Design of a High- Throughput Distributed Shared-Buffer NoC Router Rohit Sunkam Ramanujam*, Vassos Soteriou † , Bill Lin*, Li-Shiuan Peh ‡ *Dept. of Electrical Engineering, UCSD, USA † Dept. of Electrical Engineering, CUT, Cyprus ‡ Dept. of Electrical Eng. and Computer Science, MIT, USA 1

Design of a High-Throughput Distributed Shared-Buffer NoC Router Rohit Sunkam Ramanujam*, Vassos Soteriou †, Bill Lin*, Li-Shiuan Peh ‡ *Dept. of Electrical.
Dec 21, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Design of a High-Throughput Distributed Shared-Buffer NoC Router
Rohit Sunkam Ramanujam*, Vassos Soteriou†, Bill Lin*, Li-Shiuan Peh‡
*Dept. of Electrical Engineering, UCSD, USA†Dept. of Electrical Engineering, CUT, Cyprus
‡Dept. of Electrical Eng. and Computer Science, MIT, USA
2
Chip Multiprocessor
Uniprocessor
•Power wall•Frequency wall•ILP wall•Non-Recurring Engineering costs•Time to market
Chip Multiprocessors are a reality …
Sources: Intel Inc. and Tilera Inc.

3
The need for a Network on Chip (NoC)
• Scalable communication• Modular design• Efficient use of wires• A new way to organize and build VLSI systems
Compute UnitRouter

4
The Problem – Delivering high throughput in NoCs
• Why Care?– NoCs in CMPs connect general-purpose processors.– Future applications unknown → traffic unknown. – Exploiting parallelism needs fine-grained interaction
between cores. – Can expect high traffic volume for current and future
applications running on many-core processors.– E.g. Cache coherence between large number of
distributed shared L2 caches.

5
An important design choice that affects throughput
• Router microarchitecture – How well does a router multiplex packets onto its
output links?

6
NoC routers – Current design
cycle = 1cycle = 2
Input 1
Input 2
Output 1
Output 2
Maximal Matching: Input 1 → Output 1Maximal Matching: Input 2 → Output 1
Output 2 is unutilized in cycle 3 although there is a flit destined for output 2. Bottleneck: Maximal matching used for arbitration is not good enough.
(70-80% efficiency)
Input Buffered Routers (IBRs) – Flits buffered at the input ports
cycle = 3
Crossbar

7
Output queueing to the rescue …
cycle = 1cycle = 2cycle = 3
Input 1
Input 2
Output 1
Output 2
Output links are always utilized when there are flits available.Better multiplexing of flits onto output links higher throughput. ⇒
Crossbar
Output buffered router (OBR) – Flits buffered at the output ports

8
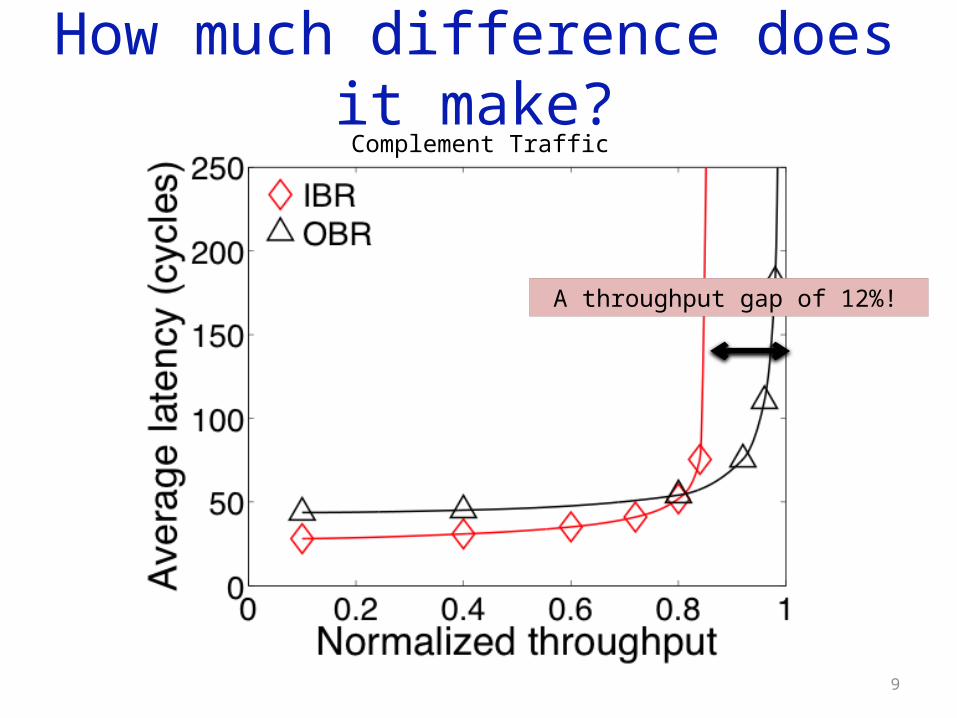
How much difference does it make?
A throughput gap of 18%!
Uniform Traffic
9
A throughput gap of 12%!
Complement Traffic
How much difference does it make?

