* Corresponding author. E-mail address: bdg@iis.fhg.de (K. Brandenburg) Signal Processing: Image Communication 15 (2000) 423}444 MPEG-4 natural audio coding Karlheinz Brandenburg!,*, Oliver Kunz!, Akihiko Sugiyama" !Fraunhofer Institut fu ( r Integrierte Schaltungen IIS, D-91058 Erlangen, Germany "NEC C&C Media Research Laboratories, 1-1, Miyazaki 4-chome, Miyamae-ku, Kawasaki 216-8555, Japan Abstract MPEG-4 audio represents a new kind of audio coding standard. Unlike its predecessors, MPEG-1 and MPEG-2 high-quality audio coding, and unlike the speech coding standards which have been completed by the ITU-T, it describes not a single or small set of highly e$cient compression schemes but a complete toolbox to do everything from low bit-rate speech coding to high-quality audio coding or music synthesis. The natural coding part within MPEG-4 audio describes traditional type speech and high-quality audio coding algorithms and their combination to enable new functionalities like scalability (hierarchical coding) across the boundaries of coding algorithms. This paper gives an overview of the basic algorithms and how they can be combined. ( 2000 Elsevier Science B.V. All rights reserved. 1. Introduction Traditional high-quality audio coding schemes like MPEG-1 Layer-3 (aka .mp3) have found their way into many applications including widespread acceptance on the Internet. MPEG-4 audio is scheduled to be the successor of these, building and expanding on the acceptance of earlier audio cod- ing formats. To do this, MPEG-4 natural audio coding has been designed to "t well into the philos- ophy of MPEG-4. It enables new functionalities and implements a paradigm shift from the linear storage or streaming architecture of MPEG-1 and MPEG-2 into objects and presentation rendering. While most of these new functionalities live within the tools of MPEG-4 structured audio and audio BIFS, the syntax of the `classicala audio coding algorithms within MPEG-4 natural audio has been de"ned and amended to implement scalability and the notion of audio objects. This way MPEG-4 natural audio goes well beyond classic speech and audio coding algorithms into a new world which we will see unfold in the coming years. 2. Overview The tools de"ned by MPEG-4 natural audio coding can be combined to di!erent audio coding algorithms. Since no single coding paradigm was found to span the complete range from very low bit-rate coding of speech signals up to high-quality multi-channel audio coding, a set of di!erent algo- rithms has been de"ned to establish optimum cod- ing e$ciency for the broad range of anticipated applications (see Fig. 1 and [9]). The following list introduces the main algorithms and the reason for 0923-5965/00/$ - see front matter ( 2000 Elsevier Science B.V. All rights reserved. PII: S 0 9 2 3 - 5 9 6 5 ( 9 9 ) 0 0 0 5 6 - 9

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

*Corresponding author.E-mail address: [email protected] (K. Brandenburg)
Signal Processing: Image Communication 15 (2000) 423}444
MPEG-4 natural audio coding
Karlheinz Brandenburg!,*, Oliver Kunz!, Akihiko Sugiyama"
!Fraunhofer Institut fu( r Integrierte Schaltungen IIS, D-91058 Erlangen, Germany"NEC C&C Media Research Laboratories, 1-1, Miyazaki 4-chome, Miyamae-ku, Kawasaki 216-8555, Japan
Abstract
MPEG-4 audio represents a new kind of audio coding standard. Unlike its predecessors, MPEG-1 and MPEG-2high-quality audio coding, and unlike the speech coding standards which have been completed by the ITU-T, itdescribes not a single or small set of highly e$cient compression schemes but a complete toolbox to do everythingfrom low bit-rate speech coding to high-quality audio coding or music synthesis. The natural coding part withinMPEG-4 audio describes traditional type speech and high-quality audio coding algorithms and their combination toenable new functionalities like scalability (hierarchical coding) across the boundaries of coding algorithms. This papergives an overview of the basic algorithms and how they can be combined. ( 2000 Elsevier Science B.V. All rightsreserved.
1. Introduction
Traditional high-quality audio coding schemeslike MPEG-1 Layer-3 (aka .mp3) have found theirway into many applications including widespreadacceptance on the Internet. MPEG-4 audio isscheduled to be the successor of these, building andexpanding on the acceptance of earlier audio cod-ing formats. To do this, MPEG-4 natural audiocoding has been designed to "t well into the philos-ophy of MPEG-4. It enables new functionalitiesand implements a paradigm shift from the linearstorage or streaming architecture of MPEG-1 andMPEG-2 into objects and presentation rendering.While most of these new functionalities live withinthe tools of MPEG-4 structured audio and audio
BIFS, the syntax of the `classicala audio codingalgorithms within MPEG-4 natural audio has beende"ned and amended to implement scalability andthe notion of audio objects. This way MPEG-4natural audio goes well beyond classic speech andaudio coding algorithms into a new world whichwe will see unfold in the coming years.
2. Overview
The tools de"ned by MPEG-4 natural audiocoding can be combined to di!erent audio codingalgorithms. Since no single coding paradigm wasfound to span the complete range from very lowbit-rate coding of speech signals up to high-qualitymulti-channel audio coding, a set of di!erent algo-rithms has been de"ned to establish optimum cod-ing e$ciency for the broad range of anticipatedapplications (see Fig. 1 and [9]). The following listintroduces the main algorithms and the reason for
0923-5965/00/$ - see front matter ( 2000 Elsevier Science B.V. All rights reserved.PII: S 0 9 2 3 - 5 9 6 5 ( 9 9 ) 0 0 0 5 6 - 9

Fig. 1. Assignment of codecs to bit-rate ranges.
their inclusion into MPEG-4. The following sec-tions will give more detailed descriptions for eachof the tools used to implement the coding algo-rithms. The following lists the major algorithms ofMPEG-4 natural audio. Each algorithm was de-"ned from separate coding tools with the goals ofmaximizing the overlap of tools between di!erentalgorithms and maximizing the #exibility in whichtools can be used to generate di!erent #avors of thebasic coding algorithms.
f HVXC Low-rate clean speech coderf CELP Telephone speech/wideband speech coderf GA General Audio coding for medium and high
qualitiesf TwinVQ Additional coding tools to increase the
coding e$ciency at very low bit-rates.
In addition to the coding tools used for thebasic coding functionality, MPEG-4 provides tech-niques for additional features like bit stream scala-bility. Tools for these features will be explained inSection 7.
3. General Audio Coding (AAC-based)
This key component of MPEG-4 Audio coversthe bit-rate range of 16 kbit/s per channel up tobit-rates higher than 64 kbit/s per channel. UsingMPEG-4 General Audio quality levels between
`better than AMa up to `transparent audio qual-itya can be achieved. MPEG-4 General Audiosupports four so-called Audio Object Types (see thepaper on MPEG-4 Pro"ling in this issue), whereAAC Main, AAC LC, AAC SSR are derived fromMPEG-2 AAC (see [2]), adding some functional-ities to further improve the bit-rate e$ciency. Thefourth Audio Object Type, AAC LTP is unique toMPEG-4 but de"ned in a backwards compatibleway.
Since MPEG-4 Audio is de"ned in a way that itremains backwards compatible to MPEG-2 AAC,it supports all tools de"ned in MPEG-2 AACincluding the tools exclusively used in Main Pro"leand scalable sampling rate (SSR) Pro"le, namelyFrequency domain prediction and SSR "lterbankplus gain control.
Additionally, MPEG-4 Audio de"nes ways forbit-rate scalability. The supported methods for bit-rate scalability are described in Section 7.
Fig. 2 shows the arrangement of the buildingblocks of an MPEG-4 GA encoder in the process-ing chain. These building blocks will be describedin the following subsections. The same buildingblocks are present in a decoder implementation,performing the inverse processing steps. For thesake of simplicity we omit references to decodingin the following subsections unless explicitly neces-sary for understanding the underlying processingmechanism.
3.1. Filterbank and block switching
One of the main components in each transformcoder is the conversion of the incoming audiosignal from the time domain into the frequencydomain.
MPEG-2 AAC supports two di!erent ap-proaches to this. The standard transform isa straightforward modi"ed discrete cosine trans-form (MDCT). However, in the AAC SSR AudioObject Type a di!erent conversion using a hybrid"lter bank is applied.
3.1.1. Standard xlterbankThe "lterbank in MPEG-4 GA is derived from
MPEG-2 AAC, i.e. it is an MDCT supporting block
424 K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444
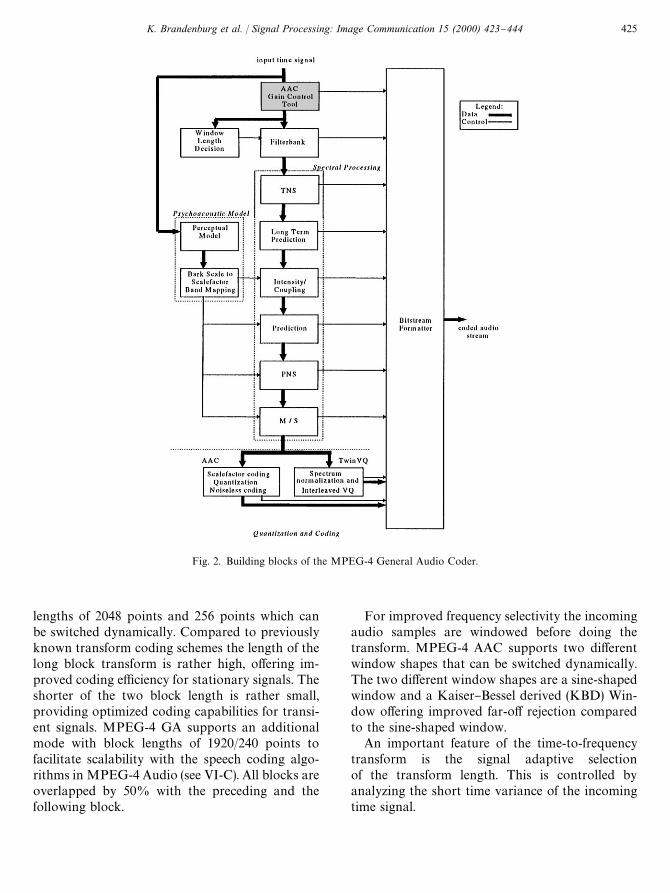
Fig. 2. Building blocks of the MPEG-4 General Audio Coder.
lengths of 2048 points and 256 points which canbe switched dynamically. Compared to previouslyknown transform coding schemes the length of thelong block transform is rather high, o!ering im-proved coding e$ciency for stationary signals. Theshorter of the two block length is rather small,providing optimized coding capabilities for transi-ent signals. MPEG-4 GA supports an additionalmode with block lengths of 1920/240 points tofacilitate scalability with the speech coding algo-rithms in MPEG-4 Audio (see VI-C). All blocks areoverlapped by 50% with the preceding and thefollowing block.
For improved frequency selectivity the incomingaudio samples are windowed before doing thetransform. MPEG-4 AAC supports two di!erentwindow shapes that can be switched dynamically.The two di!erent window shapes are a sine-shapedwindow and a Kaiser}Bessel derived (KBD) Win-dow o!ering improved far-o! rejection comparedto the sine-shaped window.
An important feature of the time-to-frequencytransform is the signal adaptive selectionof the transform length. This is controlled byanalyzing the short time variance of the incomingtime signal.
K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444 425

