iaas Documentation Release 0.1.0 NorCAMS Aug 19, 2019

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

iaas DocumentationRelease 0.1.0
NorCAMS
Aug 19, 2019


Contents
1 Contents 31.1 Getting started . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.1.1 For end users of UH-IaaS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.1.2 For UH-IaaS developer and operators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.1.3 For team and project status information . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.1.4 Customers and local adminstrators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Design . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2.1 Locations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.2.2 Physical hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.2.3 Networking overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51.2.4 Virtual machines . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2.5 Development hardware requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3 Security . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.3.1 [2019] System documentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.3.2 [2019] Management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.3.3 [2019] Secure communication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.3.4 [2019] API endpoints . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171.3.5 [2019] Identity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191.3.6 Dashboard . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221.3.7 [2019] Compute . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261.3.8 [2019] Block Storage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 281.3.9 [2019] Shared File Systems . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 291.3.10 [2019] Networking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 301.3.11 [2019] Object Storage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 321.3.12 Message queuing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 321.3.13 [2019] Data processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341.3.14 Databases . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 341.3.15 Tenant data privacy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 361.3.16 [2019] Instance security management . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
1.4 Howtos and guides . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 411.4.1 Build docs locally using Sphinx . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 411.4.2 Git in the real world . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 421.4.3 Install KVM on CentOS 7 from minimal install . . . . . . . . . . . . . . . . . . . . . . . . 421.4.4 Configure a Dell S55 FTOS switch from scratch . . . . . . . . . . . . . . . . . . . . . . . . 421.4.5 Install cumulus linux on ONIE enabled Dell S4810 . . . . . . . . . . . . . . . . . . . . . . 441.4.6 Create Cumulus VX vagrant boxes for himlar dev . . . . . . . . . . . . . . . . . . . . . . . 45
i

1.4.7 Routed, virtual network interfaces for guest VMs on controllers . . . . . . . . . . . . . . . 461.4.8 Configure iDRAC-settings on Dell 13g servers with USB stick . . . . . . . . . . . . . . . . 481.4.9 Using vncviewer to access the console . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 481.4.10 Building puppet-agent for PPC-based Cumulus Linux . . . . . . . . . . . . . . . . . . . . . 491.4.11 How to create the designate-dashboard RPM package . . . . . . . . . . . . . . . . . . . . . 49
1.5 Team operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 491.5.1 Getting started . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 491.5.2 Development . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 531.5.3 Operations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 681.5.4 Installation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1041.5.5 Tips and tricks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 114
1.6 Status . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1211.6.1 Teamdeltakere og roller . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1221.6.2 Vakt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1221.6.3 Navnekonvensjon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1231.6.4 Kontaktpunkter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1251.6.5 List historie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1261.6.6 Rapporter og referat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1281.6.7 Planer og designvalg . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2061.6.8 Arkiv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2231.6.9 Hardware overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 239
1.7 Kundeinformasjon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2411.7.1 Priser og flavors . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2411.7.2 Prosjektinformasjon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 244
ii

iaas Documentation, Release 0.1.0
This documentation are intended for the team working on UH-IaaS, and people involved in the project.
End user documentation are found at http://docs.uh-iaas.no
In addition to information about development and operations, we also have a section in Norwegian about the currentstatus.
Contents 1

iaas Documentation, Release 0.1.0
2 Contents

CHAPTER 1
Contents
1.1 Getting started
1.1.1 For end users of UH-IaaS
• Documentation at http://docs.uh-iaas.no
• Status at https://status.uh-iaas.no
1.1.2 For UH-IaaS developer and operators
• Team operations
1.1.3 For team and project status information
This will be in Norwegian only.
• Status
1.1.4 Customers and local adminstrators
This will be in Norwegian only.
• Kundeinformasjon
1.2 Design
High-level documents describing the IaaS platform design
3
iaas Documentation, Release 0.1.0
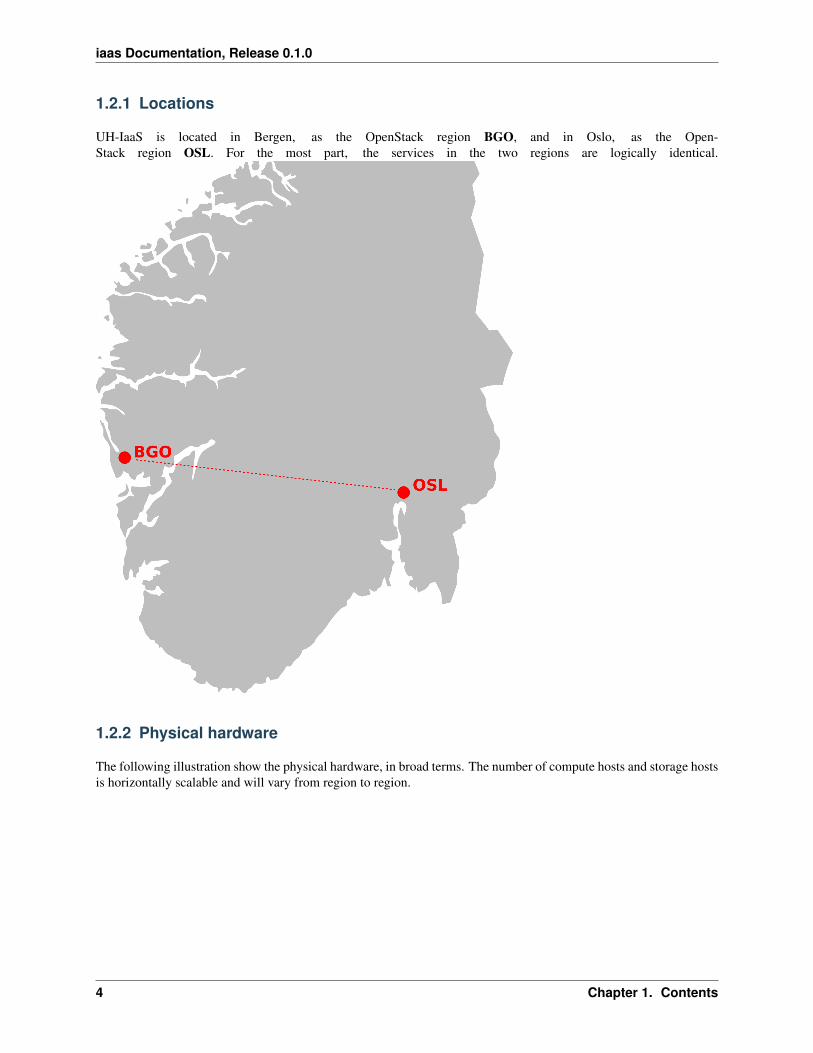
1.2.1 Locations
UH-IaaS is located in Bergen, as the OpenStack region BGO, and in Oslo, as the Open-Stack region OSL. For the most part, the services in the two regions are logically identical.
1.2.2 Physical hardware
The following illustration show the physical hardware, in broad terms. The number of compute hosts and storage hostsis horizontally scalable and will vary from region to region.
4 Chapter 1. Contents

iaas Documentation, Release 0.1.0
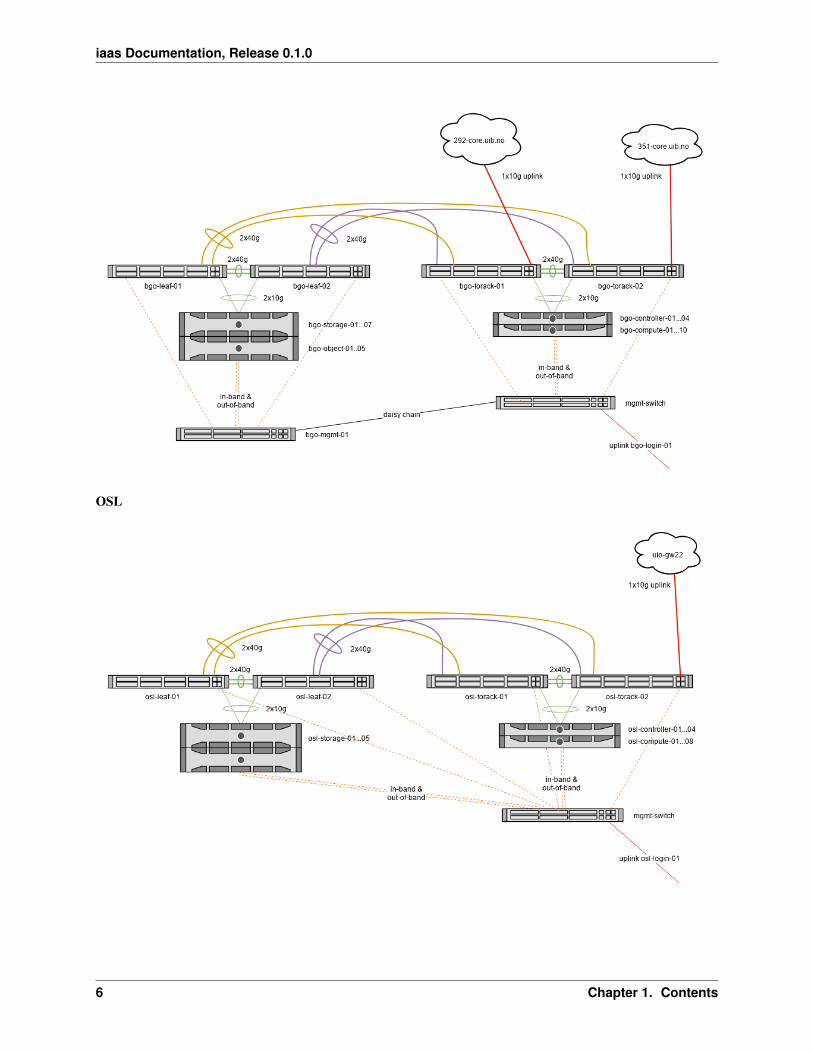
The illustration shows these types of physical components:
Management switch Network ethernet switch used for internal networking, i.e. non-routed RFC1918 addresses.These are only used for management tasks.
Public switch A switch that has access to Internet. These switches also perform layer 3 routing, and are used toprovide access to the public services in UH-IaaS.
Controller hosts Servers that are running virtual machines manually with libvirt (i.e. not managed by OpenStack).All OpenStack components such as the dashboard, API services etc. are running as virtual machines on thesehosts.
Compute hosts Servers that are used as compute hosts in OpenStack. Customer’s virtual machines are running onthese servers.
Storage hosts Servers that are part of the Ceph storage cluster. They provide storage services to OpenStack (e.g.storage volumes).
1.2.3 Networking overview
Physical networking connections of each site:
BGO
1.2. Design 5
iaas Documentation, Release 0.1.0
OSL
6 Chapter 1. Contents

iaas Documentation, Release 0.1.0
1.2.4 Virtual machines
The illustration below shows the various virtual machines running on the controller hosts.
Some of the virtual machines have a purely administrative purpose, some provide internal infrastructure services, andsome are running OpenStack components.
Some virtual machines are scaled out horizontally, typically one on each controller host, mostly this applies on Open-Stack services. This is done for efficiency and redundancy reasons.
OpenStack components
These VMs are purely running OpenStack components.
image-01 Runs the OpenStack Image component, Glance.
dashboard-01 Runs the OpenStack Dashboard component, Horizon.
novactrl-[01..n] Usually three VMs in a redundant setup, runs the controller part (e.g. API) of the OpenStack Com-pute component, Nova.
volume-01 Runs the OpenStack Volume component, Cinder.
telemetry-01 Runs the OpenStack metering component, Ceilometer.
network-[01..n] Usually three VMs in a redundant setup, runs the OpenStack Network component, Neutron.
1.2. Design 7

iaas Documentation, Release 0.1.0
identity-01 Runs the OpenStack Identity component, Keystone.
Infrastructure services
These VMs are running various infrastructure services, that are used by either the OpenStack components, or otherinfrastructure or administrative services, or both.
proxy-01 Proxy service for Internet access for the infrastructure nodes that are not on any public network.
ns-01 Autoritative DNS server.Available publicly as ns.<location>.uh-iaas.no.
resolver-0{1,2} Resolving (caching) DNS servers. These servers are running in a redundant setup via the Anycastprotocol. Available publicly as resolver.<location>.uh-iaas.no.
api-01 Runs HAProxy for all API services. Available publicly as api.uh-iaas.no.
db-global-01 MariaDB (MySQL) database that is cross-regional. This database is synced to the other region.
db-regional-01 MariaDB (MySQL) database that is regional. Contains only data that is localized to this region.
console-01 Provides console services for instances in OpenStack, available via the dashboard.
mq-01 Runs a message queue (RabbitMQ) that OpenStack uses for internal communication and messaging.
access-01 Provides authentication services via Dataporten.
metric-01 Collects data points for measuring performance counters and other things.
status-01 Provides a graphical view of performance counters and other metric data. Available publicly as https://status.uh-iaas.no/
nat-linux-0{1,2} Two nodes that functions as a NAT-ing proxy for instances, in order to give instances with a IPv6only network access to the outside world via their internal IPv4 address.
cephmon-[01..n] Runs the cephmon service for the Ceph storage cluster.
Administrative services
These VMs are running on a separate controller host, because they need to be up and running during maintenance onother VMs.
admin-01 Runs Foreman for e.g. provisioning tasks, and functions at Puppetmaster for all hosts.
monitor-01 Runs Sensu for monitoring tasks.
logger-01 Log receiver for all hosts.
builder-01 Runs our builder service, for building OpenStack images.
1.2.5 Development hardware requirements
A key point is that each location is built from the same hardware specification. This is done to simplify and limitinfluence of external variables as much as possible while building the base platform.
The spec represents a minimal baseline for one site/location.
8 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Networking
4x Layer 3 routers/switches
• Connected as routed leaf-spine fabric (OSPF)
• At least 48 ports 10gb SFP+ / 4 ports 40gb QSFP
• Support for ONIE/OCP preferred
1x L2 management switch
• 48 ports 1GbE, VLAN capable
• Remote management possible
Cabling and optics
• 48x 10GBase-SR SFP+ tranceivers
• 8x 40GBase-SR4 QSFP+ tranceivers
• 4x QSFP+ to QSFP+, 40GbE passive copper direct attach cable, 0.5 meter
• 4x 3 or 5 meter QSFP+ to QSFP+ OM3 MTP fiber cable
Servers
3x management nodes
• 1u 1x12 core with 128gb RAM
• 2x SFP+ 10gb and 2x 1gbE
• 2x SSD drives RAID1
• Room for more disks
• Redundant PSUs
3x compute nodes
• 1u 2x12 core with 512Gb RAM
• 2x SFP+ 10Gb and 2x 1GbE
• 2x SSD drives RAID1
• Room for more disks
• Redundant PSUs
5x storage nodes
• 2u 1x12 core with 128gb RAM
• 2x SFP+ 10Gb and 2x 1GbE
• 8x 3.5” 2tb SATA drives
• 4x 120gb SSD drives
• No RAID, only JBOD
• Room for more disks (12x 3.5” ?)
• Redundant PSUs
Comments
1.2. Design 9

iaas Documentation, Release 0.1.0
• Management and compute nodes could very well be the same chassis with different specs. Possibly evenhigher density like half width would be considered, but not blade chassis (it would mean non-standard ca-bling/connectivity)
• Important key attribute for SSD drives is sequential write performance. SSDs might be PCIe connected.
• 2tb disks for storage nodes to speed up recovery times with Ceph
1.3 Security
Warning: This document is currently under review/construction.
This document is an attempt to write up all the security measures that can, will or should be implemented. The basisis the OpenStack Security Guide on openstack.org. We use the sections in the security guide, and try to answer thefollowing questions:
1. Is this security measure implemented? and if not:
2. What are the potential security impact?
3. Other concerns?
4. Should this be implemented?
For each recommendation, there is at least one check that can have one of four different values:
• [PASS] This check has been passed
• [FAIL] This check is failed
• [----] This check has not been considered yet
• [N/A] This check is not applicable
• [DEFERRED] This check has been postponed, will be considered at a later time
1.3.1 [2019] System documentation
REVISION 2019-02-21
Contents
• [2019] System documentation
– System Inventory
Impact LowImplemented percent 75% (3/4)
System Inventory
From OpenStack Security Guide: System documentation:
10 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Documentation should provide a general description of the OpenStack environment and cover all systemsused (production, development, test, etc.). Documenting system components, networks, services, andsoftware often provides the bird’s-eye view needed to thoroughly cover and consider security concerns,attack vectors and possible security domain bridging points. A system inventory may need to captureephemeral resources such as virtual machines or virtual disk volumes that would otherwise be persistentresources in a traditional IT system.
The UH-IaaS infrastructure is, from hardware and up, managed completely by the UH-IaaS group, and thereforeindependent of each institution. Except for networking interface and physical hardware management, there are nodependencies on the institutions. Links to infrastructure documentation:
[PASS] Hardware inventory A high-level view of the hardware inventory is outlined in the document Physicalhardware.
[PASS] Software inventory A high-level view of the software inventory is outlined in the document Virtual ma-chines.
[PASS] Network topology A high-level view of the network topology is outlined in the document Networkingoverview.
[DEFERRED] Services, protocols and ports FIXME
1.3.2 [2019] Management
REVISION 2019-02-21
Contents
• [2019] Management
– Continuous systems management
* Vulnerability management
* Configuration management
* Secure backup and recovery
* Security auditing tools
– Integrity life-cycle
* Secure bootstrapping
* Runtime verification
* Server hardening
– Management interfaces
* Dashboard
* OpenStack API
* Secure shell (SSH)
* Management utilities
* Out-of-band management interface
1.3. Security 11

iaas Documentation, Release 0.1.0
Impact MediumImplemented percent 64% (11/17)
Continuous systems management
From OpenStack Security Guide: Management - Continuous systems management:
A cloud will always have bugs. Some of these will be security problems. For this reason, it is criticallyimportant to be prepared to apply security updates and general software updates. This involves smartuse of configuration management tools, which are discussed below. This also involves knowing when anupgrade is necessary.
Vulnerability management
Updates are announced on the OpenStack Announce mailing list. The security notifications are alsoposted through the downstream packages, for example, through Linux distributions that you may be sub-scribed to as part of the package updates.
[PASS] Triage When we are notified of a security update, this is discussed at the next morning meeting. We willthen decide the impact of the update to our environment, and take proper action.
[PASS] Testing the updates We have test clouds in each location (currently OSL and BGO) which in most respectsare identical to the production clouds. This allows for easy testing of updates.
[PASS] Deploying the updates When testing is completed and the update is verified, and we are satisfied with anyperformance impact, stability, application impact etc., the update is deployed in production. This is done via thefollowing procedure:
• Patching
Configuration management
Deployment of both physical and virtual nodes in UH-IaaS is done using Ansible playbooks, which are maintainedon GitHub. The configuration managements is completely automated via Puppet. The Puppet code and hieradata ismaintained on GitHub. All changes are tracked via Git.
[PASS] changes
Secure backup and recovery
If we at some point decide to take backup of the infrastructure or instances, we should include the backup proceduresand policies in the overall security plan.
[PASS] Backup procedure and policy We do not take backup of anything (yet).
Security auditing tools
We should consider using SCAP or similar security auditing tools in combination with configuration management.
[FAIL] Security auditing tools Security auditing tools such as SCAP adds complexity and significant delays in thepipeline. Therefore, this is not a priority at this time.
12 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Integrity life-cycle
From OpenStack Security Guide: Management - Integrity life-cycle:
We define integrity life cycle as a deliberate process that provides assurance that we are always runningthe expected software with the expected configurations throughout the cloud. This process begins withsecure bootstrapping and is maintained through configuration management and security monitoring.
Secure bootstrapping
The Security Guide recommends having an automated provisioning process for all nodes in the cloud. This includescompute, storage, network, service and hybrid nodes. The automated provisioning process also facilitates securitypatching, upgrades, bug fixes, and other critical changes. Software that runs with the highest privilege levels in thecloud needs special attention.
[PASS] Node provisioning We use PXE for provisioning, which is recommended. We also use a separate, isolatednetwork within the management security domain for provisioning. The provisioning process is handled byAnsible.
[FAIL] Verified boot It is recommended to use secure boot via TPM chip to boot the infrastructure nodes in thecloud. TPM adds unwanted complexity and we don’t use it.
[PASS] Node hardening We do general node hardening via a security baseline which we maintain via Puppet. Thesecurity baseline is based on best practice from the OS vendor, as well as our own experience.
Runtime verification
From OpenStack Security Guide:
Once the node is running, we need to ensure that it remains in a good state over time. Broadly speaking,this includes both configuration management and security monitoring. The goals for each of these areasare different. By checking both, we achieve higher assurance that the system is operating as desired.
[FAIL] Intrusion detection system At the moment we don’t see the need to run an IDS system.
Server hardening
This mostly includes file integrity management.
[FAIL] File integrity management (FIM) We should consider a FIM tool to ensure that files such as sensitivesystem or application configuration files are no corrupted or changed to allow unauthorized access or maliciousbehaviour.
• We don’t run a specific FIM tool, but our configuration management system (Puppet) functions as a watch-dog for most important files.
Management interfaces
From OpenStack Security Guide: Management - Management interfaces:
It is necessary for administrators to perform command and control over the cloud for various operationalfunctions. It is important these command and control facilities are understood and secured.
OpenStack provides several management interfaces for operators and tenants:
• OpenStack dashboard (horizon)
1.3. Security 13

iaas Documentation, Release 0.1.0
• OpenStack API
• Secure shell (SSH)
• OpenStack management utilities such as nova-manage and glance-manage
• Out-of-band management interfaces, such as IPMI
Dashboard
[PASS] Capabilities The dashboard is configured via Puppet, and shows only capabilities that are known to workproperly. Buttons, menu items etc. that doesn’t work or provides capabilities that UH-IaaS doesn’t offer aredisabled in the dashboard.
[DEFERRED] Security considerations There are a few things that need to be considered (from ‘OpenStack Secu-rity Guide‘_):
• The dashboard requires cookies and JavaScript to be enabled in the web browser.
– FIXME: Users should be warned according to EU law.
• The web server that hosts the dashboard should be configured for TLS to ensure data is encrypted.
– FIXME: Ensure TLS 1.2
• Both the horizon web service and the OpenStack API it uses to communicate with the back end are sus-ceptible to web attack vectors such as denial of service and must be monitored.
– (pass) We have monitoring in place
• It is now possible (though there are numerous deployment/security implications) to upload an image filedirectly from a user’s hard disk to OpenStack Image service through the dashboard. For multi-gigabyteimages it is still strongly recommended that the upload be done using the glance CLI.
– (pass) Image uploading is done directly to Glance via a redirect in dashboard.
• Create and manage security groups through dashboard. The security groups allows L3-L4 packet filteringfor security policies to protect virtual machines.
– (pass) The default security group blocks everything. Users can edit security groups through the dash-board.
OpenStack API
[DEFERRED] Security considerations
There are a few things that need to be considered (from ‘OpenStack Security Guide‘_):
• The API service should be configured for TLS to ensure data is encrypted.
– FIXME: Ensure TLS 1.2
• As a web service, OpenStack API is susceptible to familiar web site attack vectors such as denial of serviceattacks.
– (pass) We have monitoring in place
14 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Secure shell (SSH)
[N/A] Host key fingerprints Host key fingerprints should be stored in a secure and queryable location. One partic-ularly convenient solution is DNS using SSHFP resource records as defined in RFC-4255. For this to be secure,it is necessary that DNSSEC be deployed.
• Host keys are wiped periodically to avoid conflicts and ensure that reinstalled hosts function correctly.SSH access is done through a single entry point and host keys are not important.
Management utilities
[PASS] Security considerations There are a few things that need to be considered (from ‘OpenStack SecurityGuide‘_):
• The dedicated management utilities (*-manage) in some cases use the direct database connection.
– (pass) We don’t use dedicated management utilities unless strictly necessary
• Ensure that the .rc file which has your credential information is secured.
– (pass) Credential information is stored securely.
Out-of-band management interface
[PASS] Security considerations There are a few things that need to be considered (from ‘OpenStack SecurityGuide‘_):
• Use strong passwords and safeguard them, or use client-side TLS authentication.
– (pass) We have strong passwords that are stored securely
• Ensure that the network interfaces are on their own private(management or a separate) network. Segregatemanagement domains with firewalls or other network gear.
– (pass) OOB interfaces are on a private network
• If you use a web interface to interact with the BMC/IPMI, always use the TLS interface, such as HTTPS orport 443. This TLS interface should NOT use self-signed certificates, as is often default, but should havetrusted certificates using the correctly defined fully qualified domain names (FQDNs).
– (n/a) OOB interfaces are on a closed network and trusted CA is not necessary.
• Monitor the traffic on the management network. The anomalies might be easier to track than on the busiercompute nodes.
– (n/a) Not necessary due to closed network.
1.3.3 [2019] Secure communication
REVISION 2019-02-21
Contents
• [2019] Secure communication
– Certification authorities
1.3. Security 15

iaas Documentation, Release 0.1.0
– TLS libraries
– Cryptographic algorithms, cipher modes, and protocols
Impact HighImplemented percent 50% (3/6)
From OpenStack Security Guide: Secure communication:
There are a number of situations where there is a security requirement to assure the confidentiality orintegrity of network traffic in an OpenStack deployment. This is generally achieved using cryptographicmeasures, such as the Transport Layer Security (TLS) protocol.
Bottom line is that all endpoints, whether they are internal or external, should be secured with encryption. TLS isstrongly preferred, due to recent published security vulnerabilities in SSL.
There are a number of services that need to be addressed:
• Compute API endpoints
• Identity API endpoints
• Networking API endpoints
• Storage API endpoints
• Messaging server
• Database server
• Dashboard
Certification authorities
The security guide recommends that we use separate PKI deployments for internal systems and public facing services.In the future, we may want to use separate PKI deployments for different security domains.
[PASS] Customer facing interfaces using trusted CA All customer facing interfaces should be provisioned usingCertificate Authorities that are installed in the operating system certificate bundles by default. It should justwork without the customer having to accept an untrusted CA, or having to install some third-party software. Weneed certificates signed by a widely recognized public CA.
• We use Digicert Terena CA on all customer facing interfaces.
[FAIL] Internal endpoints use non-public CA As described above, it is recommended to use a private CA forinternal endpoints.
• db connection between regions use non-public CA
• internal connections within regions use private networks and using a CA for these provide very little addedvalue
TLS libraries
From OpenStack Security Guide:
The TLS and HTTP services within OpenStack are typically implemented using OpenSSL which has amodule that has been validated for FIPS 140-2.
We need to make sure that we’re using an updated version of OpenSSL.
16 Chapter 1. Contents

iaas Documentation, Release 0.1.0
[PASS] Ensure updated OpenSSL UH-IaaS is based on CentOS, and uses the OpenSSL library from that distro.We need to make sure that OpenSSL is up-to-date.
• OpenSSL and all other packages are manually updated once a month.
Cryptographic algorithms, cipher modes, and protocols
The security guide recommends using TLS 1.2, as previous versions are known to be vulnerable. Furthermore, itis recommended to limit the cipher suite to ECDHE-ECDSA-AES256-GCM-SHA384. It is acceptable to acceptHIGH:!aNULL:!eNULL:!DES:!3DES:!SSLv3:!TLSv1:!CAMELLIA in cases where we don’t control both end-points.
[FAIL] Ensure TLS 1.2 Make sure that only TLS 1.2 is used. Previous versions of TLS, as well as SSL, should bedisabled completely.
• We support TLS 1.1 and 1.2 on dashboard
[DEFERRED] Limit cipher suite on public endpoints Limit the cipher suite on public facing endpoints to the gen-eral HIGH:!aNULL:!eNULL:!DES:!3DES:!SSLv3:!TLSv1:!CAMELLIA.
[N/A] Limit cipher suite on internal endpoints Limit the cipher suite on public facing endpoints to ECDHE-ECDSA-AES256-GCM-SHA384.
• Not using a internal CA so this doesn’t apply in our case
1.3.4 [2019] API endpoints
REVISION 2019-02-21
Contents
• [2019] API endpoints
– API endpoint configuration recommendations
* Internal API communications
* Paste and middleware
* API endpoint process isolation and policy
* API endpoint rate-limiting
Impact HighImplemented percent 85% (6/7)
From OpenStack Security Guide: API endpoints:
The process of engaging an OpenStack cloud is started through the querying of an API endpoint. Whilethere are different challenges for public and private endpoints, these are high value assets that can posea significant risk if compromised.
API endpoint configuration recommendations
1.3. Security 17

iaas Documentation, Release 0.1.0
Internal API communications
From OpenStack Security Guide:
OpenStack provides both public facing and private API endpoints. By default, OpenStack componentsuse the publicly defined endpoints. The recommendation is to configure these components to use the APIendpoint within the proper security domain.
Services select their respective API endpoints based on the OpenStack service catalog. These servicesmight not obey the listed public or internal API end point values. This can lead to internal managementtraffic being routed to external API endpoints.
[PASS] Configure internal URLs in the Identity service catalog The guide recommends that our Identity servicecatalog be aware of our internal URLs. This feature is not utilized by default, but may be leveraged throughconfiguration. See API endpoint configuration recommendations for details.
• All services have configured admin, internal and public endpoints.
[PASS] Configure applications for internal URLs It is recommended that each OpenStack service communicatingto the API of another service must be explicitly configured to access the proper internal API endpoint. See APIendpoint configuration recommendations.
All service to service communication use internal endpoints within a region. This includes:
• volume to identity
• image to identity
• network to identity
• compute to identity
• compute to image
• compute to volume
• compute to network
Paste and middleware
From OpenStack Security Guide:
Most API endpoints and other HTTP services in OpenStack use the Python Paste Deploy library. Froma security perspective, this library enables manipulation of the request filter pipeline through the appli-cation’s configuration. Each element in this chain is referred to as middleware. Changing the order offilters in the pipeline or adding additional middleware might have unpredictable security impact.
[N/A] Document middleware We should be careful when implementing non-standard software in the middleware,and this should be thoroughly documented.
• We are not using any non-standard middleware
API endpoint process isolation and policy
From OpenStack Security Guide:
You should isolate API endpoint processes, especially those that reside within the public security domainshould be isolated as much as possible. Where deployments allow, API endpoints should be deployed onseparate hosts for increased isolation.
[N/A] Namespaces Linux supports namespaces to assign processes into independent domains.
18 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• All service backends run on different virtual hosts.
[PASS] Network policy We should pay special attention to API endpoints, as they typically bridge multiple securitydomains. Policies should be in place and documented, and we can use firewalls, SELinux, etc. to enforce propercompartmentalization in the network layer.
• The API endpoints are protected via a load balancer and strict firewalls. SELinux are running in enforcedmode.
[PASS] Mandatory access controls API endpoint processes should be as isolated from each other as possible. Thisshould be enforced through Mandatory Access Controls (e.g. SELinux), not just Discretionary Access Controls.
• SELinux is running in enforced mode on all nodes (virtual and physical) that are involved in API endpoints.
API endpoint rate-limiting
From OpenStack Security Guide:
*Within OpenStack, it is recommended that all endpoints, especially public, are provided with anextra layer of protection, by means of either a rate-limiting proxy or web application firewall.*
[DEFERRED] Rate-limiting on API endpoints FIXME: Add rate-limiting to HAProxy
1.3.5 [2019] Identity
REVISION 2019-02-21
Contents
• [2019] Identity
– Authentication
* Invalid login attempts
* Multi-factor authentication
– Authentication methods
– Authorization
* Establish formal access control policies
* Service authorization
* Administrative users
– Policies
– Checklist
Impact HighImplemented percent 88% (16/18)
From OpenStack Security Guide: Identity:
Identity service (keystone) provides identity, token, catalog, and policy services for use specifically byservices in the OpenStack family. Identity service is organized as a group of internal services exposedon one or many endpoints. Many of these services are used in a combined fashion by the frontend, for
1.3. Security 19

iaas Documentation, Release 0.1.0
example an authenticate call will validate user/project credentials with the identity service and, uponsuccess, create and return a token with the token service.
Authentication
Ref: OpenStack Security Guide: Identity - Authentication
Invalid login attempts
[PASS] Prevent or mitigate brute-force attacks A pattern of repetitive failed login attempts is generally an indi-cator of brute-force attacks. This is important to us as ours is a public cloud. We need to figure out if ouruser authentication service has the possibility to block out an account after some configured number of failedlogin attempts. If not, describe policies around reviewing access control logs to identify and detect unauthorizedattempts to access accounts.
• Users are automatically banned from logging in after a number of authentication requests.
Multi-factor authentication
[PASS] Multi-factor authentication for privileged accounts
We should employ multi-factor authentication for network access to privileged user accounts. This willprovide insulation from brute force, social engineering, and both spear and mass phishing attacks thatmay compromise administrator passwords.
• While authentication to service accounts is possible from the “outside”, administrative actions arenot possible unless connecting from the “inside”. In order to access the “inside”, 2-factor authenti-cation is required.
Authentication methods
Ref: OpenStack Security Guide: Identity - Authentication methods
[N/A] Document authentication policy requirements We should document (or provide link to external documen-tation) the authentication policy requirements, such as password policy enforcement (password length, diversity,expiration etc.).
• Regular users are set up after autentication through Dataporten. Their password are auto-generated andrandom, the logic used is currently only documented in code (github:nocams-himlar-db-prep).
Authorization
Ref: OpenStack Security Guide: Identity - Authorization
The Identity service supports the notion of groups and roles. Users belong to groups while a grouphas a list of roles. OpenStack services reference the roles of the user attempting to access the service.The OpenStack policy enforcer middleware takes into consideration the policy rule associated with eachresource then the user’s group/roles and association to determine if access is allowed to the requestedresource.
20 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Establish formal access control policies
[N/A] Describe formal access control policies The policies should include the conditions and processes for creat-ing, deleting, disabling, and enabling accounts, and for assigning privileges to the accounts.
• We use an external authentication point
[DEFERRED] Describe periodic review We should periodically review the policies to ensure that the configurationis in compliance with approved policies.
• FIXME: Work in progress.
Service authorization
[PASS] Don’t use “tempAuth” file for service auth The Compute and Object Storage can be configured to use theIdentity service to store authentication information. The “tempAuth” file method displays the password in plaintext and should not be used.
• tempAuth is not used.
[FAIL] Use client authentication for TLS The Identity service supports client authentication for TLS which maybe enabled. TLS client authentication provides an additional authentication factor, in addition to the user nameand password, that provides greater reliability on user identification.
• The negative implications for the user experience by implementing this is considered to outweight the extrasecurity gained by this.
[PASS] Protect sensitive files The cloud administrator should protect sensitive configuration files from unautho-rized modification. This can be achieved with mandatory access control frameworks such as SELinux, including/etc/keystone/keystone.conf and X.509 certificates.
• SELinux is running in enforcing mode.
Administrative users
We recommend that admin users authenticate using Identity service and an external authentication servicethat supports 2-factor authentication, such as a certificate. This reduces the risk from passwords that maybe compromised. This recommendation is in compliance with NIST 800-53 IA-2(1) guidance in the use ofmulti-factor authentication for network access to privileged accounts.
[PASS] Use 2-factor authentication for administrative access Administrative access is provided via a login ser-vice that requires 2-factor authentication.
Policies
Ref: OpenStack Security Guide: Identity - Policies
[PASS] Describe policy configuration management Each OpenStack service defines the access policies for its re-sources in an associated policy file. A resource, for example, could be API access, the ability to attach to avolume, or to fire up instances. The policy rules are specified in JSON format and the file is called policy.json.Ensure that any changes to the access control policies do not unintentionally weaken the security of any resource.
• We are using default policies, with overrides to disable certain capabilities.
1.3. Security 21

iaas Documentation, Release 0.1.0
Checklist
Ref: OpenStack Security Guide: Identity - Checklist
See the above link for info about these checks.
[PASS] Check-Identity-01: Is user/group ownership of config files set to keystone? Ownership set toroot:keystone or keystone:keystone
[PASS] Check-Identity-02: Are strict permissions set for Identity configuration files? Not all files in check listexists, the rest is OK
[N/A] Check-Identity-03: is TLS enabled for Identity? Endpoint runs on the load balancer
[PASS] Check-Identity-04: Does Identity use strong hashing algorithms for PKI tokens? Yes, set to bcrypt
[PASS] Check-Identity-05: Is max_request_body_size set to default (114688)? Yes
[N/A] Check-Identity-06: Disable admin token in /etc/keystone/keystone.conf Enabled in keystone.conf, but theservice itself is disabled.
[PASS] Check-Identity-07: insecure_debug false in /etc/keystone/keystone.conf Yes
[PASS] Check-Identity-08: Use fernet token in /etc/keystone/keystone.conf Yes
1.3.6 Dashboard
Last changed: 2019-08-19
Contents
• Dashboard
– Domain names, dashboard upgrades, and basic web server configuration
* Domain names
* Basic web server configuration
* Allowed hosts
* Horizon image upload
– HTTPS, HSTS, XSS, and SSRF
* Cross Site Scripting (XSS)
* Cross Site Request Forgery (CSRF)
* HTTPS
* HTTP Strict Transport Security (HSTS)
– Front-end caching and session back end
* Front-end caching
* Session back end
– Static media
– Secret key
– Cookies
22 Chapter 1. Contents

iaas Documentation, Release 0.1.0
– Cross Origin Resource Sharing (CORS)
– Checklist
Impact HighImplemented percent 52% (15/29)
From OpenStack Security Guide: Dashboard:
Horizon is the OpenStack dashboard that provides users a self-service portal to provision their own re-sources within the limits set by administrators. These include provisioning users, defining instance flavors,uploading VM images, managing networks, setting up security groups, starting instances, and accessingthe instances through a console.
Domain names, dashboard upgrades, and basic web server configuration
Ref: OpenStack Security Guide: Dashboard - Domain names, dashboard upgrades, and basic web server configuration
Domain names
From OpenStack Security Guide:
We strongly recommend deploying dashboard to a second-level domain, such as https://example.com,rather than deploying dashboard on a shared subdomain of any level, for examplehttps://openstack.example.org or https://horizon.openstack.example.org. We also advise against de-ploying to bare internal domains like https://horizon/. These recommendations are based on thelimitations of browser same-origin-policy.
[FAIL] Use second-level domain We are not given our own second-devel domain. The dashboard is available as“dashboard.uh-iaas.no”.
[DEFERRED] Employ HTTP Strict Transport Security (HSTS) If not using second-level domain, we are advisedto avoid a cookie-backed session store and employ HTTP Strict Transport Security (HSTS)
• We need to revisit this as soon as possible.
Basic web server configuration
From OpenStack Security Guide:
The dashboard should be deployed as a Web Services Gateway Interface (WSGI) application behind anHTTPS proxy such as Apache or nginx. If Apache is not already in use, we recommend nginx since it islightweight and easier to configure correctly.
[PASS] Is dashboard deployed as a WSGI application behind an HTTPS proxy? Yes, dashboard is deployedusing mod_wsgi on an Apache server.
Allowed hosts
From OpenStack Security Guide:
1.3. Security 23

iaas Documentation, Release 0.1.0
Configure the ALLOWED_HOSTS setting with the fully qualified host name(s) that are served by theOpenStack dashboard. Once this setting is provided, if the value in the “Host:” header of an incomingHTTP request does not match any of the values in this list an error will be raised and the requestor willnot be able to proceed. Failing to configure this option, or the use of wild card characters in the specifiedhost names, will cause the dashboard to be vulnerable to security breaches associated with fake HTTPHost headers.
[DEFERRED] Is ALLOWED_HOSTS configured for dashboard? FIXME
Horizon image upload
It is recommended that we disable HORIZON_IMAGES_ALLOW_UPLOAD unless we have a plan to prevent re-source exhaustion and denial of service.
[DEFERRED] Is HORIZON_IMAGES_ALLOW_UPLOAD disabled? We are currently willing to accept the riskof DoS by allowing image uploads.
HTTPS, HSTS, XSS, and SSRF
Ref: OpenStack Security Guide: Dashboard - HTTPS, HSTS, XSS, and SSRF
Cross Site Scripting (XSS)
From OpenStack Security Guide:
Unlike many similar systems, the OpenStack dashboard allows the entire Unicode character set in mostfields. This means developers have less latitude to make escaping mistakes that open attack vectors forcross-site scripting (XSS).
[N/A] Audit custom dashboards Audit any custom dashboards, paying particular attention to use of themark_safe function, use of is_safe with custom template tags, the safe template tag, anywhere autoescape is turned off, and any JavaScript which might evaluate improperly escaped data.
• We are not using custom dashboards
Cross Site Request Forgery (CSRF)
From OpenStack Security Guide:
Dashboards that utilize multiple instances of JavaScript should be audited for vulnerabilities such asinappropriate use of the @csrf_exempt decorator.
[N/A] Audit custom dashboards We are not using custom dashboards
HTTPS
From OpenStack Security Guide:
Deploy the dashboard behind a secure HTTPS server by using a valid, trusted certificate from a recognizedcertificate authority (CA).
[PASS] Use trusted certificate for dashboard We are using a trusted CA
24 Chapter 1. Contents

iaas Documentation, Release 0.1.0
[PASS] Redirect to fully qualified HTTPS URL HTTP requests to the dashboard domain are configured to redi-rect to the fully qualified HTTPS URL.
HTTP Strict Transport Security (HSTS)
It is highly recommended to use HTTP Strict Transport Security (HSTS).
[DEFERRED] Use HSTS FIXME: Revisit this ASAP
Front-end caching and session back end
Ref: OpenStack Security Guide: Dashboard - Front-end caching and session back end
Front-end caching
[PASS] Do not use front-end caching tools We are not using front-end caching.
Session back end
It is recommended to use django.contrib.sessions.backends.cache as our session back end with mem-cache as the cache. This as opposed to the default, which saves user data in signed, but unencrypted cookies stored inthe browser.
[DEFERRED] Consider using caching back end FIXME: Revisit this
Static media
Ref: OpenStack Security Guide: Dashboard - Static media
The dashboard’s static media should be deployed to a subdomain of the dashboard domain and served bythe web server. The use of an external content delivery network (CDN) is also acceptable. This subdomainshould not set cookies or serve user-provided content. The media should also be served with HTTPS.
[DEFERRED] Static media via subdomain FIXME: Implemented this.
[N/A] Subdomain not serving cookies or user-provided content FIXME: Make sure
[N/A] Subdomain via HTTPS FIXME: Make sure
Secret key
Ref: OpenStack Security Guide: Dashboard - Secret key
The dashboard depends on a shared SECRET_KEY setting for some security functions. The secret keyshould be a randomly generated string at least 64 characters long, which must be shared across allactive dashboard instances. Compromise of this key may allow a remote attacker to execute arbitrarycode. Rotating this key invalidates existing user sessions and caching. Do not commit this key to publicrepositories.
[----] Randomly generated string at least 64 characters long Randomly generated, but much shorter than 64chars
[PASS] Not in public repo We have internal stores for secret keys.
1.3. Security 25

iaas Documentation, Release 0.1.0
Cookies
Ref: OpenStack Security Guide: Dashboard - Cookies
[----] Session cookies should be set to HTTPONLY FIXME: Make sure
[PASS] Never configure CSRF or session cookies to have a wild card domain with a leading dot Configured in/etc/openstack-dashboard/local_settings:
CSRF_COOKIE_SECURE = True
[PASS] Horizon’s session and CSRF cookie should be secured when deployed with HTTPS Configured in/etc/openstack-dashboard/local_settings:
SESSION_COOKIE_SECURE = True
Cross Origin Resource Sharing (CORS)
Ref: OpenStack Security Guide: Dashboard - Cross Origin Resource Sharing (CORS)
Configure your web server to send a restrictive CORS header with each response, allowing only thedashboard domain and protocol
[----] Restrictive CORS header FIXME: Make sure
Checklist
Ref: OpenStack Security Guide: Dashboard - Checklist
See the above link for info about these checks.
[N/A] Check-Dashboard-01: Is user/group of config files set to root/horizon? The “horizon” group does not ex-ist in our case. The local_settings file has user/group “root root”:
# ls -l /etc/openstack-dashboard/local_settings-rw-r--r--. 1 root root 30438 Oct 20 10:44 /etc/openstack-dashboard/local_settings
[N/A] Check-Dashboard-02: Are strict permissions set for horizon configuration files? As the horizon userdoesn’t exist, and there are no real users, the only system users that needs to read the the local_settings fileare root and apache. In our case, there is no reason to restrict the access to this file more than we already have,using mode 0644.
[----] Check-Dashboard-03: Is USE_SSL parameter set to True? FIXME
[PASS] Check-Dashboard-04: Is CSRF_COOKIE_SECURE parameter set to True? Yes
[PASS] Check-Dashboard-05: Is SESSION_COOKIE_SECURE parameter set to True? Yes
[----] Check-Dashboard-06: Is SESSION_COOKIE_HTTPONLY parameter set to True? FIXME
[----] Check-Dashboard-07: Is password_autocomplete set to False? Is “off” the default?
[----] Check-Dashboard-08: Is disable_password_reveal set to True? Is “true” the default?
1.3.7 [2019] Compute
REVISION 2019-02-25
26 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Contents
• [2019] Compute
– Hypervisor selection
– Hardening the virtualization layers
* Physical hardware (PCI passthrough)
* Minimizing the QEMU code base
* Compiler hardening
* Mandatory access controls
– How to select virtual consoles
– Checklist
Impact HighImplemented percent 78% (7/9)
From OpenStack Security Guide: Compute:
The OpenStack Compute service (nova) is one of the more complex OpenStack services. It runs in manylocations throughout the cloud and interacts with a variety of internal services. The OpenStack Computeservice offers a variety of configuration options which may be deployment specific. In this chapter we willcall out general best practice around Compute security as well as specific known configurations that canlead to security issues. In general, the nova.conf file and the /var/lib/nova locations should be secured.Controls like centralized logging, the policy.json file, and a mandatory access control framework shouldbe implemented. Additionally, there are environmental considerations to keep in mind, depending on whatfunctionality is desired for your cloud.
Hypervisor selection
Ref: OpenStack Security Guide: Compute - Hypervisor selection
We are using KVM.
Hardening the virtualization layers
Ref: OpenStack Security Guide: Compute - Hardening the virtualization layers
Physical hardware (PCI passthrough)
Many hypervisors offer a functionality known as PCI passthrough. This allows an instance to have di-rect access to a piece of hardware on the node. For example, this could be used to allow instances toaccess video cards or GPUs offering the compute unified device architecture (CUDA) for high perfor-mance computation. This feature carries two types of security risks: direct memory access and hardwareinfection.
[N/A] Ensure that the hypervisor is configured to utilize IOMMU Not applicable as PCI passthrough is dis-abled.
1.3. Security 27

iaas Documentation, Release 0.1.0
[PASS] Disable PCI passthrough PCI passthrough is disabled. We may enable PCI passthrough for special com-pute nodes with GPU etc., but these will be confined in spesialized availability zones and not generally available.
Minimizing the QEMU code base
Does not apply. We are using precompiled QEMU.
Compiler hardening
Does not apply. We are using precompiled QEMU.
Mandatory access controls
[PASS] Ensure SELinux / sVirt is running in Enforcing mode SELinux is running in enforcing mode on all hy-pervisor nodes.
How to select virtual consoles
Ref: OpenStack Security Guide: Compute - How to select virtual consoles
[PASS] Is the VNC service encrypted? Yes. Communication between the customer and the public facing VNCservice is encrypted.
Checklist
Ref: OpenStack Security Guide: Compute - Checklist
See the above link for info about these checks.
[PASS] Check-Compute-01: Is user/group ownership of config files set to root/nova? Yes
[PASS] Check-Compute-02: Are strict permissions set for configuration files? Yes
[PASS] Check-Compute-03: Is keystone used for authentication? Yes
[FAIL] Check-Compute-04: Is secure protocol used for authentication? Communication is completely on theinside on a private network, which we consider to be an acceptible risk.
[FAIL] Check-Compute-05: Does Nova communicate with Glance securely? Communication is completely onthe inside on a private network, which we consider to be an acceptible risk.
1.3.8 [2019] Block Storage
REVISION 2019-02-25
Contents
• [2019] Block Storage
– UH-IaaS block storage description
– Checklist
28 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Impact HighImplemented percent 55% (5/9)
From OpenStack Security Guide: Block Storage:
OpenStack Block Storage (cinder) is a service that provides software (services and libraries) to self-service manage persistent block-level storage devices. This creates on-demand access to Block Storageresources for use with OpenStack Compute (nova) instances. This creates software-defined storage viaabstraction by virtualizing pools of block storage to a variety of back-end storage devices which canbe either software implementations or traditional hardware storage products. The primary functions ofthis is to manage the creation, attaching and detaching of the block devices. The consumer requires noknowledge of the type of back-end storage equipment or where it is located.
UH-IaaS block storage description
We have deployed a cinder backend based on Ceph, the clustered file system. Every compute node isgiven read/write access to a pool where instance block volumes are stored. The connection is made withthe ceph rbd client.
Checklist
Ref: OpenStack Security Guide: Block Storage - Checklist
See the above link for info about these checks.
[PASS] Check-Block-01: Is user/group ownership of config files set to root/cinder? Yes
[PASS] Check-Block-02: Are strict permissions set for configuration files? Yes
[PASS] Check-Block-03: Is keystone used for authentication? Yes
[FAIL] Check-Block-04: Is TLS enabled for authentication? Communication is completely on the inside on aprivate network, which we consider to be an acceptible risk.
[FAIL] Check-Block-05: Does cinder communicate with nova over TLS? Communication is completely on theinside on a private network, which we consider to be an acceptible risk.
[FAIL] Check-Block-06: Does cinder communicate with glance over TLS? Communication is completely onthe inside on a private network, which we consider to be an acceptible risk.
[N/A] Check-Block-07: Is NAS operating in a secure environment? We do not have a NAS in our environment.
[PASS] Check-Block-08: Is max size for the body of a request set to default (114688)? Yes
[FAIL] Check-Block-09: Is the volume encryption feature enabled? We do not offer encrypted volumes at thistime.
1.3.9 [2019] Shared File Systems
REVISION 2019-02-25
Contents
• [2019] Shared File Systems
1.3. Security 29

iaas Documentation, Release 0.1.0
From OpenStack Security Guide: Shared File Systems:
The Shared File Systems service (manila) provides a set of services for management of shared file systemsin a multi-tenant cloud environment, similar to how OpenStack provides for block-based storage manage-ment through the OpenStack Block Storage service project. With the Shared File Systems service, you cancreate a remote file system, mount the file system on your instances, and then read and write data fromyour instances to and from your file system.
Note: Does not apply. We are not using Manila.
1.3.10 [2019] Networking
REVISION 2019-03-14
Contents
• [2019] Networking
– Networking services
* L2 isolation using VLANs and tunneling
* Network services
– Networking services security best practices
* OpenStack Networking service configuration
– Securing OpenStack networking services
* Networking resource policy engine
* Security groups
* Quotas
– Checklist
Impact HighImplemented percent 85% (12/14)
From OpenStack Security Guide: Networking:
OpenStack Networking enables the end-user or tenant to define, utilize, and consume networking re-sources. OpenStack Networking provides a tenant-facing API for defining network connectivity and IPaddressing for instances in the cloud in addition to orchestrating the network configuration. With thetransition to an API-centric networking service, cloud architects and administrators should take into con-sideration best practices to secure physical and virtual network infrastructure and services.
Networking services
Ref: OpenStack Security Guide: Networking - Networking services
30 Chapter 1. Contents

iaas Documentation, Release 0.1.0
L2 isolation using VLANs and tunneling
Does not apply. We’re using Calico, in which L2 isn’t employed at all.
Network services
[PASS] Use Neutron for security groups The calico neutron network plugin provides a rich security feature set.Calico uses neutron security groups and implements the rules with iptables on the compute hosts. Thus, securityrulesets can be described down to instance level.
Networking services security best practices
Ref: OpenStack Security Guide: Networking - Networking services security best practices
[PASS] Document how Calico is used in UH-IaaS infrastructure We enable the calico plugin as the neutron coreplugin system wide. Thus, no L2 connectivity is provided between instances, and as a design feature, no projectisolation on L3 connectivity. In other words, there is no such thing as a private network, even for RFC 1918address spaces. This design relies on security groups to provide isolation and pr project security.
[N/A] Document which security domains have access to OpenStack network node As a consequence of ournetwork design, no network nodes are deployed.
[N/A] Document which security domains have access to SDN services node We do not use SDN service nodes.
OpenStack Networking service configuration
[PASS] Restrict bind address of the API server: neutron-server Neutron API servers is bound to interal networkonly.
Securing OpenStack networking services
Ref: OpenStack Security Guide: Networking - Securing OpenStack networking services
Networking resource policy engine
From OpenStack Security Guide:
A policy engine and its configuration file, policy.json, within OpenStack Networking provides a method toprovide finer grained authorization of users on tenant networking methods and objects. The OpenStackNetworking policy definitions affect network availability, network security and overall OpenStack security.
[PASS] Evaluate network policy User creation of networks, virtual routers and networks is prohibited by policy.Only administrator created networking resources are available for projects and users.
Security groups
‘‘nova.conf‘‘ should always disable built-in security groups and proxy all security group calls to theOpenStack Networking API when using OpenStack Networking.
[PASS] Set firewall_driver option in nova.conf firewall_driver is set to nova.virt.firewall.NoopFirewallDriverso that nova-compute does not perform iptables-based filtering itself.
1.3. Security 31

