2007-12-06 1 SZTUCZNE SIECI NEURONOWE Architektura – Typy – Przeznaczenie Procedury uczenia Zastosowania Literatura 1. J. śurada, M. Barski, W. Jędruch, Sztuczne sieci neuronowe, PWN 1996 2. R. Tadeusiewicz, Sieci neuronowe, AOW 1993 3. J. Korbicz, et al.., SSN, AOW 1994 4. R. Tadeusiewicz, Elementarne wprowadzenie do techniki sieci neuronowych, AOW 1998 Mózg/komputer – jak to działa? N L E V Metoda obliczeń Toleran cja na błędy Uc ze nie Inteligencja 10 14 synaps 10 -6 m 30 W 100 Hz Równoległa rozproszona TAK T A K zazwyczaj tak 10 8 tranzy- storów 10 -6 m 30 W (CPU) 10 9 Hz Szeregowa centralna NIE ? nie (narazie) MÓZG – WZORZEC DOSKONAŁY KOMPUTER – TWÓR DOSKONALONY SSN – niekonwencjonalne przetwarzanie • Programowanie • Działanie sekwencyjne • Pamięci ROM/RAM (algorytmy + dane) • Podatne na uszkodzenia • Wysoka PRECYZJA obliczeń • UCZENIE • RÓWNOLEGŁOŚĆ • ARCHITEKTURA + WAGI POŁĄCZEŃ • ODPORNE NA DEFEKTY • Obliczenia JAKOŚCIOWE

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

2007-12-06
1
SZTUCZNE SIECI NEURONOWE
Architektura – Typy – Przeznaczenie
Procedury uczenia
Zastosowania
Literatura1. J. śurada, M. Barski, W. Jędruch,
Sztuczne sieci neuronowe, PWN 1996
2. R. Tadeusiewicz, Sieci neuronowe,
AOW 1993
3. J. Korbicz, et al.., SSN, AOW 1994
4. R. Tadeusiewicz, Elementarne
wprowadzenie do techniki sieci
neuronowych, AOW 1998
Mózg/komputer – jak to działa?
N L E VMetoda obliczeń
Tolerancja na błędy
Uczenie
Inteligencja
1014 synaps 10-6m 30 W 100 HzRównoległarozproszona
TAKTAK
zazwyczaj tak
108 tranzy-storów
10-6m30 W (CPU)
109HzSzeregowacentralna
NIE ?nie (narazie)
MÓZG – WZORZEC DOSKONAŁYKOMPUTER – TWÓR DOSKONALONYSSN – niekonwencjonalne przetwarzanie
• Programowanie• Działanie sekwencyjne• Pamięci ROM/RAM
(algorytmy + dane)• Podatne na
uszkodzenia• Wysoka PRECYZJA
obliczeń
• UCZENIE• RÓWNOLEGŁOŚĆ• ARCHITEKTURA +
WAGI POŁĄCZEŃ• ODPORNE NA
DEFEKTY• Obliczenia
JAKOŚCIOWE

2007-12-06
2
Problem rozpoznaniagdzie tu jest pies? PRZEZNACZENIE SSN
• Klasyfikacja (grupowanie, identyfikacja/US Navy + General Dynamics, Univ. of Pensylvania+TRW)
• Aproksymacja (nieliniowa, wielowymiarowa)
• Pamięci asocjacyjne (rozpoznawanie obrazów)
• Optymalizacja (szeregowanie zadań, planowanie)
• Prognozowanie procesów (energetyka, giełda, medycyna-EKG/EEG )
• Automatyka, robotyka (sterowanie adaptacyjne/ NASA, sieć ALVINN)
Rozpoznanie znaków kodowanych w matrycy 8x10
wejścia
wyjścia
warstwy pośrednie (ukryte)
44444 844444 76cznegoalfanumeryznaku kod
Problemy:
rozpoznanie negatywu, niestabilność
uczenie warstw ukrytych, architektura
sposób kodowania
Schemat sztucznego neuronu(Mc Cullocha-Pittsa: y = 1, e > θ; y = 0, e < θ)
- i-ty sygnał wejściowy
- łączne pobudzenie neuronu
- charakterystyka neuronu
