PRIVACY FOR CONTINUAL DATA PUBLISHING Junpei Kawamoto, Kouichi Sakurai (Kyushu University, Japan) This work is partly supported by Grants-in-Aid for Scientific Research (B)(23300027), Japan Society for the Promotion of Science (JSPS)

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

PRIVACY FOR CONTINUAL DATA PUBLISHING
Junpei Kawamoto, Kouichi Sakurai
(Kyushu University, Japan)
This work is partly supported by Grants-in-Aid for Scientific Research (B)(23300027), Japan Society for the Promotion of Science (JSPS)
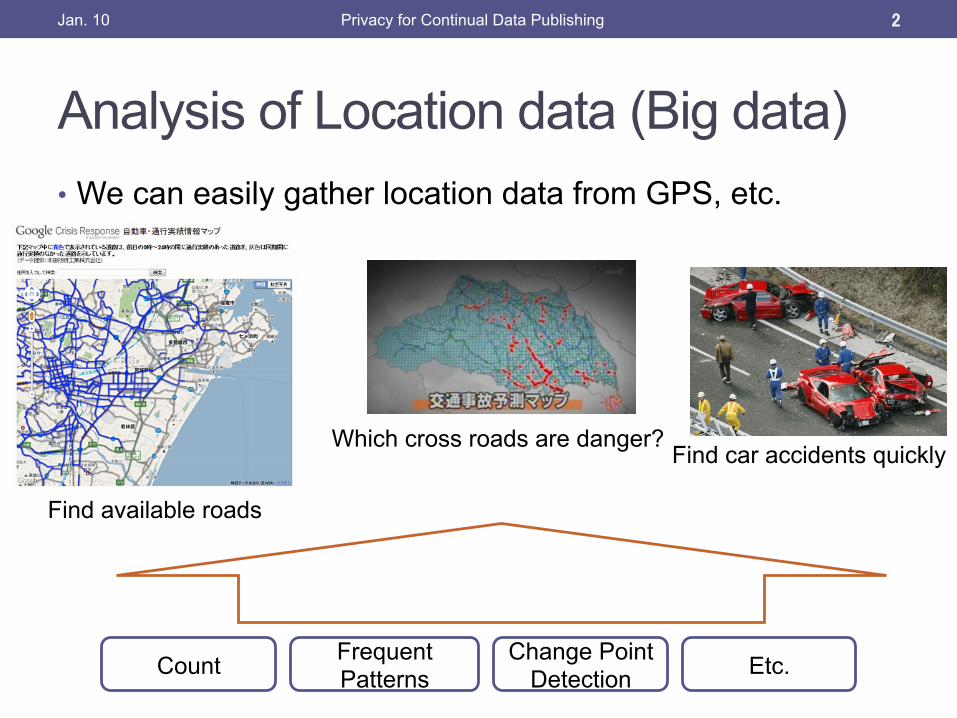
Analysis of Location data (Big data) • We can easily gather location data from GPS, etc.
Jan. 10
Find available roads
Which cross roads are danger?
Change Point Detection
Frequent Patterns
Etc. Count
Find car accidents quickly
2 Privacy for Continual Data Publishing
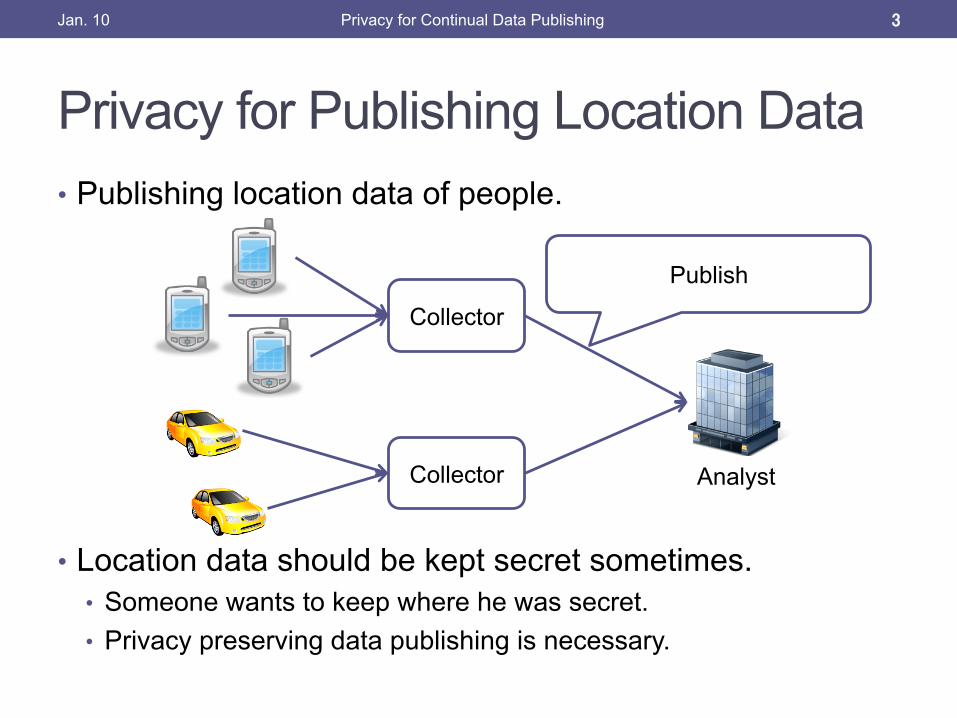
Privacy for Publishing Location Data
• Publishing location data of people.