iaas Documentation, Release 0.1.0
[FAIL] Set security_group_api option in nova.conf It is recommended that security_group_api is set to neutronso that all security group requests are proxied to the OpenStack Networking service.
We do not set the security_group_api option at all.
Quotas
[N/A] Document choices wrt. networking quotas As users can not create networking resources, no quotas apply.
Checklist
Ref: OpenStack Security Guide: Networking - Checklist
See the above link for info about these checks.
[PASS] Check-Neutron-01: Is user/group ownership of config files set to root/neutron? Yes
[PASS] Check-Neutron-02: Are strict permissions set for configuration files? Yes
[PASS] Check-Neutron-03: Is keystone used for authentication? Yes
[PASS] Check-Neutron-04: Is secure protocol used for authentication? Yes
[FAIL] Check-Neutron-05: Is TLS enabled on Neutron API server? The negative implications for the user ex-perience by implementing this is considered to outweight the extra security gained by this.
1.3.11 [2019] Object Storage
REVISION 2019-03-14
Contents
• [2019] Object Storage
From OpenStack Security Guide: Object Storage:
OpenStack Object Storage (swift) is a service that provides software that stores and retrieves data overHTTP. Objects (blobs of data) are stored in an organizational hierarchy that offers anonymous read-only access, ACL defined access, or even temporary access. Object Store supports multiple token-basedauthentication mechanisms implemented via middleware.
Note: Does not apply. We are not using Swift.
1.3.12 Message queuing
Last changed: 2019-08-19
Contents
• Message queuing
32 Chapter 1. Contents

iaas Documentation, Release 0.1.0
– Messaging security
* Messaging transport security
* Queue authentication and access control
* Message queue process isolation and policy
Impact HighImplemented percent 0% (0/8)
From OpenStack Security Guide: Message queuing:
Message queues effectively facilitate command and control functions across OpenStack deployments.Once access to the queue is permitted no further authorization checks are performed. Services accessiblethrough the queue do validate the contexts and tokens within the actual message payload. However, youmust note the expiration date of the token because tokens are potentially re-playable and can authorizeother services in the infrastructure.
OpenStack does not support message-level confidence, such as message signing. Consequently, you mustsecure and authenticate the message transport itself. For high-availability (HA) configurations, you mustperform queue-to-queue authentication and encryption.
Note: We are using RabbitMQ as message queuing service back end.
Messaging security
Ref: OpenStack Security Guide: Message queuing - Messaging security
Messaging transport security
From OpenStack Security Guide:
We highly recommend enabling transport-level cryptography for your message queue. Using TLS for themessaging client connections provides protection of the communications from tampering and eavesdrop-ping in-transit to the messaging server.
[DEFERRED] Ensure TLS is used for RabbitMQ
• TLS is NOT used for the messaging service. Should be considered.
[DEFERRED] Use an internally managed CA
• No CA as TLS is not used
[DEFERRED] Ensure restricted file permissions on certificate and key files
• No CA as TLS is not used
Queue authentication and access control
From OpenStack Security Guide:
1.3. Security 33

iaas Documentation, Release 0.1.0
We recommend configuring X.509 client certificates on all the OpenStack service nodes for client connec-tions to the messaging queue and where possible (currently only Qpid) perform authentication with X.509client certificates. When using user names and passwords, accounts should be created per-service andnode for finer grained auditability of access to the queue.
[DEFERRED] Configure X.509 client certificates on all OpenStack service nodes
• Currently no TLS/user certificates set up
[DEFERRED] Any user names and passwords are per-service and node
• Currently common password. ?????
Message queue process isolation and policy
[----] Use network namespaces Network namespaces are highly recommended for all services running on Open-Stack Compute Hypervisors. This will help prevent against the bridging of network traffic between VM guestsand the management network.
• FIXME: Ensure and document
[DEFERRED] Ensure queue servers only accept connections from management network FIXME: Ensure anddocument
[DEFERRED] Use mandatory access controls FIXME: SELinux in enforcing mode on all nodes
1.3.13 [2019] Data processing
REVISION 2019-03-14
Contents
• [2019] Data processing
From OpenStack Security Guide: Data processing:
The Data processing service for OpenStack (sahara) provides a platform for the provisioning and man-agement of instance clusters using processing frameworks such as Hadoop and Spark. Through the Open-Stack dashboard or REST API, users will be able to upload and execute framework applications whichmay access data in object storage or external providers. The data processing controller uses the Orches-tration service to create clusters of instances which may exist as long-running groups that can grow andshrink as requested, or as transient groups created for a single workload.
Note: Does not apply. We are not using Sahara.
1.3.14 Databases
Last changed: 2019-08-19
Contents
34 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• Databases
– Database back end considerations
– Database access control
* Database authentication and access control
* Require user accounts to require SSL transport
* Authentication with X.509 certificates
* Nova-conductor
– Database transport security
* Database server IP address binding
* Database transport
From OpenStack Security Guide: Databases:
The choice of database server is an important consideration in the security of an OpenStack deployment.Multiple factors should be considered when deciding on a database server, however for the scope of thisbook only security considerations will be discussed. OpenStack supports a variety of database types (seeOpenStack Cloud Administrator Guide for more information). The Security Guide currently focuses onPostgreSQL and MySQL.
Note: We are using MariaDB 10.1 with packages directly from upstream repo.
Database back end considerations
Ref: OpenStack Security Guide: Databases - Database back end considerations
[DEFERRED] Evaluate existing MySQL security guidance See link above for details.
• FIXME: Evaluate and document
Database access control
Ref: OpenStack Security Guide: Databases - Database access control
Database authentication and access control
From OpenStack Security Guide:
Given the risks around access to the database, we strongly recommend that unique database user accountsbe created per node needing access to the database.
[PASS] Unique database user accounts per node Each service run on different host, and each host has a uniqueuser.
[PASS] Separate database administrator account The root user is only used to provision new databases and users.
[DEFERRED] Database administrator account is protected FIXME: Document this
1.3. Security 35

iaas Documentation, Release 0.1.0
Require user accounts to require SSL transport
[DEFERRED] The database user accounts are configured to require TLS All databases support TLS, but onlyDB replication between location requires TLS.
Authentication with X.509 certificates
[DEFERRED] The database user accounts are configured to require X.509 certificates FIXME: Document this
Nova-conductor
[PASS] Consider turning off nova-conductor OpenStack Compute offers a sub-service called nova-conductorwhich proxies database connections over RPC.
We use nova conductor, and nova compute have access to it over the message bus. The RPC messaging bus arenot encrypted, but run on a private network. This is acceptable risk.
Database transport security
Ref: OpenStack Security Guide: Databases - Database transport security
Database server IP address binding
[PASS] Database access only over an isolated management network Database replication is done over publicnetwork, with TLS and firewall to restrict access.
Database transport
[DEFERRED] The database requires TLS All databases support TLS transport, but only DB replication betweenlocations requires TLS.
1.3.15 Tenant data privacy
Last changed: 2019-08-19
Contents
• Tenant data privacy
– Data privacy concerns
* Data residency
* Data disposal
· Data not securely erased
· Instance memory scrubbing
· Cinder volume data
36 Chapter 1. Contents

iaas Documentation, Release 0.1.0
· Image service delay delete feature
· Compute soft delete feature
· Compute instance ephemeral storage
– Data encryption
* Volume encryption
* Ephemeral disk encryption
* Block Storage volumes and instance ephemeral filesystems
* Network data
– Key management
Impact HighImplemented percent 0% (0/?)
From OpenStack Security Guide: Tenant data privacy:
OpenStack is designed to support multitenancy and those tenants will most probably have different datarequirements. As a cloud builder and operator you need to ensure your OpenStack environment canaddress various data privacy concerns and regulations.
Data privacy concerns
Ref: OpenStack Security Guide: Tenant data privacy - Data privacy concerns
Data residency
From OpenStack Security Guide:
Numerous OpenStack services maintain data and metadata belonging to tenants or reference tenant in-formation.
Tenant data stored in an OpenStack cloud may include the following items: - Object Storage objects -Compute instance ephemeral filesystem storage - Compute instance memory - Block Storage volume data- Public keys for Compute access - Virtual machine images in the Image service - Machine snapshots -Data passed to OpenStack Compute’s configuration-drive extension
Metadata stored by an OpenStack cloud includes the following non-exhaustive items: - Organization name- User’s “Real Name” - Number or size of running instances, buckets, objects, volumes, and other quota-related items - Number of hours running instances or storing data - IP addresses of users - Internallygenerated private keys for compute image bundling
Data disposal
From OpenStack Security Guide:
OpenStack operators should strive to provide a certain level of tenant data disposal assurance. Best prac-tices suggest that the operator sanitize cloud system media (digital and non-digital) prior to disposal,release out of organization control or release for reuse. Sanitization methods should implement an appro-priate level of strength and integrity given the specific security domain and sensitivity of the information.
1.3. Security 37

iaas Documentation, Release 0.1.0
The security guide states that the cloud operators should do the following:
[DEFERRED] Track, document and verify media sanitization and disposal actions
• OSL: Media are shredded before being disposed
• BGO: unknown
[DEFERRED] Test sanitation equipment and procedures to verify proper performance
• OSL: Equipment has been properly tested
• BGO: unknown
[PASS] Sanitize portable, removable storage devices prior to connecting such devices to the cloud infrastructure
• Portable, removable media are never connected to the cloud infrastructure
[DEFERRED] Destroy cloud system media that cannot be sanitized
• OSL: Media are destroyed using a shredder
• BGO: unknown
Data not securely erased
Regarding erasure of metadata, the security guide suggests using database and/or system configuration for auto vacu-uming and periodic free-space wiping.
[DEFERRED] Periodic database vacuuming Not implemented at this time. We will revisit this at a later time.
[FAIL] Periodic free-space wiping of ephemeral storage We’re not doing this, as we consider this to be an ac-ceptable risk.
Instance memory scrubbing
As we’re using KVM, which relies on Linux page management, we need to consult the KVM documentation aboutmemory scrubbing.
[----] Consider automatic/periodic memory scrubbing FIXME: Consult KVM doc, consider if this is neededand document
Cinder volume data
From OpenStack Security Guide:
Use of the OpenStack volume encryption feature is highly encouraged. This is discussed in the DataEncryption section below. When this feature is used, destruction of data is accomplished by securelydeleting the encryption key.
[DEFERRED] Consider volume encryption Nice to have, but adds complexity. We will revisit this.
[FAIL] Secure erasure of volume data We’re not doing this, as we consider this to be an acceptable risk.
38 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Image service delay delete feature
From OpenStack Security Guide:
OpenStack Image service has a delayed delete feature, which will pend the deletion of an image for adefined time period. It is recommended to disable this feature if it is a security concern
[PASS] Consider disabling delayed delete Considered, we don’t think this is a security concern.
Compute soft delete feature
From OpenStack Security Guide:
OpenStack Compute has a soft-delete feature, which enables an instance that is deleted to be in a soft-delete state for a defined time period. The instance can be restored during this time period.
[PASS] Consider disabling compute soft delete Considered, we don’t think this is a security concern.
Compute instance ephemeral storage
From OpenStack Security Guide:
The creation and destruction of ephemeral storage will be somewhat dependent on the chosen hypervisorand the OpenStack Compute plug-in.
[DEFERRED] Document ephemeral storage deletion FIXME: Document how this works in our environment
Data encryption
From OpenStack Security Guide: Tenant data privacy - Data encryption:
The option exists for implementers to encrypt tenant data wherever it is stored on disk or transported overa network, such as the OpenStack volume encryption feature described below. This is above and beyondthe general recommendation that users encrypt their own data before sending it to their provider.
Volume encryption
[DEFERRED] Consider volume encryption Postponed.
Ephemeral disk encryption
[PASS] Consider ephemeral disk encryption Considered.
Block Storage volumes and instance ephemeral filesystems
[DEFERRED] Consider which options we have available FIXME: Document
[PASS] Consider adding encryption Considered.
1.3. Security 39

iaas Documentation, Release 0.1.0
Network data
[PASS] Consider encrypting tenant data over IPsec or other tunnels Considered. Not a security concern in ourcase.
Key management
From OpenStack Security Guide: Tenant data privacy - Key management:
The volume encryption and ephemeral disk encryption features rely on a key management service (forexample, barbican) for the creation and secure storage of keys. The key manager is pluggable to facilitatedeployments that need a third-party Hardware Security Module (HSM) or the use of the Key ManagementInterchange Protocol (KMIP), which is supported by an open-source project called PyKMIP.
[DEFERRED] Consider adding Barbican FIXME: Consider and document
1.3.16 [2019] Instance security management
REVISION 2019-03-14
Contents
• [2019] Instance security management
– Security services for instances
* Entropy to instances
* Scheduling instances to nodes
* Trusted images
* Instance migrations
* Monitoring, alerting, and reporting
Impact HighImplemented percent 67% (4/6)
From OpenStack Security Guide: Instance security management:
One of the virtues of running instances in a virtualized environment is that it opens up new opportunitiesfor security controls that are not typically available when deploying onto bare metal. There are severaltechnologies that can be applied to the virtualization stack that bring improved information assurance forcloud tenants.
Deployers or users of OpenStack with strong security requirements may want to consider deploying thesetechnologies. Not all are applicable in every situation, indeed in some cases technologies may be ruledout for use in a cloud because of prescriptive business requirements. Similarly some technologies inspectinstance data such as run state which may be undesirable to the users of the system.
Security services for instances
Ref: OpenStack Security Guide: Instance security management - Security services for instances
40 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Entropy to instances
From OpenStack Security Guide:
The Virtio RNG is a random number generator that uses /dev/random as the source of entropy by default,however can be configured to use a hardware RNG or a tool such as the entropy gathering daemon (EGD)to provide a way to fairly and securely distribute entropy through a distributed system.
[PASS] Consider adding hardware random number generators (HRNG) We do not consider HRNG necessaryfor a deployment of this scale. This may be revisited in the future.
Scheduling instances to nodes
From OpenStack Security Guide:
Before an instance is created, a host for the image instantiation must be selected. This selection is per-formed by the nova-scheduler which determines how to dispatch compute and volume requests.
[PASS] Describe which scheduler and filters that are used For normal workloads, we use the default novascheduling filters, and all compute hosts are considered equal in features and performance. For specializedresources such as HPC workloads we have different filters.
Trusted images
From OpenStack Security Guide:
In a cloud environment, users work with either pre-installed images or images they upload themselves. Inboth cases, users should be able to ensure the image they are utilizing has not been tampered with.
[PASS] Maintain golden images We provide updated upstream cloud images for popular linux distributions, aswell as the latest Windows Server versions.
[FAIL] Enable instance signature verification This is not something that we will prioritize at this time. It alsorequires the setup and management of additional services.
Instance migrations
[FAIL] Disable live migration While live migration has its risks, the benefits of live migration for outweigh thedisadvantages. We have live migration enabled.
Monitoring, alerting, and reporting
[PASS] Aggrgate logs, e.g. to ELK Compute host logs are sent to an ELK stack.
1.4 Howtos and guides
This is a collection of howtos and documentation bits with relevance to the project.
1.4.1 Build docs locally using Sphinx
This describes how to build the documentation from norcams/iaas locally
1.4. Howtos and guides 41

iaas Documentation, Release 0.1.0
RHEL, CentOS, Fedora
You’ll need the python-virtualenvwrapper package from EPEL
sudo yum -y install python-virtualenvwrapper# Restart shellexit
Ubuntu (trusty)
sudo apt-get -y install virtualenvwrapper make# Restart shellexit
Build docs
# Make a virtual Python environment# This env is placed in .virtualenv in $HOMEmkvirtualenv docs
# activate the docs virtualenvworkon docs# install sphinx into itpip install sphinx sphinx_rtd_theme
# Compile docscd iaas/docsmake html
# Open in modern internet browser of choicexdg-open _build/html/index.html
# Deactivate the virtualenvdeactivate
1.4.2 Git in the real world
Fix and restore a “messy” branch
http://push.cwcon.org/learn/stay-updated#oops_i_was_messing_around_on_
1.4.3 Install KVM on CentOS 7 from minimal install
See http://mwiki.yyovkov.net/index.php/Linux_KVM_on_CentOS_7
1.4.4 Configure a Dell S55 FTOS switch from scratch
This describes how to build configure a Dell Powerconnect S55 switch as management switch for our iaas from scratch.
42 Chapter 1. Contents
iaas Documentation, Release 0.1.0
Initial config
You will need a laptop with serial console cable. Connect the cable to the rs232 port in front of the switch. Open aconsole to ttyUSBx using screen, tmux, putty or other useable software.
Then power on the switch.
After the switch has booted, you can now enter the enable state:
> enable
The switch will default to jumpstart mode, trying to get a config from a central repository. We will disable it by typing:
# reload-type normal
Now we need to provide an ip address, create user with a passord and set enable password in order to provide sshaccess:
# configure(conf)# interface managementethernet 0/0(conf-if-ma-0/0)# ip address 10.0.0.2 /32(conf-if-ma-0/0)# no shutdown(conf-if-ma-0/0)# exit(conf)# management route 0.0.0.0 /0 10.0.0.1(conf)# username mylocaluser password 0 mysecretpassword(conf)# enable password 0 myverysecret(conf)# exit# write# copy running-config startup-config
Now you can ssh to the switch using your new user from a computer with access to the switch’s management network.
Configure the switch itself
Let’s configure the rest! We start by shutting down all ports:
> enable# configure(conf)# interface range gigabitethernet 0/0-47(conf-if-range-gi-0/0-47)# switchport(conf-if-range-gi-0/0-47)# shutdown(conf-if-range-gi-0/0-47)# exit
If you want to use a port channel (with LACP) for redundant uplink to core you can create one. If you don’t, omit allreferences to it later in the document:
(conf)# interface port-channel 1(conf-if-po-1)# switchport(conf-if-po-1)# no shutdown(conf-if-po-1)# exit
Assign interfaces to the port channel group:
(conf)# interface range gigabitethernet 0/42-43(conf-if-range-gi-0/42-43)# no switchport(conf-if-range-gi-0/42-43)# port-channel-protocol LACP(conf-if-range-gi-0/42-43)# port-channel 1 mode active
(continues on next page)
1.4. Howtos and guides 43
iaas Documentation, Release 0.1.0
(continued from previous page)
(conf-if-range-gi-0/42-43)# no shutdown(conf-if-range-gi-0/42-43)# exit
Define in-band and out-of-band VLANs:
(conf)# interface vlan 201(conf-if-vl-201)# description "iaas in-band mgmt"(conf-if-vl-201)# no ip address(conf-if-vl-201)# untagged GigabitEthernet 0/22-33,38-41(conf-if-vl-201)# tagged Port-channel 1(conf-if-vl-201)# exit(conf)# interface vlan 202(conf-if-vl-201)# description "iaas out-of-band mgmt"(conf-if-vl-201)# no ip address(conf-if-vl-201)# untagged GigabitEthernet 0/0-10(conf-if-vl-201)# tagged Port-channel 1(conf-if-vl-201)# exit(conf)# exit
Congratulations! Save the config and happy server provisioning:
# write# copy running-config startup-config
1.4.5 Install cumulus linux on ONIE enabled Dell S4810
The project will be using Dell PowerConnect S4810 switches with ONIE installer enabled by default instead of FTOS.This enables easy installation of cumulus linux to the switches.
Configure dhcpd and http server
You will need a running http server with a copy of the cumulus image:
# ls /var/www/htmlCumulusLinux-2.5.0-powerpc.binonie-installer-powerpc
“onie-installer-powerpc” is a symlink to the bin-file. The symlink is used by ONIE to identify an image to download.Read here about the order ONIE tries to download the install file:
http://opencomputeproject.github.io/onie/docs/user-guide/
Now, for the dhcp server to serve out an IP address and URL for ONIE to download from, dhcp option 114 (URL) isused. This example utilizes ISC dhcpd:
option default-url = "http://192.168.0.1/onie-installer-powerpc";
This option can be host, group, subnet or system wide. Read more about different dhcp servers and other methodshere:
https://support.cumulusnetworks.com/hc/en-us/articles/203771426-Using-ONIE-to-Install-→˓Cumulus-Linux
44 Chapter 1. Contents

iaas Documentation, Release 0.1.0
When you power up the switch, it will by default be a dhcp client and accept an offered IP address, after which youcan ssh to the ONIE installer with user root without password. However, if option 114 is specified, it will downloadthe image and immediatly install it, and then reboot the switch. When the installation is complete, you can ssh to theswitch using default cumulus login.
1.4.6 Create Cumulus VX vagrant boxes for himlar dev
This describes how to create (or update) the norcams/net vagrant box which is based on the Cumulus VX test appliance.
Requirements
• An account with access to the norcams organisation on Hashicorp Atlas system at https://atlas.hashicorp.com/norcams
• An account on cumulusnetworks.com to download the vagrant appliance from https://cumulusnetworks.com/cumulus-vx/download/
• A current vagrant installation with virtualbox and libvirt providers working
Prepare virtualbox and libvirt box files
Install the vagrant-mutate plugin:
vagrant plugin install vagrant-mutate
Download and rename the cumulus vagrant box, then add and convert it:
mv Downloads/CumulusVX*virtualbox.box /path/to/norcams-net-2.5.6-virtualbox.boxvagrant box add norcams/net /path/to/norcams-net-2.5.6-virtualbox.boxvagrant mutate norcams/net libvirt
Verify that the box is available for both providers:
vagrant box list
Repackage the libvirt box (this command takes a while to complete . . . ):
vagrant box repackage norcams/net libvirt 0mv package.box norcams-net-2.5.6-libvirt.box
You should now have two box files, one for libvirt and one for virtualbox.
ls *.boxnorcams-net-2.5.6-libvirt.boxnorcams-net-2.5.6-virtualbox.box
Publish to Atlas
In order for vagrant autoupdate to work we need to publish both these files on a webserver somewhere and point totheir locations from a provider and version configuration on Atlas.
• Publish both box files somewhere where they can be downloaded from a public URL.
• Log in at https://atlas.hashicorp.com/norcams
1.4. Howtos and guides 45

iaas Documentation, Release 0.1.0
• Find the norcams/net box at https://atlas.hashicorp.com/norcams/boxes/net
• Add a new version, if needed
• Create providers for “virtualbox” and “libvirt”. The URL should point at the location of the respective box file,e.g http://somewhere/files/norcams-net-2.5.6-virtualbox.box
1.4.7 Routed, virtual network interfaces for guest VMs on controllers
This describes how to setup a routed network interface for a guest VM running on a controller host. This is anadaptation of the general calico way of setting up networks from neutron data and some information from https://jamielinux.com/docs/libvirt-networking-handbook/custom-routed-network.html
Requirements
• BIRD running on the controller host pointed at one or more route reflector instances and a bird.conf similar tothe one on the compute nodes
• A VM running in libvirt on the controller host with eth0 connected to the br0 host bridge (mgmt network).
Prepare the outgoing default gateway interface
Traffic originating from inside the guest need to have a gateway to send packets to. This will be a dummy interfacewith the same IP on each of the controller hosts. In this example we’ll generate a random MAC address in the formatlibvirt expects and use that to create a dummy dev01 service network IP interface om the host that we will later routeto from within the guest.
modprobe dummymac=$(hexdump -vn3 -e '/3 "52:54:00"' -e '/1 ":%02x"' -e '"\n"' /dev/urandom)ip link add virgw-service address $mac type dummyip addr add 172.31.16.1/24 dev virgw-serviceip link set dev virgw-service up
This will bring up a virtual gateway interface that will be able to receive traffic from inside the guest instances on thiscontroller host and deliver it to the kernel to be routed. However, we only want this interface to be used for outgoingtraffic FROM the guests. But there is a problem - when we “up” the interface in the last step above an entry for the172.31.16.0/24 network will be made in the kernel routing table:
[root@dev01-controller-03 ~]# ip route | grep virgw-service172.31.16.0/24 dev virgw-service proto kernel scope link src 172.31.16.1
This leads to all and any traffic to that network being routed back over the virgw-service interface, we don’t want that.To fix this (and this is what Calico does, too) we remove the route that was created
ip route del 172.31.16.0/24
We’ve now prepared the virgw-service interface on the controller host to act as a dummy gateway for the servicenetwork on guest instances.
Add a tunnel interface connecting the host with a guest VM
First we make a tap interface on the controller host and give it a recognizable name - it seems like only a single dashis allowed in the name? The settings for the device are derived from what calico does on the compute nodes:
46 Chapter 1. Contents

iaas Documentation, Release 0.1.0
ip tuntap add dev tap-dev01db02 mode tap one_queue vnet_hdrip tuntapip tuntap help
Next, we need to define this tap device in the libvirt domain config for the guest VM. Make sure the domain is notrunning first.
virsh shutdown dev01-db-02
Generate an xml block describing the new guest network interface with a new random mac address - target deviceshould be the tap device we just created on the host
<interface type='ethernet'><mac address='52:54:00:xx:xx:xx'/><script path='/bin/true'/><target dev='tap-dev01db02'/><model type='virtio'/><address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/>
</interface>
Copy and paste this xml block below the current interface definition in the domain xml:
virsh edit dev01-db-01
Make configuration changes to libvirt to allow this interface type
This is already documented in step 1) of the Calico compute node documentation at http://docs.projectcalico.org/en/stable/redhat-opens-install.html?highlight=cgroup_device_acl#compute-node-install
Boot the guest and set up the interface
On the controller host you should now be able to boot the guest with the new interface added. We also need to createthe host route to the new service IP that now will be available and bring up the tap device.
virsh start dev01-db-02ip link set dev tap-dev01db02 upip route add 172.31.16.18/32 dev tap-dev01db02
Log in to the VM from the mgmt network and set up the new interface manually, then verify that it works:
sudo ssh iaas@dev01-db-02sudo -iip addrip addr add 172.31.16.18/24 dev eth1ip linkip link set dev eth1 up# switch default gwip route del defaultip route add default via 172.31.16.1
To make configuring services that use the new interface easier - use the new service IP interface as the default gw forthe guest.
You should now be able to ping the outside dummy gateway using the new interface
1.4. Howtos and guides 47

iaas Documentation, Release 0.1.0
ping -I eth1 172.31.16.1
On the controller host, verify that bird knows about the host route, e.g
[root@dev01-controller-03 ~]# birdcl show routeBIRD 1.4.5 ready.0.0.0.0/0 via 172.31.1.1 on br0 [kernel1 21:38:10] * (10)172.31.16.18/32 dev tap-dev01db02 [kernel1 21:41:33] * (10)172.31.34.0/24 dev eth1.912 [direct1 21:38:10] * (240)172.31.35.0/24 dev eth1.913 [direct1 21:38:10] * (240)
In order for a VM to reach an address on it’s same subnet, proxy-arp has to be enabled on the tap interface. Then thehost computer with the router will offer it’s own mac address from the tap interface and then route the traffic.
[root@dev01-controller-03 ~]# echo 1 > /proc/sys/net/ipv4/conf/tap-dev01db02/proxy_arp
1.4.8 Configure iDRAC-settings on Dell 13g servers with USB stick
With Dell PowerEdge 13g servers the iDRAC base management controller can be configured automatically by readingsettings from an xml file located on a USB stick. The USB port to be used is labelled with a wrench icon.
By default, Dell PE 13g servers will auto apply config in this manner if the default username and/or password is notchanged, so typically new servers are prime targets.
Create USB stick and copy files to it
You will need a USB stick formatted with fat32 and a directory called:
System_Configuration_XML
Two files are needed:
config.xmlcontrol.xml
These xml files can be exported from an already configured server, or better still, git cloned from
https://github.com/norcams/dell-idracdirect
Apply profile to server iDRAC
Provide power to the server, but do not insert the USB stick just yet. Power on the server, and wait for the POSTprocess to finish. After POST has finished, insert the USB stick to the port in front of the server with the wrench label.If the server provides a display, it will show first importing, then applying. After some odd 10 seconds the server willreboot. You will notice, as all lights will go out. Remove the USB stick and proceed to the next server.
1.4.9 Using vncviewer to access the console
We configure the bmc (baseboard management controller) on our servers to enable a VNC server feature. Accessing theconsole through VNC is easier and faster than using the Java-based console available through the bmc web interface.
On CentOS/RedHat/Fedora, install the needed VNC client packages:
48 Chapter 1. Contents

iaas Documentation, Release 0.1.0
yum -y install tigervnc tigervnc-server-minimalvncpasswd # -> enter the idrac password and confirmvncviewer -passwd ~/.vnc/passwd 1.2.3.4:5901
The tigervnc-server-minimal package is needed in order to get the vncpasswd utility. This creates a passwd file that isused for providing a password when connecting to the VNC server. The VNC server on the bmc’s is listening on port5901. Only a single connection is allowed by the server.
1.4.10 Building puppet-agent for PPC-based Cumulus Linux
Puppet bruker sitt eget byggeverktøy kalt Vanagon for puppet-agent. Det kjøres mot en remote target, i vårt tilfelleen Debian Wheezy installasjon for PowerPC. En versjon som kan kjøres i qemu kan lastes ned fra http://folk.uib.no/ava009/debian_wheezy_ppc.img.tar.gz (0c27128c6ea2dad8f6d9cb8364e378a7). Er en i bestittelse av en fysiskPowerPC-basert maskin (f.eks. en gammel Mac) vil byggingen gå betraktelig raskere der.
Vanagon forsøker å SSH’e som root til target, imaget over tillater dette (med passord). En kan også lage en SSH-nøkkelsom man legger inn hos root-brukeren på byggeboksen. Sett så VANAGON_SSH_KEY=<full-sti-til-privatnøkkel>hvor du kjører Vanagon.
For å bygge for Debian 7 PPC trenger er en gcc, boost, cmake, yaml-cpp, gettext og binutils i riktige versjoner. En fårdisse ved å klone https://github.com/norcams/pl-build-tools-vanagon, bygge verktøyene med Vanagon og installeredem på target hvor puppet-agent skal bygges. Plattformen heter debian-7-powerpc (finnes kun i norcams-fork).
Deretter kloner en https://github.com/norcams/puppet-agent, sjekker ut branchen 1.10.9-powerpc og bygger fordebian-7-powerpc (kun i i norcams-fork).
1.4.11 How to create the designate-dashboard RPM package
1. Install tools:
yum install rpm-build
2. Get designate-dashboard from GitHub:
git clone https://github.com/openstack/designate-dashboard.gitcd designate-dashboardgit checkout stable/pike
3. Build RPM:
python setup.py bdist_rpm
1.5 Team operations
This is internal information about development and operations for the IaaS team.
1.5.1 Getting started
This is information for new team members. Every team member should be familiar with this information.
1.5. Team operations 49

iaas Documentation, Release 0.1.0
Work with source code on github
Source code
When we speak of the source code, we typically refer to norcams/himlar on Github. This is the puppet code, hieradataand bootstrap scripts to get every component up and running the way we need.
First make sure you have a Github account and then fork the norcams/himlar repo. You should try to make this repothe origin and then add another remote for norcams/himlar
Policy
When you need to make a change the rule of thumb is the following:
• Minor changes can be done directly to master on norcams/himlar. E.g. hieradata for one location, minor codechange for none critical components.
• All other changes will need a PR (pull request) on Github
• All code change should also be deployed first on a development location (e.g. dev01)
2FA on jumphosts (login nodes)
As an extra securiy measure there is now implemented Two-factor authentication for access to the login nodes, andthus the management network. The two components used are
• SSH keys and
• TOTP
The latter by using the Google Authenticator mobile (or compatible) app on the client side.
Basic procedure for access
To get access to the internal infrastructure one has to first go through any of the login nodes:
• osl-login-01.iaas.uio.no
• bgo-login-01.iaas.uib.no
All user logins must be authenticated by providing two independent components:
1. SSH key exchange
2. TOTP verification code
The public part of the user SSH key is provisioned using Puppet by publisizing the key in hieradata:
common/modules/accounts.yaml
In addition the user must be allocated membership of the wheel group (same file).
The TOTP setup is done by executing /usr/bin/google-authenticator.
From this point on any login for this account requires a verification code (in addition to the automatic exchange ofrelevant SSH keys).1
1 In the initial set up phase - to enable exisitng users to convert to 2FA - access through SSH keys only is allowed. The “switch” for this isthe availability of the user configuration file. To disable this behaviour remove the option nullok from any line in /etc/pam.d/google-authenticator-wheel-only (though hieradata: common/roles/login.yaml and key googleauthenticator::pam::mode::modes:).
50 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Step-by-step setup
• add SSH public key to hieradata: file: common/modules/accounts.yaml
key: accounts::ssh_keys
• set up user to become member of the wheel group: file: as above
key: accounts::users
• ensure the account is created on hosts with the login role: file: common/roles/login.yaml
key: accounts::accounts
• on login nodes, as the user after the account is created:
1. execute google-authenticator and reply to the questions
Recommended answers:
– Do you want authentication tokens to be time-based (y/n) y
– Do you want me to update your “/home/i<user name>/.google_authenticator” file(y/n) y
– Do you want to disallow multiple uses of the same authentication token? This restricts youto one login about every 30s, but it increases your chances to notice or even prevent man-in-the-middle attacks (y/n) n
– By default, tokens are good for 30 seconds and in order to compensate for possible time-skewbetween the client and the server, we allow an extra token before and after the current time.If you experience problems with poor time synchronization, you can increase the windowfrom its default size of 1:30min to about 4min. Do you want to do so (y/n) n
– If the computer that you are logging into isn’t hardened against brute-force login attempts,you can enable rate-limiting for the authentication module. By default, this limits attackersto no more than 3 login attempts every 30s. Do you want to enable rate-limiting (y/n) y
2. Provide the user with the secret key which is printed, the QR code drawn or the URL displayed - all afterthe initial question.
3. Install a TOTP client application on any of the compatibel user devices (mobile phone, tablets etc). Rec-ommended application is Google Authenticator.
4. In the TOTP application set up a new account following its instructions. The easiest method is if the appprovides a mean to configure it through scanning a QR code and the user can be shown the QR code drawnduring server initialization, alternatively using the URL. Otherwise enter the secret key printed.
Login procedure
1. log in to a login node from an account with access to the private part of the SSH key provided
2. when prompted start the TOTP/2FA application on the user device and enter the 6 digits displayed
3. login should be successfull
Important: It is paramount that the user device and the login node are in sync with regards to time!
1.5. Team operations 51

iaas Documentation, Release 0.1.0
Transfer to new device
If the previous device is lost, then the set up procedure should be repeated to configure a new code. But in those caseswhere a new device (mainly a phone) is purchased etc, and one still has full control of the old, it is possible to recreatethe required QR-code like this:
1. username=<username>
2. location=osl (or location=bgo)
3. secret=$(sudo head -1 /home/${username}/.google_authenticator)
4. qrencode -o $username.png -s 5 -lM “otpauth://totp/${location}-login-01?secret=$secret”
5. display ${username}.png
6. rm ${username}.png
Note: Remember to do this on both login nodes!
Emergency code
If the situation should arise where the user does not have access to the device where the 2FA application is installed,he/she can log in using any of the one time passcodes created duirng setup:
• someone with access to the user configuration file2 must retrieve one of the passcodes listed at the bottom
• log in as usual but enter the retrieved emergency code in place of a proper verification code
• after a successful login this particular emergency code is rendered invalid
Secret repository
For data that should not be publically available (on GitHub or elsewhere) there is a in-house repository named secretsThis contains these areas:
• hieradata
Data used by the himlar code. This area is controlled by git
• nodes
For files only used by or on specific systems
• common
Non-host specific files, like licenses and proprietary binaries
hieradata
Data in here is accessed and controlled by git at git@git.<domain> in hieradata/secrets.
This repo should not be accessed outside our locations and you will need your SSH key to get access to the git repo(try ssh -A <user>@<loc>-login-01).
For retrieval and update of data, follow this routine:2 Default $home/.google_authenticator
52 Chapter 1. Contents

iaas Documentation, Release 0.1.0
git clone [email protected]:hieradata/secretscd secrets... edit ...git commit ...git push
For activation consult the Deployment section of this documentation.
nodes and common
Data under these sections are stored manually under the respective directory on any of the login nodes. Afterwardsdata should be synced between the locations using the script described below.
Data under common can be stored arbitrarily. For nodes create a directory name by the shortform of the hostname (i.e.non-FQDN). For data utilized by ansible driven jobs the structure might be dictated by the playbook used. One ofthose is the SSL certificate distribution.
Syncronization of data between repositories
Note: The script described here is not yet fully functional!
The login node in OSL is defined as master, the implication being:
- data which exists on several locations is set to the content of the osl data- data which exists solely on the slave is copied to the master
To syncronize, run as yourself after any change:
cd /opt/repo/secrets./secret-sync.sh [delete]
The delete option removes any files on slave(s) which does not exist on the master. Use this with caution!
The rquirements for this to work is that all files and directories are owned and writeable by group wheel!
1.5.2 Development
Puppet design policy
This the policy for himlar puppet code.
Definitions
• himlar: puppet code at https://github.com/norcams/himlar
• module: upstream module listed in Puppetfile
• profile: a puppet module with classes for norcams adaptations. Found in himlar under profile/
• hieradata: hierarchical yaml files with config data under hieradata/
1.5. Team operations 53

iaas Documentation, Release 0.1.0
Profile
• hieradata should include profile classes
• all modules should be included in a profile class (never in hieradata)
• profile classes should have boolean options to enable a feature with default value set to false
• enabling of profile features should be done either in
– hieradata/common/modules/profile.yaml for global settings
– hieradata/common/role/ for enabling for only one role
• each openstack role should have one class named after itself that will include feature classes
• location hieradata override should always be done in the same module/role file as in the common version ofmodule/role
• module hieradata should be grouped by module classes
Hieradata
• global hiera variables referenced in other hiera files should have generic names and never full class names (e.g.openstack_version and not cinder::db::mysql::password)
• profile hashes that needs to be merged should use the same naming as autoloaded input class variables (e.g.profile::openstack::designate::bind_servers)
Vagrant
Development in vagrant
Last changed: 2019-08-19
Before you start you need to set up vagrant either with virtualbox or libvirt libvirt. Then following these steps will getyou up and running with vagrant.
Source code from git
First make a fork of https://github.com/norcams/himlar and clone that repo to a local folder called himlar. This will berefered to as $himlar in this documentation:
mkdir $himlarcd $himlargit clone [email protected]:<github-username>/himlar .
Generate CA files
Last changed: 2019-08-19
Warning: If you have problems with the CA: delete provision/ca, check out all files tracked in git and rerunbootstrap.sh
54 Chapter 1. Contents

iaas Documentation, Release 0.1.0
You will need to generate a CA key pair with openssl to sign the certificate used in vagrant to test TLS for endpoint.First make sure openssl is installed on your host computer (if not, run the scipts and copy all the .pem files back toyour host):
cd $himlarcd provision/caecho "YOUR_SECRET" > passfile./bootstrap.sh
NB! You must run the script from the provision/ca directory!
The CA chain .pem file can be found in:
$himlar/provision/ca/certs/intermediate/ca-chain.cert.pem
If you trust that no one will have access to your passfile, you could add $himlar/provision/ca/certs/intermediate/intermediate.cert.pem to your browser to avoid warnings.
Use in puppet
In puppet, this CA is used to generate certificates defined in the hash:
profile::application::openssl::certs
Nodeset
Last changed: 2019-08-19
There are different sets of nodes to use in vagrant. The node set can be changed by setting the environment variablecalled HIMLAR_NODESET.
Default nodeset
The default nodeset uses the vagrant location. Here we have added all the important roles into one node calledvagrant-api-01. The reset of the nodes are optional (like dashboard, access and compute).
Full nodeset
The full nodeset uses the dev location. Here all roles have nodes matching the test and production locations. Thiswill require more resources on the vagrant host (16GB+ RAM, 4+ Cores). To use the full nodeset:
export HIMLAR_NODESET=full
Other nodeset
There are also other special case nodeset. To see all nodeset and change them edit $himlar/nodes.yaml.
1.5. Team operations 55

iaas Documentation, Release 0.1.0
Vagrant up
The nodes in vagrant should be started in stages. Each stage should complete before the next one are started.
First stage:
• db-01
• mq-01
• api-01
• dashboard-01 (optional)
• access-01 (optional)
• monitor-01 (optional)
• logger-01 (optional)
• proxy-01 (optional)
• admin-01 (optional)
Second stage:
• identity-01
Main stage:
• novactrl-01
• image-01
• volume-01
• network-01
• console-01 (optional)
• metric-01 (optional)
• telemetry-01 (optional)
Last stage:
• compute-01
Final fixes
A few final stages are needed to start an instance in vagrant.
Host aggregate and AZ
After running vagrant up compute you will need to run vagrant provison novactrl to add the newly created computenode to a host aggregate and the correct availability zone (AZ).
56 Chapter 1. Contents
iaas Documentation, Release 0.1.0
Metadata api
We need to restart openstack-nova-metadata-api on compute-01. This can be done with ansible:
ansible-playbook -e "myhosts=vagrant-compute name=openstack-nova-metadata-api.service→˓" lib/systemd_restart.yaml
Flavors
Flavors are missing. m1 can be added with himlarcli/flavor.py or openstack cli.
Image
You will need a public cirros image to test with. One way to quickly fix this are to use himlarcli/image.py and editconfig/images/cirros.yaml and set it to be public. You can then just run:
./image.py update -i cirros.yaml
Dataporten
See more about setting up dataporten in vagrant
After running destroy/up only himlarcli/dataporten.py will be needed.
To create a dataporten user in vagrant after setting dashboard up, we can use himlarcli/access.py to add a userrequest to the queue and process the request and add the user.
Working with web services in vagrant
Last changed: 2019-08-19
Here are some tips to working with the difference web services like dashboard, access and API in vagrant.
/etc/hosts
You will need to update the /etc/hosts on the machine where you run your browser or API calls. Look incommon.yaml for the location you are working with, and add all public address. Example for full nodeset:
172.31.24.56 access.dev.iaas.intern172.31.24.51 dashboard.dev.iaas.intern172.31.24.51 status.dev.iaas.intern172.31.16.81 identity.trp.dev.iaas.intern172.31.24.86 api.dev.iaas.intern172.31.24.86 compute.api.dev.iaas.intern172.31.24.86 network.api.dev.iaas.intern172.31.24.86 image.api.dev.iaas.intern172.31.24.86 identity.api.dev.iaas.intern172.31.24.86 volume.api.dev.iaas.intern
1.5. Team operations 57
iaas Documentation, Release 0.1.0
sshuttle
If you work on a remote vagrant host you will need to have access to vagrants public net. This can be done withsshuttle:
sshuttle -r <remote host> 172.31.24.0/24
Vagrant with virtualbox
Last changed: 2019-08-19
You first will need to install the virutalbox and vagrant packages for your operating system. This have been tested onUbuntu and OSX and works without any other configuration.
Vagrant with libvirt
Last changed: 2019-08-19
Contents
• Vagrant with libvirt
– Requirements
– Setting up the Vagrant environment
– Tips and tricks
Requirements
In order to deploy the virtual machines in Vagrant, the host running the VMs must med the following requirements:
Operating system libvirt capable (tested on RHEL/Fedora)Memory 16 GB minimum, 32 GB recommendedDisk space 8 GB minimum on /var/lib/libvirt
Setting up the Vagrant environment
In order to deploy the Vagrant environment, follow this guide.
1. Make sure that the requirements are met
2. Ensure that CPU virtualization extensions are enabled on the host. You’ll probably need to enter BIOS setup forthis.
3. Create a file /etc/polkit-1/rules.d/10-libvirt.rules with the following contents:
polkit.addRule(function(action, subject) {if ((action.id == "org.libvirt.unix.manage"
|| action.id == "org.libvirt.unix.monitor")&& subject.isInGroup("wheel")) {
(continues on next page)
58 Chapter 1. Contents
iaas Documentation, Release 0.1.0
(continued from previous page)
return polkit.Result.YES;}
});
4. Install Vagrant and libvirt. In this case, it is assumed that you’re running Fedora and have the RPMFusionrepositories available:
dnf -y install vagrant vagrant-libvirt libvirt-daemon-kvm
If you are running RedHat, you may also need to install:
yum install libvirt-devel
5. Install Vagrant plugins for libvirt:
vagrant plugin install vagrant-libvirt
6. Start the libvirtd service, and make sure that it is started at boot:
systemctl start libvirtd.servicesystemctl enable libvirtd.service
7. Add the user that will be running Vagrant to the wheel group:
usermod -G wheel -a <username>
Tips and tricks
Add the following in your ~/.bashrc or similar to always use the same nodeset (example for nodeset “dns”):
# Himlarexport HIMLAR_NODESET=dns
Script to provision a node, and keep the output:
#!/bin/bash
host=$1
[ -d /tmp/himlar ] || mkdir /tmp/himlar
vagrant rsync $host | tee /tmp/himlar/$hostvagrant provision $host | tee -a /tmp/himlar/$host
Script to take all nodes up, in the correct order (uses the script provision.sh above):
#!/bin/bash
declare -a nodes=( 'db''api''identity''mq''dashboard''ns'
(continues on next page)
1.5. Team operations 59

iaas Documentation, Release 0.1.0
(continued from previous page)
'resolver-01''resolver-02''admin''image''network''compute''novactrl''volume''dns' )
for node in "${nodes[@]}"; dovagrant up $nodeprovision.sh $nodeprovision.sh $node
done
for node in "${nodes[@]}"; doprovision.sh $node
done
Testing in Vagrant
Last changed: 2019-08-19
Warning: This might be outdated.
Connecting to Horizon
Horizon is the web GUI component in OpenStack. If you’ve followed the Setting up the Vagrant environment guideearlier, you should now start the nodes:
vagrant up apivagrant up dashboard
Connect a browser to the Horizon GUI:
https://172.31.24.51/
If the VMs are running on a remote host, the best approach will be to use an SSH tunnel. Create an SSH tunnel with:
ssh -L 8443:172.31.24.51:443 <username>@<hostname>
After creating the SSH tunnel, point your browser to:
https://localhost:8443/
Note that authentication through Feide Connect (aka “Dataporten”) uses redirection and is not possible when connect-ing through an SSH tunnel.
60 Chapter 1. Contents
iaas Documentation, Release 0.1.0
Setting up local user and tenant
Logging into the VMs is fairly simple. In order to set up a demo user and tenant, log into the master VM:
vagrant ssh master
Become root:
sudo -i
API authentication configuration
The norcams/himlar repo is available from within the vagrant VM as /opt/himlar. Run the 00-credentials_setup.sh script:
/opt/himlar/tests/00-credentials_setup.sh
This will create 3 files in your home directory:
openstack.config Defines the demo username etc. Used by other testskeystonerc_admin Sets environment variables for administratorkeystonerc_demo Sets environment variables for demo user
In order to “become” the OpenStack administrator, you then only need to source the ~/keystonerc_admin file:
. ~/keystonerc_admin
To switch to the demo user, source the ~/keystonerc_demo file:
. ~/keystonerc_demo
Create demo user and project (tenant)
This can be accomplished simply by running:
/opt/himlar/tests/01-keystone-create_demo_user.sh
But for the sake of learning, you may want to to this manually as shown below:
1. Source the file that defines the administrator environment:
source ~/keystonerc_admin
2. Create a demo tenant (project):
openstack project create --or-show demoproject
3. Create a demo user and set the password:
openstack user create --or-show --password himlar0pen demo
4. Associate the demo user with the demo tenant:
1.5. Team operations 61

iaas Documentation, Release 0.1.0
openstack user set --project demoproject demo
5. Show the demo user:
openstack user show demo
Upload an image to Glance
This can be accomplished simply by running:
/opt/himlar/tests/02-glance-import_cirros_image.sh
But for the sake of learning, you may want to to this manually as shown below:
1. Source the file that defines the administrator environment:
source ~/keystonerc_admin
2. Download CirrOS image:
curl -o /tmp/cirros.img http://download.cirros-cloud.net/0.3.4/cirros-0.3.4-x86_→˓64-disk.img
3. Upload and create the image in Glance:
openstack image create "CirrOS test image" --disk-format qcow2 --public --file /→˓tmp/cirros.img
Note: This can also be accomplished by using Glance directly:
glance image-create --name "CirrOS test image" \--disk-format qcow2 --container-format bare \--visibility public --file /tmp/cirros.img
4. List images:
openstack image list
Optionally, list images using the Nova API:
nova image-list
Create a network security group
This can be accomplished simply by running:
/opt/himlar/tests/03-neutron-create_security_group_and_rules.sh
But for the sake of learning, you may want to to this manually as shown below:
1. Source the file that defines the administrator environment:
62 Chapter 1. Contents

iaas Documentation, Release 0.1.0
source ~/keystonerc_admin
2. Create a network security group called “test_sec_group”:
openstack security group create test_sec_group
3. Add a rule which allows incoming SSH:
openstack security group rule create --proto tcp --dst-port 22 test_sec_group
4. Add a rule which allows incoming ICMP:
openstack security group rule create --proto icmp test_sec_group
5. Show the newly created security group:
openstack security group show test_sec_group --max-width 70
Note: This could have been done using the Neutron API instead of the generic openstack command:
neutron security-group-create test_sec_groupneutron security-group-rule-create --direction ingress --protocol tcp \
--port_range_min 22 --port_range_max 22 test_sec_groupneutron security-group-rule-create --protocol icmp --direction ingress test_sec_groupneutron security-group-show test_sec_group
Running himlarcli in vagrant
You will need access to both the public and transport net on the host you plan to run himlarcli. This should work onthe same host where you run vagrant.
Himlarcli source code
Clone the repo from https://github.com/norcams/himlarcli and follow the instructions in the README.
config.ini
You will need a working config.ini file for himlarcli. You could either copy the one from vagrant/dev-proxy-01 nodeor from /opt/himlarcli/ on login.
Make sure that the following elementer in config.ini are correct:
• auth_url
• password (see hieradata/vagrant/common.yaml)
• region
• keystone_cachain
The openstack endpoints used in himlarcli must also resolv. This can be done by editing /etc/hosts on the host.
1.5. Team operations 63

