Massive High-Performance Massive High-Performance Global File Systems for Grid Global File Systems for Grid Computing Computing - By Phil Andrews, Patricia Kovatch, Christopher Jordan - Presented by Han S Kim

Massive High-Performance Global File Systems for Grid Computing -By Phil Andrews, Patricia Kovatch, Christopher Jordan -Presented by Han S Kim.
Dec 20, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Massive High-Performance Massive High-Performance Global File Systems for Grid ComputingGlobal File Systems for Grid Computing
-By Phil Andrews, Patricia Kovatch, Christopher Jordan
-Presented by Han S Kim
Han S Kim Concurrent Systems Architecture Group
OutlineOutline
II IntroductionIntroduction
IIII GFS via Hardware Assist: SC’02GFS via Hardware Assist: SC’02
IIIIII Native WAN-GFS: SC’03Native WAN-GFS: SC’03
IVIV True Grid Prototype: SC’04True Grid Prototype: SC’04
VV Production Facility: 2005Production Facility: 2005
VIVI Future WorkFuture Work
Han S Kim Concurrent Systems Architecture Group
II IntroductionIntroductionIntroductionIntroduction

Han S Kim Concurrent Systems Architecture Group
1.1. IntroductionIntroduction- The Original Mode of Operation for Grid Computing- The Original Mode of Operation for Grid Computing
To submit the user’s job to the ubiquitous grid.
The job would run on the most appropriate computational platform available.
Any data required for the computation would be moved to the chosen compute facility’s local disk.
Output data would be written to the same disk.
The normal utility used for the data transfer would be GridFTP.

Han S Kim Concurrent Systems Architecture Group
1.1. IntroductionIntroduction- In Grid Supercomputing,- In Grid Supercomputing,
The very large size of the data sets used. The National Virtual Observatory
consists of approximately 50 Terabytes, is used as input by several applications.
Some applications write very large amounts of data The Southern California Earthquake Center simulation
Writes close to 250 Terabytes in a single run
Other applications require extremely high I/O rates The Enzo application-AMR Cosmological Simulation code
Multiple Terabytes per hour is routinely written and read.

Han S Kim Concurrent Systems Architecture Group
1.1. IntroductionIntroduction- Concerns about Grid Supercomputing- Concerns about Grid Supercomputing
The normal approach of moving data back and forth may not translate well to a supercomputing grid, mostly relating to the very large size of the data sets used.
These size and required transfer rates are not conducive to routine migration of wholesale input and output data between grid sites.
The computation system may not have enough room for a required dataset or output data.
The necessary transfer rates may not be achievable.

Han S Kim Concurrent Systems Architecture Group
1.1. IntroductionIntroduction- In this paper..- In this paper..
Show
How a Global File System, where direct file I/O operations can be performed across a WAN can obviate these concerns.
A series of large-scale demonstrations

Han S Kim Concurrent Systems Architecture Group
IIII GFS via Hardware Assist: SC’02GFS via Hardware Assist: SC’02GFS via Hardware Assist: SC’02GFS via Hardware Assist: SC’02

Han S Kim Concurrent Systems Architecture Group
Global File Systems were still in the concept stage.
Two Concerns The latencies involved in a widespread network such as the TeraGr
id The file systems did not yet have the capability of exportation acro
ss a WAN
2. GFS via Hardware Assist: SC’022. GFS via Hardware Assist: SC’02 - At That Time… - At That Time…

Han S Kim Concurrent Systems Architecture Group
Used hardware capable of encoding Fibre Channel frames within IP packets (FCIP)
Internet Protocol-based storage networking technology developed by IETF
FCIP mechanisms enable the transmission of Fiber Channel information by tunneling data between storage area network facilities over IP networks.
2. GFS via Hardware Assist: SC’022. GFS via Hardware Assist: SC’02 - Approach - Approach

