S EMINARARBEIT Advances in Financial Machine Learning ausgef¨ uhrt am Institut f¨ ur Finanz- und Versicherungsmathematik TU Wien unter der Anleitung von Assist. Prof. Dipl.-Ing. Dr.techn. Stefan Gerhold durch Philipp Ladislaus Wilhelm Knoll Matrikelnummer: 01617936 Wien, am 24.02.2019

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

S E M I N A R A R B E I T
Advances inFinancial Machine Learning
ausgefuhrt am
Institut fur
Finanz- und Versicherungsmathematik
TU Wien
unter der Anleitung von
Assist. Prof. Dipl.-Ing. Dr.techn. Stefan Gerhold
durch
Philipp Ladislaus Wilhelm Knoll
Matrikelnummer: 01617936
Wien, am 24.02.2019

Inhaltsverzeichnis
1 Einleitung 1
2 Machine Learning Allgemein 22.1 Uberwachtes Lernen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2.1.1 Klassifikationsprobleme . . . . . . . . . . . . . . . . . . . . . . . . . 22.1.2 Regressionsprobleme . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Unuberwachtes Lernen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.2.1 Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2.2 Dimensionsreduzierung . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.3 Algorithmen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.3.1 Aufbau von ML-Systemen . . . . . . . . . . . . . . . . . . . . . . . . 42.3.2 Perceptron . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.3.3 ADALINE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3.4 Entscheidungsbaume . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3 Financial Data 93.1 Arten von Finanzdaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.1.1 Fundamentale Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.1.2 Marktdaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.1.3 Analysen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.1.4 Alternative Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3.2 Bars . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.2.1 Standard-Bars . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103.2.2 Information-Driven Bars . . . . . . . . . . . . . . . . . . . . . . . . . 12
4 Data Labels 134.1 Fixed-Time-Horizon Methode . . . . . . . . . . . . . . . . . . . . . . . . . . 134.2 Three-Barrier-Methode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144.3 Meta-Labeling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
5 Ensemble Methoden 155.1 Verzerrung-Varianz-Dilemma . . . . . . . . . . . . . . . . . . . . . . . . . . 155.2 Bootstrap Aggregation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 165.3 Random Forest . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175.4 Boosting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
6 Cross-Validation 196.1 k-fold Cross-Validation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
i

Inhaltsverzeichnis
6.2 Cross-Validation fur Financial ML . . . . . . . . . . . . . . . . . . . . . . . 196.2.1 Bereinigte CV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
7 Hyperparameter Tuning 227.1 Gridsearch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 227.2 Random Search . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Abbildungsverzeichnis 24
Literaturverzeichnis 24
ii

1 Einleitung
Machine Learning (ML) ist aus unserer heutigen Welt kaum mehr wegzudenken, und findetauf verschiedene Arten Anwendung, die uns oft gar nicht bewusst sind. Auch in der Finan-zwelt kommt Machine Learning immer mehr zum Einsatz und erfullt dabei immer mehrFunktionen, die einst nur wenige, erfahrene Menschen erfullen konnten. Financial MachineLearning besitzt jedoch Tucken und Probleme, weswegen gelegentlich fur Financial MLspezifische Methoden und Tricks angewandt werden mussen, anstatt einfach ubliche Algo-rithmen zu benutzen.
Kapitel 2 dieser Arbeit widmet sich ML im Allgemeinen, die verschiedenen Arten vonProblemstellungen und der generelle Aufbau von ML Systemen werden behandelt, bevorim letzten Abschnitt einige simple Algorithmen ausfuhrlich erklart werden. In Kapitel 3werden die verschiedenen Arten von Finanzdaten, die fur Financial ML verwendet werden,und wie diese aufbereitet und strukturiert werden konnen, diskutiert. Kapitel 4 erklartVorgehensweisen, wie die fur Klassifikationsprobleme benotigten Labels bei Finanzdatenerstellt werden konnen. Kapitel 5, 6 und 7 widmen sich Themen, die fur alle Anwendungenvon ML von großer Bedeutung sind, jedoch werden auch deren Besonderheiten im finanz-mathematischen Kontext behandelt.
Grundlage dieser Seminararbeit ist das Buch Advances in Financial Machine Learningvon Marcos Lopez de Prado [2], wahrend sich Kapitel 2 hauptsachlich auf Python MachineLearning von Sebastian Raschka [3] bezieht.
1

