Caffe Framework Tutorial2 Layer, Net, Test

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Caffe Framework Tutorial2
Layer, Net, Test

Index• Layer
– Data– ImageData– Convolution– Pooling– ReLU– InnerProduct– LRN
• Net– Mnist– CIFAR-10– ImageNet (Ilsvrc12)
• Net change Test– Mnist– CIFAR-10
• 64x64x3 Image Folder• 64x64x3 Image Resize To 32x32x3

Data Layerlayer { name: "data" type: "Data" top: "data" top: "label" include { phase: TRAIN } transform_param { mean_file: "examples/cifar10/mean.binaryproto" } data_param { source: "examples/cifar10/ilsvrc12_train_lmdb" batch_size: 100 backend: LMDB }}
• Required– source: the name of the direc-
tory containing the database– batch_size: the number of inputs
to process at one time• Optional
– backend [default LEVELDB]: choose whether to use a LEVELDB or LMDB
LevelDB ,LMDB : efficient databases
• Example– Data.mdb(41MB)– Lock.mdb(8.2kB

ImageData Layerlayer { name: "data" type: "ImageData" top: "data" top: "label" transform_param { mirror: false crop_size: 227 mean_file: "data/ilsvrc12/imagenet_mean.binaryproto" } image_data_param { source: "examples/_temp/file_list.txt" batch_size: 50 new_height: 256 new_width: 256 }}
• Required– source: name of
a text file, with each line giving an image file-name and label
– batch_size: number of im-ages to batch together

Convolution Layerlayer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1“ param { lr_mult: 1 } # learning rate for the filters param { lr_mult: 2 } # learning rate for the biases convolution_param { num_output: 32 # learn 32 filters kernel_size: 5 # each filter is 5x5 pad: 2 stride: 1 # step 1 pixels between each filter appli-cation weight_filler { type: "gaussian“# initialize the filters from a Gaussian std: 0.0001 # default mean: 0 } # initialize the biases to zero (0) bias_filler { type: "constant" } }}
• Required– num_output (c_o): the number
of filters– kernel_size (or kernel_h and k
ernel_w): specifies height and width of each filter
• Strongly Recommended– weight_filler [default type:
'constant' value: 0]• Optional
– pad [default 0]: specifies the number of pixels to (implicitly) add to each side of the input
– stride [default 1]: specifies the intervals at which to apply the filters to the input

Pooling Layerlayer { name: "pool1" type: "Pooling" bottom: "conv1" top: "pool1" pooling_param { pool: MAX kernel_size: 3 stride: 2 }}
• Required– kernel_size : specifies height and width of
each filter• Optional
– pool [default MAX]: the pooling method. Currently MAX, AVE, or STOCHASTIC
– pad [default 0]: specifies the number of pixels to (implicitly) add to each side of the input
– stride [default 1]: specifies the intervals at which to apply the filters to the input
• 예 ) stride 2 : step two pixels (in the bottom blob) between pooling regions
?

ReLU Layer (Rectified-Linear and Leaky-ReLU)
Rectified 정류된 , Leaky-ReLU 새는 , 구멍이 난
layer { name: "relu1" type: "ReLU" bottom: "conv1" top: "conv1" }
• Parameters optional• negative_slope [default 0]:
– specifies whether to leak the negative part by multiplying it with the slope value rather than setting it to 0.
• Input x, Compute Output y• y = x (if x > 0)• y = x * negative_slope (if x
<= 0)

Why ReLU, Drop-Out!• Drop-Out
– 2014. Toronto. paper title• Dropout : A Simple Way to Prevent Neural Networks from Overfitting• The key idea is to randomly drop units (along with their connections) from
the neural network during training– Regularizer 의 일종– Hidden Node 를 모두 훈련시키지 않고 , Random 하게 Drop Out 시킨다
• 관련된 Weight 들은 훈련되지 않는다 .
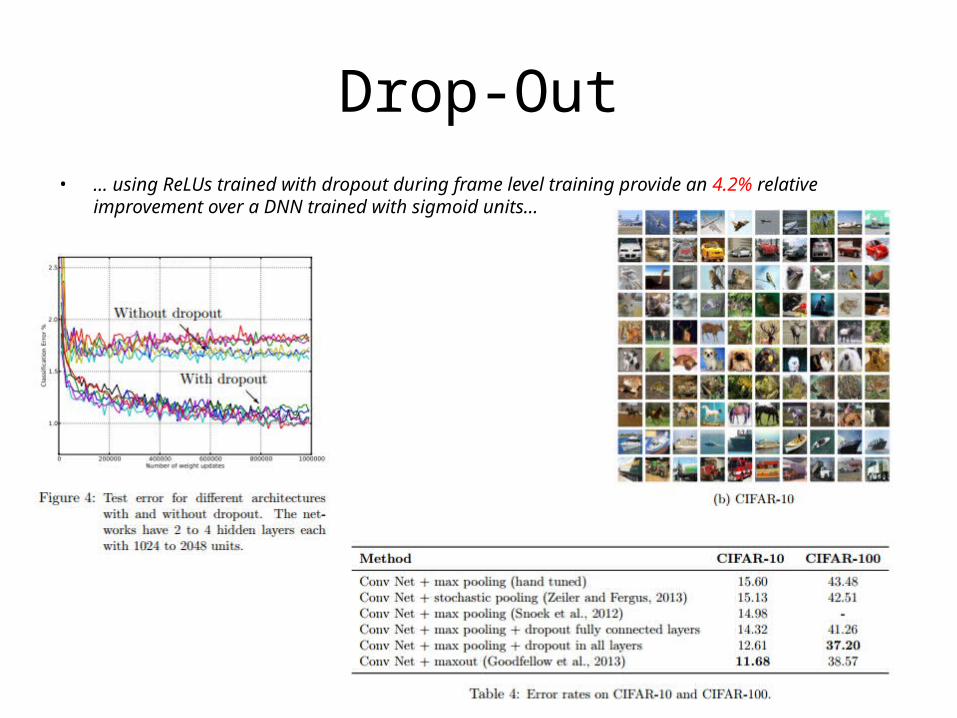
Drop-Out• … using ReLUs trained with dropout during frame level training provide an 4.2% rela-
tive improvement over a DNN trained with sigmoid units…

