“Semantic Search – Fact and Fiction” Workshop “Semantic Idol” Demonstration Booklet Thursday November 12, 2009 Friday November 13, 2009 Roma / Italy

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 1/20
“Semantic Search – Fact and Fiction” Workshop
“Semantic Idol” Demonstration Booklet
Thursday November 12, 2009 Friday November 13, 2009
Roma / Italy

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 2/20
- 2 -
Planning
Selected project will have:- 5 minutes introduction- 10 minutes demo- 5 minutes Q&A
Due to the tight planning, no overtime will be authorized.
The expert panel will be composed of:- Wernher Behrendt
(http://www.salzburgresearch.at/contact/team_detail.php?person=35 ): SemanticExpert. Werner will represent the interests of IKS
- Sandro Groganz (http://sandro.groganz.com/ ). Open Source Marketing expert.
Sandro will represent the interests of the end-users.- Stéphane Croisier (http://stephanecroisier.jahia.com/ ). Co-Founder and Product
Strategy Manager at Jahia. Stéphane will represent the interests of the CMSindustry.
Thursday November 12, 200917.15 - 18:30
1. Deri (Axel Polleres - http://axel.deri.ie/~axepol/ - and Juergen Umbrich)2. Trialox (Reto Bachmann-Gmür - http://trialox.org/ )3. Kiwi (Rolf Sint - http://showcase.kiwi-
project.eu/KiWi/wiki/home.seam?cid=9588 )
Friday November 13, 200910:00 - 13:00
4. Yahoo! Research (Peter Mika - http://research.yahoo.com/Peter_Mika )5. Salsadev (Stéphane Gamard - http://www.salsadev.com/ )6. Scribo / Nuxeo (Olivier Grisel and Stefane Fermigier - http://www.scribo.ws /
http://www.nuxeo.com )7. Zemanta (Tomaž Šolc - http://www.zemanta.com/)
8. Trezorix (Sander van der Meulen - http://www.trezorix.com )9. Sourcesense (Tommaso Teofili - http://www.sourcesense.com/ )10. Semantic Technology LAB (Aldo Gangemi and Alfio Massimiliano Gliozzo -
http://stlab.istc.cnr.it/ )11. Semantic MediaWiki (Tran Duc Thanh, Markus Kroetsch - Karlsruher Institut
für Technologie - http://www.aifb.uni-karlsruhe.de/ )
(Moderated by Stéphane Croisier from Jahia – http://www.jahia.com )

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 3/20
- 3 -
Some related user stories
http://wiki.iks-project.eu/index.php/User-stories Feel free to add new user stories to complete the use cases.
Story 01: Search and Disambiguation in Docs
I have a collection of 30'000 documents, and I want to find the five documents that talkabout or where edited by John Smith. Problem is, there are three John Smiths in mycompany, and the two others appear in lots of documents.
Story 03: Similarity-based Image Search
I'm working with a digital asset management system, and I want to find images that aresimilar to the one I'm looking at, either in terms of the real-world objects that the imagesrepresent, or in terms or graphical similarity (colors, shapes, etc.)
Story 04: Spatio-temporal Content Queries in near-natural Language
When visiting a house rental website, I can formulate queries like “recent pages that talkabout houses to rent in the French part of Switzerland” and the website search engineunderstands them.
Story 05: Assistance with Semantic Tagging
To create content in my CMS, I type plain text, and the system offers a list of tags that
describe my content, and a list of links to entities (people, companies, etc.) that my texttalks about. I can then interactively refine those lists of tags and links.
Story 06: Context-aware Content Delivery
I'm a hotel manager and I'm adding info about a music show that takes place in my hotelnext Friday. Internet users should be able to find this info using queries like "events thattake place at the end of next week within 10km of where I am now", without having toknow about my website.
Story 09: Similarity based document search
I consult or create a new document in my CMS by typing in a HTML edit form or by
uploading a document with textual content (PDF, office file, XML file, ...). I want theuser interface to show the list of the 5 most similar documents already in the CMS basedon the latent semantic meaning of the terms occurring in those document without havingto manually tag structured document properties such as DublinCore : subjects.

