NADEGE DESIREE YAMEOGO ANALYSE DE LA DEMANDE R ´ ESIDENTIELLE D’ ´ ELECTRICIT ´ E ` A PARTIR D’ENQU ˆ ETES IND ´ EPENDANTES : CORRECTION DE BIAIS DE S ´ ELECTION ET D’ENDOG ´ EN ´ EIT ´ E DANS UN CONTEXTE DE CLASSES LATENTES. Th` ese pr´ esent´ ee ` a la Facult´ e des ´ etudes sup´ erieures de l’Universit´ e Laval dans le cadre du programme de doctorat D´ epartement d’ ´ Economique pour l’obtention du grade de Philosophiae Doctor (Ph.D) FACULT ´ E DES SCIENCES SOCIALES UNIVERSIT ´ E LAVAL QU ´ EBEC 2008 c Nad` ege D´ esir´ ee Yam´ eogo, 2008

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

NADEGE DESIREE YAMEOGO
ANALYSE DE LA DEMANDE RESIDENTIELLE
D’ELECTRICITE A PARTIR D’ENQUETES
INDEPENDANTES : CORRECTION DE BIAIS
DE SELECTION ET D’ENDOGENEITE DANS
UN CONTEXTE DE CLASSES LATENTES.
These presenteea la Faculte des etudes superieures de l’Universite Laval
dans le cadre du programme de doctorat Departement d’Economiquepour l’obtention du grade de Philosophiae Doctor (Ph.D)
FACULTE DES SCIENCES SOCIALESUNIVERSITE LAVAL
QUEBEC
2008
c©Nadege Desiree Yameogo, 2008

Resume
Differentes methodes sont proposees pour estimer la demande d’electricite condi-
tionnelle au mode de chauffage. Un modele logit mixte GAR(1) avec heterogeneite est
utilise pour estimation le modele de choix du mode de chauffage. Comme la tarification
de l’electricite entraıne une endogeneite du prix marginal, un modele a classes latentes
est propose et son estimation est faite selon une approche classique ou une approche
bayesienne. Puisque le menage choisit son mode de chauffage pour plusieurs annees,
nous captons l’aspect dynamique a partir de donnees d’enquetes independantes en uti-
lisant deux approches. D’abord, nous creons des pseudo-panels composes de cohortes et
nous estimons la demande d’electricite par les moindres carres quasi-generalises et par
l’algorithme de l’echantillonnage de Gibbs. Ensuite, nous creons un panel simule avec
lequel nous estimons la demande d’electricite conditionnelle en combinant l’algorithme
de l’augmentation des donnees et l’echantillonnage de Gibbs.

Resume
L’objectif de cette these est de faire une analyse de la demande residentielle d’electricite
conditionnelle au choix du mode de chauffage de l’eau et de l’espace de la province de
Quebec. Plusieurs approches sont proposees afin de corriger differents problemes qui
sont poses.
L’electricite est vendue selon une tarification en deux parties et son prix marginal
depend de la quantite demandee, entraınant une endogeneite du prix. Cette tarification
cree deux classes latentes (non observables) de menages. La methode du maximum de
vraisemblance en deux etapes dans un contexte de classes latentes est proposee tout en
corrigeant le probleme de selection du choix du mode. Le modele de choix est estime
avec un logit mixte a erreurs autoregressives generalisees d’ordre un (GAR(1)).
A partir du logit mixte, des taux d’escompte individuels ont ete estimes en supposant
de l’heterogeneite deterministe entre les menages. Le taux moyen obtenu est tres proche
du taux sur le marche financier.
Comme le choix du mode de chauffage est fait pour plusieurs annees, il est impor-
tant de pouvoir capter l’aspect dynamique dans le comportement de consommation
des menages. Seules des donnees d’enquetes independantes sont disponibles, il n’y a
pas donnees de panel. Deux approches sont alors proposees pour resoudre le probleme
d’informations manquantes.
La premiere approche consiste a creer des pseudo-panels, composes de cohortes de
menages ayant des caracteristiques communes. Dans ce cas, la demande d’electricite est
estimee d’une part, selon la methode des moindres carres quasi-generalises, et d’autre
part, en utilisant l’echantillonnage de Gibbs pour tenir compte de l’heterogeneite entre
des groupes de cohortes.
La seconde approche consiste a simuler un panel afin de garder l’information au ni-
veau des menages. La demande d’electricite conditionnelle au choix du mode de chauf-

Resume iv
fage et au choix de la classe est estimee en combinant l’algorithme de l’augmentation
des donnees (pour simuler les donnees manquantes) et celui de l’echantillonnage de
Gibbs (pour estimer les parametres du modele). Les resultats des differentes methodes
proposees sont tres satisfaisants.

Abstract
The objective of this thesis is to analyze Quebec residential electricity demand
conditional on the choice of space and water heating alternatives. Several approaches
are proposed to solve various problems.
Electricity is sold according a two part tariff, and its marginal price depends on the
quantity that the household buys. This leads to an endogeneity problem. This tariff
creates two latent (unobservable) classes of households. We propose to use a two-step
maximum likelihood method while taking into account the latent classes problem and
the selection bias coming from the choice of heating alternatives. We used a mixed logit
model with a generalized autoregressive errors of order one to estimate the choice model.
We suppose a deterministic grouped heterogeneity between households and the results
are used to mesure individual discount rates. The average discount rate turns out to be
very close to the financial market rate. Since the choice of heating alternative is made by
the household for several years, it is important to be able to get the dynamic behavior
of household electricity consumption. There is no panel data and the only available data
are independent cross-sectional surveys, . Two approaches are proposed to solve this
problem of missing information. The first approach consists in creating a pseudo-panel
data, composed by cohorts of households sharing some characteristics. In this case,
electricity demand is estimated using on the one hand, a feasible generalized least-
squares method to correct errors heteroscedasticity and autocorrelation, and using on
the other hand the Gibbs sampler algorithm to take into account random heterogeneity
between groups of cohorts. In the second approach, we simulated a panel data which
keeps information at the household level. Electricity demand conditional on the choice
of the heating alternative and the class choice is estimated by combining the data
augmentation algorithm (which simulates missing data) and the Gibbs sampling (which
estimates model parameters). Short-run and long-run elasticities are calculated for each
of our models. The results that we obtained for all our models are very satisfactory.

Avant-propos
On ne peut ecrire seul une these de doctorat sans l’appui d’autres personnes. J’ai eu
la chance d’avoir beaucoup de personnes qui m’ont soutenue durant toutes ces annees.
Je tiens d’abord a remercier mon directeur, Mr Jean-Thomas Bernard, qui m’a fait
confiance avant meme que je n’arrives ici au Canada. Je tiens a le remercier pour son
appui, ses conseils et ses encouragements dont j’ai beneficies durant toutes ces annees.
Je remercie mon co-directeur Mr Denis Bolduc, pour son aide, et particulierement dans
la conception des programmes informatiques. Par ses qualites de bon pedagogue, il m’a
donne sans le savoir la passion pour l’econometrie. Mes remerciements vont a Mme
Lynda Khalaf, pour ses conseils et encouragements qui m’ont ete tres precieux durant
ces annees, et surtout durant les moments difficiles. Je remercie tous les professeurs du
departement et particulierement ceux qui m’ont enseignee. Il m’ont permis d’approfon-
dir et d’aimer davantage l’economie et le metier d’enseignant. Mes remerciements vont
a Mme Martine Guay et tout le personnel du departement que j’ai cotoye durant toutes
ces annees.
Les etudes doctorales ne peuvent pas etre faites dans de bonnes conditions sans
aide financiere. Je remercie la Chaire de l’Energie Electrique et le Groupe de Recherche
en Economie de l’Energie, de l’Environnement et des Ressources Naturelles (GREEN)
qui ont finance mes etudes doctorales depuis le debut. Mes remerciements vont aussi
a l’Institut d’Hydro-Quebec en Environnement, Developpement et Societe (IHQEDS)
pour le financement accorde a cette recherche.
Je remercie tous les membres de ma famille, particulierement ma mere, Justine,
mon pere Paul, et ma soeur Bertille, pour leur appui inconditionnel tout au long de
mes etudes au Burkina Faso comme au Canada. Je remercie Dieudonne, qui m’a soutenu
moralement durant toutes ces annees de dur labeur. Je remercie toutes mes amies et tous
mes amis de meme que mes collegues de travail, avec qui j’ai eu des discussions parfois
fructueuses : Marie-Helene, Agnes, Guy, Chritian et Daniela, Myra, Dany, Therese et
Gerald Arbour,... Je remercie Marie, son epoux et Emanuel qui m’ont soutenue durant
ces moments difficiles passes loin de ma famille.

a Justine, Dieudonne, Bertille et Paul

Table des matieres
Resume ii
Resume iii
Abstract v
Avant-propos vi
Table des matieres viii
Liste des tableaux xii
Table des figures xiv
1 Introduction 1
2 Revue de la litterature 6
2.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Le probleme de la simultaneite entre choix discret et choix continu . . . 7
2.3 Le probleme de la tarification non lineaire . . . . . . . . . . . . . . . . 10
2.4 Methodes d’estimation des modeles continus avec des panels . . . . . . 15
2.4.1 Les donnees de panel . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4.2 Methodes d’estimation des donnees de panel . . . . . . . . . . . 17
2.5 Methodes d’estimation des modeles a choix discret avec des panels . . . 25
2.5.1 Estimation du logit a effets fixes et aleatoires : le maximum de
vraisemblance conditionnel . . . . . . . . . . . . . . . . . . . . . 26
2.5.2 Probit a effets aleatoires . . . . . . . . . . . . . . . . . . . . . . 27
2.5.3 Methodes d’estimation de modeles dynamiques avec des panels . 28
2.5.4 Approche semiparametrique . . . . . . . . . . . . . . . . . . . . 30
2.5.5 Correction de biais de selection de donnees de panel . . . . . . . 30
2.6 Methodes d’estimation des donnees longitudinales incompletes . . . . . 31
2.6.1 Les donnees longitudinales incompletes . . . . . . . . . . . . . . 32
2.6.2 Les pseudo-panels conventionnels . . . . . . . . . . . . . . . . . 32
2.6.3 Modeles lineaires statiques . . . . . . . . . . . . . . . . . . . . . 33

Table des matieres ix
2.6.4 Modeles lineaires dynamiques . . . . . . . . . . . . . . . . . . . 37
2.6.5 Modele de choix discret avec des pseudo-panels . . . . . . . . . 40
2.6.6 Quelques etudes empiriques ayant porte sur les pseudo-panels . 41
2.7 Autres approches pour solutionner le probleme de donnees manquantes 43
2.7.1 L’imputation multiple (IM) . . . . . . . . . . . . . . . . . . . . 43
2.7.2 L’algorithme esperance maximisation (EM) . . . . . . . . . . . . 46
2.8 Survol de quelques methodes bayesiennes . . . . . . . . . . . . . . . . . 50
2.8.1 La methodologie MCMC (markov chain monte carlo) . . . . . . 51
2.8.2 Echantillonnage de Gibbs . . . . . . . . . . . . . . . . . . . . . 52
2.8.3 L’algorithme d’augmentation des donnees (AD) . . . . . . . . . 54
Bibliographie 57
3 Estimation de la demande d’electricite avec un modele a classes la-
tentes 67
3.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
3.2 Revue de la litterature . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
3.3 Le modele econometrique de choix discret/continu . . . . . . . . . . . . 72
3.4 Le modele de choix du mode de chauffage : le logit mixte . . . . . . . . 73
3.5 Le modele de demande conditionnelle au choix du mode . . . . . . . . . 78
3.6 La demande d’electricite conditionnelle au choix de la tranche de consom-
mation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
3.7 Estimation par le maximum de vraisemblance en information limitee . 83
3.8 Description des donnees . . . . . . . . . . . . . . . . . . . . . . . . . . 85
3.9 Resultats du modele de choix du mode de chauffage . . . . . . . . . . . 88
3.10 Resultats de l’estimation du modele de demande . . . . . . . . . . . . . 92
3.10.1 Interpretation des resultats du modele de choix de la classe . . . 96
3.10.2 Resultats du modele de demande conditionnelle . . . . . . . . . 97
3.10.3 Tests d’endogeneite du prix marginal . . . . . . . . . . . . . . . 102
3.11 Estimation du taux d’escompte individuel . . . . . . . . . . . . . . . . 103
3.12 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 109
Bibliographie 111
4 Estimation de la demande d’electricite avec des pseudo-panels de co-
hortes 116
4.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
4.2 Revue des ecrits anterieurs . . . . . . . . . . . . . . . . . . . . . . . . . 117
4.3 Modeles statiques de demande d’electricite avec des pseudo-panels . . . 121
4.3.1 La construction des cohortes . . . . . . . . . . . . . . . . . . . . 122
4.3.2 Le modele a effets fixes . . . . . . . . . . . . . . . . . . . . . . . 124

Table des matieres x
4.3.3 Resultats de l’estimation du modele a effets fixes . . . . . . . . 126
4.3.4 Modele a effets fixes avec heteroscedasticite . . . . . . . . . . . 128
4.3.5 Modele a effets fixes avec heteroscedasticite et correlation serielle 131
4.3.6 Analyse de sensibilite : elasticites prix et revenu de la demande 135
4.4 Modeles dynamiques de demande d’electricite . . . . . . . . . . . . . . 136
4.4.1 Le modele dynamique . . . . . . . . . . . . . . . . . . . . . . . 137
4.4.2 Analyse de sensibilite : elasticites prix et revenu . . . . . . . . . 142
4.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
Bibliographie 146
5 Estimation bayesienne de modeles a parametres aleatoires 150
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
5.2 Revue des ecrits anterieurs . . . . . . . . . . . . . . . . . . . . . . . . . 151
5.3 Modele statique a parametres aleatoires homogenes . . . . . . . . . . . 156
5.3.1 Simulation de β . . . . . . . . . . . . . . . . . . . . . . . . . . . 158
5.3.2 Simulation de h . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
5.3.3 Simulation de σ2θ . . . . . . . . . . . . . . . . . . . . . . . . . . 159
5.3.4 Resultats et interpretation . . . . . . . . . . . . . . . . . . . . . 159
5.4 Modele statique a parametres heterogenes . . . . . . . . . . . . . . . . 160
5.4.1 Simulation de βg . . . . . . . . . . . . . . . . . . . . . . . . . . 161
5.4.2 Simulation de hg . . . . . . . . . . . . . . . . . . . . . . . . . . 161
5.4.3 Resultats empiriques et interpretations . . . . . . . . . . . . . . 162
5.5 Modele dynamique de demande d’electricite . . . . . . . . . . . . . . . 164
5.5.1 Resultats de l’estimation du modele dynamique . . . . . . . . . 165
5.6 Analyse de sensibilite : elasticites prix et revenu de la demande . . . . . 169
5.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173
Bibliographie 174
5.8 Les annexes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
5.8.1 Annexe A : repartition des cohortes . . . . . . . . . . . . . . . . 175
5.8.2 Annexe B : Graphiques des simulations . . . . . . . . . . . . . . 177
5.8.3 Annexe C : Tests d’hypothese de restrictions non lineaires . . . 198
6 Analyse de la demande conditionnelle : approche bayesienne 201
6.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201
6.2 Revue de la litterature . . . . . . . . . . . . . . . . . . . . . . . . . . . 202
6.3 Modele de choix du mode de chauffage : le logit mixte . . . . . . . . . . 206
6.4 Methodologie bayesienne . . . . . . . . . . . . . . . . . . . . . . . . . . 211
6.4.1 Echantillonnage de Gibbs . . . . . . . . . . . . . . . . . . . . . 211
6.4.2 L’algorithme de l’augmentation des donnees . . . . . . . . . . . 212

Table des matieres xi
6.4.3 Estimation bayesienne des modeles a classes latentes . . . . . . 214
6.5 Estimation d’un modele statique de demande d’electricite . . . . . . . . 215
6.5.1 Modele de demande conditionnelle a la classe et au mode de chauf-
fage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215
6.5.2 Etape de la simulation des donnees manquantes . . . . . . . . . 218
6.5.3 Etape de la simulation des parametres . . . . . . . . . . . . . . 220
6.5.4 Experience Monte Carlo sur le modele a classes latentes . . . . . 223
6.5.5 Resultats empiriques et interpretations . . . . . . . . . . . . . . 226
6.6 Estimation d’un modele de demande dynamique . . . . . . . . . . . . . 237
6.6.1 Etapes additionnelles : simulation de yt−1 et de y0 . . . . . . . . 239
6.6.2 Resultats et interpretation . . . . . . . . . . . . . . . . . . . . . 241
6.6.3 Analyse de sensibilite : elasticite prix et revenu du modele dyna-
mique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 251
6.7 Conclusion et recommandations . . . . . . . . . . . . . . . . . . . . . . 255
6.8 Annexe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256
6.8.1 Graphiques pour la convergence des tirages . . . . . . . . . . . . 256
6.8.2 Determination de la loi a posteriori des exogenes . . . . . . . . . 261
Bibliographie 263
7 Conclusion 268

Liste des tableaux
3.1 Exemple : pourquoi deux classes latentes ? . . . . . . . . . . . . . . . . 82
3.2 Repartition echantillonnale par source d’energie . . . . . . . . . . . . . 86
3.3 Frequences echantillonnales selon le mode de chauffage . . . . . . . . . 86
3.4 Description des variables utilisees . . . . . . . . . . . . . . . . 86
3.4 Description des variables utilisees . . . . . . . . . . . . . . . . 87
3.4 Description des variables utilisees . . . . . . . . . . . . . . . . 88
3.5 Resultats modele discret (couts moyens specifiques) . . . . 89
3.6 Resultats du modele de demande conditionnelle . . . . . . . . . . . . 93
3.6 Resultats du modele de demande conditionnelle . . . . . . . . . . . . 94
3.6 Resultats du modele de demande conditionnelle . . . . . . . . . . . . 95
3.7 Elasticites . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
3.8 Resultats du modele sans classes . . . . . . . . . . . . . . . . . . . . . . 98
3.9 Resultats du modele discret (couts moyens generiques) . . 107
3.10 Taux d’escompte estimes . . . . . . . . . . . . . . . . . . . . . . . . . . 108
4.1 Modele statique a effets fixes . . . . . . . . . . . . . . . . . . . 127
4.2 Modele avec Heteroscedasticite . . . . . . . . . . . . . . . . . 128
4.2 Modele avec Heteroscedasticite . . . . . . . . . . . . . . . . . 129
4.2 Modele avec Heteroscedasticite . . . . . . . . . . . . . . . . . 130
4.3 Erreurs heteroscedastique et AR(1) . . . . . . . . . . . . . . . . . . . . . 132
4.3 Erreurs heteroscedastique et AR(1) . . . . . . . . . . . . . . . . . . . . . 133
4.3 Erreurs heteroscedastique et AR(1) . . . . . . . . . . . . . . . . . . . . . 134
4.4 Elasticites du modele statique . . . . . . . . . . . . . . . . . . . . . . . 136
4.5 Resultats du modele dynamique a effets fixes . . . . . . . . 138
4.5 Resultats du modele dynamique a effets fixes . . . . . . . . 139
4.6 Modele dynamique avec Heteroscedasticite et AR(1) . . . . . . . . . . . . 140
4.6 Modele dynamique avec Heteroscedasticite et AR(1) . . . . . . . . . . . . 141
4.6 Modele dynamique avec Heteroscedasticite et AR(1) . . . . . . . . . . . . 142
4.7 Elasticites des modeles dynamiques . . . . . . . . . . . . . . . . . . . . . 144
5.1 Resultats du modele statique a parametres homogenes . . . . . . . . . . . 160
5.2 Resultats du modele statique a parametres aleatoires . . . . . . . . . . . 163

Liste des tableaux xiii
5.2 Resultats du modele statique a parametres aleatoires . . . . . . . . . . . 164
5.3 Resultats du modele dynamique a parametres homogenes . . . . . . . . . . 167
5.4 Resultats du modele dynamique a parametres aleatoires . . . . . . . . . . 167
5.4 Resultats du modele dynamique a parametres aleatoires . . . . . . . . . . 168
5.4 Resultats du modele dynamique a parametres aleatoires . . . . . . . . . . 169
5.5 Elasticites des modeles a parametres homogenes . . . . . . . . . . . . . . 171
5.6 Elasticites des modeles a parametres aleatoires . . . . . . . . . . . . . . 172
5.7 repartition des cohortes : base 1989 . . . . . . . . . . . . . . . . . . . . . 176
5.8 repartition des cohortes : base 1994 . . . . . . . . . . . . . . . . . . . . . 176
5.9 repartition des cohortes : base 1999 . . . . . . . . . . . . . . . . . . . . . 176
5.10 repartition des cohortes : base 2002 . . . . . . . . . . . . . . . . . . . . . 177
6.1 Resultats de l’experience Monte Carlo . . . . . . . . . . . . . . . . . . . 225
6.2 Resultats du modele statique de demande conditionnelle . . . . . . . . 227
6.2 Resultats du modele statique de demande conditionnelle . . . . . . . . 228
6.2 Resultats du modele statique de demande conditionnelle . . . . . . . . 229
6.3 Modele statique sans classes . . . . . . . . . . . . . . . . . . . . . . . . 235
6.3 Modele statique sans classes . . . . . . . . . . . . . . . . . . . . . . . . 236
6.4 Elasticites du modele statique . . . . . . . . . . . . . . . . . . . . . . . . 237
6.5 Tarif D de quelques annees . . . . . . . . . . . . . . . . . . . . . . . . . 246
6.6 Prix moyens en dollars constant . . . . . . . . . . . . . . . . . . . . . . 246
6.7 Comparaison prix de vente moyen avec pays industrialises . . . . . . . 246
6.8 Resultats du modele dynamique de demande conditionnelle . . . . . . 248
6.8 Resultats du modele dynamique de demande conditionnelle . . . . . . 249
6.8 Resultats du modele dynamique de demande conditionnelle . . . . . . 250
6.9 Modele dynamique sans classes . . . . . . . . . . . . . . . . . . . . . . . 252
6.10 Elasticites du modele dynamique . . . . . . . . . . . . . . . . . . . . . . 254

Table des figures
2.1 tarif de prix croissant en deux blocs . . . . . . . . . . . . . . . . . . . . 11
4.1 Manquante de vrai panel, enquetes independantes . . . . . . . . 123
5.1 estimation coefficient du prix de l’electricite du modele statique homogene177
5.2 estimation coefficient du revenu net du modele statique homogene . . . 178
5.3 estimation coefficient de hdd du modele statique homogene . . . . . . . 178
5.4 estimation coefficient de cdd du modele statique homogene . . . . . . . 178
5.5 simulation de la variance de l’erreur du modele statique homogene . . . 179
5.6 simulation effet inobservable du modele statique homogene . . . . . . . 179
5.7 estimation coefficient prix electricite du modele statique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 180
5.8 estimation coefficient du revenu du modele statique a parametres heterogenes180
5.9 estimation coefficient de hdd du modele statique a parametres heterogenes181
5.10 estimation coefficient de cdd du modele statique a parametres heterogenes181
5.11 simulation prix region1 du modele statique a parametres heterogenes . 181
5.12 estimation coefficient revenu region1 du modele statique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
5.13 estimation coefficient du prix region3 du modele statique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
5.14 estimation coefficient du revenu region3 du modele statique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
5.15 estimation coefficient de hdd region3 du modele statique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
5.16 moyenne des coefficients simules du prix du modele dynamique a pa-
rametres heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184
5.17 moyenne des coefficients simules du revenu de l’electricite du modele
dynamique a parametres heterogenes . . . . . . . . . . . . . . . . . . . 184
5.18 moyenne des coefficients simules de la consommation passee du modele
dynamique a parametres heterogenes . . . . . . . . . . . . . . . . . . . 185
5.19 moyenne des coefficients simules de hdd du modele dynamique a pa-
rametres heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185

Table des figures xv
5.20 moyenne des coefficients simules de cdd du modele dynamique a pa-
rametres heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
5.21 estimation coefficient du prix region1 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 186
5.22 estimation coefficient du revenu net region1 du modele dynamique a pa-
rametres heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 186
5.23 estimation coefficient de la consommation passee region1 du modele dy-
namique a parametres heterogenes . . . . . . . . . . . . . . . . . . . . . 186
5.24 estimation coefficient de hdd region1 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
5.25 estimation coefficient de cdd region1 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
5.26 estimation coefficient du prix region2 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
5.27 estimation coefficient du revenu net region2 du modele dynamique a pa-
rametres heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
5.28 estimation coefficient de la consommation passee region2 du modele dy-
namique a parametres heterogenes . . . . . . . . . . . . . . . . . . . . . 188
5.29 estimation coefficient de hdd region2 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 188
5.30 estimation coefficient de cdd region2 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
5.31 estimation coefficient du prix region3 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
5.32 estimation coefficient du revenu net region3 du modele dynamique a pa-
rametres heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 189
5.33 estimation coefficient de la consommation passee region3 du modele dy-
namique a parametres heterogenes . . . . . . . . . . . . . . . . . . . . . 190
5.34 estimation coefficient de hdd region3 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 190
5.35 estimation coefficient de cdd region3 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
5.36 estimation coefficient du prix region4 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
5.37 estimation coefficient du revenu net region4 du modele dynamique a pa-
rametres heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191
5.38 estimation coefficient de la consommation passee region4 du modele dy-
namique a parametres heterogenes . . . . . . . . . . . . . . . . . . . . . 192
5.39 estimation coefficient de hdd region4 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192

Table des figures xvi
5.40 estimation coefficient de cdd region4 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 192
5.41 estimation coefficient du prix region5 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
5.42 estimation coefficient du revenu net region5 du modele dynamique a pa-
rametres heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 193
5.43 estimation coefficient de la consommation passee region5 du modele dy-
namique a parametres heterogenes . . . . . . . . . . . . . . . . . . . . . 193
5.44 estimation coefficient de hdd region5 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
5.45 estimation coefficient de cdd region5 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
5.46 estimation coefficient du prix region8 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
5.47 estimation coefficient du revenu net region8 du modele dynamique a pa-
rametres heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
5.48 estimation coefficient de la consommation passee region8 du modele dy-
namique a parametres heterogenes . . . . . . . . . . . . . . . . . . . . . 195
5.49 estimation coefficient de hdd region8 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 195
5.50 estimation coefficient de cdd region8 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
5.51 estimation coefficient du prix region9 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196
5.52 estimation coefficient du revenu net region9 du modele dynamique a pa-
rametres heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
5.53 estimation coefficient de la consommation passee region9 du modele dy-
namique a parametres heterogenes . . . . . . . . . . . . . . . . . . . . . 197
5.54 estimation coefficient de hdd region9 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197
5.55 estimation coefficient de cdd region9 du modele dynamique a parametres
heterogenes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 198
6.1 simulation du coefficient de prix electricite classe1 . . . . . . . . . . . . 256
6.2 simulation du coefficient de prix bi-energie classe1 . . . . . . . . . . . . 256
6.3 simulation du coefficient de prix gaz naturel classe1 . . . . . . . . . . . 257
6.4 simulation du coefficient de prix mazout classe1 . . . . . . . . . . . . . 257
6.5 simulation du coefficient du revenu augmente classe1 . . . . . . . . . . 257
6.6 simulation du coefficient de cdd classe1 . . . . . . . . . . . . . . . . . . 258
6.7 simulation du coefficient de hdd classe1 . . . . . . . . . . . . . . . . . . 258
6.8 simulation du coefficient de prix electricite classe2 . . . . . . . . . . . . 258

Table des figures xvii
6.9 simulation du coefficient de prix mazout classe2 . . . . . . . . . . . . . 259
6.10 simulation du coefficient du revenu augmente classe2 . . . . . . . . . . 259
6.11 simulation du coefficient de cdd classe2 . . . . . . . . . . . . . . . . . . 259
6.12 simulation du coefficient de hdd classe2 . . . . . . . . . . . . . . . . . . 260
6.13 simulation coefficient de la dependante retardee classe1 . . . . . . . . . 260
6.14 simulation coefficient de la dependante retardee classe2 . . . . . . . . . 260

Chapitre 1
Introduction
L’analyse de la demande residentielle d’energie et d’electricite en particulier, est
habituellement basee sur le principe des modeles de choix discret/continu. Le menage
n’utilise pas l’energie comme un bien final, mais il a besoin de l’energie pour satisfaire
ses besoins de chauffage de l’espace et de l’eau, l’eclairage, le fonctionnement d’appa-
reils electromenagers, comme les refrigerateurs, congelateurs, televiseurs, ordinateurs,
machine a laver,... Pour pouvoir consommer une quantite donnee d’energie, le menage
doit choisir une modalite ou alternative qui est un ensemble d’appareils utilisant soit
l’electricite, la bi-energie, le mazout, le gaz naturel, le bois, ou toute combinaison de
l’une et l’autre des formes. Dans cette these, nous nous limiterons aux besoins de chauf-
fage de l’eau et de l’espace du menage. Le choix de la quantite est relie au choix de la
modalite et le choix de la modalite depend aussi du choix de la quantite. Toute methode
d’estimation qui ignore cette interdependance donnerait des estimateurs biaises et non
convergents. Il existe deux principales approches pour l’estimation des modeles de choix
discret/continu :
– l’estimation en information complete qui consiste a estimer simultanement les
parametres du modele continu et du modele discret,
– l’estimation en information limitee consistant a estimer separement les parametres
des deux modeles.
Dubin et McFadden (1984) furent les premiers a proposer une methode d’estimation
qui prend en compte cette interdependance. L’un des objectifs poursuivis dans cette
these est d’analyser la demande d’electricite des menages quebecois tout en prenant en
compte ce probleme d’interdependance entre choix discret et choix continu ; et pour y
arriver, nous utiliserons l’approche en deux etapes ou l’approche en information limitee.
Il se trouve aussi que dans la province de Quebec, l’electricite, qui est utilisee par tous
les menages meme si pour certains, c’est uniquement pour les besoins de base, produite

Chapitre 1. Introduction 2
et distribuee par Hydro-Quebec, est tarifee selon la quantite consommee. Il existe en
effet deux blocs de prix : un premier prix p1 est fixe si la consommation journaliere ne
depasse pas le seuil des 30 kWh, et un deuxieme prix p2 > p1 est fixe si elle depasse ce
seuil. Comme on peut le constater, le prix marginal de l’electricite depend de la quantite
consommee et cette derniere depend aussi du prix. Il y a donc un probleme d’endogeneite
du prix. En plus de ce probleme, il faut savoir que la consommation journaliere du
menage n’est pas directement observable par le chercheur. Hydro-Quebec connaıt la
consommation au deux mois du menage ; seul le menage est capable de controler sa
consommation journaliere a travers son compteur. Au cours d’une annee, le menage a
six factures, soit une facture aux deux mois. Mais seule la consommation annuelle est
observable dans les bases de donnees. Il y a des moments ou le menage peut consommer
en dessous du seuil de 30 kWh et des moments ou il peut consommer au dela de ce seuil.
Un de nos objectifs consiste a inferer, a partir de ses caracteristiques socio-economiques,
la probabilite qu’un menage soit dans l’une ou l’autre tranche de consommation. La
structure tarifaire de l’electricite cree deux groupes ou classes de consommateurs qui ne
sont pas directement observables, que nous appelons classes latentes. Plusieurs auteurs
se sont interesses au probleme de l’endogeneite du prix. Mais aucun n’a essaye de
corriger ce probleme dans un contexte de classes latentes. Nous proposons dans cette
these une approche permettant de corriger a la fois le probleme de biais de selection et
le probleme d’endogeneite du prix dans un contexte de classes latentes. Les modeles a
classes latentes sont generalement utilises dans un contexte ou la variable dependante est
discrete. Ils ont ete introduits en premier par Lazarsheld (1950) pour un modele de choix
dichotomique. Par la suite, beaucoup de travaux sur les modeles a classes latentes ont
essentiellement porte sur les modeles polytomiques. Nous proposons d’etendre ce type
de modeles dans un contexte ou la variable dependante est continue, qui correspond en
fait a la demande d’electricite dans notre cas. De plus, nous estimons de facon specifique
les parametres du modele latent et implicitement les valeurs de la probabilite de choisir
une classe donnee. Les modeles a classes latentes peuvent etre estimes soit selon une
approche classique consistant a faire une estimation par le maximum de vraisemblance
ou soit selon une approche bayesienne en utilisant une methode MCMC (Markov Chain
Monte Carlo). Nous exploiterons l’une ou l’autre des deux approches dependamment
de la situation ou du probleme a resoudre.
Nous estimerons dans un premier temps un modele de demande d’electricite a partir
d’une seule base de donnees d’enquete, celle de 1989, ou nous corrigerons a la fois le
probleme de biais de selection et le probleme d’endogeneite du prix dans un contexte
de classes latentes.
La demande d’electricite implique l’usage d’appareils de chauffage (modalite) qui sont
des biens durables. Le choix d’une modalite necessite implicitement que le menage fasse
un arbitrage entre le present et le futur. Ce type d’arbitrage fait intervenir la notion

Chapitre 1. Introduction 3
de taux d’escompte. Dans les travaux anterieurs portant sur l’estimation du taux d’es-
compte individuel, les auteurs comme Hausman (1984), Dubin et McFadden (1984),...
supposent implicitement l’hypothese d’homogeneite entre les individus. Tout se passe
comme s’ils estimaient un taux d’escompte d’un agent representatif. Winter (1995) a
souligne les limites de cette approche. L’hypothese de consommateurs homogenes est
souvent une hypothese trop forte, surtout dans le contexte de la consommation d’energie
ou les comportements des individus peuvent changer selon la modalite choisie. Lors-
qu’un menage choisit une modalite, il fait implicitement un arbitrage entre choisir un
systeme dont les couts d’achat sont eleves, mais les couts futurs d’exploitation, sur
toute la duree de vie du systeme de chauffage, sont faibles ou inversement. L’hypothese
d’homogeneite implicitement imposee dans les travaux anterieurs pourrait etre a l’ori-
gine des valeurs trop elevees des taux obtenues. En effet, les valeurs estimees du taux
d’escompte qu’ils obtiennent depassent les taux d’interet sur les cartes de credit. Nous
proposons dans cette these une methode d’estimation des taux d’escompte qui prend
en compte l’heterogeneite entre les groupes de menages, ces derniers etant definis se-
lon les modalites. Cette methode, a savoir, le logit mixte GAR(1) avec heterogeneite
(deterministe) entre les modalites, donnerait des valeurs estimees des taux d’escompte
beaucoup plus realistes.
Puisque la consommation d’energie residentielle fait intervenir des biens durables, il
est important de pouvoir prendre en compte l’aspect dynamique dans les ajustements
des menages. L’ideal serait d’avoir des donnees de panel qui permettent de suivre les
memes individus sur plusieurs annees. Cependant, il n’existe pas de donnees de pa-
nel portant sur la consommation d’energie des menages de la province de Quebec.
Il existe cependant plusieurs bases de donnees d’enquete (ou coupes transversales)
independantes menees par Hydro-Quebec. Dans ces bases, un menage present a une
periode donnee n’est plus retracable dans les autres periodes. Nous avons en fait un
probleme de manque d’information importante pour chaque menage. Deaton (1985) a
suggere d’exploiter ce type de bases de donnees pour construire, a partir de criteres
bien definis, des cohortes d’individus assez homogenes pouvant etre suivies a chaque
periode. Les moyennes des variables de ces cohortes vont constituer les unites de ce
qu’il appelle les pseudo-panels. Cette approche transforme l’information au niveau in-
dividuel en une information au niveau des groupes. Les resultats en decoulant ne sont
pas necessairement inferieurs a ceux qu’on obtiendrait si on avait de vraies donnees de
panel. Les pseudo-panels ne sont pas sujets aux problemes d’attrition ou d’apprentis-
sage. L’estimation des modeles avec des pseudo-panels se fait le plus souvent en utili-
sant la methode d’estimation a effets fixes. Tres souvent, les auteurs ne cherchent pas a
verifier s’il y a un probleme d’heteroscedasticite ou d’autocorrelation des erreurs. Or, s’il
s’averait que l’un et/ou l’autre de ces problemes existe, les tests d’hypothese et les in-
tervalles de confiance ne seraient plus valides. Cette situation implique que les decisions

Chapitre 1. Introduction 4
de politiques economiques qui en decouleraient seraient mauvaises. Il est donc impor-
tant de verifier ces problemes surtout dans un contexte ou les donnees sont groupees
en cohortes. Nous exploiterons la methode des moindres carres quasi-generalises pour
corriger ces problemes.
Dans les travaux portant sur les pseudo-panels, les chercheurs supposent habituel-
lement que les coefficients de pente de toutes les cohortes sont identiques, meme si on
sait que les cohortes sont assez heterogenes entre elles. Cette heterogeneite est sou-
vent traduite a travers la constante du modele (modeles a effets fixes) ou le terme
d’erreur (effets aleatoires). S’il existe de l’heterogeneite entre les cohortes, elle pour-
rait probablement se manifester aussi a travers les coefficients d’interet (coefficients de
pente). Si la methode d’estimation ne la prend pas en compte, les estimateurs qui en
resulteraient pourraient etre biaises. Robertson et Symons (1992) et Pesaran et Smith
(1995), dans le cadre des donnees de panel, ont discute des biais potentiels qui pour-
raient se manifester dans l’estimation des elasticites de long-terme si l’heterogeneite des
parametres est ignoree. Nous proposons, dans le cadre des pseudo-panels, de prendre en
compte l’heterogeneite en utilisant une approche d’estimation des modeles a parametres
aleatoires. Ces modeles peuvent etre estimees de differentes manieres, pour les donnees
de panels : les moindres carres generalises, le maximum de vraisemblance, l’estima-
tion selon la regle de Stein, l’approche empirique bayesienne ou l’approche iterative
bayesienne (Maddala et al. (1997)). Nous proposons d’utiliser l’approche bayesienne
basee sur l’algorithme de l’echantillonnage de Gibbs. A notre connaissance, le modele
developpe est nouveau dans la litterature sur les pseudo-panels.
L’une des limites de l’approche de Deaton est que l’information au niveau mi-
croeconomique est transformee a un niveau macroeconomique. Il en resulte une cer-
taine perte d’efficacite et de degres de liberte. Paquet (2002) et Paquet et Bolduc
(2004) ont propose une approche alternative a celle de Deaton qui permet de garder
l’information au niveau individuel. Leur approche consiste a utiliser l’algorithme de
l’augmentation des donnees developpe par Tanner et Wong en 1987, pour simuler les
donnees manquantes, puisque nous sommes dans un contexte de donnees manquantes.
En combinant cet algorithme a l’algorithme de l’echantillonnage de Gibbs, ils ont pu
estimer les parametres de leurs modeles tout en completant les donnees manquantes.
Des donnees simulees ont ete utilisees pour fin d’illustration dans un contexte de panels
incomplets et non de coupes transversales independantes. Nous proposons d’etendre
leur demarche au probleme qui nous concerne. Nous exploiterons l’algorithme de l’aug-
mentation des donnees et celui de l’echantillonnage de Gibbs pour simuler les donnees
manquantes et estimer les parametres de nos modeles. Nous corrigerons simultanement
le probleme de selection et celui de l’endogeneite du prix dans un contexte de classes
latentes. Notre demarche est novatrice dans la litterature econometrique et elle permet

Chapitre 1. Introduction 5
permet de corriger plusieurs problemes importants qui sont rattaches a la demande
d’electricite residentielle.
Le chapitre 2 presente une synthese des travaux anterieurs. Le chapitre (3) analy-
sera la demande d’electricite a partir d’une seule base de donnees d’enquete tout en
corrigeant le probleme de biais de selection, le probleme d’endogeneite du prix et celui
de l’heterogeneite du taux d’escompte individuel. Le chapitre (4) utilisera l’approche de
Deaton pour estimer un modele statique et dynamique de demande d’electricite avec
des effets fixes tout en corrigeant les problemes d’heteroscedasticite et d’autocorrelation
des erreurs. Le chapitre (5) developpe un modele statique et dynamique de demande
d’electricite qui tient compte de l’heterogeneite entre les cohortes. Ce chapitre utilisera
des cohortes de menages (au sens de Deaton) et les parametres seront estimes grace
a l’algorithme de l’echantillonnage de Gibbs. Dans le chapitre (6), nous tenterons de
pallier a la principale limite de l’approche de Deaton qui transforme les informations au
niveau microeconomique en information en terme de groupe. Pour pouvoir garder l’in-
formation au niveau du menage tout en corrigeant le biais de selection et d’endogeneite,
nous exploiterons l’approche proposee par Paquet et Bolduc (2004). Nous developpons
un modele a classes latentes statique et dynamique qui utilise un panel simule. Nous
terminerons au chapitre (7) par une conclusion, des recommandations de politiques
economiques et enfin par des propositions de recherches futures. Il convient de noter
que dans la presentation du travail, il y a certaines repetitions. Cela se justifie par le
fait que nous avons voulu ecrire des papiers differents, chacun constituant un ensemble
a part entiere. Dans un souci de ne pas perdre le fil des idees pour chaque papier,
certains elements juges necessaires ont ete reproduits afin de permettre une meilleure
comprehension de chacun des papiers, et dans l’eventualite de publications futures.

Chapitre 2
Revue de la litterature
2.1 Introduction
Dans ce chapitre, nous faisons une synthese des travaux anterieurs ayant porte sur
des sujets qui sont relies a nos objectifs. Nous sommes en effet interesses a analyser
la demande d’electricite des menages de la province de Quebec. Si on veut s’interesser
a la demande d’electricite residentielle, trois points importants devraient etre pris en
compte. Le premier point concerne le choix de la forme d’energie par le menage pour le
chauffage. Pour pouvoir utiliser l’electricite ou toute autre forme d’energie, le menage
doit choisir des appareils qui vont lui permettre de maximiser son utilite (besoins de
chauffage de l’eau, de l’espace, fonctionnement d’appareils electromenagers,...). Nous
appellerons modalite ou alternative toute forme d’energie ou de combinaison d’energie
permettant de faire fonctionner les appareils du menage. Le choix d’une modalite af-
fecte son utilite et de cette utilite, l’on peut deriver la quantite d’energie necessaire pour
satisfaire ses besoins. Il y a donc une interdependance entre le choix de la modalite et
la quantite d’energie qu’il consomme. Cette situation cree un probleme de selection.
Un des objectifs sera de resoudre ce probleme de selection dans le modele de demande
d’electricite. Le second point important a noter est que les menages de la province
utilisent l’electricite qui est produite et distribuee par Hydro-Quebec, societe d’Etat
mandatee a cette fin. Hydro-Quebec utilise une tarification par tranche. Elle fixe un
premier prix lorsque la consommation journaliere (qui est malheureusement non obser-
vable) du menage est inferieure ou egale a 30 kWh et un deuxieme prix superieur au
premier si sa consommation depasse ce seuil. Le prix marginal de l’electricite depend
de la quantite consommee qui depend aussi du prix. Il y a donc un probleme d’en-
dogeneite. Nous tenterons egalement de resoudre ce probleme dans notre modele. Le
dernier point est que les donnees dont nous disposons sont des donnees d’enquetes

Chapitre 2. Revue de la litterature 7
independantes. Les menages presents dans une enquete ne sont plus retracables dans
les autres enquetes. Or, le choix d’une modalite est fait pour plusieurs annees. Une
bonne analyse de la demande d’energie necessiterait d’avoir des donnees de panel qui
permettraient de suivre les memes individus durant plusieurs annees. Un autre objectif
de la these sera de resoudre ce probleme de manque de donnees de panels. La section
(2.2) donne une synthese des travaux ayant porte sur la question de la simultaneite
entre choix discret et choix continu, la section (2.3) s’interesse au probleme de la non
linearite du prix, les sections (2.4) et (2.5) portent sur les methodes de traitement des
donnees de panels. Les travaux ayant porte sur le probleme de manque de panels ou
donnees manquantes sont synthetises dans les sections (2.6), (2.7) et (2.8).
2.2 Le probleme de la simultaneite entre choix dis-
cret et choix continu
L’analyse de la demande des consommateurs nous conduit parfois a des situations
ou les choix discrets sont relies aux choix continus. Ceci s’explique par le fait que ces
deux types de choix sont derives de la meme decision de maximisation de l’utilite de
l’agent considere (consommateur ou menage). Par exemple, un consommateur peut etre
confronte a la situation suivante :
– choisir la marque d’un produit (un bien durable par exemple) et la quantite de ce
produit,
– choisir le type d’assurance et le montant a allouer a cette assurance,
– choisir une localite et le moyen de transport a utiliser pour y arriver,
– choisir le type d’energie pour les besoins de chauffage et la quantite de cette
energie,...
Dans un tel contexte, le choix discret optimal depend du choix continu et vice versa.
Les modeles qui ignorent cette interdependance produisent des estimateurs biaises et
non convergents. King (1980) fut le premier a souligner cette interdependance. Il sup-
pose que le choix du type d’habitation et la demande de services pour la maison sont
des decisions conjointes. Il propose d’estimer le modele par la methode du maximum
de vraisemblance en information complete. Dans la formulation de sa fonction de vrai-
semblance, il a considere la demande non conditionnelle plutot que la demande condi-
tionnelle au choix du type de maison.
En ce qui concerne la demande d’energie, et d’electricite en particulier, on peut dire
qu’il s’agit d’une demande derivee. L’energie ne procure pas une utilite en soit, mais
ce sont les biens ou les services qu’elle produit qui procurent de l’utilite au menage.

Chapitre 2. Revue de la litterature 8
Le menage se sert de l’energie pour satisfaire ses besoins, notamment de chauffage de
l’espace, de l’eau, l’eclairage, le fonctionnement d’appareils electromenagers, etc. Il doit
choisir le type d’energie qu’il prefere (mazout, gaz naturel, electricite, bi-energie, bois
ou une combinaison de l’une et l’autre) et la quantite de cette energie. Notons que
le choix du type d’energie implique le choix de systemes de chauffage de l’eau et de
l’espace correspondants. La consommation d’energie peut alors etre analysee comme
un modele de choix discret (choix du type d’energie ou de systeme de chauffage) et de
choix continu (quantite ou usage de cette energie).
Apres les tentatives de King (1980), Dubin et McFadden (1984) se sont interesses a
la demande d’electricite et au choix d’appareils electromenagers des menages des Etats-
Unis. Ils furent les premiers a proposer une methode qui prend reellement en compte
l’interdependance entre choix discret et choix continu. Leur demarche se resume en
deux grandes etapes. La premiere etape consiste a estimer d’abord le modele discret
par la methode du maximum de vraisemblance et a constituer ensuite les correcteurs
de biais de selection associe l’alternative choisie. A cette etape, ils utilisent un logit
polytomique pour modeliser le choix du mode de chauffage. Dans la deuxieme etape,
ils estiment la demande conditionnelle a l’alternative choisie en ajoutant les correcteurs
de biais obtenus a la premiere etape. La methode de la forme reduite et celle des
variables instrumentales sont ensuite utilisees pour estimer les parametres du modele.
Les estimateurs obtenus sont convergents. D’autres auteurs se sont interesses par la
suite aux modeles de choix discrets/continus. Nous en donnons un bref resume.
Hanemann (1984) s’est interesse a l’estimation de la demande de produits de marques
differentes. Le consommateur doit choisir parmi plusieurs marques de produits celle qu’il
prefere et la quantite dont il a besoin. Il propose d’estimer les parametres du modele
par la methode du maximum de vraisemblance en information complete. Cependant,
il specifie la fonction de vraisemblance comme le produit de la probabilite de choisir
une marque par la densite inconditionnelle de la demande plutot que la densite condi-
tionnelle qui prendrait en compte l’interdependance entre les deux choix. Hanemann
(1984) a plutot considere la demande conditionnelle au choix de l’alternative au lieu
de la probabilite de choix de l’alternative conditionnelle a la demande. Il se retrou-
vait alors avec des integrales multiples dans les deux parties de la densite conjointe.
Cela rend l’estimation assez complexe, et en presence de plusieurs alternatives dans
le modele discret, rien ne garantit une convergence vers le maximum global. Compte
tenu de la complexite de la fonction de vraisemblance, il propose alors la methode
en deux etapes du maximum de vraisemblance en information limitee. A la premiere
etape, il propose d’estimer un modele logit polytomique. Ensuite, il fait une regression
par les moindres carres ordinaires (MCO) ou les moindres carres generalises (MCG)
du modele de demande conditionnelle (avec le correcteur de biais de selection). Les

Chapitre 2. Revue de la litterature 9
estimes sont recuperes pour servir comme valeurs initiales pour la seconde etape. Cette
derniere consiste a estimer la fonction de vraisemblance. Les estimateurs obtenus sont
convergents.
Bernard, Bolduc et Belanger (1996) ont estime un modele de demande d’electricite
des menages quebecois. A la difference du modele de Dubin et McFadden (1984), ils
supposent un logit mixte pour le modele discret. Ce modele a l’avantage de prendre
en compte la correlation potentielle qui pourrait exister entre les neuf (9) alternatives
considerees. Le modele de demande est estime en utilisant la methode a variables ins-
trumentales et la forme reduite.
Sanga (1999) a utilise deux approches (maximum de vraisemblance en information
complete et en information limitee) pour estimer la demande d’electricite des menages
quebecois. Il introduit une certaine correlation entre les modalites du modele discret en
utilisant un modele probit polytomique. Dans l’estimation par le maximum de vraisem-
blance en information complete, l’interdependance entre choix discret et choix continu
a ete prise en compte grace a une bonne formulation de la fonction de densite conjointe.
Cette fonction est decomposee en une densite conditionnelle (probabilite de choisir une
alternative conditionnelle a la demande) et en une densite marginale (densite de la
fonction de demande) de maniere a permettre son estimation. Il a utilise l’approche par
simulation (simulateur GHK) pour evaluer la vraisemblance qui comporte des integrales
multiples. Le principal avantage de l’estimation en une seule etape est le gain en ef-
ficacite. Cette methode est cependant assez complexe, et a cause de la simultaneite
dans l’estimation des parametres du modele discret et du modele continu, une erreur
de specification sur l’une ou l’autre des composantes aurait des repercussions sur les
proprietes des estimateurs de tous les parametres. Or, en estimant les parametres de
facon separee (methode en deux etapes), une erreur qui survient dans une partie est
limitee a cette partie seulement. C’est pour cette raison de robustesse que les cher-
cheurs preferent souvent l’estimation en deux etapes que celle en une seule etape.
Dans son estimation par le maximum de vraisemblance en information limitee, Sanga
a considere l’interdependance entre choix discret et continu en introduisant des cor-
recteurs de biais de selection de type Heckman (1979) dans le modele de demande
conditionnelle d’electricite.
Vaage (2000) s’inspire des travaux d’Hanemann (1984) pour estimer la demande
residentielle d’energie des menages norvegiens. Il n’utilise pas la methode du maxi-
mum de vraisemblance en information limitee comme Hanemann. Apres avoir estime le
modele de choix discret par un logit polytomique, il construit les correcteurs de biais
de selection et estime ensuite le modele de demande conditionnelle par les MCO de la
meme facon que Dubin et McFadden (1984).

Chapitre 2. Revue de la litterature 10
Nesbakken (2001) estime un modele de choix du systeme de chauffage de l’espace
et un modele de demande d’energie de facon simultanee en utilisant la methode du
maximum de vraisemblance en information complete. Contrairement aux autres au-
teurs, elle suppose que le choix discret et le choix continu ne sont pas des decisions
contemporaines : le choix du systeme de chauffage se fait lors de la construction de la
maison tandis que le choix de la quantite d’energie a consommer se fait a la periode cou-
rante. Cette hypothese conduit a inclure les couts fixes et les couts d’operation (couts
esperes) dans la fonction d’utilite indirecte, par contre dans la fonction de demande,
seuls les couts fixes interviennent. Elle suppose un modele logit polytomique pour la
partie discrete et une loi normale par la partie continue. Elle ne prend cependant pas en
compte de correlation potentielle entre les alternatives. L’estimation par le maximum
de vraisemblance en information complete a ete possible essentiellement parce qu’elle
n’avait pas beaucoup d’alternatives de chauffage (quatre alternativement seulement)
et elle n’a pas pris en compte la correlation qui pourrait exister entre les alternatives.
Neanmoins, les estimateurs obtenus sont plus efficaces que ceux de la methode en deux
etapes.
Liao et Chang (2002) se sont interesses a la demande d’energie pour le chauffage de
l’espace et de l’eau des personnes agees aux USA. Ils ont estimes le modele de choix
discret en utilisant un logit polytomique et la demande conditionnelle au choix par les
moindres carres ponderes. Leurs resultats indiquent que plus l’age augmente, plus les
besoins de chauffage de l’espace augmentent, mais les besoins d’eau chaude baissent.
La demande de gaz naturel et de mazout des personnes agees serait plus importante
que leur demande d’electricite.
Comme nous l’avons souligne au depart, dans ce travail, les menages qui nous
concernent sont confrontes a une tarification par tranche. Par consequent, dans la sec-
tion suivante, nous faisons une revue des travaux ayant porte sur la tarification non
lineaire ou par tranche.
2.3 Le probleme de la tarification non lineaire
Supposons que le menage fait face a un tarif de prix croissant selon la quantite
consommee et decrit par le graphique (2.1). Precisons que lorsque l’on s’interesse a la
tarification de l’energie, on s’interesse particulierement au prix marginal. Le prix moyen
de l’electricite (ou toute autre forme d’energie) est en effet egal au cout total de cette
electricite divisee par la quantite totale d’electricite consommee. Le prix marginal de
l’electricite est egale a la valeur du kilowatt-heures (kWh) marginal consommee. Donc,

Chapitre 2. Revue de la litterature 11
dans tout le reste du chapitre, il sera essentiellement question du prix marginal.
Fig. 2.1 – tarif de prix croissant en deux blocs
x
P
P
x
1
2
*
P
Le graphique (2.1) represente la structure tarifaire d’Hydro-Quebec. La societe fixe le
prix de l’electricite selon la quantite consommee par le menage sur une periode donnee.
Si la consommation journaliere moyenne du menage est en dessous de ou egale a 30
kWh, le prix marginal est fixe a p1, et si elle depasse les 30 kWh, Hydro-Qebec fixe un
prix p2 > p1 pour toutes les quantites au dessus des 30 kWh.
Comme on peut le constater, le prix marginal est non lineaire, rendant la contrainte
budgetaire du menage non lineaire. Ainsi, lorsque le prix marginal est determine selon
la tranche d’energie consommee, il devient une variable endogene et on dira que le prix
marginal est non lineaire.
On sait depuis les travaux d’Houthakker (1951) que les prix par tranche de consom-
mation ont des implications econometriques importantes. Taylor (1975) a souligne le
biais potentiel qui resulterait de l’estimation des elasticites de la demande lorsque la
structure des prix est non lineaire. Selon Taylor (1975), la non linearite de la contrainte
budgetaire du consommateur a des consequences sur l’equilibre du consommateur, la
fonction de demande et les courbes d’Engel. Lorsque les prix sont non lineaires, on a
un probleme d’endogeneite du prix. En effet, la quantite demandee depend du prix et
le prix est fixe selon la quantite demandee. Il en resulte un biais du a l’endogeneite du
prix.
Plusieurs auteurs ont cherche a resoudre ce probleme de biais provenant de la non
linearite des prix. On peut citer pour la demande d’electricite, Acton, Mitchell et Mowill
(1976), Barnes, Gillingham et Hageman (1981), Dubin (1985a et 1985b), McFadden,
Puig et Kirshner (1977), Taylor (1975), Herrigues et al. (1994), Reiss et White (2005) ;
pour l’eau, Billings et Agthe (1980, 1981), Foster et Beattie (1985a et 1985b) ; pour le gaz
naturel, Barnes, Gillingham et Hageman (1982), Polzin (1984), etc... Dans les travaux
anterieurs, il existe une variete de methodes d’estimation des modeles de demande avec

Chapitre 2. Revue de la litterature 12
endogeneite du prix. Herriges et al. (1994) ont fait une synthese.
Lorsqu’il y a un probleme de variable explicative endogene, les estimateurs des
MCO sont biaises. Plusieurs alternatives existent : l’estimation par la forme reduite,
les variables instrumentales, le maximum de vraisemblance structurel, le maximum de
vraisemblance structurel modifie, la methode des moments generalises (GMM),...
L’approche par la forme reduite consiste a utiliser un sous-ensemble du tarif de prix
ou une combinaison d’elements du tarif comme variables explicatives dans le modele
de demande. Taylor (1975) proposait d’utiliser a la fois le prix marginal et moyen. Mc-
Fadden (1977) a utilise trois prix differents pour capter tous les effets de la tarification.
L’estimation par la forme reduite a cependant deux limites importantes :
– un probleme d’identification des parametres peut se poser lorsqu’il n’y a pas assez
de variabilite au niveau du point de rupture : le seuil de changement de prix est
constant comme c’est le cas pour les donnees qui nous concernent. Il serait alors
difficile de passer de la forme reduite au modele original.
– la forme reduite est souvent ad hoc, donnant ainsi lieu a peu de justification quant
aux variables a inclure dans le modele.
Pour fin d’illustration, supposons le tarif decrit ci-apres :
pe = pe (x, p1, p2, x∗)
≡ p1
≡ p2
si
si
x ≤ x∗
x > x∗ ,
ou pe est le prix a l’equilibre du consommateur, x est la quantite demandee, x∗ est le
seuil de changement d’une tranche a l’autre, p1 et p2 sont les differents prix. Supposons
un modele de demande lineaire defini comme suit :
x = α0 + α1pe + α2revenu + ε.
avec ε un terme d’erreur. Substituons le prix par son expression :
x = α0 + α1pe (x, p1, p2, x∗) + α2revenu + ε.
L’estimation par la forme reduite consiste a supposer que pe est une fonction lineaire
de variables explicatives :
x = α0 + [β1p1 + β2p2 + β∗x∗] + α2revenu + ε.
On peut constater que lorsque le seuil (x∗) est une constante, un probleme d’identifi-
cation se pose puisqu’il y aura deux constantes dans le modele. Donc, le β∗ ne sera pas
identifiable. De plus, rien ne prouve que le prix d’equilibre est une fonction lineaire de
variables explicatives, on pourrait supposer une autre forme fonctionnelle.

Chapitre 2. Revue de la litterature 13
L’estimation par variables instrumentales (VI) permet aussi de resoudre le biais du
a l’endogeneite du prix. La demarche consiste a trouver de bons instruments pour le
prix. Cette methode a ete utilisee par Barnes, Gillingham et Hagemann (1981), Haus-
man, Kinnucan et McFadden (1979), Hausman et Trimble (1984). L’estimation par va-
riables instrumentales est techniquement superieure a l’estimation par la forme reduite
parce qu’elle permet de resoudre non seulement le biais d’endogeneite du prix, mais
aussi de specifier l’equation de demande en coherence avec la theorie neoclassique de
maximisation de l’utilite. Cependant, les estimateurs obtenus ne sont pas les meilleurs.
En revenant au modele illustratif, l’estimation par VI pourrait consister a prendre
pe = P (pe = p1 |revenu) × p1 + P (pe = p2 |revenu) × p2 comme instrument pour pe.
Une autre alternative est le maximum de vraisemblance structurel (MVS) initia-
lement propose par Burtless et Hausman (1978). Cette methode a ete utilisee par
Dubin (1985b) pour estimer la demande d’electricite. Le MVS consiste a resoudre le
probleme de maximisation de l’utilite du consommateur sous une contrainte budgetaire
non lineaire. Le terme d’erreur aleatoire intervenant dans la fonction d’utilite directe
traduirait soit de l’heterogeneite aleatoire dans les preferences et/ou des erreurs de me-
sures dans les variables explicatives. La solution au probleme de maximisation est une
fonction de demande definie de facon specifique pour chaque bloc. La loi du terme d’er-
reur permet de construire la fonction de vraisemblance a maximiser. Cependant, il se
peut que les probabilites qui entrent dans la fonction de vraisemblance soient negatives.
Herriges et al. (1994) proposent la methode du maximum de vraisemblance structurel
modifie pour resoudre ce probleme. Leur methode consiste a controler les probabilites
pour eviter des valeurs negatives. Supposons que la fonction d’utilite indirecte est definie
de la facon suivante :
max U (x,G, ε)
sc
p1x + G ≤ revenu
p2x + G ≤ revenu + (p2 − p1) x∗,
ou G indique les depenses pour les autres biens. Supposons que l’equation de demande
qui en resulte est definie par :
x =
f (p1, revenu, ε)
x∗
f (p2, revenu + (p2 − p1) x∗, ε)
si ε ≤ ε1
si ε1 ≤ ε ≤ ε2
si ε > ε2.
Les probabilites negatives viennent du fait qu’il peut arriver que (ε1 > ε2) rendant
P (ε1 ≤ ε ≤ ε2) < 0. Cependant, pour la structure tarifaire qui nous concerne, ce
probleme est ecarte puisque la partie du milieu sera incluse dans la premiere de sorte
qu’on se limite a deux parties et non trois.

Chapitre 2. Revue de la litterature 14
Reiss et White (2005) se sont interesses a l’estimation de la demande d’electricite
en supposant que la consommation totale est egale a la somme de la consommation
de chaque appareil du menage. Ils agregent la demande d’electricite a travers le temps
puisque le menage achete les appareils de chauffage et electromenagers pour plusieurs
periodes. Dans un tel contexte, la fonction de vraisemblance devient assez complexe a
maximiser de sorte que rien ne garantit que la solution obtenue correspond au maxi-
mum global. Dans leur etude, il fut impossible meme de maximiser leur fonction de
vraisemblance. Pour cette raison, ils ont utilise la methode des moments generalises
pour estimer les parametres du modele. Leur analyse leur a permis d’evaluer les effets
d’une modification de la structure de tarification non lineaire de l’electricite de l’etat
de Californie. En 2001, la structure tarifaire de l’electricite de la Californie est passee
d’un tarif de deux parties a un tarif a cinq parties non lineaires.
Il n’existe pas encore de travaux prenant en compte a la fois le probleme de la si-
multaneite entre choix discret et choix continu et le probleme de l’endogeneite du prix.
On s’interesse soit a l’un soit a l’autre des problemes, mais pas aux deux a la fois. Ce-
pendant, si nous voulons estimer la demande d’electricite des menages avec la structure
tarifaire d’Hydro-Quebec, nous devons resoudre simultanement ces deux problemes pour
obtenir des estimateurs convergents. Notre modele serait ainsi beaucoup plus adapte a
la realite. Au chapitre (3) nous utiliserons la methode du maximum de vraisemblance
a information limitee qui a l’avantage de corriger a la fois le biais de selection venant
du choix du mode de chauffage et le biais d’endogeneite du prix. Nous nous servirons
de modele a classes latentes pour prendre en compte l’heterogeneite entre les classes de
consommation et le logit mixte servira a prendre en compte la correlation potentielle
entre les alternatives. L’estimation du modele se fera avec une seule base de donnees
d’enquete, celle de 1989 d’Hydro-Quebec. Or, l’analyse de la demande d’electricite ou
d’energie en general devrait prendre en compte l’aspect intertemporel dans le compor-
tement de consommation des menages. Il serait beaucoup plus interessant de suivre les
memes menages sur plusieurs annees afin de bien comprendre leur comportement de
consommation. Pour y arriver, il faut utiliser des donnees de panel ; il s’agit de plusieurs
donnees d’enquete, menees a differentes periodes, et qui interrogent les memes individus
a chaque periode. Il existe dans la litterature des outils pour le traitement des donnees
de panel. Les sections (2.4) et (2.5) font une revue des modeles utilisant les donnees de
panel. Cependant, nous ne disposons malheureusement pas de donnees de panel. Nous
avons plutot des series de donnees d’enquete independantes : les menages d’une enquete
ne sont plus retracables dans les autres enquetes. On peut le voir comme un probleme
de donnees manquantes. Il existe aussi dans la litterature des techniques permettant de
se servir de ce type de donnees pour avoir des panels synthetiques. Les sections (2.6) et
(2.7) font une synthese des outils pour le traitement de ce type donnees. Les pseudo-
panels et les panels ont certaines proprietes en commun de sorte qu’il est important

Chapitre 2. Revue de la litterature 15
de bien connaıtre les outils pour le traitement de vrais panel, ceci permettra de mieux
comprendre les methodes utilisees pour les pseudo-panels.
2.4 Methodes d’estimation des modeles continus avec
des panels
Nous decrivons d’abord les donnees de panel et ensuite nous nous interesserons aux
methodes utilisees pour leur traitement.
2.4.1 Les donnees de panel
Les donnees de panel sont constituees d’observations tirees de facon repetees a
differentes periodes. Ainsi, pour un meme individu, il y a plusieurs observations corres-
pondantes. Les panels ont a la fois une dimension de coupe transversale et une dimension
de serie chronologique. Contrairement aux coupes transversales, il est possible de suivre
un individu donne dans le temps avec les donnees de panel. Contrairement aux series
chronologiques, on peut observer plusieurs series (ou variables) avec les donnees panel.
En observant plusieurs coupes transversales a travers le temps, il est possible d’analyser
les aspects dynamique et statique d’un probleme donne. Les termes «longitudinal» et
«panel» sont souvent utilises pour designer la meme chose.
Hsiao (2001) et Baltagi (2005) ont fait un survol de la litterature sur les donnees
de panel. Les donnees de panel ont un certain nombre d’avantages par rapport aux
donnees purement en coupes transversales ou de series chronologiques. L’un de ces
avantages est le nombre plus important d’observations ; cela permet d’ameliorer la
precision des estimes des parametres. Les donnees de panel ont aussi l’avantage de pou-
voir resoudre le probleme de multicolinearite. Lorsque les variables explicatives varient
dans les deux dimensions (temporelle et transversale), elles ont tendance a etre moins
fortement correlees. Avec les donnees de panel, il est possible de reduire le probleme de
la multicolinearite en introduisant des differences entre les individus a travers les effets
individus. En outre, avec les panels, il est possible de mesurer des effets qui ne sont pas
facilement identifiables avec des coupes transversales ou des series chronologiques. Les
panels permettent de controler l’heterogeneite individuelle.
Les donnees panel offrent la possibilite de reduire les biais d’omission de variables
pertinentes grace a une transformation du modele en difference ; cette transformation a

Chapitre 2. Revue de la litterature 16
pour but d’eliminer les variables specifiques aux individus mais invariantes dans le temps
et qui sont correlees avec le terme d’erreur. Soulignons aussi que les panels simplifient
l’inference statistique. Avec les series chronologiques, il est important de savoir si les
series sont stables, integrees ou explosives. Mais avec les donnees de panel, tant que
la dimension transversale approche l’infinie, la distribution limite des coefficients reste
normale, que la dimension temporelle soit fixee ( Anderson et Hsiao 1982) ou tende vers
l’infini (Levin et Lin 1993, Phillips et Moon 1999).
Avec les panels, on peut mieux analyser la dynamique d’ajustement des agents
economiques. Les coupes transversales ne permettent pas de suivre les memes individus
et de percevoir les changements dans leur comportement suite a des changements de
certains facteurs (comme le prix, le revenu,...). Un autre avantage important est que
les panels (au niveau individuel) sont des mesures plus precises que les memes panels
au niveau agrege (groupes ou cohortes d’individus). En gardant les panels au niveau
individuel, cela reduirait le biais provenant de l’agregation a travers les groupes ou
cohortes d’individus.
Les panels ont cependant certaines limites. Il y a d’abord les problemes de collecte
des donnees. Cela inclut le probleme de disponibilite de la population d’interet, les non-
reponses (les individus peuvent ne pas vouloir cooperer ou il peut y avoir des erreurs
dans les questionnaires), la frequence des interviews, l’espace entre les interviews, la
periode de reference.
Les panels peuvent avoir un probleme d’erreurs de mesure. Ces erreurs de mesure
peuvent se produire soit parce que la personne interrogee a donne une fausse reponse
(volontairement ou non), ou soit parce que la question posee n’est pas assez claire ou
precise.
Les panels souffrent aussi du probleme d’attrition. Puisque ce sont les memes indi-
vidus qui sont suivis sur plusieurs periodes, il peut arriver que certains ne soient plus
observables a partir d’une periode donnee. Les non reponses augmentent typiquement
a travers le temps. Les non reponses peuvent se produire dans les donnees de coupes
transversales comme dans les donnees de panel. Mais ce probleme est beaucoup plus
serieux avec les panels. Par exemple, les repondants peuvent disparaıtre definitivement
du panel (quitter, mourir, ou ne trouvent plus d’interet a participer aux entrevues).
L’attrition peut devenir problematique parce qu’elle peut creer un biais de selection.
Le biais de selection se produit lorsque les individus de l’echantillon ne sont plus tires
de facon aleatoire mais sont selectionnes en suivant le critere selon lequel l’individu est
observable sur toute la periode consideree. Dans un tel contexte, il peut arriver d’ex-
clure un pourcentage non negligeable d’observations de l’echantillon. Ainsi, une bonne

Chapitre 2. Revue de la litterature 17
partie de l’information ne sera pas utilisee dans l’analyse et l’echantillon ne serait plus
le resultat d’un tirage aleatoire. Une solution a ce probleme serait d’utiliser un panel
rotatif, qui est en fait un panel ou a chaque periode, on change un pourcentage fixe des
repondants.
Il existe deux types de donnees de panel : les panels balances et les panels non
balances. Avec les panels balances, chaque individu ou observation apparaıt a chaque
periode. Par contre, avec les panels non balances, certains individus peuvent etre presents
a toutes les periodes tandis que d’autres sont presents seulement a quelques periodes.
Pour ces derniers, il manque de l’information pour certaines periodes. Le traitement de
ce type de panel necessite une approche qui permet de tenir compte de ce probleme.
Dans tout le reste du document, nous considerons uniquement le cas de panel balances
pour simplifier notre analyse. Ainsi, le terme panel sous-entendra panel balance.
Les panels s’etalent souvent sur une tres courte periode. Cela n’est pas necessairement
negatif puisqu’en s’etalant sur plusieurs periodes, le probleme d’attrition pourrait s’ag-
graver et la base de donnees pourrait etre trop lourde a manipuler.
2.4.2 Methodes d’estimation des donnees de panel
Lorsqu’on dispose de panels complets, il existe des methodes d’estimation appro-
priees pour ce type de donnees. Lorsqu’il s’agit d’un modele lineaire, on peut utiliser
les modeles a effets fixes ou a effets aleatoires.
Supposons le modele suivant comme dans Wooldridge (2003) :
yit = θi + β1xi1t + β2xi2t + .... + βkxikt + uit (2.1)
i = 1, 2, ....N t = 1, 2, ....T.
Le terme θi est parfois appele effet individuel ou heterogeneite non observee. Les hy-
potheses sur θi determinent s’il s’agit d’un modele a effets fixes ou d’un modele a effets
aleatoires. Lorsqu’il s’agit d’un modele a effets fixes, θi est alors une constante specifique
a chaque observation i. Lorsqu’il s’agit d’un modele a effets aleatoires, le terme θi est
considere comme une variable aleatoire avec une loi donnee (souvent la normale). Dans
le language de l’econometrie moderne, le terme «effets aleatoires» est synonyme d’ab-
sence de correlation entre variables explicatives observees et effet non observe (θi).
Le terme «effets fixes» signifie qu’il est possible d’avoir une certaine correlation entre
les variables explicatives observees et l’effet non observe (θi). Ainsi, lorsqu’il y a une
correlation potentielle entre les xit et l’effet non observe, le modele a effet aleatoire ne
sera pas approprie. Nous discuterons plus loin des criteres de choix entre modele a effets
fixes et modele a effets aleatoires.

Chapitre 2. Revue de la litterature 18
Modeles a effets fixes
Dans la definition d’un modele a effets fixes, on suppose qu’il existe des facteurs non
observables et non aleatoires qui expliqueraient mieux le modele. Ces facteurs traduisent
une forme d’heterogeneite non aleatoire et peuvent etre specifiques au temps (indice par
t) ou a l’individu (indice par i).
Dans la plupart des donnees de panel, le nombre d’observations depasse le nombre
de periodes. L’heterogeneite entre les observations expliqueraient une proportion plus
grande de variabilite comparativement a l’heterogeneite entre les periodes. Ainsi, on
utiliserait souvent des variables binaires pour exprimer l’heterogeneite entre les periodes.
Dans un modele a effets fixes, on peut s’interesser soit uniquement a l’heterogeneite
entre les observations (on parlera de modele a effets fixes de base), ou soit uniquement
a l’heterogeneite entre les periodes ou enfin on pourrait s’interesser aux deux formes
d’heterogeneite a la fois. Supposons le cas d’un panel balance. L’heterogeneite entre les
observations s’ecrit de facon formelle comme suit :
yit = θi + β1xi1t + β2xi2t + .... + βkxikt + uit (2.2)
i = 1, 2, ....N
t = 1, 2, ....T.
L’heterogeneite entre les periodes se traduit par :
yit = λt + β1xi1t + β2xi2t + .... + βkxikt + uit (2.3)
i = 1, 2, ....N
t = 1, 2, ....T.
Un modele a effets fixes avec les deux formes d’heterogeneite s’ecrit :
yit = θi + λt + β1xi1t + β2xi2t + .... + βkxikt + uit (2.4)
i = 1, 2, ....N
t = 1, 2, ....T.
Le modele a effets fixes de base suppose qu’il n’existe ni correlation serielle de uit
(correlation a travers le temps) ni correlation contemporaine (correlation entre les in-
dividus). Il existe differentes methodes d’estimation des modeles a effets fixes.
Estimation en difference premiere Supposons pour simplifier que nous disposons
d’un panel a deux periodes. La generalisation se fait tres facilement lorsqu’on a plus de

Chapitre 2. Revue de la litterature 19
deux periodes. Comme dans Woodridge (2003), supposons le modele lineaire multiple
suivant :
yit = β0 + δ0D2t + β1xi1t + β2xi2t + .... + βkxikt + θi + uit
i = 1, 2, ....N, t = 1, 2
D2t =
0
1
si t = 1
si t = 2.
La composante θi englobe tout ce qui est non observable, invariant dans le temps et
qui affecterait la variable dependante yit. Supposons que θi est fixe. Il s’agit en d’autres
termes d’un modele a effets fixes avec a la fois de l’heterogeneite entre les observations
(θi) et de l’heterogeneite entre les periodes (intercept pour chaque periode). L’estimation
en difference premiere permet de se debarrasser de θi puisqu’il est le meme entre les
deux periodes. Elle consiste a ecrire le modele pour chaque periode et a prendre la
difference :
yi1 = β0 + β1xi1 + β2xi21.... + βkxik1 + θi + ui1
yi2 = β0 + δ0 + β1xi12 + β2xi21.... + βkxik1 + θi + ui2.
En soustrayant la premiere equation de la deuxieme, on obtient :
yi2 − yi1 = δ0 + β1(xi12 − xi11) + β2(xi22 − xi21) +
.... + βk(xik2 − xik1) + (ui2 − ui1) (2.5)
4yi = δ0 + β14xi1 + β24xi2 + ................ + βk4xik + 4ui
= = δ0 + ∆X ′iβ + 4ui,
avec : 4yi = yi2 − yi1 et 4xik = xik2 − xik1.
Pour obtenir des estimateurs convergents des βk par les MCO, il faut imposer un
certain nombre d’hypotheses. Soit : Xit = (x1it, x2it, ....xkit), Xt = (X1t, X2t, ....XNt) le
vecteur des variables exogenes du modele pour la periode t et soit X = (X1, X2, ...XT ).
Soit U le vecteur des termes d’erreurs. Les hypotheses suivantes doivent etre imposees :
1. Hypothese 1 : le terme d’erreur en difference est orthogonal a toutes les va-
riables explicatives en difference, conditionnellement aux effets non observes θi :
E (∆X ′4U) = 0. ∆Z etant le vecteur contenant la variable ∆zi definie precedemment.
Ceci implique que les variables explicatives sont strictement exogenes ; en d’autres
termes. Cette hypothese rend l’estimateur en difference premiere de β non biaise
conditionnellement aux variables explicatives observees.
2. Hypothese 2 : elle concerne la condition de rang. La matrice des variables ex-
plicatives en difference est de plein rang k. Si le modele contient k variables ex-
plicatives, alors, on doit avoir : rang de E [4X ′4X] = k. Cette hypothese ecarte

Chapitre 2. Revue de la litterature 20
les situations ou il existe des variables explicatives invariantes dans le temps de
meme que la colinearite parfaite entre les variables variant dans le temps. Ainsi,
si Xt contient une variable invariante dans le temps pour toutes les observations,
4X aura une colonne composee entierement de zero de sorte que la condition de
rang ne peut plus etre respectee. Les estimateurs MCO seront convergents s’il y
a des variations des (xit) dans le temps.
Ces deux premieres hypotheses sont essentielles pour avoir des estimateurs sans
biais de β. Les hypotheses suivantes sont posees pour avoir des estimateurs effi-
caces.
3. Hypothese 3 : la variance du terme d’erreur en difference est constante dans le
temps :
V (4uit |Xit, θi ) = σ2u ∀t. Ceci assure l’homoscedasticite des erreurs en difference.
4. Hypothese 4 : les erreurs suivent une marche aleatoire, donc, les erreurs en
difference premiere ne sont pas autocorrelees : Cov(4uit,4uis |Xit, θi ) = 0
5. Hypothese 5 : conditionnellement aux variables explicatives, les 4uit sont iden-
tiquement et independamment distribues selon une loi normale.
Appliquer les MCO au modele (2.5) donnerait des estimateurs convergents et effi-
caces de β.
L’estimation en difference premiere est une methode parmi d’autres pour eliminer
l’effet fixe θi. Une alternative serait de faire une estimation selon la transformation
«within» ou la transformation «between». Ces deux dernieres methodes constituent ce
que nous appellerons transformation a effets fixes.
Transformation «within» Soit le modele lineaire multiple a effets fixes defini par :
yit = β1xi1t + β2xi2t + ..... + βkxikt + θi + uit t = 1, 2, ....T (2.6)
= x′itβW + θi + uit,
avec βW le vecteur des coefficients de pentes de cette transformation. Prenons la moyenne
par rapport au temps des deux cotes de l’egalite :
yi = β1xi1 + β2xi2 + ..... + βkxik + θi + ui (2.7)
yi =1
T
T∑
t=1
yit xik =1
T
T∑
t=1
xikt ui =1
T
T∑
t=1
uit.
Comme θi est fixe a travers le temps, il apparaıt dans les deux equations de sorte qu’il
peut etre elimine :
yit − yi = β1 (xi1t − xi1) + β2 (xi2t − xi2) + ..... + βk (xikt − xik) + ui − uit..yit = β1
..xi1t + β2
..xi2t + ..... + βk
..xikt +
..uit. (2.8)

Chapitre 2. Revue de la litterature 21
Cette transformation s’appelle la transformation «within». Dans l’equation (2.8), l’effet
non observe (θi) a disparu. On peut donc estimer l’equation (2.8) par les MCO empiles
sur les nouvelles variables. L’estimateur «within» est donne par :
βW =
[T∑
t=1
N∑
i=1
(xit − xi)′ (xit − xi)
]−1 [ T∑
t=1
N∑
i=1
(xit − xi)′ (yit − yi)
].
On peut recuperer les estimateurs des effets non observes de la facon suivante :
θi = yi − βW xi i = 1, 2, ....N.
Un certain nombre d’hypotheses doivent etre remplies pour que l’estimateur de βW soit
sans biais et efficace. Ces hypotheses sont :
1. Hypothese 1 : les variables explicatives sont strictement exogenes conditionnel-
lement aux effets fixes : E (uit |Xit, θi ) = 0
2. Hypothese 2 : rang(∑T
t=1 E( ..x′it
..xit
))= k. Si Xit contient un element qui ne
varie pas dans le temps, alors l’element correspondant dans..xit sera egal a zero
pour tout t et pour tout i. Cette hypothese montre explicitement pourquoi les
variables explicatives constantes dans le temps ne sont pas permises dans l’analyse
des modeles a effets fixes.
Les hypotheses suivantes sont imposees pour que l’estimateur de βW soit efficace.
3. Hypothese 3 : la variance des erreurs est constante :
V (uit |Xit, θi ) = V (uit) = σ2u ∀t
4. Hypothese 4 : ∀t 6= s, les erreurs ne sont pas autocorrelees conditionnellement
a toutes les variables explicatives et aux effets fixes : Cov(uit, uis |Xit, θi ) = 0
5. Hypothese 5 : les erreurs sont independamment et identiquement distribuees
normalement, conditionnellement a Xit et a θi : uit ∼ N (0, σ2u)
Transformation «between» Une autre alternative a l’estimation en difference premiere
serait d’utiliser la transformation «between». Cette methode consiste a appliquer les
MCO au modele (2.7) en incluant une constante.
yi = β0 + β1xi1 + β2xi2 + ..... + βkxik + θi + ui
= x′iβB + θi + ui,
avec βB le vecteur des coefficients de pentes du modele. Comme on peut facilement
le remarquer, il y a plus de parametres a estimer que d’observations1 : on a N +
K parametres a estimer tandis qu’on n’a N observations. Le modele n’est donc pas
estimable.1Habituellement, lorsqu’il n’y a pas d’effets fixes, le modele est estimable. Mais, a cause de la
presence des effets fixes, il n’y a pas suffisamment d’observations pour que le modele soit estimable.

Chapitre 2. Revue de la litterature 22
Transformation a effets fixes ou estimation en difference premiere ?
Parmi les estimateurs a effets fixes (estimateur «within» et estimateur «between»),
lequel choisir ? Comme on peut le constater, l’estimateur «between» ignore une quantite
importante d’information sur les changements dans le temps des variables. Dans un tel
contexte, l’estimateur «within» serait preferable a l’estimateur «between».
Parmi les differentes methodes (transformation a effets fixes et methode en difference
premiere), laquelle choisir ? Lorsqu’on a un panel a deux periodes, les estimateurs a ef-
fets fixes et en difference premiere sont identiques. On choisira alors l’estimateur qui
est plus facile a implementer (estimateur en difference premiere). Si le modele com-
porte plus de deux periodes, alors les estimateurs a effets fixes et en difference premiere
ne sont plus les memes. Les deux estimateurs etant sans biais, le critere de selection
sera celui de l’efficacite. Ceci suppose l’hypothese d’homoscedasticite du terme d’er-
reur. En l’absence d’autocorrelation du terme d’erreur uit, l’estimateur a effets fixes est
superieur a l’estimateur en difference premiere. Dans beaucoup d’applications, l’esti-
mateur a effets fixes est beaucoup plus utilise que celui en difference premiere. Mais
si on a une autocorrelation serielle positive, et si uit suit une marche aleatoire, alors
4uit n’est pas seriellement correlee. Dans ce cas, l’estimateur en difference premiere est
meilleur a l’estimateur a effets fixes. Dans le cas contraire, il n’est pas souvent facile de
faire une comparaison des deux types d’estimateurs (Baltagi (1995), Woodridge (2002)
, Woodridge (2003),....). Mais si les Xis sont correles avec uit pour t 6= s, les deux types
d’estimateurs ne sont plus convergents. On peut utiliser le test de Hausman (1978) pour
verifier s’il y a effectivement une correlation entre les Xis et les uit.
Modele a effets aleatoires
Considerons le modele suivant :
yit = β0 + β1xi1t + βkxi2t + .... + β1xikt + θi + uit t = 1, 2, ....T (2.9)
= X ′itβRE + θi + uit, (2.10)
avec βRE le vecteur des coefficients de pentes du modele a effets aleatoires. On pourrait
toujours inclure des variables binaires pour prendre en compte l’heterogeneite entre les
periodes, mais par souci de simplification, nous nous limiterons au cas simple. Supposons
que l’effet inobservable θi est aleatoire et qu’il n’est pas correle avec les variables explica-
tives. Ainsi, l’effet inobservable devient un autre terme d’erreur. Posons : vit = θi +uit ;
soit le vecteur des nouveaux termes d’erreur : vi = (vi1, vi2, .....viT ). Supposons que
E (v′ivi) = Ω.