2 Machine Learning Allgemein
Bevor wir uns den Besonderheiten des Financial Machine-Learnings widmen, sollten wirMachine-Learning (im folgenden mit ML abgekurzt) im Allgemeinen diskutieren. In die-sem Kapitel werden wir also zugrundeliegende Definitionen, Methoden und Algorithmeneinfuhren, und so den Grundstock fur die folgenden Kapitel legen.Das Grundziel von Machine-Learning ist es, anhand einer großen Menge von Daten Vorher-sagen zu erstellen, und zwar nicht, indem die Daten von Menschen auf Muster untersuchtwerden, und ”per Hand” Regeln festgelegt werden, sondern durch den Computer selbst. DieAnwendungen von ML sind zahlreich, und haben besonders in den letzten Jahren massivan Bedeutung erlangt. Stimmerkennung, Spamfilter, Schachcomputer und Suchmaschinenverwenden ML, es ist also aus unserem heutigen Leben kaum mehr wegzudenken. Im Allge-meinen kann man zwischen zwei Arten von ML unterscheiden, welchen wir uns nun widmenwollen.
2.1 Uberwachtes Lernen
Hierbei ist es das Ziel, anhand von bereits gelabelter Trainingsdaten ein Modell zu erstellen,oder zu ”lernen”, mit dem Vorhersagen uber noch unbekannte Daten gemacht werdenkonnen. Der Ausdruck ”uberwacht” bezieht sich darauf, dass die Trainingsdaten vorabmit Labeln versehen werden mussen. Diese Art des ML lasst sich weiter unterteilen inKlassifikations- und Regressionsprobleme.
2.1.1 Klassifikationsprobleme
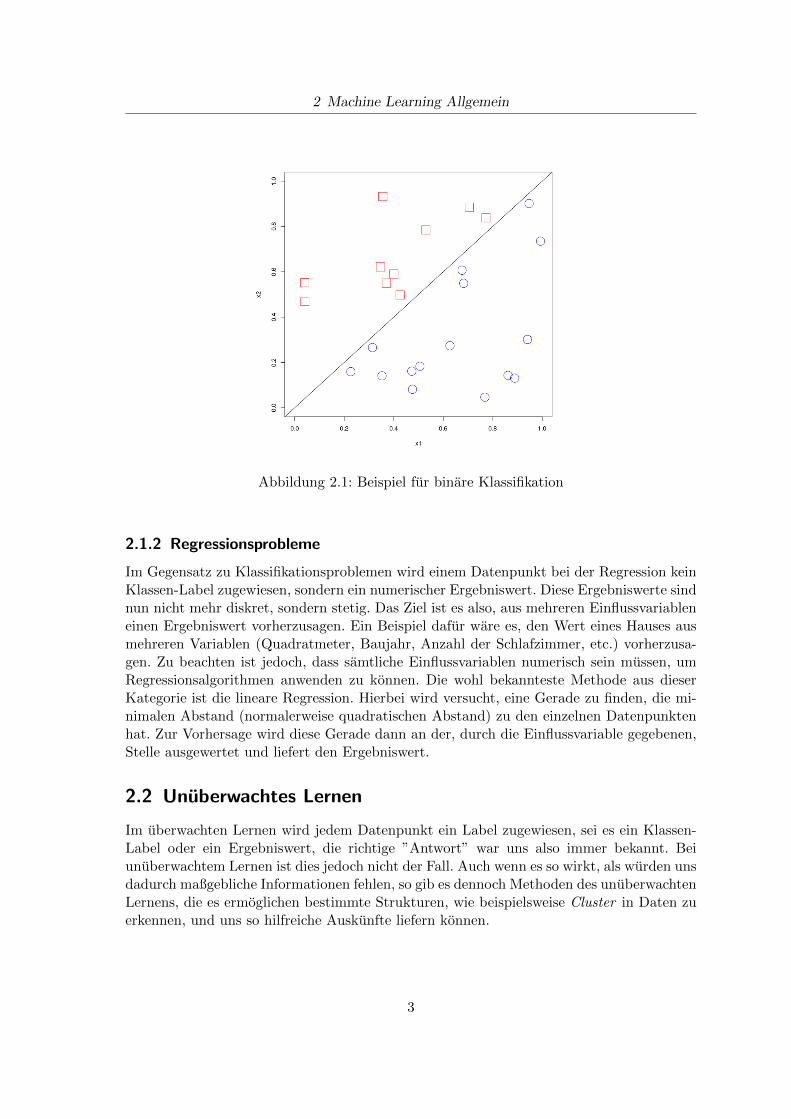
Bei Klassifikationsproblemen soll dem unbekannten Datensatz ein Klassenlabel zugewiesenwerden. Diese Klassenlabel sind ungeordnete, diskrete Werte, die die Zugehorigkeit zu ei-ner Klasse symbolisieren. Ein gutes Beispiel hierfur sind binare Klassifikationsprobleme,bei welchen nur zwei Klassenlabel moglich sind, oft durch 0 und 1 dargestellt. In dieseKlasse fallen beispielsweise Spamfilter, die erkennen sollen ob es sich bei einer Email umSpam (0) oder eine herkommliche Nachricht (1) handelt. Im Kontext der Finanzmathe-matik konnte ein Algorithmus beispielsweise vorhersagen, ob man zu einem bestimmtenZeitpunkt mit einer gewissen Aktie handeln soll und ob man dabei eine Long- oder Short-Position einnehmen soll. Abbildung 2.1 soll als Beispiel fur eine binare Klassifikation dienen.Die eingezeichneten Datenpunkte konnen als bereits mit Labeln versehene Trainingsdatenverstanden werden und die schwarze Linie als die vom Algorithmus bestimmte Entschei-dungsgrenze, also eine Hyperebene die die zwei Klassen teilt und neuen Datenpunkten, jenachdem auf welcher Seite der Entscheidungsgrenze sie liegen, ein Label zuordnet.
2
2 Machine Learning Allgemein
Abbildung 2.1: Beispiel fur binare Klassifikation
2.1.2 Regressionsprobleme
Im Gegensatz zu Klassifikationsproblemen wird einem Datenpunkt bei der Regression keinKlassen-Label zugewiesen, sondern ein numerischer Ergebniswert. Diese Ergebniswerte sindnun nicht mehr diskret, sondern stetig. Das Ziel ist es also, aus mehreren Einflussvariableneinen Ergebniswert vorherzusagen. Ein Beispiel dafur ware es, den Wert eines Hauses ausmehreren Variablen (Quadratmeter, Baujahr, Anzahl der Schlafzimmer, etc.) vorherzusa-gen. Zu beachten ist jedoch, dass samtliche Einflussvariablen numerisch sein mussen, umRegressionsalgorithmen anwenden zu konnen. Die wohl bekannteste Methode aus dieserKategorie ist die lineare Regression. Hierbei wird versucht, eine Gerade zu finden, die mi-nimalen Abstand (normalerweise quadratischen Abstand) zu den einzelnen Datenpunktenhat. Zur Vorhersage wird diese Gerade dann an der, durch die Einflussvariable gegebenen,Stelle ausgewertet und liefert den Ergebniswert.
2.2 Unuberwachtes Lernen
Im uberwachten Lernen wird jedem Datenpunkt ein Label zugewiesen, sei es ein Klassen-Label oder ein Ergebniswert, die richtige ”Antwort” war uns also immer bekannt. Beiunuberwachtem Lernen ist dies jedoch nicht der Fall. Auch wenn es so wirkt, als wurden unsdadurch maßgebliche Informationen fehlen, so gib es dennoch Methoden des unuberwachtenLernens, die es ermoglichen bestimmte Strukturen, wie beispielsweise Cluster in Daten zuerkennen, und uns so hilfreiche Auskunfte liefern konnen.
3

2 Machine Learning Allgemein
2.2.1 Clustering
Mit Hilfe dieser Methode konnen ungelabelte Daten in verschiedene Gruppen eingeteiltwerden. Dabei werden in einem Cluster jene Datenpunkte zusammengefasst, die sich un-tereinander ahnlicher sind, als den Restlichen. Aufgrund der Einteilung in ”Klassen” wirddiese Mehtode oft als unuberwachte Klassifikation bezeichnet. Clustering ermoglicht es,Daten besser zu Strukturieren und Zusammenhange in einem Datensatz zu finden.
2.2.2 Dimensionsreduzierung
In vielen Fallen besitzen unsere Datenpunkte eine hohe Dimension, zu jeder Beobachtungstehen uns also viele gemessene/beobachtete Werte zur Verfugung. Je hoher jedoch die-se Dimension ist, desto mehr Speicherplatz, und noch viel wichtiger, Rechenleistung wirdbenotigt. Bei der Dimensionsreduzierung wird versucht, die Datenpunkte in einen Raumgeringerer Dimension uberzufuhren und damit optimierter arbeiten zu konnen. Diese Me-thode findet daher besonders im Preprocessing Anwendung.
2.3 Algorithmen
Im folgenden werden einige einfache Algorithmen naher vorgestellt. Hierbei handelt es sichum Klassifikationsalgorithmen, da diese fur finanzmathematische Anwendungen, wie siein folgenden Kapiteln behandelt werden, von großer Relevanz sind. Zuerst werden wir je-doch den Aufbau von ML-Systemen naher untersuchen und die notwendige mathematischeNotation behandeln.
2.3.1 Aufbau von ML-Systemen
Die einzelnen Schritte eines ML-Systems lassen sich wie folgt zusammenfassen:
• Preprocessing
• Training
• Evaluierung
• Vorhersage
Im Preprocessing werden die rohen Daten aufbereitet und strukturiert, um sie uberhauptfur den ML-Algorithmus verwendbar zu machen. Wie genau dies zu geschehen hat, hangtnaturlich von dem rohen Datensatz, aber auch von dem verwendeten Algorithmus ab, dennum optimale Ergebnisse zu erzielen, erfordern manche Methoden Mittelwert-bereinigteund/oder standardisierte Datenpunkte. In manchen Fallen empfiehlt sich an dieser Stelleauch die in 2.2.2 kurz diskutierte Dimensionsreduzierung.Wahrend dem Training lernt der Algorithmus aus den Trainingsdaten, um spater mit Hilfedieser erlernten Informationen Vorhersagen uber noch fremde Daten zu tatigen. Der ge-naue Lernprozess hangt von dem gewahlten Algorithmus ab, wobei dessen Wahl wiederumabhangig von der Problemstellung ist, denn je nach Aufgabe schneiden manche Methoden
4