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 4/20
- 4 -
1
stParticipant: DERI
Thursday November 12, 2009: 17h20 – 17h40 Fri, 03 Jul 2009 from Stephane Corlosquet <stephane.corlosquet at deri dot org>
Below is the architecture that DERI would like to suggest for the IKS Semantic SearchEngine. The figure [1] contains a set of CMS sites complying to the best practises of RDFdata publishing, which include RDFa, a local schema export (site vocabulary), aSPARQL endpoint. We have worked on a set of modules for Drupal detailed in atechnical report at [2], but their features could be generalized to other CMSs. The sitescan request to be included in the IKS search engine via a form on the IKS search enginesite or programmatically via a ping. Pings are also used in the case where a specificresource/page has been updated on a given site in order for the search engine to schedulea recrawl of the resource as soon as possible.
The semantic search engine stack is composed of several layers of data gathering,parsing, validation and indexing. The search engine first gathers the data by crawling thesites, it then parses the RDF data with the any23 parser [3], a java library that extractsstructured data in RDF format from a variety of Web documents (supports microformats,RDFa and other common RDF serialization formats). If needed, the NxParser [4] cleansup the data and formats it in n-quads [5]. Before a site can be included in the IKS searchengine, it first goes through the RDFAlerts validator, which ensures the RDF datacontained in the sites complies with the RDF publishing best practices. RDFAlerts alsodoes some RDF consistency checking. Additionally, other IKS specific policies regardingthe sites included in the search engine could be added here. Finally, the SWSE engine [6]takes care of the indexing and storage of the data. Powered by YARS2, it providesdistributed storage and retrieval facilities. Indexing structures are optimized for retrievalof RDF statements including context (quads) while minimizing the need for joins, plusLucene fulltext indexing for efficient keyword searches. SWSE's SPARQL endpointallows to plugin any RDF visualization tool, e.g. VisiNav [7] for example. See thescreencast at [8] (1'36) for the possibilities offered by VisiNav.
[1] http://srvgal65.deri.ie/files/iks_search_engine_cloud.pdf [2] http://www.deri.ie/fileadmin/documents/DERI-TR-2009-04-30.pdf [3] http://code.google.com/p/any23/ [4] http://sw.deri.org/2006/08/nxparser/ [5] http://sw.deri.org/2008/07/n-quads/ [6] http://www.swse.org/ [7] http://visinav.deri.org/ [8] http://www.youtube.com/watch?v=r4WgTRIRoa0
Mon, 05 Oct 2009 - From: Axel Polleres <axel.polleres at deri dot org>
First of all kindest apologies for the late response to [1].

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 5/20
- 5 -
We have/had to sort out things since the main developer of the SWSE search engine andarchitecture, Andreas Harth, moved to the AIFB, Uni Karlsruhe, and in the course of themove, we had some delays in answering the questions of what setup we could provide.
The current, but inofficial, status of SWSE/yars2 is the following:* we are working on a licensing model for the software* as a short-term goal we are working on making at least a non-commercial/academicbinary available (discussions on whether/how we'll open source the system are ongoing)* if needed we could discuss whether/how we can make binaries available for project usewithin IKS for testing purposes
What we can offer out-of-the box without additional resources is:* a single server setup hosted on one of our servers* periodical crawls of a provided list of CMS URIs of interest [as long as we are overall <
50M statements, <100K documents the resources we could free easily at the momentshould be sufficient]* a yars2 instance for the crawled data, including* a SPARQL endpoint on top of the yars2 index* an instance of the current SWSE user interface [2] on top of the yars2 index
Additional notes:- The update frequency of the index mainly depends on the number of statements wehave to parse, clean and process.
We'd hope that is sufficient for the current project needs, if not, please let us know in
what ranges your requirements would be. Without additional resources we are notcapable of offering a more advanced setup of SWSE/yars2 short term (could includedistributed index build, distributed yars2 instances, distributed SPARQL processing,reasoning [4] on the crawled data, but we'd suggest to get things going small and then seewhere we'd get from there.
Such a setup could be the starting point for a semantic search engine for IKS and on topof that demonstrate the feasibility of a federated CMS infrastructure as we sketch it in [3,Section 5.2], so we'd be very excited about getting this going in collaboration with IKSand then explore further opportunities jointly!
Best,Axel, Juergen, Aidan
Dr. Axel PolleresDigital Enterprise Research Institute, National University of Ireland,Galwayemail: axel.polleres at deri dot org url: http://www.polleres.net/
[1] http://lists.iks-project.eu/pipermail/iks-community/2009-July/000028.html [2] http://swse.deri.org/