Chapitre 2. Revue de la litterature 23
L’estimation du modele exige que les hypotheses suivantes soient satisfaites pour
avoir la convergence de de l’estimateur de βRE :
1. Hypothese d’exogeneite stricte des variables explicatives : E (uit |Xi, θi ) = 0
2. Hypothese d’orthogonalite entre l’effet inobservable et les variables explicatives
observees : E (θi |Xi ) = E (θi) = 0
3. Condition de rang : rang [E (X ′iΩXi)] = k
Ces trois conditions permettent d’avoir la convergence de l’estimateur.
4. On peut ajouter d’autres hypotheses afin d’avoir une forme particuliere pour la
matrice de variance covariance :
E(u2
it
)= σ2
u t = 1, 2, ....T
E (uiu′i |Xi, θi ) = σ2
uIT
E (uitujs) = 0 ∀ t 6= s ou i 6= j,
E(θ2
i |Xi
)= σ2
θ
V (vit) = σ2θ + σ2
u, Cov(vit, vis) = σ2θ ∀t 6= s
Cov(vit, vjs) = 0 ∀t et s si i 6= j.
Sous l’hypothese (4), nous avons une autocorrelation serielle positive et les MCO ne
sont pas appropries puisque les tests d’hypothese qui en decouleront seront invalides.
Pour eliminer la correlation serielle, on utilise les MCG. L’estimateur des MCG est
donne par :
βRE =
(N∑
i=1
X ′iΩ
−1Xi
)−1( N∑
i=1
X ′iΩ
−1yi
).
Sous ces hypotheses, l’estimateur de βRE sera convergent et efficace. Fuller et Battese
(1974) ont demontre que l’estimateur MCG peut aussi s’obtenir en deux etapes en
estimant par MCO le modele en quasi-difference. Soit λ = 1−[
σ2u
σ2u+Tσ2
θ
]1/2
(0 ≤ λ ≤ 1).
Soit vit = θi + uit. La transformation s’effectue de la facon suivante :
yit = β0 + β1xi1t + β1xi2t + .... + β1xikt + vit
yit = β0 + β1xi1t + β1xi2t + .... + β1xikt + vit
λyit = λβ0 + β1λxi1 + β1λxi2 + .... + β1λxik + λvi
yit − λyit = β0 (1 − λ) + β1 (xi1t − λxi1t) + .... + β1 (xikt − λxik) + (vit − λvi) .
On applique ensuite les MCO a la derniere equation. Le modele transforme contient les
cas limites suivants :

Chapitre 2. Revue de la litterature 24
1. λ = 1 correspond a l’estimation a effets fixes
2. λ = 0 correspond aux MCO empiles.
Effets fixes ou effets aleatoires
Apres avoir defini les deux types d’effets (fixes et aleatoires), lequel choisir ? Si on
ne peut pas considerer les observations comme des tirages aleatoires a partir d’une
grande population (donnees sur des etats ou sur des provinces), alors les θi seraient des
parametres a estimer ; donc un modele a effets fixes serait approprie. Utiliser un modele
a effets fixes equivaut a permettre differentes constantes pour chaque observation. Dans
les situations ou le vecteur Xt ne varie pas beaucoup dans le temps, les methodes
d’estimation a effets fixes ou en difference premiere peuvent donner des estimes imprecis.
Si on decide de traiter θi comme une variable aleatoire, l’on doit savoir si les θi sont
correles ou non avec les variables explicatives. Certains auteurs croient qu’en supposant
que les θi sont aleatoires, cela signifie automatiquement qu’un modele a effets aleatoires
est approprie. Si on peut supposer que les θi ne sont pas correles avec les variables
explicatives, alors la methode a effets aleatoires est appropriee. Mais si les θi sont
correles avec une ou plusieurs variables explicatives, alors les methodes a effets fixes
ou en difference premiere sont preferables. Si l’on utilise cependant le modele a effets
aleatoires, les estimateurs des coefficients de pente ne seront pas convergents.
La comparaison des estimateurs a effets fixes ou aleatoires peut se faire par l’in-
termediaire d’un test pour savoir s’il existe une correlation entre les θi et les Xit. Il
s’agit du test d’endogeneite de Hausman (1978). Hausman a propose un test base sur la
difference entre les estimateurs a effets fixes et les estimateurs a effets aleatoires. Comme
l’estimateur a effets fixes est convergent lorsque θi et Xit sont correles, et que l’estima-
teur a effets aleatoires ne l’est pas, un test statistiquement significatif s’interpreterait
comme une evidence contre l’hypothese d’effets aleatoires.
Enfin, on peut noter que l’estimateur a effets fixes peut poser des problemes d’identi-
fication car les effets fixes sont specifiques aux individus et ils doivent tous etre estimes.
Plus il y a d’observations, plus on aura des effets fixes a estimer et plus le probleme
d’identification va se poser. Lorsqu’on suppose que les effets sont fixes, donc un intercept
specifique a chacun des N individus, plus N augmente, plus il y aura de parametres a
estimer : c’est le probleme de parametres d’incidence. Ce probleme est resolu lorsqu’on
utilise l’approche par la differenciation pour eliminer ces parametres. Cependant, si on
suppose qu’en plus des constantes, les coefficients de pentes sont fixes et specifiques aux
individus, le probleme de parametres incidents devient difficile a resoudre, rendant les

Chapitre 2. Revue de la litterature 25
estimateurs non convergents. (Hsiao (2001), Wooldridge, (2002)).
2.5 Methodes d’estimation des modeles a choix dis-
cret avec des panels
Certains auteurs se sont interesses a l’estimation de modele a variable dependante
discrete avec des panels. Nous retenons le modele suivant de Wooldridge (2002) comme
modele illustratif :
y∗it = Xitβ + θi + εit t = 1, 2, ....T i = 1, .....N
yit =
1
0
si y∗it > 0
sinon
P (yit = 1 |Xit, θi ) = G (Xitβ + θi) ,
avec : y∗it une variable latente inobservable, Xit est un vecteur de variables exogenes. Le
terme d’erreur εit peut suivre une loi normale (standard) ou logistique. La fonction G
est une densite cumulative de la loi du terme d’erreur. Le terme θi est un effet individuel
inobservable. Comme dans le cas lineaire, l’effet inobservable peut etre fixe ou aleatoire.
S’il est suppose fixe, il devient alors un parametre a estimer en meme temps que β. Le
probleme de parametres incidents peut se poser, rendant les estimateurs parfois non
convergents (Neyman et Scott (1948), Chamberlain (1984), Arellano et Honore (2001),
Honore (2002), Wooldridge (2002)). Si le terme d’erreur εit suit une loi normale, alors la
probabilite serait P (yit = 1 |Xit, θi ) = Φ (Xitβ + θi), avec Φ(.) la densite cumulative de
la normale. Les parametres du modele peuvent etre estimes par la methode du maximum
de vraisemblance. Cependant, plus N est grand, plus il y aura de parametres a estimer.
Cela pourrait causer un probleme d’identification si N est tres grand et que T est faible
comme c’est le plus souvent le cas ; le probleme de parametres d’incidence peut alors se
produire avec les modeles discrets. Le modele probit ne semble pas approprie lorsque les
effets inobservables sont fixes mais il serait mieux indique en presence d’effets aleatoires.
Le logit est plus approprie lorsqu’il s’agit d’effets fixes. La sous-section suivante presente
l’approche proposee par Chamberlain (1984).

Chapitre 2. Revue de la litterature 26
2.5.1 Estimation du logit a effets fixes et aleatoires : le maxi-
mum de vraisemblance conditionnel
Lorsque les effets sont fixes, la forme de la fonction de vraisemblance devient :
L =T∏
t=1
N∏
i=1
[Λ (xitβ + θi)
yit [1 − Λ (xitβ + θi)]1−yit
], (2.11)
ou Λ est la densite cumulative de la loi logistique. Andersen (1973) et plus recemment
Hsiao (2003) ont montre que pour T = 2, l’estimateur de β obtenu en maximisant le
log-vraisemblance (2.11) tend asymptotiquement vers 2β quand N −→ ∞. Donc, l’es-
timateur du maximum de vraisemblance n’est pas convergent en presence d’effets fixes.
Chamberlain (1984), Lee (2000) et Wooldrige (2002) ont estime le modele logit a effets
fixes par le maximum de vraisemblance conditionnel. Ils n’imposent aucune restriction
sur l’effet inobservable mais eliminent cet effet en se servant d’un sous ensemble des va-
leurs prises par la variable dependante. Supposons que T = 2. L’approche du maximum
de vraisemblance conditionnel consiste a trouver une statistique exhaustive pour θi2.
Lorsque yi1 + yi2 =∑
yit = 0 ou 2, la contribution a la vraisemblance de ces observa-
tions est nulle car la probabilite correspondant a ces valeurs est egale a 1 (θi = −∞ ou
∞ respectivement). (Voir Hsiao (1992) pour une demonstration detaillee). L’ensemble
des alternatives pour lesquelles yi1 + yi2 = 1 = ni (ni etant le nombre de fois dans le
temps que l’individu n a choisi la modalite i, en d’autres termes : ni =T∑
t=1
yit), a par
contre une contribution dans la fonction de vraisemblance. Cet ensemble est (0, 1) et
(1, 0). Soit :
wi = 1 si (yi1, yi2) = (0, 1)
= 0 si (yi1, yi2) = (1, 0).
Alors, les probabilites conditionnelles sont :
P (wi = d |yi1 + yi2 = 1) =exp [(xi2 − xi1) β]d
1 + exp [(xi2 − xi1) β]
d = 0, 1
P (yi2 = 1 |xi, θi, yi1 + yi2 = 1) = Λ [(xi2 − xi1) β]
P (yi1 = 1 |yi1 + yi2 = 1) = 1 − Λ [(xi2 − xi1) β] ,
avec Λ(.) la fonction de densite cumulee de la loi logistique. La fonction log-vraisemblance
est alors :
L = 1 [ni = 1] (wi log Λ [(xi2 − xi1) β] + (1 − wi) log (1 − Λ [(xi2 − xi1) β])) .
2Soit Y la matrice contenant les donnees. s(Y ) est une statistique exhaustive pour un parametre θ
si la loi conditionnelle de Y sachant s ne depend pas de θ (Gourieroux et Monford, 1996).

Chapitre 2. Revue de la litterature 27
Comme on peut le remarquer, la fonction log-vraisemblance ne depend plus des pa-
rametres d’incidence (θi). L’approche se generalise pour tout T > 2 ; on exclut l’en-
semble des alternatives pour lesquelles∑
t yit = 0 ou∑
t yit = T , puisqu’elles ne contri-
buent pas a la vraisemblance. Pour les autres ensembles, une statistique exhaustive de
ci serait∑
t yit = ni. La log-vraisemblance serait de la forme :
L = log
exp
(T∑
t=1
yitxitβ
)[∑
a∈Ri
dtxitβ
]−1 ,
avec Ri le sous-ensemble de RT tel que dt = (0, 1) ,∑
t dt = ni.
Une limite a cette approche qui est semiparametrique est qu’il n’est pas possible
d’evaluer les effets partiels moyens qui sont pourtant important pour les modeles discrets
(Wooldridge, 2002).
2.5.2 Probit a effets aleatoires
Comme il a ete souligne auparavant, le probit a effets fixes est sujet au probleme de
parametres d’incidence. Pour cette raison, le probit est plus approprie lorsque les effets
sont aleatoires. Wooldridge (2002) a formule un modele probit bivarie a effets aleatoires
en supposant dans un premier temps que l’effet inobservable n’est pas correle avec les
variables explicatives. Il suppose plus precisement que l’effet inobservable suit une loi
normale de moyenne nulle et de variance constante : ci |xit ∼ N (0, σ2c ). La densite de
l’observation i a la periode t est definie par :
f(y1, y2, ....yT ; β, σ2
c
)=
∞∫
−∞
[T∏
t=1
(Φ (xitβ + c)yt [1 − Φ (xitβ + c)]1−yt
) 1
σc
φ
(c
σc
)dc
].
Cette densite comporte une integrale et son evaluation necessite des methodes numeriques.
Lorsqu’il s’agit d’un modele probit polytomique avec J modalites, il y aura une integrale
de dimension (J − 1). La presence d’integrales multiples rend l’estimation du probit as-
sez complexe. Une alternative serait la methode par simulation qui consiste a remplacer
les integrales par des sommes en faisant des tirages dans des lois donnees (Paquet
(2002)).
Il existe aussi dans la litterature des methodes d’estimation du modele probit avec
l’hypothese de correlation entre variables exogenes et l’effet inobservable. Chamberlain
(1980) fut le premier a proposer un tel modele. Wooldridge (2002) s’est egalement
interesse au meme modele en se basant sur l’approche de Chamberlain (1980). La

Chapitre 2. Revue de la litterature 28
difference avec le probit a effets aleatoires et exogeneite stricte vient du fait que la loi
de l’effet aleatoire depend des exogenes du modele. Ainsi, l’esperance de l’effet aleatoire
n’est plus nulle mais depend des exogenes du modele.
2.5.3 Methodes d’estimation de modeles dynamiques avec des
panels
Comme dans le modele statique ou il a ete question de faire la distinction entre les
modeles lineaires a effets fixes et les modeles lineaires a effets aleatoires, nous faisons
ici aussi la meme distinction avec les modeles lineaires dynamiques. Un certain nombre
d’auteurs se sont interesse a l’estimation des modeles lineaires dynamiques a effets fixes.
Parmi eux, citons : Balestra et Nerlove (1966), Nickell (1981), Anderson et Hsiao (1982),
Arellano (1988), Sevestre et Trognon (1992), Arellano et Bond (1991), Wooldridge (2000
et 2002) et Lee (2000), etc... Soit le modele autoregressif d’ordre un ou AR(1) defini
par :
yit = ρyi,t−1 + x′itβ + θi + εit t = 1, 2, ....T i = 1, .....N, (2.12)
ou θi est un effet inobservable et εit un terme d’erreur. Selon Lee (2000), l’hypothese de
stationnarite (|ρ| < 1) n’est pas habituellement necessaire pour les inferences lorsque
T est fixe. Mais, l’hypothese |ρ| < 1 est pertinente pour la plupart des applications
empiriques. Lorsque les variables explicatives ne sont pas correlees avec l’effet fixe et
qu’il n’y a pas de variable endogene retardee dans le modele, alors l’estimation du
modele selon la transformation within de β est convergente. Cependant, si l’on inclut
une variable endogene retardee dans le modele, l’estimateur des MCO du modele selon
la transformation within de β n’est plus convergent lorsque T est faible (Nickell 1981).
Cependant, si T est grand, cet estimateur est convergent (Voir Lee (2000) pour plus
de details). Dans les etudes empiriques, T est souvent fixe de sorte qu’il est necessaire
de trouver un estimateur pour ce type de probleme. Pour resoudre ce probleme de
non convergence, on peut utiliser la methode a variables instrumentales (Anderson et
Hsiao (1982), Arellano (1988), Sevestre et Trognon (1992), Arellano et Bond (1991)).
Cependant, le choix des instruments n’est pas toujours facile. Il existe essentiellement
deux criteres de choix des instruments (Lee, 2000) :
- le degre de correlation serielle entre les termes d’erreurs
- l’exogeneite des variables explicatives.
La methode a variables instrumentales est assez limitee compte tenu des difficultes
liees au choix des instruments. Plusieurs auteurs se sont interesses a la recherche de
bons instruments selon les differents cas possibles, Lee (2000) en donne un resume.

Chapitre 2. Revue de la litterature 29
En ce qui concerne les modeles a effets aleatoires dynamiques, ils peuvent etre es-
times par la methode des moindres carres generalises qui ne prend cependant pas en
compte l’information sur la premiere observation de la variable dependante (qui est yi0).
L’introduction de la variable endogene retardee necessite de prendre en consideration la
premiere observation : on parle alors de condition initiale (Heckman , 1981). Wooldridge
(2000) et Lee (2000) demontrent l’importance de yi0 sur le comportement asymptotique
de l’estimateur de β pour T fixe et N grand. Pour cette raison, on privilegie les methodes
qui prennent en compte la premiere observation. Barghava et Sargan (1983) proposent
un estimateur par maximum de vraisemblance inconditionnel qui tient compte de yi0.
Chamberlain (1984), Blundell et Smith (1991), Sevestre et Trognon (1990) adoptent
egalement l’approche par le maximum de vraisemblance inconditionnel. Arellano et
Bover (1995), Blundell et Bond (1998), Haln (1999) et Im et al. (1999) utilisent la
methode des moments generalises. Cependant, les differentes methodes proposees sont
peu flexibles et complexes surtout lorsqu’il s’agit de modeles non lineaires. Wooldridge
(2000) propose alors une methode plus flexible surtout avec les modeles non lineaires :
le maximum de vraisemblance conditionnel. Cette methode a egalement ete utilisee
par Lee (2000). La methode du maximum de vraisemblance conditionnelle proposee
consiste a definir la densite marginale de l’effet inobservable en fonction de la premiere
observation, de sorte qu’il n’est plus necessaire de definir la densite de cette derniere :
f (y1i, y2i, ....yT i; β, θ) =
∫
Rm
f (y1i, y2i, ....yT i |yi0, θ, xit ) h (c |yi0, xit, λ0 ) dθ
=
∫
Rm
T∏
t=1
f (yit |yi0, θ, xit ) h (θ |yi0, λ0 ) dθ,
ou Rm indique une integration sur tout le domaine de R avec m la dimension de c.
f (yit |yi0, c, xit ) est la densite de yit conditionnelle aux variables exogenes et a l’obser-
vation initiale yi0. h (c |yi0, λ0 ) est la densite marginale de l’effet aleatoire qui depend
de l’observation initiale. La fonction log-vraisemblance a maximiser est alors egale a :
L =N∑
i=1
log
∫
Rm
T∏
t=1
f (yit |yi0, c, xit ) h (a |yi0, λ0 ) da,
ou a est le terme d’erreur de l’equation de l’effet aleatoire. On pourrait aussi considerer
le modele (2.12) comme un modele avec de l’heteroscedasticite ou le terme d’erreur
serait : ηit = θi + εit. Cette facon de proceder permet de se debarrasser de l’integrale
lorsque m = 1.
L’estimation des modeles non lineaires est plus facile lorsqu’on utilise l’approche
du maximum de vraisemblance conditionnelle proposee par Andersen (1973) et utilisee
entre autres par Chamberlain (1984), Wooldridge (2000, 2002),... Le logit a effets fixes

Chapitre 2. Revue de la litterature 30
semble assez complexe a estimer en presence de variable endogene retardee a cause
essentiellement du probleme de parametres d’incidence. Les modeles a effets aleatoires
semblent mieux appropries lorsqu’on inclut une variable endogene retardee dans le
modele (Lee, 2000).
2.5.4 Approche semiparametrique
L’estimation du logit a effets fixes avec donnees de panel n’impose pas de loi sur l’ef-
fet inobservable. De ce fait, le logit a effets fixes peut etre considere comme un modele
semiparametrique. L’approche semiparametrique consiste a ne pas imposer d’hypothese
sur la distribution du terme d’interet (terme d’erreur du modele ou effets inobservables).
Certains auteurs ont propose d’utiliser l’approche semiparametrique pour estimer les
modeles non lineaires avec donnees de panel : Manski (1987), Honore et Kyriazidou
(2000), Arellano et Honore (2001), Honore (2002). La plupart de ces auteurs utilisent la
regression par les noyaux. Comme l’a souligne Lee (2000), l’approche semiparametrique
est limitee essentiellement pour deux raisons : la premiere etant le probleme de la
convergence (la convergence peut ne pas se faire au rythme de√
N , on parlera de la
malediction de la dimensionnalite) ; la seconde limite vient du fait que l’approche semi-
parametrique ne permet pas de calculer les effets partiels ou les effets partiels moyens
(average partial effects) qui semblent assez importants lorsqu’il s’agit des probabilites
de choix.
2.5.5 Correction de biais de selection de donnees de panel
Quoique les modeles avec des panels soient largement utilises en economie, il existe
peu de travaux concernant l’estimation de ces modeles en presence de probleme de
selection. (Vella et Verbeek 1999). De plus, les donnees de panel permettent de traiter
le probleme d’heterogeneite entre les observations, de sorte que le probleme de selection
et la question de l’heterogeneite non observee doivent parfois etre resolus simultanement
(Hausman et Wise (1979), Nijman et Verbeek (1992), Rosholm et Smith (1994)). La
plupart des auteurs qui se sont interesses a ce probleme ont utilise soit l’estimation par
le maximum de vraisemblance en information complete ou l’estimation en deux etapes
(maximum de vraisemblance conditionnelle ou methode des moments conditionnels).
Verbeek et Nijman (1992) et Wooldridge (1995) supposent la normalite du terme d’er-
reur du modele et de l’effet inobserve (conduisant a l’estimation par le maximum de
vraisemblance) tandis que Kyriazidou (1997 et 2001) ecarte cette hypothese pour utili-
ser l’approche en deux etapes proposee par Heckman (1974 et 1976). Vella et Verbeek

Chapitre 2. Revue de la litterature 31
(1999) utilisent aussi l’approche en deux etapes (moments conditionnels et maximum
de vraisemblance en information limitee) dans le but de contourner les difficultes liees
au maximum de vraisemblance en information complete. Wooldridge (2005) considere
un modele a effets fixes qu’il estime en utilisant les doubles moindres carres lineaires.
A notre connaissance, il n’y a pas encore eu de travaux qui aient traite simul-
tanement l’heterogeneite non observee et le probleme de selection et/ou d’endogeneite
avec donnees de panel en supposant un modele polytomique pour l’equation de selection.
Pour ce travail, nous essayerons d’estimer un modele de pseudo-panel qui prend en
compte ces problemes.
Comme nous l’avons precise auparavant, nous ne disposons pas de donnees de pa-
nel. Un des objectifs de cette these est d’exploiter les differentes donnees d’enquetes
independantes disponibles pour obtenir des panels synthetiques ou pseudo-panels. Les
menages de chaque enquete apparaissent une seule periode et ne sont plus retracables
dans les autres periodes d’enquete. Il existe dans la litterature des techniques permet-
tant d’avoir des pseudo-panels a partir de plusieurs coupes transversales independantes.
La section suivante fait la synthese des travaux portant sur ce sujet.
2.6 Methodes d’estimation des donnees longitudi-
nales incompletes
Nous avons presente dans les sections precedentes les outils pour le traitement
des donnees de panel balancees ou completes. Cela va nous permettre d’aborder le
probleme des donnees de panel incomplets. Si nous arrivons a resoudre le probleme
de donnees incompletes, alors, nous pourrons etendre certaines methodes d’estimation
des panels complets aux panels incomplets. Nous disposons en effet de quatre bases de
donnees d’enquetes independantes d’Hydro-Quebec portant toutes sur la consomma-
tion d’electricite des menages quebecois (enquete de 1989, 1994, 1999 et 2002). Nous
cherchons a capter les aspects dynamiques ou intertemporels de la consommation des
menages etant donne que ces derniers utilisent des biens durables pour satisfaire leurs
besoins en energie. A defaut de vraies donnees de panel, il est possible de creer des
pseudo-panels pour atteindre nos objectifs. Nous nous interesserons dans un premier
temps aux etudes portant sur les pseudo-panels conventionnels (selon l’approche de
Deaton (1985)) et dans un second temps, nous aborderons les etudes portant sur les
pseudo-panels obtenus par la simulation (approche bayesienne).

Chapitre 2. Revue de la litterature 32
2.6.1 Les donnees longitudinales incompletes
Lorsque les bases de donnees disponibles comportent de l’information manquante,
on parlera alors de donnees longitudinales incompletes. L’information manquante peut
concerner soit des variables d’un certain nombre d’individus pour certaines periodes,
ou soit certaines observations de la dimension transversales ne sont pas observees a
certaines periodes. Ainsi, l’information manquante peut etre partielle ou totale pour
certaines observations a certaines periodes. Par exemple, dans les etudes empiriques,
il peut arriver que la base de donnees disponible soit composee d’individus observes
sur toutes les periodes ; cependant, il peut y avoir aussi des individus pour lesquels
certaines variables ne sont pas observables (variables explicatives et/ou dependantes).
Certains individus peuvent aussi ne pas etre observables a certaines periodes. Dans le
cas extreme, il s’agit de coupes transversales independantes ou les unites sont observees
une seule fois contrairement aux donnees de panel ou les individus sont observes a
chaque periode. On parlera alors de panel incomplets.
Les panels incomplets comportent un certain nombre d’avantages (avantages ob-
serves aussi avec les panels) : possibilite d’etudier l’aspect dynamique, richesse de
l’information concernant les variables socio-economiques, possibilite de tenir compte
de l’heterogeneite entre les individus,... Avec les panels incomplets, l’effet d’appren-
tissage est moins probable, etant donne qu’un meme menage se retrouve a moins de
periodes, voir meme une seule periode (cas extreme d’une serie de coupes transver-
sales independantes). Les donnees longitudinales comportent cependant certains in-
convenients essentiellement d’ordre methodologique. Il faut en effet developper des
techniques appropriees pour tenir compte de l’information manquante. A chaque type
d’information manquante (variables manquantes ou individus manquantes a certaines
periodes), il faut utiliser une technique appropriee.
2.6.2 Les pseudo-panels conventionnels
Dans beaucoup de pays, et surtout dans les pays en developpement, il y a tres peu
de donnees de panel ; cependant, il existe beaucoup de series de donnees d’enquete
independantes. Les donnees de panel sont souvent couteuses a collecter puisqu’il faut
suivre les memes individus sur plusieurs periodes (annee, mois, jour,...). De plus, les
panels sont sujets au probleme d’attrition. Avec les donnees en coupes transversales, les
individus qui font l’objet de l’enquete changent d’une periode a l’autre de sorte que leur
collecte est beaucoup moins contraignante. C’est pourquoi dans beaucoup de pays, les
donnees de panel sont tres rares ou parfois inexistantes alors qu’il existe d’importantes

Chapitre 2. Revue de la litterature 33
donnees de coupes transversales. Mais les coupes transversales ne permettent pas de
suivre un individu donne dans le temps pour pouvoir capter les aspects dynamique ou
intertemporel de son comportement. Comment donc se servir de ces coupes transversales
pour pallier au manque de donnees de panel ?
Deaton (1985) fut le premier a proposer une solution a ce probleme. Il suggere de
remplacer les observations par des moyennes de cohortes. Une cohorte est definie comme
un ensemble d’individus ayant des caracteristiques communes. Si l’individu ne peut pas
etre suivi dans le temps, la cohorte peut par contre etre suivie dans le temps. Il suppose
un modele lineaire dans les parametres. Si le modele dans sa version individuelle contient
des effets fixes, alors sa version de cohortes aura aussi des effets fixes. Etant donne que
l’on dispose d’echantillon de cohortes et non de la population entiere de cohortes, les
moyennes des cohortes sont une approximation des moyennes de la population et par
consequent, sont des variables avec des erreurs de mesure. L’estimation de ce type de
modele necessite des techniques d’estimation appropriees aux variables avec erreurs de
mesure. Au lieu d’avoir de vrais panels, Deaton propose de constituer des pseudo-panels
composees de cohortes d’individus. Cela n’implique pas necessairement que les resultats
qui en decouleront seront inferieurs a ceux qu’on obtiendrait si on disposait de vraies
donnees de panel. On sait en effet que les panels souffrent frequemment de probleme
d’attrition. Il peut arriver que certains individus decident de quitter le groupe faisant
l’objet de l’enquete pour differentes raisons. Ces departs font qu’il n’est pas possible
d’observer certains individus a partir d’une periode donnee. Avec les pseudo-panels, ce
probleme est ecarte puisque les individus ne sont plus les memes d’une periode a l’autre.
Le probleme d’attrition ne se pose plus avec les pseudo-panels. De plus, on peut etendre
le nombre de periodes avec les pseudo-panels si ont dispose de coupes transversales
sur ces periodes. Dans les travaux anterieurs portant sur les pseudo-panels, on peut
distinguer les modeles lineaires et les modeles non lineaires (choix discrets) comme
dans le cas des vrais panels. Nous aborderons d’abord les methodes d’estimation des
modeles lineaires (statiques et dynamiques) et ensuite celles des modeles non lineaires.
2.6.3 Modeles lineaires statiques
Plusieurs auteurs se sont penches sur l’estimation de modeles statiques avec des
pseudo-panels. Partons du modele propose par Deaton (1985) :
yht = xhtβ + θh + vht (2.13)
ou xht est un vecteur de variables explicatives, θh est l’effet fixe et yht est la variable
dependante, l’indice h indique le menage et t indique le temps. Deaton propose de

Chapitre 2. Revue de la litterature 34
constituer des cohortes d’individus ayant des caracteristiques communes. Le modele
sous sa version moyennes de cohortes s’ecrit :
yct = xctβ + θct + vct (2.14)
yct =1
nc
∑
h∈c
yht vct =1
nc
∑
h∈c
vht, (2.15)
avec nc la taille de la cohorte c, θct est la moyenne des effets fixes des membres de la
cohorte c. Notons que ce terme est fonction du temps contrairement aux effets fixes
non observes de la moyenne de population de cohortes. Cela s’explique par le fait qu’on
n’observe pas les memes individus d’une periode a une autre, donc, la moyenne de
la cohorte est fonction du temps. Il peut arriver que les variables explicatives soient
correlees avec θct. Il est donc important de specifier le type d’effets a inclure dans le
modele (effets fixes ou aleatoires). Nous avons vu que dans le cas de vrais panels ce
choix n’est pas souvent facile, il en est de meme avec les pseudo-panels. Les effets fixes
peuvent conduire aux problemes d’identification alors que les effets aleatoires peuvent
produire des estimateurs non convergents si la correlation potentielle entre les effets
inobservables et les variables explicatives (si elle existe) n’est pas prise en compte. Pour
ces raisons, le modele (2.14) n’est pas approprie pour avoir des estimateurs convergents,
a moins que la taille des cohortes soit suffisamment grande de sorte que θct soit une
bonne approximation de θc. Dans ce cas, le modele (2.14) peut etre estime en remplacant
les θct par des variables binaires specifiques‘aux cohortes. Deaton (1985) propose une
approche alternative a ce probleme. Lorsque le nombre d’observations dans chaque
cohorte n’est pas suffisamment grand, on peut ecrire la version du modele (2.13) avec
les vraies moyennes de la population de cohortes de la facon suivante :
y∗ct = x∗
ctβ + θc + v∗ct. (2.16)
y∗ct et x∗
ct sont les moyennes non observables de la population de la cohorte c et θc
est l’effet specifique a la cohorte c. Puisque la vraie moyenne de la population d’une
cohorte est la meme dans le temps, θc est constant dans le temps. Si les moyennes
de la population de cohortes etaient observables, l’equation (2.16) peut etre utilisee
pour estimer β en se basant sur les methodes d’estimation des donnees de panel, panel
compose de C cohortes sur T periodes. Cependant, les moyennes des cohortes yct et xct
sont des mesures imparfaites des vraies moyennes de la population de cohortes (y∗ct et
x∗ct). Donc, yct et xct sont des variables avec erreurs de mesure des vraies moyennes de
la population. Pour l’effet inobservable, Deaton suppose qu’il ne contient pas d’erreur
de mesure. Il suppose que les variables avec erreurs de mesure, yct et xct suivent une loi
normale definie comme suit :
(yct
xct
)∼ N
[(y∗
ct
x∗ct
);
(σ00 σ′
σ Σ
)].

Chapitre 2. Revue de la litterature 35
Verbeek et Nijman (1993) definissent une classe d’estimateurs pour β indexe par un
parametre α ∈ [0, 1] comme suit :
β = (Mxx − αΣ)−1 (Mxy − ασ)
avec :
Mxx =1
CT
T∑
t=1
C∑
c=1
(xct − xc)′ (xct − xc)
Mxy =1
CT
T∑
t=1
C∑
c=1
(xct − xc)′ (yct − yc)
xc =1
T
T∑
t=1
xct et yc =1
T
T∑
t=1
yct.
L’estimateur propose par Deaton (1985) qui corrige pour la presence d’erreurs de mesure
est obtenu en fixant α = 1 :
β =
[T∑
t=1
C∑
c=1
(x′cxc − Σ)
]−1 [ T∑
t=1
C∑
c=1
(x′cyc − σ)
].
Dans la pratique cependant, les problemes d’erreurs de mesure sur les variables sont
ignores des lors que la taille de chaque cohorte est suffisamment grande ; la variation
temporelle des effets non observables est alors ignoree. L’estimateur le plus souvent
utilise est l’estimateur «within». Il est caracterise par α = 0 :
βW =
[T∑
t=1
C∑
c=1
(xct − xc)′ (xct − xc)
]−1 [ T∑
t=1
C∑
c=1
(xct − xc)′ (yct − yc)
].
Cet estimateur est connu sous le nom d’estimateur «within» car il utilise l’information
provenant de la variabilite entre les observations d’une meme cohorte. Pour que cet
estimateur converge, Verbeek et Nijman (1992) montrent qu’il faut que la taille des
cohortes soit suffisamment grande en plus des deux conditions d’orthogonalite suivantes3 :
p limnc−→∞
1
CT
T∑
t=1
C∑
c=1
(xct − xc) vct = 0
p limnc−→∞
1
CT
T∑
t=1
C∑
c=1
(xct − xc) θct = 0.
3nc provient de l’expression de la moyenne : xct = 1
nc
∑h∈c xht

Chapitre 2. Revue de la litterature 36
Ils utilisent des donnees sur les depenses de consommation pour montrer que le biais
provenant des erreurs de mesure devient negligeable lorsque la taille des cohortes est
grande (100, 200 individus).
Collado (1997) estime plusieurs modeles avec des pseudo panels. Elle estime d’abord
un modele statique lineaire avec effets aleatoires. Son modele est le suivant :
yit = x′itβ + θi + vit (2.17)
θi ∼ iid(0, σ2
θ
)vit ∼ iid
(0, σ2
v
)
E (xitvis) = 0 ∀ t, s.
Si les effets individuels sont correles avec les variables explicatives et si on dispose de
coupes transversales independantes, le modele ne peut pas etre estime en utilisant les
techniques des donnees de panel. Supposons que l’equation (2.17) s’ecrive avec les vraies
moyennes de la population de cohortes de la facon suivante :
y∗ct = x∗′
ctβ + θ∗c + v∗ct (2.18)
θ∗c ∼ iid(0, σ2
θ∗)
vct ∼ iid(0, σ2
v∗).
Ce modele ne peut pas etre directement estime car les vraies moyennes de la po-
pulation de cohortes ne sont pas observables. Cependant, l’on observe des moyennes
d’echantillons de cohortes definies comme suit :
yct = y∗ct + ζct
xct = x∗ct + ηct,
ou ζct et ηct sont des erreurs de mesure dont la loi conjointe est :
(ζct
ηct
)∼ iid
((0
0
),
1
nc
[σ2
ζ σ′ηζ
σηζ Ση
]), (2.19)
ou nc est le nombre d’individus par cohorte ; on suppose pour simplifier, qu’il est le
meme pour toutes les cohortes. La matrice des erreurs de mesure dans l’equation (2.19)
est generalement inconnue mais peut etre estimee en se servant des donnees. L’equation
(2.18) peut se reecrire de la maniere suivante :
yct = x′ctβ + θ∗c + uct (2.20)
uct = v∗ct + ζct − η′
ctβ.
Pour estimer ce modele, Collado (1997) utilise l’estimation en difference premiere pour
eliminer les effets aleatoires :
4yc2 = 4x′c2β + 4uc2 (2.21)
.............................
4ycT = 4x′cT β + 4ucT .

Chapitre 2. Revue de la litterature 37
Contrairement aux vraies donnees de panel, les variables explicatives du modele (2.21)
sont correlees avec le terme d’erreur a travers les erreurs de mesure. La matrice Zc
definie par :
Zc =
x′c1.....x
′cT
. . .
x′c1.....x
′cT
peut servir comme matrice d’instruments pour ce probleme. Cette matrice est ensuite
utilisee pour estimer les parametres par la methode des moments generalises corrigee
des erreurs de mesure (GMMC). Il est important de noter a ce niveau que l’estimateur
GMMC de β (note βGMMC) obtenu avec un vrai panel coıncide avec l’estimateur «wi-
thin». Cependant, ce resultat ne tient plus lorsqu’on utilise des pseudo-panels. De plus,
cet estimateur n’a pas son equivalent avec les estimateurs obtenus par Deaton (1985).
L’estimateur «within» de Deaton est base sur la restriction suivante :
E((xct − xc)
′ (uct − uc) − Aβ − a)
= 0,
A et a dependent de la matrice de covariance des erreurs de mesure. L’estimateur en
difference premiere de Deaton est base sur la restriction :
E (4xct4uct − Bβ − b) = 0
B et b dependent de la matrice de covariance des erreurs de mesure. Les estimateurs de
Deaton sont donc bases sur des combinaisons lineaires de restrictions sur les moments ;
par consequent, l’estimateur βGMMC est au moins aussi efficace que ceux de Deaton.
2.6.4 Modeles lineaires dynamiques
Moffit (1993) estime un modele dynamique et statique avec effets fixes en utilisant
des variables instrumentales. Son modele est defini comme suit :
yit = αyit−1 + X ′itβ + fi + εit, (2.22)
ou : Xit est un vecteur (K × 1) de regresseurs potentiellement correles avec l’effet fixe
note fi. Si α 6= 0, il s’agit d’un modele dynamique. Precisons que le modele est dit
dynamique des lors qu’on inclut une variable endogene retardee. Si α = 0, il s’agit d’un
modele statique.
Il suppose un vecteur Zi de dimension (L×1) de variables invariantes dans le temps
pour l’individu i. Ces variables peuvent inclure non seulement des variables binaires pour
les cohortes mais aussi des variables socio-demographiques (race, sexe, nombre d’annees

Chapitre 2. Revue de la litterature 38
de scolarite, localisation, ...). Soit Wit un vecteur (M × 1) de variables qui varient dans
le temps mais qui ne sont pas correlees avec l’effet fixe fi. Alors, les projections lineaires
sur lesquelles la methode a variables instrumentales est basee sont les suivantes :
X ′it = δ1Wit + δ2Zi + wit (2.23)
fi = Z ′iγ + vi,
avec wit et vi etant des termes d’erreur. Soit : U = [X Z] et U =[X Z
]ou X represente
la prediction de X obtenue suite a une regression par les MCO de l’equation (2.23).
L’estimateur a variables instrumentales de β et de γ est donne par :(U
′U)−1
U′y. La
convergence de cet estimateur exige la condition suivante : p lim[
1NT
U′v]
= 0 avec plim
la probabilite limite et v le vecteur contenant les termes d’erreur vi. Cette condition
equivaut a dire que U est de plein rang (K + L), condition souvent difficile a remplir.
Quant au modele autoregressif (sans effets fixes), Moffit (1993) utilise le meme principe
de variables instrumentales mais en remplacant la variable endogene retardee par sa
valeur predite provenant d’une regression anterieure obtenue par MCO.
Collado (1997) estime un modele dynamique avec effets aleatoires defini comme
suit :
yit = αyit−1 + x′itβ + θi + vit (2.24)
θi ∼ iid(0, σ2
θ
)vit ∼ iid
(0, σ2
v
).
La version avec les vraies moyennes de la population de cohortes est :
yct = αyct−1 + x′ctβ + θ∗c + uct (2.25)
uct = v∗ct + ζct − αζct−1 − η′
ctβ
t = 2, ...T c = 1, ....C.
A la difference de Moffit (1993), Collado utilise la methode des moments generalises
pour corriger les erreurs de mesure. Elle developpe deux types d’estimateurs : l’estima-
teur «within» et l’estimateur en difference premiere. L’estimateur «within» corrige des
erreurs de mesure est convergent seulement si T −→ ∞. Cependant, dans les travaux
empiriques, on ne dispose pas toujours de donnees sur un grand nombre de periodes et
par consequent, l’estimation «within» n’est pas une technique appropriee. L’estimateur
en difference premiere serait une bonne alternative puisqu’il exige que C −→ ∞ pour
avoir la convergence.
Girma (2000) estime egalement un modele dynamique base sur des coupes trans-
versales independantes. Il utilise l’approche en quasi-difference pour deriver son modele

Chapitre 2. Revue de la litterature 39
qu’il estime par la methode des moments generalise (GMM). L’avantage avec cette ap-
proche est qu’elle peut etre implementee avec seulement 2 coupes transversales. On
n’a pas besoin d’avoir un grand nombre de coupes transversales sur plusieurs periodes.
McKenzie (2001 et 2004) suppose specifiquement de l’heterogeneite deterministe entre
les cohortes. Le modele qu’il estime est le suivant :
yc(t),t = αc + βcyc(t),t−1 + x′c(t),tγc + wc(t) + uc(t),t (2.26)
yc(t),t = αc + βcyc(t−1),t−1 + x′c(t),tγc + εc(t),t (2.27)
εc(t),t = βc
(yc(t),t−1 − yc(t−1),t−1
)+ wc(t) + uc(t),t.
avec zc(t) = 1nc
∑nc
c=1 znt. L’indice c(t) indique qu’il s’agit de la cohorte c de la periode
t. Sa demarche consiste a etendre le modele de Moffit (1993) tout en incluant des effets
specifiques aux cohortes. Le probleme avec ce modele est que la variable dependante
retardee(yc(t),t−1
)est correlee avec le terme d’erreur. Les estimateurs des MCO sont
biaises. Il propose alors une estimation par MCO en deux etapes qui consistent d’abord
a instrumenter yc(t),t−1 par yc(t−1),t−1 et ensuite a appliquer les MCO. Ce dernier esti-
mateur contient un biais devenant negligeable a mesure que la taille de chaque cohorte
devient grande.
Verbeek et Vella (2004) apportent des critiques importantes aux estimateurs de Mof-
fit (1993), Girma (2000) et McKenzie (2004). Ces derniers utilisent implicitement ou
explicitement l’approche par variables instrumentales pour estimer un modele AR(1)
incluant des variables exogenes. Avec des pseudo-panels, ils remplacent la variable
dependante retardee par un instrument obtenu a partir d’une regression auxiliaire.
Ensuite, ils estiment le modele dynamique de differentes manieres : par la methode des
MCO, les variables instrumentales et les GMM. Le modele de Verbeek et Vella est defini
comme suit :
yc(t),t = αy∗c(t),t−1 + x′
c(t),tβ + ε∗c(t),t
ε∗c(t),t = εc(t),t + α(yc(t),t−1 − y∗
c(t),t−1
).
Une estimation convergente par les MCO exige deux conditions : d’une part que εc(t),t ne
soit pas correle avec y∗c(t),t−1 et d’autre part que l’erreur de prediction
(yc(t),t−1 − y∗
c(t),t−1
)
ne soit pas correlee avec xc(t),t. Ces deux hypotheses peuvent cependant etre problematiques
dans les applications empiriques. La premiere hypothese exclut la possibilite qu’il y ait
des effets de cohortes dans les variables inobservables. Il s’agit d’une hypothese non
raisonnable et trop restrictive pour l’analyse empirique. Pourtant, elle a ete imposee
par Moffit (1993), Girma (2000) et dans une partie des travaux de McKenzie (2004).
Selon donc Verbeek et Vella (2004), l’estimateur propose par Moffit (1993) n’est pas
convergent a moins qu’il n’y ait aucun regresseur invariant dans le temps ou que les
variables exogenes qui varient dans le temps n’aient aucune autocorrelation. Selon Ver-
beek et Vella, l’approche de Girma (2000) utilise une mauvaise approximation de la

Chapitre 2. Revue de la litterature 40
variable endogene retardee comme instrument et on n’a aucun gain en utilisant cette
approche assez compliquee. Ils proposent alors un estimateur a variable instrumentale
augmentee en supposant le modele suivant :
yc(t),t = αy∗c(t),t−1 + x′
c(t),tβ + z′c(t)λ + ηc(t),t (2.28)
E(ηc(t),tzc(t)
)= 0,
ou λ est un vecteur de coefficients de variables invariantes dans le temps incluant un
intercept. Ils estiment l’equation (2.28) par la methode des variables instrumentales en
utilisant zc(t) en interaction avec des variables binaires comme instruments. L’estimateur
a variables instrumentales augmentees qu’ils obtiennent a partir de la transformation
«within» est convergent. Cela exige cependant des cohortes de grande taille de sorte
a reduire le biais echantillonnal de l’estimateur. Ce biais existe aussi dans l’estimateur
«within» des modeles dynamiques avec de vrais panels et est meme plus grand que le
biais de l’estimateur «within» avec des pseudo-panels.
2.6.5 Modele de choix discret avec des pseudo-panels
Collado (1998) estime, a partir d’une serie de coupes transversales independantes,
un modele de choix discret avec des effets individuels aleatoires. Elle propose deux types
d’estimateurs : un estimateur a distance minimale et un estimateur de type «within».
Son modele est le suivant :
y∗it = x′
itβ + ηit + vit
yit =
1
0
si y∗it > 0
sinon
ou y∗it est une variable latente inobservable associee a l’individu i a la periode t.
E (ηit |xi1, ..........., xiT ) = x′i1λ1 + ...............x′
iT λT .
Le modele latent sous sa forme reduite est :
y∗it = x′
i1πt1 + ...............x′iT πtT + εit
πts = λs si t 6= s πtt = β + λt si t 6= s.
Comme les donnees disponibles ne sont pas de vrais panels, il faut considerer plutot des
moyennes de cohortes contenant des erreurs de mesure :
y∗ct = x′
c1πt1 + ...............x′cT πtT + ε∗it.

Chapitre 2. Revue de la litterature 41
Les parametres θ = (β ′, λ′)′ sont estimes en utilisant un estimateur a distance minimale
defini par :
θMD = arg min [π − π]′ W−1 [π − π] ,
ou π = (π1, ............πT ) et W est n’importe quel estimateur convergent de la variance
asymptotique de π. L’estimateur de type «within» est obtenu a partir du modele sui-
vant :
y∗ct = x∗′
ctβ + η∗ct + v∗
ct
qu’on peut ecrire de facon plus condensee comme suit :
y∗c = X∗′
c β + η∗ce + v∗
c .
Le modele en deviation par rapport aux moyennes intra-cohortes s’ecrit :
y∗c = X∗
c β + v∗c
y∗c = Qy∗
c X∗c = QX∗
c v∗c = Qv∗
c .
L’estimateur de type «within» est defini alors par :
βWG =
(C∑
c=1
X ′cXc
)−1( C∑
c=1
X ′cΠ
′xc
)
Π = (IT β′ + eλ′) .
L’avantage de l’estimateur de type «within» par rapport a l’estimateur a distance mi-
nimale est qu’il est tres facile a calculer et n’exige pas l’estimation des parametres
de nuisances λ. Mais son inconvenient est qu’il est moins efficace que l’estimateur a
distance minimale. L’approche de Collado (1998) oblige a avoir un nombre limite de
cohortes. Dans son experience Monte Carlo, elle a choisi 50 cohortes. Cette taille est
faible (perte d’information) comparativement aux donnees d’enquete pouvant contenir
des milliers d’observations.
Moffit (1993) a aussi estime un modele non lineaire a effets fixes avec des pseudo-
panels. Son modele est defini de la meme maniere que celui de Collado (1998). Mais
sa methode d’estimation est differente. Il estime un modele probit et un modele de
probabilite lineaire. Dans les deux cas, la convergence est atteinte seulement si la taille
des echantillons de coupes transversales tend vers l’infini.
2.6.6 Quelques etudes empiriques ayant porte sur les pseudo-
panels
Les pseudo-panels ont beaucoup servi dans les etudes empiriques depuis l’article de
Deaton (1985). Ils ont permis de mieux analyser la theorie du cycle de vie des agents

Chapitre 2. Revue de la litterature 42
economiques, etant donne que cette theorie exige d’avoir de l’information au sujet des
agents sur plusieurs periodes. Browning, Deaton et Irish (1985) ont estime l’offre de
travail et la demande de biens des menages britanniques tout au long de leur cycle de
vie en utilisant des pseudo-panels. Blundell et Meghir (1991) ont estime des modeles de
cycle de vie de l’offre de travail et de la demande de biens avec des pseudo-panels. De
meme, Blundell, Browning et Meghir (1994) ont analyse le comportement des menages
britanniques, tout au long de leur cycle de vie, a partir de pseudo-panels. Alessie et
al. (1997) ont modelise la consommation de biens durables et non durables dans un
contexte intertemporel en se servant de pseudo-panels. L’equation d’Euler qu’ils ont
estime a ete definie au niveau des cohortes. Gardes et al. (1996) ont utilise des coupes
transversales et des pseudo-panels pour estimer les elasticites revenus de court et de
long terme de la consommation des canadiens. Ils ont utilise la transformation «within»
et la transformation «between» avec un modele AIDS (almost ideal demand system)
et QAIDS (quadratic almost ideal demand system) pour obtenir les elasticites. Les
elasticites obtenues par la transformation «within» different significativement de celles
obtenues par la transformation «between». De plus, les elasticites de court terme sont
differentes de celles de long terme, difference qui s’expliquerait par les erreurs de mesure
ou les erreurs de specification. Gardes et Loisy (1997) ont utilise des pseudo-panels
pour estimer l’elasticite du revenu minimum par rapport au revenu declare. Ils ont
cherche a verifier l’hypothese selon laquelle la croissance economique cree de nouveaux
besoins contribuant ainsi au maintien de l’insatisfaction des consommateurs. Ils ont
utilise la transformation «within» et la transformation «between» tout en corrigeant
l’heteroscedasticite qui survient a cause de l’aggregation des menages en cellules de
cohortes.
Gassner (1998) s’est servi de pseudo-panels pour etudier la demande d’acces au
telephone des menages britanniques. Son approche consiste a estimer les parametres
du modele de choix discret en se servant de l’estimateur de type «within». Pour cela,
il a suppose que la variable dependante binaire est une fonction lineaire des variables
explicatives. L’estimateur obtenu est biaise mais le biais s’annule a mesure que la taille
de chaque cohorte tend vers l’infini.
Beaudry et Green (2000) ont utilise aussi des pseudo-panels pour etudier l’evolution
des gains hebdomadaires des travailleurs a temps plein. Skoufias et Suryahadi (2002)
ont examine, a partir de pseudo-panels, comment les caracteristiques de la distribution
(la mediane et la dispersion) des salaires entre travailleurs sont affectees par la crois-
sance economique et la contraction de la production durant la periode 1986 a 1998 en
Indonesie. Dargay et Vythoulkas (1997) et Dargay (2002) ont utilise des pseudo-panels
pour estimer des modeles dynamiques dans le domaine des transports.

Chapitre 2. Revue de la litterature 43
Il existe d’autres methodes pour traiter le probleme de donnees incompletes. Ces
methodes feront l’objet des sections suivantes.
2.7 Autres approches pour solutionner le probleme
de donnees manquantes
Le traitement des donnees manquantes peut se faire en suivant une approche clas-
sique ou une approche bayesienne. Nous presentons quelques techniques utilisees dans
la litterature pour contourner le probleme.
2.7.1 L’imputation multiple (IM)
L’imputation multiple a ete introduite d’abord par Rubin (1978) qui l’a ensuite
decrite en detail en 1987. L’imputation multiple est une approche Monte Carlo pour
l’analyse de bases de donnees incompletes. Dans l’IM, les donnees manquantes Ymis sont
remplacees par des valeurs simulees notees : Y 1mis, Y
2mis, ....Y
mmis. Cela revient a constituer
m bases de donnees completes. Chacune des m bases de donnees est analysee en se
servant des methodes standards pour les bases de donnees completes. L’imputation
simple consiste a se limiter a creer une seule base de donnees complete. L’analyse
de l’IM peut se faire selon l’approche classique ou selon l’approche bayesienne. Nous
presentons d’abord les grands traits de l’IM classique.
Supposons un modele de regression lineaire simple avec des donnees manquantes :
Y = X ′β + u u ∼ N(0, σ2
).
Soit θ = (β, σ2) le vecteur des parametres du modele ou une fonction des parametres du
modele. Si on a m imputations on aura θ1, ...θm estimes. Soit Wd, d = 1, ...m la variance
associee a chaque estime. Rubin (1987) donne la regle suivante pour combiner les deux
parametres. L’estimateur ponctuel de l’IM est donne par :
θm =1
m
m∑
d=1
θd.
La matrice de variance covariance associee a θm notee (T ) a deux composantes : la
variance intra-imputation (within-imputation) et la variance inter-imputation (between-

Chapitre 2. Revue de la litterature 44
imputation). La matrice de variance covariance intra-imputation est definie par :
WD =1
m
m∑
d=1
Wd.
La matrice de variance covariance inter-imputation est :
BD =1
m − 1
m∑
d=1
(θd − θm
)(θd − θm
)′.
Ainsi, la matrice de variance-covariance de θm est donnee par :
T = WD +
(1 +
1
m
)BD.
Le terme(1 + 1
m
)joue le role de correcteur pour un nombre fini d’imputations. S’il n’y
a pas de donnees manquantes, alors les estimes des parametres sont tous identiques
et la variance inter-imputation s’annule de sorte que la variance totale est egale a la
variance intra-imputation W D.
L’IM peut aussi etre vue sous l’angle bayesien. Rubin (1978) propose de relier la
distribution a posteriori des donnees observees a la distribution a posteriori de la base
complete comme suit :
p (θ |Yobs, Ymis ) ∝ p (θ) L (θ |Yobs, Ymis )
p (θ |Yobs ) =
∫p (θ, Ymis |Yobs ) dYmis
=
∫p (θ |Ymis, Yobs ) p (Ymis |Yobs ) dYmis, (2.29)
avec Ymis le vecteur des observations manquantes et Yobs le vecteur des donnees ob-
servees. L’equation (2.29) implique que la distribution a posteriori de θ qui est p (θ |Yobs )
peut etre simulee en faisant d’abord un tirage des valeurs manquantes (Y dmis, d indique le
numero de l’imputation, d = 1, ....m) a partir de leur distribution jointe (p (Ymis |Yobs )).
Il faut ensuite imputer les valeurs manquantes pour completer la base de donnees. En-
fin, on doit faire un tirage de θ a partir de distribution a posteriori de la base complete
p(θ∣∣Y d
mis, Yobs
). L’IM approxime en fait l’integrale (2.29) sur toutes les valeurs man-
quantes comme une moyenne :
p (θ |Yobs ) ≈ 1
D
m∑
d=1
p(θ∣∣Y d
mis, Yobs
),
ou : Y dmis ∼ p (Ymis |Yobs ) sont des tirages de Ymis de la distribution a posteriori predictive
des valeurs manquantes. Si les moyenne et variance a posteriori resument adequatement

Chapitre 2. Revue de la litterature 45
la distribution a posteriori, alors l’equation (2.29) peut etre remplacee par :
E (θ |Yobs ) = E [E (θ |Ymis, Yobs ) |Yobs ] (2.30)
V (θ |Yobs ) = E [V (θ |Ymis, Yobs ) |Yobs ] + V [E (θ |Ymis, Yobs ) |Yobs ] . (2.31)
Si D est grand, les equations (2.30) et (2.31) peuvent etre approximees en utilisant les
valeurs simulees des observations manquantes comme suit :
E (θ |Yobs ) ≈∫
1
D
m∑
d=1
p(θ∣∣Y d
mis, Yobs
)dθ = θm
V (θ |Yobs ) ≈ 1
D
m∑
d=1
Vd +1
m − 1
m∑
d=1
(θd − θm
)(θd − θm
)′,
ou : θd = E(θ∣∣Y d
mis, Yobs
)est l’estime de θ a partir de la base de donnees complete de
l’imputation d, et θm = 1D
∑md=1 θd, Vd est la variance a posteriori de la base complete(
Y dmis, Yobs
)de l’imputation d. Il y a donc une similitude avec l’approche classique de
l’IM.
L’IM presente un certain nombre d’avantages. Elle permet de creer plusieurs bases
de donnees completes. Avec ces bases completes, on peut appliquer les procedures sta-
tistiques habituelles fournies dans les logiciels statistiques. L’IM garde l’information au
niveau individuel, ceci permet de conserver une certaine efficacite contrairement a l’ap-
proche a pseudo-panels qui regroupe les individus en cohortes. Les tests statistiques qui
decoulent de l’IM sont generalement valides car l’IM incorpore l’incertitude causee par
les donnees manquantes. Mais si l’on se limite a une seule imputation, l’inference statis-
tique serait invalide. En effet, une seule valeur imputee ne peut a elle seule representer
toute l’incertitude sur la valeur manquante. Les analyses qui supposent que les donnees
d’une seule imputation sont equivalentes aux donnees observees sous-estiment en general
l’incertitude, meme si l’information manquante est correctement modelisee et des impu-
tations aleatoires sont realisees. L’induction qui decoule de l’imputation simple ne tient
pas compte de la variabilite attribuable a l’incertitude sur les donnees manquantes.
L’IM peut remedier a ce probleme tout en conservant les avantages de l’imputation
simple. Le seul desavantage de l’IM par rapport a l’imputation simple est qu’elle de-
mande beaucoup d’espace memoire et de temps de traitement. Mais avec les grands
progres au niveau informatique, ce probleme ne se pose presque pas. Enfin, l’IM a un
autre avantage du au fait qu’elle a un haut degre d’efficacite meme si m est petit. Ru-
bin (1987) montre qu’avec seulement 3 a 5 imputations, on peut obtenir d’excellents
resultats ; donc, il n’est pas necessaire que m soit tres grand pour gagner en efficacite.
L’IM est appropriee pour les cas ou le nombre d’observations manquantes n’est pas
tres grand. Par exemple, lors d’une enquete, certains individus peuvent choisir de ne

Chapitre 2. Revue de la litterature 46
pas repondre a certaines questions soit parce qu’ils ne savent pas quoi repondre ou soit
parce qu’ils ne veulent pas divulger une information confidentielle. Si le pourcentage
de non-reponses est faible (5% ou moins), alors l’elimination de ces observations peut
etre une solution raisonnable au probleme de donnees manquantes. Cependant, dans un
ensemble multivavrie ou plusieurs variables peuvent avoir des valeurs manquantes, les
observations ayant au moins une donnee manquante represente une proportion impor-
tante de la base de donnees. Dans ce cas, une elimination des observations ayant des
donnees manquantes conduirait a une perte d’efficacite car une partie importante de
l’information est ignoree. L’IM est bien appropriee pour resoudre le probleme des non-
reponses. Mais, lorsqu’on dispose d’un ensemble de coupes transversales independantes,
les individus observes une periode donnee ne sont plus presents dans les autres periodes.
L’information manquante va concerner toutes les variables du modele pour tous les in-
dividus lorsqu’on passe d’une periode a une autre. Le probleme de donnees manquantes
est alors plus crucial et l’IM n’est pas vraiment appropriee. Gregoire (2004) utilise l’IM
pour analyser la demande d’electricite des menages Quebecois dans un contexte ou le
nombre d’observations manquantes etait important. Vidal (2006) a aussi utilise cette
technique avec deux bases de donnees d’enquetes completement independantes. Les
resultats n’ont pas ete satisfaits.
2.7.2 L’algorithme esperance maximisation (EM)
L’algorithme EM est une technique generale d’estimation par maximum de vraisem-
blance en presence de donnees manquantes. L’algorithme formalise une vieille idee ad
hoc qui consistait a : (1) remplacer les valeurs manquantes par les valeurs estimees etant
donnes les parametres, (2) estimer les parametres en supposant que les valeurs man-
quantes sont donnees par leurs valeurs estimees, (3) re-estimer les valeurs manquantes
en supposant que les nouveaux estimes des parametres sont corrects, (4) re-estimer les
parametres, et ainsi de suite jusqu’a la convergence (Little et Rubin 2002, Gelman et
al. (2000)). Bien que des cas speciaux de cet algorithme soient apparus avant les annees
1970 dans la litterature statistique, c’est seulement en 1977 que Dempster, Laird et
Rubin ont introduit le terme esperance maximisation, formalise cet algorithme et defini
ses proprietes. L’algorithme se base sur l’interdependance qui existe entre les observa-
tions manquantes et les parametres du modele. Schafer (2000) suppose que la base de
donnees comporte des donnees manquantes avec Y = Yobs+Ymis ou Yobs est le vecteur de
donnees observees et Ymis est celui des donnees manquantes. L’information manquante
peut concerner la variable dependante tout comme les variables explicatives du modele.
Soit θ le vecteur des parametres du modele a estimer. Toute l’information pertinente sur
les parametres est contenue dans la fonction de vraisemblance des donnees observees
(L (θ |Yobs )) ou dans la loi a posteriori des donnees observees P (θ |Yobs ). Dans n’importe

Chapitre 2. Revue de la litterature 47
quelle situation ou on a des donnees manquantes, la distribution complete des donnees
(Y ) peut etre factorisee comme suit :
P (Y |θ ) = P (Yobs |θ ) P (Ymis |Yobs, θ ) . (2.32)
Le principe de l’algorithme EM est base sur l’equation (2.32). On peut constater que
les termes de l’equation sont fonction chacun du parametre inconnu et en prenant le
logarithme de (2.32), cela conduit a :
l (θ |Y ) = l (θ |Yobs ) + log P (Ymis |Yobs, θ ) + c, (2.33)
avec : l (θ |Y ) = log P (Y |θ ) la log-vraisemblance des donnees completes,
l (θ |Yobs ) = log L (θ |Yobs ) la log-vraisemblance des donnees observees, et c est une
constante arbitraire.
Le terme P (Ymis |Yobs, θ ) est appele loi predictive des donnees manquantes etant
donne θ. Ce terme joue un role central dans l’algorithme EM parce qu’il capte l’in-
terdependance qui existe entre Ymis et θ. Et comme Ymis est inconnu, on ne peut pas
calculer P (Ymis |Yobs, θ ). En prenant la moyenne par rapport a la distribution predictive
P (Ymis |Yobs, θt ) ou θt est la valeur prealablement estimee des parametres inconnus, on
obtient :
Q(θ∣∣θt)
= l (θ |Yobs ) + H(θ∣∣θt)
(2.34)
Q(θ∣∣θt)
=
∫l (θ |Y ) P
(Ymis
∣∣Yobs, θt)dYmis
H(θ∣∣θt)
=
∫P (Ymis |Yobs, θ ) P
(Ymis
∣∣Yobs, θt)dYmis.
Un resultat central de Dempster, Laird et Rubin (1977) est que si θt+1 est la valeur
de θ qui maximise le terme Q (θ |θt ), dans ce cas, θt+1 est meilleur a θt au sens que
la log-vraisemblance des donnees observees est au moins aussi grande que celle de θt.
Autrement dit :
l(θt+1 |Yobs
)≥ l(θt |Yobs
).
La log-vraisemblance ne diminue pas en passant d’une iteration a une autre. L’algo-
rithme pour une seule iteration comporte 2 grandes etapes :
1. L’etape E ou etape du calcul de l’esperance qui correspond a completer les donnees
manquantes. Dans cette etape, Q (θ |θt ) est calcule en prenant la moyenne de
la fonction log-vraisemblance de la base complete l (θ |Y ) sur toutes les valeurs
possibles de P (Ymis |Yobs, θt ). Pour la premiere iteration, on donne des valeurs de
depart aux parametres (soit θ0) et on deduit la valeur predite des observations
manquantes Ymis. Cette etape augmente les donnees en completant les donnees
manquantes.

Chapitre 2. Revue de la litterature 48
2. l’etape M ou etape de la maximisation consiste a estimer les parametres par
maximum de vraisemblance etant donnee la base de donnees complete obtenue a
la premiere etape. En d’autres termes, θt+1 est obtenu en maximisant Q (θ |θt )
On repete ces deux etapes de maniere a obtenir une sequence de θt, t = 0, 1, 2......Sous certaines conditions donnees par Dempster, Laird et Rubin (1977) et Wu (1983),
cette sequence converge surement vers un point stationnaire de la log-vraisemblance de
la base de donnees observees. Dempster, Laird et Rubin (1977) ont montre que le taux
de convergence est determine par la fraction d’information manquante.
Prenons un exemple de l’algorithme EM lorsque la loi de probabilite du modele de
la base de donnees complete appartient a une famille particuliere de loi. On peut voir
que dans certains problemes (donnees incompletes qui sont purement categorielles),
l’etape E correspond a completer les donnees manquantes Ymis par sa moyenne ou
son esperance notee E (Ymis |Yobs, θ = θt ). Cependant, dans certains problemes, ce n’est
plus le cas. En particulier, lorsque la loi de probabilite de la base complete fait partie
de la famille exponentielle, la log vraisemblance de la base de donnees complete de n
observations iid peut s’ecrire en fonction des statistiques exhaustives comme suit :
l (θ |Y ) = η (θ)′ T (Y ) + nf (θ) + c,
ou η (θ) = [η1 (θ) , η2 (θ) , ....., ηs (θ)]′ est la forme canonique du vecteur de parametres
θ, et T (Y ) = [T1 (θ) , T2 (θ) , ....., Ts (θ)]′ est une statistique exhaustive de la base de
donnees complete. Precisons que T (Y ) est une exhaustive pour θ si la loi condition-
nelle de Y sachant T ne depend pas de θ. Toute l’information sur θ est concentree
en T (Gourieroux et Monfort, 1996). On peut constater que l (θ |Y ) est une fonction
lineaire des statistiques exhaustives et l’etape E dans ce cas remplace les Ti (θ) par
E [Ti (θ) |Yobs, θt ], pour i = 1, 2, ...s. En d’autres termes, l’etape E ne complete pas les
elements manquants de Y par sa moyenne, mais plutot complete les portions man-
quantes des statistiques exhaustives de la base de donnees complete. Lorsqu’ils s’agit
de modeles de la famille exponentielle, les elements E [Ti (θ) |Yobs, θt ] sont sous forme
explicite ce qui facilite le calcul dans l’etape E. L’etape M est aussi facile a implementer
dans beaucoup de situations. L’element Q (θ |θt ) aura la meme forme fonctionnelle que
la log-vraisemblance l (θ |Y ). Donc, il n’y aura pas de difference de calcul entre trouver
θt+1a partir de Q (θ |θt ) et trouver l’estimateur du maximum de vraisemblance a partir
de la fonction log-vraisemblance de la base complete.
Prenons un exemple de donnees d’une seule variable qui suit une loi normale iden-
tiquement et independamment distribuee (Little et Rubin(2002)) : yi ∼ iid N (µ, σ2)
ou yi pour i = 1, 2, ...., r sont observes mais yi i = r + 1, .....n sont manquantes.
L’esperance de chaque yi non observe etant donne Yobs et θ = (µ, σ2) est egale a µ.

Chapitre 2. Revue de la litterature 49
Log-vraisemblance de la base complete est une fonction lineaire des deux statistiques
exhaustives qui sont :∑n
i=1 yi et∑n
i=1 y2i . L’etape E de l’algorithme consiste a calculer
l’esperance de chacune des statistiques exhaustives :
E
(n∑
i=1
yi
∣∣Yobs, θt
)=
r∑
i=1
yi + (n − r) µt
E
(n∑
i=1
y2i
∣∣Yobs, θt
)=
r∑
i=1
y2i + (n − r)
[(µt)2
+(σt)2]
θt =(µt, σt
).
Notons que si on n’avait aucune valeur manquante, l’estimateur du maximum de vrai-
semblance de µ serait :µ =∑n
i=1 yi/n et celui de σ2 serait : σ2 = (∑r
i=1 y2i ) /n −
(∑n
i=1 yi/n)2. L’etape M utilise les statistiques exhaustives obtenues a l’etape E pour
obtenir de nouvelles valeurs des parametres :
µt+1 = E
(n∑
i=1
yi
∣∣Yobs, θt
)/n
(σt+1
)2= E
(n∑
i=1
y2i
∣∣Yobs, θt
)−(µt+1
)2.
L’algorithme est approprie pour les situations ou il est facile d’effectuer les deux
etapes. Dans de telles situations, il permet d’atteindre le maximum global unique de la
fonction de vraisemblance. Cependant, il peut arriver que l’algorithme EM ne converge
pas vers le maximum global. D’apres Little et Rubin (2002), un inconvenient de l’algo-
rithme EM est que la convergence peut etre peniblement lente lorsqu’on a une fraction
importante de donnees manquantes. Comme d’autres algorithmes, l’algorithme EM a
aussi certaines limites :
1. EM peut converger vers differents points suivant les valeurs initiales choisies,
2. la log vraisemblance peut comporter une region plate, ce qui signifie un continuum
de solutions,
3. la convergence peut etre trop lente si la quantite d’information manquante est
tres importante : plus la quantite d’information manquante est importante, plus
lente sera la convergence.
Etant donne notre principal objectif, qui est d’estimer un modele de choix dis-
cret/continu a partir de coupes transversales independantes, la quantite d’information
manquante pour chaque coupe transversale est tres elevee et la complexite du modele
fait que ce algorithme n’est pas approprie.

Chapitre 2. Revue de la litterature 50
Paquet (2002), Boucher (2003), Paquet et Bolduc (2004) proposent une nouvelle
approche pour estimer les modeles (lineaires et non lineaires) dans un contexte de
panels incomplets (avec le cas extreme de series de coupes transversales independantes).
Il s’agit d’une approche bayesienne qui consiste a combiner l’echantillonnage de Gibbs et
l’algorithme de l’augmentation des donnees pour completer les donnees manquantes tous
en estimant les parametres du modele. Nous nous inspirerons aussi de leur demarche
pour completer les donnees manquantes et estimer les parametres. La section suivante
fait un survol des etudes anterieures traitant de ce sujet.
2.8 Survol de quelques methodes bayesiennes
La methodologie bayesienne est essentiellement fondee sur le theoreme de Bayes
qui relie l’information a priori (information disponible avant que les donnees ne soient
observees), la nouvelle information et la distribution a posteriori. Supposons un modele
lineaire :
Y = Xβ + ε
ε ∼ N (0, Σ) .
Posons θ = (β, Σ) le vecteur des parametres du modele. Pour estimer le parametre θ
de facon conjointe, on peut se servir de la relation suivante :
f (θ,X, Y ) = f (θ |X,Y ) g (X,Y ) (2.35)
= g (X,Y |θ ) f (θ) . (2.36)
En divisant (2.35) et (2.36) par g (X,Y ), on obtient la distribution a posteriori qui est
la distribution d’interet :
f (θ |X,Y ) =g (X,Y |θ ) f (θ)
g (X,Y ).
f (θ,X, Y ) : est la distribution a posteriori des parametres d’interet.
g (X,Y |θ ) : est la fonction de vraisemblance des donnees, souvent notee L (θ |X,Y )
f (θ) : est la distribution a priori des parametres d’interets.
g (X,Y ) : est une constante de proportionnalite.
On peut alors reecrire la derniere equation comme suit :
f (θ |X,Y ) ∝ L (θ |X,Y ) × f (θ) .

Chapitre 2. Revue de la litterature 51
L’echantillonnage de Gibbs utilise cette relation pour estimer les parametres d’interet
et l’augmentation des donnees l’utilise pour imputer les donnees manquantes dans des
contextes multivaries. Les deux techniques sont fondees essentiellement sur la methodologie
MCMC.
2.8.1 La methodologie MCMC (markov chain monte carlo)
Les MCMC (Markov Chain Monte Carlo) sont un ensemble de techniques pour
faire des tirages pseudo aleatoires a partir de distributions de probabilite. L’objectif du
MCMC est de generer une ou plusieurs valeurs d’une variable aleatoire Z habituelle-
ment multidimensionnelle. Il s’agit de faire de la simulation Monte Carlo sur une chaıne
markovienne ergodique.
Une sequence de variables aleatoires zi est une chaıne markovienne du premier ordre si
la distribution conditionnelle p (zi |zi−1, zi−2, ....) est une fonction des valeurs precedentes
zi−1 seulement :
p (zi |zi−1, zi−2, ....) = p (zi |zi−1 )
Par exemple, un processus autoregressif d’ordre 1 (AR(1)) est une chaıne markovienne
d’ordre 1. On sait que la moyenne d’un echantillon de N observations d’un processus
AR(1) est un estimateur convergent de l’esperance inconditionnelle du processus si le
processus est stationnaire. L’analyse de la convergence des chaınes markoviennes se sert
d’un concept semblable qui est l’ergodicite.
Une sequence est ergodique si on peut passer de n’importe quelle realisation A de la
chaıne a n’importe quelle realisation B , meme si la transition de z = A a z = B
exige de passer par quelques realisations intermediaires (A −→ C −→ B). Si la chaıne
markovienne est ergodique, alors la sequence des lois conditionnelles p (zi |z0 )∞i=1
converge vers la loi marginale stable p (z) pour n’importe quelle valeur de depart z0. La
dependance de la chaıne aux valeurs de depart s’estompe ainsi progressivement.
Supposons que la convergence se realise avant la realisation n. Alors, la sequence des
N prochaines realisations zin+Ni=n+1 constitue un echantillon dans lequel les observa-
tions sont correlees et ont la meme densite inconditionnelle. De plus, la moyenne
echantillonnale N−1∑n+N
i=n+1 g (zi) converge presque surement vers la moyenne de la
population E [g (z |.)].
L’analyse bayesienne s’interesse souvent aux caracteristiques de la distribution a
posteriori p (z |.) telle que l’esperance ou la variance. L’esperance est exprimee souvent
sous forme d’integrale dont la forme analytique est souvent difficile a evaluer. Les ex-
pressions analytiques des integrales de la distribution a posteriori et de la moyenne a
posteriori existent seulement pour quelques cas particuliers, tel que le modele lineaire
normal. Pour des modeles plus complexes, ces integrales exigent des techniques d’esti-

Chapitre 2. Revue de la litterature 52
mation numeriques. Par ailleurs, si la dimension de z est grande, la tache est encore
plus ardue.
Les methodes d’echantillonnage se servant des chaınes markoviennes se sont tres vite
repandues ces annees grace aux progres rapides en informatique. Gordon et Belanger
(2003) donnent un survol des techniques d’echantillonnage de type MCMC.
2.8.2 Echantillonnage de Gibbs
L’echantillonnage de Gibbs est la technique MCMC la plus simple. Sa popularite
date de l’application faite par German et German (1984) de la distribution Gibbs pour
modeliser les images satellites. Son applicabilite s’etend cependant a un grand eventail
de problemes. L’echantillonnage de Gibbs d’apres Casella et George (1992), est une tech-
nique pour generer des variables aleatoires d’une distribution (marginale) de facon indi-
recte sans toutefois avoir a calculer la densite. Gelfand (2000) definit l’echantillonnage
de Gibbs comme un outil pour obtenir des echantillons a partir de fonctions de densites
jointes non standard. Ces echantillons proviennent en fait de distributions condition-
nelles associees a la densite jointe.
Soit : θ = (θ1, θ2, ........θJ) ou θj est un element ou un sous ensemble de θ. Si le
modele est assez complexe, la distribution marginale f (θ) = f (θ1, θ2, ........θJ) ne sera
pas standard. Par exemple, si on s’interesse a la densite marginale du premier element,
on doit integrer la densite conjointe par rapport aux autres elements de sorte a obtenir
la fonction a integrales multiples suivante :
f (θ1) =
∞∫
−∞
∞∫
−∞
.......
∞∫
−∞
f (θ1, θ2, θ3........θl) dθ2dθ3dθ4......dθl.
La presence d’integrales multiples posent de serieux problemes si on veut calculer cer-
tains moments (moyenne ou variance). Cependant, la densite conditionnelle f (θ1 |θ−1 )
est souvent facile a calculer (ou θ−1 = (θ2, ........θJ) represente les elements autres que
celui qui nous interesse, θ1). Dans le but d’eviter des calculer onereux en temps, Ger-
man et German (1984) ont propose la technique d’echantillonnage de Gibbs basee sur
la theorie des chaınes markoviennes.
Supposons une distribution conjointe P (θ) = P (θ1, θ2, ........θJ) et les distributions

Chapitre 2. Revue de la litterature 53
conditionnelles suivantes :
θ1 ∼ P (θ1 |θ2, ........θJ )
θ2 ∼ P (θ2 |θ1, θ3........θJ )...
θJ ∼ P (θJ |θ1, θ2........θJ−1 ) .
Supposons que ces distributions conditionnelles sont plus simples et plus faciles a cal-
culer ; de plus supposons qu’il est possible de simuler des tirages artificiels de θj ∼P (θj |θ−j ) . Alors, l’algorithme de l’echantillonnage de Gibbs est defini selon les 3
etapes suivantes :
– Etape 1 : Donner des valeurs de depart aux parametres : θ01, θ
02, ........θ
0J et poser
i = 1.
– Etape 2 : Effectuer les tirages conditionnels suivants :
θi1 ∼ P
(θ1
∣∣θi−12 , ........θi−1
J
)
θi2 ∼ P
(θ2
∣∣θi1, θ
i−13 ........θi−1
J
)(2.37)
...
θiJ ∼ P
(θJ
∣∣θi1, θ
i2........θ
iJ−1
).
– Etape 3 : Poser i = i + 1 et retourner a l’etape i.
l’ensemble constitue un tour et un element dans (5.8) constitue une iteration.
Notons que cet algorithme decrit une chaıne markovienne du premier ordre parce
que la distribution conditionnelle d’un tirage depend de la realisation precedente. De
plus, si la densite P (θj |θ−j ) est positive pour toutes les valeurs possibles de θj, on
dira alors que la chaıne est ergodique. Dans ce cas, la sequence converge vers sa dis-
tribution stable P (θ) pour toute valeur de depart θ0. De plus, comme nous l’avons
souligne anterieurement, si la sequence converge avant l’iteration n, alors la moyenne
echantillonnale N−1∑n+N
i=n+1 g (θi) est un estimateur convergent simule de la moyenne a
posteriori de la population E [g (θ |.)].L’echantillonnage de Gibbs servira donc a simuler les parametres de nos modeles dans
un context de donnees manquantes.

Chapitre 2. Revue de la litterature 54
2.8.3 L’algorithme d’augmentation des donnees (AD)
L’algorithme de l’echantillonnage de Gibbs est tres similaire a l’algorithme de l’aug-
mentation des donnees developpe par Tanner et Wong (1987). Supposons, comme dans
Schafer (1997), qu’un vecteur aleatoire z est partitionne en deux sous vecteurs :
z = (u, v) . (2.38)
Soit P (z) la densite jointe qui n’est pas facile a simuler. Cependant, les densites condi-
tionnelles P (u |v ) = f (u |v ) et P (v |u) = h (v |u) sont faciles a simuler. Supposons
qu’a l’iteration t, on a :
Z(t) =(z
(t)1 , z
(t)2 , ............z(t)
m
)
=[(
u(t)1 , v
(t)1
),(u
(t)2 , v
(t)2
), ........
(u(t)
m , v(t)m
)].
Ceci constitue un echantillon de taille m tire de la distribution qui approxime la distri-
bution d’interet P (z).
Tanner et Wong (1987) montrent que la distribution de Z (t) converge vers P (z)
quand t −→ ∞. Ce resultat n’exige pas que m soit grand. En particulier, si m = 1, l’al-
gorithme d’augmentation des donnees se reduit a un cas particulier de l’echantillonnage
de Gibbs avec z = (u, v).
La technique d’augmentation des donnees est souvent utilisee dans les problemes avec
donnees manquantes. On cherche a rendre ces problemes plus faciles a analyser une fois
que la base de donnees est completee. L’algorithme EM est aussi un exemple d’utilisa-
tion du principe de l’augmentation des donnees dans un context classique.
Supposons que la base de donnees disponible comporte des donnees manquantes et no-
tons : Y = (Yobs, Ymis).
Ymis = yimt, ximt contient a la fois des variables endogenes et exogenes manquantes.
Yobs = yint, xint contient a la fois des variables endogenes et exogenes observees.
Dans beaucoup de problemes avec donnees manquantes, la densite a posteriori des
donnees observees P (θ |Yobs ) n’est pas facile a manipuler ni facile a simuler ; il arrive
frequemment d’ailleurs qu’elle ne soit pas connue. En effet, cette densite est sous forme
d’integrale :
P (θ |Yobs ) =
∫
Ymis
P (θ |Yobs, Ymis ) dYmis.
On utilise la technique d’augmentation des donnees pour contourner ces difficultes. En
effet, si on augmente les donnees observees par des valeurs predites de Ymis, alors, la
densite a posteriori de la base complete P (θ |Yobs, Ymis ) devient beaucoup plus facile a
manipuler. En revenant a la definition de z (2.38), on a dans ce cas particulier : z =

Chapitre 2. Revue de la litterature 55
(Ymis, θ). L’algorithme AD utilise la dependance qui existe entre les densites P (θ |Yobs )
et P (Ymis |Yobs ) de facon a calculer P (θ |Yobs ). En effet :
P (θ |Yobs, Ymis ) P (Ymis, Yobs) = P (Ymis |Yobs, θ ) P (θ, Yobs)
P (θ |Yobs, Ymis ) P (Ymis, Yobs) = P (Ymis |Yobs, θ ) P (θ |Yobs ) P (Yobs)
P (θ |Yobs ) =P (θ |Yobs, Ymis ) P (Ymis, Yobs)
P (Ymis |Yobs, θ ) P (Yobs)
=P (θ |Yobs, Ymis ) P (Ymis |Yobs ) P (Yobs)
P (Ymis |Yobs, θ ) P (Yobs)
=P (θ |Yobs, Ymis ) P (Ymis |Yobs )
P (Ymis |Yobs, θ )
∝ P (θ |Yobs, Ymis ) P (Ymis |Yobs ) .
Donc :
P (θ |Yobs ) ∝ P (θ |Yobs, Ymis ) P (Ymis |Yobs ) .
De plus, nous avons :
P (Ymis |Yobs ) =
∫
θ
P (Ymis, θ |Yobs ) dθ
=
∫
θ
P (Ymis |Yobs, θ ) P (θ |Yobs ) dθ.
Il faut pouvoir effectuer des tirages dans les distributions conditionnelles suivantes :
P (θ |Yobs, Ymis ) et P (Ymis |Yobs, θ ). L’algorithme AD comporte en fait deux grandes
etapes :
– (etape-I ou etape de l’imputation) : conditionnellement aux parametres θt, faire
des tirages des valeurs manquantes de la densite predictive de Ymis :
Y t+1mis ∼ P
(Ymis
∣∣Yobs, θt). (2.39)
– (etape-P ou etape a posteriori) : conditionnellement aux valeurs predites obtenues
a l’etape I, faire des tirages de nouvelles valeurs des parametres a partir de la
densite a posteriori de la base complete :
θt+1 ∼ P(θ∣∣Yobs, Y
t+1mis
). (2.40)
Repeter a plusieurs reprises (2.39) et (2.40) en se donnant des valeurs de depart
θ0.
On obtient alors une sequence de valeurs θt, Y tmis : t = 1, 2...... Cette sequence
converge vers sa densite stable qui est P (θ, Ymis |Yobs, ).
Les sous-sequences θt, : t = 1, 2..... et Y tmis : t = 1, 2..... ont leurs distributions
conditionnelles stables qui sont respectivement P (θ |Yobs ) et P (Ymis |Yobs ).

Chapitre 2. Revue de la litterature 56
On peut constater que l’algorithme EM est tres similaire a l’algorithme AD. En effet,
l’implementation de l’etape I de l’algorithme AD est tres similaire a l’implementation
de l’etape E de l’algorithme EM. Et l’etape M correspond a la maximisation de la
vraisemblance de la base complete alors que dans l’algorithme AD, l’etape P correspond
a un tirage aleatoire de la densite a posteriori de la base complete.
Paquet (2002) utilise l’algorithme d’echantillonnage de Gibbs et d’augmentation
des donnees pour estimer des modeles lineaires et discrets dans un contexte de donnees
longitudinales incompletes (panels partiellement incomplets). Deux grandes etapes ca-
racterisent l’approche utilisee : la premiere etape consiste a simuler les donnees man-
quantes en utilisant l’algorithme AD. La seconde etape consiste a simuler le vecteur
des parametres etant donne les donnees completees. Dans chacune des etapes, elle se
sert du principe des densites conditionnelles des observations ou des parametres, etant
donne l’information disponible. Pour les differents modeles (lineaires ou discrets) qui
ont fait l’objet de ses application avec donnees simulees, elle a incorpore des effets
individuelles aleatoires. L’approche conventionnelle a aussi ete utilisee pour fin de com-
paraison. L’approche proposee semblerait plus efficace que celle proposee par Deaton
(1985). Elle a l’avantage de garder l’information au niveau microeconomique contraire-
ment aux pseudo-panels conventionnels qui regroupent les individus en cohortes.
Nous comptons utiliser ces deux dans nos travaux dans le but de faire une ana-
lyse assez complete de la demande d’energie des menages de la province de Quebec.
Nous nous interesserons a la fois aux modeles statiques et aux modeles dynamiques.
Nous chercherons a resoudre les problemes de biais de selection provenant du choix des
modes de chauffage et le biais d’endogeneite provenant de la tarification non lineaire de
l’electricite.

Bibliographie
[1] Acton, J. P., Mitchell, B., M., and Mowill, R., S. (1976) : «Residential Demand
for Electricity in Los Angeles : An Econometric Study of Disaggregate Data»,
Rand-Report R-1899-NSF, Rand Corporation, Santa Monica, CA.
[2] Alessie R., Devereux M. P. et Weber G. (1997) : «Intertemporal Consumption, Du-
rables and Liquidity Constraints : a Cohort Analysis», European Economic Review,
Vol. 41, pp.27-59.
[3] Amemiya, T. (1985) : Advanced econometrics, Havard Univertsity Press, Cam-
bridge 1985
[4] Anderson, T. W. and Hsiao, C. (1982) : «Formulation and Estimation of Dynamic
Models using Panel Data», Journal of Econometrics, Vol.18, p.47-82.
[5] Arellano, M (1988) : «A Note on the Anderson-Hsiao Estimator for Panel Data»,
Mimeo Instutite of Economics, Oxford Universtity.
[6] Arellano, M and B. Honore (2001) : Panel Data Models : Some Recent Develop-
ments, Capiter 53 in J. Heckman and Leamer, eds., Handbook of Econometrics
(North-Holland Amsterdam), p.3229-3296.
[7] Arellano, M. and S. Bond (1991) : «Some Tests of Specification for Panel Data :
Monte Carlo Evidence and an Application to Employment Equations», Review of
Economic Studies, Vol.58, p.277-297.
[8] Balestra, P. and M. Nerlove (1966) : «Pooling Cross-Section and Time-Series Data
in the Estimation of a Dynamic Models : the Demand for Natural Gas», Econo-
metrica, Vol.34, p.585-612.
[9] Baltagi B. H. (1995) : Econometric Analysis of Panel Data, Wiley and Sons.
[10] Baltagi B. H. (2005) : Econometric Analysis of Panel Data, Third Ed., Wiley and
Sons.
[11] Barnes, R., Gillingham, R., and Hagemann, R. (1981) : «The Short-Run Residential
Demand for Electricity», The Review of Economics and Statistics, Vol. 62, p. 541-
551.

Bibliographie 58
[12] Beaudry P. and Green D. (2000) : «Cohort Patterns in Canadian Earnings : As-
sessing the Role of Skill Premia in Inequality Trends», Canadian Journal of Eco-
nomics, Vol.33, No.4
[13] Belanger, D. (1992) : «Estimation des Probabilites de Choix Reliees au Probleme
d’Evaluation de la Demande d’Electricite Residentielle au Quebec», These de
Maıtrise, Universite Laval.
[14] Bernard, J-T, Bolduc, D. and Belanger, D. (1996) : «Quebec Residential Electricity
Demand : A Microeconometric Aproach», The Canadian Journal of Economics,
vol. 29, No.1 , p. 92-113.
[15] Baltagi B. H. (2005) : Econometric Analysis of Panel Data, 3e ed. Wiley and Sons.
[16] Billings, R., B. (1982) : «Specification of Bolck Rate Price Variable in Demand
Models», Land Economics, Vol. 56, p. 73-84.
[17] Billings, R. B. and Agathe, D. E. (1980) : «Price Elasticities for Water : A Case
of Increasing Bloc Rates», Land Economics, Vol. 56, p.73-84.
[18] Billings, R. B. and Agathe, D. E. (1981) : «Price Elasticities for Water : A Case
of Increasing Bloc Rates : Reply», Land Economics, Vol. 57, p.276-278.
[19] Biron, E. (1981) : «Estimating Economic Relations from Incomplete Cross-
Section/Time-Series Data», Journal of Econometrics, Vol. 16, p.221-236.
[20] Biron, E. and Jansen, E. S. (1983) : «Individual Effects in a System of Demand
Functions», Scandinavian Journal of Economics, Vol. 85, p.461-483.
[21] Blundell, R. and R. S. Smith (1991) : «Conditions Initiales et Estimation Efficace
dans les Modeles Dynamiques sur les Donnees de Panel», Annales d’Economie et
de Statistiques, Vol.20-21, p.109-123.
[22] Blundell, R. and Bond, S. (1998) : «Initial Conditions and Moment Restrictions in
Dynamic Panel Data Models», Journal of Econometrics, Vol.87, p.117-143.
[23] Blundell R., Browing M et Meghir C. (1985) : «Consumer Demand and the Life-
Cycle Allocation of Household Expenditures», The Review of Economic Studies,
Vol. 61 No. 1, pp 57-80.
[24] Blundell R. et Meghir C. H. (1990) : «Panel Data and Life-Cycle Models», Contri-
butions to Econometrics, Vol. 192, pp. 231-252.
[25] Boucher, N. (2003) : «Predicting National Data on the Use of Private Vehicles in
Canada for the 1980-1996 Period : an Application of the Bayesian Approach of
Gibbs Sampling with Data Augmentation», PhD. thesis, Queen University
[26] Browning, M., Deaton, A. and Irish, M. (1985) : «A profitable Approach to Labor
Supply and Commodity Demands over the Life-Cycle», Econometrica, Vol. 53,
No.3 pp503-544

Bibliographie 59
[27] Burtless, G., and Hausman, J., A. (1978) : «The Effect of Taxation of Labor Sup-
ply : Evaluating the Gray Neagtive Income Taxe Experiment», Journal of Political
Economy, 86, 276-278.
[28] Carlin B. P. and Louis Thomas (2000) : «Bayes and Empirical Bayes Methods for
Data Analysis», New York, Chapman and Hill/CRC
[29] Casella G. and George E. I. (1992) : «Explaining the Gibbs Sampler», The Ame-
rican Statitician, Vol. 46, No. 3, p. 167-174.
[30] Chamberlain G. (1984) : Panel Data. Handbook of Econometrics. Vol.II, Griliches
and Introligator M. D.
[31] Chamberlain G. (1980) : «Analysis of Covariance with Qualitative Data», The
Review of Economic Studies, Vol. 47, No. 1
[32] Collado D. M. (1997) : «Estimating dynamic Models from Time Series of Inde-
pendent Cross-Sections», Journal of Econometrics, Vol,82, pp37-62
[33] Davis, L. W. (2004) : «The Role of Durables Goods in Households Water and
Energy Consumption : The Case of Front Loading Clothes Washers», Job Market
Paper, University of Wisconsin
[34] Dargay, J. (2002) : «Determinants of Cars Ownership in Rural and Urban Areas :
a Pseudo-panel Analysis», Transportation Research Part E, 38, pp. 351-366.
[35] Dargay, J. and Vythoulkas, C. (1998) : «Estimation of Dynamic Transport De-
mand Models Using Pseudo-panel Data», ESCR Transport Studies Unit Centre
for Transport Studies, University College London.
[36] Dargay J. M. et Vythoulkas P. C. (1999) : «Estimation of a dynamique car ow-
nership model : a pseudo panel approach», Journal of Transport Economics and
Policy, 33, pp. 283-302.
[37] Dargay J. M. (2002) : «Determinants of Car Ownership in Rural and Urban Areas :
a Pseudo-Panel Analysis», Tansportation Research E, 38(5), pp. 351-366.
[38] Dargay J. M. et Vythoulkas P. C. (1997) :«Estimation of a dynamique car owner-
ship model : a pseudo panel approach», ESCR Transport Studies Unit, Ref. 97/47,
University College London
[39] Deaton Angus (1985) : «Panel Data from Time Series of Cross-sections», Journal
of Econometrics, vol. 30 pp 109-126.
[40] Dempster A. P., Laird M. N. and Rubin B. D. (1977) : Maximum Likelihood from
Incomplete Data via le EM Algorithm», Journal of the Royal Statistical Society,
Series B (Methodological), Vol. 39, No. 1, pp. 1-38.
[41] Dubin J. A and Mcfadden D. L. (1984) : « Econometric Analysis of Residential
Electricity Appliance Holdings and Consumpton», Econometrica, 52(2), pp.345-
362.

