Linked Lists

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Linked Lists

Linked List• List – linear collection of data items.
• Data processing frequently involves storing and processing data organized into lists.
• Arrays – are also list – disadvantage of arrays– Predefined size– Insertions and Deletions are difficult– Cannot increase size as and when required– Known as dense list or static data structures
• Solution – store each element in the list contain a field called a link or pointer, which contains the address of the next element in the list.
• No need of adjacent memory space• Hence, insertion and deletion become easier.

Linked Lists
• Linked List or one –way list – a linear collection of data elements, called nodes.
• A linked list is a data structure which can change during execution.–
• Successive elements are connected by pointers.
• Last element points to NULL.
• It can grow or shrink in size during execution of a program.
• It can be made just as long as required.
• It does not waste memory space.

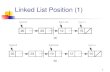
Linked Lists
infonext
elem node
A 1005 2000 1010 NULLB C D
1000 1005 2000 1010
START
End of the List
Points to the address of
first node in the list

Linked Lists
Null
START
Special case – list has no nodes. Such a list is called
NULL list or empty list

Insertion in Linked Lists

Deletion in Linked Lists

Arrays versus Linked Lists
• Arrays are suitable for:– Inserting and deleting an element at the end.– Randomly accessing any element.– Searching the list for a particular value.
• Linked Lists are suitable for:– Inserting an element.– Deleting an element.– In situations where total number of elements
cannot be predicted in advance.

Types of Linked Lists
• Depending on the way in which the links are used to maintain adjacency, several different types of linked lists are possible.
• Singly Linked List

Types of Linked Lists
• Circular Linked List : The pointer from the last element in the list points back to the first element

Types of Linked Lists
• Doubly Linked List : – Pointers exist between adjacent nodes in both directions– The list can be traversed either forward or backward– Usually two pointers are maintained to keep track of the
list, head and tail.

Basic Operations on a Linked Lists
• Creating a list• Traversing a list• Inserting an element in the list• Deleting an element from the list• Concatenating two lists into one

Creating a List
• LIST – Linked list
• Requires two arrays INFO, LINK
• INFO[K] – contains information part
• LINK[K] – contains next pointer field of a node of list
• START – which contains the location of the beginning of the list.

Creating a List
9
O
R
K
N
E
6
11
Null
3
7
INFO LINK
1
2
3
4
5
6
7
8
9
10
11
12
START
START = 9LINK[9] = 3, INFO[3]=OLINK[3] =6, INFO[6]=RLINK[6] = 11, INFO[11]=E, LINK[11] = 7INFO[7]=KLINK[7] = NULL - End

Creating a List
Struct Node
{
int info;
Struct node *next;
}*Start
/* Pointer type variable that can point to structure */
/* For example int k=10, to point k we will create integer type pointer variable as int *ptr. Now ptr = &k. */
/* same way to point structure we need structure type pointer hence, struct node * next – which will point to structure. */

Algorithm for Traversing a Linked List
(Traversing a Linked List) : List – linked list in a memory. The variable PTR points to the node currently being processed.
1. Set PTR := START /* PTR = START = 1000*/
2. Repeat Steps 3 and 4 while PTR ≠ NULL.
3. Apply PROCESS to INFO[PTR].
4. Set PTR:= LINK[PTR]. [PTR now points to the next node.]
5. [End of step 2 loop]
6. Exit.
A 1005 2000 1010 NULLB C D
1000 1005 2000 1010
START = 1000

Algorithm for Traversing a Linked List
(Traversing a Linked List) : List – linked list in a memory. The variable PTR points to the node currently being processed.
1. Set PTR := START /* PTR = START = 1000*/
2. Repeat Steps 3 and 4 while PTR ≠ NULL.
3. Apply PROCESS to INFO[PTR].
4. Set PTR:= LINK[PTR]. [PTR now points to the next node.]
5. [End of step 2 loop]
6. Exit.
A 1005 2000 1010 NULLB C D
1000 1005 2000 1010
START = 1000 PTR = 1000
Process INFO[PTR]=
INFO[1000]=A
Set PTR = LINK[PTR]=
LINK[1000]= 1005

Algorithm for Traversing a Linked List
(Traversing a Linked List) : List – linked list in a memory. The variable PTR points to the node currently being processed.
1. Set PTR := START /* PTR = START = 1000*/
2. Repeat Steps 3 and 4 while PTR ≠ NULL.
3. Apply PROCESS to INFO[PTR].
4. Set PTR:= LINK[PTR]. [PTR now points to the next node.]
5. [End of step 2 loop]
6. Exit.
A 1005 2000 1010 NULLB C D
1000 1005 2000 1010
START = 1000 PTR = 1005
Process INFO[PTR]=
INFO[1005]=B
Set PTR = LINK[PTR]=
LINK[1005]= 2000