Rectified-Linear unit(ReLU)
• Drop-Out 은 학습이 느리다 .– Drop Out 된 weight 들은 학습이 일어나지 않는다 .
• Non-Linear Activation Function 의 교체– 일반적으로 사용되는 Logistic Sigmoid, tanh 대신 ReLu 사용
• ReLU 의 장점– reduced likelihood of the gradient to vanish– Sparsity
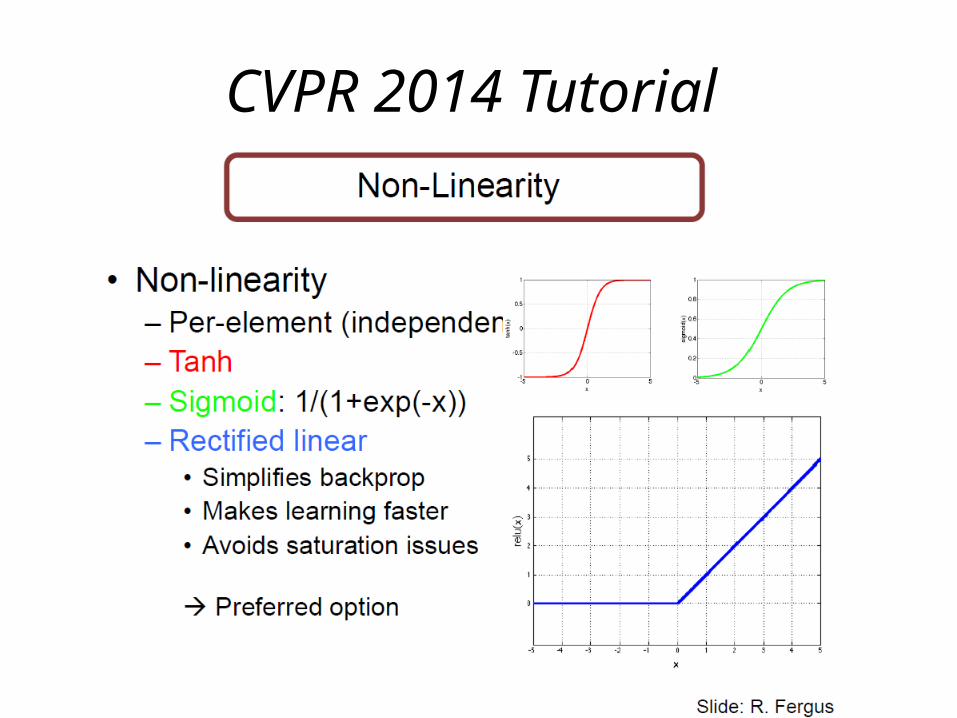
CVPR 2014 Tutorial

InnerProduct Layerlayer { name: "ip1" type: "InnerProduct" bottom: "pool3" top: "ip1" param { lr_mult: 1 } # learning rate for the filters param { lr_mult: 2 } # learning rate for the biases inner_product_param { num_output: 64 weight_filler { type: "gaussian" std: 0.1 } bias_filler {type: "constant“ } # initialize the biases to zero (0) }}
• Required– num_output (c_o): the num-
ber of filters• Input
– n * 컬러채널 * height * width• Output
– n * c_o

LRN Layer (Local Response Normaliza-tion)
layer { name: "norm1" type: "LRN" bottom: "pool1" top: "norm1" lrn_param { local_size: 5 alpha: 0.0001 beta: 0.75 }}
• performs a kind of “lateral inhibi-tion - 측면억제 ( 側面抑制 )” by nor-malizing over local input regions
• Each input value is divided by (1+(α/n)∑ix2i)β, – where n is the size of each local region,
and the sum is taken over the region centered at that value
• Optional– local_size [default 5]: the number of
channels to sum over (for cross chan-nel LRN) or the side length of the square region to sum over (for within channel LRN)
– alpha [default 1]: the scaling parame-ter
– beta [default 5]: the exponent

CIFAR-10 (2010, Hinton/Krizhevsky)
• 10 classes • 32x32 color image• 6,000 images per
class• 5,000 training / 1,000
test images per class• 전체 60,000 장 =
(5,000+1,000) 개 * 10개 클래스