Bibliographie 60
[42] Dubin, J. A. (1982) : «Econometric Theory and Estimation of the Demand for
Consumer Durable Goods and thier Utilization : Appliance Choice and the Demand
of Electricity», Report No. MIT-EL 82-035-WP, MIT Energy Laboratory, MIT,
Cambridge, MA 02139, USA
[43] Dubin, J. A. (1985a) : Consumer Durable Choice and the Demand for Electricity,
Amsterdam : North-Holland.
[44] Dubin, J. A. (1985b) : «Evidence of Block Switching in Demand Subject to De-
cling Block Rates-A New Approach», Social Science Working Paper 583, California
Institute of Technology, Dept. of Economics.
[45] Dublin, J., J. and McFadden, D. (1984) : «An Econometric Analysis of Residential
Electric Apliance Holdings and Consumption», Econometrica, Vol. 52, No. 2, p.
345-362.
[46] Foster, H., S., Jr., and Beattie, B., R. (1981a) : «Urban Residential Demand for
Water in the United Stated : Reply», Land Economics, 57, 257-265.
[47] Foster, H., S., Jr., and Beattie, B., R. (1981b) : «On the Specification of Price in
Studies of Consumer Demand Under Block Price Scheduling», Land Economics,
57, 624-629.
[48] Fuller, W. A. and Battese, G. E. (1974) : «Estimation of Linear Models with
Cross-Error Structure», Journal of Econometrics, Vol.2, p.67-78.
[49] Gardes F., Langlois S. et Richaudeau D. (1996) : «Cross-Section versus Times-
Series Income Elasticities of Canadian Consumption», Economics letters, Vol.51,
pp169-175.
[50] Gardes F. et Loisy C. (1997) : «La Pauvrete selon les Menages : une Evaluation
Subjective et Indexee sur leur Revenu», Economie et Statistique, No.308-309-310,
pp95-113.
[51] Gassner K. (1998) : «An estimaion of UK Telephone Access Demand Using Pseudo-
Panel Data», Utilities Policy, Vol.7, pp 143-154.
[52] Gately, D. (1980) : «Individual Discount Rates and the Purchase and Utilization of
the Energy-Using Durables : Comment», Bell Journal of Economics, 11, 373-374
[53] Gelman A., Carlin J. B., Stern H. B. and Rubin D. B. (2000) : Bayesian Data
Analysis, New York, Chapman and Hill/CRC.
[54] Gelfand A. E. (2000) : «Gibbs Sampling», Journal of the American Statistical
Asssociation, Vol. 95, No. 452, p. 1300-1304.
[55] German, S. and German, D. (1984) : «Stochastic Relaxation, Gibbs Distribution
and the Bayesian Restoration if Images», IEEE Transactions on Pattern Analysis
and Michine Intelligence, 6, pp. 721-741.

Bibliographie 61
[56] Girma S. (2000) : «A Quasi-Differencing Approach to dynamique Modeling from
a Time Series of Independent Cross-Sections», Journal of Econometrics, Vol.98,
pp365-383.
[57] Goett, A. (1978) : «Appliance Fuel Choice : an Application od Discrete Multivariate
Analysis», PhD. Thesis, Department of Economics, University of California, USA
[58] Goett, A. (1983) : «Household Appliance Choice : Revision of the Residential End-
Use Energy Planning System», Final Report of Research Project 1918-1, Electric
Power Research Institute, California, USA
[59] Gordon S. et Belanger, G. (2003) : «Echantillonnage de Gibbs et autres appli-
cations econometriques des chaınes markoviennes», Working Paper, Departement
d’Economique, Universite Laval.
[60] Gourieroux C. and Monfort A. (1996) : Simulation-based Econometrics Methods,
Oxford University Press, Core Lectures.
[61] Gourvernement du Quebec 1989, 1994, 1999, 2002 : Position Concurrentielle des
Formes d’energie, Ministere des Ressources Naturelles.
[62] Gregoire, C. (2004) : «L’imputation Multiple», These de Maıtrise, Uniervsite Laval.
[63] Haln, J. (1999) : «How Informative is the Initial Condition in the Dynamic Panel
Model with Fixed Effects ?», Journal of Econometrics, Vol.93, p.309-326.
[64] Hanemann, W. M. (1984) : «Discrete/Continuous Models of Consumer Demand»,
Econometrica, Vol. 52, No. 3, p. 541-562
[65] Hausman, J.A. (1978) : «Specification Tests in Econometrics», Econometrica,
Vol.46 No.6, p.1251-1271.
[66] Hausman, J.A. (1979) : «Individual Discount Rates and the Purchase and Utili-
sation of Energy-Using Durables», The Bell Journal of Economics, Vol. 10, No. 1,
p. 33-54.
[67] Hausman, J.A. (1985) : «The Econometrics of Nonlinear Budget Sets», Econome-
trica, Vol. 53, No. 6, p. 1225-1282
[68] Hausman, J.A., Kinnucan, M., and McFadden, D. (1979) : «A Two-Level Electri-
city Demand Model», Journal of Econometrics, Vol. 10, p. 263-289.
[69] Hausman, J. A. and Trimble, J. (1984) : «Appliance Purchase and Usage Adapta-
tion to a Permanent Time-of-Day Electricity Rate Schedule», Journal of Econo-
metrics, Vol. 26, p.115-139.
[70] Hausman, J. A. and D. Wise (1979) : «Attrition Bias in Experimental and Panel
Data : the Gary Income Maintenance Experiment», Econometrica, Vol.47, p.455-
473.
[71] Heckman, J. J (1978) : «Dummy endogenous variables in a simultaneous equations
system», Econometric, Vol 46, No.4, p. 931-959

Bibliographie 62
[72] Heckman, J. J (1979) : «Sample selection bias as a specification error», Econome-
trica, Vol. 47, No.1, p. 153-162
[73] Herriges, J., A. and King, K., K. (1994) : «Residential Demand for Electricity
under Inverted Block Rates : Evidence from a Controlled Experiment», Journal of
Business and Economic Statistics, Vol. 12, No. 4, p. 419-430.
[74] Honore, B. E. (2002) : «Nonlinear Models with Panel Data», Portuguese Economic
Journal, Vol.1, p.163-179.
[75] Honore, B. E. and E. Kyriazidou (2000) : «Panel Data Discrete Choice Models
with Lagged dependent Variables», Econometrica, Vol.70, p.839-874.
[76] Houthakker, H. S. (1950) : «Revealed Preference and the Utility Function», Eco-
nomica, Vol. 17, p.159-174
[77] Hsiao, C. (1992) : «Logit and Probit Models», Working Paper 9210, South Cali-
fornia, Department of Economics.
[78] Hsiao, C. (2001) : «Panel Data Models», Chapiter 16 in B. H. Baltagi, ed., A Com-
panion to Theorical Econometrics (Blackwell publishers, Massachusetts), p.349-
365.
[79] Hsing, Y. (1994) : «Estimation of Residential Demand for Electricity with the
Cross-Sectionally Correlated and Timewise Autoregressive Model», Resource and
Energy Economics, Vol. 16, p.255-263
[80] Hydro-Quebec (2005) : Comparaison des Prix de l’Electricite dans les Grandes
Villes Nord-Americaines
[81] Hydro-Quebec, 1989, 1994, 1999, 2002 : Tarifs d’Electricite
[82] Im, K. S., S. C. Ahn, P. Schmidt and J. M. Wooldridge (1999) : «Efficient Es-
timation of Panel Data Models with Strictly Exogenous Explanatory Variables»,
Journal of Econometrics, Vol.93, p.177-201.
[83] King, M. A. (1980) : «An Econometric Model of Tenure Choice and Demand for
Housing as Joint Decision», Journal of Public Economics, Vol. 14
[84] Kyriazidou, E. (1997) : «Estimation of a Panel Data Sample Selection Model»,
Econometrica, Vol.65, p.1335-1364.
[85] Kyriazidou, E. (2001) : «Estimation of Dynamic Panel Data Sample Selection
Model», Review of Economic Studies, Vol.68, p.543-572.
[86] Lee, C.-J. (2000) : «Dynamic Unobserved Effects for Continuous and Binary Pres-
ponse», Ph.D Thesis, Michigan State University.
[87] Lee, L. F.(1978) : «Unionism and Wage Rates : A Simultaneous Equations Mo-
dels with Qualitative and Limited Dependent Variables», International Economic
Review, Vol. 19, p. 415-433.

Bibliographie 63
[88] Lee, L. F. and Griffiths, W. E. (1978) : «The Prio Likelihood and Best Linear
Unbiased Prediction in Stochastic Parameter Models», Unpublished Manuscript,
Unversity of Minnesota, Dpt of Economics.
[89] Liao Hue-Chu and Chang Tsai-Feng (2002) : « Space-heating and Water-heating
Energy Demands of the Aged in the US», Energy Economics 24 , 267-284
[90] Little R. J. A. and Rubin D. B. (2002) : Statistical Analaysis with Missing Data,
second ed.Wiley Series in Probability and statistics.
[91] Levin, A., C. F. Lin and C. Chu (2002) : «Unit Root Test in Panel Data : Asymp-
totic and Finite Sample Properties», Journal of Econometrics, Vol. 108, p.1-25.
[92] Maddala, G., S., Trost, R., P., Li, H. and Joutz, F. (1997) : «Estimation of Short-
Run and Long-Run Elasticities of Energy Demand from Panel Data Shrinkage
Estimators», Journal of Business and Economic Statistics, Vol. 15, No. 1, pp. 90-
100.
[93] Manski, C. F. (1987) : «Semiparametric Analysis of Random Effects Linear Moedls
from Binary Panel Data», Econometrica, Vol.55, p.357-362.
[94] McFadden, D., Puig, C., and Kirshner, D. (1977) : «Determinants of the Long-
Run Demand for Electricity», In the Proceeding of the Business and Economic
Statistics Section, American Statistical Association, p. 109-119.
[95] McKenzie D. J. (2001) : «Dynamic Pseudo-Panel Theory and Analysis of Consump-
tion in Taiwan and Mexico». Ph.D Disservation, Yale University
[96] McKenzie D. J. (2004) : «Asymptotic Theory for heterogeneous dynamique
Pseudo-Panels», Journal of Econometrics, Vol.120, pp.235-262.
[97] Moffit R. (1993) : «Identification and Estimation of dynamique Models with a Time
Series of Repeated Cross-Sections», Journal of Econometrics, Vol.59, pp99-123.
[98] Nesbakken, R. (2001) : «Energy Consumption for Space Heating : a Discrete-
Continuous Aproach», Scandinavian Journal of Economics, Vol.103, No.1, p. 165-
184
[99] Nijman T. et Verbeek M. (1990) : «Estimation of Time-dependent Parameters in
Linear Models using Cross-Sections, Panels, or Both», Journal of Econometrics,
Vol.46, pp333-346.
[100] Neyman, J. and Scott, E. L. (1948) : «Consistent Estimation from Partillay
Consistent Observations», Econometrica, Vol.16, p.1-32.
[101] Nickell, S. (1981) : «Biases in Dynamic Models with Fixed Effects», Econometrica,
Vol.49, p.1417-1426.
[102] Paquet M-F. (2002) : «Une Approche a Simulation pour le Traitement de Donnees
Longitudinales Incompletes», These de Doctorat, Universite Laval.

Bibliographie 64
[103] Paquet M. F. and Bolduc D. (2004) : «Le Probleme des Donnees Longitudinales
Incompletes : une nouvelle Approche», L’Actualite Economique, Vol. 80, 2/3, p.
341
[104] Phillips, P. C. B. and Moon, H. (1999) : «Linear Regression Limit Theory for
Nonstationary Panel Data», Econometrica, Vol. 57, p. 1057-1111.
[105] Poyer, D. A. and Williams, M. (1993) : «Residential Energy Demand : Additional
Empirical Evidence by Minority Household type», Energy Economics, Vol. 15,
p.93-100.
[106] Polzin, P. E. (1984) : «The Specification of Price in Studies of Consumer Demand
Under Block Price Scheduling», in the Proceedings of the Business and Economic
Statistics Section, American Statictical Association, p. 109-119.
[107] Raj B. et Baltagi B. H. (1992) : «Can Cohort Data Be Treated as Genuine Panel
data ?», Studies in Empirical Economics, Vol. 17, No. 1, pp. 9-23
[108] Reiss, P. and White M.W. (2005) : «Household Electricity Demand Revisited»,
Review of Economic Studies, Vol. 72, p. 853-883.
[109] Richarson, S. and Green, P. (1997) : «On Bayesian Analysis of Mixtures with
and Unknown Number of Components» (with discussion), Journal of the Royal
Statistical Society, Ser. B, p.731-792.
[110] Robertson, D. and Symons, J. (1992) : «Some Strange Properties of Panel Data
Estimators», Journal of Applied Econometrics, Vol.7, p.175-189.
[111] Rubin D. B. (1976) : «Inference and Missing Data», Biometrika, 63, pp.581-592.
[112] Rubin D. B. (1978) : «Multiple Imputations in Sample Surveys- a Phenomenologi-
cal Bayesian Approach to Nonresponse», The Proceedings of the Survey Research
Methods Section of The American Statistical Assciation, p. 20-34.
[113] Rubin D. B. (1986) : «Statistical Matching Using File Concatenation with Ad-
justed Weight and Multiple Imputations», Journal of Business and Economic Sta-
tistics, 4, pp. 87-94.
[114] Rubin D. B. (1987) : Multiple Imputation for Nonresponse in Surveys, New York,
J. Wiley and Sons.
[115] Rubin D. B. (1996) : «Multiple Imputation after 18+ Years», Journal of the
American Statistical Association, 91, pp. 473-489.
[116] Rubin D. B. and Schenker N. (1986) : «Multiple Imputation for Interval Estima-
tion from Simple Random with Ignorable Nonresponse», Journal of the American
Statistical Association,81, pp. 366-374.
[117] Sanga, D. M. (1999) : «Estimation des Modeles Econometriques de Choix Dis-
crets/Continus avec Choix Polytomiques Interdependants : une Approche par Si-
mulation», These de Doctorat, Universite Laval

Bibliographie 65
[118] Schafer J. L. (1997) : Analysis of Incomplete Multivariate Data, New York, Chap-
man and Hill.
[119] Schafer J. L. (2000) : «Analysis of Incomplete Multivariate Data», Monographs
on Statistics and Applied Probabilities 72. Chapman and Hall/CRC.
[120] Sevestre, P. and A. Trogon (1992) : «Linear Dynamic Models», in Laszlo Matayas
eds., The Econometrics of Panel Data, Handbook of Theory and Applications,
p.97-117.
[121] Skoufias, E. and A. Suryahadi (2002) : «A Cohort Cnalysis of Wages in Indonesia»,
Applied Economics, Vol. 34, No. 13, pp. 1703-1710.
[122] Tanner M. A. and Wong Wing Hung (1987) : «The Calculation of Posteriori
Distributions by Data Augmentation», Journal of the American Statistical Assso-
ciation, Vol. 82, No. 398, p. 528-540.
[123] Taylor, L., D., (1975) : «The Demand for Electricity : A Survey», The Bell Journal
of Economics, Vol. 6, No. 1, p. 74-110.
[124] Vaage K. (2000) : «Heating Technology and Energy Use : a Discret/Continuous
Choice Approach to Norwegian Household Energy Demand», Energy Economics,
Vol.22, No.6, p. 649-666
[125] Verbeek M. et T. Nijman (1993) : «Minimum MSE Estimation of a Regression
Model with Fixed Effects frm a Series of Cross-Sections», Journal od Econometrics,
Vol.59, pp125-136.
[126] Verbeek M. et T. Nijman (1993) : «Can Cohort Data Be Treated As Genuine
Panel data ?», Empirical Economics, Vol. 17, pp. 9-23.
[127] Verbeek M. et Vella F. (2004) : «Estimating dynamique Models from Repeated
Cross-Sections», Journal of Econometrics, Vol., pp.
[128] Vidal, V. (2006) : «Echantillonnage de Gibbs avec Augmentation de Donnees et
Imputation Multiple», These de Maıtrise, Universite Laval.
[129] Winter Russel, S. (1997) : «Discounting and its Impact on Durables Buying De-
cisions», Marketing Letters, Vol. 8, No.1, p. 109-118
[130] Wooldridge, J. M. (1995) : «Selection Corrections for Panel Data Models un-
der Conditional Mean Independence Assumptions», Journal of of Econometrics,
Vol.68, p.115-132.
[131] Wooldridge, J. M. (2000) : «The Initial Conditions problem in Dynamic, Nonlinear
Panel Data Models with Unobserved Heterogeneity», Working Paper, Department
of Economics, Michigan State University
[132] Wooldridge, J. M. (2002) : Econometric Analysis of Cross-Section and Panel
Data, MIT Press, Massachusetts.
[133] Wooldridge, J. M. (2003 and 2005) : Introductory Econometrics, A Modern Ap-
proach, 2e ed., Michigan State University, Thomson South-Western.

Bibliographie 66
[134] Wu, C. F. J. (1983) : «Generalized Linear Models with Random Effects : a Gibbs
Sampling Approach», Journal of the American Statistical Association, Vol. 86, pp.
79-86.

Chapitre 3
Estimation de la demande
d’electricite avec un modele a
classes latentes
3.1 Introduction
Dans ce chapitre, nous sommes interesses a l’estimation de la demande d’electricite
conditionnelle au choix du mode de chauffage. De plus, l’electricite est tarifee selon la
quantite journaliere consommee, de sorte que le prix marginal depend de la quantite
et la quantite consommee depend aussi du prix marginal. Notons aussi que la consom-
mation journaliere n’est pas observable de sorte que cela aboutit a un modele avec
deux groupes (ou classes) de menages qui ne sont pas observables. Nous corrigeons
le probleme de biais de selection en utilisant l’approche en deux etapes proposee par
Dubin et McFadden (1984), ou dans la premiere etape, nous utilisons un modele logit
mixte avec erreurs autoregressives generalisees d’ordre un pour calculer les correcteurs
de biais, et dans la seconde etape, nous estimons, par le maximum de vraisemblance
en information limitee, la demande conditionnelle au choix du mode et de la classe en
utilisant un modele a classes latentes. Les elasticites prix directe, prix croise et revenu
de la demande d’electricite sont egalement evaluees pour chacune des deux classes. Le
modele de demande sans classes qui corrige cependant le biais de selection est estime
pour des fins de comparaisons. Etant donne que la consommation d’energie fait interve-
nir des biens durables, nous estimons aussi des taux d’escompte specifiques au systeme
de chauffage choisi. Dans les etudes anterieures, les taux d’escompte individuels sont
estimes en supposant l’hypothese d’homogeneite entre les agents economiques ; ils sont

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes68
cependant tres eleves (superieurs aux taux d’interet sur les cartes de credit). Une prise
en compte de l’heterogeneite entre les individus pourraient aboutir a des valeurs de taux
d’escompte beaucoup plus proches de la realite. Dans ce chapitre, nous developpons de
nouveaux outils : un modele a classes latentes tenant compte de l’endogeneite du prix
marginal et nous proposons une nouvelle facon d’estimer les taux d’escompte en sup-
posant une certaine heterogeneite entre les individus. La section (3.2) fait un resume
des travaux anterieurs, la section (3.3) presente le modele de choix discret/continu, la
section (3.4) presente le logit mixte avec erreurs GAR(1). Le modele de demande condi-
tionnelle au choix du mode de chauffage est presente a la section (3.5). La section (3.6)
presente le modele de demande conditionnelle au choix de la tranche de consommation ;
la section (3.7) decrit la methode d’estimation du maximum de vraisemblance utilisee.
Les donnees sont presentees a la section (3.8). Nous presenterons ensuite les resultats de
nos estimations aux sections (3.9 et 3.10 ). La question du taux d’escompte individuel
est traitee dans la section (3.11) et enfin nous conclurons a la section (3.12).
3.2 Revue de la litterature
Nous sommes parfois confrontes, dans le cadre de l’analyse de la demande, a des
situations ou les choix continus sont relies aux choix discrets. Cela vient du fait que les
deux types de choix sont derives de la meme decision de maximisation de l’utilite de
l’agent considere. Dans un tel contexte, toute estimation qui ignore cette simultaneite
produirait des estimateurs biaises et non convergents. King (1980) fut le premier a
souligner cette interdependance en se servant du choix du type d’habitation ou de
propriete comme exemple. Il propose d’estimer le modele par la methode du maximum
de vraisemblance en information complete ; cette methode n’a cependant pas pu corriger
le biais de selection : il a considere la demande non conditionnelle plutot que la demande
conditionnelle. Apres les tentatives de King (1980), Dubin et McFadden (1984) se sont
interesses a la demande d’electricite et au choix d’appareils electromenagers des menages
des Etats-Unis. Ils furent les premiers a proposer une methode d’estimation appropriee
aux modeles de choix discrets/continus qui corrigerait le probleme de biais de selection.
Leur demarche se resume en deux grandes etapes. La premiere etape consiste a estimer
d’abord le modele de choix par la methode du maximum de vraisemblance et a constituer
ensuite les correcteurs de biais de selection correspondant a l’alternative (ou modalite)
choisie. Dans la deuxieme etape, ils estiment la demande conditionnelle a l’alternative
choisie en ajoutant les correcteurs de biais obtenus dans la premiere etape. La demande
conditionnelle est ensuite estimee en utilisant la methode des variables instrumentales,
la forme reduite ou en introduisant directement les correcteurs. Les estimateurs obtenus
sont convergents.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes69
Bernard, Bolduc et Belanger (1996) ont aussi estime un modele de demande d’electricite
des menages quebecois en utilisant la demarche precedente. A la difference de Dubin et
McFadden (1984) qui ont utilise un logit polytomique pour la partie discrete, eux ont
plutot suppose un logit mixte avec des erreurs autoregressives generalisees d’ordre un
ou GAR(1) ; le GAR(1) permet en effet de prendre en compte la correlation potentielle
entre les alternatives de chauffage.
Hanemann (1984) s’est interesse a l’estimation de la demande de produits de marques
differentes en se servant de la methode du maximum de vraisemblance en information
complete. Cependant, il a utilise la densite inconditionnelle (plutot que la densite condi-
tionnelle) qui ne corrige pas le biais de selection. Il propose alors la methode en deux
etapes du maximum de vraisemblance en information limitee. A la premiere etape, il
estime un modele logit polytomique. Ensuite, a la deuxieme etape, il utilise les moindres
carres ordinaires (MCO) ou les moindres carres generalises (MCG du) du modele de
demande conditionnelle (avec les correcteurs de biais de selection). Les estimes sont
recuperes pour servir comme valeurs initiales pour la seconde etape. Il n’a cependant
pas fait une application empirique de sa methode.
Sanga (1999) utilise deux approches (maximum de vraisemblance simulee en infor-
mation complete et en information limitee) pour estimer la demande d’electricite des
menages quebecois. Il utilise par contre un modele probit poltomique et non un logit
mixte comme dans Bernard, Bolduc et Belanger (1996).
Vaage (2000) aussi utilise la methode en deux etapes pour estimer la demande
d’energie des menages Norvegiens. Nesbakken (2001), comme Sanga (1999) estime la de-
mande d’energie en se servant du maximum de vraisemblance en information complete.
Liao et Chang (2002) ont estime la demande d’energie pour le chauffage de l’espace et
de l’eau des personnes agees aux USA en se servant de l’approche en deux etapes.
Tous ces travaux ont ete effectues dans un contexte de prix lineaire. Dans notre
etude, nous interessons a estimer un modele de demande d’electricite (donc un modele
de choix discret/continu) en prenant explicitement en compte la tarification d’Hydro-
Quebec, societe mandatee pour la production et la vente de l’electricite au Quebec.
Hydro-Quebec utilise en effet une tarification croissante par tranche : un premier prix
(p1) est fixe lorsque la consommation journaliere du menage ne depasse pas les 30 kilo-
watt/heures (kWh) et un autre prix (p2 > p1), pour toutes les quantites au dessus des 30
kWh. Le prix (marginal) depend donc de la demande, mais il constitue aussi une variable
explicative dans l’equation de demande. Il se pose alors un probleme d’endogeneite du
prix. En presence d’une structure de tarification par tranche, les menages doivent choisir
le mode de chauffage ainsi que la tranche ou classe de consommation d’energie. Toute

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes70
estimation du modele de demande d’electricite (avec prix non lineaire) qui ignore ce
probleme d’endogeneite produirait des estimateurs biaises et non convergents, meme si
on corrigeait pour le probleme de selection du au choix du mode de chauffage. On sait
depuis le papier d’Houthakker (1951), que les prix par tranche de consommation ont
des implications econometriques importantes. Taylor (1975) soulignait le biais potentiel
qui resulterait de l’estimation des elasticites de la demande lorsque la structure des prix
est non lineaire. Selon lui, la non linearite de la contrainte budgetaire du consommateur
a des consequences sur la fonction de demande, les courbes d’Engel et l’equilibre du
consommateur.
Plusieurs auteurs ont tente de resoudre le biais provenant de la non linearite des prix.
On peut citer pour la demande d’electricite,Taylor (1975), McFadden, Acton, Mitchell
et Mowill (1976), Puig et Kirshner (1977), Barnes, Gillingham et Hageman (1981),
Dubin (1985a et 1985b), Herrigues et King (1994), Reiss et White (2005) ; pour l’eau,
il y a les travaux de Billings et Agthe (1980, 1981), Foster et Beattie (1985a et 1985b) ;
pour le gaz naturel, Barnes, Gillingham et Hageman (1982), Polzin (1984), etc.
Il existe une variete de methodes d’estimation des modeles de demande avec en-
dogeneite du prix. Herriges et King (1994) en donnent une synthese. Lorsqu’il y a un
probleme de variable explicative endogene, les estimateurs des moindres carres ordi-
naires (MCO) sont biaises. Plusieurs methodes d’estimation peuvent alors etre utilisees
pour corriger ce biais.
L’estimation par la forme reduite fut utilisee dans les travaux de Taylor (1975), Barnes,
Gillingham et Hagemann (1981), Hausman, Kinnucan et McFadden (1979), Hausman
et Trimble (1984). Cette methode a cependant deux limites importantes : probleme
d’identification et approche ad hoc. L’estimation par les variables instrumentales est
techniquement superieure a l’estimation par la forme reduite parce qu’elle permet de
resoudre non seulement le biais d’endogeneite du prix, mais aussi elle permet de specifier
l’equation de demande en coherence avec la theorie neoclassique de maximisation de
l’utilite. Cependant, les estimateurs obtenus ne sont pas les meilleurs. L’estimation par
le maximum de vraisemblance structurel a ete utilisee dans les travaux de Burtless et
Hausman (1978) et ceux de Dubin (1985b). Cependant, il se peut que les probabilites
qui entrent dans la fonction de vraisemblance soient negatives. Herriges et King (1994)
proposent alors la methode du maximum de vraisemblance structurel modifie. Enfin,
il y a la methode des moments generalises (GMM) qui fut utilisee par Reiss et White
(2005) pour estimer un modele de demande dynamique.
Comme nous pouvons le constater, il n’existe pas encore de travaux qui aient pris
en compte a la fois le probleme de la simultaneite entre choix discret et choix continu
et le probleme de l’endogeneite du prix. On s’interesse soit a l’un soit a l’autre des

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes71
deux problemes, mais pas au deux a la fois. La structure des donnees dont nous dispo-
sons implique que si nous voulons estimer la demande d’electricite des menages avec la
structure de tarification d’Hydro-Quebec, nous devons resoudre simultanement ces deux
problemes pour obtenir des estimateurs convergents. Notre modele serait ainsi beaucoup
plus adapte a la realite. Dans cette etude, nous utiliserons la methode du maximum
de vraisemblance simule a information limitee qui a l’avantage de corriger a la fois le
biais de selection venant du choix du mode de chauffage et le biais d’endogeneite du
prix. La tarification d’Hydro-Quebec cree implicitement deux classes de menages qui
ne sont pas directement observables dans la base de donnees disponible. Nous propo-
sons d’utiliser un modele a classes latentes pour corriger le probleme d’endogeneite du
prix. Les modeles a classes latentes sont souvent utilises dans un contexte de variable
dependante discrete ; ils permettent de prendre en compte l’heterogeneite qui existe
entre differents groupes d’observations. La notion de classes latentes fut introduite en
1950 par Lazarsheld pour un modele dichotomique. Vingt ans plus tard, Goodman
(1974) rend son modele applicable en developpant un algorithme pour obtenir les esti-
mateurs du maximum de vraisemblance des parametres. Les modeles a classes latentes
peuvent s’appliquer a des variables discretes ou continues. Dans un modele a classes
latentes, les coefficients sont specifiques aux groupes. Dans notre etude, nous avons
affaire a des classes latentes puisque les deux groupes de consommateurs ne sont pas
directement observables. Cela vient du fait que la consommation journaliere du menage
n’est pas directement observable dans la base de donnees de l’etude. Nous avons uni-
quement l’information sur la consommation annuelle du menage ainsi que le nombre de
jours de consommation, et donc a la limite, nous pouvons connaıtre sa consommation
journaliere moyenne sur une annee.
La plupart des travaux portant sur les modeles a classes latentes traitent de modeles
a variables dependante discrete plutot que de modeles continus : Gopinath (1995),
Greene et Singer (2003), Vermunt et Magidson (2005), Shen et Hashinmoto (2006), etc.
Par ailleurs, les auteurs ne s’interessent pas a estimer le modele latent (modele de choix
de la classe) de facon explicite ; ils se contentent seulement d’estimer la valeur de la
probabilite. Dans ce chapitre, nous etendons les modeles a classes latentes au cas ou la
variable dependante est continue et nous developpons un modele latent qui permettra
d’estimer a la fois les parametres du modele de choix de la classe et les valeurs des
probabilites qu’un menage choisisse une classe donnee. A notre connaissance, il s’agit
d’une premiere dans la litterature.
L’analyse de la demande d’electricite nous amene a nous interesser aussi a la ques-
tion de biens durables puisque le menage utilise des equipements pour le chauffage de
l’eau et de l’espace. La decision du menage portant sur le choix du type de systeme de
chauffage fait intervenir la notion de taux d’escompte, puisqu’il est question de prendre

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes72
des decisions inter-temporelles. Les travaux anterieurs (notamment ceux de Hanneman
(1979), Goett (1980), Gately (1980), Greene (1983), Dubin (1982), Houston (1983),
Dubin et McFadden (1984)) ont souvent surestime le taux d’escompte des menages. Ils
supposent implicitement l’hypothese d’homogeneite entre les individus dans l’estimation
du taux d’escompte des menages. Winter (1997) soulignait les limites associees au fait
qu’on suppose le meme taux d’escompte pour tous les menages. Il propose plutot d’es-
timer un taux d’escompte implicite pour chaque menage ou chaque groupe de menages.
Supposer que le taux d’escompte change entre les individus uniquement a travers leur
revenu ne serait pas suffisant pour tenir compte de l’heterogeneite qui existe entre ces
derniers. Les autres comme Hanneman (1979), Dubin et McFadden (1984) ont suppose
que le taux d’escompte variait entre les menages uniquement a travers leur revenu. La
sur-estimation du taux d’escompte pourrait etre due a une mauvaise specification du
modele de choix. Nous proposons alors d’estimer un taux d’escompte pour chaque type
de consommateurs c’est-a-dire des taux d’escompte implicites par groupe de menages
qui tiennent compte de leur heterogeneite tout en etant fonction de leur revenu. Nous
considerons uniquement l’hypothese d’heterogeneite deterministe. Les taux d’escompte
peuvent egalement etre estimes en supposant de l’heterogeneite aleatoire, mais nous lais-
sons ceci pour des travaux futurs. Nous presenterons dans un premier temps le modele
discret/continu, ensuite, nous decrirons a la section (3.4) le logit mixte avec erreurs
GAR(1).
3.3 Le modele econometrique de choix discret/continu
L’agent economique qui fait l’objet de notre etude est le menage. Celui-ci est appele
a prendre trois decisions :
– choisir le mode de chauffage de l’eau et de l’espace parmi un ensemble de Cn
modalites. Soit j le mode de chauffage choisi par le menage : j ∈ Cn, avec Cn
le nombre de modalites disponible pour l’individu n. Nous indicons l’ensemble
des choix possibles par n parce qu’il peut arriver qu’un menage n’ait pas acces
a une modalite donnee (exemple : le gas naturel n’est pas disponible a tous les
menages). Le menage choisira le mode j si l’utilite procuree par ce mode est la
plus grande, comparee aux autres modes.
– choisir la tranche de consommation a laquelle il va appartenir a travers le mode
d’utilisation de l’electricite : mode d’usage intensif ou non intensif. Nous utiliserons
l’indice s pour designer la classe de consommation du menage. Dans notre etude,
s ne prendra que deux valeurs : 1 et 2.
– choisir finalement la quantite d’electricite a consommer. Ce dernier choix est relie
au choix de la tranche puisque c’est la quantite journaliere d’electricite consommee

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes73
qui va determiner la classe. Soit yjn la quantite d’electricite demandee. Cette quan-
tite est determinee a partir de l’identite de Roy appliquee a la fonction d’utilite
indirecte.
Notre objectif est de modeliser les trois choix en utilisant la methode du maximum
de vraisemblance en information limitee. Nous comptons utiliser un modele a classes
latentes qui permet de tenir compte des trois choix en meme temps. Il s’agit en d’autres
termes d’estimer la demande d’electricite conditionnelle au choix du mode de chauffage
et au choix de la classe. Les sections suivantes presentent les trois modeles de choix.
3.4 Le modele de choix du mode de chauffage : le
logit mixte
Supposons que le menage n (n = 1, ..., N) fait face a un ensemble d’alternatives
possibles Cn. Le menage doit faire un choix parmi un ensemble de systemes de chauffage
de l’eau et de l’espace. Ces systemes fonctionnent soit au gaz naturel, au mazout, a
l’electricite, au bois, ou une combinaison de l’une ou l’autre des energies. Le menage
choisit l’alternative j avec j ∈ Cn dans le but de maximiser son utilite. Nous supposons
une fonction d’utilite indirecte qui satisfait les proprietes classiques de maximisation
de l’utilite. Apres avoir choisi un mode de chauffage (ou portefeuille d’appareils), le
menage l’utilise pour produire des services dont le processus de production necessite de
l’energie.
Supposons que le menage maximise sa fonction de l’utilite (Ujn). Etant donne le
mode de chauffage choisi, le menage a une fonction d’utilite indirecte conditionnelle de
la forme :
Ujn (j, rev − rj,x, Pe, Pm, Pg, Pbie, εj, η) , (3.1)
ou Pe est le prix de l’electricite, Pm le prix du mazout, Pg le prix du gaz naturel et Pbie
le prix de la bi-energie ; εj est l’ensemble des caracteristiques non observables du mode
de chauffage, η est l’ensemble des caracteristiques non observables du menage, rj est
le cout total normalise du mode j, rev est le revenu du menage et x est un vecteur de
variables exogenes. Nous supposons comme dans Dubin et McFadden (1984) que le cout
total (rj) est compose du cout fixe et du cout moyen normalise associes a la modalite
choisie :
rj =∑
i∈Cn
Piqij + ρjrcj
ρj = ρ0j + ρ1jrevj,

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes74
avec ρj le taux d’escompte associe au systeme de chauffage j. Cn est l’ensemble des
energies disponibles pour le menage n. qij est la quantite annuelle consomme de l’energie
i du menage qui a choisi la modalite j. Les details concernant le calcul des couts fixes
et couts moyens sont dans Belanger (1992).
Le menage choisit l’alternative j si et seulement si : Ujn > Uin ∀i 6= j. Definissons
la variable binaire djn comme suit :
djn =
1 si Ujn > Uin ∀ j ∈ Cn ∧ i 6= j
0 sinon
La fonction d’utilite Ujn se decompose en 2 elements : une partie deterministe (Vjn)
et une autre aleatoire (εjn) :
Ujn = Vjn + εjn.
La partie deterministe est specifiee comme suit :
Vjn = Xjnβ,
ou X est un vecteur de toutes les variables exogenes du modele. La probabilite que le
menage n choisisse l’alternative j est :
Pn (j) = P (Ujn > Uin ∀ i 6= j)
= P (Vjn + εjn > Vin + εin ∀ i 6= j)
= P (εin − εjn < Vjn − Vin ∀ i 6= j) . (3.2)
Nous supposons un modele autoregressif generalise d’ordre un (ou GAR(1)) :
Ujn = Vjn + εjn
εjn = σjξjn + vjn
ξjn = ρ∑
i6=j
wij,nξin + ζjn ζjn ∼ N(0, 1) (3.3)
vjn ∼ iid Gumbel, (3.4)
avec : σj l’ecart-type associe a l’alternative j, ρ est un coefficient de correlation et les
wij,n sont des poids qui respectent∑i6=j
wij = 1 ∀i pour un n donne. Le parametre ρ
est un coefficient de correlation qui mesure le degre de linearite entre chaque ξin et son
”voisin” correspondant, soit ξjn pour j = 1, ...Jn. De plus, nous imposons la restriction
selon laquelle (−1 < ρ < 1) dans le but d’assurer la stabilite du processus defini dans

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes75
l’equation (3.3). Les poids wij,n sont des fonctions parametriques decrivant l’influence
de chaque erreur sur les autres erreurs. On definit ces poids de la facon suivante :
wij,n =w∗
ij,n
Jn∑j=1
w∗ij,n
, ∀i 6= j et wii,n = 0 ∀i (3.5)
w∗ij,n = g
(R1
ij,n, R2ij,n, ..., RL
ij,n, θ1, θ2, ..., θH
), ∀i 6= j et wii,n = 0 ∀i,
ou il y a H parametres θh et L variables Rlij,n.
Le modele (GAR(1)) fut introduit par Ben-Akiva et Bolduc (1991) et Bolduc (1992)
dans le contexte de l’estimation du probit polytomique. Le GAR(1) permet de reduire
le nombre de parametres de nuisance lors de l’estimation des elements de la matrice
de variance-covariance des erreurs. L’approche du GAR(1) permet de modeliser de
facon parcimonieuse la structure de correlation des erreurs avec seulement quelques
parametres. Elle peut egalement modeliser des formes tres generales de dependances
entre les erreurs. Un des avantages de cette approche est que le nombre de parametres
a estimer ne croıt pas necessairement avec le nombre de modalites. Cette hypothese
s’avere utile puisqu’elle reduit enormement les difficultes de calcul lors de l’estimation.
L’hypothese du GAR(1) a ete egalement utilisee dans les travaux de Belanger (1992)
et Bernard, Bolduc et Belanger (1996). Nous retenons la meme structure de correlation
comme dans les travaux de ces derniers auteurs, avec une legere modification au niveau
des poids. Nous avons modifie certains poids et les colonnes correspondant a la modalite
7 (electricite/electricite) ont ete modifiees. En effet, nous ne considerons pas le modele
de choix en deviation par rapport a une modalite de reference comme ce fut le cas dans
les travaux de Bernard, Bolduc et Belanger (1996). La matrice de correlation retenue
est la suivante :
0 1 0 0 0 0 0 0 0
1 0 0 0 0 0 0 0 0
0 0 0 1 0.4 0.4 0.7 0 0
0 0 1 0 0.4 0.4 1 0 0
0 0 0.4 0.4 0 1 0.4 0 0
0 0 0.4 0.4 1 0 0 0 0
0 0 0 0.7 1 0.4 0 0 0
0 0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 1 0
La derniere hypothese (3.4) : vjn ∼ iid Gumbel permet d’avoir un modele logit mixte
(ou modele a noyau logistique). La particularite du logit mixte est que la partie aleatoire
du modele comporte deux elements : un terme d’erreur normal et un autre terme qui

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes76
suit une distribution Gumbel i.i.d. Le logit mixte permet de prendre en compte la
correlation potentielle qui existe entre les alternatives. S’il existe une correlation entre
les alternatives et que celle-ci n’est pas prise en compte dans la specification du modele,
les estimateurs seront biaises et non convergents. La non prise en compte de la structure
de correlation peut etre consideree comme une omission d’information pertinente dans
le modele. Le logit mixte a comme cas particulier le logit lorsqu’il n’existe aucune
correlation entre les alternatives, ceci s’obtient lorsqu’on impose que ρ = 0 et que
σj = 0 ∀j. Le logit mixte possede certains avantages par rapport au modele probit,
logit ou plus generalement les modeles GEV (generalized extreme value). En effet, le
logit mixte corrige les limites associees au logit en prenant en compte l’heterogeneite
entre les observations, des formes flexibles de substitution et la correlation entre les
facteurs non observables a travers le temps. De plus, contrairement au modele probit,
le logit mixte n’est pas contraint a avoir un terme d’erreur normalement distribue ; le
terme d’erreur peut suivre entre autre une loi triangulaire, log-normale, etc. (McFadden
et Train (2000), Train (2002) et Ben-Akiva et al. (2001)).
Le modele decrit plus haut peut aussi s’ecrire sous forme vectorielle, de facon beau-
coup plus compacte :
dn = [d1n, ...dJn
]′
(3.6)
Un = Xnβ + εn, (3.7)
ou dn, Un et εn sont des vecteurs (Jn × 1) et Xn est une matrice de dimension (Jn ×K)
avec K le nombre de parametres de la partie deterministe de l’utilite. Les hypotheses
du modele se resument dans les points suivants :
a. εn = Tnξn + vn avec Tn une matrice diagonale (Jn × Jn) qui contient les ecart-type
σj sur sa diagonale
b. ξn = ρWnξn + ζn, ζn ∼ N (0, IJn)
c. ζjn et vn sont des vecteurs (Jn × 1), Wn est une matrice (Jn × Jn) dont les elements
sont definis en (3.5) et IJnest une matrice identite de dimension Jn.
L’hypothese (b.) permet d’ecrire que : ξn = (I − ρWn)−1 ζn = P−1n ζn avec Pn =
(I − ρWn). En substituant cette derniere expression dans l’equation de l’utilite (3.7),
on obtient :
Un = Xnβ + TnP−1n ζn + vn.
Sous ces hypotheses, on a :
E (Un) = Xnβ
V (Un) = Ψn = TnP−1n P−1′
n Tn +π2
6IJn
.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes77
Evaluons maintenant les probabilites de choix des modes de chauffage. Selon la
definition du modele, la probabilite qu’un individu n choisisse l’alternative j est une
integrale sur tout le domaine de ξn :
P (j) =
∫· · ·∫
Λn (j |ξn ) h (ξn) dξn, (3.8)
ou :
Λn (j |ξn ) =eVjn+σjξn
∑i
eVin+σiξn.
La probabilite (3.8) contient des integrales multiples et cela necessite l’utilisation des
methodes numeriques pour son evaluation. Il y aura autant d’integrales qu’il y a d’al-
ternatives. Si le nombre d’alternatives est grand (superieur a 3), l’estimation numerique
devient ardue et exigerait beaucoup de temps de calcul. Une alternative est l’approche
par simulation proposee par McFadden (1989) ainsi que Pakes et Pollard (1989). Cette
approche consiste a remplacer les probabilites ayant des integrales multiples par des
simulateurs lisses. La procedure consiste dans une premiere etape a tirer des valeurs de
ξn a partir de sa fonction de densite. Soit ξsn le seme tirage du vecteur ξn. La seconde
etape consiste a calculer la probabilite logistique associee a chacun des s tirages. La
troisieme etape consiste a repeter la premiere et deuxieme etapes plusieurs fois et a
prendre ensuite la moyenne des resultats obtenus. On obtient finalement la probabilite
simulee suivante :
P (j) =1
S
S∑
s=1
Λn (j |ξsn ) , (3.9)
avec :
Λn (j |ξsn ) =
eVjn+σjξsn
∑i
eVin+σiξsn
qui est en fait la probabilite du logit polytomique conditionnelle a une valeur donnee
ξsn du vecteur ξn. Pour S grand, la probabilite P (j) est un estimateur convergent et
asymptotiquement sans biais de P (j). Nous estimons le modele par la methode du
maximum de vraisemblance simule (MVS) (Goureroux et Monfort, 1996). Le MVS et
le maximum de vraisemblance (MV) se confondent lorsque S tend vers l’infini de sorte
que les proprietes asymptotiques du MVS sont evidemment les memes que celles du
MV. Une alternative au MVS serait la methode des moments simules (MMS) qui exige
la simulation de chaque probabilite ; le MVS exige par contre de simuler uniquement la
probabilite de l’alternative choisie. Lorsqu’il y a beaucoup d’alternatives, comme c’est le
cas dans cette etude, le MVS est alors preferable au MMS. Vekeman, Bolduc et Bernard
(2004) ont aussi utilise la methode du MVS pour estimer un modele de choix des modes
de transport. Ils ont utilise un logit mixte avec erreur composee. L’article de McFadden
et Train (2000) donnent plus de details sur le logit mixte et les methodes utilisees pour
son estimation.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes78
3.5 Le modele de demande conditionnelle au choix
du mode
Depuis les travaux de Dubin et McFadden (1984), les praticiens realisent de plus en
plus que les choix discrets et continus sont inter-relies. Cela implique que l’esperance
conditionnelle du terme d’erreur de l’equation de demande est non nulle : E [ηjn |εjn ] 6=0. Ce dernier terme constitue un biais de selection. De ce fait, l’equation de demande
d’electricite etant donne la modalite j doit s’ecrire en tenant compte du biais de selection
du au choix du mode de chauffage :
yjn = Wjnθ + ηjn (3.10)
= Wjnθ + E (ηjn |εjn ) + ajn, (3.11)
ou ajn est un terme d’erreur que nous supposons de moyenne nulle, W est un vecteur
de variables explicatives. Pour simplifier la notation, nous ecrivons que E [ηjn |εjn ] =
E [ηjn |j ]. En nous basant sur Dubin et McFadden (1984), supposons que la distribution
de ηjn conditionnelle a (ε1n, ...., εJn
) a une moyenne egale a σ√
2/λ∑
j∈Cnρjεjn et de
variance σ2(1−∑
j∈Cnρ2
j) avec les conditions suivantes :∑
j∈Cnρjεjn = 0 et
∑j∈Cn
ρ2j <
1. La premiere condition est imposee afin que le terme d’erreur de l’equation de demande
(soit ηjn) ait une moyenne centree en zero etant donnee que la moyenne du terme
d’erreur Gumbel (soit εjn) est egale a une constante donnee 1. La deuxieme condition
est imposee afin que la moyenne du terme d’erreur ηjn soit positive. Le terme λ est un
parametre d’echelle que nous fixons a 1 comme on le fait habituellement avec le modele
logit. Le ρj traduit la correlation entre le terme d’erreur de l’equation de demande et
celui de l’equation de choix du mode de chauffage.
Il existe une autre variable aleatoire (ξjn) qui devrait etre prise en compte. En effet,
pour avoir E [ηjn |j ], il faut prendre l’integrale sur tout le domaine de ξn :
E [ηjn |j ] =
∫
An
E [ηjn |j, ξjn ] f (ξn) dξn.
Un simulateur lisse et convergent de E [ηjn |j ] propose par Vekeman et al. (2004) serait :
E [ηjn |j ] =1
S
S∑
s=1
E [ηjn |j, ξsn ] , (3.12)
1Si ε ∼ Gumbel(0, 1), cas standard, alors : E(ε) = 0.5772 et V (ε) = π2
6. Donc, l’esperance du terme
d’erreur ε n’est pas nulle. Pour que le terme d’erreur du modele de demande (η) soit de moyenne nulle,
il faut necessairement imposer la condition suivante suivante :∑
i∈Cn,j 6=i ρj + ρi = 0

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes79
ou les ξsn sont des tirages dans la loi f (ξn) qui est ici une loi normale et S le nombre
total de tirages. En adoptant la specification de Dubin et McFadden (1984), l’esperance
conditionnelle de η est definie de la facon suivante :
E [ηjn |εjn, ξn ] =σ√
2
λ
∑
i∈Cn
ρiE [εin |j, ξn ] .
Cette esperance n’est pas specifique au mode choisi (j). Pour cette raison, l’indice j
sera mis en exposant et non en indice :
E[ηj
n |εjn, ξn
]=
σ√
2
λ
∑
i∈Cn
ρiE [εin |j, ξn ]
E[εj
n |j, ξn
]=
− ln Λ (j |ξn ) × λ
√3
π............si i = j
Λ(j|ξn )1−Λ(j|ξn )
ln Λ (j |ξn ) × λ√
3π
.........si i 6= j.
Donc, on deduit que :
E[ηj
n |j, ξn
]=
√6σ
π
[ ∑
i∈Cn,i6=j
(ρi
Λ (i |ξn )
1 − Λ (i |ξn )ln Λ (i |ξn )
)− ρj
ln Λ (j |ξn )
1 − Λ (j |ξn )
]
=
√6σ
π
[∑
i∈Cn
ρiΛ (i |ξn )
1 − Λ (i |ξn )(ln Λ (i |ξn ) − dij)
],
avec dij = 1 si i = j et dij = 0 sinon. De plus, nous avons la contrainte suivante :∑i∈Cn,j 6=i ρj + ρi = 0. Il s’ensuit que :
E[ηj
n |j, ξsn
]=
√6σ
π
[ ∑
i∈Cn,j 6=i
ρi
[Λ (i |ξs
n ) ln Λ (i |ξsn )
1 − Λ (i |ξsn )
+ ln Λ (j |ξsn )
]],
Donc, (3.12) devient :
E[ηj
n |j]
=1
S
S∑
s=1
[ ∑
i∈Cn,i6=j
[Λ (i |ξs
n ) ln Λ (i |ξsn )
1 − Λ (i |ξsn )
+ ln Λ (j |ξsn )
]] √6σ
πρi
Pour simplifier l’ecriture du modele, definissons l’element ω tel que l’expression suivante
soit satisfaite : ∑
i∈Cn,i6=j
(.) ≡∑
i∈Cn
ωin
(.) ,
ou :
ωin
=
1
0
si i ∈ Cn ∧ i 6= j
sinon.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes80
L’estimateur devient :
E[ηj
n |j]
=1
S
S∑
s=1
∑
i∈Cn
ωin
[Λ (i |ξs
n ) ln Λ (i |ξsn )
1 − Λ (i |ξsn )
+ ln Λ(j∣∣ξs
jn
)] √6σ
πρi
=∑
i∈Cn
ωin
[1
S
S∑
s=1
ωin
[Λ (i |ξs
n ) ln Λ (i |ξsn )
1 − Λ (i |ξsn )
+ ln Λ (j |ξsn )
]] √6σ
πρi
=∑
i∈Cn
Fijn
√6σ
πρi
E[ηj
n |j]
= Fjnτj, (3.13)
avec τi =√
6σπ
ρi un parametre a estimer.
L’estimateur de E [ηjn |j ] obtenu par le maximum de vraisemblance simule du logit
mixte est E [ηin |j ] = Fjnτi. A partir de l’equation (3.11), on sait que l’esperance condi-
tionnelle est constituee en fait par le correcteur de biais de selection2. Les probabilites
simulees vont permettre de constituer ces correcteurs qui deviennent alors des variables
explicatives dans l’equation de demande (3.11).
3.6 La demande d’electricite conditionnelle au choix
de la tranche de consommation
Apres avoir choisi le mode de chauffage, le menage doit choisir la quantite d’energie
necessaire pour satisfaire ses besoins. Il choisit en meme temps sa classe de consom-
mation. A partir de l’identite de Roy, la demande d’electricite pour les menages qui
utilisent l’alternative j est derivee comme suit :
yjn = − ∂Ujn (j, rev − rj, X, Pe, Pm, Pg, Pbie, εj, η) /∂Pe
∂Ujn (j, rev − rj, X, Pe, Pm, Pg, Pbie, εj, η) /∂rev. (3.14)
2Tous les J correcteurs seront inclus dans le modele de demande, puisque nous faisons une regression
de la demande d’electricite pour toutes les modalites et non pour une seule. Pour chaque modalite, il
y a un correcteur qui est fixe a zero compte tenu de la contrainte sur les ρi. Il est possible de faire
la regression separee pour chaque modalite, mais, compte tenu du nombre tres faible d’observations
pour certaines modalites et aussi de la complexite du modele, une regression empilee pour toutes les
modalites est preferable. Dans ce cas, il faut necessairement exclure un correcteur dans chaque equation
de demande selon la modalite choisie. Ceci pourrait faire l’objet d’autres travaux futurs ou on estimera
une equation de demande d’electricite comme (3.11) pour chaque modalite.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes81
La fonction de demande derivee a partir de l’identite de Roy est celle definie a l’equation
(3.10). Cette fonction de demande peut se decomposee de la facon suivante :
yjn = Xjnβ + Rjnλ + ηjn,
ou R est un vecteur de variables exogenes specifiques a la demande et X est un vecteur
de variables explicatives definies dans la fonction d’utilite. L’indice j est introduit pour
tenir compte de la modalite choisie par le menage. Rappelons que les couts fixes de
meme que les correcteurs de biais de selection sont specifiques a chaque modalite.
Comme nous l’avons souligne auparavant, Hydro-Quebec a une structure de tari-
fication croissante par tranche de consommation. Il existe deux classes et donc deux
prix differents. La consommation de la deuxieme tranche est plus chere que celle de la
premiere tranche. Definissons la variable y∗jn = consommation journalieren−30kWh.
Si y∗jn ≤ 0, le menage n se situe dans la premiere tranche. Si y∗
jn > 0, le menage se situe
dans la deuxieme tranche. Cependant, le chercheur ne sait pas exactement dans quelle
tranche le menage se situe puisque la consommation journaliere n’est pas directement
observable. Donc, la variable y∗jn est une variable latente, inobservable. Il existe deux
groupes de menages et chaque groupe devrait avoir des caracteristiques qui lui sont
specifiques. Ceci nous amene a introduire la notion de modele a classes latentes.
Les modeles a classes latentes sont souvent utilises pour prendre en compte l’heterogeneite
qui existe entre differents groupes d’observations. La notion de classes latentes fut in-
troduite en 1950 par Lazarsheld pour un modele dichotomique. Vingt ans plus tard,
Goodman (1974) rend son modele applicable en developpant un algorithme pour obte-
nir les estimateurs du maximum de vraisemblance des parametres du modele. Beaucoup
d’autres auteurs se sont interesses a ce type de modele et il existe des logiciels appropries
pour son estimation. Les modeles a classes latentes peuvent s’appliquer a des variables
discretes ou continues. Dans un modele a classes latentes, les coefficients sont specifiques
aux groupes ou classes. Les modeles a classes latentes seraient proches du logit mixte
(Greene et Singer (2003), Shen et al. (2006)). En effet, le logit mixte suppose que les
parametres sont specifiques aux individus (ou classes) tout en suivant une distribution
continue. Le logit mixte a aussi l’avantage de prendre en compte la correlation poten-
tielle entre les alternatives. Bien que tous les deux modeles permettent d’introduire de
l’heterogeneite entre les individus, le modele a classes latentes requiert de definir un
certain nombre de classes tandis que le logit mixte necessite qu’on definisse une loi
pour les parametres. Pour le probleme qui nous concerne, a savoir prendre en compte
les tranches de consommation dans le modele de demande, un modele a classes latentes
serait bien approprie. Precisons que dans les ecrits anterieurs, les modeles a classes la-
tentes sont utilises dans un contexte de variable dependante discrete. Dans notre etude,
nous etendons ce type de modele au cas de variable dependante continue.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes82
Le tableau (3.1) donne un exemple illustratif pour justifier l’existence de deux classes
latentes de menages. Supposons deux menages nommes A et B. L’electricite est tarifee
aux deux mois par Hydro-Quebec, donc au cours d’une annee, chaque menage recoit 6
factures differentes. Dependamment de la periode de l’annee, un menage peut consom-
mer en dessous ou au dessus du seuil des 30 kWh. L’information disponible dans les
bases de donnees d’enquete que nous utilisons concerne uniquement la consommation
annuelle de chaque menage, et son nombre de jours de consommation. Comme on peut
le constater, la moyenne obtenue a partir de la consommation annuelle ne permet pas
de dire qu’un menage a toujours ete en dessous ou au dessus du seuil des 30 kWh. Par
exemple, le menage A a une consommation moyenne de 28 kWh, ce qui est inferieur a
30 kWh. Portant au cours de l’annee, il a parfois (2 fois sur 6) consommee au dessus
du seuil. Mais soulignons que le menage est capable de suivre sa consommation au jour
le jour a travers sont compteur. Nous tenterons d’inferer les probabilites qu’un menage
soit dans une classe ou dans une autre au cours de l’annee en nous basant sur cer-
taines de ses caracteristiques. Le modele a classes latentes qui sera developpe permettra
d’estimer la demande d’electricite en tenant compte de l’existence de ces deux classes.
Tab. 3.1 – Exemple : pourquoi deux classes latentes ?facture 1 2 3 4 5 6 Moy/an Proba. Classe1 Proba. Classe2
A 35 29* 27* 23* 22* 32 28<30 0.67 0.33
B 38 36 31 25* 36 32 33>30 0.17 0.83
Supposons que le menage appartient a une des deux classes notee par s, (s = 1, 2)
avec une certaine probabilite. Soit Q(y∗
jn ≤ 0), la probabilite que le menage appar-
tienne a la premiere classe et soit Q(y∗
jn > 0)
la probabilite qu’il appartienne a la
deuxieme classe. Supposons que la consommation journaliere (y∗jn) est fonction d’un
certain nombre de variables explicatives :
y∗jn = Mjnα + ujn ujn ∼ N
(0, σ2
u
)
Q(y∗
jn ≤ 0)
= Q
(y∗
jn − Mjnα
σu
≤ −Mjnα
σu
)
= Φ
(−Mjnα
σu
)
Q(y∗
jn > 0)
= 1 − Q(y∗
jn ≤ 0)
= 1 − Φ
(−Mjnα
σu
)
Le vecteur M contient entre autres, les correcteurs de biais de selection obtenus precedemment,
etant donne que le choix de la tranche de consommation est conditionnel au choix du
mode de chauffage3. Nous fixons σu = 1 pour que le modele soit identifiable.
3La quantite demandee d’electricite etant reliee au choix du mode de chauffage, il en resulte que la
demande journaliere non observable est aussi reliee au choix de la modalite. Il faut donc corriger pour
le biais de selection dans le modele latent de choix de la classe.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes83
Le modele global a estimer comporte finalement trois composantes :
a. une composante pour le choix du mode de chauffage :
P (j) =1
S
S∑
s=1
eVjn+σjξs
n
∑i
eVin+σiξsn
.
b. une composante pour la demande conditionnelle au choix du mode de chauffage :
yjn = Wjnθ + Fjnτ + ajn,
avec Fjnτ la version estimee du correcteur du biais de selection du choix du mode de
chauffage definie a l’equation (3.13)
c. Enfin, nous avons la composante pour le choix de la tranche : Q(s = 1) = Φ (−M ′α)
si le menage est dans la premiere tranche et Q(s = 2) = 1 − Φ (−M ′α) s’il est
dans la deuxieme tranche.
Le modele final de demande conditionnelle peut s’ecrire :
yjn = Wjnθ1 + Fjnτ1 + ajn si y∗
jn ≤ 0
yjn = Wjnθ2 + Fjnτ2 + ajn si y∗jn > 0
.
L’approche en deux etape sera donc privilegiee compte tenu de la complexite du
modele. Nous estimerons d’abord les correcteurs de biais de selection et ensuite nous
les introduirons dans l’equation de demande pour ensuite estimer les parametres du
modele de demande.
3.7 Estimation par le maximum de vraisemblance
en information limitee
Il existe plusieurs methodes pour estimer les modeles de choix discret/continu. La
methode du maximum de vraisemblance en information complete estime simultanement
les parametres du modele de choix discret et ceux du modele continu. Cette methode
est souvent complexe et tres couteuse en temps de calcul. De plus, la loi conjointe des
modeles de choix discret/continu est souvent difficile a modeliser surtout lorsque les
variables proviennent de deux populations differentes (une discrete et l’autre continue).
Sanga (1999) et Nesbakken (2001) ont utilise cette approche pour estimer la demande
d’electricite.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes84
Il existe aussi la methode du maximum de vraisemblance en information limitee qui
estime separement les parametres du modele discret et ceux du modele continu. De
plus, en estimant le modele en deux etapes, des chercheurs ont montre qu’une erreur
de specification sur l’une ou l’autre des deux parties aura moins de repercussions sur
la non convergence des estimateurs de tous les parametres que lorsque le modele est
estime en une seule etape. Pour ces differentes raisons, nous estimerons le modele de
choix discret/continu par la methode du maximum de vraisemblance en information
limitee.
Etant donne que nous corrigeons a la fois pour le biais de selection provenant du
choix du mode de chauffage et pour le biais d’endogeneite provenant de la non linearite
des prix, une estimation par le maximum de vraisemblance en information limitee semble
mieux appropriee. Nous estimons a la premiere etape les parametres du modele de choix
discret (le logit mixte) en utilisant la methode du maximum de vraisemblance simulee.
Ces parametres estimes serviront a calculer les valeurs predites des probabilites simulees
qui, a leur tour serviront a construire les correcteurs de biais de selection du mode. La
deuxieme etape consistera a estimer le modele continu en conditionnant la demande
sur le choix du mode. Supposons que la densite conditionnelle de la demande pour un
menage qui appartient a la classe s et utilise le mode j est f (yjn |j, s). Le modele a
classes latentes est defini de la facon suivante :
L =N∏
n=1
∏
j∈Cn
2∑
s=1
[f (yjn |j, s) Q (s)]djn
=N∏
n=1
∏
j∈Cn
[f (yjn |j, s = 1) Q (1) + f (yjn |j, s = 2) Q (2)]djn
=N∏
n=1
∏
j∈Cn
[f (yjn |j, s = 1) Q
(y∗
jn ≤ 0)
+ f (yjn |j, s = 2) Q(y∗
jn > 0)]djn .
Supposons l’hypothese de normalite du terme d’erreur de l’equation de demande :
yjn = Wjnθs + Fjnτs + ajn s = 1, 2
ajn ∼ N(0, σ2
a
).
La densite de la demande conditionnelle a la tranche choisie est :
f (yjn |j, s) = φ (ajns) ×1
σa
=1
σa
× 1√2π
exp
(yjn − Wjnθs − Fjnτs
σa
)2
,
ou Fjn est le correcteur du biais de selection du mode de chauffage obtenu lors de la

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes85
premiere etape. Par consequent, la fonction de vraisemblance est :
L =N∏
n=1
∏
j∈Cn
1σa
φ(
yjn−Wjnθ1−Fjnτ1
σa
)(1 − Φ (Mα))
+ 1σa
φ(
yjn−Wjnθ2−Fjnτ2
σa
)Φ (Mα)
djn
,
ou nous remplacons la probabilite de choix du mode de chauffage P (j) par sa valeur
simulee P (j). La fonction log-vraisemblance a maximiser prend finalement la forme
suivante :
ln L =N∑
n=1
∑
j∈Cn
djn × ln
1σa
φ(
yjn−Wjnθ1−Fjnτ1
σa
)Φ (−Mα)
+ 1σa
φ(
yjn−Wjnθ2−Fjnτ2
σa
)(1 − Φ (−Mα))
. (3.15)
L’estimation du modele de choix du mode de chauffage se fera avec le language de
programmation FORTRAN et l’estimation du modele de demande conditionnelle4 se
fera a l’aide de STATA.
3.8 Description des donnees
Nous utilisons les donnees provenant d’une enquete postale realisee par Hydro-
Quebec en 1989 et portant sur la consommation d’electricite des menages quebecois.
Le taux de reponse au questionnaire etait de 44.9 % soit 45833 menages ayant repondu
sur un total de 101977 questionnaires expedies. Nous utilisons un sous-echantillon de
2897 observations constitue de menages ayant une maison unifamiliale (detachee, semi-
detachee ou en rangees avec entrees separees). Le questionnaire comporte des infor-
mations sur les caracteristiques socio-economiques du menage. Les informations sur
la consommation d’electricite ont ete obtenues aupres d’Hydro-Quebec, alors que les
donnees sur les prix des differentes energies considerees et sur les couts d’usage et de
capital des systemes de chauffage de l’eau et de l’espace proviennent du gouvernement
du Quebec (1990). L’information sur la disponibilite du gaz naturel pour chaque menage
provient de Gaz Metropolitain.
Les tableaux ci-dessous (3.2), (3.3) et (3.4) presentent les principales informations
disponibles dans cette base de donnees. Comme on peut le constater, plus de 81% des
menages utilisent l’electricite pour le chauffage de l’eau et de l’espace. Sur les (18) com-
binaisons possibles des differentes sources d’energie pour le chauffage de l’eau et de l’es-
pace, nous avons retenu neuf (9) modalites definies comme suit (le premier terme indique
4Il faut normalement corriger le probleme d’heteroscedasticite lorsqu’on utilise l’approche en deux
etapes. Mais cela rendra davantage plus complexe le modele. Nous laissons ce point pour des travaux
futurs ou l’efficacite des estimateurs pourra etre amelioree.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes86
le choix d’une energie pour le chauffage de l’espace et le deuxieme terme indique l’energie
choisie pour le chauffage de l’eau) : modalite (1) gaz/gaz, modalite (2) gaz/electricite,
modalite (3) bienergie/mazout, modalite (4) bienergie/electricite, modalite (5) ma-
zout/mazout, modalite (6) mazout/electricite, modalite (7) electricite/electricite, mo-
dalite (8) bois/electricite et enfin modalite (9) bois-electricite/electricite. Le tableau
(3.4) presente les principales variables utilisees dans le modele de choix du mode ou
dans le modele de demande.
Tab. 3.2 – Repartition echantillonnale par source d’energiechauffage de l’espace chauffage de l’eau
gaz naturel mazout electricite Total
gaz naturel 27 9 36
bienergie 72 201 273
mazout 12 20 32
electricite 2351 2351
bois 124 124
bois/electricite 81 81
Total 27 84 2786 2897
Tab. 3.3 – Frequences echantillonnales selon le mode de chauffageNom Pourcentage Frequence disponibilite du gaz
1. gaz/gaz 0.93 27 543
2. Gaz/electricite 0.31 9 543
3. Bienergie/mazout 2.49 72 2897
4. Bienergie/electricite 6.94 201 2897
5. Mazout/mazout 0.41 12 2897
6. Mazout/electricite 0.69 20 2897
7. Electricite/electricite 81.15 2351 2897
8. Bois/electricite 4.28 124 2897
9. bois-electricite/electricite 2.80 81 2897
Total 100 2897 21365
Tab. 3.4: Description des variables utilisees
Variable Nom Moyenne
modalites (chauffage espace-chauffage eau)
gaz/gaz (1) mode1 0.0093
Gaz/electricite (2) mode2 0.0031
Bienergie/mazout (3) mode3 0.0249
Bienergie/electricite (4) mode4 0.0694
suite a la page suivante

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes87
Tab. 3.4: Description des variables utilisees
Variable Nom Moyenne
Mazout/mazout (5) mode5 0.0041
Mazout/electrcite (6) mode6 0.0069
electricite/electricite (7) mode7 0.8115
Bois/electricite (8) mode8 0.0428
Bois-electricite/electricite (9) mode9 0.0280
cout fixe (103) coutfix 0.3913
cout fixe×revenu (105) coutfiy 1.7985
cout moyen (103) coutm 1.4077
revenu (104) rev 4.4184
annee de construction (1920-1989) datcons 1978.09
degres jour chauffage hdd 4830
degres jour de climatisation cdd 129.71
nombre de personnes dans le menage nbre residents 3.13
secteur secteur
rural 0.2592
peu urbain 0.0307
urbain 0.1046
forte densite 0.6055
surface (103 pieds carres) surf 1.6754
age du repondant age 41.53
mode d’occupation proprietaire
proprietaire 0.9082
locataire 0.0918
systeme de chauffage principal
systeme a eau chaude systeme eau chaude 0.1042
systeme a air chaud systeme air chaud 0.0411
systeme thermopompe systeme thermopompe 0.1381
plinthes plinthes 0.6151
autres autres 0.1015
type d’habitation
individuelle detachee detachee 0.8412
individuelle avec multiples entrees entrees multiples 0.0601
jumelee ou en rangee jumelee 0.0311
piscine piscine 0.1774
disponibilite du gaz naturel 0.1874
sexe sexe
suite a la page suivante

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes88
Tab. 3.4: Description des variables utilisees
Variable Nom Moyenne
homme 0.4387
femme 0.2126
nombre de pieces (1-18) nbre pieces 6.2
prix moyen electricite prixelec 4.482
prix moyen bienergie prixbie 5.438
prix moyen gaz naturel prixgn 4.174
prix moyen mazout prixm 5.901
consommation annuelle (en kWh) consommation totale 23479
Appareils electromenagers
nombre de congelateurs nbre congelateur 0.53
nombre de refrigerateurs nbre refrigerateur 1.21
climatiseur central climatiseur central 0.0725
climatiseur fenetre climatiseur fenetre 0.0618
appoint electrique appoint electrique 0.1481
appoint non electrique appoint non electrique 0.3693
thermopompe pour piscine thermopompe piscine 0.0228
Fin du tableau
3.9 Resultats du modele de choix du mode de chauf-
fage
Nous apportons les precisions suivantes qui accompagnent le tableau (3.5). L (0)
est le log-vraisemblance du modele avec la contrainte que toutes les coefficients des
variables explicatives sont fixes a zero sauf la constante. L (c) est le log-vraisemblance
lorsqu’on suppose que le modele de choix contient uniquement les constantes specifiques
aux modalites. L(θ)
est la valeur du log-vraisemblance lorsqu’on n’impose aucune
contrainte.
Les parametres du modele de choix du mode de chauffage ont ete estimes par le
maximum de vraisemblance simule, dans lequel nous avons effectue des tirages dans
une loi normale comme decrit dans la section (3.3). Nous avons effectue 100 tirages. Le
tableau (3.5) presente les resultats de l’estimation. Nous avons procede a differents tests
de specification afin de savoir si le modele avec coefficients specifiques aux variables est

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes89
Tab. 3.5: Resultats modele discret (couts moyens
specifiques)
Variables logit mixte Logit polytomique
Estimes Ecart-type t-student Estimes Ecart-type t-student
gaz/gaz -76.817 30.748 -2.498 -13.686 3.302 -4.145
gaz/electricite -33.983 11.323 -3.001 -8.170 1.672 -4.887
bienergie/mazout -9.962 1.801 -5.533 -5.330 0.988 -5.393
bienergie/electricite -7.975 1.285 -6.206 -3.351 0.741 -4.524
mazout/mazout -27.134 3.519 -7.710 -20.237 2.559 -7.908
mazout/electricite -17.561 2.092 -8.394 -12.575 2.043 -6.155
bois/electricite -45.614 9.146 -4.987 -6.995 1.055 -6.631
bois-elec/elec -63.780 14.032 -4.545 -9.563 1.184 -8.079
coutfix -2.321 1.067 -2.176 -1.882 0.608 -3.097
coutfiy 1.052 0.232 4.536 0.745 0.135 5.519
coutm1 -11.459 6.623 -1.730 -8.468 0.843 -10.041
coutm2 -21.304 7.425 -2.869 -11.379 1.229 -9.260
coutm3 -24.356 2.668 -9.131 -11.741 0.721 -16.291
coutm4 -24.558 2.723 -9.018 -12.301 0.603 -20.394
coutm5 -20.869 2.371 -8.803 -9.105 0.935 -9.742
coutm6 -22.893 2.357 -9.714 -10.640 0.743 -14.317
coutm7 -28.056 2.901 -9.671 -13.099 0.594 -22.049
coutm8 -33.592 4.291 -7.829 -18.978 1.051 -18.057
coutm9 -23.362 3.314 -7.049 -12.822 0.726 -17.663
datcons 0.133 0.071 1.867 0.084 0.034 2.458
datconv 0.605 0.078 7.788 0.345 0.037 9.405
hdd1 6.353 3.829 1.659 1.007 0.643 1.565
hdd5 3.219 0.505 6.370 2.344 0.350 6.695
hdd6 2.150 0.290 7.410 1.552 0.320 4.843
hdd8 3.821 1.203 3.177 0.561 0.182 3.084
hdd9 5.520 1.537 3.592 0.804 0.193 4.155
nbpers1 -2.935 1.450 -2.024 -1.322 0.252 -5.239
nbpers3 0.570 0.313 1.821 0.391 0.163 2.404
nbpers4 -0.429 0.191 -2.249 -0.147 0.123 -1.200
nbpers5 0.405 0.297 1.363 0.249 0.298 0.835
y1 1.030 0.951 1.083 -0.252 0.156 -1.615
y2 -1.737 0.889 -1.954 -0.624 0.205 -3.039
y3 -0.810 0.257 -3.150 -0.664 0.156 -4.264
y4 -0.687 0.198 -3.463 -0.555 0.115 -4.817
y5 -0.694 0.296 -2.343 -0.598 0.196 -3.047
y6 -0.762 0.208 -3.662 -0.656 0.165 -3.988
y8 -2.635 0.547 -4.816 -0.528 0.075 -7.040
y9 -1.101 0.310 -3.554 -0.431 0.086 -4.990
SIG1 0.248 0.083 2.988 - - -
RHO1 -0.986 0.003 -351.159 - - -
autres statistiques
L(θ)
-1321.2854 -1465.8570
L (0) -2317.3266 -2317.3266
L (c) -2255.6268 -2256.0550

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes90
plus approprie. Suite a plusieurs tests de specification, nous avons conclu que les coeffi-
cients devraient etre specifiques (par rapport aux differentes modalites) pour un certain
nombre de variables explicatives. Pour l’interpretation des resultats, nous utiliserons
la terminologie tres significatif pour dire qu’il s’agit de la significativite statistique au
seuil de 1% et significatif pour le seuil de 5% ou 10%.
Les constantes specifiques aux modalites sont toutes tres significatives. Elles sont toutes
de signe negatif. Cela traduit une forte preference pour l’electricite. On peut dire que
la modalite de reference (electricite/electricite) apporte plus d’utilite en moyenne que
les autres modalites, toutes choses egales par ailleurs.
Le cout moyen de chauffage (specifique a chaque modalite) explique significativement le
choix du mode ; seul le cout moyen specifique a la premiere modalite (gaz/gaz) n’est pas
significatif a 5% (mais il l’est a 10%). De plus, il affecterait negativement l’utilite. Plus
les couts d’exploitation sont eleves par rapport aux couts d’exploitation de la modalite
de reference, plus le menage aura tendance a preferer la modalite de reference ( soit
electricite/electricite)
Nous avons prefere que le cout fixe soit une variable generique, c’est la meilleure
specification pour le modele. Son estime a un signe est negatif et est tres significa-
tif. Son signe negatif signifie qu’une augmentation du cout fixe (par rapport au cout
fixe de la modalite de reference) reduirait l’utilite du menage.
L’estime de la variable cout fixe multiplie par le revenu est de signe positif et est tres
significatif. L’estime du revenu specifique a chaque modalite est de signe negatif et si-
gnificatif pour la plupart des modalites. L’estime du revenu specifique a la premiere
modalite est de signe positif mais n’est significatif. On peut deduire que l’augmentation
du revenu du menage rend l’electricite plus attrayante, cela se justifierait entre autres
par des raisons de bien-etre, de souplesse du systeme de chauffage tout a l’electricite,
et ses faibles couts.
L’estime de la variable date de construction est de signe positif et significatif a 10%. Les
maisons nouvellement construites affectent positivement l’utilite des menages qui choi-
sissent une modalite autre que l’electricite. L’electricite serait donc moins attrayante
pour les nouvelles constructions contrairement aux autres modalites.
L’estime de la date de conversion a une nouvelle source est de signe positif et tres
significatif. Le signe positif indique que l’utilite augmente avec les annees, pour les
menages ayant converti leur source pour une source autre que l’electricite. cela se justifie
surtout avec la baisse du prix du mazout et les changements qui se sont produits sur le
marche du gaz naturel.
L’estime de la variable degres-jours de chauffage specifique a chaque modalite est de
signe positif et est tres significatif (sauf pour la premiere modalite). Les degres-jours
de chauffage sont la somme annuelle des degres moyens journaliers en dessous de 18 C.
En effet, si la temperature est en dessous de 18 C, le chauffage est mis en marche.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes91
Dans cette base, nous utilisons des moyennes annuelles sur trente ans pour chaque ville
de la province de Quebec. Seuls les coefficients relatifs aux modalites 1, 5, 6, 8 et 9
sont significatifs. Pour ces dernieres modalites, le signe positif indique que plus il fait
trop froid (donc les degres jours sont eleves), plus ce systeme de chauffage choisi plutot
que l’electricite. Les menages qui utilisent le mazout ou le bois rentabilisent plus leur
investissement lorsqu’il y a une grande utilisation du systeme. Cela s’explique par le
fait que les menages qui utilisent de tels systemes doivent supporter de grosses depenses
en capital alors que le cout unitaire (par kWh) est plus faible que celui a l’electricite,
de sorte qu’une plus grande consommation rentabilise leur systeme et le rend plus
competitif que le systeme a l’electricite.
Le nombre de personnes dans le menages affecte negativement et de maniere significative
l’utilite des menages qui ont choisi les modalites 1 et 4. Pour ce groupe de menages, le
gaz et la bi-energie deviennent moins attrayants lorsque le nombre de personnes dans
le menage augmente.
Sans entrer dans les details du processus GAR(1), nous signalons simplement que ce
processus nous a permis de representer la structure de variance covariance a l’aide de
quelques parametres supplementaires qui sont SIG1 (ecart-type) et RHO1 (coefficient
de correlation). Le parametre SIG1 est un coefficient d’echelle qui est specifique a la
premiere modalite (gaz/gaz). Le RHO1 est un coefficient de correlation qui mesure
la structure de dependance entre les alternatives. Tous ces deux parametres sont tres
significatifs. cela confirme que les donnees sont biens representees par une specification
GAR(1). Le coefficient de correlation est de signe negatif et proche de l’unite. Cela
traduit l’existence d’une forte correlation negative entre les alternatives. Nous avons
aussi estime le meme modele d’utilite en supposant un modele logit polytomique, qui
est en fait un cas particulier du logit mixte GAR(1). Ceci nous a permis de constater
que le logit mixte donne des resultats superieur a ceux du logit polytomique. Le log-
vraisemblance du logit mixte est de (-1321.2854) tandis que celui du logit polytomique
est de (-1465.8570). Un test de ratio de vraisemblance (likelihood ratio test) nous donne :
LR = −2[−1321.2854 + 1465.8570] = 289.1432
Puisque la valeur de la statistique de test est tres grande, on a une evidence empirique
en faveur du modele logit mixte avec erreur GAR(1). Nous avons teste la significativite
globale de tous les parametres. Le log-vraisemblance du modele sous la contrainte que
tous les coefficients sont nuls est de (-2317.3266). La statistique de test LR est :
LR = −2[−1321.2854 + 2317.3266] = 1992.6824
Nous rejetons l’hypothese selon laquelle tous les coefficients ne seraient pas globalement
significatifs. Nous avons aussi teste la significativite globale de tous les coefficients de
pente. Le log-vraisemblance du modele avec seulement des constantes specifiques aux
modalites est de (-2255.6268). Le test LR associe est :
LR = −2[−1321.2854 + 2255.6268] = 1868.6828

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes92
Nous rejetons l’hypothese selon laquelle tous les coefficients de pente sont globalement
non significatifs.
3.10 Resultats de l’estimation du modele de demande
Le modele de demande conditionnelle au choix du mode de chauffage et au choix
de la tranche de consommation a ete estime par le maximum de vraisemblance simule
a information limitee. Nous avons constitue les correcteurs de biais de selection (3.13)
apres l’estimation du logit mixte. Ces correcteurs sont ensuite utilises comme variables
explicatives dans le modele de demande. Soulignons que cette approche n’a pas encore
ete utilisee dans la litterature pour estimer la demande d’electricite tout en corrigeant
le biais de selection et le biais d’endogeneite du prix marginal. Le modele a classes
latentes developpe ici est donc nouveau dans la litterature.
Le tableau (3.6) presente les resultats de l’estimation du modele de demande par le
maximum de vraisemblance simule en information limitee. Rappelons que la fonction
de vraisemblance a maximiser est celle donnee par l’equation (3.15).