To assure block synchronicity between two audiochannels with di!erent block length sequences eightshort transforms are performed in a row using 50%overlap each and specially designed transition win-dows at the beginning and the end of a shortsequence. This keeps the spacing between consecut-ive blocks at a constant level of 2048 input samples.
For further processing of the spectral data in thequantization and coding part the spectrum is ar-ranged in the so-called scalefactor bands roughlyre#ecting the bark scale of the human auditorysystem.
3.1.2. Filterbank and gain control in SSR proxleIn the SSR pro"le the MDCT is preceded by
a processing block containing a uniformly spaced4-band polyphase quadrature "lter (PQF) anda Gain control module. The Gain control can at-tenuate or amplify the output of each PQF band toreduce pre-echo e!ects.
After the gain control is performed, an MDCT iscalculated on each PQF band, having a quarter ofthe length of the original MDCT.
3.2. Frequency-domain prediction
The frequency-domain prediction improves re-dundancy reduction of stationary signal segments.It is only supported in the Audio Object Type AACMain. Since stationary signals can nearly always befound in long transform blocks, it is not supportedin short blocks. The actual implementation of thepredictor is a second-order backwards adaptivelattice structure, independently calculated for everyfrequency line. The use of the predicted values in-stead of the original ones can be controlled ona scalefactor band basis and is decided based on theachieved prediction gain in that band.
To improve stability of the predictors, a cyclicreset mechanism is applied which is synchronizedbetween encoder and decoder via a dedicated bit-stream element.
The required processing power of the frequency-domain prediction and the sensitivity to numericalimperfections make this tool hard to use on "xedpoint platforms. Additionally, the backwards adap-tive structure of the predictor makes such bit-streams quite sensitive to transmission errors.
3.3. Long-term prediction (LTP)
Long-term prediction (LTP) is an e$cient toolfor reducing the redundancy of a signal betweensuccessive coding frames newly introduced inMPEG-4. This tool is especially e!ective for theparts of a signal which have clear pitch property.The implementation complexity of LTP is signi"-cantly lower than the complexity of the MPEG-2AAC frequency-domain prediction. Because theLong-Term Predictor is a forward adaptive pre-dictor (prediction coe$cients are sent as side in-formation), it is inherently less sensitive to round-o! numerical errors in the decoder or bit errors inthe transmitted spectral coe$cients.
3.4. Quantization
The adaptive quantization of the spectral valuesis the main source of the bit-rate reduction in alltransform coders. It assigns a bit allocation to thespectral values according to the accuracy demandsdetermined by the perceptual model, realizing theirrelevancy reduction. The key components of thequantization process are the actually used quantiz-ation function and the noise shaping that isachieved via the scalefactors (see III-E). The quan-tizer used in MPEG-4 GA has been designedsimilar to the one used in MPEG 1/2 Layer-3. It isa non-linear quantizer with an x0.75 characteristic.The main advantage of this non-linear quantiz-ation over a conventional linear quantizer is theimplicit noise shaping that this quantization cre-ates. The absolute quantizer stepsize is determinedvia a speci"c bitstream element. It can be adjustedin 1.5 dB steps.
3.5. Scalefactors
While there is already an inherent noise shapingin the non-linear quantizer it is usually not su$-cient to achieve acceptable audio quality. To im-prove the subjective quality of the coded signal thenoise is further shaped via scalefactors. The way thescalefactors are working is the following: Scalefac-tors are used to amplify the signal in certain spec-tral regions (the scalefactor bands) to increasethe signal-to-noise ratio in these bands. Thus they
426 K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444

implicitly modify the bit-allocation over frequencysince higher spectral values usually need more bitsto be coded afterwards. Like the global quantizerthe stepsize of the scalefactors is 1.5 dB.
To properly reconstruct the original spectralvalues in the decoder the scalefactors have to betransmitted within the bitstream. MPEG-4 GAuses an advanced technique to code the scalefactorsas e$ciently as possible. First, it exploits the factthat scalefactors usually do not change too muchfrom one scalefactor band to another. Thus a di!er-ential encoding already provides some advantage.Second, it uses a Hu!man code to further reducethe redundancy within the scalefactor data.
3.6. Noiseless coding
The noiseless coding kernel within an MPEG-4GA encoder tries to optimize the redundancy re-duction within the spectral data coding. The spec-tral data is encoded using a Hu!man code which isselected from a set of available code books accord-ing to the maximum quantized value. The set ofavailable codebooks includes one to signal that allspectral coe$cients in the respective scalefactorband are `0a, implying that there are neither spec-tral coe$cients nor a scalefactor transmitted forthat band. The selected table has to be transmittedinside the so-called section}data, creating a certainamount of side-information overhead. To "nd theoptimum tradeo! between selecting the optimumtable for each scalefactor band and minimizing thenumber of section}data elements to be transmittedan e$cient grouping algorithm is applied to thespectral data.
3.7. Joint stereo coding
Joint stereo coding methods try to increase thecoding e$ciency when encoding stereo signals byexploiting commonalties between the left and rightsignal. MPEG-4 GA contains 2 di!erent jointstereo coding algorithms, namely mid-side (MS)stereo coding and Intensity stereo coding.
MS stereo applies a matrix to the left and rightchannel signals, computing sum and di!erence ofthe two original signals. Whenever a signal is con-centrated in the middle of the stereo image, MS
stereo can achieve a signi"cant saving in bit-rate.Even more important is the fact that by applyingthe inverse matrix in the decoder the quantizationnoise becomes correlated and falls in the middle ofthe stereo image where it is masked by the signal.
Intensity stereo coding is a method that achievesa saving in bit-rate by replacing the left and theright signal by a single representing signal plusdirectional information. This replacement is psycho-acoustically justi"ed in the higher frequency rangesince the human auditory system is insensitive tothe signal phase at frequencies above approx-imately 2 kHz.
Intensity stereo is by de"nition a lossy codingmethod thus it is primarily useful at low bit-rates.For coding at higher bit-rates only MS stereo isused.
3.8. Temporal noise shaping
Conventional transform coding schemes oftenencounter problems with signals that vary heavilyover time, especially speech signals. The main rea-son for this is that the distribution of quantizationnoise can be controlled over frequency but is con-stant over a complete transform block. If the signalcharacteristic changes drastically within sucha block without leading to a switch to shortertransform lengths, e.g. in the case of pitchy speechsignals this equal distribution of quantization noisecan lead to audible artifacts.
To overcome this limitation, a new feature calledtemporal noise shaping (TNS) (see [5]) was intro-duced into MPEG-2 AAC. The basic idea of TNSrelies on the duality of time and frequency domain.TNS uses a prediction approach in the frequencydomain to shape the quantization noise over time.It applies a "lter to the original spectrum andquantizes this "ltered signal. Additionally, quan-tized "lter coe$cients are transmitted in the bit-stream. These are used in the decoder to undo the"ltering performed in the encoder, leading to a tem-porally shaped distribution of quantization noise inthe decoded audio signal.
TNS can be viewed as a postprocessing step ofthe transform, creating a continuous signal adap-tive "lter bank instead of the conventional two-step switched "lter bank approach. The actual
K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444 427