Han S Kim Concurrent Systems Architecture Group
2. GFS via Hardware Assist:SC’022. GFS via Hardware Assist:SC’02- The Goal of This Demo- The Goal of This Demo
In that year, the annual Supercomputing conference was Baltimore.
The distance between show floor and San Diego is greater than any within the TeraGrid.
The perfect opportunity to demonstrate whether latency effects would eliminate any chance of a successful GFS at that distance.
Han S Kim Concurrent Systems Architecture Group
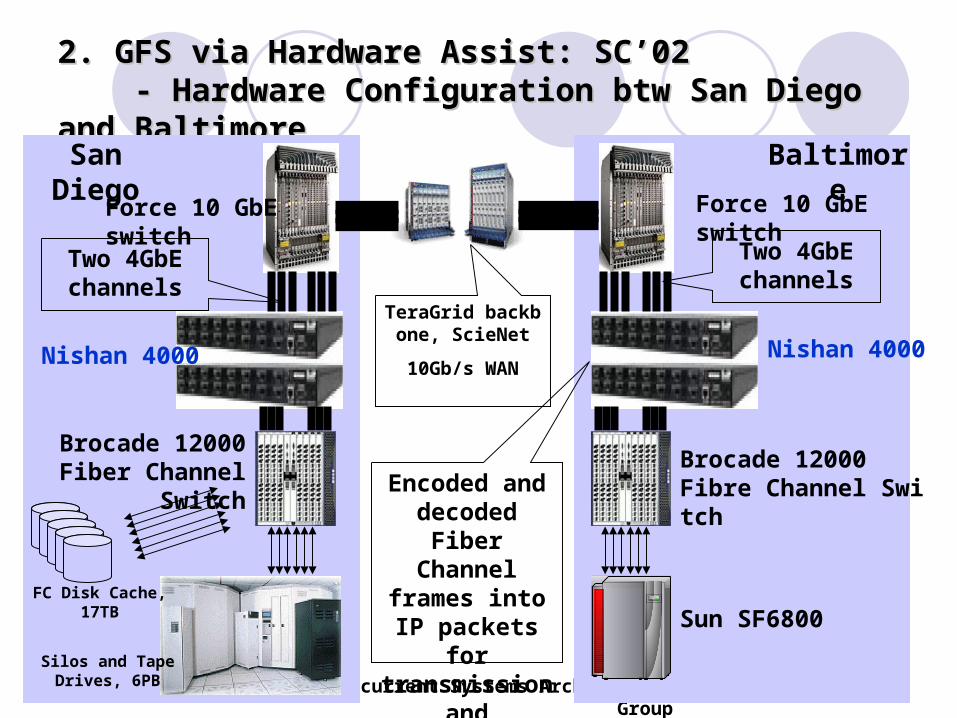
2. GFS via Hardware Assist: SC’022. GFS via Hardware Assist: SC’02 - Hardware Configuration btw San Diego and Baltimore - Hardware Configuration btw San Diego and Baltimore
Two 4GbE channels
Two 4GbE channels
Force 10 GbE switch
