CacheAware RealTime Xen Managing Shared Cache for RealTime Virtualiza<on Meng Xu

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Cache-‐Aware Real-‐Time Xen -‐-‐Managing Shared Cache for Real-‐Time Virtualiza<on
Meng Xu
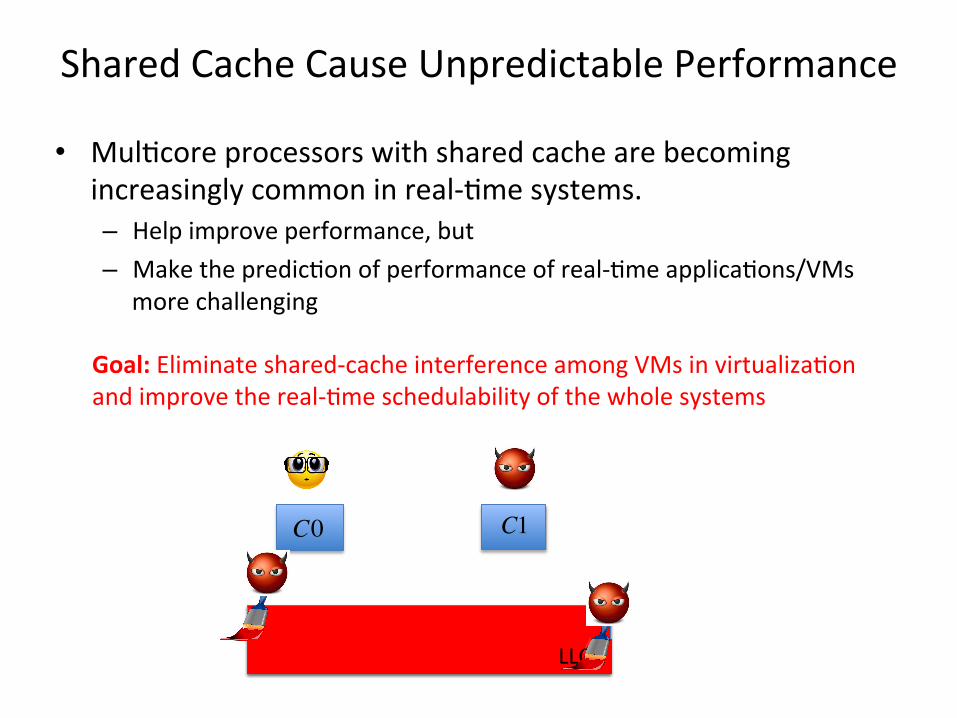
Shared Cache Cause Unpredictable Performance
• Mul<core processors with shared cache are becoming increasingly common in real-‐<me systems. – Help improve performance, but – Make the predic<on of performance of real-‐<me applica<ons/VMs
more challenging
C0 C1
LLC
Goal: Eliminate shared-‐cache interference among VMs in virtualiza<on and improve the real-‐<me schedulability of the whole systems
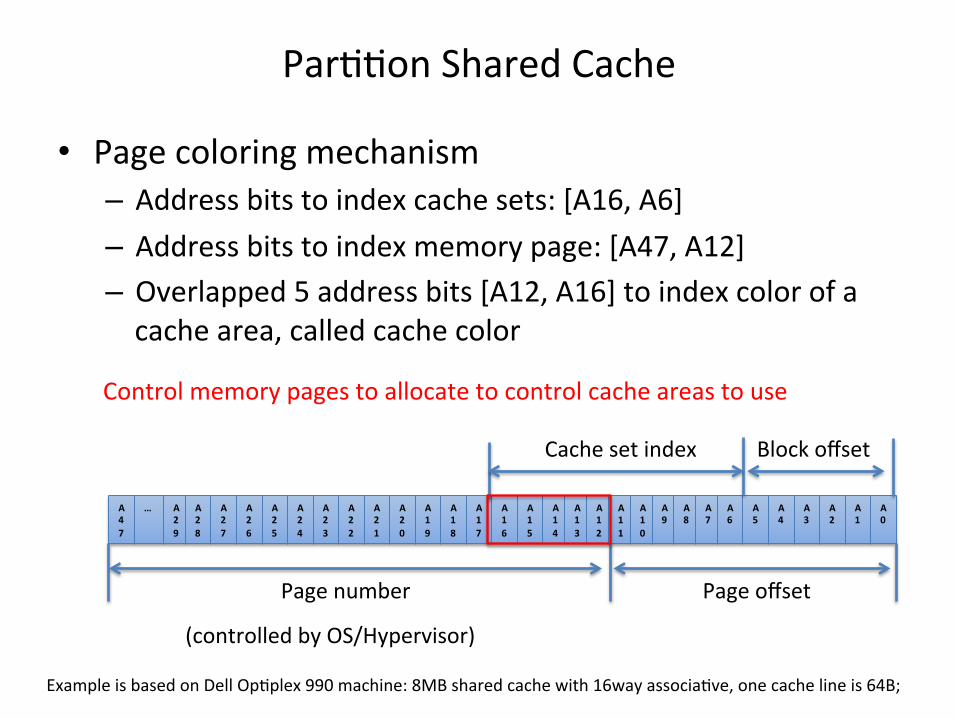
Par<<on Shared Cache
• Page coloring mechanism – Address bits to index cache sets: [A16, A6] – Address bits to index memory page: [A47, A12] – Overlapped 5 address bits [A12, A16] to index color of a cache area, called cache color
A47
… A29
A28
A27
A26
A25
A24
A23
A22
A21
A20
A19
A18
A17
A16
A15
A14
A13
A12
A11
A10
A9
A8
A7
A6
A5
A4
A3
A2
A1
A0
Page offset Page number
(controlled by OS/Hypervisor)
Block offset Cache set index