Fig. 3. Weighted interleave vector quantization.
implementation of the TNS approach withinMPEG-2 AAC and MPEG-4 GA allows for up tothree distinct "lters applied to di!erent spectralregions of the input signal, further improving the#exibility of this novel approach.
3.9. Perceptual noise substitution (PNS )
A feature newly introduced into MPEG-4 GA,i.e. not available within MPEG-2 AAC, is the per-ceptual noise substitution (PNS) (see [6]). It isa feature aiming at a further optimization of thebit-rate e$ciency of AAC at lower bit-rates.
The technique of PNS is based on the observa-tion that `one noise sounds like the othera. Thismeans that the actual "ne structure of a noise signalis of minor importance for the subjective perceptionof such a signal. Consequently, instead of transmit-ting the actual spectral components of a noisysignal, the bit-stream would just signal that thisfrequency region is a noise-like one and give someadditional information on the total power in thatband. PNS can be switched on a scalefactor bandbasis so even if there just are some spectral regionswith a noisy structure PNS can be used to save bits.In the decoder, a randomly generated noise willbe inserted into the appropriate spectral regionaccording to the power level signaled within thebit-stream.
From the above description it is obvious that themost challenging task in the context of PNS is notto enter the appropriate information into the bit-stream but reliably determining which spectral re-gions may be treated as noise-like and thus may becoded using PNS without creating severe codingartifacts. A lot of work has been done on this task,most of which is re#ected in [20].
4. TwinVQ
To increase coding e$ciency for coding of musi-cal signals at very low bit-rates, TwinVQ-basedcoding tools are part of the General Audio codingsystem in MPEG-4 audio. The basic idea is toreplace the conventional encoding of scalefactorsand spectral data used in MPEG-4 AAC by aninterleaved vector quantization applied to a nor-
malized spectrum (see [10,11]). The rest of theprocessing chain remains identical as can be seenin Fig. 2.
Fig. 3 visualizes the basic idea of the weightedinterleaved vector quantization (TwinVQ) scheme.The input signal vector (spectral coe$cients) is in-terleaved into subvectors. These subvectors arequantized using vector quantizers.
Twin VQ can achieve a higher coding e$ciencyat the cost of always creating a minimum amountof loss in terms of audio quality. Thus, the breakeven point between Twin VQ and MPEG-4 AAC isat fairly low bit-rates (below 16 kbit/s per channel).
5. Speech coding in MPEG-4 Audio
5.1. Basics of speech coding [4,12]
Most of the recent speech coding algorithms canbe categorized as a spectrum coding or a hybridcoding. Spectrum coding models the input speechsignal based on a vocal tract model which consistsof a signal source and a "lter as shown in Fig. 4.A set of parameters obtained by analyzing the inputsignal are transmitted to the receiver.
Hybrid coding synthesizes an approximatedspeech signal based on a vocal tract model. A set ofparameters used for this "rst synthesis are modi"ed
428 K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444

Fig. 4. Vocal tract model.
Fig. 5. Hybrid speech coding.
to minimize the error between the original and thesynthesized speech signals. A best parameter setcan be searched for by repeating this analysis-by-synthesis procedure. The obtained set of para-meters are transmitted to the receiver as the com-pressed data after quantization. In the decoder,a set of parameters for Source and linear prediction(LP) synthesis "ltering are recovered by inversequantization. These parameter values are used tooperate the same vocal tract model as in theencoder.
Fig. 5 depicts a block diagram of hybrid speechcoding. Source and LP Synth Filter in Fig. 5 corres-pond to those in Fig. 4. Upon parameter search, theerror between the input signal and the synthesizedsignal is weighted by a PW (perceptually weighted)"lter. This "lter has a frequency response whichtakes the human auditory system into considera-tion, thus a perceptually best parameter selectioncan be achieved.
5.2. Overview of the MPEG-4 Natural SpeechCoding Tools
MPEG-4 Natural Speech Coding Tool Set [8]provides a generic coding framework for a widerange of applications with speech signals. Its bit-rate coverage spans from as low as 2}23.4 kbit/s.Two di!erent bandwidths of the input speech signal
are covered, namely, 4 and 7 kHz. MPEG-4 Natu-ral Speech Coding Tool Set contains two algo-rithms: harmonic vector excitation coding (HVXC)and code excited linear predictive coding (CELP).HVXC is used at a low bit-rate of 2 or 4 kbit/s.Higher bit-rates than 4 kbit/s in addition to3.85kbit/s are covered by CELP. The algorithmicdelay by either of these algorithms is comparable tothat of other standards for two-way communica-tions, therefore, MPEG-4 Natural Speech CodingTool Set is also applicable to such applications.Storage of speech data and broadcast are alsopromising applications of MPEG-4 NaturalSpeech Coding Tool Set. The speci"cations ofMPEG-4 Natural Speech Coding Tool Set aresummarized in Table 1.
MPEG-4 is based on tools each of which can becombined according to the user needs. HVXC con-sists of LSP (line spectral pair) VQ (vector quantiz-ation) tool and harmonic VQ tool. RPE (regularpulse excitation) tool, MPE (multipulse excitation)tool, and LSP VQ tool form CELP. RPE tool isallowed only for the wideband mode because of itssimplicity at the expense of the quality. LSP VQ
K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444 429

Table 1Speci"cations of MPEG-4 Natural Speech Coding Tools
HVXC
Sampling frequency 8 kHzBandwidth 300}3400 HzBit-rate (bit/s) 2000 and 4000Frame size 20 msDelay 33.5}56 msFeatures Multi-bit-rate coding
Bit-rate scalability
CELP
Sampling frequency 8 kHz 16 kHzBandwidth 300}3400 Hz 50}7000 HzBit-rate (bit/s) 3850}12200 10 900}23 800
(28 bit-rates) (30 bit-rates)Frame size 10}40 ms 10}20 msDelay 15}45 ms 15}26.75 msFeatures Multi-bit-rate coding
Bit-rate scalabilityBandwidth scalability
Fig. 6. MPEG-4 Natural Speech Coding Tool Set.
1An arbitrary bit-rate may be selected with a 200 bit/s step bysimply changing the parameter values.
tool is common in both HVXC and CELP.MPEG-4 Natural Speech Coding Tools are illus-trated in Fig. 6.
5.3. Functionalities of MPEG-4 Natural SpeechCoding Tools
MPEG-4 Natural Speech Coding Tools are dif-ferent from other existing speech coding standardssuch as ITU-T G.723.1 and G.729 in the following
three new functionalities: multi-bit-rate coding,1bit-rate scalable coding, and bandwidth scalablecoding. Actually, these new functionalities charac-terize MPEG-4 Natural Speech Coding Tools. Itshould be noted that the bandwidth scalability isavailable only for CELP.
5.3.1. Multi-bit-rate codingMulti-bit-rate coding provides #exible bit-rate
selection with the same coding algorithm. It has notbeen available and di!erent codecs were needed fordi!erent bit-rates. In multi-bit-rate coding, a bit-rate is selected among multiple available bit-ratesupon establishment of a connection between thecommunicating parties. The bit-rate for CELP maybe selected with as small a step as 0.2 kbit/s. Theframe length, the number of subframes per frame,and selection of the excitation codebook are modi-"ed for di!erent bit-rates [17]. For HVXC, 2 or4 kbit/s can be selected as the bit-rate.
In addition to multi-bit-rate coding, bit-rate con-trol with a smaller step of the bit-rate is availablefor CELP by "ne-rate control (FRC). In addition tomulti-bit-rate coding, some additional bit-rates notavailable by multi-bit-rate coding are provided byFRC. The bit-rate may be deviated frame by framefrom a speci"ed bit-rate according to the input-signal characteristics. When the spectral envelope,approximated by the LP synthesis "lter, has smallvariations in time, transmission of liner-predictioncoe$cients may be skipped once every two framesfor a reduced average bit-rate [22].
Linear prediction coe$cients in the current andthe following frames are compared to decide ifthose in the following frame are to be transmittedor not. In the decoder, the missing LP coe$cientsin a frame are interpolated from those in the pre-vious and the following frames. Therefore, FRCrequires one-frame delay to make the data in thefollowing frame available in the current frame.
5.3.2. Scalable codingBit-rate and bandwidth scalabilities are useful
for multicast transmission. The bit-rate and the
430 K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444