Nishan 4000
Brocade 12000Fiber Channel Switch
Force 10 GbE switch
Nishan 4000
Brocade 12000Fibre Channel Switch
Sun SF6800
San Diego Baltimore
FC Disk Cache, 17TB
Silos and TapeDrives, 6PB
TeraGrid backbone, ScieNet
10Gb/s WAN
Two 4GbE channels
Two 4GbE channels
Encoded and decoded Fiber
Channel frames into IP packets
for transmission and reception
Han S Kim Concurrent Systems Architecture Group
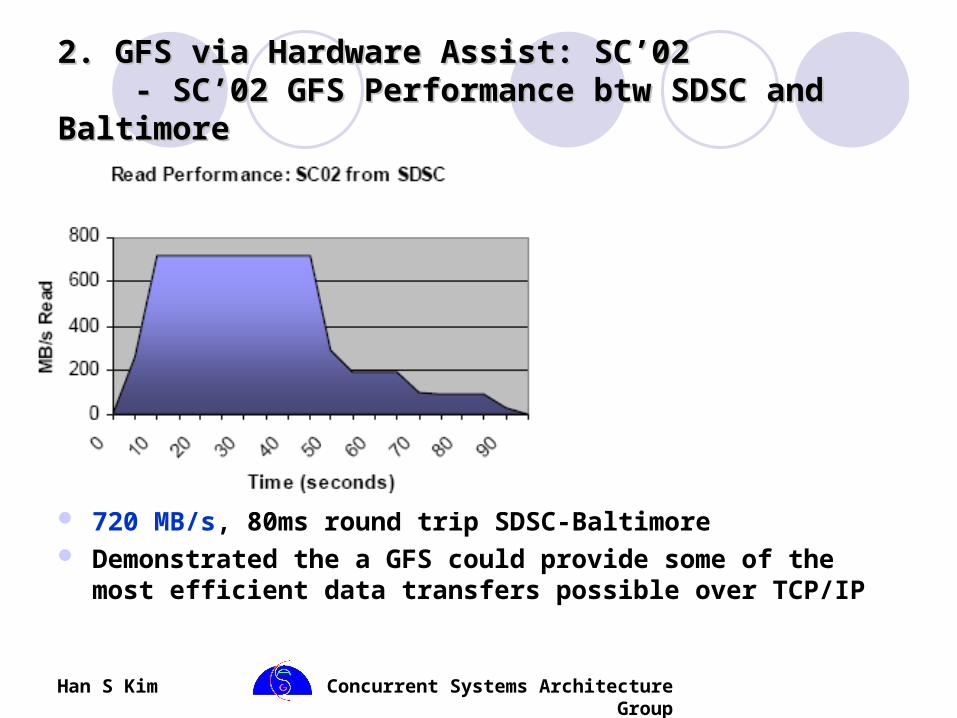
2. GFS via Hardware Assist: SC’022. GFS via Hardware Assist: SC’02 - SC’02 GFS Performance btw SDSC and Baltimore - SC’02 GFS Performance btw SDSC and Baltimore
720 MB/s, 80ms round trip SDSC-Baltimore Demonstrated the a GFS could provide some of the most
efficient data transfers possible over TCP/IP