iaas Documentation, Release 0.1.0
Testing
instance.py are good for testing both keystone and nova API, and update_images.py for testing glance API.
Setting up dataporten in vagrant
First make sure that the access and proxy-node are parts of your HIMLAR_NODESET. There should be at least onenodeset with access and proxy in nodes.yaml.
To use Dataporten to authenticate a user in access and keystone, you will first need to set up two applications athttps://dashboard.dataporten.no
More help can be found at https://docs.dataporten.no/
Login to Dataporten Dashboard, and register new application.
Redirect uri from access should be:
https://access.vagrant.iaas.intern/loginhttps://access.vagrant.iaas.intern/reset
and for dashboard:
https://identity.api.vagrant.iaas.intern:5000/v3/auth/OS-FEDERATION/websso/openid/→˓redirect
You need to add the following scope in Permissions for each application:
emailuserid-feideprofileopenid
Also make sure dashboard.vagrant.iaas.intern and access.vagrant.iaas.intern are in /etc/hosts on the machineyou are running your browser.
Then copy Client ID and Client Secret from Oauth details to:
hieradata/secrets/nodes/vagrant-access-01.secrets.yamlhieradata/secrets/nodes/vagrant-identity-01.secrets.yaml
Reference hieradata/secrets/nodes on the other locations for exact content.
To allow Dataporten login in horizon, run the dataporten script once in himlarcli as root:
./dataporten.py
Host overview
Address plan for individual hosts/nodes. Also look at the IP addressing plan for information about location specificnetwork.
64 Chapter 1. Contents
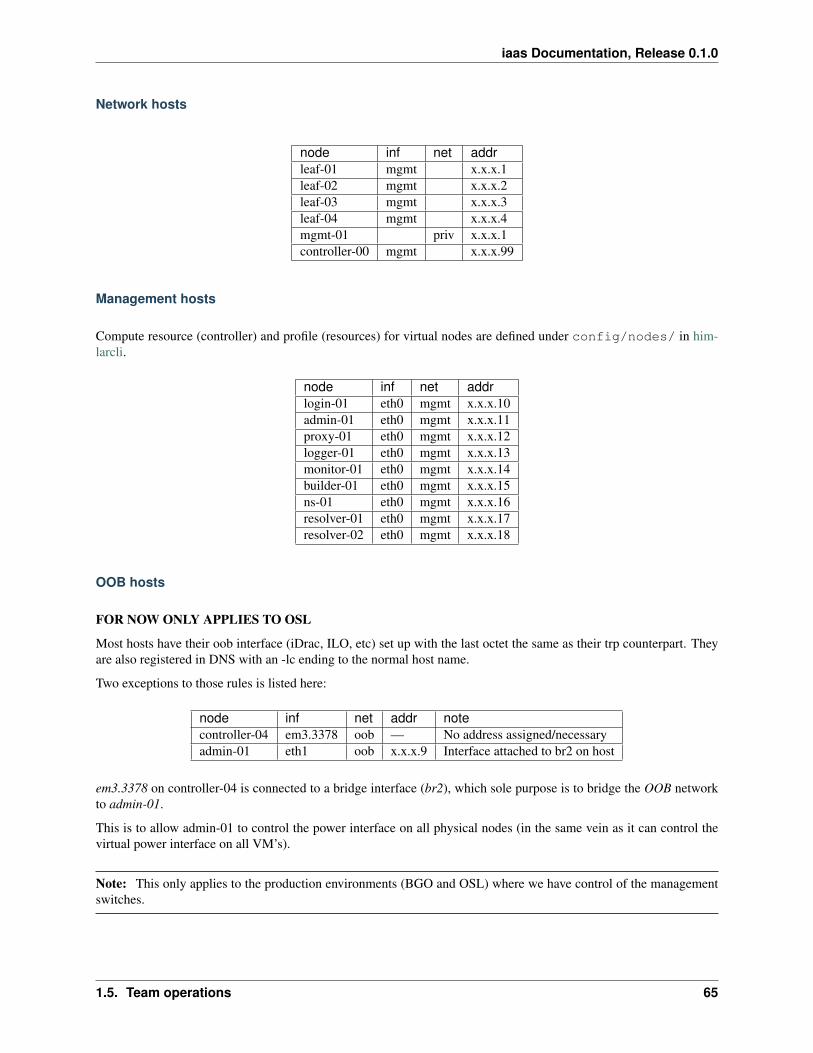
iaas Documentation, Release 0.1.0
Network hosts
node inf net addrleaf-01 mgmt x.x.x.1leaf-02 mgmt x.x.x.2leaf-03 mgmt x.x.x.3leaf-04 mgmt x.x.x.4mgmt-01 priv x.x.x.1controller-00 mgmt x.x.x.99
Management hosts
Compute resource (controller) and profile (resources) for virtual nodes are defined under config/nodes/ in him-larcli.
node inf net addrlogin-01 eth0 mgmt x.x.x.10admin-01 eth0 mgmt x.x.x.11proxy-01 eth0 mgmt x.x.x.12logger-01 eth0 mgmt x.x.x.13monitor-01 eth0 mgmt x.x.x.14builder-01 eth0 mgmt x.x.x.15ns-01 eth0 mgmt x.x.x.16resolver-01 eth0 mgmt x.x.x.17resolver-02 eth0 mgmt x.x.x.18
OOB hosts
FOR NOW ONLY APPLIES TO OSL
Most hosts have their oob interface (iDrac, ILO, etc) set up with the last octet the same as their trp counterpart. Theyare also registered in DNS with an -lc ending to the normal host name.
Two exceptions to those rules is listed here:
node inf net addr notecontroller-04 em3.3378 oob — No address assigned/necessaryadmin-01 eth1 oob x.x.x.9 Interface attached to br2 on host
em3.3378 on controller-04 is connected to a bridge interface (br2), which sole purpose is to bridge the OOB networkto admin-01.
This is to allow admin-01 to control the power interface on all physical nodes (in the same vein as it can control thevirtual power interface on all VM’s).
Note: This only applies to the production environments (BGO and OSL) where we have control of the managementswitches.
1.5. Team operations 65
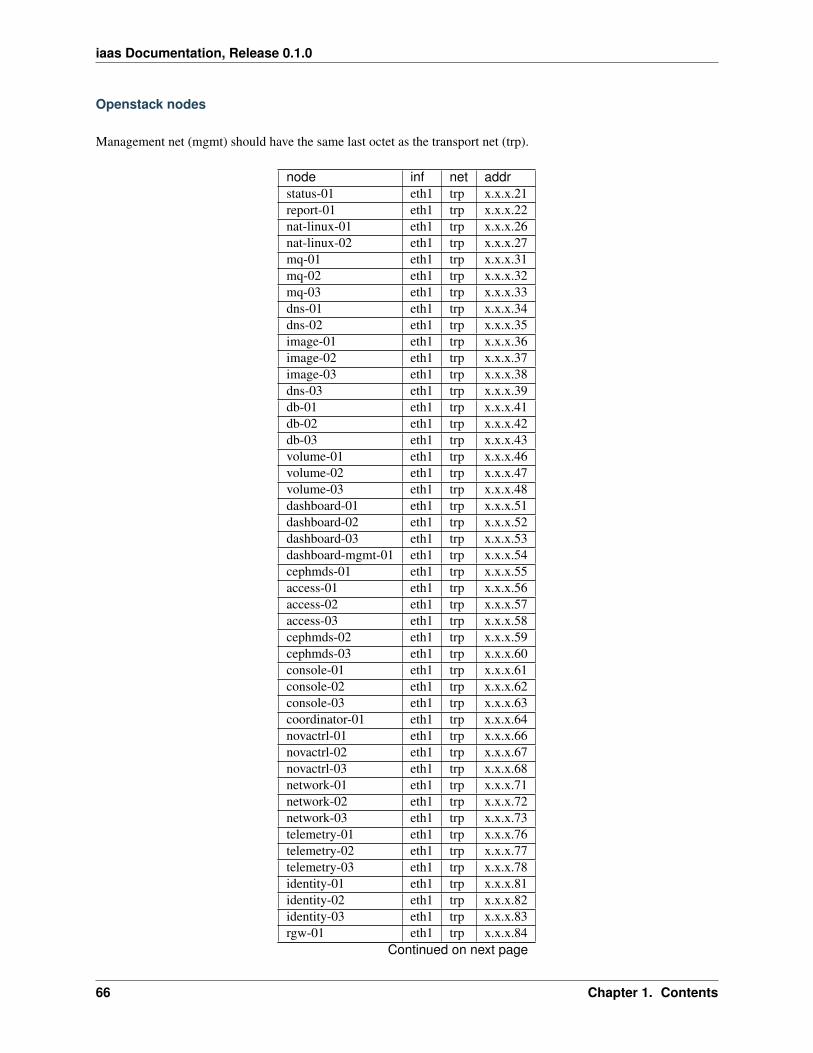
iaas Documentation, Release 0.1.0
Openstack nodes
Management net (mgmt) should have the same last octet as the transport net (trp).
node inf net addrstatus-01 eth1 trp x.x.x.21report-01 eth1 trp x.x.x.22nat-linux-01 eth1 trp x.x.x.26nat-linux-02 eth1 trp x.x.x.27mq-01 eth1 trp x.x.x.31mq-02 eth1 trp x.x.x.32mq-03 eth1 trp x.x.x.33dns-01 eth1 trp x.x.x.34dns-02 eth1 trp x.x.x.35image-01 eth1 trp x.x.x.36image-02 eth1 trp x.x.x.37image-03 eth1 trp x.x.x.38dns-03 eth1 trp x.x.x.39db-01 eth1 trp x.x.x.41db-02 eth1 trp x.x.x.42db-03 eth1 trp x.x.x.43volume-01 eth1 trp x.x.x.46volume-02 eth1 trp x.x.x.47volume-03 eth1 trp x.x.x.48dashboard-01 eth1 trp x.x.x.51dashboard-02 eth1 trp x.x.x.52dashboard-03 eth1 trp x.x.x.53dashboard-mgmt-01 eth1 trp x.x.x.54cephmds-01 eth1 trp x.x.x.55access-01 eth1 trp x.x.x.56access-02 eth1 trp x.x.x.57access-03 eth1 trp x.x.x.58cephmds-02 eth1 trp x.x.x.59cephmds-03 eth1 trp x.x.x.60console-01 eth1 trp x.x.x.61console-02 eth1 trp x.x.x.62console-03 eth1 trp x.x.x.63coordinator-01 eth1 trp x.x.x.64novactrl-01 eth1 trp x.x.x.66novactrl-02 eth1 trp x.x.x.67novactrl-03 eth1 trp x.x.x.68network-01 eth1 trp x.x.x.71network-02 eth1 trp x.x.x.72network-03 eth1 trp x.x.x.73telemetry-01 eth1 trp x.x.x.76telemetry-02 eth1 trp x.x.x.77telemetry-03 eth1 trp x.x.x.78identity-01 eth1 trp x.x.x.81identity-02 eth1 trp x.x.x.82identity-03 eth1 trp x.x.x.83rgw-01 eth1 trp x.x.x.84
Continued on next page
66 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Table 1 – continued from previous pagenode inf net addrrgw-02 eth1 trp x.x.x.85api-01 eth1 trp x.x.x.86api-02 eth1 trp x.x.x.87api-03 eth1 trp x.x.x.88cephmon-object-01 eth1 trp x.x.x.89cephmon-object-02 eth1 trp x.x.x.90cephmon-01 eth1 trp x.x.x.91cephmon-02 eth1 trp x.x.x.92cephmon-03 eth1 trp x.x.x.93cephmon-object-03 eth1 trp x.x.x.94rgw-03 eth1 trp x.x.x.95metric-01 eth1 trp x.x.x.96metric-02 eth1 trp x.x.x.97metric-03 eth1 trp x.x.x.98
Openstack hosts
node inf net addrcontroller-01 eth1 trp x.x.x.100controller-02 eth1 trp x.x.x.101controller-03 eth1 trp x.x.x.102controller-04 eth1 trp x.x.x.114compute-01* eth1 trp x.x.x.103compute-02* eth1 trp x.x.x.104compute-03* eth1 trp x.x.x.105compute-04* eth1 trp x.x.x.111compute-05* eth1 trp x.x.x.112compute-06* eth1 trp x.x.x.113compute-07* eth1 trp x.x.x.115compute-08* eth1 trp x.x.x.116storage-01* eth1 trp x.x.x.106storage-02* eth1 trp x.x.x.107storage-03* eth1 trp x.x.x.108storage-04* eth1 trp x.x.x.109storage-05* eth1 trp x.x.x.110
Ephemeral hostnames
For puppet to work and to know which node to configure we have cername (or clientcert) be constructed the followingway:
<location>-<role>-<variant/subrole>-<id>
To make it easier to know what certname a node uses we also set the hostname equal to the certname for all nodes.
When some nodes, e.g. compute, object or storage, change certname we need a way to keep track of the node otherthan certname. All physical nodes have one permanent name and mgmt IP that will follow the machine from start toend:
1.5. Team operations 67
iaas Documentation, Release 0.1.0
<location>-<role>-<id>
This will be used for A and PTR records for mgmt as well.
When a node are used in a variant/subrole we use a CNAME to map the ephemeral hostname to the permanent one.This will only be done in the location where the subrole/variant is present and removed when no longer needed.
Physical naming
When we add name tags to machines in the datacenter we use the permanent name:
[<location>-]<role>-<id>
The location part can be omitted to save space.
1.5.3 Operations
DB
Galera management
The galera cluster consist of three nodes:
• bgo-db-01
• osl-db-01
• uib-ha-02 (quorum node only)
To check the current status as root on db-01:
mysqlSHOW STATUS LIKE 'wsrep_cluster_size';
Cluster size must be 2 or greater.
Start stop quorum node
From bgo-login-01:
sudo ssh iaas@uib-ha-02sudo -isystemctl status garbd
systemctl stop garbdsystemctl start garbd
Resetting the Quorum
If one of the nodes in the cluster have wsrep_cluster_status non-Primary we will need to reset the quorum.On the node you will make the new master run this in mysql:
68 Chapter 1. Contents

iaas Documentation, Release 0.1.0
SET GLOBAL wsrep_provider_options='pc.bootstrap=YES';
Read more on how to fix this:
http://galeracluster.com/documentation-webpages/quorumreset.html
Bootstrap cluster
You will need to bootstrap the cluster if systemctl start mysqld fails on bgo-db-01 for some reason.
Warning: If there are new data on osl-db-01 this will be lost unless we have a db dump and restore it on bgo-db-01after mysqld have been started.
First stop mysqld on db-01 and garbd on uib-ha-02.
On bgo-db-01 edit /var/lib/mysql/grastate.dat and make sure:
safe_to_bootstrap: 1
Bootstrap cluster on bgo-db-01:
galera_new_cluster
Verify that mysqld are running and do a restore if necessary:
systemctl status mysqld
Start mysqld on osl-db-01 and garbd på uib-ha-02
Verify cluster size are now 3.
How to bootstrap Himlar
This document describes the procedure to initialize a new environment from a single login node. The systems to beused are all physically installed (including configuration of BIOS/iDrac) but otherwise untouched.
loc=[bgo|osl|test01|test02|local1|local2|local3|. . . ]
Prerequisites
• A login node (with an up-to-date /opt/[himlar|repo] hiearchy) which is maintained by Puppet
• No management-node installed (controller)
• hieradata/${loc}/common.yaml, hieradata/common/common.yaml, hieradata/nodes/${loc}/. . . etc. are popu-lated with relevant data
• puppet is disabled on new nodes:
ensure $loc/modules/puppet.yaml includes puppet::runmode: ‘none’
• All commands run as the admin user (root) unless noted (consult the document 2FA on jumphosts (login nodes))
• The new controller node (and all further controller and compute nodes) must have CPU virtualization extentionsenabled in BIOS
1.5. Team operations 69

iaas Documentation, Release 0.1.0
Important: When doing a complete reinstall make sure peerdns: ‘no’ is in the network configuration for the nodescontroller-01 and admin-01.
Also make sure gateway and DNS points to the login node or wherever there is a connection out and/or a resolver-reachable. This might require toggling of data in ‘common.yaml’ or the relevant node files.
This should be manipulated on the code activated on the login node from where the bootstrap process is ini-tialized befoe the run. Changes after installation of the controller node should be activated on the node itself(“/opt/himlar/hieradata”).
Procedure
1. Make sure the dhcp and tftp services are allowed through the firewall, if RHEL 7/Centos 7:
iptables -I INPUT 1 -i <mgmt interface for environment> -p udp –dport 67:68 –sport 67:68 -j ACCEPT
iptables -I INPUT 1 -i <mgmt interface for environment> -p udp –dport 69 -j ACCEPT
2. Enable NAT of relevant mgmt interface on the login node out through the public facing interface
3. On the login node:
/usr/local/sbin/bootstrap-$loc-controller-01.sh
Note: The error message “curl: (33) HTTP server doesn’t seem to support byte ranges. Cannot resume.” isharmless when the script has been previously run. If so this is just an indication that the files to be fetched arealready in place. But please make sure the files nevertheless are recent!
4. Boot the relevant physical node using the web GUI on the iDrac or with this command on the login node:
idracadm -r <idrac-IP for $loc-controller-01 to be installed> -u gaussian -p <idrac-pw> serveraction pow-ercycle
Note: Make sure the system is configured to PXE boot on the relevant (mgmt) interface on first attempt! Mightrequire BIOS setup.
Important: When the new controller is fully installed, the script started in 1) must be quit if the new system isset to primarly attempt PXE boot, otherwise it will enter an endless installation loop!
5. Log on to the freshly installed controller node:
(sudo) ssh iaas@$loc-controller-01
6. Run puppet in bootstrap mode:
bash /root/puppet_bootstrap.sh
7. Run puppet normally:
/opt/himlar/provision/puppetrun.sh
8. Punch a hole in the firewall for traffic to port 8000:
iptables -I INPUT 1 -p tcp –dport 8000 -j ACCEPT
70 Chapter 1. Contents

iaas Documentation, Release 0.1.0
9. Initiate installation of the admin node/Foreman:
/usr/local/sbin/bootstrap-$loc-admin.sh
(a) virsh list should now report the foreman instance as running
(b) The install can be monitored with vncviewer $loc-controller.01, virt-manager connected to $loc-controller-01 or your preferred vnc viewer application
(c) When the message
“Domain creation completed. Restarting guest.”
is written to the terminal from where the script was started, the system is installed and ready for use.
(d) The new controller node can be logged on to from the login node:
ssh iaas@$loc-admin-01. . . .
#. When controller node installation is complete the firewall can be restored: t
iptables -D INPUT 1 repeated until all newly inserted rules are removed. Check with iptables -L -n
1. Log on to the new admin system from the login node, optionally check the install log: /root/install.post.log
2. ensure the system time is correct
3. Put the following in hieradata/<loc>/roles/admin.yaml
profile::network::services::manage_dns_records: false
to avoid a bunch of connection timeouts to the ns node which we haven’t installed yet. (You can disable nsupdateon single puppetruns by setting the environment variable FACTER_DISABLE_NSUPDATE=1)
4. Distribute relevant rndc.key:
run the ansible job push_secrets.yaml (check tasks.md for syntax, use correct host)
NB: the secrets repo must already have the key installed
5. Run puppet in bootstrap mode:
bash /root/puppet_bootstrap.sh
6. Run puppet again:
HIMLAR_CERTNAME=<certname> /opt/himlar/provision/puppetrun.sh
This command may be run several times.
7. Configure Foreman:
(a) /opt/himlar/provision/foreman-settings.sh
(b) run the himlarcli command foreman_setup.py (remember to use the appropriate configuration file forthe environment)
Adapt if necessary foreman-settings.sh to local requirements, for instance the installdevice host parameter set-ting for the storage host group.
8. Log on to the Foreman instance now running on the address https://foreman.<mgmt domain>.
9. Sign the certificate request from the controlelr node:
Infrastructure –> Smartproxies –> $loc-admin-01.<mgmt domain> –> Puppet CA –> Sign (Action) for$loc-controller-01.<mgmt domain>
10. Set up autosigning of future certificate requests:
From location of previous action: Autosign entries –> New –> Name: *.<mgmt domain> –> Save
1.5. Team operations 71

iaas Documentation, Release 0.1.0
11. After 15 minutes (or after a manual puppet run on the node) $loc-controller-01 should be listed under Hosts –>All hosts
12. Ensure all data, modules and secrets are up to date:
Run the ansible job bin/deploy.sh $loc
13. Install the rest of the nodes in the environment:
• Install either through the Foreman GUI or using he himlarcli command node.py -c config.ini.$loc <node>install
• Using the himlarcli command the nodes will iautomatically be set up according to the nodes file for theenvironment.
• Recommended sequence:
(a) leaf nodes if applicable (make sure puppet is run afterwards)
(b) proxy-01 (make sure puppet is run afterwards)
(c) Remaining controller nodes (make sure puppet is run afterwards)
(d) Remaining nodes; may be done by executing:
node.py -c config.ini.$loc xxx full
This will install all nodes in the list <himlarcli top dir>/config/nodes/$loc.yaml.Exisiting nodes will be skipped.
Important: DO NOT run puppet on any of the nodes unless explicitly specified!
Note: Physical hosts may have to be rebooted or powered on manually. Make sure they are configuredto PXE boot on the managment interface on their first boot.
Note: As long as we have common login nodes shared between test and production environments, someadditional steps must be performed until successful install of proxy-01:
1. admin-01 must have the login node configured as resolver
2. login node must have a hole punched in the firewall for domain traffic (port 53) on the relevantmanagement interface
3. the login node must be set up to NAT outgoing traffic coming in on the relevant management inter-face (hint: “/root/test02_enable_nat.sh”)
4. admin-01 must have the login node configured as its default gateway configured
When proxy-01 is up and running all can be set back to normal.
1. Execute puppet on the node in this sequence:
(a) mq-01, logger-01
(b) db-01, db-02, dashboard-01, monitor-01
For dashboard-01 the certificates must be first distributed.
(c) cephmon-0[1-]
72 Chapter 1. Contents

iaas Documentation, Release 0.1.0
(d) identity-01, access-01
For access-01 the certificates must be first distributed.
(e) storage0[1-]
(f) volume-01, image-o1, network-01, novactrl-01, console-01
For console-01 the certificates must be first distributed.
(g) compute-0[1-]
2. Enable regular puppet execution by removing puppet::runmode: ‘none’ from 1. virsh list should now reportthe foreman instance as running #. The install can be monitored with vncviewer $loc-controller.01,
virt-manager connected to $loc-controller-01 or your preferred vnc viewer application
(a) When the message
“Domain creation completed. Restarting guest.”
Deployment of new code
With ansible
To use ansible to deployment:
cd $ANSIBLEbin/deploy.sh <loc>
Caution: Sometimes the r10k used in provision/puppetmodules.sh will not deploy a new version of apuppet module. Check deployed module version in /etc/puppetlabs/code/modules/<modulename>/metadata.json
Manual deployment
Deployment is done on the admin-01 node. From login you should reach it by running
ssh iaas@<loc>-admin-01.<domain>
Hieradata and profile
sudo -icd /opt/himlargit pull
Puppet modules
Active puppet modules reside in /etc/puppetlabs/code/modules. For minor changes in Puppetfile this should updatethe active modules from source:
1.5. Team operations 73
iaas Documentation, Release 0.1.0
cd /opt/himlarHIMLAR_PUPPETFILE=deploy provision/puppetmodules.sh
To rebuild a module from source:
rm -Rf /etc/puppetlabs/code/modules/<modulename>cd /opt/himlarHIMLAR_PUPPETFILE=deploy provision/puppetmodules.sh
To rebuild all modules from source:
rm -Rf /etc/puppetlabs/code/modules/*cd /opt/himlarprovision/puppetmodules.sh
Secrets
Secrets are stored at git@git.<domain> in hieradata/secrets. To update /opt/himlar/hieradata/secrets:
cd /opt/himlarprovision/puppetsecrets.sh
Compute management
Note all AZ names will have a region prefix not used in this document. E.g. default-1 will be bgo-default-1 in bgo.
Updated information about active aggregate and compute host lists can be found in Trello.
Organization
Each compute host should only be in one host aggregate and one availability zone.
Availability zone
We have 3 different AZ:
• default-1
• legacy-1
• iaas-team-only-1*0
Host aggregate
Each AZ have one or more host aggregates with hosts.
• central1 (default-1)
• group1 (legacy-1)
0 this is only available to limited projects (e.g. iaas-team). Note that everybody can see it, but will get a “No valid host” error if they try to useit. This is also the default AZ for new compute hosts.
74 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• group2 (legacy-1)
• group3 (legacy-1)
• placeholder1 (iaas-team-only-1)
Disk setup
Each compute host can either be setup with local disk for instances or use Ceph. This should not be changed withouta full reinstall. To see det disk setup for a compute host look inn the hieradata node file.
Aggregate management
All aggregates in legacy-1 will be managed by aggregate.py in himlarcli. This include activate (enable/disable hosts),migrate and notification.
The addition and removal of compute hosts in aggregates are manual and can be done with Openstack CLI.
Workflow example
If we need to use a standby compute host (called compute-XY) from placeholder1 in central1 we will need to do thefollowing:
• Reinstall compute-XY with correct disk setup
• Disable other hosts in iaas-team-only-1 and enable compute-XY
• Test compute-XY by staring an instance in iaas-team-only-1
• With Openstack CLI remove compute-XY from placeholder1 aggregate and add to central1
Compute reinstall
For compute host (hypervisor) management use himlarcli and hyervisor.py. This script will have sub commands forenable/disable and move between aggregate.
Before you start make sure the compute host are empty and disabled.
Ansible script
NB! Delete the running instances or migrate them to another compute node before you start!
To reinstall a compute host with ansible run:
cd <ansible-repo>bin/rebuild_compute.sh <HOST> --force
Testing
To test the compute host after a reinstall move it to the placeholder1 host aggregate og test with iaas-team-only-1 AZand iaas-team only project.
1.5. Team operations 75

iaas Documentation, Release 0.1.0
HPC Compute nodes setup and management
Hypervisor hardware
• 2x AMD EPYC 7551 32-Core Processor
• 512 GB RAM
These hosts have 8 NUMA nodes:
# numactl -H...node distances:node 0 1 2 3 4 5 6 7
0: 10 16 16 16 28 28 22 281: 16 10 16 16 28 28 28 222: 16 16 10 16 22 28 28 283: 16 16 16 10 28 22 28 284: 28 28 22 28 10 16 16 165: 28 28 28 22 16 10 16 166: 22 28 28 28 16 16 10 167: 28 22 28 28 16 16 16 10
Flavors
All flavors have the following properties:
hw_rng:allowed='True'hw_rng:rate_bytes='1000000'hw_rng:rate_period='60'
In addition, we have set a type (either “alice” or “atlas”):
type='s== alice'
We have the following flavors for HPC workloads:
Name RAM (GB) vCPU Propertiesalice.large 8 2alice.xlarge 16 4alice.2xlarge 24 8atlas.large 8 2 hw:cpu_policy=’dedicated’ hw:cpu_thread_policy=’require’atlas.xlarge 16 4 hw:cpu_policy=’dedicated’ hw:cpu_thread_policy=’require’atlas.2xlarge 24 8atlascpu.2xlarge 24 8 hw:cpu_policy=’dedicated’ hw:cpu_thread_policy=’require’
Hypervisor OS
The following parameters is set via the grub boot loader, in /etc/sysconfig/grub:
hugepagesz=2Mhugepages=245760transparent_hugepage=neverisolcpus=4-127
76 Chapter 1. Contents
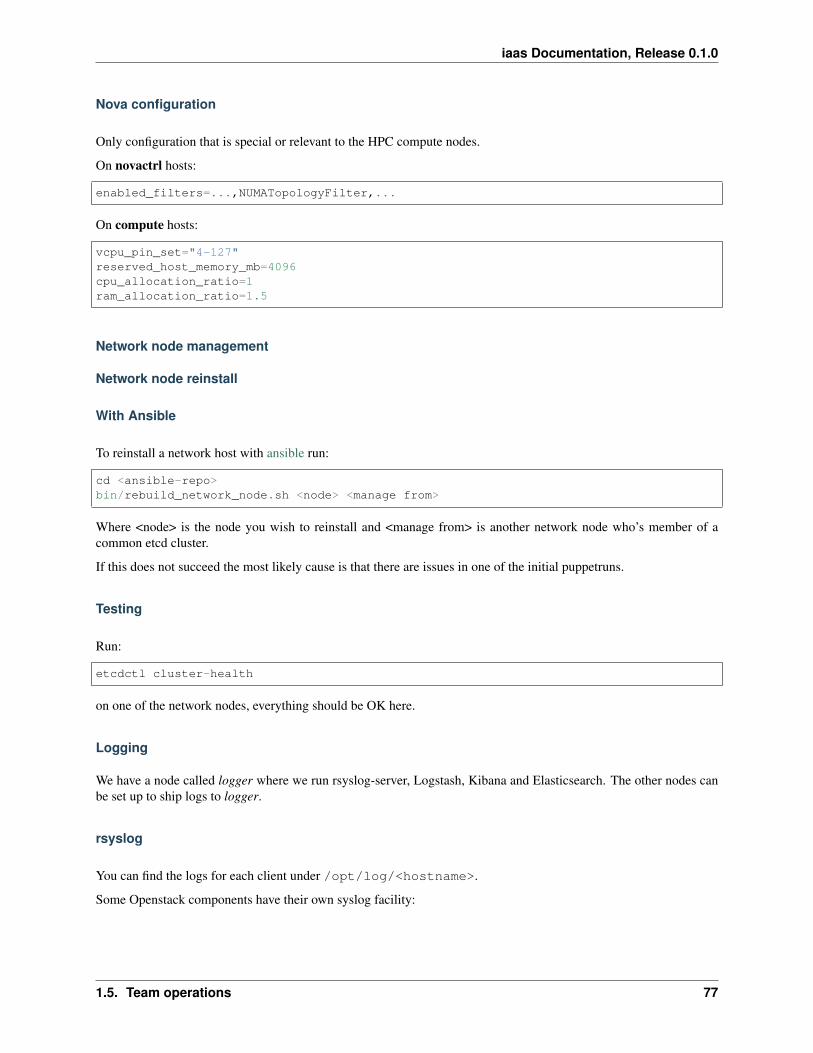
iaas Documentation, Release 0.1.0
Nova configuration
Only configuration that is special or relevant to the HPC compute nodes.
On novactrl hosts:
enabled_filters=...,NUMATopologyFilter,...
On compute hosts:
vcpu_pin_set="4-127"reserved_host_memory_mb=4096cpu_allocation_ratio=1ram_allocation_ratio=1.5
Network node management
Network node reinstall
With Ansible
To reinstall a network host with ansible run:
cd <ansible-repo>bin/rebuild_network_node.sh <node> <manage from>
Where <node> is the node you wish to reinstall and <manage from> is another network node who’s member of acommon etcd cluster.
If this does not succeed the most likely cause is that there are issues in one of the initial puppetruns.
Testing
Run:
etcdctl cluster-health
on one of the network nodes, everything should be OK here.
Logging
We have a node called logger where we run rsyslog-server, Logstash, Kibana and Elasticsearch. The other nodes canbe set up to ship logs to logger.
rsyslog
You can find the logs for each client under /opt/log/<hostname>.
Some Openstack components have their own syslog facility:
1.5. Team operations 77
iaas Documentation, Release 0.1.0
local0.* novalocal1.* horizon (apache logs)local2.* keystonelocal3.* glancelocal4.* cinderlocal5.* neutron
Kibana
Access to kibana is limited to mgmt network on each site. You will need to run sshuttle or ssh port forwarding tothe login node to gain access. Point your browser to:
bgo: http://bgo-logger-01.mgmt.iaas.intern:5601/
Foreman
Runs on <loc>-admin-01 and is the DHCP-server, puppetmaster and is used to install new hosts (nodes, computeand storage).
Kickstart templates
The templates used to install new nodes are found on: https://github.com/norcams/community-templates.git
If this repo is updated, you will need to update all admin nodes manually. Run as root on the admin server:
foreman-rake templates:sync \repo="https://github.com/norcams/community-templates.git" \branch="norcams" associate="always"
Upgrade
Foreman are upgraded by changing the foreman_version i himlar and running the foreman upgrade playbook inansible.
Ansible
The Ansible playbooks we use, are found on Github at https://github.com/norcams/ansible
In the documentation $ANSIBLE will be refered to as the directory where you have cloned the ansible repo. This willby default be $HOME/ansible.
You should clone this repo to your home catalog on each login node:
git clone [email protected]:norcams/ansible
You will need access to your SSH-key (tip: use ssh -A <login>)
Setup
Please refer to README.md
78 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Simple tasks
Read task.md for examples of useful simple tasks to perform with ansible.
Patching
Last changed: 2019-06-28
Update repo
Repo list (test and/or prod) are updated during the planing phase of an upgrade. But this is usually the repo we update:
• centos-base
• centos-extras
• centos-updates
• centos-qemu-ev
• ceph-mimic
• epel
• mariadb
• rdo-queens
• sensu
• puppetlabs-PC1
Important: Do NOT update calico-repo without extra planned testing og repackaging.
Avoid updating management repos at the same time as normal patching.
Before we start
Important: Before you start, make sure the repo is up to date with the snapshot you wish to use.
Update ansible inventory for both OSL and BGO $himlarcli/ansible_hosts.py
Set location variable according to the environment which is going to be patched:
location=bgo
or:
location=osl
Make sure all nodes will autostart with:
sudo ansible-playbook --become -e "myhosts=${location}-controller" lib/autostart_→˓nodes.yaml
1.5. Team operations 79

iaas Documentation, Release 0.1.0
Normal OS patching
For each for the production regions, BGO and OSL, do the following:
1. Upgrade virtual nodes, while excluding the httpd, mariadb and mod_ssl packages. This is usually safe to dooutside of a scheduled maintenance window:
sudo ansible-playbook -e "myhosts=${location}-nodes exclude=httpd*,MariaDB*,mod_→˓ssl" lib/yumupdate.yaml
2. While in a scheduled maintenance window, upgrade virtual nodes:
sudo ansible-playbook -e "myhosts=${location}-nodes" lib/yumupdate.yaml
3. Check if all virtual nodes are updated:
sudo ansible-playbook -e "myhosts=${location}-nodes" lib/checkupdate.yaml
4. Upgrade controller nodes:
sudo ansible-playbook -e "myhosts=${location}-controller" lib/yumupdate.yaml
5. Check if all controller nodes are updated:
sudo ansible-playbook -e "myhosts=${location}-controller" lib/checkupdate.yaml
For each controller do the following. Make sure cephmon is running without error before starting on the next controller.
1. Check ceph status on cephmon:
sudo ssh iaas@${location}-cephmon-01 'sudo ceph status'
Or, alternatively:
for i in $(seq 1 3); do sudo ssh iaas@${location}-cephmon-0$i 'sudo ceph status' ;→˓ done
2. Turn off the nodes on the controller before reboot:
sudo ansible-playbook -e "myhosts=${location}-controller-<id> action=stop" lib/→˓manage_nodes.yaml
Monitor through virt-manager or virsh list that all virtual nodes are shut down before proceeding with reboot-ing the controller.
3. Reboot the controller node:
sudo ansible-playbook -e "myhosts=${location}-controller-<id>" lib/reboot.yaml
Tip: Check that things work before rebooting controller-04, as error analysis etc. often depends on the virtual nodesrunning on controller-04.
None disruptive patching
These steps can be done without notification and can be done later then normal patching.
80 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Storage
1. Before you begin, you can avoid automatic rebalancing of the ceph cluster during maintenance. Run this com-mand on a cephmon or storage node:
ceph osd set noout
2. Upgrade storage:
sudo ansible-playbook --become -e "myhosts=${location}-storage" lib/yumupdate.yaml
3. Check if the storage nodes are upgraded:
sudo ansible-playbook --become -e "myhosts=${location}-storage" lib/checkupdate.→˓yaml
4. Reboot one storage node at the time and check ceph status before next nodes:
ceph status
5. After all nodes are rebooted, ensure that automatic rebalancing is enabled:
ceph osd unset noout
Compute
None disruptive patching will only be possible for compute nodes running in AZ <location>-default-1. Com-pute nodes in <location>-legacy-1 will need to be patched in a limited scheduled maintenance window.
Before you start check to documentation for reinstall of compute
1. You will need an empty compute node first. There will usually always be one in AZ iaas-team-only.Reinstall this first and test it. Disable all other compute nodes and enable the new one.
2. For each compute node migrate all instances to the enabled compute node (the empty one). Use himlarcli/migrate.py. Then reinstall the newly empty compute node, and start over with the next one.
3. The last compute node will now be empty and can be reinstalled, disabled and added back to the AZ iaas-team-only. Update trello status for Availability zone / Host aggregate.
Leaf
Only reboot one node at a time, and never if one node is a single point of failure.
Warning: Never patch Cumulus VX (virtual appliance). Only physical hardware. Cumulus VX are only used intesting/development.
Upgrade node:
apt-get updateapt-get dist-upgrade
Reboot node.
1.5. Team operations 81

iaas Documentation, Release 0.1.0
Testing
After patching, we should test the following:
• install new instance
• ssh to new instance
• create volume and attach to instance
• detach volume
• destroy volume
• destroy instance
Only in test01 and test02
Reinstall a compute node and repeat the tests above.
Migrate a running instances
Last changed: 2019-07-01
This document describes migrating an instance from one compute node (source) to another (target) while the instanceis running (e.g. NOT legacy). The aggregate cannot have any NUMA aware instances (e.g. Alice/Atlas workload).
Before you start
• Reinstall and test the target
• Make sure the target and source are in the same aggregate
• Make sure cpu_model (see nova.conf) is the same on target and source (e.g. Haswell-noTSX)
Migrate
We use himlarcli and migrate.py migrate to do the migration.
Tips
• Test first with --limit 1 to see that everything is working
• Use --large on first run to migrate the instances with lots of RAM first
Help
This document describes using openstack cli to migrate an instance to target and what to do when a migration timesout:
https://docs.openstack.org/nova/latest/admin/live-migration-usage.html
82 Chapter 1. Contents
iaas Documentation, Release 0.1.0
Himlar CLI
Himlar CLI is a command line tool written in Python to manage our Openstack installation through the API.
Source code: https://github.com/norcams/himlarcli
Setup
Location
Himlar CLI can be found under /opt/himlarcli on login-01 and proxy-01 nodes. Config file is distributed withpuppet under /etc/himlarcli/config.ini.
Running on login-01
When running scripts on login, you will be able to use some scripts but not access keystone admin API. So you willnot be able to run the script for user or project management here.
Since login are used for both test and production locations there are several config files under /opt/himlarcli/named config.ini.<loc>.
Deployment
There is an ansible playbook and script to update to the latest version on all nodes:
cd <ansible-repo>bin/himlarcli.sh <loc>
Script overview
Help
All script will have updated help that can be accessed with the -h options. Most of the script actions will also have itshelp description. E.G:
./image.py update -h
Options
Common options for all scripts
• --debug
• --dry-run
• -c /path/to/config.ini
• --format text|json
1.5. Team operations 83
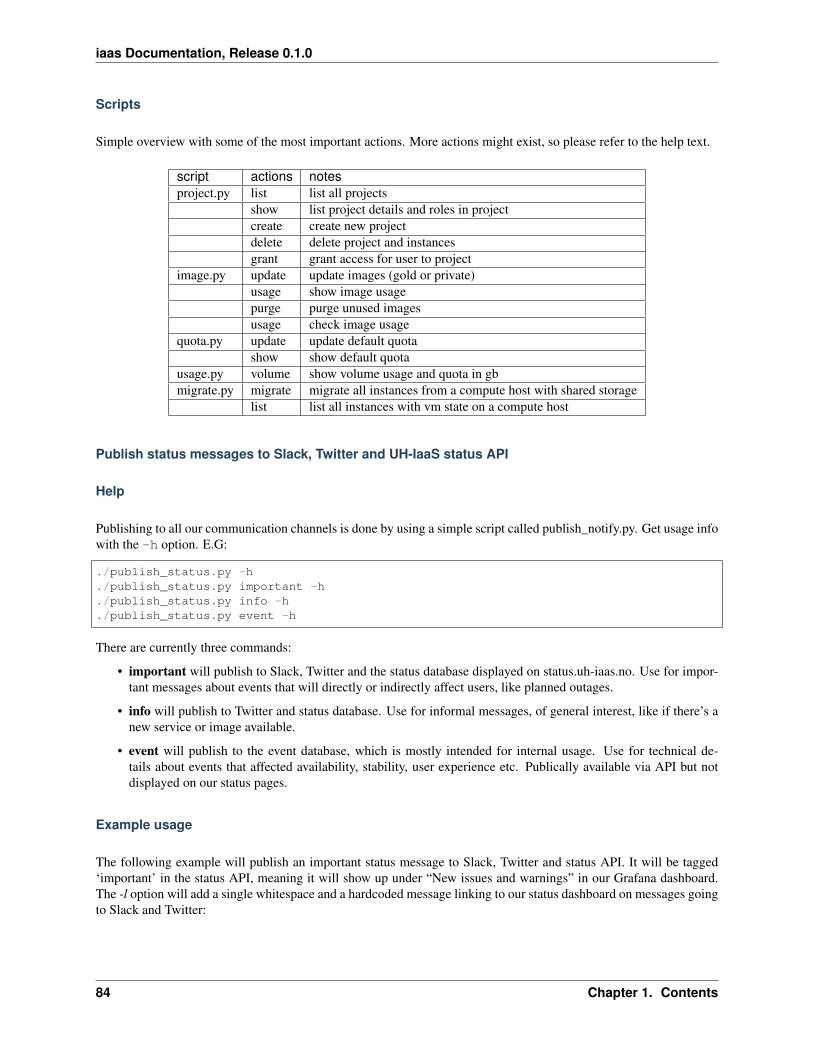
iaas Documentation, Release 0.1.0
Scripts
Simple overview with some of the most important actions. More actions might exist, so please refer to the help text.
script actions notesproject.py list list all projects
show list project details and roles in projectcreate create new projectdelete delete project and instancesgrant grant access for user to project
image.py update update images (gold or private)usage show image usagepurge purge unused imagesusage check image usage
quota.py update update default quotashow show default quota
usage.py volume show volume usage and quota in gbmigrate.py migrate migrate all instances from a compute host with shared storage
list list all instances with vm state on a compute host
Publish status messages to Slack, Twitter and UH-IaaS status API
Help
Publishing to all our communication channels is done by using a simple script called publish_notify.py. Get usage infowith the -h option. E.G:
./publish_status.py -h
./publish_status.py important -h
./publish_status.py info -h
./publish_status.py event -h
There are currently three commands:
• important will publish to Slack, Twitter and the status database displayed on status.uh-iaas.no. Use for impor-tant messages about events that will directly or indirectly affect users, like planned outages.
• info will publish to Twitter and status database. Use for informal messages, of general interest, like if there’s anew service or image available.
• event will publish to the event database, which is mostly intended for internal usage. Use for technical de-tails about events that affected availability, stability, user experience etc. Publically available via API but notdisplayed on our status pages.
Example usage
The following example will publish an important status message to Slack, Twitter and status API. It will be tagged‘important’ in the status API, meaning it will show up under “New issues and warnings” in our Grafana dashboard.The -l option will add a single whitespace and a hardcoded message linking to our status dashboard on messages goingto Slack and Twitter:
84 Chapter 1. Contents

iaas Documentation, Release 0.1.0
$ ./publish_status.py important -m "We're currently having some issues. Sorry for the→˓inconvenience." -l
Which will return:
The following message will be published: We're currently having some issues. Sorry→˓for the inconvenience. For live updates visit https://status.uh-iaas.noAre you sure you want to publish? (yes|no)?
This has to be interactively confirmed by typing yes. Notice that you should always use punctuation after the lastsentence in your message or template.
This example uses a pre-made template instead of a command-line argument as message, replacing the variables $dateand $region with -d and -r:
./publish_status.py important -t ./misc/notify_maintenance.txt -r bgo -d 'September→˓20 between 15:00 and 16:00'
Which will return:
The following message will be published: Services will be unavailable on September 20→˓between 15:00 and 16:00 in BGO due to maintenance. Running instances will not be→˓affected.Are you sure you want to publish? (yes|no)?
This example will publish an info message about a new image on Twitter and status API. It will be tagged ‘info’ in thestatus API, meaning it will show up under “News” in our Grafana dashboard:
./publish_status info -m 'New image Fedora 28 is availible."
Repository server
Introduction
For local caching of external repositories and to facilitate a repository of packages created by the UH-IaaS team etc.,a server system is installed. Because the production environment has to be carefully managed, some issues are raisedwhich is attempted resolved by this setup:
• Production servers must only run well-known versions and combinations of software (which is supposed to betested and approved before deployment)
• Possible to check state of code at any date in the past for debugging
• Possible to test new code without disturbing production environment
• Ability to maintain our software in the same manner as any external RPM repository
• Means to distribute all kind of data files without versioning
To accomplish all of this we have implemented both a system for versioned/snapshotted mirrors of any ‘external’ repo(whatever the location), a local ordinary RPM repository and a general distribution point.
• Hostname: iaas-repo.uio.no
• Alias (used in code): download.iaas.uio.no
• Access: as for normal infrastructure nodes (iaas-user from one of the login nodes)
• Repo root directory: /var/www/html/uh-iaas
1.5. Team operations 85

iaas Documentation, Release 0.1.0
• Available protocols: https
Note: The implementor accepts the fact that the naming scheme for these directories is misleading! Please read thedescription before assuming anything related to the role of the directory!
Executive Summary
repo is a locally hosted mirror of a set of external repositories. A snapshot is taken of each repo every night, thesesnapshots resides inside the snapshot directory date-stamped. For every one of these repositories (at least the oneswhich are utilized by the UH-IaaS infrastructure), there is a pointer to one of those snspshots beneath the test respectiveprod directories. Those pointers are never moved without consideration or testing, and especially the links in the proddirectory. The upshot is thus: packages and files can be trusted not to be updated or altered in an uncontrolled fashion,and is available locally at all times.
yumrepo and aptrepo should be assumed to be like any other external repositories, only these external repositoriesare coincidentally managed by the UH-IaaS team. Data configured into these are then available for consumption inthe same controlled manner as any other external repository which is mirrored locally.
rpm, nonfree and ports are free and unmanaged repositories without the forementioned snapshotting and consistentcontrol. Data located here is available instantly, but outside of any version control and without any kind of meta data.
86 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Diagram of setup
Directory description
• repo: Mirror hierarchy. This is where all defined repositories are mirrored to. Content is normally mirrorednightly.
• snapshots: Nightly snapshot of all mirrors under repo. Each snapshot is named by the date and time ofcreation.
• prod: For each repository a pointer (symbolic link) to a snapshot of the same.
• test: As for prod, but separate link.
• yumrepo: Locally maintained RPM repository. Mirrored under repo as any external repository is (nameduh-iaas).
• aptrepo: Locally maintained APT repository. Mirrored under repo as any external repository is (named uh-iaas-apt).
• rpm: Generic file distribution. No metadata, versioning, mirroring or
• nonfree Generic file distribution. No metadata, versioning, mirroring or snapshotting. Only accessible fromlogin and proxy-nodes!
• gem: Local Ruby Gem distribution. No metadata, versioning, mirroring or snapshotting.
1.5. Team operations 87

iaas Documentation, Release 0.1.0
• ports: For FreeBSD packages. No metadata, versioning, mirroring or snapshotting.
Common attributes and requirements
Packages built locally by the project are made available for use (default for the world!) by storing it in one of theprepared directories depending on whether the package is to be part of a yum repository or as a stand-alone packageor file.
The iaas group owns all files and directories under the repository root directory; the hierarchy is configured with theset group ID bit. Accordingly, all relevant repo operations can (and should) be done as the iaas user.
NOTE
Make sure new packages and files have the correct SELinux label:
sudo restorecon <file>
or:
sudo restorecon -R <directory>
Detailed descriptions
YUM repository
Directory name: yumrepo
Packages which should be maintained by ordinary package maintained procedures, are located in the YUM reposi-tory located in yumrepo. These files/packages are then considered and consumed exactly like any other, external,repository used by the project/code.
IMPORTANT
After all file operations update the repository meta data:
sudo /usr/bin/createrepo <repo root directory>/yumrepo
URL: https://download.iaas.uio.no/uh-iaas/yumrepo
Note: This repository is additionally mirrored and snapshotted as any external repository (named uh-iaas). As suchit can be reached through the test and prod interfaces described elsewhere.
Client configuration (example)
Example of client configuration in a yum repo file under /etc/yum.repos.d/:
[uh-iaas]name=UH-IaaS repobaseurl=https://download.iaas.uio.no/uh-iaas/prod/uh-iaas/enabled=1gpgcheck=0priority=10
88 Chapter 1. Contents

iaas Documentation, Release 0.1.0
APT repository
Directory name: aptrepo
APT-packages which should be maintained by ordinary package management tools on DEB-based systems, are locatedin the APT repository located in aptrepo. These files/packages are then considered and consumed exactly like anyother, external, repository used by the project/code.
The architectures and codenames supported are described in the distribution file located in the apt subdirectory ofthe repo-admin GIT repository.
Steps to import packages
1. Save new package to the incoming subdirectory inside aptrepo
2. Execute the deb repo tool inside the aptrepo directory:
reprepro -b . –confdir /etc/kelda/prod/apt includedeb wheezy incoming/*
(replace wheezy with whatever codename is considered)
3. Remove package(s) from the incoming directory
URL: https://download.iaas.uio.no/uh-iaas/aptrepo
Note: This repository is additionally mirrored and snapshotted as any external repository (named uh-iaas-apt). Assuch it can be reached through the test and prod interfaces described elsewhere.
Client configuration (example)
Example of client configuration in /etc/apt/sources.list etc:
deb [trusted=yes] https://download.iaas.uio.no/uh-iaas/prod/uh-iaas-apt wheezy main
Ruby Gem repository
Directory name: gem
Gems which are locally produced or adapted might be installed into this repository. The gems might then be installedthrough the ‘sensu_gem* puppet provider or using the –source parameter for gem install.
Steps to import gems
• upload package into the gems subdirectory
• remove all files named ‘*specs*’ (should be 6 all in all)
• remove the quick subdirecory recursively
• run as the iaas user: gem generate_index –update –directory . (ignoring errors)
For upload procedure, see below.
1.5. Team operations 89

iaas Documentation, Release 0.1.0
Standalone file archives
Directory name: rpm and nonfree
Files (RPM packages or other types) which are needed by the project but which should or cannot use the local YUMrepository, can be distributed from the generic archive located under the rpm or nonfree subdirectory. No additionaloperations required, other than the ensuring correct SELinux label as described above.
URL: https://download.iaas.uio.no/uh-iaas/rpm URL: ‘<https://download.iaas.uio.no/uh-iaas/nonfree‘_
The distinction between those two, is that nonfree is only accessible from a restricted set of IP addresses (at the timeof writing the login and proxy nodes) whereas rpm is reachable from wherever.
Upload procedure
Probably the simplest way to upload a file to the rpm (or nonfree) archive is to first place the file on an availableweb site and then download it into the archive on download:
1. upload file to a web archive (for instance https://folk.uio.no for UiO affiliated personel)
2. log in to download from one of the login nodes in the usual manner:
sudo ssh [email protected]
3. cd /var/www/html/uh-iaas/rpm
4. download the file with wget, curl or something like that
Local mirror and snapshot service
To facility tight control of the code and files used in our environment, and to ensure the availability in case of networkor external system outages, etc., a local mirror and snapshot service is implemented.
Content and description of included subdirectories:
Shortname
Longname
Description URL
repo Reposi-tory
Latest sync from external sources https://download.iaas.uio.no/uh-iaas/repo
snap-shots
Snap-shots
Regular (usually daily) snapshots of data in repo https://download.iaas.uio.no/uh-iaas/snapshots
test Test repo Pointer to a specific snapshot in time, usually newer thanprod
https://download.iaas.uio.no/uh-iaas/test
prod Pro-ductionrepo
Pointer to a specific snapshot in time with well-tested data,used in production environments
https://download.iaas.uio.no/uh-iaas/prod
Usage is normally as follows:
repo for development or other use of most up-to-date code
test test code which is aimed for next production release
prod production code
snapshots can be used to test against code from any specific date in the past
90 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Mirror
Directory: repo
Each mirrored repository is located directly beneath the repo folder. Which “external” (which might actually belocated locally) repository is to be mirrored, is defined by data in the internal repo-admin git repo (see below foraccess details). All repositories listed in the file repo.config is attempted accessed and synced. The type of repository- as defined in the configuration file for the appropriate listing - determines what actions are taken on the data. Asthis is mainly YUM repositories, the appropriate metadata commands are executed to create a proper local repository.Any YUM repo defined in the configuration must have a corresponding repo-definition in a suitable file in the yum.repos.d subdirectory (in the git repo!).
The mirroring is done once every night by a root cron job.
To access the most current data in the mirror, us this URL:
https://download.iaas.uio.no/uh-iaas/repo/
Snapshots
Directory: snapshots
Every night a cron job runs to create snapshots of all mirrored repositories (of all kinds). A snapshot subdirectory iscreated named by the current date and time. Under this, all repos can be accessed. This way any data can be retrievedfrom any data in the past on which a snapshot has been taken.
current: In the snapshots directory there is always a special “snapshot” named current. This entry is at any timelinked to the most current snapshot.
To access the snapshot library:
https://download.iaas.uio.no/uh-iaas/snapshots/
Note: The snapshot data are created using a system of hardlinks. This way unaltered data is not duplicated, whichconserves space considerably.
Test and prod
Directories: test, prod
All mirrored repos used by UH IaaS can be accessed through a static and well known historic version using the testand prod interfaces. By configuring the appropriate files in the internal repo-admin git repo, each repo might have atest and prod pointer linking to a specific snapshot of this repository. NB: each and every mirrored repo can be setup to link to separate snapshots!
Important: This is the access point to use in the production and test environments!
Configuration
Configuration for the repositories is stored in the internal git repo:
1.5. Team operations 91

iaas Documentation, Release 0.1.0
[email protected]:repo-admin
The iaas user has READ permissions and should be used to pull the configuration to the repository server.
Files
config Generic configuartion (for now the location of the repo root only)
repo.config Definition of the external repositories to mirror
test.config Which snapshots and local repositories to point to in test
prod.config Which snapshots and local repositories to point to in prod
Considerations
• test should never point to a snapshot older than what the corresponding prod are linking to
• Pointers in prod must also exist in test, the rationale being that this somewhat ensures that prod has alreadybeen tested. Links in the prod configuration which does not also exist in the test configuration will not beactivated (removed if the exists)!
• If there is more than one link listed to the same repo the most current is always the one activated.
• Existing links not listed in the current configuration will be removed!
Update procedure
1. Clone or pull the git repo locally:
[email protected]:repo-admin
This must be done on a node inside the set up (like the login nodes) due to access restrictions on the local gitrepo.
2. Edit one or both files: prod.config and/or test.config, entering or changing to reflect the date required (consultthe web page for exact timestamp to use.
3. Commit and push to the central git repo.
4. On osl-login-01 run the ansible job update_repo.yaml:
sudo ansible-playbook -e "myhosts=download" lib/update_repo.yaml
This action pull the latest config and update the pointers in test and prod.
Publicizing procedure
Normal (automatic)
rpm, nonfree and gem: Files placed inside this location is instantly accessible, provided correct SELinux labeling.No snapshotting provided!
92 Chapter 1. Contents

