Achieving Fault tolerance in databases by replication

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Achieving Fault tolerance in
databases by replication

What is replication We all must be thinking how we can achieve fault
tolerance by the help of the replication
Replication in databases is nothing but storing the
same information in synchronization at multiple
location so that in cases of the primary databases
failure a replicated can takeover.

Availability and reliability• A system goes down 1ms/hr has an availability of more
than 99.99%, but is unreliable.
• A system that never crashes but is shut down for a week once every year is 100% reliable but only 98% available

Replication strategiesThere are two basic parameters to select when designing a replication strategy: where and when.
Depending on when the updates are propagated:
• Synchronous (eager)
• Asynchronous (lazy)
Depending on Where the updates can take place:
• Primary Copy (master)
• Update Everywhere (group)
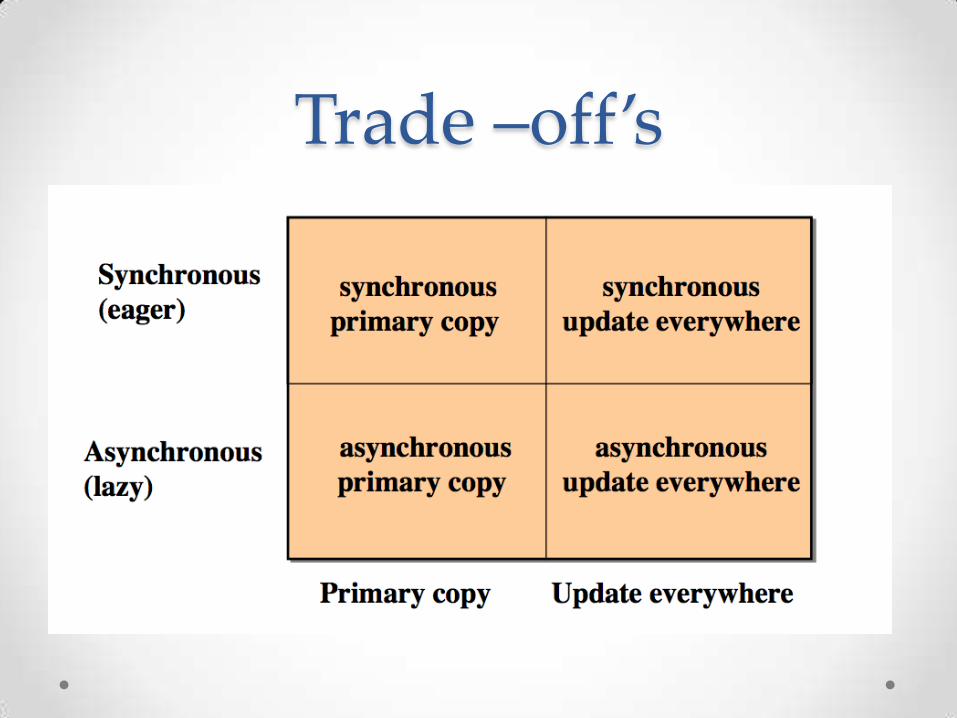
Trade –off’s

Why replication??
PERFORMANCE
Location transparency is difficult to achieve in a distributed environment. Local accesses are fast, remote accesses are slow. If everything is local, then all accesses should be fast.
FAULT TOLERANCE
Failure resilience is also difficult to achieve. If a site fails, the data it contains becomes unavailable. By keeping several copies of the data at different sites, single site failures should not affect the overall availability.

When replication is implemented in industry
When evaluating a commercial replication strategy, keep in mind:
• The customer base (who is going to use it?).
• The underlying database (what can the system do?).
• What competitors are doing (market pressure).
• There is no such thing as a “better approach”.
• The complexity of the problem

Sybase architecture

sybase• Loose consistency (= asynchronous).
• Primary copy.
• PUSH model: replication takes place by “subscription”. A site subscribes to copies of data. Changes are propagated from the primary as soon as they occur. When the changes are made they are pushed to the replicated sites.
• The goal is to minimize the time the copies are not consistent but still within an asynchronous environment there is some delay .