2 Machine Learning Allgemein
besser ab als andere, wahrend wieder einige uberhaupt nicht sinnvoll anwendbar sind (wiezum Beispiel Regressionsalgorithmen fur Klassifikationsprobleme).Bei der Evaluierung wird nun die Performance des Modells auf Testdaten untersucht. Diesesind ebenfalls wie Trainingsdaten gelabelt, wurden jedoch nicht zum Training verwendet,in der Praxis teilt man die verfugbaren Daten einfach zufallig in Trainings- und Testdaten(oft 75% und 25% respektive).Ist die Evaluierung zufriedenstellend, so kann das Modell nun verwendet werden, um Vor-hersagen aus neuen Daten zu erstellen.
2.3.2 Perceptron
Einer der einfachsten ML-Algorithmen ist das sogenannte Perceptron, welches zu denbinaren Klassifikationsalgorithmen zahlt. Bei dieser Methode wird eine Linearkombina-tionen aus den Input-werten und bestimmten Gewichten gebildet. Sollte diese Linearkom-bination einen gewissen Schwellenwert uberschreitet, wird der Datenpunkt zur Klasse 1gezahlt, sollte sie jedoch den Schwellenwert nicht uberschreiten zur Klasse −1. Um diesnun auch mathematisch zu beschreiben, wollen wir die benotigte Notation einfuhren. DerVektor x := (x1, ..., xn)T bezeichne die Input-werte und der Vektor w := (w1, ..., wn)T dieGewichte der Linearkombination, welche mit z := wTx notiert wird. Außerdem benotigenwir eine Aktivierungsfunktion φ(z), welche durch
φ(z) :=
{1 falls z ≥ θ−1 sonst
definiert ist, wobei θ den Schwellenwert der Aktivierung bezeichnet.Anstatt die Sprungfunktion φ(z) von Parameter θ abhangig zu machen, wollen wir statt-dessen x und w um die Komponenten x0 = 1 und w0 = −θ erweitern, wobei φ(z) dement-sprechend zu
φ(z) :=
{1 falls z ≥ 0
−1 sonst
umgeandert werden muss. Die Aquivalenz dieser beiden Definitionen ist klar ersichtlich.Nun haben wir erklart, wie ein bereits trainiertes Perceptron Vorhersagen trifft, jedochnicht, wie genau das Training erfolgt. Dies lasst sich einfach zusammenfassen:
1. Gewichtsvektor w initialisieren.
2. Fur jedes Trainingssample folgende Schritte ausfuhren:
• Output y berechnen.
• Gewichtsvektor aktualisieren.
Der Output eines Trainingssamples wird, wie vorher beschrieben, durch
y = φ(wTx)
5

2 Machine Learning Allgemein
berechnet, wahrend fur die Aktualisierung der Gewichte einfach ein Vektor ∆w addiertwird:
wneu = walt + ∆w
Die Eintrage ∆wi des Aktualisierungsvektors ∆w werden wie folgt berechnet:
∆wi := η(y − y)xi
Hierbei bezeichnet y das wahre Label des Samples x und η die sogenannte Lernrate, eineKonstante aus (0, 1). Perceptronen sind zwar relativ simple ML-Modelle, jedoch konvergie-ren sie nur falls die Lernrate klein genug ist und die Trainingsdaten linear trennbar sind,also eine Hyperebene existiert, sodass alle Samples aus Klasse 1 auf einer Seite liegen undalle aus Klasse −1 auf der anderen. Falls lineare Trennbarkeit nicht gegeben ist, konnenjedoch Endbedingung wie eine Maximalanzahl an Durchlaufen uber die Trainingsdatenfestgelegt werden.
2.3.3 ADALINE
Eine Art Weiterentwicklung des Perceptrons ist das sogenannte ADAptive LInear NEuron(ADALINE). Besonders interessant ist diese Methode, da an ihr einfach ein Grundverfahrendes Machine-Learnings, namlich Minimierung einer Cost-Function durch das Gradienten-verfahren, illustriert werden kann. Der große Unterschied zwischen ADALINE und Percep-tron ist, dass bei ersterem die Gewichte nicht mithilfe einer Sprungfunktion aktualisiertwerden, sondern einer linearen Funktion. In diesem Fall wird dies die Identitat φ(z) := zsein. Die Klassenlabel konnen dann durch einen Quantisierer bestimmt werden. Außerdemwird eine Cost-Function eingefuhrt, welche minimiert werden soll. Ublicherweise wird furdiese Funktion die Summe der quadratischen Fehler verwendet, also:
J(w) :=1
2
∑i
(y(i) − φ(z(i)))2
wobei y(i) das Label des i-ten Samples x(i) bezeichnet und z(i) das Skalarprodukt wTx(i).Dadurch, dass die Aktivierungsfunktion φ(z) nun stetig ist, ist unsere Cost-Function dif-ferenzierbar und außerdem konvex. Dadurch konnen wir nun das Gradientenverfahren an-wenden, um J(w) zu minimieren. Der Faktor 1
2 sorgt hierbei nur fur schonere partielleAbleitungen bei der spateren Berechnung des Gradienten. Hierbei wird der Aktualisie-rungsvektor durch einen Schritt in entgegengesetzte Richtung des Gradienten von J(w)bestimmt:
∆w := −η∇J(w)
Fur die partielle Ableitungen der Cost-Function gilt:
∂J
∂wj= −
∑i
(y(i) − φ(z(i)))x(i)j
6