Chapitre
3.
Estim
atio
nde
ladem
ande
d’electricite
avec
un
modele
acla
ssesla
tentes93
Tab. 3.6: Resultats du modele de demande conditionnelle
Variables Estimes Ecart-type t-Student Estimes Ecart-type t-Student
Modele latent : probabilite de choisir la classe1
revenu net -.1917011 .0317048 -6.05
surface -.1174278 .0754563 -1.56
age -.1543919 .0421416 -3.66
nbre residents .0204532 .0516707 0.40
correcteur1 -.0010977 .0503459 -0.02
correcteur2 -.048327 .0501641 -0.96
correcteur3 -.05895 .0976879 -0.60
correcteur4 -.1137387 .1358962 -0.84
correcteur5 .1108886 .2767555 0.40
correcteur6 .2329238 .1965562 1.19
correcteur7 -.1227042 .0623717 -1.97
correcteur8 -.0573548 .047196 -1.22
correcteur9 -.0767128 .0461606 -1.66
constante 2.265846 .3399132 6.67
Classe1 Classe2
Estimes Ecart-type t-Student Estimes Ecart-type t-Student
prixelec -2.949698 .5272192 -5.59 -14.70437 .6456266 -22.78
prixgn -.2897508 .265646 -1.09 .3424017 .1096837 3.12
prixm -1.893562 1.31882 -1.44 1.46366 .6201594 2.36
prixbie 2.928363 .9403879 3.11 4.319643 .4378725 9.87
surf 4.59347 .4294862 10.70 .6602728 .2144291 3.08
age .8425669 .258783 3.26 -.0210637 .1104251 -0.19
cdd .1587457 .0537172 2.96 069234 .0259578 2.67
suite a la page suivante

Chapitre
3.
Estim
atio
nde
ladem
ande
d’electricite
avec
un
modele
acla
ssesla
tentes94
Tab. 3.6: Resultats du modele de demande conditionnelle
Variables Estimes Ecart-type t-Student Estimes Ecart-type t-Student
conversion -.0008176 .0007765 -1.05 -.0016383 .0003305 -4.96
date construction -.201937 .2603875 -0.78 -.7014036 .0940826 -7.46
hddm 2.411937 1.136881 2.12 -.6315054 .4892462 -1.29
proprietaire 4.119597 1.529893 2.69 .7216937 .5453248 1.32
systeme airChaud 4.339682 .7532762 5.76 .5430062 .4571769 1.19
systeme eauChaude 7.2547 1.547718 4.69 1.519885 .6590753 2.31
appoint electrique 2.511133 .7523501 3.34 -1.616955 .4073606 0.24
appoint non electrique 1.322084 .601317 2.20 -1.026123 .2739395 -3.52
nbre refrigerateurs 1.605707 .5238694 3.07 .6999412 .2601967 2.69
detachee 5.142528 .9446936 5.44 1.992507 .4765685 4.18
jumelee -1.190132 1.662239 -0.72 -1.66611 .6952359 -2.40
piscine 4.318836 .7342505 5.88 1.959071 .3613901 5.42
nbre residents 1.858971 .3132679 5.93 .8393588 .1238159 6.78
dispo -2.613426 .9504773 -2.75 -.9582957 .3714531 -2.58
climatiseur fenetre .6982298 1.004315 0.70 1.064917 .5521248 1.93
revenu net -.3659881 .1849701 -1.98 .2601509 .0876406 2.97
correcteur1 9.495832 2.734658 3.47 -.0399658 .0506201 -0.79
correcteur2 -10.44348 2.790428 -3.74 -.004774 .0511984 -0.09
correcteur3 14.77724 2.90015 5.10 -.989763 .2785958 -3.55
correcteur4 12.79979 3.088544 4.14 -.1688702 .2801081 -0.60
correcteur5 11.09467 3.493339 3.18 -.0132942 .3169106 -0.04
correcteur6 -68.25484 14.02259 -4.87 .0004186 .1692137 0.00
correcteur7 15.83934 2.605257 6.08 1.126817 .1820954 6.19
correcteur8 13.2636 2.488475 5.33 .1807218 .0548722 3.29
correcteur9 13.53411 2.481166 5.45 .1957813 .0537749 3.64
suite a la page suivante

Chapitre
3.
Estim
atio
nde
ladem
ande
d’electricite
avec
un
modele
acla
ssesla
tentes95
Tab. 3.6: Resultats du modele de demande conditionnelle
Variables Estimes Ecart-type t-Student Estimes Ecart-type t-Student
constante .0694988 10.78931 0.01 54.79776 5.430179 10.09
ecart-type 1.617937 .0174602 92.66
Log likelihood = -9331.709
LogL sans correcteurs = -9393.1107
Fin du tableau

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes96
3.10.1 Interpretation des resultats du modele de choix de la
classe
Les resultats du modele latent sont presentes dans le tableau (3.6), plus precisement
le premier bloc correspondant a la probabilite d’etre dans la premiere classe (Q(s = 1)).
Comme cela a ete precise dans la section (3.6), nous associons a chaque classe, une
probabilite donnee. Les signes des coefficients sont les principaux indices qui nous per-
mettent de savoir de quelle probabilite il s’agit. Les estimes obtenus dans la partie
latente correspondent aux coefficients des variables qui sont dans la probabilite d’etre
dans la premiere classe. Pour obtenir les coefficients des variables de la probabilite d’etre
dans la deuxieme classe, il suffit d’ajouter un signe negatif aux parametres de la partie
latente du tableau, etant donne qu’il s’agit d’un modele de choix dichotomique. Comme
dans l’interpretation du modele de choix du mode de chauffage, nous adoptons ici aussi
et dans le reste du document une terminologie simplificatrice : l’expression tres signifi-
catif pour dire qu’il s’agit de la significativite statistique au seuil de 1% et significatif
pour le seuil de 5% ou 10%.
La variable revenu net des couts fixes et des couts variables explique de facon tres signi-
ficative le choix de la classe. Plus le revenu du menage est eleve, plus il a de chance d’etre
dans la deuxieme classe. La premiere classe est essentiellement composee de menages
a faibles revenus. Plus le menage est riche, plus il consommera davantage et donc il
sera dans la deuxieme classe. Cela confirme les affirmations de Dupuis et al. (2006) qui
stipulaient que la consommation d’electricite augmente avec le revenu.
La variable age explique de facon tres significative la consommation d’energie du menage.
Plus le chef de menage est age, plus sa demande d’electricite sera importante. Les per-
sonnes agees restent le plus souvent a la maison, leur besoins en electricite augmente
par consequent (principalement, ils ont besoin d’espace bien chauffe). Cela vient confir-
mer les resultats obtenus par Liao et Chang (2002). Selon leurs resultats portant sur la
demande d’energie des personnes agees aux USA, les besoins de chauffage de l’espace
augmentent avec l’age.
L’estime du nombre de personnes dans le menage n’est pas statistiquement significatif.
Nous avons aussi inclus les correcteurs de biais de selection, certains sont significatifs.
La constante est positive et significative. Cela signifie que si toutes les autres variables
du modele latent sont fixees a zero, il restera une consommation de base ou consomma-
tion minimale qui garderait le menage dans la premiere classe.
En somme, ce sont les menages riches et les menages plus agees qui sont dans la deuxieme
classe. La premiere classe est essentiellement composee de menages moins fortunes.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes97
Tab. 3.7 – ElasticitesClasse1 Classe2 sans classe
electricite -1.274 -2.667 -1.3841
E-T 0.228 0.117 0.0858
bienergie 0.671 0.859 0.730
E-T 0.216 0.087 0.081
Gaz naturel -0.111 0.119 0.123
E-T 0.102 0.038 0.042
Mazout -1.078 0.563 0.190
E-T 0.751 0.238 0.259
Revenu -0.151 0.0472 0.1083
E-T 0.076 0.016 0.014
cdd 0.236 0.036 0.056
E-T 0.080 0.0137 0.013
hdd 1.338 -0.124 -0.031
E-T 0.631 0.096 0.106
3.10.2 Resultats du modele de demande conditionnelle
Les resultats de l’estimation sont presentes au tableau (3.6). Nous avons aussi cal-
cule les elasticites prix et revenus de la demande, elles sont presentees au tableau (3.7)5.
Nous avons egalement estime le modele de demande conditionnelle au choix du mode
sans tenir compte de l’existence des deux classes. Le tableau (3.8) presente ses resultats
et les elasticites correspondantes sont dans la derniere colonne du tableau (3.7). Le
modele de demande sans les deux classes servira pour comparaison, etant donne que
c’est ce modele qui est habituellement utilise.
Soulignons que la variable dependante du modele de demande conditionnelle est la
quantite d’electricite (en kWh). Rappelons aussi que la premiere classe est composee
de menages dont la consommation journaliere est inferieure ou egale a 30 kWh et la
deuxieme classe est composee de ceux dont la consommation journaliere depasse les 30
kWh.
Les differents prix qui sont dans le modele de demande sont les prix moyens et non mar-
ginaux. Le prix marginal de l’electricite est pris en compte de facon implicite a travers
les deux classes, etant donne qu’il s’agit d’un prix non lineaire. De plus, le prix marginal
de l’electricite n’est pas vraiment variable (une constante par classe). Par ailleurs, nous
ne disposons pas d’information sur les prix marginaux des autres energies. Pour toutes
ces raisons, nous nous sommes limites a n’utiliser que les prix moyens pour lesquels
5Le terme E-T indique l’ecart-type estime des elasticites.
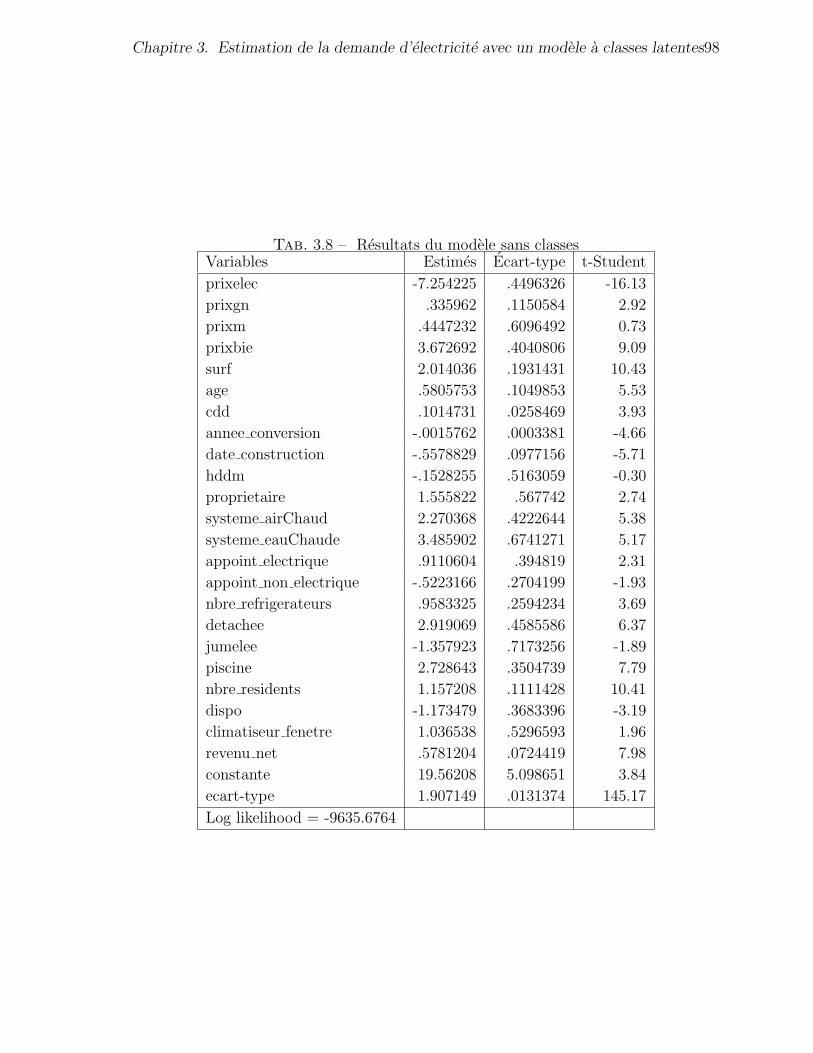
Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes98
Tab. 3.8 – Resultats du modele sans classesVariables Estimes Ecart-type t-Student
prixelec -7.254225 .4496326 -16.13
prixgn .335962 .1150584 2.92
prixm .4447232 .6096492 0.73
prixbie 3.672692 .4040806 9.09
surf 2.014036 .1931431 10.43
age .5805753 .1049853 5.53
cdd .1014731 .0258469 3.93
annee conversion -.0015762 .0003381 -4.66
date construction -.5578829 .0977156 -5.71
hddm -.1528255 .5163059 -0.30
proprietaire 1.555822 .567742 2.74
systeme airChaud 2.270368 .4222644 5.38
systeme eauChaude 3.485902 .6741271 5.17
appoint electrique .9110604 .394819 2.31
appoint non electrique -.5223166 .2704199 -1.93
nbre refrigerateurs .9583325 .2594234 3.69
detachee 2.919069 .4585586 6.37
jumelee -1.357923 .7173256 -1.89
piscine 2.728643 .3504739 7.79
nbre residents 1.157208 .1111428 10.41
dispo -1.173479 .3683396 -3.19
climatiseur fenetre 1.036538 .5296593 1.96
revenu net .5781204 .0724419 7.98
constante 19.56208 5.098651 3.84
ecart-type 1.907149 .0131374 145.17
Log likelihood = -9635.6764

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes99
l’information etait disponible.
L’estime de la variable prix moyen de l’electricite est tres significatif dans les deux
classes et est negatif. Nous constatons qu’en valeur absolue, l’effet marginal du prix
de l’electricite est plus important dans la deuxieme classe que dans la premiere. Les
elasticites prix directes sont toutes superieures a l’unite. Une augmentation de 1% du
prix de l’electricite entraınera une baisse de 1.27% de la demande d’electricite de la
premiere classe et de 2.67% de la demande de la deuxieme classe. La baisse de la
deuxieme classe est environ deux fois celle de la premiere classe. La demande d’electricite
est elastique dans les deux classes. Si on estimait le modele sans classe, l’elasticite serait
de 1.384, soit un peu plus que celle de la premiere classe mais inferieure a celle de la
deuxieme classe.
L’effet marginal du prix de la bi-energie est positif et tres significatif dans les deux
classes. L’effet marginal de la bi-energie de la deuxieme classe est presque le double de
celui de la premiere classe. Les elasticites sont egalement tres significatives. Une hausse
de 1% du prix de la bi-energie entraınera une augmentation de 0.67% de la demande de
la premiere classe des menages qui utilisent la bi-energie et de 0.86% de la demande de
la deuxieme classe. L’elasticite de la bi-energie du modele sans classe est comprise entre
celle de la premiere classe et celle de la deuxieme classe. La bi-energie et l’electricite
sont donc deux substituts.
L’estime du prix du gaz naturel n’est pas significatif dans la premiere classe mais l’est
dans la deuxieme classe. Probablement que les menages qui utilisent le gaz naturel sont
plus souvent dans la deuxieme classe. Pour cette classe, l’effet marginal du prix du gaz
est positif. Une hausse de 1% du prix du gaz naturel entraınera une hausse de la de-
mande d’electricite des menages (deuxieme classe) qui sont au gaz naturel de 0.1194%.
Le gaz naturel et l’electricite sont donc des biens substituts. L’elasticite du gaz naturel
est tres significative pour la deuxieme classe.
L’effet marginal du prix du mazout n’est pas tres significatif dans la premiere classe mais
l’est dans la deuxieme classe. Une augmentation de 1% du prix du mazout entraınera
une augmentation de 0.56% de la demande d’electricite des menages qui utilisent le
mazout et qui sont dans la deuxieme classe. Pour ces menages, le mazout et l’electricite
sont des biens substituables. Rappelons que l’effet inverse s’etait produit en 1998 : une
baisse du prix du mazout avait entraıne une forte baisse de la demande d’electricite des
menages.
En ce qui concerne l’effet marginal du revenu, nous avons obtenu des resultats sur-
prenants. L’effet marginal du revenu est negatif et significatif (a 5%) dans la premiere
classe et positif et significatif (1%) dans la deuxieme classe. Cela indique que l’electricite
est un bien inferieur pour les menages de la premiere classe tandis qu’elle est un bien
normal pour ceux de la deuxieme classe. L’elasticite revenu de la premiere classe est
de -0.15 pour la premiere classe et de 0.047 pour la deuxieme classe. Elle est de 0.11
pour le modele sans classe. Comme les resultats du modele latent indiquent que les

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes100
menages de la premiere classe sont des menages a faible revenu, donc, nous pouvons
dire qu’a mesure que le revenu du menage pauvre augmente, celui-ci achetera d’autre
biens beaucoup plus utiles que l’electricite, comme les biens alimentaires, les vetements,
les medicaments.
l’effet marginal de la variable cdd est positif et tres significatif dans les deux classes.
Il est beaucoup plus important dans la premiere classe que dans la deuxieme, ceci est
assez surprenant. Si les degres jours de climatisation augmentent de 1%, la demande
d’electricite des menages de la premiere classe augmente de 0.236% et celle des menages
de la deuxieme classe augmentera de 0.036%.
L’effet de la variable degres jours de chauffage (hdd) n’est pas significatif dans la
deuxieme classe mais l’est dans la premiere classe. Une augmentation de 1% des degres
jours de chauffage entraınera une augmentation de la demande d’electricite de 1.338%
des menages de la premiere classe.
La variable surface chauffee a un effet positif et tres significatif dans les deux classes.
Son effet est environ quatre fois plus important dans la premiere classe que dans la
deuxieme. Plus la surface a chauffer augmente, plus la demande d’electricite sera im-
portante.
L’effet de l’age est positif et significatif dans la premiere classe mais negatif et non signi-
ficatif dans la deuxieme. Plus l’age du chef de menage de la premiere classe augmente,
plus sa demande d’electricite augmente aussi.
Les effets des variables conversion de la source de chauffage et date de construction de la
maison ne sont pas significatifs dans la premiere classe, mais le sont dans la deuxieme.
Pour la deuxieme classe, une conversion de la source de chauffage permet de reduire la
demande d’electricite. Cela est assez intuitif puisque la conversion a une nouvelle source
se fait dans le but de reduire la consommation d’energie. Pour cette meme classe de
menages, les nouvelles constructions consommeraient moins d’energie.
L’effet de la variable proprietaire est positif et significatif dans la premiere classe (elle
n’est pas significative dans la deuxieme).Si le menage de la premiere classe est pro-
prietaire, cela augmente sa demande d’electricite. Implicitement, les proprietaires sont
relativement plus riches que les locataires, donc, ils auront tendance a consommer re-
lativement plus que les locataires.
Nous avons inclus des variables binaires pour certains types de systemes de chauf-
fage. L’effet de la centrale a air chaud, a eau chaude, des appoints (electriques et non
electriques) sont positifs et significatifs dans la premiere classe. L’effet de la centrale a
eau chaude est significatif et positif dans la deuxieme classe. L’appoint non electrique
a un effet negatif et significatif ; ceci a du sens car le fait d’utiliser un appareil non
electrique devrait permettre de reduire sa consommation d’electricite.
L’effet de la variable nombre de refrigerateurs est positif et tres significatif dans les
deux classes. Plus il y a de refrigerateurs dans la maison, plus les besoins en energie
augmentent.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes101
Nous avons pris en compte le type de l’habitation dans le modele. L’effet de la variable
maison detachee est positif et significatif dans les deux classes, tandis que l’effet de la
variable maison jumelee ou en rangee est de signe negatif et significatif pour la deuxieme
classe. Cela signifie que les maisons detachees consommeraient beaucoup plus d’energie
que les maisons jumelees ou en rangee. Lorsque les maisons sont jumelees, cela permet
une certaine economie d’echelle dans la consommation d’energie, mais lorsqu’elles sont
detachees les unes des autres, il y a une certaine perte d’efficacite dans la consomma-
tion.
La presence de piscine (lorsqu’elle utilise un filtre) entraıne une augmentation de la
consommation d’electricite. L’effet de cette variable est significatif dans les deux classes,
il est beaucoup plus important dans la premiere que dans la deuxieme classe.
Le nombre de residents a un effet positif et significatif dans les deux classes. Plus il y a
de personnes dans le menages, plus les besoins en electricite augmentent.
La disponibilite du gaz naturel affecte negativement la demande d’electricite. Si le gaz
est disponible dans une zone, et comme le gaz et l’electricite sont des substituts, cer-
tains menages choisiront le gaz au detriment de l’electricite.
L’effet de la variable climatiseur fenetre est positif et significatif (a 5%) dans la deuxieme
classe, mais n’est pas significatif dans la premiere. Probablement que les menages de la
premiere classe n’utilisent pas souvent le climatiseur fenetre. Pour ceux de la deuxieme
classe, la presence de climatiseur affecte positivement la demande d’electricite.
La constante n’est pas du tout significative dans la premiere classe mais elle est tres
significative dans la deuxieme.
La correction du biais de selection provenant du choix du mode de chauffage est prise
en compte a travers les neuf correcteurs inclus dans le modele. Tous les correcteurs
sont tres significatifs dans la premiere classe, quelques uns le sont dans la deuxieme
classe. Nous avons effectue un test du ratio de vraisemblance pour savoir s’il est per-
tinent de prendre en compte les correcteurs de biais de selection dans le modele. Le
log-vraisemblance du modele sans les correcteurs est : Lc = −9393.1107 et celui du
modele avec correcteurs est : Lnc = 9331.709. La statistique de test est :
LR = −2[Lc − Lnc] = −2[−9331.709 + 9393.1107] = 122.8034
Cette statistique suit asymptotiquement une chi-deux a 27 degres de liberte. Le
point critique de la chi-deux est χ2c ∈ [44.31; 50.89]. Comme la statistique calculee est
superieure a la valeur critique a 1%, on rejette donc l’hypothese nulle selon laquelle
tous les coefficients associes aux correcteurs sont egaux a zero. Il faut donc prendre en
compte les correcteurs dans le modele.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes102
3.10.3 Tests d’endogeneite du prix marginal
Nous avons procede a un test de specification pour justifier la pertinence de la prise
en compte des deux classes dans l’echantillon. Ceci revient a tester l’endogeneite du prix
marginal d’electricite. Rappelons que nous avons dissocie l’echantillon en deux classes
suite au fait que le prix marginal de l’electricite est une variable endogene. La non prise
en compte de l’endogeneite du prix entraınerait la non convergence et un biais dans les
estimations. Pour resoudre ce probleme, nous avons utilise un modele a classes latentes.
Nous avons donc dissocie notre echantillon en deux classes non observables directement.
Nous avons estime la demande en prenant en compte l’existence des classes non obser-
vables. Mais, comment pourrions-nous tester si notre hypothese d’endogeneite du prix
marginal est confirmee par les donnees ? Habituellement, le test d’endogeneite le plus
souvent utilise est le test de Hausmann (1978). Mais, avec le probleme de non linearite
qui est souleve ici, ce test n’est pas applicable, car le prix marginal conditionnel a la
classe est juste egal a une valeur (donc pas de variabilite). Pour contourner ce probleme,
nous avons utilise un test de ratio de vraisemblance, test beaucoup plus approprie pour
ce probleme. Nous testons l’hypothese nulle selon laquelle il n’existerait pas de classes,
contre l’hypothese alternative qui postule la presence de deux classes latentes. Sous
l’hypothese nulle, le modele a estimer est le modele de demande conditionnelle au choix
du mode sans consideration de classes. Ce modele est emboıte dans le modele sous l’hy-
pothese alternative (il existe deux classes), puisqu’il s’obtient en fixant la probabilite
d’etre dans la premiere classe egale a zero. Ainsi le modele sans classe est en fait iden-
tique au modele habituellement utilise (une seule partie). Les resultats de l’estimation
du modele sans classe sont presentes dans le tableau (3.8). Le log-vraisemblance du
modele contraint sous l’hypothese nulle est
L(θcontraint) = −9635.6764
Le modele non contraint (sous l’hypothese alternative) est le modele avec les deux
classes latentes. La vraisemblance du modele non contraint 6 est :
L(θNon−contraint) = −9331.709
La statistique de test de ratio de vraisemblance effectue sur le modele est :
LR = −2 [L(θcontraint) − L(θNon−contraint)]
= −2 (−9635.6764 + 9331.709)
= 607.93486Le modele contraint est emboıte dans le modele non contraint. Le premier s’obtient lorsque la
probabilite d’etre dans la premiere classe est nulle, et ceci se produit par exemple lorsque la constante
du modele est proche de l’infini. Il s’agit d’un emboıtage a la limite, et cela pourrait affecter le point
critique du test LR. Il serait interessant de developper dans le futur un test beaucoup plus approprie
au modele developpe.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes103
La statistique de test LR sous l’hypothese nulle suit asympotiquement une chi-
deux a 46 degres de liberte. Le point critique a 1% de la chi-deux a 46 degres de
liberte appartient a l’intervalle [69.96; 76, 15]. Comme LRc = 607.9348 > χ2c , on rejette
l’hypothese nulle selon laquelle il n’existe pas de classes. Nous avons donc une evidence
empirique en faveur de la presence des deux classes.
3.11 Estimation du taux d’escompte individuel
L’analyse de la demande d’electricite pour le chauffage de l’eau et de l’espace nous
amene aussi a nous interesser a la question du taux d’escompte individuel. L’electricite
n’est pas un bien directement consommable par le menage. Ce dernier a besoin de
l’electricite pour satisfaire un certain nombre de besoins comme le chauffage de l’eau
et des locaux. Pour y arriver, le menage doit choisir un systeme de chauffage pour
l’eau et un autre pour le chauffage de l’espace. Mais les systemes de chauffage dont
il est question font reference a des biens durables souvent acquis lors de l’achat (ou
meme a la construction) de la maison. A chaque systeme est associe des couts fixes et
des couts moyens anticipes, les deux etant inversement relies. Le menage doit faire un
arbitrage entre des couts d’acquisition tres eleves avec des couts d’exploitation anticipes
faibles, ou inversement. Les couts d’acquisition representent des depenses a effectuer
lors de l’achat ou de la construction de la maison, tandis que les couts moyens ou
d’exploitation anticipes representent des depenses futures qui s’etaleront sur toute la
duree de vie du systeme. Ce type d’arbitrage inter-temporel fait intervenir la notion de
taux d’escompte. Marshall A. (1890, p. 120) dans son ouvrage « Principles of Economics
», faisait reference au taux d’escompte. Selon lui, les taux auxquels les gens escomptent
le futur affecteraient non seulement leur tendance a l’epargne mais aussi leur tendance
a faire des achats qui leurs procureraient du plaisir de facon durable au detriment
de depenses pour des biens qui procureraient du plaisir a tres court terme. Fisher
(1930) definissait le taux d’escompte comme le taux de preference pour le temps ou
le taux d’impatience. Selon lui, les consommateurs qui ont des taux d’escompte tres
eleves accorderaient plus de poids au present qu’au futur et de ce fait, seraient plus
impatients que les autres consommateurs. Par exemple, si une entreprise veut evaluer
un investissement risque, elle calcule la valeur presente des flux de revenus futurs que
cet investissement peut rapporter. Formellement, ceci revient a ecrire que :
P = Fn (1 + r)−n ,
avec P la valeur actualisee des flux de revenus futurs de l’investissement, Fn est le flux de
revenu genere par l’investissement a la periode n, et r est le taux d’escompte utilise par
l’entreprise. Cette maniere de presenter le taux d’escompte permet de voir l’arbitrage

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes104
effectuer par l’entreprise entre le revenu futur et les depenses courantes. Si l’entreprise
accorde plus de poids au present qu’au futur (implicitement, elle est averse au risque),
alors elle aura un taux d’escompte tres eleve. Du point de vue des consommateurs
(menages pour ce qui nous concerne), l’arbitrage entre le present et le futur se fait
de facon similaire (Davis (2004)). A la place de l’entreprise, on pourrait considerer un
menage qui doit prendre une decision quant a savoir s’il a interet a investir ou non dans
un projet.
Pour acquerir un systeme de chauffage pour l’eau et pour l’espace, le menage peut
soit prendre un credit pour acheter ces biens ou les acheter au comptant s’il dispose
de suffisamment de richesse. Les menages plus pauvres pourraient avoir des difficultes
pour obtenir des prets tandis que les menages plus riches auront plus de facilites pour
avoir acces au credit. Nous supposons que l’achat de ces systemes de chauffage se fait
a la meme periode que l’achat de la maison de sorte que le menage est plus amene a
prendre un credit hypothecaire a un taux donne pour satisfaire ses besoins.
En supposant que le menage a acces au credit, peu importe qu’il soit riche ou pauvre, il
doit comparer le taux du credit a son taux d’escompte. Le taux d’escompte individuel lui
permettra de faire un arbitrage entre les investissements au temps present et les depenses
futures anticipees. Plusieurs travaux ont porte sur l’estimation du taux d’escompte
individuel. On peut citer entre autres les travaux de Hausman (1979), Goett (1978 et
1983), Gately (1980), Greene (1983), Dubin (1982), Dubin et McFadden (1984), Houston
(1983), Winter (1997), etc... Les taux d’escompte obtenus sont tres variables d’une
etude a l’autre. Mais la plupart des auteurs obtiennent des taux assez eleves, parfois
plus eleves que les taux d’interet sur les cartes de credits (qui est d’environ 18.5%).
Par exemple, Hausman (1979) a obtenu un taux d’escompte compris entre 24% et 26%,
dependamment de la duree de vie des appareils consideree. Dubin et McFadden (1984)
ont obtenu un taux d’escompte de 20.5% (a la moyenne des donnees). Ces differentes
valeurs depassent largement le taux d’interet sur les cartes de credit.
On a souvent suppose que dans un contexte de consommateur representatif, le taux
d’escompte serait identique a tous les consommateurs et a tous les biens. Ceci est souvent
traduit (en macroeconomie surtout) par le probleme de maximisation de l’utilite du
consommateur (Olsen et Bailey (1981)) :
Max U =T∑
t=1
v (Ct)
(1 + r)t ,
avec Ct la quantite agregee de biens consommee a la date t, v (.) est l’utilite de l’individu
a la date t, r est le taux d’escompte, T est l’horizon temporel de l’individu, suppose
parfois infini. Un des inconvenients avec ce modele est qu’on suppose que tous les
individus ont le meme taux d’escompte pour tous les biens, et donc la meme impatience
pour l’achat de ces biens (Winter, 1997). Dans la litterature economique, on suppose tres

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes105
souvent que le taux d’escompte individuel est le meme (ou defini de facon homogene) peu
importe le type de l’individu. Ceci pourrait etre une hypothese tres forte qui expliquerait
pourquoi dans les travaux anterieurs, les taux d’escompte sont souvent trop eleves.
Les travaux qui se sont penches sur le choix des systemes de chauffage de l’eau
et/ou de l’espace utilisent souvent un modele logit ou un probit pour estimer le taux
d’escompte. Le taux d’escompte implicite serait obtenu a partir des parametres associes
aux couts du capital et aux couts d’exploitation anticipes. Selon Hausman (1979), le
taux d’escompte serait inversement relie au revenu. Dubin et McFadden (1984) ont
estime un taux d’escompte en se servant d’un modele logit polytomique tout en prenant
en compte la relation inverse postulee par Hausman (1979). Le taux d’escompte qui
en resulte est tres eleve et les auteurs ont tente d’avancer plusieurs arguments pour
justifier pourquoi cette valeur refleterait mal la realite. De plus, les auteurs ont suppose
implicitement l’hypothese d’homogeneite entre les menages dans la definition du taux
d’escompte. Ils n’ont pas tenu compte du fait qu’il est possible d’avoir une certaine
heterogeneite entre les menages selon le systeme de chauffage choisi.
Nous postulons l’hypothese selon laquelle le taux d’escompte implicite eleve souvent
obtenu serait une consequence de la mauvaise specification du modele de choix du
systeme de chauffage. Dans la realite en effet, les consommateurs n’ont pas la meme
preference pour le temps surtout lorsqu’il s’agit d’achat de biens durables comme les
systemes de chauffage de l’eau et de l’espace. Winter (1997) proposait d’estimer des
taux d’escompte differents pour chaque bien et pour chaque consommateur. Pour ce qui
concerne l’achat des systemes de chauffage, les couts different selon la modalite choisie
par le menage. Certains menages vont preferer investir beaucoup au depart pour un
systeme de chauffage plus efficace et avoir des couts d’exploitation plus bas dans le futur,
tandis que d’autres consommateurs prefereront reporter les grosses depenses dans le
futur et donc investir peu pour l’acquisition du systeme de chauffage. Supposer, comme
ce fut le cas dans les etudes anterieures, que ces differents types de consommateurs ont
une preference pour le temps homogene, serait une hypothese trop forte et non coherente
avec la realite. Nous estimons que les consommateurs ont des preferences pour le temps
heterogenes selon la modalite choisie, et cette heterogeneite pourrait affecter aussi leur
taux d’escompte. Beaucoup de travaux portant sur l’achat et l’utilisation des systemes
de chauffage n’ont pourtant pas suppose l’heterogeneite du taux d’escompte selon le
systeme de chauffage choisi ; nous ne citons ici que quelques auteurs importants dans
ce domaine : Hausman (1979), Dubin et McFadden (1984).
Pour justifier notre argumentation, nous avons utilise plusieurs modeles pour fins
de comparaison : un modele logit polytomique avec des coefficients de couts moyens
specifiques aux alternatives, un autre modele logit polytomique ou cette fois, le coef-

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes106
ficient du cout moyen est commun a toutes les modalites comme c’est le cas dans les
etudes anterieures. Nous avons aussi utilise un modele logit mixte avec des erreurs au-
toregressives generalisees d’ordre un (decrit a la section (3.3)). Avec le logit mixte, nous
avons suppose dans un premier temps que le coefficient du cout moyen est specifique
a chaque modalite et dans un second temps, nous avons suppose que le coefficient du
cout moyen est commun a toutes les modalites. Nous avons procede a plusieurs tests
de specification et le meilleur modele serait le modele logit mixte avec des coefficients
de cout moyen specifiques aux modalites.
Nous avons ensuite estime les differents taux d’escompte en nous appuyant sur la
demarche de Dubin et McFadden (1984), etant donne que nous avons la meme forme
de fonction d’utilite. Le taux d’escompte generique (%) est obtenu a partir des relations
suivantes :
% = ρ0 + ρ1y ou
ρ0 =βcout fixe
βcout moyen
ρ1 =βcout fixe×revenu
βcout moyen
,
avec βcout fixe l’estime du coefficient du cout fixe, βcout moyen l’estime du coefficient de
la variable cout moyen, βcout fixe×revenu l’estime du coefficient de la variable cout fixe
multiplie par le revenu, y est le revenu moyen de l’echantillon. Le taux d’escompte
specifique a la modalite choisie (%j) est defini de facon similaire comme suit :
%j = ρ0j + ρ1jyj
ρ0j =βcout fixe
βcout moyenj
ρ1j =βcout fixe×revenu
βcout moyenj
,
avec j la modalite choisie, les autres variables ayant la meme interpretation que precedemment
(une variable indicee par j lorsque c’est le cas pour indiquer que la variable est specifique
a la modalite j) ; yj est le revenu moyen du groupe de menages ayant choisi la modalite
j dans l’echantillon. Les resultats des estimations du logit mixte et du logit polyto-
mique avec cout moyen generique sont presentes dans le tableau (3.9). Le tableau (3.5)
presente ceux du logit mixte et du logit polytomique avec couts moyens specifiques aux
modalites.
Les differents taux d’escompte estimes sont presentes dans le tableau (3.10). Les
resultats de l’estimation du modele de choix confirment effectivement la relation inverse
qui existe entre le revenu et le taux d’escompte : le coefficient (ρ1 ou ρ1j) est toujours
de signe negatif peu importe le modele considere. Nous remarquons que les modeles
avec un coefficient generique du cout moyen produisent un taux d’escompte commun
qui est largement superieur aux taux d’escompte des modeles ou la meme variable est

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes107
Tab. 3.9: Resultats du modele discret (couts moyens
generiques)
Variables logit mixte Logit polytomique
Estimes Ecart-type t-student Estimes Ecart-type t-student
mode1 -47.160 19.984 -2.360 -10.255 2.870 -3.573
mode2 -21.587 5.291 -4.080 -5.008 0.958 -5.225
mode3 -5.848 1.500 -3.899 -3.688 0.819 -4.504
mode4 -4.338 1.029 -4.216 -2.319 0.609 -3.808
mode5 -20.601 3.183 -6.472 -16.775 2.441 -6.873
mode6 -11.965 1.787 -6.696 -9.486 1.903 -4.984
mode8 -40.323 5.928 -6.803 -9.818 1.052 -9.336
mode9 -46.012 7.624 -6.035 -8.893 1.103 -8.059
coutfix -3.489 0.917 -3.804 -2.330 0.589 -3.959
coutfiy 1.032 0.199 5.191 0.787 0.131 6.014
coutm -19.035 1.391 -13.689 -9.650 0.424 -22.765
datcons 0.137 0.059 2.325 0.061 0.033 1.850
datconv 0.659 0.066 10.006 0.351 0.035 9.913
hdd1 3.798 2.982 1.274 1.067 0.545 1.958
hdd5 3.007 0.434 6.928 2.296 0.356 6.446
hdd6 2.123 0.271 7.823 1.540 0.335 4.600
hdd8 3.376 0.929 3.634 0.476 0.187 2.543
hdd9 4.478 1.062 4.217 0.880 0.191 4.612
nbpers1 0.089 1.002 0.089 -0.397 0.204 -1.945
nbpers3 0.911 0.239 3.815 0.582 0.112 5.214
nbpers4 0.038 0.131 0.289 0.026 0.082 0.317
nbpers5 1.492 0.251 5.950 1.014 0.224 4.535
y1 1.213 0.775 1.566 -0.124 0.150 -0.826
y2 -0.930 0.451 -2.063 -0.553 0.194 -2.846
y3 -0.680 0.220 -3.090 -0.676 0.148 -4.579
y4 -0.581 0.177 -3.274 -0.563 0.108 -5.212
y5 -0.438 0.235 -1.866 -0.461 0.190 -2.421
y6 -0.625 0.183 -3.406 -0.609 0.159 -3.817
y8 -2.224 0.308 -7.222 -0.658 0.074 -8.876
y9 -0.842 0.239 -3.529 -0.418 0.084 -5.000
SIG1 0.252 0.080 3.167 - - -
RHO -0.982 0.003 -375.951 - - -
Log-vraisemblance L(θ)
-1380.1825 -1545.9813
Log-vraisemblance L (0) -2317.3266 -2317.3266
Log-vraisemblance L (c) -2255.6268 -2256.0550

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes108
Tab. 3.10 – Taux d’escompte estimesModalites Logit mixte Logit polytomique
Gaz/gaz (1) 0.1973 0.2172
Gaz/electricite (2) 0.1068 0.1626
Bi-energie/mazout (3) 0.0913 0.1545
Bi-energie/electricite (4) 0.0927 0.1504
Mazout/mazout (5) 0.1092 0.2035
Mazout/electricite (6) 0.0997 0.1744
Electricite/electricite (7) 0.0810 0.1411
Bois/electricite (8) 0.0681 0.0979
Bois-electricite/electricite (9) 0.0974 0.1443
moyenne ponderee 0.0835 0.1411
moyenne non ponderee 0.1048 0.1606
taux d’escompte avec couts moyens generiques 0.181 0.238
autres informations pour 1989
taux d’interet hypothecaire 0.1205
taux d’inflation 0.0447
taux de depreciation (habitation) 0.015
taux d’escompte estime sur le marche financier 0.0908' 0.091
specifique aux modalites. Cela indique un biais vers le haut du taux estime. De plus,
nous remarquons que le logit polytomique donne des taux d’escompte plus grands et
plus proches de ceux obtenus anterieurement, taux d’escompte depassant souvent le
taux d’interet sur les cartes de credit. Le modele logit mixte semble mieux representer
la realite car les taux d’escompte individuels obtenus sont plus bas et plus proches du
taux d’escompte sur le marche financier (ce taux d’escompte est d’environ 9% et est
egal au taux d’interet reel hypothecaire (7.6%) auquel on ajoute le taux de depreciation
qui est de 1.5%). Les taux sur le marche financier sont obtenus aupres de Statistique
Canada pour l’annee 1989. Le taux d’escompte moyen est de 8.35% pour le modele
logit mixte tandis qu’il est de 14.11% pour le logit polytomique avec coefficients de
cout moyen specifiques aux modalites.
Pour les modeles dont le coefficient du cout moyen est generique, le taux d’escompte
est de 18.1% pour le modele logit mixte tandis qu’il est de 23.8% pour le logit polyto-
mique. Dans le logit mixte, seuls les menages ayant choisi la premiere modalite (gaz/gaz)
ont un taux d’escompte de 19.73%, legerement superieur au taux sur les cartes de credit
(18.5%), les autres menages ont des taux d’escompte qui varient de 6.8% a 10.9%. Avec
le logit polytomique, le taux d’escompte specifiques aux alternatives varient de 9.8% a
21.9%.

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes109
Pour le modele logit mixte retenu, on peut dire que les menages qui ont choisi
la modalite gaz/gaz sont les plus impatients (taux d’escompte de 19.73%) tandis que
les moins impatients sont les menages qui ont choisi la modalite bois/electricite (taux
d’escompte de 6.8%). Les menages qui ont choisi la premiere modalite sont disposes
a investir beaucoup d’argent pour acquerir des appareils de chauffage plus efficaces
et payer des couts d’exploitation tres bas sur toute la duree de vie des appareils. Les
menages qui ont choisi la modalite 8 (bois/electricite) ont une attitude contraire a celle
des menages de la premiere modalite. Supposer que ces deux types de menages ont la
meme preference pour le temps serait donc une hypothese trop forte. Ces deux types
de menages ont des caracteristiques qui leurs sont speficiques.
On peut egalement remarquer que les menages qui ont le taux d’escompte le plus
eleve sont relativement plus vieux (age moyen de 51 ans) et plus riches (revenu moyen
de 57.500$ par annee) et ceux qui ont le plus bas taux d’escompte sont relativement
plus jeunes (39 ans en moyen) et plus pauvres (revenu moyen de 32.500$ par annee).
Rappelons que l’age moyen de l’echantillon est de 41 ans et le revenu moyen est de
44.000$ environ. L’age serait positivement relie au taux d’escompte, confirmant ainsi les
resultats de Little (1984). Cela est assez intuitif puisque l’horizon de vie des personnes
plus agees est plus court que celui des plus jeunes. Le present (contrairement au futur)
aurait beaucoup plus de poids pour un individu relativement plus age que pour un
autre relativement plus jeune. Les personnes agees auraient tendance a avoir un taux
d’escompte plus eleve que la moyenne et inversement pour les personnes plus jeunes. En
somme, une mauvaise specification du modele de choix du mode de chauffage produirait
des estimateurs du taux d’escompte biaises vers le haut.
3.12 Conclusion
Dans cette etude, nous nous sommes interesses a l’estimation d’un modele de de-
mande d’electricite qui corrige a la fois le biais de selection du au choix du mode de
chauffage mais aussi l’endogeneite du prix marginal de l’electricite. L’estimation du
modele est realisee dans un contexte de modele de choix discret/continu comme cela
fut propose par Dubin et McFadden (1984). Le modele discret a ete estime grace aux
techniques de maximisation par simulation. Nous avons estime les correcteurs de biais
de selection pour les inclure comme variables explicatives dans le modele de demande.
Les donnees utilisees pour fin d’application proviennent d’Hydro-Quebec et portent sur
la consommation d’electricite des menages de la province de Quebec. Hydro-Quebec
applique une tarification non lineaire : le prix marginal est fixe selon la consommation
journaliere du menage. Cette derniere n’est cependant pas observable. Pour resoudre

Chapitre 3. Estimation de la demande d’electricite avec un modele a classes latentes110
le probleme d’endogeneite du prix marginal, nous avons developpe un modele a classes
latentes puisque les classes de consommateurs ne sont pas directement observables du
point de vue du chercheur. Le modele de demande conditionnelle au choix du mode
de chauffage et au choix de la classe de consommation est finalement estime par la
methode du maximum de vraisemblance en information limitee. L’approche utilisee
semble bien representer les donnees. Un test de specification a permis de confirmer la
necessite de tenir compte de l’existence des deux classes non observables. Il est ressorti
que les menages qui sont dans la deuxieme classe (ceux qui consomment le plus) sont
des menages a revenu eleve mais aussi des menages dont le chef est relativement plus
age. Les menages de la deuxieme classe sont beaucoup plus sensibles a la hausse du
prix de l’electricite. La premiere classe serait composee de menages a faibles revenus.
L’electricite serait un bien inferieur pour les menages de la premiere classe tandis qu’il
est un bien normal pour ceux de la deuxieme classe. Il est egalement ressorti que les
autres formes d’energies sont des substituts pour l’electricite. Les correcteurs de biais
de selection sont pour la plupart statistiquement significatifs (surtout pour la premiere
classe). Certains effets marginaux sont plus importants dans dans premiere classe et
moins dans la deuxieme, et inversement pour d’autres effets marginaux. Il n’a donc pas
ete possible de tirer une tendance generale pour les deux classes.
Le fait d’avoir utilise une seule coupe transversale pourrait constituer une limite
dans notre analyse de la demande d’electricite. Par exemple, le fait d’avoir une seule
periode n’a pas permis d’avoir de la variabilite dans le prix marginal de l’electricite.
Pour cette raison, nous avons utilise le prix moyen de l’electricite a la place du prix
marginal pour calculer les elasticites prix directes. Une analyse inter-temporelle de la
demande permettrait de mieux capter le comportement de consommation d’electricite
des menages. De plus, comme l’energie fait intervenir des biens durables, il est im-
portant de suivre les menages sur une certaine periode. Les chapitres qui vont suivre
tenterons de prendre en compte l’aspect inter-temporel du comportement de consomma-
tion d’electricite des menages quebecois, a partir d’enquetes independantes. Pour cela,
nous allons creer un speudo-panel dans le but de pallier au manque de vrais donnees
de panel. Nous exploiterons l’approche conventionnelle proposee par Deaton (1985) de
meme que l’approche bayesienne qui combine les algorithmes de l’echantillonnage de
Gibbs et d’augmentation des donnees.

Bibliographie
[1] Acton, J. P., Mitchell, B., M., and Mowill, R., S. (1976) : «Residential Demand
for Electricity in Los Angeles : An Econometric Study of Disaggregate Data»,
Rand-Report R-1899-NSF, Rand Corporation, Santa Monica, CA.
[2] Amemiya, T. (1984) : Tobit models : a surveys, Journal of Econometrics, Vol.24 ,
p. 3-61.
[3] Amemiya, T. (1985) : Advanced econometrics, Havard Univertsity Press, Cam-
bridge 1985
[4] Barnes, R., Gillingham, R., and Hagemann, R. (1981) : «The Short-Run Residential
Demand for Electricity», The Review of Economics and Statistics, Vol. 62, p. 541-
551.
[5] Belanger, D. (1992) : «Estimation des Probabilites de Choix Reliees au Probleme
d’Evaluation de la Demande d’Electricite Residentielle au Quebec», These de
Maıtrise, Universite Laval.
[6] Ben-Akiva and Bolduc D. (1991) : «Multinomial Probit with Autoregressive Er-
ror Structure», Cahier de Recherche 9123, Departement d’Economique, Universite
Laval.
[7] Ben-Akiva M., Bolduc, D. and Walker, J. (2001) : «Specification, Identification
and Estimation of the Logit Kernel (or Continuous Mixed Logit) Model», Draft
[8] Bernard, J-T, Bolduc, D. and Belanger, D. (1996) : «Quebec Residential Electricity
Demand : A Microeconometric Aproach», The Canadian Journal of Economics,
vol. 29, No.1 , p. 92-113.
[9] Bolduc D. (1992) : «Generalized Autoregressive Errors in the Multinomial Probit
Model», Transportation Research-B, Vol. 26B, No. 2.
[10] Billings, R., B. (1982) : «Specification of Bolck Rate Price Variable in Demand
Models», Land Economics, Vol. 56, p. 73-84.
[11] Billings, R. B. and Agathe, D. E. (1980) : «Price Elasticities for Water : A Case
of Increasing Bloc Rates», Land Economics, Vol. 56, p.73-84.

Bibliographie 112
[12] Billings, R. B. and Agathe, D. E. (1981) : «Price Elasticities for Water : A Case
of Increasing Bloc Rates : Reply», Land Economics, Vol. 57, p.276-278.
[13] Burtless, G., and Hausman, J., A. (1978) : «The Effect of Taxation of Labor Sup-
ply : Evaluating the Gray Neagtive Income Taxe Experiment», Journal of Political
Economy, 86, 276-278.
[14] Davis, L. W. (2004) : «The Role of Durables Goods in Households Water and
Energy Consumption : The Case of Front Loading Clothes Washers», Job Market
Paper, University of Wisconsin
[15] Dubin, J. A. (1982) : «Econometric Theory and Estimation of the Demand for
Consumer Durable Goods and thier Utilization : Appliance Choice and the Demand
of Electricity», Report No. MIT-EL 82-035-WP, MIT Energy Laboratory, MIT,
Cambridge, MA 02139, USA
[16] Dubin, J. A. (1985a) : Consumer Durable Choice and the Demand for Electricity,
Amsterdam : North-Holland.
[17] Dubin, J. A. (1985b) : «Evidence of Block Switching in Demand Subject to De-
cling Block Rates-A New Approach», Social Science Working Paper 583, California
Institute of Technology, Dept. of Economics.
[18] Dubin, J., J. and McFadden, D. (1984) : «An Econometric Analysis of Residential
Electric Apliance Holdings and Consumption», Econometrica, Vol. 52, No. 2, p.
345-362.
[19] Fisher, I. (1930) : The Theory of Interest, New York : Macmillan
[20] Foster, H., S., Jr., and Beattie, B., R. (1981a) : «Urban Residential Demand for
Water in the United Stated : Reply», Land Economics, 57, 257-265.
[21] Foster, H., S., Jr., and Beattie, B., R. (1981b) : «On the Specification of Price in
Studies of Consumer Demand Under Block Price Scheduling», Land Economics,
57, 624-629.
[22] Gately, D. (1980) : «Individual Discount Rates and the Purchase and Utilization of
the Energy-Using Durables : Comment», Bell Journal of Economics, 11, 373-374
[23] Goett, A. (1978) : «Appliance Fuel Choice : an Application od Discrete Multivariate
Analysis», PhD. Thesis, Department of Economics, University of California, USA
[24] Goett, A. (1983) : «Household Appliance Choice : Revision of the Residential End-
Use Energy Planning System», Final Report of Research Project 1918-1, Electric
Power Research Institute, California, USA
[25] Goodman, L. A. (1974), «Exploratory Latent Structure Analysis Using Both Iden-
tifiable and Unidentifiable Models», Biometrika, Vol. 61 p.215-231.
[26] Gopinath D. A. (1995) : «Modeling Heterogeneity in Discrete Choice Processes :
Application to Travel Demand», Ph.D ThesisMIT

Bibliographie 113
[27] Gourieroux C. and Monfort A. (1996) : Simulation-based Econometrics Methods,
Oxford University Press, Core Lectures.
[28] Greene, D. L. (1983) : «A Note on the Implicit Consumer Discounting of Automo-
bile Fuel Economy-Reviewing Available Evidence», Transportation Research Part
B-Methodological, 17, 491-498
[29] Greene W. H. and Hensher D. (2002) : «A Latent Class Model for Discrete Choice
Analysis : Contrasts with Mixed Logit», Transportation Research Part B (37) 681-
698.
[30] Hanemann, W. M. (1984) : «Discrete/Continuous Models of Consumer Demand»,
Econometrica, Vol. 52, No. 3, p. 541-562
[31] Hausman, J.A. (1978) : «Specification Tests in Econometrics», Econometrica,
Vol.46 No.6, p.1251-1271.
[32] Hausman, J.A. (1979) : «Individual Discount Rates and the Purchase and Utili-
sation of Energy-Using Durables», The Bell Journal of Economics, Vol. 10, No. 1,
p. 33-54.
[33] Hausman, J.A. (1985) : «The Econometrics of Nonlinear Budget Sets», Econome-
trica, Vol. 53, No. 6, p. 1225-1282
[34] Hausman, J.A., Kinnucan, M., and McFadden, D. (1979) : «A Two-Level Electri-
city Demand Model», Journal of Econometrics, Vol. 10, p. 263-289.
[35] Hausman, J. A. and Trimble, J. (1984) : «Appliance Purchase and Usage Adapta-
tion to a Permanent Time-of-Day Electricity Rate Schedule», Journal of Econo-
metrics, Vol. 26, p.115-139.
[36] Heckman, J. J (1978) : «Dummy endogenous variables in a simultaneous equations
system», Econometrics, Vol 46, No.4, p. 931-959
[37] Heckman, J. J (1979) : «Sample selection bias as a specification error», Econome-
trica, Vol. 47, No.1, p. 153-162
[38] Herriges, J., A. and King, K., K. (1994), «Residential Demand for Electricity un-
der Inverted Block Rates : Evidence from a Controlled Experiment», Journal of
Business and Economic Statistics, Vol. 12, No. 4, p. 419-430.
[39] Houston, D. A. (1981) : «Implicit Discount Rates and the Purchase of Untried
Energy-Saving Durabes Goods», The Journal of Consumer Research, Vol. 10, No.2,
p. 236-246
[40] Houthakker, H. S. (1950) : «Revealed Preference and the Utility Function», Eco-
nomica, Vol. 17, p.159-174
[41] King, M. A. (1980) : «An Econometric Model of Tenure Choice and Demand for
Housing as Joint Decision», Journal of Public Economics, Vol. 14

Bibliographie 114
[42] Lazarsfeld, P. F. (1950) : «The Logical and Mathematical Foundation of Latent
Structure Analysis & The Interpretation and Mathematical Foundation of Latent
Structure Analysis», S. A. Stouffer et al. (eds.) Measurement and Prediction 362-
472. Princeton, NJ : Princeton University Press.
[43] Larsen, B., M. and Nesbakken, R.(2004) : «Household Electricity End-use
Consumption : Results from Econometrics and Engineering Models», Energy Eco-
nomics, Vol.26, p. 179-200
[44] Lee, L. F.(1978) : Unionism and Wage Rates : «A Simultaneous Equations Mo-
dels with Qualitative and Limited Dependent Variables», International Economic
Review, Vol. 19, p. 415-433.
[45] Liao Hue-Chu and Chang Tsai-Feng (2002) : « Space-heating and Water-heating
Energy Demands of the Aged in the US», Energy Economics 24 , 267-284
[46] Marshall, A. (1890) : Principles of Economics, London, Macmillan
[47] McFadden, D. (1989) : «A Method of Simulated Moments for Estimation of the
Multinomial Probit Models without Numerical Integration», Econometrica, Vol.
57, Issue 5.
[48] McFadden, D., Puig, C., and Kirshner, D. (1977) : «Determinants of the Long-
Run Demand for Electricity», In the Proceeding of the Business and Economic
Statistics Section, American Statistical Association, p. 109-119.
[49] McFadden, D. and Train, K. (2000) : «Mixed MNL Models for Discrete Response»,
Journal of Applied Econometrics 15(5) 447-470.
[50] Marshall, A. (1890) : Principles of Economics, London, MacMillan
[51] Nesbakken, R. (2001) : «Energy Consumption for Space Heating : a Discrete-
Continuous Aproach», Scandinavian Journal of Economics, Vol.103, No.1, p. 165-
184
[52] Olsen, R.J. (1978) : «Note on the Uniqueness of the Maximum Likelihood Estima-
tor for the Tobit Model», Econometrica, Vol. 46, No.5, p. 1211-1215
[53] Olsen, R.J. and Bailey, M. J (1981) : «Positive Time Preference», The Journal of
Political Economy, Vol. 89, No. 1, p.1-25
[54] Pakes, A. and D. Pollard (1989) : «Simulation and the Asymtotics of Optimization
Estimations», Econometrica, Vol. 57, Issue 5.
[55] Polzin, P. E. (1984) : «The Specification of Price in Studies of Consumer Demand
Under Block Price Scheduling», in the Proceedings of the Business and Economic
Statistics Section, American Statictical Association, p. 109-119.
[56] Reiss, P. and White M.W. (2005) : «Household Electricity Demand Revisited»,
Review of Economic Studies, Vol. 72, p. 853-883.

Bibliographie 115
[57] Sanga, D. M. (1999) : «Estimation des Modeles Econometriques de Choix Dis-
crets/Continus avec Choix Polytomiques Interdependants : une Approche par Si-
mulation», These Ph.D, Universite Laval
[58] Shen J., Sakata Y and Hashimoto Y. (2006) : « A Comparison between Latent
Class Model and Mixed Logit Model for Transport Model Choice : Evidences from
two Datasets of Japan», Discussion Paper 06-05, Osaka University, Japan
[59] Taylor, L., D., (1975) : «The Demand for Electricity : A Survey», The Bell Journal
of Economics, Vol. 6, No. 1, p. 74-110.
[60] Train, K. (1985) : «Discount Rates in Consumers’ Energy Related Decisions : A
Review of the Litterature», Energy, Vol. 10, No. 12, p. 1243-1253
[61] Train, K. (1993) : Continuous/Discrete Models. Qualitative Choice Analysis :
Theory, Econometrics, and an Aplication Aplication to Automobile Demand. Cam-
bridge : The MIT Press
[62] Train, K. (2002) : Discrete Choice Methods with Simulation, Cambridge University
Press.
[63] Vaage K. (2000) : «Heating Technology and Energy Use : a Discret/Continuous
Choice Approach to Norwegian Household Energy Demand», Energy Economics,
Vol.22, No.6, p. 649-666
[64] F. Vekeman, F., Bolduc D. and Bernard J-T (2004) : «Household Vehicles Choice
and Use : What a more Disaggregated Approach Reveals ?», Working Paper, De-
partment of Economics, Universite Laval.
[65] Vermunt J. K. and Magidson J. (2000) : «Latent Class Cluster Analysis», Statis-
tical Innovations Inc. Tiburg University
[66] Vermunt J. K. and Magidson J. (2005) : « Factor Analysis with categorical indica-
tors : A comparison between traditional and latent class approaches», In A. Van
der Ark, M.A. Croon and K. Sijtsma (eds), New Developments in Categorical Data
Analysis for the Social and Behavioral Sciences, 41-62. Mahwah : Erlbaum.
[67] Winter Russel, S. (1997) : «Discounting and its Impact on Durables Buying Deci-
sions», Marketing Letters, Vol. 8, No.1, p. 109-118

Chapitre 4
Estimation de la demande
d’electricite avec des pseudo-panels
de cohortes
4.1 Introduction
Nous cherchons a analyser la demande d’electricite des menages de la province de
Quebec a partir de bases de donnees d’enquetes (ou coupes transversales) independantes.
Pour cela, nous constituons des cohortes comme l’a suggere pour la premiere fois Dea-
ton (1985). Deux criteres seront utilises pour constituer les cohortes : la superficie de
l’habitation ainsi que la region ou est situe le menage. Apres avoir cree les cohortes,
nous exploiterons les methodes classiques pour analyser la demande d’electricite de
la province. Habituellement, avec un modele a effets fixes (pour des pseudo-panels),
les auteurs ne cherchent plus a verifier si les tests d’hypothese sont vraiment valides.
Nous savons en effet qu’en presence d’heteroscedasticite et/ou d’autocorrelation des
erreurs, les variances des estimateurs des moindres carres ordinaires sont biaisees, et
donc les tests d’hypothese et intervalles de confiance ne sont plus valides. En presence
d’heteroscedasticite et/ou d’autocorrelation des erreurs, la methode des moindres carres
quasi-generalises permet d’avoir des estimateurs convergents des variances des estima-
teurs. Nous proposons de verifier les caracteristiques des termes d’erreurs en presence
d’effets fixes et de faire les corrections necessaires s’il y a lieu afin d’avoir des tests
d’hypotheses valides. Nous estimons un modele de demande d’electricite statique et un
modele de demande dynamique avec erreurs heteroscedastiques et autoccorrelees. Les
elasticites prix et revenus sont egalement calculees et sont comparees aux valeurs qu’on

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes117
obtiendrait si aucune correction n’est faite.
Nous presentons a la section (4.2) la revue des ecrits anterieurs, la section (4.3) porte
sur le modele statique de demande d’electricite, a la section (4.4), nous analyserons
le modele dynamique de demande d’electricite, et enfin, la section (4.5) donne une
conclusion.
4.2 Revue des ecrits anterieurs
Pour analyser le comportement de consommation des menages, les donnees de panels
sont souvent appropriees. Avec les donnees de panel, il est possible de suivre les memes
individus au cours d’une periode donnee. Les donnees de panel sont constituees d’ob-
servations tirees de facon repetees a differentes periodes. Ainsi, pour un meme individu,
il y a plusieurs observations correspondantes. Les panels ont a la fois une dimension de
coupe transversale et une dimension de serie chronologique. Contrairement aux coupes
transversales, il est possible de suivre un individu donne dans le temps avec les donnees
de panel. Contrairement aux series chronologiques, on peut observer plusieurs series (ou
variables) avec les donnees panel. En observant plusieurs coupes transversales a travers
le temps, il est possible d’analyser les aspects dynamique et statique d’un probleme
donne.
Les donnees de panel ont un certain nombre d’avantages par rapport aux donnees
purement en coupes transversales ou de series chronologiques. Hsiao (2001) et Bal-
tagi (2005) donnent un survol des avantages et limites des donnees de panel. Un de
ces avantages est le nombre plus important d’observations ; cela permet d’ameliorer
la precision des estimateurs. Les donnees de panel ont aussi l’avantage de pouvoir
resoudre le probleme de multicolinearite. Lorsque les variables explicatives varient dans
les deux dimensions (temporelle et transversale), elles ont tendance a etre moins for-
tement correlees. Avec les donnees de panel, il est possible de reduire le probleme de
la multicolinearite en introduisant des differences entre les individus a travers les effets
individus. En outre, avec les panels, il est possible de mesurer des effets qui ne sont
pas facilement identifiables avec des coupes transversales ou des series chronologiques.
Les donnees de panel offrent la possibilite de reduire les biais d’omission de variables
pertinentes grace a une transformation du modele en difference ; cette transformation
a pour but d’eliminer les variables specifiques aux individus mais invariantes dans le
temps et qui sont correlees avec le terme d’erreur. Soulignons aussi que les panels sim-
plifient l’inference statistique. Avec les series chronologiques, il est important de savoir
si les series sont stables, integrees ou explosives. Mais avec les donnees de panel, tant
que la dimension transversale approche l’infinie, la distribution limite des coefficients

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes118
reste normale, que la dimension temporelle soit fixee ( Anderson et Hsiao 1982) ou tend
vers l’infini (Levin et Lin 1993, Phillips et Moon 1999).
Les panels souffrent cependant du probleme d’attrition. Puisque ce sont les memes
individus qui sont suivis sur plusieurs periodes, il peut arriver que certains ne soient plus
observables a partir d’une periode donnee. Les non-reponses augmentent habituellement
avec le temps. L’attrition peut devenir problematique parce qu’elle peut creer un biais
de selection. Le biais de selection se produit lorsque les individus de l’echantillon ne
sont plus tires de facon aleatoire mais sont selectionnes en suivant le critere selon lequel
l’individu est observable sur toute la periode consideree. Dans un tel contexte, il peut
arriver d’exclure un pourcentage non negligeable d’observations de l’echantillon. Ainsi,
une bonne partie de l’information ne sera pas utilisee dans l’analyse et l’echantillon
ne serait plus le resultat d’un tirage aleatoire. Une solution au probleme d’attrition
serait d’utiliser un panel rotatif ou un pseudo-panel. Un panel rotatif est un panel dans
lequel on decide de changer un pourcentage fixe des individus interroges. Biorn (1981) a
propose un panel rotatif ou le pourcentage d’individus manquants a la deuxieme periode
doit etre remplace par de nouveaux individus dans le but de garder la meme taille de
l’echantillon. Biorn et Jansen (1983) ont considere un panel rotatif sur les menages
Norvegiens dans lequel la moitie des menages est remplacee a la seconde periode par
de nouveaux menages. Les pseudo-panels sont un cas extreme de panel rotatif, car
a chaque periode, c’est tous les individus de l’echantillon qui sont remplaces par de
nouveaux individus.
Dans beaucoup de pays, et particulierement dans les pays en developpement, les
donnees de panel sont rares ou meme inexistantes ; cependant, il existe beaucoup de
series de coupes transversales independantes. En effet, les donnees de panel sont souvent
couteuses a collecter puisqu’il faut suivre les memes individus sur plusieurs periodes
(annees, mois, jours...). De plus, elles sont sujettes au probleme d’attrition. Avec les
donnees en coupes transversales, les individus qui font l’objet de l’enquete changent
d’une periode a l’autre de sorte que leur collecte est beaucoup moins contraignante.
Cependant, les coupes transversales ne permettent pas de suivre un individu donne
dans le temps pour pouvoir capter l’aspect dynamique de son comportement. Comment
donc se servir de ces coupes transversales pour pallier au manque de donnees de panel ?
Deaton (1985) fut le premier a proposer une solution a ce probleme. Il suggere
de remplacer les observations par des moyennes de cohortes ; ces moyennes de cohortes
constituent un panel synthetique ou un pseudo-panel. Une cohorte est definie comme un
ensemble d’individus ayant des caracteristiques communes. Les cohortes sont construites
a partir de criteres invariants dans le temps. Si l’individu ne peut pas etre suivi dans le
temps, la cohorte peut par contre etre suivie dans le temps. Etant donne qu’on dispose

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes119
d’echantillons de cohortes et non de la population entiere de cohortes, les moyennes
des cohortes sont une approximation des moyennes de la population et par consequent,
sont des variables avec des erreurs de mesure. Deaton propose alors d’estimer le modele
en tenant compte de ces erreurs de mesure. Lorsque le nombre d’individus par cohorte
est suffisamment grand, les erreurs de mesure peuvent alors etre ignorees (Browning,
Deaton et Irish (1985)). Rappelons que le probleme d’erreur de mesure existe aussi
avec les vrais panels. Suite a l’article de Deaton (1985), les modeles avec cohortes se
sont repandus dans la litterature a travers le temps dans le but de pallier au manque
de vrais panels. L’utilisation de pseudo-panels n’implique pas necessairement que les
resultats qui en decouleront seront inferieurs a ceux qu’on obtiendrait si on disposait de
vrais panels. On sait que les panels souffrent frequemment de probleme d’attrition. En
effet, il peut arriver que certains individus decident de quitter le groupe faisant l’objet
de l’enquete pour differentes raisons. Ces departs font qu’il est difficile d’observer tous
individus a chacune des periodes considerees. Avec les pseudo-panels, ce probleme est
ecarte puisque les individus ne sont plus les memes d’une periode a l’autre, eliminant
ainsi le probleme d’attrition. De plus, on peut etendre le nombre de periodes avec les
pseudo-panels si on dispose de coupes transversales sur ces periodes.
Comme avec les donnees de panels on est amene a introduire des effets individuels,
il en est de meme avec les pseudo-panels. Il faut choisir le type d’effet individuel : effets
fixes ou effets aleatoires. Rappelons que lorsque les regresseurs ne sont pas correles
avec les effets individuels, l’estimateur a effets fixes et l’estimateur a effet aleatoire
sont convergents, le dernier etant plus efficace que le premier. Cependant, si les effets
individuels sont correles avec un ou plusieurs regresseurs du modele, l’estimateur a effet
aleatoire n’est plus convergent mais l’estimateur a effets fixes est approprie. Apres avoir
choisi le type d’effets individuels de meme que le type de modele (modele statique ou
modele dynamique), il faut ensuite choisir la methode d’estimation.
Il existe dans la litterature plusieurs methodes d’estimation : estimation within, esti-
mation a variables instrumentales (VI) (comme les doubles moindres carres), estimation
par la methode des moments generalises,... Dans le contexte des pseudo-panels, l’esti-
mateur within ou a variables instrumentales sont les plus utilises. Deaton et al. (1985)
ont estime la consommation des menages des Royaumes-Unis en se servant de l’esti-
mateur within. Dargay et Vythoulkas (1998) et Dargay (2002) ont analyse un modele
de demande dynamique de voitures des menages des Royaumes-Unis en utilisant un
modele a effets fixes qu’ils estiment par la methode du maximum de vraisemblance.
Gardes et Loisy (1997) ont utilise des pseudo-panels pour estimer l’elasticite du re-
venu minimum par rapport au revenu declare. Ils ont cherche a verifier l’hypothese selon
laquelle la croissance economique cree de nouveaux besoins contribuant ainsi au main-

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes120
tien de l’insatisfaction des consommateurs. Ils ont utilise la transformation «within» et
la transformation «between» tout en corrigeant l’heteroscedasticite qui survient a cause
de l’aggregation des menages en cellules de cohortes.
Nous avons note cependant que lorsque les auteurs utilisent le modele a effets fixes,
la plupart ne cherchent pas a verifier s’il y a un probleme d’heteroscedasticite et/ou
d’autocorrelation des erreurs. On suppose implicitement l’homoscedasticite et l’absence
de correlation serielle. Hors, nous savons qu’en presence d’heteroscedasticite et ou d’au-
tocorrelation des erreurs, les tests d’hypotheses (tests de significativite individuelle des
parametres, tests de significativite globale,....) ne sont plus valides car les variances
des estimes sont biaisees. Dans un tel contexte, le test de Hausman (1978), pour sa-
voir s’il faut ou non inclure des effets fixes, ne serait plus valide. Il est donc important
de verifier au prealable si l’hypothese d’homoscedasticite (et l’absence de correlation
serielle) est valide et si elle est rejetee, il faut corriger le modele afin de pouvoir effec-
tuer de bons tests d’hypothese et de pouvoir ainsi faire de bonnes interpretations des
resultats. Dans le contexte de vrais panels, Garcia-Cerrutti (2000) ont utilise l’approche
des moindres carres generalises pour corriger a la fois un probleme d’heteroscedasticite
et de correlation serielle des erreurs dans un modele de demande dynamique d’electricite
avec des effets aleatoires. Dans ce travail, nous essayerons a partir de donnees de
pseudo-panels, d’estimer un modele statique et dynamique de demande d’electricite
des menages de la province de Quebec tout en pretant une attention particuliere au
probleme d’heteroscedasticite et de correlation serielle.
Le modele de demande d’electricite sera analyse avec des cohortes que nous avons
construites a partir d’une serie de coupes transversales independantes. Rappelons que
lorsqu’il s’agissait d’estimer la demande d’electricite des individus (menages), nous
etions obliges de corriger le biais de selection en introduisant des correcteurs obte-
nus dans une etape ulterieure. Nous avions egalement corrige le biais d’endogeneite du
au fait que le prix marginal de l’electricite est non lineaire, et pour cela, nous avions
utilise un modele a classes latentes. Lorsque nous passons de donnees individuelles a
des donnees groupees (macro) (en d’autres termes, nous passons aux cohortes), ces
deux problemes (biais de selection et biais d’endogeneite) ne se posent plus. En effet, le
choix du mode de chauffage n’est pas specifique a chaque cohorte ; dans chaque cohorte
construite, ils existe differents menages avec differentes modalites. De ce fait, nous n’es-
timons plus la demande conditionnelle avec les cohortes, mais nous estimons la demande
d’electricite ou encore la demande d’electricite d’un groupe donne de menages. Donc,
la question de biais de selection ne se pose plus a ce niveau.
Par ailleurs, pour ce qui concerne le probleme d’endogeneite du prix marginal de
l’electricite, nous avions utilise un modele a deux classes, les classes etant definies de

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes121
la facon suivante : si la variable consommation journaliere moyenne moins 30 kWh est
negative, alors le menage est dans la premiere classe avec un prix marginal d’electricite
(p1), et si cette variable est positive, le menage se retrouve dans la deuxieme classe
avec un prix marginal d’electricite (p2 > p1). Dans le contexte des cohortes, nous avons
constate que cette variable ne prenait qu’un seul signe (elle est toujours positive), ce qui
indique que toutes les cohortes se retrouvent dans la deuxieme classe. L’effet de groupe
l’emporte sur l’effet individuel. Il n’y a alors qu’une seule classe de consommateurs
(cohortes). Ceci est assez intuitif car la majorite des menages consomment en moyenne
plus de 30 kWh par jour, de sorte qu’au niveau macro (cohortes), toutes les cohortes
se retrouvent dans la deuxieme classe. Par consequent, nous nous retrouvons avec un
seul groupe de cohortes et donc avec une seule equation de demande, qui correspond a
l’equation de la deuxieme classe. En somme, en considerant les pseudo-panels au lieu
de vrais panels ou meme des coupes transversales ou les observations sont gardees au
niveau individuel, le modele de demande d’electricite se simplifie enormement.
4.3 Modeles statiques de demande d’electricite avec
des pseudo-panels
Lorsqu’on s’interesse a la demande d’electricite (ou l’energie en general), il est im-
portant de pouvoir suivre les menages sur une certaine periode. En effet, le menage
ne consomme pas l’electricite comme un bien final ; il l’utilise pour faire fonctionner
ses appareils de chauffage de l’eau ou de l’espace dans le but de maximiser son utilite.
Cela implique donc que le menage doit s’acheter des appareils pour le chauffage de
l’eau et celui de l’espace. Ces appareils sont des biens durables ou semi-durables dont
la duree de vie ne se limite pas a une annee. Dans un tel contexte, il est important
de suivre le menage sur une certaine periode pour mieux connaıtre son comportement
de consommation. Pour pouvoir suivre les memes individus sur plusieurs periodes, les
donnees de panels sont appropriees. Avec les donnees de panel, ce sont les memes in-
dividus qui sont enquetes a chaque periode. Or, pour le probleme qui nous concerne, il
n’existe pas de donnees de panel dans la province de Quebec qui nous permettrait de
suivre les memes menages sur plusieurs periodes. Les donnees disponibles sont plutot
constituees de plusieurs coupes transversales independantes. Comme dans d’autres pays,
les donnees de panel sont presqu’inexistantes, mais il existe plusieurs coupes transver-
sales independantes. Pour pallier au probleme de manque de panel, Deaton (1985)
suggere de creer des cohortes, composees de menages partageant un certain nombre
de caracteristiques communes. Les moyennes de cohortes representent les unites qui
composent les pseudo-panels. Selon Deaton (1985), comme les moyennes des cohortes

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes122
sont des variables avec erreurs de mesure des vraies moyennes de la population de co-
hortes, il faut utiliser les methodes d’estimation qui corrigent pour la presence d’erreur
de mesure. A partir d’un modele statique a effets fixes, il propose un estimateur wi-
thin qui corrige pour la presence d’erreurs de mesure ; son estimateur est convergent
lorsque le nombre d’individus par cohorte est fixe. Verbeek et Nijman (1993) modifie-
ront par la suite l’estimateur de Deaton dans le but d’atteindre la convergence lorsque
le nombre de periodes (T ) est fixe et lorsque le nombre d’individus par cohorte (C) est
fixe. Lorsque le nombre d’individus par cohorte est suffisamment grand, les erreurs de
mesure peuvent alors etre ignorees. Dans les applications empiriques en effet, la plupart
des auteurs ignorent les erreurs de mesure : Browning, Deaton et Irish (1985), Blundell
et al. (1985), Moffit (1993),... L’estimateur le plus souvent utilise est alors l’estimateur
within.
4.3.1 La construction des cohortes
Les cohortes doivent etre construites selon des regles bien etablies. Les variables
servant de criteres ne doivent pas changer d’une cohorte a l’autre et elles doivent etre
observables a chaque periode. Par exemple, Deaton (1985), Browning et al. (1985) ont
utilise l’annee de naissance comme critere pour construire les cohortes : les individus
nes par exemple en 1945 peuvent etre retrouves en 1990. Le probleme qui se pose
inevitablement est l’arbitrage entre le nombre de cohortes (C) et le nombre d’individus
par cohortes (nc). Si C est grand, alors nc sera petit, impliquant que les moyennes de co-
hortes contiendraient une certaine imprecision des vraies moyennes de la population de
cohortes. Mais si C est faible alors nc sera grand. Verbeek et Nijman (1992b) demontrent
que nc doit etre suffisamment grand pour que l’estimateur within soit convergent.
Avec les donnees d’Hydro-Quebec, nous disposons de quatre grosses bases de donnees
provenant d’enquetes independantes de 1989, 1994, 1999 et 2002. Ces enquetes ont porte
sur la consommation d’electricite des menages de la province de Quebec. Nous avons
extrait 2897 observations de l’enquete de 1989, 4850 de celle de 1994, 3129 de l’enquete
de 1999 et 2159 de l’enquete de 2002. La figure (4.1) ci-dessous presente les donnees et
decrit le probleme de manque de vrai panel. Un menage enquete en 1994 par exemple
ne peut pas etre retrouve dans l’enquete de 1989 ou celle de 1999. Il en est de meme
pour les autres menages des autres enquetes.
Comme criteres de construction des cohortes, nous avons choisi la region et la taille
de la maison. La province est en effet divisee en neuf (9) regions administratives et nous
estimons que les menages vivant dans la meme region partagent un certain nombre de
caracteristiques communes. Les comportements des menages concernant la consomma-

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes123
Fig. 4.1 – Manquante de vrai panel, enquetes independantes
tion d’energie devrait changer d’une region a l’autre. Comme l’objectif est d’analyser
la demande d’electricite, un element important dans la demande est la taille de la mai-
son : nous estimons que les maisons peuvent etre reparties en trois (3) groupes : les
petites (moins de 1000 pieds carres), les moyennes (entre 1000 et 2000 pieds carres) et
les grandes (plus de 2000 pieds carres) surface. Nous supposons que les menages gardent
les memes systemes de chauffage entre 1989 et 2002 ; par consequent, ils gardent la meme
maison. S’il y a des deplacements, nous supposons que les menages ne peuvent pas oc-
cuper plus d’une maison a la fois. Les menages qui quittent leur maison iront occuper
les maisons d’autres menages et laisseront leur maison a d’autres menages. Ces derniers
auraient des caracteristiques similaires aux premiers de sorte qu’on arrive finalement
a un continuum de menages. Nous supposons que les maisons ne restent pas vides et
que les deplacements se font dans la meme province. Dans le pire des cas, les menages
qui quittent completement la province sont remplaces par des menages immigrants qui
occuperont les maisons des premiers. Ces hypotheses sont assez realistes etant donne
que le but du travail est d’estimer la demande d’electricite des menages de la province.
Nous n’analysons pas de maniere specifique les caracteristiques socio-demographiques
des individus qui nous obligeraient a avoir les memes individus sur toute la periode
de l’etude. Nous avons juste besoin de certaines informations sur le menage pour ana-
lyser sa demande d’electricite. L’energie est indirectement consommee par le menage
a travers des appareils. Ces appareils ne sont pas a la limite intrinsequement lies aux
individus.

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes124
Avec ces deux variables (region et surface chauffee) nous avons une combinaison
de 9 × 3 = 27 cohortes possibles. Mais, nous avons regroupes certaines cohortes qui ne
comportaient pas suffisamment d’observations de sorte que nous avons finalement garde
25 cohortes. La taille moyenne des cohortes est de 131 observations, certaines cohortes
en contiennent plus, d’autres moins. Precisons que certaines cohortes ne contiennent pas
beaucoup d’observations parce que la population de ces cohortes n’est pas tres grande
au depart. En effet, dans la province de Quebec, il y a des regions de forte densite et
d’autres de faible densite. cela se reflete aussi dans la base de donnees de l’enquete de
sorte qu’on supposera que pour ces regions, on peut admettre qu’on a suffisamment
d’observations representatives de la population de depart. Les tableaux (5.7 a 5.10) a
l’annexe (5.8.1) presentent les differentes cohortes des quatre (4) periodes d’enquete 1.
4.3.2 Le modele a effets fixes
Supposons que le modele de demande d’electricite derivee d’apres l’identite de Roy
est defini comme suit :
ynt = Xntβ + θn + εnt n = 1, 2...Nt t = 1, ...T, (4.1)
l’indice n indique le menage et l’indice t la periode ; ynt est la demande d’electricite du
menage n a la periode t, Xnt est un vecteur de variables explicatives exogenes, θn est un
effet individuel inobservable, εnt est un terme d’erreur. Lorsqu’on dispose d’un ensemble
de coupes transversales independantes, les Nt individus presents a chaque enquete ne
sont pas necessairement les memes, un menage enquete a la periode t ne peut pas etre
retrouve a la periode precedente ou a la periode suivante. Donc, l’indice n change d’une
periode a l’autre. On peut donc ecrire n(t) pour etre beaucoup plus precis, mais pour
ne pas alourdir le texte, nous gardons l’indice n tout en ayant en tete qu’il s’agit bien
de n(t).
Etant donne que nous n’avons pas de vrais panels, nous construisons des cohortes
et utilisons les moyennes de cohortes comme unites constituant les pseudo-panels. Lors-
qu’on regroupe les individus en cohortes et qu’on calcule la moyenne dans chaque co-
horte, on aboutit au modele suivant :
yct = Xctβ + θc + εct c = 1, 2...C t = 1, ...T, (4.2)
avec : yct = 1nc
∑nc
n=1 ynt. Nous supposons que nous disposons de suffisamment d’ob-
servations par cohortes de sorte que les erreurs de mesure des moyennes de cohortes
1Comme le chapitre 5 et ce chapitre utilisent les memes cohortes, nous avons prefere presenter les
differents tableaux une seule fois pour economiser de l’espace. Donc, les tableaux dont il est question
ici sont dans le chapitre 5

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes125
peuvent etre ignorees. L’effet inobservable peut etre un effet aleatoire ou un effet fixe.
Rappelons que lorsqu’il s’agit d’effet fixe, l’estimateur le plus souvent utilise et le plus
approprie est l’estimateur within. Lorsqu’on estime que les effets inobservables sont des
effets aleatoires, la methode d’estimation appropriee est la methode des moindres carres
generalises (faisable). Beaucoup d’auteurs se limitent aux effets fixes lorsqu’ils ont des
pseudo-panels : Deaton (1985), Browning et al. (1985), Moffit (1993),... Cela se justifie
par le fait que les variables explicatives contiennent des erreurs de mesure qui cause-
raient une correlation entre regresseurs et terme d’erreur. Et lorsqu’on estime qu’il peut
y avoir une correlation entre les regresseurs et le terme d’erreur (qui comporte l’effet
inobservable), alors l’estimateur within est convergent tandis que l’estimateur a effet
aleatoire ne l’est pas. Mais si la correlation est nulle (cov(θc, Xct
)= 0), alors les deux
estimateurs (effet fixe et effet aleatoire) sont tous convergents mais l’estimateur a effet
aleatoire est asymptotiquement efficace.
Dans un tel contexte, l’estimateur le plus souvent utilise est l’estimateur within
defini de la facon suivante :
βW =
[1
CT
C∑
c=1
T∑
t=1
(Xct − Xc
)′ (Xct − Xc
)]−1 [
1
CT
C∑
c=1
T∑
t=1
(Xct − Xc
)′(yct − yc)
],
avec : Xct = 1nc
∑ncn=1 Xnt Xc = 1
T
∑Tt=1 Xct
Moffit (1991) propose une autre methode d’estimation lorsqu’il s’agit d’effets fixes.
Il propose d’utiliser la methode des variables instrumentales. L’estimateur a variables
instrumentales propose est identique a l’estimateur within lorsqu’on utilise les variables
binaires des cohortes comme instruments.
Pour s’assurer du bon choix du type d’effets inobservables, Hausman (1978) a pro-
pose un test dans le contexte des donnees de panel. Mais son test peut s’appliquer aux
pseudo-panels puisqu’il s’agit du meme probleme.
Hausman propose de comparer l’estimateur des MCG obtenu lorsque les effets sont
aleatoires (soit βMCG) a l’estimateur within (βW ). Les deux estimateurs sont convergents
sous l’hypothese nulle selon laquelle : cov(θc, Xct
)= 0. Sous l’hypothese alternative :
cov(θc, Xct
)6= 0, les deux estimateurs vont diverger de sorte que leur difference serait
importante. Hausman suggere d’utiliser la statistique de test suivante : q = βMCG− βW .
Sous H0, p lim q = 0. La variance de q est :
V (q) = V(βMCG − βW
)= V
(βMCG
)+ V
(βW
)− 2cov
(βMCG, βW
)
cov(βMCG − βW , βW
)= cov
(βMCG, βW
)− V
(βW
)= 0
=⇒ cov(βMCG, βW
)= V
(βW
).

