CENTRO UNIVERSITARIO DE IXTLAHUACA, A. C. Unidad de Extensión y Vinculación Universitaria Centro Integral de Servicios Académicos, Empresariales y Comunitarios ANÁLISIS ESTADÍSTICO CON SPSS ® preedición Ing. Jesús Antonio Vilchis Juárez 2009

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

CENTRO UNIVERSITARIO DE IXTLAHUACA, A. C. Unidad de Extensión y Vinculación Universitaria
Centro Integral de Servicios Académicos, Empresariales y
Comunitarios
ANÁLISIS
ESTADÍSTICO CON SPSS
®
preedición
Ing. Jesús Antonio Vilchis Juárez
2009

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 1
INTRODUCCIÓN
Desde sus orígenes, las computadoras se han empleado en el procesamiento estadístico de datos. En los primeros años, las dificultades de accesibilidad a las computadoras, así como sus propias limitaciones, hacían selectivos los cálculos estadísticos de gran dimensión. Pero es con la expansión de la microinformática cuando se eliminan las acotaciones en los cálculos numéricos de gran dimensión y los problemas de acceso a las máquinas, lo que desemboca en facilidad para llevar acabo investigaciones estadísticas en todos los campos de la ciencia (Economía, Ciencias sociales, Educación, Ciencias de la Salud, etc.). Aunque los campos de aplicación de la estadística sean diferentes, los métodos son comunes, lo que ha dado lugar a la estandarización automatizada de las técnicas estadísticas, apareciendo una amplia variedad de paquetes estadísticos que difieren entre sí en los aspectos de capacidad, facilidad de uso, entornos de aplicación, extensión, precio, documentación y otras características similares. Entre estos paquetes estadísticos se encuentra SPSS (Statistical Package for the Social Sciences), paquete estadístico para las ciencias sociales, producto que fue creado en 1968 por la Compañía spss inc. (elaborado por Hull y Nie) y en 1992 se desarrolla la primera versión para Windows; y que tal vez sea el paquete estadístico con más difusión a nivel mundial. SPSS se desarrolló inicialmente para procesamiento por lotes (procesos batch) y aún se puede trabajar así en determinados entornos. No obstante, la evolución del proceso de datos ha hecho que el programa vaya adaptándose a los nuevos entornos de ventanas y a las interfaces avanzadas de los sistemas operativos actuales. Hoy en día SPSS es un software estadístico modular muy popular que implementa gran variedad de temas estadísticos en los distintos módulos del programa. SPSS es un sistema global para el análisis de datos. SPSS puede adquirir datos de casi cualquier tipo de archivo y utilizarlos para generar informes tabulares, gráficos y diagramas de distribuciones y tendencias, estadísticos descriptivos y análisis estadísticos complejos. El SPSS es de gran ayuda para descubrir los patrones y tendencias de los datos que no se aprecian cuando solo se utilizan hojas de cálculo y bases de datos, no se requieren demasiados conocimientos de estadística para efectuar análisis avanzados y previsiones que permitan tomar mejores decisiones. El SPSS contiene todos los procedimientos mas utilizados en el análisis estadístico básico, entre estos procedimientos se encuentran las tablas estadísticas y los gráficos interactivos y dinámicos que permiten obtener

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 2
mejores informes, en un entorno grafico, utilizando menús descriptivos y cuadros de dialogo sencillos que realizan gran parte del trabajo. Los pasos básicos a seguir para realizar cualquier análisis de datos estadísticos con SPSS son lo siguientes (figura 1):
1. La introducción de datos en SPSS, puede ser de forma directa o abriendo un archivo de datos, una hoja de calculo, o un archivo de texto, o bien introducir sus datos directamente en el editor de datos.
2. Seleccionar un procedimiento para realizar análisis estadístico o seleccionar un procedimiento para crear gráficos.
3. Seleccionar las variables que se desean utilizar en el análisis. 4. Ejecutar el procedimiento y observar los resultados.
1 IMPORTACION O
CAPTURA DE
DATOS A SPSS
2
SELECCIÓN DE UN
PROCEDIMIENTO
EN LOS MENUS
3
SELECCIÓN DE LAS
VARIABLES PARA
EL ANALISIS
4
EXAMEN DE
RESULTADOS
Figura 1: Proceso general para usar SPSS.