Fig. 7. Scalabilities in MPEG-4/CELP.
Table 2Bandwidth scalable bit-streams
Core bit-stream Enhancement bit-stream(bit/s) (bit/s)
3850}4650 9200, 10 400, 11 600, 12 4004900}5500 9467, 10 667, 11 867, 12 6675700}10 700 10 000, 11 200, 12 400, 13 200
11 000}12 200 11 600, 12 800, 14 000, 14 800
bandwidth can be independently selected for eachreceiver by simply stripping o! a part of thebit-stream. Scalabilities necessitate only a singleencoder to transmit the same data to multiplepoints connected at di!erent rates. Such a case canbe found in connections between a cellular networkwith mobile terminals and a digital network with"xed multimedia terminals as well as in multipointteleconferencing. The encoder generates a singlecommon bit-stream by scalable coding for all therecipients instead of independent bit-streams at dif-ferent bit-rates.
The scalable bit-stream has a layered structurewith the core bit-stream and enhancement bit-streams. The bit-rate control is performed byadjusting the combination of the enhancement bit-streams depending on the speci"ed bit-rate. Thecore bit-stream guarantees, at least, reconstructionof the original speech signal with a minimumspeech quality. Additional enhancement bit-streams, which may be available depending on thenetwork condition, will increase the quality of thedecoded signal. HVXC and CELP may be used togenerate the core bitstream when the enhancementbit-streams are generated by TwinVQ or AAC.They can also generate both the core and the en-hancement bit-streams. Scalabilities in MPEG-4/CELP are depicted in Fig. 7.
Scalabilities include bit-rate scalability andbandwidth scalability. These scalabilities reducesignal distortion or achieve better speech qualitywith high-frequency components by adding en-hancement bit-streams to the core bit-stream.These enhancement bit-streams contain detailedcharacteristics of the input signal or componentsin higher frequency bands. For example, theoutput of Decoder A in Fig. 7 is the minimum-quality signal decoded from the 6 kbit/s corebit-stream. The Decoder B output is a high-qualitysignal decoded from an 8kbit/s bit-stream.Decoder C provides a higher-quality signal de-coded from a 12kbit/s bitstream. On the otherhand, the Decoder D output has a wider band-width. This wideband signal is decoded from a 22kbit/s bitstream. The high-frequency componentsof 10 kbit/s provides increased naturalness thanDecoder C. Bandwidth scalability is provided onlyby the MPE tool.
The unit bit-rate for the enhancement bit-streams in bit-rate scalability is 2 kbit/s for thenarrowband and 4 kbit/s for the wideband. In caseof bandwidth scalable coding, the unit bit-rate forthe enhancement bit-streams depends on the totalbit-rate and is summarized in Table 2.
5.4. Outline of the algorithms
5.4.1. HVXCA basic blockdiagram of HVXC is depicted in
Fig. 8. HVXC "rst performs LP analysis to "nd theLP coe$cients. Quantized LP coe$cients are
K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444 431

Fig. 8. HVXC.
Fig. 9. CELP.
supplied to the inverse LP "lter to "nd the predic-tion error. The prediction error is transformed intoa frequency domain and the pitch and the envelopeof the spectrum are analyzed. The envelope is quan-tized by weighted vector quantization in voicedsections. In unvoiced sections, closed-loop searchof an excitation vector is carried out.
5.4.2. CELPFig. 9 shows a blockdiagram of CELP. The LP
coe$cients of the input signal are "rst analyzed andthen quantized to be used in an LP synthesis "lterdriven by the output of the excitation codebooks.Encoding is performed in two steps. Long-termprediction coe$cients are calculated in the "rststep. In the second step, a perceptually weightederror between the input signal and the output of theLP synthesis "lter is minimized. This minimizationis achieved by searching for an appropriatecodevector for the excitation codebooks. Quan-
tized coe$cients, as well as indexes to the codevec-tors of the excitation codebooks and the long-termprediction coe$cients, form the bit-stream. The LPcoe$cients are quantized by vector quantizationand the excitation can be either MPE [19] orregular pulse excitation RPE [13].
MPE and RPE both model the excitation signalby multiple pulses, however, a di!erence exists inthe degrees of freedom for pulse positions. MPEallows more freedom on the interpulse distancethan RPE which has a "xed interpulse distance.Thanks to such a #exible interpulse distance, MPEachieves better coding quality than RPE [7]. Onthe other hand, RPE requires less computationsthan MPE by trading o! its coding quality. Sucha low computational requirement is useful in thewideband coding where the total computationshould naturally be higher than in the narrowbandcoding. The excitation signal types of MPEG-4/CELP are summarized in Table 3.
432 K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444

Table 3CELP excitation signal
Excitation Bandwidth Features
MPE Narrow, wide Quality, scalabilityRPE Wide Complexity
Fig. 10. MPEG-4/CELP with MPE.
5.5. MPEG-4/CELP with MPE
MPEG-4/CELP with MPE is the most completecombination of the tools in MPEG-4 NaturalSpeech Coding Tools. It provides all the three newfunctionalities. Therefore, it is useful to explainMPEG-4/CELP with MPE in more detail to showhow these functionalities are realized in thealgorithm.
A blockdiagram of the encoder of MPEG-4/CELP with MPE is depicted in Fig. 10. It consistsof three modules; a CELP core encoder, a bit-ratescalable (BRS) tool, and a bandwidth extension(BWE) tool. The CELP core encoder provides thebasic coding functions which have been explainedwith Fig. 9 in Section 5.4.2. The BRS tool is usedto provide the bit-rate scalability. The residualof the narrowband signal, mode information,LP coe$cients, quantized LSP coe$cients,and multipulse excitation signal are transferredfrom the core encoder to the BRS tool as the inputsignals. The BWE tool is used for the bandwidthscalability.
Quantized LSP coe$cients and the pitch delayindexes as well as the wideband speech to be en-
coded are supplied from the core encoder to theBWE tool.
In addition to these input signals, the narrow-band multipulse excitation is needed in the BWEtool. This excitation is supplied from either the BRStool when the bit-rate scalability is implemented, orfrom the core encoder. When the bandwidth scala-bility is provided, a downsampled narrowbandsignal is supplied to the core encoder. Because ofthis downsampling operation, an additional 5-mslook-ahead of the input signal is necessary forwideband signals.
5.5.1. CELP core encoderFig. 11 depicts a blockdiagram of the CELP core
encoder. It performs LP analysis and pitch analysison the input speech signal. The obtained LP coe$-cients, the pitch lag (phase or delay), the pitch andMPE gains, and the excitation signal are encodedas well as mode information. The LP coe$cients inthe LSP domain are encoded frame by frame bypredictive VQ. The pitch lag is encoded subframeby subframe by adaptive codebooks. The MPE ismodeled by multiple pulses whose positions andpolarities ($1) are encoded. The pitch and theMPE gains are normalized by an average subframepower followed by multimode encoding [19]. Theaverage subframe power is scalar-quantized in eachframe.
5.5.1.1. LSP quantization. A two-stage partial pre-diction and multistage vector quantization (PPM-VQ) [21] is employed for LSP quantization. This
K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444 433
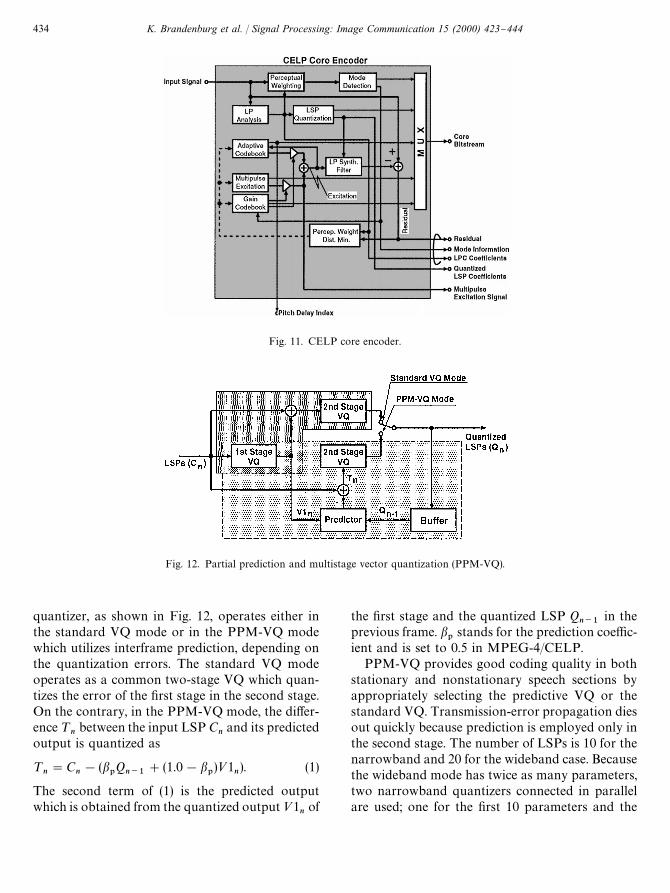
Fig. 11. CELP core encoder.
Fig. 12. Partial prediction and multistage vector quantization (PPM-VQ).
quantizer, as shown in Fig. 12, operates either inthe standard VQ mode or in the PPM-VQ modewhich utilizes interframe prediction, depending onthe quantization errors. The standard VQ modeoperates as a common two-stage VQ which quan-tizes the error of the "rst stage in the second stage.On the contrary, in the PPM-VQ mode, the di!er-ence ¹
nbetween the input LSP C
nand its predicted
output is quantized as
¹n"C
n!(b
1Q
n~1#(1.0!b
1)<1
n). (1)
The second term of (1) is the predicted outputwhich is obtained from the quantized output<1
nof
the "rst stage and the quantized LSP Qn~1
in theprevious frame. b
1stands for the prediction coe$c-
ient and is set to 0.5 in MPEG-4/CELP.PPM-VQ provides good coding quality in both
stationary and nonstationary speech sections byappropriately selecting the predictive VQ or thestandard VQ. Transmission-error propagation diesout quickly because prediction is employed only inthe second stage. The number of LSPs is 10 for thenarrowband and 20 for the wideband case. Becausethe wideband mode has twice as many parameters,two narrowband quantizers connected in parallelare used; one for the "rst 10 parameters and the
434 K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444