Han S Kim Concurrent Systems Architecture Group
IIIIII Native WAN-GFS: SC’03Native WAN-GFS: SC’03Native WAN-GFS: SC’03Native WAN-GFS: SC’03

Han S Kim Concurrent Systems Architecture Group
3. Native WAN-GFS: SC’033. Native WAN-GFS: SC’03 - Issue and Approach - Issue and Approach
Issue: Whether Global File Systems were possible without hardware FCIP encoding.
SC’03 was the chance to use pre-release software from IBM’s General Parallel File System (GPFS) A true wide area-enabled file system Shared-Disk Architecture Files are striped across all disks in the file system
Parallel access to file data and metadata
Han S Kim Concurrent Systems Architecture Group
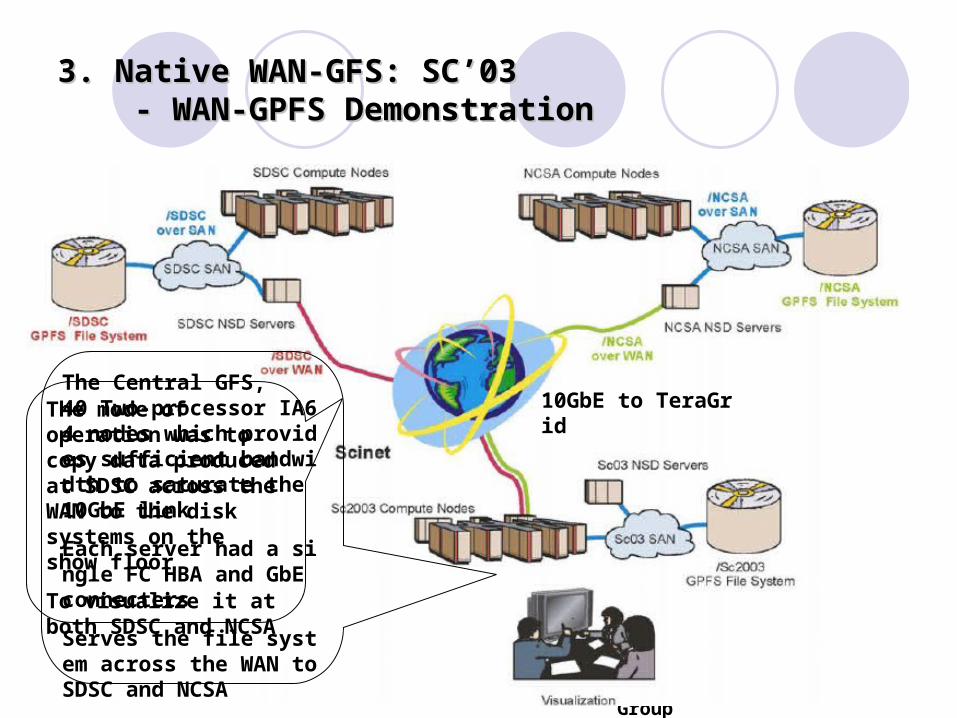
3. Native WAN-GFS: SC’033. Native WAN-GFS: SC’03 - WAN-GPFS Demonstration - WAN-GPFS Demonstration
The Central GFS,40 Two-processor IA64 nodes which provides sufficient bandwidth to saturate the 10GbE link
