Signal Processing 66 (1998) 337 — 355 Robust audio watermarking using perceptual masking1 Mitchell D. Swanson!,*, Bin Zhu!, Ahmed H. Tewfik!, Laurence Boney" ! Department of Electrical Engineering, University of Minnesota, Minneapolis, MN 55455, USA " Ecole Nationale Supe & rieure des Te & le & communications/SIG, 46 rue Barrault, 75634 Paris Cedex 13, France Received 10 February 1997; received in revised form 11 November 1997 Abstract We present a watermarking procedure to embed copyright protection into digital audio by directly modifying the audio samples. Our audio-dependent watermarking procedure directly exploits temporal and frequency perceptual masking to guarantee that the embedded watermark is inaudible and robust. The watermark is constructed by breaking each audio clip into smaller segments and adding a perceptually shaped pseudo-random sequence. The noise-like watermark is statistically undetectable to prevent unauthorized removal. Furthermore, the author representation we introduce resolves the deadlock problem. We also introduce the notion of a dual watermark: one which uses the original signal during detection and one which does not. We show that the dual watermarking approach together with the procedure that we use to derive the watermarks effectively solves the deadlock problem. We also demonstrate the robustness of that watermarking procedure to audio degradations and distortions, e.g., those that result from colored noise, MPEG coding, multiple watermarks, and temporal resampling. ( 1998 Elsevier Science B.V. All rights reserved. Zusammenfassung Wir stellen ein Wasserzeichen-Verfahren zur Einbettung des Urheberrechtsschutzes in digitale Audiodaten vor, wobei die Audiosignalwerte direkt modifiziert werden. Unser audioabha¨ ngiges Wasserzeichen-Verfahrennu¨ tzt unmittelbar die Wahrnehmungsverdeckung in Zeit-und Frequenzbereich aus, um sicherzustellen, da¨s das eingebettete Wasserzeichen unho¨ rbar und robust ist. Das Wasserzeichen wird konstruiert, indem jeder Audioabschnitt in kleinere Segmente zerteilt wird und eine wahrnehmungsgerechtgeformte Pseudozufallsfolge hinzuaddiert wird. Das gera¨ uschartige Wasserzeichen ist statistisch nicht erkennbar, um unautorisiertes Entfernen zu verhindern. Weiters lo¨st die von uns eingefu¨hrte Autorendarstellung das Pattstellungsproblem. Wir fu¨hren auch den Begriff dualer Wasserzeichen ein: eines, das das Originalsignal wa¨hrend der Erkennung benutzt, und eines, das es nicht benutzt. Wir zeigen, da¨s der Ansatz mit dualen Wasserzeichen in Verbindung mit dem Verfahren, das wir zur Herleitung der Wasserzeichen einsetzen, das Pattstellun- gsproblem wirksam lo¨st. Wir zeigen auch die Robustheit des Wasserzeichen-Verfahrens gegenu¨ber Audiosto¨rungen und -verzerrrungen, z.B. jenen, die von farbigem Rauschen, MPEG-Codierung, mehrfachen Wasserzeichen, und Abtastratenwandlung herru¨hren. ( 1998 Elsevier Science B.V. All rights reserved. Re´ sume´ Nous pre´sentons dans cet article une proce´dure de watermarking permettant d’inte´grer une protection de droits d’auteur dans des donne´es audio nume´riques par modification directe des e´chantillons audio. Cette proce´dure exploite * Corresponding author. 1 This work was supported by AFOSR under grant AF/F49620-94-1-0461. Patent pending, Media Science, Inc., 1996. 0165-1684/98/$19.00 ( 1998 Elsevier Science B.V. All rights reserved. PII S0165-1684(98)00014-0

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Signal Processing 66 (1998) 337—355
Robust audio watermarking using perceptual masking1
Mitchell D. Swanson!,*, Bin Zhu!, Ahmed H. Tewfik!, Laurence Boney"
! Department of Electrical Engineering, University of Minnesota, Minneapolis, MN 55455, USA" Ecole Nationale Supe& rieure des Te& le& communications/SIG, 46 rue Barrault, 75634 Paris Cedex 13, France
Received 10 February 1997; received in revised form 11 November 1997
Abstract
We present a watermarking procedure to embed copyright protection into digital audio by directly modifying theaudio samples. Our audio-dependent watermarking procedure directly exploits temporal and frequency perceptualmasking to guarantee that the embedded watermark is inaudible and robust. The watermark is constructed by breakingeach audio clip into smaller segments and adding a perceptually shaped pseudo-random sequence. The noise-likewatermark is statistically undetectable to prevent unauthorized removal. Furthermore, the author representation weintroduce resolves the deadlock problem. We also introduce the notion of a dual watermark: one which uses the originalsignal during detection and one which does not. We show that the dual watermarking approach together with theprocedure that we use to derive the watermarks effectively solves the deadlock problem. We also demonstrate therobustness of that watermarking procedure to audio degradations and distortions, e.g., those that result from colorednoise, MPEG coding, multiple watermarks, and temporal resampling. ( 1998 Elsevier Science B.V. All rights reserved.
Zusammenfassung
Wir stellen ein Wasserzeichen-Verfahren zur Einbettung des Urheberrechtsschutzes in digitale Audiodaten vor, wobeidie Audiosignalwerte direkt modifiziert werden. Unser audioabhangiges Wasserzeichen-Verfahren nutzt unmittelbar dieWahrnehmungsverdeckung in Zeit-und Frequenzbereich aus, um sicherzustellen, das das eingebettete Wasserzeichenunhorbar und robust ist. Das Wasserzeichen wird konstruiert, indem jeder Audioabschnitt in kleinere Segmente zerteiltwird und eine wahrnehmungsgerecht geformte Pseudozufallsfolge hinzuaddiert wird. Das gerauschartige Wasserzeichenist statistisch nicht erkennbar, um unautorisiertes Entfernen zu verhindern. Weiters lost die von uns eingefuhrteAutorendarstellung das Pattstellungsproblem. Wir fuhren auch den Begriff dualer Wasserzeichen ein: eines, das dasOriginalsignal wahrend der Erkennung benutzt, und eines, das es nicht benutzt. Wir zeigen, das der Ansatz mit dualenWasserzeichen in Verbindung mit dem Verfahren, das wir zur Herleitung der Wasserzeichen einsetzen, das Pattstellun-gsproblem wirksam lost. Wir zeigen auch die Robustheit des Wasserzeichen-Verfahrens gegenuber Audiostorungenund -verzerrrungen, z.B. jenen, die von farbigem Rauschen, MPEG-Codierung, mehrfachen Wasserzeichen, undAbtastratenwandlung herruhren. ( 1998 Elsevier Science B.V. All rights reserved.
Resume
Nous presentons dans cet article une procedure de watermarking permettant d’integrer une protection de droitsd’auteur dans des donnees audio numeriques par modification directe des echantillons audio. Cette procedure exploite
*Corresponding author.1This work was supported by AFOSR under grant AF/F49620-94-1-0461. Patent pending, Media Science, Inc., 1996.
0165-1684/98/$19.00 ( 1998 Elsevier Science B.V. All rights reserved.PII S 0 1 6 5 - 1 6 8 4 ( 9 8 ) 0 0 0 1 4 - 0

directement les masquages perceptuels temporel et frequentiel pour garantir que le filigrane numerique (watermark) estinaudible et robuste. Le watermark est construit en fragmentant chaque morceau audio en segments plus petits et enajoutant une sequence pseudo-aleatoire modelee perceptuellement. Le watermark semblable a du bruit est indetectablestatistiquement afin d’empecher une suppression non autorisee de celui-ci. De plus, la representation de l’auteur que nousintroduisons resoud le probleme de l’impasse. Nous introduisons egalement la notion de watermark dual: l’un qui utilisele signal original lors de la detection et l’autre non. Nous montrons que l’approche de watermarking dual combinee avecla procedure que nous utilisons pour deriver les watermarks resoud effectivement le probleme de l’impasse. Nous mettonsegalement en evidence la robustesse de cette procedure de watermarking vis-a-vis des degradations et distorsions audio,telles que celles qui resultent d’un bruit colore, d’un codage MPEG, de watermarks multiples, et de re-echantillonnagetemporel. ( 1998 Elsevier Science B.V. All rights reserved.