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes126
Donc, on peut reecrire que :
V (q) = V(βMCG
)− V
(βW
)= Ψ.
Le test de Hausman est alors donne par :
m = q′ [V (q)]−1 q
=(βMCG − βW
)′ [V(βMCG
)− V
(βW
)]−1 (βMCG − βW
)∼ χ2
C−1,
ou C est le nombre d’effets fixes dans le modele. Notons que le test de Hausman est en
fait un test de Wald. Tres souvent, la variance Ψ n’est pas connue et doit donc etre rem-
placee par un estimateur convergent Ψ. On utilise alors la matrice de covariance estimee
des estimateurs de pente du modele avec variables binaires des cohortes (dummies) et
celle du modele a effets aleatoires.
4.3.3 Resultats de l’estimation du modele a effets fixes
Le tableau (4.1) presente les resultats du modele a effets fixes. Pour s’assurer que
le modele a effets fixes est approprie, nous avons effectue un test de Hausman comme
presente ci-dessus. La statistique de test de Hausman est de l’ordre de 123.24468, la
valeur critique du chi-deux a 5% et 24 degres de liberte est de 36.42. Donc, m =
123.24468 > 36.42. On rejette l’hypothese nulle d’absence de correlation entre le terme
d’erreur et les variables explicatives. Le modele a effets fixes est donc approprie puisqu’il
donne des estimateurs convergents. Le tableau (4.1) donne les resultats de l’estimation
du modele.
Seuls les effets marginaux du prix de l’electricite et de la variable hdd (degres jours
de chauffage) sont statistiquement significatifs a 5%.
Nous avons effectue un test de significativite globale sur les (C−1) effets specifiques
aux cohortes. Il s’agit d’un test de Fischer defini par :
F (C − 1, CT − C − K) =(R2
W − R2MCG) / (C − 1)
(1 − R2MCG) / (CT − C − K)
,
avec K le nombre de coefficients de pentes. La valeur de la statistique de test est
F (24, 69) = 3.36. La valeur critique a 5% est Fc ∈ [1.57; 1.62]. Comme la statistique
calculee est superieure a la valeur critique, on rejette l’hypothese nulle selon laquelle
tous les effets fixes sont egaux a zero. Les effets specifiques aux cohortes sont donc
globalement significatifs.
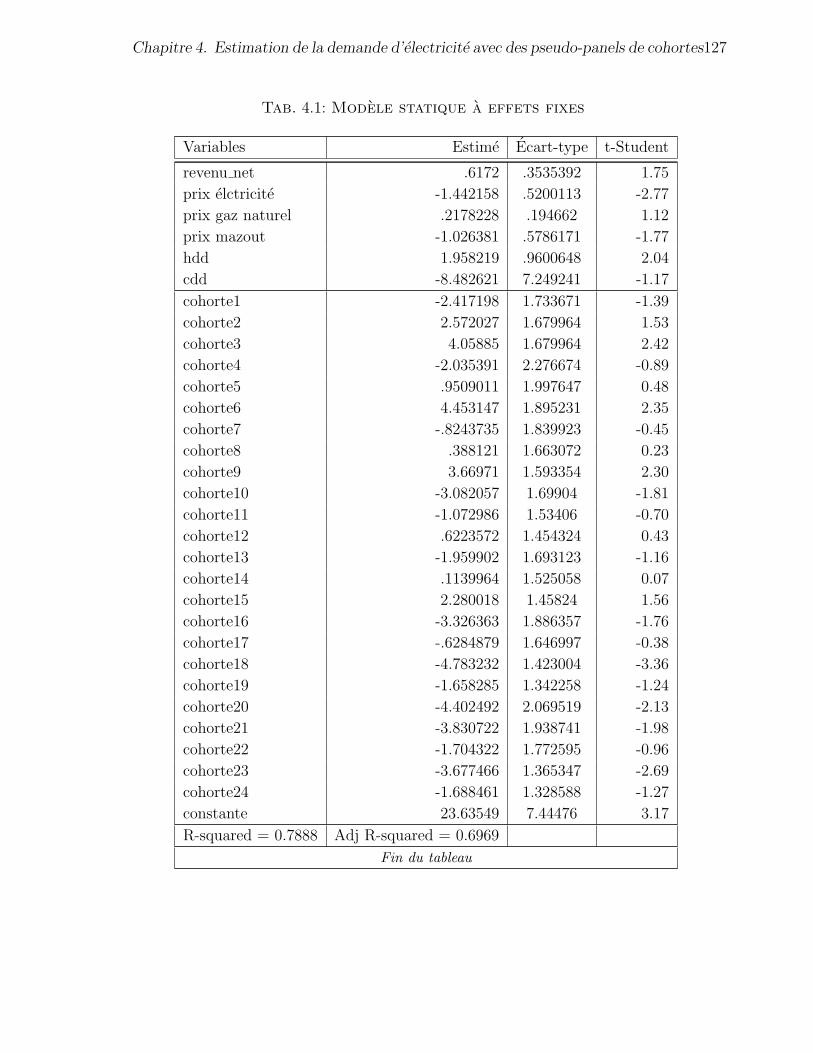
Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes127
Tab. 4.1: Modele statique a effets fixes
Variables Estime Ecart-type t-Student
revenu net .6172 .3535392 1.75
prix elctricite -1.442158 .5200113 -2.77
prix gaz naturel .2178228 .194662 1.12
prix mazout -1.026381 .5786171 -1.77
hdd 1.958219 .9600648 2.04
cdd -8.482621 7.249241 -1.17
cohorte1 -2.417198 1.733671 -1.39
cohorte2 2.572027 1.679964 1.53
cohorte3 4.05885 1.679964 2.42
cohorte4 -2.035391 2.276674 -0.89
cohorte5 .9509011 1.997647 0.48
cohorte6 4.453147 1.895231 2.35
cohorte7 -.8243735 1.839923 -0.45
cohorte8 .388121 1.663072 0.23
cohorte9 3.66971 1.593354 2.30
cohorte10 -3.082057 1.69904 -1.81
cohorte11 -1.072986 1.53406 -0.70
cohorte12 .6223572 1.454324 0.43
cohorte13 -1.959902 1.693123 -1.16
cohorte14 .1139964 1.525058 0.07
cohorte15 2.280018 1.45824 1.56
cohorte16 -3.326363 1.886357 -1.76
cohorte17 -.6284879 1.646997 -0.38
cohorte18 -4.783232 1.423004 -3.36
cohorte19 -1.658285 1.342258 -1.24
cohorte20 -4.402492 2.069519 -2.13
cohorte21 -3.830722 1.938741 -1.98
cohorte22 -1.704322 1.772595 -0.96
cohorte23 -3.677466 1.365347 -2.69
cohorte24 -1.688461 1.328588 -1.27
constante 23.63549 7.44476 3.17
R-squared = 0.7888 Adj R-squared = 0.6969
Fin du tableau

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes128
4.3.4 Modele a effets fixes avec heteroscedasticite
Plusieurs raisons peuvent nous amener a penser que le terme d’erreur du modele
(4.2) est heteroscedastique. En effet, les cohortes sont des regroupements de plusieurs
menages partageant un certain nombre de caracteristiques. Il est donc raisonnable de
penser qu’il pourrait exister une certaine forme d’heteroscedasticite groupee entre les
cohortes. Si cette hypothese est verifiee, alors, les tests d’hypothese ne sont plus valides
memes si les estimateurs sont convergents. Supposons que la variance du terme d’erreur
est specifique a chaque cohorte :
yct = Xctβ + εct V (εct) = σ2c c = 1, 2...C.
L’indice c indique la cohorte et C = 25. Pour simplifier l’ecriture, nous incluons les
effets fixes dans le vecteur Xct. L’estimation de ce modele peut se faire par la methode
des moindres carres quasi-generalises (MCQG). Dans une premiere etape, on estime le
modele par les MCO et on recupere les residus notes ect. Ces residus sont ensuite utilises
pour estimer la variance specifique a chaque cohorte :
σ2c =
e′cec
T=
(yc − Xcβ
)′ (yc − Xcβ
)
T.
La derniere etape consiste a estimer le modele transforme par MCO qui corrige l’heroscedasticite :
yct
σc
=Xct
σc
β +εct
σc
.
L’estimateur des MCQG de β est alors donne par :
β =
[X
′Ω−1X
]−1 [X
′Ω−1y
]
=
[C∑
c=1
1
σ2c
X′cXc
]−1 [ C∑
c=1
1
σ2c
X′cyc
].
Etant donne σ2c , l’estimateur de β par les MCQG correspond a l’estimateur du maximum
de vraisemblance. Les resultats de l’estimation sont presentes dans le tableau (4.2).
Tab. 4.2: Modele avec Heteroscedasticite
Variables Estime Ecart-type t-Student
revenu net .7385276 .2418165 3.05
pelec marg -1.751766 .2466844 -7.10
prixgn .185615 .0929948 2.00
suite a la page suivante
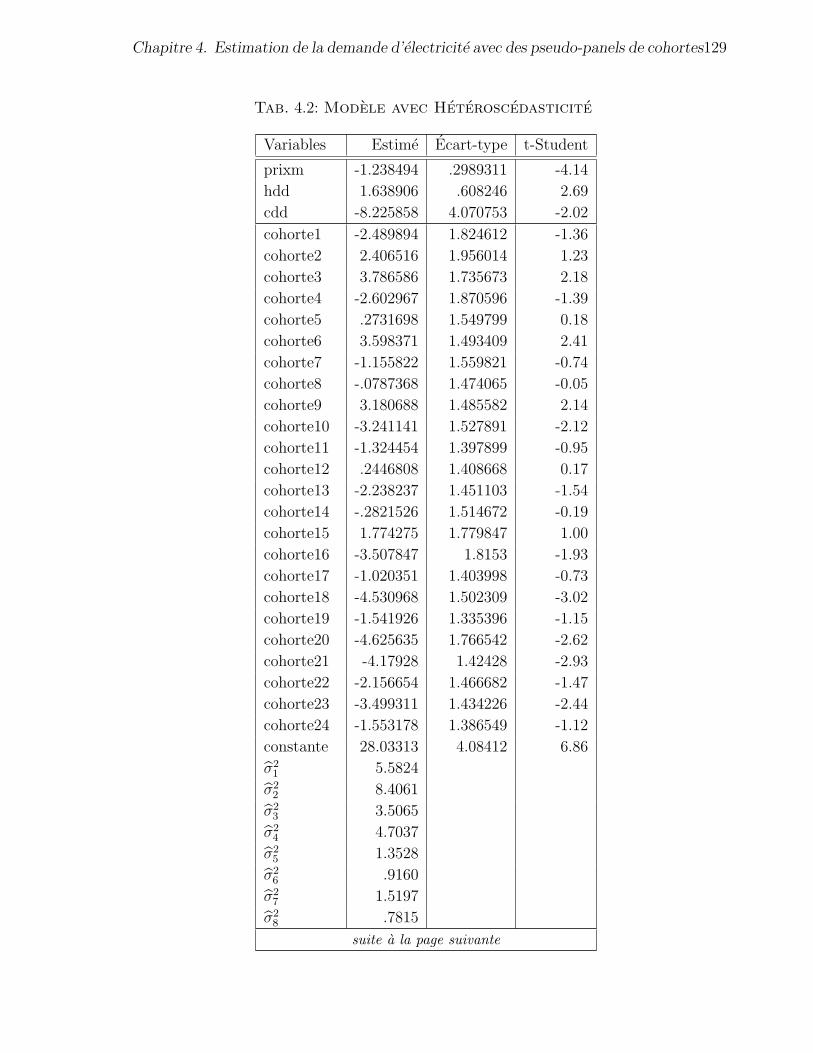
Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes129
Tab. 4.2: Modele avec Heteroscedasticite
Variables Estime Ecart-type t-Student
prixm -1.238494 .2989311 -4.14
hdd 1.638906 .608246 2.69
cdd -8.225858 4.070753 -2.02
cohorte1 -2.489894 1.824612 -1.36
cohorte2 2.406516 1.956014 1.23
cohorte3 3.786586 1.735673 2.18
cohorte4 -2.602967 1.870596 -1.39
cohorte5 .2731698 1.549799 0.18
cohorte6 3.598371 1.493409 2.41
cohorte7 -1.155822 1.559821 -0.74
cohorte8 -.0787368 1.474065 -0.05
cohorte9 3.180688 1.485582 2.14
cohorte10 -3.241141 1.527891 -2.12
cohorte11 -1.324454 1.397899 -0.95
cohorte12 .2446808 1.408668 0.17
cohorte13 -2.238237 1.451103 -1.54
cohorte14 -.2821526 1.514672 -0.19
cohorte15 1.774275 1.779847 1.00
cohorte16 -3.507847 1.8153 -1.93
cohorte17 -1.020351 1.403998 -0.73
cohorte18 -4.530968 1.502309 -3.02
cohorte19 -1.541926 1.335396 -1.15
cohorte20 -4.625635 1.766542 -2.62
cohorte21 -4.17928 1.42428 -2.93
cohorte22 -2.156654 1.466682 -1.47
cohorte23 -3.499311 1.434226 -2.44
cohorte24 -1.553178 1.386549 -1.12
constante 28.03313 4.08412 6.86
σ21 5.5824
σ22 8.4061
σ23 3.5065
σ24 4.7037
σ25 1.3528
σ26 .9160
σ27 1.5197
σ28 .7815
suite a la page suivante

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes130
Tab. 4.2: Modele avec Heteroscedasticite
Variables Estime Ecart-type t-Student
σ29 1.0244
σ210 .4784
σ211 .3065
σ212 1.4995
σ213 .8193
σ214 2.9559
σ215 6.1830
σ216 5.0996
σ217 .4029
σ218 3.1199
σ219 .8286
σ220 2.6598
σ221 .2864
σ222 1.0682
σ223 3.5051
σ224 2.5861
σ225 7.6153
Log likelihood = -156.1297
Fin du tableau
Pour tester l’hypothese nulle d’homoscedasticite du modele, nous utilisons le test du
ratio de vraisemblance (LR pour likelihood ratio). La fonction log-vraisemblance sous
l’hypothese d’homoscedasticite est :
ln L0 = −CT
2ln 2π − CT
2ln σ2 − 1
2
C∑
c=1
T∑
t=1
[yct − Xctβ
]′ [yct − Xctβ
]
σ2.
Sous l’hypothese alternative d’heteroscedasticite, la fonction log-vraisemblance est :
ln L1 = −CT
2ln 2π − 1
2
C∑
c=1
T ln σ2c −
1
2
C∑
c=1
T∑
t=1
[yct − Xctβ − θc
]′ [yct − Xctβ − θc
]
σ2c
.
La statistique de test est :
LR = −2 [ln L0 − ln L1] ∼ χ2C−1
.
La valeur du log-vraisemblance sous H0 est : L0 = −183.3154 et celle sous l’hypothese
d’heteroscedasticite est : L1 = −156.1297. La valeur de la statistique LR est : LR =

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes131
54.37. La valeur critique du chi-deux est : χ224,5% = 39.36 ; on rejette donc H0 au seuil de
5%. En conclusion, le terme d’erreur n’est pas homoscedastique. Apres la correction de
l’heteroscedasticite, nous constatons que les statistiques de Student sont plus grandes,
les estimes des coefficients de pente sont tous statistiquement significatifs au seuil de
5%. Il est donc important de corriger l’heteroscedasticite pour obtenir des tests valides.
4.3.5 Modele a effets fixes avec heteroscedasticite et correlation
serielle
Compte tenu des resultats du test LR, nous supposerons pour la suite que la variance
de l’erreur n’est pas homoscedastique. Supposons qu’il n’existe pas de correlation entre
les cohortes, plus precisement :
corr (εct, εks) = 0 si c 6= k.
Supposons cependant qu’il existe une correlation entre les termes d’erreurs de deux
periodes differentes :
εct = ρεct−1 + uct
V (εct) = σ2c =
σ2uc
1 − ρ2,
ou ρ est le coefficient d’autocorrelation et σ2c est la variance specifique a chaque co-
horte. Dans ce modele, nous supposons a la fois de l’heteroscedasticite et de l’auto-
correlation des erreurs. Le terme d’erreur suit en fait un processus autoregressif d’ordre
un (ou AR(1)). Pour estimer ce modele, nous devons d’abord corriger le probleme d’au-
tocorrelation en utilisant la transformation de Prais-Winsten (1954). Un estimateur
convergent de ρ note par ρ est :
ρ =
∑Cc=1
∑Tt=1 ectect−1∑C
c=1
∑Tt=2 e2
ct
ect = yct − Xctβ,
avec ect les residus de la regression des MCO. Le ρ est ensuite recupere pour effectuer
la transformation de Prais-Winsten de la facon suivante :
Y ∗c =
√1 − ρ2yc1
yc2 − ρyc1...
ycT − ρycT−1
X∗c =
√1 − ρ2Xc1
Xc2 − ρXc1
...
XcT − ρXcT−1.

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes132
Les donnees transformees sont utilisees dans une seconde regression par MCO pour
obtenir des estimateurs convergents des variances :
σ2uc =
e′∗ce∗cT
=
(Y ∗c − X∗cβ
)′ (Y ∗c − X∗cβ
)
T.
Apres avoir obtenu des estimateurs convergents des variances, ils sont utilises pour
transformer le modele de sorte a corriger l’heteroscedasticite :
β =
[X
′∗Ω
−1X∗
]−1 [X∗
′Ω−1y∗
]
=
[C∑
c=1
1
σ2uc
X′∗cX∗c
]−1 [ C∑
c=1
1
σ2uc
X′∗cy∗c
].
Conditionnellement a ρ, les estimateurs de β et σ2uc par les MCG correspondent a ceux
du maximum de vraisemblance (Greene, 2003). La fonction log-vraisemblance est :
ln L = −1
2ln 2π − 1
2
C∑
c=1
T ln
[σ2
uc
1 − ρ2
]− 1
2
C∑
c=1
T∑
t=1
[yct − Xctβ
]′ [yct − Xctβ
]
σ2c
.
Les resultats de l’estimation sont donnes dans le tableau (4.3). Les parametres du
modele peuvent aussi etre estimes de facon iterative comme dans les travaux de Obe-
rhofer et Kmenta (1974). Comme l’a note Greene (2003), cette procedure n’est pas
necessairement meilleure.
Tab. 4.3: Erreurs heteroscedastique et AR(1)
Variables Estime Ecart-type t-Student
revenu net .6681975 .2340717 2.85
pelec marg -1.890073 .2274265 -8.31
prixgn .2186211 .0888686 2.46
prixm -1.291938 .2838837 -4.55
hdd 1.237069 .5848032 2.12
cdd -6.924017 3.870414 -1.79
cohorte1 -2.040675 1.466644 -1.39
cohorte2 3.10831 1.544003 2.01
cohorte3 4.540684 1.435885 3.16
cohorte4 -3.446144 1.605437 -2.15
cohorte5 -.3695903 1.32581 -0.28
cohorte6 3.098054 1.250655 2.48
cohorte7 -1.635418 1.328303 -1.23
cohorte8 -.421821 1.236856 -0.34
suite a la page suivante

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes133
Tab. 4.3: Erreurs heteroscedastique et AR(1)
Variables Estime Ecart-type t-Student
cohorte9 2.855164 1.192159 2.39
cohorte10 -3.375336 1.272062 -2.65
cohorte11 -1.45073 1.151959 -1.26
cohorte12 .0755473 1.155748 0.07
cohorte13 -2.537264 1.199643 -2.12
cohorte14 -.5510944 1.219404 -0.45
cohorte15 1.48284 1.423668 1.04
cohorte16 -3.748977 1.496833 -2.50
cohorte17 -1.216339 1.160432 -1.05
cohorte18 -4.170202 1.180676 -3.53
cohorte19 -1.196916 1.05465 -1.13
cohorte20 -4.356801 1.437122 -3.03
cohorte21 -3.996954 1.16711 -3.42
cohorte22 -1.87687 1.194698 -1.57
cohorte23 -3.373312 1.209076 -2.79
cohorte24 -1.463929 1.120043 -1.31
constante 31.25113 3.838271 8.14
σ21 5.1941835
σ22 6.5342976
σ23 4.292325
σ24 2.4605299
σ25 .17748612
σ26 .37009621
σ27 .61783052
σ28 .93305238
σ29 .78685749
σ210 1.04243
σ211 .507171
σ212 1.20919
σ213 .184374
σ214 1.66861
σ215 5.29729
σ216 3.63777
σ217 .323159
σ218 1.6752
σ219 .370896
suite a la page suivante

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes134
Tab. 4.3: Erreurs heteroscedastique et AR(1)
Variables Estime Ecart-type t-Student
σ220 3.59636
σ221 .157379
σ222 1.03062
σ223 2.09437
σ224 1.1418
σ225 6.01092
Log likelihood =-147.8451
ρ = -0.2925
Fin du tableau
Nous avons effectue un test LR pour savoir si les erreurs sont a la fois heteroscedastiques
et autocorrelees.
LR = −2 [ln L1 − ln L] ∼ χ2C
avec lnL1 le log-vraisemblance du modele heteroscedastique et lnL le log-vraisemblance
du modele avec heteroscedasticite et AR(1). La valeur du log-vraisemblance du modele
avec de l’heteroscedasticite est lnL1 = −156.1297 et celle du modele avec heteroscedasticite
et AR(1) est lnL = −147.8451. La statistique de test est alors egale a : LR = 16.5692 et
la valeur critique de la chi-deux a un degre de liberte est χ21 = 37.65. 2 Comme la valeur
du test est superieure a celle du point critique, nous avons une evidence empirique en
faveur du modele avec erreurs heteroscedastique et AR(1). La statistique de test nous
permet de confirmer que les erreurs sont heteroscedatiques et seriellement correlees.
Comme on peut le constater, tous les coefficients d’interet (coefficients de pente) sont
tres significatifs (au seuil de 5%), a l’exception du coefficient de la variable cdd (qui est
cependant significatif a 10%). De plus, ils ont les bons signes. Nous concluons que le
modele avec erreurs heteroscedastiques et AR(1) represente mieux les donnees. Ainsi,
comme ce modele est le meilleur, cela implique que les ecart-types des estimateurs du
modele sous l’hypothese d’heteroscedasticite sont biaises et ainsi, les tests d’hypothese
sur ces derniers sont invalides. De meme, les ecart-types du modele sous l’hypothese
d’effets fixes homoscedastiques ne sont pas valides.
2Sous l’hypothese de AR(1), nous avons suppose que le coefficient d’autocorrelation est commun
a toutes les cohortes et sous l’hypothese d’heteroscedasticite simple, nous n’avons aucun coefficient
d’autocorrelation.

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes135
4.3.6 Analyse de sensibilite : elasticites prix et revenu de la
demande
Le tableau (4.4) presente les differentes elasticites prix directe, prix croisees et revenu
de la demande d’electricite. L’elasticite prix directe de la demande est definie par :
η =∂Qe
∂Pe
× Pe
Qe
,
avec Qe la demande d’electricite et Pe le prix marginal de l’electricite. Elle donne la
variation directe de la demande d’electricite suite a une variation du prix de l’electricite.
η = −0.488 sous l’hypothese d’erreurs heteroscedastiques et AR(1). Cela signifie qu’une
augmentation de 1% du prix marginale de l’electricite entraınerait une baisse de 0.488%
de la demande globale de la province. On peut egalement noter qu’un test de Student
nous permet de dire que cette elasticite est tres significative (t = 8.295). On peut aussi
noter que l’elasticite du modele homoscedastique est inferieure a celle du modele avec
de l’heteroscedasticite uniquement, qui elle aussi est inferieure a celle du modele avec
heteroscedasticite et AR(1).
Nous avons egalement estime deux elasticites prix croisees. L’elasticite prix croisee d’un
bien est definie comme etant egale a la variation de la demande d’un bien suite a la
variation du prix d’un autre bien :
ηc =∂Qe
∂Pj
× Pj
Qe
,
avec Pj le prix d’un bien autre que l’electricite (mazout ou gaz naturel pour ce qui
nous concerne). Sous l’hypothese d’heteroscedasticite et AR(1), l’elasticite prix croisee
du gaz est de (0.042) et est tres significative : une hausse de 1% du prix du gaz naturel
entraıne une augmentation de 0.042% de la demande d’electricite. Le gaz naturel et
l’electricite sont alors deux biens substituables. Si le prix du gaz naturel augmente,
les menages qui utilisent le gaz vont diminuer leur consommation en gaz au profit de
l’electricite. Nous remarquons que l’elasticite du modele retenu est superieure a celles
des deux autres modeles.
L’elasticite prix croisee du mazout est de (-0.373) et est tres significative. Une aug-
mentation de 1% du prix du mazout entraınera une baisse de (-0.373%) de la demande
d’electricite. Le mazout et l’electricite sont donc deux biens complementaires. Cela a du
sens puisque beaucoup de menages utilisent le mazout en combinaison avec l’electricite
pour leur chauffage (le chauffage en bienergie ou en electricite/mazout). Remarquons
que cette valeur de l’elasticite est comprise entre celle du modele homoscedastique et
celle du modele avec heteroscedasticite seulement.
Nous avons enfin calcule l’elasticite revenu de la demande d’electricite :
ηr =∂Qe
∂R× R
Qe
.

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes136
L’elasticite revenu de la demande est de (0.153) et est tres significative. Elle est comprise
entre celle du modele homoscedastique et celle du modele avec heteroscedasticite seule-
ment. Une hausse de 1% du revenu entraınera une hausse de (0.153%) de la demande
d’electricite, donc une hausse moins de 1%. L’electricite est donc un bien ordinaire.
Tab. 4.4 – Elasticites du modele statique
effets fixes heterosc. heterosc. et AR(1)
elasticite-prix electricite (directe) -0.372 -0.452 -0.488
E-T (0.1342) (0.064) (0.059)
elasticite prix gaz naturel (croisee) 0.0423 0.0360 0.042
E-T (0.0378) (0.018) (0.0172)
elasticite prix mazout (croisee) -0.2964 -0.358 -0.373
E-T (0.1671) (0.086) (0.082)
elasticite revenu 0.1418 0.17 0.153
E-T (0.0812) (0.056) (0.054)
4.4 Modeles dynamiques de demande d’electricite
Un certain nombre d’auteurs se sont interesses a l’estimation de modeles dynamiques
avec des pseudo-panels : Moffit (1993), Collado (1997), Girma (2000), McKenzie (2001
et 2004), Verbeek et Vella (2004). On parle de modele dynamique lorsqu’on intro-
duit une variable endogene retardee dans le modele. Moffit (1993) etend l’approche
de Deaton (1985) a l’estimation de modeles dynamiques a partir de coupes transver-
sales independantes. Il interprete l’estimateur within comme un estimateur a variables
instrumentales base sur des pseudo-panels et qui utilise les variables binaires des co-
hortes. Les erreurs de mesure sont ignorees dans son modele etant donne que le nombre
d’observations par cohorte tend vers l’infini. Moffit suggere de remplacer la variable
dependante retardee ynt−1 par une valeur predite obtenue a partir de donnees dispo-
nibles a la periode t−1. Collado (1997) propose des estimateurs des moments generalises
(GMM) qui corrigent les erreurs de mesure des modeles dynamiques. Son estimateur est
convergent lorsque le nombre de cohortes tend vers l’infini, pour des valeurs fixes de T
et du nombre d’observations par cohorte. Elle propose egalement un estimateur within
qui corrige les erreurs de mesure, cet estimateur est convergent a mesure que T tend
vers l’infini. Une simulation Monte Carlo a ete effectuee pour etudier la performance
en echantillon fini de ses estimateurs. Il est ressorti que la correction des erreurs de
mesure est importante et que les estimateurs corriges reduiraient le biais. Par ailleurs,
si T est fixe, les estimateurs GMM sont meilleurs aux estimateurs within. Girma (2000)
propose une methode alternative a la methode des GMM pour l’estimation des modeles

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes137
dynamiques avec des coupes transversales independantes. Contrairement a l’approche
de Deaton (1985) qui consistait a prendre la moyenne des individus d’une meme cohorte,
son approche consiste a utiliser une transformation par quasi-differenciation entre deux
individus quelconque d’un meme groupe. Les proprietes asymptotiques des estimateurs
sont conditionnelles au fait qu’il faut avoir beaucoup d’observations dans chaque groupe.
L’avantage avec cette approche est qu’elle peut etre implementee avec seulement deux
coupes transversales. On n’a pas besoin d’avoir un grand nombre de coupes transver-
sales sur plusieurs periodes. McKenzie (2001) s’est interesse au probleme d’estimation de
modeles dynamiques a partir de pseudo-panels non balances. Precisons que les pseudo-
panels non balances sont des pseudo-panels ou T , la periode maximale d’etude, est
remplace par Tc ; cela signifie que la periode maximale de disponibilite de l’information
depend de chaque cohorte. Lorsqu’on a des pseudo-panels non balances, cela cree des
contraintes non lineaires sur les parametres. Plusieurs methodes d’estimation sont alors
suggerees comme les moindres carres non lineaires, l’estimation a distance minimale,...
Ces estimateurs sont convergents et asymptotiquement normaux pour T fixe et nc → ∞.
Dans un autre article, McKenzie ( 2004) introduit de l’heterogeneite deterministe entre
les cohortes. Il suppose precisement que les parametres sont specifiques a chaque co-
horte. Il developpe une theorie asymptotique pour les pseudo-panels en s’appuyant sur
les travaux de Phillips et Moon (1999).
Verbeek et Vella (2004) ont apporte des critiques aux estimateurs proposes par Moffit
(1993), Girma (2000) et McKenzie (2004). Ils montrent que l’estimateur de Moffit (1993)
n’est pas convergent a moins que les variables exogenes soient invariantes dans le temps
ou n’ont aucune autocorrelation. Ils proposent alors une approche alternative basee
sur les variables instrumentales et qui consiste a utiliser l’estimateur within avec les
moyennes des cohortes. L’estimateur «within» a variables instrumentales augmentees
qu’ils proposent est convergent ; cependant cette convergence exige un grand nombre
de cohortes pour pouvoir reduire le biais de l’estimateur. Ce biais existe aussi dans
l’estimateur «within» des modeles dynamiques utilisant de vrais panels, et il est meme
plus grand que le biais de l’estimateur «within» avec les pseudo-panels. Cet estimateur
converge sous les memes conditions que celles proposees par Collado (1997) mais ces
conditions ne sont pas facilement satisfaites dans les applications empiriques.
4.4.1 Le modele dynamique
Supposons que le modele de demande d’electricite est defini selon l’equation sui-
vante :
ynt = αynt−1 + Xntβ + θn + εnt n = 1, 2...Nt t = 1, ...T. (4.3)

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes138
Comme dans le modele statique ou l’information passee n’etait pas disponible, nous
utilisons l’approche de Deaton (1985) qui consiste a prendre la version moyennes des
cohortes :
yct = αyct−1 + Xctβ + θc + εct c = 1, 2...C t = 1, ...T.
Pour estimer ce modele, nous utilisons la methode des variables instrumentales qui
consiste a instrumenter la variable dependante retardee yct−1. L’approche utilisee est
assez proche de celle proposee par Moffit (1993) mais sous sa version moyennes de
cohortes comme l’ont suggere Verbeek et Vella (2004). Nous supposons que yct−1 depend
de variables variant dans le temps et de variables invariant dans le temps (comme les
variables binaires des cohortes) :
yct−1 = W ct−1a1 + Zca2 + εct−1,
avec W ct−1 un vecteur de variables qui varient dans le temps3 et Zc un vecteur de
variables invariant dans le temps incluant les effets fixes specifiques aux cohortes4. Apres
avoir instrumente yct−1, nous estimons le modele par la methode des moindres carres
ordinaires. Quant a la premiere observation, nous utilisons aussi une autre regression
auxiliaire pour la recuperer. Nous supposons que l’observation initiale est fonction d’un
certain nombre de variables invariant dans le temps et est definie comme suit :
yc0 = Zcb1 + vc0.
Les resultats de l’estimation sont presentes au tableau (4.5).
Tab. 4.5: Resultats du modele dynamique a ef-
fets fixes
Variables Estime Ecart-type t-Student
Variables Estime Ecart-type t-Student
cons anP .5170141 .3283345 1.57
revenu net .5528357 .3521903 1.57
pelec marg -1.755511 .5516658 -3.18
prixgn .5709668 .2956242 1.93
prixm -.8514604 .583189 -1.46
hdd 1.184587 1.069464 1.11
cdd -9.258611 7.189656 -1.29
cohorte1 1.100116 2.816372 0.39
cohorte2 3.180768 1.706599 1.86
suite a la page suivante
3Les variables qui varient dans le temps et qui ont ete choisies pour constituer Wct−1 sont : les degres
jours de chauffage (hdd), les degres jours de climatisation (cdd) et le prix marginal de l’electricite.4Dans notre application empirique, nous avons choisi uniquement les effets specifiques aux cohortes

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes139
Tab. 4.5: Resultats du modele dynamique a ef-
fets fixes
Variables Estime Ecart-type t-Student
cohorte3 3.743946 1.674224 2.24
cohorte4 -.0136661 2.59285 -0.01
cohorte5 1.34713 1.992521 0.68
cohorte6 2.853339 2.132768 1.34
cohorte7 .2112252 1.935659 0.11
cohorte8 .6303453 1.652698 0.38
cohorte9 2.0327 1.888451 1.08
cohorte10 -1.012113 2.134044 -0.47
cohorte11 -.2490677 1.605526 -0.16
cohorte12 .4483511 1.443215 0.31
cohorte13 .0981261 2.124772 0.05
cohorte14 .9696756 1.60383 0.60
cohorte15 1.795547 1.475291 1.22
cohorte16 -1.114574 2.335935 -0.48
cohorte17 -.0403331 1.671876 -0.02
cohorte18 -1.723582 2.399564 -0.72
cohorte19 -.4291699 1.54049 -0.28
cohorte20 .5350633 3.745028 0.14
cohorte21 .590691 3.400571 0.17
cohorte22 1.393288 2.635503 0.53
cohorte23 -1.58633 1.894362 -0.84
cohorte24 -.5960213 1.486405 -0.40
cons 14.8531 9.239461 1.61
R-squared = 0.7962 Adj R-squared = 0.7033 F( 31, 68)=8.57
Fin du tableau
Precisons que la variable cons anP est la consommation annuelle de la periode
precedente. Comme on peut le constater, un test de significativite individuelle indique
que la plupart des estimes ne sont pas significatifs (en particulier, seul l’estime de la
variable prix de l’electricite est significatif a 1%). Un test de Wald pour la significa-
tivite globale des effets fixes uniquement indique que ceux-ci ne sont pas globalement
significatifs (W= 0.61). On serait donc tente d’exclure les effets fixes du modele. La
statistique de test de Fischer( F (31, 68) = 8.57) (dont la p-value est egale a zero) in-
dique que tous les coefficients du modele sont globalement significatifs. Pourtant, les
signes des estimes sont conformes aux attentes. A la vue de tous ces resultats, on est

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes140
porte a croire qu’il pourrait exister soit un probleme d’heteroscedasticite ou soit un
probleme d’autocorrelation ou les deux, ceci entraınant des biais dans les variances des
estimateurs des MCO.
Comme dans le cas du modele statique presente precedemment, supposons que le
terme d’erreur du modele est seriellement correle et est heteroscedastique :
εct = ρεct−1 + uct
V (εct) = σ2c =
σ2uc
1 − ρ2.
Comme dans la section precedente, le modele peut etre estime par la methode des
moindres carres quasi-generalises : la premiere etape consistera a estimer le coeffi-
cient d’autocorrelation commun a toutes les cohortes pour corriger le probleme d’au-
tocorrelation. A la deuxieme etape, on corrige l’heteroscedasticite pour obtenir des
estimateurs dont les variances sont convergentes. La demarche est la meme que celle
effectuee avec le modele statique, et nous ne la repeterons pas a nouveau. Les resultats
de la regression par les MCQG sont presentes au tableau (4.6).
Tab. 4.6: Modele dynamique avec Heteroscedasticite et
AR(1)
Variables Estime Ecart-type t-Student
cons anP .6164317 .1470966 4.19
revenu net .329807 .2362842 1.40
pelec marg -1.961809 .236709 -8.29
prixgn .6060003 .1277783 4.74
prixm -1.119214 .2924707 -3.83
hdd .2040774 .6102746 0.33
cdd -6.184466 3.854286 -1.60
cohorte1 1.866262 1.760028 1.06
cohorte2 3.846228 1.545563 2.49
cohorte3 4.307 1.395605 3.09
cohorte4 -1.744625 1.68578 -1.03
cohorte5 -.2562666 1.345449 -0.19
cohorte6 1.148856 1.383164 0.83
cohorte7 -.9429972 1.365099 -0.69
cohorte8 -.3662461 1.210054 -0.30
cohorte9 .8300997 1.304951 0.64
cohorte10 -1.450074 1.329133 -1.09
cohorte11 -.7575846 1.147127 -0.66
suite a la page suivante

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes141
Tab. 4.6: Modele dynamique avec Heteroscedasticite et
AR(1)
Variables Estime Ecart-type t-Student
cohorte12 -.1817363 1.150077 -0.16
cohorte13 -.5609136 1.301616 -0.43
cohorte14 .2809824 1.223438 0.23
cohorte15 .9599508 1.383933 0.69
cohorte16 -1.794702 1.539853 -1.17
cohorte17 -.8161492 1.180051 -0.69
cohorte18 -.9224034 1.416723 -0.65
cohorte19 .1987281 1.108386 0.18
cohorte20 .7210995 1.848759 0.39
cohorte21 .6805055 1.650625 0.41
cohorte22 1.524573 1.429822 1.07
cohorte23 -1.231933 1.332008 -0.92
cohorte24 -.3925002 1.175754 -0.33
cons 21.33348 4.622642 4.61
σ21 5.2897031
σ22 6.5706749
σ23 3.7829192
σ24 2.894408
σ25 .23762125
σ26 .47230221
σ27 .97634242
σ28 .47618843
σ29 .9558614
σ210 .46551761
σ211 .20820747
σ212 1.0448476
σ213 .15323077
σ214 1.4526517
σ215 4.5521254
σ216 2.8969085
σ217 .40602174
σ218 1.4666186
σ219 .38202435
σ220 1.9795251
σ221 .22698583
suite a la page suivante

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes142
Tab. 4.6: Modele dynamique avec Heteroscedasticite et
AR(1)
Variables Estime Ecart-type t-Student
σ222 .63675816
σ223 2.2665462
σ224 1.4666116
σ225 6.1677877
Log likelihood = -143.4006
ρ = -0.3106
Wald chi2(31) = 1236.95
Fin du tableau
La plupart des estimes des parametres de pente sont statistiquement significatifs
aux seuil usuel a l’exemption du celui de la variable hdd, cdd et du revenu net.
Nous avons effectue un test du ratio de vraisemblance pour confirmer l’hypothese
d’erreurs heteroscedastiques. Plus precisement, la valeur du log-vraisemblance sous l’hy-
pothese d’homoscedasticite est lnL0 = −181.5247 et celle du modele avec unique-
ment de l’heteroscedasticite est lnL1 = −152.2155. La statistique de test LR est :
LR = −2(−181.5247 + 152.2155) = 58.62. La valeur critique du test est : χ224,5% =
36.42 < LR ; donc l’hypothese d’homoscedasticite est rejetee. Par ailleurs, nous avons
teste l’hypothese d’heteroscedasticite avec AR(1). La valeur du log-vraisemblance sous
cette derniere hypothese est lnL = −143.4006. La statistique de test est : LR =
−2(−152.2155 + 143.4006) = 17.63 > χ21,5% = 3.84. Donc, on a une evidence empi-
rique en faveur d’erreurs heteroscedastiques et AR(1) comme dans le modele statique.
Un test de Wald a aussi ete effectue sur les effets fixes. Apres avoir corrige le
modele, il est ressorti que les effets fixes sont globalement significatifs : la statistique
de test pour la significativite globale des coefficients specifiques aux cohortes est :
W = 47.43 > χ224,5%. Pourtant, avant la correction, les effets fixes n’etaient pas glo-
balement significatifs.
4.4.2 Analyse de sensibilite : elasticites prix et revenu
Nous avons calcule les elasticites prix directes, croisees et revenu de la demande
d’electricite. L’annexe (5.8.3) presente la demarche suivie pour calculer la variance de
l’elasticite de long terme. Mise a part l’elasticite revenu de court terme, les autres

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes143
elasticites de court terme (CT) et de long terme (LT) sont sous evaluees lorsqu’aucune
correction n’est faite sur le modele. Par ailleurs, comparativement aux elasticites obte-
nues dans le modele statique, les elasticites de long terme sont nettement superieures a
celles du modele statique.
En ce qui concerne les elasticites prix directes ou croisees de court terme, nous
remarquons qu’elles sont toutes inferieures en valeur absolue a celles de long terme.
Cela confirme la seconde loi de la demande. Cette loi postule en effet que l’elasticite
de LT doit etre plus grande que celle de CT. En d’autres mots, les consommateurs
peuvent trouver plus de substituts dans le long terme que dans le CT, etant donne
une certaine periode d’ajustement. A court terme, on s’attend a ce que la demande
soit inelastique et a LT on s’attend a ce qu’elle soit plus elastique. Lorsque le prix
d’une forme d’energie change, les changements a long terme dans la consommation des
cohortes devraient etre beaucoup plus importants que les changements a court terme.
Cela se justifie par le fait que les cohortes utilisent des biens durables dont elles ne
peuvent s’en departir sur le champ suite a une hausse du prix de l’energie utilisee. A
court terme, les cohortes changent leurs comportements (par exemple une baisse de
l’utilisation de l’energie suite a une hausse de son prix) et avec le temps, elles vont
investir dans de nouveaux equipements pour lesquels les depenses sont relativement
moins couteuses.
Ainsi, si le prix de l’electricite augmente de 1%, la demande d’electricite va baisser de
0.51% a court terme, mais a long terme, elle baissera de 1.32% (soit plus de trois fois la
baisse du court terme). Ainsi, si le prix de l’electricite augmente de 1%, on s’attend a
ce que les cohortes de menages baissent de plus de 1% leur consommation a long terme.
L’elasticite prix croisee de court terme du gaz naturel est de 0.118 et est significative a
1%, alors que celle de long terme est de 0.31 mais n’est pas significative. Si le prix du gaz
naturel augmente de 1%, les cohortes augmenteront leur demande en electricite de 0.12%
a court terme. L’electricite et le gaz naturel sont donc deux biens complementaires.
L’elasticite prix croisee de court terme du mazout est de -0.323 et significative a 1%,
tandis que celle de long terme est de -0.84, et egalement significative. Ainsi, si le prix
du mazout augmente de 1%, les cohortes baisseront leur consommation en electricite
d’environ 0.32% a court terme et a long terme, elles la baisseront d’environ 0.8%.
L’elasticite revenu de court terme est 0.076 et celle de long terme est de 0.198, toutes
les deux n’etant pas significatives.
Dans la litterature, il existe plusieurs valeurs estimees des elasticites de la demande
d’electricite. Dahl (1993) a fait une synthese des valeurs des elasticites obtenues dans
le passe ; elle est arrivee a la conclusion selon laquelle les valeurs obtenues sont tres
variables d’une etude a l’autre, d’une base de donnees a l’autre. D’autres auteurs plus
recents ont aussi abouti a la meme conclusion : Poyer et Williams (1993), Hsing (1994),
Maddala et al. (1997), Poyer et al. (1997), Silk et Joutz (1997),...

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes144
Par exemple, Hsing (1994) a utilise un modele qui corrige pour l’heteroscedasticite
et la correlation dans le but d’etudier la demande d’energie de cinq etats au sud des
Etats-Unis d’Ameriques sur la periode 1981-1990. Il aboutit a une valeur estimee du
parametre de la dependante retardee de 0.561, avec des elasticites revenu, prix directe
et prix croisee de 0.397, -0.239 et 0.143 respectivement. Garcia-Cerrutti (2000) a estime
la demande d’energie (electricite et gaz naturel) de 44 regions de la Californie pour la
periode 1983 a 1997. Il utilise la methode des moindres carres generalises qui corrige
l’heteroscedasticite et l’autocorrelation. Il compare ensuite ses resultats a ce qu’il ob-
tiendrait s’il utilisait l’approche iterative de Swamy. Pour ces deux modeles (le modele
de Swamy (1974) et son modele) il obtient respectivement 0.116 et 0.148 pour l’elasticite
revenu, -0.132 et -0.172 pour l’elasticite prix directe, -0.044 et -0.096 pour l’elasticite
prix croisee de la demande d’electricite de court terme. Pour le gaz naturel, il obtient
une elasticite revenu negative et non significative (-0.235). Comme on peut le constater,
il existe plusieurs valeurs estimees des differentes elasticites.
Tab. 4.7 – Elasticites des modeles dynamiques
dynamique simple heterosc. et AR(1)
elasticite prix electriciteCT -0.4530 -0.506
E-T (0.1423) (0.061)
elasticite prix electriciteLT -0.9380 -1.318
E-T (0.793) (0.529)
elasticite prix gaz naturelCT 0.1108 0.118
E-T (0.0574) (0.025)
elasticite prix gaz naturelLT 0.2294 0.306
E-T (0.2584) (0.507)
elasticite prix mazoutCT -0.2459 -0.323
E-T (0.1699) (0.084)
elasticite prix mazoutLT -0.5091 -0.842
E-T (1.088) (0.389)
elasticite revenuCT 0.1270 0.076
E-T (0.0809) (0.054)
elasticite revenuLT 0.2630 0.198
E-T (0.179) (0.158)
4.5 Conclusion
Comme les resultats des modeles statiques et dynamiques nous le demontrent, il
est important de verifier si les erreurs du modele sont homoscedastiques ou non, s’il y

Chapitre 4. Estimation de la demande d’electricite avec des pseudo-panels de cohortes145
a de l’autocorrelation ou non, lorsqu’on estime un modele avec des effets individuels.
Nous avons utilise le test de Hausman (1978) pour confirmer la presence d’effets fixes
et nous avons utilise des tests du ratio de vraisemblance pour tester l’hypothese d’ho-
moscedasticite et de correlation serielle. La plupart des elasticites prix et revenu de
la demande de court et de long termes sont significatives aux seuil usuel de signifi-
cativite. Ces elasticites sont souvent sous-estimes sous l’hypothese d’homoscedasticite
(hypothese la plus couramment utilisee). On peut egalement noter que les cohortes
s’ajustent de facon plus importante a long terme qu’a court terme lorsqu’il y a des
variations de prix et/ou de revenu. Cela s’explique aisement par le fait que les chan-
gements de court terme sont limites puisqu’il est question de biens durables souvent
acquis pour une longue periode.
Nous avons suppose tout au long de ce travail l’hypothese d’heterogeneite qui se ma-
nifeste uniquement a travers la constante du modele : nous avons suppose un modele
ou seules la constante change d’une cohorte a l’autre. Or, rien ne nous dit que cette
heterogeneite se limite a la constante. Puisqu’il s’agit de cohortes et non de menages
individuels, il est fort probable que les coefficients de pente (de meme que la constante)
changent d’une cohorte a l’autre. Supposer que les coefficients de pente sont identiques
pour toutes les cohortes serait une hypothese assez forte. Par exemple, supposer qu’un
menage (ou sa cohorte) qui est a Montreal a le meme comportement de consommation
qu’un menage (ou sa cohorte) qui reste dans une zone rurale serait une hypothese refu-
table. Dans le prochain chapitre, nous tenterons de prendre en compte l’heterogeneite
entre des groupes de cohortes.

Bibliographie
[1] Alessie R., Devereux M. P. et Weber G. (1997) : «Intertemporal Consumption, Du-
rables and Liquidity Constraints : a Cohort Analysis», European Economic Review,
Vol. 41, pp.27-59.
[2] Anderson, T. W. and Hsiao, C. (1982) : «Formulation and Estimation of Dynamic
Models using Panel Data», Journal of Econometrics, Vol.18, p.47-82.
[3] Baltagi B. H. (1995) : Econometric Analysis of Panel Data, Wiley and Sons.
[4] Baltagi B. H. (2005) : Econometric Analysis of Panel Data, 3e ed. Wiley and Sons.
[5] Baltagi B. H. (2005) : Econometric Analysis of Panel Data, Third Ed., Wiley and
Sons.
[6] Beaudry P. and Green D. (2000) : «Cohort Patterns in Canadian Earnings : As-
sessing the Role of Skill Premia in Inequality Trends», Canadian Journal of Eco-
nomics, Vol.33, No.4
[7] Biron, E. (1981) : «Estimating Economic Relations from Incomplete Cross-
Section/Time-Series Data», Journal of Econometrics, Vol. 16, p.221-236.
[8] Biron, E. and Jansen, E. S. (1983) : «Individual Effects in a System of Demand
Functions», Scandinavian Journal of Economics, Vol. 85, p.461-483.
[9] Blundell R., Browing M et Meghir C. (1985) : «Consumer Demand and the Life-
Cycle Allocation of Household Expenditures», The Review of Economic Studies,
Vol. 61 No. 1, pp 57-80.
[10] Blundell R. et Meghir C. H. (1990) : «Panel Data and Life-Cycle Models», Contri-
butions to Econometrics, Vol. 192, pp. 231-252.
[11] Browning, M., Deaton, A. and Irish, M. (1985) : «A profitable Approach to Labor
Supply and Commodity Demands over the Life-Cycle», Econometrica, Vol. 53,
No.3 pp503-544
[12] Collado D. M. (1997) : «Estimating dynamic Models from Time Series of Inde-
pendent Cross-Sections», Journal of Econometrics, Vol,82, pp37-62
[13] Dahl, C. (1993) : «A Survey of Energy Demand Elasticities in Support of the
Development of the NEMS», Workin Paper prepared for United States Department
of Energy, Colorado School of Mines, Department of Mineral Economics.

Bibliographie 147
[14] Dargay, J. (2002) : «Determinants of Cars Ownership in Rural and Urban Areas :
a Pseudo-panel Analysis», Transportation Tresearch Part E, 38, pp. 351-366.
[15] Dargay, J. and Vythoulkas, C. (1998) : «Estimation of Dynamic Transport De-
mand Models Using Pseudo-panel Data», ESCR Transport Studies Unit Centre
for Transport Studies, University College London.
[16] Dargay J. M. et Vythoulkas P. C. (1999) : «Estimation of a dynamique car ow-
nership model : a pseudo panel approach», Journal of Transport Economics and
Policy, 33, pp. 283-302.
[17] Dargay J. M. (2002) : «Determinants of Car Ownership in Rural and Urban Areas :
a Pseudo-Panel Analysis», Tansportation Research E, 38(5), pp. 351-366.
[18] Dargay J. M. et Vythoulkas P. C. (1997) : «Estimation of a dynamique car owner-
ship model : a pseudo panel approach», ESCR Transport Studies Unit, Ref. 97/47,
University College London
[19] Deaton Angus (1985) : «Panel Data from Time Series of Cross-sections», Journal
of Econometrics, vol. 30 pp 109-126.
[20] Garcia-Cerruti, Miguel L. (2000) : Estimating Elasticities of Residential Energy
Demand from Panel County Data using Dynamic Random Variables Models with
Heteroskedastic and Autocorrelated Error Terms, Resource and Energy Economics,
Vol. 22, pp. 355-366.
[21] Gardes F., Langlois S. et Richaudeau D. (1996) : «Cross-Section versus Times-
Series Income Elasticities of Canadian Consumption», Economics letters, Vol.51,
pp169-175.
[22] Gardes F. et Loisy C. (1997) : «La Pauvrete selon les Menages : une Evaluation
Subjective et Indexee sur leur Revenu», Economie et Statistique, No.308-309-310,
pp95-113.
[23] Garcia-Cerruti, M. L. (2000) : «Estimating Elasticities of Residential energy De-
mand from Panel County Data Using Random Variables Models with Heteros-
cedasticity and Correlation Error Term», Resource and Energy Economy, Vol.22,
pp.355-366
[24] Gassner K. (1998) : «An estimaion of UK Telephone Access Demand Using Pseudo-
Panel Data», Utilities Policy, Vol.7, pp 143-154.
[25] Girma S. (2000) : «A Quasi-Differencing Approach to dynamique Modeling from
a Time Series of Independent Cross-Sections», Journal of Econometrics, Vol.98,
pp365-383.
[26] Greene, W. (2003) : Econometrics Analysis, Fith Ed., Prince Hall, Upper Saddle
River, New Jersey.
[27] Hausman, J.A. (1978) : «Specification Tests in Econometrics», Econometrica,
Vol.46 No.6, p.1251-1271.

Bibliographie 148
[28] Hsiao, C. (2001) : «Panel Data Models», Chapiter 16 in B. H. Baltagi, ed., A Com-
panion to Theorical Econometrics (Blackwell publishers, Massachusetts), p.349-
365.
[29] Hsing, Y. (1994) : «Estimation of Residential Demand for Electricity with the
Cross-Sectionally Correlated and Timewise Autoregressive Model», Resource and
Energy Economics, Vol. 16, p.255-263
[30] Levin, A., C. F. Lin and C. Chu (2002) : «Unit Root Test in Panel Data : Asymp-
totic and Finite Sample Properties», Journal of Econometrics, Vol. 108, p.1-25.
[31] Maddala, G. S., Trost, R. P. Li, H., and Joutz, F. (1994) : «Estimation of Short-
Run and Long-Run Elasticities of Energy Demand from Panel using Shrinkage
Estimators», Journal of Business and Economic Statistics, Vol. 15, p.90-100.
[32] McKenzie D. J. (2001) : «Dynamic Pseudo-Panel Theory and Analysis of Consump-
tion in Taiwan and Mexico», Ph.D Disservation, Yale University
[33] McKenzie D. J. (2004) : «Asymptotic Theory for heterogeneous dynamique
Pseudo-Panels», Journal of Econometrics, Vol.120, pp.235-262.
[34] Moffit R. (1993) : «Identification and Estimation of dynamique Models with a Time
Series of Repeated Cross-Sections», Journal of Econometrics, Vol.59, pp99-123.
[35] Nijman T. et Verbeek M. (1990) : «Estimation of Time-dependent Parameters in
Linear Models using Cross-Sections, Panels, or Both», Journal of Econometrics,
Vol.46, pp333-346.
[36] Oberhofer, W. and J. Kmenta (1974) : «A General Procedure for Obtaining
Maximum Likelihood Estimates in Generalized Regression Models», Econometrica,
Vol.42, p.579-590.
[37] Phillips, P. C. B. and Moon, H. (1999) : «Linear Regression Limit Theory for
Nonstationary Panel Data», Econometrica, Vol. 57, p. 1057-1111.
[38] Poyer, D. A. and Williams, M. (1993) : «Residential Energy Demand : Additional
Empirical Evidence by Minority Household type», Energy Economics, Vol. 15,
p.93-100.
[39] Silk, J. I. and Joutz, F. L. (1997) : «Short- and Long-Run Elasticities in US Resi-
dential Elestricity Demand : a Co-Integration Approach», Energy Economics, Vol.
19, p. 493-513.
[40] Skoufias, E. and A. Suryahadi (2002) : «A Cohort Cnalysis of Wages in Indonesia»,
Applied Economics, Vol. 34, No. 13, pp. 1703-1710.
[41] Swamy, P. A. V. B. (1974) : Linear Models with Random Coefficients, In Zarembka,
P. (ed), Frontiers in Econometrics. Academic Press, London, p. 143-168.
[42] Raj B. et Baltagi B. H. (1992) : «Can Cohort Data Be Treated as Genuine Panel
data ?», Studies in Empirical Economics, Vol. 17, No. 1, pp. 9-23

Bibliographie 149
[43] Verbeek M. et T. Nijman (1993) : «Minimum MSE Estimation of a Regression
Model with Fixed Effects frm a Series of Cross-Sections», Journal od Econometrics,
Vol.59, pp125-136.
[44] Verbeek M. et T. Nijman (1993) : «Can Cohort Data Be Treated As Genuine Panel
data ?», Empirical Economics, Vol. 17, pp. 9-23.
[45] Verbeek M. et Vella F. (2005) : Estimating dynamique Models from Repeated
Cross-Sections», Journal of Econometrics, Vol.127, pp.83-102

Chapitre 5
Estimation bayesienne de modeles a
parametres aleatoires
5.1 Introduction
L’objectif principal de ce travail est d’estimer des modeles de demande d’electricite
a parametres heterogenes a partir de donnees d’enquetes d’independantes. Nous ana-
lyserons plus precisement l’aspect dynamique dans la consommation d’electricite des
menages de la province de Quebec. Pour cette province il n’y a pas de panel permettant
de capter l’aspect dynamique dans le comportement des individus. L’alternative que
nous utilisons est de constituer un pseudo-panel compose de cohortes. Les individus
qui composent une cohorte sont supposes etre assez homogenes. Par ailleurs, dans la
definition des cohorte, on suppose une certaine heterogeneite entre des individus de
cohortes differentes. Il serait donc important que le modele tienne compte formellement
de l’heterogeneite qui existerait entre les cohortes.
Dans la litterature, les modeles qui sont habituellement utilises dans le context des
pseudo-panels sont des modeles a effets fixes. Dans ces modeles, l’heterogeneite est
uniquement prise en compte a travers la constante du modele. Hors, l’heterogeneite
peut aussi se manifester a travers les coefficients de pente, qui sont les coefficients
d’interet. McKenzie (2001 et 2004) a utilise l’hypothese d’heterogeneite deterministe
entre les cohortes et les parametres ont ete estimes selon les methodes classiques. Dans
ce papier, nous proposons plutot de l’heterogeneite aleatoire qui permet une certaine
flexibilite dans le modele. Notre approche est assez proche de celle de Maddala et al.
(1997) qui ont plutot utilise de vraies donnees de panel. Nous developpons a la fois des

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 151
modeles statique et dynamique avec parametres heterogenes. Nous proposons d’utiliser
les techniques d’estimation bayesienne qui consistent a combiner l’echantillonnage de
Gibbs et l’augmentation des donnees. L’echantillonnage de Gibbs servira a estimer les
parametres tandis que l’algorithme de l’augmentation des donnees sera utilise dans
le modele dynamique pour completer les donnees manquantes qui sont : la variable
dependante retardee et la premiere observation. Ces deux variables sont habituellement
instrumentees dans le contexte de vrais panels pour avoir des estimateurs convergents.
Nous estimons aussi des modeles statique et dynamique avec parametres homogenes
pour fin de comparaison.
Il est ressorti de nos resultats que la prise en compte de l’heterogeneite entre les
cohortes donnent de meilleures estimations. Nous avons estime des elasticites prix et
revenu de la demande specifiques a chaque region de la province de Quebec. Lorsque
l’heterogeneite n’est pas consideree, cela conduit a une sous-estimation des valeurs des
elasticites. De plus, le modele dynamique avec parametres homogenes surevalue l’ajus-
tement de long terme des cohortes par rapport au modele avec heterogeneite. L’ap-
proche proposee est novatrice dans le domaine des pseudo-panels en ce sens qu’elle
est la premiere qui suggere d’utiliser les techniques de simulation pour resoudre des
problemes importants dans l’analyse de la demande d’energie ou d’electricite en parti-
culier. Cette demarche pourrait aussi s’appliquer a tout autre domaine ou des problemes
similaires se posent.
La section (5.2) presente un resume des ecrits anterieurs portant sur le sujet, la
section (5.3) elabore le modele de demande a parametres homogenes (modele habituel-
lement considere), la section (5.4) presente le modele de demande statique, la section
(5.5) presente le modele de demande dynamique d’electricite, la section (5.6) analyse
les elasticites prix et revenu de la demande et nous concluons a la section (5.7).
5.2 Revue des ecrits anterieurs
Dans l’analyse des donnees de panel ou de pseudo-panel, il est habituel d’estimer
les modeles en supposant que les coefficients sont les memes pour toutes les observa-
tions. On empile alors les donnees (peu importe s’il existe ou non des groupes dans
les donnees) pour estimer les parametres communs a tous. L’heterogeneite intervient
souvent a travers les effets fixes ou aleatoires (ou les erreurs composees). Avec les effets
fixes individuels, on permet a chaque observation ou cohorte d’avoir une constante qui
lui est specifique. Quant aux coefficients de pente, on suppose habituellement qu’ils sont
communs a tous. L’hypothese d’homogeneite des coefficients de pente est souvent une

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 152
hypothese trop forte. Pour le cas des pseudo-panels qui nous concerne, les unites qui
font l’objet d’etude sont les cohortes qui sont en fait des groupes d’individus supposes
assez homogenes entre eux et ayant un certain nombre de caracteristiques en commun.
De plus, on suppose implicitement que les menages de cohortes differentes sont suffi-
samment heterogenes. En regroupant les individus en differentes cohortes, l’hypothese
d’homogeneite entre cohortes devient alors une hypothese trop forte. Par exemple, il
semble logique de penser que les menages qui sont dans la meme region et qui ont
sensiblement la meme taille de maison (petite, moyenne ou grande superficie) ont des
comportements de consommation d’electricite assez proches (exemple, les menages qui
vivent a Montreal, ou ceux qui vivent dans la region de Quebec ont chacun des ca-
racteristiques specifiques).
Il est donc raisonnable de supposer qu’il existe une certaine forme d’heterogeneite
entre les cohortes. Dans le contexte des pseudo-panels, seul Mckenzie (2001, 2004)
a introduit l’hypothese d’heterogeneite entre les cohortes. Il a suppose en effet de
l’heterogeneite deterministe entre les cohortes : les parametres du modele sont specifiques
a chaque cohorte et ils sont estimes selon les methodes classiques habituelles : moindres
carres ordinaires (MCO), moindres carres quasi-generalises (MCQG), methode a va-
riables instrumentales,... Il propose d’utiliser le test de Wald pour tester l’hypothese
nulle d’homogeneite entre les cohortes. Dans son application empirique portant sur la
consommation en Taiwan et au Mexique, il est ressorti que les cohortes de jeunes avaient
une croissance de la consommation plus forte que les cohortes de vieux au cours de la
periode 1976-1996.
Il existe dans les ecrits anterieurs portant sur les vrais panels d’autres formes
d’heterogeneite : l’heterogeneite entre les individus (ou modele a parametres aleatoires)
et l’heterogeneite entre les periodes. Dans ce travail, nous nous limitons a l’heterogeneite
entre les observations (cohortes plus precisement). Cette forme d’heterogeneite a ete
particulierement utilisee dans le contexte de vrais panels (par exemple, Maddala et
al. 1997). Robertson et Symons (1992) et Pesaran et Smith (1995) ont discute des
biais potentiels qui pourraient exister dans l’estimation des elasticites de long terme
si l’heterogeneite est ignoree. Lorsqu’on suppose une forme d’heterogeneite aleatoire,
cela revient a supposer que les parametres proviennent d’une distribution commune.
Generalement, on s’interesse a l’estimation de la moyenne (commune) de cette distribu-
tion. En utilisant les modeles a parametres aleatoires, cela permet de reduire le nombre
de parametres a estimer en supposant que les coefficients sont tires d’une meme distri-
bution qui est fonction de ses premiers moments (moyenne et variance). Les modeles a
parametres aleatoires peuvent etre estimes soit par une approche classique (estimation
par le maximum de vraisemblance, les moindres carres generalises,...) ou soit selon une
approche bayesienne (approche iterative ou approche basee sur la simulation).

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 153
Maddala et al. (1997), dans le contexte de vrais panels, ont propose une approche
bayesienne permettant d’estimer les parametres aleatoires. Leur approche est inspiree
de celle de Smith (1973). Ils estiment les parametres conjointement et de facon iterative.
Ils utilisent cette approche pour estimer les elasticites de court et de long terme de la
demande d’electricite de 49 etats des Etats-Unis. Ils comparent leurs estimateurs a l’es-
timateur obtenu par la regle de Stein, a l’estimateur de l’approche empirique de Bayes et
a celui du maximum de vraisemblance. L’estimateur propose selon la methode iterative
serait superieur aux autres estimateurs surtout en presence de variables endogenes re-
tardees dans le modele.
Supposons que le modele a parametres aleatoires est defini comme suit :
yn = Xnβn + εn (5.1)
βn ∼ N (µ, Σ) (5.2)
=⇒ βn = µ + un
un ∼ N (0, Σ)
εn ∼ N(0, σ2
n
).
Le modele (5.1) peut encore s’ecrire :
yn = Xnµ + vn
vn ∼ N (0, Ψn)
Ψn = XnΣX ′n + σ2
nI.
En supposant que les εn sont independants, l’estimateur des MCG de µ est :
µ =
[N∑
n=1
X ′nΨ−1
n Xn
]−1( N∑
n=1
X ′nΨ−1
n yn
).
Comme les parametres Σ et σ2n sont souvent inconnus, Swamy (1970) a propose une
procedure en deux etapes qui utilise les estimateurs βnMCO ainsi que les εn, les residus
des MCO pour obtenir des estimateurs sans biais de Σ et σ2n. Les estimateurs proposes
par Swamy (1970) sont :
Σ =1
N − 1
N∑
n=1
(βnMCO − 1
N
N∑
n=1
βnMCO
)(βnMCO − 1
N
N∑
n=1
βnMCO
)′
− 1
N
∑
n
(X ′nXn)
−1σ2
n
σ2n =
ε′nεn
T − K.
Cette procedure donne des estimateurs asymptotiquement efficaces seulement si le vec-
teur Xn ne contient pas de variable endogene retardee. Lee et Griffiths (1978) ont derive

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 154
le meilleur estimateur lineaire (statique) sans biais de βn base sur l’approche de la vrai-
semblance a priori evoquee prealablement par Edwards (1969). Leurs estimateurs sont
tres proches de ceux de Maddala et al. (1997). Ces derniers auteurs ont en effet postule
une loi a posteriori normale pour βn. Si µ, Σ et σ2n sont connus, la loi a posteriori de βn
sera aussi une normale compte tenu de l’equation (5.2) :
βn =
[1
σ2n
X ′nXn + Σ−1
]−1(1
σ2n
X ′nXnβnMCO + Σ−1µ
)
V(βn
)=
[1
σ2n
X ′nXn + Σ−1
]−1
.
En presence de variables endogenes retardees, la normalite de la loi a posteriori tient
uniquement en asymptotique et sous les conditions de regularite imposees dans les
modeles de regression dynamiques. Ils supposent une loi a priori non informative pour
µ de sorte que la moyenne de sa loi a posteriori serait : µ = 1N
∑n βn. Comme les
parametres de nuisance Σ et σ2n sont souvent inconnus, Smith (1973) a suppose une loi
Wishart pour Σ−1 et des lois χ2 inverse independantes pour les σ2n. Les estimateurs des
parametres de nuisance sont finalement :
σ2n =
(yn − Xnβn
)′ (yn − Xnβn
)
T + 2
Σ =1
N − K − 1
[R +
∑
n
(βn − µ
)(βn − µ
)′]
,
ou R est une matrice diagonale de petites valeurs positives (exemple : 0.001).
Nous proposons dans ce chapitre une methode bayesienne d’estimation similaire a
celle de Maddala et al. (1997). A la difference de ces derniers, nous proposons d’utili-
ser l’algorithme de l’echantillonnage de Gibbs pour estimer les parametres aleatoires.
L’echantillonnage de Gibbs est une methode d’estimation bayesienne. La methodologie
bayesienne est essentiellement fondee sur le theoreme de Bayes qui relie l’information
a priori (information disponible avant que les donnees ne soient observees), la nouvelle
information et la distribution a posteriori. Supposons un modele lineaire :
Y = Xβ + ε
ε ∼ N (0, Σ) .
Posons θ = (β, Σ) le vecteur des parametres du modele. Si on veut estimer le vecteur
de parametres θ de facon conjointe, on peut se servir de la relation suivante :
f (θ,X, Y ) = f (θ |X,Y ) g (X,Y ) (5.3)
= g (X,Y |θ ) f (θ) . (5.4)

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 155
En divisant (5.3) et (5.4) par g (X,Y ), on obtient la distribution a posteriori qui est la
distribution d’interet :
f (θ |X,Y ) =g (X,Y |θ ) f (θ)
g (X,Y )
f (θ |X,Y ) : distribution a posteriori des parametres d’interet ;
g (X,Y |θ ) = L (θ |X,Y ) : fonction de vraisemblance des donnees
f (θ) : distribution a priori des parametres d’interet
g (X,Y ) : constante de proportionnalite.
On peut alors reecrire la derniere equation comme suit :
f (θ |X,Y ) ∝ L (θ |X,Y ) × f (θ)
L’echantillonnage de Gibbs utilise cette relation pour estimer les parametres d’interet.
C’est la technique MCMC (Markov Chain Monte Carlo) la plus simple. Sa popularite
date de l’application faite par German et German (1984) de la distribution de Gibbs
pour modeliser les images satellites. Gelfand (2000) definit l’echantillonnage de Gibbs
comme un outils pour obtenir des echantillons a partir de fonctions de densite jointes non
standard. Ces echantillons proviennent en fait de distributions conditionnelles associees
a la densite jointe. Rappelons que les MCMC sont un ensemble de techniques pour
faire des tirages pseudo aleatoires a partir de distributions de probabilite. L’objectif du
MCMC est de generer une ou plusieurs valeurs d’une variable aleatoire Z habituellement
multidimensionnelle. Il s’agit de faire de la simulation Monte Carlo sur une chaıne
markovienne ergodique. (Voir Gordon et Belanger, 2003 pour un survol sur ce sujet).
Nous utiliserons la technique d’echantillonnage de Gibbs pour estimer dans un pre-
mier temps un modele statique de demande d’electricite. Nous supposerons d’abord un
modele ou les parametres sont homogenes et ensuite nous supposerons de l’heterogeneite
entre les cohortes : les cohortes sont reparties en neuf (9) groupes heterogenes, mais
au sein de chaque groupe, nous supposons que les menages sont homogenes. Ces 9
groupes sont en fait les 9 regions administratives de la province de Quebec qui sont :
Manicouanga (1), Saint Laurent (2), Richelieu (3), Montmorency (4), Les Laurentides
(5), La Mauricie (6), La Grande (7), Matapedia (8) et enfin Saguenay (9). Dans un
second temps, nous etendrons la meme approche au modele dynamique de demande
d’electricite. Dans le modele dynamique, la variable dependante retardee de meme que
la premiere observation seront considerees comme des donnees manquantes que nous
simulerons en nous servant de l’algorithme de l’augmentation des donnees propose par
Tanner et Wong (1987). L’approche developpee ici est la premiere dans le contexte de
pseudo-panels, nous n’avons pas pu trouve dans les travaux anterieurs une demarche
semblable, qui pourtant pourrait etre d’une tres grande utilite dans un contexte de
coupes transversales independantes.

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 156
5.3 Modele statique a parametres aleatoires homogenes
Supposons que l’equation de demande au niveau du menage n a la periode t est
definie de la facon suivante :
ynt = Xntβ + θnt + εnt (5.5)
εnt ∼ N(0, σ2
ε
)
θnt ∼ N(0, σ2
θ
).
Notons l’inverse de la variance σ−2ε = h. Etant donne que nous ne disposons pas d’infor-
mation au niveau des menages pour chacune des periodes considerees, nous optons de
considerer des cohortes de menages definies au sens de Deaton (1985) dont nous pouvons
suivre l’evolution dans le temps. Pour construire les cohortes, nous devons regrouper les
menages suivant des criteres bien etablis. Nous avons choisi comme criteres la superficie
et la region d’habitation. La variable superficie de l’habitat est regroupee en 3 blocs : les
petites maisons (moins de 1000 pieds carres) les maisons moyennes (entre 1000 et 2000
pieds carres) et les grandes maisons (plus de 2000 pieds carres). En ce qui concerne la
variable region, nous avons garde le decoupage d’Hydro-Quebec qui consiste a diviser
toute la province de Quebec en 9 regions administratives. Nous supposons que durant
toute la periode consideree (1989 a 2002), les menages ont garde le meme systeme de
chauffage ; par consequent, nous supposons aussi que la superficie habitee et chauffee n’a
pas change, ou du moins si le menage a demenage, il choisira une maison qui a le meme
systeme de chauffage. Comme les enquetes sont menees dans la meme province d’une
periode a l’autre, nous estimons que meme si les individus demenagent, cela n’affecte
pas les maisons, les nouveaux occupants continueront d’utiliser les memes systemes de
chauffage. Nous considerons en quelque sorte un continuum de menages. Considerons
la version moyennes de cohortes du modele (5.5) :
yct = Xctβ + θct + εct, (5.6)
avec θct des effets individuels. La version population de cohortes est definie par :
y∗ct = X∗
ctβ + θ∗ct + εct. (5.7)
L’etoile indique que la variable n’est pas observable, puisqu’on ignore la moyenne de la
population entiere de cohortes. Les variables yct et Xct representent les moyennes de la
population (y∗ct et X∗
ct respectivement) mais avec erreurs de mesure. Nous supposons
que le nombre d’individus par cohorte est suffisamment grand de sorte que l’on peut
ignorer les erreurs de mesure.

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 157
Ecrivons le modele sous forme matricielle de maniere a le simplifier :
y =
y1
y2...
yC
X =
X1
X2
...
XC
ε =
ε1
ε2
...
εC
y = Xβ + θ + ε
ou chaque zc contient T observations et chaque z contient CT observations1. L’esti-
mation des parametres se fera avec l’algorithme de l’echantillonnage de Gibbs. Soit :
θ = (θ1, θ2, ........θJ) ou θj est un element ou un sous ensemble de θ. Si le modele est assez
complexe, la distribution marginale f (θ) = f (θ1, θ2, ........θJ) ne sera pas standard. Par
exemple, si on s’interesse a la densite marginale du premier element, on doit integrer
la densite conjointe par rapport aux autres elements de sorte a obtenir la fonction a
integrales multiples suivante :
f (θ1) =
∞∫
−∞
∞∫
−∞
.......
∞∫
−∞
f (θ1, θ2, θ3........θl) dθ2dθ3dθ4......dθl.
La presence d’integrales multiples posent de serieux problemes si on veut calculer cer-
tains moments (moyenne ou variance). Cependant, la densite conditionnelle f (θ1 |θ−1 )
est souvent facile a calculer (ou θ−1 = (θ2, ........θJ) represente les elements autres que
celui qui nous interesse, θ1). Dans le but d’eviter des calculer onereux en temps, Ger-
man et German (1984) ont propose la technique d’echantillonnage de Gibbs basee sur
la theorie des chaınes markoviennes.
Supposons une distribution conjointe P (θ) = P (θ1, θ2, ........θJ) et les distributions
conditionnelles suivantes :
θ1 ∼ P (θ1 |θ2, ........θJ )
θ2 ∼ P (θ2 |θ1, θ3........θJ )...
θJ ∼ P (θJ |θ1, θ2........θJ−1 ) .
Supposons que ces distributions conditionnelles sont plus simples et plus faciles a cal-
culer ; de plus supposons qu’il est possible de simuler des tirages artificiels de θj ∼P (θj |θ−j ) . Alors, l’algorithme de l’echantillonnage de Gibbs est defini selon les 3
etapes suivantes :
1y est de dimension (CT × 1), X est de dimension (CT × K), ε est de dimension (CT × 1), β est
de dimension (K × 1) et θ est de dimension (CT × 1).

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 158
– Etape 1 : Donner des valeurs de depart aux parametres : θ01, θ
02, ........θ
0J et poser
i = 1.
– Etape 2 : Effectuer les tirages conditionnels suivants :
θi1 ∼ P
(θ1
∣∣θi−12 , ........θi−1
J
)
θi2 ∼ P
(θ2
∣∣θi1, θ
i−13 ........θi−1
J
)(5.8)
...
θiJ ∼ P
(θJ
∣∣θi1, θ
i2........θ
iJ−1
).
– Etape 3 : Poser i = i + 1 et retourner a l’etape i.
L’ensemble constitue un tour et un element dans (5.8) constitue une iteration. No-
tons que cet algorithme decrit une chaıne markovienne du premier ordre parce que la
distribution conditionnelle d’un tirage depend de la realisation precedente. De plus,
si la densite P (θj |θ−j ) est positive pour toutes les valeurs possibles de θj, on dira
alors que la chaıne est ergodique. Dans ce cas, la sequence converge vers sa distri-
bution stable P (θ) pour toute valeur de depart θ0. De plus, comme nous l’avons
souligne anterieurement, si la sequence converge avant l’iteration n, alors la moyenne
echantillonnale N−1∑n+N
i=n+1 g (θi) est un estimateur convergent simule de la moyenne a
posteriori de la population E [g (θ |.)].L’echantillonnage de Gibbs servira donc a simuler les parametres de nos modeles dans
un context de donnees manquantes.
5.3.1 Simulation de β
Si les croyances a priori sur β sont une normale P (β) = N (b0, B0), et si h = σ−2ε
est connu de meme que les donnees, alors sa distribution a posteriori sera aussi une
normale :
P(β∣∣y,X, h
)= N
(b, B
)
B = B0 + h × XX
b = B−1 [
b0B0 + h × Xy].

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 159
5.3.2 Simulation de h
Etant donne β, si la distribution a priori de h est une loi gamma : P (h) = G (a0, A0),
alors sa distribution a posteriori sera aussi une gamma :
P(h∣∣β, y,X
)= G (a1, A1)
a1 = a0 +CT
2A1 = A0 +
εε′
2avec : ε = y − Xβ.
5.3.3 Simulation de σ2θ
Etant donne les autres parametres du modele, si les croyances a priori sur σ−2θ sont
une gamma : P(σ−2
θ
)= G (c0, C0), alors sa distribution a posteriori serait aussi une
gamma :
P(σ−2
θ
∣∣y,X, h)
= G(c, C
)
C = C0 +
∑c θ2
c
2
c = c0 +CT
2.
5.3.4 Resultats et interpretation
Nous avons effectue 6000 tirages et nous avons enleve les 10% (soit les 600) premieres
valeurs simulees afin de permettre a l’algorithme de se defaire de l’influence des valeurs
de depart. Le tableau (5.1) presente la moyenne des 5400 tirages de chaque parametre et
son ecart-type. Dans ce modele, nous avons suppose que les parametres sont les memes
pour toutes les cohortes. Tous les estimes sont significatifs2 a 1%. L’effet individuel qui
traduit une heterogeneite non observable a une variance significative a 1%.
Nous avons aussi trace les graphiques (histogrammes et convergence) qui sont dans
l’annexe (5.8.2). Les graphiques qui presentent les valeurs estimees en fonction du
2Etant donne que les lois a posteriori des estimateurs des coefficients sont normales (les graphiques
de convergence indiquent que les estimes suivent une loi normale) et que les tirages sont faits de facon
independante les uns des autres, les conditions d’un test de Student (au sens classique) sont reunies.
Nous utilisons donc le test de Student pour juger de la significativite individuelle des estimes obtenus
selon l’approche par la simulation.

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 160
nombre de tirages indiquent que tous les estimateurs sont convergents. Nous nous ser-
virons de ces resultats pour effectuer une comparaison avec le modele a parametres
heterogenes de la section suivante.
Tous les coefficients estimes sont significatifs a 1% et ont le signe attendu. La variable
cdd (cooling degree days) pour la demande d’electricite n’a pas le meme signe que dans
les travaux de Maddala et al. (1997) de meme que ceux de Gracia-Cerrutti (2000). Ces
derniers avaient obtenu un signe positif signifiant que si cdd augmente, indiquant qu’il
fait plus chaud et donc les menages americains augmentent leur demande d’energie pour
fin de climatisation. Selon nos resultats, l’estime de la variable cdd est plutot de signe
negatif. Cela indique que si cdd augmente, donc il fait plus chaud, les menages quebecois
n’ont plus besoin de chauffer leur maison, et par consequent, la demande d’electricite
pour le chauffage va baisser. A Quebec, la penetration des systemes de climatisation est
un phenomene assez recent et de plus, tres peu de menages climatisent leur maison. On
s’attendait a ce que l’estime de la variable cdd ait un signe positif. Dans les resultats de
Maddala et al. (1997) et ceux de Gracia-Cerrutti (2000), la variable cdd avait cependant
un signe negatif pour la demande de gaz naturel. Une augmentation des degres jour
de climatisation entraınerait une baisse de la demande d’electricite. La variable hdd
(degres jours de chauffage) a le bon signe : plus il fait froid (hdd augmente), plus les
besoins de chauffage augmentent, plus la demande d’electricite augmente aussi.
Tab. 5.1 – Resultats du modele statique a parametres homogenes
Variables Moyenne ecart-type t-Student Min Max
pelec marg -3.165289 .1894613 16.703 -3.959758 -2.513447
revenu net 2.085332 .0974224 21.4096 1.747453 2.427006
hdd 1.346503 .26744 5.0348 .248548 2.234885
cdd -.7869049 .16167 4.8673 -1.339625 -.1509901
cst 22.81251 1.799671 12.6759 14.78075 28.42545
h 4.939011 .7124093 6.9328 2.68575 7.91684
sig2theta 1.871035 .5208126 3.5925 .7328739 5.674028
5.4 Modele statique a parametres heterogenes
Dans cette section, nous voulons estimer un modele a effets aleatoires en prenant en
compte l’heterogeneite entre les groupes de cohortes. Nous avons regroupe les cohortes
en 9 groupes distincts : puisque chaque cohorte se retrouve dans une des 9 regions
administratives du Quebec, nous les avons donc regroupees selon ces 9 regions. Nous
aurions voulu considerer plutot l’heterogeneite entre les unites de cohortes, mais la

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 161
dimension temporelle du pseudo-panel est tres petite (4 periodes), limitant davantage
le nombre de parametres a estimer par cohorte. En d’autres termes, puisqu’on a 25
cohortes sur 4 periodes, l’heterogeneite a travers les cohortes exigerait d’estimer 25
fois le nombre de parametres du modele, avec seulement 4 observations par cohorte
consideree. Cela poserait inevitablement un probleme de parametres d’incidence. Pour
cette raison, nous avons prefere estimer un modele a effets aleatoires avec heterogeneite
groupees selon les regions.
Le modele a effets aleatoires groupes selon les regions est defini comme suit :
ygt = Xgtβg + εgt (5.9)
g = 1, 2, ...G avec : G << C t = 1, 2, ...T εgt ∼ N(0, h−1g ).
Nous supposons que les coefficients sont specifiques a chaque region de la province.
5.4.1 Simulation de βg
Si la variance hg est connue, et si les croyances a priori sur βg sont une normale
P (βg) = N (b0g, B0g), alors la distribution a posteriori de βg sera aussi une normale :
P(βg
∣∣y,X, h)
= N(bg, Bg
)
Bg = B0g + hg × XgXg
bg = B−1
g
[b0gB0g + hg × Xgyg
].
Apres avoir estime βg le vecteur des coefficients specifiques au groupe g, nous calculons
la moyenne pour toute la province notee par : 1Gµ =
∑Gg=1 βg.
5.4.2 Simulation de hg
Etant donne les parametres βg et les donnees, si la distribution a priori de hg est une
inverse gamma : P (hg) = IG (a0g, A0g), alors la distribution a posteriori de hg serait
aussi une inverse gamma :
P(hg
∣∣y,X)
= IG (a1g, A1g)
a1g = a0g +CgT
2A1g = A0g +
εgε′g
2εgt = ygt − Xgtβg.