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 6/20
- 6 -
[3] Stéphane Corlosquet, Renaud Delbru, Tim Clark, Axel Polleres, and Stefan Decker.Produce and consume linked data with drupal! In Proceedings of the 8th InternationalSemantic Web Conference (ISWC 2009), Lecture Notes in Computer Science,Washington DC, USA, October 2009. Available athttp://www.polleres.net/publications/corl-etal-2009iswc.pdf [4] Aidan Hogan, Andreas Harth, and Axel Polleres. Scalable authoritative owl reasoningfor the web. International Journal on Semantic Web and Information Systems, 5(2), 2009.Available at http://www.deri.ie/fileadmin/documents/DERI-TR-2009-04-21.pdf
Wed, 4 Nov 2009 From: Axel Polleres <axel.polleres at deri dot org>
I will (together with Juergen Umbrich, who shall send a separate mail) our ideason Semantic Search over networked, RDF-enabled Drupal sites [1].
Our approach is to regularly crawl and index those sites with a specialised instance of ourhouse-made semantic search engine SWSE [2] which offers not only a search interfacebut also a SPARQL endpoint that let' you query over those sites. Additionally, if youwant to have specific, current site information our Drupal modules enable separate liveSPARQL endpoints locally on the sites. See also the architecture that Stéphane postedearlier on this list. [3]
Axel Polleres
1. Stéphane Corlosquet, Renaud Delbru, Tim Clark, Axel Polleres, and Stefan Decker.Produce and consume linked data with Drupal! In Proceedings of the 8 th InternationalSemantic Web Conference (ISWC 2009), Lecture Notes in Computer Science,Washington DC, USA, October 2009. Springer. Best paper award In-Use track.
http://www.polleres.net/publications/corl-etal-2009iswc.pdf 2. http://swse.deri.org/ 3. http://www.interactive-knowledge.org/content/iks-search-engine-proposal

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 7/20
- 7 -
2
ndParticipant: Trialox
Thursday November 12, 2009: 17h45 – 18h05 Mon, 19 Oct 2009 From: Reto Bachmann-Gmür <reto.bachmann at trialox dot org>
Dear IKS Community,
Some of you already met me at the IKS requirement meeting in Salzburg, I'm lookingforward to meeting you again and more of you next month in Rome.
For those I didn't already met I'm quickly introducing myself here.
I'm working with trialox [1] a startup founded last year at the University of Zurich. We'reworking on open source software that makes it easy to develop semantic web enabledapplications. Our system is based on OSGi technologies and support various RDF storesas backend. The principal supported languages are Java and Scala. As we are near the endof a major Sprint, I'll be posting more information on this software foundation very soon.
Basing on this foundation we're also building a Web Content Management Systemleveraging semantic web technologies especially for the benefit of not-for-profitorganizations. We are working together with the WWF [2] to build a system that allowsbetter access to their vast and distributed content, both with their public website as wellas the internal information infrastructure.
All our products are open source and we're looking to build a community around the opensource projects, as well as business partners we could help implementing semanticsolutions for their customers.
So that's what I've been working on for a bit more than a year now. Before I've beenworking in England for Talis and for HP Laboratories. At HP Labs I was working withthe Jena team and implemented a system for versioning as well as tracking provenance of RDF Graphs.
My passion (or is it addiction?) for the semantic web dates back to 2002. I startedimplementing the annotea protocol as a decentralized exchange system and continued theidea of decentralized, trust and relevance based information exchange with the knobotopen source project.
Cheers,reto
1. http://trialox.org/ 2. http://www.panda.org/