Example is based on Dell Op<plex 990 machine: 8MB shared cache with 16way associa<ve, one cache line is 64B;
Control memory pages to allocate to control cache areas to use
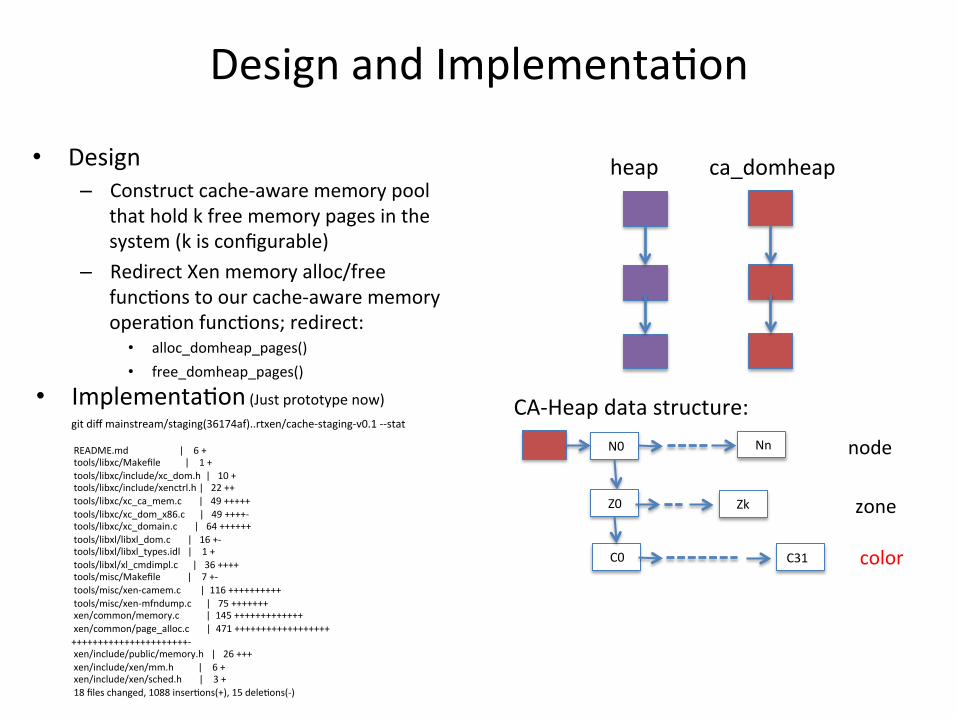
Design and Implementa<on
heap ca_domheap
N0 Nn
Z0 Zk
C0 C31
CA-‐Heap data structure:
node
zone
color
• Design – Construct cache-‐aware memory pool
that hold k free memory pages in the system (k is configurable)
– Redirect Xen memory alloc/free func<ons to our cache-‐aware memory opera<on func<ons; redirect: • alloc_domheap_pages() • free_domheap_pages()
README.md | 6 + tools/libxc/Makefile | 1 + tools/libxc/include/xc_dom.h | 10 + tools/libxc/include/xenctrl.h | 22 ++ tools/libxc/xc_ca_mem.c | 49 +++++ tools/libxc/xc_dom_x86.c | 49 ++++-‐ tools/libxc/xc_domain.c | 64 ++++++ tools/libxl/libxl_dom.c | 16 +-‐ tools/libxl/libxl_types.idl | 1 + tools/libxl/xl_cmdimpl.c | 36 ++++ tools/misc/Makefile | 7 +-‐ tools/misc/xen-‐camem.c | 116 ++++++++++ tools/misc/xen-‐mfndump.c | 75 +++++++ xen/common/memory.c | 145 +++++++++++++ xen/common/page_alloc.c | 471 ++++++++++++++++++++++++++++++++++++++++-‐ xen/include/public/memory.h | 26 +++ xen/include/xen/mm.h | 6 + xen/include/xen/sched.h | 3 + 18 files changed, 1088 inser<ons(+), 15 dele<ons(-‐)