iaas Documentation, Release 0.1.0
yumrepo and aptrepo: Files placed inside this location is instantly accessible, provided correct SELinux labeling.No snapshotting provided through this interface! For this use the SNAPSHOT, TEST or PROD interfacesinstead.
repo: Any repositories which are mirrored (including YUMREPO) have new files accessible here after the mirroringjob is run during night time. The version available is always the most recent!
snapshots: Every night after mirror job completion a snapshot of the current mirrors are taken. Any of these snapshotsare available through this interface below a directory named by the timestamp [YYYY-MM-DD-hhmm]. Themost current snapshot is additionally presented as “current”.
test and prod: These interfaces should be seen as a static representation of data from specific date/times. Eachmirrored repository (if configured to be listed here) is listed with a link to a specific snapshot of the repo inquestion. The PROD repository is what is used in the production environment and should never be more recentthan TEST (this is actually prohibited by the setup routine for these pointers). Data is available concurrentlywith the snapshots it is linked to.
Manual routine for instant publicizing
rpm, nonfree, gem and ports: Nothing required!
yumrepo and aptrepo: New files are available through the ordinary interfaces after mirroring and snapshotting. Thisis usually done nightly, but the routines might be run manually if necessary:
1. sudo /opt/kelda/repoadmin.sh -e prod sync
2. sudo /opt/kelda/repoadmin.sh -e prod snapshot
Caveats
• Any changes in the local YUM or APT repository (yumrepo resp. aptrepo) is not accessible through themirror interface (repo) until after the next upcoming mirror job (usually during the next night, check crontabon the mirror server for details). After this, the data should be accessible under the repo link.
• New data mirrored is available under the snapshot link only after the next snapshot run (check crontab fordetails). This is normally scheduled for some time after the nightly mirror job.
• Data stored in any of the local repositories are instantly accessible when accessed using the direct URL’s aslisted above.
Purging of old/unused data
For conservation of disk space there is a janitor script which may be used to remove (purge) snapshots which are nolonger used:
/usr/local/sbin/snapshot_cleanup.sh
Note: Only snapshots older than the oldest snapshot still referenced by any test or prod pointers may be deleted.
Invocation:
/usr/local/sbin/snapshot_cleanup.sh [-d|u] [-t <YYYY-MM-DD-HHMM> ]
-u: print usage text and exit
1.5. Team operations 93
iaas Documentation, Release 0.1.0
-d: dry-run (just print what would otherwise be deleted)-t: purge snapshots older than timestamp provided
Timestamp format equals format used by kelda (config fields and snapshotdirectory naming)
If no -t argument provided then all snapshots older than oldest still inuse are removed!
For now there is no automatic invocation, and any cleanup should be done manually. User confirmation is requested.
SSL certificates
Generation
Generation for *.iaas.uio.no and *.iaas.uib.no are done following each organizations normal process.*.uh-iaas.no are done at UNINETT.
For self signed certificates we use our own Root CA git repo on login:
[email protected]:ca_setup
This repo should also all key, certs and config files for all certs in use.
Naming conventions
Type Filenamecachain /etc/pki/tls/certs/cachain.pemkey /etc/pki/tls/private/<CNAME>.key.pemcert /etc/pki/tls/certs/<CNAME>.cert.pem
<CNAME> is the certificate CNAME.
Storage
All three files should be stored on login under full path with root set at /opt/repo/secrets/nodes/<HOSTNAME>/
Distribution
There is an ansible playbook to push secrets to nodes (see tasks.md for more info). This requires that a YAML configfile describes the files and mode. Example of inventory/host_vars/bgo-db-01.yaml:
secret_files:cert:
path: '/etc/pki/tls/certs/db01.bgo.uhdc.no.cert.pem'mode: '0644'owner: 'root'group: 'root'
key:path: '/etc/pki/tls/private/db01.bgo.uhdc.no.key.pem'
(continues on next page)
94 Chapter 1. Contents

iaas Documentation, Release 0.1.0
(continued from previous page)
mode: '0644'owner: 'root'group: 'root'
cafile:path: '/etc/pki/tls/certs/cachain.pem'mode: '0640'owner: 'root'group: 'mysql'
DNS
We use the domains uh-iaas.no and uhdc.no.
Architecture
The illustration below shows the architecture of the DNS infrastructure. This is within a single location. In our case,with two or more locations, the NS nodes act as master/slave for each other. One NS node is the master for a givenzone, and the others act as slaves for that zone.
1.5. Team operations 95

iaas Documentation, Release 0.1.0
We have two resolving DNS nodes in each location. They are set up in a redundant fashion where anycast is used toachieve redundancy. The idea is that instances in BGO will use the BGO resolver as primary and the OSL resolver assecondary, and vice versa for OSL instances.
Public zone: uh-iaas.no
This zone is delegated to:
• ns1.uh-iaas.no (master - located in OSL)
• ns2.uh-iaas.no (slave - located in BGO)
Editing this zone is done via Puppet hieradata. Since the OSL NS-host (ns1.uh-iaas.no) is master for this zone, editingthis zone should be done in hieradata/osl/common.yaml.
In this zone we have the following records:
RECORD TYPE VALUEaccess.uh-iaas.no A 158.39.77.250access-bgo.uh-iaas.no A 158.39.77.250access-osl.uh-iaas.no A 158.37.63.250api.uh-iaas.no A 158.39.77.250dashboard.uh-iaas.no A 158.39.77.254dashboard-bgo.uh-iaas.no A 158.39.77.254dashboard-osl.uh-iaas.no A 158.37.63.254ns1.uh-iaas.no A 158.37.63.251ns2.uh-iaas.no A 158.39.77.251report.uh-iaas.no A 158.39.77.250report-bgo.uh-iaas.no A 158.39.77.250report-osl.uh-iaas.no A 158.37.63.250request.uh-iaas.no A 158.39.77.250status.uh-iaas.no A 158.39.77.250status-bgo.uh-iaas.no A 158.39.77.250status-osl.uh-iaas.no A 158.37.63.250ns1.uh-iaas.no AAAA 2001:700:2:82ff::251ns2.uh-iaas.no AAAA 2001:700:2:83ff::251docs.uh-iaas.no CNAME uh-iaas.readthedocs.iowww.uh-iaas.no CNAME norcams.github.iouh-iaas.no MX 10 uninett-no.mx1.staysecuregroup.comuh-iaas.no MX 20 uninett-no.mx2.staysecuregroup.net
Internally delegated zone: osl.uh-iaas.no
This zone is delegated to:
• ns1.uh-iaas.no (master - located in OSL)
• ns2.uh-iaas.no (slave - located in BGO)
Editing this zone is done via Puppet hieradata. Since the OSL NS-host (ns1.uh-iaas.no) is master for this zone, editingthis zone should be done in hieradata/osl/common.yaml.
In this zone we have the following records:
96 Chapter 1. Contents
iaas Documentation, Release 0.1.0
RECORD TYPE VALUEcompute.api.osl.uh-iaas.no A 158.37.63.250identity.api.osl.uh-iaas.no A 158.37.63.250image.api.osl.uh-iaas.no A 158.37.63.250metric.api.osl.uh-iaas.no A 158.37.63.250network.api.osl.uh-iaas.no A 158.37.63.250placement.api.osl.uh-iaas.no A 158.37.63.250volume.api.osl.uh-iaas.no A 158.37.63.250console.osl.uh-iaas.no A 158.37.63.250resolver.osl.uh-iaas.no A 158.37.63.252resolver.osl.uh-iaas.no AAAA 2001:700:2:82ff::252
Internally delegated zone: bgo.uh-iaas.no
This zone is delegated to:
• ns1.uh-iaas.no (slave - located in OSL)
• ns2.uh-iaas.no (master - located in BGO)
Editing this zone is done via Puppet hieradata. Since the BGO NS-host (ns2.uh-iaas.no) is master for this zone, editingthis zone should be done in hieradata/bgo/common.yaml.
In this zone we have the following records:
RECORD TYPE VALUEcompute.api.bgo.uh-iaas.no A 158.39.77.250identity.api.bgo.uh-iaas.no A 158.39.77.250image.api.bgo.uh-iaas.no A 158.39.77.250metric.api.bgo.uh-iaas.no A 158.39.77.250network.api.bgo.uh-iaas.no A 158.39.77.250placement.api.bgo.uh-iaas.no A 158.39.77.250volume.api.bgo.uh-iaas.no A 158.39.77.250console.bgo.uh-iaas.no A 158.39.77.250resolver.bgo.uh-iaas.no A 158.39.77.252resolver.bgo.uh-iaas.no AAAA 2001:700:2:83ff::252
Internal zone: uhdc.no
The following zones in uhdc.no has been delegated to us:
ZONE NSbgo.uhdc.no ns1.uh-iaas.no (slave) ns2.uh-iaas.no (master)osl.uhdc.no ns1.uh-iaas.no (master) ns2.uh-iaas.no (slave)test01.uhdc.no alf.uib.no begonia.uib.notest02.uhdc.no ns1.uio.no ns2.uio.no
Editing these zones is done via Puppet hieradata. Most of the records should be present in hiera-data/common/common.yaml.
1.5. Team operations 97

iaas Documentation, Release 0.1.0
Test domains
For public domain in test we have a delegated subdomains:
REGION DOMAINtest01 test.iaas.uib.notest02 test.iaas.uio.no
OpenStack Designate (DNS)
Warning: This document is under construction. Designate is not yet in production.
Managing top-level domains (TLDs)
We manage a list of legal top-level domains, in which the users can create their zones. With such a list in place, zonesmay only be created with the TLDs listed there. Without such a list, any TLD would be legal, and users could alsoregister zones such as “com”, thus preventing any other user to create a domain under the “.com” TLD.
A list of all valid top-level domains is maintained by the Internet Assigned Numbers Authority (IANA) and is updatedfrom time to time. The list is available here:
• http://data.iana.org/TLD/tlds-alpha-by-domain.txt
This list can be imported into Designate via the himlarcli command dns.py:
# download the TLD list from IANAcurl http://data.iana.org/TLD/tlds-alpha-by-domain.txt -o /tmp/tlds-alpha-by-domain.→˓txt
# import the TLD list into designate./dns.py tld_import --file /tmp/tlds-alpha-by-domain.txt
The tld_import action will add any TLDs which aren’t already registered, with a special comment that marks theTLD as being bulk imported. Any registered TLDs that aren’t on the import list, and also have the special bulk importcomment, will be deleted. This means that we can add our own TLDs if needed, as they will not be deleted by the bulkimport. The bulk import as show above is designed to run automatically by cron etc.
The himlarcli command also have actions to create, delete and update a TLD, and to view the list or a specific TLD.
Managing blacklists
Blacklisting is done to prevent users from creating domains that we don’t want them to create. This is mostly done toprotect a domain from eventual future use. In order to prevent any users from creating the domain foo.com and anysubdomains:
./dns.py blacklist_create \--comment 'Protect domain foo.com including any subdomains' \--pattern '^([A-Za-z0-9_\-]+\.)*foo\.com\.$'
If we want to only protect the domain itself, but allow users to create subdomains in the domain, we can use a simplerpattern:
98 Chapter 1. Contents

iaas Documentation, Release 0.1.0
./dns.py blacklist_create \--comment 'Protect domain foo.com while allowing subdomains' \--pattern '^foo\.com\.$'
Listing the blacklists is done via the blacklist_list action (the option –pretty formats the output in a table). Example:
$ ./dns.py blacklist_list --pretty+----------------------------------+--------------------------------------------------→˓+--------------------------------------+| pattern | description→˓| id |+----------------------------------+--------------------------------------------------→˓+--------------------------------------+| ^([A-Za-z0-9_\-]+\.)*foo\.com\.$ | Protect domain foo.com including any subdomains→˓| 8958bf52-8e64-4a86-87ea-2087b7bc6d60 || ^bar\.net\.$ | Protect domain bar.net while allowing subdomains→˓| b3f7fc9f-67a8-4d07-aabc-444f0e4d67c4 |+----------------------------------+--------------------------------------------------→˓+--------------------------------------+
Updating a blacklist entry is done via the blacklist_update action. Updating the comment (example):
$ ./dns.py blacklist_update --comment 'new comment' \--id b3f7fc9f-67a8-4d07-aabc-444f0e4d67c4
And updating the pattern (example):
$ ./dns.py blacklist_update --new-pattern '^tralala\.org\.$' \--id b3f7fc9f-67a8-4d07-aabc-444f0e4d67c4
Deleting a blacklist entry is done via the blacklist_delete action:
./dns.py blacklist_delete --id <ID>
Blacklisted domains
The following domains should be blacklisted in production:
1.5. Team operations 99

iaas Documentation, Release 0.1.0
DO-MAIN
PATTERN COMMENT
uh-iaas.no
^([A-Za-z0-9_\-]+\.)*uh-iaas\.no\.$
Official UH-IaaS domain, managed outside of Openstack Des-ignate
uhdc.no ^([A-Za-z0-9_\-]+\.)*uhdc\.no\.$
Official UH-IaaS domain, managed outside of Openstack Des-ignate
uio.no ^([A-Za-z0-9_\-]+\.)*uio\.no\.$
Domain belonging to UiO. Instances in UH-IaaS are not al-lowed to have UiO addresses
uib.no ^uib\.no\.$ Domain belonging to UiB. The domain itself is forbidden, butsubdomains are allowed
uio-cloud.no
^uiocloud\.no\.$ Domain belonging to UiO. The domain itself is forbidden, butsubdomains are allowed
uninett.no ^([A-Za-z0-9_\-]+\.)*uninett\.no\.$
Domain belonging to Uninett. Reserved for possible future use
ntnu.no ^([A-Za-z0-9_\-]+\.)*ntnu\.no\.$
Domain belonging to NTNU. Reserved for possible future use
uia.no ^([A-Za-z0-9_\-]+\.)*uia\.no\.$
Domain belonging to UiA. Reserved for possible future use
These are added with these commands:
./dns.py blacklist_create --pattern '^([A-Za-z0-9_\-]+\.)*uh-iaas\.no\.$' --comment→˓'Official UH-IaaS domain, managed outside of Openstack Designate'./dns.py blacklist_create --pattern '^([A-Za-z0-9_\-]+\.)*uhdc\.no\.$' --comment→˓'Official UH-IaaS domain, managed outside of Openstack Designate'./dns.py blacklist_create --pattern '^([A-Za-z0-9_\-]+\.)*uio\.no\.$' --comment→˓'Domain belonging to UiO. Instances in UH-IaaS are not allowed to have UiO addresses→˓'./dns.py blacklist_create --pattern '^uib\.no\.$' --comment 'Domain belonging to UiB.→˓The domain itself is forbidden, but subdomains are allowed'./dns.py blacklist_create --pattern '^uiocloud\.no\.$' --comment 'Domain belonging to→˓UiO. The domain itself is forbidden, but subdomains are allowed'./dns.py blacklist_create --pattern '^([A-Za-z0-9_\-]+\.)*uninett\.no\.$' --comment→˓'Domain belonging to Uninett. Reserved for possible future use'./dns.py blacklist_create --pattern '^([A-Za-z0-9_\-]+\.)*ntnu\.no\.$' --comment→˓'Domain belonging to NTNU. Reserved for possible future use'./dns.py blacklist_create --pattern '^([A-Za-z0-9_\-]+\.)*uia\.no\.$' --comment→˓'Domain belonging to UiA. Reserved for possible future use'
ETCD
How to fix etcd cluster
The etcd cluster needs to be reconfigured from time to time, and typically if a network node is reinstalled. In order toinclude a newly installed (or otherwise reset) node into an existing cluster, some action is required.
With Ansible
There’s an Ansible playbook available that automates all the steps required to bring a reinstalled node back into thecluster. Check the following before you run it:
• The node must be fully provisioned by Puppet after reinstall. etcd will fail, which is why we have this playbook,but the node must otherwise be properly installed.
100 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• The node needs a script that we deploy with Puppet located in /usr/local/sbin/bootstrap-etcd-member
• There should be no empty variables in the script. If there are, check for missing hieradata.
The playbook needs two variables:
• ‘member’ is the hostname of the node we’re bringing back into the cluster.
• ‘manage_from’ is the hostname of another node in a functioning cluster where we delete the old member andre-add the newly installed one.
The playbook will figure out the rest.
This example re-adds bgo-network-02 into the cluster, managed from bgo-network-01:
sudo ansible-playbook -e 'member=bgo-network-02 manage_from=bgo-network-01' lib/→˓reconfigure_etcd_cluster.yaml
If successful, all tasks should run without errors except ‘TASK [Bootstrap member]’ which is supposed to fail. Thistask runs etcd in the foreground asynchronously, which is needed for bootstrapping, and exits after 30 seconds. Thenit runs Puppet, which will start etcd as a systemd service.
Expanding from a single-node cluster
The above playbook will bring back a reinstalled node into an already existing multi-node cluster, however, expandingfrom a single-node cluster into a multi-node one requires a slightly different procedure.
First, the initial-cluster parameter must contain all the nodes present when bootstrapping, This is configured by Puppet,including the script we use for bootstrapping. Expand the cluster node by node; starting with the initial single nodecluster, add a second node in the configuration, then use the Ansible playbook called expand_etcd_cluster:
sudo ansible-playbook -e 'member=bgo-network-02 manage_from=bgo-network-01 member_→˓ip=172.18.0.72' lib/expand_etcd_cluster.yaml
We need to provide the IP address of the new member since we cannot fetch it from etcdctl.
If successful, all tasks should run without errors except ‘TASK [Bootstrap member]’ which is supposed to fail. Thistask runs etcd in the foreground asynchronously, which is needed for bootstrapping, and exits after 30 seconds. Thenit runs Puppet, which will start etcd as a systemd service.
Check the etcd cluster by running the following command on one of the nodes:
etcdctl cluster-health
which should report both nodes being healthy.
Then proceed with the next node.
Fix compute nodes after etcd outage
If the etcd cluster running on the network nodes has been unresponsive for an extended period of time, the followingservices need to be restarted on compute, after verifying that the cluster is healthy:
etcdetcd-grpc-proxycalico-dhcp-agentcalico-felix
(continues on next page)
1.5. Team operations 101

iaas Documentation, Release 0.1.0
(continued from previous page)
openstack-nova-computeopenstack-nova-metadata-api
We have an Ansible playbook for this task:
sudo ansible-playbook -e 'myhosts=bgo-compute' lib/restart_etcd_compute.yaml <- Fix!
Manually
If Ansible fails for some reason you can try to do the procedure manually.
Following the official docs are usually sufficient, available here:
https://coreos.com/etcd/docs/latest/v2/runtime-configuration.html
Keep the following in mind:
• Delete the old member from the cluster first, then add the new one.
• When you add the new member, etcdctl returns three environment variables you must set on the node you’rebootstrapping
• Make sure the etcd service is stopped and /var/lib/etcd is empty on the node you’re bootstrapping
• Disable puppet agent until you’re done
• The etcd commands for the node you’re bootstrapping must be run as the etcd user.
Bootstrapping example (bgo-network-01):
etcd --listen-client-urls http://0.0.0.0:2379,http://127.0.0.1:4001 --advertise-→˓client-urls http://172.18.0.71:2379 --listen-peer-urls http://0.0.0.0:2380 --→˓initial-advertise-peer-urls http://172.18.0.71:2380 --data-dir /var/lib/etcd/bgo-→˓network-01.etcd
After bootstrapping, stop etcd running in foreground, enable puppet and initiate a puppetrun. This will start the etcdservice, and you’re good to go.
uib-ha
In location uib we are running 4 nodes (2 test and 2 prod) with haproxy and corosync/pacemaker.
These nodes run load balancing/HA for different UiB only services, but can also be used for UH-IaaS services.
Access to the nodes are only available through bgo-login-01.
Domains
The service are setup with to different domains:
• uibproxy.ha.uib.no (use this for uib only services)
• pubproxy.ha.uib.no (use this for public services)
Test domains:
• uibtestproxy.ha.uib.no
102 Chapter 1. Contents
iaas Documentation, Release 0.1.0
• pubtestproxy.ha.uib.no
Each domain use 2 public IPs with round-robin A-records.
New service
The setup a new service using uib-ha you will need to follow two steps:
1. Add your domain to the domain list hash in himlar/hiaradata/uib/ha.yaml
2. Create a CNAME records to one of the 2 A-records above
Deployment
The cluster runs himlar but without any admin node:
Deploy wit ansible:
sudo ansible-playbook -e "myhosts=uib-ha-test" lib/deploy_himlar.yaml
Run puppet:
cd /opt/himlarprovision/puppetrun.sh
Management
Some tips and tricks to manage the cluster (each cluster are two nodes).
Check status:
pcs status
Set node in standby (for patching or booting):
pcs node standby <fqdn>
Set node back to online:
pcs node unstandby <fqdn>
Hardware maintenance
Dell PowerEdge servers
Upgrading firmware
Normal procedure:
1. Run Dell System Update:
dsu
1.5. Team operations 103

iaas Documentation, Release 0.1.0
2. Press a + ENTER to select all available updates
3. Press c + ENTER to commit and start the upgrade
4. When it finishes, reboot the server:
reboot
On older servers (tested on 11th gen), like we have in test, upgrading firmware on storage components may fail. If thishappens:
1. Fix libs:
cd /opt/dell/srvadmin/lib64/ln -fs libstorelibir-3.so libstorelibir.so.5
2. Run dsu again:
dsu
3. Press a + ENTER to select all available updates
4. Press c + ENTER to commit and start the upgrade
5. Return libs to default:
cd /opt/dell/srvadmin/lib64/ln -fs libstorelibir.so.5.07-0 libstorelibir.so.5
6. Verify that libs are returned to normal:
ls -l /opt/dell/srvadmin/lib64/libstorelibir.so.5
7. Reboot:
reboot
iDRAC settings
Setting proper name on the iDRAC:
racadm config -g cfgLanNetworking -o cfgDNSRacName $(hostname -s)
Hardware inventory
An easy way to get the inventory of a Dell server is to run the monitoring plugin in debug mode, from the monitorserver:
/usr/lib64/nagios/plugins/check_openmanage -H test02-controller-01 -d
1.5.4 Installation
Documentation describing installation of the IaaS platform
104 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Hardware installation
This documents how to install the hardware for our development phase.
Placement of equipment in racks
We are installing the equipment in two separate racks to provide for easier future expansion.
Installation guide
The six controller and compute nodes are installed in rack 1, the five storage nodes in the other. Each rack has a pairof layer 3 capable switches at the top. There is only a single management switch, a the top of rack 1, but if expandingthe setup we’ll have one management switch in each rack.
1.5. Team operations 105

iaas Documentation, Release 0.1.0
106 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Single rack installation (not used)
We also documented an optional single rack installation setup. In this setup the physical boxes outlined in red areconnected to routers loc-leaf-03 and 04.
We decided not to use this setup because all the sites got enough space for two racks.
1.5. Team operations 107
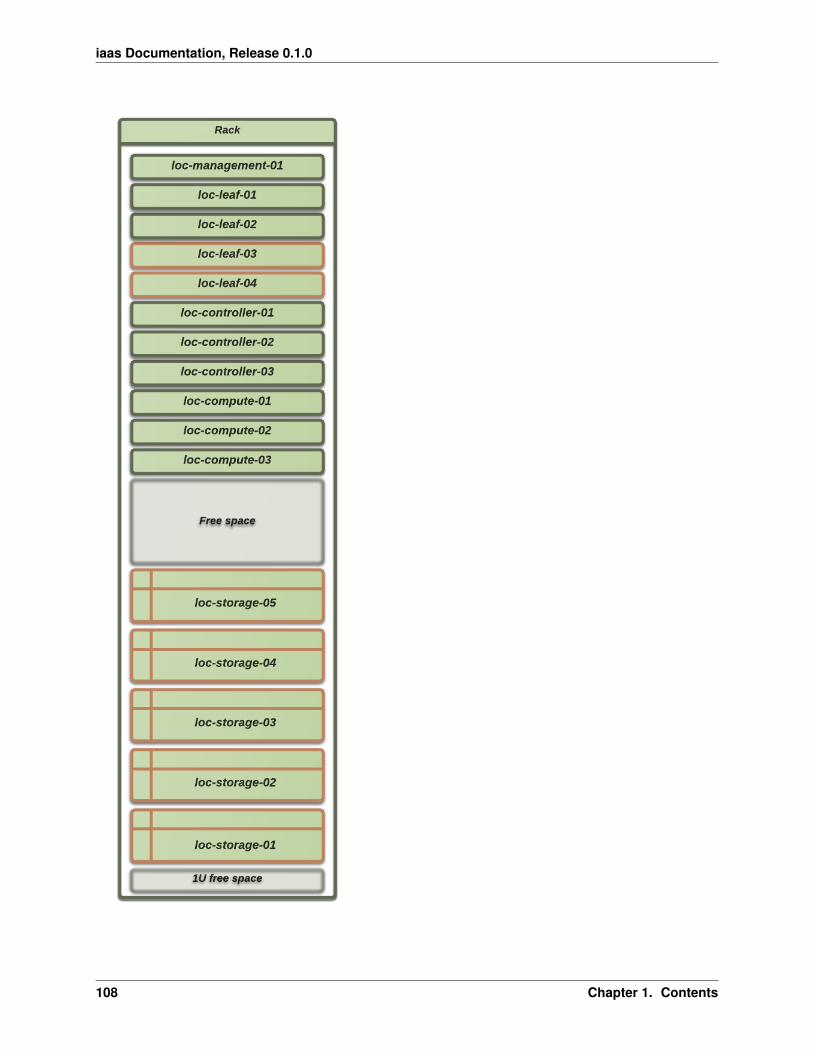
iaas Documentation, Release 0.1.0
108 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Cabling
All of the servers will be connected with dual 10G fiber links, a single 1G ethernet cable for management (PXE) anda 1G ethernet for the bare metal controller (BMC).
The layer 3 switches will be cabled as simple as possible for the first minimal product installation. Later we’ll increasethe number of physical connections for testing more designs and solutions.
Connection sheet
A LibreOffice spreadsheet documents all the connections between the hosts and devices. It is also available in HTMLformat. For the location SAFE theres is a different cabling scheme available here (in HTML).
Conceptual overview
This illustrates the cabling concept with a minmal solution for switch connectivity.
This is the same concept as above, but with additional switch cablingto to enable testing of different network design and redundancy scenarios.
1.5. Team operations 109
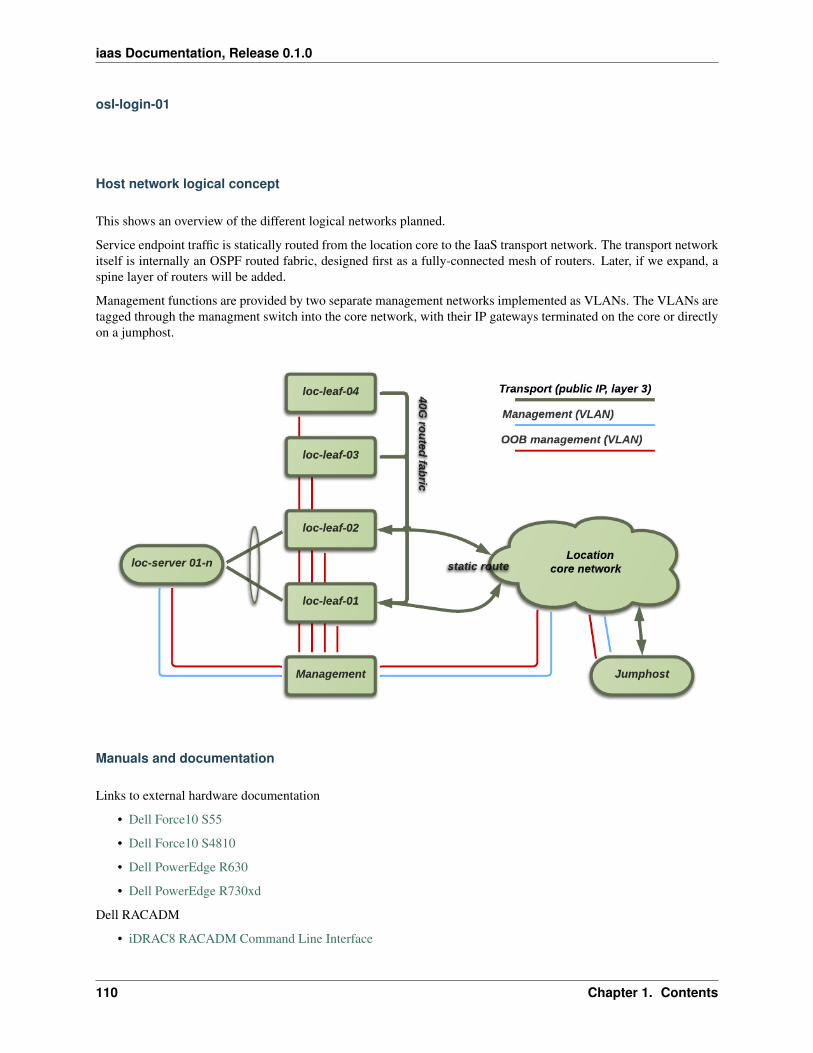
iaas Documentation, Release 0.1.0
osl-login-01
Host network logical concept
This shows an overview of the different logical networks planned.
Service endpoint traffic is statically routed from the location core to the IaaS transport network. The transport networkitself is internally an OSPF routed fabric, designed first as a fully-connected mesh of routers. Later, if we expand, aspine layer of routers will be added.
Management functions are provided by two separate management networks implemented as VLANs. The VLANs aretagged through the managment switch into the core network, with their IP gateways terminated on the core or directlyon a jumphost.
Manuals and documentation
Links to external hardware documentation
• Dell Force10 S55
• Dell Force10 S4810
• Dell PowerEdge R630
• Dell PowerEdge R730xd
Dell RACADM
• iDRAC8 RACADM Command Line Interface
110 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• iDRAC8 RACADM Command Line Interface Reference Guide
Dell iDRAC Direct
• Methods to Save and Restore PowerEdge Server Configuration Settings and Firmware Images
• Importing Server Configuration Profile From USB Device
• Creating and Managing Server Configuration Profiles
IP addressing plan
Contents
• IP addressing plan
– Instance workloads
* Public
– Infrastructure and management
* transport network
* mgmt network
* oob network
* Test02 internal gateway network
Instance workloads
This describes from what IP network and prefix an instance workload will receive its address. Normally this willhappen at boot time through DHCP.
Public
Public IPv4 network.
region env IPv4bgo prod 158.39.77.0/24bgo prod 158.39.74.0/24osl prod 158.37.63.0/24osl prod 158.39.75.0/24osl prod 158.39.48.0/24test01 test 129.177.31.64/27test02 test (10.100.200.0/24)vagrant dev (192.168.0.0/24)local1 dev (192.168.12.0/24)local2 dev (192.168.13.0/24)local3 dev (192.168.12.0/24)
Public IPv6 network.
1.5. Team operations 111
iaas Documentation, Release 0.1.0
region env Private IPv4 IPv6bgo prod 2001:700:2:8300::/56osl prod 2001:700:2:8200::/56test01 test (10.0.250.0/24) (2001:700:200:915::/64)test02 test (fd32::/64)local1 dev TBDlocal2 dev TBDlocal3 dev TBDvagrant dev (fc00:700:100:200::/64)dev dev TBD
Legacy public network not used any more
region env IPv4 IPv6trd prod 158.39.48.0/24 2001:700:2:8400::/56
Note: The networks enclosed in parentheses are not reachable outside of their locally managed routing domains.
Infrastructure and management
This describes addressing of the IaaS system and backend services.
transport network
Internal routed link network used for routing all service and storage traffic.
Network prefixes
env IPv4 prefixprod 172.18.0.0/16test 172.30.0.0/16dev 172.31.8.0/21
IP networks in use
region env Name IPv4 IPv6 VLAN BGP ASbgo prod trp 172.18.0.0/21 TBD 100 65501bgo prod link1 172.18.228.0/30 TBD 65502osl prod trp 172.18.32.0/21 TBD 100 65502osl prod link1 172.18.228.0/30 TBD 65502test01 test trp 172.30.0.0/24 TBD 65535test02 test trp 172.30.32.0/24 TBD 65536vagrant dev trp 172.31.8.0/24 TBD 65500local1 dev trp 172.31.12.0/24 TBD 100local2 dev trp 172.31.13.0/24 TBD 101
Prefix reservations per link type and location
112 Chapter 1. Contents
iaas Documentation, Release 0.1.0
env link region IPv4 prefix IPv6 prefixprod leaf-node bgo 172.18.0.0/19 TBDprod leaf-node osl 172.18.32.0/19 TBDprod leaf-node TBD 172.18.64.0/19 TBDprod gw-gw bgo 172.18.224.0/22 TBDprod gw-gw osl 172.18.228.0/22 TBDprod gw-gw TBD 172.18.232.0/22 TBD
As specified above, each region-specific transport network block is again split up in smaller prefix reservations toallow for up to 4 separated L2 switching domains.
mgmt network
Interactive ssh access, os level maintenance services
env IPv4 prefixprod 172.16.0.0/16test 172.28.0.0/17dev 172.31.0.0/21
region env IPv4 IPv6 vlanbgo prod 172.16.0.0/21 TBDosl prod 172.16.32.0/21 TBDtest01 test 172.28.0.0/24 TBDtest02 test 172.28.32.0/24 TBDvagrant dev 172.31.0.0/24 TBDlocal1 dev 172.31.4.0/24 TBD 10local2 dev 172.31.5.0/24 TBD 11
oob network
Out of band management, IPMI BMC devices.
env IPv4 prefixprod 172.17.0.0/16test 172.28.128.0/17
region env IPv4 IPv6 vlanbgo prod 172.17.0.0/21 N/Aosl prod 172.17.32.0/21 N/Atest01 test 172.28.159.0/24 N/Atest02 test 172.28.160.0/24 N/A
Management switches
region env IPv4 IPv6 vlanosl prod 10.17.32.0/24 N/Abgo prod 10.17.0.0/24 N/A
1.5. Team operations 113

iaas Documentation, Release 0.1.0
Test02 internal gateway network
Internal network between virtual leaf node (test02-leaf-01) and the host (test02-controller-00). Public traffic frominstances is routed through this network from their default gateway (leaf) via the controlelr host and then NAT’ed outon its outside interface.
Class Network IF Adress IF AdressIPv4 192.168.122.0/24 br2 1 bridge.100 2IPv6 fd96::/64 br2 1 bridge.100 2
1.5.5 Tips and tricks
Branding & Customization
Where do we use logo
• Website
• Enduser documentation
• Github
• Slack
UH-IaaS Logo
Create a new project
• ssh <user>@<loc>-login-01.<domain>
• ssh iaas@<loc>-proxy-01.<domain>
114 Chapter 1. Contents
iaas Documentation, Release 0.1.0
• sudo -i
• source openrc
• cd /opt/himlarcli
• source bin/activate
• run ./project.py
Example
./project.py create -t <admin> -a <email> -q <small> --end <enddate> --desc <→˓"description"> --dry-run --debug
Patch the compute node in vagrant
Remember to patch the compute node after running “vagrant up” for the first time.
• ssh <user>@<loc>-login-01.<domain>
• cd ansible/files/patches/
Check the “MIN_QEMU_DISCARD_VERSION” version in python-nova-newton-centos-something.diff
Log into the compute node in vagrant
• cd /usr/lib/python2.7/site-packages/nova/virt/libvirt/
Update the “MIN_QEMU_DISCARD_VERSION” version in driver.py
Finally, remember to restart nova:
• systemctl restart openstack-nova-compute.service
1.5. Team operations 115

iaas Documentation, Release 0.1.0
Test02 instance connections to outside world
Øke kvoter i etterkant
Et prosjekt får alle kvoter satt automatisk ved opprettelse, enten til default-verdiene eller til annen kvote definert vedopprettelsen via himlarcli. Vi har dog ikke noe enkelt grensesnitt for å endre kvotene på et prosjekt i etterkant (frafeks. small til medium). Man må da i stdet endre hver individuell kvote manuelt med openstack e.l.
Eksempel:
Prosjektet mikaeld-test er satt opp med kvote small i utgangspunktet. Denne skal nå endres til kvote large, men meden ytterlige økt kvote for minnebruk (opp fra 96 GB til 160 GB) og GB med snapshots (der er det allerede en økt kvotepå 600 GB mens default for large er 500 GB).
Note: Forutsetter at omgivelsesmiljø-variabler for openstack og himlarcli er definert på forhånd på ordinær måte!
1. Finn prosjekt-id:
/opt/himlarcli/project.py show mikaeld-test | grep “^id =”
Alternativt:
/opt/himlarcli/project.py list | grep mikaeld-test
2. Finn gjeldende kvoter:
openstack quota show $id
3. Finn kvoter for nytt kvote-sett:
cat /opt/himlarcli/config/quotas/large.yaml
116 Chapter 1. Contents

iaas Documentation, Release 0.1.0
4. Sett nye kvoter med utgangspunkt i det som ble funnet over:
openstack quota set –ram 163840 –instances 50 –cores 100 –snapshots 40 –volumes 20 –secgroup-rules 500–secgroups 100 $id
Hvis man også skal sette kvoten for disk-størrelse så slenger man på –gigabytes <ny kvote>
5. Bekreft med:
openstack quota show $id
6. Siste to punkter må gjentas for alle regioner (dersom det skal være likt overalt) da denne kommandoen kun tareffekt i den region det kjøres i/mot!
Dataporten in vagrant (updates)
If you create or edit Dataporten’s Client ID and Client Secret from Oauth details while vagrant identity and access areup, you need to restart httpd, in addition to rsync and provision on both identity and access.
E.g. - ssh access - systemctl restart httpd
Sjekke status på HAproxy-tjenestene
watch ‘echo “show stat” | nc -U /var/lib/haproxy/stats | cut -d “,” -f 1,2,5-11,18,24,27,30,36,50,37,56,57,62 | column-s, -t’
Liste ut IPer som aksesserer frontend_public og antall forekomster fra HAProxy-log
grep ‘frontend_public’ /opt/log/norcams.log | cut -d’ ‘ -f5 | grep -v Proxy | cut -d’:’ -f1 | sort -n | uniq -c | sort -n
Småtips rundt CEPH
Feilsøking:
https://ceph.com/geen-categorie/ceph-manually-repair-object/
Vanlige advarsler som kan overses:
Too many PGs per OSD
Den er jo permanent inntil vi får flere OSDer. Feks. fjernet vi snurredisker, og det er ikke mulig å minskeantall pger, bare øke. Eneste konsekvens er litt høyere CPU-BRUK enn nødvendig.
Clock skew detected on. . . (cephmon-instans)
Kommer etter restart og forsvinner etter en stund. Kan ignoreres.
Diverse småtterier som ikke passer i egne kapitler
Management-switch i OSL (10.17.32.1)
Denne støtter ikke en av default’e cipher som nyere ssh-klienter tilbyr. Man må derfor spesifisere denne eksplisitt nårman skal inn på switchen:
ssh [email protected] -c 3des-cbc
1.5. Team operations 117

iaas Documentation, Release 0.1.0
EPEL-repo
Ved installasjon av ‘epel-release’ e.l. kan man risikere at repodefinisjonen for EPEL-repoet settes til å peke på EPELsitt offisielle speil-nettverk i stedet for vårt snapshot-kontrollerte speil. For å finne slike feilkonfigurerte systemer kanman kjøre følgende ansible-jobb:
sudo ansible-playbook --become -e "myhosts=<whatever som vanlig>" lib/check_epel.yaml
Man vil da få feil på de hoster som er feil satt opp sammen med utskrift av linjen som ikke skal være der.
GPG-nøkkel
For Keystone brukes bl.a. GPG for å kryptere og dekryptere tokens under distribusjonen mellom identity-nodene. Nåret miljø (re)installeres eller man av andre grunner må sette opp ny GPG-nøkkel, må en ny slik genereres og distes tilalle identity-noder i miljøet.
Følgende rutine kjøres på relevant login-node:
1. /usr/local/sbin/create-gpg.sh <loc>
Genererer en ny GPG-nøkkel uten passord og evig varighet. Nøkkelen legges under node-katalogen til <loc>-identity-01 i secrets-repoet.
2. Kopier manuelt filen token-secret-key.gpg fra denne katalogen til nodekatalogene for andre deltakende noder imiljøet.
3. sudo ansible-playbook -e “myhosts=<loc>-identity” lib/push_gpg_keys.yaml
Distribuerer den genererte nøkkelen til relevante identity-noder og importerer den inn i GPG.
Utvide sensu-plugins-himlar
1. git clone [email protected]:norcams/sensu-plugins-himlar.git
2. legg til/endre filer etter behov
3. oppdater lib/sensu-plugins-himlar/version.rb (versjon)
4. tilpass ev. sensu-plugins-himlar.gemspec
5. kjør gem build sensu-plugins-himlar.gemspec
6. last opp resulterende gem-pakke til repository-serveren som beskrevet i dokumentasjonen rundt den
7. sjekk inn og push til git-repo
Avassosiere noder i Foreman
Noder i Foreman blir ikke automatisk blir avassosiert med en compute-profil når du sletter compute-profilen, og detteresulterer i en ødelagt database. Løsningen, inntil bug’en er fikset, er dette:
for h in `hammer --csv host list --search 'facts.is_virtual == true' | cut -d, -f1 |→˓tail -n +2`; do hammer host disassociate --id $h; done
118 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Er puppet disablet
Kan man se om en node har agent-kjøring disablet uten å teste med en kjøring? Om ikke annet så kan man i alle fallsjekke slik:
:: # ls -l /opt/puppetlabs/puppet/cache/state/agent_disabled.lock
Dersom filen finnes er agent-kjøring disablet, og grunnen (hvis angitt) ligger som en tekst i filen.
Samarbeidspartnere
Når databehandleravtalen er signert, kan vi gi vedkommende tilgang til UH-IaaS.
Gi tilgang via Dataporten
• Logge inn på https://dashboard.dataporten.no.
• Velge “University of Bergen”-fanen.
• Under “Applications” klikke på “UH-IaaS Dashboard” & “UH-IaaS provision project” > “Auth Providers” >“Høyere utdanning” og legge til lærestedet.
Slack og nettskjema
Huske å legge til <maildomene> for Slack-kanalen, og gi tilgang til nettskjemaet.
nocams/himlar-dp-prep
Runnig himlar-dp-prep in the development environment
In Vagrant:
vagrant ssh access/usr/local/sbin/dpapp_develop.sh(skal kjøres uten feil)cd /opt/dpapp.developsource bin/activatecp /opt/dpapp/production.ini .(update production.ini if needed, e.g. add host=0.0.0.0)systemctl stop iptablespython setup.py develop
or python setup.py installpserve --reload developent.ini
or pserve production.ini
Nettverksproblemer
Hvis det dukker opp nettverksproblemer under oppretting av nye instanaser, pleier disse stegene å hjelpe:
• Restarte neutron-server og etcd på Network
• Kjøre ansible playbook “restart_compute_services.yaml” på Compute
1.5. Team operations 119

iaas Documentation, Release 0.1.0
Setup vGPU
Compute-vgpu-42
Download and install Nvidia virtual GPU driver
Update nova.conf:
cpu_mode=customcpu_model=EPYC
[devices]enabled_vgpu_types = nvidia-<num>
[pci]passthrough_whitelist = {"address": "0000:<num>:00.0"}
To find passthrough whitelist address
ls /sys/class/mdev_bus/
To find Nvidia models
ls /sys/class/mdev_bus/*/mdev_supported_types/
Restart nova-compute
Ensure that ECC is disabled on GPU
nvidia-smi -q
Otherwise, run
nvidia-smi -g 0 --ecc-config=0
Reboot
Download and install the Nvidia GRID RPM
yum install NVIDIA-vGPU-rhel-7.6-418.66.x86_64.rpm
Download and run the Nvidia driver
./NVIDIA-Linux-x86_64-418.66-vgpu-kvm.run
vGPU Flavor
Make sure that the flavor type has right properties
• aggregate_instance_extra_specs:type: s== vgpu
• resources: VGPU=1
Install Nvidia Driver on Centos 7.6
Make sure NVIDIA is enabled
120 Chapter 1. Contents

iaas Documentation, Release 0.1.0
lshw -numeric -C display
Output:$ *-display:1 UNCLAIMEDdescription: VGA compatible controllerproduct: NVIDIA Corporation [10DE:1EB8]vendor: NVIDIA Corporation [10DE]
Disable Nouveau driver
Edit /etc/modprobe.d/blacklist.conf file, and add blacklist nouveau
Next create a new initramfs file and taking backup of existing.
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bakdracut -v /boot/initramfs-$(uname -r).img $(uname -r)
Edit /etc/default/grub file, and add the nouveau.modeset=0 into line starting withGRUB_CMDLINE_LINUX to ensure the next time you boot your VM, the Nouveau driver is disabled.
Apply the new GRUB configuration change
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
Reboot
Next download and run the Nvidia driver. If any dependency, you need to install the required packages.
yum groupinstall "Development Tools"yum install kernel-devel epel-releaseyum install dkms
Reboot to update new kernels
./NVIDIA-Linux-x86_64-418.70-grid.run
If the /etc/nvidia/gridd.conf file does not already exist, create it by copying the supplied template file /etc/nvidia/gridd.conf.template.
Edit the /etc/nvidia/gridd.conf file to set the EnableUI option to TRUE and set the ServerAddress to<licenseserver>.
sudo service nvidia-gridd start
1.6 Status
Disse sidene vil inneholde informasjon relatert til samarbeid og prosjekter rundt UH-IaaS.
UH-IaaS er et samarbeid mellom UiO og UiB om å drifte en sektorintern IaaS basert på OpenStack. All programvareog data befinner seg på dedikert hardware i USIT og UiB sine egne serverrom, og disse utgjør i dag UH-IaaS sine toseparate regioner (felles IDP, mens resten er separat).
Vi har et felles driftsteam med deltakere fra både UiO og UiB.
Planen er å kunne tilby UH-IaaS til hele sektoren. Mer om hvordan man tar tjenesten i bruk finnes på http://www.uh-iaas.no
1.6. Status 121

iaas Documentation, Release 0.1.0
1.6.1 Teamdeltakere og roller
Sist endret: 2018-01-17
Teamleder/Prosjektleder: Raymond Kristiansen, UiB (100%)
Deltakere
• Tor Lædre - UiB (100%)
• Mikael Dalsgard - UiO (60%)
• Trond Hasle Amundsen - UiO (40%)
• Anders Vaage - UiB (100%)
• Tannaz Navaie Roshandel - UiO (100%)
Tjenesteansvarlig
• Irene Husa - UiB
Koordinatorer
• Kjetil Kirkebø - UiO
• Jan Johnsen - UiB
Arbeidsdager
Name Monday Tuesday Wednesday Thursday FridayRaymond 1 1 1 1 1Mikael 0 1 1 1 0Tor 1 1 1 1 1Trond 0 1 1 0 0Anders 1 1 1 1 1Tannaz 1 1 1 1 1
1.6.2 Vakt
Sist endret: 2018-01-08
Alle i UH-IaaS deltar i en vaktordning i arbeidstiden. Vakten går over en hel uke.
122 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Rotasjon
Deltaker Uke Uke Uke UkeTrond 24 30 36 42Anders 25 31 37 43Raymond 29 32 38 44Mikael 26 33 39 45Tannaz 28 34 40 46Tor 27 35 41 47
Instruks
• Vakten er i arbeidstiden (normalt 08-16)
• Følge med på vakt-kanalen på Slack
• Svare på kundehenvendelser på Slack (#iaas) og RT (rt.uninett.no)
• Sjekke Sensu dashboard for varsler (full disk, etc)
• Sjekke Foreman dashboard for feilet puppetrun og out-of-sync noder
• Sjekke Grafana dashboard for avvik (ink. status.uh-iaas.no)
RT
Vakten har hovedansvar for åpne saker i RT (rt.uninett.no). Dette inkluderer:
• Vakten trenger ikke å tildele saker til seg selv. Alle saker som blir løst av vakten kan stå som nobody slik at deer lett å overføre til neste person.
• Prøv å svare alle nye henvendelser innen en arbeidsdag. Om det tar lengre tid å løse så skriv at vi jobber medsaken.
• Sjekk alle åpne saker (som er satt til nobody) en gang om dagen og lukk dem som kan lukkes (se under forventer på svar fra bruker)
• Dersom vi venter på mer informasjon fra bruker og ikke hører mer på 3 dager så kan vi lukke saken. Send alltidinformasjon til bruker om at de kan forsette ved å svare på eposten senere.
• Bruk morgenmøte til å få hjelp til saker du ikke kan løse selv eller er usikker på hvordan du skal løse.
1.6.3 Navnekonvensjon
Sist endret: 2018-11-30
Warning: Under arbeid.
Her følger en oversikt over hvilke navn brukes til hva og hva som menes.
Contents
1.6. Status 123

iaas Documentation, Release 0.1.0
• Navnekonvensjon
– Overordnet
* Team
* Produkt
* Tjeneste
* Lokasjoner
– Tekniske begrep
* Instans
* Node
Overordnet
Team
Teamet opererer under navnet norcams, som også er vårt navnerom på Github.
Produkt
Vi har valgt å navngi Openstack-installasjonen himlar (flertall av himmel på nynorsk). Dette navnet blir brukt pågit-repoet for konfigurajonshåndteringskoden, og andre repoer, verktøy etc som er relatert til installasjonen (f.eks.himlarcli).
Tjeneste
Vi trenger et navn på tjenesten vi selger til andre organisasjoner i UH-sektoren og våre sluttbrukere. For øyeblikketkaller vi tjenesten UH-IaaS. Vi vurderer å skifte dette navnet til UniSky.
Lokasjoner
Vi har valgt å bruke flyplasskoder for å navngi lokasjoner (regioner i Openstack). Når vi snakker om BGO så snakkervi om den installasjonen vi har på UiB og OSL er på USIT.
Tekniske begrep
Instans
Sluttbrukeren sin maskin i Openstack (eller IaaS generelt) blir omtalt som instanser. Det har vært viktig å skille instansfra virtuell maskin siden det ikke er det samme.
Node
Vi bruker node om maskiner som kjører våre Openstack, Storage eller management tjenester. En node er alltid knyttettil en rolle i himlar og kan kjøre både i dev, test og prod.
124 Chapter 1. Contents

iaas Documentation, Release 0.1.0
1.6.4 Kontaktpunkter
Sist endret: 2018-11-30
Her er oversikten over alle faste møteflater og kontaktpunkter for teamet og andre som jobber mot teamet.
Contents
• Kontaktpunkter
– Møter
* Morgenmøte
* Utvidet morgemøte
* Samling
– Kommunikasjon
* Slack
* IRC
* Epost
– Prosjektstyring
* Policy
Møter
Morgenmøte
Hver morgen kl 09:30 til 09:45 avholdes det et kort statusmøte. Agenda for møte er en kort oppsummering fra hverenkelt. Dette kan innehold hva som har skjedd siden sist, hva er planen videre og eventuelle utfordringer man trengerhjelp til. Dersom det er uløste saker i RT kan disse også fordeles/diskuteres.
Vi bruker Google Hangout til å avholde videomøter. Direkte link til vårt rom http://hangout.norcams.org
Utvidet morgemøte
Ved behov utvides morgenmøte hver onsdag med inntil en time (frem til 10:30). Her har man mulighet til å diskuterestørre tema. Agenda for ukesmøte skal ligge i Trello på forhånd. Kort skal være merket “discussion” og ligge i “Now”for at de vil bli lagt til agenda.
Samling
3-4 ganger i året avholdes det en felles workshop for hele teamet. Disse blir avholdt ved behov og strekker segvanligvis over 1-2 dager. Vi har et mål om at vi prøver å rullere på om samlingen avholdes ved UiO eller UiB.
Kommunikasjon
1.6. Status 125

iaas Documentation, Release 0.1.0
Slack
Vi har også et eget team på https://uhps.slack.com. Her har vi følgende kanaler:
• #team (privat): brukes kun av team-medlemmer som hovedkanal for chat. Trello poster også oppdateringer her.Det forventes at alle deltar her når de jobber med UH-IaaS.
• #iaas (åpen): brukes til å snakke direkte med sluttbrukere. Forventes at alle deltar her når de jobber med UH-IaaS.
• #vakt (privat): brukes av sensu til å varsle om avvik. Frivillig å delta, men det vil kreves at den som har vaktfølger med her.
• #git (åpen): commits til de viktigste repoene under norcams på Github publiseres her.
• #imagebuilder (åpen): brukes til å diskutere bruken av vårt egenutviklede verktøy imagebuilder til å byggeimages med og for UH-IaaS. Ble opprettet spesielt for å være et kontaktpunkt mellom UH-IaaS-teamet ogWindows-driftere for bygging av Windows-images.
IRC
#uh-sky på freenode var tidligere teamets hovedkanal for chat, men dette er tenkt avviklet da vi i hovedsak har flyttet tilSlack. Kan fremdeles brukes, men det er ikke obligatorisk for teamdeltagere å være pålogget. Viktige diskusjoner ogbeskjeder som angår hele teamet skal foregå på #team-kanalen på Slack Vi logger også github-repo til denne kanalen,men denne loggen skal flyttes til #git på Slack.
NB! Tidligere ble kanalen logget til https://botbot.me/freenode/uh-sky/ men denne tjenesten er avviklet f.o.m. novem-ber 2018
Epost
Vi har en epostliste for teamet og andre knyttet som er knyttet til oss. Denne listen administreres av USIT og er mentfor intern bruk.
Prosjektstyring
Vi bruker Trello til å administrere oppgaver og prosjekter. Det forventes at alle i teamet har konto og er medlem avvårt team som ligger under https://trello.com/norcams. Det vil være en blanding av åpen og lukket informasjon somligger her.
Policy
TODO
1.6.5 List historie
Skrevet desember 2018 av Raymond Kristiansen
Important: Dette dokumentet er forsatt under produksjon og ikke et ferdig produkt
126 Chapter 1. Contents

