Algorithms for Mining Maximal Frequent Itemsets -- A Survey Chaojun Lu

Algorithms for Mining Maximal Frequent Itemsets -- A Survey Chaojun Lu.
Dec 16, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Algorithms for Mining Maximal Frequent Itemsets
-- A Survey
Chaojun Lu

Introduction Frequent Itemset Extension Tree Common Techniques Some MFI-Mining Algorithms Concluding Remarks

Introduction
• Terminology and Notations
• Problem
• Solution

Terminology and Notations
set of items: I = { i1, i2, …, in}set of transactions: DB = {T1,T2,…,Tm},Ti I(k-)itemset: N I ( |N| = k )support of itemset N: supp(N)frequent itemset (fi)maximal frequent itemset (mfi)set of all frequent (k-)itemsets: FI, FIk set of all mfi: MFI
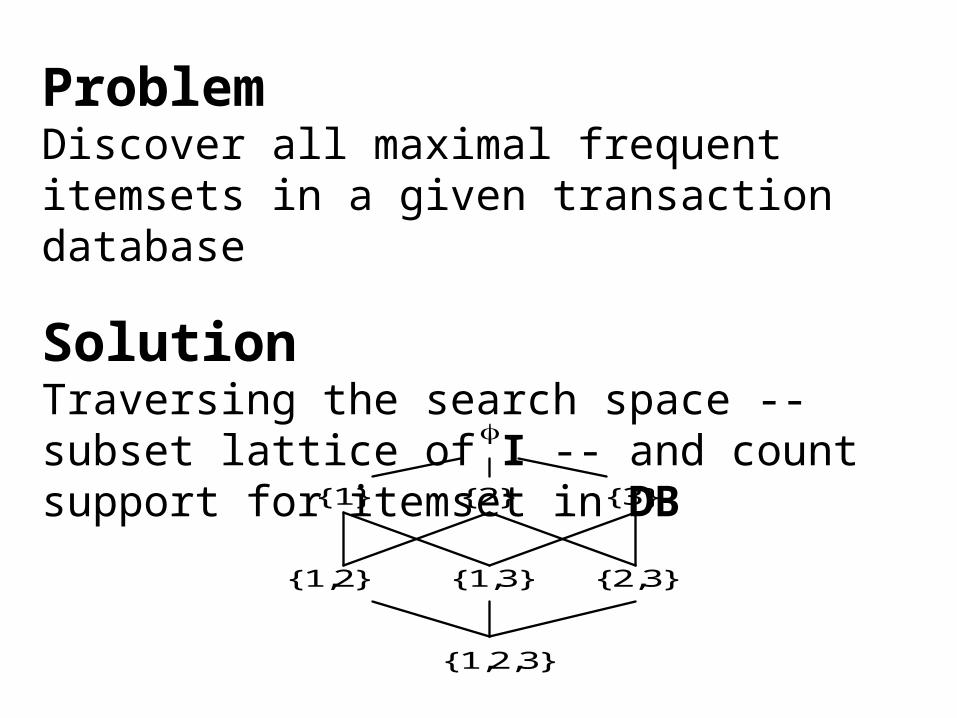
ProblemDiscover all maximal frequent itemsets in a given transaction database
SolutionTraversing the search space -- subset lattice of I -- and count support for itemset in DB
{1} {2} {3} {1,2} {1,3} {2,3} {1,2,3}

Solution(cont.)Traversing the search space by --• Brute-force: 2|I|
• Clever use of the Basic Property of itemsets: A B supp(A) supp(B) BP1: All subsets of a known frequent itemset are also frequent. BP2: All supersets of a known infrequent itemset are also infrequent.

Introduction Frequent Itemset Extension Tree Common Techniques Some MFI-Mining Algorithms Concluding Remarks

Frequent Itemset eXtension Tree
• Purpose
• Idea
• Description
• Problem Re-formulated

PurposeTo provide a general framework for analyzing and comparing existent MFI mining algorithms.
IdeaLarger frequent itemsets are generated by extending known smaller frequent itemsets with suitable items. FIXTree captures and illustrates this extension process.

Description of FIXTree• Root: • Nodes: frequent itemset Each node N is associated with its candidate extensions CX(N) and frequent extensions FX(N) defined as:CX(N) = {x | xI and N{x} may be frequent}FX(N) = {x | xCX(N) and N{x} is frequent}• Parent-Child PC: C is a frequent extension of P, i.e. C = P{x} for some xFX(P).