git diff mainstream/staging(36174af)..rtxen/cache-‐staging-‐v0.1 -‐-‐stat
• Implementa<on (Just prototype now)

Evalua<on on Worst-‐Case Execu<on Time
• Benchmark – Run PARSEC benchmark in dom1 and pollu<ng task (that accesses an array with LLC size) in dom2, measure execu<on <me in Xen and CART-‐Xen
• Synthe<c workload – Replace the benchmark with synthe<c workload which we can control the access paiern; Compare the performance under different cache access paiern
• Expected result – Execu<on <me of workload varies a lot without cache management
– Shared-‐cache interference from another domain is eliminated in CART-‐Xen by the cache par<<on mechanism.
– Execu<on <me of workload depends on the size of cache area allocated to the workload
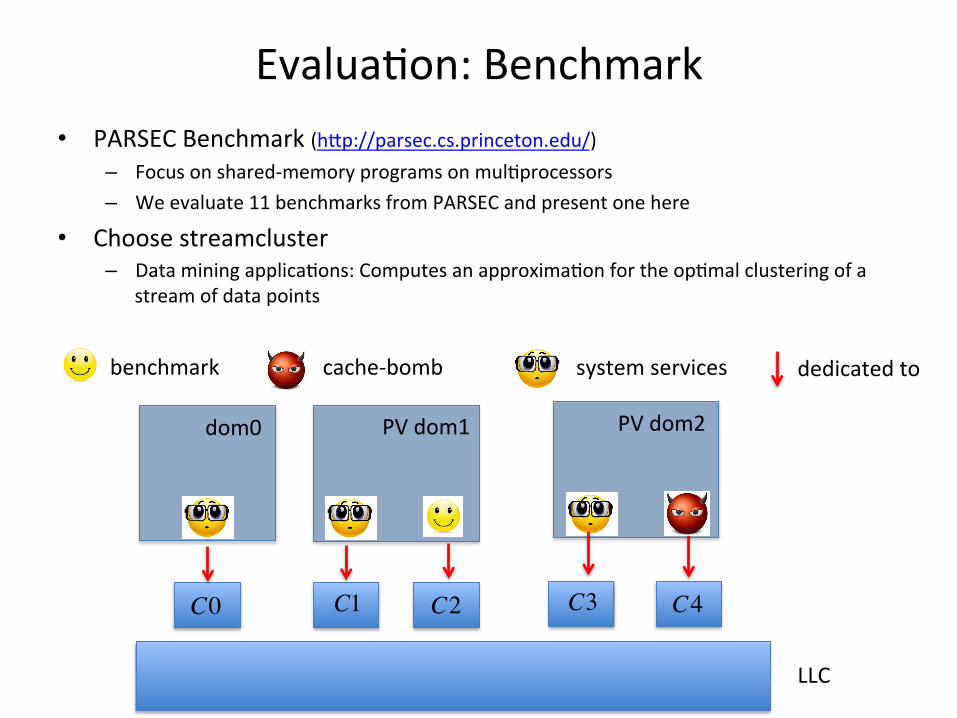
Evalua<on: Benchmark • PARSEC Benchmark (hip://parsec.cs.princeton.edu/)
– Focus on shared-‐memory programs on mul<processors – We evaluate 11 benchmarks from PARSEC and present one here
• Choose streamcluster – Data mining applica<ons: Computes an approxima<on for the op<mal clustering of a