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 8/20
- 8 -
3
rdParticipant: Kiwi
Thursday November 12, 2009: 18h10 – 18h30 Mon, 12 Oct 2009 From: Rolf Sint <rolf.sint at salzburgresearch dot at>
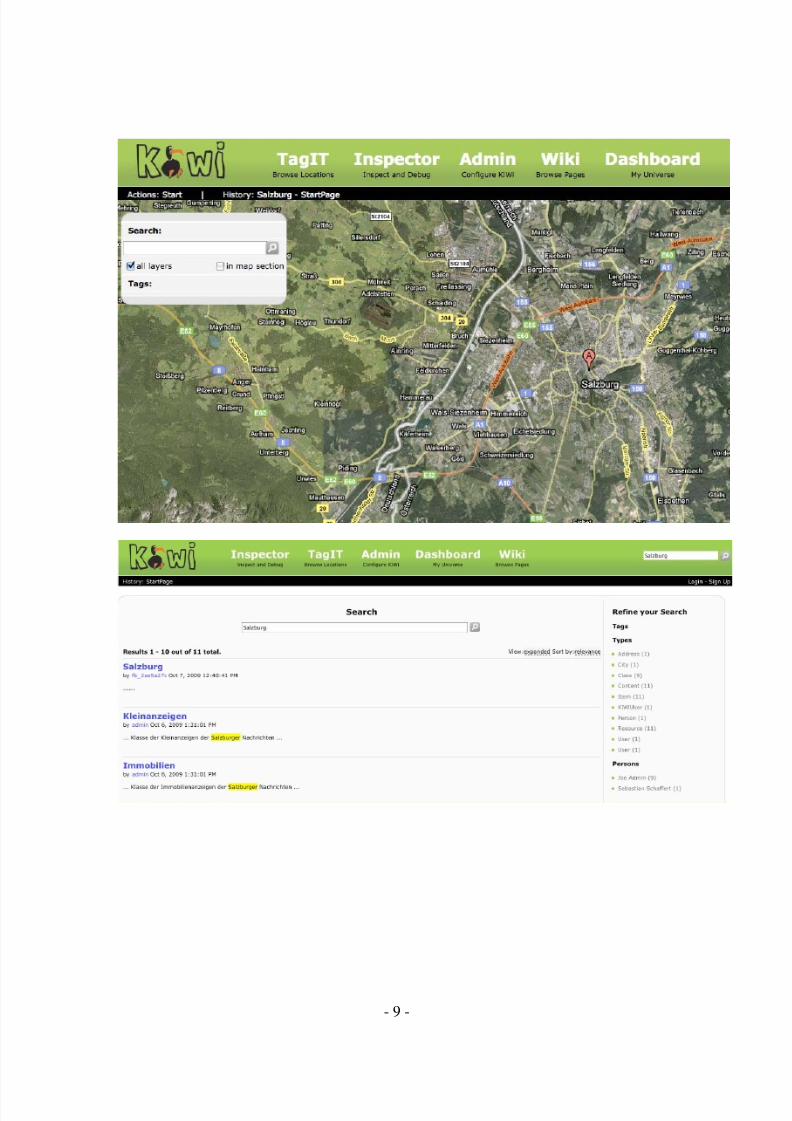
My name is Rolf Sint and I am researcher and developer at Salzburg Research. I studiedComputer Science and Management at the University of Salzburg. Currently I work onthe EU-funded project KiWi (http://www.kiwi-project.eu/ ) and I will present thesemantic search functionality in KiWi in the next IKS workshop in Rome.
The KiWi-System aims to break system boundaries in that it serves as a platform forimplementing and integrating many different kinds of social software services. And itintends to break information boundaries by allowing users to connect content and toconnect each other in new ways. KiWi is a software platform that allows users to shareand integrate knowledge more easily, naturally and tightly, and to adapt content andfunctionalities according to their personal requirements. In KiWi the navigation andsearch of content is a key issue and is realized in several ways. One possibility tonavigate within KiWi is a very flexible facetted search, which allows a dynamicconfiguration of the search facets. Please find some screenshots of the current KiWisystem attached.
You can find the running system here: http://showcase.kiwi-project.eu/KiWi anddownload KiWi at http://kenai.com/projects/kiwi/downloads
Best regardsRolf Sint
Knowledge Based Information SystemsJakob-Haringer Strasse 5/II5020 SalzburgAustria
Email rolf.sint at salzburgresearch dot atPhone +43.662.2288-430Office Jakob Haringer Str. 5 | Techno 3 | 2.OGhttp://www.salzburgresearch.at
8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 9/20
- 9 -