y - sygnał wyjściowy
ix
ϕ
∑=
=n
i
iixwe1
1x
2x
nx
Σ ( )eϕe y
1w
2w
nw
współczynniki wag
sumator aktywacja
2007-12-06
3
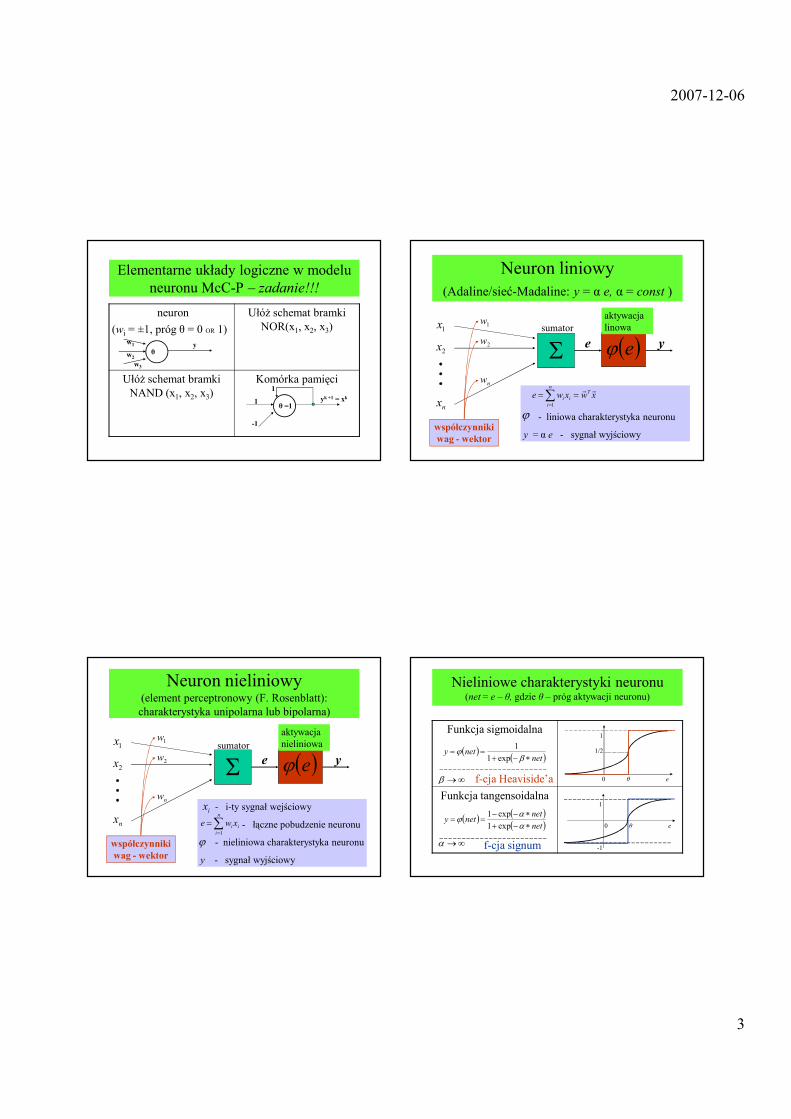
Elementarne układy logiczne w modelu neuronu McC-P – zadanie!!!
neuron
(wi = ±1, próg θ = 0 OR 1)
UłóŜ schemat bramki NOR(x1, x2, x3)
UłóŜ schemat bramki NAND (x1, x2, x3)
Komórka pamięci
θ =1
1
1
-1
yk +1 = xk
θw2
y
w3
w1
Neuron liniowy(Adaline/sieć-Madaline: y = α e, α = const )
- liniowa charakterystyka neuronu
y = α e - sygnał wyjściowy
ϕ
xwxwe Tn
i
ii
rr==∑
=1
1x
2x
nx
Σ ( )eϕe y
1w
2w
nw
współczynniki wag - wektor
sumatoraktywacja linowa
Neuron nieliniowy(element perceptronowy (F. Rosenblatt): charakterystyka unipolarna lub bipolarna)
- i-ty sygnał wejściowy
- łączne pobudzenie neuronu
- nieliniowa charakterystyka neuronu
y - sygnał wyjściowy
ix
ϕ
∑=
=n
i
iixwe1
1x
2x
nx
Σ ( )eϕe y
1w
2w
nw
współczynniki wag - wektor
sumatoraktywacjanieliniowa
Nieliniowe charakterystyki neuronu(net = e – θ, gdzie θ – próg aktywacji neuronu)
Funkcja sigmoidalna
f-cja Heaviside’a
Funkcja tangensoidalna
f-cja signum∞→α
∞→β
( )( )net
nety∗−+
==β
ϕexp1
11
0 θ e
1/2
( ) ( )( )net
netnety
∗−+∗−−
==αα
ϕexp1
exp11
0 θ e
-1

2007-12-06
4
Sieć neuronowa – układ neuronów
• Sieć jednowarstwowa – k sygnałów x∈∈∈∈Rk
wejścia podane na n niepołączonych neuronów z uwzględnieniem nxk wag wyx
∑=
=k
j
jiji xwy1
x1
x2
xk
y2
y1
ynwnk
w2k
w1k
Wxy =
( )Wxy ϕ=
Sieć neuronowa wielowarstwowa
• Sieć wielowarstwowa – kaskada 1-warstw przekazująca sygnały od wejścia do wyjścia z uwzględnieniem wag pośrednich wij(p)
Sieć wielowarstwowa problem liczby neuronów warstwy ukrytej
Struktura sieci: 36 – nu – 15 analiza błędu w epokach uczenia => optymalna liczba nu = 9 neuronów
Architektura sieci neuronowych
• Sieci jednokierunkowe (feedforward networks) – jeden kierunek przepływu sygnałów od wejść do wyjść
• Sieci rekurencyjne (feedback networks) –sieci ze sprzęŜeniem zwrotnym (Hopfielda)
• Sieci komórkowe
• Sieci rezonansowe (ART-1; ART-2)
• Sieci hybrydowe typu Counter-Propagation

2007-12-06
5
Metody uczenia sieci –modyfikacja wag
• Uczenie nadzorowane (delta, wstecznej propagacji błędu)
• Uczenie nienadzorwane (korelacyjne) –reguła Hebba, reguła Oja, instar, outstar
• Uczenie konkurencyjne (WTA, WTM)
• Metody miękkiej selekcji – algorytmy genetyczne i symulowane odpręŜanie
Perceptron prosty (element perceptronowy (F. Rosenblatt): charakterystyka unipolarna lub bipolarna)
1x
2x
nx
Σ ( )eϕe y
1w
2w
nw
wektor wag w
sumatoraktywacjanieciągła
rozszerzony wektor wejść:
rozszerzony wektor wag:
θ−⋅=⋅==∑+
=
TT1
1
~~ xwxwn
i
iixwe
[ ]1,,...,,~21 −= nxxxx
[ ]θ,,...,,~21 nwww=w
θ-1
Co potrafi element perceptronowy?