Fig. 13. Bit-rate scalable (BRS) tool.
other for the rest, respectively. The number of bitsused for LSP quantization is 22 for the narrowbandand 46 for the wideband (25 for the "rst 10 coe$-cients and 21 for the rest). The codebook has 1120words for the narrowband and 2560 words for thewideband.
5.5.1.2. Multipulse excitation. The multipulse ex-citation k
nhas ¸ pulses as in
kn"
L+i/1
smi
dn~mi
, n"0,2,N!1, (2)
where N stands for the subframe size, and miand
smi
are the position and the magnitude of the ithpulse, respectively. The pulse position is selectedfrom M
icandidates which are de"ned by the Alge-
braic code [1,14] for each pulse. The pulse magni-tude is represented only by its polarity for bitreduction. Such a simpli"ed excitation model con-tributes to reduced computations compared withconventional CELP codebooks at a low bit-ratewith a small number of pulses. On the other hand,reduction of computations is necessary for a highbit-rate with more available pulses. For example,MPE encoding by tree search [16] provides easybit-rate control by adjusting the number of pulses.E$cient coding techniques by combination searchof the pulse position and polarity and by VQ of the
pulse polarity [19] may also be applied. Theseadditional techniques help us avoid reduced qualityand heuristic parameter setting caused by well-known preselection techniques and focused search[14] for the pulse position.
5.5.2. Bit-rate scalable (BRS) toolA blockdiagram of the BRS tool [18] is shown in
Fig. 13. The actual signal to be encoded in the BRStool is the residual, which is de"ned as the di!er-ence between the input signal and the output of theLP synthesis "lter (local decode signal), suppliedfrom the core encoder. This combination of thecore encoder and the BRS tool can be considered asmultistage encoding of the MPE. However, there isno feedback path for the residual in the BRS toolconnected to the MPE in the core encoder. Theexcitation signal in the BRS tool has no in#uenceon the adaptive codebook in the core encoder. Thisguarantees that the adaptive codebook in the coredecoder at any site is identical to that in the en-coder (in terms of the codewords), which leads tothe minimum quality degradation for the frame-by-frame bit-rate change. The BRS tool adaptivelycontrols the pulse positions so that none of themcoincides with a position used in the core encoder.This adaptive pulse position control contributes tomore e$cient multistage encoding.
K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444 435
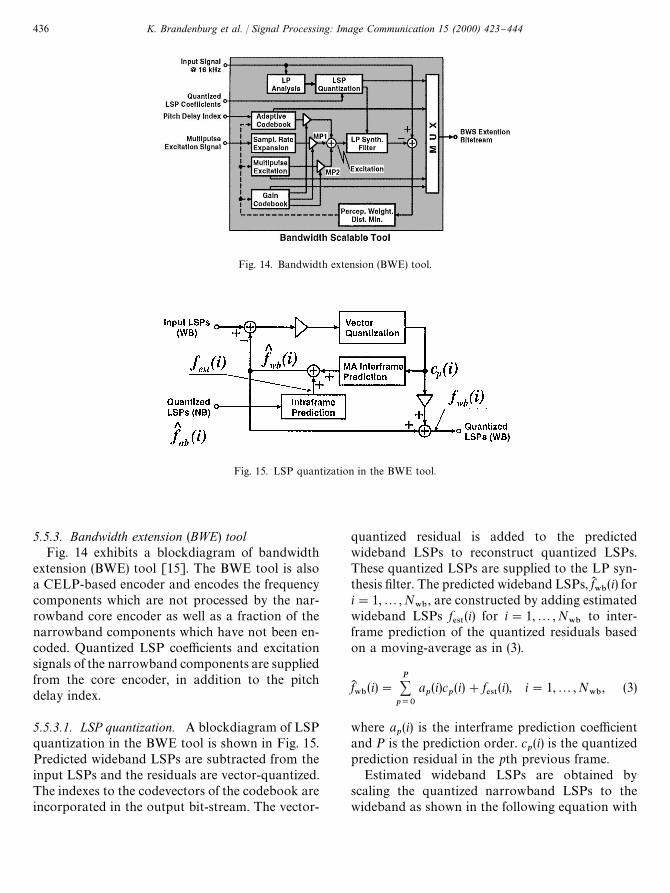
Fig. 14. Bandwidth extension (BWE) tool.
Fig. 15. LSP quantization in the BWE tool.
5.5.3. Bandwidth extension (BWE) toolFig. 14 exhibits a blockdiagram of bandwidth
extension (BWE) tool [15]. The BWE tool is alsoa CELP-based encoder and encodes the frequencycomponents which are not processed by the nar-rowband core encoder as well as a fraction of thenarrowband components which have not been en-coded. Quantized LSP coe$cients and excitationsignals of the narrowband components are suppliedfrom the core encoder, in addition to the pitchdelay index.
5.5.3.1. LSP quantization. A blockdiagram of LSPquantization in the BWE tool is shown in Fig. 15.Predicted wideband LSPs are subtracted from theinput LSPs and the residuals are vector-quantized.The indexes to the codevectors of the codebook areincorporated in the output bit-stream. The vector-
quantized residual is added to the predictedwideband LSPs to reconstruct quantized LSPs.These quantized LSPs are supplied to the LP syn-thesis "lter. The predicted wideband LSPs, fK
8"(i) for
i"1,2, N8"
, are constructed by adding estimatedwideband LSPs f
%45(i) for i"1,2, N
8"to inter-
frame prediction of the quantized residuals basedon a moving-average as in (3).
fK8"
(i)"P+p/0
ap(i)c
p(i)#f
%45(i), i"1,2,N
8", (3)
where ap(i) is the interframe prediction coe$cient
and P is the prediction order. cp(i) is the quantized
prediction residual in the pth previous frame.Estimated wideband LSPs are obtained by
scaling the quantized narrowband LSPs to thewideband as shown in the following equation with
436 K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444