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 10/20
- 10 -
4
thparticipant: Yahoo! Research
Friday November 13, 2009: 10h00 – 10h20 Fri, 25 Sep 2009 From: Peter Mika <pmika at yahoo-inc dot com>
Hi All,
My name is Peter Mika, and I work as a researcher and data architect at Yahoo!, based inBarcelona, Spain. Our research lab is part of Yahoo! Research [1] and has beenestablished in 2006. We are covering a wide range of topics, including multimedia,distributed systems, data mining (in particular, web mining), and NLP.
As a researcher, my personal interests revolve around semantic technologies and theSemantic Web, and the application of the technologies to web search, from queryinterpretation, through ranking to result presentation. We are doing quite a few things inthis area, one particular initiative I wanted to mention is that we have recently startedorganizing a semantic search evaluation campaign. If anyone is interested I would behappy to discuss that as well.
On the product side, I'm working as a data architect on KR questions related to how weconsume and use metadata inside Yahoo. As an example, many of you might have heardof SearchMonkey, which allows site owners and developers to create applications thatchange the way search results are presented, by using metadata associated with thosepages [2]. I'm also doing a part of the evangelism, talking to our communities of developers and publishers, which gives me a fair bit of understanding of how peoplerelate to semantic technologies 'in the wild'.
Best,Peter
[1] http://research.yahoo.com [2] http://developer.search.yahoo.com/start