10
A throughput gap of 22%!
Tornado Traffic
How much difference does it make?

12
Output Buffering is great …
• OBRs offer much higher throughput than IBRs.
• OBRs have predictable delay.– Queuing delay modeled using M/D/1 queues.
• Packet delays not predictable for IBRs.

13
So why aren’t OBRs used in NoCs ?
• Implementing Output Buffering requires either:– Crossbar speedup of P, where P is the number of ports.
Not practical for aggressively clocked designs.– Output buffers with P write ports and a PxP2 crossbar.
Has huge area and power penalties.
.
.
.
Input 2
Input P-1
Input 1Output 1
.
.
.
Output P-1
Crossbar
14
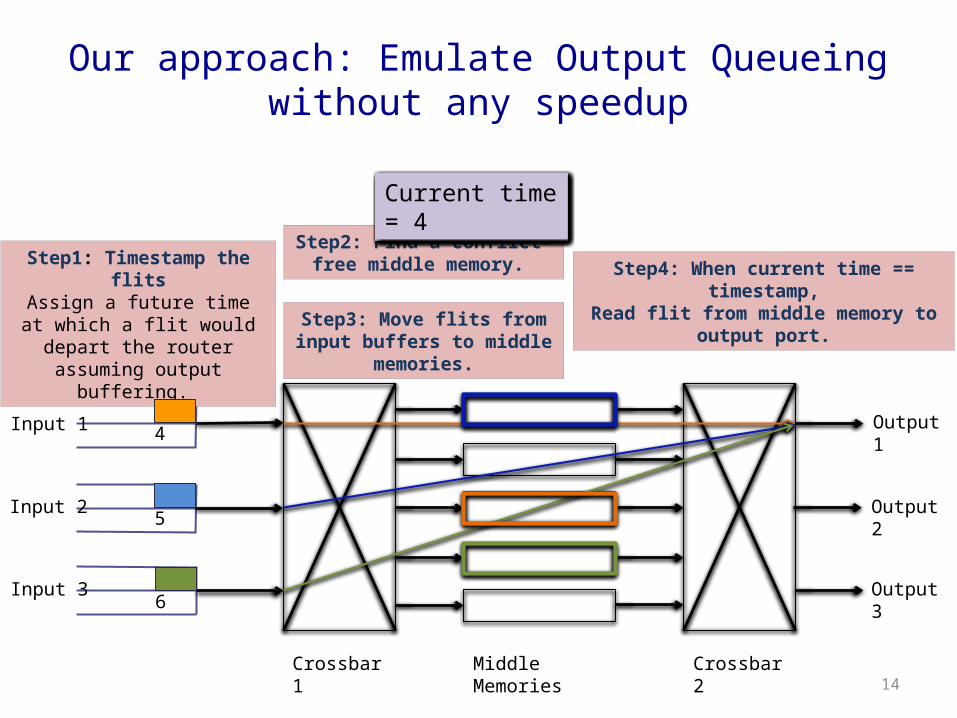
Our approach: Emulate Output Queueing without any speedup
Input 1
Input 2
Input 3
Crossbar 1 Crossbar 2Middle Memories
Output 1
Output 2
Output 3
Step1: Timestamp the flitsAssign a future time at which a
flit would depart the router assuming output buffering.
5
6
Step2: Find a conflict-free middle memory. Step4: When current time == timestamp,
Read flit from middle memory to output port.
Current time = 1Current time = 2Current time = 3Current time = 5Current time = 6
4
Step3: Move flits from input buffers to middle memories.
Current time = 4

15
Arrival and Departure Conflicts
• Arrival Conflicts – With P input ports, a flit can have an arrival conflict with P-1 other flits.
• Departure Conflicts – With P output ports, a flit can have a departure conflict with P-1 other flits.
• By Pigeon hole principle, 2P-1 middle memories needed to avoid all arrival and departure conflicts.

16
The Distributed Shared-Buffer Router (DSB)
• Aims at emulating the packet servicing scheme of an OBR with limited buffers and no speedup.
– First-Come-First-Served servicing of flits.
Objectives:– Close the performance gap between OBRs with infinite buffers
and IBRs (high throughput).– Make a feasible design → low power and area overhead.– Make packet delays more predictable for delay sensitive NoC
applications.

