class Phrases
freq
Every Morning everyday in the morning | every morning | morning
At Bedtimeeveryday before sleeping | everyday after dinner |every night | after dinner |at bedtime | before sleeping
Twice a daytwice a day | 2 times a day | two times a day |2 times per day | two times per day
Three times a day 3 times a day | 3 times per day | 3 times every dayEvery six hours every 6 hours | every six hoursEvery week every week | weekly | once a week
Twice a weektwice a week | two times a week |2 times a week | twice per week | two times per week |2 times per week
Three times a week 3 times a week | 3 times per weekEvery month every month | monthly | once a monthOtherNone
route
Pill tablet | pill | capsule | mgInjection pen | shot | injector | injection | injectTopical cream cream | gel | ointment | lotionNasal spray spray | nasal conversation transcript.Medicated patch patchOphthalmic solution ophthalmic | drops | dropOral solution oral solutionOtherNone
change
Take take | start | put you on | continueStop stop | offIncrease increaseDecrease reduce | decreaseOtherNone
Table 8: Phrases used in the phrase based baseline. These are also the most frequently occurring phrases in thefree-form annotations.
Related Documents