2 Machine Learning Allgemein
Daher folgt fur den Aktualisierungsvektor:
∆wj = η∑i
(y(i) − φ(z(i)))x(i)j
Da die Berechnung uber die gesamten Trainingsdaten bei großen Datenmengen sehr auf-wendig wird, empfiehlt sich in diesem Fall das sogenannte iterative Gradientenverfahren.Hierbei wird der Gewichtsvektor nicht mit der Summe der quadratischen Fehler, sondernmit dem Fehler jedes einzelnen Samples iterativ aktualisiert:
∆w = η(y(i) − φ(z(i)))x(i)j
2.3.4 Entscheidungsbaume
Eine weiteres Klassifikationsmodell ist der sogenannte Entscheidungsbaum. Hierbei wirdeine Entscheidung basierend auf mehreren ”Fragen” an das Sample getroffen, welche ausden Trainingsdaten gelernt werden. Dabei wird an jedem Knoten anhand des Features (derKomponente des Samples) geteilt, welches den hochsten Informationsgewinn liefert. Dieswird solange wiederholt, bis die Endknoten pur sind (nur noch Samples aus einer Klassebeinhalten), da dies jedoch zu sehr viele Ebenen im Baum und Overfitting fuhren kann,wird ublicherweise ein Limit fur die Tiefe des Baums gesetzt.
Informationsgewinn
Der Informationsgewinn IG ist eine Funktion die an jedem Split maximiert werden sollund durch
IG(Dp, f) := I(Dp)−m∑j=1
Nj
NpI(Dj)
definiert ist. Dp und Dj bezeichnen hierbei die Daten an dem Parent- beziehungsweise demj-ten Child-Knoten, Np und Nj die Anzahl der Samples and Parent-und Child-Knoten, fdas Feature an dem der Split durchgefuhrt und I ein Impurity-Maß. Oft werden nur binareEntscheidungsbaume verwendet, wodurch der Index j nur zwei Werte annehmen kann,dann wird meist die Notation Dleft, Dright und Nleft, Nright verwendet. Die drei haufigstenImpuritymaße sind Entropie (IH), der Gini-Index (IG) und der Klassifikationsfehler (IE),welche wir nun definieren wollen:
IH(t) :=−c∑i=1
p(i|t) log2(p(i|t))
IG(t) :=
c∑i=1
(p(i|t)(−(p(i|t))
IE(t) :=1−max{p(i|t)}
Der Anteil der Samples an einem Knoten t, welche zur Klasse i gehoren, wird p(i|t) be-zeichnet.
7
2 Machine Learning Allgemein
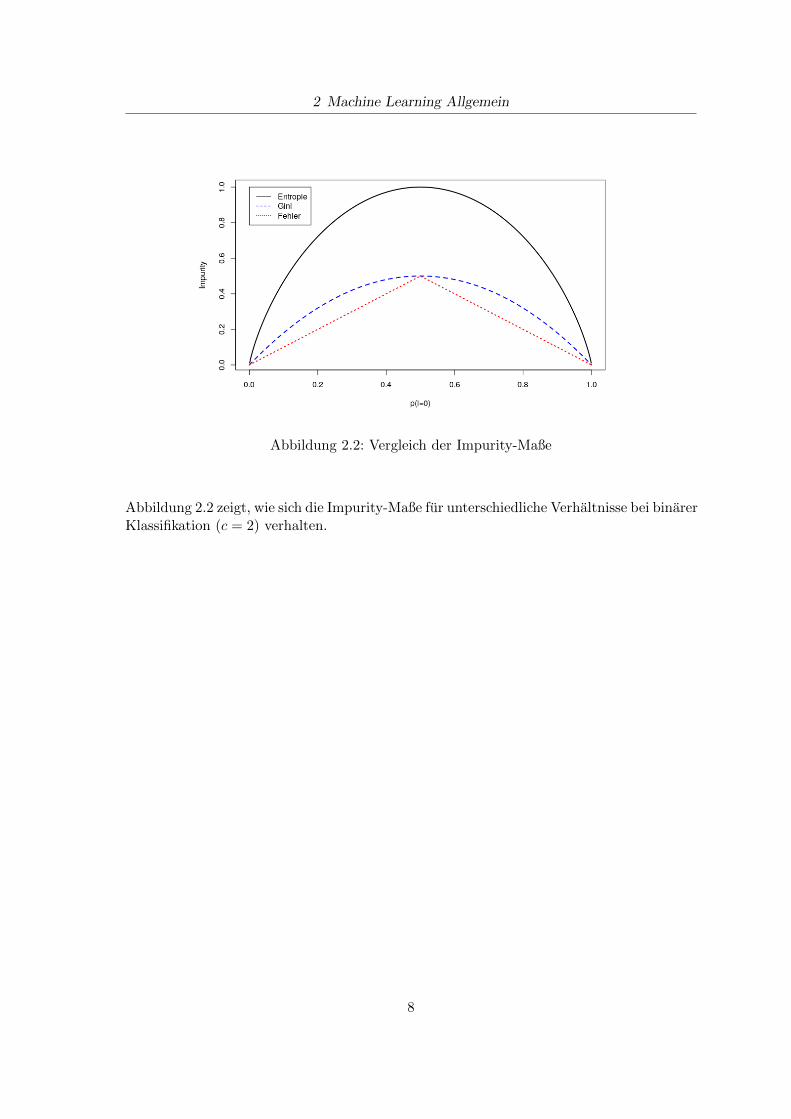
Abbildung 2.2: Vergleich der Impurity-Maße
Abbildung 2.2 zeigt, wie sich die Impurity-Maße fur unterschiedliche Verhaltnisse bei binarerKlassifikation (c = 2) verhalten.
8

3 Financial Data
Dieses Kapitel wird sich mit der Strukturierung roher Finanzdaten befassen, welche benotigtwird, um ML-Algorithmen uberhaupt anwenden zu konnen. Zuvor wollen wir jedoch dieverschiedenen Kategorien relevanter Daten diskutieren.
3.1 Arten von Finanzdaten
Bevor wir uns der Strukturierung und den eigentlichen ML-Algorithmen zuwenden konnen,mussen wir zuerst herausfinden welche Daten fur diese Anwendung brauch- und verwendbarsind. Diese lassen sich ublicherweise in vier Typen unterteilen:
• Fundamentale Daten
• Marktdaten
• Analysen
• Alternative Daten
welche wir nun einzeln naher diskutieren wollen.
3.1.1 Fundamentale Daten
Bei fundamentalen Daten handelt es sich um Informationen aus beispielsweise Bilanzen, Zu-lassungsantragen oder Gewinn- und Verlustrechnungen, uber die normalerweise quartarlichberichtet wird. Bei Daten dieser Art ist es notwendig, zu berucksichtigen, dass diese Datenoft verzogert publiziert oder nachtraglich geandert werden. Um falsche Schlusse aus diesenDatierungsfehlern zu vermeiden, sollte man darauf achten, Werte nicht zu Zeitpunkten zuverwenden, an denen sie noch nicht bekannt waren und ursprungliche Werte nicht einfachdurch die geanderten zu ersetzen.Da diese Daten ublicherweise offentlich sind, ist es unwahrscheinlich Informationen zu er-halten, die Konkurrenten noch nicht bekannt sind. Jedoch konnen sie oft in Kombinationmit anderen Datentypen genutzt werden.
3.1.2 Marktdaten
Marktdaten beinhalten die gesamte Trading-Aktivitat an einer Borse oder Handelsplatt-form. Dabei handelt es sich hauptsachlich um FIX-Daten (Financial Information eXchange),welche eine Rekonstruierung des Orderbuchs ermoglichen. Mit diesen Informationen lassensich beispielsweise bestimmte Trading-Algorithmen erkennen, oder der Anteil an mensch-lichen GUI-Tradern bestimmen (da diese oft mit runden Betragen/Stuckzahlen handeln).
9

3 Financial Data
Diese Daten benotigen massive Aufbereitung und Strukturierung, vor allem auch, da sieim Uberfluss generiert werden (oft uber 10 TB pro Tag).
3.1.3 Analysen
Analysen sind Daten die, im Gegensatz zu bereits vorgestellten Datentypen, nicht einfachverfugbar sind, sondern von spezialisierten Firmen angeboten werden. Diese Analysen ba-sieren auf einer Kombination aus anderen Datentypen oder auch mehreren Analysen. Dabeiwerden beispielsweise Geschaftsmodelle, Konkurrenz, Prognosen aber auch Stimmungsbil-der in Nachrichten und Social-Media untersucht. Zum einen liefern solche Analysen bereitsaufbereitete Daten, zum anderen konnen diese jedoch teuer sein, und auch Konkurrentenzur Verfugung stehen.
3.1.4 Alternative Daten
Zu alternativen Daten zahlen Informationen, die von Personen (Nachrichten, Social-Media,etc.), Geschaftsprozessen (Transaktionen, Corporate-Data,etc.) oder Messungen (Satelli-tenbilder, Wetter, Uberwachungskameras) generiert werden. Zu letzteren zahlen zum Bei-spiel die Beobachtung von Tankschiff-Bewegungen oder Nutzung der Parkplatze durch Sa-telliten. Alternative Daten sind also im Vergleich zu den anderen Datentypen am schwie-rigsten zu beschaffen und analysieren, zahlen aber auch zu vielversprechendsten. So deutenbeispielsweise gestiegene Tankschiff-Bewegungen auf hohere Absatze bei Erdolunternehmenhin, lange bevor sich dies in GuVs, Analysen oder an der Borse erkenntlich macht.
3.2 Bars
Um auf gesammelte Daten nun ML-Algorithmen anwenden zu konnen, ist es notwendigdie rohen Daten zu strukturieren, die relevanten Informationen zu extrahieren und diese ineinem passenden Format zu speichern. Hierfur bieten sich besonders Tabellen und Dataf-rames an, deren Reihen im Financial-ML oft als ”Bars”bezeichnet werden. Im folgendenAbschnitt werden wir einige Arten vorstellen solche Bars zu erzeugen, sowie die Vor- undNachteile dieser Methoden diskutieren.
3.2.1 Standard-Bars
Time-Bars
Time-Bars sind die wohl intuitivste und bekannteste Art von Bars. Hierbei werden diegewunschten Daten einfach in vorgegebenen Zeitintervallen abgerufen. Die typischen Infor-mationen in Time-Bars sind:
• Zeitstempel
• Volumengewichteter Durschnittspreis (VWAP)
• Eroffnungskurs
10