({1,2,3,4,5}/{1,2,3,4})
1 ({2,3,4}/{2,4}) 2 ({3,4}/{3,4})
12 ({4}/{4}) 14 (/)
124 (/)
23 ({4}/) 24 (/)
3… 4…
Example
Problem Re-formulatedGenerate as small a FIXTree containing MFI as possible while searching the subset lattice of I.

Introduction Frequent Itemset Extension Tree Common Techniques Some MFI-Mining Algorithms Concluding Remarks

Common Techniques
• Search Strategies
• Pruning Strategies
• Dynamic Reordering
• Data Representation for Fast Support Counting
• Frequency Determination

Search StrategiesWe can generate the FIXTree via:• Breadth-first• Depth-first • Hybrid
For MFI-mining, it’s unnecessary to generate and count all nodes. Instead, we try to generate as fewer nodes of the FIXTree as possible, so long as MFI can be identified.

Pruning StrategiesBasicPS1: Prune node N’s infrequent extension subtree.
1 ({2,3,4}/{2,4})
12 ({4}/{4}) 14 (/)13
Note: This strategy greatly improves a PURE DFS algorithm for mining long patterns.

Pruning Strategies(cont.)BasicPS2: Node N’s CX(N) comes from its parent-node P’s FX(P). Let N=P{x}, xFX(P), then CX(N) = {y | yFX(P) and y > x}
1 ({2,3,4}/{2,4})
12 ({4}/…) 14 (/…)
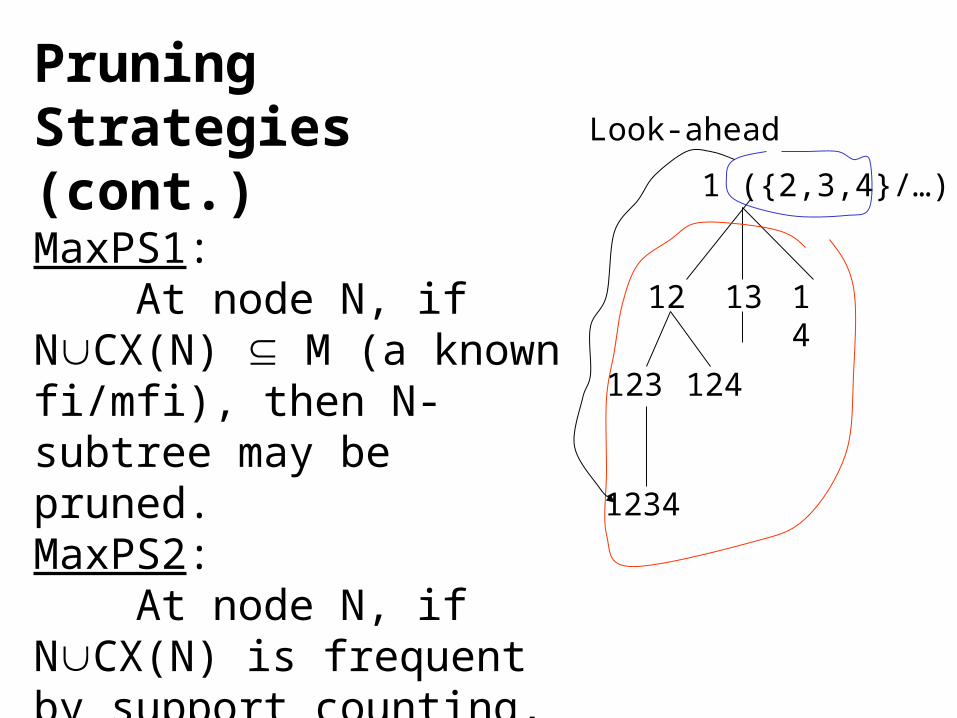
Pruning Strategies (cont.)MaxPS1: At node N, if NCX(N) M (a known fi/mfi), then N-subtree may be pruned.MaxPS2: At node N, if NCX(N) is frequent by support counting, then all N’s children may be pruned ( and a possible new mfi is produced).
1 ({2,3,4}/…)
12 14 13
123 124
1234
Look-ahead

Pruning Strategies(cont.)MaxPS3: At node N, NCX(N) is frequent, then all N’s right-hand-side siblings may be pruned. (Those branches won’t produce new mfi.)
({1,2,3,4,5}/{1,2,3,4})
2 ({3,4}/…) 3… 4…1…