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 162
5.4.3 Resultats empiriques et interpretations
Le tableau (5.2) presente les resultats de l’estimation. Lorsqu’une variable se ter-
mine par un chiffre, cela signifie qu’il s’agit du coefficient specifique a une region donnee.
Les variables qui ne se terminent pas avec un chiffre representent les moyennes des va-
leurs estimees des parametres specifiques aux groupes de cohortes (ces valeurs estimees
sont dans le dernier bloc du tableau). Nous remarquons tout d’abord que la plupart
des coefficients de pente sont tres significatifs (au seuil de 1%) sauf ceux de la region6
(Mauricie). Les estimes du prix marginal et du revenu net ont le bon signe.
Une hausse du prix marginal de l’electricite entraıne une baisse de la demande d’electricite
des cohortes, l’amplitude de cette baisse varie cependant d’une region a l’autre. La
region6 a l’effet marginal (pelec marg) le plus bas en valeur absolue (-0.343) tandis que
la region2 a l’effet marginal le plus eleves en valeur absolue (-9.18). Mais en moyenne,
l’effet marginal du prix de l’electricite est de -3.56 pour toute la province. Cette valeur
est assez proche (neanmoins legerement superieure en valeur absolue) de celle du modele
empile ou a parametres homogenes (qui est -3.16).
Une hausse du revenu net des cohortes entraıne une augmentation de la demande
d’electricite. Cette augmentation est sensiblement la meme d’une region a l’autre (les
estimes du revenu net vont de 2.04 pour la region4 a 2.97 pour la region7). En moyenne,
l’effet marginal du revenu sur la demande d’electricite est de 2.47. Cette valeur est assez
proche (neanmoins legerement superieure) de celle du modele a parametres homogenes
(2.085).
Le signe de l’estime de la variable hdd est positif pour toutes les regions a l’exception
de celle de la region8 (Matapedia). L’effet marginal de hdd varie enormement d’une
region a l’autre : de 0.86 pour la region6 (Mauricie) a 66.82 pour la region2 (Saint
Laurent) et -0.45 pour la region8 (Matapedia). En moyenne, pour toute la province,
l’effet marginal de hdd est de 12.17. Cette valeur est nettement plus grande que celle
du modele a parametres homogenes qui est de 1.35.
Le signe de la variable cdd change d’une region a l’autre : de -13.98 pour la region8
(Matapedia) a 24.19 pour la region2 (St Laurent). En moyenne, pour la province, l’effet
marginal est de -2.16. Cette valeur est plus grande en valeur absolue que celle du modele
a parametres homogenes (-0.78).
En somme, le modele qui ne suppose pas l’heterogeneite entre les cohortes tend a sous-
estimer en general les valeurs estimees des coefficients.
Nous avons trace des graphiques pour connaıtre l’allure des valeurs estimees de meme
que leur convergence. Ces graphiques (de 5.7 a 5.15) sont presentes en annexe (5.8.2). Il
ressort que pour les 5400 tirages effectues et retenus, tous les parametres estimes sont
convergents. Toutes les valeurs tirees ont une distribution approximativement normale.
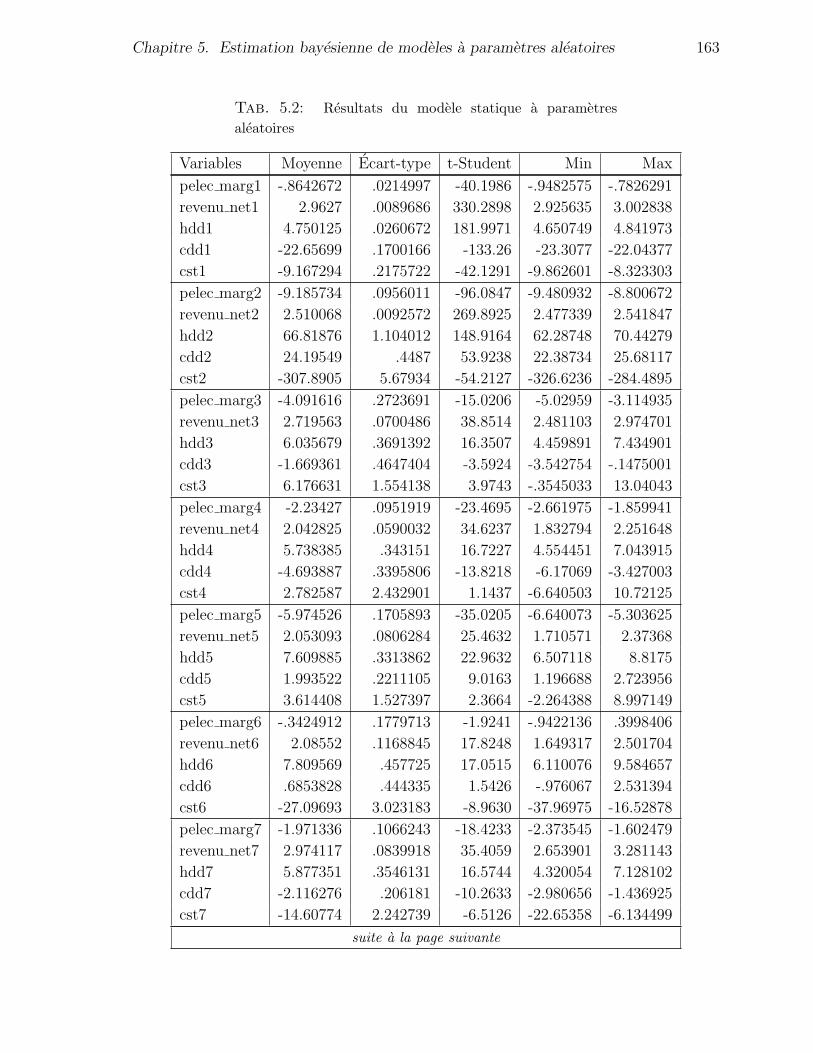
Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 163
Tab. 5.2: Resultats du modele statique a parametres
aleatoires
Variables Moyenne Ecart-type t-Student Min Max
pelec marg1 -.8642672 .0214997 -40.1986 -.9482575 -.7826291
revenu net1 2.9627 .0089686 330.2898 2.925635 3.002838
hdd1 4.750125 .0260672 181.9971 4.650749 4.841973
cdd1 -22.65699 .1700166 -133.26 -23.3077 -22.04377
cst1 -9.167294 .2175722 -42.1291 -9.862601 -8.323303
pelec marg2 -9.185734 .0956011 -96.0847 -9.480932 -8.800672
revenu net2 2.510068 .0092572 269.8925 2.477339 2.541847
hdd2 66.81876 1.104012 148.9164 62.28748 70.44279
cdd2 24.19549 .4487 53.9238 22.38734 25.68117
cst2 -307.8905 5.67934 -54.2127 -326.6236 -284.4895
pelec marg3 -4.091616 .2723691 -15.0206 -5.02959 -3.114935
revenu net3 2.719563 .0700486 38.8514 2.481103 2.974701
hdd3 6.035679 .3691392 16.3507 4.459891 7.434901
cdd3 -1.669361 .4647404 -3.5924 -3.542754 -.1475001
cst3 6.176631 1.554138 3.9743 -.3545033 13.04043
pelec marg4 -2.23427 .0951919 -23.4695 -2.661975 -1.859941
revenu net4 2.042825 .0590032 34.6237 1.832794 2.251648
hdd4 5.738385 .343151 16.7227 4.554451 7.043915
cdd4 -4.693887 .3395806 -13.8218 -6.17069 -3.427003
cst4 2.782587 2.432901 1.1437 -6.640503 10.72125
pelec marg5 -5.974526 .1705893 -35.0205 -6.640073 -5.303625
revenu net5 2.053093 .0806284 25.4632 1.710571 2.37368
hdd5 7.609885 .3313862 22.9632 6.507118 8.8175
cdd5 1.993522 .2211105 9.0163 1.196688 2.723956
cst5 3.614408 1.527397 2.3664 -2.264388 8.997149
pelec marg6 -.3424912 .1779713 -1.9241 -.9422136 .3998406
revenu net6 2.08552 .1168845 17.8248 1.649317 2.501704
hdd6 7.809569 .457725 17.0515 6.110076 9.584657
cdd6 .6853828 .444335 1.5426 -.976067 2.531394
cst6 -27.09693 3.023183 -8.9630 -37.96975 -16.52878
pelec marg7 -1.971336 .1066243 -18.4233 -2.373545 -1.602479
revenu net7 2.974117 .0839918 35.4059 2.653901 3.281143
hdd7 5.877351 .3546131 16.5744 4.320054 7.128102
cdd7 -2.116276 .206181 -10.2633 -2.980656 -1.436925
cst7 -14.60774 2.242739 -6.5126 -22.65358 -6.134499
suite a la page suivante
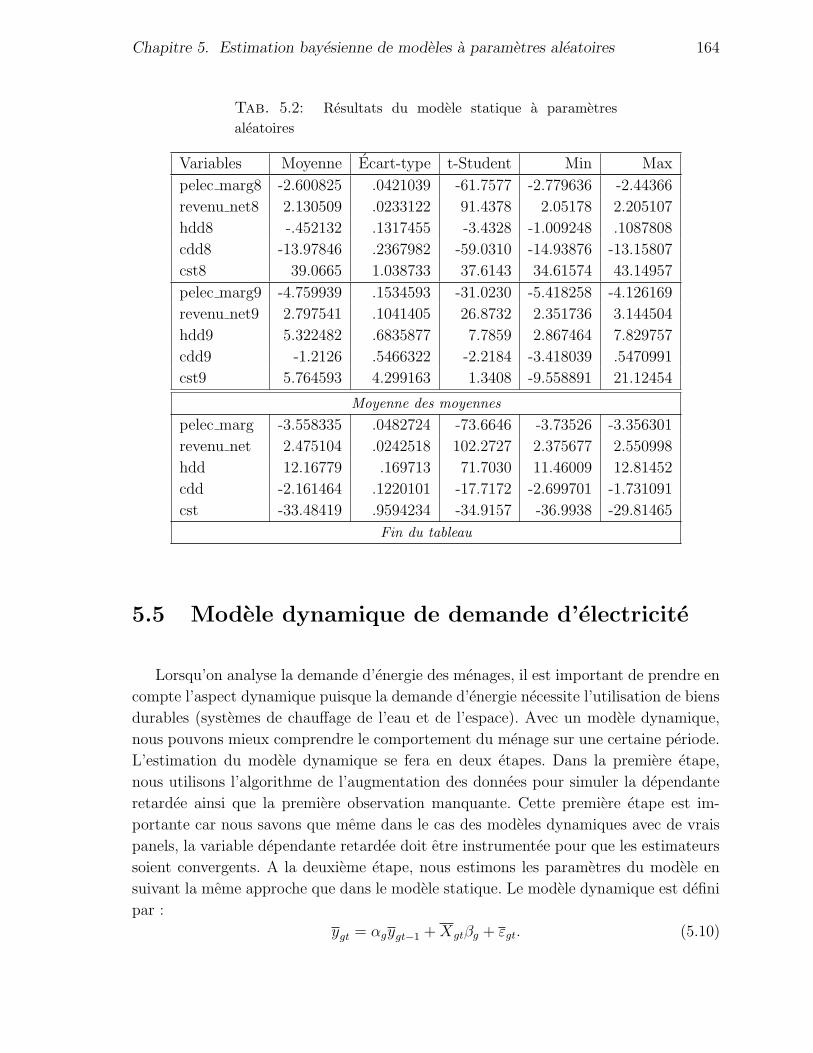
Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 164
Tab. 5.2: Resultats du modele statique a parametres
aleatoires
Variables Moyenne Ecart-type t-Student Min Max
pelec marg8 -2.600825 .0421039 -61.7577 -2.779636 -2.44366
revenu net8 2.130509 .0233122 91.4378 2.05178 2.205107
hdd8 -.452132 .1317455 -3.4328 -1.009248 .1087808
cdd8 -13.97846 .2367982 -59.0310 -14.93876 -13.15807
cst8 39.0665 1.038733 37.6143 34.61574 43.14957
pelec marg9 -4.759939 .1534593 -31.0230 -5.418258 -4.126169
revenu net9 2.797541 .1041405 26.8732 2.351736 3.144504
hdd9 5.322482 .6835877 7.7859 2.867464 7.829757
cdd9 -1.2126 .5466322 -2.2184 -3.418039 .5470991
cst9 5.764593 4.299163 1.3408 -9.558891 21.12454
Moyenne des moyennes
pelec marg -3.558335 .0482724 -73.6646 -3.73526 -3.356301
revenu net 2.475104 .0242518 102.2727 2.375677 2.550998
hdd 12.16779 .169713 71.7030 11.46009 12.81452
cdd -2.161464 .1220101 -17.7172 -2.699701 -1.731091
cst -33.48419 .9594234 -34.9157 -36.9938 -29.81465
Fin du tableau
5.5 Modele dynamique de demande d’electricite
Lorsqu’on analyse la demande d’energie des menages, il est important de prendre en
compte l’aspect dynamique puisque la demande d’energie necessite l’utilisation de biens
durables (systemes de chauffage de l’eau et de l’espace). Avec un modele dynamique,
nous pouvons mieux comprendre le comportement du menage sur une certaine periode.
L’estimation du modele dynamique se fera en deux etapes. Dans la premiere etape,
nous utilisons l’algorithme de l’augmentation des donnees pour simuler la dependante
retardee ainsi que la premiere observation manquante. Cette premiere etape est im-
portante car nous savons que meme dans le cas des modeles dynamiques avec de vrais
panels, la variable dependante retardee doit etre instrumentee pour que les estimateurs
soient convergents. A la deuxieme etape, nous estimons les parametres du modele en
suivant la meme approche que dans le modele statique. Le modele dynamique est defini
par :
ygt = αgygt−1 + Xgtβg + εgt. (5.10)

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 165
Comparativement au modele statique de la section precedente, dans ce modele, nous
avons inclus la variable dependante retardee. Pour estimer ce modele, nous devons
d’abord remplacer la dependante retardee par un bon instrument. Pour cela, nous utili-
serons l’algorithme de l’augmentation des donnees qui simulera les valeurs de la variable
ygt−1. Supposons que ygt−1 est fonction de variables qui varient dans le temps et de va-
riables invariantes dans le temps :
ygt−1 = agW gt−1 + Zgbg + εgt−1,
avec W gt−1 un vecteur de variables qui varient dans le temps et Zg un vecteur de
variables invariantes dans le temps incluant les effets specifiques aux cohortes. Si le
terme d’erreur suit une loi normale, alors ygt−1 suivra aussi une loi normale. Ainsi, il
est possible d’effectuer des tirages de ygt−1 a partir d’une loi normale :
si : εgt ∼ iidN(0, σ2
εg
)
=⇒ ygt−1 ∼ iidN[(
agW gt−1 + Zgbg
), σ2
εg
].
Quant a la premiere observation qui est une donnee manquante, nous la simulerons
egalement. Supposons que l’observation initiale depend d’un certain nombre de variables
invariantes dans le temps et est definie comme suit :
yg0 = Zgb∗g + εg0
=⇒ yg0 ∼ N[Zgb
∗g, σ
2εg
].
Apres avoir simule la variable dependante retardee ainsi que la premiere observation,
l’algorithme de l’echantillonnage de Gibbs est utilise pour estimer les parametres du
modele. L’estimation de βg se fera de la meme maniere que dans le modele statique
mais cette fois, nous ajouterons le parametre de la dependante retardee qui est αg.
L’estimation de hg se fera egalement comme dans le modele statique. La demarche
pour estimer les parametres etant la meme que celle du modele statique, nous ne la
repeterons plus a ce niveau. Signalons que nous n’avons pas inclus de constante pour
chaque groupe. Puisqu’il est question ici d’un modele dynamique, on peut ou non inclure
la constante si celle-ci s’avere pertinente. Nous avons estime le modele en incluant une
constante specifique a chaque groupe et il s’est avere que son inclusion deteriorait la
plupart des estimes du modele. Le modele sans constante s’averait meilleur que le
modele avec constante.
5.5.1 Resultats de l’estimation du modele dynamique
Comme dans le modele statique, nous avons estime le modele dynamique avec des
parametres homogenes dans le but de faire la comparaison avec le modele a parametres

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 166
heterogenes. Les resultats de l’estimation sont presentes dans le tableau (5.3). Tous les
coefficients sont significatifs aux seuils usuels. De plus, ils ont chacun le signe attendu.
Les resultats de l’estimation du modele avec heterogeneite sont presentes au tableau
(5.4). La plupart des coefficients ont le signe attendu. L’estime du parametre de la
consommation de la periode precedente devrait etre de signe positif. A l’exception de
ceux de la region6 et de la region7 (ils ne sont pas significatifs), les autres estimes sont
tous de signe positif. Les valeurs estimees varient d’une region a l’autre, allant de 0.15
(pour la region 9) a 0.68 (pour la region 5). Notons que pour les valeurs inferieures a
0.3 (en valeur absolue), les estimes ne sont pas significatifs (0.15 pour la region 9 et 0.22
pour la region 7, -0.19 pour la region 6 et -0.22 pour la region 7). En moyenne, l’effet
marginal de la consommation passee est de 0.32 et est significatif au seuil de 1%. Cette
valeur est a peu pres la moitie de celle du modele avec parametres homogenes (0.63).
Pour l’effet marginal du prix de l’electricite, on note que tous les estimes ont le bon
signe (negatif) et sont significatifs excepte celui de la region 6 (qui n’est pas significatif).
On note aussi que les valeurs estimees varient sensiblement d’une region a l’autre, allant
de -0.57 pour la region1 a -4.5 pour la region 9. En moyenne, l’effet marginal du prix
marginal de l’electricite est environ de -2.00 pour toute la province. Cette valeur est
plus grande en valeur absolue que celle du modele avec parametres homogenes (-1.36).
Les estimes de la variable revenu net ont le bon signe et sont significatifs aux usuels
sauf ceux de la region 4 , la region 5 et la region 6. Les valeurs qui sont statistiquement
significatives vont de 1.00 (region 2) a 3.5 (pour la region 7). En moyenne , dans la
province, l’effet marginal du revenu net est de 1.75 et est significatif a 1%. Cette valeur
est beaucoup plus grande que celle obtenu dans le modele a parametres homogenes.
Les estimes de la variable degres jour de chauffage (hdd) ont tous le signe positif, signe
attendu. Ils sont tous significatifs (a 5%) sauf celui de la region 6 qui l’est seulement
a 10%. Les valeurs estimees vont de 1.35 (pour la region 1) a 5.66 (pour la region 9).
Si les degres jours de chauffage augmentent, la demande d’electricite augmente aussi,
augmentation variant d’une region a l’autre. En moyenne, l’effet marginal de hdd est
de 3.75 pour toute la province. Cette valeur est beaucoup plus elevee que celle obtenue
dans le modele avec homogeneite (qui est de 1.12).
Les estimes de la variable degres jour de climatisation (cdd) varient enormement d’une
region a l’autre, soit de -26.05 pour la region 1 a 3.13 pour la region 5. En moyenne
dans la province, l’effet marginal de cdd est de -4.58. En moyenne, si les degres jours de
climatisation augmentent, la demande d’electricite baisse dans la plupart des regions.
Cette baisse vient du fait que les menages ont plus l’habitude de chauffer leur maison
que de les climatiser. Plus il fait chaud, moins on a besoin de chauffer la maison.
Comparativement aux resultats de Maddala et al. (1997), nous pouvons souligner que
la plupart des estimes ont les signes attendus (ce qui n’etait pas le cas pour les resultats
de Maddala et al.), de plus, la plupart sont significatifs aux seuils usuels. Nous pouvons
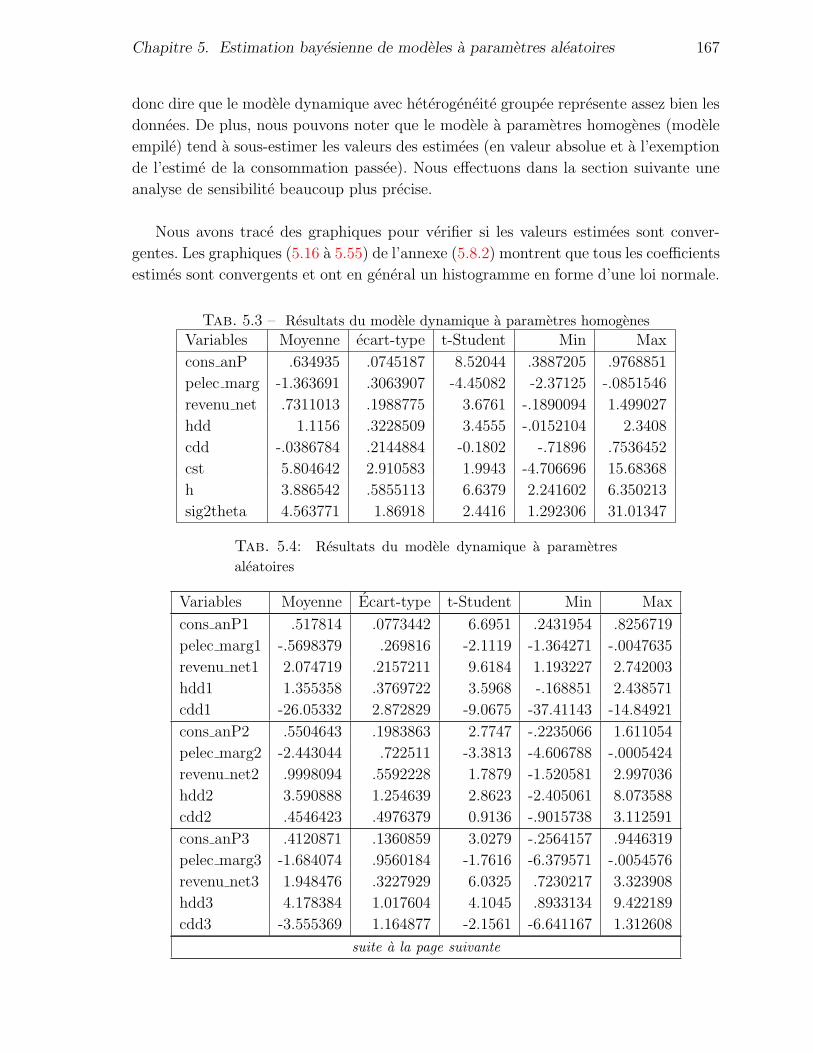
Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 167
donc dire que le modele dynamique avec heterogeneite groupee represente assez bien les
donnees. De plus, nous pouvons noter que le modele a parametres homogenes (modele
empile) tend a sous-estimer les valeurs des estimees (en valeur absolue et a l’exemption
de l’estime de la consommation passee). Nous effectuons dans la section suivante une
analyse de sensibilite beaucoup plus precise.
Nous avons trace des graphiques pour verifier si les valeurs estimees sont conver-
gentes. Les graphiques (5.16 a 5.55) de l’annexe (5.8.2) montrent que tous les coefficients
estimes sont convergents et ont en general un histogramme en forme d’une loi normale.
Tab. 5.3 – Resultats du modele dynamique a parametres homogenes
Variables Moyenne ecart-type t-Student Min Max
cons anP .634935 .0745187 8.52044 .3887205 .9768851
pelec marg -1.363691 .3063907 -4.45082 -2.37125 -.0851546
revenu net .7311013 .1988775 3.6761 -.1890094 1.499027
hdd 1.1156 .3228509 3.4555 -.0152104 2.3408
cdd -.0386784 .2144884 -0.1802 -.71896 .7536452
cst 5.804642 2.910583 1.9943 -4.706696 15.68368
h 3.886542 .5855113 6.6379 2.241602 6.350213
sig2theta 4.563771 1.86918 2.4416 1.292306 31.01347
Tab. 5.4: Resultats du modele dynamique a parametres
aleatoires
Variables Moyenne Ecart-type t-Student Min Max
cons anP1 .517814 .0773442 6.6951 .2431954 .8256719
pelec marg1 -.5698379 .269816 -2.1119 -1.364271 -.0047635
revenu net1 2.074719 .2157211 9.6184 1.193227 2.742003
hdd1 1.355358 .3769722 3.5968 -.168851 2.438571
cdd1 -26.05332 2.872829 -9.0675 -37.41143 -14.84921
cons anP2 .5504643 .1983863 2.7747 -.2235066 1.611054
pelec marg2 -2.443044 .722511 -3.3813 -4.606788 -.0005424
revenu net2 .9998094 .5592228 1.7879 -1.520581 2.997036
hdd2 3.590888 1.254639 2.8623 -2.405061 8.073588
cdd2 .4546423 .4976379 0.9136 -.9015738 3.112591
cons anP3 .4120871 .1360859 3.0279 -.2564157 .9446319
pelec marg3 -1.684074 .9560184 -1.7616 -6.379571 -.0054576
revenu net3 1.948476 .3227929 6.0325 .7230217 3.323908
hdd3 4.178384 1.017604 4.1045 .8933134 9.422189
cdd3 -3.555369 1.164877 -2.1561 -6.641167 1.312608
suite a la page suivante

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 168
Tab. 5.4: Resultats du modele dynamique a parametres
aleatoires
Variables Moyenne Ecart-type t-Student Min Max
cons anP4 .5355461 .2236354 2.3949 -.3403449 1.429359
pelec marg4 -1.148883 .4891357 -2.3497 -3.110823 -.0074561
revenu net4 .8231053 .5390008 1.5271 -1.291398 2.847436
hdd4 3.348685 1.174226 2.8521 -1.139545 7.801832
cdd4 -2.806912 1.156823 -2.4291 -5.626341 2.511082
cons anP5 .6762941 .210533 3.2128 -.298628 1.660328
pelec marg5 -3.530369 .9321005 -3.7871 -7.108625 -.0485347
revenu net5 .447657 .5687525 0.7871 -2.169626 2.889652
hdd5 3.85586 1.456594 2.6474 -1.616587 10.0941
cdd5 3.129683 .7090963 4.4142 1.175993 6.419063
cons anP6 -.1901492 .6674757 -0.2848 -4.993971 3.045418
pelec marg6 -.9130979 .9984096 -0.9149 -12.62987 -.0002715
revenu net6 2.029616 1.630885 1.2444 -5.513525 13.06026
hdd6 4.747465 2.792149 1.7003 -7.275952 24.399
cdd6 -1.771557 1.634886 -1.0835 -13.54366 14.58572
cons anP7 -.2257151 .4275768 -0.5278 -3.0253 .8968959
pelec marg7 -2.412242 1.055874 -2.2843 -10.63322 -.0575934
revenu net7 3.59612 1.442717 2.4926 -.4390677 13.77392
hdd7 4.405299 1.489528 2.9586 .7892206 14.3657
cdd7 -3.362623 .8089361 -4.1565 -9.7223 .0164313
cons anP8 .4910895 .1954758 2.5120 -.7474549 1.257829
pelec marg8 -.7828563 .3227895 -2.4250 -2.29553 -.0006975
revenu net8 1.356919 .4348624 3.1195 -.2553755 4.071198
hdd8 2.599561 .719388 3.6141 -.0499376 6.956209
cdd8 -6.50051 1.246016 -5.267 -10.44973 -1.734685
cons anP9 .146972 .133826 1.0970 -.3264337 1.145255
pelec marg9 -4.499363 .3493064 -12.9840 -5.64748 -2.378198
revenu net9 2.514809 .2916827 8.6130 .5108625 3.679819
hdd9 5.660573 .53547 17.1027 1.459319 7.545402
cdd9 -.7820147 .3309281 -2.3625 -2.273902 .1642447
Moyenne des moyennes
cons anP .3238225 .1001232 3.240 -.2304264 .6235989
pelec marg -1.998196 .2401303 -8.2810 -3.089453 -1.191059
revenu net 1.754581 .2681055 6.5446 .9005185 2.938539
hdd 3.749119 .4454658 8.4247 2.345731 6.156491
suite a la page suivante

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 169
Tab. 5.4: Resultats du modele dynamique a parametres
aleatoires
Variables Moyenne Ecart-type t-Student Min Max
cdd -4.583109 .4589998 -9.9847 -6.169567 -3.066297
Fin du tableau
5.6 Analyse de sensibilite : elasticites prix et revenu
de la demande
Dans cette section, nous analysons a la fois les elasticites prix et revenu du modele
statique et du modele dynamique. Le modele statique tend a representer l’etat station-
naire de l’economie de sorte que nous nous attendons a ce que les elasticites du modele
statique soient assez proches des elasticites de long terme du modele dynamique. Nous
avons aussi calcule les elasticites des modeles a parametres homogenes dans le but
de pouvoir effectuer des comparaisons. Ces comparaisons se justifient parce qu’on a
tendance souvent a ignorer l’hypothese d’heterogeneite dans beaucoup de travaux em-
piriques.
Pour le modele a parametres homogenes, les elasticites obtenues (voir tableau 5.5)
sont toutes statistiquement significatives aux seuils usuels et ont les signes attendus.
Les elasticites du modele statique sont assez proches des elasticites de long terme du
modele dynamique.
Interessons-nous maintenant aux elasticites du modele a parametres heterogenes. Le
tableau (5.6) presente les resultats. Les elasticites prix et revenu du modele statique
avec heterogeneite ont les bons signes et sont toutes statistiquement significatives au
seuil de 1%, a l’exception de l’elasticite revenu de la region 3 qui n’est pas significative.
(Les ecart-type sont presentes entre parentheses). L’elasticite prix de l’electricite du
modele statique est negative pour toutes les regions. Elle varie enormement d’une region
a l’autre. Elle va de -0.095 pour la region6 a -2.36 pour la region 2. Si le prix de
l’electricite augmente de 1%, la demande d’electricite va baisser, cette baisse sera plus
faible pour les cohortes qui habitent la region de la Mauricie (0.095%) alors qu’elle
sera plus importante dans la region du Saint Laurent (baisse de 2.36%). La demande
d’electricite est presque inelastique en Mauricie tandis qu’elle tres elastique dans le
Saint Laurent (depasse la hausse du prix qui est de 1%). En moyenne, la hausse de 1%
du prix de l’electricite entraınera une baisse de 0.92% (≈ 1%) dans toute la province.

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 170
Donc, la demande d’electricite a une elasticite presque unitaire dans toute la province.
L’elasticite revenu de la demande du modele statique est approximativement la
meme pour toutes les regions. L’elasticite revenu de la region 3 (Richelieu) est proche
de zero et non significative. Les autres sont par contre toutes significatives et varient
entre 0.45 et 0.69. Si le revenu net augmente de 1%, toutes les cohortes augmenteront
leur consommation d’electricite : les cohortes de la region8 (Matapedia) augmenteront
de 0.45% tandis que celles du Saint Laurent l’augmenteront de 0.69%. En moyenne, on
observera dans la province une hausse de 0.57%.
Pour ce qui est du modele dynamique, nous remarquons d’abord que toutes les
elasticites prix de court terme sont inferieures en valeur absolue a celles du long terme,
confirmant ainsi la seconde loi de la demande. Les cohortes reagissent beaucoup plus
fortement a long terme qu’a court terme suite a un changement de prix. Il existe une
periode d’ajustement durant laquelle les menages font un arbitrage entre garder leur
systeme ou le changer avec un autre qui couterait relativement moins cher.
Les elasticites prix de court terme sont toutes significatives a 1% a l’exception de celle
de la region6 (Mauricie). Elles varient enormement d’une region a l’autre et sont de signe
negatif. L’elasticite prix la plus petite est celle de la region1 (Manicouanga avec -0.13)
et la plus elevee est celle de la region9 (Saguenay avec -1.16). Si le prix de l’electricite
augmente de 1%, a court terme, les menages qui vivent dans la region du Manicouanga
sont ceux qui vont le moins baisser leur consommation (baisse de 0.13%), tandis que
ceux de la region du Saguenay seront ceux qui baisseront le plus leur consommation
(1.16%). La demande d’electricite est elastique dans la region de Saguenay tandis qu’elle
est inelastique dans le Manicouanga. En moyenne, dans la province, une baisse de 1%
du prix marginal de l’electricite entraınera une baisse de 0.52% de la demande de toute
la province dans le court terme. Cette valeur est beaucoup plus elevee en valeur absolue
que celle obtenue par Maddala et al. (1997) qui etait de -0.157.
Les elasticites prix de long terme ne sont pas toutes significatives. Elles varient de
-0.21 pour la region6 (Mauricie) a -2.77 pour la region5 (les Laurentides). A long terme,
la demande d’electricite des menages qui sont dans les Laurentides est tres elastique
tandis que celle des menages qui restent en Mauricie est inelastique. En moyenne, si le
prix de l’electricite augmente de 1%, la demande d’electricite baissera de 0.76% ; cette
valeur est assez proche de celle obtenue dans le modele statique. Elle est par contre
beaucoup plus elevee en valeur absolue que celle obtenue par Maddala et al. (1997) soit
-0.239. Cette difference viendrait du fait que dans leurs resultats, certains etats avaient
une elasticite prix directe positive (0.242), une valeur qui ne semble pas logique a priori.
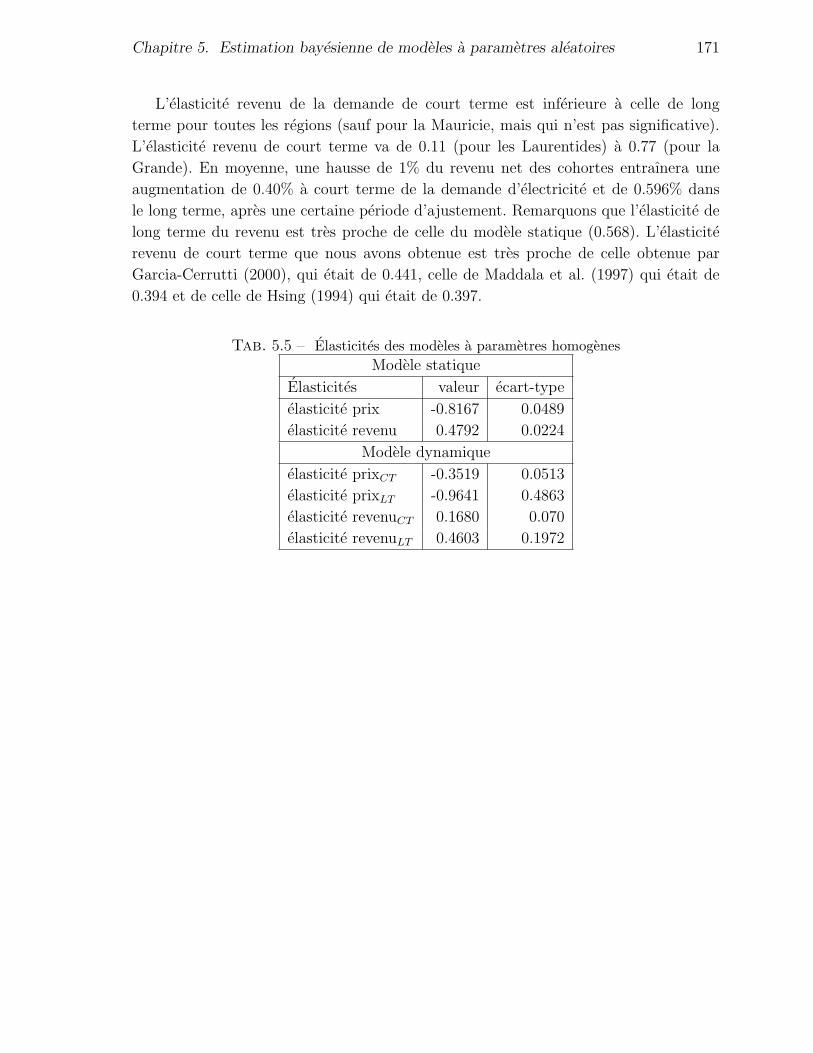
Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 171
L’elasticite revenu de la demande de court terme est inferieure a celle de long
terme pour toutes les regions (sauf pour la Mauricie, mais qui n’est pas significative).
L’elasticite revenu de court terme va de 0.11 (pour les Laurentides) a 0.77 (pour la
Grande). En moyenne, une hausse de 1% du revenu net des cohortes entraınera une
augmentation de 0.40% a court terme de la demande d’electricite et de 0.596% dans
le long terme, apres une certaine periode d’ajustement. Remarquons que l’elasticite de
long terme du revenu est tres proche de celle du modele statique (0.568). L’elasticite
revenu de court terme que nous avons obtenue est tres proche de celle obtenue par
Garcia-Cerrutti (2000), qui etait de 0.441, celle de Maddala et al. (1997) qui etait de
0.394 et de celle de Hsing (1994) qui etait de 0.397.
Tab. 5.5 – Elasticites des modeles a parametres homogenes
Modele statique
Elasticites valeur ecart-type
elasticite prix -0.8167 0.0489
elasticite revenu 0.4792 0.0224
Modele dynamique
elasticite prixCT -0.3519 0.0513
elasticite prixLT -0.9641 0.4863
elasticite revenuCT 0.1680 0.070
elasticite revenuLT 0.4603 0.1972
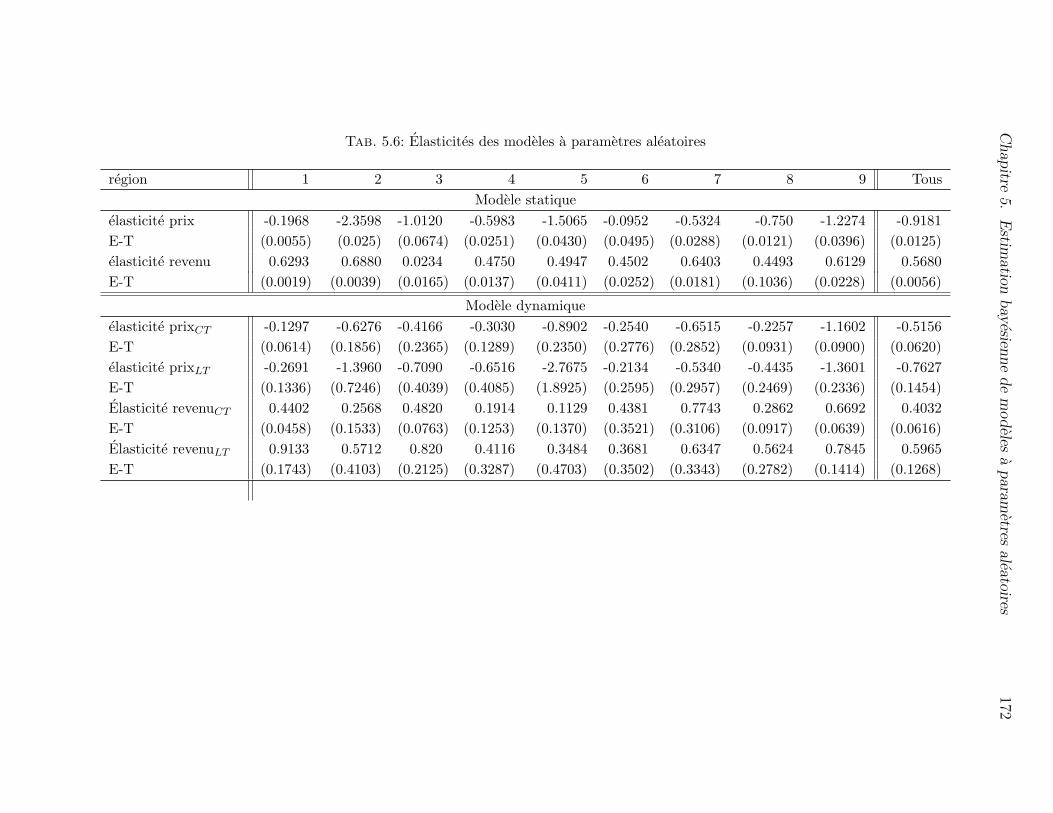
Chapitre
5.
Estim
atio
nbayesien
ne
de
modeles
apara
metres
alea
toires
172
Tab. 5.6: Elasticites des modeles a parametres aleatoires
region 1 2 3 4 5 6 7 8 9 Tous
Modele statique
elasticite prix -0.1968 -2.3598 -1.0120 -0.5983 -1.5065 -0.0952 -0.5324 -0.750 -1.2274 -0.9181
E-T (0.0055) (0.025) (0.0674) (0.0251) (0.0430) (0.0495) (0.0288) (0.0121) (0.0396) (0.0125)
elasticite revenu 0.6293 0.6880 0.0234 0.4750 0.4947 0.4502 0.6403 0.4493 0.6129 0.5680
E-T (0.0019) (0.0039) (0.0165) (0.0137) (0.0411) (0.0252) (0.0181) (0.1036) (0.0228) (0.0056)
Modele dynamique
elasticite prixCT -0.1297 -0.6276 -0.4166 -0.3030 -0.8902 -0.2540 -0.6515 -0.2257 -1.1602 -0.5156
E-T (0.0614) (0.1856) (0.2365) (0.1289) (0.2350) (0.2776) (0.2852) (0.0931) (0.0900) (0.0620)
elasticite prixLT -0.2691 -1.3960 -0.7090 -0.6516 -2.7675 -0.2134 -0.5340 -0.4435 -1.3601 -0.7627
E-T (0.1336) (0.7246) (0.4039) (0.4085) (1.8925) (0.2595) (0.2957) (0.2469) (0.2336) (0.1454)
Elasticite revenuCT 0.4402 0.2568 0.4820 0.1914 0.1129 0.4381 0.7743 0.2862 0.6692 0.4032
E-T (0.0458) (0.1533) (0.0763) (0.1253) (0.1370) (0.3521) (0.3106) (0.0917) (0.0639) (0.0616)
Elasticite revenuLT 0.9133 0.5712 0.820 0.4116 0.3484 0.3681 0.6347 0.5624 0.7845 0.5965
E-T (0.1743) (0.4103) (0.2125) (0.3287) (0.4703) (0.3502) (0.3343) (0.2782) (0.1414) (0.1268)

Chapitre 5. Estimation bayesienne de modeles a parametres aleatoires 173
5.7 Conclusion
Nous avons pu estimer a partir de pseudo-panels de cohortes, des modeles de de-
mande d’electricite statiques et dynamiques. Nous avons pu egalement calculer les
differentes elasticites prix et revenus de la demande. Plusieurs conclusions peuvent etre
tirees. Il ressort des resultats que la non prise en compte de l’heterogeneite entre les
cohortes conduit a une sous-estimation des valeurs des elasticites. De plus, le modele dy-
namique avec parametres homogenes surevalue l’ajustement de long terme des cohortes
par rapport au modele qui prend en compte l’heterogeneite. Ce resultat confirme les
resultats obtenus au chapitre (4) portant sur l’approche classique avec des coefficients
de pente homogenes pour toutes les cohortes.
En comparant les elasticites de court terme et celles de long terme, nous constatons
que nos resultats confirment la seconde loi de la demande qui dit que les elasticites de
court terme doivent etre inferieures en valeur absolue a celle de long terme compte tenu
du temps d’ajustement dont les menages ont besoin pour choisir de bons substituts. Ce
resultat est aussi coherent avec le fait que dans le contexte de la demande d’energie, il
est beaucoup question de choix de systemes de chauffage qui sont des biens durables
dont l’achat est effectue dans le but de satisfaire des besoins sur plusieurs annees.
Par ailleurs, les resultats obtenus dans ce chapitre sont comparables avec ceux ob-
tenus dans certains travaux anterieurs (Maddala et al. (1997), Hsing (1994), Garcia-
Cerrutti (2000)). Nos resultats sont meilleurs dans le sens que les estimes ont les bons
signes et sont pour la plupart statistiquement significatifs aux seuils usuels. Maddala
et al. (1997) par exemple, dont l’approche est similaire a la notre, avaient abouti a
des estimes dont les signes etaient parfois aberrants (raison pour laquelle ils n’ont pas
presente certains resultats).
En conclusion, il est important de prendre en compte l’heterogeneite entre les co-
hortes. Les resultats confirment en effet que les comportements des cohortes, et im-
plicitement des menages, changent d’une region a l’autre de la province. L’approche
bayesienne semble bien representer les donnees. Cette facon de proceder serait une
premiere pour les etudes portant sur les pseudo-panels. Elle constitue une bonne alter-
native a l’approche classique surtout en ce qui concerne les modeles dynamiques (tel
que notes par Maddala et al. (1997)). Une des limites de cette approche serait principa-
lement la programmation sur ordinateur. Une fois ce probleme resolu, elle devient une
approche beaucoup plus attrayante que l’approche classique.

Bibliographie
[1] Browning, M., Deaton, A. and Irish, M. (1985) : «A profitable Approach to Labor
Supply and Commodity Demands over the Life-Cycle», Econometrica, Vol. 53,
No.3 pp503-544
[2] Deaton Angus (1985) : «Panel Data from Time Series of Cross-sections» Journal
of Econometrics, vol. 30 pp 109-126.
[3] Gelfand A. E. (2000) : Gibbs Sampling, Journal of the American Statistical Assso-
ciation, Vol. 95, No. 452, p. 1300-1304.
[4] German, S. and German, D. (1984) : Stochastic Relaxation, Gibbs Distribution and
the Bayesian Restoration if Images, IEEE Transactions on Pattern Analysis and
Michine Intelligence, 6, pp. 721-741.
[5] Gordon S. et Belanger, G. (2003) : Echantillonnage de Gibbs et autres applica-
tions econometriques des chaınes markoviennes , Working Paper, Departement
d’Economique, Universite Laval.
[6] Hsing, Y. (1994) : Estimation of Residential Demand for Electricity with the Cross-
Sectionally Correlated and Timewise Autoregressive Model, Resource and Energy
Economics, Vol. 16, p.255-263
[7] Lee, L. F. and Griffiths, W. E. (1978) : The Prio Likelihood and Best Linear Unbia-
sed Prediction in Stochastic Parameter Models, Unpublished Manuscript, Unversity
of Minnesota, Dpt of Economics.
[8] Levin, A., C. F. Lin and C. Chu (2002) : Unit Root Test in Panel Data : Asymptotic
and Finite Sample Properties, Journal of Econometrics, Vol. 108, p.1-25.
[9] Maddala, G. S., Trost, R. P. Li, H., and Joutz, F. (1994) : Estimation of Short-
Run and Long-Run Elasticities of Energy Demand from Panel using Shrinkage
Estimators, Journal of Business and Economic Statistics, Vol. 15, p.90-100.
[10] Garcia-Cerruti, Miguel L. (2000) : Estimating Elasticities of Residential Energy
Demand from Panel County Data using Dynamic Random Variables Models with
Heteroskedastic and Autocorrelated Error Terms, Resource and Energy Economics,
Vol. 22, pp. 355-366.

Bibliographie 175
[11] McKenzie D. J. (2001) : Dynamic Pseudo-Panel Theory and Analysis of Consump-
tion in Taiwan and Mexico. Ph.D Disservation, Yale University
[12] McKenzie D. J. (2004) : Asymptotic Theory for heterogeneous dynamique Pseudo-
Panels, Journal of Econometrics, Vol.120, pp.235-262.
[13] Maddala, G., S., Trost, R., P., Li, H. and Joutz, F. (1997) : Estimation of Short-
Run and Long-Run Elasticities of Energy Demand from Panel Data Shrinkage
Estimators, Journal of Business and Economic Statistics, Vol. 15, No. 1, pp. 90-
100.
[14] McKenzie D. J. (2001) : Dynamic Pseudo-Panel Theory and Analysis of Consump-
tion in Taiwan and Mexico. Ph.D Disservation, Yale University
[15] McKenzie D. J. (2004) : Asymptotic Theory for heterogeneous dynamique Pseudo-
Panels, Journal of Econometrics, Vol.120, pp.235-262.
[16] Moffit R. (1993) : Identification and Estimation of dynamique Models with a Time
Series of Repeated Cross-Sections, Journal of Econometrics, Vol.59, pp99-123.
[17] Pesaran, M. K and Simths, R. (1995) : Estimating Long-Run Relationships from
Dynamic Heterogeneous Panels, Journal of Applied Econometrics, Vol.68, p.79-113.
[18] Robertson, D. and Symons, J. (1992) : Some Strange Properties of Panel Data
Estimators, Journal of Applied Econometrics, Vol.7, p.175-189.
[19] Smith, A. F. M. (1973) : A General Bayesian Linear Model, Journal of the Royal
Statistical Society, Vol. 75, Ser. B. 35, pp.67-75.
[20] Swamy, P. A. V. B. (1970) : Efficient Inference in a Random Coefficient Regression
Model, Econometrica, Vol. 38, pp. 311-323.
[21] Tanner M. A. and Wong Wing Hung (1987) : The Calculation of Posteriori Distri-
butions by Data Augmentation, Journal of the American Statistical Asssociation,
Vol. 82, No. 398, p. 528-540.
5.8 Les annexes
5.8.1 Annexe A : repartition des cohortes
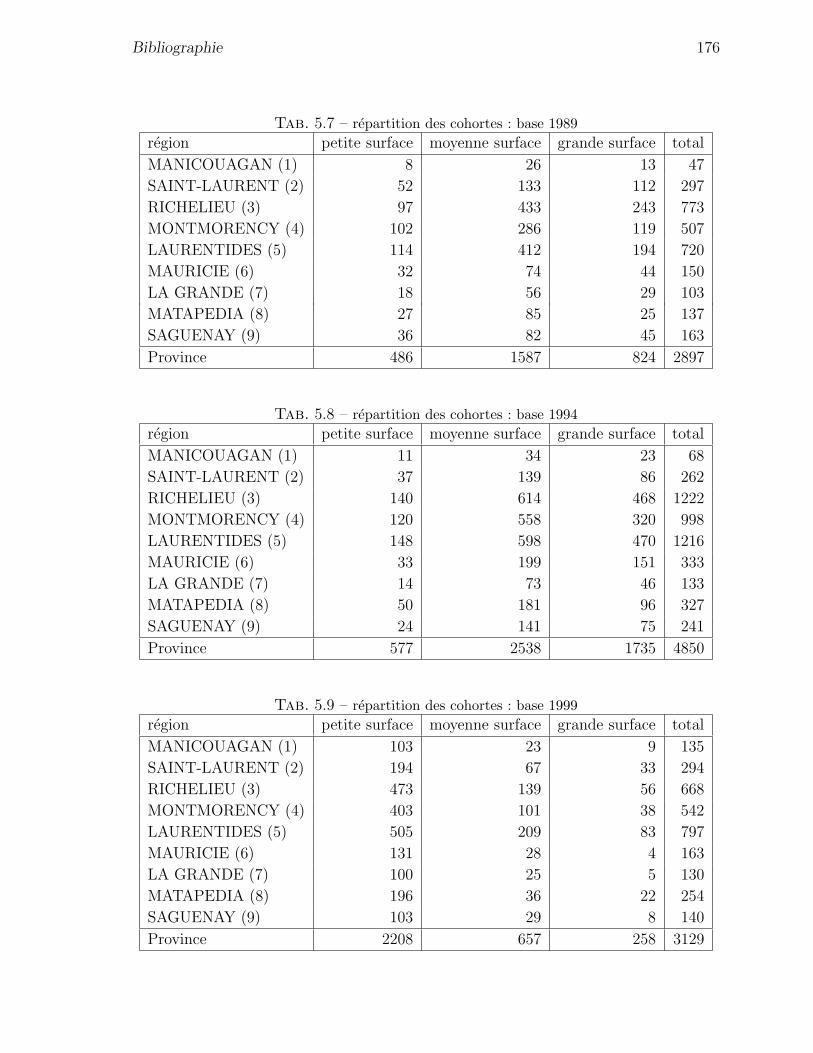
Bibliographie 176
Tab. 5.7 – repartition des cohortes : base 1989
region petite surface moyenne surface grande surface total
MANICOUAGAN (1) 8 26 13 47
SAINT-LAURENT (2) 52 133 112 297
RICHELIEU (3) 97 433 243 773
MONTMORENCY (4) 102 286 119 507
LAURENTIDES (5) 114 412 194 720
MAURICIE (6) 32 74 44 150
LA GRANDE (7) 18 56 29 103
MATAPEDIA (8) 27 85 25 137
SAGUENAY (9) 36 82 45 163
Province 486 1587 824 2897
Tab. 5.8 – repartition des cohortes : base 1994
region petite surface moyenne surface grande surface total
MANICOUAGAN (1) 11 34 23 68
SAINT-LAURENT (2) 37 139 86 262
RICHELIEU (3) 140 614 468 1222
MONTMORENCY (4) 120 558 320 998
LAURENTIDES (5) 148 598 470 1216
MAURICIE (6) 33 199 151 333
LA GRANDE (7) 14 73 46 133
MATAPEDIA (8) 50 181 96 327
SAGUENAY (9) 24 141 75 241
Province 577 2538 1735 4850
Tab. 5.9 – repartition des cohortes : base 1999
region petite surface moyenne surface grande surface total
MANICOUAGAN (1) 103 23 9 135
SAINT-LAURENT (2) 194 67 33 294
RICHELIEU (3) 473 139 56 668
MONTMORENCY (4) 403 101 38 542
LAURENTIDES (5) 505 209 83 797
MAURICIE (6) 131 28 4 163
LA GRANDE (7) 100 25 5 130
MATAPEDIA (8) 196 36 22 254
SAGUENAY (9) 103 29 8 140
Province 2208 657 258 3129
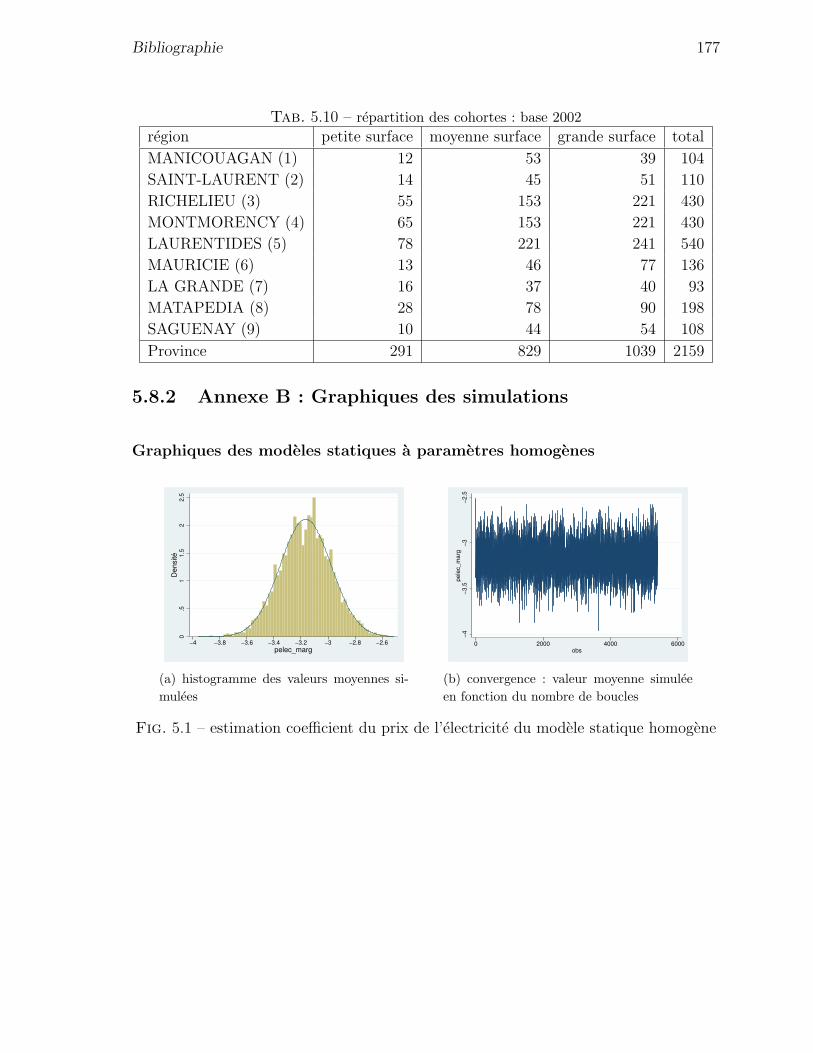
Bibliographie 177
Tab. 5.10 – repartition des cohortes : base 2002
region petite surface moyenne surface grande surface total
MANICOUAGAN (1) 12 53 39 104
SAINT-LAURENT (2) 14 45 51 110
RICHELIEU (3) 55 153 221 430
MONTMORENCY (4) 65 153 221 430
LAURENTIDES (5) 78 221 241 540
MAURICIE (6) 13 46 77 136
LA GRANDE (7) 16 37 40 93
MATAPEDIA (8) 28 78 90 198
SAGUENAY (9) 10 44 54 108
Province 291 829 1039 2159
5.8.2 Annexe B : Graphiques des simulations
Graphiques des modeles statiques a parametres homogenes
0.5
11.
52
2.5
Den
sité
−4 −3.8 −3.6 −3.4 −3.2 −3 −2.8 −2.6pelec_marg
(a) histogramme des valeurs moyennes si-
mulees
−4−3
.5−3
−2.5
pele
c_m
arg
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.1 – estimation coefficient du prix de l’electricite du modele statique homogene
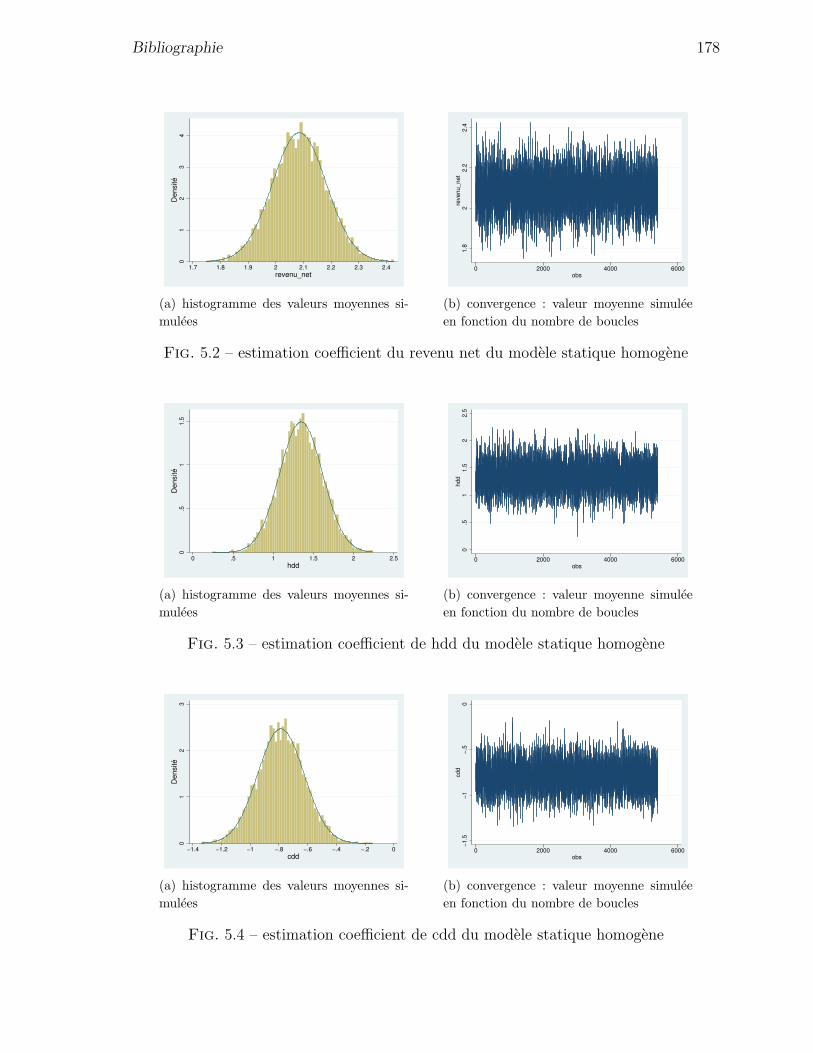
Bibliographie 178
01
23
4D
ensi
té
1.7 1.8 1.9 2 2.1 2.2 2.3 2.4revenu_net
(a) histogramme des valeurs moyennes si-
mulees
1.8
22.
22.
4re
venu
_net
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.2 – estimation coefficient du revenu net du modele statique homogene
0.5
11.
5D
ensi
té
0 .5 1 1.5 2 2.5hdd
(a) histogramme des valeurs moyennes si-
mulees
0.5
11.
52
2.5
hdd
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.3 – estimation coefficient de hdd du modele statique homogene
01
23
Den
sité
−1.4 −1.2 −1 −.8 −.6 −.4 −.2 0cdd
(a) histogramme des valeurs moyennes si-
mulees
−1.5
−1−.
50
cdd
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.4 – estimation coefficient de cdd du modele statique homogene
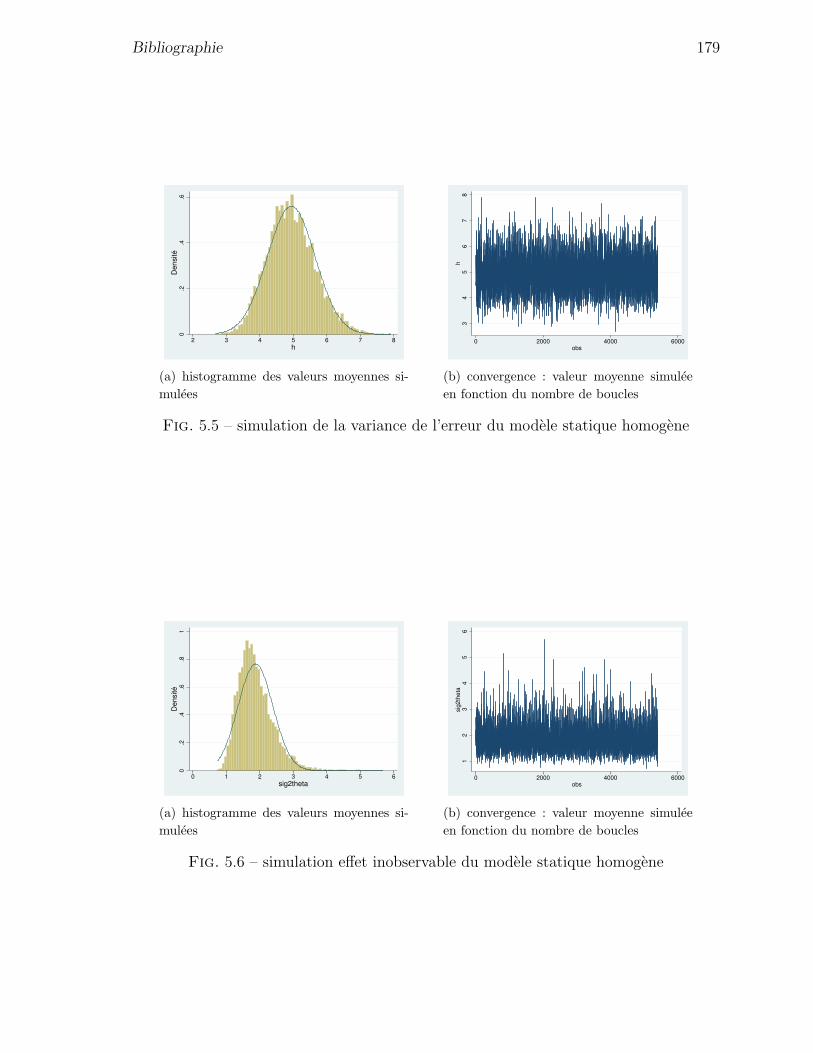
Bibliographie 179
0.2
.4.6
Den
sité
2 3 4 5 6 7 8h
(a) histogramme des valeurs moyennes si-
mulees
34
56
78
h
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.5 – simulation de la variance de l’erreur du modele statique homogene
0.2
.4.6
.81
Den
sité
0 1 2 3 4 5 6sig2theta
(a) histogramme des valeurs moyennes si-
mulees
12
34
56
sig2
thet
a
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.6 – simulation effet inobservable du modele statique homogene

Bibliographie 180
Graphiques des modeles statiques a parametres heterogenes
02
46
810
Den
sité
−3.75 −3.7 −3.65 −3.6 −3.55 −3.5 −3.45 −3.4 −3.35pelec_margS
(a) histogramme des valeurs moyennes si-
mulees
−3.7
−3.6
−3.5
−3.4
−3.3
pele
c_m
argS
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.7 – estimation coefficient prix electricite du modele statique a parametres
heterogenes
05
1015
20D
ensi
té
2.35 2.4 2.45 2.5 2.55revenu_netS
(a) histogramme des valeurs moyennes si-
mulees
2.35
2.4
2.45
2.5
2.55
reve
nu_n
etS
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.8 – estimation coefficient du revenu du modele statique a parametres heterogenes

Bibliographie 181
0.5
11.
52
2.5
Den
sité
11.4 11.6 11.8 12 12.2 12.4 12.6 12.8hddS
(a) histogramme des valeurs moyennes si-
mulees
11.5
1212
.513
hddS
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.9 – estimation coefficient de hdd du modele statique a parametres heterogenes
01
23
4D
ensi
té
−2.8 −2.6 −2.4 −2.2 −2 −1.8 −1.6cddS
(a) histogramme des valeurs moyennes si-
mulees
−2.8
−2.6
−2.4
−2.2
−2−1
.8cd
dS
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.10 – estimation coefficient de cdd du modele statique a parametres heterogenes
05
1015
20D
ensi
té
−.94 −.92 −.9 −.88 −.86 −.84 −.82 −.8 −.78pelec_marg1
(a) histogramme des valeurs moyennes si-
mulees
−.95
−.9
−.85
−.8
−.75
pele
c_m
arg1
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.11 – simulation prix region1 du modele statique a parametres heterogenes
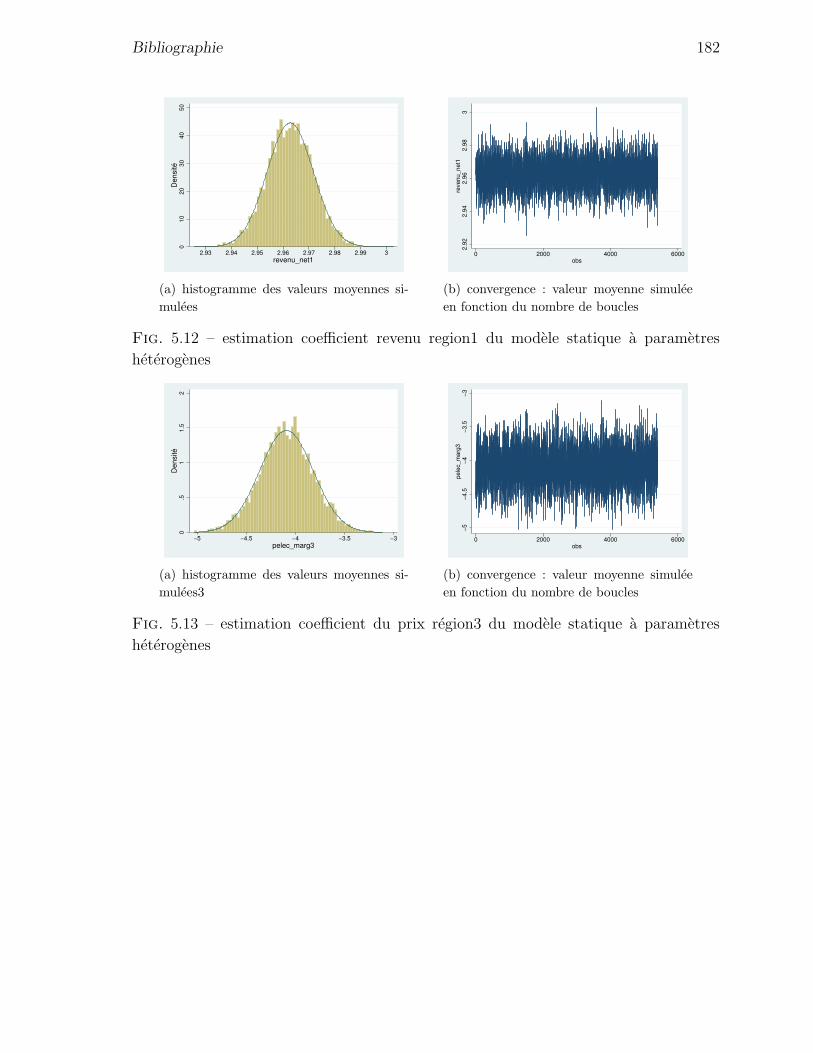
Bibliographie 182
010
2030
4050
Den
sité
2.93 2.94 2.95 2.96 2.97 2.98 2.99 3revenu_net1
(a) histogramme des valeurs moyennes si-
mulees
2.92
2.94
2.96
2.98
3re
venu
_net
1
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.12 – estimation coefficient revenu region1 du modele statique a parametres
heterogenes
0.5
11.
52
Den
sité
−5 −4.5 −4 −3.5 −3pelec_marg3
(a) histogramme des valeurs moyennes si-
mulees3
−5−4
.5−4
−3.5
−3pe
lec_
mar
g3
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.13 – estimation coefficient du prix region3 du modele statique a parametres
heterogenes
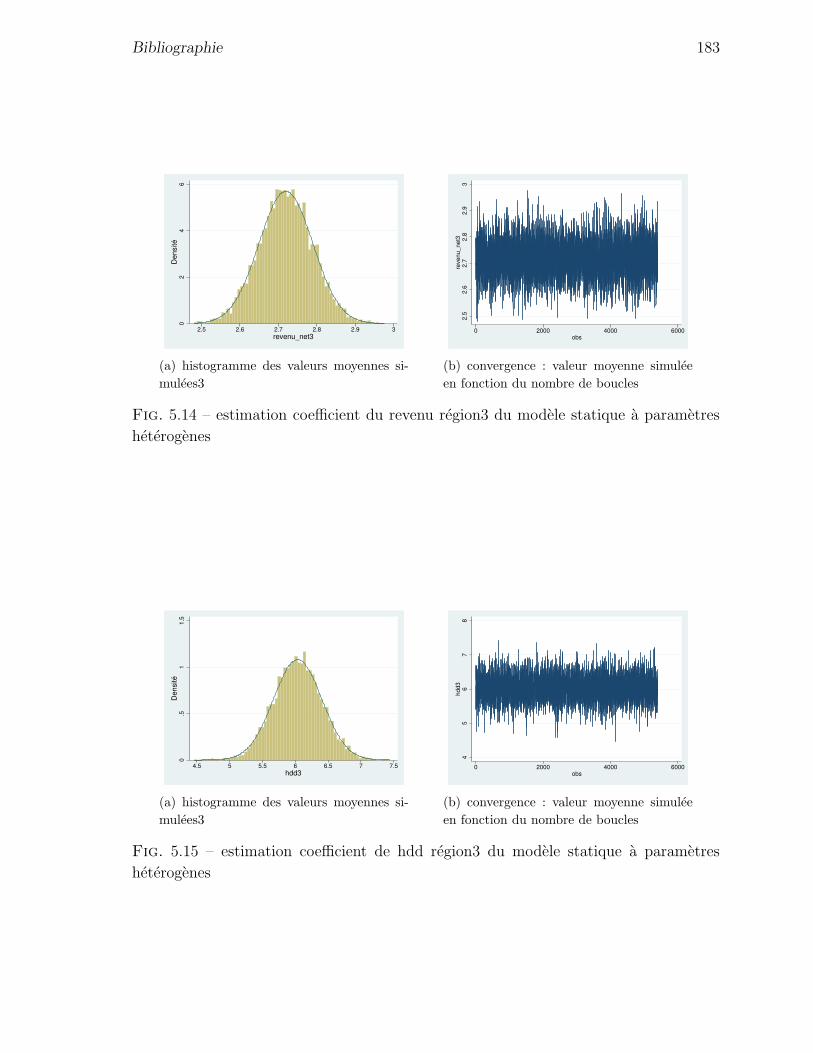
Bibliographie 183
02
46
Den
sité
2.5 2.6 2.7 2.8 2.9 3revenu_net3
(a) histogramme des valeurs moyennes si-
mulees3
2.5
2.6
2.7
2.8
2.9
3re
venu
_net
3
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.14 – estimation coefficient du revenu region3 du modele statique a parametres
heterogenes
0.5
11.
5D
ensi
té
4.5 5 5.5 6 6.5 7 7.5hdd3
(a) histogramme des valeurs moyennes si-
mulees3
45
67
8hd
d3
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.15 – estimation coefficient de hdd region3 du modele statique a parametres
heterogenes

Bibliographie 184
Graphiques des modeles dynamiques a parametres heterogenes
0.5
11.
5D
ensi
té
−4 −3 −2 −1 0 1 2pelec_margDr
(a) histogramme des valeurs moyennes si-
mulees
−4−2
02
pele
c_m
argD
r
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.16 – moyenne des coefficients simules du prix du modele dynamique a parametres
heterogenes
0.5
11.
5D
ensi
té
−2 −1 0 1 2 3revenu_netDr
(a) histogramme des valeurs moyennes si-
mulees
−2−1
01
23
reve
nu_n
etD
r
0 2000 4000 6000obs
(b) convergence
Fig. 5.17 – moyenne des coefficients simules du revenu de l’electricite du modele dyna-
mique a parametres heterogenes

Bibliographie 185
01
23
4D
ensi
té
−.5 0 .5 1 1.5 2cons_anPDr
(a) histogramme des valeurs moyennes si-
mulees
−.5
0.5
11.
52
cons
_anP
Dr
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.18 – moyenne des coefficients simules de la consommation passee du modele
dynamique a parametres heterogenes
0.2
.4.6
.8D
ensi
té
−4 −2 0 2 4 6 8hddDr
(a) histogramme des valeurs moyennes si-
mulees
−4−2
02
46
hddD
r
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.19 – moyenne des coefficients simules de hdd du modele dynamique a parametres
heterogenes
0.2
.4.6
.8D
ensi
té
−7 −6 −5 −4 −3 −2cddDr
(a) histogramme des valeurs moyennes si-
mulees
−7−6
−5−4
−3−2
cddD
r
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.20 – moyenne des coefficients simules de cdd du modele dynamique a parametres
heterogenes
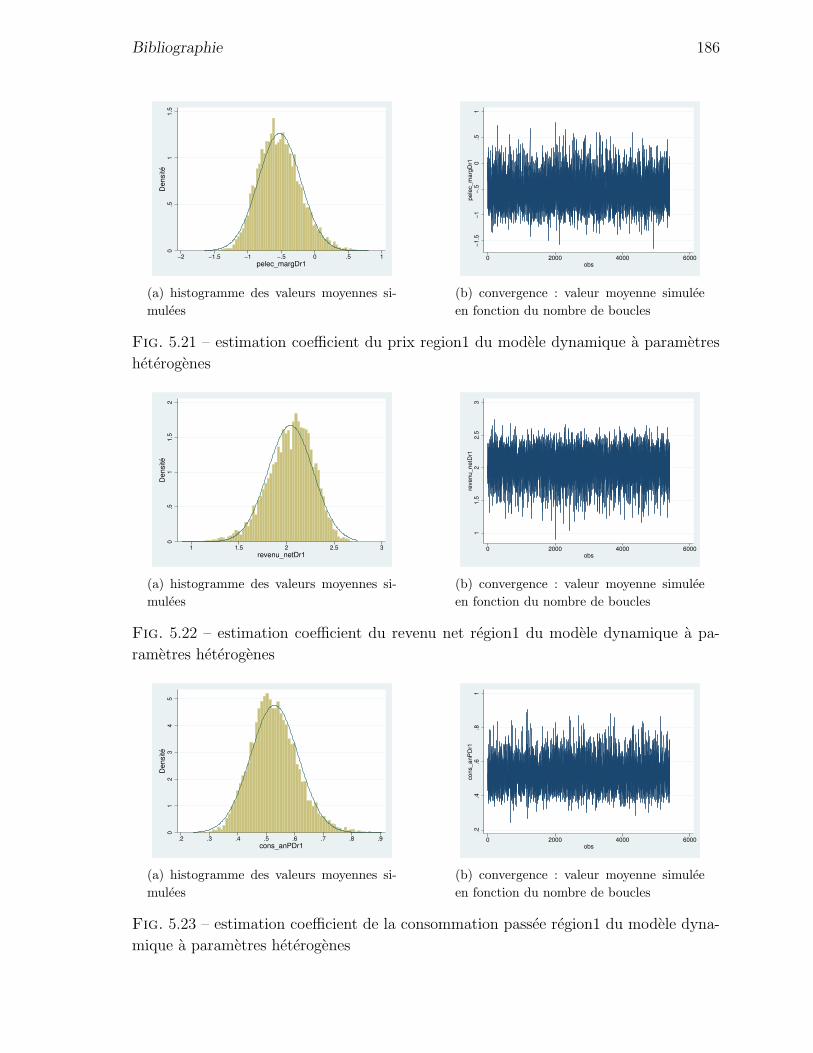
Bibliographie 186
0.5
11.
5D
ensi
té
−2 −1.5 −1 −.5 0 .5 1pelec_margDr1
(a) histogramme des valeurs moyennes si-
mulees
−1.5
−1−.
50
.51
pele
c_m
argD
r1
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.21 – estimation coefficient du prix region1 du modele dynamique a parametres
heterogenes
0.5
11.
52
Den
sité
1 1.5 2 2.5 3revenu_netDr1
(a) histogramme des valeurs moyennes si-
mulees
11.
52
2.5
3re
venu
_net
Dr1
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.22 – estimation coefficient du revenu net region1 du modele dynamique a pa-
rametres heterogenes
01
23
45
Den
sité
.2 .3 .4 .5 .6 .7 .8 .9cons_anPDr1
(a) histogramme des valeurs moyennes si-
mulees
.2.4
.6.8
1co
ns_a
nPD
r1
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.23 – estimation coefficient de la consommation passee region1 du modele dyna-
mique a parametres heterogenes

Bibliographie 187
0.2
.4.6
.81
Den
sité
−.5 0 .5 1 1.5 2 2.5hddDr1
(a) histogramme des valeurs moyennes si-
mulees
−10
12
3hd
dDr1
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.24 – estimation coefficient de hdd region1 du modele dynamique a parametres
heterogenes
0.0
5.1
.15
Den
sité
−40 −35 −30 −25 −20 −15cddDr1
(a) histogramme des valeurs moyennes si-
mulees
−40
−35
−30
−25
−20
−15
cddD
r1
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.25 – estimation coefficient de cdd region1 du modele dynamique a parametres
heterogenes
0.2
.4.6
Den
sité
−7 −6 −5 −4 −3 −2 −1 0 1pelec_margDr2
(a) histogramme des valeurs moyennes si-
mulees
−6−4
−20
2pe
lec_
mar
gDr2
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.26 – estimation coefficient du prix region2 du modele dynamique a parametres
heterogenes

Bibliographie 188
0.2
.4.6
.8D
ensi
té
−2 −1 0 1 2 3 4revenu_netDr2
(a) histogramme des valeurs moyennes si-
mulees
−20
24
reve
nu_n
etD
r2
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.27 – estimation coefficient du revenu net region2 du modele dynamique a pa-
rametres heterogenes
0.5
11.
52
Den
sité
−.5 0 .5 1 1.5cons_anPDr2
(a) histogramme des valeurs moyennes si-
mulees
−.5
0.5
11.
5co
ns_a
nPD
r2
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.28 – estimation coefficient de la consommation passee region2 du modele dyna-
mique a parametres heterogenes
0.1
.2.3
.4D
ensi
té
−2 0 2 4 6 8 10 12hddDr2
(a) histogramme des valeurs moyennes si-
mulees
−50
510
15hd
dDr2
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.29 – estimation coefficient de hdd region2 du modele dynamique a parametres
heterogenes

Bibliographie 189
0.2
.4.6
.8D
ensi
té
−2 −1 0 1 2 3 4cddDr2
(a) histogramme des valeurs moyennes si-
mulees
−2−1
01
23
cddD
r2
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.30 – estimation coefficient de cdd region2 du modele dynamique a parametres
heterogenes
0.1
.2.3
Den
sité
−5 0 5 10 15pelec_margDr3
(a) histogramme des valeurs moyennes si-
mulees
−50
510
15pe
lec_
mar
gDr3
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.31 – estimation coefficient du prix region3 du modele dynamique a parametres
heterogenes
0.2
.4.6
.81
Den
sité
−2 −1 0 1 2 3 4revenu_netDr3
(a) histogramme des valeurs moyennes si-
mulees
−10
12
3re
venu
_net
Dr3
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.32 – estimation coefficient du revenu net region3 du modele dynamique a pa-
rametres heterogenes
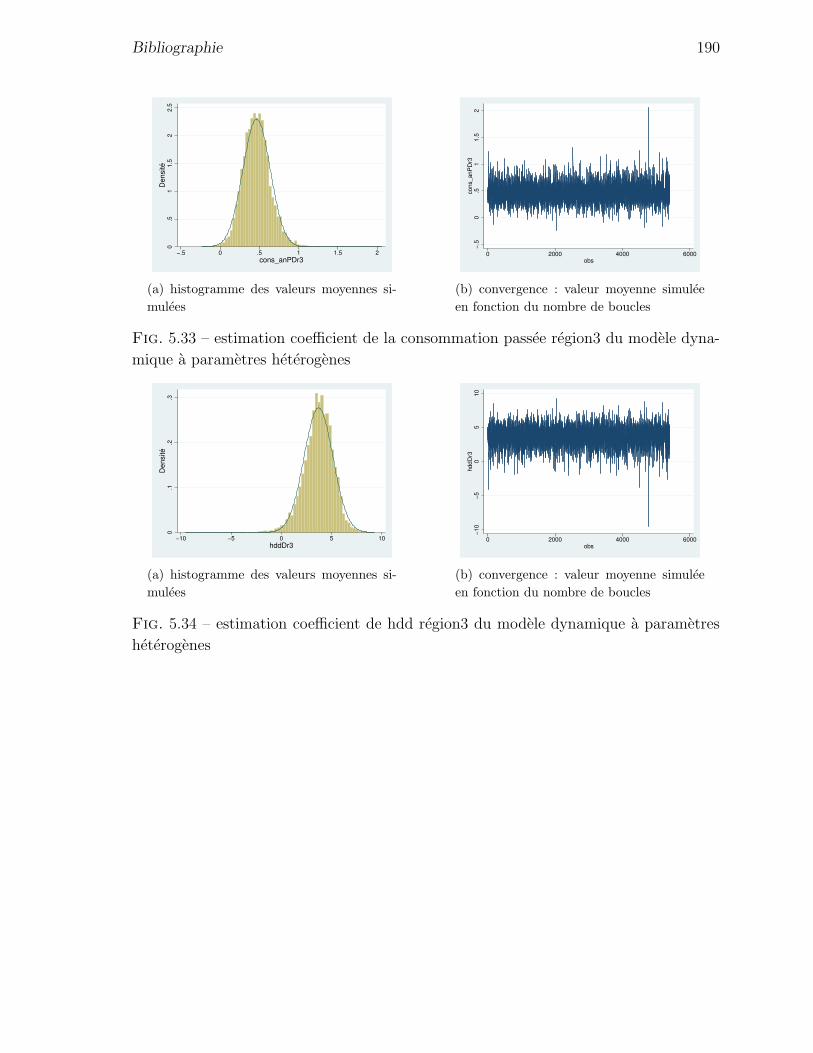
Bibliographie 190
0.5
11.
52
2.5
Den
sité
−.5 0 .5 1 1.5 2cons_anPDr3
(a) histogramme des valeurs moyennes si-
mulees
−.5
0.5
11.
52
cons
_anP
Dr3
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.33 – estimation coefficient de la consommation passee region3 du modele dyna-
mique a parametres heterogenes
0.1
.2.3
Den
sité
−10 −5 0 5 10hddDr3
(a) histogramme des valeurs moyennes si-
mulees
−10
−50
510
hddD
r3
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.34 – estimation coefficient de hdd region3 du modele dynamique a parametres
heterogenes

Bibliographie 191
0.0
5.1
.15
.2.2
5D
ensi
té
−20 −15 −10 −5 0cddDr3
(a) histogramme des valeurs moyennes si-
mulees
−20
−15
−10
−50
cddD
r3
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.35 – estimation coefficient de cdd region3 du modele dynamique a parametres
heterogenes
0.2
.4.6
.8D
ensi
té
−4 −3 −2 −1 0 1 2pelec_margDr4
(a) histogramme des valeurs moyennes si-
mulees
−4−2
02
pele
c_m
argD
r4
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.36 – estimation coefficient du prix region4 du modele dynamique a parametres
heterogenes
0.2
.4.6
.8D
ensi
té
−3 −2 −1 0 1 2 3 4revenu_netDr4
(a) histogramme des valeurs moyennes si-
mulees
−4−2
02
4re
venu
_net
Dr4
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.37 – estimation coefficient du revenu net region4 du modele dynamique a pa-
rametres heterogenes
Bibliographie 192
0.5
11.
52
Den
sité
−1 −.5 0 .5 1 1.5 2cons_anPDr4
(a) histogramme des valeurs moyennes si-
mulees
−10
12
cons
_anP
Dr4
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.38 – estimation coefficient de la consommation passee region4 du modele dyna-
mique a parametres heterogenes
0.1
.2.3
.4D
ensi
té
−4 −2 0 2 4 6 8 10hddDr4
(a) histogramme des valeurs moyennes si-
mulees
−50
510
hddD
r4
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.39 – estimation coefficient de hdd region4 du modele dynamique a parametres
heterogenes
0.1
.2.3
.4D
ensi
té
−8 −6 −4 −2 0 2 4cddDr4
(a) histogramme des valeurs moyennes si-
mulees
−10
−50
5cd
dDr4
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.40 – estimation coefficient de cdd region4 du modele dynamique a parametres
heterogenes

Bibliographie 193
0.1
.2.3
.4.5
Den
sité
−8 −6 −4 −2 0 2 4pelec_margDr5
(a) histogramme des valeurs moyennes si-
mulees
−10
−50
5pe
lec_
mar
gDr5
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.41 – estimation coefficient du prix region5 du modele dynamique a parametres
heterogenes
0.2
.4.6
.8D
ensi
té
−3 −2 −1 0 1 2 3revenu_netDr5
(a) histogramme des valeurs moyennes si-
mulees
−4−2
02
4re
venu
_net
Dr5
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.42 – estimation coefficient du revenu net region5 du modele dynamique a pa-
rametres heterogenes
0.5
11.
52
Den
sité
−.5 0 .5 1 1.5 2cons_anPDr5
(a) histogramme des valeurs moyennes si-
mulees
−.5
0.5
11.
52
cons
_anP
Dr5
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.43 – estimation coefficient de la consommation passee region5 du modele dyna-
mique a parametres heterogenes
Bibliographie 194
0.1
.2.3
Den
sité
−4 −2 0 2 4 6 8 10hddDr5
(a) histogramme des valeurs moyennes si-
mulees
−50
510
hddD
r5
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.44 – estimation coefficient de hdd region5 du modele dynamique a parametres
heterogenes
0.2
.4.6
Den
sité
1 2 3 4 5 6 7 8cddDr5
(a) histogramme des valeurs moyennes si-
mulees
02
46
8cd
dDr5
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.45 – estimation coefficient de cdd region5 du modele dynamique a parametres
heterogenes
0.5
11.
5D
ensi
té
−3 −2 −1 0 1 2pelec_margDr8
(a) histogramme des valeurs moyennes si-
mulees
−2−1
01
2pe
lec_
mar
gDr8
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.46 – estimation coefficient du prix region8 du modele dynamique a parametres
heterogenes

Bibliographie 195
0.2
.4.6
.81
Den
sité
−2 −1 0 1 2 3 4revenu_netDr8
(a) histogramme des valeurs moyennes si-
mulees
−20
24
reve
nu_n
etD
r8
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.47 – estimation coefficient du revenu net region8 du modele dynamique a pa-
rametres heterogenes
0.5
11.
52
Den
sité
−1 −.5 0 .5 1 1.5 2cons_anPDr8
(a) histogramme des valeurs moyennes si-
mulees
−10
12
cons
_anP
Dr8
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.48 – estimation coefficient de la consommation passee region8 du modele dyna-
mique a parametres heterogenes
0.2
.4.6
Den
sité
−4 −2 0 2 4 6 8hddDr8
(a) histogramme des valeurs moyennes si-
mulees
−50
510
hddD
r8
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.49 – estimation coefficient de hdd region8 du modele dynamique a parametres
heterogenes

Bibliographie 196
0.1
.2.3
.4D
ensi
té
−12 −10 −8 −6 −4 −2 0 2cddDr8
(a) histogramme des valeurs moyennes si-
mulees
−15
−10
−50
cddD
r8
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.50 – estimation coefficient de cdd region8 du modele dynamique a parametres
heterogenes
0.5
11.
5D
ensi
té
−6 −5.5 −5 −4.5 −4 −3.5 −3 −2.5pelec_margDr9
(a) histogramme des valeurs moyennes si-
mulees
−6−5
−4−3
−2pe
lec_
mar
gDr9
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.51 – estimation coefficient du prix region9 du modele dynamique a parametres
heterogenes
Bibliographie 197
0.5
11.
5D
ensi
té
.5 1 1.5 2 2.5 3 3.5 4revenu_netDr9
(a) histogramme des valeurs moyennes si-
mulees
01
23
4re
venu
_net
Dr9
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.52 – estimation coefficient du revenu net region9 du modele dynamique a pa-
rametres heterogenes
01
23
Den
sité
−.4 −.2 0 .2 .4 .6 .8 1 1.2cons_anPDr9
(a) histogramme des valeurs moyennes si-
mulees
−.5
0.5
11.
5co
ns_a
nPD
r9
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.53 – estimation coefficient de la consommation passee region9 du modele dyna-
mique a parametres heterogenes
0.2
.4.6
.8D
ensi
té
1 2 3 4 5 6 7 8hddDr9
(a) histogramme des valeurs moyennes si-
mulees
02
46
8hd
dDr9
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.54 – estimation coefficient de hdd region9 du modele dynamique a parametres
heterogenes
Bibliographie 198
0.5
11.
5D
ensi
té
−3 −2.5 −2 −1.5 −1 −.5 0 .5cddDr9
(a) histogramme des valeurs moyennes si-
mulees
−3−2
−10
1cd
dDr9
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 5.55 – estimation coefficient de cdd region9 du modele dynamique a parametres
heterogenes
5.8.3 Annexe C : Tests d’hypothese de restrictions non lineaires
Comme on peut le remarquer, le concept d’elasticite de court terme ou de long terme
a ete largement utilise. Il est important de savoir si ces elements sont statistiquement
significatifs ou non. Rappelons que le modele est defini en niveau, autrement dit, nous
n’avons pas utilise de transformation logarithmique. Une transformation logarithmique
de toutes les variables du modele permettrait d’obtenir directement les ecart-type des
elasticites, puisque les coefficients de pentes seraient aussi les elasticites. Cependant,
nous avons garde le modele en niveau pour deux principales raisons. La premiere vient
du fait que la demande d’electricite est derivee directement de la fonction d’utilite
indirecte du menage. Cette fonction d’utilite est definie en terme exponentiel comme
dans les travaux de Dubin et McFadden (1984). La forme de la fonction de demande
est obtenue directement en appliquant l’identite de Roy a la fonction d’utilite indirecte.
Cette fonction de demande n’est pas exprimee en terme logarithmique. Pour garder une
coherence dans tous nos travaux, nous gardons les variables qui entrent dans la fonction
de demande en niveau et non logarithme. La seconde raison vient du fait que nous avons
une tarification non lineaire. Hydro-Quebec a fixe un seuil de 30kWh en dessous duquel
elle fixe un prix marginal p1 et au dela duquel elle fixe un prix p2 > p1. Donc, le signe de
la variable (qui est egale a la difference entre la consommation journaliere non observable
et le seuil de 30 kWh) est tres important. Si le modele de demande est exprime des
le depart en log, il sera difficile de determiner correctement le signe de cette variable.
Car le log de la difference n’est pas egal a la difference des log. Pour ce qui concerne la
demande d’electricite des cohortes, elle est obtenue en prenant la moyenne de tous les
menages appartenant a la meme cohorte. Ainsi, nous gardons la demande des cohortes
en niveau dans le but de rester coherent avec l’ensemble des autres chapitres. Garder
les variables du modele en niveau ajoute une etape supplementaire pour obtenir les

Bibliographie 199
ecart-type des elasticites. Les elasticites n’etant pas directement donnees, pour savoir
si elles sont statistiquement significatives ou pas, il faut calculer leurs variances.
Pour tester la significativite des differentes elasticites, nous avons utilise le principe
des tests d’hypothese de restrictions non lineaires. En effet, l’elasticite est une fonction
non lineaire de parametres lorsque le modele est exprime en niveau (mais si le modele
est exprime en log-log, ces calculs ne sont plus necessaires puisque les tests peuvent se
faire directement, les ecart-types etant directement donnes). Par exemple, l’elasticite
de court terme du prix est :
η =∂Q
∂P
P
Q= β
P
Q= g (β)
avec Q la quantite et P le prix. Pour simplifier l’ecriture et aussi pour le generaliser (au
cas d’une elasticite revenu par exemple ou d’une elasticite prix-croisee), posons PQ
= X
L’elasticite de long terme est definie par :
θ =η
1 − α= g (η, α)
avec α le coefficient de la variable dependante retardee du modele dynamique.
Pour tester la significativite d’une elasticite, cela revient a effectuer un test de res-
triction non lineaire. Le principe general des tests de restrictions non lineaires (une seule
restriction en ce qui nous concerne) est donne par :
H0 : g (β) = r
H1 : g (β) 6= r
La statistique de test est :
z =g (β) − r
ecart − type estime [V (g (β) − r)]∼ t [N − K]
Le test de significativite de l’elasticite impose que r = 0 de sorte que la statistique de
test devient :
z =g (β)
ecart − type estime [V (g (β))]∼ t [N − K]
La variance peut etre approximee par :
V[g(β)]
≈
(∂g (β)
∂β
)′V(β)(∂g (β)
∂β
)
Pour le cas de l’elasticite de court terme, on a :
g (β) = η = βX
V[g(β)]
= X2V(β)

Bibliographie 200
La variance de l’elasticite de long terme est donnee par :
g (η, α) = θ =η
1 − α
V(θ)
=
(∂θ
∂η
)2
V (η) +
(∂θ
∂α
)2
V (α) + 2Cov [η, α]
=
(∂θ
∂η
)2
V (η) +
(∂θ
∂α
)2
V (α) + 2XCov[β, α
]

Chapitre 6
Analyse de la demande
conditionnelle : approche
bayesienne
6.1 Introduction
Dans ce travail, nous sommes interesses a l’analyse de la demande d’electricite a par-
tir d’une serie d’enquetes independantes. L’objectif poursuivi est d’utiliser une approche
permettant de simuler des panels ou l’information est gardee au niveau individuel. Nous
disposons en effet de plusieurs enquetes independantes qui ne nous permettent pas de
suivre les memes menages sur plusieurs periodes. Puisque chaque menage apparaıt seule-
ment dans une seule enquete, nous faisons face a un probleme de donnees manquantes.
Apres avoir completer les donnees, nous estimerons les parametres d’un modele de
demande statique et d’un modele dynamique ou nous corrigeons a la fois le biais de
selection provenant du choix du mode de chauffage et aussi le biais d’endogeneite du a la
structure tarifaire de l’electricite. Le probleme de biais de selection sera corrige a partir
d’un modele logit mixte avec erreurs autoregressives generalisees d’ordre un (Ben-Akiva
et Bolduc, 1991). Le probleme d’endogeneite du prix marginal de l’electricite sera cor-
rige a travers le modele a classes latentes que nous avons developpe. Nous utiliserons
une approche bayesienne, initialement proposee par Paquet (2002), Paquet et Bolduc
(2004) qui combine l’algorithme de l’augmentation des donnees pour obtenir des pa-
nels simules et l’echantillonnage de Gibbs pour estimer les parametres du modele. La
methodologie proposee pour analyser la demande d’electricite est une premiere car dans
les travaux anterieurs, les auteurs se contentent le plus souvent de corriger un des trois

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 202
problemes poses. La section(6.2) presente la revue des ecrits anterieurs, la section (6.4)
decrit la methodologie bayesienne utilisee, la section(6.5) presente le modele statique
ainsi que les resultats de l’estimation, la section (6.6) etend l’approche proposee au
modele de demande dynamique et nous concluons a la section (6.7).
6.2 Revue de la litterature
Dans le chapitre (3), nous avons estime un modele de demande d’electricite en
tenant compte du choix du mode de chauffage et de la tranche de consommation ;
nous nous sommes interesses a un modele d’une seule periode, soit une seule coupe
transversale. L’aspect intertemporel ne pouvait pas etre pris en compte etant donne
qu’on n’avait qu’une seule periode d’etude qui etait celle de 1989. Pour consommer
l’energie, le menage doit choisir un systeme de chauffage (de l’eau et de l’espace) pour
plusieurs annees. Le systeme de chauffage est en fait un bien durable, par consequent, le
choix ne se fait pas a chaque periode. Pour analyser le comportement de consommation,
il serait interessant de suivre les memes menages sur plusieurs periodes. Les donnees de
panel sur ces menages peuvent nous permettre de les suivre durant differentes annees.
Les panels interrogent les memes individus a plusieurs reprises tandis que les donnees
de coupe transversale n’interrogent qu’une seule fois le meme individu.
Les donnees de panel ont en effet plusieurs avantages comparees aux donnees de
coupes transversales (ou donnees d’enquete) ou les series chronologiques. Hsiao (2001)
et Baltagi (2005) donnent les avantages et les limites des donnees de panel. Avec les
panels, il est possible de controler l’heterogeneite individuel. Les donnees de panel sont
des donnees qui comportent beaucoup plus d’information, plus de variabilite, moins de
colinearite entre les variables, plus de degres de liberte et plus d’efficacite.
Les panels ont cependant certaines limites. Il y a d’abord les problemes de collecte
des donnees. Cela inclut le probleme de disponibilite de la population d’interet, les non-
reponses (les individus peuvent ne pas vouloir cooperer ou il peut y avoir des erreurs
dans les questionnaires), la frequence des entrevues, l’espace entre les entrevues et la
periode de reference.
Comme d’autres types de donnees, les panels peuvent donner lieu a un probleme d’er-
reurs de mesure. Ces erreurs de mesure peuvent se produire soit parce que la personne
interrogee a donne une fausse reponse (volontairement ou non), ou soit parce que la
question posee n’est pas assez claire ou precise.
Les panels sont aussi sujets au probleme de selection. Par exemple, le questionnaire peut
etre adresse a un groupe d’individus tres specifique, et en n’interrogeant que ces indi-

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 203
vidus, on exclut automatiquement les autres. On se retrouve alors avec un echantillon
tronque qui causerait un biais de selection dans les estimations (Hausman et Wise,
1979). Il y a aussi le probleme d’attrition. Les non-reponses peuvent se produire dans les
donnees de coupes transversales comme dans les donnees de panel. Mais ce probleme est
beaucoup plus serieux avec les panels. Par exemple, les repondants peuvent disparaıtre
definitivement du panel (quitter, mourir ou ils ne trouvent plus d’interet a participer
aux entrevues). Une solution a ce probleme serait d’utiliser un panel rotatif, qui est en
fait un panel ou a chaque periode, on change un pourcentage fixe des repondants.
Les panels s’etalent souvent sur une tres courte periode. Cela n’est pas necessairement
negatif puisqu’en s’etalant sur plusieurs periodes, le probleme d’attrition pourrait s’ag-
graver et la base de donnees pourrait etre trop lourde a manipuler.
Dans la province de Quebec, il n’existe pas de donnees de panel portant sur la
consommation d’energie des menages. Les donnees dont nous disposons sont des coupes
transversales independantes. Il s’agit de donnees d’enquetes d’Hydro-Quebec de 1989,
1994, 1999 et 2002. Il sera alors difficile de faire une bonne analyse de la dynamique
d’ajustement des menages. Le probleme avec ce type de donnees est qu’il est impossible
de suivre le meme menage sur plusieurs annees : on ne peut pas retracer un menage
donne a chacune des quatre (4) enquetes. Les menages presents dans une enquete sont
absents dans les autres enquetes comme cela est decrit sur la figure 4.1. Les donnees
manquantes sont indiquees par les points d’interrogation.
Il s’agit donc d’un probleme de donnees manquantes. Ce manque de donnees est tres
prononce comparativement aux cas habituels ou on a que quelques observations man-
quantes. Lorsqu’il s’agit de quelques individus manquants, les observations manquantes
peuvent etre completees en utilisant soit l’algorithme EM (esperance maximisation) ou
l’imputation multiple qui sont parfois beaucoup plus appropries. Parfois aussi, s’il ne
s’agit qu’un faible pourcentage d’information manquante (5% ou moins), il suffit juste
d’eliminer ces observations de la base de donnees.
L’algorithme EM est une technique generale d’estimation par maximum de vraisem-
blance en presence de donnees manquantes. L’algorithme formalise une vieille idee ad
hoc qui consistait a : (1) remplacer les valeurs manquantes par les valeurs estimees etant
donnes les parametres, (2) estimer les parametres en supposant que les valeurs man-
quantes sont donnees par leurs valeurs estimees, (3) re-estimer les valeurs manquantes
en supposant que les nouveaux estimes des parametres sont corrects, (4) re-estimer
les parametres, et ainsi de suite jusqu’a la convergence (Little et Rubin 2002, Gelman
et al. (2000)). Bien que des cas particuliers de cet algorithme soient apparus avant
les annees 1970 dans la litterature statistique, c’est seulement en 1977 que Dempster,
Laird et Rubin ont introduit le terme esperance maximisation, formalise cet algorithme

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 204
et obtenu ses proprietes. L’algorithme se base sur l’interdependance qui existe entre
les observations manquantes et les parametres du modele. Schafer (2000) donne une
definition formelle de l’algorithme. L’algorithme EM pour une seule iteration comporte
deux grandes etapes :
1. L’etape E ou etape du calcul de l’esperance qui consiste a completer les donnees
manquantes.
2. l’etape M ou etape de la maximisation qui consiste a estimer les parametres par
maximum de vraisemblance etant donnee la base de donnees complete obtenue a
la premiere etape.
L’algorithme est approprie pour les situations ou il est facile d’effectuer les deux
etapes. Dans de telles situations, il permet d’atteindre le maximum global unique de la
fonction de vraisemblance. Cependant, il peut arriver que l’algorithme EM ne converge
pas vers le maximum global. D’apres Little et Rubin (2002) un inconvenient de l’algo-
rithme EM est que la convergence peut etre peniblement lente lorsqu’on a une fraction
importante de donnees manquantes. Comme d’autres algorithmes, l’algorithme EM a
certaines limites :
1. EM peut converger vers differents points suivant les valeurs initiales choisies,
2. la fonction log-vraisemblance peut comporter une region plate, ce qui signifie un
continuum de solutions,
3. la convergence peut etre trop lente si la quantite d’information manquante est
tres importante : plus la quantite d’information manquante est importante, plus
lente sera la convergence.
Il existe d’autres approches pour resoudre le probleme de donnees manquantes,
comme l’imputation simple et l’imputation multiple. L’imputation multiple a ete intro-
duite en premier par Rubin (1978) qui l’a ensuite decrite en detail en 1987. L’imputa-
tion multiple (IM) est une approche Monte Carlo pour l’analyse de bases de donnees
incompletes. Dans l’IM, les donnees manquantes sont remplacees par des valeurs si-
mulees. Cela revient a constituer m bases de donnees completes. Chacune des m bases
de donnees est analysee en se servant des methodes standard pour les bases de donnees
completes. L’analyse de l’IM peut se faire selon l’approche classique ou selon l’approche
bayesienne ( Rubin, 1978). L’imputation simple consiste a se limiter a creer une seule
base de donnees complete. L’IM est appropriee pour les cas ou le nombre d’observations
manquantes n’est pas tres grand. Par exemple, lors d’une enquete, certains individus
peuvent choisir de ne pas repondre a certaines questions soit parce qu’ils ne savent pas
quoi repondre ou soit parce qu’ils ne veulent pas divulger une information confidentielle.
Si le pourcentage de non-reponse est faible (5% ou moins), alors l’elimination de ces
observations peut etre une solution raisonnable au probleme de donnees manquantes.
Cependant, dans un ensemble multivarie ou plusieurs variables peuvent avoir des va-
leurs manquantes, les observations ayant au moins une donnee manquante representent

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 205
une proportion importante de la base de donnees. Dans ce cas, une elimination des
observations ayant des donnees manquantes conduirait a une perte d’efficacite car une
partie importante de l’information est ignoree. L’IM est bien appropriee pour resoudre
le probleme de non-reponse. Mais, lorsqu’on dispose d’un ensemble de coupes transver-
sales independantes, les individus observes une periode donnee ne sont plus presents
dans les autres periodes. L’information manquante va concerner toutes les variables du
modele pour tous les individus lorsqu’on passe d’une periode a l’autre. Le probleme
de donnees manquantes est alors plus serieux et l’IM risque fort de ne pas donner des
resultats satisfaisants. Gregoire (2003) et Vidal (2006) ont utilise cet algorithme, mais
les resultats n’etaient pas satisfaisants.
En somme, pour le probleme qui nous concerne, l’algorithme EM de meme que
l’imputation multiple ne sont pas appropries. D’autres solutions existent pour pal-
lier a ce probleme de donnees manquantes : constituer des cohortes d’individus qu’on
peut suivre a chaque periode (Deaton, 1985), ou utiliser une approche bayesienne telle
que l’algorithme de l’augmentation des donnees developpe par Tanner et Wong (1987)
pour completer les donnees manquantes. Cet algorithme peut etre combine avec l’algo-
rithme de l’echantillonnage de Gibbs pour estimer les parametres, une fois les donnees
completees. Cette approche a ete utilisee par Paquet (2002) et Paquet et Bolduc (2004).
La difference entre ces deux approches est importante. L’approche de Deaton (chapitres
4 et 5) regroupe les observations en cohortes, de sorte qu’au final, le nombre de cohortes
est tres faible par rapport au nombre d’individus des bases de depart. Cette approche
transforme les donnees microeconomiques en des donnees macroeconomiques : on passe
de 13035 menages distincts a 25 cohortes qu’on peut suivre sur quatre periodes avec
les pseudo-panels. L’approche bayesienne quant a elle garde l’information au niveau
individuel (on garde les 13035 menages qu’on essaie de suivre sur les quatre periodes),
permettant ainsi de garder les memes individus sur toutes les periodes. Son avantage est
qu’elle produit une certaine efficacite. Dans ce chapitre, nous utiliserons cette approche
pour completer d’abord les donnees manquantes et ensuite simuler les parametres de
notre modele de demande d’electricite. Nous procederons comme dans le chapitre (3)
en definissant d’abord un modele de choix du mode de chauffage, un modele de choix
de la tranche de consommation d’electricite et un modele de demande conditionnelle
d’electricite. Puisque nous supposons que le choix du mode de chauffage est effectue
une seule fois, pour la periode 1989-2002, le modele de choix du mode de chauffage
sera estime juste pour une seule periode. Ce choix est valable pour les autres periodes
considerees dans l’etude. Cela vient du fait que le choix de systemes de chauffage est
valable sur plusieurs periodes, puisque ce sont des biens durables. Mais, quant au choix
de la quantite a consommer ainsi que de la tranche (ou classe) de consommation, il
s’agit de choix qui se font chaque jour et donc a chacune des periodes considerees.
Cela simplifie largement la demarche puisque le probleme de donnees manquantes se

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 206
posera uniquement dans le modele de demande conditionnelle. L’approche bayesienne
sera donc utilisee uniquement pour le modele de demande conditionnelle. Cette facon
de proceder pour completer les donnees manquantes nous permet d’avoir des panels
synthetiques ou panels simules. Ces panels simules ont un certain nombre d’avantages
par rapport au vrais panels. D’abord, avec le panel simule, le probleme d’attrition (qui
est courant et important avec les vrais panels) est resolu. En effet, il ne s’agit pas des
vrais individus qui sont presents a chaque periode, mais plutot des individus fictifs, au
sens ou nous imaginons que si le meme individu etait present a toutes les enquetes,
il aurait alors telles autres caracteristiques. Par exemple, pour un menage enquete en
1989, il n’est pas present en 1994, ni en 1999, ni en 2002. Mais, avec les caracteristiques
qui lui sont propres, nous pouvons imaginer que s’il etait present dans les enquetes de
1994, 1999 et 2002, il aurait un certain nombre de caracteristiques (d’autres ne change-
ront pas, comme les systemes de chauffage, le sexe..., et d’autres changeront de facon
deterministe comme son age, ou de facon aleatoire comme son revenu, etc.). L’approche
par la simulation simulera alors l’individu fictif avec toutes ses caracteristiques pour les
annees durant lesquelles il est absent.
6.3 Modele de choix du mode de chauffage : le logit
mixte
La demande d’electricite n’est pas une demande de bien final, le menage utilise en
effet l’electricite ou d’autres formes d’energies pour satisfaire ses besoins de chauffage
(eau et espace) et ses besoins de base (comme l’eclairage, le fonctionnement des ap-
pareils electromenagers,...). La demande d’electricite est donc une demande derivee,
elle provient de l’utilite que procure les appareils et systemes de chauffage. Nous nous
limiterons essentiellement aux besoins de chauffage de l’eau et de l’espace. L’equation
de la demande d’electricite s’obtient a partir de l’identite de Roy. Estimer la demande
d’electricite sans tenir compte du modele de choix du mode de chauffage conduirait a
des estimateurs biaises et non convergents. Nous avons en fait un probleme de selection
qu’il faut corriger. Durbin et McFadden (1984) ont propose une methode pour corriger
le biais de selection. Nous avons, au chapitre (3) utilise une approche pour ce meme
probleme de selection dans le contexte d’une seule coupe transversale : nous avions uti-
lise un modele logit mixte pour le choix du mode de chauffage, et a partir de ce modele,
nous avions construit des correcteurs de biais de selection pour chaque modalite. Dans
ce chapitre, nous adopterons la meme demarche, mais pour toutes les bases de donnees
qui font l’objet de l’etude. Le modele de choix du mode est invariant dans le temps,
on l’estime pour chaque base et les correcteurs sont les memes pour toutes les periodes

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 207
pour chaque menage. Il n’y a pas a ce niveau un probleme de donnees manquantes.
Les parametres seront estimes par la methode du maximum de vraisemblance simulee
comme au chapitre (3).
Nous posons l’hypothese suivante : le menage fait le choix des systemes de chauffage
de l’eau et de l’espace une fois pour toute sur la periode 1989-2002. De ce fait, le choix
du mode de chauffage est invariant dans le temps (nous supposons que le choix est
effectue en 1989 ou avant pour simplifier le probleme et ce choix est valable au moins
jusqu’en 2002). Cette hypothese est justifiee parce que le menage fait un choix de biens
durables. Les systemes de chauffage de l’eau et de l’espace sont des biens durables.
Le modele de choix du mode de chauffage du menage est defini par la fonction
d’utilite suivante comme dans les travaux de Dubin et McFadden (1984) et Bernard,
Bolduc et Belanger (1996) :
U (j, rev − rj, X, Pe, Pm, Pg, Pbie, εj, η)
avec Pe est le prix de l’electricite, Pm le prix du mazout, Pg le prix du gaz naturel et
Pbie le prix de la bi-energie ; εj est l’ensemble des caracteristiques non observables du
mode de chauffage, η est l’ensemble des caracteristiques non observables du menage, rj
est le cout total du mode, rev est le revenu du menage et X est un vecteur de variables
exogenes.
Le menage choisit l’alternative j si et seulement si : Ujn > Uin ∀i 6= j. Definissons la
variable binaire djn comme suit :
djn =
1
0
si Ujn > Uin ∀ j ∈ Cn ∧ i 6= j
sinon.
La fonction d’utilite Ujn se decompose en deux elements : une partie deterministe (Vjn)
et une autre aleatoire (εjn) :
Ujn = Vjn + εjn
La partie deterministe est specifiee comme suit :
Vjn = Xjnβ,
ou Xjn est un vecteur de toutes les variables exogenes du modele de choix.
La probabilite que le menage n choisisse l’alternative j est :
Pn (j) = P (Ujn > Uin ∀ i 6= j)
= P (Vjn + εjn > Vin + εin ∀ i 6= j)
P (εin − εjn < Vin − Vjn ∀ i 6= j) .