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 11/20
- 11 -
5
thparticipant: salsaDev
Friday November 13, 2009: 10h25 – 10h45 Wed, 23 Sep 2009 from Stephane Gamard <stephane.gamard at salsadev dot com>
Dear IKS community members,
My name is Stéphane Gamard, founder and CTO of salsaDev - an Information Accesscompany. We've joined the IKS community and upon John's recommendation it is mypleasure to briefly present our company, what we do and give you a sneak preview of what we'll be showing at the up-comming IKS workshop in November.
Information overload, non-structured data, dirty and miss-tagged/classified informationput a strain on the knowledge-worker. Timely access to critical and relevant informationcan be become a daunting and time consuming task, especially when the user only has avague and/or non-explicit idea of the information sought.
salsaDev uses a technology emerged from language acquisition research at the RensselaerPolytechnic Institute to index textual information at a conceptual level. Our approach toinformation access is not a replacement solution, but a high-value added feature:knowledge workers are provided with a sense-centric/meaning-aware access to theirrelevant content.
A very pragmatic and typical user cases: An IP lawyer, while filling for a patent, mustread, evaluate and discriminate tremendous amount of non-relevant information (toooften also out of the scope of his own area of expertise). A sense-based system such assalsaDev's can read the patent application and provide meaning-based related informationthat might be of interest.
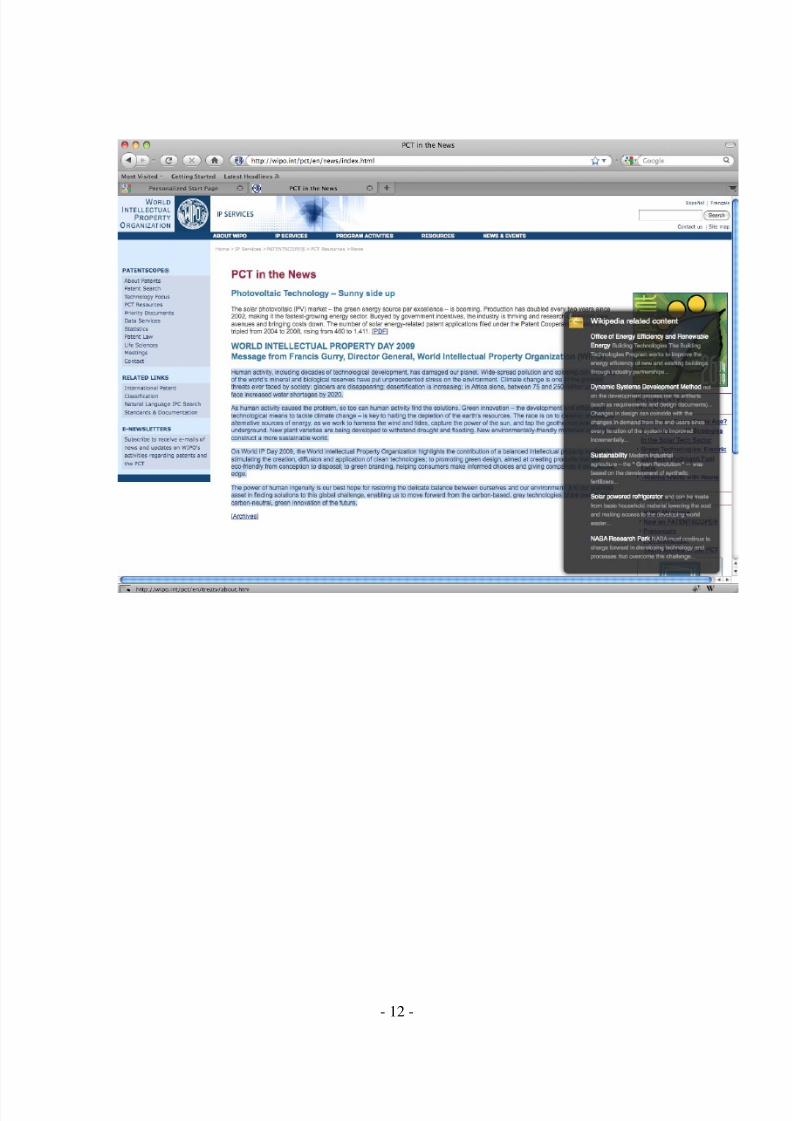
salsaDev provides a service platform enabling innovative and meaning-based informationmanagement. I've attached a screenshot of our latest demo (which we'll showcase duringthe next IKS workshop). In the screenshot a user highlights parts of a website. OurFirefox plugin (embedded JS popup at the bottom right) sends the highlighted content tosalsaDev and retrieves related articles. In this example we've used wikipedia as the sourceof a "some-what" structured information data-set.
This is salsaDev in a nutshell (an extended one I am aware). I am sure this shortpresentation raises more questions than it answers, so please feel free to send me anyquestions you might have. In the mean time and in preparation for the next workshop Iwish you all a very semantic day
Cheers,Stephane
8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 12/20

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 13/20

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 14/20
- 14 -
[6] http://wiki.iks-project.eu/index.php/User-stories#Story_09:_Similarity_based_document_search [7] http://jira.nuxeo.org/secure/IssueNavigator.jspa?reset=true&pid=10273&status=1
Looking forward to meeting you all in Roma,Olivier - http://twitter.com/ogrisel
Wed, 21 Oct 2009 From: Olivier Grisel ogrisel at nuxeo dot com
Just to make it more explicit, for the demo session I should be ableto showcase the current state of the Scribo project that mainlyfocuses on IKS user story #5 and a prototype of similarity search inpictures (IKS user story #3).
http://wiki.iks-project.eu/index.php/User-stories#Story_05:_Assistance_with_Semantic_Tagging
http://wiki.iks-project.eu/index.php/User-stories#Story_03:_Similarity-based_Image_Search
Best,Olivier