SPSS - PAQUETE ESTADÍSTICO
QUÉ ES UN PAQUETE ESTADÍSTICO. Un paquete estadístico es un conjunto de programas y subprogramas conectados de manera que funcionan de manera conjunta; es decir, para pasar de uno a otro no se necesita salir del programa y volver a él. Un paquete estadístico permite aplicar a un mismo fichero de datos un conjunto ilimitado de procedimientos estadísticos de manera sincronizada, sin salir del programa. De esta forma, la utilidad del conjunto integrado es mayor que la suma de las partes. En cierto modo, un paquete estadístico es similar a un paquete ofimático (por ejemplo, Office de Microsoft). SPSS es uno de los principales paquetes estadísticos. Otros importantes ejemplos de paquetes estadísticos son SAS, Statistica, Mathlab, Statgraphics y Minitab. En el pasado, había otros paquetes estadísticos, como BMDP y Systat, hoy absorbidos por la firma SPSS.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 3
SPSS analiza con detenimiento las variables implicadas en la investigación, con el propósito de construir un modelo único que sea capaz de explicar lo que aconteció, tanto antes como después del análisis estadístico. De alguna forma, SPSS trata de obtener información privilegiada a partir de la base de datos. Todas las características de SPSS abren un amplio campo de investigación. SPSS es una tecnología que:
Automatiza el proceso de descubrimiento del conocimiento. Ayuda a centrarse en un área de interés. Permite predecir resultados. Permite encontrar patrones dentro de un fichero de datos. Amplía las capacidades ofrecidas por otras herramientas.
UTILIDAD DEL SPSS. El paquete estadístico SPSS tiene muchas utilidades, ya que puede ser utilizado como:
1. Hoja de cálculo. SPSS permite realizar funciones aritméticas, algebraicas y trigonométricas sobre un fichero de datos. En este sentido, SPSS puede compararse, salvando las diferencias, a aplicaciones como Excel o Lotus.
2. Gestor de bases de datos. SPSS permite gestionar de modo dinámico la información de un fichero de datos, pues se pueden actualizar los cambios operados (como ordenar, filtrar, etc.) o realizar informes personalizados de acuerdo con distintos criterios, etc. En este sentido, SPSS puede compararse, salvando las diferencias, a un gestor de bases de datos como Microsoft Access, Dbase, Oracle o Foxpro.
3. Generador de informes. SPSS permite preparar de modo elegante atractivos informes de una investigación realizada, permitiendo incorporar en un mismo archivo el texto del reporte, las tablas y resultados estadísticos que el reporte necesite presentar e, incluso, los gráficos que se pudiesen generar. Todo ello apoyado por la posibilidad de exportar los reportes a una página web de modo completamente ágil. En este sentido, el paquete estadístico SPSS puede compararse, salvando las diferencias, a otros realizadores de reportes, como Microsoft Access.
4. Analizador de datos. SPSS tiene la capacidad de extraer de un fichero de datos toda la información recogida, ya sea superficial o profunda, permitiendo realizar procedimientos estadísticos descriptivos, inferenciales y multivariantes. En este sentido, SPSS puede compararse a programas como SAS, Statgraphics o Minitab.
5. Ejecutor de Minerías de Datos.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 4
SPSS puede llevar a cabo búsquedas inteligentes, para extraer información que permanecía oculta, elaborando árboles de decisión, segmentaciones de mercados o diseños de redes neuronales de inteligencia artificial. En este sentido, SPSS puede compararse a programas como SAS.
PARTES DEL SPSS. SPSS está compuesto por varios programas o rutinas y subprogramas o subrutinas. A los programas de SPSS se les llama módulos; a los componentes de un programa (es decir, a los subprogramas), se les conoce con el nombre de procedimientos. Así, por ejemplo, el paquete estadístico SPSS tiene, entre otros, los siguientes programas o módulos:
Avanzado Base Profesional Tendencias
A su vez, el módulo Base tiene, por ejemplo, los siguientes subprogramas o procedimientos: 1. Archivo (File) 2. Frecuencias (Frequencies) 3. Descriptivos (Descriptives) 4. Tablas de Contingencia (Crosstabs) Por otra parte, el paquete estadístico SPSS se ha desarrollado a partir de la adquisición o creación de otros paquetes, como CHAID, CONJOINT, etc. A su vez, SPSS permite abrir ficheros de datos de otras aplicaciones y utilizarlas dentro de SPSS. SPSS Y EL DATA MINING. El Data Mining (DM) es una metodología de trabajo específicamente concebida para descubrir filones de información en el interior de una montaña de datos.