Keywords: Copyright protection; Masking; Digital watermarking
1. Introduction
Efficient distribution, reproduction, and manip-ulation have led to wide proliferation of digitalmedia, e.g., audio, video, and images. However,these efficiencies also increase the problems asso-ciated with copyright enforcement. For this reason,creators and distributors of digital data are hesitantto provide access to their intellectual property. Theyare actively seeking reliable solutions to the prob-lems associated with copyright protection of multi-media data.
Digital watermarking has been proposed asa means to identify the owner or distributor ofdigital data. Watermarking is the process of encod-ing hidden copyright information in digital data bymaking small modifications to the data samples.Unlike encryption, watermarking does not restrictaccess to the data. Once encrypted data is decrypted,the media is no longer protected. A watermark isdesigned to permanently reside in the host data.When the ownership of a digital work is in question,the information can be extracted to completelycharacterize the owner.
To function as a useful and reliable intellectualproperty protection mechanism, the watermarkmust be:f embedded within the host media;f perceptually inaudible within the host media;f statistically undetectable to ensure security and
thwart unauthorized removal;f robust to manipulation and signal processing
operations on the host signal, e.g., noise, com-
pression, cropping, resizing, D/A conversions, etc.;and
f readily extracted to completely characterize thecopyright owner.In particular, the watermark may not be stored
in a file header, a separate bit stream, or a separatefile. Such copyright mechanisms are easily removed.The watermark must be inaudible within the hostaudio data to maintain audio quality. The water-mark must be statistically undetectable to thwartunauthorized removal by a ‘pirate’. A watermarkwhich may be localized through averaging, correla-tion, spectral analysis, Kalman filtering, etc., maybe readily removed or altered, thereby destroyingthe copyright information.
The watermark must be robust to signal distor-tions, incidental and intentional, applied to the hostdata. For example, in most applications involvingstorage and transmission of audio, a lossy codingoperation is performed on the audio to reducebit-rates and increase efficiency. Operations whichdamage the host audio also damage the embeddedwatermark. The watermark is required to survivesuch distortions to identify the owner of the data.Furthermore, a resourceful pirate may use a varietyof signal processing operations to attack a digitalwatermarking. A pirate may attempt to defeata watermarking procedure in two ways: (1) damagethe host audio to make the watermark undetectable,or (2) establish that the watermarking scheme isunreliable, i.e., it detects a watermark when none ispresent. The watermark should be impossible todefeat without destroying the host audio.
338 M.D. Swanson et al. / Signal Processing 66 (1998) 337–355

Finally, the watermark should be readily extrac-ted given the watermarking procedure and theproper author signature. Without the correct signa-ture, the watermark cannot be removed. The ex-tracted watermark must correctly identify the ownerand solve the deadlock issue (cf. Section 2) whenmultiple parties claim ownership.
Watermarking digital media has received a greatdeal of attention recently in the literature and theresearch community. Most watermarking schemesfocus on image and video copyright protection, e.g.,[1—3,7,10,14,15,18,19,22,24]. A few audio water-marking techniques have been reported. Severaltechniques have been proposed in [1]. Using a phasecoding approach, data is embedded by modifyingthe phase values of Fourier transform coefficientsof audio segments. Embedding data as spread spec-trum noise have also been proposed. A third tech-nique, echo coding, employs multiple decayingechoes to place a peak in the cepstrum at a knownlocation. Another audio watermarking technique isproposed in [21], where Fourier transform coeffi-cients over the middle frequency bands are replacedwith spectral components from a signature. somecommercial products are also available. TheICE system from Central Research Laboratoriesinserts a pair of very short tone sequencesinto an audio track. An audio watermarkingproduct MusiCode is available from ARIS techno-logies.
Most schemes utilize the fact that digital mediacontain perceptually insignificant componentswhich may be replaced or modified to embed copy-right protection. However, the techniques do notdirectly exploit spatial/temporal and frequencymasking. Thus, the watermark is not guaranteedinaudible. Furthermore, robustness is not maxi-mized. The amount of modification made to eachcoefficient to embed the watermark are estimatedand not necessarily the maximum amount possible.In this paper, we introduce a novel watermarkingscheme for audio which exploits the human auditorysystem (HAS) to guarantee that the embeddedwatermark is imperceptible. As the perceptual char-acteristics of individual audio signals vary, thewatermark adapts to and is highly dependent onthe audio being watermarked. Our watermark isgenerated by filtering a pseudo-random sequence
(author id) with a filter that approximates thefrequency masking characteristics of the HAS. Theresulting sequence is further shaped by the temporalmasking properties of the audio. Based on pseudo-random sequences, the noise-like watermark isstatistically undetectable. Furthermore, we will showin the sequel that the watermark is extremely robustto a large number of signal processing operationsand is easily extracted to prove ownership.
The work presented in this paper offers severalmajor contributions to the field, including
A perception-based watermarking procedure: Theembedded watermark adapts to each individualhost signal. In particular, the temporal and fre-quency distribution of the watermark are dictatedby the temporal and frequency masking character-istics of the host audio signal. As a result, theamplitude (strength) of the watermark increasesand decreases with host, e.g., lower amplitude in‘quiet’ regions of the audio. This guarantees thatthe embedded watermark is inaudible while havingthe maximum possible energy. Maximizing theenergy of the watermark adds robustness to attacks.
An author representation which solves the deadlockproblem: An author is represented with a pseudo-random sequence created by a pseudo-randomgenerator [13] and two keys. One key is authordependent, while the second key is signal dependent.The representation is able to resolve rightful owner-ship in the face of multiple ownership claims.
A dual watermark. The watermarking schemeuses the original audio signal to detect the presenceof a watermark. The procedure can handle virtuallyall types of distortions, including cropping, temporalrescaling, etc., using a generalized likelihood ratiotest. As a result, the watermarking procedure isa powerful digital copyright protection tool. Weintegrate this procedure with a second watermarkwhich does not require the original signal. The dualwatermarks also address the deadlock problem.
In the next section, we introduce our noise-likeauthor representation and the dual watermarkingscheme. Our frequency and temporal masking mod-els are reviewed in Section 3. Our watermarkingdesign and detection algorithms are introduced inSections 4 and 5. Finally, experimental resultsare presented in Section 6. Watermark statisticsand fidelity results for four test audio signals are
M.D. Swanson et al. / Signal Processing 66 (1998) 337—355 339

presented. The robustness of our watermarkingprocedure is illustrated for a wide assortment ofsignal processing operations and distortions. Wepresent our conclusion in Section 7.
2. Author representation, dual watermarking andthe deadlock problem
Data embedding algorithms may be used toestablish ownership and distribution of data. Infact, this is the application of data embedding orwatermarking that has received most attention inthe literature. Unfortunately, most current water-marking schemes are unable to resolve rightfulownership of digital data when multiple ownershipclaims are made, i.e., when a deadlock problemarises. The inability of many data embedding algo-rithms to deal with deadlock, first described byCraver et al. [4], is independent of how the water-mark is inserted in the multimedia data or howrobust it is to various types of modifications.
Today, no scheme can unambiguously determineownership of a given multimedia signal if it doesnot use an original or other copy in the detectionprocess to at least construct the watermark to bedetected. A pirate can simply add his or her water-mark to the watermarked data or counterfeita watermark that correlates well or is detected inthe contested signal. Current data embeddingschemes used as copyright protection algorithmsare unable to establish who watermarked the datafirst. Furthermore, none of the current data embed-ding schemes has been proven to be immune tocounterfeiting watermarks that will correlate wellwith a given signal as long as the watermark is notrestricted to partially depend in a non-invertiblemanner on the signal.
If the detection scheme can make use of theoriginal to construct the watermark, then it may bepossible to establish unambiguous ownership of thedata regardless of whether the detection schemesubtracts the original from the signal under consid-eration prior to watermark detection or not. Spe-cifically, [5] derives a set of sufficient conditionsthat watermarks and watermarking schemes mustsatisfy to provide unambiguous proof of ownership.For example, one can use watermarks derived from
pseudo-random sequences that depend on the signaland the author. Ref. [5] establishes that this willwork for all watermarking procedures regardless ofwhether they subtract the original from the signalunder consideration prior to watermark detectionor not. Ref. [20] independently derived a similarresult for a restricted class of watermarkingtechniques that rely on subtracting a signalderived from the original from the signal underconsideration prior to watermark detection.The signal-dependent key also helps to thwartthe ‘mix-and-match’ attack described in [5].