stream of data points
benchmark cache-‐bomb
C0 C1 C2
system services dedicated to
dom0
C3 C4
PV dom1 PV dom2
LLC
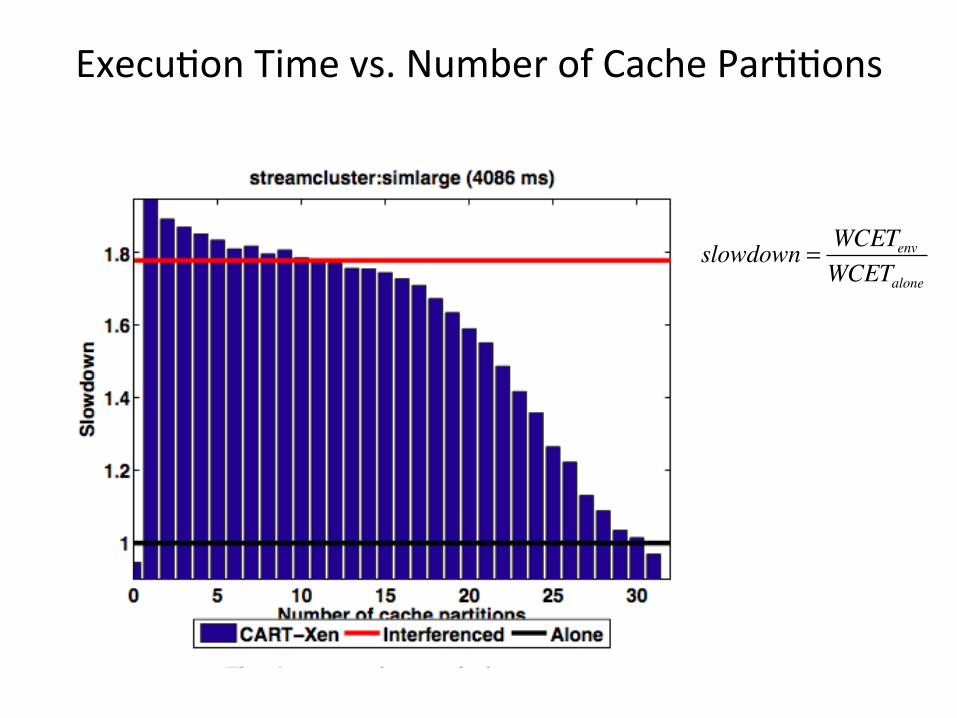
Execu<on Time vs. Number of Cache Par<<ons
slowdown = WCETenvWCETalone

Evalua<on: Synthe<c Workload
Access pa7ern Defini=on Visualiza=on
seq-‐each-‐line
Sequen<ally access each cache line
seq-‐each-‐line-‐stride-‐page
First sequen<ally access the first cache line in each page of the array, and then access the second cache line in each page
random-‐in-‐page
Each page holds 64 cache lines; randomly access the 64 cache lines in each page; but sequen<ally access each page
random-‐full
An array has (size/64) cache lines, randomly access all these cache lines
Replace PARSEC benchmark with synthe=c workload Measure latency of accessing an array with size s for 1024 <mes and pick 99% quan<le;
Different cache-‐access pa7ern (e.g., sequen=al or random ) may affect latency of cache access (due to HW prefetch in cache, TLB miss)
(1) (2)
(2)(1)
(1)(2)
(1)(2)
NB: Only show the result of seq-‐each-‐line access paiern in the slide now. We have data and figures for all four access paierns.