Sybase• Persistent queues are used to store changes in case of
disconnection.
• The Log Transfer Manager monitors the log of Sybase SQL Server and notifies any changes to the replication server. It acts as a light weight process that examines the log to detect committed transactions (a wrapper). Usually runs in the same system as the source database.
• When a transaction is detected, its log records are sent to the:

Syabse• The Replication Server usually runs on a different
system than the database to minimize the load.
• It takes updates, looks who is subscribed to them and send them to the corresponding replication servers at the remote site.

ClustRa • It was designed with a focus of scalability, high
performance and fault tolerance.
• The replicated databases is in hot standby mode.
• It makes use of the 2 phase commit Protocol as well.
• It can tolerate both types of fault -media failures as
well as disk failures.
• It makes use of heartbeat messages being sent by
each node in order to detect faults and a missing
hear beat signifies that there is a fault.

Evaluation of ClustRa• Clustra has an availability of 99.999% and lies in the
class 5 and a downtime of no more than 5 minutes
in a year.
• When evaluating the effectiveness of ClustRa
against failures it was done in the experiment by
injecting faults in the data buffers which is the
primary component of the database.
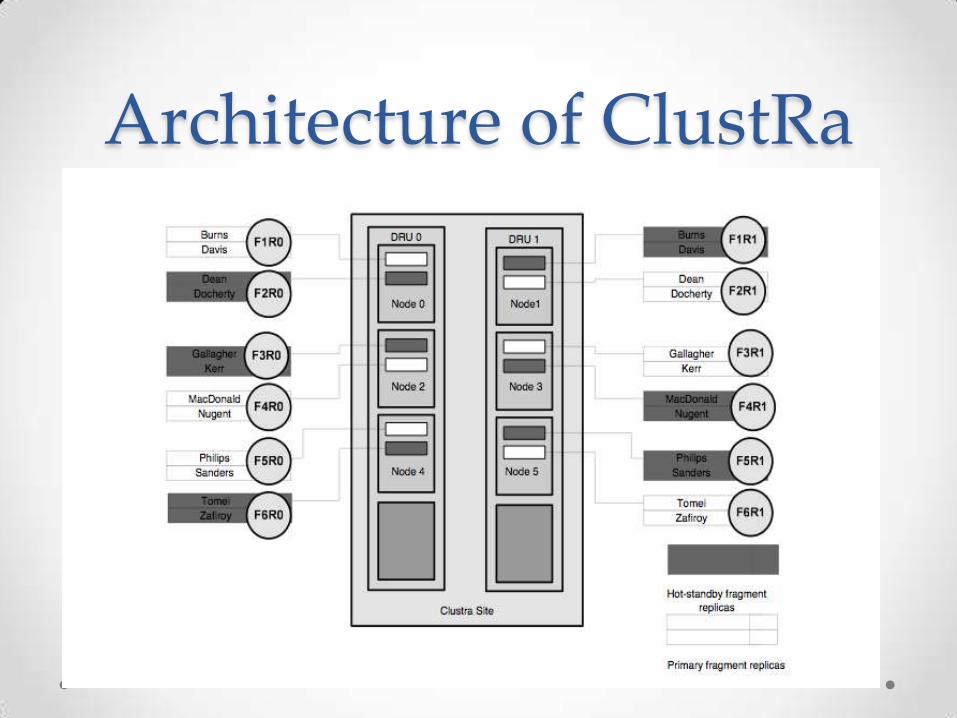
Architecture of ClustRa