Fig. 16. Coding quality of MPEG-4 Natural Speech CodingTools.
2FS1016 is a US Department of Defence (DoD) standard thatis most commonly used as a reference at a bit-rate lower than5 kbit/s.
a scaling factor b(i):
f%45
(i)"Gb(i) fK
/"(i) for i"1,2,N
/",
0.0 for i"N/"#1,2,N
8",
(4)
fK/"
(i) represents the ith quantized narrowband LSP.This algorithm provides better quantization pre-
cision for low-order LSPs ( f8"
(i), i"1,2,N/"
)as well as for high-order LSPs ( f
8"(i),
i"N/"#1,2, N
8"). This is because the residual
LSPs to be vector-quantized contain narrowbandLSP residuals which have not been taken care of inthe narrowband core encoder.
5.5.3.2. Multipulse excitation. The excitationsignal in the bandwidth extension tool is repre-sented by an adaptive codebook, two MPE signals,and their gains as shown in Fig. 14. The pitchdelay of the adaptive codebook is searched for fromthe vicinity of its estimation obtained from thenarrowband pitch-delay. One of the two MPEsignals (MP1) is an upsampled version of thenarrowband MPE signal and the other (MP2)is an exclusive MPE signal in the bandwidth exten-sion tool. The adaptive codebook and the gains forMP2 are vector-quantized and the gains for MP1are scalar-quantized. These quantizations areperformed to minimize the perceptually weightederror.
5.6. Coding quality of MPEG-4 Natural SpeechCoding Tools
Coding quality of CELP [7] is depicted inFig. 16(a) and (b). The narrowband mode withMPE, which supports multiple bit-rates witha single algorithm, exhibits comparable quality tothose of other standards (ITU-T G.723.1, G.729,ETSI GSM-EFR) optimized at a single bit-rate.The wideband mode with MPE at 17.9 kbit/s pro-vides comparable quality to those of ITU-T G.722at 56 kbit/s and MPEG-2 Layer III at 24 kbit/s.
Speech quality by scalable coding naturally isdegraded compared to nonscalable coding becauseof split loss of the bit-stream. However, MPEG-4CELP is successful in minimizing the di!erence inspeech quality between scalable and nonscalablecoding thanks to its algorithmic features.
Fig. 16(c) exhibits the coding quality of HVXC[7]. MPEG-4/HVXC clearly outperforms the refer-ence, FS1016 [3] at 4.8 kbit/s.2
6. Scalability
(Bit-stream) scalability is the ability of an audiocodec to support an ordered set of bit-streamswhich can produce a reconstructed sequence.Moreover, the codec can output useful audio whencertain subsets of the bit-stream are decoded. The
K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444 437

minimum subset that can be decoded is called thebase layer. The remaining bit-streams in the set arecalled enhancement or extension layers. Dependingon the size of the extension layers we talk aboutlarge step or small step (granularity) scalability.Small step scalability denotes enhancement layersof around 1 kbit/s (or smaller). Typical data ratesfor the extension layers in a large step scalable sys-tem are 16 kbit/s or more. Scalability in MPEG-4natural audio largely relies on di!erence encoding,either in time domain or, as in the case of AAClayers, of the spectral lines (frequency domain).
6.1. Comparison to simulcast
A trivial way to implement bit-stream scalabilityis the simulcast of several bit-streams at di!erentbit-rates. Especially in the case of just two layers ofscalability, this solution has to be checked againsta more complex `reala scalable system. Dependingon the size of the enhancement layers, a scalablesystem has to take a hit in compression e$ciencycompared to a similar non-scalable system. Depend-ing on the algorithm, this cost (in terms of bit-ratefor equivalent quality) can vary widely. For thescalable systems de"ned in MPEG-4 natural audio,the cost has been estimated in several veri"cationtests. In each of the cases, the scalable system per-formed better than the equivalent simulcast system.In the optimum case it may be found that thescalable system is improved over the equivalentnon-scalable system at the same bit-rate. This isexpected to happen only for certain combinationsand signal classes. An example for this e!ect is thecombination of a speech core coder based onCELP (building on a model of the human vocaltract to enhance the speech quality) and enhance-ment layers based on AAC (to get higher qualityespecially for non-speech signals and at higher bit-rates). This combination may perform better thanAAC for speech signals alone. While the e!ect hasbeen demonstrated during the core experimentprocess, it did not show up in the veri"cation testresults.
Scalability is at the heart of the new MPEG-4audio functionalities. Some sort of scalability hasbeen built into all of the MPEG-4 natural audiocoding algorithms.
6.2. Types of scalability in MPEG-4 natural audio
MPEG-4 natural audio allows for a large num-ber of codec combinations for scalability. The com-binations for the speech coders are described inthe paragraphs explaining MPEG-4 CELP andHVXC. The following list contains the main combi-nations for MPEG-4 general audio (GA):
f AAC layers only,f Narrow-band CELP base layer plus AAC,f TwinVQ base layer plus AAC.
Depending on the application, either of thesepossibilities can provide optimum performance. Inall cases where good speech quality at low bit-ratesis a requirement for the case of reception of the corelayer only (like for example in a digital broadcast-ing system using hierarchical channel coding), thespeech codec base layer is preferred. If, on the otherhand, music should be of reasonable quality fora very low bit-rate core layer (for example forInternet streaming of music using scalability), theTwinVQ base layer provides the best quality. Ifthe base layer is allowed to work at somewhathigher bit-rates (like 16 bit/s or more), a systembuilt from AAC layers only can deliver the bestoverall performance.
6.3. Block length considerations
In the case of combining speech coders andGeneral Audio coding, special consideration has tobe given to the frame length of the underlying cod-ing algorithms. This is trivial in the case of di!erentAAC layers at the same sampling frequency. Forthe speech coders in MPEG-4 natural audio, theframe length is a multiple of 10ms which does notmatch the frame lengths normally used in MPEG-4GA. To accommodate these di!erent frame length,two modi"cations have been done to the scalablesystem:
AAC modixed block length. A modi"ed AACworks at a basic block length of 960 samples (in-stead of the usual 1024). This translates to a blocklength of 20ms at 48 kHz sampling frequency. Atthe other main sampling frequencies for scalableMPEG-4 AAC, the basic block length of the AACenhancement layers is again a multiple of 10ms.
438 K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444

Table 4Overview of scalability modes
Layer N NB CELP mono TwinVQ mono TwinVQ stereo AAC mono AAC stereo
Narrowband CELP mono X X XTwinVQ mono X XTwinVQ stereo X XAAC mono X XAAC stereo X
Super frame structure. To keep a frame a singledecodable instance of audio data, several datablocks may be combined into one super-frame. Forexample, at a sampling frequency of 16 kHz anda core block length for a CELP core of 20 ms, threeCELP blocks and one block of AAC enhancementlayers are combined into one super-frame.
6.4. Mono}stereo scalability
At low bit-rates, mono transmission is often pre-ferred to stereo at the same total bit-rates. Mostlisteners evaluate the degradation due to the over-head of stereo transmission to be more annoyingthan the loss of stereo. For higher bit-rates, stereotransmission is virtually a requirement today.Therefore, stereo enhancement layers can be addedas enhancement layers to both mono and stereolower layers.
6.5. Overview of scalability modes in MPEG-4natural audio
Table 4 lists the possibilities for scalability layerswithin MPEG-4 natural audio. All narrowbandCELP (mono), TwinVQ (mono), TwinVQ (stereo),AAC (mono) and AAC (stereo) can be used as corelayers. Enhancement layers can be of the types NBCELP mono (on top of CELP only), TwinVQmono (on top of TwinVQ mono only), TwinVQstereo (on top of TwinVQ stereo only), AAC mono(on top of NB CELP, TwinVQ mono or AACmono) or AAC stereo (on top of any of the othercodecs).
6.6. Frequency-selective switch (FSS) module
Not in all cases the di!erence signal between theoutput of a lower layer and the original (frequencydomain) signal is the best input to code an enhance-ment layer. If, for instance a scalable coder usinga CELP core coder would be used to encode musi-cal material, the output of the CELP coder may beable to help the enhancement layers in terms ofgetting an easier signal to encode. To enable more#exible coding of enhancement layers, a frequencyselective switch (FSS) module has been introduced.It basically consists of a bank of switches operatingindependently on a scalefactor band basis. For eachscalefactor band, one of two inputs into the systemcan be selected.
6.7. Upsampling xlter tool
For scalability spanning a wider range of bit-rates (from speech quality to CD quality), it is notrecommended to run the core coders at the samesampling frequency as the enhancement layercoders. To accommodate this requirement, an up-sampling "lter tool has been de"ned. It uses theMDCT (very similar to the IMDCT already pres-ent in the AAC decoder) algorithm to perform the"ltering. A number of zeroes is inserted into thetime domain waveform and used as the input tothe MDCT. The output values can then directlycombined with MDCT values from a higher samp-ling frequency "lter bank. The prototype "lter inthis case is the MDCT window function and is thesame as used in the AAC IMDCT.
K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444 439