Pruning Strategies(cont.)DFMaxPS: In DFS, AFTER the recursive call DFS(Ni), check if the leftmost path N{i,…,n}is frequent. If yes, then Ni’s right-hand-side siblings may be pruned. (These won’t produce new mfi.)
N(…/{1,2,…n})
Ni ({i+1,…,n}) N(i+1) NnN1 …

Pruning Strategies(cont.)EquivPS: At node N, if for some xCX(N), supp(N{x}) = supp(N), then N can be replaced by N{x}, with CX(N{x}) = CX(N)-{x}
N ({x,y,z}/…)
Ny… Nz…Nx…
Nx ({y,z}/…)
Nxy… Nxz…
Nxy… Nxz…Itemsets containing N but not x cannot be mfi

Dynamic Reordering• The item order in which to extend itemsets greatly affects MFI mining algorithms• Two heuristics:DR1 At node N, reorder all xFX(N) in supp(Nx) increasing order.
1 {2,3,4}
12 {4,3}
123124{3}
1243
13{4}
134
14

Dynamic Reordering(cont.)
DR2 Reorder items of FX() (i.e. FI1) in decreasing order of IF(x) with xFI1, where
IF(x) = {y | yFI1 and xy is infrequent}.
Notes:1. |M(x)| |FI1|-|IF(x)| where M(x) is the size of
the longest mfi containing x2. DR2 + DR1 for FI1.3. Compute FI1 and FI2 before use of DR2.

Data Representation• Data representation transaction set of items bitstring tid-list for each item(set) FP-tree vertical bitmap for each item(set) diffset• Count support on the entire DB or sub-DB?• Counting techniques

Frequency DeterminationWe can determine a frequent itemset N via:• Direct counting supp(N) in DB• A known frequent superset of N• Lower Bound of supp(N) exceeding minsup

Lower Bound Technique• Obtain a lower-bound on supp(N) based on support information of N’s subsets.
supp(N{x}) = supp(N)-drop(N,x) supp(N)-drop(M,x) where MN.supp(NX) supp(N)-drop(M,x) where MN.

Lower Bound Technique(cont.)• LB-PSWe already have supp(N),supp(N1),supp(N2),supp(N3), so we can computeSupp(N123) = supp(N)-drop(N,1)-drop(N,2)-drop(N,3) and check if it is minsup?If yes, then prune N2 and N3 branches. (cf. MaxPS3)
N2 ({3}/…) N3N1 ({2,3}/…)
N (…/{1,2,3})

Introduction Frequent Itemset Extension Tree Common Techniques Some MFI-Mining Algorithms Concluding Remarks

Some MFI-Mining Algorithms
• Apriori
• Pincer- Search
• FP-growth
• Max-Miner
• DepthProject
• MAFIA
• GenMax

Apriori
Breadth-first
Key steps:
Given FIk
Generate Ck+1
Join (Extending FIk using BasicPS2)
Prune (BP2)
Support Counting Ck+1 to obtain FIk+1

Apriori(cont.)Symmetry of FI-mining problem
FIk
Count Ck+1
FIk+1IFk+1
Count Ck
IFk
{1,2,…,n}
extension
reduction
Extension-based vs Reduction-basedFrequent vs Infrequent