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 208
Nous supposons comme dans le chapitre precedent un modele logit mixte avec erreurs
autoregressives generalisees d’ordre un (GAR(1)) (developpe par Ben-Akiva et Bolduc
1991) :
Ujn = Vjn + εjn
Ujn = Vjn + σjξjn + vjn
εjn = σjξjn + vjn
ξjn = ρ∑
i6=j
wijξin + ζjn.
Le modele peut s’ecrire sous forme vectorielle de facon compacte comme suit :
dn = [d1n, ..., djnn]′
Un = Xnβ + εn,
ou dn, Un et εn sont des vecteurs de dimension (Jn×1) et Xn est une matrice (Jn×Jn).
εn = Tnξn + vn
ou Tn est une matrice diagonale de dimension (Jn × Jn) qui contient les ecart-type σj
sur sa diagonale et
ξn = ρWnξn + ζn ζn ∼ N(0, IJn),
avec n = 1, ..., N , j ∈ Cn et vn un vecteur contenant les termes (vjn) qui suivent une
loi Gumbel iid.
Le modele de demande qui decoule de cette utilite indirecte est la meme a toutes
les periodes et prend la forme suivante :
yjnt = WjntB + ηjnt. (6.1)
Comme nous l’avons souligne auparavant, la demande d’electricite est une demande
derivee. Le menage exprime ses besoins en electricite conditionnellement aux systemes
de chauffage choisis. Il y a une simultaneite entre choix discret et choix continu. Toute
methode d’estimation qui ignore cette simultaneite produit des estimateurs biaises et
non convergents. Comme dans le chapitre (3) ou nous avons utilise les correcteurs
obtenus selon l’approche de Durbin et MacFadden (1984) et Vekeman et al. (2004),
dans ce chapitre egalement, nous adopterons la meme demarche. Nous savons, a partir
de l’equation (6.1), que : E (ηjn |εjn ) = E (ηjn |j ) 6= 0. Nous utiliserons directement les
resultats obtenus au chapitre (3) concernant la formulation des correcteurs de biais de
selection issus de ce modele.
yjnt = WjntB + ηjnt
= WjntB + E (ηjnt |j ) + ujnt, (6.2)

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 209
ou ujnt est un terme d’erreur que nous supposons de moyenne nulle. Nous omettons
l’indice t puisque le choix du mode de chauffage se fait une seule fois pour une longue
periode. Un simulateur lisse et convergent de E [ηjn |j ] propose par Vekeman et al.
(2004) serait :
E [ηjn |j ] =1
S
S∑
s=1
E [ηjn |j, ξsn ] , (6.3)
ou les ξsn sont des tirages dans la loi f (ξn) qui est ici une loi normale et S le nombre
total de tirages. En adoptant la specification de Dubin et McFadden (1984), l’esperance
conditionnelle de η est definie de la facon suivante :
E [ηjn |εjn, ξn ] =σ√
2
λ
∑
i∈Cn
ρiE [εin |j, ξn ] .
Cette esperance n’est pas specifique au mode choisi (j). Pour cette raison, l’indice j
sera mis en exposant et non en indice :
E[ηj
n |εjn, ξn
]=
σ√
2
λ
∑
i∈Cn
ρiE [εin |j, ξn ]
E[εj
n |j, ξn
]=
− ln Λ (j |ξn ) × λ
√3
π............si i = j
Λ(j|ξn )1−Λ(j|ξn )
ln Λ (j |ξn ) × λ√
3π
.........si i 6= j.
Donc, on deduit que :
E[ηj
n |j, ξn
]=
√6σ
π
[ ∑
i∈Cn,i6=j
(ρi
Λ (i |ξn )
1 − Λ (i |ξn )ln Λ (i |ξn )
)− ρj
ln Λ (j |ξn )
1 − Λ (j |ξn )
]
=
√6σ
π
[∑
i∈Cn
ρiΛ (i |ξn )
1 − Λ (i |ξn )(ln Λ (i |ξn ) − dij)
],
avec dij = 1 si i = j et dij = 0 sinon. De plus, nous avons la contrainte suivante :∑i∈Cn,j 6=i ρj + ρi = 0. Il s’ensuit que :
E[ηj
n |j, ξsn
]=
√6σ
π
[ ∑
i∈Cn,j 6=i
ρi
[Λ (i |ξs
n ) ln Λ (i |ξsn )
1 − Λ (i |ξsn )
+ ln Λ (j |ξsn )
]].
Donc, (6.3) devient :
E[ηj
n |j]
=1
S
S∑
s=1
[ ∑
i∈Cn,i6=j
[Λ (i |ξs
n ) ln Λ (i |ξsn )
1 − Λ (i |ξsn )
+ ln Λ (j |ξsn )
]] √6σ
πρi.
Pour simplifier l’ecriture du modele, definissons l’element ω tel que l’expression suivante
soit satisfaite : ∑
i∈Cn,i6=j
(.) ≡∑
i∈Cn
ωin
(.) ,

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 210
ou :
ωin
=
1
0
si i ∈ Cn ∧ i 6= j
sinon.
L’estimateur devient :
E[ηj
n |j]
=1
S
S∑
s=1
∑
i∈Cn
ωin
[Λ (i |ξs
n ) ln Λ (i |ξsn )
1 − Λ (i |Asn )
+ ln Λ(j∣∣ξs
jn
)] √6σ
πρi
=∑
i∈Cn
ωin
[1
S
S∑
s=1
ωin
[Λ (i |ξs
n ) ln Λ (i |ξsn )
1 − Λ (i |ξsn )
+ ln Λ (j |ξsn )
]] √6σ
πρi
=∑
i∈Cn
Fijn
√6σ
πρi
E[ηj
n |j]
= Fjnτi (6.4)
avec τi =√
6σπ
ρi un parametre a estimer.
L’estimateur de E [ηjn |j ] obtenu a partir du logit mixte est E [ηj
n |j ] = Fjnτi.
Ce correcteur entre dans l’equation de la demande conditionnelle (6.2). L’estimateur
de E [ηjn |j ] est obtenu apres la maximisation par simulation de la fonction de vraisem-
blance du logit mixte et a la forme E[ηj
n |j]
= Fnτ . Ces correcteurs de biais de selection
sont inclus par la suite dans le modele de demande comme des variables explicatives.
Les correcteurs de biais de selection ayant ete obtenus, nous les incluons dans le
modele de demande conditionnelle au choix du mode de chauffage comme nouvelles
variables explicatives. Le probleme de selection etant resolu, comme au chapitre (3),
il faut egalement corriger l’endogeneite du prix marginal de l’electricite. Rappelons
qu’Hydro-Quebec utilise une tarification par tranche (comme decrite au chapitre (3)).
Cette tarification non lineaire rend le prix marginal endogene. Toute estimation qui
ignore ce probleme donnerait des estimateurs biaises et non convergents. Au chapitre
(3), nous avons developpe un modele a classes latentes pour corriger ce probleme. Nous
etendrons ce nouveau modele au cas dynamique dans ce chapitre egalement.
Apres avoir defini le modele de demande conditionnelle (au choix du mode et au
choix de la classe), nous devons passer a son estimation. Or, comme cela a ete sou-
ligne auparavant, les bases de donnees disponibles sont des enquetes independantes que
nous considerons comme un «panel» avec donnees manquantes. Nous utilisons a cet
effet l’approche bayesienne qui combine l’algorithme de l’augmentation des donnees
(pour completer les donnees manquantes) et l’echantillonnage de Gibbs pour estimer
les parametres du modele.

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 211
6.4 Methodologie bayesienne
La methodologie bayesienne est essentiellement fondee sur le theoreme de Bayes qui
relie l’information a priori (information disponible avant l’usage des donnees), la nou-
velle information et la distribution a posteriori. L’echantillonnage de Gibbs utilise cette
relation pour estimer les parametres d’interet et l’algorithme de l’augmentation des
donnees l’utilise pour imputer les donnees manquantes dans des contextes multivaries.
Les deux techniques sont fondees essentiellement sur la methodologie MCMC (Markov
Chain Monte Carlo). Les MCMC sont un ensemble de techniques pour faire des tirages
pseudo aleatoires a partir de distributions de probabilite. L’objectif du MCMC est de
generer une ou plusieurs valeurs d’une variable aleatoire habituellement multidimen-
sionnelle. Il s’agit de faire de la simulation Monte Carlo sur une chaıne markovienne
ergodique. On peut consulter l’article de Gordon et Belanger (2003) pour un survol des
techniques d’echantillonnage de type MCMC.
6.4.1 Echantillonnage de Gibbs
L’echantillonnage de Gibbs est la technique MCMC la plus simple. Sa popularite
date de l’application faite par German et German (1984) de la distribution Gibbs pour
modeliser les images satellites. Son applicabilite s’etend cependant a une grande variete
de problemes. L’echantillonnage de Gibbs d’apres Casella et George (1992), est une tech-
nique pour generer des variables aleatoires d’une distribution (marginale) de facon indi-
recte sans toutefois avoir a calculer la densite. Gelfand (2000) definit l’echantillonnage
de Gibbs comme un outils pour obtenir des echantillons a partie de fonctions de densite
jointes non standard. Ces echantillons proviennent en fait de distributions condition-
nelles associees a la densite jointe. Soit : θ = (θ1, θ2, ........θJ) ou θj est un element
ou un sous-ensemble de θ. Si le modele est assez complexe, la distribution marginale
f (θ) = f (θ1, θ2, ........θJ) ne sera pas standard. Par exemple, si on s’interesse a la den-
site marginale du premier element, on doit integrer la densite conjointe par rapport aux
autres elements pour obtenir la fonction a integrales multiples suivante :
f (θ1) =
∞∫
−∞
∞∫
−∞
.......
∞∫
−∞
f (θ1, θ2, θ3........θJ) dθ2dθ3dθ4......dθJ .
La presence d’integrales multiples pose de serieux problemes si on veut calculer certains
moments (moyenne ou variance). Cependant, la densite conditionnelle f (θ1 |θ−1 ) est
souvent facile a calculer (ou θ−1 = (θ2, ........θJ) represente les elements autres que celui
qui nous interesse soit θ1). Dans le but d’eviter des calculs onereux, German et German

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 212
(1984) ont propose la technique d’echantillonnage de Gibbs basee sur la theorie des
chaınes markoviennes et donc qui exploite plus les densites conditionnelles au lieu des
densites conjointes souvent plus complexes.
6.4.2 L’algorithme de l’augmentation des donnees
La technique d’augmentation des donnees (AD) est souvent utilisee pour solutionner
les problemes avec donnees manquantes. On cherche a rendre ces problemes plus faciles a
analyser une fois que la base de donnees est completee. Supposons que la base de donnees
disponible comporte des donnees manquantes et notons : Y = (Yobs, Ymis). Le vecteur
Ymis = yimt, ximt contient a la fois des variables endogenes et exogenes manquantes.
Yobs = yint, xint contient a la fois des variables endogenes et exogenes observees.
Dans beaucoup de problemes avec donnees manquantes, la densite a posteriori des
donnees observees P (θ |Yobs ) n’est pas facile a manipuler ni facile a simuler ; il arrive
frequemment d’ailleurs qu’elle ne soit pas connue. En effet, cette densite est sous forme
d’integrale :
P (θ |Yobs ) =
∫
Ymis
P (θ |Yobs, Ymis ) dYmis.
On utilise la technique d’augmentation des donnees pour contourner ces difficultes. En
effet, si on augmente les donnees observees par des valeurs predites de Ymis, alors, la
densite a posteriori de la base complete P (θ |Yobs, Ymis ) devient plus facile a analy-
ser. L’algorithme AD utilise la dependance qui existe entre les densites P (θ |Yobs ) et
P (Ymis |Yobs ) de facon a calculer P (θ |Yobs ). En effet :
P (θ |Yobs, Ymis ) P (Ymis, Yobs) = P (Ymis |Yobs, θ ) P (θ, Yobs)
P (θ |Yobs, Ymis ) P (Ymis, Yobs) = P (Ymis |Yobs, θ ) P (θ |Yobs ) P (Yobs)
P (θ |Yobs ) =P (θ |Yobs, Ymis ) P (Ymis, Yobs)
P (Ymis |Yobs, θ ) P (Yobs)
=P (θ |Yobs, Ymis ) P (Ymis |Yobs ) P (Yobs)
P (Ymis |Yobs, θ ) P (Yobs)
=P (θ |Yobs, Ymis ) P (Ymis |Yobs )
P (Ymis |Yobs, θ )
∝ P (θ |Yobs, Ymis ) P (Ymis |Yobs )
P (θ |Yobs ) ∝ P (θ |Yobs, Ymis ) P (Ymis |Yobs ) .

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 213
De plus, nous avons :
P (Ymis |Yobs ) =
∫
θ
P (Ymis, θ |Yobs ) dθ
=
∫
θ
P (Ymis |Yobs, θ ) P (θ |Yobs ) dθ.
Il faut donc pouvoir faire des tirages dans les distributions conditionnelles suivantes :
P (θ |Yobs, Ymis ) et P (Ymis |Yobs, θ ). L’algorithme AD comporte en fait deux grandes
etapes :
– (etape-I ou etape de l’imputation) : conditionnellement aux parametres θt, faire
des tirages des valeurs manquantes de la densite predictive de Ymis :
Y t+1mis ∼ P
(Ymis
∣∣Yobs, θt). (6.5)
– (etape-P ou etape a posteriori) : conditionnellement aux valeurs predites obtenues
a l’etape I, faire des tirages de nouvelles valeurs des parametres a partir de la
densite a posteriori de la base complete :
θt+1 ∼ P(θ∣∣Yobs, Y
t+1mis
)(6.6)
Repeter a plusieurs reprises (6.5) et (6.6) en se donnant des valeurs de depart θ0.
On obtient alors une sequence de valeurs θt, Y tmis : t = 1, 2...... Cette sequence
converge vers sa densite stable qui est P (θ, Ymis |Yobs, ). Les sous-sequences :
θt, : t = 1, 2.....
et Y t
mis : t = 1, 2.....
ont leurs distributions conditionnelles stables qui sont respectivement P (θ |Yobs )
et P (Ymis |Yobs ).
Dans ce travail, nous disposons de plusieurs coupes transversales independantes.
L’ideal serait d’avoir des donnees de panel qui permettraient de tenir compte de l’as-
pect intertemporel de la demande d’electricite. La consommation d’energie necessite
le choix de systemes de chauffage ; ce choix est fait pour satisfaire des besoins pour
plusieurs annees. Donc, il est important de pouvoir suivre les memes menages sur une
certaine periode afin de mieux capter leur comportement de consommation. Les series
de coupes transversales independantes ne permettent pas de suivre les memes individus
sur plusieurs annees. Pour pallier a ce probleme, plusieurs approches peuvent etre uti-
lisees : constituer des cohortes (individus ayant un certain nombre de caracteristiques en
commun) qu’on peut suivre dans le temps (ceci a fait l’objet des chapitres 4 et 5 ), ou si-
muler les donnees manquantes. Puisqu’il ne s’agit pas des memes menages d’une enquete

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 214
a l’autre, les menages presents dans une enquete seront absents dans l’enquete suivante
(ou precedente). Nous nous servirons de l’algorithme d’augmentation des donnees pour
completer les donnees manquantes. Une fois les donnees manquantes completees, nous
utiliserons l’algorithme de l’echantillonnage de Gibbs pour estimer les parametres tout
en corrigeant le biais de selection du choix du mode et le biais d’endogeneite provenant
du choix de la classe. Pour corriger le choix de la classe, au chapitre (3), nous avons
developpe un modele a classes latentes et l’estimation du modele a ete faite selon la
methode du maximum de vraisemblance. Il existe aussi dans la litterature bayesienne
une methode d’estimation de ce type de modele. La section suivante presente la methode
d’estimation des modeles a classes latentes selon l’approche bayesienne.
6.4.3 Estimation bayesienne des modeles a classes latentes
Dans les ecrits anterieurs, un certain nombre de travaux ont porte sur l’estimation
bayesienne des modeles a classes latentes. L’estimation des modeles a classes latentes
selon l’approche bayesienne a ete largement utilisee dans les domaines tels que le mar-
keting, la psychiatrie, les statistiques,... On en denombre tres peu dans le domaine de
l’econometrie. La plupart des auteurs qui se sont interesses a l’estimation bayesienne
des modeles a classes latentes ont utilise une des methodes MCMC. On peut citer
entre autres : Diebolt et Robert (1994), Fruhwirth-Schnatter (1999a, 1999b, 2001),
Lenk et DeSarbo (1999), Allenby et al. (1998), Meng et Wong (1996), Richardson et
Green (1997), Roeder et Wasserman (1997), Stephens (1997) Fruhwirth-Schnatter et
al. (2002),...
Nous nous inspirons un peu de l’approche utilisee dans les travaux de Fruhwirth-
Schnatter et al. (2002). Leur modele a fait l’objet d’une application dans un contexte
de modele a choix discret portant sur le marche d’eau minerale en Australie . Ils n’ont
pas estime les parametres du modele de choix de la classe, il ont plutot suppose que la
probabilite de choisir une classe peut etre simulee a partir d’une loi de Dirichlet. Nous
pensons en effet que la probabilite de choix d’une classe depend d’un certain nombre
de variables explicatives (par exemple, le fait d’utiliser des appareils energivores comme
des climatiseurs,... pourrait augmenter la chance qu’un menage se retrouve dans la
deuxieme classe). Rappelons que dans notre modele, nous ne disposons que de deux
classes : la classe des menages qui consomment moins de (ou egale a) 30 kWh par jour
et celle des menages qui consomment au dela des 30 kWh. Nous proposons d’utiliser
l’approche par la simulation pour estimer les parametres du modele latent pour le choix
de la classe ; les differentes valeurs simulees correspondront a des probabilites simulees.
Cette approche est beaucoup plus concrete que celle utilisee par Fruhwirth-Schnatter et
al. (2002) dans laquelle la probabilite de choisir une classe ne depend d’aucune variable

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 215
explicative. De plus, ils ont suppose que le nombre de classes n’etait pas connu au
depart, ce qui n’est pas le cas dans notre modele.
6.5 Estimation d’un modele statique de demande
d’electricite
Dans cette etude, contrairement au cas habituel de modele a classes latentes, nous
supposons qu’il existe deux classes. Nous supposons que les probabilites dependent d’un
certain nombre de variables explicatives. Nous simulerons d’abord les donnees man-
quantes, ensuite, nous estimerons les parametres du modele. Definissons tout d’abord
les equations du modele.
6.5.1 Modele de demande conditionnelle a la classe et au mode
de chauffage
Hydro-Quebec utilise un tarif croissant par partie. En effet, la structure tarifaire a
deux parties : si la consommation journaliere du menage ne depasse pas les 30 kWh,
Hydro-Quebec fixe un prix par unite consommee de p1 et si sa consommation journaliere
est superieur aux 30 kWh, chaque kWh additionnel coutera au menage p2 avec p1 < p2.
Ces prix varient d’une annee a l’autre (mais durant la periode 1998 et 2004, Hydro-
Quebec a gele ses prix en les gardant a ceux de Mai 1998). Donc, le prix marginal depend
de la quantite consommee et cette quantite consommee depend aussi du prix marginal.
Il y a donc un probleme d’endogeneite. Un autre probleme qui se pose aussi est que
la consommation journaliere n’est pas directement observable par le chercheur comme
cela a ete decrit au chapitre (3). Hydro-Quebec se base sur la consommation totale d’un
cycle de mesurage d’environ deux mois pour approximer la consommation journaliere
moyenne. Mais le consommateur a la possibilite de suivre sa consommation au jour le
jour et peut donc controler le niveau de consommation. En optant pour un tarif en
deux parties, Hydro-Quebec cree deux classes de consommateurs : les consommateurs
de la premiere classe (consommation journaliere ne depassant pas les 30 kWh) et ceux
de la deuxieme classe (consommation journaliere depassant les 30 kWh). La prise en
compte de ces classes dans l’estimation de la demande d’electricite peut se faire grace
aux modeles a classes latentes que nous avons developpe. Pour le probleme qui nous
concerne, le nombre de classes est connu (deux classes). De plus, nous n’imposons pas de
restrictions sur les parametres des classes, en d’autres termes, nous n’imposons pas de

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 216
contraintes sur les parametres comme c’est le cas dans la plupart des travaux anterieurs.
L’estimation des modeles a classes latentes peut se faire soit par une approche
classique qui consiste a maximiser la vraisemblance de l’echantillon comme cela a ete fait
dans le chapitre (3), ou soit par une approche bayesienne. L’avantage avec l’approche
bayesienne est qu’il est possible d’estimer a la fois les parametres du modele et de
simuler les donnees manquantes.
Definissons la variable y∗jnt = consommation journalierent − 30kWh ; avec j la
modalite choisie par le menage n. Si y∗jnt ≤ 0, le menage n se situe dans la premiere
tranche a la periode t. Si y∗jnt > 0, le menage se situe dans la deuxieme tranche a
la periode t. Cependant, le chercheur ne sait pas exactement dans quelle tranche le
menage se situe car sa consommation journaliere n’est pas directement observable. Il
existe deux groupes de menages et chaque groupe devrait avoir des caracteristiques
qui lui sont specifiques. Le choix de la classe devrait dependre d’un certain nombre de
facteurs. Nous admettons que le choix de la tranche change d’une annee a l’autre, mais
il peut aussi arriver qu’un menage reste dans la meme classe durant les periodes de
l’etude.
Les modeles a classes latentes sont souvent utilises pour prendre en compte l’heterogeneite
qui existe entre differents groupes d’observations. Dans un modele a classes latentes, les
coefficients sont specifiques aux groupes ou classes. Supposons que le menage considere
appartient a une des deux classes notee par s, (s = 1, 2) avec une certaine probabi-
lite. Soit Q(y∗
jnt ≤ 0), la probabilite qu’un menage appartienne a la premiere classe
et soit Q(y∗
jnt > 0)
la probabilite qu’il appartienne a la deuxieme classe. Supposons
que la consommation journaliere (y∗jnt) est fonction d’un certain nombre de variables
explicatives regroupees dans le vecteur Mjnt :
y∗jnt = Mjntα + ujnt ujnt ∼ N
(0, σ2
u
)
Q(y∗
jnt ≤ 0)
= Q
(y∗
jnt − Mjntα
σu
≤ −Mjntα
σu
)(6.7)
= Φ
(−Mjntα
σu
)= π1jnt
Q(y∗
jnt > 0)
= 1 − Q(y∗
jnt ≤ 0)
= 1 − Φ
(−Mjntα
σu
)= π2jnt
.
Le vecteur Mjnt contient aussi les correcteurs de biais de selection obtenus dans une
etape anterieure, etant donne que le choix de la tranche de consommation est condi-
tionnelle au choix du mode de chauffage, justifiant ainsi l’ajout de l’indice j. En condi-
tionnant sur le choix de la tranche et celui du mode de chauffage, le modele de demande

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 217
d’electricite peut s’ecrire comme suit :
yjnt = xjntδs + xjnγs + ϑn + εjnt s = 1, 2
ϑn ∼ N(0, σ2
ϑ
)εjnt ∼ N
(0, σ2
ε
)
yjnt =
xjntδ1 + xjnγ1 + ϑn + εjnt si y∗
jnt ≤ 0
xjntδ2 + xjnγ2 + ϑn + εjnt si y∗jnt > 0
(6.8)
yjnt =
Xjntβ1 + ϑn + εjnt si y∗
jnt ≤ 0
Xjntβ2 + ϑn + εjnt si y∗jnt > 0
, (6.9)
avec : xjnt un vecteur de variables exogenes qui varient dans le temps, et xjn est un
vecteur de variables exogenes invariantes dans le temps (ce vecteur contient aussi les
correcteurs de biais de selection du choix du mode de chauffage). L’indice s = 1, 2
indique la classe du menage en question, le terme ϑn est un effet individuel aleatoire
que nous supposons normale comme dans les travaux de Collado (1997).
Nous ne disposons cependant pas d’information sur les periodes precedentes au sujet
du meme menage. De ce fait, on ne peut pas suivre un menage donne dans le temps.
Une facon de resoudre ce probleme est de constituer des cohortes a partir de la base
de donnees disponible comme l’avait propose Deaton (1985). Un des inconvenients avec
cette methode est que l’information est analysee a un niveau agrege (cohortes) et non a
un niveau desagrege (menage). On passe de NT observations a CT << NT observations
avec les pseudo-panels conventionnels. Il y a donc une perte d’efficacite dans l’utilisation
de l’information. Une solution a ce probleme de perte d’information consiste a utiliser
l’approche bayesienne qui combine l’echantillonnage de Gibbs et l’augmentation de
donnees. Cette approche a l’avantage de garder l’information au niveau desagrege et
donc elle n’entraıne pas de perte d’information. Nous definissons d’abord le modele a
classes latentes et ensuite nous presenterons les differentes etapes de l’estimation.
Pour simplifier la notation, nous omettons l’indice j. Le modele de demande condi-
tionnelle (6.9) peut s’ecrire de facon plus condensee pour le menage n de la facon
suivante :
yn = Xnβ + ϑn + εn (6.10)
ϑn ∼ N(0, σ2
ϑ
)εn ∼ N
(0, σ2
εIT
),
avec Xn =(XnD
(1)n XnD
(2)n
)le vecteur des variables exogenes et β = [β1 β2]
′ le vecteur
des parametres, D(s)n est un vecteur compose de (0, 1), le 1 indiquant que le menage n
a choisi la classe s. Nous pouvons aussi ecrire le modele sous forme matricielle :
Y = Xβ + w (6.11)
w = ϑ + ε,

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 218
avec
ϑ ∼ N (0, Σϑ) ε ∼ N (0, Σε) w ∼ N (0, Ω)
Σϑ = σ2ϑIN Σε = σ2
εINT .
Notons que : Y est de dimension (NT × 1), X est de dimension (NT × 2K), Ω est
de dimension (NT × NT ) , β est de dimension (2K × 1), etant donne que nous avons
suppose l’existence de deux classes latentes dans le modele. ϑ est de dimension (N × 1)
et ε est de dimension (NT × 1). La matrice de variance covariance du terme d’erreur
w est alors definie par :
Ω = E (ww′) = E (ϑϑ′) + E (εε′) (6.12)
= Σϑ ⊗ (IN ⊗ ιT ) + Σε ⊗ (IN ⊗ IT )
Nous supposons que les vecteurs ϑ et ε sont independants. Nous imposons l’hypothese
iid (independamment et identiquement distribue) pour les elements de w.
Pour simuler les donnees manquantes des variables exogenes, nous utilisons des
regressions auxiliaires. Ainsi, si on a L variables explicatives (avec L = 2K), les
equations auxiliaires sont :
x1n = z1nγ1 + ε1n
x2n = z2nγ2 + ε2n
...
xLn = zLnγL + εLn
εln ∼ N(0, τ 2).
Le modele sous la forme matricielle est :
X∗n = vec(Xn) =
z1n 0 . . . 0
0 z2n . . . 0...
. . . . . ....
0 0 0 zLn
γ1
γ2
...
γL
+
ε1n
ε2n
...
εLn
X∗n = Znγ + e e ∼ N(0, V ), (6.13)
avec V = τ 2INT , I est une matrice identite de dimension (NT ), Xn et vec(Xn) sont des
matrices de dimension (NT × L) et (NT × 1) respectivement.
6.5.2 Etape de la simulation des donnees manquantes
Cette etape se divise en trois parties. Nous indicons les variables par m pour indiquer
qu’il s’agit de donnees manquantes. Nous utilisons l’algorithme de l’augmentation des

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 219
donnees pour completer les donnees manquantes.
Etape 1 : Simulation de ynt(m)
Etant donnees Xnt(m) ou l’indice (m) indique qu’il s’agit d’une observation man-
quante, etant donne aussi les parametres du modele, il est possible de simuler yjnt(m) a
partir de :
ynt(m) = Xnt(m)β + ϑn(m) + εnt(m).
Et puisque nous avons suppose l’hypothese de normalite du terme d’erreur, nous simu-
lerons les valeurs de ynt(m) a partir d’une loi normale :
ynt(m) ∼ N(Xnt(m)β, σ2
ϑ + σ2ε
).
Etape 2 : Simulation de Xnt(m)
Pour simuler les valeurs manquantes de Xnt(m) nous devons utiliser la regression
auxiliaire (6.13). Pour obtenir la distribution conditionnelle, nous exploitons les hy-
potheses du modele. En effet, on a :
p[Y(m)
∣∣X(m), ϑn(m)
]∝ exp
(−1
2
(Y(m) − X(m)β
)′Ω−1
m
(Y(m) − X(m)β
))(6.14)
p[X(m)
∣∣Zm, ϑn(m)
]∝ exp
(−1
2
(X(m) − Z(m)γ
)′Ω−1
m
(X(m) − Z(m)γ
)), (6.15)
Ωm etant l’element m de la matrice de variance covariance definie en (6.12). En combi-
nant les equations (6.14) et (6.15), nous pouvons ecrire la densite conditionnelle d’interet
comme suit :
p[X(m)
∣∣Y(m), ϑ(m)
]=
p(X(m), Y(m)
∣∣Z(m)
)
p(Y(m)
) (6.16)
p[X(m)
∣∣Y(m), ϑ(m)
]∝ p
(X(m), Y(m)
∣∣Z(m)
)
p[X(m)
∣∣Y(m), ϑn(m)
]∝ p
(Y(m)
∣∣X(m)
)p(X(m)
∣∣Z(m)
).
Lorsqu’il s’agit du cas scalaire, la densite conditionnelle prend la forme :
P(xknt(m) |.
)∝ exp
−
(β2
k
φ+ 1
τ2
)
2
xknt(m) −
βk
φ
(yt(m) − β−kx−knt(m) − ϑn(m)
)− 1
τ2 γznt(m)(β2
k
φ+ 1
τ2
)
2 ,

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 220
avec P(xknt(m) |.
)= P
(xknt(m)
∣∣ynt(m), x−knt(m), znt(m), ϑn(m)
). L’annexe (6.8) donne les
differentes etapes du calcul. Cette expression est tout simplement le noyau d’une dis-
tribution normale :
P(xknt(m) |.
)∝ N
−
β2
kφ
+ 1τ2
2
xknt(m) −
θkφ (yt(m)−β−kx
−knt(m)−ϑn(m))− 1τ2 γznt(m)
β2k
φ+ 1
τ2 ,
(β2
k
φ+ 1
τ2
)−1
.
L’indice (−k) indique toutes les variables exogenes autres que celle qui nous interesse et
φ = σ2ϑ +σ2
ε . En supposant que les autres elements sont connus, nous pouvons proceder
ainsi pour simuler toutes les variables exogenes.
Etape 3 : Simulation de Mnt(m)
Rappelons que Mnt est la matrice de variables exogenes du modele latent. Nous
simulerons Mnt(m) de la meme maniere que nous avons simule les Xnt(m), c’est-a-dire
a partir d’une distribution normale. Cela est justifie par le fait que certaines variables
contenues dans Xnt pourraient se retrouver dans Mnt.
6.5.3 Etape de la simulation des parametres
Apres avoir simule les donnees manquantes, nous pouvons alors estimer les pa-
rametres en exploitant l’algorithme de l’echantillonnage de Gibbs.
Etape 4 : simulation de β = (δ1, δ2, γ1, γ2)
Nous estimons de facon conjointe les parametres des deux classes en utilisant l’echantillonnage
de Gibbs. Si les croyances a priori sur le vecteur des parametres β sont decrites par une
loi normale p (β) = N(b, B
−1), si les donnees sont completees et si les autres pa-
rametres du modele sont connus, alors, le modele est reduit a une simple regression
avec variance connue. La distribution a posteriori de β est alors egale a :
p (β |Y,X ) = N(b, B−1
),
avec
B = X ′X + B b = B−1(X ′Y − bB
).

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 221
Etape 5 : Simulation de ϑ
Reecrivons l’equation de demande de la facon suivante : Y = Y − Xβ = ϑ + ε
(Y
ϑ
)∼ NMV
[(ϑ
ϑ
),
(Ω Σϑ ⊗ INT
Σϑ ⊗ INT Σϑ
)]
avec : ϑ = 0 etant donne les hypothese faites sur les termes d’erreur.
Nous pouvons alors deduire que :
P (ϑ |β,X, Y, Σϑ, Σε ) = NMV(µϑ| Y , Σϑ| Y
)
avec :
µϑ| Y = (Σϑ ⊗ INT )′ Ω−1Y
Σϑ| Y = Σϑ − (Σϑ ⊗ INT )′ Ω−1 (Σϑ ⊗ INT ) .
Pour le cas d’un seul individu, la loi conditionnelle prend la forme suivante :
P(ϑn
∣∣β,X, Y, σ2ϑ, σ
2ε
)= N
[∑Tt=1 ynt
T + 1σ2
ϑ
,
(T +
1
σ2ϑ
)−1]
1
avec : ynt = ynt − Xntβ.
Nous fixons la variance σ2ϑ pour que le modele soit identifiable.
Etape 6 : Simulation de σ2ε
Etant donne β et les donnees completees, si la loi a priori sur σ2ε est une inverse
gamma : P (σ−2ε ) = IG
(c, C
), alors la loi a posteriori de σ2
ε sera aussi une inverse
gamma :
p(σ−2
ε |β,X, Y)
= IG(c, C
)
avec : c = c +N
2C = C +
∑Nn=1 εnε
′n
2.
Il s’agit d’une distribution inverse gamma de moyenne cC et de variance cC2 connues.
Dans la pratique, nous prenons en compte les estimations de chacune des deux classes en
passant par les esperances conditionnelles. En ecrivant le modele en terme d’esperance
conditionnelle, nous pouvons facilement recuperer les residus pour ensuite estimer la
matrice de variance-covariance du modele. Le modele de demande peut s’exprimer en

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 222
terme d’esperance conditionnelle comme suit :
ynt = Xntβ + ϑn + εjnt (6.17)
= E (ynt) + εjnt
= E (ynt |s = 1) × Q (s = 1) + E (ynt |s = 2, ) × Q (s = 2) + εjnt
= Xntβ1 × π1nt + Xntβ2 × π2nt + εjnt,
εjnt etant le terme d’erreur du modele de demande conditionnelle.
Etape 7 : Simulation de α
Etant donnees Y , X, M , σ2w et β, il est possible d’estimer les parametres qui inter-
viennent dans la probabilite d’etre dans une classe donnee. Si les croyances a priori sur
α sont une normale : p (α) = N (α, ∆−1), alors, la distribution a posteriori de laquelle
nous pouvons tirer α sera aussi une normale :
p (α |M,Y ∗, s1, s2 ) = N(α, ∆−1
)
avec : ∆ = M ′M + ∆ α = ∆−1 (M ′Y ∗ − α∆) π1nt + π2nt = 1,
avec πsnt la probabilite que le menage n soit dans la classe s comme definie a l’equation
(6.7) ; Y ∗ est le vecteur de la variable latente.
Etape 8 : Simulation de σ2u
Etant donne y∗jnt la dependante non observable, Mjnt les exogenes et α le vecteur des
parametres, nous pouvons recuperer les erreurs de la maniere suivante : ujnt = y∗jnt −
Mjntα. Si les croyances a priori sur σ2u sont une loi inverse gamma : p (σ−2
u ) = G (a,A),
alors on peut simuler σ2u a partir d’une distribution inverse gamma egalement :
p(σ−2
u |α,M, Y ∗ ) = G(a, A
)
avec : a = a +N
2A = A +
uu′
2
Il s’agit d’une inverse gamma de moyenne aA et de variance aA2, toutes deux connues.
Nous fixons cette variance a 1 pour que le modele soit identifiable.

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 223
Etape 9 : simulation de τ 2
Etant donne X, Z et γ, nous pouvons recuperer le vecteur des erreurs de la maniere
suivante : ε = X − Zγ. Si les croyances a priori sur τ 2 suivent une loi inverse gamma :
p (τ−2) = G (d,D), alors on peut simuler τ 2 a partir d’une distribution inverse gamma
egalement :
p(τ−2 |γ,W,Z
)= G
(d, D
)
avec : d = d +N
2D = D +
εε′
2.
Il s’agit d’une inverse gamma de moyenne dD et de variance dD2, toutes deux connues.
Etape 10 : simulation de γ
Etant donne Z et τ 2, la regression auxiliaire (6.13) est un modele de regression avec
variance connue. Si les croyances a priori sur γ sont une normale : p (γ) = N (γ, Υ−1),
alors, la distribution a posteriori de γ sera aussi une normale :
p (γ |τ, Z ) = N(γ, Υ−1
)
Υ =
(Z ′Z
τ 2
)+ Υ γ = Υ
[(Z ′Z
τ 2
)+ γΥ
].
6.5.4 Experience Monte Carlo sur le modele a classes latentes
Une experience Monte Carlo a ete effectuee afin d’evaluer la performance du modele
a classes latentes qui a ete developpe. Rappelons que le probleme consistait a esti-
mer une equation de demande conditionnelle au choix de deux classes non observables.
Nous avions alors defini un modele pour la demande et un autre modele pour le choix
de la classe. Dans cette experience, nous definissons une equation lineaire et une autre
equation pour le modele latent, c’est-a-dire pour le choix de la classe. Nous supposons
qu’il existe deux classes inobservables. Supposons un panel complet a deux periodes.
Nous evacuons le probleme de donnees manquantes, puisque le but est de verifier si
toutes choses egales par ailleurs, le modele a classes latentes donne des resultats sa-
tisfaisants. Pour le modele observe, supposons un modele lineaire avec deux variables

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 224
explicatives et une constante :
ynt = β0 + β1xnt1 + β2xnt2 + εnt
avec :
xn1 =
(xn11
xn21
)∼ N
[(0
0
),
(3 0
0 3.5
)]
xn2 =
(xn12
xn22
)∼ N
[(0
0
),
(1.3 0
0 2
)]
εn =
(εn1
εn2
)∼ N
[(0
0
),
(1 0
0 1
)].
Avec deux classes, fixons la valeurs des parametres comme suit :
β10 = 0.25 β2
0 = 3
β11 = −0.7 β2
1 = −7
β12 = 2 β2
2 = 3 σ2 = 0.25.
Supposons que le modele latent est defini comme suit :
y∗nt = α0 + α1mnt + unt
avec :
Mn =
(mn1
mn2
)∼ N
[(0
0
),
(1.2 0
0 2.5
)]
un =
(un1
un2
)∼ N
[(0
0
),
(1 0
0 1
)].
Les valeurs donnees aux parametres du modele latent sont :
α0 = 0.5 α1 = 3.7.
Le choix de la classe est fait de la facon suivante :
ynt = β10 + β1
1xnt + β12xnt + εnt si y∗
nt ≤ 0
ynt = β20 + β2
1xnt + β22xnt + εnt si y∗
nt > 0.
Nous avons simule 4000 observations au total. Nous avons utilise l’algorithme de
l’echantillonnage de Gibbs comme decrit ci-dessus pour estimer les parametres du
modele. Nous avons effectue d’abord 1000 tirages et ensuite 6000 tirages ; nous avons en-
leve les 10% premieres valeurs pour permettre a l’algorithme de se defaire de l’influence
des valeurs de depart. Les resultats sont presentes au tableau (6.1).
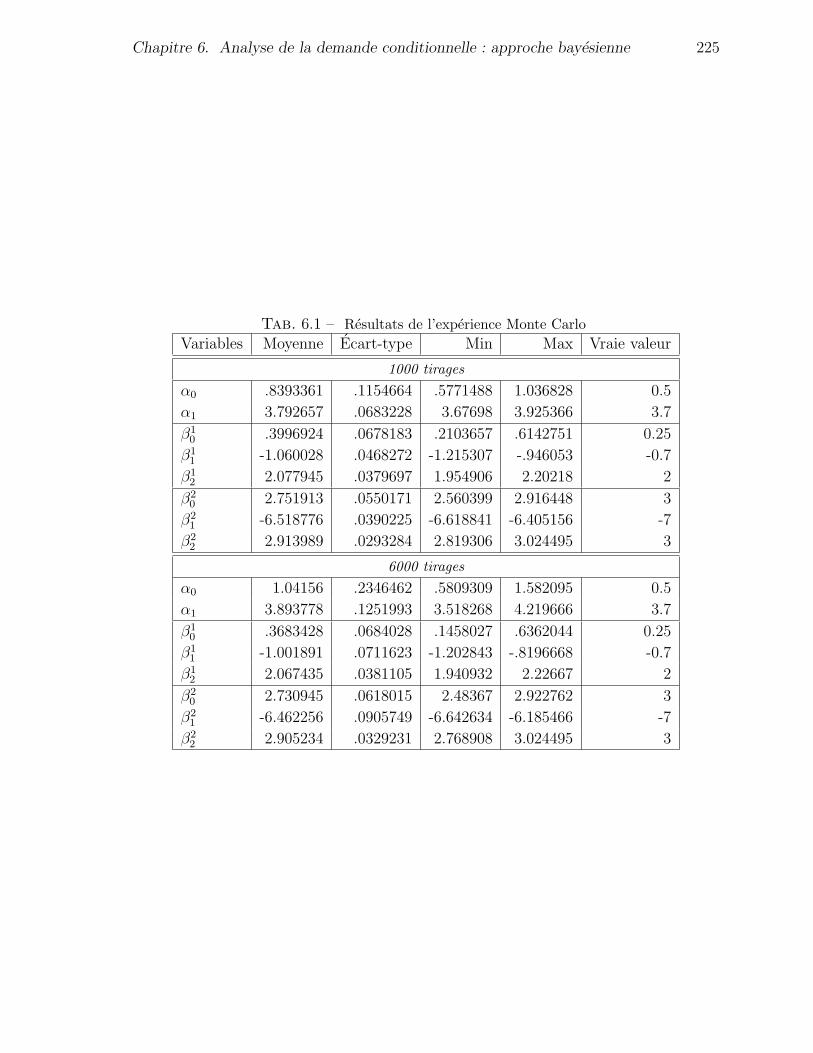
Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 225
Tab. 6.1 – Resultats de l’experience Monte Carlo
Variables Moyenne Ecart-type Min Max Vraie valeur
1000 tirages
α0 .8393361 .1154664 .5771488 1.036828 0.5
α1 3.792657 .0683228 3.67698 3.925366 3.7
β10 .3996924 .0678183 .2103657 .6142751 0.25
β11 -1.060028 .0468272 -1.215307 -.946053 -0.7
β12 2.077945 .0379697 1.954906 2.20218 2
β20 2.751913 .0550171 2.560399 2.916448 3
β21 -6.518776 .0390225 -6.618841 -6.405156 -7
β22 2.913989 .0293284 2.819306 3.024495 3
6000 tirages
α0 1.04156 .2346462 .5809309 1.582095 0.5
α1 3.893778 .1251993 3.518268 4.219666 3.7
β10 .3683428 .0684028 .1458027 .6362044 0.25
β11 -1.001891 .0711623 -1.202843 -.8196668 -0.7
β12 2.067435 .0381105 1.940932 2.22667 2
β20 2.730945 .0618015 2.48367 2.922762 3
β21 -6.462256 .0905749 -6.642634 -6.185466 -7
β22 2.905234 .0329231 2.768908 3.024495 3

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 226
Comme on peut le constater, la plupart des valeurs obtenues sont proches des vraies
valeurs. Tout d’abord, tous les signes sont corrects et toutes les valeurs estimees sont
statistiquement significatives au seuil de 1%. La constante du modele latente a une
moyenne qui est presque le double de la vraie valeur. Mais pour ce qui est des coefficients
des deux classes, qui sont les coefficients d’interet, toutes les estimes sont assez proches
des vraies valeurs de depart.
6.5.5 Resultats empiriques et interpretations
Le tableau (6.2) presente les resultats de l’estimation bayesienne du modele de de-
mande statique avec un panel simule. A partir des quatre bases de donnees d’enquete
(1989, 1994, 1999 et 2002), nous avons construit un panel simule tout en gardant le
meme nombre d’observations. C’est comme si nous avons un panel de 130352 menages
que nous avons suivi en 1989, 1994, 1999 et 2002. Nous avons simule les donnees man-
quantes et estime les parametres du modele simultanement.
La premiere partie du tableau presente les coefficients estimes du modele latent, ou
modele de choix de la classe, et la derniere partie presente les estimes du modele de
demande de la classe1 (lorsque la consommation journaliere est inferieure ou egale a
30 kWh) et de la classe2 (si la consommation journaliere depasse les 30 kWh). Nous
interpretons dans un premier temps les estimes du modele de choix de la classe et
dans un second temps, nous nous interesserons aux resultats du modele de demande
conditionnelle.
2Les 13035 observations sont la somme des observations des quatre bases de donnees : 2897 obser-
vations pour l’enquete de 1989, 4850 observations pour celle 1994, 3129 pour l’enquete de 1999 et enfin
2159 observations pour celle de 2002.

Chapitre
6.
Analy
sede
ladem
ande
conditio
nnelle
:appro
che
bayesien
ne
227
Tab. 6.2: Resultats du modele statique de demande condi-
tionnelle
Variables Moyenne Ecart-type Min Max Moyenne Ecart-type Min Max
Modele latent
surf .9307073 .005774 .9119956 .9507542
systeme plinthes -.3155197 .0111963 -.3515644 -.278529
systeme-air-chaud .1497021 .0162897 .090245 .2022296
systeme-eau-chaude -.1609059 .0248379 -.2440916 -.0708636
systeme thermop -.6594631 .0181368 -.7302276 -.5982333
systeme convectair -1.096412 .0220973 -1.172506 -1.005492
nbre refrigerateurs .1759727 .0080955 .1439458 .2094434
maison detachee 4.320145 .0258599 4.222261 4.414021
maison jumelee 1.399692 .0303405 1.296213 1.524894
climatiseur central .4040354 .0217762 .3375888 .4860479
climatiseur fenetre .4775089 .0152718 .4201961 .5357873
correcteur1 .1119521 .0023776 .1039549 .1197522
correcteur2 .3970023 .0023244 .3892315 .4052929
correcteur3 -1.303473 .0079418 -1.329628 -1.274627
correcteur4 .4182431 .0055556 .3977959 .4362388
correcteur5 -2.229231 .0065911 -2.256227 -2.205665
correcteur6 -1.566491 .0055432 -1.587362 -1.544538
correcteur7 4.882422 .0051584 4.866739 4.902759
correcteur8 -.2166533 .0025109 -.2260688 -.206557
correcteur9 -.0818318 .0024643 -.0899981 -.0735316
montreal .5805794 .0211695 .4947817 .6649718
nbre Resid Aug 5.612193 .0043212 5.594985 5.627344
suite de a la page suivante
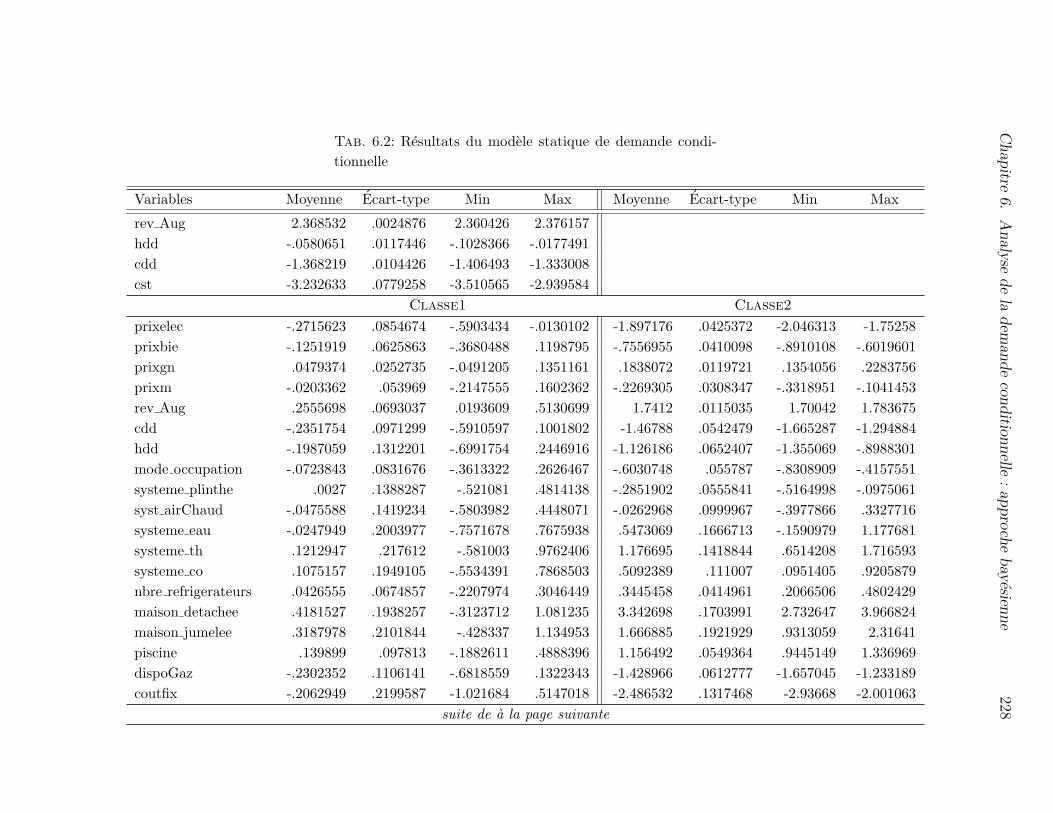
Chapitre
6.
Analy
sede
ladem
ande
conditio
nnelle
:appro
che
bayesien
ne
228
Tab. 6.2: Resultats du modele statique de demande condi-
tionnelle
Variables Moyenne Ecart-type Min Max Moyenne Ecart-type Min Max
rev Aug 2.368532 .0024876 2.360426 2.376157
hdd -.0580651 .0117446 -.1028366 -.0177491
cdd -1.368219 .0104426 -1.406493 -1.333008
cst -3.232633 .0779258 -3.510565 -2.939584
Classe1 Classe2
prixelec -.2715623 .0854674 -.5903434 -.0130102 -1.897176 .0425372 -2.046313 -1.75258
prixbie -.1251919 .0625863 -.3680488 .1198795 -.7556955 .0410098 -.8910108 -.6019601
prixgn .0479374 .0252735 -.0491205 .1351161 .1838072 .0119721 .1354056 .2283756
prixm -.0203362 .053969 -.2147555 .1602362 -.2269305 .0308347 -.3318951 -.1041453
rev Aug .2555698 .0693037 .0193609 .5130699 1.7412 .0115035 1.70042 1.783675
cdd -.2351754 .0971299 -.5910597 .1001802 -1.46788 .0542479 -1.665287 -1.294884
hdd -.1987059 .1312201 -.6991754 .2446916 -1.126186 .0652407 -1.355069 -.8988301
mode occupation -.0723843 .0831676 -.3613322 .2626467 -.6030748 .055787 -.8308909 -.4157551
systeme plinthe .0027 .1388287 -.521081 .4814138 -.2851902 .0555841 -.5164998 -.0975061
syst airChaud -.0475588 .1419234 -.5803982 .4448071 -.0262968 .0999967 -.3977866 .3327716
systeme eau -.0247949 .2003977 -.7571678 .7675938 .5473069 .1666713 -.1590979 1.177681
systeme th .1212947 .217612 -.581003 .9762406 1.176695 .1418844 .6514208 1.716593
systeme co .1075157 .1949105 -.5534391 .7868503 .5092389 .111007 .0951405 .9205879
nbre refrigerateurs .0426555 .0674857 -.2207974 .3046449 .3445458 .0414961 .2066506 .4802429
maison detachee .4181527 .1938257 -.3123712 1.081235 3.342698 .1703991 2.732647 3.966824
maison jumelee .3187978 .2101844 -.428337 1.134953 1.666885 .1921929 .9313059 2.31641
piscine .139899 .097813 -.1882611 .4888396 1.156492 .0549364 .9445149 1.336969
dispoGaz -.2302352 .1106141 -.6818559 .1322343 -1.428966 .0612777 -1.657045 -1.233189
coutfix -.2062949 .2199587 -1.021684 .5147018 -2.486532 .1317468 -2.93668 -2.001063
suite de a la page suivante

Chapitre
6.
Analy
sede
ladem
ande
conditio
nnelle
:appro
che
bayesien
ne
229
Tab. 6.2: Resultats du modele statique de demande condi-
tionnelle
Variables Moyenne Ecart-type Min Max Moyenne Ecart-type Min Max
coutm -1.124679 .2287656 -2.012711 -.2936653 -5.714736 .1114345 -6.140579 -5.238469
nbre Resid Aug .6835497 .1505822 .1140503 1.19972 3.929162 .0206121 3.861329 4.00886
age .1496158 .0331249 .0255302 .3102966 1.163346 .0186117 1.088789 1.232113
correcteur1 -.0026871 .014561 -.0623405 .0509988 -.0768471 .0172636 -.1419165 -.0185896
correcteur2 .0008973 .0146728 -.0525974 .0582592 .1700156 .0174634 .109775 .239759
correcteur3 -.1190988 .052989 -.2942762 .0630643 -.5947681 .0640375 -.7991508 -.346376
correcteur4 -.0797875 .0443514 -.2238057 .0923691 .1490336 .0367279 .0090355 .3007672
correcteur5 .0092462 .0458009 -.1708724 .1774694 -1.342013 .0552614 -1.560515 -1.138114
correcteur6 -.0263735 .0391128 -.1535638 .1216813 -.7545114 .0428243 -.9530813 -.5858495
correcteur7 .2429218 .1061439 -.1121451 .6052834 2.569295 .0308946 2.460853 2.684673
correcteur8 -.0264531 .0167171 -.0887928 .0352466 -.0399313 .0179092 -.1039357 .0182023
correcteur9 -.0144949 .015751 -.0650561 .0422789 .1594203 .0173819 .1034005 .2283756
cst 4.170694 1.255694 -.1191594 9.10605 25.44619 .5737589 22.99682 27.57408
h .0546871 .0003381 .0531751 .0558467
Fin du tableau

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 230
Sur la base des resultats du modele latent, nous pouvons directement deduire qu’il
s’agit precisement des parametres estimes de la probabilite que le menage se retrouve
dans la deuxieme classe. Nous remarquons aussi que tous les estimes sont statistique-
ment tres significatifs (au seuil de 1%).
L’estime du parametre de la variable surface (surf) est positif et significatif au seuil de
1%. Plus la surface habitee et chauffee est grande, plus la probabilite que le menage
soit dans la deuxieme classe est forte. Les grandes surfaces necessitent beaucoup plus
d’electricite que les petites.
Le fait d’avoir un systeme de climatisation augmente les chances d’etre dans la deuxieme
classe. Cela est logique puisque la climatisation necessite de l’electricite.
La variable revenu, qui a ete simulee par l’algorithme de l’augmentation des donnees,
a un estime de signe positif. Les menages qui ont un revenu eleve ont beaucoup plus
de chance de se retrouver dans la deuxieme classe. Un revenu relativement eleve donne
plus de latitude au menage dans ses choix de consommation comme l’achat d’appareils
de luxe (souvent energivores). Les menages qui sont le plus souvent dans la deuxieme
classe sont des menages relativement riches que les menages qui sont le plus souvent
dans la premiere classe.
La variable nombre de personnes a un estime de signe positif et statistiquement si-
gnificatif au seuil de 1%. Plus il y a de personnes dans le menage, plus la demande
d’electricite sera importante et plus il y aura de chance que le menage soit dans la
deuxieme classe.
Le fait que le menage soit dans la region de Montreal augmente ses chances d’etre dans
la deuxieme classe. Les menages qui vivent dans la region de Montreal ont peu acces au
bois et ils ont moins de systemes d’appoint que dans les autres regions. Par consequent,
la consommation d’electricite des menages de Montreal est relativement plus elevee que
celle des menages des autres regions.
Nous avons inclus dans le modele latent le type de systeme de chauffage utilise. Seule
la centrale a air chaud augmente les chances d’etre dans la deuxieme classe. Les autres
systemes ont des estimes de signe negatif indiquant qu’ils exigent relativement moins
d’electricite que les autres. Le systeme de convectair a une amplitude relativement plus
grande que les autres ; si le menage a un systeme de convectair, il a de tres fortes
chances d’etre dans la premiere classe. Le systeme de chauffage ne semble donc pas etre
un element determinant pour que le menage choisisse la deuxieme classe. Le chauffage de
l’espace ne peut donc pas a lui seul determiner si le menage est dans la deuxieme classe
ou non. Les systemes de chauffage residuels (n’ayant pas ete inclus dans le modele)
sont : le systemes de plinthes (electriques et non electriques), le systeme radiant a
rayonnement dans le plafond, la fournaise murale ou plancher et la fournaise a bois ou
a poele,... Precisons que nous avons garde les systemes de chauffages qui sont presents
dans toutes les enquetes, les enquetes les plus recentes ayant plus de systemes que les
autres.

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 231
Plus le nombre de refrigerateurs est important, plus cela augmente les chances d’etre
dans la deuxieme classe.
Le type d’habitation est egalement utilise pour determiner le choix de la classe : les mai-
sons detachees et les maisons jumelees3. Les maisons detachees affectent relativement
plus la probabilite d’etre dans la deuxieme classe. Les maisons detachees ne permettent
pas de faire des economies dans la consommation d’electricite. Cela s’explique par le
fait que les maisons detachees ont quatre murs tandis que les maisons jumelees n’ont
que trois murs. Les besoins en electricite seront donc plus importantes dans une maison
detachee que dans une maison jumelee.
La variable degres jours de climatisation (cdd) a un estime de signe negatif et significatif
au seuil de 1%. S’il y a une augmentation de cdd, cela indique qu’il fait plus chaud ; par
consequent, les menages n’ont plus besoin de l’electricite pour leurs besoins de chauf-
fage. La climatisation dans la province de Quebec est un phenomene assez recent et tres
peu de menages l’utilisent. Les menages sont habitues a chauffer leurs maisons plutot
qu’a les climatiser. Ainsi, une augmentation de cdd tend a amener le menage dans la
premiere classe.
La variable degres jours de chauffage (hdd) a un estime de signe negatif et signifi-
catif. Nous nous attendons plutot a un signe positif, car les degres jour de chauffage
necessitent de l’electricite.
Nous avons inclus les correcteurs de biais de selection dans le modele latent. Rap-
pelons que le choix de la classe est effectue en meme temps que le choix de la quantite
d’electricite a consommer (consommation journaliere). Par consequent, il faut considerer
la demande journaliere conditionnelle au choix du mode de chauffage. Tous les estimes
des correcteurs sont significatifs au seuil de 1%.
La constante est negative et significative au seuil de 1%. Cela signifie que si toutes les
variables sont fixees a zero, le menage aura moins de chance d’etre dans la deuxieme
classe. Ceci a du sens, en effet, un menage qui utilise juste l’electricite pour les besoins
de base sera dans la premiere classe et non la deuxieme, puisque sa consommation est
faible.
Interessons-nous a present aux estimes du modele de demande conditionnelle au
choix du mode et au choix de la classe. Remarquons tout d’abord que la plupart des
estimes sont statistiquement significatifs aux seuils usuels. Les estimes qui sont signifi-
catifs sont plus grands en valeur absolue dans la deuxieme classe que dans la premiere.
Cela signifie que les menages qui sont dans la deuxieme classe sont beaucoup plus sen-
sibles aux changements que ceux qui sont dans la premiere classe. Ainsi, les effets du
prix de l’electricite, du gaz naturel, du mazout et de la bi-energie sont plus importants
3La variable binaire exclue est celle des maisons individuelles en rangee attachees des deux cotes ;
ce type de maison a en fait moins de murs a chauffer que les deux autres.

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 232
dans la deuxieme classe que dans la premiere.
Si le prix marginal de l’electricite augmente, la demande d’electricite baissera da-
vantage dans la deuxieme classe que dans la premiere. Le tableau (6.4) presente les
elasticites prix et revenu de la demande. Si le prix marginal de l’electricite augmente de
1%, la demande d’electricite baissera de 0.1616% dans la premiere classe alors qu’elle
baissera de 0.4412% dans la deuxieme classe. Ainsi, si le prix augmente, les menages de
la deuxieme classe sont incites a economiser davantage l’electricite. Comme les menages
de la premiere classe economisaient deja, donc leur baisse sera moins importante. Souli-
gnons que les elasticites prix directes de l’electricite des deux classes sont significatives
au seuil de 1%. Le terme E-T dans le tableau (6.4) est utilise pour designer l’ecart-type
estime.
L’elasticite prix de la bi-energie est de -0.0443 pour la premiere classe et de -0.1875 pour
la deuxieme classe ; les deux etant statistiquement significatives au seuil de 1%. Comme
l’electricite, les menages de la deuxieme classe reagissent tres fortement a la hausse
du prix de la bi-energie 4 que les menages de la premiere classe. Pour les menages qui
sont au tarif DT, la bi-energie et l’electricite sont des complements. Dans la realite, le
menage peut utiliser une combinaison de ces deux formes d’energie ou l’une ou l’autre
dependamment du tarif choisi et de la temperature.
Si le prix du mazout augmente, tous les menages qui utilisent principalement le mazout
baisseront leur demande d’electricite, mais ceux de la deuxieme classe baisseront da-
vantage leur consommation. L’elasticite prix du mazout est de -0.0145 pour la premiere
classe (non significatif) et de -0.0975 pour la deuxieme classe (et statistiquement tres
significative au seuil de 1%). Il est probable que les menages qui sont souvent dans la
premiere classe n’utilisent pas le mazout comme source de chauffage. Il est aussi probable
que les menages qui sont dans la deuxieme classe et qui utilisent le mazout, l’utilisent
en combinaison avec l’electricite. Pour ces menages, le mazout est un complement pour
l’electricite.
Le gaz naturel a un effet positif sur la demande d’electricite. Si le prix du gaz naturel
augmente de 1%, la demande d’electricite des menages qui utilisent le gaz augmentera
de 0.032% dans la premiere classe et de 0.0732 dans la deuxieme classe. Le gaz naturel
est donc un substitut a l’electricite.
L’effet du revenu est beaucoup plus important dans la deuxieme classe que dans la
premiere. Une hausse du revenu de 1% entraıne une augmentation de la demande
d’electricite de 0.1384% dans la premiere classe et de 0.371% dans la deuxieme classe.
Les menages qui sont dans la deuxieme classe sont des menages riches ; une augmenta-
4Precisons que la tarification de la bi-energie n’est pas la meme pour tous les menages qui l’utilisent.
Il y a les menages qui sont au tarif D et ceux qui sont au tarif DT. Ces derniers ont un compteur
leur permettant de changer de l’electricite a une autre forme d’energie comme le gaz ou le mazout,
dependamment de la temperature. Le prix varie donc d’un tarif a l’autre.

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 233
tion du revenu leur permet de consommer plus.
Comme dans la partie latente, les variables cdd et hdd ont des estimes negatifs. On
pourrait penser que plus le nombre de degres jours de chauffage augmente (donc, plus
il fait tres froid durant l’hiver), plus les menages ont interet a utiliser une autre forme
d’energie que l’electricite pour leur besoins de chauffage. Plus le nombre de degres jours
de climatisation augmente (plus il fait tres chaud durant l’ete), moins les menages ont
besoin de chauffer leurs maisons, et donc leur demande d’electricite va baisser. Comme
nous l’avons souligne plus haut, la climatisation est un phenomene assez recent au
Quebec comparativement a d’autres regions du reste du monde ou les menages sont
plus habitues a climatiser leur maisons plutot qu’a les chauffer. Le signe de l’estime de
hdd n’est cependant pas le signe attendu.
La variable mode d’occupation affecte negativement la demande d’electricite, son effet
est significatif dans la deuxieme classe mais ne l’est pas dans la premiere. Ainsi, si le
menage est proprietaire, sa demande d’electricite sera importante et s’il est locataire,
sa demande sera relativement plus faible. Le menage proprietaire a beaucoup plus de
marge de manoeuvre que le menage locataire. Il est probable aussi que les menages
proprietaires soient le plus souvent dans la deuxieme classe.
La disponibilite du gaz naturel dans la zone affecte negativement et de facon significa-
tive la demande d’electricite ; cela a du sens car le gaz naturel est un bon substitut a
l’electricite.
La presence de piscine permanente affecte positivement la demande d’electricite a tra-
vers son moteur de chauffage. Durant les periodes froides, le menage chauffera sa piscine
et cela augmentera sa consommation d’electricite.
L’age affecte positivement et significativement la demande d’electricite. Plus l’age aug-
mente, plus la demande d’electricite augmente. Les personnes plus agees ont tendance
a etre le plus souvent a la maison, et en etant a la maison, ils doivent satisfaire a chaque
moment leurs besoins en energie tels que le chauffage ou la climatisation, l’eau chaude,...
Ce resultat concorde avec les resultats obtenus par Liao et Chang (2002) : selon eux,
aux Etats-Unis, la consommation d’energie augmente avec l’age et particuliere chez les
personnes agees. De plus, l’effet de l’age est dix fois plus grand dans la deuxieme classe
que dans la premiere. Les personnes agees qui sont dans la deuxieme classe consomment
dix fois plus d’electricite que les personnes agees qui sont dans la premiere classe. La
deuxieme classe tend a regrouper des menages relativement plus riches, de sorte que
les personnes agees de cette classe ont plus de marge de manoeuvre que les personnes
agees de l’autre classe.
L’effet du nombre de residents dans le menage est beaucoup plus important dans la
deuxieme classe que dans la premiere. Plus il y a de personnes dans le menage, plus la
demande d’electricite augmente et cette augmentation sera plus importante si le menage
est dans la deuxieme classe.
Les variables binaires relatives au type de systeme de chauffage utilise ont des coeffi-

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 234
cients qui sont significatifs dans la deuxieme classe mais ne le sont pas dans la premiere
classe. Les systemes de plinthes affectent negativement la demande d’electricite des
menages de la deuxieme classe. Les thermopompe et les centrales a eau chaude af-
fectent positivement la demande.
L’estime du nombre de refrigerateurs n’est pas significatif dans la premiere classe mais
l’est dans la deuxieme classe. Plus il y a de refrigerateurs dans la maison, plus la consom-
mation du menage de la deuxieme classe sera importante.
Nous avons inclus les variables cout moyen (ou cout d’operation) et cout fixe comme
cela a ete fait dans les travaux de Dubin et McFadden (1984). La demande d’electricite
est definie comme etant une fonction du revenu net qui se decompose en revenu, en
couts fixes et en couts d’operation. Nous nous attendons a ce que les coefficients des
deux couts soient negatifs. L’estime de la variable cout fixe (coutfix) n’est pas signifi-
cative dans la premiere classe mais l’est dans la deuxieme classe. Les estimes des deux
coefficients des deux classes sont tous de signe negatif, ce qui repond a nos attentes.
La variable cout moyen (coutm) est significative dans les deux classes et de signe negatif.
Cela repond aussi a nos attentes etant donne que ces couts interviennent de facon
negative dans la fonction de demande.
Les variables maison detachee et jumelee affectent positivement la demande d’electricite
et ceci est d’autant plus important si le menage est dans deuxieme classe. Dans les deux
classes, l’on note que l’effet de la variable maison detachee est plus important que celui
de la variable maison jumelee ; cela s’explique par le fait que les maisons detachees ont
quatre murs a chauffer tandis que les maisons jumelees n’ont que trois.
La constante est positive et significative au seuil de 1% dans les deux classes ; elle est
cinq fois plus grande dans la deuxieme classe que dans la premiere. Si toutes les autres
variables sont fixees a zero dans les deux classes, alors la consommation de base moyenne
serait approximativement de 4.170 (multiplie par 1000) dans la premiere classe et de
25.4462 (multiplie par 1000). Pour les besoins de base (eclairage, fonctionnement d’ap-
pareils electromenagers,...), un menage de la deuxieme classe consommerait plus de six
fois ce qu’un menage de la premiere classe consomme. En somme, la deuxieme classe est
composee de grands consommateurs et la premiere est composee de menages economes
en terme de consommation d’electricite.
Les estimes des variables binaires specifiques aux differents systemes de chauffage 5 sont
tous significatifs dans la deuxieme classe, mais ne le sont pas dans la premiere classe.
Tous les correcteurs de biais de selection sont significatifs au seuil de 1% dans la
deuxieme classe. Dans la premiere classe, seul les correcteur3 et correcteur7 sont signi-
ficatifs. Probablement les menages qui sont dans la premiere classe utilisent la modalite
5Nous les avons inclus pour remplacer les variables binaires specifiques aux differentes modalites.
Bernard, Bolduc et Belanger (1996) ont inclus 8 des 9 variables binaires dans leur modele. Dans notre
cas, leur inclusion n’a pas ameliore les resultats, certainement a cause de leur nombre plus eleve (soit
16 pour les deux classes).