Fig. 17. Scalability example.
6.8. A scalability example
The following example illustrates the combineduse of a number of the tools implementing scalabil-ity. Fig. 17 shows the decoding of a non-GA (i.e.CELP) mono plus AAC stereo combination andcan be found in ISO/IEC International Standard14496-3 (MPEG-4 audio). A mono CELP is com-bined with a single stereo AAC layer. Temporalnoise shaping (TNS) is applied to the MDCT coe$-cients calculated from the upsampled CELPdecoder output. Three FSS (frequency selectiveswitch) modules either combine the upsampled andTNS processed output signal from the core coderwith the AAC decoded spectral data or use just theAAC spectral data. Full M/S processing is possiblein this combination to enhance the stereo codinge$ciency. A core only decoder just uses the CELPdata and applies normal CELP post"ltering. TheCELP output for higher-quality decoding is notpost"ltered. Depending on the number of scalabil-ity layers, much more complex structures need tobe built for MPEG-4 audio scalable decoding.
7. Audio pro5les and levels
In order to maximize interoperability, onlya small number of pro"les have been de"ned for
MPEG-4 Audio. Given the rather large number ofcoding tools and object types, this leads to theinclusion of a relatively large number of audioobject types even in the more simple pro"les. Someof the audio pro"les (e.g. main pro"le) contain bothnatural and structured audio object types. The fol-lowing table lists only the audio pro"les containingnatural audio object types:
Speech coding proxle. This pro"le contains theCELP and HVXC object types as well as an inter-face to text-to-speech (TTS).
Scalable proxle. This pro"le contains the lowercomplexity AAC object types (LC, LTP), both inMPEG-2 (IS 13818-7) style and using the syntaxwhich enables scalability (MPEG-4 style). In addi-tion, the TwinVQ and speech coding object typesand all the tools for scalable audio are part of thispro"le. It is expected, that most early applicationswill use this pro"le.
Main proxle. This is the `do-it-alla pro"le ofMPEG-4 natural and structured audio. It containsall the MPEG-4 audio coding tools.
A hierarchical organisation of the pro"les sup-ports the `design for interoperabilitya: The speechcoding pro"le is contained in all the other pro"lescontaining natural audio coding tools, the scalableaudio pro"le is contained in the main pro"le.
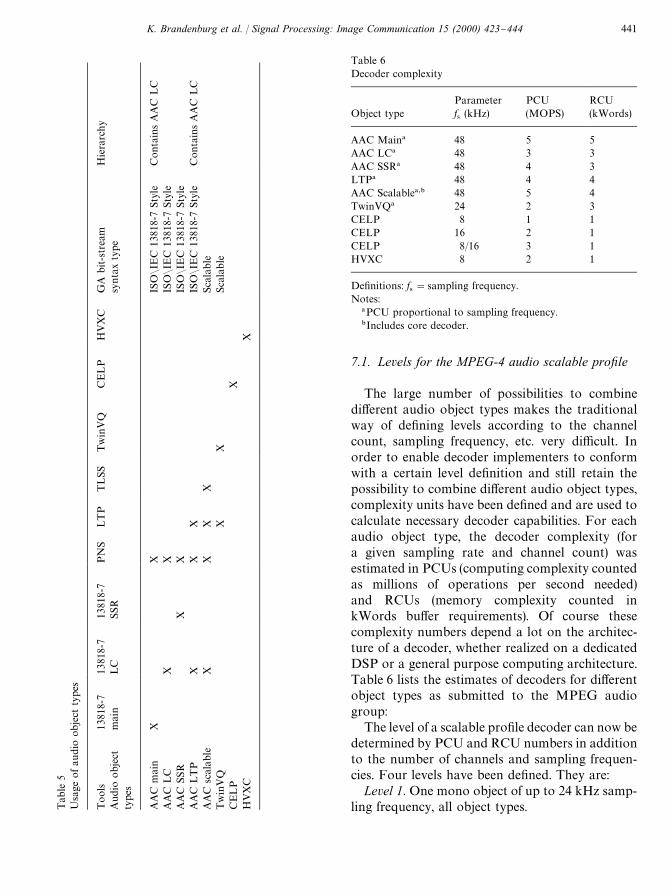
Table 5 lists all the tools of MPEG-4 natural audioand their use in the di!erent audio objects types.
440 K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444
Tab
le5
Usa
geofau
dio
obje
ctty
pes
Tool
sA
udio
obj
ect
type
s
1381
8-7
mai
n13
818-
7LC
1381
8-7
SSR
PN
SLT
PTL
SSTw
inV
QC
EL
PH
VX
CG
Abit-s
trea
msy
nta
xty
peH
iera
rchy
AA
Cm
ain
XX
ISO
CIE
C13
818-
7St
yle
Con
tain
sA
AC
LC
AA
CL
CX
XIS
OCI
EC
1381
8-7
Styl
eA
AC
SSR
XX
ISO
CIE
C13
818-
7St
yle
AA
CL
TP
XX
XIS
OCI
EC
1381
8-7
Styl
eC
onta
ins
AA
CLC
AA
Csc
alab
leX
XX
XSca
lable
Tw
inV
QX
XSc
alab
leC
EL
PX
HV
XC
X
Table 6Decoder complexity
Parameter PCU RCUObject type f
4(kHz) (MOPS) (kWords)
AAC Main! 48 5 5AAC LC! 48 3 3AAC SSR! 48 4 3LTP! 48 4 4AAC Scalable!," 48 5 4TwinVQ! 24 2 3CELP 8 1 1CELP 16 2 1CELP 8/16 3 1HVXC 8 2 1
De"nitions: f4"sampling frequency.
Notes:!PCU proportional to sampling frequency."Includes core decoder.
7.1. Levels for the MPEG-4 audio scalable proxle
The large number of possibilities to combinedi!erent audio object types makes the traditionalway of de"ning levels according to the channelcount, sampling frequency, etc. very di$cult. Inorder to enable decoder implementers to conformwith a certain level de"nition and still retain thepossibility to combine di!erent audio object types,complexity units have been de"ned and are used tocalculate necessary decoder capabilities. For eachaudio object type, the decoder complexity (fora given sampling rate and channel count) wasestimated in PCUs (computing complexity countedas millions of operations per second needed)and RCUs (memory complexity counted inkWords bu!er requirements). Of course thesecomplexity numbers depend a lot on the architec-ture of a decoder, whether realized on a dedicatedDSP or a general purpose computing architecture.Table 6 lists the estimates of decoders for di!erentobject types as submitted to the MPEG audiogroup:
The level of a scalable pro"le decoder can now bedetermined by PCU and RCU numbers in additionto the number of channels and sampling frequen-cies. Four levels have been de"ned. They are:
Level 1. One mono object of up to 24 kHz samp-ling frequency, all object types.
K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444 441