iaas Documentation, Release 0.1.0
NANSen-rapporten
Periode: Frem til og med 2012
I 2012 ble det skrevet en av Olav Kvittem (UNINETT), Nils Johan Lysnes (UiT), Ole Ingvard Langfeldt (NTNU),Morten Werner Forsbring (UiO) og Jarle Bjørgeengen (UiO) om “Den Norske Akademiske NettSkyen”.
https://www.uninett.no/sites/default/files/webfm/nansen_nansen-rapport-v1b.pdf
Denne konkludere bl.a. med at det er ønskelig å etablering av en UH-intern IaaS-sky.
UH-intern IaaS (UH-IaaS MK1)
Periode: 2013-2015
Personell: Jan Ivar Beddari (UiO/UiB), Mikael Dalsgard (UiO), Tor Lædre (UiB), Erlend Midttun (NTNU), HegeTrosvik (UiO)
Interessen for IaaS var økende i sektoren og flere, deriblant UiB, startet å se på Openstack som et mulig teknologivalgnår det gjaldt å bygge en IaaS.
21. november 2013 ble det avholdt en IaaS workshop hvor deltakere fra UNINETT, UiO, NTNU, UiT og UiB deltok.Det ble der landet på at vi ønsket en community IaaS for sektoren som bør bygges separat, felles og i samarbeid.
Det var et ønske om å danne en arbeidsgruppe i sektoren med personer som kan bygge en IaaS proof-of-concept medrask leveranse av “minimumsprodukt”. Dette ble starten på det teamet som skulle jobbe med det som idag er UH-IaaS.
I prosjektplanen ble det lagt opp til at det skulle være et felles prosjekt som gikk i et år frem til sommeren 2015 meddedikerte ressurser. Det forelå ingen klar leveranse sommeren 2015 og teknisk styringsgruppe for prosjektet var enigom å la prosjektet forsette ut 2015 for å kunne oppnå leveransen.
Milepæler
• Første felles samling i Tromsø (april 2014)
• Prosjektplan klar (juni 2014)
• Prosjektstart (september 2014)
• Hardware kjøpt inn (november 2014)
• Openstack Summit Paris (november 2014)
• Demo april 2015 (UIBs IT-forum, Bergen)
Lenker
• Prosjektplan
• Sluttrapport av Jan Ivar Beddari
UH-IaaS (MK 2)
Periode: 2016-
Personell:
1.6. Status 127

iaas Documentation, Release 0.1.0
1.6.6 Rapporter og referat
Her vil man finne ukesrapporter og referat fra fellessamlinger.
Fellessamlinger
Workshop 1 - 2019
Samling i ved USIT 6. og 7.mars 2019.
Agenda og referat ble ført i Trello. Siden alt som ligger i Trello er i konstant endring ligger det en kopi av alt som blediskutert under.
Innhold
• Workshop 1 - 2019
– Arbeidsplan våren 2019
* Oppgaver
* Dersom tid
– Diskusjon
* Brukerundersøkelse
* Serverrom og HW
* Nye Openstack komponenter
Arbeidsplan våren 2019
Oppgaver
• CERN HW - installasjon, testing og tuning
• vGPU
• Object storage i pilot
Dersom tid
• Se mer på Manila
Diskusjon
Brukerundersøkelse
Vi brukte mye tid på å diskutere og lage en brukerundersøkels. Resultatet finnes her https://nettskjema.uio.no/user/form/preview.html?id=113758
Det er ikke klart til publisering enda, men vi håper å få det ut til brukere så snart som mulig.
128 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Serverrom og HW
• plassering av ny hardware
• befaring OSL
• større utvidelser (f.eks. flere rack)
• overvåkning
• nettverkskabler: direct attach copper cable vs fiber optics
• CEPH Nautilus - diskovervåkning
Nye Openstack komponenter
Ting vi bør vurdere å se på
• cyborg - gpu
• mistral
• rally
• (cloudkitty)
• (zuul)
Workshop 1 - 2018
Samling i ved USIT 6. og 7. mars 2018.
Agenda og referat ble ført i Trello. Siden alt som ligger i Trello er i konstant endring ligger det en kopi av alt som blediskutert under.
Innhold
• Workshop 1 - 2018
– Arbeidsplan vår 2018
* Mindre oppgaver
* Tilgang til andre enn FEIDE-konto
* Uprioriterte oppgaver:
– Oppgaver til fremtidig plan
* Trove
Arbeidsplan vår 2018
Mindre oppgaver
• Anycast for DNS mot resolver-noder
• Sette opp twitter-konto for varsling (ink prøve å lage et varslingsystem som oppdaterer alt samtidig)
1.6. Status 129

iaas Documentation, Release 0.1.0
• Oppgradering til pike før sommeren
• Reset API password Vi kan legge inn en knapp i access som kjører en reset api passord
• Ceph dashboard Setter det opp på mgmt og via haproxy på api
Tilgang til andre enn FEIDE-konto
Mulig løsning:
• brukere lager ad-hoc gruppe i dataporten først
• oppgir id til gruppen ved bestilling
• vi legger inn gruppe id som metadata til prosjekt
• cronjob som sjekker dataporten api og gir tilgang til dem som ligger i gruppen (vi må sjekke om vi kan semedlemmer i en gruppe med dataporten api)
Uprioriterte oppgaver:
• Heat
• Manilla (med CephFS backend)
• Grafana dashboard på status (ekstern) og monitor (intern):
– (status) flytte driftsmeldinger og nyheter ut av grafana på status
– (status) legg inn mer statistikk om bruk på status (f.eks. brukte cores i az/region)
– (monitor)lage dashboard for vakt med så mye info som mulig
– (monitor) all info om host
Oppgaver til fremtidig plan
Trove
Trenger db-folk til å sette opp.
Krav til tjenesten:
• geo-redundant
• transaksjonsstøtte (RDB)
Workshop 2 - 2018
Samling i ved UiB 19. og 20. septemver 2018.
Agenda og referat ble ført i Trello. Siden alt som ligger i Trello er i konstant endring ligger det en kopi av alt som blediskutert under.
Innhold
130 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• Workshop 2 - 2018
– Diskusjon
* IP-adressering med CERN-workloads
* Driftede instanser
* Forbedre brukeropplevelsen
* Windows image-bygging - framdrift
* Alternativ til cumulus
* Nettverksdesign med CERN-rigg
* Branding på dashboard
* Forslag til å forbedre arbeidsmetoder
– Arbeidsplan høst 2018
* Oppgaver
* Uprioriterte oppgaver:
· Manilla
· Oppdatere status
· GPU
Diskusjon
IP-adressering med CERN-workloads
Hvis vi skal basere oss på public IPv4-adresser har vi et stort kapasitetsproblem. Kan vi (de) bruke IPv6?
De skal prøve å bruke IPv6 network.
Kommentar fra Raymond: det viser seg at de kan bruke IPv6 for alt annet enn slurm og det kan kjøres på innsiden meddualstack.
Driftede instanser
Vi lager felles system for image administrasjon, men lar hver org bestemme innholdet i imaget.
Forbedre brukeropplevelsen
• minimere planlagt nedetid (HA) lagsiktig plan (db, ekstern HA)
• responsivt API/GUI (LB) lager eget trello-board for tiltak og analyse
• forbedre kommunikasjon med brukere
• forbedre dokumentasjon se på forslag til forbedring
• spørre brukere (nettskjema)
– hvordan fikk de høre om uh-iaas
1.6. Status 131

iaas Documentation, Release 0.1.0
– hva savner du
– hva fungerer ikke
– hvem er brukeren (org ikke person)
– begrensninger i uh-iaas
• eksempler lage et repo på github
Windows image-bygging - framdrift
Vi tar en kickstart (trondham) Se på problem med IPv6
Alternativ til cumulus
Vi kan bruke OpenSwitch til det meste (unntatt spine og kanskje switchene til compute).
Nettverksdesign med CERN-rigg
Det er kanskje rom for innkjøp av noe nettverksutstyr i forbindelse med CERN-riggene. Vi må (bør) bygge omnettverket, forhåpentligvis i en en leaf/spine-arkitektur.
Budsjett vil avgjøre hva vi får til. Vi ønsker 2 nye spine og kan bruke de 2 vi tok ut til storage.
Branding på dashboard
Bytte OS-logo med UH-IaaS på dashboard-siden.
• Bytte til samme logo vi har på twitter
• lage logo uten nav
Forslag til å forbedre arbeidsmetoder
Er det ting vi kan gjøre for å forbedre kommunikasjonen i teamet og måten vi jobber på:
• trello (ink PR) vi dropper egne kort for PR, vi linker til trello i PR
• slack/irc slack vs irc: vi bruker slack til melding er som alle trenger å få med seg, ellers kan man bruke det manvil, endre ikke varsling på disse nå, kan vurder flere kanaler som alle er medlem av (kan spørre brukere)
• github
• hangout/videochat
• morgenmøte strenger på tidsbruk på runden, ta tekniske diskusjoner til slutt
• jobbe sammen to og to (uib/uio)
• deltid/fulltid ser ut til å fungere greit
132 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Arbeidsplan høst 2018
Oppgaver
• Fullføre oppgradering til Pike
• Oppgradere til Queens
• Object storage
Uprioriterte oppgaver:
Manilla
Manila i Pike kan bruke CephFS som backend delt ut via NFS, som er den prefererte metoden. Kan fungere som enpilot/beta.
Sannsynligvis er Openstack Queens det beste for prodsetting, med NFS-ganesha >2.7. Da bør vi kunne oppnå HA påtjenesten, kanskje til og med A/A pNFS. Bør være knall i padden.
Oppdatere status
• vi skal bruke grafana
• vi lager en forsiden (som skal vises fint på mobil) og flere underside
• driftsmeldinger
• nyheter
• tilstand (alle api endpoint, dashboard, access) - grønn - (gul) - rød
• antall ipv4-addr i bruk/igjen
• ledige resurser (grønt/rød start ny instans)
• piwik / loganalyse??
• dager siden siste event
• eventlog
• responstid api
Datakilder
• himlarcli -> statsd
• statsd -> graphite eller gnocchi
GPU
Om vi får mulighet det så se på vGPU eller PCI passthrough GPU. Krever tilgang til hardware siden vi ikke har pengertil å kjøpe dette selv.
1.6. Status 133

iaas Documentation, Release 0.1.0
Workshop 1 - 2017
Samling i ved USIT 2. og 3. februar 2017.
Agenda og referat ble ført i Trello. Siden alt som ligger i Trello er i konstant endring ligger det en kopi av alt som blediskutert under.
Arbeidsplan vår 2017
Ceilometer
Må først vurdere skalere rabbitmq.
Hvordan minimere bruken av root-disk til instanser
• Trenger å bygge egne image med discard
• Sjekke at image properties er satt rett på alle image (også snapshot)
• Løste problem med libvirt 2.0 (trenger 1.2, 2.1, patch)”
Nettverk: Fremtidig uplink
Vi har snakket om å koble UH-IaaS direkte til UNINETT både ved UiB og UiO. Er dette problematisk?
• Petter tar kontakt med UNINETT for å høre om vi kan få flyttet uplink til i bgo og osl til UNINETT
Calico 2.0
Designate
Må bli enig om hva vi setter $domain til i designate. Forslag:
• <sone>.uh-iaas.no
• <nytt-domene.no>
Vi lager A-records for alle instans-IPer på formen ip-xxx-xxx-xxx-xxx.vm.$domain.
Finne ut om vi vil sette opp slave-master på innsiden av UH-IaaS eller bruker uio og uib sine DNS-tjenester.
Implementere IPv6 for instanser
Sette opp FreeBSD NAT bokser på controllere. Petter har kontakter som kan hjelpe å sette det opp.
Hvordan vil vi lage object storage?
Krav:
• Vi trenger å lage et HW plan med realistisk priser.
• Pris på HW kan avgjøre valg av software
134 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• Tilby snapshot
• Keystone som IDP
• Til release 2 skal det være tilgang til en object storage (kan være pilot)
Plan for test:
• Vi ønsker å teste både openstack swift og ceph.
• Ta en avgjørelse på hva vi bruker i release 2
HW:
• public ip til test02
• bruke test01-storage til å teste openstack swift
• lage nytt ceph-cluster i test01
• lage openstack swift i test02 på gammel HW (3 1U, og 2 4U)
• Bruker VMer for egen gateway for swift og ceph objectstorage
Åpne dashboard og api for verden?
• Ønsker å kjøre selinux på dashboard og api.
• Avsjekk på sikkerhetsdokumentet for api og dashboard
• Sjekke om UNINETT har en form for blacklist eller filter vi kan bruke
Access:
• Trenger en koderevisjon av access
• Trenger en sikkerhets vurdering av access.
Markedsføring
Webside:
• vi trenger en forside å sende nye brukere til
• lager et git repo på github og setter opp github-pages for norcams.github.io
• www.uh-iaas.no vil da vise disse sidene
• vi kan ta utgangspunkt i design som ligger på iaas.uhsky.no
• vi kan få KA til å hjelpe til med navn og logo
Skaffe brukere:
• bruke faggruppe for skyteknologi til å promotere tjenesten til andre
• fokus på snakke med miljøene lokalt først
• hjelpe it-avd og usit med å ta det i bruk
Newton
Oppgradere til neste versjon av openstack: newton
1.6. Status 135

iaas Documentation, Release 0.1.0
Puppet 4
Prøver å få til en oppgradering av puppet etter newton. Dersom newton fungerer bedre med puppet 4 må vi vurdere åta det før.
Uprioriterte arbeidsoppgaver
Ekstra HW (osl-controller-04)
Ønsker en ny controller-04 i OSL også som kan kjøre management noder: logger, admin, monitor, etc vurdere iaas-vagrant01
Oppetid og kapasitet på tjenester (HA, LB)
Kapasitet (LB):
• Setter opp 3 backend noder for alle api (nova, volume, glance, neutron)
• Teste litt mer før vi sett opp 3 backends for keystone
Oppetid (HA):
• vi kan speile databasene for å få høyere oppetid
• se på mulighet for å bruker ruting og anycast til api failover
Lastbalanserer:
• sette opp to nye eksterne last-balanserer for å få HA på public tjenestene våre og tilby en enkel LBaaS”
Andre tema
I hvor stor grad bør vi bruke institusjonenes tjenester for perifere administrative ting, kontra å sette opp ogdrifte selv? (overvåkning, logging, grafing, etc.)
• det er ikke brukt mye tid på logging og monitor (metrics) til nå
• vi vil måtte bruke tid på logg-filtre og graf-dashboard, dette vil være det samme uansett hvor det kjører”
Nettverk: Redundant uplink OSL
Ved UiB har vi link ut fra UH-IaaS fra både leaf-01 og leaf-02 (de er koblet i samme switch, men gir oss redundans),mens i UiO har vi nå kun en fra leaf-02. Har vi mulighet til å gjøre det samme ved UiO?
• Vi kobler rett til UNINETT
Nettverk: NAT-tjeneste OSL
Når vi skal implementere IPv6 så trenger vi en tjeneste for NAT på IPv4. Vi ønsker at instansene kjører med publicIPv6 og privat IPv4 (som da trenger NAT ut). Ved UiB vil vi få levert denne tjenesten av nettverksgruppen. Klarer viå få til noe bed UiO?
• Setter opp NAT på controllere
Vi bør se på mulighet for å bruke Gluster på compute
136 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Workshop 1 - 2016
Agenda Workshop 1-2016
Første felles workshop for prosjektet i 2016 blir i Oslo 15. og 16.mars.
Agenda
Tirsdag 15.mars
Sted: Domus Academica, Juridisk eksamenssal, UiO
1. Presentasjon av deltakere og kompetanse
2. Verktøy, dokumentasjon, møter, etc
3. Node-/komponentoversikt: gjennomgang
4. Nettverksoversikt: gjennomgang
5. Annet?
Onsdag 16.mars
Sted: Møterom Awk (3118), IFI, UiO
1. Leveranseplan
• Brukerdokumentasjon, kundeoppfølging
• Sikkerhetsgjennomgang
• Pilotering, hvem skal få tilbud?
• Jus, hvilke type data kan være med ut i piloten
2. Diskusjonstema
• DNS, dhcp, brukerhåndtering, logging, overvåking
3. Teknisk gjennomgang
• puppet
Tid og sted: Avholdt i Oslo 15. og 16.mars.
Tilstede: Kjetil, Petter, Trond, Mikael, Hege (kun 15.) Jarle, Geir, Øyvind, Tor og Raymond
Disclaimer: Referat basert på notatene til Petter og redigert av Raymond. Om noen av dem som var tilstede oppfattetting på en annen måte vennligst gi beskjed til Raymond.
Contents
• Workshop 1 - 2016
– Tirsdag 15. mars
* Dokumentasjon
* github
1.6. Status 137

iaas Documentation, Release 0.1.0
* IRC-kanalen
* Trello
* Lucidchart
* Møter
* Websider
* Nytt dev-anlegg
* Lisenser
* Kontotilganger
* Definisjoner
* Todo-liste
* Utestående for pilot
* SLA for piloten
– Onsdag 16. mars
* Videre plan
* Annet
Tirsdag 15. mars
Vi innledet med en rask presentasjon og diskusjon rundt dagens agenda.
Det ble avklart at USIT setter av ressurser i hele dager. Alle må føre inn i ressurs-planen.
Ansvaret for sikkerhetavklaringer ligger hos Kjetil Kirkebø
Det må avklares hvor det juridiske eierskapet ligger. Forslaget er at UiB tar eierskapet og at UiO skriver databehan-dleravtale med UiB. Kjetil og Raymond tar dette videre.
Vi begynte med å tegne opp en skisse over prosjektet og forsøke å skape oss en felles oversikt. Hege har tegning overnettverk og Raymond har begynt på en tegning over noder/tjenester.
Det må undersøkes hvordan SE-linux og Calico kan løse. Idag er må SE-linux disables. Calico ser ut til være denbeste løsningen pr. idag.
Dokumentasjon
Raymond har ansvaret for dokumentsjon:
• Trond skriver brukerdokumentasjonen
• Raymond skriver referat o.l
Teknisk dokumentasjonen skrives på engelsk og prosjektdokumentasjonen skrives på norsk. Raymond omorganisererdokumentasjonen noe.
138 Chapter 1. Contents

iaas Documentation, Release 0.1.0
github
Vi må bestemme hva som skal ligge ute på git-hub. Passord er fjernet, men må endres. De skal ikke ligge på github.Passord-regime må forbedres.
Arkitektur ligger nå åpent og vi forsetter med det inntil videre.
Bruk av github må dokumenteres og det må lages felles rutiner. Vi tar en gjennomgang på onsdagen og dokumenterersamtidig. Det er behov for å rydde i repo‘er og automatisering.
Nye hieradata kan legges rett på master. Store hieradata endringer og alle kodeendringer skal ikke legges direkte innpå master. Det er god rutine å benytte pull-request for gjennomsyn. Det er ikke lov å ta egne pull-requests.
IRC-kanalen
Det er krevende å følge med på irc-kanalen. Ikke alle har kapasitet til å følge med daglig. Morgenmøte og hovedpunk-ter på epostliste er steder for felles oppdateringer.
Trello
Vi forsetter med Trello av mangel på alternativ. Det er mulig vi bør se på en ny organiseringer av oppgaver. Idag erdet litt for mange saker og det er vanskelig å få oversikt. Raymond tar ansvar for en omstrukturering. Trello har ogsåen god mobilapp.
Lucidchart
UiB har fått 10 lisenser (som Tor og Raymond bruker). Det er utfordring med at flere kan gjøre endringer. Vi trengerå et alternativ hvor alle kan gjøre endringer og råfilene ligger på et felles sted. yEd sees på som alternativ.
Møter
Morgenmøter forsetter klokken 09:30. Lengre møter avtales ved behov på onsdager klokken 10:00. Det må avklaresinnen morgenmøte på tirsdagen om det skal være onsdagsmøte.
Websider
Vi fokuserer på leveranse og nedprioritere «markedsføring» på web.
Nytt dev-anlegg
Dev-anlegg er egentlig et testanlegg. Vi har et anlegge i Bergen (dev01) som fungerer, men vi trenger også et i Oslo.Det bør være mulig, men vi trenger hardware. Trond går på skattejakt. Vi trenger disker for å teste Ceph. Anlegget iTrondheim må avklares. Kjetil hører med Ola Ervik.
Lisenser
Vi må avklare hvilken lisens vi skal bruke på IaaS-kode.
1.6. Status 139

iaas Documentation, Release 0.1.0
Kontotilganger
Kjetil sjekker hvem som har tilgang og kontoer. Det er behov for rydding. (Raymond: denne er jeg usikker på hvagjelder)
Definisjoner
• Instans = Virtuell maskin for sluttbruker på compute
• Node = Kjører tjenester i infrastrukturen. Kan være VM, container eller fysisk.
• Dashboard = kjører Openstack Horizon
Todo-liste
Kjetil hadde en del ting han ønsket å få med her, det kom også flere forslag fra deltakere.
Raymond: Ansvarlige er forslag fra møte, det vil nok bli endringer. Listen er nok mer som en huskeliste enn noenendelig plan eller liste.
• Sikkerhet(Mikael/Trond)
– Må på plass før 1.bruker
• Jus(Kan komme på sikt)
• Dok(Brukerdok=Trond og Tekniskdok=Raymond). Dokumentasjon av rutiner og enkle oppgaver med git-hub,puppet og vagrant eller andre rutineroppgaver
• SLA
• Definere tjenester
– API
– Portal/dashboard
– Fakturering
• Teknisk:
– Puppet(Raymond)
– Data-porten(Øyvind)
– Nett(Hege)
– Lagring(Tor/Geir)
• Utenfor?:
– DNS
– Overvåking
– Logging
140 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Utestående for pilot
• Service og public nett over transport
• Logging internt
• Sikkerhet må avklares
• Brukerdokumentasjon (Trond)
– Tydelig oversikt over hva som kan forventes0
– Hva får du/får du ikke
– Hva er IaaS
• Overvåking (kan være aktuelt på sikt, men er da sannsynligvis bruk av UiOs løsninger)
SLA for piloten
• Det er et vedlikeholdvindu hver 4 uke for tjenester (API/Dashboard)
• Hver compute-instansene skal termineres hver 3 uke (en hver uke) Vi må være tydelige på at instansene ikkevarer evig (de slettes når compute restartes)
• Best effort!
• Brukerhenvendelser går vi slack-kanalen uhps.slack.com direkte til oss
• Det er ingen backup.
• Alle data vil bli slettet i august/september når vi slår sammen keystone
Onsdag 16. mars
Videre plan
• Pilot(20 april):
– Vi setter en plan for produksjon av pilot til 20 april, med forbehold om at sikkerhet går som det skal
– Første onsdagsmøte brukes til sikkerhet og legge en fremdriftsplan for sikkerhet
– Vi trenger et par reinstallasjoner før vi er klar 20. april
– Møte med Espen forsøkes 5 april
– Raymond tar muligens en tur til Oslo den 15, samtidig med planlagt møte med Aryan fra UiS
– Begynne å logging lokalt i IaaS
– Sette opp dev-rigg i Oslo. Helst så lik som mulig
– Tilgjengelig for alle ved UiO og UiB
• August/september:
– Ønskes en full reinstallering når vi slår sammen keystone
– Vi ønsker å samle inn behov og tilbakemeldinger via nettskjema
– Det er ønske om en oversikt over hva løsningen gir i sammenheng med brukerdokumentasjonen
– Finne brukere
1.6. Status 141

iaas Documentation, Release 0.1.0
– Image bygging:
* Base ordner prosjektet
* Ekstern hjelp(HPC) hjelper til
– Drift:
* Hva og hvordan?
* DNS
· IP-adresse endrer seg etter 3 uker
· Vi trenger en dynamisk løsning for kobling mot DNS
· Noen må se på DNS rimelig raskt
· Heat?
• Full produksjon 1 oktober 2016:
– Ny SLA må på plass
– Det må avklares om det skal være en tjeneste for “UH-sky” Inntil det er klart er dette en tjeneste for UiOog UiB
Annet
• Object storage ønskes på planen frem i tid, men ikke i første fase og det må inn nye ressurser. Bør gjøres iinnenfor dagens prosjektgruppe/rammer. Forventninger må tydeliggjøres av Raymond.
• UiB har lovet at det er ressurser utenfor prosjektet som vil lage og vedlikeholde images. UiO har også grup-peringer som sannsynligvis kan delta. “Noen” må holde dette.
Workshop 2 - 2016
Tid og sted: Avholdt 22.juni i Bergen
Tilstede: Trond, Mikael, Øyvind, Tor og Raymond
Agenda for samlingen var å diskutere endelig nettverksdesign og plan for produksjonssetting til høsten.
Innhold
• Workshop 2 - 2016
– Nettverksdesign
* “KISS”-modulen
– Tilbakemeldinger fra brukere
– Veien fra pilot til produksjon
* Valg av platform
* Hardware
* Felles keystone (to regioner)
* Hvilke tjenester må være på plass?
142 Chapter 1. Contents

iaas Documentation, Release 0.1.0
* Fellesprosjekter
* SLA
* Sikkerhet
* Driftsplan
– Overvåkning og trending
– Etter møte
Nettverksdesign
• konsensus om å gå for “KISS-modell” (se under)
• undersøke om cumulus støtter aktiv-aktiv LACP TODO
• mgmt, oob og public nett med calico ligger fast og ble ikke diskutert
• vi skal kjøre puppet på leaf
• undersøke muligheten for å koble leaf rett på uninett på hver lokasjon TODO
“KISS”-modulen
Fra epost til Tor 2016-06-21 12:24:
En logisk sett enklere modell er å fjerne service-nett-overlayet og alleruterne (bortsett fra på compute). Man bonder da transport-interfacene,og all kommunikasjon mellom tjenestene går direkte på L2 medtransport-IPer. Logisk sett får man da:
- transport
Tilbakemeldinger fra brukere
• få brukere ved UiB. Her har vi en jobb å gjøre TODO
• folk venter på at det skal være i produksjon før de vil ta det i bruk
• vi trenger eksempel på use case TODO
• spørreskjema til brukere i august TODO
Veien fra pilot til produksjon
Valg av platform
Server OS: CentOS 7 Openstack: RDO
Vurdere om vi skal bytte RDO med egenpakking.
På leaf ønsker vi cumulus linux.
Ceph: kjører vi CentOS 7 og open source ceph repo
1.6. Status 143

iaas Documentation, Release 0.1.0
Alle repo skal ha et lokalt repo slik at vi har kontroll på pakkinstallsjonene.
Hardware
Vi må tenke litt mer på hvordan vi ønsker å ha det i forhold til os-disker.
• diskutere os disk til instanser, live migrate
• teste lokalt cache av image på compute TODO
• mer storage?
Felles keystone (to regioner)
Planen er forsatt å slå sammen bgo og osl til en openstack installasjon med felles keystone. Vi vil da får to regioner.
• Teste MariaDB med Galera (multi-master) TODO
• Alternativ er en master (skriv) med multiple read, en på hver lokasjon
Hvilke tjenester må være på plass?
• DNS TODO
• Privatnett TODO
• Golden images (vedlikeholdt) TODO
Fellesprosjekter
Må være på plass, men spørs om det må gjøres via Dataporten eller om det i en tidlig fase kan gjøres via semimanuellescripts. Fellesprosjektene må ha tilgang til dashboard og api.
SLA
Begynne på SLA og terms of service for prod. TODO
Sikkerhet
Jobben må fullføres. Oppfølgingsmøte med IT-sikkerhet@UIO når vi er nærmere produksjon.
Driftsplan
Hvordan drifte uten at brukere merker det?
Hovedkonsepter:
• Redundans på komponenter
• Mulighet for live migration (usikkert, må testes og utredes) TODO
• Nedetid på fysiske hoster m.m. uten at brukere merker det
144 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• Kontinuerlig forbedring
• Kontinuerlig utrulling
• Kontinuerlig patching
• Kontinuerlig alt
Overvåkning og trending
Raymond sjekker ut DataDog for dette. Det koster penger pr host.
Etter møte
TODO gjøres om til kort i trello.
Workshop 3 - 2016
Tid og sted: 7. og 8. september 2016
Tilstede: Trond, Mikael, Tor og Raymond
Dette ble en ren workshop hvor man jobbet med å få den nye versjonen av Openstack mitaka til å fungere. Det visteseg å være veldig nyttig å sitte å jobbe sammen og ikke via video eller chat.
Endringsrapport
Endringsuke 22
Mandag 29.mai
Patching av alle tjenester mellom 12 og 14.
Avvik:
• Peker for prod-repo ble ikke endret slik at ingen nye pakker kom inn.
• Vi kunne ikke starte nye instanser etterpå
• bgo-storage sluttet å fungere etter reboot.
Resultat:
Selve patcherutinen gikk bra, men vi opplevde at vi ikke kunne starte nye instanser etterpå.
Alle noder bortsett fra compute ble rebootet i forbindelse med patching. I OSL ble problemet løst kl 14:30, mens det iBGO så ut til at feilen kom tilbake rundt 15:00, og ble ikke løst før vi rebootet bgo-novactrl-01 tirsdag kl 13:15.
Vi er usikre på hvor problemet lå men i OSL løste det seg med en restart av nova-scheduler, mens i BGO endte manopp med å reboote hele novactrl-01.
Problemet så ut til å være knyttet til at openstack-tjenestene på novactrl-01 ikke fikk snakke med AMQP, men det varikke noe problem på bgo-mq-01 som hele tiden snakket med compute.
1.6. Status 145

iaas Documentation, Release 0.1.0
Det så i tillegg ut til at storage i BGO sluttet å fungere etter reboot. Mens i OSL var 20 OSD ikke tilgjengelig forCeph.
Tirsdag 30.mai
Migrering av instanser i host aggregate group1 til group3.
Avvik:
• bgo-compute-06 var ikke reinstallert etter endringsuken i april og måtte reinstalleres rett før migrering bleigangsatt
• bgo-compute-03 og bgo-compute-06 manglet begge 2 kritiske patcher
• bgo-image-01 hadde ikke lagring og API-kall som trenger storage medførte at hele API gikk i heng.
• group3 ble ikke aktivert før vi startet i BGO slik at 40 instanser gikk til group2 i stedet for group3.
• osl-network-01 fikk for mye å gjøre og gikk ned under migreringen. 8 instanser endte opp i error state.
• Migrering i OSL tok ikke med seg disk-delta fra gammel til ny compute-node. Det medførte at alle instaner bleresatt til slik de var ved installasjon.
Resultat
Resultatet av migreringen ble at kun de instanser i BGO som ble migrert til feil gruppe (group2) fungerte. Resten måttefikses manuelt og ble ikke ferdig før kl 22. Disk til instansene måtte flyttes manuelt med rsync og alle instansene måtteskrus av og på manuelt.
Forbedringer
• Sjekkliste for om en compute-node er klar til å taes i bruk
• Ikke reinstaller de tomme compute-nodene før (rett i forkant av) neste migrering
• aggregate.py: –sleep >= 180 sek pluss sleep(2) mellom hver instans
• aggregate.py: –hard-limit feature som stopper etter –limit noder
• Dokumentere migrerings-rutinene bedre
Pike oppgradering
2018-10-17 keystone
Vi oppgraderte alle identity noder i bgo og osl uten nedetid på tjenesten mellom 08:00 og 09:00 17.oktober. Opp-graderingen var automatisert med ansible og gikk som planlagt med kun et par sekunder med nedetid på involvertetjenster.
146 Chapter 1. Contents

iaas Documentation, Release 0.1.0
2018-10-31 horizon
Dashboard (horizon) ble oppgradert med minimal nedetid for brukere, total ca 10 minutter. Igjen ble ansible brukt ogoppgradering gikk etter planen.
2018-11-13 Full oppgradering
Resten av tjenstene ble oppgradert med en planlagt full nedetid 13. november mellom 14:00-16:00
Utfordringer under oppgradering
Ansible jobbene
De fleste ansible-jobbene inneholdt enten ting som ikke fungerte eller inneholdt jobber som ikke skulle ha vært der.De ble rettet under generalprøven (test02) og under oppgradering av prod. Dette var hovedgrunnen til at vi ble ca 1time forsinket.
osl-compute-01
Denne ønsket å forbli på ocata, mens alt annet ble oppgradert. Dette medførte at man i osl-legacy-1 ikke kun starteen ny instans her og legge til et volume (volume attach feilet). Feilen viste seg å være en syntaks feil i nodefilen.Dette resultert i at puppet run via ansible valgte å bruke en gammel cached catalog som da gav oss tilbake ocata.Dersom man kjørte puppet agent -t så fikk man den forventede feilmeldingen som ville gjort at dette ble oppdagetunder oppgraderingen. Feilen ble oppdaget under testing onsdag formiddag og rettet.
nova service i osl
Etter oppgradering var det ikke lenger mulig å bruke nova api til f.eks å liste ut instanser. openstack server list gavfølgende feilmelding:
This service is older (v15) than the minimum (v16) version of the rest of thedeployment. Unable to continue.
Problemet viste seg å være gamle servicer med lavere versjon som lå igjen i database. Det lå mange gamle der, mendet var kun to av dem som måtte slettes. Det ble gjort manuelt i databasen og problemet løste seg.
Oppsummering
Planen var å ha nedetid fra 14-16. Det gikk ellers greit. Vi brukte ca 2 timer totalt som også var planlagt, men vibegynte ca 1 time etter planen og ble derfor også ikke ferdig før rundt 17. Vi fant et par feil som oppstod siden vihadde blokkert api for andre enn oss selv. Vi trenger nok å legge inn flere tilganger fra system slik at vi kan teste utenå slippe alle inn.
Endel av feilene i ansible og problemet på osl-compute-01 er relatert til hvordan vi kjører puppet via ansible. Dettekrever en nye gjennomgang før neste oppgradering.
1.6. Status 147

iaas Documentation, Release 0.1.0
Etter oppgradering
Nettverk til instanser i bgo
I løpet av onsdag formiddag så vi at bgo begynte å slite med å få IP på nye instanser og IPv6 forsvant fra eksisterende.Problemet begynte med enkeltinstanser, men etter at vi begynte feilsøking og stoppet puppet på bgo-network-0[1-3] såble begynte alle å slite. Synderen etter en dag med feilsøking viste seg å være puppetrun på osl-network-0[1-3]. Disseendret gateway i bgo til osl sin gateway slik at instansene ikke lenger fikk nett. Det viste seg at neutron-modulen leserregion_name fra en annen seksjon i pike enn i ocata. I ocata brukes det som settes under [keystone_authtoken], mensi pike forventer den å finne region_name i [neutron] (en seksjon som ikke finnes eller opprettes av puppet). Løsningenble å sette dette som en custom config i hieradata.
Merarbeid: ca 1 dag (to personer) for å forhindre at feilen oppstod. Deretter ca 1 dag (1 person) å finne ut hvorfordet skjedde og finne en løsning på det.
Tilgang til access
Etter oppgradering begynte access å gi Internal server error når man prøvde å provisjonere et nytt prosjekt. Feilenoppstod ikke før man kom tilbake fra Dataporten og ble ikke oppdaget under testing etter oppgraderingen eller i test.Problemet så ut til å skyldes selinux så ved å stoppe puppet og sette selinux til permissive fungerte tjenesten igjen. Vioppdaget feilen først selv, men glemte å stoppe puppet slikt at feil kom tilbake og ble rapportert inn av en bruker.
Ukesrapport
2019
Uke 3
av Raymond Kristiansen, UH IaaS, 18.januar 2019
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 3
– Status
– Utfordringer
– Planlagte aktiviteter
– Annet
Status
Vi hadde vedlikeholdsvindu 18. des (BGO) og 19. des (OSL) mellom 15-16. Vinduet ble brukt til å oppgradere defleste nodene til CentOS 7.6. Selve oppgradering gikk etter planen og stort sett innenfor det varslede vinduet.
16. januar ble kaldmigreing av instanser i availability zone (AZ) legacy for å kunne patch compute noder i group3(to noder). Instansene ble migrert over på en compute node i group2 slik at vi fikk frigitt en node og flyttet tilAZ default. Brukere av berørte instanser ble varslet direkte med informasjon om at instansen ville bli bootet. Det
148 Chapter 1. Contents

iaas Documentation, Release 0.1.0
ble problemer med å utføre migreringen slik at tidspunktet ikke ble helt som varslet (nedetiden per instans ble somvarslet). Problemene medførte at vi måtte deaktivere de andre compute nodene når vi migrerte for å være sikker på atinstansene havnet på rett compute node. Deaktiveringen skjedde en liten periode i hver region mellom 16:30 og 18:00.
Vi har startet en test med erasure coding (EC) av pool i Ceph clusteret. Vi har et prosjekt som tester med et 5 TB stortvolume i BGO og vi vil følge med på hvordan det påvirker ytelsen i resten av clusteret.
Hardware for å kjøre CERN Alice workloads i BGO er nå bestilt. Totalt er det snakk om over 50 servere og 3 nyerack.
Vi har også fått noen nye compute noder med GPU i OSL for testing. Disse vil bli satt opp og installert når vi får dennye mgmt-switchen som er bestilt.
Vi har også bytte logo for UH-IaaS. Samtidig har vi endret fargeprofiler tilsvarende den nye logoen.
Utfordringer
Vi begynner å gå tom for compute ressurser, spesielt i OSL. Vi har flyttet en compute node fra availability zone legacytil default som vil avhjelpe på kort sikt. Men vi trenger flere compute noder dersom vi ikke skal begynne å sletteinstanser.
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Oppgradere til ny Openstack-versjon: Queens
• testing av DNSaaS med Designate
• Pilot objektlagring
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 6
av Raymond Kristiansen, UH IaaS, 8. februar 2019
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 6
– Status
– Utfordringer
– Planlagte aktiviteter
1.6. Status 149

iaas Documentation, Release 0.1.0
– Annet
Status
Vi oppgraderte UH-IaaS til Openstack versjon queens onsdag 6. februar. Selve oppgraderingen gikk uten problemeri det avsatte vinduet som ble varslet. I forbindelse med oppgraderingen av keystone, måtte vi gjøre endre i måten vibruker Dataporten til federerte brukere. Dette medførte at vi under testing fikk ny bruker i dashboard og dermed mistetbl.a. SSH-nøklene til den gamle brukeren. Dette ble løst under oppgradering ved å manuelt oppdatere database slik atalle beholdt den gamle federerte brukeren i UH-IaaS.
I forbindelse med utvidelse i OSL har vi bestemt oss for å flytte test02 slik at vi får frigjort et rack ved siden av detutstyret vi har idag. Planen er å flytte test02 tirsdag 12. februar. Vi vil da kunne montere de nye compute nodene somer kjøpt inn til CERN Atlas workloads i dette racket.
UH-IaaS har nå lansert DNS som en tjeneste. Alle som har et eget domene (eller kontrollerer et subdomene) kan nåbruke UH-IasS til å administrere det. Vi bruker Openstack Designate som både kan brukes via dashboard eller viaAPI.
Det er bestilt inn to nye compute noder til OSL for å avlaste her.
Hardware til CERN workload i BGO har begynt å dukke opp, men vi har forsatt ikke fått rack slik at vi kan startemonteringen.
Utfordringer
Vi vil snart gå tom for public IP-addresser. Vi har idag 2 C-nett i hver region. Vi har nytt et ledig C-nett som idagrutes til OSL, men som ikke er i bruk. Dette er tenkt å bruke til testing av redundant uplink, men kan etter det brukesav instanser i OSL.
Planlagte aktiviteter
• Montering og flytting av ny hardware
• Testing av vGPU
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Pilot objektlagring
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 8
av Raymond Kristiansen, UH IaaS, 25. februar 2019
Oppdatert informasjon om status finnes alltid i Trello
Contents
150 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• Uke 8
– Status
– Utfordringer
– Planlagte aktiviteter
– Annet
Status
Mye tid de to siste uken har gått med til arbeid relatert til ny hardware. Det er 9 nye compute i OSL og ca 50 nyestorage, network og compute i BGO.
Vi har startet revidering av sikkerhetsdokumentet som forarbeid til en full ROS analyse. Dokumentet vil gi oss en godstart på det arbeidet.
Vi ser også på bruk av Ceph til object storage i Openstack. Den vil da bli satt opp med samme støtte for API somswift, Swift API og S3 API, via keystone.
I forbindelse med en supportsak startet vi også å se litt mer på retningslinjer for kreditering av publikasjoner sombenytter seg av UH-IaaS. Vi forhører oss med UB (UiB) om hva som må til for å f.eks. benytte CRISTIN i forbindelsemed registering av publikasjoner i sektoren.
Vi har nå også gold image for Windows 2019 (core og standard) i tillegg til 2016.
Samlingen i vår blir i Oslo 6. og 7. mars.
Utfordringer
Vi vil snart gå tom for public IP-addresser. Vi har idag 2 C-nett i hver region. Vi har nytt et ledig C-nett som idagrutes til OSL, men som ikke er i bruk. Dette er tenkt å bruke til testing av redundant uplink, men kan etter det brukesav instanser i OSL.
Planlagte aktiviteter
• Montering og installasjon ny hardware
• Sikkerhetsgjennomgang/ROS
• Testing av vGPU
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Pilot objektlagring
Annet
• Se https://trello.com/norcams for oppdaterte planer.
1.6. Status 151

iaas Documentation, Release 0.1.0
Uke 10
av Raymond Kristiansen, UH IaaS, 11. mars 2019
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 10
– Status
– Utfordringer
– Planlagte aktiviteter
– Annet
Status
Arbeidet med nye hardware forsetter. Vi er straks klar med alle de nye compute nodene (minus vGPU noden) i OSLog all ny hardware for CERN Alice T1 er straks ferdig montert og kablet i BGO.
Vi nærmere oss en løsning med eget Ceph cluster for object storage og planen er å ha klar en pilot av med S3 og swifti BGO denne uken.
Samling 6. og 7. mars hos USIT. Referat blir publisert her når det er klart. Vi brukte her tid på å forbedrede enspørreundersøkelse som vi planlegger å sende ut i løpet av de neste ukene.
Vi planlegger et kort avbrudd neste tirsdag 19. mars for å patche alle noder (med unntak av legacy zonen).
Utfordringer
Vi vil snart gå tom for public IP-addresser. Vi har idag 2 C-nett i hver region. Vi har nytt et ledig C-nett som idagrutes til OSL, men som ikke er i bruk. Dette er tenkt å bruke til testing av redundant uplink, men kan etter det brukesav instanser i OSL.
Planlagte aktiviteter
• Montering og installasjon ny hardware
• Sikkerhetsgjennomgang/ROS
• Testing av vGPU
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Pilot objektlagring
Annet
• Se https://trello.com/norcams for oppdaterte planer.
152 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Uke 12
av Raymond Kristiansen, UH IaaS, 25. mars 2019
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 12
– Status
– Utfordringer
– Planlagte aktiviteter
– Annet
Status
Onsdag 20. mars hadde vi nedetid på tjenestene i rundt 2 timer for patching. Arbeidet ble annonsert i de vanligekanalene og ble gjennomført i det varslede vinduet.
I forbindelse med utvidelse av BGO til en sekundærhall (HIB) måtte vi oppdatere lag 2 nettet med to nye switcher. Iforbindelse med dette hadde vi i en periode om kvelden onsdag 20. mars enkelte brudd og svekket ytelse i nettet BGO.Det inkluderer nettet til instansene. Dette arbeidet var kritisk for å kunne komme videre med CERN-nodene som ermontert på HIB. Sekundærhallen på HIB er planlagt ny primærhall for BGO i løpet av 2019/2020.
De nye compute-nodene i OSL er klar til bruk, og arbeidet forsetter med CERN Alice T1 nodene i BGO. Disse bleinstallert i uke 12. Vi jobber med med testing av utstyret.
Vi har nå klar en pilot av med S3 og swift i BGO. Vi tester litt først i det stille før vi annonserer en åpen pilot.
I uke 12 gikk vi tom for offentlig IPv4-addresser i OSL. Vi har nå tatt i bruk et ekstra C-nett i OSL. Dette er den vifikk i starten til bruk i TRD. Dette var tenkt brukt til testing av ny uplink i OSL. Vi trenger derfor en ny blokk (helstpermanet, men iallefall til låns) før vi kan fullføre bytte av uplink fra USIT til Uninett.
Utfordringer
Vi vil snart gå tom for public IP-addresser. Vi har løst det midlertidig i OSL med en 3. C-nett, men i BGO vil vi snartogså være tom.
Planlagte aktiviteter
• Installasjon ny hardware
• Sikkerhetsgjennomgang/ROS
• Testing av vGPU
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Teste pilot objektlagring
1.6. Status 153

iaas Documentation, Release 0.1.0
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 26
av Raymond Kristiansen, UH IaaS, 01. juli 2019
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 26
– Status
– Utfordringer
– Planlagte aktiviteter
– Annet
Status
Veldig lenge siden forrige rapport. Vi har brukt omtrent all tid på å klargjøre og hjelpe til med få kjørt Atlas og Alicepå UH-IaaS. Begge deler har tatt lenger tid enn planlagt, men vi tror vi nærmer oss nå.
Onsdag 26. juni hadde vi nedetid på tjenestene i rundt 3 timer for patching og oppgradering. Arbeidet ble annonserti de vanlige kanalene. I forbindelse med oppgradering av Calico fikk vi et problem med multiregion som medførte atdet ikke var mulig å starte nye instanser i OSL før etter ca 2 timer etter varslet nedetid. Siden det var sent på dagen ogsommer antar vi at få brukere var berørt.
Vi har satt opp en compute host med en GPU som kan tilby vgpu til instanser. Vi har for øyeblikket et prosjekt somtester dette (de samme som har betalt for hosten).
Vi håper å få oppgradert til Rocky i løpet av juli. Planen er kjøre en test i uke 27 og oppgradere i uke 28/29.
Utfordringer
Vi vil snart gå tom for public IP-addresser. Vi har løst det midlertidig i OSL med en 3. C-nett, men i BGO vil vi snartogså være tom.
Planlagte aktiviteter
• Oppgradere til Rocky
• Sikkerhetsgjennomgang/ROS
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Teste pilot objektlagring
154 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Annet
• Se https://trello.com/norcams for oppdaterte planer.
2018
Uke 3
av Raymond Kristiansen, UH IaaS, 22.januar 2018
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 3
– Status
* Puppet 4
* Sentral lagring
* Objektlagring
* Annet
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Pga ferieavvikling i desember ble det endel færre arbeidstimer denne måneden.
I forbindelse med meltdown og specter tok vi en full runde med OS-patching i uke 3. Mye av tiden så langt i januarhar gått med til testing og kunnskapsinnhenting i forbindelse med disse. Endringene ble utført i annonsert tidsvinduetter planen.
Puppet 4
De fleste har jobbet med dette siden desember og vi nærmer oss nå målet. Selve omleggingen vil skje i slutten avjanuar/begynnelse av februar. Arbeidsmengden med omleggingen har vært større enn antatt så vi brukt litt lenger tidenn planlagt.
Sentral lagring
Vi la om til sentral lagring som default i BGO i 17. januar. Ingen kjørende instanser har blitt flyttet, men nye vil fåsentral lagring. Vi fikk noen utfordringen som medførte at vi utsatte endringene i OSL til disse er løst. Planen er ålegge om OSL i uke 4.
1.6. Status 155

iaas Documentation, Release 0.1.0
Objektlagring
Vi har satt opp en PoC av Openstack Swift som ser ut til å fungere. Vi trenger mer tid til testing og tilpassing avtjenesten. Planen er å installere den i BGO når vi er ferdig med Puppet 4 oppgradering.
Annet
Det jobbes videre med å sette opp Designate (DNS) og Ceilometer (telemetri).
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
• Oppgradering til Puppet versjon 4
• Objektlagring
Utfordringer
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 5
av Raymond Kristiansen, UH IaaS, 05.februar 2018
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 5
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Vi har nå satt opp sentral os-disk som default og live migrering ser ut til å fungerer som planlagt etter litt testing. Lokalos-disk er forsatt tilgjengelig som en “legacy” tjeneste. Planen er å flytte alle på et senere tidspunkt og avvikle lokaldisk når antallet og konsekvensen er mindre (krever også en konvertering av disken).
Vi er i siste fase med testing av puppet 4 og kommer til å fullføre oppgraderingen de neste to ukene.
156 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
• Oppgradering til Puppet versjon 4
• Objektlagring
Utfordringer
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 8
av Raymond Kristiansen, UH IaaS, 26.februar 2018
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 8
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Puppet 4 oppgraderingen er fullført og ble gjennomført uten annen nedetid enn restart av enkelte tjenester (maks 1-2minutter).
Vi har gjort fremskritt både når det gjelder Ceilometer og Designate (DNS). Vi jobber nå med å sette opp Ceilometeri test og regner med at vi om kort tid bytter til å bruke egne navnetjenere til å håndtere uh-iaas.no og uhdc.no.
I forbindelse med arbeidet med å sette opp Ceilometer så har vi nå også satt opp en metric tjeneste (metric as a service).Vi er usikker på om dette er en tjeneste vi også skal tilby sluttbrukere eller om dette skal være kun for intern bruk.
Vi starter nå arbeidet med å oppgradere til neste version av Openstack. Dette ble utsatt før nyttår for å kunne taoppgraderingen av Puppet først.
Vi jobber også med å planlegge en samling for hele teamet i uke 10 hos USIT.
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
1.6. Status 157

iaas Documentation, Release 0.1.0
• Jobbe videre med Designate og Ceilometer
• Objektlagring
• Oppgradere til ny Openstack versjon ocata
Utfordringer
• Vi har slitt med å få nok strøm til de 4 “nye” compute-nodene i BGO. Vi har nå fått ny PSU, men for å ta den ibruk må alle 4 skrues av. 2 av dem er idag default zone i BGO og har kjørende instanser.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 11
av Raymond Kristiansen, UH IaaS, 20.mars 2018
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 11
– Status
* Uforutsette hendelser
· Del 1
· Del 2
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Vi hadde teamsamling ved USIT 6. og 7. mars. Det vil bli skrevet et kort referat.
Vi holder på å legge om DNS slik at vi selv kan håndtere både uh-iaas.no og uhdc.no. Vi har lagt om test01 ogverifisert at oppsettet vårt fungerer. Planen er å rulle det ut i prod de neste ukene.
Vi har også laget et oppsett for objektlagring med begrenset støtte for S3-API. Dette vil bli testet ut de neste ukene førvi klargjør en pilot.
Uforutsette hendelser
I uke 11 hadde vi to hendelser ved UiB som var utenfor vår kontroll. Disse hendelsene medførte nedetid for tjenestenevåre og stopp av instanser for endel brukere.
158 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Del 1
Onsdag 14.mars kl 14.50 mistet BGO sin uplink pga. problemer med en gateway ved UiB. Vi har ikke redundantuplink, og dette medførte at hele BGO mistet nettet. Dette inkluderte alle fellestjenester som API, dashboard, statusog access. Kjørende instanser i OSL ble ikke berørt. Vi har også en tredje lokasjon for quorum i database-clusteretsom forsatt var oppe. Dette sikret alt fungerte igjen straks nettforbindelsen var gjenopprettet. Nettet kom og gikk fremtil rundt 16.30, da problemene ble løst. Kjørende instanser i BGO ble ikke påvirket på andre måter enn at nettet varborte en stund.
Tiltak for å unngå dette i fremtiden er redundant uplink i begge lokasjoner. Det har vært jobbet med å koble ossdirekte til UNINETT over lengre tid, men det ser ikke ut som det blir en løsning her med det første. Vi vurderer ågjøre andre tiltak i mellomtiden. Vi har også planer om å benytte en ekstern HA-løsning for å gjøre felles tjenestermindre avhengig av en enkelt lokasjon som idag (BGO).
Del 2
Fredag 16.mars kl 10.25 gikk strømmen i store deler av Bergen sentrum, inkludert UiB sin datahall hvor BGO står.Sikringen til UPS gikk også og hele BGO mistet strømmen og stoppet opp. Dette medførte at alle fellestjenester ogalle instanser i BGO ble stoppet. Etter 10-15 min fikk man UPS og aggregate opp og BGO fikk igjen strøm. Instanseri bgo-legacy-1 startet automatisk og var tilgjengelig i løpet av kort tid.
Nedetiden hadde ført til problemer med database-clusteret, og det tok ca. 1 time før alle fellestjenester var oppe.I tillegg var det problemer for instanser i bgo-default-1 som bruker sentral disk. For det første startet ikke en avcompute nodene opp av seg selv etter strømbruddet og måtte manuelt startes. Det andre problemet var at alle instanseri bgo-default-1 ikke klarte å fullføre oppstart og ble hengende uten et kjørende OS.
Problemet ble lokalisert til å være med den sentral lagringen (Ceph). Problemet ble løst kl 16.00. Deretter ble alleinstanser i bgo-default-1 manuelt sjekket og fikk en kald restart. Alle instanser og tjenester fungerte tilsynelatendeigjen fra ca. kl 17.15. Det var ca. 80 kjørende instanser i bgo-default-1 som ble berørt.
Vi vet forsatt ikke nøyaktig hvorfor lagringen fikk problemer etter strømstansen.
Det er litt begrenset med tiltak vi kan gjøre her. Vi ser på muligheten for å gjøre database-clusteret mer robust, samt åbenytte en ekstern HA-løsning for å gjøre felles tjenester mindre avhengig av en enkelt lokasjon som idag (BGO).
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate
• Pilot objektlagring
• Oppgradere til ny Openstack-versjon: Ocata
Utfordringer
• Vi har slitt med å få nok strøm til de 4 “nye” compute-nodene i BGO. Vi har nå fått ny PSU, men for å ta den ibruk må alle 4 skrus av. 2 av dem er i dag default zone i BGO og har kjørende instanser.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
1.6. Status 159