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 235
3 (bi-energie/electricite) et 7 (electricite/electricite). Ces deux modalites sont parmi les
moins cheres aussi, confirmant que la premiere classe est principalement composee de
menages a faibles revenus. Il est donc important d’inclure dans l’equation de demande
les correcteurs de biais de selection du choix du mode de chauffage.
Les graphiques de convergence montrent la convergence des differents tirages des
estimes des parametres6. Nous avons exclus les 10% premieres valeurs simulees afin de
permettre a l’algorithme de ne pas dependre des valeurs de depart. L’allure de tous
les graphiques (moyenne en fonction du nombre de tirages) indiquent que les valeurs
simulees convergent vers la moyenne des tirages.
Nous avons aussi estime le modele de demande conditionnelle au choix du mode en
ne tenant pas compte des deux classes. Le tableau (6.3) presente le modele de demande
qui ne corrige pas pour l’endogeneite du prix marginal. Les signes des coefficients sont
pour la plupart les memes que dans le modele avec les deux classes. En general, le modele
sans classe tend a surestimer les valeurs des parametres du modele de la premiere classe
et a sous-estimer les valeurs de ceux de la deuxieme classe. De plus, nous remarquons
que tous les correcteurs sont statistiquement tres significatifs au seuil de 1%, indiquant
que la correction pour le biais de selection est importante.
Enfin, nous notons que la constante est negative et n’est pas significative. Cela
pose un probleme puisque la constante representerait la consommation de base. Nous
concluons donc que l’estime de la constante est biaise.
En somme, en ne prenant pas en compte l’endogeneite du prix marginal de l’electricite,
les estimateurs obtenus sont biaises et non convergents. Les elasticites prix du gaz na-
turel, du revenu, de hdd et de cdd du modele sans classe sont superieures a celles des
deux classes.
Tab. 6.3: Modele statique sans classes
Variables Moyenne Ecart-type Min Max
prixelec -1.858805 .0366465 -1.990745 -1.739214
prixbie -.6668927 .0341371 -.7943268 -.5428016
prixgn .1774433 .0106191 .1369859 .2123366
prixm -.1380657 .0264551 -.2467523 -.0467931
rev Aug 1.766807 .0111111 1.722506 1.811354
cdd -1.444081 .044749 -1.600038 -1.254171
suite a la page suivante
6Par soucis d’economie d’espace, nous presentons uniquement les graphiques de convergence du
modele dynamique. Mais les graphiques non presentes pourront etre fournis sur demande.
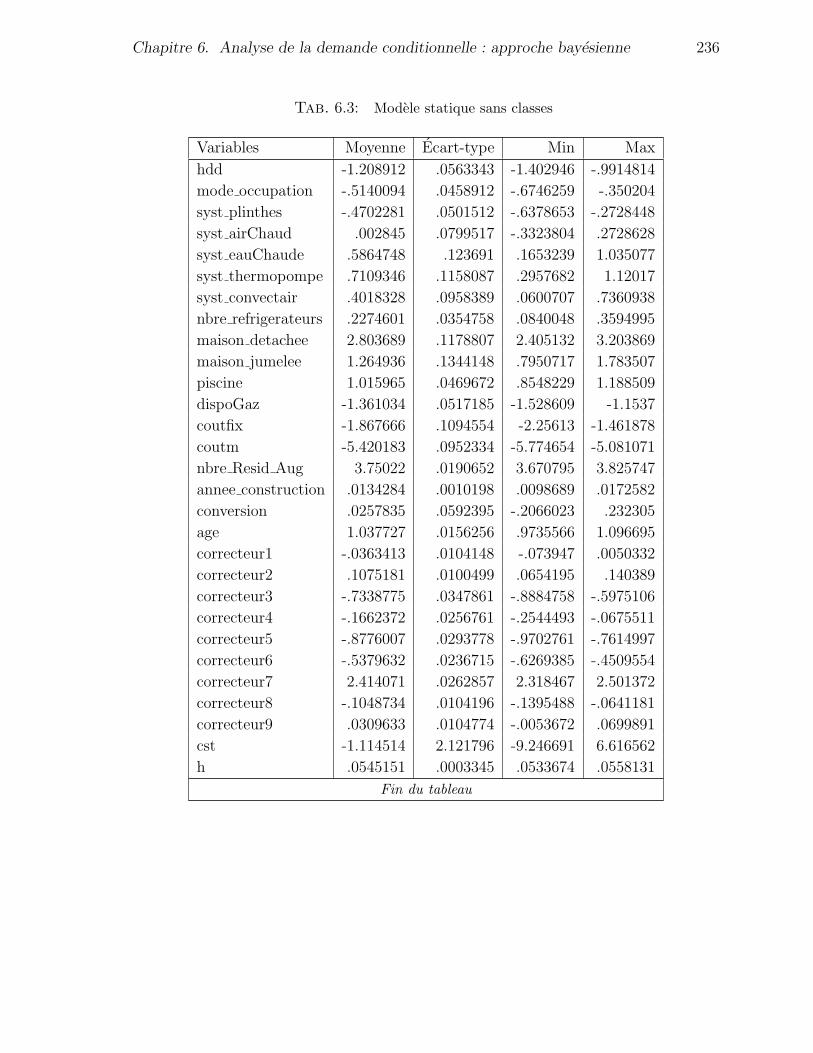
Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 236
Tab. 6.3: Modele statique sans classes
Variables Moyenne Ecart-type Min Max
hdd -1.208912 .0563343 -1.402946 -.9914814
mode occupation -.5140094 .0458912 -.6746259 -.350204
syst plinthes -.4702281 .0501512 -.6378653 -.2728448
syst airChaud .002845 .0799517 -.3323804 .2728628
syst eauChaude .5864748 .123691 .1653239 1.035077
syst thermopompe .7109346 .1158087 .2957682 1.12017
syst convectair .4018328 .0958389 .0600707 .7360938
nbre refrigerateurs .2274601 .0354758 .0840048 .3594995
maison detachee 2.803689 .1178807 2.405132 3.203869
maison jumelee 1.264936 .1344148 .7950717 1.783507
piscine 1.015965 .0469672 .8548229 1.188509
dispoGaz -1.361034 .0517185 -1.528609 -1.1537
coutfix -1.867666 .1094554 -2.25613 -1.461878
coutm -5.420183 .0952334 -5.774654 -5.081071
nbre Resid Aug 3.75022 .0190652 3.670795 3.825747
annee construction .0134284 .0010198 .0098689 .0172582
conversion .0257835 .0592395 -.2066023 .232305
age 1.037727 .0156256 .9735566 1.096695
correcteur1 -.0363413 .0104148 -.073947 .0050332
correcteur2 .1075181 .0100499 .0654195 .140389
correcteur3 -.7338775 .0347861 -.8884758 -.5975106
correcteur4 -.1662372 .0256761 -.2544493 -.0675511
correcteur5 -.8776007 .0293778 -.9702761 -.7614997
correcteur6 -.5379632 .0236715 -.6269385 -.4509554
correcteur7 2.414071 .0262857 2.318467 2.501372
correcteur8 -.1048734 .0104196 -.1395488 -.0641181
correcteur9 .0309633 .0104774 -.0053672 .0699891
cst -1.114514 2.121796 -9.246691 6.616562
h .0545151 .0003345 .0533674 .0558131
Fin du tableau
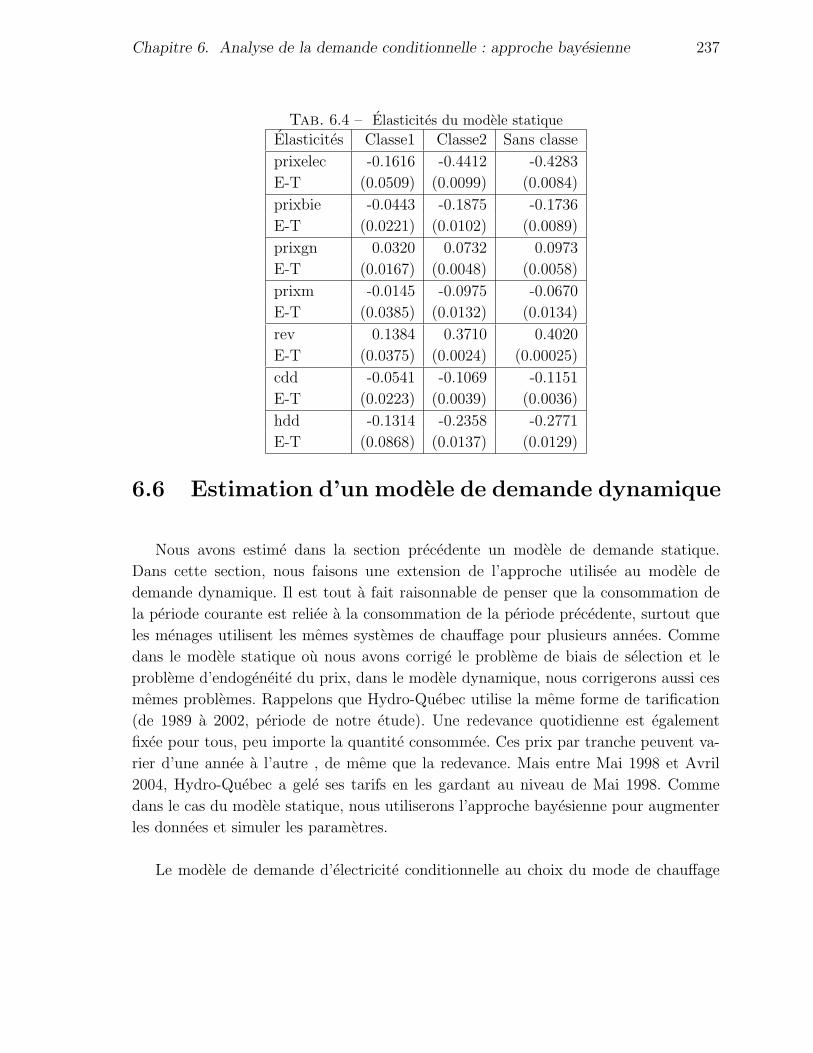
Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 237
Tab. 6.4 – Elasticites du modele statique
Elasticites Classe1 Classe2 Sans classe
prixelec -0.1616 -0.4412 -0.4283
E-T (0.0509) (0.0099) (0.0084)
prixbie -0.0443 -0.1875 -0.1736
E-T (0.0221) (0.0102) (0.0089)
prixgn 0.0320 0.0732 0.0973
E-T (0.0167) (0.0048) (0.0058)
prixm -0.0145 -0.0975 -0.0670
E-T (0.0385) (0.0132) (0.0134)
rev 0.1384 0.3710 0.4020
E-T (0.0375) (0.0024) (0.00025)
cdd -0.0541 -0.1069 -0.1151
E-T (0.0223) (0.0039) (0.0036)
hdd -0.1314 -0.2358 -0.2771
E-T (0.0868) (0.0137) (0.0129)
6.6 Estimation d’un modele de demande dynamique
Nous avons estime dans la section precedente un modele de demande statique.
Dans cette section, nous faisons une extension de l’approche utilisee au modele de
demande dynamique. Il est tout a fait raisonnable de penser que la consommation de
la periode courante est reliee a la consommation de la periode precedente, surtout que
les menages utilisent les memes systemes de chauffage pour plusieurs annees. Comme
dans le modele statique ou nous avons corrige le probleme de biais de selection et le
probleme d’endogeneite du prix, dans le modele dynamique, nous corrigerons aussi ces
memes problemes. Rappelons que Hydro-Quebec utilise la meme forme de tarification
(de 1989 a 2002, periode de notre etude). Une redevance quotidienne est egalement
fixee pour tous, peu importe la quantite consommee. Ces prix par tranche peuvent va-
rier d’une annee a l’autre , de meme que la redevance. Mais entre Mai 1998 et Avril
2004, Hydro-Quebec a gele ses tarifs en les gardant au niveau de Mai 1998. Comme
dans le cas du modele statique, nous utiliserons l’approche bayesienne pour augmenter
les donnees et simuler les parametres.
Le modele de demande d’electricite conditionnelle au choix du mode de chauffage

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 238
et au choix de la classe de consommateur peut s’ecrire comme suit :
yjnt = asy∗jnt−1 + xntδs + xjnλs + ϑn + εjnt s = 1, 2
ϑn ∼ N(0, σ2
ϑ
)εjnt ∼ N
(0, σ2
ε
)
yjnt =
a1y
∗jnt−1 + xntδ1 + xjnλ1 + ϑn + εjnt si y∗
jnt ≤ 0
a2y∗jnt−1 + xntδ2 + xjnλ2 + ϑn + εjnt si y∗
jnt > 0(6.18)
yjnt =
Xjntβ1 + ϑn + εjnt si y∗
jnt ≤ 0
Xjntβ2 + ϑn + εjnt si y∗jnt > 0
, (6.19)
avec : y∗jnt−1 la demande d’electricite du menage n a la periode precedente (information
non disponible), xjnt est un vecteur de variables exogenes qui varient dans le temps, et
xjn est un vecteur de variables exogenes invariantes dans le temps (ce vecteur contient
aussi les correcteurs de biais de selection du choix du mode de chauffage). L’indice s
indique la classe du menage, le terme ϑn est un effet individuel aleatoire que nous suppo-
sons normal. Nous avons ajoute l’indice j parce qu’il s’agit de la demande conditionnelle
au choix du mode. Cette demande conditionnelle se traduit par la presence des correc-
teurs de biais de selection, qui dependent de la modalite choisie par le menage. Nous
avons egalement regroupe toutes les variables explicatives (y compris la dependante
retardee) ensemble sous Xn =(XnD
(1)n XnD
(2)n
)et le vecteur de parametres corres-
pondant est β = [a1, a2, δ1, δ2, λ1, λ2]. Le modele de demande dynamique peut s’ecrire
en matriciel sous la forme de l’equation (6.11) comme dans le cas statique.
L’estimation des modeles de panels dynamiques (avec N −→ ∞ et T fixe) necessite
la prise en compte d’effets aleatoires ; les effets fixes ne sont pas appropries puisqu’ils
rendraient les estimateurs biaises ( Nickell (1981) et Lee (2000) pour une demonstration
detaillee). Avec l’approche bayesienne, ce choix ne se pose pas, puisqu’on suppose que
tous les parametres suivent une loi a priori donnee.
Par ailleurs, on sait que le traitement des premieres observations de la variable
dependante (yjn0, n = 1, ...N, j ∈ Cn) joue un role important dans la procedure d’esti-
mation ; dans les ecrits anterieurs, on parle souvent de conditions initiales. Les methodes
d’estimation (telle que le maximum de vraisemblance) qui supposent que y0 est exogene
donnent des estimateurs qui pourraient etre biaises. Bhargava et Sargan (1983) ont
suggere de prendre la premiere observation comme une variable endogene qui serait
reliee aux effets individuels. Ils estiment ensuite les parametres du modele par la
methode du maximum de vraisemblance en information limitee. D’autres auteurs ont
utilise leur approche, comme Chamberlain (1984), Blundell et Smith (1991). Il existe
d’autres methodes pour le traitement des conditions initiales (Lee (2000) donne une
synthese des differents travaux qui ont porte sur ce sujet et propose aussi une autre
approche basee sur celle de Wooldridge (2000) dans le cadre de vrais panels). L’ap-

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 239
proche de Bhargava et Sargan (1983) semble plus appropriee a notre probleme. Nous
supposons que la premiere observation est definie en fonction de variables exogenes de
la facon suivante :
yjn0 = a0 +T∑
t=0
K1∑
k=1
∑
j∈Cn
akxkjnt +
K2∑
k=1
bkxkjn + εjn0, (6.20)
avec K1 le nombre de variables exogenes qui varient avec le temps et K2 le nombre de
variables exogenes invariantes dans le temps, j etant toujours la modalite choisie par le
menage n, et Cn indique le nombre total de modalites disponibles pour le menage. Le
terme d’erreur est suppose suivre une loi normale.
Lorsqu’on traite de panels dynamiques, la question de savoir si les series sont sta-
tionnaires ou non est essentielle lorsqu’on utilise une approche classique. Si le processus
generateur d’une variable n’est pas stationnaire, il n’est pas possible de deriver la fonc-
tion de vraisemblance des observations. Cependant, avec l’approche bayesienne, le fait
qu’une serie ou variable soit ou non stationnaire n’a aucune importance. Les estimateurs
peuvent etre obtenus sans avoir a imposer de restrictions de stationnarite. Nandram et
Petrucelli (1997) ont montre qu’imposer faussement l’hypothese de stationnarite a une
serie qui ne l’est pas en realite causerait un biais dans l’estimation. L’echantillonnage
de Gibbs permet d’estimer les parametres, que les variables soient stationnaires ou non.
Selon les memes auteurs, on peut estimer les parametres par l’approche bayesienne
sans avoir a conditionner sur les variables dependantes passees (conditionner sur tous
les ynt−p, si on a un AR(p)). Il suffit de tenir compte de la condition d’initialisation
dans la procedure d’estimation ; l’initialisation porte en effet sur y0 defini a l’equation
(6.20).
6.6.1 Etapes additionnelles : simulation de yt−1 et de y0
L’estimation du modele de demande d’electricite conditionnelle au choix du mode
et au choix de la classe se fera suivant la meme demarche utilisee pour le modele
statique, avec quelques etapes additionnelles. En plus des etapes suivies dans le cadre
du modele statique, nous devons ajouter deux autres etapes supplementaires. Cette
section comporte plusieurs parties : l’initialisation qui permet de simuler les premieres
observations (yn0), ensuite la simulation des exogenes manquantes, puis la simulation de
la variable dependante et enfin la simulation de la dependante retardee. Nous indicons
les variables par m pour indiquer qu’il s’agit de donnee manquante. Nous utilisons
l’algorithme de l’augmentation des donnees pour completer les donnees manquantes.

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 240
Etape 0 : simulation de yj0(m)
L’equation (6.20) servira a simuler les conditions initiales, conditionnellement aux
variables exogenes et aux parametres du modele. En imposant l’hypothese de normalite
du terme d’erreur, cela permet de simuler les observations initiales de la facon suivante :
yj0(m) ∼ N(µy0, σ
2ε
)n = 1, ....N j ∈ Cn,
etant donne µy0 = E(y0(m)) et σ2ε de l’equation (6.20).
Etape 1bis : Simulation de yjt−1(m)
Nous savons que meme avec de vraies donnees de panel, il faut instrumenter la va-
riable dependante retardee pour avoir des estimateurs convergents (Anderson et Hsiao
(1981), Moffit (1993)). Pour cette raison, nous supposerons que la dependante retardee
est definie en fonction d’un certain nombre de variables explicatives variantes dans le
temps et invariantes dans le temps (approche utilisee par Moffit (1993) dans le cadre de
pseudo-panels de cohortes). Nous supposons que la variable dependante de la premiere
periode (soit yn0) est connue. Conditionnellement a yn0, on peut simuler yt−1(m). Sup-
posons que :
yjt−1(m) = Wjt−1(m)α1 + Wj(m)α2 + εjt−1(m)
Wjt−1(m) etant un vecteur de variables variantes dans le temps et Wj(m) est un vecteur
de variables invariantes dans le temps. En supposant que les W sont donnes, si les autres
parametres du modele sont connus, et si le terme d’erreur suit une normale, alors il est
possible de faire des tirages de yjt−1(m) a partir d’une normale :
yjt−1(m) ∼ N(Wjt−1(m)α1 + Wj(m)α2, σ
2ε
).
Les valeurs de la variable dependante retardee seront simulees en tenant compte des
deux classes. Les autres etapes qui restent sont les memes que dans le modele statique.
Nous simulerons les exogenes comme a l’etape (2) du modele statique. Dans la partie
estimation des parametres, les etapes (4 a 10) seront repetees ici egalement avec une
legere modification a l’etape (4) pour l’estimation du vecteur des parametres β. A cette
etape, nous inclurons les parametres a1 et a2 qui sont les coefficients de la dependante
retardee de la classe 1 et 2 respectivement. Il n’y a aucune autre modification a apporter
dans les autres etapes.

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 241
6.6.2 Resultats et interpretation
Les resultats de l’estimation du modele de demande dynamique sont presentes au
tableau (6.8). Precisons que le premier bloc represente les estimes des parametres de la
probabilite d’etre dans la deuxieme classe, il s’agit donc des estimes du modele latent.
Le deuxieme bloc (reparti entre les deux classes) represente les estimes du modele de
demande conditionnelle au choix de la classe et au choix du mode de chauffage.
Nous remarquons que tous les estimes du modele de choix de la classe sont tres si-
gnificatifs (au seuil de 1%). Plus la surface de l’habitation est grande, plus la probabilite
que le menage soit dans la deuxieme classe est forte. Les grandes maisons necessitent
beaucoup plus d’energie. Les maisons de type detachees et jumelees affectent positi-
vement la probabilite d’etre dans la deuxieme classe 7. Les menages qui utilisent un
systeme de chauffage thermopompe ou un systeme de chauffage convectaire ont moins
de chance d’etre dans la deuxieme classe. La climatisation de la maison affecte positive-
ment la probabilite d’etre dans la deuxieme classe. Le nombre de refrigerateurs affecte
positivement la probabilite d’etre dans la deuxieme classe.
La variable binaire specifique a la region de Montreal a un estime de signe positif et
significatif au seuil de 1%. La region de Montreal regroupe pas mal de consommateurs
de la deuxieme classe. Cela vient du fait que les menages habitant cette region ont tres
peu de flexibilite quand au choix des systemes de chauffage que les menages des autres
regions. Par exemple les systemes d’appoint ou le bois, qui permettent de reduire la
consommation d’electricite, leurs sont peu accessibles.
La variable revenu a un estime de signe positif. Plus le revenu du menage est eleve,
plus il aura de chance d’etre dans la deuxieme classe. Donc, les menages riches sont ceux
qui consomment le plus d’electricite. Un menage pauvre aura plus de chance d’etre dans
la premiere classe. La variable nombre de personnes dans le foyer affecte positivement
la probabilite d’etre dans la deuxieme classe. Plus il y a de personnes dans le menage,
plus les besoins en electricite augmentent et plus la probabilite que le menage soit dans
la deuxieme classe augmente.
L’estime de la variable degres-jours de chauffage (hdd) a le bon signe et est significatif
au seuil de 1%. Plus hdd augmente, indiquant qu’il fait plus froid, plus les besoins de
chauffage augmentent et plus la probabilite que le menage soit dans la deuxieme classe
augmente.
7La variable binaire que nous avons exclus du modele est celle des maisons individuelles en rangee,
attachees des deux cotes. Avec ce type de maison, le nombre de murs a chauffer est inferieurs (2) a ces
ces autres types d’habitation.

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 242
La variable degres jours de climatisation (cdd) a un estime de signe negatif et signi-
ficatif au seuil de 1%. Plus cdd augmente, indiquant qu’il fait chaud, moins les menages
de la province chauffent leurs maisons. Comme souligne precedemment, le phenomene
de climatisation est assez recent dans la province et le chauffage est une activite plus
courante, a cause des conditions climatiques de la province.
Nous remarquons, qu’a l’exception des correcteurs, les estimes les plus grands en
valeur absolue sont ceux du nombre de personnes dans le foyer, le revenu, le type d’ha-
bitation et les degres jours de chauffage. Plus les valeurs de ces variables augmentent,
plus la probabilite que le menage se retrouve dans la deuxieme classe est forte. En
d’autres mots, les familles riches, celles qui sont nombreuses, celles qui ont de grandes
maisons et celles qui ont des maisons detachees ou jumelees sont celles qui sont le
plus souvent dans la deuxieme classe et donc celles qui consomment le plus. Les hivers
rudes ou les regions les plus froides augmentent les chances des menages d’etre dans la
deuxieme classe.
La constante est negative, signifiant que si toutes les autres variables sont fixees a
zero, le menage aura moins de chance d’etre dans la deuxieme classe. Les correcteurs
de biais de selection sont aussi tous significatifs ; donc la correction pour le biais de
selection est tres importante dans le modele de choix de la classe.
En ce qui concerne les estimes du modele de demande conditionnelle aux deux choix
(mode de chauffage et classe), nous remarquons que les estimes des variables de la
deuxieme classe sont tous superieurs en valeurs absolues a ceux de la premiere classe,
indiquant que les menages de la deuxieme classe classe sont beaucoup plus sensibles
aux changements que ceux de la premiere classe.
L’effet marginal du prix marginal de l’electricite (prixelec) est negatif et significatif
au seuil de 1% dans les deux classes. Plus le prix marginal de l’electricite augmente,
plus la demande d’electricite baisse et cette baisse est plus importante dans la deuxieme
classe que dans la premiere. L’effet du prix de la bi-energie (prixbie) est negatif et
significatif seulement dans la deuxieme classe. La bi-energie n’explique pas la demande
d’electricite de la premiere classe. L’effet marginal du prix du gaz naturel (prixgn)
est positif et significatif dans les deux classes. Plus le prix du gaz naturel augmente,
plus la demande d’electricite augmente dans les deux classes, et cette augmentation
est d’autant plus forte que le menage est dans la deuxieme classe. Le gaz naturel et
l’electricite sont donc des biens substituts. Pour les deux classes, le prix du mazout
(prixm) n’explique pas significativement la demande d’electricite.
L’effet marginal du revenu (rev Aug) est positif et significatif seulement a 10% dans

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 243
la premiere classe, et tres significatif (1%) dans la deuxieme classe. Plus le revenu
augmente, plus la demande d’electricite augmente dans les deux classes, augmentation
plus forte dans la deuxieme classe que dans la premiere.
La variable degres jours de chauffage (hdd) a un estime positif significatif au seuil
de 1% dans les deux classes. Plus il fait froid (periodes hivernale, ou dans les regions
les plus froides), plus la demande d’electricite augmente, et cette hausse est beaucoup
plus importante dans la deuxieme classe que dans la premiere.
L’effet de la variable degres jours de climatisation (cdd) n’est pas significatif dans la
premiere classe, mais est significatif a 10% dans la deuxieme classe. Pour cette derniere
classe, plus cdd augmente, plus il fait chaud, moins les menages utilisent l’electricite
pour leurs besoins de chauffage.
L’effet marginal de la variable mode d’occupation est negatif et significatif seulement
dans la deuxieme classe. Rappelons que cette variable est codee de 1 a 3, le 1 pour
proprietaire, 2 pour coproprietaire et 3 pour locataire. Ainsi, les locataires consomment
moins d’electricite tandis que les proprietaires en consomment plus dans la deuxieme
classe. Cela s’explique par le fait que les proprietaires ont beaucoup plus d’appareils
que les locataires.
Le choix des systemes de chauffages n’explique pas significativement la demande
d’electricite des menages de la premiere classe, mais leurs effets sont significatifs dans
la deuxieme classe. Le type d’habitation affecte positivement la demande d’electricite :
la maison de type detachee a un effet plus important que la maison jumelee, pour toutes
les classes. Cela s’explique pour le fait que la maison detachee a quatre murs a chauffer
tandis que la maison jumelee n’en a que trois. L’effet marginal de la maison jumelee
n’est cependant pas significatif dans la premiere classe. Dans cette derniere classe, les
menages habitent certainement plus les maisons jumelees.
La piscine n’explique pas significativement la demande d’electricite de la premiere
classe, mais son effet est significatif au seuil de 1% et positif dans la deuxieme classe.
La presence de piscine, a travers la chauffe-piscine, necessite de l’electricite.
L’effet marginal des variables cout fixe (coutfix) et cout moyen (coutm) sont negatifs
dans les deux classes, celui du cout fixe n’etant pas significatif dans la premiere classe.
Les couts affectent negativement la demande d’electricite, cela resulte meme de la for-
mule de l’equation de demande. La disponibilite du gaz naturelle dans la zone d’habi-
tation affecte negativement et de facon significative la demande d’electricite.

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 244
Le nombre de residents (nbre residents) a un effet marginal positif et significatif
au seuil de 1% dans les deux classes. Plus il y a de personnes dans le menage, plus
la demande d’electricite augmente. L’age affecte positivement et de facon significative
la demande d’electricite. Plus l’age augmente, plus la demande d’electricite augmente,
augmentation plus forte dans la deuxieme classe que dans la premiere. Cela vient du fait
que les personnes agees restent le plus souvent a la maison, donc elles doivent chauffer
le plus souvent leurs maisons durant les periodes froides, ou les climatiser durant les
periodes chaudes de l’annee.
Pour la deuxieme classe, presque tous les estimes des variables sont statistiquement
significatives au seuil de 1%, a l’exception de celui de la variable prix du mazout. Tous
les estimes des correcteurs (sauf celui du correcteur8) sont statistiquement significatifs,
indiquant que la correction pour le biais de selection est necessaire pour cette classe.
La correction n’est cependant pas necessaire pour la premiere classe.
Dans le modele dynamique, la difference avec le modele statique est principalement
la presence de la variable endogene retardee notee Lcons anAug. La consommation de la
periode precedente etant une donnee non disponible, nous l’avons simulee en utilisant
l’algorithme de l’augmentation des donnees. L’estime de la dependante retardee est
positif (signe attendu) et significatif au seuil de 1% pour la deuxieme classe tandis
qu’il est negatif et non significatif dans la premiere classe. Selon la seconde loi de la
demande, l’estime de la consommation de la periode precedente devrait etre positif de
sorte a permettre que les elasticites de court terme soient plus faibles que celles de long
terme. Dans le contexte de la demande d’electricite residentielle, les changements de
prix entraınent des changements de la demande a court terme mais des changements
plus importants a long terme. Les menages peuvent a court terme reduire un peu leur
demande, mais a long terme, ils choisiront un systeme de chauffage qui est relativement
moins couteux. Pour la deuxieme classe, le signe de l’estime de la consommation retardee
permet de confirmer cette loi. De plus, nous remarquons que pour la premiere classe, son
estime est tres faible tout en etant non significatif. Pour cette classe, la consommation
retardee n’explique pas de facon significative la consommation courante. Si les menages
de la deuxieme classe, qui sont les plus sensibles aux variations, ont des changements
de long terme qui ne sont pas tres differents de ceux de court terme (l’effet marginal
de la consommation retardee etant tres faible : 0.033), il est tout a fait raisonnable que
les menages de la premiere classe ne reagissent pas plus a long terme qu’a court terme.
Pour la premiere classe, il se pourrait que les changements de long terme ne soient pas
statistiquement plus importants que les changements de court terme, et donc a la limite,
il n’y aurait pas plus de changements a long terme qu’a court terme. Cela a du sens
puisque si ces menages utilisent la quantite d’energie juste necessaire pour satisfaire
leur besoins, ils ne pourront pas baisser leur consommation plus qu’un seuil donne dans

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 245
le long terme, lorsque certains changements se produisent (comme la hausse du prix de
l’electricite).
Il est important de noter egalement que la consommation d’electricite au Quebec a
une certaine particularite. D’abord, La province de Quebec est une grande productrice
d’hydro-electricite. Sa production represente environ 50% de la puissance installee au
Canada en terme d’hydro-electricite. Le prix de l’electricite au Quebec est aussi parmi
les plus bas au monde. En 2002, le Quebec etait le deuxieme plus grand consomma-
teur d’electricite au monde derriere la Norvege avec une consommation moyenne de 27
207 kWh par habitant, et en 2003, Quebec etait premier au monde. La consommation
d’electricite par habitant au Quebec est restee relativement stable durant la majeure
partie des annees 1990. Apres une chute de 7% en 1998 (suite a une baisse du prix du
mazout), la consommation d’electricite a connu des hausses. Ces hausses s’expliquent
principalement par l’augmentation de la competitivite des prix de l’electricite compa-
rativement aux prix du mazout leger et du gaz naturel. Les prix de ces energies ont
beaucoup grimpe depuis 1998 avec comme consequence une hausse d’environ 20% de la
consommation d’electricite (entre 1998 et 2003). Entre Mai 1998 et Avril 2004, Hydro-
Quebec avait gele ses prix, les gardant au niveau de Mai 1998. Le tableau (6.5) presente
la tarification d’hydro-Quebec de quelques annees, nous ne presentons que le tarif D
qui est le tarif le plus utilise pour les menages. Le tableau 6.6 compare le prix moyen
de l’electricite par rapport au prix moyen des autres formes d’energies dans la province.
Enfin, le tableau 6.7 compare le prix de vente moyen de l’electricite au Quebec par
rapport a quelques pays industrialises. On constate que dans la province de Quebec,
l’electricite n’est pas vendue a son cout d’opportunite, elle est vendue a un prix beau-
coup plus bas. Cela pourrait expliquer pourquoi l’effet marginal la dependante retardee
est relativement faible, traduisant de faibles changements dans le long terme pour la
deuxieme classe. Les menages n’ont pas vraiment interet a changer leurs systemes de
chauffage au profit d’autres formes d’energies que l’electricite, puisque cette derniere
est vendue a un prix tres competitif.
Nous avons exclus la constante du modele de demande conditionnelle. Comme nous
avons un modele dynamique, il est possible de ne pas inclure la constante dans le modele
si elle n’est pas pertinente. Nous avions estime le meme modele avec une constante et
les estimes de la dependante retardee des deux classes etaient de signe negatif, ce qui
n’est pas theoriquement justifiable. Pour cette raison, nous avons estime le modele sans
constante et les resultats sont plus satisfaisants.
Les graphiques (6.1 et 6.14) montrent la convergence de tirages des differents es-
timateurs des parametres. Nous avons prefere ne presenter que quelques graphiques
pour economiser de l’espace. Les autres graphiques pourront etre fournis sur demande.

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 246
Tab. 6.5 – Tarif D de quelques anneesannee redevance p1 p2
1989 31.70 3.76 4.46
1993 37.60 4.51 5.46
1994 37.70 4.54 5.54
1996 37.90 4.59 5.79
1997 38.50 4.66 5.88
1998-2002 4.74 5.97
Tab. 6.6 – Prix moyens en dollars constant
annee Electricite Gaz naturel Mazout IPC
1989 5.22 13.20 32.46 89.02
1994 5.69 12.83 35.69 102.00
1999 5.75 12.57 33.45 110.32
2002 5.14 14.33 40.49 118.55
Tab. 6.7 – Comparaison prix de vente moyen avec pays industrialisesannee Qc USA France RU Norvege Allemagne Australie
2001 6.2 13.1 12.0 14.9 6.9 16.5 8.8
2002 6.1 13.3 12.9 15.7 3.8 18.3 9.7

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 247
Comme dans le modele statique, les autres tirages convergent toutes vers la moyenne
des tirages.
Nous avons aussi estime le modele de demande sans les deux classes, il s’agit de l’es-
timation faite habituellement si on ne corrige pas pour l’endogeneite du prix marginal.
Les resultats sont presentes au tableau (6.9). Nous remarquons que tous les estimes qui
sont statistiquement significatifs ont les memes signes que dans le modele avec classes.
L’effet marginal de la dependante retardee (qui est egal a 0.61 et significatif au seuil
de 1%) est beaucoup plus important que les effets obtenus pour les deux classes : il
vaut plus de 18 fois celui de la deuxieme classe. Le modele sans classe surestime donc
le coefficient d’ajustement de long terme des menages. Avec ce modele, les ajustements
des menages sont les memes peu importe la quantite qu’ils consomment. Ce modele
ne corrige pas pour l’endogeneite du prix marginal de l’electricite, par consequent les
estimateurs qui en decoulent sont biaises et non convergents.
Comme nous pouvons le remarquer, l’approche par la simulation donne des resultats
satisfaisants tant du cote du modele statique que du cote du modele dynamique, avec
et sans la correction de l’endogeneite. Tous les graphiques indiquent la convergence des
tirages. Cette approche a ete utilisee par Bernier-Martel (2003) et Vidal (2006) pour
l’estimation de modeles a variable dependante discrete (estimation du choix du mode
de transport), mais les resultats qu’ils ont obtenus n’etaient pas satisfaisants (probleme
de convergence).

Chapitre
6.
Analy
sede
ladem
ande
conditio
nnelle
:appro
che
bayesien
ne
248
Tab. 6.8: Resultats du modele dynamique de demande condi-
tionnelle
Variables Moyenne Ecart-type Min Max Moyenne Ecart-type Min Max
Modele latent
surf .8053653 .0057747 .7866445 .8254184
syst plintes .412864 .0111871 .3768592 .4498259
syst airChaud .8265344 .0162922 .767087 .8790817
syst eauChaude .4010582 .0248429 .3178867 .4911104
syst thermopompe -.1062571 .0181284 -.1770167 -.0450317
syst convectair -1.222884 .0220832 -1.298967 -1.132012
nbre refrigerateurs .321185 .008092 .2891684 .3546381
maison detachee 5.268571 .0258582 5.170697 5.362463
maison jumelee 2.319284 .0303369 2.215795 2.444474
climatiseur central .4902232 .0217813 .4237933 .5722097
climatiseur fenetre .3695003 .0152668 .312193 .4277806
correcteur1 .1016286 .0023776 .0936277 .1094283
correcteur2 .3928439 .0023229 .3850721 .4011269
correcteur3 -1.267888 .0079403 -1.294028 -1.23907
correcteur4 .3996153 .0055558 .3791714 .4176137
correcteur5 -2.251663 .0065907 -2.278672 -2.22806
correcteur6 -1.642364 .005544 -1.663225 -1.620412
correcteur7 4.908011 .0051466 4.892428 4.928285
correcteur8 -.178237 .00251 -.1876499 -.16814
correcteur9 -.0513887 .002464 -.0595561 -.0430866
montreal .4141185 .0211552 .3286342 .498473
nbre Resid Aug 5.655535 .004292 5.638442 5.670697
suite de a la page suivante
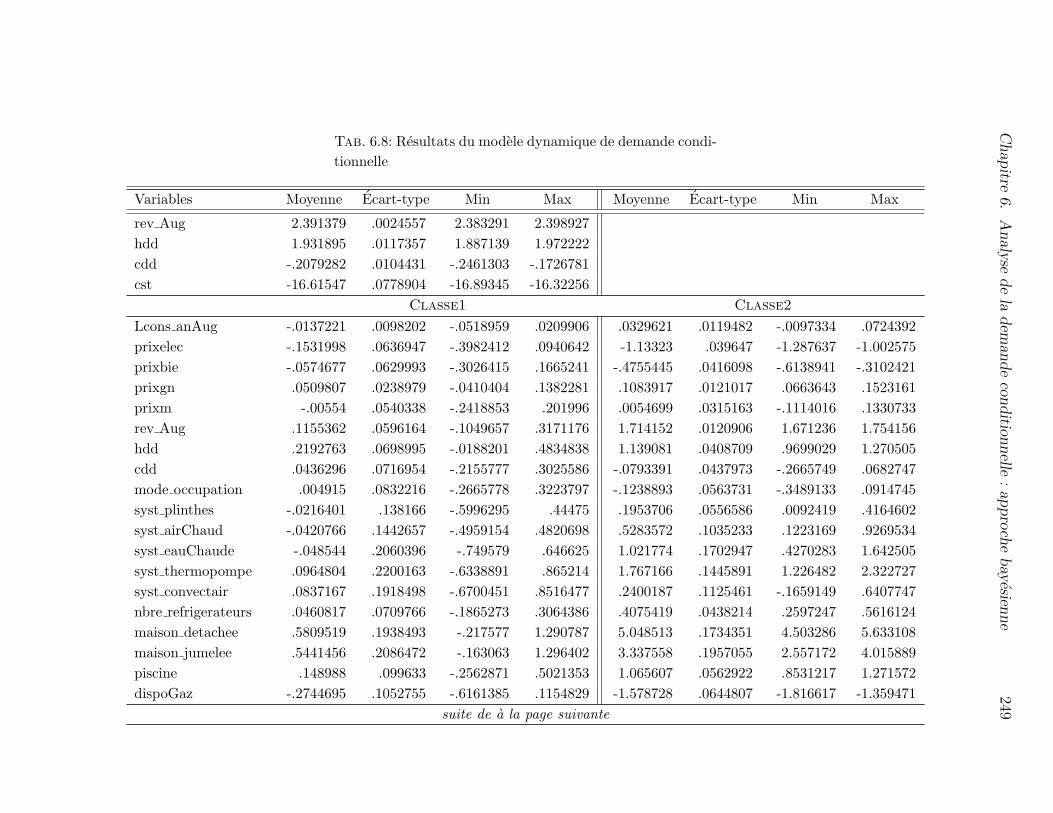
Chapitre
6.
Analy
sede
ladem
ande
conditio
nnelle
:appro
che
bayesien
ne
249
Tab. 6.8: Resultats du modele dynamique de demande condi-
tionnelle
Variables Moyenne Ecart-type Min Max Moyenne Ecart-type Min Max
rev Aug 2.391379 .0024557 2.383291 2.398927
hdd 1.931895 .0117357 1.887139 1.972222
cdd -.2079282 .0104431 -.2461303 -.1726781
cst -16.61547 .0778904 -16.89345 -16.32256
Classe1 Classe2
Lcons anAug -.0137221 .0098202 -.0518959 .0209906 .0329621 .0119482 -.0097334 .0724392
prixelec -.1531998 .0636947 -.3982412 .0940642 -1.13323 .039647 -1.287637 -1.002575
prixbie -.0574677 .0629993 -.3026415 .1665241 -.4755445 .0416098 -.6138941 -.3102421
prixgn .0509807 .0238979 -.0410404 .1382281 .1083917 .0121017 .0663643 .1523161
prixm -.00554 .0540338 -.2418853 .201996 .0054699 .0315163 -.1114016 .1330733
rev Aug .1155362 .0596164 -.1049657 .3171176 1.714152 .0120906 1.671236 1.754156
hdd .2192763 .0698995 -.0188201 .4834838 1.139081 .0408709 .9699029 1.270505
cdd .0436296 .0716954 -.2155777 .3025586 -.0793391 .0437973 -.2665749 .0682747
mode occupation .004915 .0832216 -.2665778 .3223797 -.1238893 .0563731 -.3489133 .0914745
syst plinthes -.0216401 .138166 -.5996295 .44475 .1953706 .0556586 .0092419 .4164602
syst airChaud -.0420766 .1442657 -.4959154 .4820698 .5283572 .1035233 .1223169 .9269534
syst eauChaude -.048544 .2060396 -.749579 .646625 1.021774 .1702947 .4270283 1.642505
syst thermopompe .0964804 .2200163 -.6338891 .865214 1.767166 .1445891 1.226482 2.322727
syst convectair .0837167 .1918498 -.6700451 .8516477 .2400187 .1125461 -.1659149 .6407747
nbre refrigerateurs .0460817 .0709766 -.1865273 .3064386 .4075419 .0438214 .2597247 .5616124
maison detachee .5809519 .1938493 -.217577 1.290787 5.048513 .1734351 4.503286 5.633108
maison jumelee .5441456 .2086472 -.163063 1.296402 3.337558 .1957055 2.557172 4.015889
piscine .148988 .099633 -.2562871 .5021353 1.065607 .0562922 .8531217 1.271572
dispoGaz -.2744695 .1052755 -.6161385 .1154829 -1.578728 .0644807 -1.816617 -1.359471
suite de a la page suivante
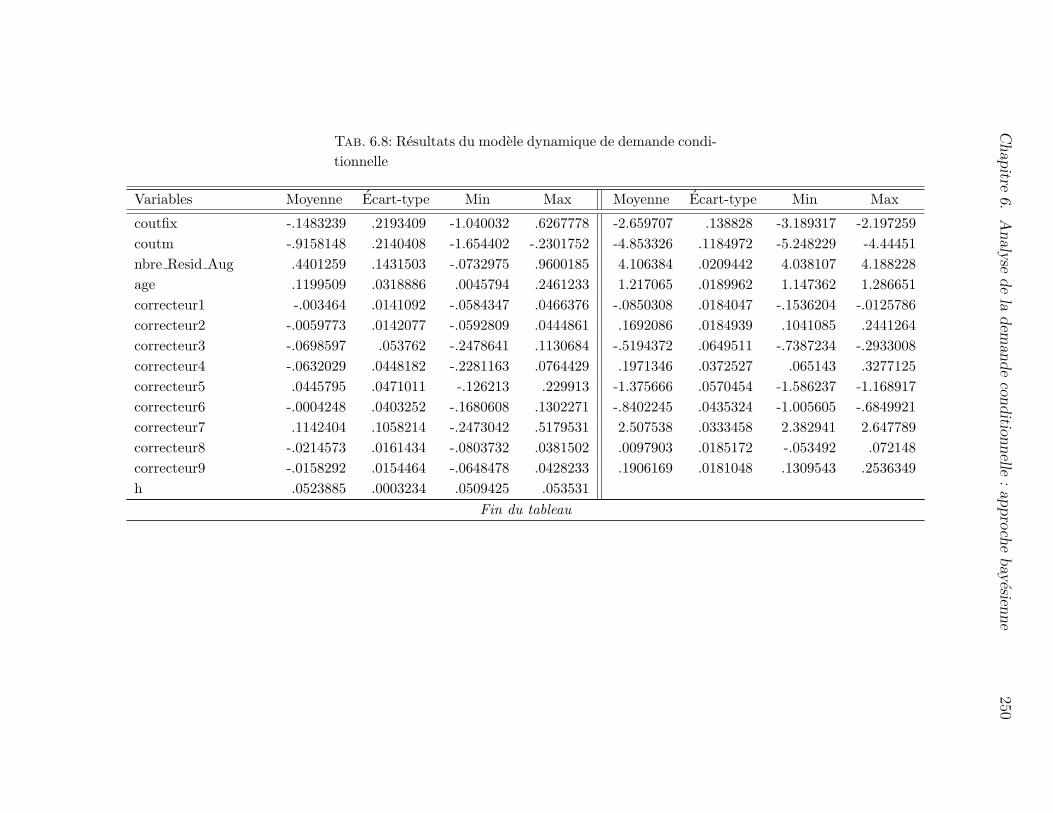
Chapitre
6.
Analy
sede
ladem
ande
conditio
nnelle
:appro
che
bayesien
ne
250
Tab. 6.8: Resultats du modele dynamique de demande condi-
tionnelle
Variables Moyenne Ecart-type Min Max Moyenne Ecart-type Min Max
coutfix -.1483239 .2193409 -1.040032 .6267778 -2.659707 .138828 -3.189317 -2.197259
coutm -.9158148 .2140408 -1.654402 -.2301752 -4.853326 .1184972 -5.248229 -4.44451
nbre Resid Aug .4401259 .1431503 -.0732975 .9600185 4.106384 .0209442 4.038107 4.188228
age .1199509 .0318886 .0045794 .2461233 1.217065 .0189962 1.147362 1.286651
correcteur1 -.003464 .0141092 -.0584347 .0466376 -.0850308 .0184047 -.1536204 -.0125786
correcteur2 -.0059773 .0142077 -.0592809 .0444861 .1692086 .0184939 .1041085 .2441264
correcteur3 -.0698597 .053762 -.2478641 .1130684 -.5194372 .0649511 -.7387234 -.2933008
correcteur4 -.0632029 .0448182 -.2281163 .0764429 .1971346 .0372527 .065143 .3277125
correcteur5 .0445795 .0471011 -.126213 .229913 -1.375666 .0570454 -1.586237 -1.168917
correcteur6 -.0004248 .0403252 -.1680608 .1302271 -.8402245 .0435324 -1.005605 -.6849921
correcteur7 .1142404 .1058214 -.2473042 .5179531 2.507538 .0333458 2.382941 2.647789
correcteur8 -.0214573 .0161434 -.0803732 .0381502 .0097903 .0185172 -.053492 .072148
correcteur9 -.0158292 .0154464 -.0648478 .0428233 .1906169 .0181048 .1309543 .2536349
h .0523885 .0003234 .0509425 .053531
Fin du tableau

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 251
6.6.3 Analyse de sensibilite : elasticite prix et revenu du modele
dynamique
Les elasticites de court terme (CT) et de long terme (LT) du modele de demande
conditionnelle sont presentees au tableau (6.10). Nous avons ajoute les elasticites du
modele dynamique qui ne prend pas en compte les deux classes pour fin de comparaison.
La premiere remarque qui peut etre faite est que les elasticites de la deuxieme classe
sont superieures (en valeur absolue) a celles de la premiere classe. Les menages de la
deuxieme classe sont beaucoup plus sensibles aux changements que ceux de la premiere
classe. Nous n’avons pas calcule les elasticites de long terme de la premiere classe
etant donne que l’estime de la variable dependante retardee n’est pas significative. Les
elasticites de long terme du modele sans classes sont superieures a celles de la deuxieme
classe, a cause de l’estime de la dependante retardee qui est de 0.61 dans le modele sans
classe alors qu’il n’est que de 0.033 dans la deuxieme classe. Le fait que cet estime soit
tres grand dans le modele sans classe implique que les changements a long terme sont
nettement plus importants que les changements a court terme des menages lorsqu’on
ne corrige pas l’endogeneite du prix de l’electricite, ce qui est en contradiction avec la
situation atypique de la province.
Les elasticites prix directes de l’electricite sont significatives aux seuils usuels pour
les deux classes. Une augmentation de 1% du prix de l’electricite entraınera une baisse
a court terme de la demande d’electricite de 0.03% dans la premiere classe et de 0.29%
dans la deuxieme classe. La baisse de la deuxieme classe represente approximativement
10 fois celle de la premiere classe. A long terme, la hausse du prix de l’electricite entraıne
une baisse d’environ 0.3% de la demande de la deuxieme classe, ce qui n’est pas vraiment
tres different de celle de court terme. Pour le modele sans classe, la meme hausse du
prix de l’electricite entraıne une baisse de 0.257% a court terme et de 0.659% a long
terme, soit plus du double de la baisse de court terme.
Comme nous l’avons dit a la section precedente, a cause de la forte competitivite
du prix de l’electricite, les autres formes d’energies coutent relativement plus cheres.
Les menages gagnent par exemple en gardant leurs systemes de chauffage a l’electricite,
tout en procedant a de petits ajustements suite aux variations de prix marginal de
l’electricite.
L’elasticite-prix croisee de la bi-energie de court terme est de -0.134 pour la deuxieme
classe et significative au seuil de 1%. L’elasticite de long terme (-0.1386) est legerement
superieure a celle de court terme. L’electricite et la bi-energie sont des complements
pour la deuxieme classe. Nous ne l’avons pas calculee pour la premiere classe puisque
l’effet marginal de la bi-energie n’y est pas significatif. Il faut noter egalement que les
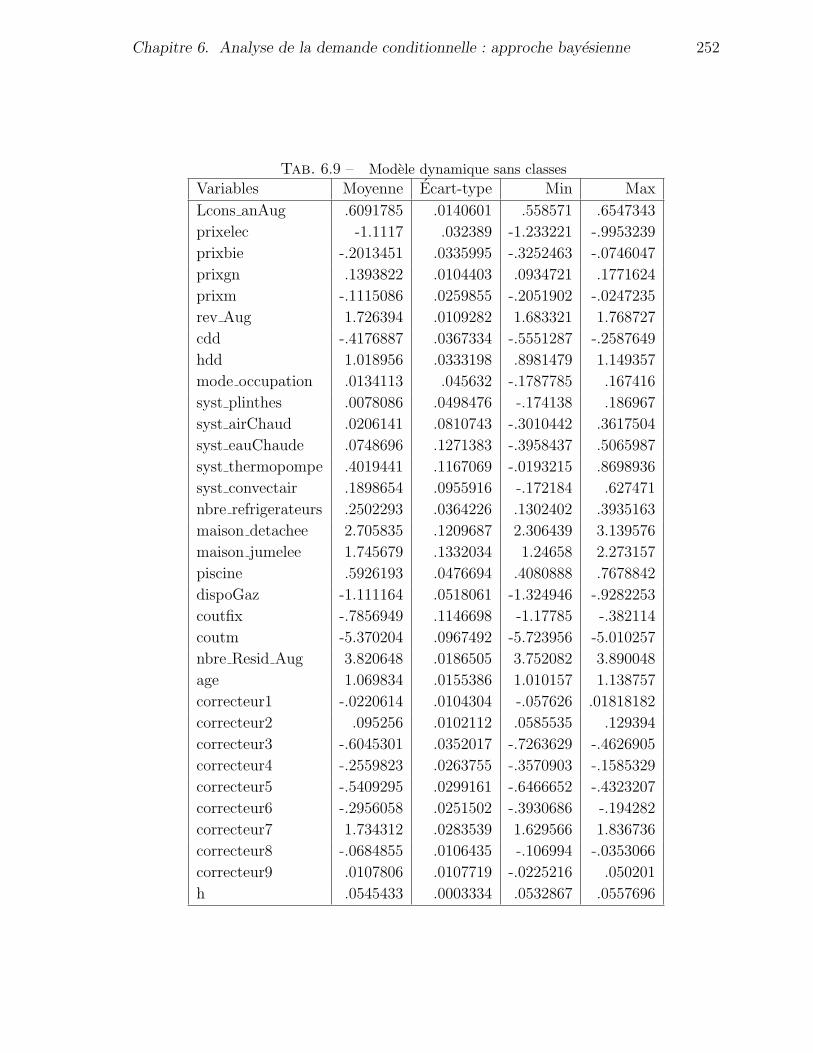
Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 252
Tab. 6.9 – Modele dynamique sans classes
Variables Moyenne Ecart-type Min Max
Lcons anAug .6091785 .0140601 .558571 .6547343
prixelec -1.1117 .032389 -1.233221 -.9953239
prixbie -.2013451 .0335995 -.3252463 -.0746047
prixgn .1393822 .0104403 .0934721 .1771624
prixm -.1115086 .0259855 -.2051902 -.0247235
rev Aug 1.726394 .0109282 1.683321 1.768727
cdd -.4176887 .0367334 -.5551287 -.2587649
hdd 1.018956 .0333198 .8981479 1.149357
mode occupation .0134113 .045632 -.1787785 .167416
syst plinthes .0078086 .0498476 -.174138 .186967
syst airChaud .0206141 .0810743 -.3010442 .3617504
syst eauChaude .0748696 .1271383 -.3958437 .5065987
syst thermopompe .4019441 .1167069 -.0193215 .8698936
syst convectair .1898654 .0955916 -.172184 .627471
nbre refrigerateurs .2502293 .0364226 .1302402 .3935163
maison detachee 2.705835 .1209687 2.306439 3.139576
maison jumelee 1.745679 .1332034 1.24658 2.273157
piscine .5926193 .0476694 .4080888 .7678842
dispoGaz -1.111164 .0518061 -1.324946 -.9282253
coutfix -.7856949 .1146698 -1.17785 -.382114
coutm -5.370204 .0967492 -5.723956 -5.010257
nbre Resid Aug 3.820648 .0186505 3.752082 3.890048
age 1.069834 .0155386 1.010157 1.138757
correcteur1 -.0220614 .0104304 -.057626 .01818182
correcteur2 .095256 .0102112 .0585535 .129394
correcteur3 -.6045301 .0352017 -.7263629 -.4626905
correcteur4 -.2559823 .0263755 -.3570903 -.1585329
correcteur5 -.5409295 .0299161 -.6466652 -.4323207
correcteur6 -.2956058 .0251502 -.3930686 -.194282
correcteur7 1.734312 .0283539 1.629566 1.836736
correcteur8 -.0684855 .0106435 -.106994 -.0353066
correcteur9 .0107806 .0107719 -.0225216 .050201
h .0545433 .0003334 .0532867 .0557696

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 253
menages qui sont au tarif bi-energie ont en fait deux tarifs differents : il y a ceux qui
sont au tarif D (electricite) et ceux qui sont au tarif DT (tarif bi-energie). Cela pourrait
explique pourquoi l’effet dans la premiere classe n’est pas significatif. Dans le modele
sans classe, l’elasticite de court terme est de -0.056 et celle de long terme est de -0.144
soit plus du double de celle de court terme, toutes deux etant significatives au seuil de
1%.
L’elasticite-prix croisee de court terme du gaz naturel est 0.0125 (significative a 5%)
pour la premiere classe et de 0.0265 pour la deuxieme classe (ou elle est significa-
tive a 1%). Une hausse du prix du gaz naturel entraınera une hausse de la demande
d’electricite de 0.012% pour la deuxieme classe et de plus du double pour la deuxieme
classe. Le gaz naturel et l’electricite sont des substituts. Le modele sans classe surestime
les deux elasticites.
L’effet marginal du prix du mazout n’est pas significatif dans les deux classes mais l’est
dans le modele sans classes. Pour ce modele, l’elasticite-prix croisee de court terme du
mazout est de -0.032 et celle de long terme est de -0.082. Le mazout et l’electricite
sont des bien complementaires pour le modele sans classes tandis qu’ils sont des biens
independants pour le modele avec classes. L’independance semble assez intuitif puis-
qu’un menage qui chauffe au mazout utilise des systemes de chauffage specifiques a
cette forme d’energie et qui ne peuvent en principe etre utilises directement avec une
autre forme d’energie telle que l’electricite.
L’elasticite-revenu de court terme de la demande est positive et significative a 1% dans
la deuxieme classe et a 10% dans la premiere. Une hausse du revenu de 1% entraınera
une hausse a court terme de 0.026% la demande de la premiere classe et de 0.39% la
demande de la deuxieme classe. L’effet revenu est donc beaucoup plus important dans la
deuxieme classe, et tres faible dans la premiere. D’apres les resultats du modele latent,
les menages qui sont dans la deuxieme classe sont plus riches que ceux qui sont dans
la premiere, et une hausse du revenu les amene a consommer davantage d’electricite.
L’electricite a la limite serait un bien necessaire pour les menages de la premiere classe.
L’elasticite de long terme du modele sans classe est d’environ l’unite. Cette valeur serait
trop elevee puisqu’elle implique qu’une hausse du revenu de 1% entraınera une hausse
de la demande d’electricite de 1% a long terme. C’est comme si toute la hausse de
revenu est affectee uniquement a la consommation d’electricite, ce qui est enorme.
L’elasticite de la variable degres jours de chauffage est positive et significative au seuil
de 1% dans les deux classes ainsi que dans le modele sans classes. Si la temperature en
hiver baisse de 1%, la demande d’electricite a court terme augmente d’environ 0.05%
dans la premiere classe et de 0.264% dans la deuxieme. Une fois de plus, la deuxieme
classe reagit plus fortement aux changements que la premiere. L’elasticite de long terme
du modele sans classe est plus de deux fois celle de la deuxieme classe.
Les resultats du modele sans classe indiquent que tous les menages reagissent de la
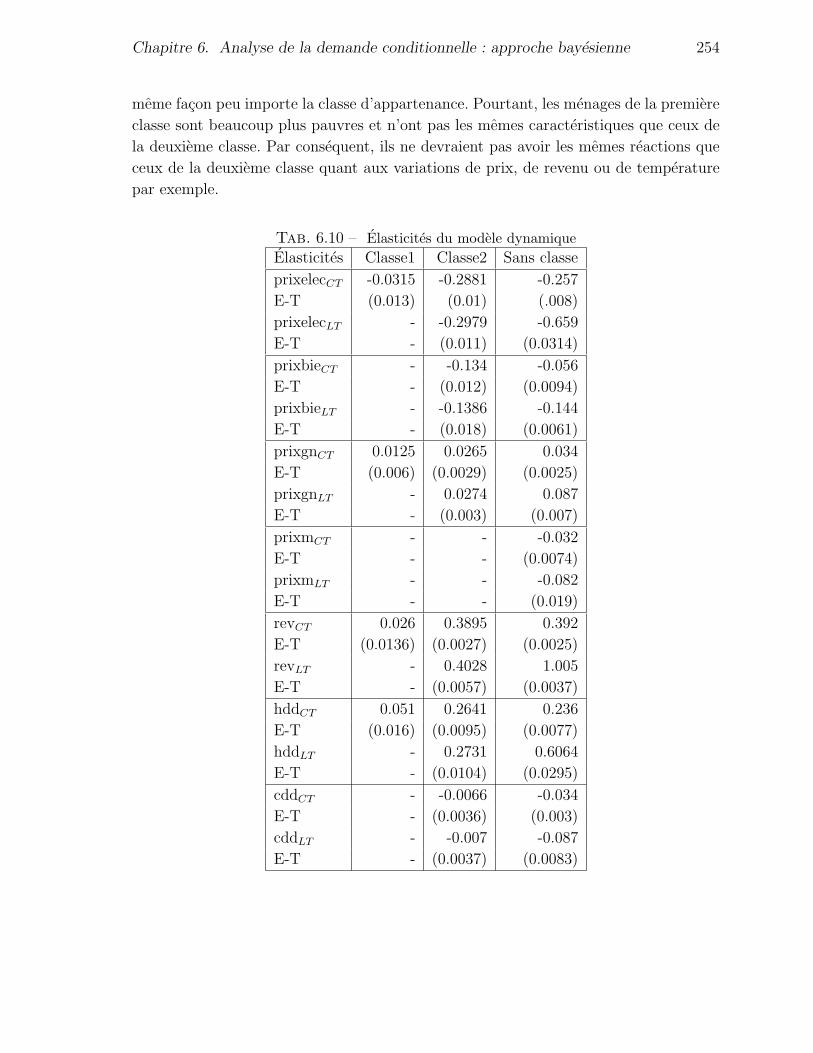
Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 254
meme facon peu importe la classe d’appartenance. Pourtant, les menages de la premiere
classe sont beaucoup plus pauvres et n’ont pas les memes caracteristiques que ceux de
la deuxieme classe. Par consequent, ils ne devraient pas avoir les memes reactions que
ceux de la deuxieme classe quant aux variations de prix, de revenu ou de temperature
par exemple.
Tab. 6.10 – Elasticites du modele dynamique
Elasticites Classe1 Classe2 Sans classe
prixelecCT -0.0315 -0.2881 -0.257
E-T (0.013) (0.01) (.008)
prixelecLT - -0.2979 -0.659
E-T - (0.011) (0.0314)
prixbieCT - -0.134 -0.056
E-T - (0.012) (0.0094)
prixbieLT - -0.1386 -0.144
E-T - (0.018) (0.0061)
prixgnCT 0.0125 0.0265 0.034
E-T (0.006) (0.0029) (0.0025)
prixgnLT - 0.0274 0.087
E-T - (0.003) (0.007)
prixmCT - - -0.032
E-T - - (0.0074)
prixmLT - - -0.082
E-T - - (0.019)
revCT 0.026 0.3895 0.392
E-T (0.0136) (0.0027) (0.0025)
revLT - 0.4028 1.005
E-T - (0.0057) (0.0037)
hddCT 0.051 0.2641 0.236
E-T (0.016) (0.0095) (0.0077)
hddLT - 0.2731 0.6064
E-T - (0.0104) (0.0295)
cddCT - -0.0066 -0.034
E-T - (0.0036) (0.003)
cddLT - -0.007 -0.087
E-T - (0.0037) (0.0083)

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 255
6.7 Conclusion et recommandations
L’objectif poursuivi dans ce travail etait d’estimer un modele de demande d’electricite
a partir de series de coupes transversales independantes, tout en corrigeant le biais de
selection du choix du mode de chauffage et le biais d’endogeneite du prix marginal de
l’electricite. Nous avons estime un modele statique et un modele dynamique en utili-
sant une approche bayesienne. Habituellement, les modeles qui analysent la demande
d’electricite ou d’energie en general utilisent de vraies donnees de panel et ne traitent
pas simultanement le probleme de selection du mode de chauffage et le probleme d’en-
dogeneite du prix marginal. Ils se limitent le plus souvent a un de ces trois problemes
(completer les donnees manquantes, ou corriger un des biais). Or, dans le cadre de
la demande d’electricite de la province de Quebec, la structure meme des donnees
fait de sorte que si ces problemes ne sont pas corriges simultanement, il en resulterait
des estimateurs biaises et non convergents. De plus, si l’on veut analyser la demande
d’electricite en profondeur, on ne peut pas se limiter a une seule coupe transversale qui
ne peut capter l’aspect dynamique ou inter-temporel dans les decisions des menages. Or,
l’aspect dynamique est assez important puisque le menage utilise les memes systemes
de chauffage sur plusieurs annees.
Puisque nous n’avons pas de vrais panels, mais des series d’enquetes independantes,
nous faisions donc face a un probleme de donnees manquantes ; les menages enquetes
durant une periode ne sont plus retracables au cours des autres periodes. Nous avons
donc utilise l’algorithme de l’augmentation des donnees pour simuler les donnees man-
quantes. Une fois les donnees completees, nous avons estimer le modele de demande
conditionnelle. Le probleme de biais de selection provenant de la simultaneite entre le
choix du mode de chauffage et le choix de la quantite est corrige a partir d’un modele
logit mixte avec erreurs autoregressives generalisees d’ordre un. Le probleme de l’en-
dogeneite du prix marginal de l’electricite est corrige en developpant un modele a classes
latentes. Il s’agit d’une approche non encore utilisee a notre connaissance dans le cadre
d’un modele a variable dependante continue. Les modeles a classes latentes sont le plus
souvent utilises dans le cadre de modele de choix discrets et les parametres du modele la-
tent ne font habituellement pas l’object d’estimation. Nous avons utilise l’algorithme de
l’echantillonnage de Gibbs pour estimer les parametres du modele apres avoir complete
les donnees manquantes avec l’algorithme de l’augmentation des donnees. L’approche
proposee dans ce travail est novatrice surtout dans le contexte de la situation atypique
de la demande d’electricite de la province de Quebec. Les resultats obtenus sont tres
satisfaisants et les modeles de demande proposes representent bien les donnees.

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 256
6.8 Annexe
6.8.1 Graphiques pour la convergence des tirages0
24
68
Den
sité
−.4 −.3 −.2 −.1 0 .1prixelec_F
(a) histogramme des valeurs moyennes
−.4
−.3
−.2
−.1
0.1
prix
elec
_F
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.1 – simulation du coefficient de prix electricite classe1
02
46
8D
ensi
té
−.3 −.2 −.1 0 .1 .2prixbie_F
(a) histogramme des valeurs moyennes
−.3
−.2
−.1
0.1
.2pr
ixbi
e_F
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.2 – simulation du coefficient de prix bi-energie classe1
Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 257
05
1015
20D
ensi
té
−.05 0 .05 .1 .15prixgn_F
(a) histogramme des valeurs moyennes
−.05
0.0
5.1
.15
prix
gn_F
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.3 – simulation du coefficient de prix gaz naturel classe1
02
46
8D
ensi
té
−.2 −.15 −.1 −.05 0 .05 .1 .15prixm_F
(a) histogramme des valeurs moyennes
−.2
−.1
0.1
.2pr
ixm
_F
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.4 – simulation du coefficient de prix mazout classe1
02
46
8D
ensi
té
−.1 −.05 0 .05 .1 .15 .2 .25 .3rev_Aug_F
(a) histogramme des valeurs moyennes
−.1
0.1
.2.3
rev_
Aug
_F
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.5 – simulation du coefficient du revenu augmente classe1
Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 258
02
46
Den
sité
−.2 −.1 0 .1 .2 .3cdd_F
(a) histogramme des valeurs moyennes
−.2
−.1
0.1
.2.3
cdd_
F
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.6 – simulation du coefficient de cdd classe1
02
46
Den
sité
0 .1 .2 .3 .4 .5hdd_F
(a) histogramme des valeurs moyennes
0.1
.2.3
.4.5
hdd_
F
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.7 – simulation du coefficient de hdd classe1
02
46
810
Den
sité
−1.3 −1.25 −1.2 −1.15 −1.1 −1.05 −1prixelec_Sd
(a) histogramme des valeurs moyennes
−1.3
−1.2
−1.1
−1pr
ixel
ec_S
d
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.8 – simulation du coefficient de prix electricite classe2
Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 259
05
1015
Den
sité
−.35 −.3 −.25 −.2 −.15 −.1prixm_Sd
(a) histogramme des valeurs moyennes
−.35
−.3
−.25
−.2
−.15
−.1
prix
m_S
d
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.9 – simulation du coefficient de prix mazout classe2
010
2030
40D
ensi
té
1.67 1.68 1.69 1.7 1.71 1.72 1.73 1.74 1.75rev_Aug_Sd
(a) histogramme des valeurs moyennes
1.66
1.68
1.7
1.72
1.74
1.76
rev_
Aug
_Sd
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.10 – simulation du coefficient du revenu augmente classe2
02
46
810
Den
sité
−.25 −.2 −.15 −.1 −.05 0 .05 .1cdd_Sd
(a) histogramme des valeurs moyennes
−.3
−.2
−.1
0.1
cdd_
Sd
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.11 – simulation du coefficient de cdd classe2

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 260
02
46
810
Den
sité
.95 1 1.05 1.1 1.15 1.2 1.25 1.3hdd_Sd
(a) histogramme des valeurs moyennes
.91
1.1
1.2
1.3
hdd_
Sd
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.12 – simulation du coefficient de hdd classe2
010
2030
40D
ensi
té
−.05 −.04 −.03 −.02 −.01 0 .01 .02Lcons_anAug_F
(a) histogramme des valeurs moyennes
−.06
−.04
−.02
0.0
2Lc
ons_
anA
ug_F
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.13 – simulation coefficient de la dependante retardee classe1
010
2030
40D
ensi
té
−.01 0 .01 .02 .03 .04 .05 .06 .07Lcons_anAug_Sd
(a) histogramme des valeurs moyennes
−.02
0.0
2.0
4.0
6.0
8Lc
ons_
anA
ug_S
d
0 2000 4000 6000obs
(b) convergence : valeur moyenne simulee
en fonction du nombre de boucles
Fig. 6.14 – simulation coefficient de la dependante retardee classe2

Chapitre 6. Analyse de la demande conditionnelle : approche bayesienne 261
6.8.2 Determination de la loi a posteriori des exogenes
Ecrivons le modele de facon compacte pour ne pas allourdir la demonstration :
ynt = aynt−1 + Xntθ + ϑn + εjnt
Le modele de regression auxilliaire s’ecrit :
xnt = γznt + εnt
Les densites conditionnelles pour le cas scalaire sont :

Chapitre
6.
Analy
sede
ladem
ande
conditio
nnelle
:appro
che
bayesien
ne
262P (ynt |ynt−1, xnt, znt, ϑ) ∝ exp
[− 1
2φ(ynt − ϑn − aynt−1 − xkntθk − xntθ−k)
2
]
P (xknt |znt, ϑ) ∝ exp
[− 1
2τ 2(xknt − γznt)
2
]
P (xknt |ynt, ynt−1,znt, ϑ) =P (xknt, ynt |znt, ynt−1 )
P (ynt |ynt−1 )
∝ P (xknt, ynt |znt, ynt−1 )
∝ P (ynt |ynt−1, xknt, x−knt, znt, ϑ) × P (xknt |znt, x−knt, ϑ)
∝ exp
[− 1
2φ(ynt − ϑn − aynt−1 − xkntθk − x−kntθ−k)
2
]× exp
[− 1
2τ 2(xknt − γznt)
2
]
∝ exp
− 1
2φ
y2nt − 2ϑnynt − 2aynt−1ynt − 2θkxkntynt + 2aϑnynt−1 + 2θ−kx−kntxknt
−2θ−kx−kntynt + 2θ−kx−kntynt−1 + 2θ−kx−kntϑn
+2aθkynt−1xknt + 2θkϑnxknt + ϑ2n + a2y2
nt−1 + x2kntθ
2k + x2
−kntθ2−k
× exp
[− 1
2τ 2
(x2
nt − 2γzntxnt + γ2z2nt
)]
∝ exp
[− 1
2φ
(−2θkxntynt + 2aθkynt−1xnt + 2θkϑnxnt + 2θ−kx−kntxknt + x2
ntθ2k
)− 1
2τ 2
(x2
nt − 2γzntxnt
)]
Ecrivons la densite conditionnelle de sorte a isoler x2nt et xnt de la facon suivante :
P (xknt |ynt, ynt−1,x−knt, znt, ϑ) ∝ exp
[−1
2
((1
2φx2
ntθ2k +
1
2τ 2x2
nt
)−(
2θkxntynt − 2aθkynt−1xnt − 2θkϑnxnt − 2θ−kx−kntxknt
φ
)+
2
τ 2γzntxnt
)]
∝ exp
[−1
2
((θ2
k
φ+
1
τ 2
)x2
nt − 2θk
(ynt − aynt−1 − θ−kx−knt − ϑn
φ
)xnt +
2
τ 2γzntxnt
)]
∝ exp
−
(θ2k
φ+ 1
τ2
)
2
x2
nt − 2θk
ynt − aynt−1 − θ−kx−knt − ϑn
φ(
θ2k
φ+ 1
τ2
)
xnt −
−2γznt
τ 2(
θ2k
φ+ 1
τ2
)xnt
∝ exp
−
(θ2k
φ+ 1
τ2
)
2
xnt −
θk
φ(ynt − aynt−1 − θ−kx−knt − ϑn) − 1
τ2 γznt(θ2k
φ+ 1
τ2
)
2
Ceci represente le noyau de la densite d’une normale, soit :
N
θk
φ(ynt − aynt−1 − θ−kx−knt − ϑn) − 1
τ2 γznt(θ2k
φ+ 1
τ2
)
,
(θ2
k
φ+
1
τ 2
)−1

Bibliographie
[1] Allenby, G. M., Arora, N. and Ginter, J. L. (1998) : «On Heterogeneity of Demand»,
Journal of Marketing research, Vol. 35, p.384-389.
[2] Anderson, T. W. and Hsiao, C. (1982) : «Formulation and Estimation of Dynamic
Models using Panel Data», Journal of Econometrics, Vol.18, p.47-82.
[3] Baltagi B. H. (2005) : Econometric Analysis of Panel Data, 3e ed. Wiley and Sons.
[4] Bhargava, A. and Sargan, J. D. (1983) : «Estimting Dynamic Random Effects
Models From Panel Data Covering Short Time Periods», Econometrica, Vol. 51,
p.1635-1660.
[5] Bernard, J-T., D. Bolduc and D. Belanger (1996) : «Quebec Residential Electricity
Demand : a Microeconometric Approach», The Canadian Journal of Economics,
Vol. 24 (1), pp. 92-113.
[6] Ben-Akiva, M. and D. Bolduc (1991) : «Multinomial Probit with Autoregres-
sive Error Structure», Working Paper 91-22, Groupe de Recherche en Econo-
mie de l’Energie, de l’Environnement et des Ressources Naturelles, Departement
d’Economique, Universite Laval.
[7] Bernier-Martel, N. (2005) : «Echantillonnage de Gibbs et Augmentation de
Donnees : Une Alternative aux Pseudo-panels», These de Maıtrise, Universite La-
val.
[8] Blundell, R. and R. S. Smith (1991) : «Conditions Initiales et Estimation Efficace
dans les Modeles Dynamiques sur les Donnees de Panel», Annales d’Economie et
de Statistiques, Vol.20-21, p.109-123.
[9] Boucher, N. (2003) : «Predicting National Data on the Use of Private Vehicles in
Canada for the 1980-1996 Period : an Application of the Bayesian Approach of
Gibbs Sampling with Data Augmentation», PhD. Thesis, Queen University
[10] Carlin B. P. and Louis Thomas (2000) : Bayes and Empirical Bayes Methods for
Data Analysis, New York, Chapman and Hill/CRC
[11] Casella G. and George E. I. (1992) : « Explaining the Gibbs Sampler», The Ame-
rican Statitician, Vol. 46, No. 3, p. 167-174.

Bibliographie 264
[12] Chamberlain G. (1984) : Panel Data. Handbook of Econometrics. Vol.II, Griliches
and Introligator M. D.
[13] Chamberlain G. (1980) :« Analysis of Covariance with Qualitative Data», The
Review of Economic Studies, Vol. 47, No. 1
[14] Dempster A. P., Laird M. N. and Rubin B. D. (1977) : «Maximum Likelihood from
Incomplete Data via le EM Algorithm», Journal of the Royal Statistical Society,
Series B (Methodological), Vol. 39, No. 1, pp. 1-38.
[15] Diebolt, J. and Robert, C. P. (1994) : «Estimation of Finite Mixture Distributions
through Bayesian Sampling», Journal of the Royal Statistical Society, Ser. B, 56,
p.363-375.
[16] Dubin J. A and Mcfadden D. L. (1984) : «An Econometric Analysis of Residential
Electricity Appliance Holdings and Consumpton», Econometrica, 52(2), pp.345-
362.
[17] Dupuis, F., Durcoher, B., Montmarquette, C. and Robert, M. (2006) : «Le Defi
des Finances Publiques : Le Redressement de la Situation Fiscale du Quebec,
un Defi a la fois Prioritaire et Incontournable», CIRANO (Centre de Recherche
Interuniversitaire de Recherche en Analyse des Organisations).
[18] Fruhwirth-Shnatter, S. (1999) : «Model Likelihoods and Bayes Factors for Swit-
ching and Mixture Models», Preprint Vienna University of Economics and Business
Administration.
[19] Fruhwirth-Shnatter, S. (2001) : «MCMC of Estimation of Classical and Dyna-
mic Switching and Mixture Models», Journal of American Statistical Association,
Vol.96, p.194-209.
[20] Fruhwirth-Shnatter, S., Otter, T. and Tuchler, R. (2002) : «A Full Bayesian Ana-
lysis of Multivariate Latent Class Models with an Application to Metric Conjoint
Analysis», Adaptative Information and Modelling in Economics and Management
Science, Vienna University of Econimucs and Business Administration, Working
Paper No.89.
[21] Gelman A., Carlin J. B., Stern H. B. and Rubin D. B. (2000) : Bayesian Data
Analysis, New York, Chapman and Hill/CRC.
[22] Gelfand A. E. (2000) : «Gibbs Sampling», Journal of the American Statistical
Asssociation, Vol. 95, No. 452, p. 1300-1304.
[23] German, S. and German, D. (1984) : «Stochastic Relaxation, Gibbs Distribution
and the Bayesian Restoration if Images», IEEE Transactions on Pattern Analysis
and Michine Intelligence, 6, pp. 721-741.
[24] Gordon S. et Belanger, G. (2003) : «Echantillonnage de Gibbs et autres appli-
cations econometriques des chaınes markoviennes», Working Paper, Departement
d’Economique, Universite Laval.

Bibliographie 265
[25] Gourieroux C. and A. Monfort (1996) : Statistique et Modeles Econometriques, Vol.
1, Ed. Economica
[26] Gregoire, C. (2004) : L’imputation Multiple», These de Maıtrise, Uniervsite Laval.
[27] Hausman, J. A. and D. Wise (1979) : «Attrition Bias in Experimental and Panel
Data : the Gary Income Maintenance ExperimentZ, Econometrica, Vol.47, p.455-
473.
[28] Heckman, J. (1979) : «Sample Selection Bias as a Specification Error», Econome-
trica, 47 (1), pp. 153-161.
[29] Hsiao, C. (2001) : «Panel Data Models», Chapiter 16 in B. H. Baltagi, ed., A Com-
panion to Theorical Econometrics (Blackwell publishers, Massachusetts), p.349-
365.
[30] Hydro-Quebec (2005) : Comparaison des Prix de l’Electricite dans les Grandes
Villes Nord-Americaines
[31] Lee, C.-J. (2000) : «Dynamic Unobserved Effects for Continuous and Binary Pres-
ponse», Ph.D Thesis, Michigan State University.
[32] Lenk, P. J. and DeSarbo, W. S. (1999) : «Bayesian Inference for Finite Mixture of
Generalized Linear Models with Random Effects», Journal of Time Series Analy-
sis, Vol. 15, p.523-539.
[33] Liao Hue-Chu and Chang Tsai-Feng (2002) : «Space-heating and Water-heating
Energy Demands of the Aged in the US», Energy Economics 24 , 267-284
[34] Little R. J. A. and Rubin D. B. (2002) : Statistical Analaysis with Missing Data,
second ed.Wiley Series in Probability and statistics.
[35] McFadden, D. (1989) : «A Method of Simulated Moments for Estimation of Dis-
crete Response Models Without Numerical Integration», Econometrica, Vol. 57
(5), pp. 995-1026.
[36] Meng, X. L. and Wong, W. H. (1996) : «Simulating Ratios of Normalising
Constants via a Simple Identity», Statistica Sinica, Vol. 6, p.831-860.
[37] Moffit R. (1993) : «Identification and Estimation of dynamique Models with a Time
Series of Repeated Cross-Sections», Journal of Econometrics, Vol.59, pp99-123.
[38] Pakes, A. and D. Pollard (1989) : «Simulation and the Aymptotics of Optimization
Estimators», Econometrica, vl. 57 (5), pp 1027-1057.
[39] Paquet M-F. (2002) : «Une Approche a Simulation pour le Traitement de Donnees
Longitudinales Incompletes», These de Doctorat, Universite Laval.
[40] Paquet M. F. and Bolduc D. (2004) : «Le Probleme des Donnees Longitudinales
Incompletes : une nouvelle Approche», L’Actualite Economique, Vol. 80, 2/3, p.
341

Bibliographie 266
[41] Richarson, S. and Green, P. (1997) : «On Bayesian Analysis of Mixtures with
and Unknown Number of Components» (with discussion), Journal of the Royal
Statistical Society, Ser. B, p.731-792.
[42] Roeder, K. and Wasserman, L. (1997) : «Pratical Bayesian Density Estimatin using
Mixtures of Normals», Journal of the American Association, Vol.92, p.894-902.
[43] Rubin D. B. (1976) : «Inference and Missing Data», Biometrika, 63, pp.581-592.
[44] Rubin D. B. (1978) : «Multiple Imputations in Sample Surveys- a Phenomenologi-
cal Bayesian Approach to Nonresponse», The Proceedings of the Survey Research
Methods Section of The American Statistical Assciation, p. 20-34.
[45] Rubin D. B. (1986) : «Statistical Matching Using File Concatenation with Adjusted
Weight and Multiple Imputations», Journal of Business and Economic Statistics,
4, pp. 87-94.
[46] Rubin D. B. (1987) : Multiple Imputation for Nonresponse in Surveys, New York,
J. Wiley and Sons.
[47] Rubin D. B. (1996) : «Multiple Imputation after 18+ Years», Journal of the Ame-
rican Statistical Association, 91, pp. 473-489.
[48] Rubin D. B. and Schenker N. (1986) : «Multiple Imputation for Interval Estima-
tion from Simple Random with Ignorable Nonresponse», Journal of the American
Statistical Association,81, pp. 366-374.
[49] Schafer J. L. (1997) : Analysis of Incomplete Multivariate Data, New Yrok, Chap-
man and Hill.
[50] Schafer J. L. (2000) : «Analysis of Incomplete Multivariate Data», Monographs on
Statistics and Applied Probabilities 72. Chapman and Hall/CRC.
[51] Stephens, M. (1997) : «Bayesian Methods for Mixtures of Normal Distributions»,
Ph.D Thesis, University of Oxford.
[52] Tanner M. A. and Wong Wing Hung (1987) : «The Calculation of Posteriori Distri-
butions by Data Augmentation», Journal of the American Statistical Asssociation,
Vol. 82, No. 398, p. 528-540.
[53] Vekeman, F., D. Bolduc and Bernard, J-T. (2004) : Households’, «Vehicles Choices
and Use : What a More Disaggregated Approach Reveals ?», Working Paper,
GREEN, Departement d’Economique, Universite Laval.
[54] Vidal, V. (2006) : «Echantillonnage de Gibbs avec Augmentation de Donnees et
Imputation Multiple», These de Maıtrise, Universite Laval.
[55] Wooldridge, J. M. (2000) : «The Initial Conditions problem in Dynamic, Nonlinear
Panel Data Models with Unobserved Heterogeneity», Working Paper, Department
of Economics, Michigan State University

Bibliographie 267
[56] Wu, C. F. J. (1983) : «Generalized Linear Models with Random Effects : a Gibbs
Sampling Approach», Journal of the American Statistical Association, Vol. 86, pp.
79-86.

Chapitre 7
Conclusion
L’objectif principal poursuit dans cette these est de faire une analyse de la de-
mande d’electricite en exploitant des bases de donnees d’enquetes independantes obte-
nues aupres d’Hydro-Quebec. L’analyse de la demande d’electricite devrait tenir compte
de l’interdependance qui existe entre le choix des systemes de chauffage de l’eau et de
l’espace et le choix de la quantite d’electricite a consommer par le menage. Une approche
en deux etapes a ete utilisee pour estimer les parametres du modele de demande. Dans
une premiere etape le choix du mode de chauffage a ete estime par un modele logit mixte
avec erreurs autoregressives generalisees d’ordre un ou GAR(1) ; ce modele a permis de
prendre en compte la correlation entre les modalites. Les resultats de cette premiere
etape ont permis de calculer les correcteurs de biais de selection qui sont ensuite intro-
duits dans le modele de demande. Les parametres du modele de demande conditionnelle
sont ensuite estimes a la seconde etape. Etant donne qu’Hydro-Quebec utilise une tarifi-
cation par tranche, le prix marginal de l’electricite est une variable endogene, qui cause
un biais d’endogeneite dans le modele de demande. Pour corriger ce biais d’endogeneite,
nous avons developpe un modele a classes latentes. La structure tarifaire de l’electricite
ainsi que l’information disponible sur les menages creent deux classes de menages qui
ne sont pas directement observables. Dans les travaux anterieurs ayant porte sur les
modeles a classes latentes, la variable dependante du modele est habituellement une
variable discrete. Nous avons pu etendre le principe d’estimation des modeles a classes
latentes aux modeles avec variables dependantes continues. Les parametres du modele
latent sont egalement estimes, contrairement aux methodes existantes qui n’estiment
pas ces parametres mais plutot la valeur de la probabilite de choisir une classe donnee.
Le chapitre (3) a utilise la base de donnees de l’enquete de 1989 pour estimer la
demande d’electricite conditionnelle aux choix du mode de chauffage et de la classe
de consommation. Il est ressorti que le modele avec classes latentes est meilleur au

Chapitre 7. Conclusion 269
modele qui ne tient pas compte des classes. La premiere classe, celle ou la consommation
journaliere du menage ne depasse pas les 30kWh, serait composee de menages a faibles
revenus, donc beaucoup plus vulnerables. De plus, nous avons estime, a partir du modele
logit mixte avec erreurs GAR(1), des taux d’escompte individuels. Ces taux d’escompte
sont specifiques a chaque modalite. Les valeurs obtenues, contrairement a celles des
etudes anterieures, sont tres satisfaisants et la moyenne des taux est tres proche du
taux d’escompte sur le marche financier. La non prise en compte de l’heterogeneite
entre les individus pourrait justifier les valeurs enormes des taux d’escompte souvent
obtenues.
Dans les autres chapitres, nous avons cherche a prendre en compte la dynamique
dans les ajustements des menages, meme si nous n’avions que des donnees d’enquetes
independantes. Deux approches, classique et bayesienne, ont ete exploitees afin de pou-
voir corriger le probleme de manque de panel.
Nous avons exploite l’approche de Deaton qui consiste a creer des cohortes de menages
que l’on peut suivre dans le temps. Avec cette approche, la demande d’electricite est
desormais une demande agregee au niveau des cohortes. Avec le modele de demande
agregee, il n’a plus ete necessaire de prendre en compte le probleme de la simultaneite
entre choix discret et choix continu, puisque les cohortes sont des groupes de menages
ayant differentes modalites. La demande d’electricite d’une cohorte n’est donc pas une
demande conditionnelle a une modalite donnee. Il n’a pas ete non plus necessaire d’utili-
ser un modele a classes latentes, car toutes les cohortes se retrouvaient dans la deuxieme
classe. Avec le pseudo-panel cree, deux methodes d’estimation ont ete proposees : l’une
classique et l’autre bayesienne.
Au chapitre (4), nous avons pu estimer un modele statique et un modele dynamique
avec des effets fixes en utilisant les methodes classiques d’estimation. Nous avons cor-
rige simultanement le probleme d’heteroscedasticite groupee et de correlation serielle
en utilisant la methode des moindres carres quasi-generalises.
Generalement, lorsqu’on a des donnees groupees, il est logique de penser qu’il existe de
l’heterogeneite entre les groupes. Dans la litterature sur les pseudo-panels, il n’existe pas
de travaux ayant pris en compte explicitement l’heterogeneite, mis a part les modeles
a effets fixes qui ne s’interessent cependant pas aux parametres d’interet. Nous avons
propose d’utiliser l’algorithme de l’echantillonnage de Gibbs pour estimer un modele
statique et un modele dynamique avec des parametres heterogenes. L’heterogeneite est
consideree entre les neuf (9) regions administratives de la province de Quebec et les
resultats obtenus sont tres satisfaisants. Le comportement des cohortes change d’une
region a l’autre ; la hausse du prix de l’electricite par exemple n’aura pas les memes
consequences chez les cohortes vivant dans une zone urbaine que chez celles qui sont
dans une zone rurale. Les elasticites de court terme sont plus faibles que celles de long
terme, confirmant la seconde loi de la demande. Cette facon d’exploiter les pseudo-

Chapitre 7. Conclusion 270
panels est novatrice et serait tres utile dans les prises de decisions, puisqu’elle a permis
d’avoir des elasticites specifiques a chacune des neuf (9) regions de la province.
Nous avons aussi propose d’utiliser la methode par simulation pour obtenir un panel
simule afin de garder l’information au niveau des menages. Le chapitre (6) a exploite
cette approche bayesienne qui combine l’algorithme de l’augmentation des donnees avec
celui de l’echantillonnage de Gibbs pour completer les donnees manquantes tout en es-
timant les parametres du modele. Nous avons corrige a la fois le probleme de la simul-
taneite entre choix discret et choix continu, le probleme de l’endogeneite du prix margi-
nal et enfin le probleme de donnees manquantes. Nous avons estime a la fois un modele
statique et un modele dynamique dans un contexte de classes latentes. Les resultats
obtenus sont tres satisfaisants. Les effets marginaux des variables explicatives de la
premiere classe sont inferieurs a ceux des menages de la deuxieme classe. La premiere
classe est composee de menages a faibles revenus et donc beaucoup plus vulnerables
que les menages de la deuxieme classe. De plus, les changements de long terme ne sont
pas tres differents des changements de court terme dans le modele dynamique. Cela
est du a la situation particuliere de l’electricite dans la province. Nous recommandons
a Hydro-Quebec de tenir compte de l’existence et des caracteristiques de chacune des
classes de consommateurs dans ses politiques de tarification de l’electricite.
Certaines extensions pourraient etre apportees a ce travail, tant du cote du modele
de choix discret (ou choix du mode de chauffage) comme du cote du modele continu
qui est le modele de demande d’electricite. Par exemple, il serait interessant d’utiliser
un modele logit mixte avec heterogeneite aleatoire des parametres, en ce qui concerne
le modele de choix du mode de chauffage. Nous pouvons aussi envisager un modele
dynamique pour le modele de choix du mode de chauffage, en supposant que le menage,
a certaines periodes, change son systeme de chauffage. Cela necessiterait des donnees
sur toute la duree de vie des differents systemes.
En ce qui concerne le modele de demande d’electricite avec le panel simule, il serait
interessant de considerer la situation ou les termes d’erreur sont seriellement correles,
afin de voir si cela ameliore les resultats. Nous pourrions aussi envisager d’etendre le
modele a classes latentes aux vraies donnees de panel si celles-ci existent. Le modele a
classes latentes developpe dans cette these peut s’appliquer a tout autre domaine ou des
problemes similaires aux notres peuvent se poser : le domaine de l’energie en general,
l’economie du travail, l’economie de la sante, le marketing,... Les approches proposees
peuvent s’appliquer a des situations ou il existe de vraies donnees de panel, a des situa-
tions ou il existe des panels non balancees et a des situations avec donnees manquantes
(quelques observations sont manquantes, ou le cas extreme de coupes transversales
independantes comme le notre)

Chapitre 7. Conclusion 271
Il serait aussi interessant d’utiliser un critere bayesien de selection de modeles afin
de savoir si le modele a classes latentes est statistiquement meilleure au modele sans
classes dans un contexte de donnees manquantes, comme dans un contexte de vrais
panels. Nous avons utilise au chapitre (3) un test du ratio de vraisemblance dans le cas
d’une seule base de donnees. Il s’agit d’un test emboıte a la limite.
Par exemple, on pourrait aussi chercher a savoir si la structure tarifaire de l’electricite
est la structure socialement optimale. En d’autres termes, on pourrait chercher a savoir
si le prix marginal de l’electricite est vraiment le prix de marche ? Est-ce que le seuil des
30 kWh est le seuil socialement optimal ? Est-ce que la hausse du prix de l’electricite
devrait-elle se faire de facon uniforme peu importe la tranche de consommation ?
Les politiques de tarification de l’electricite devraient tenir compte d’une certaine
forme d’equite inter-generationnelle, surtout en matiere de protection de l’environne-
ment. Il ne faudrait pas non plus que les hausses de prix de l’electricite se fassent au
detriment de l’environnement. Car, si les menages venaient a changer leurs choix au
profit d’energies moins propres que l’electricite, cela pourrait se faire au detriment de
l’environnement (et augmenter les gaz a effets de serre). Des debats de societes doivent
etre faits, comme c’est le cas avec le projet Rabaska qui consiste a construire un termi-
nal de gaz naturel liquefie. Des choix dechirants et necessaires doivent etre faits, avec
l’appui de la societe civile, en matiere de sauvegarde de l’environnement, de meilleure
utilisation de l’electricite a son prix de marche, tout en assurant un developpement
economique durable de la province toute entiere.
Related Documents