Ilsvrc12(ImageNet large Scale Visual Recognition Challenge 2012)
• AlexNet• 1.3 million high-resolution images– Resize to 224x224x3
• Class 1,000• 150,000 per class• Net– five convolutional layers – two globally connected layers – final 1000-way softmax.
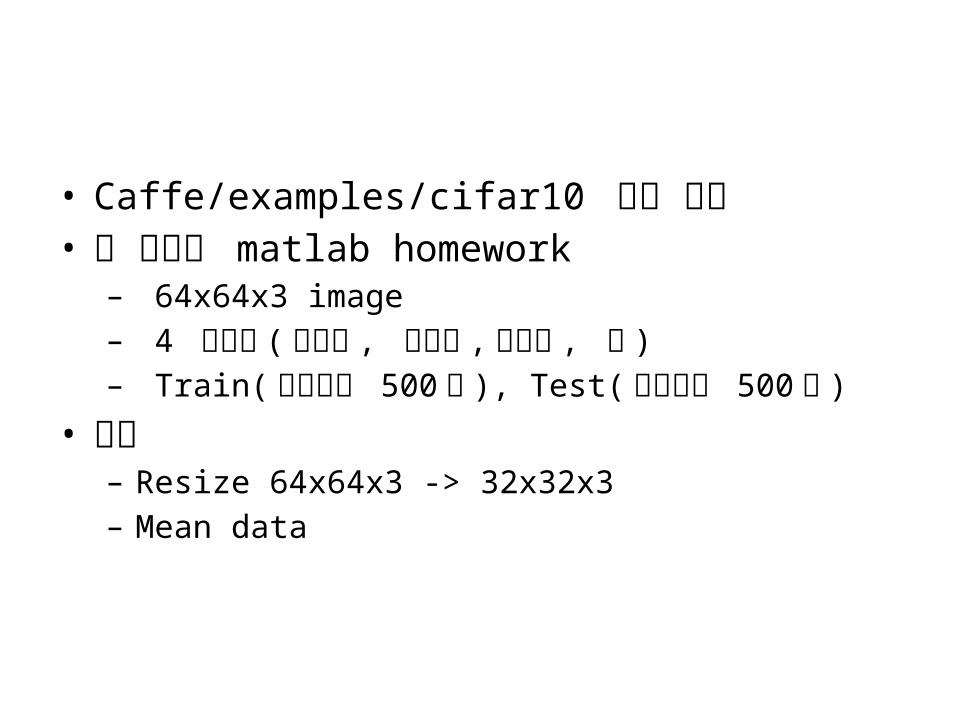
• Caffe/examples/cifar10 모델 사용• 응 교수의 matlab homework– 64x64x3 image– 4 클래스 ( 비행기 , 자동차 , 고양이 , 개 )– Train( 클래스당 500 개 ), Test( 클래스당 500 개 )
• 준비– Resize 64x64x3 -> 32x32x3– Mean data
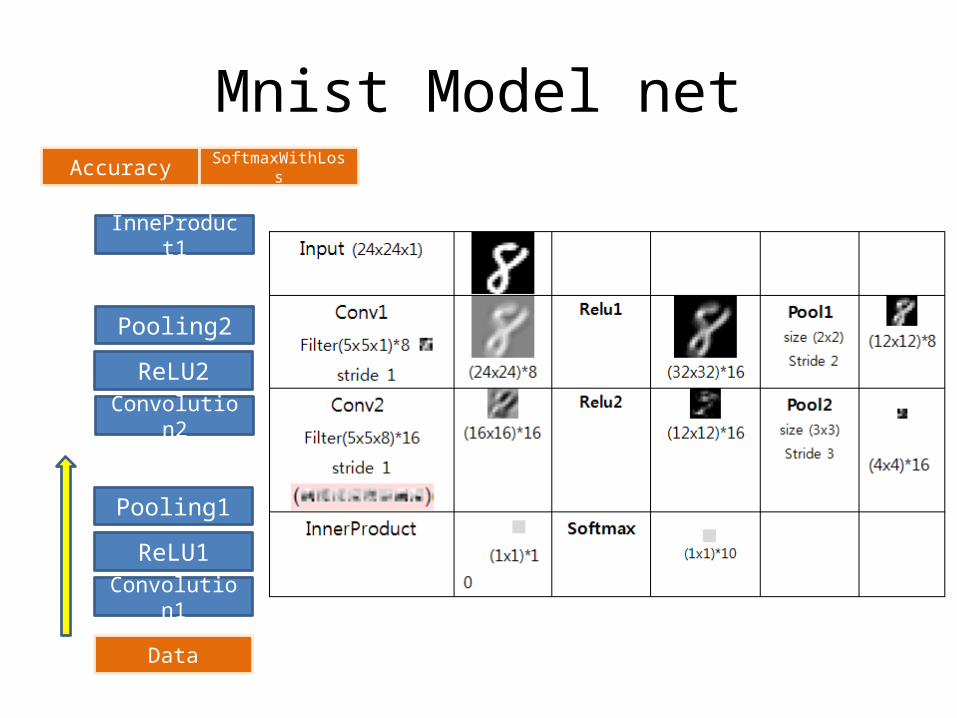
Mnist Model net
Convolu-tion1
Pooling1
Convolu-tion2
Pooling2
ReLU1
InneProd-uct1
Accuracy
Data
SoftmaxWithLoss
ReLU2
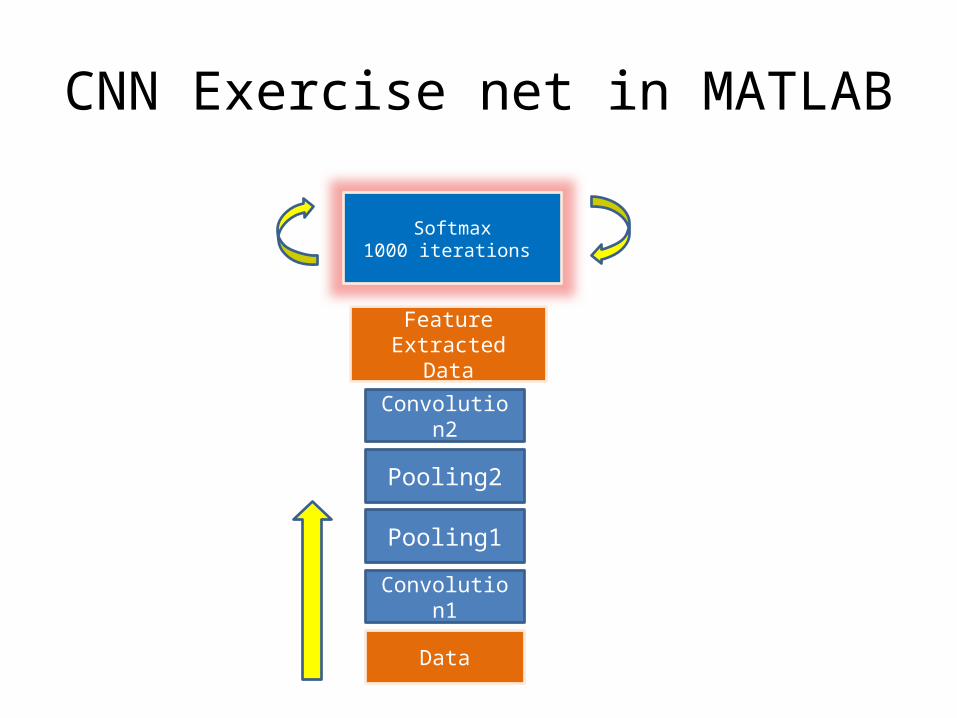
CNN Exercise net in MATLAB
Convolu-tion1