Pincer-Search
Hybrid Search (Top-down + Bottom-up)
Key steps: initially CMFI={I}
Given FIk-1, Ck , CMFI and MFI
Count Ck CMFI to obtain FIk , IFIk and new MFI
Use MFI to prune FIk (BP1, MaxPS)
Use IFIk to update CMFI
Generate Ck+1
Join (Extending FIk using BasicPS2)
Recover missing candidates
Prune (BP2)
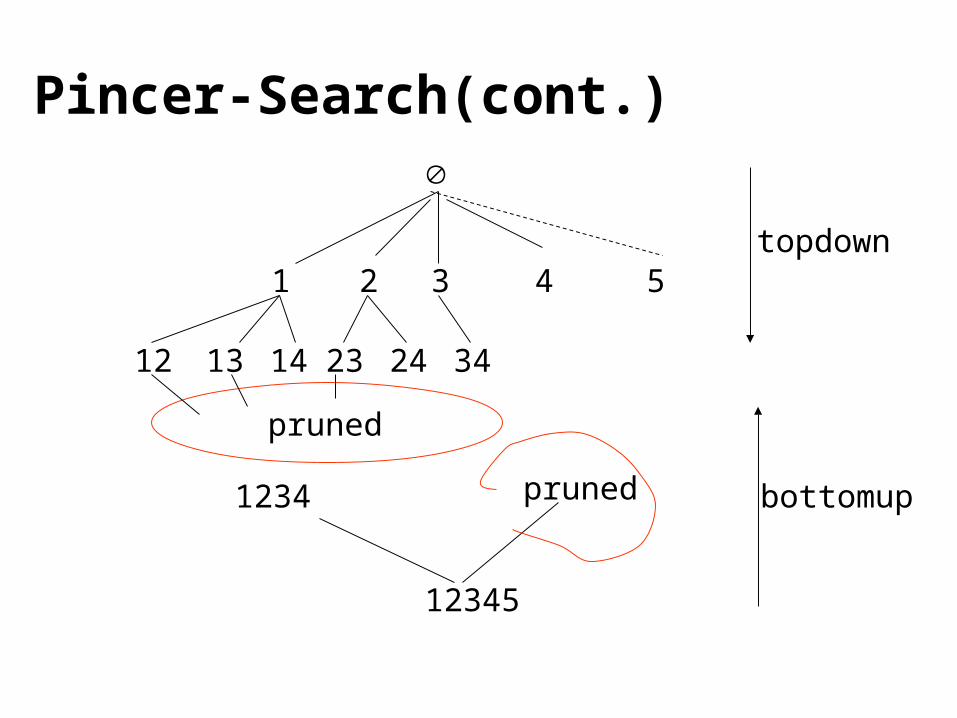
Pincer-Search(cont.)
21 3 4 5
12345
1234 pruned
12 13 14 23 24 34
pruned
bottomup
topdown

FP-Growth
FP-tree: a compact form of DB/sub-DB
Key steps: FP-growth(N,N-tree)
if N-tree is a single path N{x,y,z}
then a possible mfi is found Nx Ny Nz
else { extend N with xFX(N)
construct Nx-tree
FP-growth(N{x},Nx-tree)}
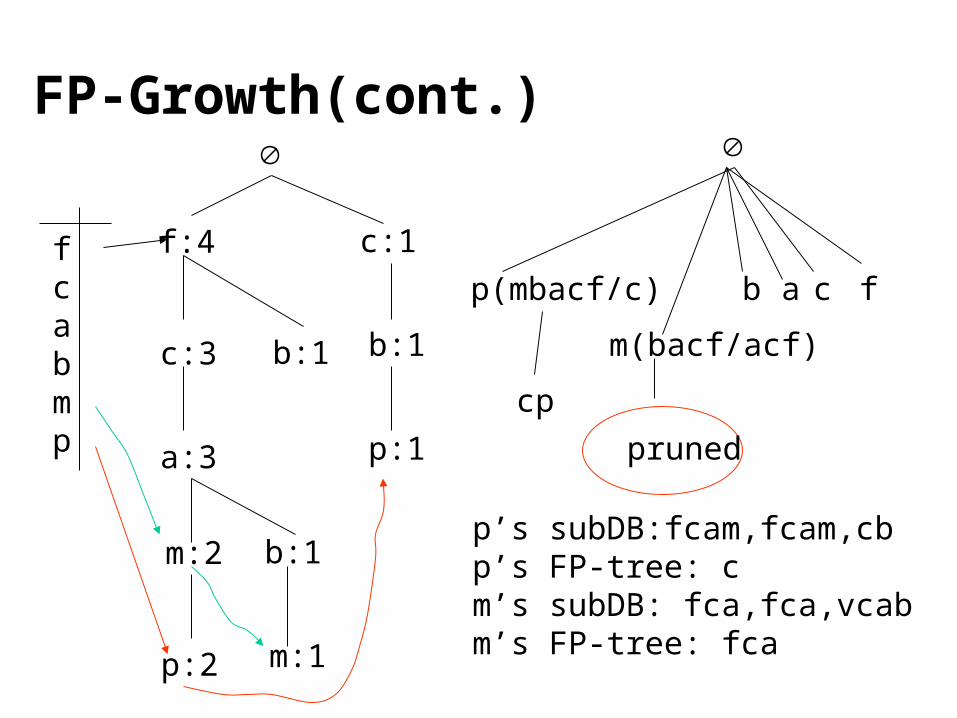
FP-Growth(cont.)
fcabmp
f:4
c:3
a:3
m:2
p:2
b:1
m:1
b:1
c:1
b:1
p:1
p(mbacf/c)
m(bacf/acf)
b a c f
cp
pruned
p’s subDB:fcam,fcam,cbp’s FP-tree: cm’s subDB: fca,fca,vcabm’s FP-tree: fca