17
DSB RouterInnovations
– Router pipeline with new stages for:• Timestamping flits• Finding a conflict free middle memory
– Complexity and delay-balanced pipeline stages for a high-clocked, high-performance implementation.
– New flow control to prevent packet dropping when resources are unavailable.
– Evaluate power-performance tradeoff of DSB architectures with fewer than 2P-1 middle memories.

18
Evaluation
• Cycle accurate flit level simulator.• Mesh topology – Each router has 5 ports,
NSEW + Injection/Ejection.• Dimension Ordered Routing (DOR) – decouple
effects of routing algorithm on network performance.

19
Evaluation – Traffic traces • 3 Synthetic traffic traces:
– Uniform– Bit Complement (Complement)– Tornado
• Real traffic/memory traces from running multiple threads (49 threads 7x7 Mesh) of ⇒eight SPLASH-2 benchmarks:– Complex 1D FFT, LU decomposition, Water-
nsquared, Water-spatial, Ray tracer, Barnes-Hut, Integer Radix sort, Ocean simulation.

20
Performance on Uniform traffic
A throughput gap of just 9%
21
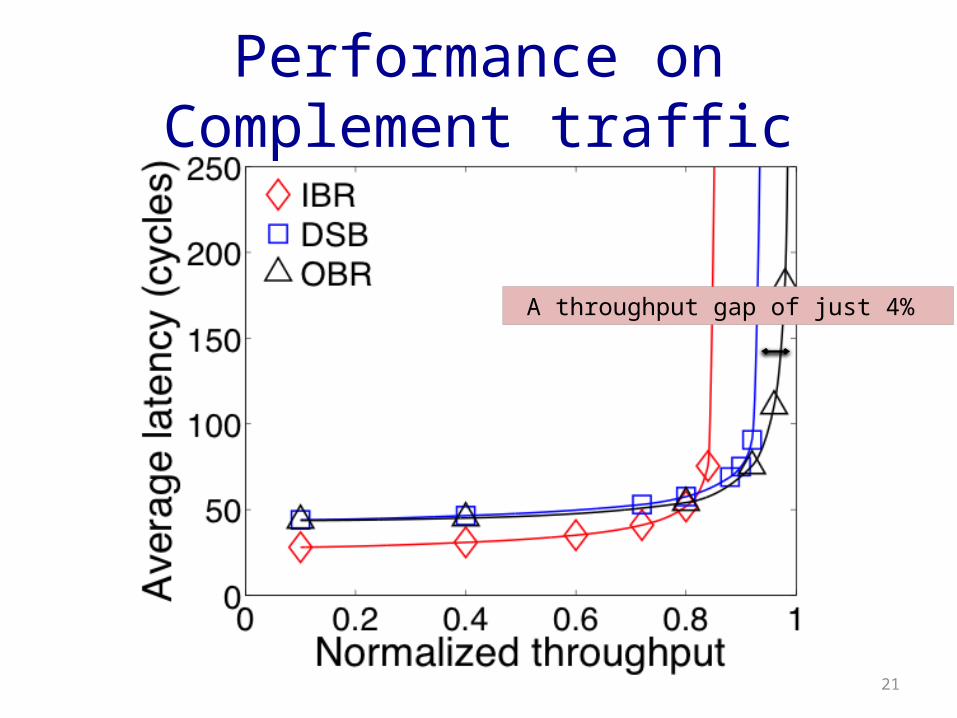
Performance on Complement traffic
A throughput gap of just 4%

22
Performance on Tornado traffic
A throughput gap of just 8%

23
FFT LU
WATER-N
SQARED
WATER-SPATIAL
RADIX
RAYTRACE
BARNES
OCEAN0
0.20.40.60.8
11.21.41.6 IBR200 DSB200 OBR-5stage
Performance of DSB on SPLASH-2 benchmarksPerformance of DSB is very close to an OBR with same number of pipeline
stages.Small difference in packet latency between OBR and DSB routers is mainly due to
the limited buffering in the DSB router.Huge performance improvements over IBR in traces exhibiting high
contention and demanding high bandwidth.
97%
64% 72%
Raytrace, Barnes and Ocean traces have very little contention.For these traces, IBR has lower latency because of a shorter pipeline.