Se puede definir al DM mediante las siguientes 3 características:
Es un proceso sucesivo y racional de toma de decisiones.
Supone la aplicación de técnicas estadísticas avanzadas.
Representa un método alternativo de creación de preguntas.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 5
En definitiva, y a modo de símil, el DM equivaldría al arduo trabajo de un minero que, tras mucho cavar y desechar materiales inservibles, encuentra un diamante. Igualmente, en el terreno que nos ocupa (Tratamiento y Difusión de la Información), será el investigador (minero) el encargado de pulir y dar forma a ese diamante (información privilegiada) para proponer nuevas estrategias que fructifiquen en futuros beneficios empresariales.
Con la aplicación consecutiva y racional de las distintas técnicas estadísticas de SPSS se pueden realizar todas las funciones que componen el DM. De este modo, se pueden obtener nuevos e inesperados hallazgos, que darán paso irremediablemente a nuevas preguntas, consiguiendo así una potente metodología de extracción de información privilegiada que, desde el comienzo de la investigación, estaba oculta en la mina de datos.
En este sentido, SPSS puede incorporar las herramientas del DM en un proceso:
1. Sistemático: La información aportada por el paquete estadístico SPSS al DM se convierte en un sistema inteligente de toma de decisiones.
2. Iterativo: La información obtenida por el paquete estadístico SPSS en una fase del proceso del DM se reutiliza en la siguiente fase, como un flujo.
SPSS Y EL DATA WAREHOUSE. El Data Warehouse (DW) nació para dar respuesta a nuevas necesidades de la empresa moderna, más volcada en la administración de información que en la creación de la misma. Se puede resumir la génesis del DW en los siguientes factores:
La aparición de enormes cantidades de información.
La dificultad para encontrar información útil en el momento y forma adecuados.
La insuficiencia del servicio ofrecido por el DW y el Reporting para responder a preguntas cuyo planteamiento se hace inviable a partir de soluciones clásicas.
SPSS ofrece una magnífica plataforma de gestión de los datos del DW. SPSS Y MODELADO ESTADÍSTICO. El uso de técnicas estadísticas avanzadas se llama también modelado. Los avances en el software están convirtiendo a SPSS en algo más práctico. Nuevos productos para consumidores de información (frente a constructores de modelos) están facilitando este proceso. Las herramientas de modelado de SPSS se pueden clasificar en los dos grupos:

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 6
Herramientas dirigidas por la teoría. El usuario, a priori, divide las variables en dos grupos bien diferenciados: Variable dependiente, VD (respuesta) y Variable Independiente, VI (predictores).
Herramientas dirigidas por datos. No se otorga a priori a las variables ningún papel. El rol de estas técnicas es formar grupos de variables que creen un perfil de los sujetos.
Modelado Dirigido por la Teoría.
El modelado dirigido por la teoría realiza el contraste de hipótesis:
Sustenta o desaprueba ideas preconcebidas.
Especifica el modelo, basándose en el conocimiento previo.