iaas Documentation, Release 0.1.0
Uke 18
av Raymond Kristiansen, UH IaaS, 9.mai 2018
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 18
– Status
* Utfordringer
– Planlagte aktiviteter
– Annet
Status
Pga ferie og fridager har fremdriften de siste uken ikke vært like stor som vi skulle ha håpet. Resten av mai blir nokikke stort bedre, men vi regner med å være tilbake for fult noen uker i juni/juli før sommerferien starter for de fleste.
Oppgraderingen til ocata går videre og vi regner med å kjøre det ut i test i løpet av de neste uken. Oppgradering avbgo og osl vil bli tatt i juni når jeg og Tor er tilbake fra Openstack summit.
Vi har fått byttet PSUer i bgo slik at vi nå har 10 compute noder der (2 av dem er ikke tatt i bruk enda).
Utfordringer
Vi fikk rapporter om problemer med dashboard (openstack horizon) i vår. Det tok endel tid og ressurser å feilsøkesiden det kun oppstod med enkelte nettlesere. Problemet hadde med sesjonshåndteringen å gjøre, og vi lagrer nåsesjonsdata i en egen database for å unngå problemet helt.
Vi fikk også problemer med en hard limit i nettverksutstyret vårt. Siden vi kjørte flest instanser i osl oppdaget viproblemet der først. Grensen er på 256 host-ruter som medførte at vi ikke fikk IPv6 på nye instanser når antallet ruteroversteg 256 (ca 220 instanser). IPv6 blir bl.a. brukt til DNS så for alle praktiske formål var instansen ubrukelig. Viløste det akutte problemet med å slette demo instanser og oppfordre alle brukere om å benytte bgo til nye instanser.Det ble bestilt nye rutere i osl og vi hadde 2 rutere som kunne settes inn i bgo. Vi bytte rutere i bgo torsdag 3.mai ogi osl tirsdag 8.mai for en permanent løsning. Både feilesøkingen og forberedelser til bytte har tatt mye resurser sidendet ble oppdaget i uke 16. Det jobbes også med å få en redundant uplink i osl.
Pga ferie og konferanser blir det begrenset bemanning i mai. Vi regner med at vi skal klare å ha minst en på jobb hverdag.
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate
• Pilot objektlagring
• Oppgradere til ny Openstack-versjon: Ocata
160 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 31
av Raymond Kristiansen, UH IaaS, 6.august 2018
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 31
– Status
– Utfordringer
– Planlagte aktiviteter
– Annet
Status
Lang tid siden forrige rapport så dette blir en kort oppsummering siden sist.
Vi har oppgradert Openstack versjon fra Newton til Ocata. Dette tok mye lenger tid enn planlagt. Arbeidet blepåbegynt i april, mens selve oppgraderingen ble utført 19. juli. Oppgraderingen ble varslet på forhånd og medførtenedetid på tjenesten, mens kjørende instanser ikke ble påvirket. Arbeidet tok ca 2,5 time og det meste gikk etterplanen. Vi fikk litt problemer med volum-tjenesten i OSL, slik at den ikke var tilgjengelig før det var gått ca 4 timer.
Planen er å starte på oppgradering til Pike med en gang, og vi kommer til å ta med oss erfaringene med Ocata når vilegger planen for Pike. Målet et at tidsrammen fra start til fullføring nå blir 3-4 uker.
Telemetri-tjenesten er nå operativ slik at vi nå kan få rapporter om bruk pr time. Dette kan senere brukes til faktura-grunnlag.
Det har blitt satt opp egne DNS-tjenere som skal brukes til instansene. Disse er satt opp som to par slik at vi totalt får4 DNS-tjenere. Vi bruke anycast slik at det blir en IP-addresse pr par i hver lokasjon. Vi vil da kunne ta ned en tjenerper lokasjon uten at brukere blir påvirket og vi skal kunne kjøre med mindre forstyrrelser med kun 1 av 4 kjørende.Disse vil bli satt i produksjon i nær fremtid.
Vi har også satt opp egne NS-tjenere som skal være autorative for våre domener (uh-iaas.no og uhdc.no). Vi vil da hafull kontroll på domenene våre, og er ikke avhengig av tjenester hos UNINETT, UiO og UiB.
Det er også jobbet med å skru på SElinux på alle tjenester som er eksponert mot Internett, med unntak av compute iførste omgang. Vi har kjørt det i test i noen måneder nå og kommer til å skru det på i prod om kort tid.
Det er planlagt en større patching av servere i uke 32 som også inkluderer oppgradering fra CentOS 7.4 til 7.5.
Utfordringer
Vi begynner å gå tom for compute ressurser, spesielt i OSL. Der har vi delt ut litt over 900 VCPUs og 2,7 TB RAMfordelt på 6 aktive compute hoster. Vi kan forsatt overprovisjonere litt mer, men i løpet av høsten må vi ha flerecompute hoster.
1.6. Status 161

iaas Documentation, Release 0.1.0
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Oppgradere til ny Openstack-versjon: Pike
• Jobbe videre med Designate
• Pilot objektlagring
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 35
av Raymond Kristiansen, UH IaaS, 3.september 2018
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 35
– Status
– Utfordringer
– Planlagte aktiviteter
– Annet
Status
Alle noder med unntak av compute for legacy-1 ble patchet og bootet i uke 32. Det gikk etter planen og uten over-raskelser selv om vi oppgraderte fra CentOS 7.4 til 7.5.
Vi kjører nå egne navnetjenere for uh-iaas.no og sonene <loc>.uhdc.no. Dette gjør at vi kan oppdatere alle DNS-navnvi bruker uten avhengighet til andre.
Vi samler nå også inn litt ekstra informasjon om instanser som kjører i UH-IaaS. I første omgang er det kun snakk omoppetid og antall pakker som ikke er installert. Antall pakker som ikke er installert vil enten være sikkerhetsoppda-teringer eller vanlige pakker som kan oppdateres.
Vi har jobbet med en del endringer som har kjørt i test en stund og vil bli rullet ut i prod de neste ukene:
• oppgradering av Ceph (inkludert reinstall av storage noder)
• skru på SElinux på alle tjenster som er eksponert mot Internett
• ta i bruk egne DNS-tjenere for alle instanser
Vi kommer til å prøve å få skrudd av instanser som kjører i availability zone (AZ) legacy-1 slik at vi kan flytte computenoder til AZ default-1 som sliter med høyt minnebruk. I førte omgang vil vi prøve å få brukere til å skru av frivilligsamt terminere demo-instanser her.
Det er planlagt en ny samling i Bergen i høst. Vi jobber med å få til noe i uke 38.
162 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Utfordringer
Vi begynner å gå tom for compute ressurser, spesielt i OSL. Der har vi nå gikk vekk ca 3 ganger så mange VCPUs somvi har logiske kjerner (6 ganger mot fysiske kjerner). Vi kan forsatt overprovisjonere litt mer, men i løpet av høstenmå vi ha flere compute hoster.
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Oppgradere til ny Openstack-versjon: Pike
• Jobbe videre med Designate
• Pilot objektlagring
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 37
av Raymond Kristiansen, UH IaaS, 17.september 2018
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 37
– Status
– Utfordringer
– Planlagte aktiviteter
– Annet
Status
Lørdag 15. september var det brudd planlagt vedlikehold ved UiB. Det medførte et varslet mindre brudd i nettverket tiltjenester og instanser i BGO. Det mest kritiske var database-clusteret som vi stoppet manuelt for å unngå ‘split brain’.Et større problem oppstod ved testing av UPS som medførte at 4 compute noder i BGO mistet strømme. Disse varnede i ca 30 minutter. 68 kjørende instanser gikk også ned i denne perioden. Disse kom opp igjen når compute nodenekom tilbake.
I forbindelse med oppgradering av Ceph fikk vi litt problemer med OSL. Antall OSDer (disker) er for få etter at vibygget om med SSD til OS-disker. Dette medførte problemer ved oppgradering og reinstallasjon. Brukere opplevdeat volumet de hadde på instansen ikke lenger var responsivt. OS-disken ble ikke berørt og stikkprøver vi utførte klarteikke å gjenskape problemet brukere opplevde. Problemene var størst 7. september når vi tok den første storage nodeni OSL. Tiltak ble tatt for de resterende nodene slik at problemene for brukerne ble mindre eller fraværende på de andrestorage-nodene.
1.6. Status 163

iaas Documentation, Release 0.1.0
SELinux er nå satt til enforcing på på alle noder som er eksponert mot internett. Vi tester det nå på compute og viletter hvert også skrue det på på de resterende nodene (interne noder som logger, monitor, foreman, etc).
Vi har brukt litt tid på å lage et system for å varsle brukere. Vi kan nå varsle brukere på både Twitter og Slack enkeltnår det oppstår problemer. Vi lagrer også alle varsler i egen database som er tilgjengelig for alle via et API.
Det har til tider vært treg respons på enkelte API. Vi har jobbet med å øke ressursene og skalere opp tjenestene. Visamler også inn metrics og kommer til å jobbe med å forbedre dette kontinuerlig.
Vi bruker nå egne DNS-servere som resolver på alle instanser.
Det blir samling i Bergen for hele teamet denne uken, 19. og 20. september. Vi skal da lage en grov plan for arbeidetde neste 6 månedene.
Utfordringer
Vi begynner å gå tom for compute ressurser, spesielt i OSL. Der har vi nå gikk vekk ca 3 ganger så mange VCPUs somvi har logiske kjerner (6 ganger mot fysiske kjerner). Vi kan forsatt overprovisjonere litt mer, men i løpet av høstenmå vi ha flere compute hoster.
Vi ser også at vi også sliter litt med Ceph i OSL. Vi trenger 2 nye storage noder slik at OSL blir like stor som BGO.Vi har rammer til Dell servere og 2 TB disker vi kan bruke til disse.
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Oppgradere til ny Openstack-versjon: Pike
• testing av DNSaaS med Designate
• Pilot objektlagring
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 39
av Raymond Kristiansen, UH IaaS, 1.oktober 2018
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 39
– Status
– Utfordringer
– Planlagte aktiviteter
– Annet
164 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Status
Vi hadde samling i Bergen 19. og 20. september. Egen rapport blir skrevet fra samlingen.
Vi har brukt litt tid på å forbedre oppsettet av noder for kontrollplanet. Vi har laget nye noder og endret navn på gamle.Dette er et kontinuerlig arbeid som vil forsette i tiden fremover.
Vi er ferdig med forarbeidet for oppgradering til Openstack Pike. Vi ønsker først å oppgradere identity (keystone) ifart uten nedetid. Oppgraderingen vil derfor denne gangen kreve litt mer planlegging enn tidligere. Deretter tar vioppgraderingen av resten som normalt med planlagt nedetid på tjenestene.
Det er bestilt 2 nye storage noder i OSL for å avhjelpe utfordringene vi har hatt med for få OSDer.
SELinux er nå også i drift på compute.
Utfordringer
Vi begynner å gå tom for compute ressurser, spesielt i OSL. Der har vi nå gikk vekk ca 3 ganger så mange vCPUs somvi har logiske kjerner (6 ganger mot fysiske kjerner). Vi kan forsatt overprovisjonere litt mer, men i løpet av høstenmå vi ha flere compute hoster.
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Oppgradere til ny Openstack-versjon: Pike
• testing av DNSaaS med Designate
• Pilot objektlagring
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 41
av Raymond Kristiansen, UH IaaS, 15.oktober 2018
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 41
– Status
– Utfordringer
– Planlagte aktiviteter
– Annet
1.6. Status 165

iaas Documentation, Release 0.1.0
Status
Vi har nå startet oppgradering til pike i test. For identity har vi testet bruk av rolling upgrade for identity. Dvs at vioppgraderer identity i fart uten at brukere skal merke at tjenesten er utilgjengelig. Dersom testene går bra er planen åoppgradere Openstack Keystone (identity) til Pike i uke 42.
Vi har jobbet videre med å sette opp flere backends for Openstack tjenestene med mål om å bedre oppetid ved planlagtvedlikehold og øke ytelsen. De som gjenstår nå er image og volume tjenestene.
De siste ukene har også gått med til å feilsøke og overvåke tilgjengeligheten av DHCP lease for IPv6 adresser påinstanser. Vi har fått rapporter om at windows instanser har mistet IPv6, men har selv ikke klart å gjenskape problemet.Vi har også laget en patchet versjon av dnsmasq (som brukers som dhcp-server) som tvinger instansene til å godtalengre levetid på IPv6 adressen. Vi tester nå denne for å finne ut vi vil ta den i bruk. Siden vi bruker IPv6 til DNSresolvere vil et fravær av IPv6 også medføre manglende DNS. Dette er har vært tidkrevende å feilsøke siden vi ikkeser problemer på DHCP-serveren eller klarer å overvåke IPv6 i andre instanser enn dem vi tester på.
Utfordringer
Vi begynner å gå tom for compute ressurser, spesielt i OSL. Der har vi nå gikk vekk ca 3 ganger så mange vCPUs somvi har logiske kjerner (6 ganger mot fysiske kjerner). Vi kan forsatt overprovisjonere litt mer, men i løpet av høstenmå vi ha flere compute hoster.
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Oppgradere til ny Openstack-versjon: Pike
• testing av DNSaaS med Designate
• Pilot objektlagring
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 46
av Raymond Kristiansen, UH IaaS, 19.november 2018
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 46
– Status
– Utfordringer
– Planlagte aktiviteter
– Annet
166 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Status
Reiser og ferie har medført litt begrenset produktivitet de siste ukene. Det gjelder også rapporteringen.
Oppgradering til Pike er nå fullført. Det finnes en egen side som forklarer hvordan det gikk.
ELK-stacken (elasticksearch, logstash og kibana) er nå oppgradert til nyeste versjon. Vi har frem til å kjørt på en parår gammel versjon. Dette vil også forhåpentligvis gjøre det enklere å bruke spesielt Kibana i feilsøking.
De nye storage nodene i OSL er nå installert og satt i produksjon. Vi har også gjenbrukt disker fra ombyggingen tilSSD slik ta kapasiteten for både volum (HDD) og OS-disk (SSD) nå er større.
Vi har begynt å se på bruk av Redfish til hardware overvåkning og har satt det opp i BGO og OSL. Vi har også testetlitt med Dell sitt Open Manage til hardware overvåkning.
Deler at teamet var også i Berlin i uke 46 og deltok på Openstack Summit.
Referat for samlingen vi hadde i høst er nå lagt inn her også.
Utfordringer
Vi begynner å gå tom for compute ressurser, spesielt i OSL. Der har vi nå gikk vekk ca 3 ganger så mange vCPUs somvi har logiske kjerner (6 ganger mot fysiske kjerner). Vi kan forsatt overprovisjonere litt mer, men i løpet av høstenmå vi ha flere compute hoster.
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Oppgradere til CentOS 7.6
• testing av DNSaaS med Designate
• Pilot objektlagring
• Oppgradere til ny Openstack-versjon: Queens
Annet
• Se https://trello.com/norcams for oppdaterte planer.
2017
Uke 9
av Raymond Kristiansen, UH IaaS, 07.mars 2017
Dette er en samlerapport over 2017 frem til og med uke 9.
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 9
1.6. Status 167

iaas Documentation, Release 0.1.0
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
• Hovedfokus siden november 2016 har vært å få flere brukere. Vi har nå ca 250 brukere, 10 prosjekter og ca 300kjørende instanser. Oppdaterte tall på https://status.uh-iaas.no
• I januar 2017 fikk UiA tilgang til UH-IaaS og ble lovet inntil 200 instanser i en pilot for å dekke studentinstanserfor 3 emner. Dette har økt bruken betraktelig i 2017.
• I tillegg til å finne brukere har vi brukt endel tid på å hjelpe brukere å ta i bruk UH-IaaS. Dette gjelder bl.a.tilpassing av image og prosjekter.
• Vi har også brukt tid på å lage egne image slik at vi kan frigjøre diskbruk over tid. Filer som blir slettet på eninstans blir ikke automatisk frigitt på den underliggende lagringen. Det vil føre til at diskbruken for instansersom lever lenge vil gradvis øke til maks selv som disken er tynnprovisjonert. Vi har gjort endringer i Openstackog jobber nå med å få satt opp en egen imagebuilder.
• Videreutvikling av tjenesten blitt nedprioritet etter vi gikk i produksjon i november 2016 og frem til nå. Vijobber nå med en utviklingsplan for 2017. Denne er ikke klar enda siden prioriteringen vil være avhengig aveksternfinansierte oppgaver. Det vil komme en mer detaljert plan i Trello
• De to utviklingsløpene vi har for tiden er Designate (DNS) og Ceilometer (telemetri og forbruksdata). Designateer ikke langt unna produksjon, mens Ceilometer vil kreve mer tid før den er klar.
• Vi har fått tilgang til RT (Request Tracker) hos UNINETT slik at vi kan ta imot support-henvendelser på epost([email protected]).
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
• Vaktordning i arbeidstiden for RT, Slack (brukersupport) og Sensu (monitorering)
• Lage halvårsplan for våren 2017
Utfordringer
• Vi har IP-addresser til ca 480 instanser. Per nå har vi ca 300. Vi er i dialog med UNINETT om tilgang til flereadresser og har også fått hjelp av nettgruppen ved USIT i dialogen med UNINETT.
• Dersom diskbruken for OS i instanser forsetter å øke vil vi om ikke altfor lenge trenge mer disk. Vi har pengerigjen fra i fjor til å kjøpe mer disk. Vi ligger nå i BGO på 20-40% bruk på de aktive compute nodene.
• Vi har fått penger fra UNINETT for 2 ekstra stillinger i 2017. 1. februar fikk vi en ekstra person ved UiB, mensvi ikke har fått noen ekstra person ved UiO enda. Det vil medføre at de planlagte leveransene knyttet til avtalenmed UNINETT for 1. juli 2017 med stor sannsynlighet ikke vil bli levert. Dette vil først og fremst ramme objectstorage.
168 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• Det vil kreve midler til hardware for å øke kapasiteten og videreutvikle tjenesten. Dette behovet vil det med høysannsynlighet komme allerede i 2017. Det vi ser nå at vi vil trenge midler til er mer compute, langvarig løsningpå diskutfordringene nevnt over og object storage. Vi jobber med å tallfeste kortsiktige og langsiktige løsninger.
Annet
• Planen er å lage en kort rapport hver uke (klar sense mandag morgen). For mer detaljert oppfølging vil manbruke Trello. Tilgang til lukkede tavler vil bli gitt til dem som trenger det utenfor teamet.
Uke 10
av Raymond Kristiansen, UH IaaS, 14.mars 2017
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 10
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
All fokus siste uken har vært på å hjelpe brukere, og spesielt med å bygge image. Det tar relativt mye tid for å hjelpeen liten gruppe personer, men vi har likevel valgt å gjøre det for å skape positivitet rundt tjenesten.
Oppdatert statistikk over bruk finnes på https://status.uh-iaas.no
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
• Vaktordning i arbeidstiden for RT, Slack (brukersupport) og Sensu (monitorering)
• Lage halvårsplan for våren 2017
Utfordringer
Ingen endringer på dette siste uken. Så jeg lar det stå.
• Vi har IP-addresser til ca 480 instanser. Per nå har vi ca 300. Vi er i dialog med UNINETT om tilgang til flereadresser og har også fått hjelp av nettgruppen ved USIT i dialogen med UNINETT.
• Dersom diskbruken for OS i instanser forsetter å øke vil vi om ikke altfor lenge trenge mer disk. Vi har pengerigjen fra i fjor til å kjøpe mer disk. Vi ligger nå i BGO på 20-40% bruk på de aktive compute nodene.
1.6. Status 169

iaas Documentation, Release 0.1.0
• Vi har fått penger fra UNINETT for 2 ekstra stillinger i 2017. 1. februar fikk vi en ekstra person ved UiB, mensvi ikke har fått noen ekstra person ved UiO enda. Det vil medføre at de planlagte leveransene knyttet til avtalenmed UNINETT for 1. juli 2017 med stor sannsynlighet ikke vil bli levert. Dette vil først og fremst ramme objectstorage.
• Det vil kreve midler til hardware for å øke kapasiteten og videreutvikle tjenesten. Dette behovet vil det med høysannsynlighet komme allerede i 2017. Det vi ser nå at vi vil trenge midler til er mer compute, langvarig løsningpå diskutfordringene nevnt over og object storage. Vi jobber med å tallfeste kortsiktige og langsiktige løsninger.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 11
av Raymond Kristiansen, UH IaaS, 22.mars 2017
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 11
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
UiA tok i UH-IaaS bruk i et nytt emne i uke 11, denne gangen med kursprosjekt. Vi fikk da testet at skriptene våre forå opprette og gi tilgang til kursprosjekt fungerte som det skulle. De fikk også tilgang til en egen flavor slik at de kankjøre et spesiallaget image for kurset.
Vi jobber også med å ferdigstille et image builder verktøy vi skal benytte for å lage våre GOLD images. Dette er ogsåplanen at andre kan gjenbruke det til å lage egne image.
Vi har fått tildelt to nye /24-blokker med IPv4-adresser så vi vil nå mest sannsynlig klare oss til vi får på plass IPv6støtte (planlagt leveranse juni 2017).
Oppdatert statistikk over bruk finnes på https://status.uh-iaas.no
Planlagte aktiviteter
• Ferdigstille image builder
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
• Vaktordning i arbeidstiden for RT, Slack (brukersupport) og Sensu (monitorering)
170 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• Lage halvårsplan for våren 2017
Utfordringer
Ingen endringer på dette siste uken. Så jeg lar det stå.
• Dersom diskbruken for OS i instanser forsetter å øke vil vi om ikke altfor lenge trenge mer disk. Vi har pengerigjen fra i fjor til å kjøpe mer disk. Vi ligger nå i BGO på 20-40% bruk på de aktive compute nodene. Vi jobbermed en plan for å bygge om Ceph-clusteret til å kunne også håndtere OS-disk.
• Vi har fått penger fra UNINETT for 2 ekstra stillinger i 2017. 1. februar fikk vi en ekstra person ved UiB, mensvi ikke har fått noen ekstra person ved UiO enda. Det vil medføre at de planlagte leveransene knyttet til avtalenmed UNINETT for 1. juli 2017 med stor sannsynlighet ikke vil bli levert. Dette vil først og fremst ramme objectstorage.
• Det vil kreve midler til hardware for å øke kapasiteten og videreutvikle tjenesten. Dette behovet vil det med høysannsynlighet komme allerede i 2017. Det vi ser nå at vi vil trenge midler til er mer compute, langvarig løsningpå diskutfordringene nevnt over og object storage. Vi jobber med å tallfeste kortsiktige og langsiktige løsninger.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 14
av Raymond Kristiansen, UH IaaS, 11.april 2017
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 14
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Pga. ferie ble det ikke laget rapport for uke 12 og 13.
Onsdag 5. april flyttet vi ca 180 maskiner mellom to sett av compute hosts. Dette er første gang vi migrerer så mangepå en gang og første gang vi har automatisert migreringen. For de første 150 instansene gikk alt som planlagt, menfor de siste 30 fikk vi problemer med netverks-APIet som medførte ekstra nedetid på 5-10 min for disse instansene.Problemene med APIet har vi også sett i test, men dette er første gang vi opplever det i produksjon. Det vil bli enprioritert oppgave å løse dette.
Vi har også et stykke på vei med å sette opp en IPv4 NAT-tjeneste for IPv6 slik at instanser også får en privat IPv4adresse. Dette var mye mer komplisert enn først antatt, men vi føler vi nå har en løsning som gjør at vi kan tilby IPv6i løpet av sommeren som planlagt.
1.6. Status 171

iaas Documentation, Release 0.1.0
Det meste av tiden har blitt brukt til feilsøking, drift og til å hjelpe brukere.
Oppdatert statistikk over bruk finnes på https://status.uh-iaas.no
Planlagte aktiviteter
• Ferdigstille image builder
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
• IPv6 til instanser
• Plan for å bygge om Ceph-clusteret
• Vaktordning i arbeidstiden for RT, Slack (brukersupport) og Sensu (monitorering)
Utfordringer
Ingen endringer på dette siste uken. Så jeg lar det stå.
• Dersom diskbruken for OS i instanser forsetter å øke vil vi om ikke altfor lenge trenge mer disk. Vi har pengerigjen fra i fjor til å kjøpe mer disk. Vi ligger nå i BGO på 50-60% bruk på de aktive compute nodene. Vi jobbermed en plan for å bygge om Ceph-clusteret til å kunne også håndtere OS-disk.
• Vi har fått penger fra UNINETT for 2 ekstra stillinger i 2017. 1. februar fikk vi en ekstra person ved UiB, mensvi ikke har fått noen ekstra person ved UiO enda. Det vil medføre at de planlagte leveransene knyttet til avtalenmed UNINETT for 1. juli 2017 med stor sannsynlighet ikke vil bli levert. Dette vil først og fremst ramme objectstorage.
• Det vil kreve midler til hardware for å øke kapasiteten og videreutvikle tjenesten. Dette behovet vil det med høysannsynlighet komme allerede i 2017. Det vi ser nå at vi vil trenge midler til er mer compute, langvarig løsningpå diskutfordringene nevnt over og object storage. Vi jobber med å tallfeste kortsiktige og langsiktige løsninger.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 16
av Raymond Kristiansen, UH IaaS, 25.april 2017
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 16
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
172 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Status
Pga. påske ble det ikke laget rapport for uke 15.
Vi har jobbet litt med å automatisere prosjektadministrasjon, blant annet personer som bytter epost-adresse og derformister tilgangen til ressursene i UH-IaaS.
Det er laget planer for demo-prosjekt og lagring
Ellers har har endel tid forsvunnet til andre ting enn UH-IaaS.
Resten av tiden har blitt brukt i all hovedsak på pågående arbeid med
• designate
• ceilometer
• imagebuilder
• NAT og IPv6
Planlagte aktiviteter
• Ferdigstille image builder
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
• IPv6 til instanser
• Vaktordning i arbeidstiden for RT, Slack (brukersupport) og Sensu (monitorering)
Utfordringer
• Mangel på SSD gjør at diskene vi har bestilt til OSL ikke kommer før i juni. Vi ser på muligheten for brukeandre disker midlertidig for å unngå at alt stopper opp før diskene ankommer.
• Dersom diskbruken for OS i instanser forsetter å øke vil vi om ikke altfor lenge trenge mer disk. Vi har pengerigjen fra i fjor til å kjøpe mer disk. Vi ligger nå i BGO på 50-60% bruk på de aktive compute nodene. Vi jobbermed en plan for å bygge om Ceph-clusteret til å kunne også håndtere OS-disk.
• Pga forsinkelse med å få ansatt en ekstra person ved USIT vil det medføre at de planlagte leveransene knyttet tilavtalen med UNINETT for 1. juli 2017 ikke vil bli levert. Dette vil først og fremst ramme object storage.
• Det vil kreve midler til hardware for å øke kapasiteten og videreutvikle tjenesten. Dette behovet vil det med høysannsynlighet komme allerede i 2017. Det vi ser nå at vi vil trenge midler til er mer compute, langvarig løsningpå diskutfordringene nevnt over og object storage. Vi jobber med å tallfeste kortsiktige og langsiktige løsninger.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
1.6. Status 173

iaas Documentation, Release 0.1.0
Uke 19
av Raymond Kristiansen, UH IaaS, 15.mai 2017
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 19
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Pga. UNINETT fagdager og andre arrangementer er det ikke skrevet rapport siden uke 16.
Som tidligere har det endel tid forsvunnet til andre ting enn UH-IaaS.
Ellers jobbes det videre med påbegynte oppgaver.
Planlagte aktiviteter
• Ferdigstille image builder
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
• IPv6 til instanser
• Vaktordning i arbeidstiden for RT, Slack (brukersupport) og Sensu (monitorering)
Utfordringer
• Dersom diskbruken for OS i instanser forsetter å øke vil vi om ikke altfor lenge trenge mer disk. Vi har pengerigjen fra i fjor til å kjøpe mer disk. Vi ligger nå i BGO på 70-80% bruk på de aktive compute nodene. Vi jobbermed en plan for å bygge om Ceph-clusteret til å kunne også håndtere OS-disk.
• Pga forsinkelse med å få ansatt en ekstra person ved USIT vil det medføre at de planlagte leveransene knyttet tilavtalen med UNINETT for 1. juli 2017 ikke vil bli levert. Dette vil først og fremst ramme object storage.
• Det vil kreve midler til hardware for å øke kapasiteten og videreutvikle tjenesten. Dette behovet vil det med høysannsynlighet komme allerede i 2017. Det vi ser nå at vi vil trenge midler til er mer compute, langvarig løsningpå diskutfordringene nevnt over og object storage. Vi jobber med å tallfeste kortsiktige og langsiktige løsninger.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
174 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Uke 22
av Raymond Kristiansen, UH IaaS, 2.juni 2017
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 22
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Vi bruker for tiden litt tid på å få bruk til UH-IaaS. Det vil si at vi deltar på workshops og andre prosjekter somUNINETT sitt researchlab.
Hovedfokus de siste ukene er å jobbe med en løsning for sentral lagring av instansene sin OS-disk. Vi jobber nåmed å teste dette ut og håper å være klar til innkjøp av flere SSD-disker om ikke lang tid. Mer informasjon ligger ilagringsplanen.
Vi hadde endringsuke denne uken. Det vil si at vi både oppdaterte tjenestene rundt UH-IaaS og migrerte instanser forå oppdater compute nodene. Det gikk ikke helt etter planen. Det er skrevet en full rapport med detaljer om hva somgikk galt.
Ellers jobbes det videre med påbegynte oppgaver.
Planlagte aktiviteter
• Ferdigstille image builder
• Teste oppsettet med sentral OS-disk
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
• IPv6 til instanser
• Oppgradere til Openstack Newton
Utfordringer
• Dersom diskbruken for OS i instanser forsetter å øke vil vi om ikke altfor lenge trenge mer disk. Vi har pengerigjen fra i fjor til å kjøpe mer disk. Vi ligger nå i BGO på 70-80% bruk på de aktive compute nodene. Vi jobbermed en plan for å bygge om Ceph-clusteret til å kunne også håndtere OS-disk.
• Pga forsinkelse med å få ansatt en ekstra person ved USIT vil det medføre at de planlagte leveransene knyttet tilavtalen med UNINETT for 1. juli 2017 ikke vil bli levert. Dette vil først og fremst ramme object storage.
1.6. Status 175

iaas Documentation, Release 0.1.0
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 30
av Raymond Kristiansen, UH IaaS, 31.juli 2017
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 30
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Samlerapport for sommeren. De fleste har vært på ferie så aktivitetsnivået har vært lavt i perioden.
Vi er ferdig med imagebuilder, et verktøy for å bygge egne image, som er tilgjengelig for alle å bruke her https://github.com/norcams/imagebuilder
I tillegg til imagebuilder har vi også skrevet om hvordan vi håndterer de imagene vi tilbyr (GOLD). Dette gjør at vihar mye bedre kontroll på disse og kan letter gjøre tilpassinger i fremtiden.
Vi er i gang med oppgradering av Openstack til versjon newton. Vi vil gjøre selve oppgraderingen i flere steg, og vilstarte med keystone i begynnelsen av august.
Demo-prosjekt er nå implementert for alle nye som registrerer seg og vi har oppdatert brukerdokumentasjonen (lesmer om demo-prosjekt).
Vi er også i sluttfasen med å få klargjort IPv6 for instanser. Vi regner med at vi kan tilby IPv6 i løpet av august.
Vi hadde endringsuke i uke 27. Det vil si at vi både oppdaterte tjenestene rundt UH-IaaS og migrerte instanser for åoppdater compute nodene. Denne gangen gikk dette mye bedre. Vi fikk som før litt lenger nedetid på tjenestene ennvarslet under oppgradering, men ellers gikk det greit. Migreringen gikk uten feil denne gangen og alle instanser komtilbake etter en reboot som varslet.
Vi planlegger en samling i begynnelsen på september.
Planlagte aktiviteter
• Oppgradere til Openstack Newton
• IPv6 til instanser
• Teste oppsettet med sentral OS-disk
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
176 Chapter 1. Contents

iaas Documentation, Release 0.1.0
• Jobbe videre med Designate og Ceilometer
Utfordringer
• Vi jobber med en plan for å bygge om Ceph-clusteret til å kunne også håndtere OS-disk. Det har vist segproblematisk å få bestilt disker fra Dell. Dette vil bli et akutt problem dersom vi får mange nye brukere iUH-IaaS før vi får mer disk.
• Pga forsinkelse med å få ansatt en ekstra person ved USIT vil det medføre at de planlagte leveransene knyttet tilavtalen med UNINETT for 1. juli 2017 ikke vil bli levert. Dette vil først og fremst ramme object storage.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 33
av Raymond Kristiansen, UH IaaS, 21.august 2017
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 33
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Tannaz Navaie Roshandel startet i teamet ved USIT 15. august. Hun er finansiert av UNINETT ved UH-sky og skaljobbe med UH-IaaS i et år.
Vi har oppgradert alle Openstack-komponenter til Newton bortsett fra Nova (compute) og Horizon (dashboard). Sålangt har det ikke vært store overraskelser. Oppgraderingen har blitt gjort i fart, og har kun medført nedetid på denaktuelle tjenesten på 2-3 minutter.
Planen er å starte med å måle bruk 1. september. Vi må før den tid lage en plan for avvikling av personlig prosjekt ogfullføring av implementasjonen av demo- prosjekt (les mer om demo-prosjekt).
Vi planlegger en felles samling i Bergen 6. og 7. september. Vi vil da se på planer for høsten 2017. Hovedfokus blir ihøst blir objektlagring.
Hardware for piloten av objektlagring er bestilt ved UiB.
1.6. Status 177

iaas Documentation, Release 0.1.0
Planlagte aktiviteter
• Fullføre oppgradering til Openstack Newton
• IPv6 til instanser
• Teste oppsettet med sentral OS-disk
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
Utfordringer
• Vi venter på eksterne for å få fullført implementering av IPv6.
• Vi jobber med en plan for å bygge om Ceph-clusteret til å kunne også håndtere OS-disk. Det har vist segproblematisk å få bestilt disker fra Dell. Dette vil bli et akutt problem dersom vi får mange nye brukere iUH-IaaS før vi får mer disk.
• Pga forsinkelse med å få ansatt en ekstra person ved USIT vil det medføre at de planlagte leveransene knyttet tilavtalen med UNINETT for 1. juli 2017 ikke vil bli levert. Dette vil først og fremst ramme object storage.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 35
av Raymond Kristiansen, UH IaaS, 4.september 2017
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 35
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Vi forsetter oppgraderingen av Openstack til newton. Vi hadde noen utfordringer med oppgradering av Nova (com-pute), men jobber for å løse disse nå. Det medførte at compute API var nede i ca 60 min i BGO. Oppgradering av OSLble utsatt.
Planen er å fullføre oppgraderingen denne og neste uke. Brukere vil først og fremst merke at dashboard (horizon) erblitt oppgradert og ting ser litt forskjellig ut der.
178 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Vi har nå fått montert gammel hardware i Bergen til å teste sentral OS-disk. Når er ferdig med testingen vet vi om vigår for ombygging av dagens Ceph-cluster eller må forsette med OS-disk på lokal disk på compute inntil vi har pengertil nytt Ceph-cluster.
I er nesten i mål med IPv6. Det som gjenstår er å legge til støtte i image og teste.
Vi planlegger en felles samling i Bergen 6. og 7. september. Vi vil da se på planer for høsten 2017. Hovedfokus blir ihøst blir objektlagring.
Planlagte aktiviteter
• Fullføre oppgradering til Openstack Newton
• IPv6 til instanser
• Teste oppsettet med sentral OS-disk
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
Utfordringer
• Pga forsinkelse med å få ansatt en ekstra person ved USIT medføret det at de planlagte leveransene knyttet tilavtalen med UNINETT for 1. juli 2017 ikke ble levert. Vi har forsatt mål om å levere pilot for objektlagring iløpet av 2017.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 37
av Raymond Kristiansen, UH IaaS, 18.september 2017
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 37
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Oppgradering til newton fullføres i uke 38 med oppgradering av horizon (dashboard). Dette er den komponentenbrukere vil oppleve størst endring med. Vi varsler på status.uh-iaas.no og Slack.
1.6. Status 179

iaas Documentation, Release 0.1.0
I forbindelse med test av sentral OS-disk har vi funnet ut at det først bør oppgraderes til neste LTS-versjon av Ceph(luminious). Planen er å ta inn det vi taper i tid på oppgraderingen med at sentral OS-disk blir mindre omfattende.
Vi hadde samling 6. og 7. september. I tillegg til fokus på de oppgavene vi allerede er i gang med så vil vi ogsåprioritere oppgradering til Puppet 4 i løpet av høsten 2017.
Vi jobber med å sette opp flere backend-noder av Openstack-tjenestene. Dette vil bidra til til at vi kan takler høyerelast (LB) og at tjenestene blir mer redundant (HA). Dette vil være et pågående arbeid som vil strekke seg ut i 2018,med mål om å kunne gjøre vedlikehold uten nedetid for brukere.
Vi vil starte arbeidet med avvikling av personlig prosjekt i uke 38. Alle brukere vil bli varslet på epost om endringene.Vi vil også lage et nettskjema for å forenkle bestilling av nye prosjekt.
Planlagte aktiviteter
• Fullføre oppgradering til Openstack Newton
• IPv6 til instanser
• Oppgradere Ceph
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
Utfordringer
• Pga forsinkelse med å få ansatt en ekstra person ved USIT medføret det at de planlagte leveransene knyttet tilavtalen med UNINETT for 1. juli 2017 ikke ble levert. Vi har forsatt mål om å levere pilot for objektlagring iløpet av 2017.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 39
av Raymond Kristiansen, UH IaaS, 9.oktober 2017 (en uke forsinket pga ferie)
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 39
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
180 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Status
Vi er nå ferdig med oppgradering av Openstack til newton og Ceph til luminious. Oppgraderingen gikk uten storeproblemer.
Vi hadde endringsuke i uke 39 (26. OSL og 27. BGO). I tillegg til vanlig patching og restart av alle bokser (medunntak av compute) har vi nå satt opp lastbalansering av netverks API (kjører nå 3 backends i prod). Vi har tidligerehatt problemer med ytelsen her, men etter endringer ser det ut til at disse problemene er løst. Selve patchingen gikkogså mye bedre en tidligere, og alle systemer fungerte som normal når tjenestene kom opp igjen. Total ble vinduet fornedetid rundt 60 min.
Vi har laget et nettskjema for å forenkle bestilling av prosjekter i UH-IaaS:
https://skjema.uio.no/iaas-project
Oppdatering av default kvote og demo prosjekt for all ble utført 29. september. Alle brukere skal også ha fått epostom endringen. I ettertid ser det ut til at flere ønsker å bruke UH-IaaS til mer enn testing og vi har sett en økning ibestilling av nye prosjekt via nettskjema. Dette vil nok medføre at vi må bruke litt mer tid på oppretting av prosjektog brukerstøtte de neste ukene.
Planlagte aktiviteter
• Oppgradere til CentOS 7.4
• IPv6 til instanser
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
Utfordringer
• Vi må oppgradere til CentOS 7.4 for å kunne ta i bruk de nye serverne som ble kjøpt til compute (OSL) ogobjektlagring (BGO). Maskinene er for ny til å fungere med 7.3 drivere.
• Pga forsinkelse med å få ansatt en ekstra person ved USIT medføret det at de planlagte leveransene knyttet tilavtalen med UNINETT for 1. juli 2017 ikke ble levert. Vi har forsatt mål om å levere pilot for objektlagring iløpet av 2017.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 41
av Raymond Kristiansen, UH IaaS, 16.oktober 2017
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 41
1.6. Status 181

iaas Documentation, Release 0.1.0
– Status
– Planlagte aktiviteter
– Utfordringer
– Annet
Status
Det har vært høstferie i Oslo og Bergen de to siste ukene så teamet har vært mindre bemannet enn normalt.
Vi har jobbet mye med forbedring av test og utviklingsmiljø og oppdatering av dokumentasjon de siste ukene.
Etter at epost om avvikling av personlig prosjekt gikk ut har vi sett en økning i antall bestillinger og henvendelsergenerelt. Vakten har derfor fått en god del mer å gjøre enn tidligere.
Planlagte aktiviteter
• Oppgradere til CentOS 7.4
• IPv6 til instanser
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
Utfordringer
• Vi må oppgradere til CentOS 7.4 for å kunne ta i bruk de nye serverne som ble kjøpt til compute (OSL) ogobjektlagring (BGO). Maskinene er for ny til å fungere med 7.3 drivere.
• Pga forsinkelse med å få ansatt en ekstra person ved USIT medføret det at de planlagte leveransene knyttet tilavtalen med UNINETT for 1. juli 2017 ikke ble levert. Vi har forsatt mål om å levere pilot for objektlagring iløpet av 2017.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
Uke 47
av Raymond Kristiansen, UH IaaS, 27.november 2017 (sykdom og ferieavvikling har medført hull i rapporteringen)
Oppdatert informasjon om status finnes alltid i Trello
Contents
• Uke 47
– Status
– Planlagte aktiviteter
182 Chapter 1. Contents

iaas Documentation, Release 0.1.0
– Utfordringer
– Annet
Status
IPv6 ble rullet ut i slutten av oktober. Alle nye instanser vil nå også få offentlig IPv6-adresser (dualstack). Vi vil ogsåtilby et eget nett med privat IPv4 (med NAT) og offentlig IPv6 (IPv6).
Vi har bygget om Ceph-cluster vårt til også å kunne brukes til sentral OS-disk for instanser. Planen er først å gjøre enintern test med de nye compute-hostene. Det er ikke avgjort om vi ønsker å flytte eksisterende instanser inn i den nyelagringen eller om vi kun skal tilby det for nye instanser.
Vi hadde endringsuke i uke 47. Patching og omstart av tjenester ble utført i OSL tirsdag mellom 15-16 uten problemer.Onsdag fikk vi problemer med en pakke som medførte at database-klusteret ikke kom tilbake. IDP-tjensten (keystone)var derfor nede til rundt kl 19:00. Resten av tjenestene kom tilbake som normalt til kl 16. Vi har nå oppgradert tilCentOS 7.4.
Planlagte aktiviteter
• Fortsette å hjelpe brukere med å ta i bruk tjenesten
• Jobbe videre med Designate og Ceilometer
• Teste sentral OS-disk
• Oppgradering til Puppet versjon 4
• Objektlagring
Utfordringer
• Pga forsinkelse med å få ansatt en ekstra person ved USIT medføret det at de planlagte leveransene knyttet tilavtalen med UNINETT for 1. juli 2017 ikke ble levert. Vi har forsatt mål om å levere pilot for objektlagring iløpet av 2017.
Annet
• Se https://trello.com/norcams for oppdaterte planer.
2016
Uke 8
av Raymond Kristiansen, UH IaaS, 26.februar 2016
Contents
• Uke 8
1.6. Status 183

iaas Documentation, Release 0.1.0
– Fullført
– Tentative fremdrift
– Avklaringer
Fullført
• Puppetkode for Cinder med Ceph backend. Denne kjører nå i dev01
• Puppetkode for Dataporten applikasjon for provisjonering av personlig prosjekt i keystone. Denne kjører pådpapp node i dev01. Denne applikasjonen kjøres ikke på forsvarlig måte og må endres før endelig produksjon.
Tentative fremdrift
• Flytte alle hemmeligheter ut av hieradata som ligger på github og over i et lokalt gitrepo før reinstall.
• Reinstall av osl og bgo med Ceph lagring og Dataporten-innlogging 8.mars
• Sikkerhetsgjennomgang og dokumentasjon
• Felles workshop for hele teamet
Avklaringer
• Detaljert oversikt over medlemmer og deltakelse fra alle teammedlemmer fra UiB og UiO.
• Avklare ressurser fra UNINETT for å fullføre Dataporten (FEIDE connect) integrasjon for grupper
Uke 9
av Raymond Kristiansen, UH IaaS, 03. mars 2016
Contents
• Uke 9
– Fullført
– Under arbeid
– Planlagt fremdrift
– Avklaringer
Fullført
• Løsning for håndtering av hemmeligheter er satt opp på osl-login-01 og bgo-login-01. Vi bruker gitolite forspeiling av data.
184 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Under arbeid
I forbindelse med testing av applikasjonen som skal provisjonere personlig prosjekt i keystone så oppstod det endelutfordringer som ikke kom opp i testen på dev01. Vi jobber derfor nå med følgende:
• Flytte brannmur for åpne endepunkt til noden fremfor å ha det på leaf
• Flytte dashboard over på egen node. Vi ser også for oss at denne noden også kjører proxy for de åpne APIene.
Planlagt fremdrift
• Flytte alle hemmeligheter ut av hieradata som ligger på github
• Reinstall av osl og bgo med Ceph lagring og Dataporten-innlogging 9.mars
• Felles workshop for hele teamet i uke 11.
• Sikkerhetsgjennomgang og dokumentasjon
Avklaringer
Samme som sist uke.
• Detaljert oversikt over medlemmer og deltakelse fra alle teammedlemmer fra UiB og UiO.
• Avklare ressurser fra UNINETT for å fullføre Dataporten (FEIDE connect) integrasjon for grupper
Uke 10
av Raymond Kristiansen, UH IaaS, 11. mars 2016
Contents
• Uke 10
– Fullført
– Under arbeid
– Planlagt fremdrift
Fullført
• Ny node dashboard som kjører horizon og har en API proxy for tilgang til fra klienter som ikke har tilgang tilinternt service-nett.
• Reinstall av bgo med cinder (ceph backend) og FEIDE connect innlogging. Vi kan provisjonere personligprosjekt og logge inn og starte instanser med blokklagring.
• Reinstall av osl pågår mens rapporten skrives.
1.6. Status 185

iaas Documentation, Release 0.1.0
Under arbeid
• Flytte alle hemmeligheter ut av hieradata som ligger på github
• Sette opp et nytt dev-anlegg ved UiO
Planlagt fremdrift
• Felles workshop for hele teamet i Oslo 15. og 16.mars
• Sikkerhetsgjennomgang og dokumentasjon
Uke 13
av Raymond Kristiansen, UH IaaS, 04. april 2016
Contents
• Uke 13
– Fullført
– Under arbeid
– Planlagt fremdrift
– Avklaringer
Fullført
• Sikring av API endepunkt med TLS er klar i kode. Mangler litt hieradata før kan rulles ut alle steder.
• Alle passord er flyttet ut av git-repoet som ligger på github.com
• Sikkerhetsdokument er på plass. Vi kan nå begynne å jobbe med de delene som skal på plass til piloten.(../../security/index)
Under arbeid
• Brukerdokumentasjon er påbegynt og forsetter frem mot piloten går på luften. (../../enduser/index)
• Reinstall av OSL torsdag 7.april
• Sette opp et nytt dev-anlegg ved UiO
Planlagt fremdrift
• Piloten er planlagt klar 18.april.
• Sikkerhetsgjennomgang og dokumentasjon
186 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Avklaringer
• Vi har basert innlogging og provisjonering på FEIDE connect som er planlagt avskrudd 15. april. Dataportensom skal avløse denne tjenesten er ikke klar for UiO og UiB idag. Nødløsning blir lokale konto dersom vi ikkehar dette på plass.
Uke 14
av Raymond Kristiansen, UH IaaS, 08. april 2016
Contents
• Uke 14
– Fullført
– Under arbeid
– Planlagt fremdrift
Fullført
• Sikring av API endepunkt med TLS er klar på dev01, osl og bgo
• Alle passord er nå blitt endret
• Tofaktor er satt opp på login-nodene og alle må ha tatt det i bruk til piloten går live 18.april.
Under arbeid
• Kode for å kjøre service- og public-nett til nodene over transportnett. I test på dev01
• Brukerdokumentasjon er påbegynt og forsetter frem mot piloten går på luften.
• Sette opp et nytt dev-anlegg ved UiO
• Node med rsyslog server og logstash til å finne feil i piloten.
• Flytting fra FEIDE connect til Dataporten for innlogging og provisionering
Planlagt fremdrift
• Piloten er planlagt klar til bruk 18.april. Innlogging er avhengig av hva som skjer med Dataporten. Nødløsningblir lokale konto dersom vi ikke har dette på plass.
• Sikkerhetsgjennomgang og dokumentasjon. Blir et møte i Oslo 15. april.
Uke 15
av Raymond Kristiansen, UH IaaS, 18. april 2016
1.6. Status 187

iaas Documentation, Release 0.1.0
Contents
• Uke 15
– Fullført
– Under arbeid
– Planlagt fremdrift
Fullført
• Møte med sikkerhetsgruppen ved USIT. Vi er klar for pilot så lenge det jobbes med avsjekk av sikkerhetsdoku-mentet vårt fremover.
• Flyttet fra FEIDE connect (ble skrudd av 15. april) til Dataporten for autentisering. UiO er forsatt ikke inn påDataporten, men vil være inne i løpet av noen dager.
• Sikring av access-noden. Python-applikasjonen for å provisjonere prosjekter kjører nå i apache med mod_wsgiog med https. Denne autentisere også nå mot Dataporten.
Under arbeid
• Kode for å kjøre service- og public-nett til nodene over transportnett. I test på dev01
• Brukerdokumentasjon er påbegynt og forsetter frem mot piloten går på luften.
• Sette opp et nytt dev-anlegg ved UiO
Planlagt fremdrift
• osl og bgo skal være klar for vanlige brukere ved starten av 19.april.
• Annonsere at tjenstene er klar for pilot:
– Raymond og Tor vil være i Trondheim på UNINETT-konferanse 20. og 21.
– Trond skal fortelle om tjenesten på USIT sin konferanse denne uken.
• Avtalt nytt møte med sikkerhetsgruppen ved USIT i begynnelsen av juni for oppfølging av sikkerhetsdoku-mentet.
Uke 16
av Raymond Kristiansen, UH IaaS, 22. april 2016
Contents
• Uke 16
– Fullført
– Under arbeid
188 Chapter 1. Contents

iaas Documentation, Release 0.1.0
– Planlagt fremdrift
Fullført
• bgo ble klar for pilot denne uken. Demo ble holdt både på UiO, UiB og på UNINETT sin tekniske samling.
• console-tilgang skal igjen være tilgjengelig for instanser via dashboard
• Status-siden som kan brukes som inngangsport for nye brukere: http://status.iaas.uib.no
Under arbeid
• Sette opp et nytt dev-anlegg ved UiO
Planlagt fremdrift
• osl har for øyeblikket litt problemer med nettverk og er derfor ikke klar til å brukes i pilot. Regner med at detblir fikset neste uke.
• Se på mulighet for API-tilgang når brukere logger inn via Dataporten.
• Finne brukere til piloten.
• Brukerstøtte for dem som har tatt det piloten i bruk.
• Neste uke blir jeg og Tor bort i 3 dager på IPv6-kurs, og 3. og 4. mai er UiB sin årlige it-konferanse. Det kanpåvirke fremdriften de to neste ukene.
Uke 17
av Raymond Kristiansen, UH IaaS, 30. april 2016
Contents
• Uke 17
– Fullført
– Under arbeid
– Planlagt fremdrift
Fullført
• bgo er tilbake etter problemene som oppstod etter strømstans fredag 29.april
• Begrenset aktivitet i prosjektet denne uken pga ipv6 kurs ved UiB.
1.6. Status 189