An author can construct a watermark that de-pends on the audio signal and the author andprovides unambiguous proof of ownership as fol-lows. The author has two random keys x
1and
x2
(i.e., seeds) from which a pseudo-randomsequence y can be generated using a suitablepseudo-random sequence generator [16]. Populargenerators include RSA, Rabin, Blum/Micali, andBlum/Blum/Shub [6]. With the two proper keys,the watermark may be extracted. Without the twokeys, the data hidden in the signal is statisticallyundetectable and impossible to recover. Note thatclassical maximal length pseudo noise sequence(i.e., m-sequence) generated by linear feedback shiftregisters are not used to generate a watermark.Sequences generated by shift registers are crypto-graphically insecure: one can solve for the feedbackpattern (i.e., the keys) given a small number ofoutput bits y.
The noise-like sequence y may be used to derivethe actual watermark hidden into the audio signalor control the operation of the watermarking algo-rithm, e.g., determine the location of samples thatmay be modified. The key x
1is author dependent.
The key x2
is signal dependent. The key x1
is thesecret key assigned to (or chosen by) the author.Key x
2is computed from the audio signal which the
author wishes to watermark. It is computed fromthe signal using a one-way hash function. Forexample, the tolerable error levels supplied bymasking models (see Section 3) are hashed in [20]to a key x
2. Any one of a number of well-known
secure one-way hash functions may be used tocompute x
2, including RSA, MD4 [17], and SHA
[12]. For example, the Blum/Blum/Shub pseudo-random generator uses the one way function
340 M.D. Swanson et al. / Signal Processing 66 (1998) 337–355

y"gn(x)"x2mod n where n"pq for primes p and
q so that p"q"3mod4. It can be shown thatgenerating x or y from partial knowledge of y iscomputationally infeasible for the Blum/Blum/Shubgenerator.
The signal-dependent key x2makes counterfeiting
very difficult. The pirate can only provide key x1
tothe arbitrator. Key x
2is automatically computed
by the watermarking algorithm from the originalsignal. As it is computationally infeasible to invertthe one-way hash function, the pirate is unable tofabricate a counterfeit original which generatesa desired or predetermined watermark.
Deadlock may also be resolved using the dualwatermarking scheme of [20]. That scheme employsa pair of watermarks. One watermarking procedurerequires the original data set for watermark detec-tion. This paper provides a detailed description ofthat procedure and of its robustness. The secondwatermarking procedure does not require the orig-inal data set. A data embedding technique whichsatisfies the restrictions outlined in [5] can be usedto insert the second watermark. The second water-mark need not be highly robust to editing of theaudio segment since, as we shall see below, it ismeant to protect the audio clip that a pirate claimsto be his original. The robustness level of most ofthe recent watermarking techniques that do notrequire the original for watermark detection is quiteadequate. The arbitrator would expect the originalto be of a high enough quality. This limits theoperations that a pirate can apply to an audio clipand still claim it to be his high-quality originalsound. The watermark that requires the originalaudio sequence for its detection is very robust as weshow in this paper.
In case of deadlock, the arbitrator simply firstchecks for the watermark that requires the originalfor watermark detection. If the pirate is clever andhas used the attack suggested in [4] and outlinedabove, the arbitrator would be unable to resolvethe deadlock with this first test. The arbitratorsimply then checks for the watermark that does notrequire the original audio sequence in the audiosegments that each ownership contender claims tobe his original. Since the original audio sequence ofa pirate is derived from the watermarked copyproduced by the rightful owner, it will contain the
watermark of the rightful owner. On the otherhand, the true original of the rightful owner will notcontain the watermark of the pirate since the piratehas no access to that original and the watermarkdoes not require subtraction of another data set forits detection.
3. Audio masking
Audio masking is the effect by which a faint butaudible sound becomes inaudible in the presence ofanother louder audible sound, i.e., the masker [9].The masking effect depends on the spectral andtemporal characteristics of both the masked signaland the masker. Our watermarking proceduredirectly exploits both frequency and temporal mask-ing characteristics to embed an inaudible and robustwatermark.
3.1. Frequency masking
Frequency masking refers to masking betweenfrequency components in the audio signal. If twosignals, which occur simultaneously, are close to-gether in frequency, the stronger masking signalmay make the weaker signal inaudible. The maskingthreshold of a masker depends on the frequency,sound pressure level (SPL), and tone-like or noise-like characteristics of both the masker and themasked signal [13]. It is easier for a broadbandnoise to mask a tonal, than for a tonal signal tomask out a broadband noise. Moreover, higher-frequency signals are more easily masked.
The human ear acts as a frequency analyzer andcan detect sounds with frequencies which vary from10 to 20 000Hz. The HAS can be modeled by a setof 26 band-pass filters with bandwidths that increasewith increasing frequency. The 26 bands are knownas the critical bands. The critical bands are definedaround a center frequency in which the noise band-width is increased until there is a just noticeabledifference in the tone at the center frequency. Thus,if a faint tone lies in the critical band of a loudertone, the faint tone will not be perceptible.
Frequency masking models are readily obtainedfrom the current generation of high-quality audio
M.D. Swanson et al. / Signal Processing 66 (1998) 337—355 341
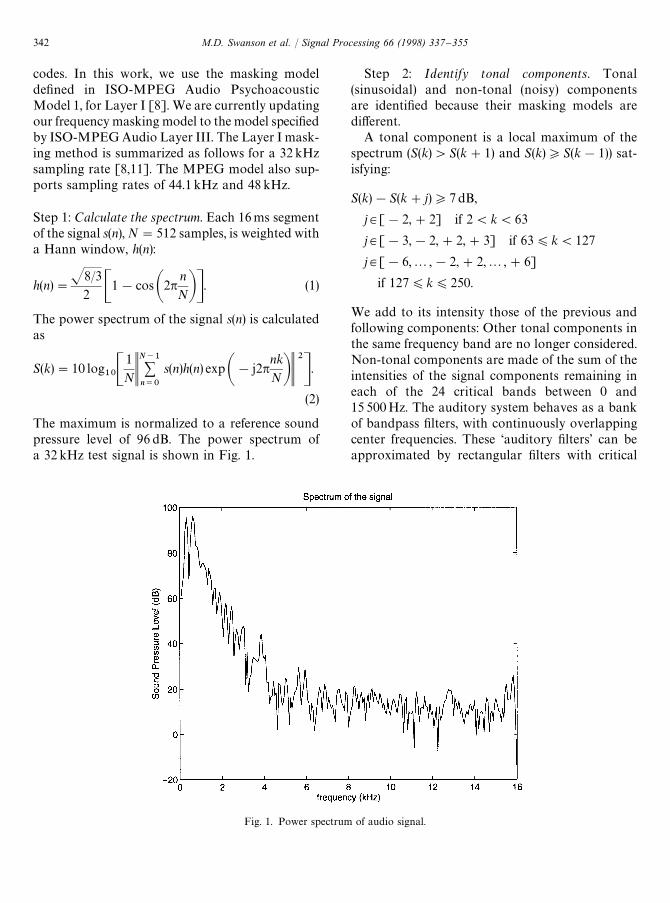
Fig. 1. Power spectrum of audio signal.
codes. In this work, we use the masking modeldefined in ISO-MPEG Audio PsychoacousticModel 1, for Layer I [8]. We are currently updatingour frequency masking model to the model specifiedby ISO-MPEG Audio Layer III. The Layer I mask-ing method is summarized as follows for a 32 kHzsampling rate [8,11]. The MPEG model also sup-ports sampling rates of 44.1 kHz and 48kHz.
Step 1: Calculate the spectrum. Each 16ms segmentof the signal s(n), N"512 samples, is weighted witha Hann window, h(n):
h(n)"J8/3
2 C1!cosA2pn
NBD. (1)
The power spectrum of the signal s(n) is calculatedas
S(k)"10 log10C
1
NKKN~1+n/0
s(n)h(n) expA!j2pnk
NBKK2
D.(2)
The maximum is normalized to a reference soundpressure level of 96 dB. The power spectrum ofa 32 kHz test signal is shown in Fig. 1.
Step 2: Identify tonal components. Tonal(sinusoidal) and non-tonal (noisy) componentsare identified because their masking models aredifferent.
A tonal component is a local maximum of thespectrum (S(k)'S(k#1) and S(k)*S(k!1)) sat-isfying:
S(k)!S(k#j)*7 dB,
j3[!2,#2] if 2(k(63
j3[!3,!2,#2,#3] if 63)k(127
j3[!6,2,!2,#2,2,#6]
if 127)k)250.