Pooling1
Convolu-tion2
Pooling2
Softmax1000 iterations
Data
Feature Ex-tracted Data
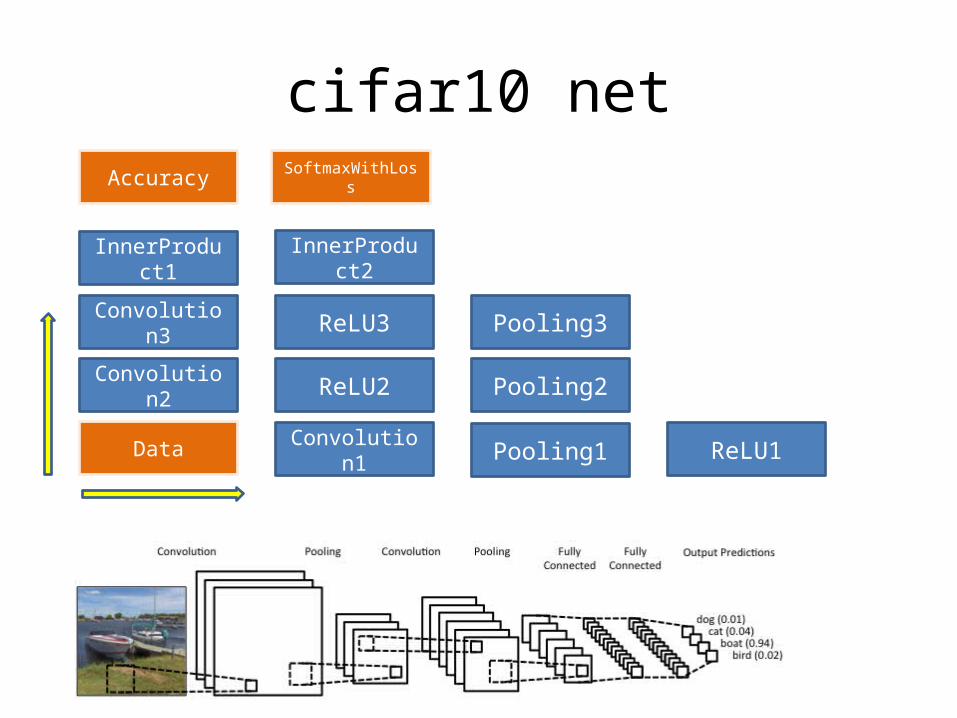
cifar10 net
Convolu-tion1 Pooling1
Convolu-tion2 Pooling2
ReLU1
ReLU2
Convolu-tion3 Pooling3ReLU3
InnerProd-uct1
InnerProd-uct2
Accuracy
Data
SoftmaxWithLoss
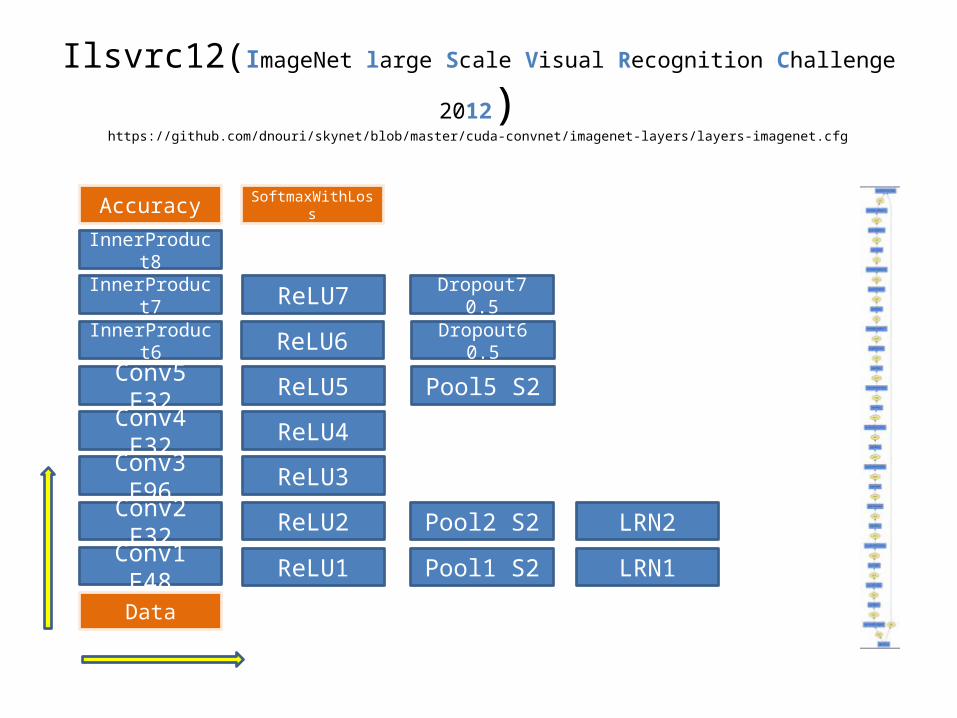
Ilsvrc12(ImageNet large Scale Visual Recognition Challenge 2012)https://github.com/dnouri/skynet/blob/master/cuda-convnet/imagenet-layers/layers-imagenet.cfg
Conv1 F48 ReLU1
Conv2 F32 Pool2 S2
Pool1 S2ReLU2
Conv3 F96
Conv4 F32
ReLU3
InnerProd-uct8
Accuracy
Data
SoftmaxWith-Loss
LRN1LRN2
ReLU4
Conv5 F32 ReLU5 Pool5 S2
InnerProd-uct6 ReLU6 Dropout6 0.5
InnerProd-uct7 ReLU7 Dropout7 0.5