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 15/20
- 15 -
7
thparticipant: Zemanta
Friday November 13, 2009: 11h15 – 11h35 Thu, 15 Oct 2009 From: "Tomaž Šolc" <tomaz.solc at zemanta dot com>
Hi everyone!
My name is Tomaž Šolc. I am head of reseaarch at Zemanta, working from ourheadquarters in Ljubljana, Slovenia. I have a degree in electrical engineering and I amdeveloping algorithms for natural language analysis and the proprietary triple store usedby our content suggestion system.
Zemanta's content suggestion system is the main product of our company - it takes afragment of plain text as its input and provides images and articles related to the topic of the text as well as relevant tags and automatic explanatory in-text links. It achieves thatby first annotating the text with several components (like named entity extraction, wordsense disambiguation, classification) and then using the annotated text to search throughcollections of similarly annotated objects. This system can be used as an assistant forbloggers and other authors: suggestions can be either automatically or manually appliedto enrich news articles and blog posts.
From the perspective of semantic search, Zemanta is an interesting example of automaticsemantic query construction by extracting key concepts from a longer piece of text. Sinceto some degree we use external third-party search APIs we also had to address theproblem of how to construct traditional keyword queries from semantically annotatedtext.
At the demo session of the next IKS workshop I would like to show a live demo of oursystem [1] and explain a little bit what is happening behind the curtains. How exactly theannotations look like, how our word sense disambiguation works and how we use open-source solutions like Lucene to search large collections of documents.
[1] http://www.zemanta.com/demo
Best regardsTomaž--Tomaž Šolc, Research & DevelopmentZemanta Ltd, London, LLjubljanawww.zemanta.com mail: tomaz at zemanta dot comblog: http://www.tablix.org/~avian/blog
8th
participant: TrezorixFriday November 13, 2009: 11h40 – 12h00

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 16/20
- 16 -
Tue, 3 Nov 2009 from: "Sander van der Meulen" <sander at trezorix dot nl>
Hi All,
My name is Sander van der Meulen and I am Technical Manager at Trezorix. Trezorixwas founded in the year 2000 and is located in Delft, The Netherlands.
At Trezorix we develop knowledge networks, connecting all sorts of knowledge sourcesinto networks with optimized findability. Most of this development is done withinprojects, with knowledge institutions like museums, libraries, ministries, universities, andpartner companies, for example the RNA project [1] and Sterna project [2].
Our main software product is the RNA Toolset, a semantic web based innovative toolsfor working with content, metadata and reference structures. The goal of the RNAToolset is to create an open environment for knowledge workers to create and edit theircontent, and to enable the knowledge workers to publish the content to a semanticallyrich search environment.
The roadmap for the development of the RNA Toolset points to implementing a federatedSesame/OWLim RDF layer with RDFS and OWL support as the search platform.Currently we only have RDF configurations in our test environments. In our productionenvironments we've successfully implemented Solr as the search platform, providingsuperb free text and facet searching. But the lack of relational constructs and inferencing
capabilities in Solr force us to move to the richer RDF environment for more complexknowledge systems.
Looking forward to meeting you all in Rome.
Best regards,
Sander van der Meulen
References:
1. http://www.rnaproject.org/ 2. http://www.sterna-net.eu/

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 17/20
- 17 -
9
thparticipant: Sourcesense
Friday November 13, 2009: 12h05 – 12h25 Fri, 23 Oct 2009 From: Tommaso Teofili <tommaso.teofili at gmail dot com>
Hi all,my name is Tommaso Teofili and I am new to IKS. I am a software engineer atSourcesense [1], a european company specialized in the integration of open sourceprojects. We as Sourcesense strongly believe in open source and everyone in thecompany is encouraged to contribute to the projects he's working on. Many of uscontribute and commit to open source projects like Infinispan, JBoss portal, Alfresco,Apache POI, Apache Chemistry, Scarlet, WURFL and others [2].
Before joining Sourcesense I started studying, using and then contributing to ApacheUIMA [3] for my graduation thesis (since November 2008), then on August 2009 Igained the committership.
At the moment the project is on his way towards the 2.3.0 release and possibly become anApache TLP [4]. During this period I realized some prototypes of applications usingUIMA for semantic search, one of which I am going to show during the workshop.
Hope to meet you all in Rome.CheersTommaso Teofili
[1] : http://www.sourcesense.com [2] : http://opensource.sourcesense.com [3] : http://incubator.apache.org/uima [4] : http://wiki.apache.org/incubator/October2009