Y contrasta la validez del modelo. Algunas de las herramientas de modelado dirigido por la teoría son:
1. Análisis de la Varianza (ANOVA) 2. Análisis de la Asociación o Correlación 3. Análisis de Series Temporales 4. Análisis de la Regresión 5. Análisis Discriminante
Modelado Dirigido por los Datos. El modelado dirigido por los datos crea automáticamente modelos, partiendo de patrones. También debe contrastarse antes de ser aceptado como válido. Algunas de las herramientas de modelado dirigido por los datos son: Reducción de Datos (Factorial, ante todo) Análisis Cluster Escalamiento Óptimo Análisis Conjunto
LA ESTADÍSTICA Y LA INVESTIGACIÓN. La estadística es una rama de las matemáticas aplicadas, dedicada al desarrollo de técnicas especiales para el óptimo manejo, descripción, entendimiento y razonamiento de datos, provenientes de observaciones. La estadística ha demostrado gran utilidad para el máximo aprovechamiento de los datos recolectados en cualquier proceso de investigación. Permite presentar los datos de modo ordenado para resolver problemas como diseño de experimentos y toma de decisiones.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 7
Actualmente se emplean con gran aceptación técnicas estadísticas para llevar a cabo estudios en diversas áreas como lo es la investigación de mercados, el control de calidad, el diseño de experimentos, etc. LOS ROLES DE LA ESTADÍSTICA. La estadística como tal hace hincapié en ganar conocimientos a través del proceso de sistematizar las observaciones y realizar inferencias o razonamientos a partir de esas observaciones. La estadística apoya el diseño de la investigación por lo menos en: 1. definición de elementos de estudio 2. características generales, criterios de inclusión y de eliminación 3. definición, control y vigilancia de la validez interna y externa 4. selección de la muestra, evitando sesgos de selección 5. tamaño de la muestra 6. determinar qué, cuándo, cómo y con qué medir, cuántas veces 7. Validez y confiabilidad de las mediciones 8. eliminación de sesgos durante la construcción 9. planear el análisis estadístico Para llevar a cabo lo anterior es preciso comprender perfectamente el fenómeno de interés; dicho fenómeno ayudara a definir de manera correcta el problema. Problema: declaración precisa de lo que se pretende conocer y por qué se quiere conocer. Método: el plan definido para llevar a cabo la investigación, es decir, cómo será adquirido el conocimiento. Usualmente es conveniente considerar el método en términos de: 1. El tipo particular de método de investigación 2. Los sujetos a estudiar (personas a ser estudiadas, fenómenos, eventos),
materiales, o procedimientos 3. Los análisis estadísticos TIPOS DE MÉTODOS. Resolver un problema de investigación requiere el diseño de un plan para la reunión de los datos. Desde un punto de vista general, tales planes caen dentro de dos principales categorías, las características que las distingue es que las observaciones pueden ser conducidas sin intentar manipular las variables bajo estudio, o los investigadores pueden imponer manipulaciones particulares en

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 8
las variables a ser estudiadas y entonces observar las consecuencias de la manipulación, estos dos enfoques se definen como:
metodo descriptivo: plan de investigación que se emprende para definir las características, relaciones o ambas, entre variables basadas en observaciones sistemáticas de esas variables.
metodo experimental: plan de investigación que se emprende para probar relaciones entre variables basadas en observaciones sistemáticas de variables que son manipuladas por el investigador.
El método descriptivo implica observación pero no el control directo sobre las variables. Por ejemplo:
Algunos estudios descriptivos comunes incluyen estudios de contenido de mensajes, encuestas de opinión pública, raitings de radiodifusión, uso de material educativo nuevo, actitudes de profesores encaminadas a la integración de los grupos, etc.
La clave fundamental en todas estas investigaciones es que alguna situación existente esta siendo estudiada. En el método experimental se prueban hipótesis de causa–efecto, es decir, manipulaciones en una variable causarán cambios en otra variable. Las dos variables se clasifican en dependiente e independiente.
variable independiente (VI): fenómeno que es manipulado por el investigador y que se presume produce un efecto en otro fenómeno.
variable dependiente (VD): fenómeno que es afectado por manipulaciones del investigador o por otro fenómeno.
CLASIFICACIÓN DE TÉCNICAS ESTADÍSTICAS Las Técnicas Estadísticas se pueden clasificar de dos formas: según las características de la VD y la(s) VI(s) y según el propósito del método estadístico. Las Técnicas Estadísticas según las características de la VD y la(s) VI(s) a su vez, en Descriptivas y Explicativas. De este modo, se obtienen tres grandes categorías:
Técnicas Estadísticas Descriptivas (figura 2).

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 9
Figura 2. Métodos descriptivos.
Técnicas Estadísticas Explicativas (figura 3).
Técnicas Estadísticas Según Propósito (figura 4).

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 10
Figura 3. Métodos explicativos.