3 Financial Data
• Schlusskurs
• Hochstpreis
• Tiefstpreis
• Gehandeltes Volumen
Obwohl Time-Bars oft fur verschiedenste Anwendungen verwendet werden, bringen siedoch einige Probleme mit sich. Zum einen ist die Handelsaktivitat an einer Borse vonder Tageszeit abhangig, direkt nach Eroffnung wird mehr gehandelt als beispielsweiseum die Mittagszeit herum. Daher kommt es bei Time-Bars zu einem Oversampling vonDaten wahrend niedrig-frequentierten Zeiten und zu einem Oversampling wahrend hoch-frequentierten Zeiten. Zum anderen besitzen Time-Bars oft unerwunschte Eigenschaftenwie serielle Abhangigkeit oder nicht-normalverteilte Returns.
Tick-Bars
Bei Tick-Bars werden ahnliche Informationen wie bei Time-Bars gesammelt, jedoch nichtin fixen Zeitintervallen, sondern nach einer gewissen Anzahl von Transaktionen. Der Begriff”Tick”bezeichnet eine Kursveranderung, die durch Transaktionen entsteht. Tick-Bars sindTime-Bars zu bevorzugen, da mehrere Studien bestatigen, dass samplen nach Transakti-onsanzahl eher zu IID normalverteilten Returns fuhrt. Dies ist von besonderer Bedeutung,da viele statistische Methoden vorraussetzen, das die Beobachtungen durch einen IID-Gaußschen-Prozess generiert wurden. Problematisch ist jedoch, dass Fragmentierung vonTransaktionen zu Unterscheden in Tick-Bars fuhrt, da zum Beispiel eine Order der Große100 zu einem Tick fuhrt, wahrend die selbe Transaktion, aufgeteilt in 100 Orders der Große1, 100 Ticks erzeugt. Dieses Problem umgehen die im folgenden vorgestellten Volume-Bars.
Volume-Bars
Wie der Name bereits vermuten lasst, werden die gewunschten Daten bei Volume-Barsgesamplet, sobald eine gewisse Menge der beobachteten (z.B.) Aktie, gehandelt wurde.Volume-Bars sind besonders nutzlich, da sie nicht von Fragmentierung beeinflusst werdenund noch bessere statistische Eigenschaften als Tick-Bars besitzen, darunter auch, dassReturns noch naher an IID-normalverteilten Zufallsvariablen liegen.
Dollar-Bars
Anstatt nach Ticks oder Volumen zu samplen besteht auch die Moglichkeit, zu samplen,nach dem eine gewisse Geldmenge gehandelt wurde. Naturlich kann sich dies auf beliebigeWahrungen beziehen, der gelaufige Ausdruck ist dennoch Dollar-Bars. Die Volume- undTick-Bars die pro Tag erstellt werden, kann uber Jahre hinweg stark variieren, bei Dollar-Bars bleibt diese jedoch einigermaßen konstant. Außerdem ist die Anzahl der verfugbarenAktien nicht konstant, da Unternehmen neue Aktien emittieren oder, vor allem in denletzten Jahren, haufig auch zuruckkaufen. Dollar-Bars bleiben jedoch relativ konsistent bei
11

3 Financial Data
Veranderungen in der Anzahl der verfugbaren Aktien. Im Gegensatz zu den anderen Bar-Typen, sollte man bei Dollar-Bars dennoch keinen konstanten Geldwert wahlen, sonderndiesen beispielsweise als Funktion der derzeitigen Marktkapitalisierung wahlen.
3.2.2 Information-Driven Bars
Diese Art von Bars ist etwas komplexer als die vorhergegangenen, da sie jedoch mathe-matisch interessanter sind, werden wir sie dennoch kurz diskutieren. Der Hintergrundge-danke hinter Information-Driven-Bars ist, ofter zu samplen, wenn neue Information denMarkt erreicht. Um den Rahmen dieser Arbeit nicht zu sprengen, werden wir uns auf Tick-Imbalance-Bars konzentrieren.
Tick-Imbalance-Bars
Wir betrachten eine Folge von Ticks {(pt, vt)}t=1,...,T , wobei pt den Preis und vt das ge-handelte Volumen zu Tick t bezeichnet. Durch die sogenannte Tick-Regel wird eine Folge{bt}t=1,...,T definiert:
bt :=
bt−1 falls ∆pt = 0
|∆pt|∆pt
falls ∆pt 6= 0
Wie unschwer zu erkennen ist, ist bt ∈ {−1, 1}. Außerdem gelte die Anfangsbedingung,dass b0 dem Endwert des direkt vorhergegangenen Bars entspricht. Die Tick-Imbalance zuZeitpunkt T ist definiert als
θT :=
T∑t=1
bt
Wir mochten nun jedes mal samplen, wenn die Tick-Imbalance unsere Erwartung uberschreitet.Dazu berechnen wir die Erwartung von bt zu Beginn des Bars, also E0[θT ] =E0[T ](P[bt = 1] − P[bt = −1]), wobei E0[θT ] die erwartete Lange des Bars bezeichnet.P[bt = 1] und P[bt = −1] bezeichnen die Wahrscheinlichkeiten, dass ein Tick als Kauf oderVerkauf gezahlt wird. Da die Summe dieser Wahrscheinlichkeiten 1 ergibt, folgt E0[θT ] =E0[T ](2P[bt = 1] − 1). E0[T ]und P[bt = 1] konnen mithilfe von exponentiell-gewichtetengleitenden Durchschnitten aus vorherigen Bars geschatzt werden. Als Tick-Imbalance-Barwerden dann die Ticks T ∗ bezeichnet, die folgende Bedingung erfullen:
T ∗ = argminT
{|θT | ≥ E0[T ]|2P[bt = 1]− 1|}
12

4 Data Labels
Im vorherigen Kapitel, wurde erklart, wie Daten in Tabellen oder Dataframes gespeichertwerden konnen. Mit Hilfe von unuberwachten ML-Algorithmen konnen darin z.B. Clustererkannt werden, um diese Daten jedoch fur uberwachte Algorithmen zu verwenden, mussendiese erst mit Labels versehen werden. In manchen Anwendungen ist die Wahl der Labelsintuitiv, bei Financial ML stehen uns jedoch wieder einige Moglichkeiten zur Verfugung,die im folgenden diskutiert werden.
4.1 Fixed-Time-Horizon Methode
Bei dieser Methode werden die einzelnen Observationen mit yi ∈ {−1, 0, 1} gelabelt, jenachdem, ob sie in einem fixen Zeithorizont zu einem Verlust oder Ertrag fuhren. Um diesmathematisch genauer zu erklaren betrachten wir eine Eigenschaftsmatrix (eine Matrixwie sie in Kapitel 3 diskutiert wurden). Diese Matrix X habe nun I Reihen, {Xi}i=1,...,I ,gezogen aus Bars mit Indizes t = 1, ..., T , wobei I ≤ T gilt. Jeder Beobachtung Xi wirdnun ein Label yi zugeordnet und zwar wie folgt:
yi :=
−1 falls rti,0,ti,0+h < −τ0 falls |rti,0,ti,0+h| ≤ τ1 falls rti,0,ti,0+h > τ
Hierbei bezeichnet τ eine vorgegebene fixe Schwelle, ti,0 ist der Index des Bars direkt nachder Beobachtung Xi und ti,0 +h ist der Index des h-ten Bars nach ti,0. rti,0,ti,0+h bezeichnetden Return uber einen Horizont h, gegeben durch:
rti,0,ti,0+h :=pti,0+h
pti,0− 1
Diese Methode des Labeling besitzt jedoch zwei große Nachteile. Zum Ersten besitzen Time-Bars, wie bereits in Abschnitt 3.2.1 behandelt, schlechte statistische Eigenschaften. ZumZweiten wird bei dieser Methode die schwankende Volatilitat ignoriert, was zu ”falschen”Labels fuhren kann, da die Schwelle τ nicht von der Volatilitat abhangt, sondern konstantgewahlt wird. Um dies zu losen konnte man eine variable Schwelle verwenden, beispielsweisedie exponentiell-gewichtete Standardabweichung vorheriger Returns. Außerdem bieten sichhier Volume- oder Dollar-Bars an, welche geringere Abweichung der Volatilitat besitzen.Ein Problem, dass jedoch nicht so leicht gelost werden kann, ist die Vernachlassigung vonStop-Loss-Limits bei dieser Methode. Praktisch gesehen macht es wenig Sinn eine Strate-gie zu entwerfen, bei der Gewinne und Verlust von Positionen berucksichtigt werden, dieschon langst verkauft wurden. Diese Problematik wird jedoch bei der nachsten Methodeberucksichtigt.
13