Dla określonego wektora wag w perceptron ocenia „wysoko” te wejścia x, dla których kąt α z wektorem w jest mały, bo wówczas pobudzenie jest duŜe: w xT = cos(α) dla unormowanych wektorów wag i wejść
hiperpłaszczyzna dzieląca przestrzeń obrazów x na 2 półprzestrzenie decyzyjne:
y = 0 oraz y = 1
w xT - θ = 0x1
x2
wy = 1
y = 0
α
Co to znaczy uczyć sieć?
• Uczenie sieci to modyfikacja wag: tak, aby sygnał wejściowy x dawał na wyjściu sieci obraz poŜądany:
zamiast obrazu pierwotnego:
• Błąd uczenia:
ww ~→
( )T~ xw ⋅=ϕz
( )Txw ⋅=ϕy
yz −=δ

2007-12-06
6
1. Podaj wstępny wektor wag w(0), i = 1
2. Podaj wzorzec ui i wyznacz obraz yi (dla w(i-1))
3. Gdy obraz yi jest zgodny z poŜądanym zi => (5)
4. Gdy i yi = 0 => w(i) = w(i-1)+ η uiGdy i yi = 1 => w(i) = w(i-1) - η ui
5. i = i +1 => (1)
Reguła perceptronowa(algorytm uczenia z nadzorem)
0≠−= iii yzδ0≠−= iii yzδ
(1) Jak dobrać strategię prezentacji wzorców i wybór wag wstępnych?
(2) Warunek zbieŜności uczenia � LINIOWA SEPARACJA {ui}!!!
Perceptron 2-warstwowy (rozwiązuje zadanie XOR)
warstwa wyjściowa: y = H(v x’T – θ0)
warstwa ukryta: x’k = H(wk xT – θk) dzieli przestrzeń wejść k-razy na 2-półpłaszczyzny, więc cała warstwa ukryta dzieli ją na podzbiory, z których jeden jest wypukły – tu neurony są zapalone uk = 1
1x
2x
Σ
( )eϕv1
y
11w
21w
θ2-1
Σv2
Σ12w
22w
( )eϕ
( )eϕ
θ1-1
θ0-1
1-warstwowe klasyfikatory(minimalno-odległościowe maszyny liniowe)
gi(x)=(wi)T.xfunkcje decyzyjne
xw1
wR
++
+gR(x)
g2(x)
g1(x)selektor
maxklasa
ix
ix= j dla x∈Pj
Pj – wzorzec klasy j
wektor obrazu z przestrzeni wymiaru n
Cel: podział przestrzeni obrazów na obszary decyzyjne przynaleŜne kaŜdej klasie wzorców Pj (1≤ j ≤ R) wg. minimum odległości:
min ||x – Pi||2 = xTx – 2(PiT.x – Pi
T.Pi/2)
⇒⇒⇒⇒ wi =Pi oraz win+1= –Pi
TPi/2
sij: gi(x) - gj(x) = 0linie decyzyjne
Przykład: maszyna liniowa dla 3 klas(metoda analityczna)
P1
P2
P3x1
x2
obszar klasy 1
obszar klasy 2
obszar klasy 3
−
−=
=
=
4
8;
4
2;
2
8321 PPPwzorce:
funkcje dyskryminacyjne:
g1(x)=(w1)T.x = 8x1+2x2 - 34
g2(x)=(w2)T.x = 2x1+4x2 – 10
g1(x)=(w1)T.x = -8x1- 4x2 - 40
−
−
−
=
−
=
−
=
40
4
8
;
10
4
2
;
34
2
8321 www
s12 : 3x1 - x2 – 12 = 0
s13 : 8x1 + 3x2 + 3 = 0
s23 : 5x1 - 4x2 – 15 = 0
linie rozdzielające (hiperpłaszczyzny):

2007-12-06
7
Sieć klasyfikująca 3 obszary wg uczenia
x
w1
w3+
g3(x)+
g2(x)+
g1(x)
w2y2
y3
y1 rozproszone lub lokalne kodowanie klas
Uczenie dychotomizatora (2 klasy)
klasa 1: wT x1 > 0 (x1∈P1) oraz klasa 2: wT x2 < 0 (x2∈P2)
Zgodnie z regułą delta modyfikacje wag następują przez +/- ηxk :
gdzie „+” dla x1∈P1, a „-” dla x2∈P2
(aktywacja bipolarna - signum)
(aktywacja unipolarna – skok 0/1)
( ) ( ) ( ) k
kkkk yd xww 211 −±=+
( ) ( ) ( ) k
kkkk yd xww 1 −±=+
zakończenie procesu, gdy od pewnego czasu t modyfikacje zanikną:
w(t+1) = w (t+2)= .... = w*
Uczenie dychotomizatora (c.d.)