• Location data should be kept secret sometimes. • Someone wants to keep where he was secret. • Privacy preserving data publishing is necessary.
Jan. 10
Collector
Collector Analyst
Publish
3 Privacy for Continual Data Publishing
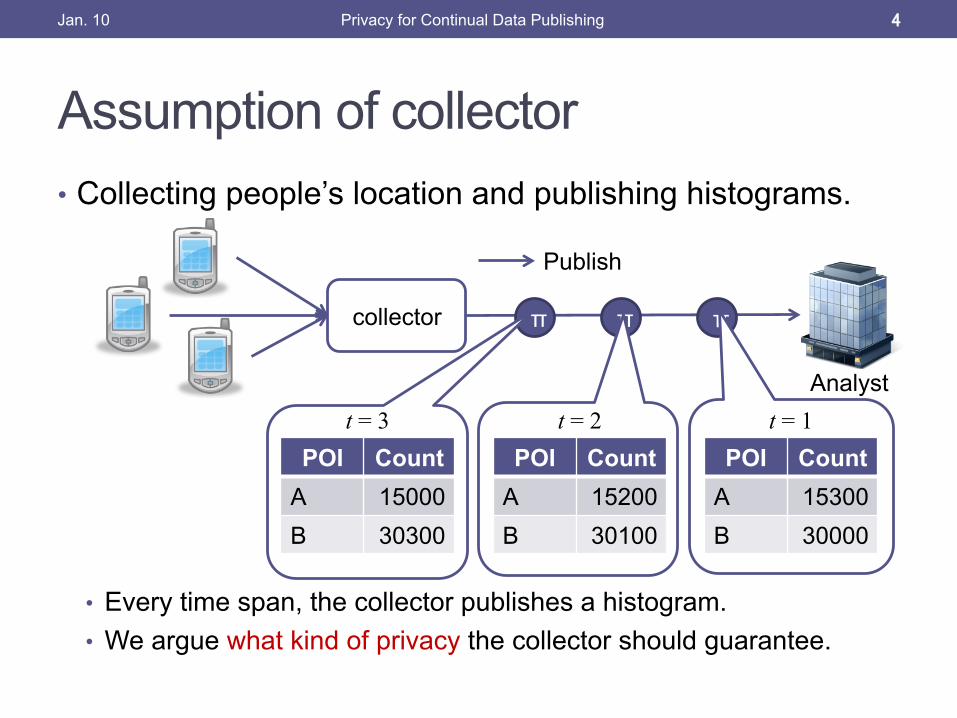
Assumption of collector • Collecting people’s location and publishing histograms.
• Every time span, the collector publishes a histogram. • We argue what kind of privacy the collector should guarantee.
Jan. 10
collector
Analyst
π
POI Count A 15300
B 30000
t = 1
ππ
POI Count A 15200
B 30100
t = 2
POI Count A 15000
B 30300
t = 3
Publish
4 Privacy for Continual Data Publishing

Related Work: Differential Privacy1
• Privacy definition of de facto standard. • Keeps any person’s locations are in histograms secret, • Adds Laplace-noises to histograms,
• Guarantees privacy for attacks using any kind of knowledge.
• Added noises are too big in less-populated areas.
Jan. 10 5
[1] C.Dwork, F.McSherry, K.Nissim, A.Smith, “Calibrating noise to sensitivity in private data analysis”, Proc. of the Third Conference on Theory of Cryptography, pp. 265-284, 2006.