Evalua<on: Environment
Environment Defini=on
na<ve-‐alone cache-‐base alone in na<ve Linux
na<ve-‐pollute cache-‐base runs with cache-‐bomb on different cores in na<ve Linux
RTXen-‐alone cache-‐base alone in dom1 with dedicated VCPU, nothing in dom2 with dedicated VCPU;
RTXen-‐pollute cache-‐base alone in dom1 with dedicated VCPU, cache-‐bomb in dom2 with dedicated VCPU
CARTXen-‐alone cache-‐base alone in dom1 with dedicated VCPU and cache colors [0-‐15]; nothing in dom2 with dedicated VCPU and cache colors [16-‐31]; (dom1 and dom2 each has half cache area)
CARTXen-‐pollute cache-‐base alone in dom1 with dedicated VCPU and cache colors [0-‐15]; cache-‐bomb in dom2 with dedicated VCPU and cache colors [16-‐31]; (dom1 and dom2 each has half cache area)
cache-‐base: synthe<c workload to measure latency of accessing an array cache-‐bomb: keep pollu<ng the LLC RTXen: Xen with RTDS scheduler CARTXen: Xen with RTDS scheduler and sta<c cache par<<on
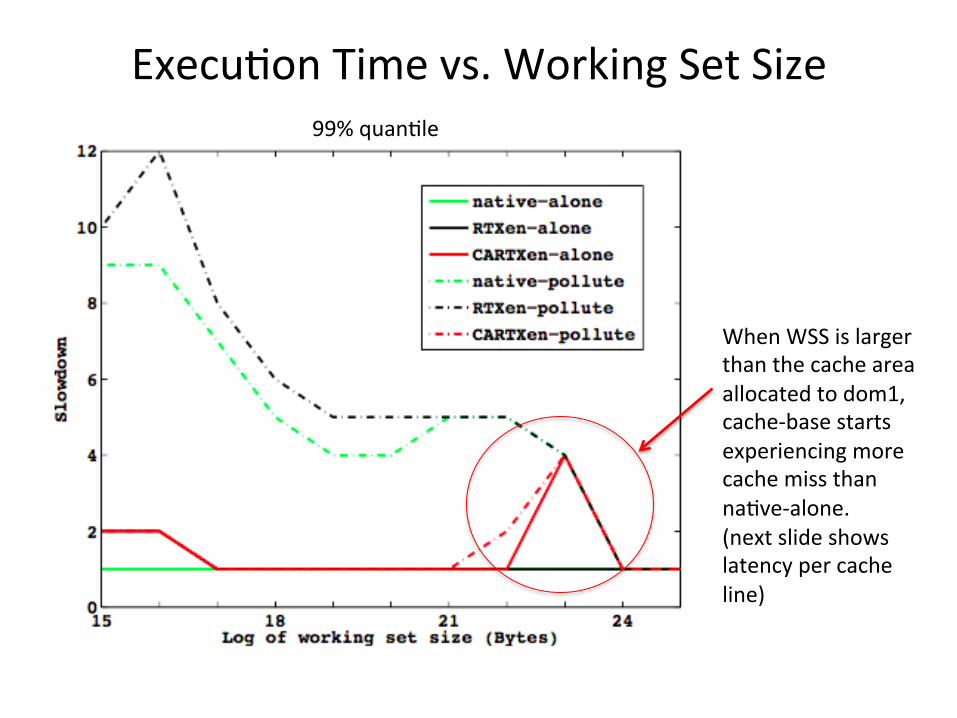
Execu<on Time vs. Working Set Size
When WSS is larger than the cache area allocated to dom1, cache-‐base starts experiencing more cache miss than na<ve-‐alone. (next slide shows latency per cache line)
99% quan<le
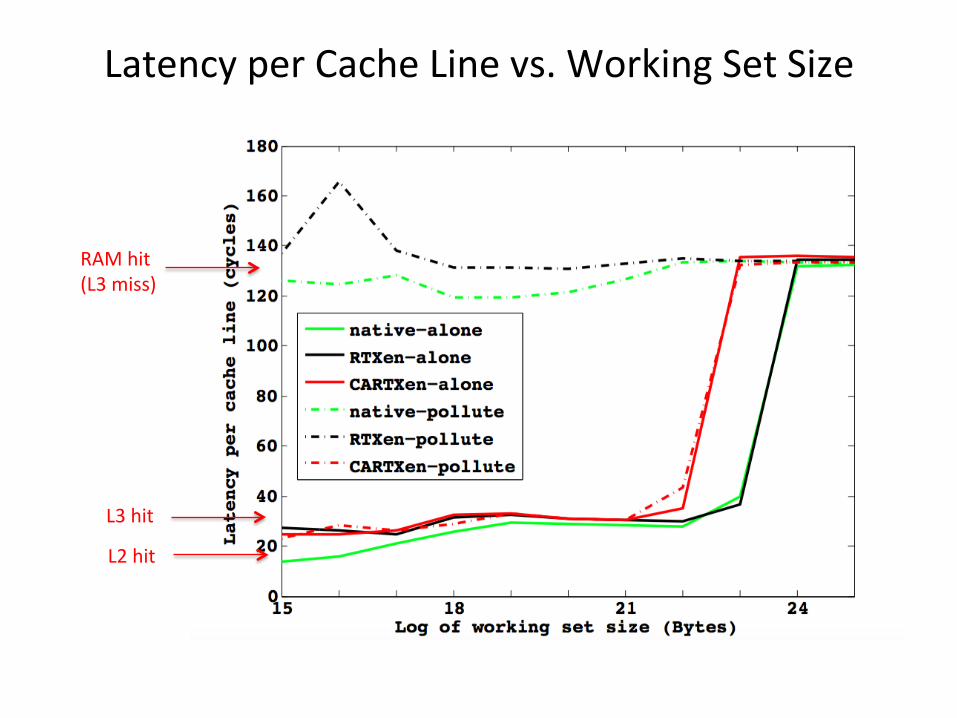
Latency per Cache Line vs. Working Set Size
L2 hit
L3 hit
RAM hit (L3 miss)

Conclusion & Discussion & WiP
• Conclusion & Discussion – Cache par<<on can effec<vely eliminate shared-‐cache interference and provide determinis<c execu<on <me of task;