We add to its intensity those of the previous andfollowing components: Other tonal components inthe same frequency band are no longer considered.Non-tonal components are made of the sum of theintensities of the signal components remaining ineach of the 24 critical bands between 0 and15 500Hz. The auditory system behaves as a bankof bandpass filters, with continuously overlappingcenter frequencies. These ‘auditory filters’ can beapproximated by rectangular filters with critical
342 M.D. Swanson et al. / Signal Processing 66 (1998) 337–355
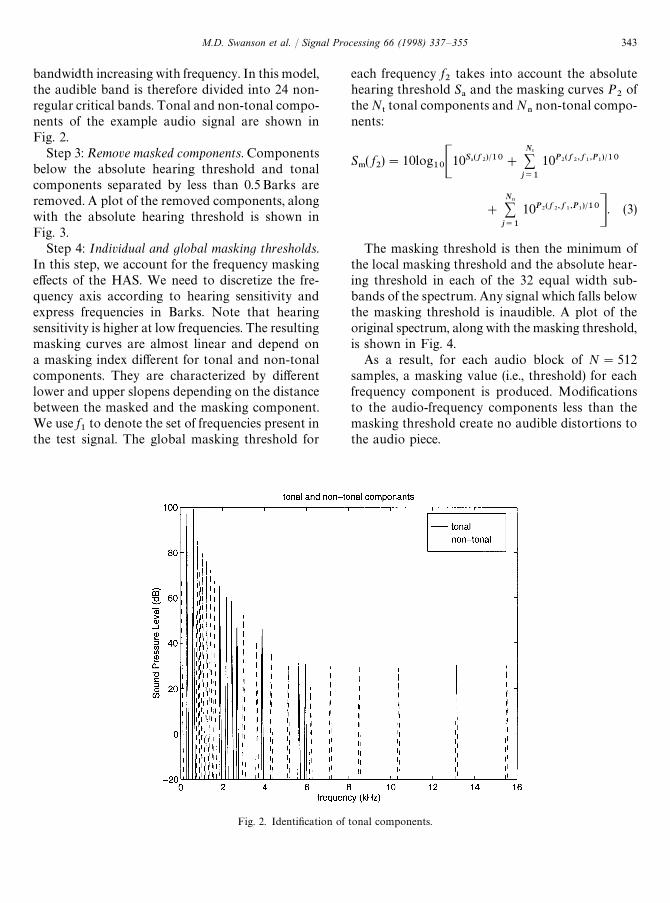
Fig. 2. Identification of tonal components.
bandwidth increasing with frequency. In this model,the audible band is therefore divided into 24 non-regular critical bands. Tonal and non-tonal compo-nents of the example audio signal are shown inFig. 2.
Step 3: Remove masked components. Componentsbelow the absolute hearing threshold and tonalcomponents separated by less than 0.5Barks areremoved. A plot of the removed components, alongwith the absolute hearing threshold is shown inFig. 3.
Step 4: Individual and global masking thresholds.In this step, we account for the frequency maskingeffects of the HAS. We need to discretize the fre-quency axis according to hearing sensitivity andexpress frequencies in Barks. Note that hearingsensitivity is higher at low frequencies. The resultingmasking curves are almost linear and depend ona masking index different for tonal and non-tonalcomponents. They are characterized by differentlower and upper slopens depending on the distancebetween the masked and the masking component.We use f
1to denote the set of frequencies present in
the test signal. The global masking threshold for
each frequency f2
takes into account the absolutehearing threshold S
!and the masking curves P
2of
the N5tonal components and N
/non-tonal compo-
nents:
S.( f
2)"10log
10C10S!(f2)@10#N5
+j/1
10P2(f2,f1,P1)@10
#
N/
+j/1
10P2(f2,f1,P1)@10D. (3)
The masking threshold is then the minimum ofthe local masking threshold and the absolute hear-ing threshold in each of the 32 equal width sub-bands of the spectrum. Any signal which falls belowthe masking threshold is inaudible. A plot of theoriginal spectrum, along with the masking threshold,is shown in Fig. 4.
As a result, for each audio block of N"512samples, a masking value (i.e., threshold) for eachfrequency component is produced. Modificationsto the audio-frequency components less than themasking threshold create no audible distortions tothe audio piece.
M.D. Swanson et al. / Signal Processing 66 (1998) 337—355 343

Fig. 3. Removal of masked components.
3.2. Temporal masking
Temporal masking refers to both pre- andpost-masking. Pre-masking effects render weakersignals inaudible before the stronger masker isturned on, and post-masking effects renderweaker signals inaudible after the strongermasker is turned off. Pre-masking occurs from 5to 20ms before the masker is turned on whilepost-masking occurs from 50 to 200 ms after themasker is turned off [13]. Note that temporal andfrequency masking effects have dual localizationproperties. Specifically, frequency masking effectsare localized in the frequency domain, while tem-poral masking effects are localized in the timedomain.
We approximate temporal masking effects usingthe envelope of the host audio. The envelope ismodeled as a decaying exponential. In particular,the estimated envelope t(i) of signal s(i) increaseswith the signal and decays as e~at. An audiosignal, along with its estimated envelope, is shownin Fig. 5.
4. Watermark design
Each audio signal is watermarked with a uniquenoise-like sequence shaped by the masking phe-nomena. The watermark consists of (1) an authorrepresentation (cf. Section 2), and (2) spectral andtemporal shaping using the masking effects of theHAS.
Our watermarking scheme is based on a re-peated application of a basic watermarkingoperation on smaller segments of the audio signal.A diagram of our audio watermarking techniqueis shown in Fig. 6. The length N audio signalis first segmented into blocks s
i(k) of length
512 samples, i"0,1,2,xN/512y!1, and k"0,1,2,511. The block size of 512 samples is dictatedby the frequency masking model we employ. Blocksizes of 1024 have also been used. The algorithmworks as follows. For each audio segment s
i(k):
1. compute the power spectrum Si(k) of the audio
segment si(k) (Eq. (2));
2. compute the frequency mask Mi(k) of the power
spectrum Si(k) (cf. Section 3.1);
344 M.D. Swanson et al. / Signal Processing 66 (1998) 337–355
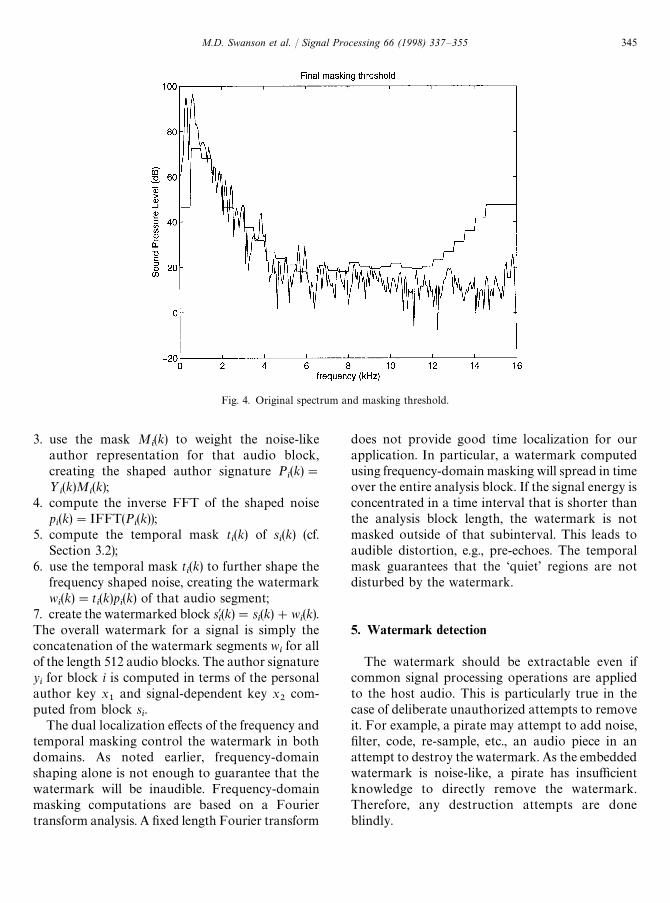
Fig. 4. Original spectrum and masking threshold.
3. use the mask Mi(k) to weight the noise-like
author representation for that audio block,creating the shaped author signature P
i(k)"
½i(k)M
i(k);
4. compute the inverse FFT of the shaped noisepi(k)"IFFT(P
i(k));
5. compute the temporal mask ti(k) of s
i(k) (cf.