⎟⎟⎠
⎞⎜⎜⎝
⎛ −−
φµ
φ||exp
21 x
The number of people in a less-populated area
Privacy for Continual Data Publishing

Related Work: Differential Privacy1
• Privacy definition of de facto standard • Keeps any person’s locations are in histograms secret • Adds Laplace-noises to histograms
• Guarantees privacy for attacks using any kind of knowledge
• Added noises are too big in less-populated areas
Jan. 10 6
[1] C.Dwork, F.McSherry, K.Nissim, A.Smith, “Calibrating noise to sensitivity in private data analysis”, Proc. of the Third Conference on Theory of Cryptography, pp. 265-284, 2006.
⎟⎟⎠
⎞⎜⎜⎝
⎛ −−
φµ
φ||exp
21 x
The number of people in a less-populated area
Privacy for Continual Data Publishing
Our objective: to construct privacy definition for private histograms with
preserving utilities of outputs as much as possible
vs.
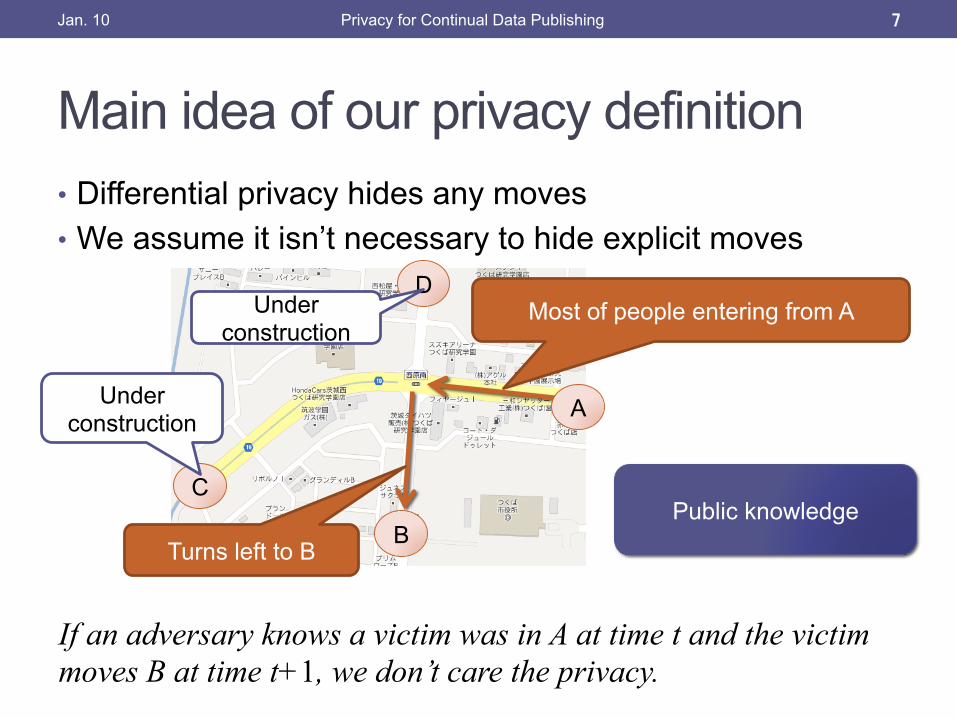
Main idea of our privacy definition
• Differential privacy hides any moves • We assume it isn’t necessary to hide explicit moves
Jan. 10
Turns left to B
A
Most of people entering from A
B
C
D Under
construction
Under construction
If an adversary knows a victim was in A at time t and the victim moves B at time t+1, we don’t care the privacy.
7 Privacy for Continual Data Publishing
Public knowledge

Main idea of our privacy definition • Employing Markov process to argue explicit/implicit moves
• We assume if outputs don’t give more information than the Markov process to adversaries, the outputs are private
• We employ “Adversarial Privacy”2 • A privacy definition bounds information outputs give adversaries.
Jan. 10
0.5
0.5
0.1 0.9
Markov process
A B
[2] V.Rastogi, M.Hay, G.Miklau, D.Suciu, “Relationship Privacy: Output Perturbation for Queries with Joins”, Proc. of the ACM Symposium on Principles of Database Systems, pp.107-116, 2009.