Each server had a single FC HBA and GbE connecters
Serves the file system across the WAN to SDSC and NCSA
The mode of operation was to copy data produced at SDSC across the WAN to the disk systems on the show floor
To visualize it at both SDSC and NCSA
10GbE to TeraGrid
Han S Kim Concurrent Systems Architecture Group
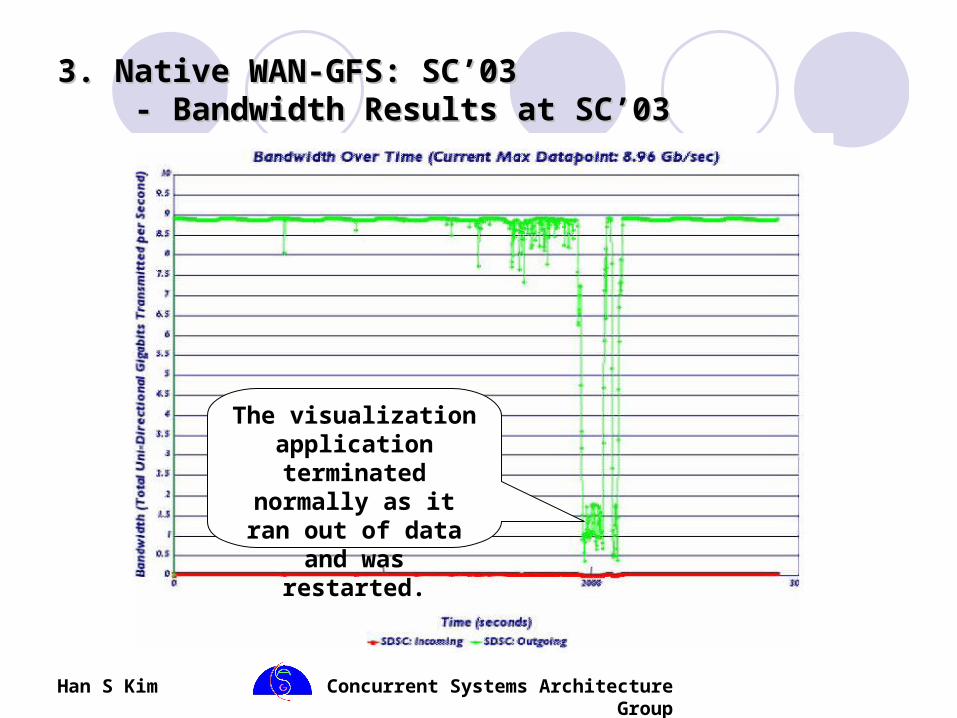
3. Native WAN-GFS: SC’033. Native WAN-GFS: SC’03 - Bandwidth Results at SC’03 - Bandwidth Results at SC’03
The visualization application terminated
normally as it ran out of data and was restarted.
Han S Kim Concurrent Systems Architecture Group
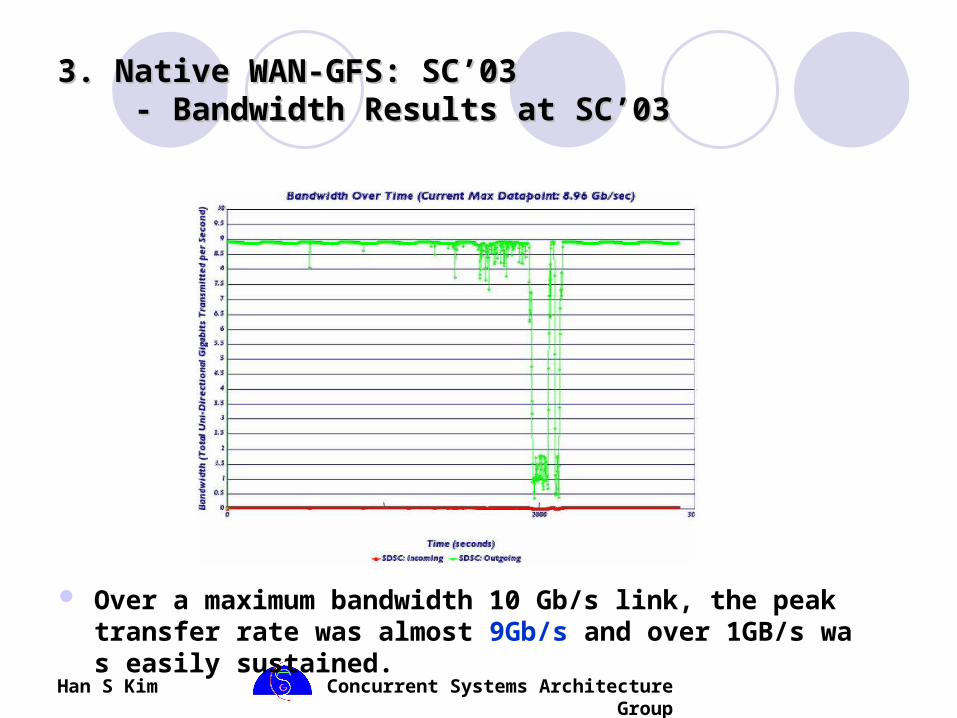
3. Native WAN-GFS: SC’033. Native WAN-GFS: SC’03 - Bandwidth Results at SC’03 - Bandwidth Results at SC’03
Over a maximum bandwidth 10 Gb/s link, the peak transfer rate was almost 9Gb/s and over 1GB/s was easily sustained.