Level 2. One stereo or two mono objects of up to24 kHz sampling frequency.
Level 3. One stereo or two mono objects of up to48 kHz sampling frequency.
Level 4. One 5.1 channel object or a #exiblecon"guration of objects up to 48 kHz sampl-ing frequency and a PCU up to 30 and RCU upto 19.
Acknowledgements
The authors would like to thank JuK rgen Kollerfrom Fraunhofer Institut Integrierte Schaltungenfor the support while writing this paper as wellas Dr. Kazunori Ozawa, Dr. Masahiro Serizawa,and Mr. Toshiyuki Nomura of C&C Media Re-search Laboratories, NEC Corporation, for theirvaluable comments and discussions. Thanks toBodo Teichmann and Bernhard Grill for supply-ing "gures. Part of the work at Fraunhofer IISwas supported by the European Commission(ACTS MoMuSys) and the Bavarian Ministryfor Economy, Transportation and Technology.MPEG-4 natural audio is the joint e!ort ofnumerous people who worked hard to makethe vision of a #exible multimedia coding systema reality. We want to mention the work of PeterSchreiner, the chair of the audio subgroup inMPEG, and David Meares, the audio secretary,and all the others who worked together to createMPEG-4 audio.
References
[1] J-P. Adoul, P. Mabilleau, M. Delprat, S. Morissette, FastCELP coding based on algebraic codes, in: Proceedings ofICASSP'87, April 1987, pp. 1957}1960.
[2] M. Bosi, K. Brandenburg, S. Quackenbusch, K. Akagiri,H. Fuchs, J. Herre, L. Fielder, M. Dietz, Y. Oikwa,G. Davidson, ISO/IEC MPEG-2 Advanced AudioCoding, presented at the 101st Convention of the AudioEngineering Society, J. Audio Eng. Soc. (Abstracts) 44(December 1996) 1174, preprint 4382.
[3] J.P. Campbell, T.E. Tremain, V.C. Welch, The DOD4.8KBPS standard (Proposed Federal Standard 1016), in:Advances in Speech Coding, Kluwer Academic Publishers,Boston, 1991, pp. 121}133.
[4] A. Gersho, Advances in speech and audio compression,Proc. IEEE 82 (6) (June 1994) 900}918.
[5] J. Herre, J.D. Johnston, Enhancing the performance ofperceptual audio coders by using temporal noise shaping(TNS), Presented at the 101st Convention of the AudioEngineering Society, preprint 4384.
[6] J. Herre, D. Schulz, Extending the MPEG-4 AAC codecby perceptual noise substitution, Presented at the 104stConvention of the Audio Engineering Society, preprint4720.
[7] ISO/IEC JTC1 SC29/WG11, Report on the MPEG-4Speech Codec Veri"cation Test, ISO/IEC JTC1/SC29/WG11 N2424, October 1998.
[8] ISO/IEC JTC1 SC29/WG11, ISO/IEC FDIS 14496-3Subparts 1, 2, 3, Coding of Audio}Visual Objects } Part 3:Audio, ISO/IEC JTC1 SC29/WG11 N2503, October 1998.
[9] ISO/IEC JTC1 SC29/WG11 N2725, Overview of theMPEG-4 Standard, Seoul, 1999.
[10] N. Iwakami, T. Moriya, Transform domain weightedinterleave vector quantization (Twin VQ), Presented atthe 101st Convention of the Audio Engineering Society,preprint 4377.
[11] N. Iwakami, T. Moriya, The integrated "lterbank basedscalable MPEG-4 audio coder, Presented at the 105thConvention of the Audio Engineering Society, preprint4810.
[12] N.S. Jayant, High-quality coding of telephone speech andwideband audio, IEEE Commun. Mag. (January 1990)10}20.
[13] P. Kroon, E.F. Deprettere, R.J. Sluyter, Regular-pulseexcitation } A novel approach to e!ective and e$cientmultipulse coding of speech, IEEE Trans. SP ASSP-34 (5)(October 1986) 1054}1063.
[14] C. La#amme, J.-P. Adoul, R. Salami, S. Morissette,P. Mabilleau, 16 kbps wideband speech coding techniquebased on algebraic CELP, in: Proceedings of ICASSP'91,May 1991, pp. 13}16.
[15] T. Nomura, M. Iwadare, M. Serizawa, K. Ozawa, A bitrateand bandwidth scalable CELP coder, in: Proceedings ofICASSP 98, May 1998, Vol. I, pp. 341}344.
[16] T. Nomura, K. Ozawa, M. Serizawa, E$cient pulse excita-tion search methods in CELP, Nat. Conf. Proc. Acoust.Soc. J. 2-P-5 (March 1996) 311}312.
[17] T. Nomura, M. Serizawa, K. Ozawa, An MP-CELPspeech coding algorithm with bit rate control, in: Proceed-ings of the IEICE General Conference, SD-5-3, March1997, pp. 348}349.
[18] T. Nomura, M. Serizawa, K. Ozawa, An embeddedMP-CELP speech coding algorithm using adaptive pulse-position control, in: Proceedings of IEICE Society Confer-ence, September 1997, Vol. D, pp. D-14}10.
[19] K. Ozawa, M. Serizawa, T. Miyanao, T. Nomura,M. Ikekawa, S. Taumi, M-LCELP speech coding at 4 kb/swith multi-mode and multi-codebook, IEICE Trans.E77-B (9) (September 1994) 1114}1120.
[20] D. Schulz, Improving audio codecs by noise substitution,J. AES 44 (7/8) (July/August 1996) 593}598.
442 K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444

[21] N. Tanaka, T. Morii, K. Yoshida, K. Honma, A multi-mode variable rate speech coder for CDMA cellular sys-tems, in: Proceedings of IEEE Vehicular Technology Con-ference 96, April 1996, pp. 198}202.
[22] R. Taori, R.J. Sluijter, A.J. Gerrits, On scalability in CELPcoding systems, in: Proceedings of IEEE Speech CodingWorkshop 97, September 1997, pp. 67}68.
Karlheinz Brandenburg wasborn in Erlangen, Germany in1954. He received M.S. (Di-plom) degrees in Electrical En-gineering in 1980 and inMathematics in 1982 from Er-langen University. In 1989 heearned his Ph.D. in ElectricalEngineering, also from Erlan-
gen University, for work on digital audio codingand perceptual measurement techniques. The tech-niques described in his thesis form the basis forMPEG-1/2 Audio Layer-3, MPEG-2 AdvancedAudio Coding (AAC) and most other modernaudio compression schemes. From 1989 to 1990 hewas with AT&T Bell Laboratories in Murray Hill,NJ, USA. He worked on the ASPEC perceptualcoding technique and on the de"nition of theISO/IEC MPEG/Audio Layer-3 system. In 1990 hereturned to Erlangen University to continue theresearch on audio coding and to teach a course ondigital audio technology. Since 1993 he is depart-ment head at the Fraunhofer Institute fuK r Inte-grierte Schaltungen (FhG-IIS) in Erlangen,Germany. He has presented numerous papers atAES conventions and IEEE conferences. Togetherwith Mark Kahrs, he edited the book `Applicationsof Digital Signal Processing to Audio and Acous-ticsa. In 1994 he received the AES FellowshipAward for his work on perceptual audio codingand psychoacoustics. In 1998 he received the AESsilver medal award for `sustained innovation andleadership in the development of the art and scienceof perceptual encodinga. Dr. Brandenburg isa member of the technical committee on Audio andElectroacoustics of the IEEE Signal Processing So-ciety. He has worked within the MPEG-Audiocommittee since its beginnings in 1988. He servedas editor of MPEG-1 Audio, MPEG-2 Audio andas adhoc chair for a number of adhoc groups dur-
ing the development of MPEG-2 Advanced AudioCoding and MPEG-4 Audio. From 1995 on,under his direction Fraunhofer IIS developedcopyright protection technology including secureenvelope techniques (MMP, Multimedia Protec-tion Protocol) and watermarking. Dr. Branden-burg has been granted 24 patents and has severalmore pending.
Oliver Kunz was born in 1968in Hagen, Germany. He re-ceived his M.S. (Diplom) fromBochum University in 1995.His master thesis at the chair ofProf. Blauert was on a realtimemodel of binaural localisationof sound sources. He joined thedepartment Audio/Multimedia
at the Fraunhofer Institut fuK r Integrierte Schaltun-gen (FhG-IIS) in 1995. He worked on the imple-mentation and optimisation of a high-qualityrealtime MPEG Layer-3 encoder for the digitalradio system WorldSpace and actively contributedto the standardisation of MPEG-2 AAC. SinceJanuary 1998 he is head of the Audio Coding groupat FhG-IIS. Responsibilities of this group rangefrom quality optimisation of state-of-the-art codingschemes and contributions to international stan-dardisation bodies to audio broadcast system re-lated issues.
Akihiko Sugiyama received theB. Eng., M. Eng., and Dr. Eng.degrees in electrical engineer-ing from Tokyo MetropolitanUniversity, Tokyo, Japan, in1979, 1981, and 1998, respec-tively. He joined NEC Cor-poration, Kawasaki, Japan, in1981 and has been engaged in
research on signal processor applications to trans-mission terminals, subscriber loop transmissionsystems, adaptive "lter applications, and high-"del-ity audio coding. In the 1987 academic year, he wason leave at the Faculty of Engineering and Com-puter Science, Concordia University, Montreal,P.Q., Canada, as a Visiting Scientist. From 1989 to
K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444 443

1994, he was involved in the activities of the AudioSubgroup, ISO/IEC JTC1/SC29/WG11 (known asMPEG/Audio) for international standardization ofhigh-quality audio data compression as a memberof the Japanese delegation. His current interests liein the area of signal processing and circuit theory.Dr. Sugiyama is a member of the Institute of Electri-cal and Electronic Engineers (IEEE) and the Instituteof Electronics, Information and CommunicationEngineers (IEICE) of Japan. He served as an asso-ciate editor for the IEEE Transactions onSignal Processing from 1994 to 1996. He is alsoa member of the Technical Committee for Audioand Electroacoustics, IEEE Signal ProcessingSociety. He is currently serving as an associate editor
for the Transactions of the IEICE on Fundamentalsof Electronics, Communications and ComputerSciences. He received the 1988 Shinohara Memor-ial Academic Encouragement Award from IEICE.He is a coauthor of International Standards forMultimedia Coding (Yokohama, Japan: Maruzen,1991), MPEG/International Standards for MultimediaCoding (Tokyo, Japan: Ohmusha, 1996), DigitalBroadcasting (Tokyo, Japan: Ohmusha, 1996), andDigital Signal Processing for Multimedia Systems(New York: Marcel Dekker, Inc., 1999). Dr.Sugiyama is the inventor of 50 registered patents inthe US, Japan, Canada, Australia, and EuropeanPatent Committee (EPC), in the "eld of signal pro-cessing and communications.
444 K. Brandenburg et al. / Signal Processing: Image Communication 15 (2000) 423}444
Related Documents


![EfficientBit AllocationAlgorithmFor MPEG-4 Audio · as MPEG-1/2/4 audio coding standards and Dolby AC-3 [1]. The MPEG-4 Advanced Audio Coding (AAC) is one ofthe mostrecent-generation](https://static.cupdf.com/doc/110x72/5b3b16727f8b9a26728c2604/efficientbit-allocationalgorithmfor-mpeg-4-audio-as-mpeg-124-audio-coding.jpg)