Algorithm for Traversing a Linked List
(Traversing a Linked List) : List – linked list in a memory. The variable PTR points to the node currently being processed.
1. Set PTR := START /* PTR = START = 1000*/
2. Repeat Steps 3 and 4 while PTR ≠ NULL.
3. Apply PROCESS to INFO[PTR].
4. Set PTR:= LINK[PTR]. [PTR now points to the next node.]
5. [End of step 2 loop]
6. Exit.
A 1005 2000 1010 NULLB C D
1000 1005 2000 1010
START = 1000 PTR = 1005
Process INFO[PTR]=
INFO[2000]=C
Set PTR = LINK[PTR]=
LINK[2000]= 1010

Algorithm for Traversing a Linked List
(Traversing a Linked List) : List – linked list in a memory. The variable PTR points to the node currently being processed.
1. Set PTR := START /* PTR = START = 1000*/
2. Repeat Steps 3 and 4 while PTR ≠ NULL.
3. Apply PROCESS to INFO[PTR].
4. Set PTR:= LINK[PTR]. [PTR now points to the next node.]
5. [End of step 2 loop]
6. Exit.
A 1005 2000 1010 NULLB C D
1000 1005 2000 1010
START = 1000 PTR = 1005
Process INFO[PTR]=
INFO[1010]=D
Set PTR = LINK[PTR]=
LINK[1010]= NULL

Algorithm for Printing a Linked List
(Printing a Linked List) : List – linked list in a memory. This procedure prints the information at each node of the list.
PRINT (INFO, LINK, START)
1. Set PTR := START
2. Repeat Steps 3 and 4 while PTR ≠ NULL
3. Write: INFO[PTR].
4. Set PTR:= LINK[PTR]. [PTR now points to the next node.]
5. [End of step 2 loop]
6. Exit.

Algorithm for counting total number of nodes in a Linked List
List – linked list in a memory. This procedure finds the total number of elements in the LIST.
COUNT (INFO, LINK, START, NUM)
1. Set PTR := START [Initialize Pointer]
2. Set NUM:=0. [ Initialize Counter]
3. Repeat Steps 3 and 4 while PTR ≠ NULL
4. Set NUM : = NUM+1. [Increase NUM by 1]
5. Write: INFO[PTR].
6. Set PTR:= LINK[PTR]. [PTR now points to the next node.]
7. [End of step 2 loop]
8. Exit.

Searching an element in an unsorted Linked List
List – linked list in a memory. This procedure search location (LOC) of particular ITEM in a list.
Set LOC = NULL
SEARCH (INFO, LINK, START, ITEM,LOC)
1. Set PTR := START [Initialize Pointer]
2. Repeat Steps 3 while PTR ≠ NULL:
If ITEM = INFO[PTR], then:
Set LOC:= PTR and EXIT
Else:
Set PTR:=LINK[PTR]
[End of IF Structure]
[End of Step 2 loop.]
3. Exit.

Searching an element in a sorted Linked List
List – linked list in a memory. This procedure search location (LOC) of particular ITEM in a list.
Set LOC = NULL
SEARCH (INFO, LINK, START, ITEM,LOC)
1. Set PTR := START [Initialize Pointer]
2. Repeat Steps 3 while PTR ≠ NULL:
3. If ITEM < INFO[PTR], then:
Set PTR:=LINK[PTR]. [PTR now points to next_node]
Else If ITEM =INFO[PTR], then:
Set LOC:=PTR and Exit
Else:
Set LOC:=NULL, and Exit
[End of IF Structure]
[End of Step 2 loop.]
4. Set LOC:=NULL.
5. Exit.

Memory Allocation, Garbage Collection
• For insertion- provide unused memory space to the new nodes.
• Some mechanism required where unused memory space of deleted nodes become available for future use.
• With linked list – maintain a special list which consists of unused memory cells.
• Special list is known as list of available space or the free storage list or the free pool.

Memory Allocation, Garbage Collection
9
O
R
K
N
E
6
11
Null
10
3
4
7
8
INFO LINK
1
2
3
4
5
6
7
8
9
10
11
12
START
12
AVAIL

Garbage Collection
• Suppose some memory space becomes reusable because a node is deleted from a list or an entire list is deleted from a program.
• We want the space available for future use. - One way to bring this about is to immediately reinsert the space into the free storage list.
• The operating system of a computer may periodically collect all the deleted space onto the free storage list – any technique which does this collection is called garbage collection.
• Garbage Collection works in two steps:– First the computer runs through all lists, tagging those cells which are
currently in use
– And then computer runs through the memory, collecting all untagged space onto the free storage list.