Figura 4. Métodos multivariables.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 11
Resultados: declaración precisa de todos los conocimientos que se adquirieron. Un buen plan de análisis es aquel que ha sido elaborado con extrema precaución, se entiende el problema a resolver y por tal motivo se sabe qué clase de técnica será para llegar a los resultados esperados. En pocas palabras el rol de la estadística consiste en proveer herramientas que podamos utilizar para llevar a cabo todo tipo de investigaciones, ya sea de tipo cuantitativo o incluso de tipo cualitativo. El uso de la estadística implica responsabilidad, pues es necesario conocer con qué clase de datos se cuenta, ya que estos suelen dividirse en diferentes categorías. En varias clases de estudios, las mediciones se centran en cada individuo que compone la población o la muestra, típicamente se les denomina sujetos. Los materiales en un estudio incluyen todas las herramientas que el investigador haya empleado para realizar la investigación. En un experimento, los materiales incluyen todo aquello que el investigador haya utilizado para manipular la variable independiente, además de instrumentos para medir. Los procedimientos en un estudio se refieren a la manera precisa en la cual los materiales han sido aplicados a los sujetos y cómo se han guiado los datos en el estudio. Generalmente los procedimientos influyen en el tipo de estadísticas a utilizar. Se deberá identificar qué procedimientos estadísticos se utilizarán, y qué criterios serán utilizados en el razonamiento de los resultados que se obtengan de la población bajo estudio. La selección del método estadístico depende, por supuesto, de qué tipo de deducciones matemáticas se tengan que realizar, qué características de la población interesan (promedios, dispersiones, etc.), qué comparaciones poblacionales se pueden hacer y qué tipo de escala de medición se utilizará. ESCALAS DE MEDICIÓN. Escala nominal o clasificatoria. Asignación de números o símbolos para nombrar subclases que representan características únicas. A veces es llamada escala clasificatoria, la escala nominal es la escala más débil de medición. De las cuatro escalas de medición, ésta implica la menor información acerca de las observaciones. Por ejemplo:
Si los investigadores clasifican las observaciones en categorías mutuamente excluyentes, como dividir la gente por el color de sus ojos (una clase), en subclases (ojos azules, cafés, verdes), están utilizando una escala nominal. No hay ninguna intención de ordenamiento entre las categorías.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 12
Diferentes clases de observaciones pueden ser identificadas numéricamente. Por ejemplo:
En cuanto a los ojos, los colores pueden numerarse de la siguiente manera: Azul=1, café=2, verde=3. El uso de los números implica únicamente la operación de numeración.
La escala nominal consiste simplemente en la división de características (clases) en subclases mutuamente excluyentes, es decir, diferentes unas de otras, pero que en conjunto forman la clase total de características del fenómeno de estudio. Escala ordinal o de rango. Asignación de números o símbolos para el propósito de identificar relaciones ordenadas de algunas características. El orden no cuenta con intervalos especificados. Al igual que la escala nominal, la escala ordinal es débil. Lo importante de la escala ordinal, es que entre subclase se presenta un orden, esto es, cada subclase puede ser comparada con cualquier otra subclase en términos de una relación de ―mayor que‖, o ―menor que‖. Se debe tener en cuenta que la escala ordinal no indica la diferencia en cuanto a magnitud entre categorías ordenadas. Por ejemplo:
Los cuestionarios utilizados en las encuestas a menudo utilizan escalas ordinales.
Los niños del kinder ven la televisión: 1. Demasiado 2. Un poco 3. No la ven
Por favor ordene en orden de importancia, para usted, los siguientes medios de comunicación para mantenerse informado (radio, periódicos, televisión, revistas)
1______________________________ 2______________________________ 3______________________________ 4______________________________ 5______________________________
En ambos casos arriba mencionados los números son asignados para indicar el orden relativo de las respuestas, pero no se asume que la diferencia entre, 1 y 2 es igual a la diferencia entre 3 y 4, del mismo modo la diferencia entre 2 y 4 no es el doble en cuanto a la magnitud, de la diferencia entre 1 y 3. En pocas palabras nada esta dicho o asumido en cuanto a la magnitud de los intervalos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 13
entre números, pero sí es un hecho que ―2‖ es menor que ―3‖, o ―6‖ es mayor que ―5‖, y así sucesivamente los números son únicamente etiquetas. Otros ejemplos:
Tecnología baja, tecnología media, tecnología alta Ordenar los niños por altura (sin medirlos)
En esta escala de medición pueden asignarse números a las observaciones, pero la distancia entre ellos no se conoce. (Se sabe que un niño es mas alto que el que lo antecede, pero no se sabe cuanto mas alto, y el siguiente no tiene por que ser mas alto como él lo es respecto de su anterior). Escala de intervalo. Las observaciones medidas en esta escala son susceptibles de clasificarse en categorías, pueden ser ordenadas de menor a mayor y además puede medirse la distancia entre dos observaciones. En esta escala de medida se requiere una unidad de distancia de un cero, aunque ambos sean arbitrarios. Ejemplos:
La temperatura; que usualmente se mide en grados Celcius o Fahrenheit. La unidad de medida y el cero son arbitrarios.