4 Data Labels
4.2 Three-Barrier-Methode
Bei dieser Methode werden, ahnlich zu Bollinger-Bandern, zwei horizontale Barrieren inAbhangigkeit der geschatzten Volatilitat definiert, welche die Profit-Taking- und Stop-Loss-Limits darstellen. Außerdem wird eine dritte, vertikale Barriere eingefuhrt, die als”Ablaufdatum” der Position dient. Je nachdem welche Barriere zuerst beruhrt wird, wirdein anderes Label gewahlt, bei der oberen horizontalen Barriere 1, bei der unteren −1 undbei der vertikalen Barriere 0, oder, in manchen Anwendungen sinnvoller, das Vorzeichen, desReturns. Im Gegensatz zur Fixed-Time-Horizon Methode ist diese Methode pfadabhangig,daher muss der gesamte Pfad im Intervall [ti,0, ti,0 + h] (wobei ti,0 + h hier die Position dervertikalen Barriere beschreibt) bekannt sein. Den Zeitpunkt zu dem das erste mal eine derBarrieren beruhrt wird, bezeichnen wir mit ti,1, wobei selbstverstandlich ti,0 +h ≤ ti,1 gilt.Der Return zwischen ti,0 und der ersten Beruhrung wird als rti,0,ti,1 bezeichnet.
4.3 Meta-Labeling
Meta-Labeling bezeichnet das Labeling von Datenpunkten, basierend, oder abhangig, vonbereits bestimmten Labeln. Hierunter fallt beispielsweise sogenanntes ”Labeling for Si-ze” basierend auf der bereits bekannten (und gelableten) ”Side”. Die Position (long odershort) die zu einem bestimmten Zeitpunkt angenommen werden soll, ist also schon durchbestimmte Indikatoren (beispielsweise Crossing-Moving-Averages) oder bereits diskutier-te Labeling-Methoden bekannt. Nun kann ,z.B. mit der Three-Barrier-Methode, ermitteltwerden, ob sich ein Eingehen dieses Trades uberhaupt lohnen wurde. Entscheidend ist hier-bei, dass die Stop-Loss- und Profit-Taking-Limits nicht mehr symmetrisch sein mussen,da sie Position ja bereits bekannt ist. Eine mogliche Wahl fur diese Limits ware beispiels-weise die zweifache tagliche Standardabweichung als Stop-Loss- und die einfache taglicheStandardabweichung als Profit-Taking-Grenze. Die Labels wurden dann analog zur bereitsgenannten Three-Barrier-Methode, je nachdem welche Barriere zuerst uberschritten wird,bestimmt.
14

5 Ensemble Methoden
In diesem Kapitel, mochten wir uns den Ensemblemethoden widmen. Hierbei handelt es sichum ML-Methoden, die aus mehreren Algorithmen der gleichen Art, die oft auf Bootstrapsdes Trainingssets trainiert werden, kombiniert werden. Die Motivation dahinter ist diedaraus erhoffte Reduzierung von Verzerrung (Bias) und/oder Varianz. Wobei es sich dabeigenau handelt, wird im folgenden Abschnitt behandelt werden, bevor wir uns zwei Artenvon Ensemble Methoden genauer widmen werden.
5.1 Verzerrung-Varianz-Dilemma
ML- Algorithmen besitzen im Allgemeinen drei große Fehlerquellen: Verzerrung, oft auchals Bias bezeichnet, Varianz und Rauschen, auch genannt Noise.
• Verzerrung entsteht durch falsche Annahmen des Algorithmus, welcher bei hoherVerzerrung daran scheitert, die wichtigen Relationen des Datensets zu erkennen. Dieswird als Underfitting bezeichnet.
• Varianz bezeichnet den Fehler der von kleinen Schwankungen in den Trainingsdatenausgeht. Der Algorithmus modelliert bei hoher Varianz also das Rauschen und nichtdie eigentlichen Outputs. Dies wird als Overfitting bezeichnet.
• Rauschen sind Fehler durch Varianz der Observationen, die nicht reduziert unddurch kein Modell erklart werden konnen. Hierunter fallen beispielsweise Messfehler.
Wir wollen dieses Problem nun mathematisch betrachten. Sei dazu {xi}i=1,...,n eine Mengean Beobachtungen mit dazugehorigen, reellwertigen Labels {yi}i=1,...,n. Angenommen, esexistiert eine Funktion f , sodass y = f(x) + ε gilt, wobei ε hierbei einen White-Noise-Prozess bezeichnet. Nun soll unser Algorithmus eine Funktion f finden, die f moglichst gutapproximiert. Als Maß fur die Genauigkeit der Annaherung dient die mittlere quadratischeAbweichung E[(yi − f(xi))
2], welche minimiert werden soll. Diese Abweichung kann wiefolgt zerlegt werden:
E[(yi − f(xi))2] =
E[f(xi)− f(xi)]︸ ︷︷ ︸Verzerrung
2
+ Var[f(xi)]︸ ︷︷ ︸Varianz
+ σ2ε︸︷︷︸Rauschen
Dies kann folgend hergeleitet werden:
Beweis. Aus der Tatsache, dass f(xi) deterministisch ist und aus E[ε] = 0 folgt
E[yi] = E[f(xi) + ε] = E[f(xi)] + E[ε] = f(xi)
15