A -> A: explicit A -> B: implicit
Focus privacy of this move
8
Public
Privacy for Continual Data Publishing

Adversarial Privacy
• The definition
• p(X): adversaries’ prior belief of an event X • p(X | O): adversaries’ posterior belief of X after observing an output O • The output O is ε-adversarial private iff for any X,
p(X | O) ≦ eε p(X)
• We need to design X and O for the problem applied adversarial privacy • X: a person is in POI lj at time t i.e. Xt = lj • O: published histogram at time t i.e. π(t)
• p: an algorithm computing adversaries’ belief • We design p for some adversary classes depended on use cases
Jan. 10 9
One of the our contributions
Privacy for Continual Data Publishing

Adversary Classes
• Markov-Knowledge Adversary (MK) • Guessing which POI a victim is in at time t • Utilizing the Markov process and output histograms before time t
• Any-Person-Knowledge Adversary (APK) • Guessing which POI a victim is in at time t • Utilizing the Markov process and output histograms before time t
and which POI the victim was in at time t – 1
Jan. 10 10 Privacy for Continual Data Publishing

Adversary Classes
• Markov-Knowledge Adversary (MK) • Guessing which POI a victim is in at time t • Utilizing the Markov process and output histograms before time t
• Any-Person-Knowledge Adversary (APK) • Guessing which POI a victim is in at time t • Utilizing the Markov process and output histograms before time t
and which POI the victim was in at time t – 1
Jan. 10 11 Privacy for Continual Data Publishing
APK class is stronger than ML class. Today, we focus on APK classes.

Beliefs of APK-class adversaries
• Prior belief before observing output π(t) • Posterior belief after observing output π(t)
•
• Thus, output π(t) is ε-adversarial private for APK class iff • ∀li, lj,
Jan. 10 12
p(Xt = l j | Xt−1 = li, (π(t −1)tP)t,π(t −1);P)
p(Xt = l j | Xt−1 = li,π(t),π(t −1);P)
p(Xt = l j | Xt−1 = li,π(t),π(t −1);P)p(Xt = l j | Xt−1 = li, (π(t −1)
tP)t,π(t −1);P)≤ eε
Privacy for Continual Data Publishing

Computing private histograms
• Loss of modified histogram • π0(t): original histogram at time t π(t): adversarial private histogram at time t
• Problem of computing adversarial private histograms • a optimization problem • minimize loss(π(t), π0(t)) • s.t. ∀li, lj,
• We employ a heuristic algorithm to solve this.
Jan. 10 13
loss(π(t),π 0 (t))= π(t)−π 0 (t) 2
p(Xt = l j | Xt−1 = li,π(t),π(t −1);P)p(Xt = l j | Xt−1 = li, (π(t −1)
tP)t,π(t −1);P)≤ eε