Overflow and Underflow
• Sometimes new data are to be inserted into a data structure but there is no available space, the free storage list is empty.
• This situation is called overflow.
• When AVALI=NULL – Overflow
• When one want to delete data from a data structure that is empty – underflow.
• When START = NULL - Underflow

Insertion algorithms
• Inserting node at the beginning of the list (at first position)• Insert a node after the node with a given location (in between)• Insert a node at the end of the list (last position)• ITEM – new information to be added to the list.• Steps:
(a) Check is space available in the AVAIL list. If AVAIL = NULL print Overflow
(b) Else remove first node from the AVAIL list. Assign it to he NEW
NEW:=AVAIL AVAIL:=LINK[AVAIL]
(c ) Copy new information into the new node. INFOR[NEW]:= ITEM
ITEM
NEW
AVAIL

Inserting at the beginning of a List
• INSFIRST(INFO,LINK,START,AVAIL,ITEM): This algorithm inserts ITEM as the first node in the list.
1. [OVERFLOW?] If AVAIL = NULL then: write overflow and exit
2. [Remove first node from AVAIL list]
Set NEW: = AVAIL and AVAIL:=LINK[AVAIL].
3. Set INFO[NEW]=:ITEM [Copies new data into new node]
4. Set LINK[NEW]:=START. [New node now points to original first node]
5. Set START:=NEW [changes START so it points to the new node]
6. Exit.

Inserting after a given node
• To insert after particular location (LOC) in a linked list.
• If LOC = NULL then list is empty and item is inserted as first node.
• Else LINK[NEW]:=LINK[LOC]
• LINK[LOC]:=NEW

Inserting after a given node
• INSLOC(INFO, LINK, START, AVAIL, LOC, ITEM): This algorithm inserts ITEM so that ITEM follows the node with location LOC or inserts ITEM as the first node when LOC=NULL.
1. [OVERFLOW?] If AVAIL=NULL, then write OVERFLOE, and exit.
2. [REMOVE first node from AVAIL list.]
Set NEW:=AVAIL and AVAIL:=LINK[AVAIL]
3. Set INFO[NEW]:= ITEM [Copies new data into new node.]
4. If LOC:=NULL, then [Insert as first node]
Set LINK[NEW]:= NULL and START := NEW
Else [Insert after node with location LOC]
Set LINK[NEW]:=LINK[LOC] and LINK[LOC]:= NEW
End of If structure
5. Exit.

Inserting into a sorted linked list• Item must be inserted between nodes A and B so that
INFO(A) < ITEM <= INFO(B)
Procedure finds the location LOC of node A, that is, finds the location LOC of the last node in LIST whose value is less than ITEM.

Inserting into a sorted linked listFINDA(INFO, LINK, START, ITEM, LOC): This procedure finds the location LOC of the last node in a sorted list such that INFO[LOC] < ITEM or sets LOC = NULL
1. [List empty?] If START = NULL, then: Set LOC:=NULL and return
2. [Special case?] If ITEM < INFO[START], then set LOC:= NULL and return
3. Set SAVE:= START and PTR:=LINK[START]. [Initializes pointer]
4. Repeat Steps 5 and 6 while PTR ≠ NULL
5. If ITEM < INFO[PTR], then Set LOC:= SAVE and return
[End of If Structure]
6. Set SAVE:=PTR and PTR:=LINK[PTR]. [Update Pointers.]
7. [End of Step 4 loop].
8. Set LOC:=SAVE
9. Return

Inserting into a sorted linked listINSERT(INFO, LINK,START, AVAIL, ITEM): This algorithm inserts ITEM into a sorted linked list.
1. [Use procedure FINDA to find the location of the node preceding ITEM] Call FINDA(INFO, LINK, START, ITEM, LOC)
2. [OVERFLOW?] If AVAIL=NULL, then: write: Overflow and Exit
3. [Remove first node from AVAIL list] Set NEW:=AVAIL and AVAIL:= LINK[AVAIL]
4. Set INFO[NEW]:=ITEM
5. If LOC:=NULL, then set LINK[NEW]:=START and START:=NEW
6. Else Set LINK[NEW]:=LINK[LOC] and LINK[LOC]:=NEW
7. [End of If structure]
8. Exit