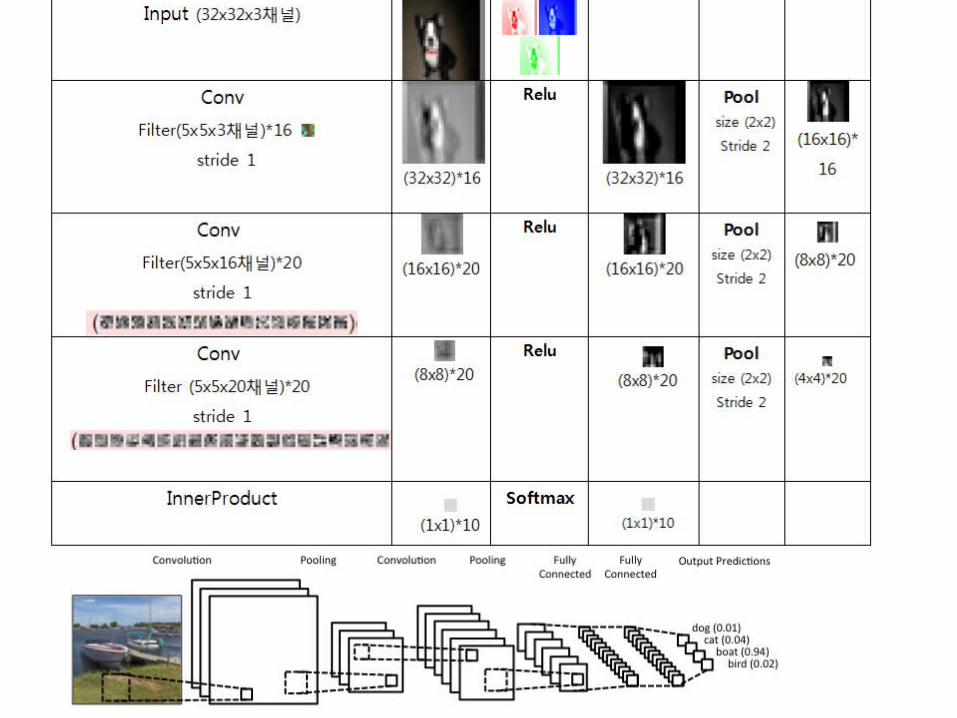
Network Visualizationhttp://cs.stanford.edu/people/karpathy/convnetjs/
• Conv (32x32x16)
– filter (5x5x3)– stride 1
• relu (32x32x16)
• pool (16x16x16)– Filter (2x2,)
• conv (16x16x20)– Filter (5x5x16)
• relu (16x16x20)
• pool (8x8x20)– Filter (2x2)
• conv (8x8x20)– Filter (5x5x20)
• relu (8x8x20)• pool (4x4x20)
– Filter (2x2)
• InnerProduct– (1x1x10)
• softmax – (1x1x10)
'airplane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck

Network Visualizationhttp://cs.stanford.edu/people/karpathy/convnetjs/
• Conv (32x32x16)
– filter (5x5x3)– stride 1
• relu (32x32x16)• pool (16x16x16)
– Filter (2x2,)• conv (16x16x20)
– Filter (5x5x16)• relu (16x16x20)• pool (8x8x20)
– Filter (2x2)• conv (8x8x20)
– Filter (5x5x20)• relu (8x8x20)• pool (4x4x20)
– Filter (2x2)
• InnerProduct– (1x1x10)
• softmax – (1x1x10)
• Input (32x32x3)
'airplane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck

ImageNet 사용법• 보조 데이터 다운로드
– $ ./data/ilsvrc12/get_ilsvrc_aux.sh • backup folder : caffe/examples/imagenet • 수정 Create_imagenet.sh
– RESIZE=false -> RESIZE=true• Create the leveldbs with
– $ ./examples/imagenet/create_imagenet.sh• Create mean data
– $ ./examples/imagenet/make_imagenet_mean.sh– 생성 : data/ilsvrc12/imagenet_mean.binaryproto
• Train Start– $ ./build/tools/caffe train --solver=models/bvlc_reference_caffenet/
solver.prototxt

ImageNet Data Prepare• Requirement
– Save Image Files• /path/to/imagenet/train/n01440764/n01440764_10026.JPEG • /path/to/imagenet/val/ILSVRC2012_val_00000001.JPEG
– Describe Folder • train.txt
– n01440764/n01440764_10026.JPEG 0– n01440764/n01440764_10027.JPEG 1
• val.txt– ILSVRC2012_val_00004614.JPEG 954– ILSVRC2012_val_00004615.JPEG 211
• Let’s Make lmdb– $ ./examples/imagenet/create_imagenet.sh
• ilsvrc12_train_lmdb for Train• ilsvrc12_val_lmdb for validate
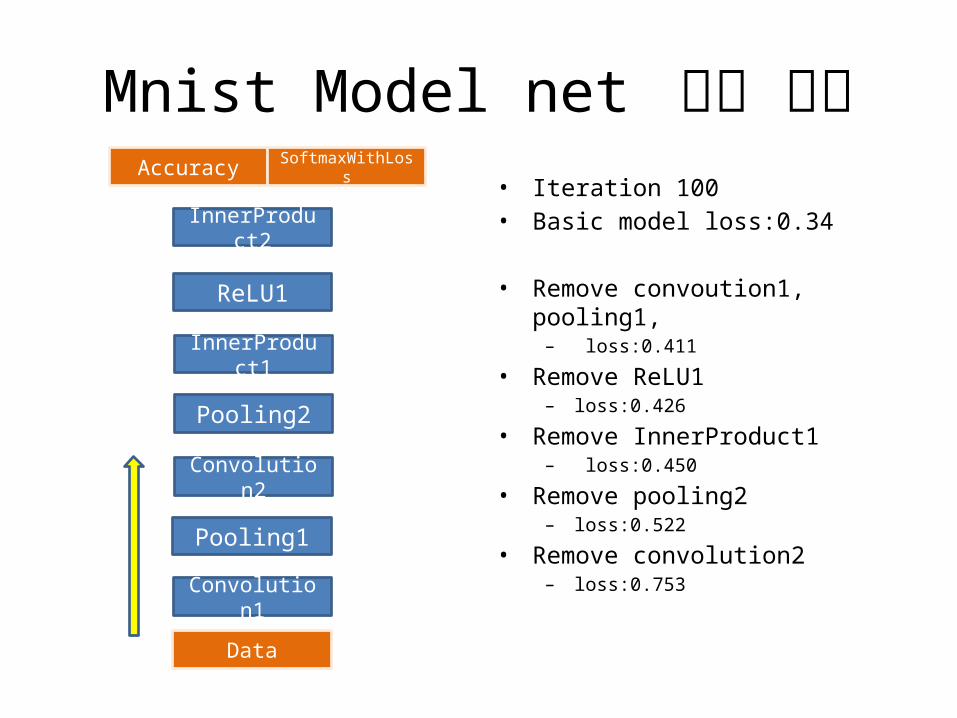
Mnist Model net 수정 실험• Iteration 100• Basic model loss:0.34
• Remove convoution1, pool-ing1,– loss:0.411
• Remove ReLU1 – loss:0.426
• Remove InnerProduct1– loss:0.450
• Remove pooling2– loss:0.522
• Remove convolution2– loss:0.753Convolu-
tion1
Pooling1
Convolu-tion2
Pooling2
ReLU1InnerProd-
uct1
InnerProd-uct2
Accuracy
Data
SoftmaxWithLoss