Han S Kim Concurrent Systems Architecture Group
IVIV True Grid Prototype: SC’04True Grid Prototype: SC’04True Grid Prototype: SC’04True Grid Prototype: SC’04

Han S Kim Concurrent Systems Architecture Group
4. True Grid Prototype: SC’044. True Grid Prototype: SC’04 - The Goal of This Demonstration - The Goal of This Demonstration
To implement a true grid prototype of what a GFS node on the TeraGrid would look like.
The possible dominant modes of operation for grid supercomputing: The output of a very large dataset to a central GFS repository, follo
wed by its examination and visualization at several sites, some of which may not have the resources to ingest the dataset whole.
The Enzo application Writes on the order of a Terabyte per hour: enough for 30Gb/s Tera
Grid connection With the post processing visualization they could check how quick
ly the GFS could provide data in a scenario. Ran at SDSC, writing its output directly the GPFS disks in Pittsbur
gh.

Han S Kim Concurrent Systems Architecture Group
4. True Grid Prototype: SC’044. True Grid Prototype: SC’04 - Prototype Grid Supercomputing at SC’04 - Prototype Grid Supercomputing at SC’04
30Gb/s
40Gb/s
40Gb/s

Han S Kim Concurrent Systems Architecture Group
4. True Grid Prototype: SC’044. True Grid Prototype: SC’04- Transfer Rates- Transfer Rates
The aggregate performance: 24Gb/s
The momentary peak: over 27Gb/s
The rates were remarkably constant.
Three 10Gb/s connections between the show floor and the TeraGrid backbone

Han S Kim Concurrent Systems Architecture Group
VV Production Facility: 2005Production Facility: 2005Production Facility: 2005Production Facility: 2005

Han S Kim Concurrent Systems Architecture Group
5. Production Facility: 20055. Production Facility: 2005- The needs for Large Disk- The needs for Large Disk
By this time, the size of datasets had become large. The NVO dataset was 50 Terabytes per location, which was a notic
eable strain on storage resources. If a single, central, site could maintain the dataset this would be e
xtremely helpful to all the sites who could access it in an efficient manner.
Therefore, a very large amount of spinning disk would be required.