Deletion from a Linked list
A 1005 2000 1010 NULLB C D
1000 1005 2000 1010
START = 1000
Delete Node B
A 1005 2000 1010 NULLB C D
1000 1005 2000 1010
START = 1000

Deletion from a Linked list
A B C
Delete Node B
A 1005 2000 1010 NULLB C D
1000 1005 2000 1010
START = 1000
NULL
AVAIL

Deletion Algorithms• Deletion Algorithms:
– Delete a node following a given node–Delete the node with a given ITEM of information–Delete the node in beginning of the list (first node)–Delete the last node of the list
• Memory of deleted node will be added to the beginning of the AVAIL list.•LOC is the location of the deleted node N.
• Hence we can write, LINK[LOC]:=AVAIL and then AVAIL:=LOC

Algorithm to Delete a Node
Suppose START is the first position in linked list. Let Data be the element to be deleted. Hold, Temp is a temporary pointer to hold the node addresses.
•Input the Data to be deleted.•If ((START->info) is equal to Data)
(a) Temp = START
(b) START = START->next
( c ) Set free the node Temp, which is deleted
(d) Exit.
3. Hold = START
4. While ((Hold->next->next) not equal to NULL))
(a) if ((Hold->Next->Data) equal to Data))
(i) Temp = Hold->Next
(ii) Hold-> Next = Temp->Next

Algorithm to Delete a Node
(iii) Set free the node Temp, which is deleted
(iv) Exit
(b) Hold = Hold->Next
5. If ((Hold->Next->data)==Data)
(a) Temp = Hold->Next
(b) Set free the Node Temp, which is deleted
( c ) Hold->Next=NULL
(d) Exit
6. Display “Data not found’
7. Exit

Header Linked List
• A header linked list – always contains special node, called the header node at the beginning of the list.•Two types of header linked list:
• A grounded header list – header list where the last node contains the null pointer.•A circular header list – header list where the last node points back to the header node.
1005 2000 1010 NULLA B C
1000 1005 2000 1010
START = 1000
Header node
Grounded header linked list
First node

Header Linked List• LINK[START]= NULL – indicates grounded header list is empty• LINK[START]=START – indicates circular header list is empty• The location of first node is LINK[START] not START
1005 2000 1010A B C
1000 1005 2000 1010
START = 1000
Header node
Circular header linked list
First node

Header Linked List
Start =5
AVAIL =8
g
e
f
c
a
D
b
5
3
7
6
9
2
10
4
11
null
19000
19000
18000
17000
188000
16400
14000
15000
122-155
122-115
122-120
122-101
008
122-111
122-116
22-1001
NAME SSN SALARY LINK1
2
3
4
5
6
7
8
9
10
11

Traversing a Circular Header Linked List• (Traversing a Circular Header List) : Let LIST be a circular header list in memory. This algorithm traverses LIST, applying an operation PROCESS to each node of LIST.
1. Set PTR:= LINK[START]. [Initializes the Pointer PTR]
2. Repeat Steps 3 and 4 while PTR ≠ START:1. Apply PROCESS to INFO[PTR]
2. Set PTR:=LINK[PTR]. [PTR now points to the next node]
[End of Step 2 loop]
3. Exit.

Searching ITEM in a Circular Header Linked List• (Searching ITEM in a Circular Header List) : Let LIST be a circular header list in memory. This algorithm searches ITEM in a LIST.
SEARCHHL(INFO, LINK, START, ITEM, LOC) : The algorithm finds the location LOC of the node where ITEM first appears in the LIST or sets LOC=NULL
1. Set PTR:= LINK[START]
2. Repeat while INFO[PTR] ≠ ITEM and PTR ≠ START:1. Set PTR:= LINK[PTR]
[End of LOOP]
3. If INFO[PTR] = ITEM then: Set LOC:= PTR
Else
Set LOC:= NULL.
[End of IF structure]
4. Exit

TWO Way Header Lists
Null A 2000 1000 B 3000 2000 C Null
START = 1000
1000 2000 3000
5000 A 2000 1000 B 3000 2000 C 1000
START = 5000
1000 2000 3000
Two way circular header list
10005000

Traversing simple two way Header Linked List
1. Set PTR := START
2. Repeat Steps 3 and 4 while PTR ≠ NULL.
3. Apply PROCESS to INFO[PTR].
4. Set PTR:= LINK[PTR]. [PTR now points to the next node.]
5. [End of step 2 loop]
6. Exit.
If list is circular two way linked list – use traverse algorithm of circular header linked list (PPT – 44)
Related Documents