– Only support sta<c par<<on currently • WiP – Dynamically increase/decrease/migrate cache par<<ons of a domU online
– Inves<gate how cache management technique affect schedulability of whole system
– Incorporate cache management technique with real-‐<me scheduling to improve the schedulability of whole system

Facts of Hardware
• Intel(R) Xeon(R) CPU E5-‐1650 v2 – 6 Cores (12 HT) – 3.5 GHz
• L1 cache – Size: 32 KB; 64B cache line – 8-‐way associa<ve – Hit latency: 5 cycles
• L2 cache – Size: 128 KB; 64B cache line – 8-‐way associa<ve – Hit latency: 12 cycles
• LLC Cache – Size: 12 MB (6 * 2MB); 64B cache line – 16-‐way associa<ve – Hit latency: 30.5 cycles
• RAM – Size: 32 GB; 4KB page size – Access latency: 30 cycles + 53ns (215.5
cycles)
• Data TLB L2 (STLB) – Size: 64 entries; size of each line? Prefetch?
# entries in each line? – 4KB pages, 4-‐way – Miss penalty = 9 cycles. Parallel miss: 21 cycle
per access
• Data TLB L1 – Size: 64 items; size of each line? Prefetch? #
entries in each line? – 4-‐way – Miss penalty = 7 cycles. Parallel miss: 1 cycle
per access • PDE cache (? What is it for?)
– 32 items. Miss penalty = 9 cycles.
On 64 bit Linux. Item in blue is data for IvyBridge (because no available data for this processor).
Cache latency data is from hip://www.7-‐cpu.com/cpu/IvyBridge.html
NB: cache miss latency is equal to the (cache) hit latency of the next-‐level memory
Related Documents