5 Ensemble Methoden
Weiters gilt fur die Varianz von yi
Var[yi] = E[(yi − f(xi))2]
= E[(f(xi) + ε− f(xi))2]
= E[ε2]
= σ2ε
Insgesamt folgt mit der Unabhangigkeit von ε und f(xi) also
E[(yi − f(xi))2] = E[y2i − 2yif(xi) + f(xi)
2]
= E[y2i ] + E[f(xi)2]− 2E[yif(xi)]
= Var[yi] + E[yi]2 + Var[f(xi)] + E[f(xi)]
2 − 2f(xi)E[f(xi)]
Die letzte Gleichung folt aus dem Verschiebungssatz und aus:
E[yif(xi)] = E[(f(xi) + ε)f(xi)]
= E[f(xi)f(xi) + f(xi)ε]
= E[f(xi)f(xi)] + E[f(xi)] E[ε]︸︷︷︸0
= E[f(xi)]f(xi)
Weiter gilt dann:
E[(yi − f(xi))2] = Var[yi] + E[yi]
2 + Var[f(xi)] + E[f(xi)]2 − 2f(xi)E[f(xi)]
= Var[yi] + Var[f(xi)] + (f(xi)− E[f(xi)])2
= Var[yi] + Var[f(xi)] + E[f(xi)− f(xi)]2
= σ2ε + Var[f(xi)] + E[f(xi)− f(xi)]2
Ensemble-Methoden versuchen nun also Verzerrung und/oder Varianz zu verringern, umso bessere Performance zu erreichen. Generell gibt es dazu zwei Moglichkeiten, BootstrapAggregation (bagging) und Boosting, welche nun naher vorgestellt werden.
5.2 Bootstrap Aggregation
Bootstrap Aggregation (abgekurzt: Bagging) ist ein Methode, mit deren Hilfe die Varianzeines Algorithmus reduziert werden kann. Die Funktionsweise ist folgende:
1. Erzeuge N Trainingssets durch Ziehen mit Zurucklegen.
2. Trainiere N ML-Modelle, eines auf jedem Trainingsset.
16

5 Ensemble Methoden
3. Berechne die Ensemble-Vorhersage als Durschnitt/Mehrheit der Einzelprognosen.
Bei Regressionsproblemen ist die Ensembleprognose durch den Durchschnitt der einzelnenPrognosen gegeben, bei Klassifikationsproblemen durch sogenannte Majority Vote, also dieKlasse, welche am oftesten prognostiziert wurde.
Widmen wir uns nun mathematisch der Varianzverbesserung, genauer gesagt der Genauig-keitsverbesserung, da wir nur den Fall von Klassifikationsproblemen betrachten werden. Wirnehmen einen Bagging-Classifier an, der Vorhersagen uber k mogliche Klassen mit Hilfe vonMajority-Vote uber N einzelne Classifier tatigt. Diese Vorhersagen konnen nun mit {0, 1}entsprechend ihrer Korrektheit gelablet werden. Die Wahscheinlichkeit p des Classifiers, dasLabel 1 zu vergeben, also die richtige Vorhersage zu treffen, wird als Genauigkeit bezeich-net. Durchschnittlich erhalten wir also Np-mal das Label 1, die Varianz betragt bekanntlichNp(1−p). Wenn die am meisten vorhergesagte Klasse mit der tatsachlichen ubereinstimmt,liefert der Bagging-Classifier das richtige Ergebnis. Eine hinreichende Bedingung hierfur,ist, dass fur die Summe X der Labels der einzelnen Classifier gilt P[X > N
2 ]. Eine notwen-dige, nicht hinreichende Bedingung ist, dass P[X > N
k ] gilt. Die Wahrscheinlichkeit diesesEreignisses kann wie folgt berechnet werden:
P
[X >
N
k
]= 1− P
[X ≤ N
k
]= 1−
bNk c∑i=0
(N
i
)pi(1− p)N−i
Fur große N , wie N > p(p− 1k )−2, folgt damit, p > 1
k =⇒ P[X > Nk ] > p. Dies bedeutet,
das fur solche N der Bagging-Classifier eine hohere Genauigkeit erzielt, als die einzelnen,zugrundeliegenden Classifier.
5.3 Random Forest
Eine besondere Variante von Bagging sind so genannte Random Forests. Diese Methodeverwendet Entscheidungsbaume, welche in 2.3.4 diskutiert wurden. Ein großes Problem beider Verwendung von Entscheidungsbaumen ist ihre Anfalligkeit fur Overfitting, also hoheVarianz. Ein Weg um dies zu verhindern, ist die Vorgabe einer maximalen Tiefe des Baums,jedoch lasst sich auch durch die Erstellung von Random Forests eine Varianzverringerungerzielen.Das zugrundeliegende Prinzip ist der Bootstrap-Aggregation ahnlich, auch hier werdenmehrere Modelle auf Bootstraps der Trainingsdaten trainiert und kombiniert. Oft wird je-doch ein weiterer Schritt durchgefuhrt: an jedem Knoten werden nur eine zufallige Auswahlder Features betrachtet, was eine Verringerung der Korrelation der einzelnen Baume zurFolge hat.Zu guter Letzt werden die Einzelprognosen der Entscheidungsbaume uber Majority-Votingzu einer Prognose des Random-Forests kombiniert, welche nun reduzierte Varianz besitzt.Bias lasst sich hierduch, genau wie beim Bagging, jedoch nicht verringern.
17

5 Ensemble Methoden
5.4 Boosting
Eine weitere Art von Ensemble-Methode ist das sogenannte Boosting. Die Vorgangsweiselasst sich wie folgt zusammenfassen:
1. Generiere ein Trainingsset durch Ziehen mit zurucklegen entsprechend einer bestimm-ten Gewichtsverteilung (initialisiert mit Gleichverteilung).
2. Trainiere eine Modell auf diese Trainingsdaten.
3. Wenn die Genauigkeit des trainierten Modelles einen Schwellenwert uberschreitet,wird sie weiter verwendet, ansonsten verworfen.
4. Erhohe die Gewichte der falsch klassifizierten Samples, verringere die der richtig klas-sifizierten.
5. Wiederhole Schritt 1-4, bis N Modelle vorhanden sind.
6. Bestimme Vorhersagen, durch den gewichteten Durchschnitt der einzelnen Modelle.
Die Gewichte fur den 6. Schritt sind hierbei abhangig von der Genauigkeit des jeweiligenModells.
Der Wohl großte Vorteil von Boosting ist, dass, im Gegensatz zur Bootstrap-Aggregation,nicht nur Varianz, sondern auch Verzerrung reduziert werden, was bei vielen Anwendungenvorteilhaft ist.
18

6 Cross-Validation
Ein wirksamer Weg um die Perfomance eines ML-Modells zu ermitteln ist die sogenanntek-fold Cross-Validation (CV). Dieses Verfahren ist auch fur Hyperparameter Tuning (dis-kutiert in Kapitel 7) von hoher Bedeutung. Im Financial ML eroffnen sich jedoch einigeProbleme, sodass einfache CV zu tauschenden Ergebnissen fuhren kann. Im folgenden Ka-pitel mochten wir uns also zuerst der klassischen CV widmen, und dann untersuchen welcheAnpassungen notwendig sind, um sie in Financial ML anwenden zu konnen.
6.1 k-fold Cross-Validation
Bereits in Abschnitt 2.3.1 wurde erwahnt, dass es notwendig ist, die verfugbaren Daten inTrainings- und Testdaten zu unterteilen. Dieses fundamentale Prinzip kommt auch bei derk-fold Cross-Validation zum Einsatz im Gegensatz zu vorher wird dieser Prozess jedochk-mal durchgefuhrt. Angenommen uns stehen Observationen aus einem IID-Prozess zurVerfugung. Dann kann die Vorgehensweise der CV wie folgt beschrieben werden:
1. Partitioniere die Daten in k Teilmengen.
2. Fur i ∈ 1...k mache folgendes:
• Trainiere den Algorithmus auf allen Mengen außer i.
• Teste den trainierten Algorithmus auf der Menge i.
Dies liefert uns einen k × 1 Vektor mit den jeweils geforderten Performance-Daten, an-hand welcher nun erkannt werden kann, wie der Algorithmus abschneidet. Abbildung 6.1illustriert die Vorgehensweise fur den konkreten Wert k = 5.
6.2 Cross-Validation fur Financial ML
Einer der Hauptgrunde, warum k-fold Cross-Validation fur Financial ML nicht direkt an-wendbar ist, ist dass die Annahme, dass unsere Observationen von einem IID-Prozess stam-men, im Allgemeinen nicht erfullt ist. Dies hat zur Folge, dass serielle Korrelation nicht nurzwischen den einzelnen Features, sondern auch den daraus bestimmten Labels besteht alsokorrelieren Observationen aus unserem Trainingsset mit Daten aus dem Testset, wodurchdie CV an Aussagekraft verliert. Dieser Effekt wird als Leakage bezeichnet.
Leakage lasst sich auch durch mathematische Notation beschreiben. Sei dazu X ein seriell-korreliertes Feature mit dazugehorigen Labels Y . Diese Labels werden im Allgemeinen ausuberlappenden Daten generiert, d.h. dass manche Observationen sowohl fur die Ermittlungvon Yi als auch fur Yj benutzt werden. Dann gilt:
19