Strategies used in ClustRA
• Makes use of mirror nodes
• Node recovery
• Node failure
• Take back stage
• Mirror node take over stage
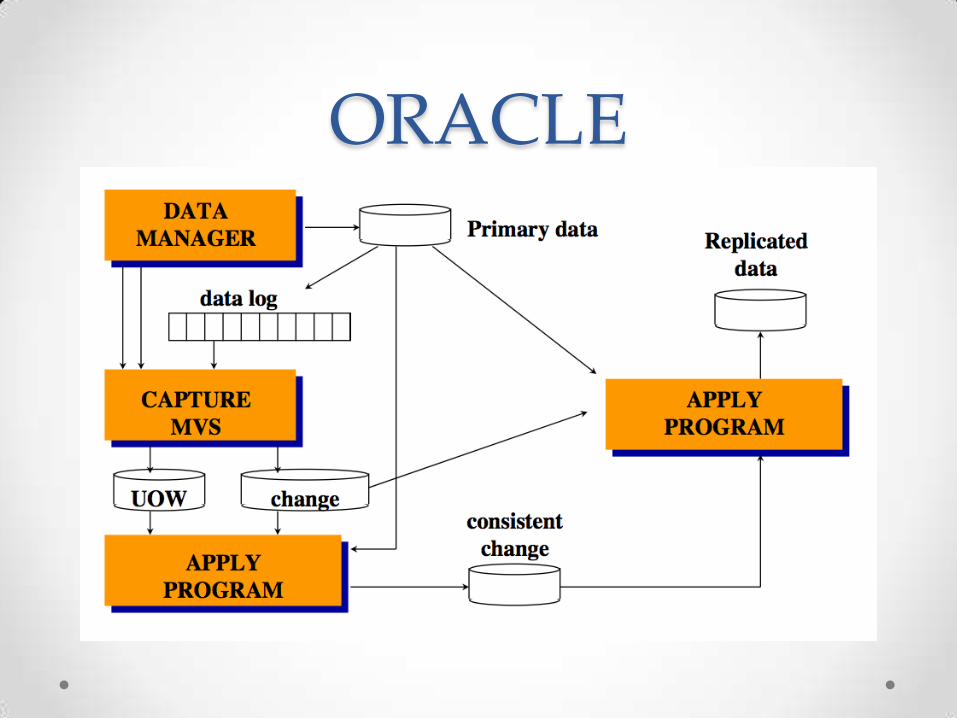
ORACLE

Oracle • Goals: Flexibility. It tries to provide a platform that
can be tailored to as many applications as possible.
It provides several approaches to replication and
the user must select the most appropriate to the
Application.
• There is no such thing as a “bad approach”, so all
of them must be supported (or as many as possible)

Design of oracle• One of the earliest implementations: Snapshot. This was
a copy of the database. Refreshing was done by getting a new copy.
• Symmetric replication: changes are forwarded at time intervals (push) or on demand (pull).
• Asynchronous replication is the default but synchronous is also possible.

Replication strategies• Implements fast recovery strategy
• Makes use of the incremental check pointing
• Lazy roll back
• Makes use of the multi master replication.

In Microsoft SQL servers• Transactional replication: Only the committed changes
made at the primary database are sent to the subscribing replica’s
• Snapshot replication :Entire state of the primary database is captured and applied to the replica. Can be scheduled periodically or manually.
• Merge replication: Different sites can modify the databases replica’s.