Section 3.2);6. use the temporal mask t
i(k) to further shape the
frequency shaped noise, creating the watermarkwi(k)"t
i(k)p
i(k) of that audio segment;
7. create the watermarked block s@i(k)"s
i(k)#w
i(k).
The overall watermark for a signal is simply theconcatenation of the watermark segments w
ifor all
of the length 512 audio blocks. The author signatureyifor block i is computed in terms of the personal
author key x1
and signal-dependent key x2
com-puted from block s
i.
The dual localization effects of the frequency andtemporal masking control the watermark in bothdomains. As noted earlier, frequency-domainshaping alone is not enough to guarantee that thewatermark will be inaudible. Frequency-domainmasking computations are based on a Fouriertransform analysis. A fixed length Fourier transform
does not provide good time localization for ourapplication. In particular, a watermark computedusing frequency-domain masking will spread in timeover the entire analysis block. If the signal energy isconcentrated in a time interval that is shorter thanthe analysis block length, the watermark is notmasked outside of that subinterval. This leads toaudible distortion, e.g., pre-echoes. The temporalmask guarantees that the ‘quiet’ regions are notdisturbed by the watermark.
5. Watermark detection
The watermark should be extractable even ifcommon signal processing operations are appliedto the host audio. This is particularly true in thecase of deliberate unauthorized attempts to removeit. For example, a pirate may attempt to add noise,filter, code, re-sample, etc., an audio piece in anattempt to destroy the watermark. As the embeddedwatermark is noise-like, a pirate has insufficientknowledge to directly remove the watermark.Therefore, any destruction attempts are doneblindly.
M.D. Swanson et al. / Signal Processing 66 (1998) 337—355 345
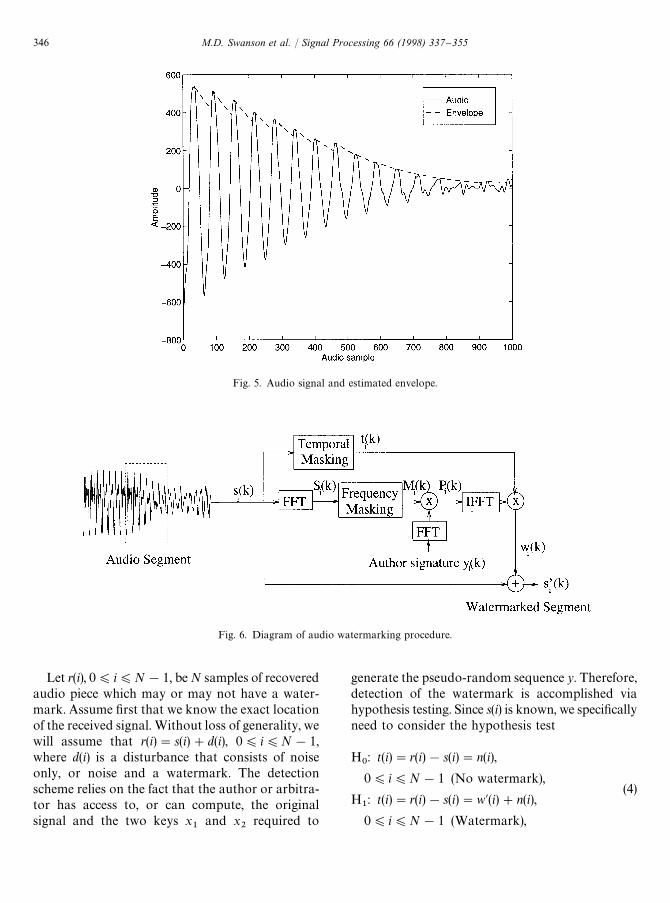
Fig. 5. Audio signal and estimated envelope.
Fig. 6. Diagram of audio watermarking procedure.
Let r(i), 0)i)N!1, be N samples of recoveredaudio piece which may or may not have a water-mark. Assume first that we know the exact locationof the received signal. Without loss of generality, wewill assume that r(i)"s(i)#d(i), 0)i)N!1,where d(i) is a disturbance that consists of noiseonly, or noise and a watermark. The detectionscheme relies on the fact that the author or arbitra-tor has access to, or can compute, the originalsignal and the two keys x
1and x
2required to
generate the pseudo-random sequence y. Therefore,detection of the watermark is accomplished viahypothesis testing. Since s(i) is known, we specificallyneed to consider the hypothesis test
H0: t(i)"r(i)!s(i)"n(i),
0)i)N!1 (No watermark),
H1: t(i)"r(i)!s(i)"w@(i)#n(i),
0)i)N!1 (Watermark),
(4)
346 M.D. Swanson et al. / Signal Processing 66 (1998) 337–355

where w@(i) is the potentially modified watermark,and n(i) is noise. The correct hypothesis is estimatedby measuring the similarity between the extractedsignal t(i) and original watermark w(i):
Sim(x,w)"+N~1
j/0t( j)w( j)
+N~1j/0
w( j)w( j)(5)
and comparing with a threshold ¹. Note that Eq. (5)implicitly assumes that the noise n(i) is white, Gaus-sian with a zero mean, even though this assumptionmay not be true. It also assumes that w(i) has notbeen modified. These two assumptions do not holdtrue in most situations. However, our experimentsindicate that, in practice, the detection test given inEq. (5) is very robust (see Section 6). Our experi-ments also indicate that a threshold ¹"0.15 yieldsa high detection performance.
Suppose now that we do not know the location ofthe observed clip r(i). Specifically, suppose thatr(i)"s(i#q)#d(i), 0)i)N!1, where, as be-fore, d(i) is a disturbance that consists of noise only,or noise and a watermark, and q is the unknowndelay corresponding to the clip. Note that q is notnecessarily an integer. In this case, we need toperform a generalized likelihood ratio test [23] todetermine whether the received signal has beenwatermarked or not. Once more, we assume thatthe noise n(i) is white, Gaussian with a zero meaneven though this may not be true. This leads us tocompare the ratio
maxq exp(!+N~1n/0
(r(i)!(s(i#q)#w(i#q)))2maxq exp(!+N~1
n/0(r(i)!s(i#q))2)
(6)
with a threshold. If this ratio is higher than thethreshold, we would declare the watermark to bepresent. Note that since q is not necessarily aninteger, computing the numerator and denominatorof Eq. (6) requires that we perform interpolation orevaluate these expressions in the Fourier domainusing Parseval’s theorem.
A generalized likelihood ratio test is also neededif one suspects that the received signal has under-gone some other types of modifications, e.g., time-scale changes.
6. Results
We illustrate the inaudible and robust nature ofour watermarking scheme on four audio pieces: thebeginning of the third movement of the sonata inB flat major D 960 of Schubert (Piano, duration12.8 s), interpreted by Vladimir Ashkenazy, a casta-net piece (Castanet, duration 8.2 s), a clarinet piece(Clarinet, duration 18.6 s), and a segment of ‘Tom’sDiner’, an a capella song by Suzanne Vega (Vega,duration 9.3 s). All of the signals are sampled at44.1kHz. The Castanets signal is one of the signalsprone to pre-echoes. The signal Vega is significantbecause it contains noticeable periods of silence.
A plot of a short portion (0.5 s) of the originalclarinet signal is shown in Fig. 7a. The correspond-ing signal with the embedded watermark is shownin Fig. 7b. The watermark is displayed in Fig. 7c.Observe that the envelope of the watermark changesover time with the signal. In particular, the magni-tude increases in more powerful regions and de-creases in quiet portions.
We test the robustness of the audio watermarkingprocedure to several degradations and distortions,including those that result from colored noise,MPEG coding, multiple watermarks, and resamp-ling. The robustness of our water-marking approachis measured by the ability to detect a watermarkwhen one is present in an audio piece, i.e., highprobability of detection. Robustness is further basedon the ability of the algorithm to reject an audiopiece when a watermark is not present, i.e., lowprobability of false alarm. For a given distortion,the overall performance may be ascertained by therelative difference between the similarity whena watermark is present (hypothesis H
1) and the
similarity when a watermark is not present (hy-pothesis H
0). In each robustness experiment, sim-
ilarity results were obtained for both hypotheses. Inparticular, the degradation was applied to the audiowhen a watermark was present. It was also appliedto the audio when a watermark was not present.The similarity was computed between the originalwatermark and the recovered signal (which may ormay not have a watermark). A large similarityindicates the presence of a watermark (H
1), while
a low similarity suggests the lack of a watermark(H
0).