212℉ − 92℉
212℉ − 152℉≠
100℃ − 33.3℃
100℃ − 66.7℃
32o 92o 152o 212o
FAHRENHEIT
congelado hirviendo
0o 33.3o 66.7o 100o CELCIUS
El nivel de daño en un cultivo. Puede clasificarse en una escala de medida con un cero arbitrario de daño:
Menos de Daño 5% 10% 20% 30%
Escala 0 1 2 3
Esta escala de medida es la primera realmente cuantitativa, como se habrá notado, las escalas de medición son ―acumulativas‖, o sea, tienen todas las propiedades del nivel anterior y algunas más. Para esta escala lo que

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 14
agregamos es que la diferencia entre dos observaciones tienen sentido (obviamente también la suma). En resumen, esta escala tiene asignación de números con el propósito de identificar relaciones ordenadas de algunas características. El orden tiene asignados intervalos arbitrarios de igual magnitud, pero un punto cero arbitrario. Cuando se considera una escala de intervalo, la atención se enfoca a las diferencias entre los valores de la escala. Escala de razón o de proporción. Asignación de números para el propósito de identificar relaciones ordenadas de algunas características, el orden tiene asignados intervalos de igual magnitud, pero con un punto cero absoluto. Con las escalas de razón se puede reflejar de manera mas acertada la realidad, que con cualquier otra escala. Las observaciones medidas en esta escala son susceptibles de clasificarse en categorías, ser ordenadas de menor a mayor, puede medirse la distancia entre dos observaciones, se tiene un cero que no es arbitrario y la razón entre dos observaciones tiene sentido, ejemplos:
rendimiento de una hectárea de maíz las estaturas de un grupo de 10 niños
36′′ − 12′′
36′′ − 24′′=
91.44𝑐𝑚 − 30.48𝑐𝑚
91.44cm − 60.96cm
0‘‘ 12‘‘ 24‘‘ 36‘‘
0cm 30.48cm 60.96cm 91.44cm
En los casos donde la investigación requiera más de una simple clasificación u orden, será preferible trabajar con escalas de razón lo mismo que en operaciones de enumeración. El siguiente esquema indica el nivel comparativo de confiabilidad entre las escalas.
Menos confiable Más confiable NOMINAL ORDINAL INTERVALO RAZÓN

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 15
Para hacer un uso apropiado y eficiente, desde el punto de vista de la informática, deben usarse los métodos estadísticos más potentes que la escala permita, de lo contrario se está perdiendo información; es decir se está haciendo un uso inapropiado de los datos. Cuando se está en la etapa de captura de datos se debe tener en cuenta, como guía, el tipo de análisis que se hará, para obtener los datos apropiados y medidos en el nivel apropiado. Es un error no capturar datos o con un nivel débil, pero igualmente es un error capturar datos con un nivel mas fuerte del necesario para el análisis posterior. Índices de tendencia central. Con frecuencia se escuchan preguntas como: ¿cuál es el ingreso per cápita de la población en México?, ¿cuántos cigarrillos se fuma un adolecente en promedio?, ¿cuál es el promedio de horas que la población urbana ve la televisión?, ¿cuál es el numero promedio de llamadas telefónicas que se reciben en un conmutador a diferentes horas del día o la noche?; en promedio ¿cuántos accidentes automovilísticos ocurren como resultado directo del alcohol o las drogas?; etc.. Una forma elemental y práctica de describir a un grupo en su totalidad es encontrar un número único que represente lo ―típico‖ o promedio de ese grupo. En matemáticas, este valor se conoce como una medida de tendencia central, ya que generalmente está localizada a la mitad o en el centro de una distribución de datos. Por lo que la tendencia central de un conjunto de datos es la disposición de estos para agruparse ya sea alrededor del centro o de ciertos valores numéricos. Se distinguen básicamente tres medidas de tendencia central:
Moda o modo: la categoría que ocurre con mayor frecuencia. Mediana: valor para el cual, cuando todas las observaciones se ordenan
de manera creciente, la mitad de estas es menor que este valor y la otra mitad mayor.
Media: suma de las puntuaciones en una distribución, dividida por el número de puntuaciones.