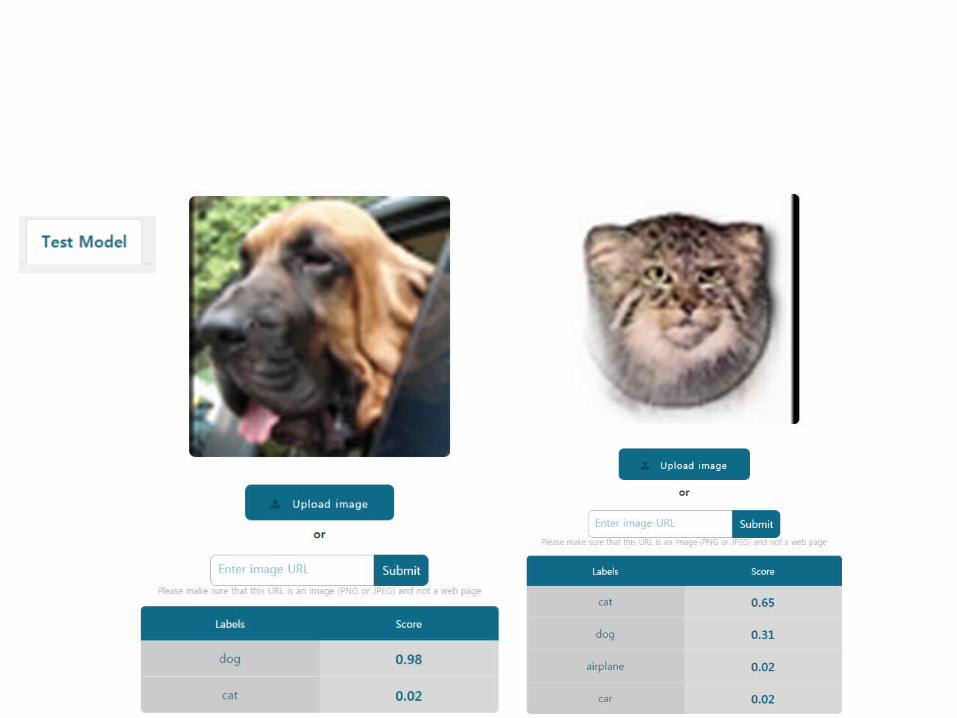
Test• Classify (Airplane, car, cat, dog)
– 이미지 사이즈 64x64x3• Model
– Matlab cnn net• softMax Layer 에서만 학습 Iteratoin = 1,000• 이미지 사이즈 조절 없음
– cifar10 net• Iteration 5000• 이미지 사이즈 64x64x3 -> 32x32x3 으로 조절해서 DB 생성
– Cifar10 net• Iteration 5000• 사이즈 조절 없이 DB 생성
– Labellio• deep learning web service

Prepare 1/2. Make .mdb• create_imagenet.sh
RESIZE=trueif $RESIZE; then RESIZE_HEIGHT=32 RESIZE_WIDTH=32else RESIZE_HEIGHT=0 RESIZE_WIDTH=0Fi
GLOG_logtostderr=1 $TOOLS/convert_imageset \ --resize_height=$RESIZE_HEIGHT \ --resize_width=$RESIZE_WIDTH \ --shuffle \ $TRAIN_DATA_ROOT \ $DATA/train.txt \ $EXAMPLE/ilsvrc12_train_lmdb
• 1. 64x64x3 이미지들을 폴더에 저장하고• 2. train.txt 파일에 이미지 경로와 라벨을 모두 적는다 .• 3. lmdb 데이터 베이스를 만든다 .
• lmdb 데이터 베이스를 만들 때 사이즈를 조절 할 수 있다 .– 사이즈를 조절 시 RESIZE=true– 사이즈를 조절 NO RESIZE=false– 사이즈를 조절 시
Data.mdb(32.9MB)– 사이즈를 조절 NO
Data.mdb(8.3MB)– Lock.mbd 크기는 항상 고정 이다 8.2
kB

Prepare 2/2. Make mean data
• make_imagenet_mean.sh
EXAMPLE=examples/imagenetDATA=data/ilsvrc12TOOLS=build/tools
$TOOLS/compute_image_mean $EXAMPLE/ilsvrc12_train_lmdb \$DATA/mean.binaryproto