w1
w2
x2
x1
w(1)
w(2)
w(3) = w(4) = w*
w(1)
w(2) = w(3) = w*
−
=
−=
1
2;
2
121 xx
( ) [ ] ( )
=+
=⇒−=
−===
=
3
2
1
31
2
113sgn;1;;
1
31
2111
11 xwydxxw
[ ] ( ) ∗=
=−
=⇒=
−=−== wxwydxx
4
0
3
21
1
232sgn;1; 2
3212
2
Klasyfikator ciągły – uczenie(algorytm gradientowy – największego spadku)
Ciągła funkcja błędu: E = ½ (d – y)2 = ½ (d – φ(wT x))2
( ) ( ) ( )( )kkk E www ∇−=+r
η1
( ) ( ) ( )( ) kkk yyd xww 2211 1−−+=+ η
Dla bipolarnej aktywacji:
Dla unipolarnej aktywacji:
( ) ( ) ( ) ( ) kkk yyyd xww −−+=+ 11 η
Uwaga: jest to rozszerzenie poznanej reguły delta dla ciągłej funkcji aktywacji
(k – czas dyskretny)
( ) 21tanh yynety −=′⇒⋅= β
( )( ) ( )yyynety −=′⇒⋅−+= − 1exp1 1β

2007-12-06
8
Algorytm gradientowy – największego spadkuPowierzchnia błędu kwadratowego
Uczenie samo-organizujące(reguła Hebba + jej modyfikacje)
Wynik obserwacji neurobiologów (efekt Pawłowa):
wzmocnienie połączenia synaptycznego wik następuje, gdy oba połączone neurony yi oraz yk są zapalone, tzn. aktywne.
Reguła Hebba to reguła korelacyjna (często rozbieŜna!!!)
wprowadzająca wzrost siły połączenia neuronów przy skorelowaniu sygnałów pre- i post- synaptycznych
( ) ( ) ( )kwkwkw ijijij ∆+=+1
( ) ( ) ( )kykxkw ijij ⋅=∆ η ( ) ( ) ( )kdkxkw ijij ⋅=∆ ηuczenie bez nadzoru uczenie z nadzorem
reguła Hebba - modyfikacje
(1) współczynnik zapominania γ zapobiega stałemu nasycaniu neuronów przy wielokrotnym wymuszeniu wzorcem xj:
( ) ( ) ( ) ( ) ( ) ( ) ( )( ) ( )kykwkxkykwkykxkw iijjiijijij ⋅−⋅=⋅−⋅=∆ γηγη
(2) Reguła Oji: wyjściowe sygnały yi modyfikują sygnał wejściowy xj (rodzaj sprzęŜenia zwrotnego)
( ) ( ) ( )( ) ( )kykwykxkw iijijij ⋅−⋅=∆ η
( ) ( ) ( )kykxkw ijij ⋅−=∆ η
(3) Reguła anty-Hebba: ujemnie spolaryzowane modyfikacje wag nie prowadzą do rozbieŜności procesu uczenia (nieoptymalne)
reguły typu Hebba – modyfikacje c.d./1/
(4) Poprawa efektywności samouczenia i samoorganizacji neuronów często osiągana jest przy uczeniu przyrostowym:
( ) ( ) ( )( ) ( ) ( )( )11 −−−−⋅=∆ kykykxkxkw iijjij η
(5) Reguła „gwiazdy wejść” (instar training): tylko wybrany i-ty neuron jest uczony rozpoznania aktualnego sygnału x
( ) ( ) ( ) ( )( )kwkxkkw ijjij −⋅=∆ η ( ) 01.0 >⋅−= kk λη