FP-Growth(cont.)
Depth-first
MaxPS (if used for MFI-mining)
Dynamic Reordering
Projected subDB
Without Candidate Generation?
Construct subDB for N CX(N)
Single path MaxPS
Mining frequent 1-itemset in subDB FX(N)

MaxMiner
Breadth-first + Pruning
Key Steps: At node N with CX(N)
Count NCX(N), N{x} for xCX(N) to get FX(N)
If NCX(N) is frequent, prune using MaxPS2
Reorder FX(N) using DR1
Generate N’s children N{x} for xFX(N)
with CX(N{x})={y | yFX(N) and y > x}
MaxPS3 + LB-PS

DepthProject
Depth-first + Pruning
Key Steps: At node N with CX(N), call DP(N,DB)
Count N{x} in DB to obtain FX(N)
Prune using DFMaxPS, MaxPS1
Project DB to obtain subDB (if necessary)
Reorder FX(N) using DR1
For each xFX(N):
DP(N{x}, subDB)
Output: a superset of MFI
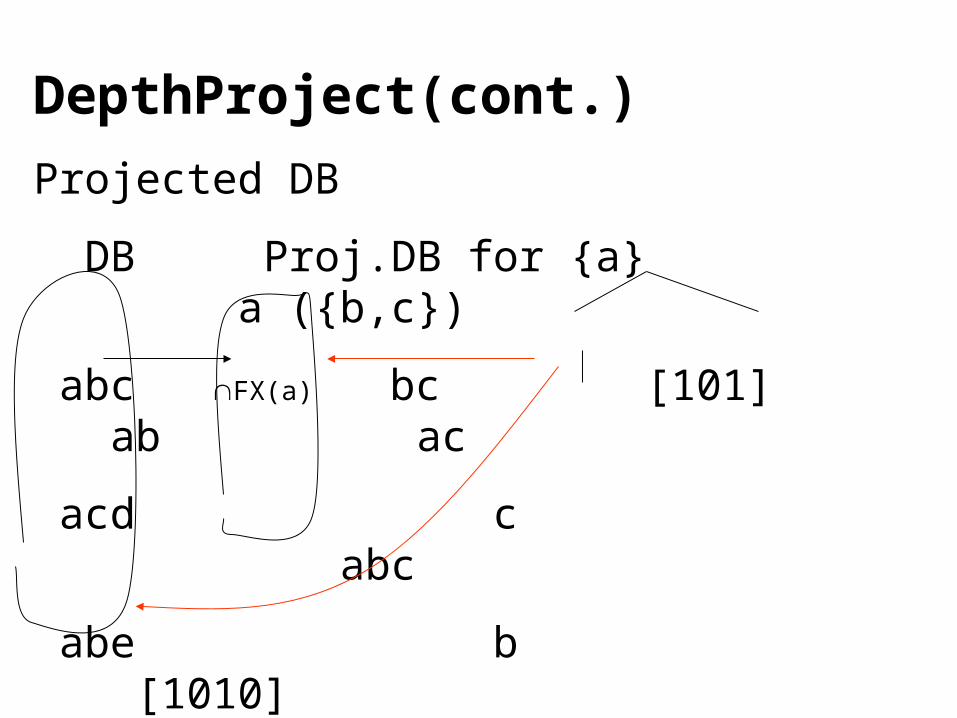
DepthProject(cont.)
Projected DB
DB Proj.DB for {a} a ({b,c})
abc FX(a) bc [101] ab ac
acd c abc
abe b [1010]
bd

DepthProject(cont.)
Project DB for some nodes on a path
Bitstring representation
Byte Counting
Bucket Counting

MAFIA
Depth-first + Pruning
Key Steps: At node N, call MAFIA(N, MFI)
If NCX(N) MFI then prune using MaxPS1
Count N{x} obtain FX(N) using EquivPS
Reorder FX(N) using DR1
For each xFX(N)
MAFIA(N{x}, MFI)
If on leftmost path, prune using DFMaxPS