M.D. Swanson et al. / Signal Processing 66 (1998) 337—355 347
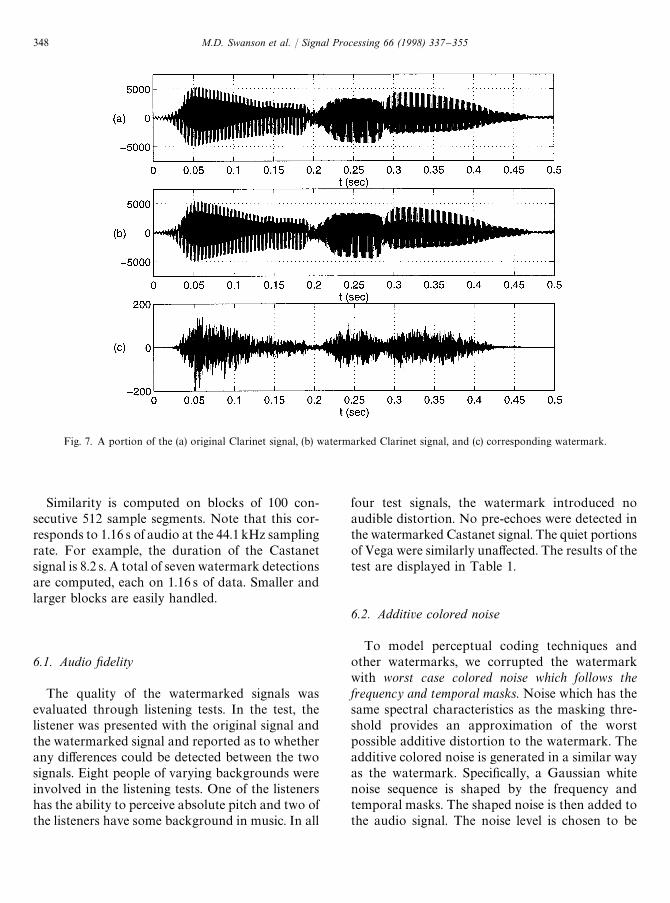
Fig. 7. A portion of the (a) original Clarinet signal, (b) watermarked Clarinet signal, and (c) corresponding watermark.
Similarity is computed on blocks of 100 con-secutive 512 sample segments. Note that this cor-responds to 1.16 s of audio at the 44.1 kHz samplingrate. For example, the duration of the Castanetsignal is 8.2 s. A total of seven watermark detectionsare computed, each on 1.16 s of data. Smaller andlarger blocks are easily handled.
6.1. Audio fidelity
The quality of the watermarked signals wasevaluated through listening tests. In the test, thelistener was presented with the original signal andthe watermarked signal and reported as to whetherany differences could be detected between the twosignals. Eight people of varying backgrounds wereinvolved in the listening tests. One of the listenershas the ability to perceive absolute pitch and two ofthe listeners have some background in music. In all
four test signals, the watermark introduced noaudible distortion. No pre-echoes were detected inthe watermarked Castanet signal. The quiet portionsof Vega were similarly unaffected. The results of thetest are displayed in Table 1.
6.2. Additive colored noise
To model perceptual coding techniques andother watermarks, we corrupted the watermarkwith worst case colored noise which follows thefrequency and temporal masks. Noise which has thesame spectral characteristics as the masking thre-shold provides an approximation of the worstpossible additive distortion to the watermark. Theadditive colored noise is generated in a similar wayas the watermark. Specifically, a Gaussian whitenoise sequence is shaped by the frequency andtemporal masks. The shaped noise is then added tothe audio signal. The noise level is chosen to be
348 M.D. Swanson et al. / Signal Processing 66 (1998) 337–355
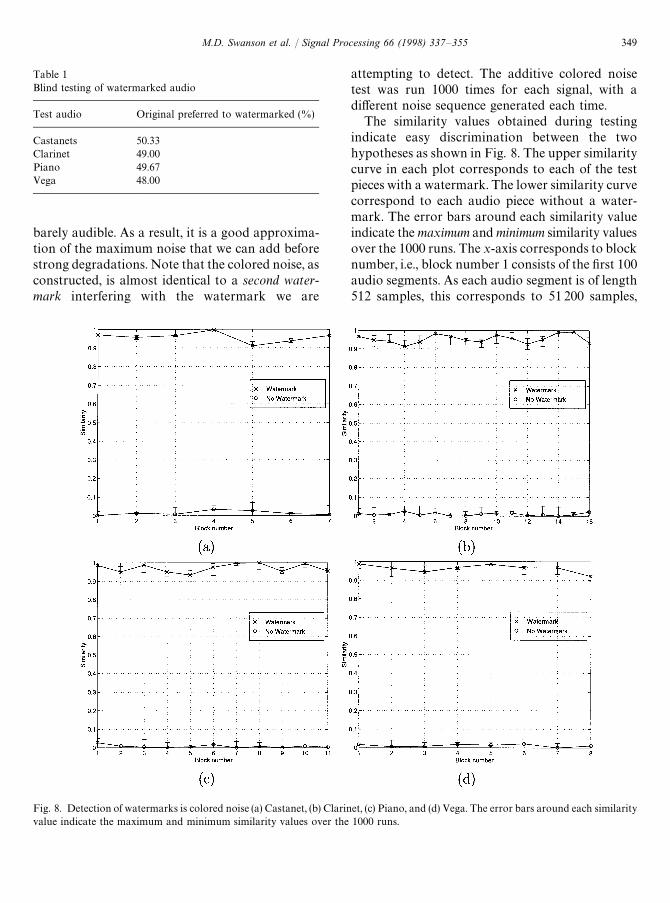
Table 1Blind testing of watermarked audio
Test audio Original preferred to watermarked (%)
Castanets 50.33Clarinet 49.00Piano 49.67Vega 48.00
Fig. 8. Detection of watermarks is colored noise (a) Castanet, (b) Clarinet, (c) Piano, and (d) Vega. The error bars around each similarityvalue indicate the maximum and minimum similarity values over the 1000 runs.
barely audible. As a result, it is a good approxima-tion of the maximum noise that we can add beforestrong degradations. Note that the colored noise, asconstructed, is almost identical to a second water-mark interfering with the watermark we are
attempting to detect. The additive colored noisetest was run 1000 times for each signal, with adifferent noise sequence generated each time.
The similarity values obtained during testingindicate easy discrimination between the twohypotheses as shown in Fig. 8. The upper similaritycurve in each plot corresponds to each of the testpieces with a watermark. The lower similarity curvecorrespond to each audio piece without a water-mark. The error bars around each similarity valueindicate the maximum and minimum similarity valuesover the 1000 runs. The x-axis corresponds to blocknumber, i.e., block number 1 consists of the first 100audio segments. As each audio segment is of length512 samples, this corresponds to 51 200 samples,
M.D. Swanson et al. / Signal Processing 66 (1998) 337—355 349
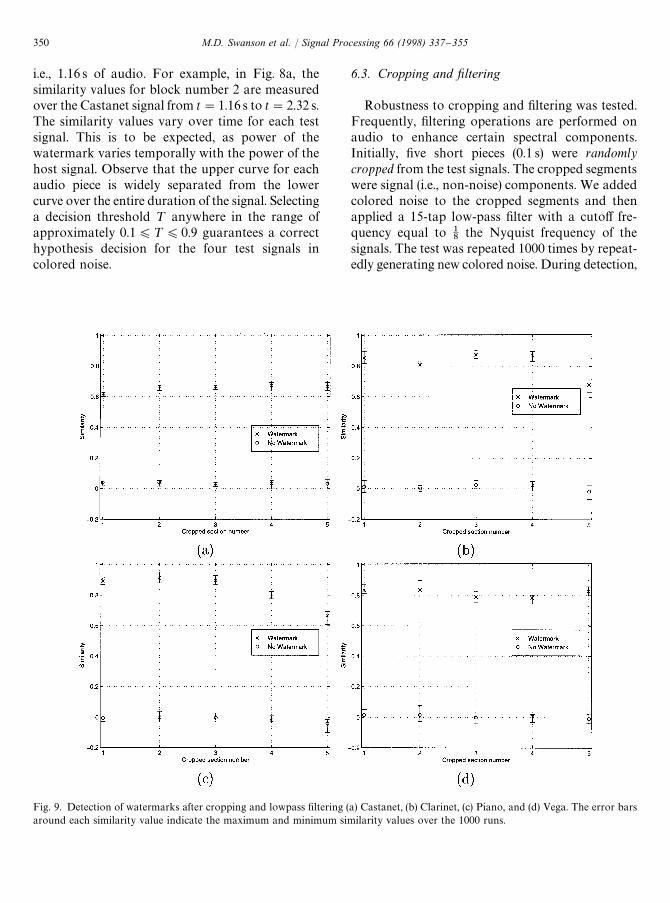
Fig. 9. Detection of watermarks after cropping and lowpass filtering (a) Castanet, (b) Clarinet, (c) Piano, and (d) Vega. The error barsaround each similarity value indicate the maximum and minimum similarity values over the 1000 runs.
i.e., 1.16 s of audio. For example, in Fig. 8a, thesimilarity values for block number 2 are measuredover the Castanet signal from t"1.16 s to t"2.32 s.The similarity values vary over time for each testsignal. This is to be expected, as power of thewatermark varies temporally with the power of thehost signal. Observe that the upper curve for eachaudio piece is widely separated from the lowercurve over the entire duration of the signal. Selectinga decision threshold ¹ anywhere in the range ofapproximately 0.1)¹)0.9 guarantees a correcthypothesis decision for the four test signals incolored noise.