(6) Reguła „gwiazdy wyjść” (outstar training): tylko wagi wybranego j-tego wejścia podlegają uczeniu wzorca y dla obrazu x
( ) ( ) ( ) ( )( )kwkykkw ijiij −⋅=∆ η ( ) 01 >⋅−= kk λη
2007-12-06
9
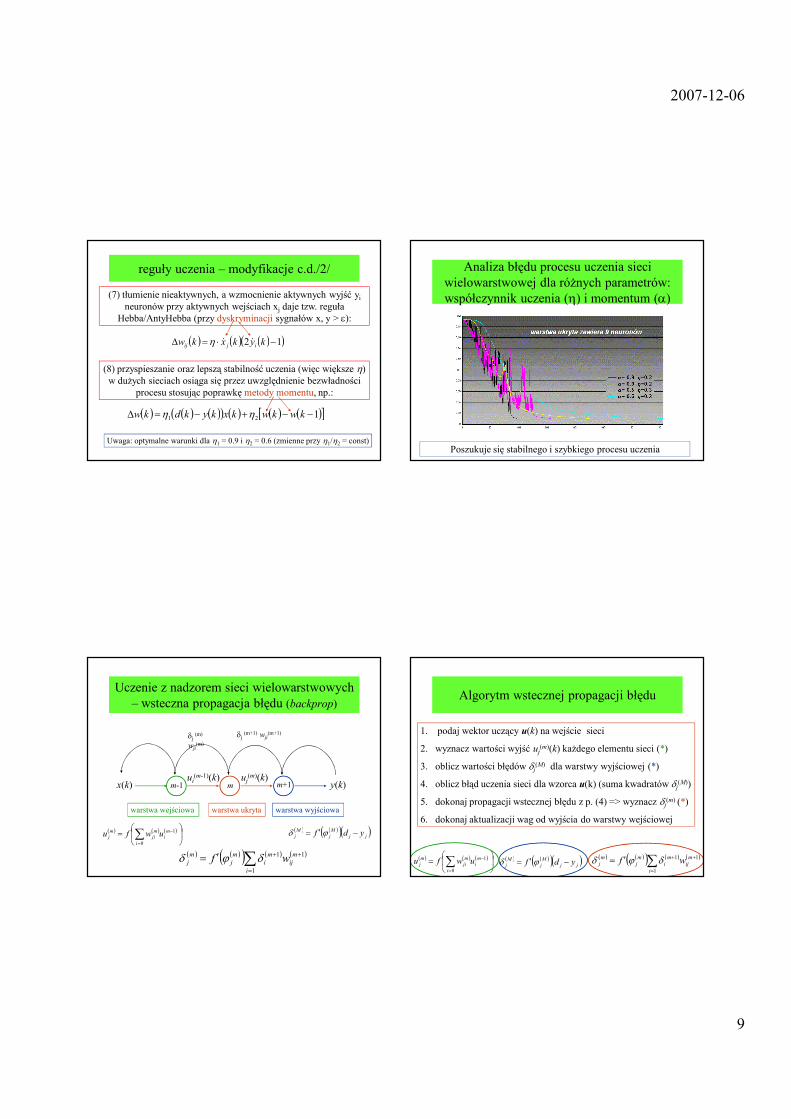
reguły uczenia – modyfikacje c.d./2/
(7) tłumienie nieaktywnych, a wzmocnienie aktywnych wyjść yineuronów przy aktywnych wejściach xj daje tzw. reguła
Hebba/AntyHebba (przy dyskryminacji sygnałów x, y > ε):
( ) ( ) ( )( )12 −⋅=∆ kykxkw ijij&&η
(8) przyspieszanie oraz lepszą stabilność uczenia (więc większe η) w duŜych sieciach osiąga się przez uwzględnienie bezwładności
procesu stosując poprawkę metody momentu, np.:
( ) ( ) ( )( ) ( ) ( ) ( )[ ]121 −−+−=∆ kwkwkxkykdkw ηη
Uwaga: optymalne warunki dla η1 = 0.9 i η2 = 0.6 (zmienne przy η1/η2 = const)
Analiza błędu procesu uczenia sieci wielowarstwowej dla róŜnych parametrów: współczynnik uczenia (η) i momentum (α)
Poszukuje się stabilnego i szybkiego procesu uczenia
Uczenie z nadzorem sieci wielowarstwowych – wsteczna propagacja błędu (backprop)
( ) ( ) ( )
= −
=∑ 1
0
m
i
i
m
ji
m
j uwfu
x(k) y(k)uj(m)(k)
warstwa wyjściowawarstwa ukrytawarstwa wejściowa
ui(m-1)(k)
mm-1 m+1
δj (m+1) wji(m+1)δj (m)
wji(m)
( ) ( )( ) ( ) ( )1
1
1 +
=
+∑′= m
ij
i
m
i
m
j
m
j wf δϕδ
( ) ( )( )( )jj
M
j
M
j ydf −′= ϕδ
Algorytm wstecznej propagacji błędu
1. podaj wektor uczący u(k) na wejście sieci
2. wyznacz wartości wyjść uj(m)(k) kaŜdego elementu sieci (*)
3. oblicz wartości błędów δj(M) dla warstwy wyjściowej (*)
4. oblicz błąd uczenia sieci dla wzorca u(k) (suma kwadratów δj(M))
5. dokonaj propagacji wstecznej błędu z p. (4) => wyznacz δj(m) (*)
6. dokonaj aktualizacji wag od wyjścia do warstwy wejściowej
( ) ( ) ( )
= −
=∑ 1
0
m
i
i
m
ji
m
j uwfu( ) ( )( ) ( ) ( )1
1
1 +
=
+∑′= m
ij
i
m
i
m
j
m
j wf δϕδ( ) ( )( )( )jj
M
j
M
j ydf −′= ϕδ

2007-12-06
10
Aktualizacja wag wg uogólnionej reguły delta
( ) ( )( ) ( )( )kukkwm
j
m
jij
1−⋅⋅=∆ δη
Uwaga: wartości błędów elementów danej warstwy ukrytej są wyznaczane przed aktualizacją wag w warstwie następnej
Uogólnioną regułę delta często uzupełnia się przyjęciem poprawki momentumw celu przyspieszenia i stabilizacji uczenia sieci