Result• Matlab cnn net
– softMax Layer 에서만 학습 Iteratoin = 1,000– 이미지 사이즈 조절 없음– Testing accuracy = 0.8
• cifar10 net– 이미지 사이즈 64x64x3 -> 32x32x3 으로 조절 해서 db 생성– Iteration 5,000, loss = 0.00059– Testing accuracy = 0.755, loss=1.58– Overfitting!
• Cifar10 net– Iteration 5000, traning loss = 0.00026– Test accuracy = 0.724, loss=1.94– worse overfitting!
• Labellio– Training accuracy = 0.66– Test accuracy = ?
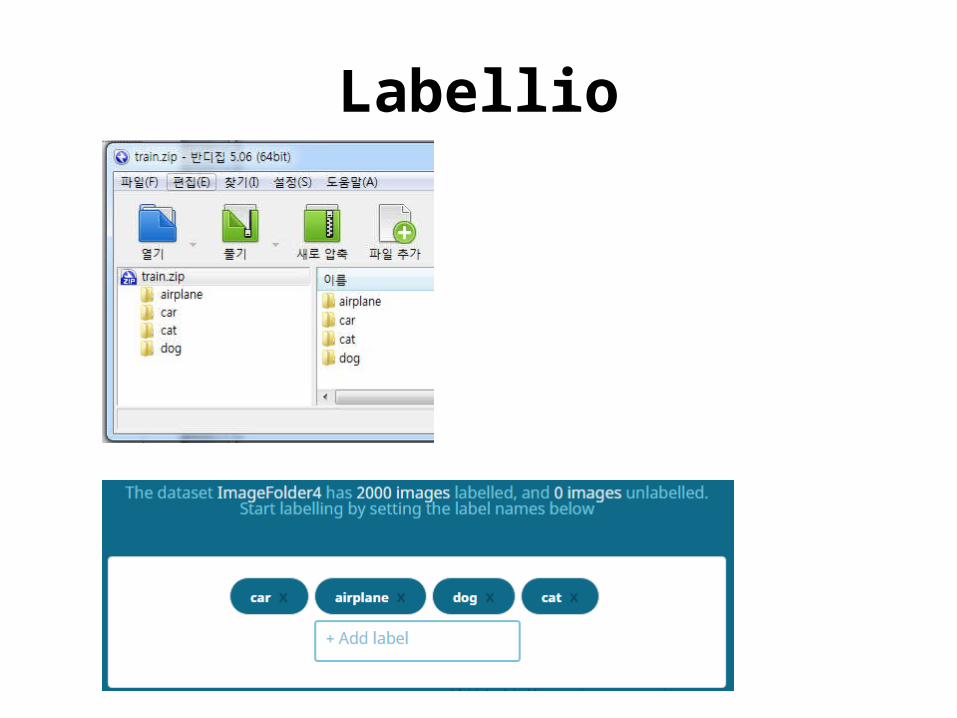
Labellio
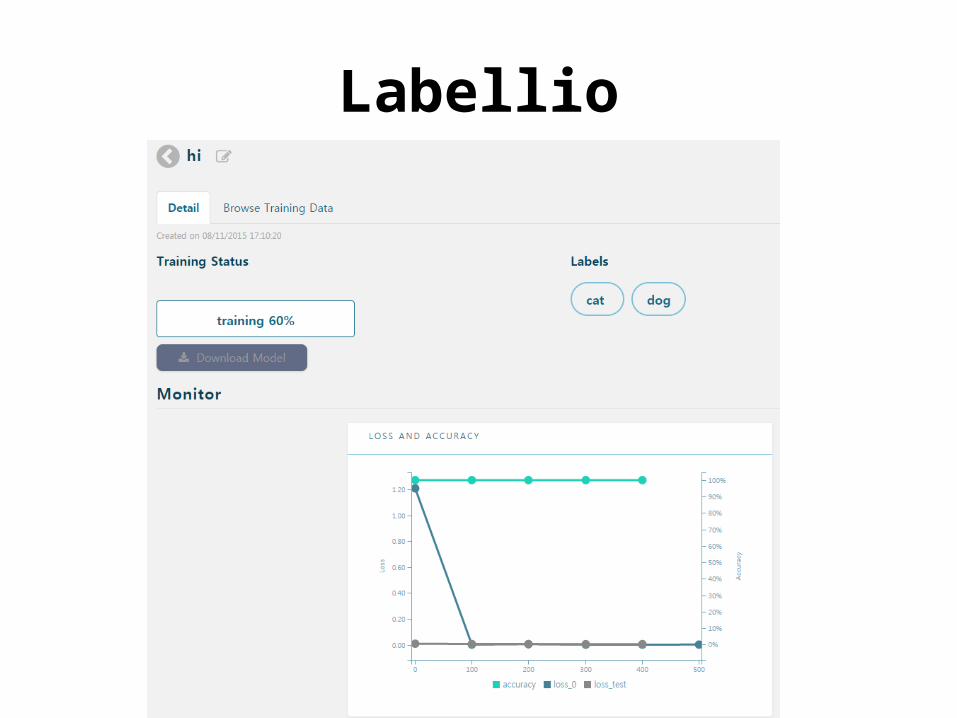
Labellio
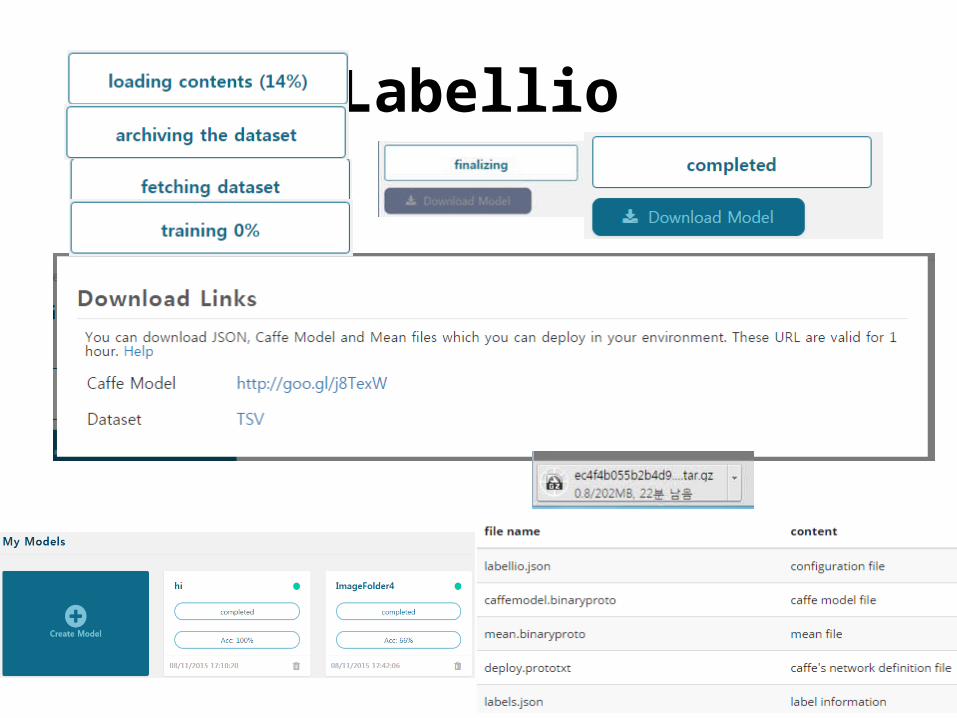
Labellio

참고• Face Feature Recognition System with
Deep Belief Networks, for Korean/KI-ISE Thesis– http://
www.slideshare.net/sogo1127/face-feature-recognition-system-with-deep-belief-networks-for-korean
• Labellio– http://devblogs.nvidia.com/parallelforall/
labellio-scalable-cloud-architecture-effi-cient-multi-gpu-deep-learning/
Related Documents