Privacy for Continual Data Publishing
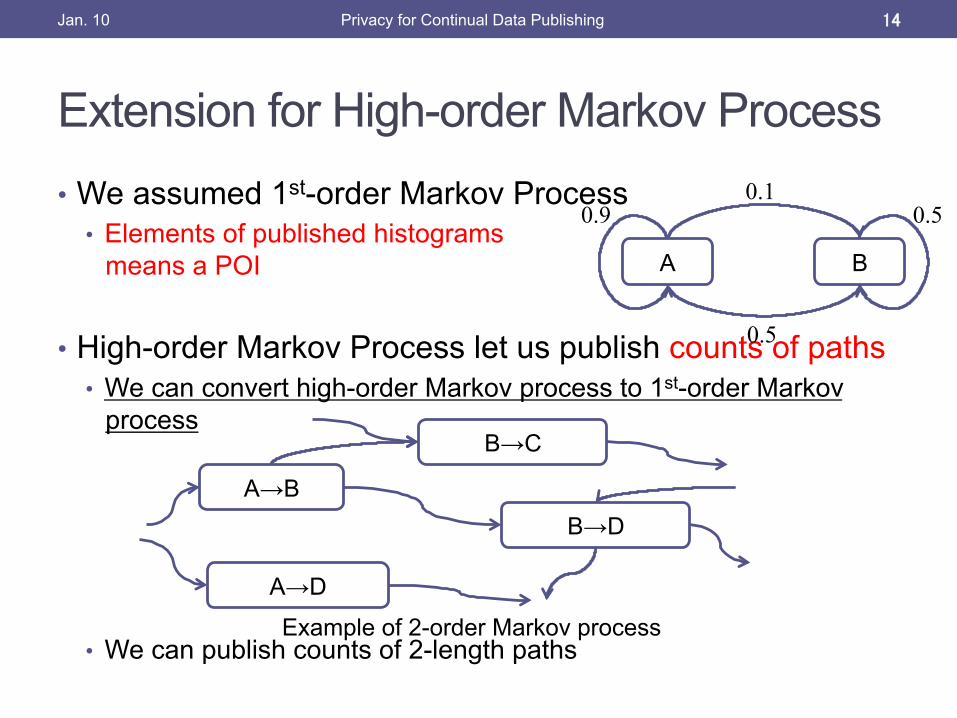
Extension for High-order Markov Process
• We assumed 1st-order Markov Process • Elements of published histograms
means a POI
• High-order Markov Process let us publish counts of paths • We can convert high-order Markov process to 1st-order Markov
process
• We can publish counts of 2-length paths
Jan. 10 14
0.5
0.5
0.1 0.9
A B
Example of 2-order Markov process
A→B
B→C
B→D
A→D
Privacy for Continual Data Publishing
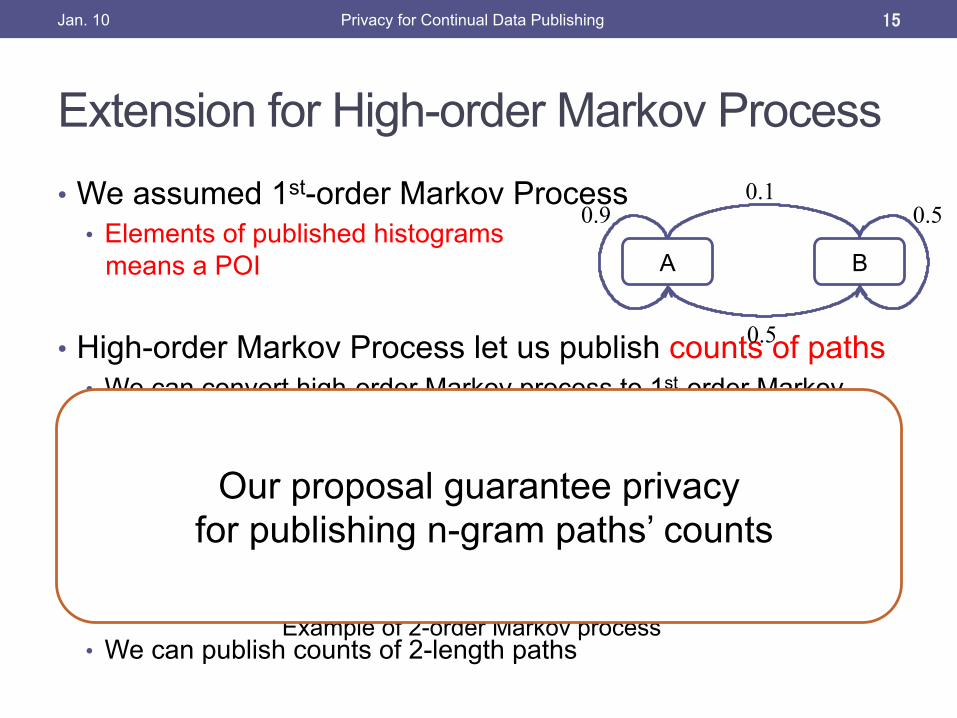
Extension for High-order Markov Process
• We assumed 1st-order Markov Process • Elements of published histograms
means a POI
• High-order Markov Process let us publish counts of paths • We can convert high-order Markov process to 1st-order Markov
process
• We can publish counts of 2-length paths
Jan. 10 15
0.5
0.5
0.1 0.9
A B
Example of 2-order Markov process
A→B
B→C
B→D
A→D
Privacy for Continual Data Publishing
Our proposal guarantee privacy for publishing n-gram paths’ counts

Evaluation
• Set two mining tasks • Change point detection • Frequent paths extraction
• Datasets • Moving people in Tokyo, 1998 provided by People Flow Project3