Sieci samoorganizujące się (bez nadzoru + WTA)
• Sieć Hamminga i MaxNet (rozpoznawanie obrazów)
• sieć Kohonena (grupowanie wektorów uczących - clustering)
• sieć ART-1 (adaptive resonance theory) – stabilne grupowanie adaptacyjne
Uczenie – stosując miarę podobieństwa wzorców poprzez
1. iloczyn skalarny wektora wejściowego i wektora wag lub
2. sąsiedztwo topologiczne, tzn. odległość neuronów w sieci pobudzonych danym obrazem wejściowym
Sieci Hamminga (1) i MaxNet (2)(klasyfikacja zaszumionego obrazu do najbliŜszej klasy wzorców wg.
odległości Hamminga – wagi nie podlegają uczeniu!)
Liczba p – neuronów warstwy (1) jest zgodna z ilością klas, tzn. Ŝe kaŜdy neuron reprezentuje jedną z dopuszczonych grup:
( )[ ] p
i
i
H sW
1 21
==
Macierz wag warstwy (H) złoŜona z p wzorców po wierszach WH
( )( )[ ] p
i
isxHDnnet
1 , =−=
Łączne pobudzenie warstwy (H) mierzone wspólnymi bitami x i s
Liniowa aktywacja y = f(net) neuronów (H) normuje sygnał wejściowy do warstwy (2) do
przedziału (0, 1)
f(net)
net
1
n0
Sieci Hamminga i MaxNet/cd.
Warstwa (2) eliminuje rekurencyjnie wszystkie wyjścia z (1) prócz maksymalnego yk ⇒⇒⇒⇒ wskazanie numeru grupy k
Aktywacja f2 w warstwie (2) jest równieŜ liniowa, ale w (0, 1)
⇒⇒⇒⇒ eliminacja kolejno najmniejszego i-tego sygnału przez f2(neti
(k)) = 0 w k-tym kroku rekurencji, gdy neti(k) < 0
Macierz wag warstwy (2) złoŜona z autopobudzających połączeń wii oraz hamujących połączeń lateralnych o sile -ε
[ ] [ ] ( )pWWijMiiM 10 oraz 1
<<−== εε

2007-12-06
11
Sieci Hamminga i MaxNet – schemat sieci
Wada sieci: załoŜona ilość klas (uczenie nieadaptacyjne => ART-1)
x1
x2
x3
x4
n/2
n/2
n/2
1
2
3
n = 4; p = 3 klasy ε = 0.2 < 1/3
y1(k+1)
y2(k+1)
y3(k+1)
y1(0)
y2(0)
y3(0)
y2(k)
y3(k)
w1i = s(1)
Sieci Hamminga i MaxNet – przykład
1 -1 1
1 -1 1
1 1 1
1 1 1
-1 1 -1
-1 1 -1
1 1 1
1 1 1
1 1 1
-1 -1 -1
-1 -1 -1
-1 -1 -1
1 1 -1
1 -1 -1
1 1 -1
Sieć ma zadanie zaklasyfikować obrazy :
x1 = x2 = x3 =
W matrycy n = 3x3 zdefiniowano p = 2 wzorce zakodowane binarnie:
s(1) = (1 -1 1 1 -1 1 1 1 1) s(2) = (1 1 1 -1 1 -1 -1 1 -1)
klasa 1 klasa 2
Sieci Hamminga i MaxNet – przykład/cd.