2 phase commit protocol

2 PHC PROBLEMS • The most common problem is of blocking
• The second is that it is a costly one.
• Decreases the availability of the involved database
• Imposes high performance overhead
• Most commercials systems make use of this protocol in order to support synchronization and consistency.
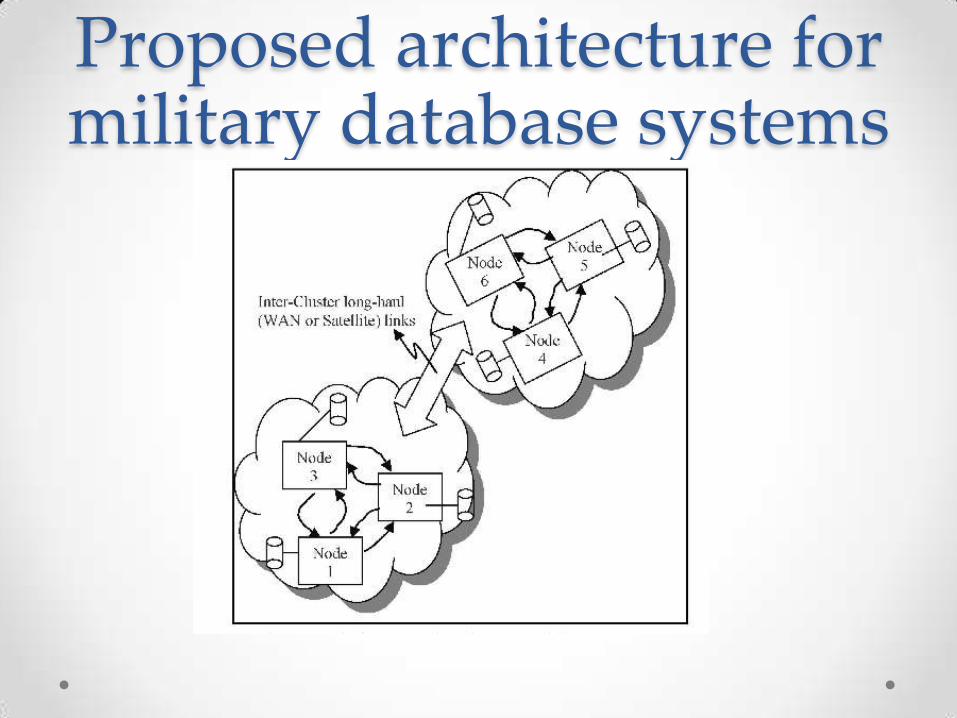
Proposed architecture for military database systems

Working • Each node in the cluster is assigned numbers.
• In case of any node failure node with the higher value becomes the coordinator in the group.
• We implement fault injection in the design phase itself and also apply it to different areas of the databases.
• Data is replicated among each node and therefore in case of any node failure or particular unit others cluster node can be used to recover from the failure.

Proposed design• No Central point of failure
• No Blocking state because making use 1 phase commit protocol
• We make use of the pull/push both approaches.
• Making use of merge replication

What we have used in the model
• Checkpoints
• To make a choice between 2 phase protocol and 1 phase protocol
• To evaluate against failures we are going to inject faults in the system at various points.
• To choose between synchronous and asynchronous model.
• To choose between centralization and decentralization

References• http://ieeexplore.ieee.org.ezproxy.library.uvic.ca/stamp/stamp.jsp?tp=&arnumb
er=781065
• http://users.encs.concordia.ca/~bcdesai/grads/steluta/references/Clustra_Conc
epts.pdf
• R.J. Ramsden, "Database synchronisation in military command and control
systems," IEEE International Conference Information-Decision-Action Systems in
Complex Organisations, pp. 115 - 117, 6-8 Apr 1992.
• D. Harel , H. Lachover , A. Naamad , A. Pnueli , M. Politi , R. Sherman and A. Shtul-
Trauring "STATEMENT: A working environment for the development of complex
reactive systems", IEEE Transactions on Software Engineering, vol. 16, no.
4, pp.403 -414 1990
• R. Chillarege and N. Bowen "Understanding Large System Failures - A Fault
Injection Experiment", Proc. 19th. Ann. Int†™l Symp. Fault Tolerant
Computing, pp.356 -363 1989 P. Bohannon , J. Parker , R. Rastogi , S. Seshadri , A.
Silberschatz and S. Sudarshan "Distributed Multi-Level Recovery in Main-Memory
Databases", Distributed and Parallel Database Systems Journal, vol. 6, no.
1, 1998







Related Documents