Índices de dispersión Existen índices que describen la variabilidad de un conjunto de datos. Variabilidad: dispersión de las observaciones en el conjunto de datos. Se distinguen básicamente tres medidas de dispersión: Rango: puntuación más alta en una distribución menos la más baja.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 16
Varianza: promedio del cuadrado de las distancias entre cada observación y la media del conjunto de observaciones.
Desviación estándar: raíz cuadrada positiva de la varianza. ESTADÍSTICAS EMPLEADAS PARA EL RESUMEN DE DATOS. Son las medidas que proveen una representación de algunas características de un grupo de datos. ¿qué hacen? 1. Media, mediana y moda proveen una medida de localidad (promedio). 2. Varianza, desviación estándar y otras estadísticas relacionadas proveen
una medida de dispersión (extensión). 3. Porcentaje, puntuación top box, y otras estadísticas relacionadas proveen
una medida de incidencia. 4. Otras estadísticas proveen una medida de sesgo (asimetría) y curtosis
(―picudez‖ de una distribución). ¿para qué se utilizan?
Para sumarizar datos clasificados, y otras variables obtenidas en la investigación.
Como datos de entrada para pruebas de significancia y otros análisis estadísticos.
Para comparar diferencias entre grupos y cambios en el tiempo, en varias evaluaciones.
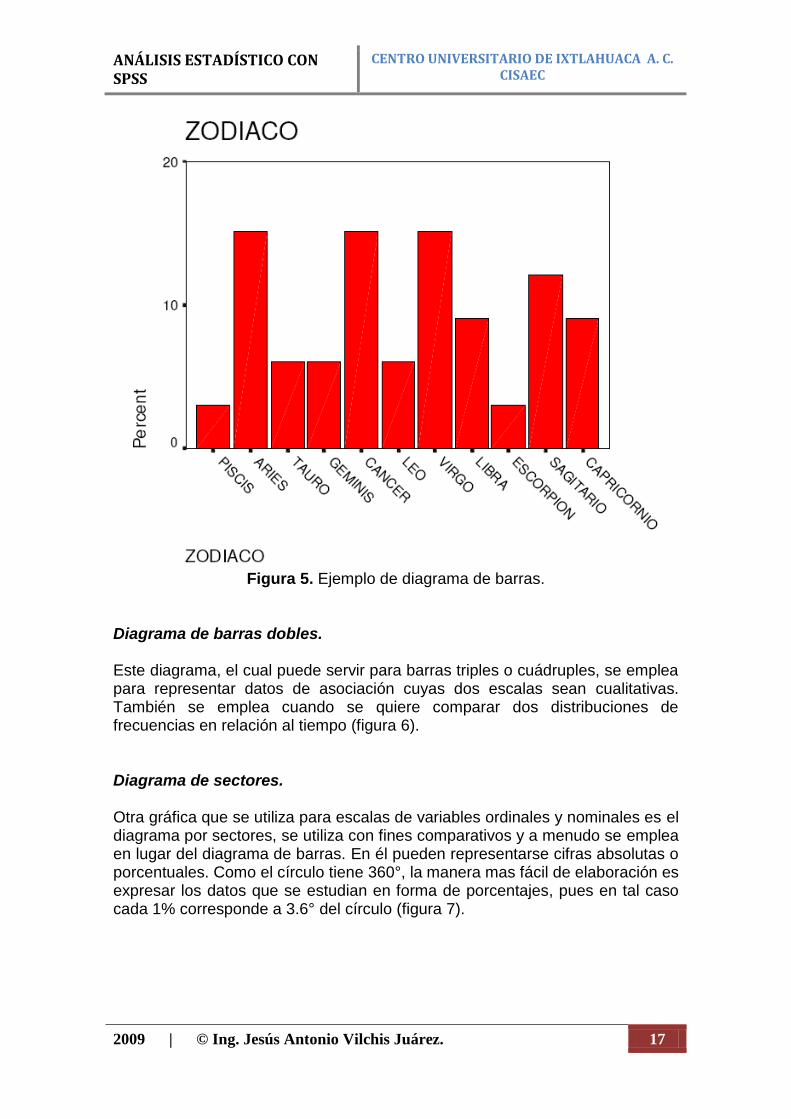
Para combinar datos de varios grupos. ¿dónde se pueden localizar? En cualquier paquete estadístico de múltiples propósitos como SAS, SPSS, STATGRAPHICS., etc.. PRESENTACIÓN GRÁFICA. Diagrama de barras. Es el procedimiento gráfico empleado para representar los datos tanto en escalas nominales como ordinales. Para cada categoría se traza una barra vertical en la que la altura de la barra representa el numero de miembros de esa clase. Las barras deben de ser siempre del mismo ancho, y el espacio que las separa no debe ser mayor que el espesor de ellas mismas (figura 5).