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 18/20
- 18 -
10
thparticipant: Semantic Technology LAB
Friday November 13, 2009: 12h30 – 12h50 Fri, 23 Oct 2009 From: Alfio Massimiliano Gliozzo <gliozzoat gmail dot com>
Dear all,
I am Alfio Massimiliano Gliozzo, researcher at the Semantic Technology Laboratory of the Italian National Research Council (CNR) where I coordinate the Natural LanguageProcessing and Information Retrieval area. You can find additional info about me and mylab here (http://stlab.istc.cnr.it/stlab/User:AlfioGliozzo).
My main research topic is hybridizing Information Retrieval, Natural LanguageProcessing and Machine learning approaches with knowledge management tools at scale.One of the applications I am interested in is Knowledge Retrieval, which is aboutretrieving structured knowledge relevant for natural language queries. This task can beperformed on large RDF/OWL knowledge bases.
I will present an application of knowledge retrieval in the next IKS workshop “SemanticSearch - Fact and Fiction” in Rome. This is a semantic search engine called “SemanticScouting” working on an RDF/OWL ontology describing the CNR organization,developed as a collaborative work by almost all members of my lab as a showcase for thecapabilities we are currently developing here.
CNR is the largest research institution in Italy, employing more than 20k researchers,organized into departments and institutes, subdivided into research units characterized bydifferent competences, research programs, and laboratories. We performed a migration of the information spread into different CNR databases into a common RDF/OWLknowledge base containing both texts (e.g. the titles of the papers wrote by anyresearcher) and structured data (e.g. relations between researchers and their institutes) [1].The result is a critical mass of data representing around 30k instances organized into 50classes and 1.8M triples.
Further, we expanded the knowledge base by performing some simple inference (e.g. theco-authorship relation) and we automatically generated relations with linked open dataresources, and in particular DBpedia categories, by exploiting advanced text processingtechniques.
Then we developed a knowledge retrieval engine whose output are entities of differenttypes, where the input are queries in either Italian or English language. Using suchentities as entry points, we can further explore the ontology following two differentmodalities: browsing the graph of relations around each entity or opening formsrepresenting relevant attributes and relations.

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 19/20

8/14/2019 Semantic Search Demo Booklet
http://slidepdf.com/reader/full/semantic-search-demo-booklet 20/20
- 20 -
11
thparticipant: Semantic MediaWiki
Friday November 13, 2009: 12h55 – 13h15 Wed, 4 Nov 2009 "Duc Tran" <Tran at aifb.uni-karlsruhe dot de>
Hi all,
I am looking forward to attend the IKS Semantic Search Workshop.
Here is some info to my contribution:
"At AIFB (Karlsruhe Institute of Technology) I work on storage, query processing, queryinterface and ranking on integrated collections of structured (RDF) data and text (DB &IR). I will demonstrate the search solutions we have developed. One is a semantic searchextension to SMW (http://semanticweb.org/wiki/Special:ATWSpecialSearch) thatcomputes completions and translations of keywords. This results in expressive structuredqueries that can use to retrieve precise answers from semantic wiki. The other called theInformation Workbench (http://iwb.fluidops.com/ ) supports the lifecycle of “interactingwith data”, i.e. from data integration, to semantic search, data manipulation, presentation,visualization up to data publishing”.
Feel free to contact me if you have any questions on these demos.
Cheers, Thanh.
------------------------------------------------------------
Tran Duc Thanh (Kim Duc Thanh)
Institut AIFB - Geb. 05.20Karlsruher Institut für Technologie (KIT)76128 Karlsruhe
Tel.: +49 (721) 608-4754Fax: +49 (721) 608-6080Mobile: +49 (1515) 8872883E-Mail: dtr at aifb.uni-karlsruhe dot de WWW: http://sites.google.com/site/kimducthanh
Related Documents