• Construct two small datasets: Shibuya and Machida • Shibuya: lots of people moving, to evaluate in urban area • Machida: less people moving, to evaluate in sub-urban area
Jan. 10 16
[3] http://pflow.csis.u-tokyo.ac.jp/index-j.html
Privacy for Continual Data Publishing
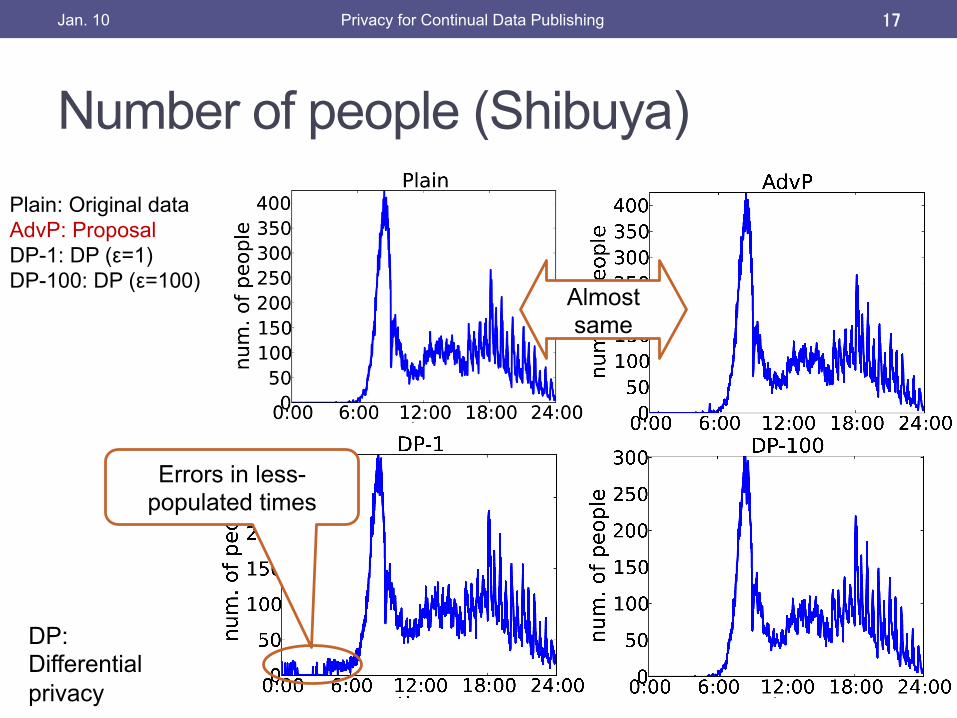
Number of people (Shibuya)
Jan. 10 17
Almost same
Errors in less-populated times
Plain: Original data AdvP: Proposal DP-1: DP (ε=1) DP-100: DP (ε=100)
Privacy for Continual Data Publishing
DP: Differential privacy
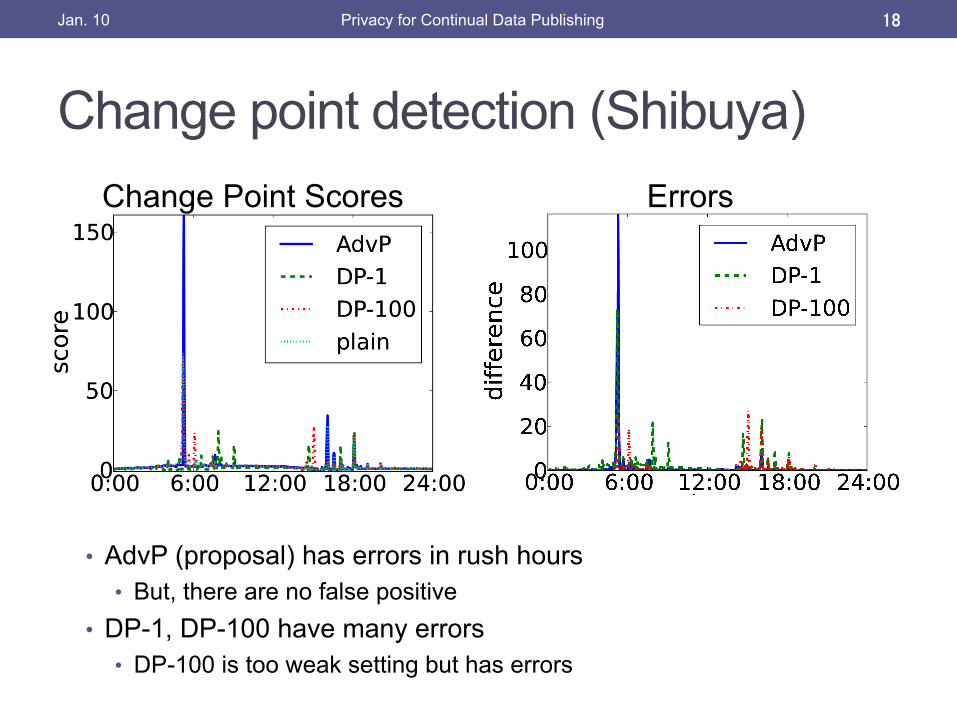
Change point detection (Shibuya)
• AdvP (proposal) has errors in rush hours • But, there are no false positive
• DP-1, DP-100 have many errors • DP-100 is too weak setting but has errors
Jan. 10 18
Change Point Scores Errors
Privacy for Continual Data Publishing
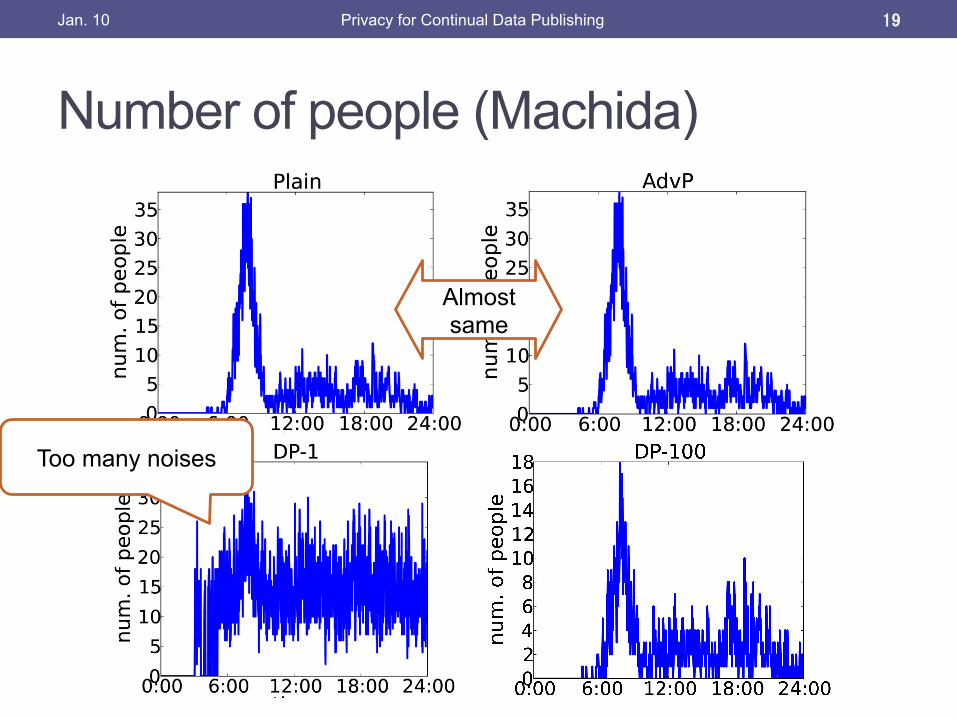
Number of people (Machida)
Jan. 10 19
Almost same
Too many noises
Privacy for Continual Data Publishing
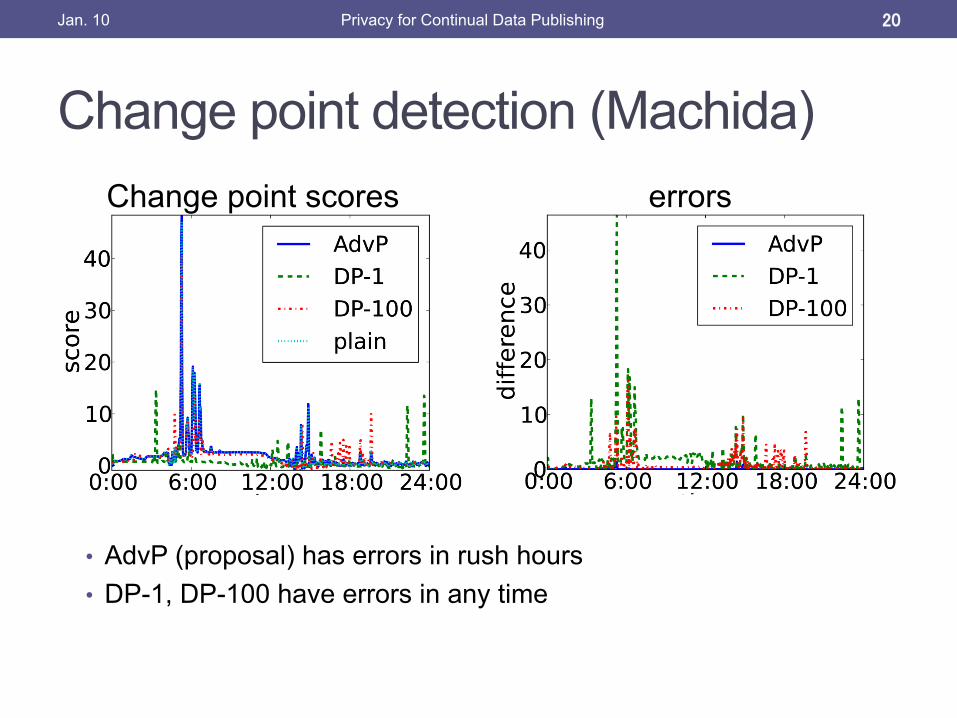
Change point detection (Machida)
• AdvP (proposal) has errors in rush hours • DP-1, DP-100 have errors in any time
Jan. 10 20
Change point scores errors
Privacy for Continual Data Publishing
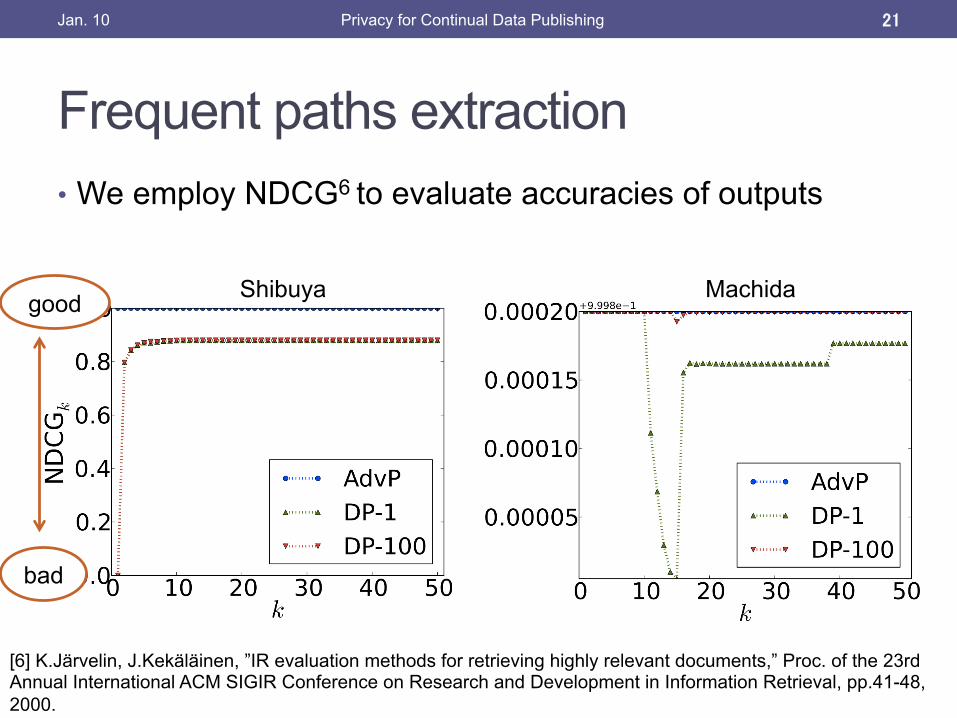
Frequent paths extraction • We employ NDCG6 to evaluate accuracies of outputs
Jan. 10 21
[6] K.Järvelin, J.Kekäläinen, ”IR evaluation methods for retrieving highly relevant documents,” Proc. of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp.41-48, 2000.
good
bad
Shibuya Machida
Privacy for Continual Data Publishing

Frequent paths extraction • We employ NDCG6 to evaluate accuracies of outputs
Jan. 10 22
[6] K.Järvelin, J.Kekäläinen, ”IR evaluation methods for retrieving highly relevant documents,” Proc. of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp.41-48, 2000.
good
bad
Shibuya Machida
Privacy for Continual Data Publishing
• Outputs by our proposal archives better results than differential privacy in both Shibuya and Machida.
• Our proposal is effective for publishing paths’ counts

Conclusion
• Propose a new privacy definition • Preserving utilities of outputs as much as possible • Assuming Markov process on people’s moves • Employing adversarial privacy framework
• Evaluations with two data mining tasks • Change point detection and frequent paths extraction • Our privacy archives better utility than differential privacy
• Future work • Applying to other mining tasks • Comparing with other privacy definitions
Jan. 10 23 Privacy for Continual Data Publishing
Related Documents