Approximately 0.5 Petabytes of Serial ATA disk drives was acquired by SDSC.
Han S Kim Concurrent Systems Architecture Group
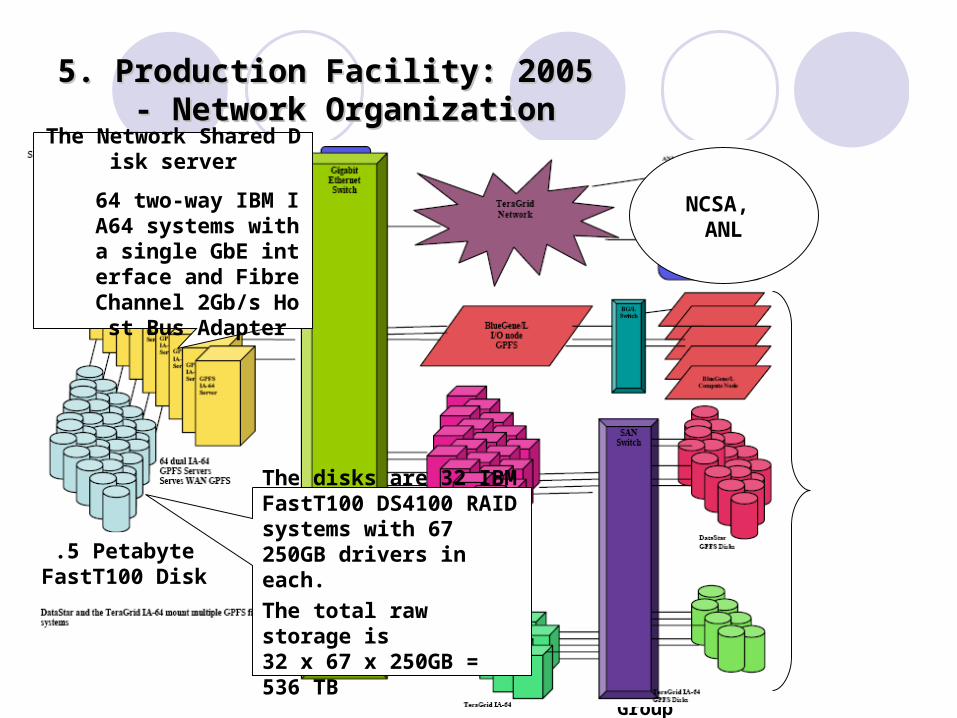
5. Production Facility: 20055. Production Facility: 2005 - Network Organization - Network Organization
.5 PetabyteFastT100 Disk
NCSA, ANL
The Network Shared Disk server
64 two-way IBM IA64 systems with a single GbE interface and Fibre Channel 2Gb/s Host B
us Adapter
The disks are 32 IBM FastT100 DS4100 RAID systems with 67 250GB drivers in each.
The total raw storage is 32 x 67 x 250GB = 536 TB
Han S Kim Concurrent Systems Architecture Group
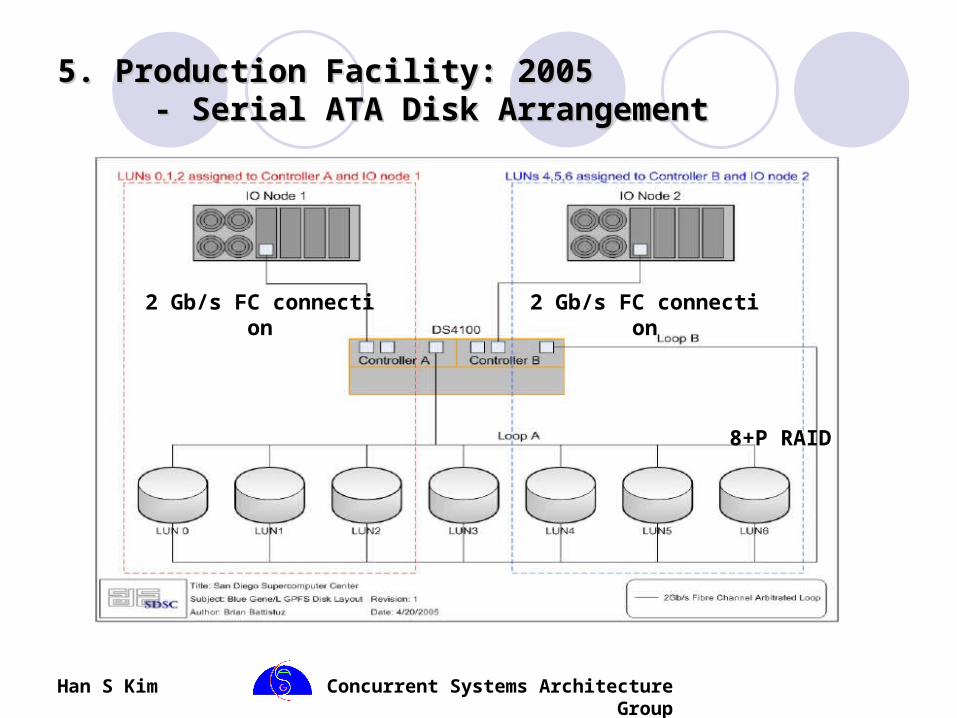
5. Production Facility: 20055. Production Facility: 2005 - Serial ATA Disk Arrangement - Serial ATA Disk Arrangement
2 Gb/s FC connection 2 Gb/s FC connection
8+P RAID

Han S Kim Concurrent Systems Architecture Group
The Number of Remote Nodes
5. Production Facility: 20055. Production Facility: 2005- Performance Scaling- Performance Scaling
Maximum of almost 6GB/s out of theoretical
maximum of 8GB/s

Han S Kim Concurrent Systems Architecture Group
5. Production Facility: 20055. Production Facility: 2005- Performance Scaling- Performance Scaling
The observed discrepancy between read and write rates is not yet understood
However, the dominant usage of the GFS is to be remote reads.

Han S Kim Concurrent Systems Architecture Group
VIVI Future WorkFuture WorkFuture WorkFuture Work

Han S Kim Concurrent Systems Architecture Group
6. Future Work6. Future Work
Next year (2006), the authors hope to connect to the DEISA computational Grid in Europe which is planning a similar approach to Grid computing, allowing them to unite the TeraGrid and DEISA Global File Systems in a multi-continent system.
The key contribution of this approach is a paradigm.
At least in the supercomputing regime, data movement and access mechanisms will be the most important delivered capability of Grid computing, outweighing even the sharing or combination of compute resources.

Han S Kim Concurrent Systems Architecture Group
Thank you !Thank you !Thank you !Thank you !
Related Documents