MAFIA(cont.)
Data Representation
Vertical bitmap and byte counting
Bitmap of item(set) N - bmp(N)
Tran. j 0/1
N
N {x}
t(N {x}) = t(N)t(x) bmp(N) AND bmp(x)
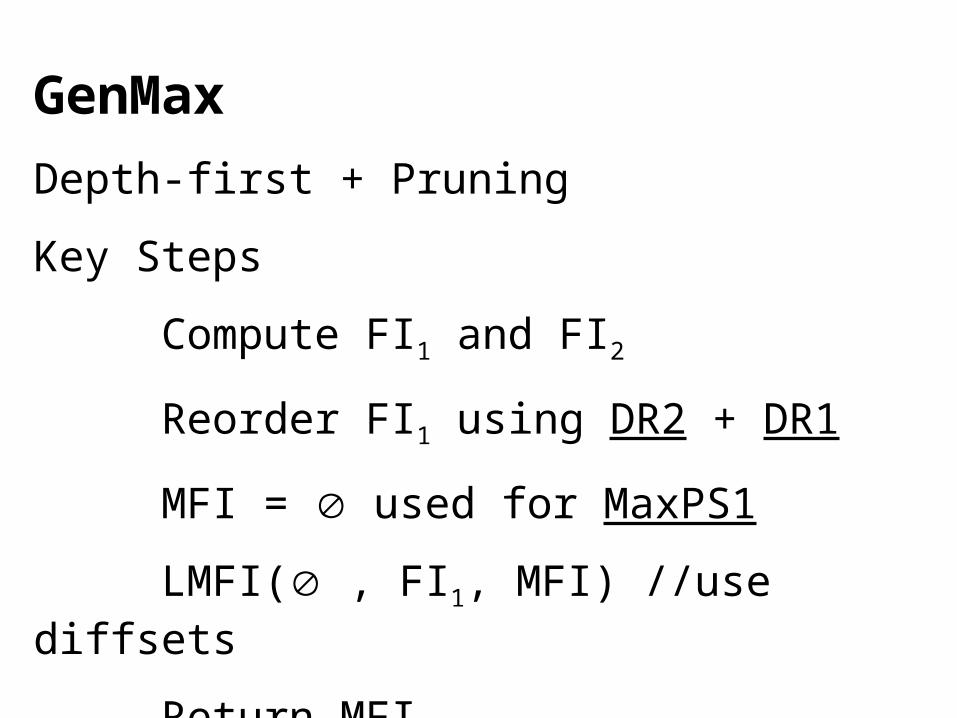
GenMax
Depth-first + Pruning
Key Steps
Compute FI1 and FI2
Reorder FI1 using DR2 + DR1
MFI = used for MaxPS1
LMFI( , FI1, MFI) //use diffsets
Return MFI

GenMax(cont.)
MFI-subset check: progressive focusing
LMFI(N,FX(N),LMFI)
For each xFX(N)
Generate N{x}with CX(N)
If NxCX(Nx) LMFI // MaxPS1
then return
Count CX(Nx) to obtain FX(Nx)
update LMFI to obtain newLMFI
LMFI(Nx, FX(Nx), newLMFI)

GenMax(cont.)
MFI-subset check optimization: check for local MFI
DR2
Data Representation: diffsets

Introduction Frequent Itemset Extension Tree Common Techniques Some MFI-Mining Algorithms Concluding Remarks

Concluding Remarks
• Independent components can fit together nicely• Search strategy: hybrid• Pruning strategy and dynamic reordering• Data projection, bitmap representation, fast
counting, compression• Different algorithms perform well under different
MFI distributions• MAFIA and GenMax: current state-of-the-art

References
R. C. Agarwal, et al. Depth first generation of long patterns.
R. J. Bayardo. Efficiently mining long patterns from databases.
D. Burdick, et al. MAFIA: a maximal frequent itemset algorithm for transactional databases.
K. Gouda, et al. Efficiently mining maximal frequent itemsets.
J. Han, et al. Mining frequent patterns without candidate generation.
D-I Lin, et al. Pincer-search: an efficient algorithm for discovering the maximum frequent set.

Thank You!
Related Documents











![EFFICIENT MAXIMAL FREQUENT ITEMSET MINING BY PATTERN … · , bcd are frequent itemsets as well. An itemset S is called a maximal frequent itemset or an MFI for short [25] if S is](https://static.cupdf.com/doc/110x72/5f1ac55f4927fa37d33484ac/efficient-maximal-frequent-itemset-mining-by-pattern-bcd-are-frequent-itemsets.jpg)