iaas Documentation, Release 0.1.0
Under arbeid
• Sette opp et nytt dev-anlegg ved UiO
• Eget service nett som erstatter transport nett på noder
Planlagt fremdrift
• osl er enda ikke klar for pilot. Vi tror vi har løsningen og vil prøve den ut i uke 18.
• Se på mulighet for API-tilgang når brukere logger inn via Dataporten.
• Finne brukere til piloten.
• Brukerstøtte for dem som har tatt det piloten i bruk.
• I uke 18 er det intern samling ved IT-avd ved UiB og en helligdag. Det vil derfor være litt mindre aktivitet iprosjektet kommende uke.
Uke 18
av Raymond Kristiansen, UH IaaS, 9. mai 2016
Contents
• Uke 18
– Fullført
– Under arbeid
– Planlagt fremdrift
Fullført
• osl ble klar for bruk 2.mai
• Begrenset aktivitet i prosjektet denne uken pga fridager og IT-forum ved UiB
Under arbeid
• Sette opp et nytt dev-anlegg ved UiO
• Eget service nett som erstatter transport nett på noder
Planlagt fremdrift
• Møte med UNINETT om bruk av Dataporten for API-tilgang i uke 19
• Finne brukere til piloten.
• Brukerstøtte for dem som har tatt det piloten i bruk.
190 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Uke 20
av Raymond Kristiansen, UH IaaS, 20. mai 2016
Contents
• Uke 20
– Fullført
– Under arbeid
– Planlagt fremdrift
– Utfordringer
Fullført
• Møte med UNINETT om Dataporten i uke 19. Samarbeid om løsninger sammen med IPnett ble diskutert.Ingenting konkret, men vi skal holde kontakten.
• Automatisering av driftsoppgaver
• Begrenset aktivitet i prosjektet denne uken pga fridager
Under arbeid
• Egen node for console. Nå over SSL og med SPICE (http://www.spice-space.org/)
• Puppetkode for konfigurasjon av Cumulus-boksene
• dev03 ved UiO begynner å ta form
• Tilgang til API blir nå gitt ved forespørsel. Dette er en manuell prosess med tilsending av passord på SMS
Planlagt fremdrift
• Neste planlagt vedlikehold 31.mai (bgo) og 1. juni (osl). Vi ønsker da å inplimentere service-nett begge steder.
• Ønsker å avholde en ny samling før sommerferien
Utfordringer
• Trenger flere pilot-brukere for å få tilbakemelding på hva vi må prioritere
• Den originale planen om å løse prosjekt for grupper via access på samme måte som for personlig prosjekt serikke ut til å fungere. Trenger nok å tenke nytt på hvordan vi skal løse dette. Har ikke vært etterspurt og vi vil tadet manuelt inntil vi finner en løsning her. Den opprinnelige planen vi ble enig om sammen med UNINETT ides 2015 finnes her:
https://github.com/norcams/himlar-connect/blob/master/README.md
1.6. Status 191

iaas Documentation, Release 0.1.0
Uke 21
av Raymond Kristiansen, UH IaaS, 30. mai 2016
Contents
• Uke 21
– Fullført
– Under arbeid
– Planlagt fremdrift
– Utfordringer
Fullført
• Lokal bruker med API-tilgang. Vi har fått ny versjon av applikasjonen som oppretter prosjektene til også åopprette brukeren. For eksisterende brukere kan vi opprette lokal bruker manuelt.
• Vi har sendt tekst til UNINETT sin tjenestekatalog.
Under arbeid
• Egen node for console. Nå over SSL og med SPICE (http://www.spice-space.org/)
• Puppetkode for konfigurasjon av Cumulus-boksene
• dev03 ved UiO begynner å ta form
Planlagt fremdrift
• Neste planlagt vedlikehold 31.mai (bgo) og 1. juni (osl). Det blir kun vanlig OS-patching denne gangen (noder+ controller)
• Ønsker å avholde en ny samling før sommerferien.
• UNINETT (UH-sky infrastruktur) ønsker møte om fremdrift og hva de evt. kan hjelpe med. Avtalt møte 2. junimed Hildegunn Vada, Jan Meijer og meg.
Utfordringer
• Trenger flere pilot-brukere for å få tilbakemelding på hva vi må prioritere
• Den originale planen om å løse prosjekt for grupper via access på samme måte som for personlig prosjekt serikke ut til å fungere. Trenger nok å tenke nytt på hvordan vi skal løse dette. Har ikke vært etterspurt og vi vil tadet manuelt inntil vi finner en løsning her. Den opprinnelige planen vi ble enig om sammen med UNINETT ides 2015 finnes her:
https://github.com/norcams/himlar-connect/blob/master/README.md
192 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Uke 22
av Raymond Kristiansen, UH IaaS, 06. mai 2016
Contents
• Uke 22
– Fullført
– Under arbeid
– Planlagt fremdrift
– Utfordringer
Fullført
• UNINETT får tilgang til pilot. Etter møte med UNINETT forrige uke ble vi enig om at de også får tilgang til åteste i piloten.
• Full stop på bgo i helgen pga av bytte av UPS. Alle instanser som kjørte fredag ble startet igjen lørdag formiddagsammen med alle tjenstene.
Under arbeid
• Egen node for console. Nå over SSL og med SPICE (http://www.spice-space.org/)
• Puppetkode for konfigurasjon av Cumulus-boksene
• dev03 ved UiO begynner å ta form
• Test av redundans på nettverk
Planlagt fremdrift
• Jeg tar nå ferie og er tilbake 14. juni.
• Ønsker å avholde en ny samling før sommerferien.
Utfordringer
• Trenger flere pilot-brukere for å få tilbakemelding på hva vi må prioritere
• Den originale planen om å løse prosjekt for grupper via access på samme måte som for personlig prosjekt serikke ut til å fungere. Trenger nok å tenke nytt på hvordan vi skal løse dette. Har ikke vært etterspurt og vi vil tadet manuelt inntil vi finner en løsning her. Den opprinnelige planen vi ble enig om sammen med UNINETT ides 2015 finnes her:
https://github.com/norcams/himlar-connect/blob/master/README.md
1.6. Status 193

iaas Documentation, Release 0.1.0
Uke 30
av Raymond Kristiansen, UH IaaS, 1. aug 2016
Contents
• Uke 30
– Fullført
– Under arbeid
– Planlagt fremdrift
– Utfordringer
– Oppdatert status
Dette er en samlerapport for alt som har skjedd i sommer og planen videre.
Fullført
• Utvilingssite i Bergen (dev01) har gjennoppstått som test01 og er satt opp med nytt nettverksoppsett.
• Meldingskøen er skilt ut på egen node og driftes nå uavhengig av de andre openstack-tjenestene.
• Nye noder for image, volume og nova relaterte tjenster er skilt ut på egne noder
Under arbeid
• Vi jobber forsatt med en testsite i Oslo. test01 vil forhåpentligvis være klar om ikke lenge.
• Det jobbes med å få på plass en tjeneste for DNS for instanser
Planlagt fremdrift
• Det er skrevet et eget dokument om leveransen og hva som skal til for å gå ../plans/production
• Vi kommer til å gjennomføre nettverksomleggingen vi ble enig om på ../meetings/2016_workshop_2 i uke 31(bgo) og uke 32 (osl)
• Søknad til UNINETT. Trond har fått redaktøransvaret for denne. Vi må ha klart et utkast senest mandag 15.au-gust som kan sendes til UNINETT. Siste frist for endelig versjon er rundt 1.september.
• Vi trenger også minst en felles samling i høst.
• Det er også ønskelig at alle i prosjekt deltar på Openstack Summit i Barcelona: https://www.openstack.org/summit/barcelona-2016
Utfordringer
• I ../plans/production har jeg skrevet at vi trenger 4 personer frem til nyttår for å komme i produksjon. Vi er nåprosjektleder (100% delt), UiB (1 person 100%) og UiO (1 person 60% og en person 40%).
194 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Oppdatert status
Arbeidet frem til leveranse 14. november vil vi oppdatere fortløpende på Trello: https://trello.com/b/loLFWWtV/iaas-release-plan
Kun større oppgaver, utfordringer og avvik vil bli oppdatert her.
Uke 34
av Raymond Kristiansen, UH IaaS, 23. aug 2016
Contents
• Uke 34
– Fullført
– Under arbeid
– Planlagt fremdrift
– Utfordringer
– Oppdatert status
Fullført
• Netverksomlegging ble utført i uke 31 og 32 som planlagt både i bgo og osl. Endel mindre problemer ble løstder og da, noen av disse midlertidig.
• Puppetkode for å splitte ut alle Openstack tjenester på egne noder er klar. Dette er en forutsetning for å kunneoppgradere uten store avbrudd i tjenestene.
• Søknaden om midler er sendt til UNINETT for høring.
Under arbeid
• Vi jobber forsatt med en testsite i Oslo. Det har tatt veldig lang tid og jeg er usikker på når den vil være operativ.
• Det jobbes med å få på plass en tjeneste for DNS for instanser.
Planlagt fremdrift
• 23. og 24. august vil vi sette i drift nye noder i for Openstack tjenester i bgo og osl
• Vi vil starte jobben med oppgradering til mitaka så raskt vi har skilt ut alle tjenestene på egne noder.
• Felles samling i Oslo, 7. og 8. september. Det er tenkt både en workshop og planlegging av leveransen inovember.
• Søknad til UNINETT. Jeg skal ha et møte med UNINETT denne uken.
• Det er også ønskelig at alle i prosjekt deltar på Openstack Summit i Barcelona: https://www.openstack.org/summit/barcelona-2016
1.6. Status 195

iaas Documentation, Release 0.1.0
Utfordringer
• I ../plans/production har jeg skrevet at vi trenger 4 personer frem til nyttår for å komme i produksjon. Vi er nåprosjektleder (100% delt), UiB (1 person 100%) og UiO (1 person 60% og en person 40%). Det ser ikke ut til åberøre datoene i leveransen, men vil kunne påvirke innholdet dersom vi støter på større utfordringer.
Oppdatert status
Arbeidet frem til leveranse 14. november vil vi oppdatere fortløpende på Trello: https://trello.com/b/loLFWWtV/iaas-release-plan
Kun større oppgaver, utfordringer og avvik vil bli oppdatert her.
Uke 38
av Raymond Kristiansen, UH IaaS, 23. sep 2016
Contents
• Uke 38
– Fullført
– Under arbeid
– Planlagt fremdrift
– Utfordringer
– Oppdatert status
Fullført
• Workshop ved USIT 7. og 8. september.
• Oppgradering til mitaka i uke 38. Utført med ansible som kunne testes i test01 og test02 først. Tok ca 60min i bgo og osl, og førte kun til små avbrudd i de forskjellige tjenesten under oppgraderingen. Alle kjørendeinstanser skal ha fungert som normalt under oppdateringen.
• Søknaden om prosjektmidler fra UH-sky er sendt til UNINETT. Usikkert når den er ferdig behandlet.
• Det er satt opp et internt monitoringstjeneste basert på Sensu. I første omgang skal det gi oss et dashboard medlitt metrics om hva som skjer.
Under arbeid
• test02 ved USIT er satt opp, men mangler forsatt public nett. Har derfor litt begrenset nytteverdi. Det jobbesmed å fullfør oppsettet, men krever nok litt hjelp av nettverk ved USIT for å få fullført.
• Det jobbes med å få på plass en tjeneste for DNS for instanser.
196 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Planlagt fremdrift
• Sette opp felles keystone database for to lokasjoner. Dette vil gjøre det mulig å ha et felles dashboard med toregioner: osl og bgo.
• Oppgradere ceph til siste versjon.
• Det er også ønskelig at alle i prosjekt deltar på Openstack Summit i Barcelona: https://www.openstack.org/summit/barcelona-2016
Utfordringer
• API-tilgang er ikke optimal slik den er satt opp nå, men det fungerer. Ser ingen enkel fiks som kan løse det førvi går i produksjon i november. Det blir da viktig å gjøre brukerne kjent med hvilke utfordringer som gjelder.
• I ../plans/production har jeg skrevet at vi trenger 4 personer frem til nyttår for å komme i produksjon. Vi er nåprosjektleder (100% delt), UiB (1 person 100%) og UiO (1 person 60% og en person 40%). Det ser ikke ut til åberøre datoene i leveransen, men vil kunne påvirke innholdet dersom vi støter på større utfordringer.
Oppdatert status
Arbeidet frem til leveranse 14. november vil vi oppdatere fortløpende på Trello: https://trello.com/b/loLFWWtV/iaas-release-plan
Kun større oppgaver, utfordringer og avvik vil bli oppdatert her.
Uke 40
av Raymond Kristiansen, UH IaaS, 10. okt 2016
Contents
• Uke 40
– Fullført
– Under arbeid
– Planlagt fremdrift
– Utfordringer
– Oppdatert status
Fullført
• Søknaden om prosjektmidler fra UH-sky er godkjent i styringsgruppen.
• Test av felles database for keystone og felles dashboard for to lokasjoner.
1.6. Status 197

iaas Documentation, Release 0.1.0
Under arbeid
• Både test01 og test02 venter på at eksternt utførte oppgaver skal løses før disse kan betegnes som fullverdigtestinstallasjoner.
• Det jobbes med å få på plass en tjeneste for DNS for instanser. Denne vil forhåpentligvis være på plass i løpetav året.
Planlagt fremdrift
• Vi vil i uke 41 ta en full reinstallasjon av begge lokasjonene. Dette vil slette alt som ligger der idag, og klargjøreoss for produksjon.
• Etter reinstallasjonen vil vi sette opp en felles keystone database. Dette vil gjøre det mulig å ha et felles dash-board med to regioner: osl og bgo.
• Oppgradere ceph til siste versjon.
• Skaffe priser for mer hardware til vi går i produksjon.
Utfordringer
• DNS tjenesten for instanser vil ikke være klar til vi går i produksjon. Hovedgrunnen er mangel på dedikertpersoner i prosjekt.
• API-tilgang er ikke optimal slik den er satt opp nå, men det fungerer. Ser ingen enkel fiks som kan løse det førvi går i produksjon i november. Det blir da viktig å gjøre brukerne kjent med hvilke utfordringer som gjelder.
• I ../plans/production har jeg skrevet at vi trenger 4 personer frem til nyttår for å komme i produksjon. Vi er nåprosjektleder (100% delt), UiB (1 person 100%) og UiO (1 person 60% og en person 40%). Det ser ikke ut til åberøre datoene i leveransen, men vil kunne påvirke innholdet dersom vi støter på større utfordringer.
Oppdatert status
Arbeidet frem til leveranse 14. november vil vi oppdatere fortløpende på Trello: https://trello.com/b/loLFWWtV/iaas-release-plan
Kun større oppgaver, utfordringer og avvik vil bli oppdatert her.
Uke 43
av Raymond Kristiansen, UH IaaS, 31. okt 2016
Contents
• Uke 43
– Fullført
– Under arbeid
– Planlagt fremdrift
– Utfordringer
198 Chapter 1. Contents

iaas Documentation, Release 0.1.0
– Oppdatert status
Fullført
• Reinstallasjon av bgo ble utført i uke 41. Vi testet de installasjon av en region fra grunnen av, samt at vi ryddetlitt i tjenesteadresser og navn.
• Reinstallasjon av ‘osl’ ble utført i uke 42. osl benytter samme keystone-database som bgo og identity-nodenei bgo og osl vil svare akkurat det samme på api-kall. Bruker trenger da kun å provisjonere tilgang en gang forbegge regioner. Vi har også kun et dashboard for begge regioner.
Under arbeid
• Både test01 og test02 venter på at eksternt utførte oppgaver skal løses før disse kan betegnes som fullverdigtestinstallasjoner.
• Det jobbes med å få på plass en tjeneste for DNS for instanser. Denne vil forhåpentligvis være på plass i løpetav året.
Planlagt fremdrift
• Oppdatere brukerdokumentasjon og sikkerhetsdokument
• Sette opp sluttbrukertjenestene på nytt domene uh-iaas.no
• Stressteste regionene for oppstart og sletting av instanser
• Se på muligheter for mer HW. Vi har fått penger av UNINETT til å utvide kapasitenten litt. Vi må finne uthvordan vi får mest mulig ut av de midlene.
Utfordringer
• DNS tjenesten for instanser vil ikke være klar til vi går i produksjon. Hovedgrunnen er mangel på dedikertpersoner i prosjekt.
• API-tilgang er ikke optimal slik den er satt opp nå, men det fungerer. Ser ingen enkel fiks som kan løse det førvi går i produksjon i november. Det blir da viktig å gjøre brukerne kjent med hvilke utfordringer som gjelder.
• I ../plans/production har jeg skrevet at vi trenger 4 personer frem til nyttår for å komme i produksjon. Vi er nåprosjektleder (100% delt), UiB (1 person 100%) og UiO (1 person 60% og en person 40%). Det ser ikke ut til åberøre datoene i leveransen, men vil kunne påvirke innholdet dersom vi støter på større utfordringer.
Oppdatert status
Arbeidet frem til leveranse 14. november vil vi oppdatere fortløpende på Trello: https://trello.com/b/loLFWWtV/iaas-release-plan
Kun større oppgaver, utfordringer og avvik vil bli oppdatert her.
1.6. Status 199

iaas Documentation, Release 0.1.0
Uke 45
av Raymond Kristiansen, UH IaaS, 11. nov 2016
Contents
• Uke 45
– Fullført
– Under arbeid
– Planlagt fremdrift
– Utfordringer
– Oppdatert status
Fullført
• Vi mener at det viktigste er klar til å gå i produksjon 14. november kl. 14. Gjennstående oppgaver blir oppdaterther: https://trello.com/b/loLFWWtV/iaas-release-plan
• Byttet til nytt domene for alle tjenestene som går ut mot brukere:
– http://docs.uh-iaas.no
– https://status.uh-iaas.no
– https://access.uh-iaas.no
– https://dashboard.uh-iaas.no
• Benchmarking av lette beregningsoppgaver er utført og vi skal kunne ta i mot denne typen workloads medgrei nok ytelse. Det vil dog kreve et spesialkonfigurert sett av compute noder beregnet kun for denne typenworkloads.
Under arbeid
• Ny hardware er klart til bestilling. Vi kjøper inn 3 nye compute noder til både osl og bgo.
• test02 venter på at eksternt utførte oppgaver skal løses før denne kan betegnes som fullverdig testinstallasjoner.
• Det jobbes med å få på plass en tjeneste for DNS for instanser. Denne vil forhåpentligvis være på plass i løpetav året.
Planlagt fremdrift
• Flere av deltakerne i prosjektet skal delta og snakke om UH-IaaS i Trondheim neste uke på UNINETT sinsamling.
• Support og testing
• Stressteste regionene for oppstart og sletting av instanser
200 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Utfordringer
• DNS tjenesten for instanser vil ikke være klar til vi går i produksjon. Hovedgrunnen er mangel på dedikertpersoner i prosjekt.
• I ../plans/production har jeg skrevet at vi trenger 4 personer frem til nyttår for å komme i produksjon. Vi er nåprosjektleder (100% delt), UiB (1 person 100%) og UiO (1 person 60% og en person 40%). Det ser ikke ut til åberøre datoene i leveransen, men vil kunne påvirke innholdet dersom vi støter på større utfordringer.
Oppdatert status
Arbeidet frem til leveranse 14. november vil vi oppdatere fortløpende på Trello: https://trello.com/b/loLFWWtV/iaas-release-plan
Kun større oppgaver, utfordringer og avvik vil bli oppdatert her.
Uke 47
av Raymond Kristiansen, UH IaaS, 29. nov 2016
Contents
• Uke 47
– Fullført
– Under arbeid
– Planlagt fremdrift
Fullført
• Produksjonssetting ble utført som planlagt 14. november. Oppdatert tall på bruk kan finnes på https://status.uh-iaas.no
Under arbeid
• Ny hardware er bestilt. Vi kjøper inn 3 nye compute noder til både osl og bgo.
• Arbeid med å få opp test02 pågår forsatt.
• Det jobbes med å få på plass en tjeneste for DNS til instanser. Denne vil forhåpentligvis være på plass i om ikkelenge.
Planlagt fremdrift
• Arbeid med det merkantile foregår ved siden av og planen er å få det klart i løpet av året.
• Stressteste regionene for oppstart og sletting av instanser
• Pga ferieavvikling så vil nye ting og rapporteringen opphøre frem til nyttår. Vi vil nå fokusere på å finne brukereog hjelpe dem å ta det i bruk.
1.6. Status 201

iaas Documentation, Release 0.1.0
2015
Uke 40
Contents
• Uke 40
– Implementasjon
– Pågående aktiviteter
– Kommende aktiviteter
Implementasjon
Oppsummering av kode som det jobbes på i øyeblikket.
• Implementasjon av Project Calico-komponentene i en egen calico2 branch av norcams/himlar
• Grunnoppsett for Consul som skal benyttes for å dele konfig-informasjon mellom datasentre
• Spesifikasjon av oppsett for lokalt LVM-oppsett for compute
• Påbegynt arbeid med Serverspec
Pågående aktiviteter
Aktiviteter i prosjektet denne uka.
Rapportering fra UH IaaS i linja
UH-sky-styringsgruppa har ønsket at rapportering fra prosjektleder i UH IaaS knyttet mot linjeorganisasjonene somdeltar. Det blir fra nå av ukentlig rapportering i dette formatet.
I den forbindelse er det også laget en prosjektplan som beskriver arbeid som gjøres framover i form av versjonertemilepæler
• http://iaas.readthedocs.org/en/latest/project/releaseplan.html
Releaseplanen vil oppdateres ukentlig så den reflekterer status fra de daglig oppdaterte verktøyene våre, Trello https://trello.com/b/m7tD31zU/iaas og GitHub https://github.com/norcams/himlar/milestones
Klargjøring av lokale test-nettverk
På UIB og NTNU er vi i gang med å etablere lokale test-oppsett av nettverkslogikken som er lik densom er planlagt for produksjon. Forenklingen i test er at det ikke er behov for failover, bare et
202 Chapter 1. Contents
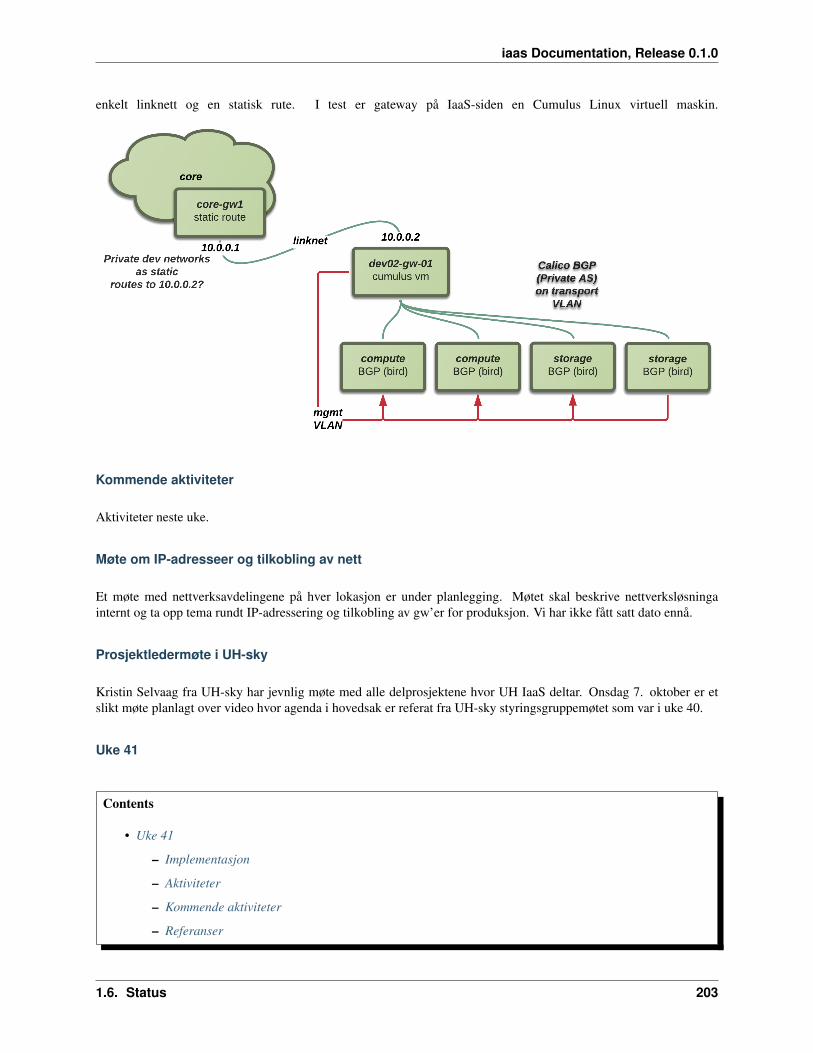
iaas Documentation, Release 0.1.0
enkelt linknett og en statisk rute. I test er gateway på IaaS-siden en Cumulus Linux virtuell maskin.
Kommende aktiviteter
Aktiviteter neste uke.
Møte om IP-adresseer og tilkobling av nett
Et møte med nettverksavdelingene på hver lokasjon er under planlegging. Møtet skal beskrive nettverksløsningainternt og ta opp tema rundt IP-adressering og tilkobling av gw’er for produksjon. Vi har ikke fått satt dato ennå.
Prosjektledermøte i UH-sky
Kristin Selvaag fra UH-sky har jevnlig møte med alle delprosjektene hvor UH IaaS deltar. Onsdag 7. oktober er etslikt møte planlagt over video hvor agenda i hovedsak er referat fra UH-sky styringsgruppemøtet som var i uke 40.
Uke 41
Contents
• Uke 41
– Implementasjon
– Aktiviteter
– Kommende aktiviteter
– Referanser
1.6. Status 203

iaas Documentation, Release 0.1.0
Implementasjon
Oppsummering av kode som det jobbes på i øyeblikket.
• Calico-nettverskoden for compute er fullført. Kode for gw til eksternt nett, som i test er en cumulus-appliance,jobbes med nå.
• compute-rollen må lett kunne byttes mellom forskjellige instans storage backends. I test har vi nå lokal lvm-disk.
• iptables-oppdateringer for å skille mgmt og transport-trafikk
• Når en har flere ruter til en server kan ikke tjenestene bindes direkte til de fysiske interfacene sine adresser, demå bindes til et såkalt dummy-interface. Tjenestene på master settes opp slik.
Aktiviteter
Aktiviteter i prosjektet denne uka.
Prosjektledermøte i UH-sky
Det ble holdt et prosjektledermøte i UH-sky hvor Jan Ivar, Anders Vinger (UH AD), Alf Hansen (Forvaltning), HåvarFosstveit (UH Skype) og Kristin Selvaag (UH-sky koordinator) deltok.
Tema på møtet var rapportering fra siste UH-sky styringsgruppemøte. Styringsgruppa har hatt fokus på å avgrense hvaUH-sky skal være. For UH IaaS innebærer dette ingen endring.
UH IaaS i statsbudsjettet?
En god nyhet denne uka var at UNINETT har fått 15 millioner til sky-satsning i forslaget til statsbudsjett. Om UH IaaSsom prosjekt får nytte av noen av disse ressursene er per nå uvisst. Vi føler det naturlig å igjen be om at UNINETTbidrar med en stilling.
Rapportering i fra UH IaaS i linja
Har ikke fått noen kommentarer på nye rapporteringsrutiner ennå. Kom gjerne med tanker omkring dette!
Klargjøring av lokale test-nettverk
På UIB er det nå satt opp et linknett med en statisk rute (OSPF) for en liten IP-serie for testmiljøet.
Har ikke hørt noe mer fra NTNU om test-nettverksoppsett der denne uka, regner med at det går på kapasitet, og at jeghører fra de snart!
Vi skal ta kontakt med USIT igjen om å få igang igjen arbeidet med utstyret som vi har hatt til test der.
Kommende aktiviteter
Aktiviteter neste uke.
204 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Møte om IP-adresseer og tilkobling av nett
Møtet om oppsett av produksjonsett blir fredag 16. oktober kl 12-13. Vi jobber med å forberede litt grunnlagsdoku-mentasjon til møtet.
Første eksterne funksjonstesting av UH IaaS
Vi planlegger første eksterne funksjonstesting med forskningsmiljø på UIB fra torsdag 15. oktober. Funksjonstestingavil skje mot testmiljøet og utstyret der, noe som naturlig nok vil begrense ytelsen.
Vi planlegger å åpne opp for at flere kan teste så snart som mulig.
Referanser
• Trello https://trello.com/b/m7tD31zU/iaas
• Github https://github.com/norcams/himlar/milestones
Uke 42
Contents
• Uke 42
– Implementasjon
– Aktiviteter
– Kommende aktiviteter
– Referanser
Implementasjon
Oppsummering av kode som det jobbes på i øyeblikket.
• Forbedre og fullautomatisere ruting og gateway-oppsett
• lvm som nova-backend hadde noen ustabiliteter og treg boot grunnet at det ser ut til å ta lang tid å konvertereqcow2-image til raw. Foreløpig har vi backet ut dette og bruker fortsatt filebackend for nova.
• Flere iptables-oppdateringer for å skille mgmt og transport-trafikk
• Sette opp eksplisitte public og internal endpoints (URL/porter å lytte på) for OpenStack-tjenestene
• Release 0.2.0 nådd som planlagt, testing er i gang på UIB
• Automatisering av openstack nettressurser, policy og lokale brukerkonti
Aktiviteter
Aktiviteter i prosjektet denne uka.
1.6. Status 205

iaas Documentation, Release 0.1.0
Oppretta kontakt med FEIDE Connect-prosjektet
Jan Ivar har vært i kontakt med Anders Lund hos UNINETT for å planlegge hva som bør gjøres videre. Selv omConnect er et pilotprosjekt uten sikker framtid i øyeblikket framstår tjenesten og det tekniske grunnlaget som ideeltfor integrasjon med UH IaaS.
Jan Ivar tar initativ til en kartlegging som skal resultere i en plan for integrasjon med Connect-piloten.
Klargjøring for pilot
Release 0.2.0 er ferdig som planlagt og testing er i gang. dev01 anlegget på UIB er oppe og kjører som det skal, dev02på NTNU er planlagt i drift i løpet av neste uke.
Klargjøring av lokale test-nettverk
UIB er fullført men neste steg for test-nett vil være å få rutet inn en IPv6 blokk. En forespørsel om dette vil bli gjort.
Knut Helge Vindheim på NTNU er i gang med oppsett av ruting/linknett for test på NTNU.
USIT vil vi ha kontakt med fredag 16. oktober ifbm nettverksmøtet som er planlagt.
Kommende aktiviteter
Aktiviteter neste uke.
Videre arbeid med dev02 testanlegg
Vi vil fokusere på å utvide testingen til dev02-anlegget basert på koden fra release 0.2.0.
Følge opp pilotbrukere
UH IaaS tar i bruk Slack for direktekommunikasjon med brukerne. Dette er en gratis chat-tjeneste som bl.a UNINETThar erfaring med fra FEIDE Connect.
Brukere kan gå til https://uhps.slack.com/signup for å logge inn og får da mulighet til å snakke med oss direkte.
Referanser
• Trello https://trello.com/b/m7tD31zU/iaas
• Github https://github.com/norcams/himlar/milestones
1.6.7 Planer og designvalg
Her ligger det informasjon om overordnede planer og designvalg. For aktive prosjekter vil prosjektstyring og oppgaverbli organisert på https://trello.com/norcams (kan krev innlogging).
Man kan anta at det som er dokumentert her er under gjennomføring eller gjennomført med mindre noe annet går fremav dokumentet.
206 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Ressursplanlegging compute
Sist endret: 2017-01-19
Oppdatering 19.januar 2017: Vi ble enig om å gå for forslag 1 i første omgang. I tillegg er det fornuftig å likeveltagge gruppene med installuke for fremtidig planlegging.
Definisjoner
N Antall compute noder per region. Idag er N=6
G En gruppe maskiner (host aggregate) Må være faktor av N
D Antall uker mellom en aktiv rotasjon
A Antall aktive compute hosts
U Ubrukte compute hosts
L Låste compute hosts
R Antall uker før en compute node blir reinstallert (patchet)
I Antall uker mellom instans restart (første restart kan komme etter D uker)
Forslag 1
• G=3
• A=2
• U=2
• L=2
• D=2
Formler
• R=D*G
• I=(G-1)*D
• N=A+U+L
Start status idag (januar 2017):
• G1 = L
• G2 = A
• G3 = L
Regler:
• U -> A
• A -> L
• L -> U (med flytting og reinsall)
1.6. Status 207

iaas Documentation, Release 0.1.0
rotasjon G1 G2 G31* U L A2 A U L3 L A U4 U L A5 A U L6 L A U
*= Vi må trikse litt for å komme ut av dagens status til rotasjon 1.
Konklusjon
Vi kan granatere å ikke restarte instaser oftere enn hver 4 uke (nye instanser kan bli restartet etter 2-4 uker). Vi fårreinstallert compute hosts hver 6 uke. Vi har alltid 2 ledige compute hosts dersom gruppen som er aktiv går full. Såved behov kan vi kjøre U -> A og A -> L.
Utnyttelsen vil da være (G-1)/G av compute nodene (G=3 gir 66%)
Forlsag 2
• G=3
• A=6
• D=2
Vi kan tagge (T) hver gruppe med ukenummer det ble reinstalert. Ved oppstart kan vi anta:
• G1 = 52
• G2 = 2
• G3 = 50
For hver rotasjon tømmer vi og reinstallere den gruppen som har vært opp lengst.
rotasjon G1 G2 G3start T=52 T=2 T=501 T=52 T=2 T=42 T=6 T=2 T=43 T=6 T=8 T=44 T=6 T=8 T=105 T=12 T=8 T=106 T=12 T=14 T=10
Konklusjon
Ved å låse den eldste gruppen som ikke reinstalleres før vi tømmer vil vi kunne sørge for at en kjørende instans aldriblir flyttet i to rotasjoner på rad. Det vil da kreve at den gruppen som mottar alle nodene har kapasitet til å ta i motalle instansene (typisk vil man måtte takle alle nye instanser de siste to ukene pluss alle som kommer fra den gruppensom blir reinstallert). For nye instanser kan vi kun love min oppetid på 5 dager (vi låser noen når vi varsler brukereom restart).
Utnyttelsen vil da være (G-1)/G av ressursene til en hver tid (G=3 gir 66%)
208 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Prosjektadministrasjon
Sist endret: 2017-03-06
All aktivitet som ikke kan utføres i personlige prosjekter krever at vi oppretter et nytt prosjekt for oppgavene og tildelerkvoter til den.
Det er ønskelig at både oppretting av nye prosjekter og prosjektadminstrasjon (legge til nye brukere til et prosjekt) kanskje ved selvbetjening, men for øyeblikket er det en manuell prosess.
Navngiving
Prosjektnavn bør være så informativt som mulig. Vi kan inkludere følgende elementer i prosjektnavn:
• org: organisatorisk tilhørighet (f.eks. uninett, uio, uia)
• type: prosjekt type (f.eks. test, student, research, course)
• navn: hvem prosjektet tilhører, grupper eller person (f.eks. osys, inf110)
Kvote
Så lenge det ikke koster penger så bør vi være restriktiv med kvotene. Utover det så er det ingen formelle krav tilstørrelse eller hvem som kan få så lenge det er kjent hva det skal brukes og formålet er innenfor kjerneområdene våre(forskning, formidling og utdanning).
Oppretting
Bruk project.py i himlarcli for å opprette prosjektet. Dersom type er definert i config/quotas.yaml vil detbli kvoten i den regionen scriptet kjøres i (f.eks. bgo). Kvoter settes per region, mens prosjektet er felles for alleregioner. For å sette kvote i andre regioner må scriptet kjøres på nytt i den aktuelle regionen. Scriptet kan også brukestil å gi andre enn eier tilgang til prosjektet (se under).
Gi tilgang
Bruk project.py i himlarcli for å gi tilgang til flere brukere i prosjektet. Eksempel:
./project.py grant -u [email protected] -p foo-bar-project
Kurs
Det er laget et eget opplegg for administrasjon av kursprosjekter. Kort fortalt fungerer det på følgende måte:
• foreleser og studenter får tilgang til sitt eget prosjekt med navn: <org>-<kurs>-<epost>
• foreleser får rollen superuser i sitt eget prosjekt og user i studentenes prosjekter
• foreleser kan lage public image i sitt prosjekt med superuser rollen
1.6. Status 209

iaas Documentation, Release 0.1.0
Verktøy
Bruk course.py i himlarcli for å opprett, liste ut eller slette kursprosjekter. Når man kjører create må man huskepå følgende:
• name: kursnavn må være på formen <org>-<kurs>. F.eks. uib-inf110
• user: er navn på foreleser som må ligge i system før man starter
• file: fil med liste over epostadressene til studentene (case sensitiv)
Studentene vil ikke få tilgang før skriptet er kjøret etter at de er i systemet. Man kan gjenta scriptet så mange gangerman vil med samme input.
Misbruk av UH-IaaS
Dersom vi får cert-meldinger på instanser så gjelder følgende instruks:
• Skru av og lås instansen (openstack server lock)
• Informer prosjektadmin via RT (epost)
• Dersom man oppnår kontakt bli enig med bruker om en løsning på problemet
• Dersom vi ikke får svar fra bruker på tre forsøk (prøv også instans user om admin feiler) så kan instansen slettes.
Dokumentasjon
Sist endret: 2017-03-06
Organisering av vår interne og offentlige dokumentasjon.
Brukerdokumentasjon
• Språk: engelsk
• Kildekode: github.com/norcams/docs-enduser
• Adresse: docs.uh-iaas.no (uh-iaas.readthedocs.org)
• Status: klar for bruk
Kan basere oss på dagens versjon. Vi trenger iallefall litt om:
• Bruk av dashboard
• Support
• SLA
• API / avansert bruk
• Changelog
• Known issues
210 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Teknisk dokumentasjon
• Språk: engelsk
• Kildekode: github.com/norcams/docs-iaas
• Adresse: iaas.readthedocs.org
• Status: i bruk, men trenger opprydding
• Design
• Overview
• Installation
• Development
• Operations
• Security
Team- og prosjektdokumentasjon
• Språk: norsk
• Kildekode: github.com/norcams/docs-iaas
• Adresse: iaas.readthedocs.org
• Status: bruke samme som teknisk dokumentasjon nå
• Teamstatus
• Planer
• Rapporter
• Policy
DNS
Sist endret: 2017-03-06
Dette er den planen vi nå bruker for DNS til interne og offentlige tjenester.
Offentlig (uh-iaas.no)
Felles
• www.uh-iaas.no: i første omgang en enkel landingside med linker til alt annet
• docs.uh-iaas.no: samme som uh-iaas.readthedocs.org
• status.uh-iaas.no: status på tjenestene og hvilke organisasjoner som er med.
• access.uh-iaas.no: dpapp for provisjonering
• dashboard.uh-iaas.no: Openstack horizon
• api.uh-iaas.no: identity public endpoint
1.6. Status 211

iaas Documentation, Release 0.1.0
Per lokasjon
• identity.api.<loc>.uh-iaas.no: identity public endpoint
• compute.api.<loc>.uh-iaas.no: compute public endpoints
• network.api.<loc>.uh-iaas.no: network public endpoints
• image.api.<loc>.uh-iaas.no: image public endpoints
• volume.api.<loc>.uh-iaas.no: volume public endpoints
• console.<loc>.uh-iaas.no: Openstack consoleproxy
• (dashboard-<loc>.uh-iaas.no: intern dashboard)
Instanser
Vi kan f.eks. legge dem under et eget subdomene under uh-iaas.no
Test regioner
Vi kan ersatte uh-iaas.no med test.iaas.uib.no (test01) og test.iaas.uio.no (test02). F.eks. dashboard.test.iaas.uio.no.
Intern (uhdc.no)
Management
Hostname blir <host>.mgmt.<loc>.uhdc.no
Transport (trp)
Tjenester blir <service>.<loc>.uhdc.no
Ressurstilgang
Last changed: 2018-10-04
Compute
Vi begrenser tilgangen til compute noder ved å begrense tilgangen til host aggregatet de står i. Hver availability zone(AZ) kan bestå av flere host aggregat slik at dette ikke vil være synlig for brukere.
Pr prosjekt
Vi kan sette filter_tenant_id i host aggregatet for å begrense tilgangen til kun de prosjektene vi oppgir. Detteskalerer veldig dårlig å bruker når det er flere enn et prosjekt som skal ha permanent tilgang.
212 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Pr flavor
Vi kan bruke AggregateInstanceExtraSpecsFilter til å begrense tilgangen til et aggregat til kun å deflavors vi ønsker.
Dette er nå satt opp for windows1 aggregatet i default-1 AZ. Det løses på følgende måte:
Vi innfører en ny property, type, som settes på host aggregate og flavor. For å kunne starte en instans må type være detsamme i flavor som i aggregate.
Dersom vi ikke velger noe vil puppet/himlarcli sette type=standard. Dvs at alle flavors kan kjøres i alle hostaggregates. Dette vil være et scheduler filter som vil fungerer binært. Dvs. alle sjekker er true/false og vil ikke kunnevektes.
Dersom vi ønsket å begrense tilgangen til et aggregate så kan vi sette type til noe annet. Husk at kravet til match gårbegge veier. Dvs. at dersom type=Z settes for aggregate agg1 så vil du ikke kunne bruke det til noen av dagens flavor(hvor type != Z). Samme gjelder for en ny flavor med type=Y. Den vil aldri kunne startes før det finnes en aktiv hostmed ledig kapasitet i et aggregate hvor også type=Y er satt (dette aggregatet vil heller ikke kunne kjøre noe annet).
Konsekvenser
• Vi vil ikke kunne teste alle flavors i placeholder1 lenger.
• en flavor kan kun ha en type
• et aggregate kan kun ha en type
• dersom resize er mulig kan man endre flavor etter at instansen er startet og derfor kjøre instanser i andre aggre-gate enn tiltenkt
Eksempler
• vi kan løse windows linsensproblemet med å lage en type=windows
• vi kan begrense tilgangen til hcp-hoster med å lage type=hpc
GPU Assisted Compute
Last changed: 2018-10-01
There is a growing interest in GPU assisted compute resources. There are different alternatives as of how to offer suchresources in UH-IaaS.
GPU vendors
There are mainly three players in the GPU compute field - NVIDIA, AMD and Intel, the former being the dominantplayer for now, the latter the latest to join. Performance wise NVIDIA has the most performant GPUs. We have notconsidered AMD GPUs for now. Newer Intel Xeon E3 ***5 series have an onboard GPU that can be used, howeverthe performance of these GPUs compared to NVIDIA of AMD is unknown to us for now.
NVIDIA enjoys the broadest software support, but many toolkits use hardware abstraction, so it is unclear if softwaresupport is an issue.
1.6. Status 213

iaas Documentation, Release 0.1.0
PCI passthrough
The traditional way of offering GPU resources in a virtual machine is by PCI passthroughing a device and present itdirectly to the vm. This is certainly doable and technically supported in OpenStack, but there severe caveats.
pros:
• High performance GPU for VMs, technically this can be cheap consumer grade video cards
cons:
• Some labour required pr card inserted in compute nodes
• Some labour required in each VM
• Does not scale very well - few VMs pr compute node
• For NVIDIA consumer grade cards it would violate their EULA - this is a blocker
Virtual GPU (vGPU)
The preferred method is by the way of virtual GPUs, one GPU card is sliced into several virtual GPUs served to manyVMs. This scales well, and is supported by all three GPU vendors. This feature is supported from the OpenStackQueens release as well. There are, however, caveats.
pros:
• High performance GPU for VMs
• The preferred way to serve GPUs to virtual machines
• Trivial configuration in OpenStack
• Scales well, many VMs pr GPU
cons:
• At least for for NVIDIA this could be cost prohibitive, incurring 5-6x price/performance compared to consumergrade cards
• Additionally, for NVIDIA GPUs, a concurrent user licence fee is necessary
Looking forward
The UH-IaaS team itself can not finance GPU assisted compute, not even for testing - at least for now, and the hithertointerested parties have not provided any financial means to mitigate the fact. There are a few things to consider lookingforward, for example
• Xeon E3 CPUs with onboard GPUs could be worth considering as a test use case, or cheap HW GPUs forstudents
• We should investigate AMD GPUs as the price/performance ratio could be better compared to NVIDIA
Telemetry and metrics
Last updated: 2018-02-21
We are collecting data from polling services and notification messages from the message queue (AMQP). The data arecollected by the telemetry node(s) running the Openstack Ceilometer, and are stored on metric node(s) in a time seriesdatabase running Gnocchi.
214 Chapter 1. Contents

iaas Documentation, Release 0.1.0
For ocata the measurments stored are described in this document
Nodes and services
Metric
This nodes are running the time series database. The metric are stored in a database and measurement are stored ondisk.
Running services
• openstack-gnocchi-metricd
• openstack-gnocchi-statsd
• httpd (gnocchi api)
Dependency nodes and services
• identity - keystone
• db - mysql
Telemetry
This nodes running polling services and collect notifications. All data are then sent to the Gnocchi API.
Running services:
• openstack-ceilometer-notification
• openstack-ceilometer-polling (namespace: central)
Dependency nodes and services
• mq - rabbitmq (notifications)
• metric - httpd (gnocchi api)
• api - haproxy (all endpoints for polling)
Compute
This nodes runs the compute polling services. It also sends notifications to the message queue. The data are sendtdirectly to the gnocchi api for storage.
Running services:
• openstack-ceilometer-polling (namespace: compute)
Dependency nodes and services
• mq - rabbitmq (notifications)
• metric - httpd (gnocchi api)
• api - haproxy (volume and image for polling instans data)
1.6. Status 215

iaas Documentation, Release 0.1.0
Users and projects
We will need users and projects in keystone to access and limit access to Gnocchi. Ceilometer also needs an adminuser for polling data from services.
Vi use the default project services in default domain. The following nodes will now also have access:
• telemetry: ceilometer (role: admin)
• metric: gnocchi (role: admin)
• monitor: monitor (role: user)
• status: statis (roles: user)
Arkiv
Gamle planer
Demo-prosjekt
Sist endret: 2017-11-29
Konsept
Vi har et mål om at alle brukere av UH-IaaS skal få mulighet til å teste det uten å måtte betale eller gå via lokalegodkjennere. Siden antall brukere er alle med konto hos en tilsluttet organisasjon så vil denne bruken kunne utgjøreen betydelig stor andel av den total bruke av UH-IaaS.
Demo-prosjekt er et forslag for å innfri målet, uten å risikere at denne bruken blir så stor at det går utover betalendebrukere.
Forventningavklaring (Terms of service)
Resurser brukt av demo-prosjekt skal kun kjøre på ledig kapasitet. Det vil si at ved kapasitetutfordringer vil alleresurser brukt av demo-prosjekt kunne bli stoppet, flyttet eller slettet. Dersom dette inntreffer skal brukerne av demo-prosjektet bli informert om hva som er endret.
Navn
Demo-prosjekt vil få navn DEMO-<navn>-<org> og merkes med type=demo Eksempel: DEMO-raymond.kristiansen-uib.no
Kvote
Kvoter blir satt per region.
216 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Compute:
• Antall instanser: 2
• vCPU: 2
• Minne: 2GB
Storage:
• Antall volume: 1
• Snapshots: 3
• Lagringsplass: 20GB
Innføring
1. Oppdaterer brukerdokumentasjonen med terms of services for demo-prosjekt
2. Alle nye som registrerer seg får nå demo-prosjekt
3. Alle eksisterende brukere får opprettet et demo-prosjekt
4. Alle eksisterende brukere får epost om at de nå har fått et demo-prosjekt og at det personlige prosjektet vil bliavviklet på en dato. Godkjenner kan bestille videreføring av personlig prosjekt.
Fremdriftsplan
Steg 1. og 2. kan utføres med en gang. Steg 3. og 4. bør gjøres samtidig og krever at man setter en dato for avslutting.Det krever også prismodell og en gjent godkjenner ved alle tilsluttede organisasjoner.
Oppdatert status
Alle gamle personlige prosjekter og instanser tilhørende ble slettet 28.november 2017.
Flavors (Utgått)
Sist endret: 2017-03-06
Her er en oversikt over hvilke flavor av instatanser som skal være tilgjengelig:
m1
m1 er tenkt som en general purpose type av flavors som alle for tilgang til. Den vil hovedsaklig bli brukt i personligeprosjekter.
Navn vCPU RAM (GiB) Disk Aggregatem1.tiny 1 0,5 1 default-1m1.small 1 2 10 default-1m1.medium 2 4 20 default-1m1.large 4 8 20 default-1
1.6. Status 217

iaas Documentation, Release 0.1.0
m2
m2 er tenkt som større maskiner for dem som trenger mer minne og cpu enn det m1 dekke.
Navn vCPU RAM (GiB) Disk Aggregatem2.large 2 8 20 default-1m2.xlarge 4 16 20 default-1m2.2xlarge 8 32 20 default-1m2.4xlarge 16 64 20 default-1
d1
d1 er en flavor type med mer disk en m1.
Navn vCPU RAM (GiB) Disk Aggregated1.small 1 2 20 default-1d1.medium 2 4 40 default-1d1.large 4 8 60 default-1
Andre typer flavor
• c1 mye cpu
• x1 mye minne
• h1 for hpc
Lagring for OS-disk
Sist endret: 2018-09-28
Alternativ 1 ble valgt og produksjonsatt.
Det vi ønsker er å benytte sentral OS-disk som default for alle instanser. For spesialiserte compute-ressurser vil detvære aktuelt med lokal OS-disk, men disse vil da være i egne availability zones (AZ).
Oversikt
• Lagring for OS-disk
– Utfordring
– Alternativ 1
* AZ navn
* Fordeler
* Ulemper
– Alternativ 2
* AZ navn
218 Chapter 1. Contents

iaas Documentation, Release 0.1.0
* Fordeler
* Ulemper
Utfordring
Hvordan kommer vi oss fra dagens løsning med lokal OS-disk til sentral OS-disk?
Alternativ 1
Vi lager en ny default AZ med nye compute noder (vi har 2 i OSL og 4 i BGO). Eksisterende instanser blir værendedere de er og ny instanser havner i ny AZ med sentral OS-disk.
AZ navn
Alt A: <loc>-default-2
Alt B: Endrer navn på <loc>-default-1 til <loc>-legacy-1 og opprette en ny <loc>-default-1
Fordeler
• Slipper å flytte instanser med høyt diskbruk (dvs ingen discard) inn i sentral lagring
• Får en gradvis flytting
Ulemper
• Hvordan hindre at nye instanser ikke havner i gammel AZ? Et prosjekt kan ha både nye og gamle instanser
Alternativ 2
Lage en ny AZ og flytte alle instanser dit. Vi starter med ledige compute-noder og så flytter vi de som er tømt overetter hvert som vi flytter. Vi har to aktive grupper med instanser idag så vi må flytte i to omganger.
AZ navn
Alt A: <loc>-default-2
<loc>-default-1 blir ledig etter flytting og kan brukes til neste default AZ.
Fordeler
• Raskere ferdig med endringen
1.6. Status 219

iaas Documentation, Release 0.1.0
Ulemper
• Vi vil flytte instanser med høyt diskbruk (dvs ingen discard) inn i sentral lagring. Det er nå ca 140 instanser utendiscard, noe som utgjør litt under 50%.
Fra pilot til produksjon
Important: Dette dokumentet er kun et internt utkast
Dette dokumentet beskiver hvilke funksjonaliet vil vil tilby, når vi lanserer og hva som trengs for å kunne sette UHIaaS i produksjon.
Funksjonalitet
Dette er en liste over ønsket funksjonalitet når vi går i produksjon:
• brukerkonto og tilgang til personlig prosjekt via Dataporten
• tilgang til to regioner fra dashboard og API
• opprette og administrere instanser via dashboard og API
• snapshot av instanser til sentral lagring
• sentral blokklagring knyttet til instanser
• felles prosjekt for en grupper av brukere
• tilgang til oppdaterte image for et utvalg av linux distroer
Leveranser
Intern leveranseplan:
Frist Leveranse1.sept Oppgradere til mitaka26.sept Felles keystone og full reinstall av bgo og osl01.nov Produksjonsklar bgo og osl14.nov Lansering1.7.17 Utvidet funksjonalitet
Det endelige målet er å være produksjonsklar 1.nov og lansere 14. november 2016
Ressurser
Personell
Vi vil trenge 4 årsverk ut året.
220 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Hardware
Hardware ved lansering per lokasjon:
Compute
Trenger å doble antall compute noder ved lansering.
3 ekstra maskiner: 3 x 125K = 375K
Storage
Dersom vi ønsker å tilby sentral lagring av OS-disk trenger vi 5 nye maskiner.
Alt 1: 5 x SSD maskiner 500K = 2500K
Alt 2: 5 x NL SAS 120K = ca 600K
Alle priser er budsjettpriser fra Dell.
Usikkerhet
• avtaler (vilkår for bruk) og jus
• sikkerheten må godkjennes
• antall ipv4 adresser vi har tilgjengelig kan begrense antall instanser
Utvidet funksjonalitet
Vi ønsker også å kunne tilby en tjeneste for objektlagring og IPv6.
Ressurser
• 2 årsverk i 6 mnd
• storage: 600K NOK per lokasjon
• api server: 125K NOK per lokasjon
Lagring
Sist endret: 2017-11-29
Oppdatert status
Vi bygget om Ceph-cluster med å fjerne halvparten av HDD og sette inn totalt 15 (3x5) SSD per region. Planen er åbruke SSD til sentral OS-disk.
1.6. Status 221