24
Input Buffered Router (IBR) pipeline
RCVA
SA ST LT
Route ComputationDetermine the output port of the flit based on the destination coordinates.
Virtual Channel AllocationReserve an output Virtual Channel (buffering) at the next hop router.
Switch ArbitrationAcquire access to the output port through the crossbar.
Switch TraversalTraverse the crossbar to reach the output link.
Link TraversalTraverse the link to reach the input buffer of the next hop router.
Input 1
Input 2
utput 1
Output 2
Crossbar

25
Distributed Shared-Buffer Router pipeline
RC
TS
CR XB1 +MM_WR LT
Route ComputationDetermine the output port of the flit based on the destination coordinates.
Timestamp AllocationAssign a timestamp to a flit for the output port requested.
Timestamp is the future time (cycle) at which the flit can depart the middle memory buffer.
Conflict Resolution + Virtual Channel AllocationConflict Resolution: Find a conflict free middle memory.
Virtual Channel Allocation: Reserve a virtual channel at the input of the next hop router.
Crossbar 1 + Middle Memory WriteFlit traverses the first crossbar and gets written into the assigned middle memory.
Middle Memory Read + Crossbar 2When the current time equals the timestamp, the flit is read from the middle
memory and traverses the second crossbar.
VA
MM_RD + XB2
Link TraversalFlit traverses the output link to reach the input buffer of the next-hop router.
Input 1
Input 2
Output 1
Output 2
Crossbar 1 Crossbar 2Middle Memory
If CR or VA fails

26
Higher throughput – At what cost?Extra
power !!RC
TS
CR XB1 +MM_WR LT
VA
MM_RD + XB2
Input 1
Input 2
Output 1
Output 2
Crossbar 1 Crossbar 2Middle Memory
TS stage instead of Switch Arbitration in IBRsExtra stage for Conflict ResolutionMiddle memory buffers – Can have fewer input buffers to compensate for extra middle memory buffers.
Two crossbars instead of one: With N middle memories, need one PxN and one PxN crossbar.

27
Power-Performance tradeoff
• Theoretically, 2P-1 middle memories needed to resolve all conflicts.
• For a 5-port mesh router, need > 9 middle memories, a 5x9 and a 9x5 crossbar – large power overhead.
• What is the impact of using fewer than 2P-1 middle memories?
28
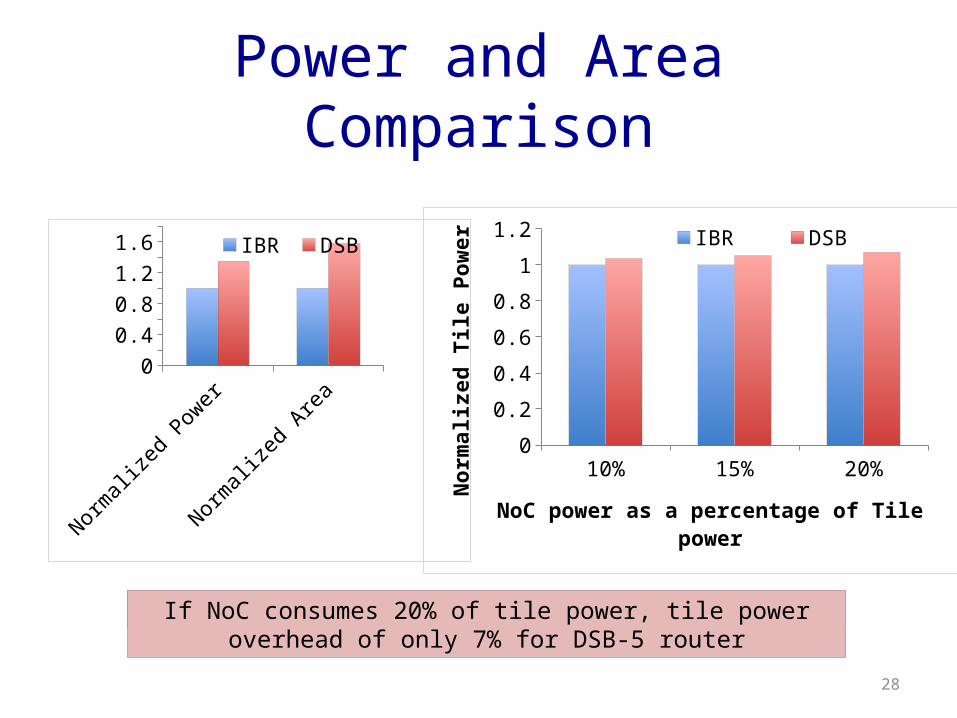
Power and Area Comparison
Router power overhead of 50% for DSB-5 routerIf NoC consumes 10% of tile power, tile power overhead of only 3.5% for DSB-5 router
If NoC consumes 20% of tile power, tile power overhead of only 7% for DSB-5 router
Normalized Power
Normalized Area
00.20.40.60.8
11.21.41.61.8 IBR DSB
10% 15% 20%0
0.2
0.4
0.6
0.8
1
1.2 IBR DSB
NoC power as a percentage of Tile power
Nor
mal
ized
Tile
Pow
er

29
Thank you
• Questions?
Related Documents