6.3. Cropping and filtering
Robustness to cropping and filtering was tested.Frequently, filtering operations are performed onaudio to enhance certain spectral components.Initially, five short pieces (0.1 s) were randomlycropped from the test signals. The cropped segmentswere signal (i.e., non-noise) components. We addedcolored noise to the cropped segments and thenapplied a 15-tap low-pass filter with a cutoff fre-quency equal to 1
8the Nyquist frequency of the
signals. The test was repeated 1000 times by repeat-edly generating new colored noise. During detection,
350 M.D. Swanson et al. / Signal Processing 66 (1998) 337–355

Fig. 10. Portions of Castanet signal (a) original, (b) watermarked, (c) watermark, (d) MPEG coded 96 kbits/s, and (e) coding error.
the GLRT described by Eq. (6) was employed toestimate the location of the crop. Detection resultsare presented in Fig. 9. For each test signal, a sim-ilarity with and without watermark is shown for thefive cropped segments. The error bars indicate themaximum and minimum similarity over 1000colored noise tests. The similarities of the water-marked segments are much larger than the non-watermarked segments.
6.4. MPEG coding
In many multimedia applications involving stor-age and transmission of digital audio, a lossy codingoperation is performed to reduce bit-rates andincrease efficiency. To test the robustness of ourwatermarking approach to coding, we addedcolored noise (cf. Section 6.2) to several water-marked and non-watermarked audio pieces andMPEG coded the result. The noise was almost
inaudible and was generated using the techniquedescribed above. We then attempted to detect thepresence of the watermark in the decoded signals.
The coding/decoding was performed using a soft-ware implementation of the ISO/MPEG-1 AudioLayer II coder with several different bit rates: 64, 96and 128kbits/s. The original and watermarkedCastanets audio track for 1000 samples neart"3.0 s is shown in Fig. 10a and b. In Fig. 10d, thesignal MPEG coded at 96kbits/s is displayed. Thecoding error shown in Fig. 10e, which is defined asthe difference between the watermarked signalFig. 10 b and the coded signal Fig. 10 d, is on theorder of 10 times greater than the watermark shownin Fig. 10c! The results of the detection tests areplotted in Fig. 11. Although the errors pro-duced by the coders are much greater than theembedded watermarks, the plots indicate easy dis-crimination between the two cases. A thresholdchosen in the range of 0.15—0.50 produces no detec-tion errors.
M.D. Swanson et al. / Signal Processing 66 (1998) 337—355 351
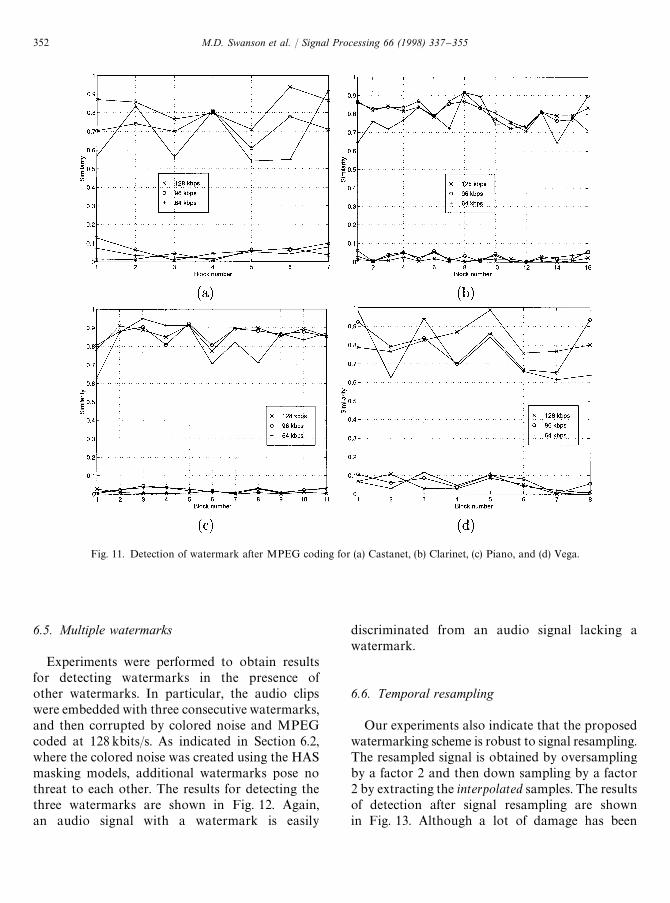
Fig. 11. Detection of watermark after MPEG coding for (a) Castanet, (b) Clarinet, (c) Piano, and (d) Vega.
6.5. Multiple watermarks
Experiments were performed to obtain resultsfor detecting watermarks in the presence ofother watermarks. In particular, the audio clipswere embedded with three consecutive watermarks,and then corrupted by colored noise and MPEGcoded at 128 kbits/s. As indicated in Section 6.2,where the colored noise was created using the HASmasking models, additional watermarks pose nothreat to each other. The results for detecting thethree watermarks are shown in Fig. 12. Again,an audio signal with a watermark is easily
discriminated from an audio signal lacking awatermark.
6.6. Temporal resampling
Our experiments also indicate that the proposedwatermarking scheme is robust to signal resampling.The resampled signal is obtained by oversamplingby a factor 2 and then down sampling by a factor2 by extracting the interpolated samples. The resultsof detection after signal resampling are shownin Fig. 13. Although a lot of damage has been
352 M.D. Swanson et al. / Signal Processing 66 (1998) 337–355
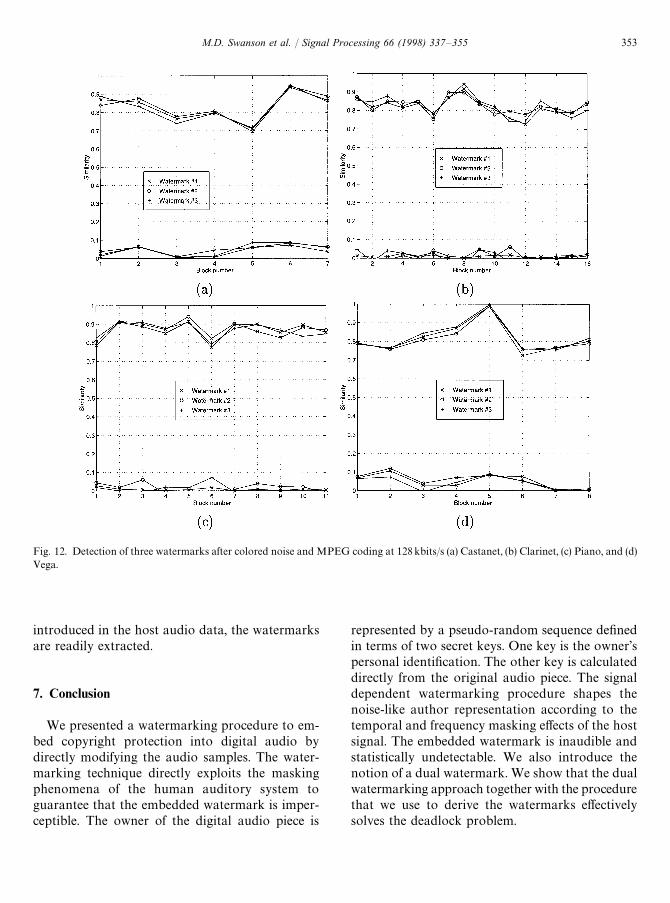
Fig. 12. Detection of three watermarks after colored noise and MPEG coding at 128kbits/s (a) Castanet, (b) Clarinet, (c) Piano, and (d)Vega.
introduced in the host audio data, the watermarksare readily extracted.