iaas Documentation, Release 0.1.0
Dagens situasjon
Vi har idag et Ceph-cluster per region med følgende oppsett:
• Antall noder: 5
• Antall disker (OSD) per node: 10
• Størrelse disk: 2TB
• Kopier: 3
• Antall pool: 1 (Openstack Cinder)
Det gir oss ca 32TB per region som brukes i sin helhet til volum-tjenesten som er block storage som kan monteres påinstanser som vanlige disker.
Fremtidig mål
Vi ønkser å kunne tilby to forskjellige lagringsløsninger til sluttebrukere, samt benytte sentral lagring til OS-diskene(den disken som følger med instansen).
Kravene til de forskjellige lagringsløsningene vil være forskjellig så det mest økonomiske på sikt er å ha det på separathardware.
De tre largringsløsningene:
• Rask lagring (SSD): intern bruk til sentral lagring av OS-disk
• Standard lagring: volum-tjenesten som idag
• Masselagring: object storage
Rask lagring
Dette er den som haster aller mest. Vi lagrer idag OS-disken lokal på compute, og vi ser at bruken av den disken erraskt økende og vil møte en fysisk begrensning i løpet av 2017 (ikke plass til mer disk). Bruken er heller ikke liktfordelt mellom compute hoster.
Standard lagring
Denne er lite brukt og dersom vi skal prise denne basert på lagringsplass og innkjøpskostnad vil det ikke være enattraktiv lagringsløsning for noen.
Dette er per idag i teorien kun en tjeneste for veldig spesielt interesserte, og er kun en proof of concept for at denteknologien vi har valgt ser ut til å fungere som planlagt. Vi ser ingen hast i å utvide denne.
Masselagring
Som en del av prosjektsøknaden til UH-Sky så er planen å kunne levere object storage i løpet av året. Hvorvidt det blirsnakk om full produksjon eller en pilot vil avhenge av investeringsmidler.
222 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Plan
Rask lagring
Dette arbeidet er prioritert. Vi har litt penger igjen fra 2016 som gjør at vi kan få dette til relativt raskt.
Planen er følgende:
• Vi kjøper inn 5 x 800GB disk til hver av storage nodene og erstatter halvparten av dagens 2TB disker.
• Lager et nytt pool kun på SSD med 2 kopier (mot 3 for de andre poolene)
• Vi får da et pool til OS-disk på 5 x 5 x 800 GB / 2 = 10TB (dagens løsning er ca 580GB per compute host, somgir ca 3,5TB)
• Pris per lokasjon blir ca 125K med de samme prisene vi fikk i januar
• På sikt kan vi doble antall SSD og også kapasiteten til 20TB og avvikle/flytte volum-tjenesten
Standard lagring
Som et resultat av endringen over vil kapasiteten her bli halvert. Ellers ingen planer.
Masselagring
Det tekniske arbeidet med å sette opp object storage var først satt til våren 2017, men pga manglende personell blittutsatt til høsten 2017.
De kravene vi så langt har satt for tjenesten er:
• Vi trenger å lage et HW plan som gir konkurransedyktige priser
• Pris på HW kan avgjøre valg av software
• Tilby snapshot
• Openstack Keystone som IDP
• To releaser en intern og en ekstern (kan være en pilot)
• Vi ønsker å teste både Openstack swift og ceph
Det er satt av rundt 400K ved UiB som kan brukes på HW til en pilot.
1.6.8 Arkiv
Dette er dokumenter fra pre 2016 og er med her for historiske grunner. Prosjektleder frem til februar 2016 var Jan IvarBeddari.
Project plan and description
UH-sky IaaS platform development
• Project plan and description
1.6. Status 223

iaas Documentation, Release 0.1.0
– Descriptive summary
* Limitations
* Prerequisites
– Project goals and success criterias
* 1. Develop, document and deliver a base IaaS platform
* 2. Integration of authentication and authorization
* 3. Further develop and verify services to cover ‘traditional workloads’
* 4. Research and suggest a solution for PaaS
* 5. Research and suggest possible SaaS servics
* 6. Research and specify a consumer-focused self-service portal
– Project milestones and scheduling
– Resources and budgeting
– Project organization and management
* Core development and engineering
* Technical steering group
* Top-level management and ownership
– Risks
– Appendix
* 1. Support for the Microsoft Windows operating system
* 2. Licensing of instances in the service
* 3. Calculating needed capacity for development
Descriptive summary
This document describes what the IaaS project will develop and deliver. The project aims to position IaaS as a commonbuilding block and vessel for future IT infrastructure and services delivery in the academic sector.
The main project activity is developing, documenting and delivering an open source IaaS platform ready for productionuse by June 15th 2015.
Additional activites that expands and builds on top of this platform are described. These activites will need to beresearched, discussed and specified in greater detail before they can be put into action. The project plan sets theearliest startup time for these activities to be February/March 2015.
The base IaaS platform will deliver these services:
• Compute
• Storage in 2 variants
– Block storage, accessible as virtual disks for compute instances
– Object storage, accessible over the network as an API
224 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Limitations
• The project will not deliver traditional backup. A common definition of backup state that backup data must beoff-site, off-grid (e.g tape). A planned property of the storage system is to be able to select that an instance willbe replicated to another location.
• The additional activites described are dependent on the base IaaS platform.
• Initial success criterias for the additional activities are described but no cost estimates (resources, budget) aregiven as part of this project plan.
Prerequisites
To be able to deliver the platform as described, on time, it is a requirement that the project get access to the neededresources
• At least 3 people must work full-time (100%) with the main project activity
• No roles less than 50%
• If split roles are used, alternating blocks of at least 3 days continuous work hours must be with the project
The project will need at least 6 months from the Locations complete milestone to delivery of the platform. This meansthat to deliver on time by 15th of June 2015 procurement of the needed hardware will need to be completed within2014. If hardware is delayed until 2015, the final delivery date will be delayed the same amount of time, countingfrom August 15th 2015, as June and July are not counted due to vacations. E.g, if Locations complete is reached inFebruary 2015 final delivery will be 15th of October 2015.
Project goals and success criterias
The project will deliver a base IaaS platform to form a buildling block for future IT infrastructure delivery in theacademic sector.
The project has defined the following activities:
1. Develop, document and deliver a base IaaS platform
2. Integration of authentication and authorization
3. Further develop and verify services to cover ‘traditional workloads’
4. Research and suggest a solution for PaaS
5. Research and suggest possible SaaS servics
6. Research and specify a consumer-focused self-service portal
Activities 1 and 2 have been passed by the UH-sky steering group in June 2014.
To describe the activities a format similar to user stories is used. The stories share a common set of definitions
service The base IaaS platform, including all services layered below
user A person within the academic sector (with an identity record in FEIDE) given rights to administer instances andservices on behalf of a tenant.
tenant An organization or unit within the Norwegian academic sector
administrator A person given responsibility and access to all the components of the service. This does not extend toaccess rights to the resources of a tenant.
small instance A compute instance defined as 1 vCPU, 4GB RAM, 10GB storage
1.6. Status 225

iaas Documentation, Release 0.1.0
large instance A compute instance defined as 4 vCPU, 16GB RAM, 100GB storage
1. Develop, document and deliver a base IaaS platform
This is the main project activity.
• The service must deliver capacity for ~750 small instances or ~275 large instanecs with a total of 100tb acces-sible storage. This capacity should be equally divided across three geo-dispersed sites.
• The project must deliver a proof-of-concept PaaS solution able to offer three standardized development environ-ments.
• The project must deliever proof-of-concept operation of at least one common service, in a SaaS-like model.
• The service must enable and document an expansion of the base platform to include (existing or new) HPCenvironments and workloads
• The service must deliver data that can be used for billing tenants. The data delivered must be usable to identifyusers, organizations and organization units.
• A user must be able to start an instance immediately after first login. The instance must be available within 60seconds.
• A user must be able to create, update and delete instanes in the service from a graphical user interface in abrowser, using an API or by using command line tools.
• A user must be able to select if an instance should have a persistent boot volume or not.
• A user must be able to assign and use more storage as needed, within a quota. Billing of storage must be perusage, not per quota.
• A user should be able to place or move an instance geographically across the available locations. The choiceshould be possible to make according to the users need for redundancy, resilience, geographical distance or otherfactors.
• A user should be able to choose that an instance is replicated to other locations automatically, thus potentiallyincreasing protection against service outages.
• A user must be given the ability to monitor service performance and quality continuously.
• An administrator must use two-factor authentication for any access to the service for systems management andmaintenance purposes.
• An administrator must be able to expand capacity, plan and execute infrastructure changes and fix errors in allparts of the service by using version-controlled code and automation. This key point should cover all operationaltasks like discovery, deployment, maintenance, monitoring and troubleshooting.
2. Integration of authentication and authorization
• A user must be able to authenticate via FEIDE and be authorized as belonging to a tenant in the service
• Any FEIDE user passwords should NOT be stored in the service
Before the service can be used in a production scenario it is neccessary to integrate central authentication and authoriza-tion. Users in the service must be identified as belonging to an organizational entity with correct billing information.
This activity must research and document a model and solution that shows how user- and organization data fromFEIDE (and other sources) can be integrated to cover the needs of the service. The model must be detailed enough tomake it possible to estimate cost and resource constraints for the solution.
226 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Limitations in the chosen solution and model must be described. Suggestions and cost estimates for more advancedid/authN/authZ models, e.g users and billing across organizational boundaries, must be discussed. An analysis andassessment of integration with the UNINETT project FEIDE Connect should be done as part of this.
3. Further develop and verify services to cover ‘traditional workloads’
The base IaaS platform is planned to be built using OpenStack, a framework for building modern scalable cloud-centricinfrastructure. Traditional enterprise workloads, defined as long-lived instances with critical data and state kept as partof the boot filesystem, is not as easily integrated into this framework. We believe a lot of our potential users wouldalso like the service to cover this class of workloads.
This activity integrates a solution tailored for traditional workloads with the base IaaS platform. Openstack and itsservice APIs are used to unify the solution so that the consumer side of the service is kept uniform. The solutioncan make use of existing infrastructure at each site/location, possibly by utilizing existing excess capacity, or later byexpansion.
A key value proposition for this activity is to confirm and further develop the requirement that any solution, knowledgeand people working in the project are part of a shared pool of resources. Existing systems and available free capacityvary greatly between locations but this must not prevent or stop all parties from participating.
Licensing is an important question that this activity must address.
4. Research and suggest a solution for PaaS
There is a definite interest in PaaS as a concept in our communities. Earlier discussions has revealed that it is verylikely we would want to deliver some form of PaaS solution on top of the IaaS platform. Today, from what we know,only UNINETT and its internal Nova project has experience with PaaS as an environment.
This activity must research and suggest a form and model for a PaaS service delivered on top of the base IaaS platform.The suggested solution must be described and cost must be estimated.
5. Research and suggest possible SaaS servics
Several of the common IT services in the sector are already today delivered in models that are close to SaaS. From ourUH-sky viewpoint it is natural to look at these services as possible future migrations to the IaaS platform. This activitymust actively approach the sector on multiple fronts to find use cases and needs that could possibly fit in a SaaS model.Early examples of such services could be software used in labs or classrooms. Is SPSS as a service possible?
6. Research and specify a consumer-focused self-service portal
This activity will define goals to enable a uniform, consumer-focused, self-service portal for all IaaS, PaaS (SaaS?)related services. A central point for consuming the services is needed.
Functional aspects we’d need solved are
• Chargeback. Automatically generated billing based on usage.
• Support for several cloud and virt providers, both private and public
• Possibility for migrating workloads/instances and data between different infrastructure providers
• Overview and monitoring of allocated resources across providers
1.6. Status 227

iaas Documentation, Release 0.1.0
There are several products today that cover most if not all of the functional aspects described. A central customer-focused portal should be developed using one of them as a base. A development project formed around this activitywill be only loosely coupled to the IaaS project but we think it would be beneficial to wait until the core functionalityof the IaaS platform is in place.
Project milestones and scheduling
The following describes planned progress and possible startup dates for the project activies
Activity DateStartup activity 1 and 2 June
2014Minimum viable product. Per activity 1, one of three physical sites installed and running. October
2014Locations complete. All sites up and running. No storage or instance uptime guaranteed. De-
cember2014
Functionally complete. All functional goals completed and operative. No storage or instance uptimeguaranteed.
Febru-ary2015
Incubation period. Pre-production tuning, testing and verification. Early customers given access. Besteffort storage consistency and instance uptime. Documenting any further development needed.
Feb.-Jun.2015
Project delivery. Activites 1, 2 delivered as described. 15.6.2015
Resources and budgeting
This part of the project plan is not public
Project organization and management
Core development and engineering
Day-to-day activties are led by technical project lead Jan Ivar Beddari. A weekly meeting for planning is held Thursdayat 13:00. Daily “morning meetings” to keep track of activites are held at 0930. Both these regular meetings are heldonline using video conferencing.
Core development and engineering team
• Erlend Midttun, NTNU
• Tor Lædre, University of Bergen
• Mikael Dalsgard, University of Oslo
• Hege Trosvik, University of Oslo
• Hans-Henry Jakbosen, University of Tromsø
• Marte Karidatter Skadsem, University of Tromsø
228 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Technical steering group
The project reports to a technical steering group with representatives from all the participating organizations. Its mainfunction is to coordinate commuication and solve issues that could possibly block progress in the project. This groupis given a mandate from the top level project management to specify its roles and functions.
Its members are
• Kjetil Otter Olsen, University of Oslo (group lead)
• Per Markussen, University of Tromsø
• Ola Ervik, NTNU Norwegian University of Science and Technology
• Raymond Kristiansen, University of Bergen
• Kristin Selvaag, UNINETT, UH-sky
• Jan Ivar Beddari, UH IaaS tech project lead
Top-level management and ownership
The UH-sky steering group represents the top level project management and project ownership. This group consistsof the IT Directors from the four larger universities and representatives from university colleges and UNINETT, theNorwegian NREN organization.
• Håkon Alstad, IT Director, NTNU Norwegian University of Science and Technology
• Lars Oftedal, IT Director, University of Oslo
• Stig Ørsje, IT Director, University of Tromsø
• Tore Burheim, IT Director, University of Bergen
• Thor-Inge Næsset, IT Manager, NHH Norwegian School of Economics
• Vidar Solheim, IT Director, HiST Sør-Trøndelag University College
• Frode Gether-Rønning, Head of IT-dept., AHO The Oslo School of Architecture and Design
• Petter Kongshaug, CEO, UNINETT
• Tor Holmen, Deputy CEO, UNINETT
Meetings in the steering group are organized by the UNINETT UH-sky program manager, Kristin Selvaag.
Risks
• The hardware investments planned will have a lifetime of at least four years. Risks involved with the investmentis considered low. All aquired hardware will be usable to its full extent in the local organizations even if theproject fails.
• Delays in progress (3 months or more) due to lack of access to resources, non-foreseen technical or organiza-tional complexities, or problems with coordinating efforts across the participants is very likely.
• Inaccuracies in cost estimates for harware (both current and futur) is not considered high. However, the projectdoes not estimate costs for production usage of the finished platform.
1.6. Status 229

iaas Documentation, Release 0.1.0
Appendix
Questions and additions for the goals and criterias
1. Support for the Microsoft Windows operating system
A basic Windows-based instance requires substantial capacity from the service when compared to a basic Linux-basedinstance.
The project aims to support Windows instances in the best way possible. Testing done within the project will determinewhat the technical solution will be. Windows will be tested in the service as large instances and performance will bemeasured and compared to our existing virtualization infrastructures.
2. Licensing of instances in the service
The project will not handle or research licensing of instances in the service. Tenants must ensure that they are properlylicensed for all instances they create using the service. Microsoft and Red Hat are examples of vendors with softwareproducts and operating systems that requires licensing.
In a future production service we recommend negotiating agreements with vendors for site licensing. This couldpotentially be more cost effective than purchasing licenses per tenant or organization. The project has so far notplanned or set aside resources towards this.
3. Calculating needed capacity for development
Back-of-a-napkin assessment of development compute capacity
• Physical cores (non-hyperthreaded): 2x12 core, 3x nodes, 3x sites = 216 cores
• Virtual cores: 4x oversubscription = 864 vCPU, 3x oversubscription = 648 vCPU
• RAM, no oversubscription = 512 GB 3x nodes, 3x sites = 4608 GB raw capacity
Instances
• Small instances: 1 vCPU, ~6 GB RAM, 10 GB disk ~ 72 instances per compute node, 648 total (at 3x cpuoversubscription)
• Large instances: 4 vCPU, ~24 GB RAM, 100 GB disk ~ 18 instanecs per compute node, 162 total (at 3x cpuoversubscription)
Release planning
Iterative release planning to reach production usage
• Release planning
– Descriptive summary
– Software versions as milestones
* 0.x.y series release goals
* 1.x.y series release goals
230 Chapter 1. Contents

iaas Documentation, Release 0.1.0
* 2.x.y series release goals
– Release plan
* 0.5.0
* 0.5.1
* 0.6.0
* 0.7.0
* 1.0.0
* 2.0.0
– Status reports
Descriptive summary
This document describes how we plan to release the IaaS service to users and the parttaking organizations.
The plan will be concentrated around our two main goals
• Enable local testing and piloting to select users at each location as soon as possible.
• Deliver a production platform as described in the main project plan.
The list of milestones is not final and will be reviewed weekly as needed by the project and its stakeholders.
Software versions as milestones
The UH IaaS project is focused on the value of continuous improvement within the constraints of a larger, deliveryfocused plan. Thus as engineers it makes sense for us to couple planning to what we are actually producing day to day- which is code and documentation.
Our milestones will use software versioning as a method of describing the iterative work needed to reach each of themain goals. For the testing and piloting phase we’ll use versioning numbers starting with 0, e.g the first deliverableand consumable service will be version 0.x.y. x and y will be numbers representing features, changes and work items.
0.x.y series release goals
This series concentrates on enabling testing and pilot access to select users at each location.
The 0 series releases will move quickly and update the environments and service as needed, in flight. Data in theservice is to be considered volatile during this phase. In release planning, if the second component in the versionnumber (x) is increased, it represents a complete rebuild of the components, and thus loss of any existing data. Ifthe last component (y) is increased, it represents a non-breaking change that only has temporarily effect on serviceavailability.
Each 0 series release will represent testing and exposing one or more changes towards the complete feature set.
Only select pilot users will have access to the systems during the 0-series.
1.x.y series release goals
This series will work towards delivery of a feature complete basic service as described by the original project plan.
1.6. Status 231

iaas Documentation, Release 0.1.0
The first 1.x.y release will enable manually provisioned access for all users to the basic IaaS service in each region.
2.x.y series release goals
This series will work towards integrating the service with federated login.
• Enabled self-service access through integration with FEIDE or FEIDE Connect.
• Consolidated user accounts across regions.
The first 2.x.y release will enable (limited) access to the service for all accounts within FEIDE.
Release plan
This is a description of the currently planned releases and what changes they represent going forward. This list isreviewed weekly to provide a summary of the current status. Data for this list is correlated from the UH IaaS Trelloboard at https://trello.com/b/m7tD31zU/iaas and GithHub milestones and issues at https://github.com/norcams/himlar/milestones
0.5.0
Due date: 15.12.2015
• Released with pilot status - manually provisioned users
• Service runs on production network and hardware
• Performance restrictions lifted
0.5.1
• Enable DNS PTR and A records on public addresses (<instance>.<region>.uhdc.no)
0.6.0
Due date: pending
• Cinder (block storage) service, Ceph backend
• FEIDE Connect integration, proof-of-concept
0.7.0
Due date: Not set
• Object storage (Swift API)
• Orchestration service (OpenStack Heat)
232 Chapter 1. Contents

iaas Documentation, Release 0.1.0
1.0.0
Due date: jan/feb 2016
• Open for production usage
• Security and update process documented and accepted by third parties
• Defined and documented what service level users are given
2.0.0
Due date: Not set
• FEIDE Connect phase 1 integration enabled
Status reports
UH IaaS will produce weekly status reports which describes ongoing and upcoming work items, problem areas andmilestone updates.
The status reports will be published on this site and emailed internally.
Sluttrapport 2015-06
Rapport til UH-sky styringsgruppe av prosjektleder Jan Ivar Beddari, den 15.6.2015
Oversikt
• Sluttrapport 2015-06
– Innledning
– Mål som ikke er leveringsklare
* 1. Develop, document and deliver a base IaaS platform
* 2. Integration of authentication and authorization
– Årsaker
* Ressurstilgang
* Manglende samkjøring av IaaS-strategi
* Sein oppstart
– Tiltak for ferdigstilling
* 1. Utsettelse av produksjonsdato til 31.12.2015
* 2. Nye ressurser knyttes til prosjektet for å jobbe med Feide og Connect
– Spørsmål om rapportering og styring
* Burde prosjektet rapportert mer i detalj om underbemanning og mangel på ressurser?
* Fungerer teknisk styringsgruppe slik som planlagt?
* Hvordan bør et UH-sky prosjekt med felles ressurspool rapportere?
1.6. Status 233

iaas Documentation, Release 0.1.0
– Referanser
Innledning
15. juni var sluttdato for UH IaaS-prosjektet slik det ble vedtatt av UH-sky styringsgruppa i juni 2014. Dette doku-mentet oppsummerer status per sluttdato med utgangspunkt i målene i den vedtatte prosjektplanen.
Mål som ikke er leveringsklare
Leveransemålene er beskrevet i prosjektplanen som aktiviteter. Akvititet 1 og 2 ble vedtatt gjennomført og tilførtressurser.
1. Develop, document and deliver a base IaaS platform
Ca 75% av målene er nådd.
Hovedlinja i arbeidet som gjenstår er å koble sammen lokasjonene slik at brukeren ser en helhetlig, sammenkoblettjeneste. Dette er et av hovedkravene for en funksjonell løsning.
Utestående oppgaver i den underliggede infrastrukturen:
• Nettverksinfrastrukturen som kobler IaaS-lokasjonene sammen med er planlagt men ikke ferdig implementert.IP-adresser har vært et diskusjonstema som nå ser ut til å løse seg ved at UH IaaS får adresser fra UNINETT.
• Prosjektet har ikke nok operativ erfaring med lagringssystemet, per juni 2015. Denne erfaringen trenger vi mertid for å bygge opp.
2. Integration of authentication and authorization
Ikke påbegynt.
Omfatter integrasjon av Feide med UH IaaS for å gi påloggingsmulighet til alle brukere i sektoren. I prosjektplanenble dette arbeidet estimert til mellom 200 og 300 timer for en enklest mulig fungerende løsning med Feide-tilknyttetpålogging.
Underveis i prosjektet har en kommet fram til at en Feide Connect pilot og integrasjon er sterkt ønsket. Dette vil værei størrelsesorden ca 600 timer.
Årsaker
Ressurstilgang
Hovedårsak til at prosjektet ved sluttdato ikke kan levere i den grad prosjektplanen forutsetter er ressursmangel gjen-nom hele prosjektperioden.
• I prosjektplanen forutsettes det 5 stillinger pluss prosjektleder i ett år, totalt 6 stillinger. Prosjektet har i praksismanglet 1/3 av dette og hatt 4 stillinger:
– Prosjektleder Jan Ivar Beddari (100%)
– Tor Lædre (UIB, 100%)
– Erlend Midttun (NTNU, 100%)
234 Chapter 1. Contents

iaas Documentation, Release 0.1.0
– Mikael Dalsgard (USIT, 60%)
– Hege Trosvik (USIT, 40%)
• UNINETT har ikke bidratt som forutsatt i prosjektplanen.
• De lokale organisasjonene har hatt vanskeligheter med å “omdirigere” eget ressursbehov bort fra personene somhar fått prosjektansvar. Dette har ført til at det har vært problematisk å få arbeidsro.
• Universitetet i Tromsø bidro ved prosjektstart med to personer i 50% som del av prosjektgruppa. Dessverreskiftet begge arbeidsgiver halvveis i prosjektperioden og prosjektet fikk et “dobbelt-tap” av både opplæringstidog kompetanse. Gitt situasjonen var det ikke å forvente at UIT skulle greie å erstatte disse ressursene forprosjektets siste 6 måneder.
Manglende samkjøring av IaaS-strategi
UH IaaS som planlagt “virtuelt datarom” er en integrert tjeneste som berører og setter krav til mange deler av organ-isasjonene i samarbeidet. Prosjektet har opplevd mangelen på en sektor-felles forståelse av UH-sky og IaaS som ensterk bremsekloss. Mange gode initativer og muligheter går tapt på grunn av dette. UH IaaS som ide for framtida eravhengig av å kunne “bygge seg inn i” alle organisasjonene i samarbeidet. Vi har ikke nok ressurser totalt sett til åkunne drive to så like tjeneste-initiativ - IPnett IaaS og UH IaaS - samtidig.
I en periode hvor det å bygge samarbeid burde være det viktigste fokuset har det for prosjektet vært svært frustrerendeå oppleve dette. Mye ekstra tid går tapt fordi en ikke har en samordnet forståelse av hva som er målet.
Sein oppstart
Det tok lengere tid enn forutsatt å identifisere og frigjøre ressurser til prosjektet. Prosjektet var ikke operativt før ioktober 2014.
Tiltak for ferdigstilling
For å fredigstille UH IaaS og levere plattformen som beskrevet i aktivitet #1 og #2 i prosjektplanen foreslår vi følgendetiltak.
1. Utsettelse av produksjonsdato til 31.12.2015
Hvis prosjektet bemannes videre på samme måte (4 personer) vil tjenesten kunne leveres som beskrevet under aktivitet#1 i prosjektplanen innen 31.12.2015.
Tjenesten vil leveres som pilot for et mindre utvalg brukere og felles systemer fra ca september 2015. Prosjektet er ikontakt med flere interesserte pilotbrukere og vil følge disse opp.
2. Nye ressurser knyttes til prosjektet for å jobbe med Feide og Connect
Aktivitet #2 i prosjektplanen vil ikke kunne gjennomføres uten tilføresel av ressurser. Feide Connect framstår forprosjektet som er en svært interessant mulighet for gjennomføring av kravene vi har satt. Å sette Connect sin pilot isammeheng med UH IaaS vil gi gode effekter både for samarbeidet i UH-sky og lokalt for de organisasjonene someventuelt avgir ressuser.
Connect sin pilot er planlagt avsluttet 15. november 2015 men trolig vil det være mulig å avtale fortsatt bruk avplattformen. Dette må avklares med UNINETT av UH-sky styringsgruppa.
1.6. Status 235

iaas Documentation, Release 0.1.0
UH IaaS ber om en ressurs på 600 timer fram til ny produksjonsdato 31.12.2015 for å utføre dette arbeidet. Tilstrekke-lig utviklings- og infrastrukturkompetanse til å kunne jobbe i kommunikasjon med Connect sine utviklere, imple-mentere løsninga og innlemme den i UH IaaS er en forutsetning.
Spørsmål om rapportering og styring
Burde prosjektet rapportert mer i detalj om underbemanning og mangel på ressurser?
Det ble i februar gjort en vurdering og diskusjon internt på om det var nødvendig å kreve prosjektet stoppet tilressursene forelå som forutsatt. På dette tidspunktet var det klart at underbemannningen på minus 2 personer ikkeuten stor innsats ville la seg løse før prosjektets sluttdato.
Prosjektleder valgte å ikke stoppe prosjektet av følgende årsaker
• Verdien av det som ble produsert av de som var daglig produktive i prosjektet var økende og positiv. Rutinersom gav arbeidsro og arbeidstid var i ferd med å etableres skikkelig. En stopp av prosjektet og eventuell seinereigangsetting ville rive vekk mye av dette.
• Å stoppe prosjektet ville virke svært negativt utad. Kostnaden ved stopp og en uviss periode venting til manglederessurser ble frigitt og en ny igangsetting virket for store.
Fungerer teknisk styringsgruppe slik som planlagt?
I løpet av det siste halvåret av prosjektet har ideen om en “teknisk styringsgruppe” beveget seg et godt stykke fra denopprinnelige ideen. Arbeidsflyten teknisk styringsgruppe var ment å støtte kan beskrives slik:
1. Tekniske behov og krav settes i prosjektet basert på prosjektplanen
2. Utfordringer kan oppstå når behov og krav møter lokal organisasjon og policy
3. Prosjektet gjør bruk av teknisk styringsgruppe for å løse dette konkret
Mandatet til teknisk styringsgruppe ble utformet for å fungere i en slik arbeidsflyt. Etter at det både fra lokale or-ganisasjoner og UH-sky prosjektkoordinator ble stilt spørsmål rundt rapportering og andre formelle prosesskrav fikkteknisk styringsgruppe en utvidet rolle. Hva den rollen nå er blitt er nokså uklart.
Teknisk styringsgruppe kan muligens fortsatt ha oppgavene som følger av det opprinnelige mandatet. Den er samtidignå i ferd med å også få en annen, bredere “UH-sky styringsfunksjon” som det også er stort behov for - men som børvære et annet bord og en annen prosess.
Hvordan bør et UH-sky prosjekt med felles ressurspool rapportere?
UH IaaS sin erfaring så langt med teknisk, operativ utvikling av infrastruktur på kryss av linjeorganisasjonene tilsierat rapportering bør skje på to måter:
• Ukentlig mot hele gruppen av nærmeste ledere for prosjektressursene
• Månedtlig, skriftlig rapport til alle interesserte ledernivåer i alle organisasjonene
Vi har ikke fått dette til så godt som ønskelig så langt. UH IaaS vil be om at organisasjonene setter av mer tid til dagligoppfølging.
236 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Referanser
• UH IaaS sin prosjektplan: http://iaas.readthedocs.org/en/latest/project/plan.html (versjon med kapittel omressurser og budsjett ligger i Agora)
• Feide Connect: http://feideconnect.no/prosjekt/
• UH IaaS daglig planlegging (trello): https://trello.com/b/m7tD31zU/iaas
Notat om drift av IaaS-tjenesten
av Jan Ivar Beddari, UH IaaS, 23.11.2015
Contents
• Notat om drift av IaaS-tjenesten
– Introduksjon
– UH Platform Services
– Organisering og ressurser
– Evaluering av UH PS
Introduksjon
IaaS-tjenesten som utvikles av UH IaaS-prosjektet er klar for produksjonssetting 15. desember 2015. Tjenestens om-fang er beskrevet av prosjektplanen og omfatter utstyr plassert ved UiB, UiO og NTNU. Prosjektet har vært bemannetmed ressurser fra disse organisasjonene i utviklingsfasen.
Når tjenesten skal i bruk for produksjon er det nøvendig å diskutere felles organisering og sette premisser for hva somskal gjelde videre. Dette dokumentet fokuserer på hvordan vi per i dag mener dette bør fungere i praksis.
UH Platform Services
Vi foreslår å opprette en distribuert, delt driftsorganisasjon kalt UH Platform Services (UH PS). Organisasjonen sittmål skal være å drifte, videreutvikle og tilrettelegge tjenester i felles drift for hele sektoren innenfor rammer satt av dedeltakende organisasjonene. I første omgang begrenses dette til IaaS-tjenesten.
I prosjektperioden har UH IaaS opparbeidet seg mye erfaring med distribuert jobbing mellom organisasjonene. Pros-jektgruppa er samlet enige om at å dedikere utførende ressurser i 100% til UH PS er nødvendig for å opprettholdeforsvarlig leveransekvalitet i produksjon. Ressursene i UH PS bør formelt tilhøre organisasjonene som deltar menmed alle arbeidsoppgaver spesifisert av en felles driftsorganisasjon. Et forslag til løsning kan være at en jobber mot enmodell med utleie av ressurser.
Oppgaver
UH PS sin primære oppgave er drift og videreutvikling av en felles plattform for IaaS som UH IaaS har lagt grunnlagetfor. Slik prosjektplanen beskriver er tre lokasjoner klare for produksjon, Bergen, Oslo og Trondheim.
UH PS vil med de ressursene som er beskrevet i dette forslaget kunne drifte disse lokasjonene uten ytterligere tilførselav personell til de når en betraktelig størrelse. UH IaaS anslår at platformen kan utvides til minst 200 fysiske lagrings-
1.6. Status 237

iaas Documentation, Release 0.1.0
og compute-noder per lokasjon uten merkostnader til personell. I en situasjon hvor deler gjøres som forenklet leveranse(f.eks bare compute) vil tallene være enda større.
UH PS vil også tilrettelegge og hjelpe til med gjenbruk av felles kode til mer spesialiserte oppgaver. HPC ved UiT,compute-ressurser i SAFE (UiB) og TSD (USIT) er eksempler på slike. UH PS vil etter avtale kunne hjelpe til meddrift og vedlikehold av disse og lignende tjenester innenfor tilgjengelige ressurser.
Support
UH PS vil ha fullt ansvar for å utarbeide dokumentasjon og rutiner så de kan fungere som 2/2.5 linje inn mot lokaleorganisasjoner sin support. En modell som gjenbruker deler av metodikk og verktøy for support av HPC i sektoren ertenkt som et utgangspunkt.
Vaktordning
UH PS ønsker ikke i utgangspunktet en egen førstelinje vaktordning. UH PS vil ha en ordning med tilkalling hvisproblemet når et visst eskalert nivå, forsøksvis mellom kl 0800-2200.
UH PS vil jobbe mot å få til enkel integrasjon og varsling inn mot de lokale organisasjonene sine eksisterendevarslingssystemer. UH PS skal selv levere alle nødvendige data for dette.
En tenker seg en modell med hospitering av denne varslingsfunksjonen, på rundgang mellom organisasjonene. Detgjøres en kontinuerlig vurdering av av denne tilnærmingen. Om erfaringene blir negative gjøres en revurdering avbehovet for egen vaktordning og varsling. I såfall vil ressursbehovet rundt dette øke.
Organisering og ressurser
Vi mener mye av den praktiske modellen fra UH IaaS kan videreføres mens den administrative siden må styrkes.UH PS sin daglige ledelse består av to roller, en teknisk leder og en merkantil/administrativ teamleder. Disse skalrapportere til de aktuelle lokale linjeorganisasjonene og til UHsky-organisasjonen.
Personellressurser
UH PS sin initielle bemanning for drift av IaaS og støttefunksjoner som beskrevet i dette forslaget vil være 5,4 still-inger.
Teamleder (40%)
Teamleder er en mindre stilling (anslått 40%) som skal være hovedkontakt mellom UH PS og de deltakende organ-isasjonene for ressurser (personell) og tjenester som UH PS har ansvaret for. Teamleder skal aktivt delta i all internplanlegging og møtevirksomhet i UH PS og det er derfor nødvendig å ha en ressurs med teknisk innsikt i denne rollen.
Teamleder har delegert lederansvar for ressursene i UH PS. Hvis en benytter en modell med utleie, som foreslåttovenfor, vil teamleder ha ansvaret for å følge opp at utleiekontrakter blir overholdt.
Teknisk leder (100%)
Teknisk leder er en stilling på linje med dagens prosjektlederrolle i UH IaaS. Teknisk leder har hovedansvar for driftog utvikling og skal også aktivt bidra til at UH PS blir et attraktivt, utadrettet felles fagmiljø til nytte for hele sektoren.
238 Chapter 1. Contents

iaas Documentation, Release 0.1.0
4 ingeniører (4x100%)
UH PS trenger fire ingeniører med seniornivå kompetanseprofiler på OpenStack, Linux operativsystem-drift, automa-tisering/programmering, lagring og nettverk.
Prosjektgruppa for UH IaaS hadde ingen ressurser i 100% med hovedvekt på nettverkskompetanse. USIT bidro med enstilling på 40% som ble en veldig viktig nøkkelressurs i prosjektet men samtidig en flaskehals med tanke på tilgjengeligtid. I UH PS vil det være spesielt viktig å ha en 100% stilling med en slik kompetanseprofil.
Det anbefales at minst en 100% ressurs er fysisk plassert på hver av de tre eksisterende IaaS-lokasjonene.
Risiko ved minimumsbemanning
Ressursene beskrevet her er et absolutt minimum for å kunne ha en forsvarlig driftssituasjon. Hvis en ønsker å re-dusere risiko for ikke-planlagt nedetid ved f.eks sykdom eller andre uforutsette hendelser må bemanningen økes medytterligere en person. Dette vil gi rom for å fordele ansvaret bredere og dermed øke tryggheten.
Budsjett til reiser og kurs
I dette forslaget administrerer UH PS ved teamleder sine egne personellressurser og bør få ansvaret for kurs og reising.Det bør bli et uttalt krav at reisevirksomhet skal holdes på et forsvarlig nivå. Erfaringene fra UH IaaS gir oss et bildepå hva vi bør forvente av kostnader til dette.
• En ansatt i UH PS vil anslagsvis delta på 4 samlinger og 4 kurs/konferanser per år. Dette anslås til ca kr 80 000.
• Teknisk leder deltar på det samme pluss fire ekstra besøk hos lokale organisasjoner per år. Ca kr 100 000.
• Teamleder deltar på samlinger og lokale møter, inntil 8 reiser per år, ca kr 50 000.
Evaluering av UH PS
Hvis UH PS realiseres bør organisasjonsformen og leveringsevnen jevnlig evalueres av ledere og organisasjonenesom har eierskapet. I en oppstartsfase bør dette skje så ofte som hver tredje måned. Det er viktig at evalueringen erstrukturert, men samtidig enkel, så både de som utfører den og mottakerene ikke føler at dette tar for mye tid.
Evalueringen bør dreie seg både om interne ting rundt organisering og kommunikasjon, og om tjenesteleveransen.Kvalitet, brukerforventning og alle aspekter ved UH PS sine funksjoner eller forventninger til de ønskes belyst.
Vi tror at i en distribuert organisasjonsmodell er ryddig rapportering fra eiere tilbake til organisasjonen viktig.
1.6.9 Hardware overview
Contents
• Hardware overview
– OSL
– BGO
1.6. Status 239

iaas Documentation, Release 0.1.0
OSL
Name RAM CPU Diskosl-controller-01 128GB Xeon E5-2680 v3 2 x 200 SSDosl-controller-02 128GB Xeon E5-2680 v3 2 x 200 SSDosl-controller-03 128GB Xeon E5-2680 v3 2 x 200 SSDosl-controller-04 256GB Xeon E5-2650L 2 x 146 15k
2 x 400 SSDosl-storage-01 128GB Xeon E5-2680 v3 2 x 200 SSD
5 x 2TB 7,2k3 x 960 SSD
osl-storage-02 128GB Xeon E5-2680 v3 2 x 200 SSD5 x 2TB 7,2k3 x 960 SSD
osl-storage-03 128GB Xeon E5-2680 v3 2 x 200 SSD5 x 2TB 7,2k3 x 960 SSD
osl-storage-04 128GB Xeon E5-2680 v3 2 x 200 SSD5 x 2TB 7,2k3 x 960 SSD
osl-storage-05 128GB Xeon E5-2680 v3 2 x 200 SSD5 x 2TB 7,2k3 x 960 SSD
osl-storage-06 96GB Xeon Silver 4116 2 x 240 SDD7 x 2TB 7,2k5 x 960 SSD
osl-storage-07 96GB Xeon Silver 4116 2 x 240 SDD7 x 2TB 7,2k5 x 960 SSD
osl-compute-01 512GB 2 x Xeon E5-2680 v3 2 x 200GB SSD2 x 400 SSD
osl-compute-02 512GB 2 x Xeon E5-2680 v3 2 x 200GB SSD2 x 400 SSD
osl-compute-03 512GB 2 x Xeon E5-2680 v3 2 x 200GB SSD2 x 400 SSD
osl-compute-04 512GB 2 x Xeon E5-2680 v4 2 x 200GB SSD2 x 400 SSD
osl-compute-05 512GB 2 x Xeon E5-2680 v4 2 x 200GB SSD2 x 400 SSD
osl-compute-06 512GB 2 x Xeon E5-2680 v4 2 x 200GB SSD2 x 400 SSD
osl-compute-07 512GB 2 x Xeon Gold 6130 2 x 960GB SSDosl-compute-08 512GB 2 x Xeon Gold 6130 2 x 960GB SSD
BGO
Name RAM CPU Diskbgo-controller-01 128GB Xeon E5-2680 v3 2 x 200 SSDbgo-controller-02 128GB Xeon E5-2680 v3 2 x 200 SSDbgo-controller-03 128GB Xeon E5-2680 v3 2 x 200 SSD
Continued on next page
240 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Table 3 – continued from previous pageName RAM CPU Diskbgo-controller-04 64GB Xeon E5-2620 v3 2 x 64 SSD (?)
2 x 200 SDD (?)9 TB HDD
bgo-storage-01 128GB Xeon E5-2680 v3 2 x 200 SSD5 x 2TB 7,2k3 x 960 SSD
bgo-storage-02 128GB Xeon E5-2680 v3 2 x 200 SSD5 x 2TB 7,2k3 x 960 SSD
bgo-storage-03 128GB Xeon E5-2680 v3 2 x 200 SSD5 x 2TB 7,2k3 x 960 SSD
bgo-storage-04 128GB Xeon E5-2680 v3 2 x 200 SSD5 x 2TB 7,2k3 x 960 SSD
bgo-storage-05 128GB Xeon E5-2680 v3 2 x 200 SSD5 x 2TB 7,2k3 x 960 SSD
bgo-storage-06 96GB Xeon Silver 4116 2 x 240 SDD7 x 2TB 7,2k5 x 960 SSD
bgo-storage-07 96GB Xeon Silver 4116 2 x 240 SDD7 x 2TB 7,2k5 x 960 SSD
bgo-compute-01 512GB 2 x Xeon E5-2680 v3 2 x 200GB SSD2 x 400 SSD
bgo-compute-02 512GB 2 x Xeon E5-2680 v3 2 x 200GB SSD2 x 400 SSD
bgo-compute-03 512GB 2 x Xeon E5-2680 v3 2 x 200GB SSD2 x 400 SSD
bgo-compute-04 512GB 2 x Xeon E5-2680 v4 2 x 200GB SSD2 x 400 SSD
bgo-compute-05 512GB 2 x Xeon E5-2680 v4 2 x 200GB SSD2 x 400 SSD
bgo-compute-06 512GB 2 x Xeon E5-2680 v4 2 x 200GB SSD2 x 400 SSD
bgo-compute-07 512GB 2 x Xeon E5-2680 v3 2 x 200GB SSDbgo-compute-08 512GB 2 x Xeon E5-2680 v3 2 x 200GB SSDbgo-compute-09 512GB 2 x Xeon E5-2680 v3 2 x 200GB SSDbgo-compute-10 512GB 2 x Xeon E5-2680 v3 2 x 200GB SSD
1.7 Kundeinformasjon
Disse sidene er laget for å gi mer informasjon til kundene av UH-IaaS. Med kunder mener man dem som bestiller ogadministrerer bruk av UH-IaaS på de tilsluttede organisasjonene.
1.7.1 Priser og flavors
Sist endret: 2018-02-28
1.7. Kundeinformasjon 241
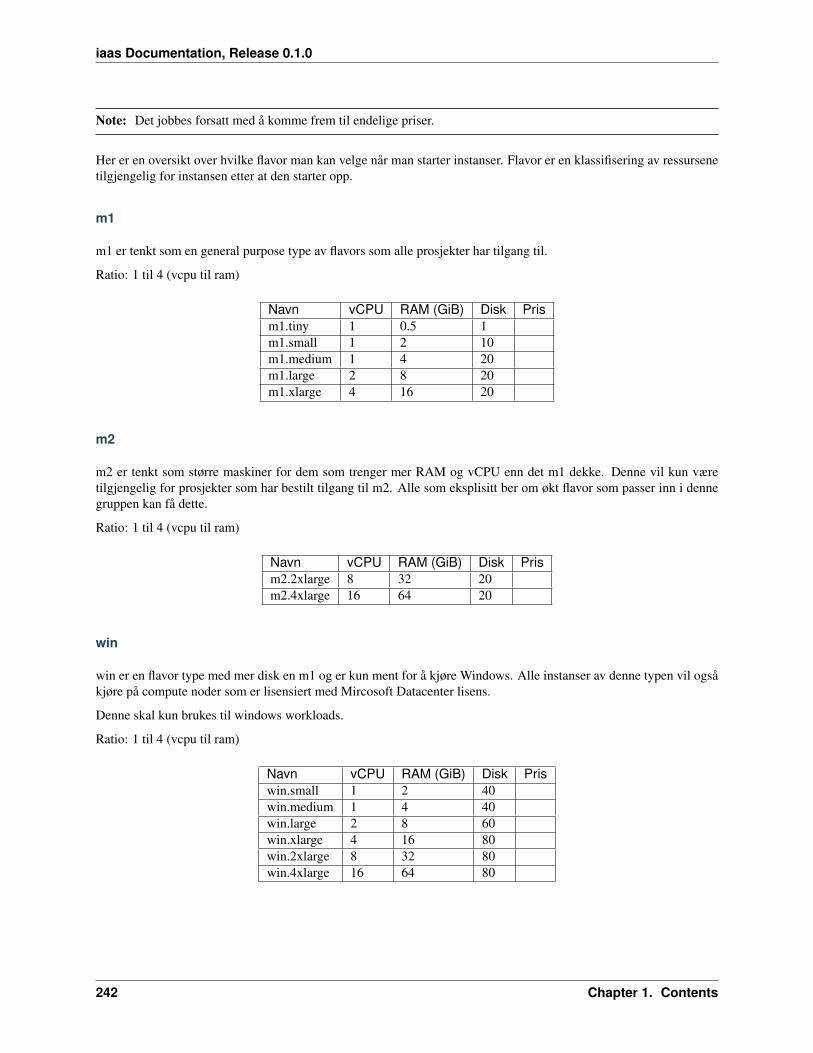
iaas Documentation, Release 0.1.0
Note: Det jobbes forsatt med å komme frem til endelige priser.
Her er en oversikt over hvilke flavor man kan velge når man starter instanser. Flavor er en klassifisering av ressursenetilgjengelig for instansen etter at den starter opp.
m1
m1 er tenkt som en general purpose type av flavors som alle prosjekter har tilgang til.
Ratio: 1 til 4 (vcpu til ram)
Navn vCPU RAM (GiB) Disk Prism1.tiny 1 0.5 1m1.small 1 2 10m1.medium 1 4 20m1.large 2 8 20m1.xlarge 4 16 20
m2
m2 er tenkt som større maskiner for dem som trenger mer RAM og vCPU enn det m1 dekke. Denne vil kun væretilgjengelig for prosjekter som har bestilt tilgang til m2. Alle som eksplisitt ber om økt flavor som passer inn i dennegruppen kan få dette.
Ratio: 1 til 4 (vcpu til ram)
Navn vCPU RAM (GiB) Disk Prism2.2xlarge 8 32 20m2.4xlarge 16 64 20
win
win er en flavor type med mer disk en m1 og er kun ment for å kjøre Windows. Alle instanser av denne typen vil ogsåkjøre på compute noder som er lisensiert med Mircosoft Datacenter lisens.
Denne skal kun brukes til windows workloads.
Ratio: 1 til 4 (vcpu til ram)
Navn vCPU RAM (GiB) Disk Priswin.small 1 2 40win.medium 1 4 40win.large 2 8 60win.xlarge 4 16 80win.2xlarge 8 32 80win.4xlarge 16 64 80
242 Chapter 1. Contents

iaas Documentation, Release 0.1.0
d1
Ratio: 1 til 4 (vcpu til ram)
d1 er en flavor type med mer disk enn m1. Denne vil kreves for å kunne kjøre Windows og vil kun være tilgjengeligfor prosjekter som har bestilt tilgang til d1.
Vær restriktiv i forhold til hvem som får tildelt tilgang til flavors i denne gruppen!
Ratio: 1 til 4 (vcpu til ram)
Navn vCPU RAM (GiB) Disk Prisd1.small 1 2 40d1.medium 1 4 40d1.large 2 8 60d1.xlarge 4 16 80d1.2xlarge 8 32 80d1.4xlarge 16 64 80
c1
c1 en er flavor type for dem som trenger mer vCPU enn m1.
Ratio: 1 til 2 (vcpu til ram)
Navn vCPU RAM (GiB) Disk Prisc1.medium 1 2 20c1.large 2 4 20c1.xlarge 4 8 20c1.2xlarge 8 16 20c1.4xlarge 16 32 20
r1
r1 er tenkt som en maskin med mer RAM som m1 og c1 dekker.
Ratio: 1 til 8 (vcpu til ram)
Navn vCPU RAM (GiB) Disk Prisr1.medium 1 8 20r1.large 2 16 20r1.xlarge 4 32 20r1.2xlarge 8 64 20r1.4xlarge 16 128 20
Andre typer flavor
Vi vil utvide med flere typer flavor etter behov.
1.7. Kundeinformasjon 243

iaas Documentation, Release 0.1.0
1.7.2 Prosjektinformasjon
Prosjekt er den arbeidsflaten man har i UH-IaaS for å konsumere ressurser. Hvert prosjekt har sin egen kvote og kanfå tilgang til egne flavors.
Alle ressurser i prosjektet, som instanser, lagring eller image, er kun tilgjengelig i prosjektet og kan ikke flyttes ellerdeles med andre prosjekter.
Prosjekttype
Sist endret: 2017-09-14
Note: Under arbeid. Dette er et utkast og ikke et endelig dokument.
Her er en beskrivelse av de forskjellige prosjekttypene vi har i UH-IaaS.
Demo
Alle brukere får tilgang til et demo-prosjekt som bare har default kvote og vil kjøre på ledig kapasitet. Ved teknisk-eller ressursutfordringer vil resurser kunne bli stoppet, flyttet eller slettet. Dersom dette inntreffer skal brukerne avdemo-prosjektet bli informert.
Demo-prosjekt vil få navn DEMO-<navn>.<org>
Felles
Dette er den vanligste form for prosjekter hvor man deler på ressursene i et prosjekt med flere brukere. Dette vil væreaktuelt for forskningsgrupper, studentforeninger eller andre typer team som jobber sammen.
Alle prosjekt trenger en administrator som er kontaktpunkt og ansvarlig for ressursbruken i prosjektet.
Personlig
Dersom det ikke er aktuelt å jobbe sammen med andre eller dele ressurser med andre kan man få opprettet et personligprosjekt. Dette vil typisk være aktuelt for studenter som trenger de samme ressursene gjennom hele studietiden ellerandre som ønkser å større kvote enn det som demo-prosjekt gir.
Alle ressurser følger brukeren og vil bli slettet når brukeren ikke lenger er tilknyttet en av de tilsluttede organisasjonene.
Personlig-prosjekt vil få navn PRIVATE-<navn>.<org>
Kurs
Kursprosjekt er midlertidige prosjekter som blir brukt i forbindelse med undervisning. Hver deltaker, undervisere ogstudenter, vil få sitt eget prosjekt. Prosjekt vil bli slettet når undervisningen er over.
244 Chapter 1. Contents

iaas Documentation, Release 0.1.0
Kvoter
Sist endret: 2017-09-14
Note: Under arbeid. Dette er et utkast og ikke et endelig dokument.
Hvor mye ressurser det er mulig å bruke i et prosjekt er styrt av kvoter. Kvoter blir satt per region, og dersom etprosjekt ikke har fått tildelt en kvote vil den automatisk få default kvote (se under).
Default kvote
Alle prosjekter som ikke har fått egen kvote i en region vil få tildelt default kvote. Alle demo-prosjekt har også defaultkvote. Denne er lik for alle og vil ikke bli endret.
kvote navn defaultInstanser instances 2vCPU cores 2Minne ram 2048 MBVolum antall volumes 1Volum størrelse gigabytes 20 GBVolum snapshot snapshots 3
Forklaring
Alle kvoter gjelder summen av alle ressurser brukt i et prosjekt i en region.
Instanser
Total antall instanser det er mulig å opprette i et prosjekt.
vCPU
Antall prosessorer (vCPU) det er mulig å tildele instanser.
Minne
Størrelsen på minne det er mulig å tildele instanser.
Volum antall
Volum er er benevnelse på blokklagringen i UH-IaaS. Volum antall sier hvor mange volum det er mulig å lage i etprosjekt.
Volum størrelse
Total størrelse av alle volum i et prosjekt.
1.7. Kundeinformasjon 245

iaas Documentation, Release 0.1.0
Volum snapshot
Totalt antall snapshot av alle volum i et prosjekt.
246 Chapter 1. Contents
Related Documents