Dla obrazu x3=(11-11-1-111-1) => yH,3 = [5/9 5/9] sieć nie rozstrzyga o klasyfikacji (!)
−−−−
−−=
111111111
111111111
2
1HW
−
−=
),(9
),(9
9
1)2(
)1(
,sxHD
sxHD
i
i
iHy
−
−=
1
1
41
41
MW dla 0< ε=1/4 <1/p( )( )k
MM
k
M f yWy 2)1( =+
Dla obrazu x1=(111111111) => yH,1 = [7/9 5/9] mamy rekurencyjnie aktywności:
=
−→
→
→
0
482.0
06.0
482.0
064.0
498.0
201.0
549.0
361.0
639.02222 ffff klasa 1 - U
Dla obrazu x2=(-1-1-1-1-1-1-1-1-1) => yH,2 = [2/9 4/9]
=
−→
→
358.0
0
358.0
076.0
361.0
014.0
389.0
111.0222 fff klasa 2 - T
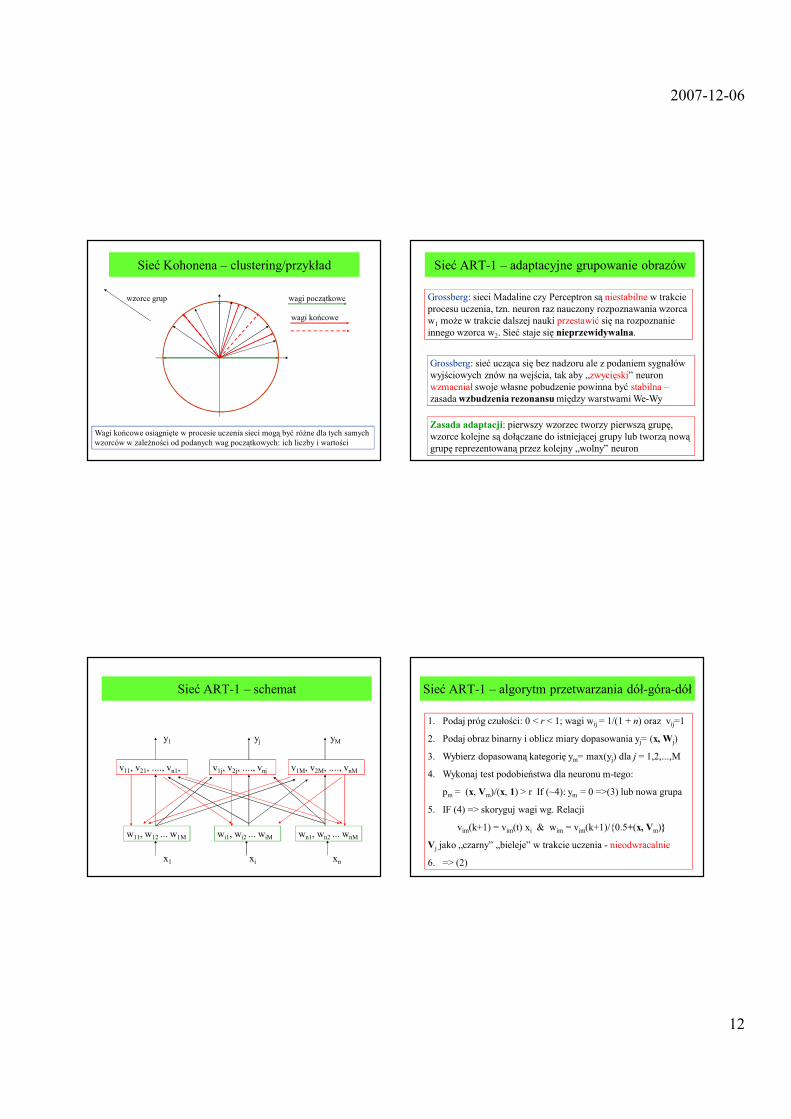
Sieć Kohonena – grupowanie obrazów
Sieć 1-warstwowa + uczenie z rywalizacją, tzn. modyfikacji ulega wektor wag najbliŜszy danemu wzorcowi (wagi są normowane):
ipi
m wxwx ˆminˆ,...,2,1
−=−=
Po zakończeniu uczenia wektory wag wskazują środki cięŜkości wykrytych grup obrazów (ilość grup jest nieznana a priori) choć gęste wzorce ściągają wektory wag (wada) + kalibracja sieci
(1) przechwytywanie wag => x’ = q x + (1- q) w0, q↑ 1
(2) Sumienie wg DeSieno � często wygrywający neuron zamiera
( )mm wxw ˆˆ −=∆ ηWarunek ten zapewnia reguła gwiazdy wejść:
2007-12-06
12
Sieć Kohonena – clustering/przykład
wagi początkowe
wagi końcowe
wzorce grup
Wagi końcowe osiągnięte w procesie uczenia sieci mogą być róŜne dla tych samych wzorców w zaleŜności od podanych wag początkowych: ich liczby i wartości
Sieć ART-1 – adaptacyjne grupowanie obrazów
Grossberg: sieci Madaline czy Perceptron są niestabilne w trakcie procesu uczenia, tzn. neuron raz nauczony rozpoznawania wzorca w1 moŜe w trakcie dalszej nauki przestawić się na rozpoznanie innego wzorca w2. Sieć staje się nieprzewidywalna.
