Materia: Sistemas Inteligentes Profesor: Dr. Luis E. Bautista Villalpando Alumnos: Hernández Garcí a Luis Alberto Universidad Autónoma de Aguascalientes Maestría en Informática y Tecnologías Computacionales APLICACION MAPREDUCE GREP Reporte de resultados

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

7/23/2019 Reporte Mapreduce Grep
http://slidepdf.com/reader/full/reporte-mapreduce-grep 1/7
Materia:
Sistemas Inteligentes
Profesor:
Dr. Luis E. Bautista Villalpando
Alumnos:
Hernández Garcí a Luis Alberto
Universidad Autónoma de Aguascalientes
Maestría en Informática y Tecnologías Computacionales
APLICACION MAPREDUCE GREP
Reporte de resultados
7/23/2019 Reporte Mapreduce Grep
http://slidepdf.com/reader/full/reporte-mapreduce-grep 2/7
EJECUCION DE SERVICIOS HDFS Y M PREDUCE Y BUSQUED DE P L BR S
W S EIN
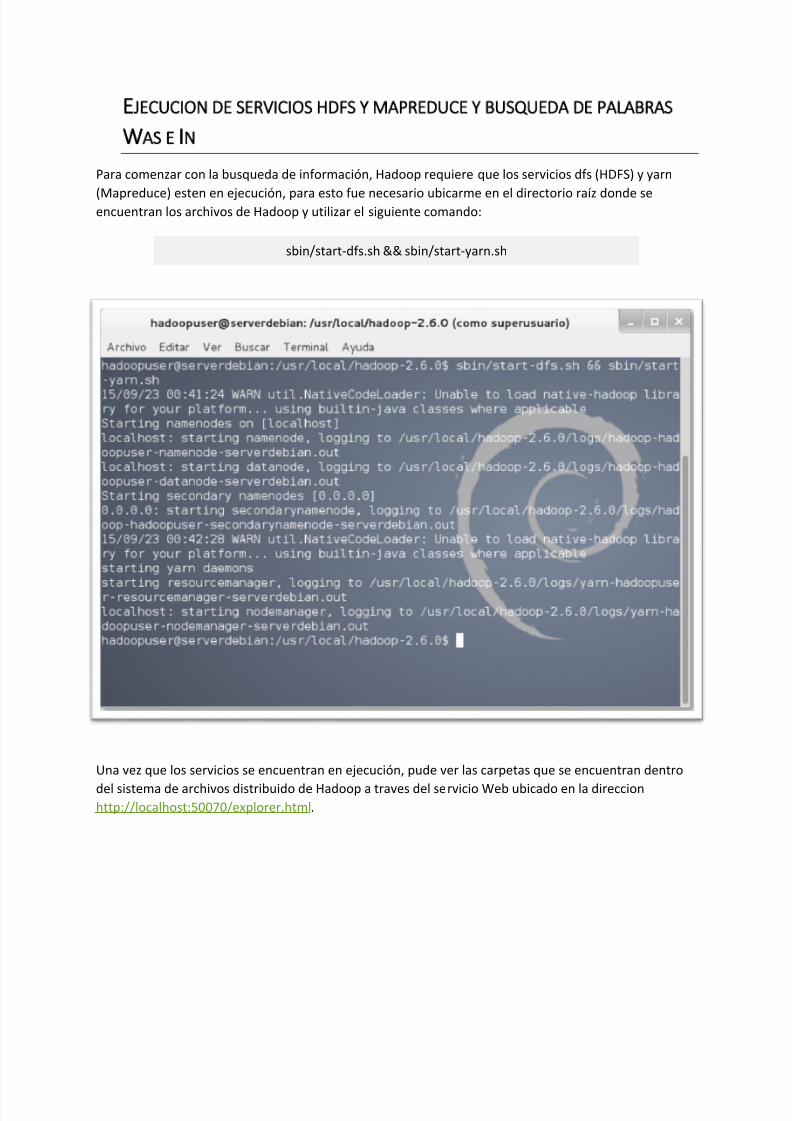
Para comenzar con la busqueda de información, Hadoop requiere que los servicios dfs (HDFS) y yarn
(Mapreduce) esten en ejecución, para esto fue necesario ubicarme en el directorio raíz donde seencuentran los archivos de Hadoop y utilizar el siguiente comando:
sbin/start-dfs.sh && sbin/start-yarn.sh
Una vez que los servicios se encuentran en ejecución, pude ver las carpetas que se encuentran dentro
del sistema de archivos distribuido de Hadoop a traves del servicio Web ubicado en la direccionhttp://localhost:50070/explorer.html.