7. Conclusion
We presented a watermarking procedure to em-bed copyright protection into digital audio bydirectly modifying the audio samples. The water-marking technique directly exploits the maskingphenomena of the human auditory system toguarantee that the embedded watermark is imper-ceptible. The owner of the digital audio piece is
represented by a pseudo-random sequence definedin terms of two secret keys. One key is the owner’spersonal identification. The other key is calculateddirectly from the original audio piece. The signaldependent watermarking procedure shapes thenoise-like author representation according to thetemporal and frequency masking effects of the hostsignal. The embedded watermark is inaudible andstatistically undetectable. We also introduce thenotion of a dual watermark. We show that the dualwatermarking approach together with the procedurethat we use to derive the watermarks effectivelysolves the deadlock problem.
M.D. Swanson et al. / Signal Processing 66 (1998) 337—355 353
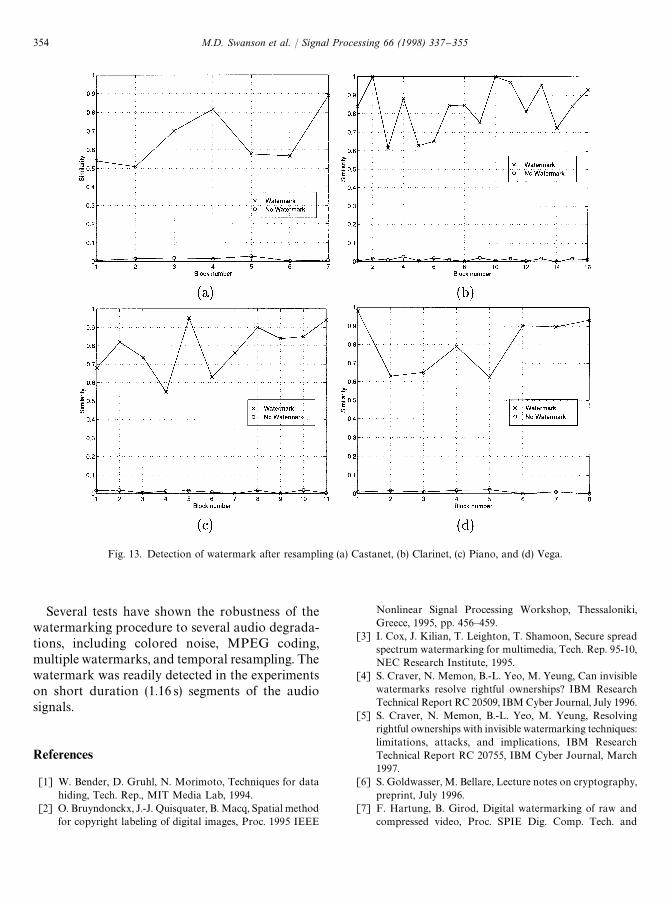
Fig. 13. Detection of watermark after resampling (a) Castanet, (b) Clarinet, (c) Piano, and (d) Vega.
Several tests have shown the robustness of thewatermarking procedure to several audio degrada-tions, including colored noise, MPEG coding,multiple watermarks, and temporal resampling. Thewatermark was readily detected in the experimentson short duration (1.16 s) segments of the audiosignals.
References
[1] W. Bender, D. Gruhl, N. Morimoto, Techniques for datahiding, Tech. Rep., MIT Media Lab, 1994.
[2] O. Bruyndonckx, J.-J. Quisquater, B. Macq, Spatial methodfor copyright labeling of digital images, Proc. 1995 IEEE
Nonlinear Signal Processing Workshop, Thessaloniki,Greece, 1995, pp. 456—459.
[3] I. Cox, J. Kilian, T. Leighton, T. Shamoon, Secure spreadspectrum watermarking for multimedia, Tech. Rep. 95-10,NEC Research Institute, 1995.
[4] S. Craver, N. Memon, B.-L. Yeo, M. Yeung, Can invisiblewatermarks resolve rightful ownerships? IBM ResearchTechnical Report RC 20509, IBM Cyber Journal, July 1996.
[5] S. Craver, N. Memon, B.-L. Yeo, M. Yeung, Resolvingrightful ownerships with invisible watermarking techniques:limitations, attacks, and implications, IBM ResearchTechnical Report RC 20755, IBM Cyber Journal, March1997.
[6] S. Goldwasser, M. Bellare, Lecture notes on cryptography,preprint, July 1996.
[7] F. Hartung, B. Girod, Digital watermarking of raw andcompressed video, Proc. SPIE Dig. Comp. Tech. and
354 M.D. Swanson et al. / Signal Processing 66 (1998) 337–355

Systems for Video Comm., Vol. 2952, October 1996, pp.205—213.
[8] ISO/CEI, Codage de l’image animee et du son associe pourles supports de stockage numerique jusqu’a environ 1,5mbit/s, Tech. Rep. 11172, ISO/CEI, 1993.
[9] J. Johnston, K. Brandenburg, Wideband coding-perceptualconsiderations for speech and music, in: S. Furui, M.Sondhi (Eds.), Advances in Speech Signal Processing,Dekker, New York, 1992.
[10] K. Matsui, K. Tanaka, Video steganography: how tosecretly embed a signature in a picture, IMA IntellectualProperty Project Proc., Vol. 1, 1994, pp. 187—206.
[11] N. Moreau, Techniques de Compression des Signaux,Masson, Paris, 1995.
[12] National Institute of Standards and Technology (NIST),Secure Hash Standard, NIST FIPS Pub. 180-1, April 1995.
[13] P. Noll, Wideband speech and audio coding, IEEE Com-mun. Vol. 31 (11) (November 1993) 34—44.
[14] I. Pitas, A method for signature casting on digital images,Proc. 1996 Int. Conf. on Image Proc., Vol. III, Lausanne,Switzerland, 1996, pp. 215—218.
[15] I. Pitas, T. Kaskalis, Applying signatures on digital images,Proc. 1995 IEEE Nonlinear Signal Processing Workshop,Thessaloniki, Greece, 1995, pp. 460—463.
[16] R. Rivest, Cryptography, in: J. van Leeuwen (Ed.), Hand-book of Theoretical Computer Science, Vol. 1, Ch. 13,MIT Press, Cambridge, MA, 1990, pp. 717—755.
[17] R. Rivest, The MD4 message digest algorithm, Advancesin Cryptology, CRYPTO 92, Springer, Berlin, 1991, pp.303—311.
[18] J.J.K.O. Ruanaidh, W.J. Dowling, F.M. Boland, Phasewatermarking of digital images, Proc. 1996 Int. Conf. onImage Proc., Vol. III, Lausanne, Switzerland, 1996, pp.239—242.
[19] M.D. Swanson, D. Zhu, A.H. Tewfik, Transparent robustimage watermarking, Proc. 1996 Int. Conf. on Image Proc.,Vol. III, Lausanne, Switzerland, 1996, pp. 211—214.
[20] M.D. Swanson, B. Zhu, A. Tewfik, Multiresolution videowatermarking using perceptual models and scene seg-mentation, to appear IEEE J. Selected Areas Commun.June 1998.
[21] J.F. Tilki, A.A. Beex, Encoding a hidden digital signatureonto an audio signal using psychoacoustic masking, Proc.1996 7th Int. Conf. on Sig. Proc. Apps. and Tech., Boston,MA, 1996, pp. 476—480.
[22] R.G. van Schyndel, A.Z. Tirkel, C.F. Osborne, A digitalwatermark, Proc. 1994 IEEE Int. Conf. on Image Proc.,Vol. II, Austin, TX, 1994, pp. 86—90.
[23] H.L. Van Trees, Detection, Estimation, and ModulationTheory, Vol. 1, Wiley, New York, 1968.
[24] R. Wolfgang, E. Delp, A watermark for digital images,Proc. 1996 Int. Conf. on Image Proc., Vol. III, Lausanne,Switzerland, 1996, 219—222.
M.D. Swanson et al. / Signal Processing 66 (1998) 337—355 355
Related Documents