Grossberg: sieć ucząca się bez nadzoru ale z podaniem sygnałów wyjściowych znów na wejścia, tak aby „zwycięski” neuron wzmacniał swoje własne pobudzenie powinna być stabilna –zasada wzbudzenia rezonansumiędzy warstwami We-Wy
Zasada adaptacji: pierwszy wzorzec tworzy pierwszą grupę, wzorce kolejne są dołączane do istniejącej grupy lub tworzą nową grupę reprezentowaną przez kolejny „wolny” neuron
Sieć ART-1 – schemat
w11, w12 ... w1M wi1, wi2 ... wiM wn1, wn2 ... wnM
x1 xi xn
v11, v21, ...., vn1, v1j, v2j, ...., vnj v1M, v2M, ...., vnM
y1 yj yM
Sieć ART-1 – algorytm przetwarzania dół-góra-dół
1. Podaj próg czułości: 0 < r < 1; wagi wij = 1/(1 + n) oraz vij=1
2. Podaj obraz binarny i oblicz miary dopasowania yj= (x, Wj)
3. Wybierz dopasowaną kategorię ym= max(yj) dla j = 1,2,...,M
4. Wykonaj test podobieństwa dla neuronu m-tego:
pm = (x, Vm)/(x, 1) > r If (~4): ym = 0 =>(3) lub nowa grupa
5. IF (4) => skoryguj wagi wg. Relacji
vim(k+1) = vim(t) xi & wim = vim(k+1)/{0.5+(x, Vm)}
Vj jako „czarny” „bieleje” w trakcie uczenia - nieodwracalnie
6. => (2)

2007-12-06
13
Sieć ART-1 – wady działania
1. Prymitywny test podobieństwa nie jest w stanie rozróŜnić (tzn. poprawnie sklasyfikować) zaszumionych wzorców
2. obniŜanie progu czułości poniŜej granicznej wartości zaburzy klasyfikacje oryginałów – zbuduje mniejszą liczbę klas
3. Aby zapamiętać i odtwarzać kolejne wzorce gdy brak juŜ wolnych neuronów do klasyfikacji naleŜy uŜyć schematów bardziej złoŜonych (Pao, Addison-Wesley, 1989 – sieci Pao)
4. Architektura sieci ART jest nieefektywna z racji liczby wag
5. Mała pojemność
Sieci pamięci skojarzeniowej – pamięci adresowane zawartością, wyszukiwanie informacji, analiza mowy
• sieć Hintona (najprostsza statyczna pamięć jednowarstwowa)
• 2-kierunkowa sieć BAM (Bidirectional Associativ Memory)
• sieć Hopfielda (optymalizacje kombinatoryczne, rozpoznawanie obrazu, analiza procesów chaotycznych,„rozwiązanie” problemu komiwojaŜera, automatyka adaptacyjna – filtry Kalmana)
Rola wzorców ortogonalnych i liniowo niezaleŜnych – pamięć absolutna
Sieć Hintona – 1-warstwowa pamięć asocjacyjna
Proces zapisu = reguła Hebba z wagami w(0) = 0
wij(k) = wij
(k-1) + fi(k) sj(k) dla s(k) = [sj] � f (k) = [fi]
s(k) f (k)
Sieć interpolacyjna (nie progowa) heteroasocjacyjna idealna dla wzorców ortogonalnych i niezaleŜnych liniowo
Sieć BAM – 2-warstwowa pamięć 2-kierunkowa
Proces zapisu = reguła Hebba z wagami w(0) = 0, η =1
wij(k) = wij
(k-1) + fi(k) sj(k) dla s(k) = [sj] � f (k) = [fi]
Wnm
Wmn
sj(k) fj
(k) Energia sieci:
E(s, f) = -sTWf
dąŜy do minimum globalnego

2007-12-06
14
Sieć Hopfielda – asynchroniczna 1-warstwowa pamięć rekurencyjna (hetero/autoasocjacyjna)
Proces zapisu = reguła Hebba z wagami wii = 0, η = ?
wij(k) = wij
(k-1) + fi(k) sj(k) dla s(k) = [sj] � f (k) = [fi]
Wnm
Wmn
sj(k) fj
(k)
Energia sieci:
E(s) = -sTWs
dąŜy do minimum globalnego
Related Documents