6 Cross-Validation
Abbildung 6.1: Aufteilung von Test und Trainingsdaten fur k = 5
• Xt ≈ Xt+1, auf Grund der seriellen Korrelation.
• Yt ≈ Yt+1, auf Grund der uberlappenden Daten.
Falls die Daten zu t und t + 1 nun in unterschiedliche Mengen, also eine Observation insTrainings-, die andere in Testset, aufgeteilt werden, tritt Leakage ein. Wenn ein Modell nunauf den Trainingsdaten trainiert wurde, welche auch (Xt, Yt) enthalten, E[Yt+1|Xt+1] pro-gnostizieren soll, so wird das Modell mit großerer Wahrscheinlichkeit Yt+1 = E[Yt+1|Xt+1|]bestimmen. Dies klingt im ersten Moment wenig problematisch, falls X ein aussagekraftigesFeature ist, wird dadurch sogar die Performance des Modells erhoht. Falls X jedoch einirrelevantes Feature ist, so lernt das Modell daraus falsche Zusammenhange, was wiederumzu falschen Erkenntnissen fuhrt.
Es gibt zwei klare Wege um Leakage zu verhindern. Zum Ersten sollte man alle Daten Yiaus dem Trainingsset entfernen, die von den Daten abhangen, die auch Daten im Testset be-stimmen. Zum Zweiten kann auch Overfitting reduziert werden, entweder durch Bootstrap-Aggregation (siehe: 5.2), oder durch vorzeitiges Stoppen der Classifier (z.B. Abschneidenvon Entscheidungsbaumen). Methoden zur Varianzreduzierung wurden schon in Kapitel 5behandelt, daher widmen wir uns im folgenden dem ersten Ansatz, der Entfernung vonUberlappungen zwischen unseren Datensets.
20

6 Cross-Validation
6.2.1 Bereinigte CV
Wir betrachten eine Observation aus dem Testset mit Label Yj und eine aus dem Trainings-set mit Label Yi, Seien Φj und Φi die jeweiligen Daten aus denen diese Labels ermitteltwerden. Unser Ziel ist es nun, alle Observationen aus dem Trainingsset zu streichen, fur dieΦj ∩ Φi 6= ∅ gilt.Das Label Yj is eine Funktion der Observationen zu den Zeitpunkten t ∈ [tj,0, tj,1], alsoYj = f([tj,0, tj,1]), fur Yi gilt analog Yi = f([ti,0, ti,1]). Dies wurde schon in Kapitel 4 bespro-chen, zum Beispiel bei der Fixed-Time-Horizon Methode, bei der das Label in Abhangigkeitvom Return rtj,0,tj,1 bestimmt wird. Ein Label Yi uberlappt also mit Yj wenn eine von dreiBedingungen erfullt ist:
1. tj,0 ≤ ti,0 ≤ tj,1
2. tj,0 ≤ ti,1 ≤ tj,1
3. ti,0 ≤ tj,0 ≤ tj,1 ≤ ti,1
Wenn nun alle Observationen aus dem Trainingsset entfernt wurden, die eine dieser Bedin-gungen erfullen, kann normale k-fold CV durchgefuhrt werden.
21

7 Hyperparameter Tuning
Viele ML-Algorithmen benutzen sogenannte Hyperparameter, Werte die dem Algorithmusals Input ubergeben werden, und maßgeblichen Einfluss auf dessen Vorgehensweise haben.Ein Beispiel dafur ware die maximale Tiefe eines Entscheidungsbaumes. Die Performanceeines trainierten Modells hangt naturlich von der Wahl der Hyperparameter ab, daherwidmen wir uns in folgendem Kapitel dem Hyperparameter-Tuning, ein Vorgang bei demversucht wird, die optimalen Hyperparameter fur eine Problemstellung zu finden.
7.1 Gridsearch
Gridsearch ist eine mogliche, simple Methode fur Hyperparameter-Tuning. Hierbei wirdeine Liste an moglichen Hyperparametern vorgegeben und zu jeder Kombination diesereine k-fold CV durchgefuhrt, um die optimalen Hyperparameter aus der gegebenen Listezu bestimmen. Da es sich hierbei um einfaches Bruteforcing handelt, ist diese Methode, vorallem fur Algorithmen mit hoher Anzahl an Parametern, sehr zeit- und rechenaufwendig.
7.2 Random Search
Um hohe Rechenzeiten zu vermeiden, kann auch Random Search angewandt werden, eineMethode, bei der die moglichen Parameter nach einer Verteilungsfunktion generiert werden.Dies bringt zwei Vorteile mit sich: erstens kann die Zahl der getesteten Parameter leichterkontrolliert werden, zweitens erhohen fur die Performance irrelevante Parameter den Re-chenaufwand nicht maßgeblich. Irrelevant in diesem Kontext bedeutet, dass die Parametereine geringe effektive Dimensionalitat besitzen, also die Performance wesentlich mehr vonmanchen Dimensionen abhangt als von anderen [1].Die Verteilungsfunktionen der einzelnen Parameter mussen selbstverstandlich sinnvoll gewahltwerden, so sollten fur stetige Parameter, stetige Verteilungen gewahlt werden und analogfur diskrete.Bei vielen ML-Algorithmen werden positive, kleine Parameter gefordert, daher kommt oftdie sogenannte logarithmische Gleichverteilung zum Einsatz. Eine Zufallsvariable X istgenau dann logarithmisch gleichverteilt wenn gilt:
log(X) ∼ U[log(a), log(b)]
22

7 Hyperparameter Tuning
Verteilungsfunktion und Dichte haben demnach folgende Form:
F (x) :=
log(x)−log(a)log(b)−log(a) falls a ≤ x ≤ b0 falls x < a
1 falls x > b
f(x) :=
{1
x log( ba)
falls a ≤ x ≤ b
0 sonst
Zu beachten ist naturlich, dass 0, aufgrund der Definition, kein zulassiger Wert fur die untereSchranke a ist, stattdessen sollte man kleine Werte wie beispielsweise 10−5 verwenden.
23

Abbildungsverzeichnis
2.1 Beispiel fur binare Klassifikation . . . . . . . . . . . . . . . . . . . . . . . . 32.2 Vergleich der Impurity-Maße . . . . . . . . . . . . . . . . . . . . . . . . . . 8
6.1 Aufteilung von Test und Trainingsdaten fur k = 5 . . . . . . . . . . . . . . 20
Literaturverzeichnis
[1] James Bergstra and Yoshua Bengio. Random search for hyper-parameter optimization.J. Mach. Learn. Res., 13:281–305, February 2012.
[2] Marcos Lopez de Prado. Advances in Financial Machine Learning. Wiley Publishing,1st edition, 2018.
[3] Sebastian Raschka. Python Machine Learning. Packt Publishing, 2015.
24
Related Documents