7/23/2019 Reporte Mapreduce Grep
http://slidepdf.com/reader/full/reporte-mapreduce-grep 3/7
Para comenzar con la busqueda de información es necesario ubicar el contenido del dataset de libros
dentro del directorio “input” del HDFS. Para ver si se encuentran estos archivos dentro del directorio
“input” puedo utilizar el servicio Web o la consola de comando. Para ver el contenido del directorio
desde la consola de comando se utilizó el comando:
bin/hadoop fs –ls /input

7/23/2019 Reporte Mapreduce Grep
http://slidepdf.com/reader/full/reporte-mapreduce-grep 4/7
En este caso los archivos ya se encontraban dentro del directorio “input”.Antes de proceder con la
búsqueda, también verifique que la carpeta output no estuviera creada dentro del sistema de archivos
distribuido de hadoop, en caso de que se encuentre se puede utilizar el siguiente comando para eliminar
la carpeta:
bin/hadoop fs –rm –R /output
Una vez verificado lo anterior, procedí a ejecutar la aplicación Mapreduce grep para la búsqueda de
incidencias de las palabras “was” e “in” dentro del dataset de libros ubicado en el directorio “input”
para lo cual se ejecutó el siguiente comando:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep /input /output 'was+|in+'
Donde “was+” buscara todas las incidencias que contengan “was” una o mas veces e “in+” buscara todas
las incidencias que contengan la palabra “in” una o mas veces, y finalmente el carácter “|” indica que se
trata de una operación “OR”.

7/23/2019 Reporte Mapreduce Grep
http://slidepdf.com/reader/full/reporte-mapreduce-grep 5/7
Una vez finalizada la búsqueda, se generó la carpeta “output” con el resultado de las incidencias
encontradas, para verificar si existía dicha carpeta se utilizó el siguiente comando:
bin/hadoop fs –ls /output
También se logró verificar la carpeta “output” a través del servicio web

7/23/2019 Reporte Mapreduce Grep
http://slidepdf.com/reader/full/reporte-mapreduce-grep 6/7
7/23/2019 Reporte Mapreduce Grep
http://slidepdf.com/reader/full/reporte-mapreduce-grep 7/7
Palabra Incidencias
in 60454
was 11760
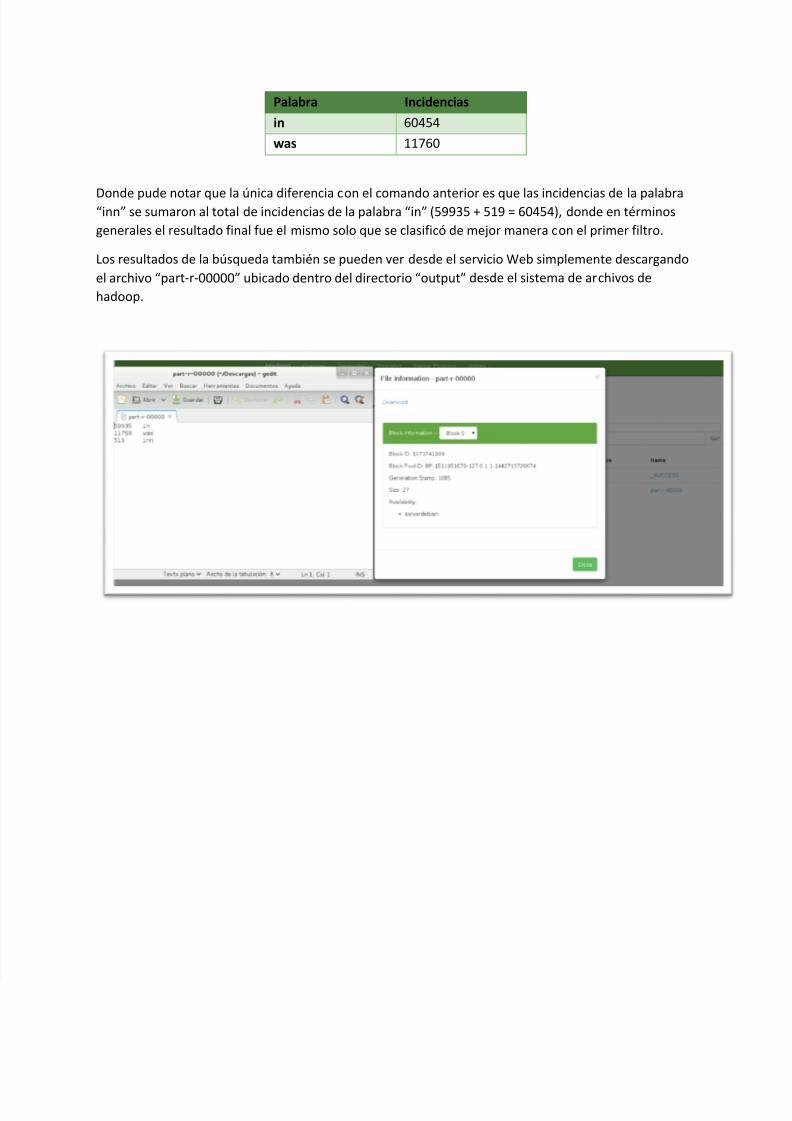
Donde pude notar que la única diferencia con el comando anterior es que las incidencias de la palabra“inn” se sumaron al total de incidencias de la palabra “in” (59935 + 519 = 60454), donde en términos
generales el resultado final fue el mismo solo que se clasificó de mejor manera con el primer filtro.
Los resultados de la búsqueda también se pueden ver desde el servicio Web simplemente descargando
el archivo “part-r-00000” ubicado dentro del directorio “output” desde el sistema de archivos de
hadoop.
Related Documents