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 17
Figura 5. Ejemplo de diagrama de barras.
Diagrama de barras dobles. Este diagrama, el cual puede servir para barras triples o cuádruples, se emplea para representar datos de asociación cuyas dos escalas sean cualitativas. También se emplea cuando se quiere comparar dos distribuciones de frecuencias en relación al tiempo (figura 6). Diagrama de sectores. Otra gráfica que se utiliza para escalas de variables ordinales y nominales es el diagrama por sectores, se utiliza con fines comparativos y a menudo se emplea en lugar del diagrama de barras. En él pueden representarse cifras absolutas o porcentuales. Como el círculo tiene 360°, la manera mas fácil de elaboración es expresar los datos que se estudian en forma de porcentajes, pues en tal caso cada 1% corresponde a 3.6° del círculo (figura 7).

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 18
Figura 6. Ejemplo de diagrama de barras dobles.
Figura 7. Ejemplo de diagrama de sectores.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 19
Histograma. La gráfica que se utiliza para representar distribuciones de frecuencias en escala cuantitativa como por ejemplo; peso, estatura; y cuantitativa discreta, como por ejemplo: numero de niños en una familia, numero de días de ausencia; etc., es el histograma. En este, el fenómeno que se estudia queda representado por una serie de rectángulos semejantes al del diagrama de barras y estos tienen una área igual o proporcional a su respectiva frecuencia. Además las barras del histograma siempre se colocan en forma vertical y deben ir unas al lado de las otras, sin que haya ningún espacio que las separe (figura 8).
Figura 8. Ejemplo de histograma.
EL PLAN DE LA INVESTIGACIÓN. Es importante considerar a fondo cada uno de los aspectos involucrados en una investigación, ya que a medida que se comprenda cada una de las partes involucradas se realizará un mejor estudio.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 20
El problema Una investigación inicia con la presencia de un problema o la necesidad de información, es imprescindible preguntarse por qué es importante estudiar el fenómeno de interés. El problema en sí mismo, se define en una declaración. Por ejemplo: ―el propósito de este estudio es determinar el promedio de estudiantes universitarios, en el Estado de México, que consumen cerveza x‖; o ¿cuál es el promedio de estudiantes universitarios, en el Estado de México, que consumen cerveza ―la corona‖? Otra manera de declarar una investigación o estudio es mediante una hipótesis. Hipótesis: declaración susceptible de ser probada (aceptada o rechazada), mediante la aplicación de razonamientos y técnicas apropiadas. Por ejemplo: ―los estudiantes universitarios del Estado de México, consumen más cerveza ―x‖ que los estudiantes universitarios de Chiapas‖. Un problema se declara en forma de hipótesis únicamente cuando hay suficientes razones para llevar a cabo predicciones futuras. Declarar un problema es muy importante, pues a partir de la declaración se elige el tipo de herramienta estadística a utilizar. Además la declaración del problema provee una definición preliminar de la población a ser estudiada; esto también tiene consecuencias en cuanto a las estadísticas que serán utilizadas. Quizá el investigador analice a la población entera y se utilicen únicamente estadísticas descriptivas, o se tome una muestra de la población y se utilicen estadísticas descriptivas y muestrales. OBSERVACIONES Y ESTADÍSTICA. Es importante comparar aquellos fenómenos que el investigador observa y la manera en que la estadística analiza y reporta esas observaciones. fenómeno: características susceptibles de ser observadas para cualquier objeto o evento. Cualquier segmento de la realidad que puede estar bajo observación. variable: característica observable de un objeto o evento que puede ser descrita de acuerdo a alguna clasificación o esquema de medición. datos: reportes de las observaciones de las variables. mediciones: asignación de números o símbolos para diferenciar características de una variable. Por ejemplo: Supóngase que el interés de los lectores de ciertos artículos se clasifica en tres clases, donde 1 significa ―mucho interés‖, 2 ―medio interés‖, 3 ―poco interés‖.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 21
Todas las observaciones, y de lo que de ellas emana (variables, escalas, mediciones, etc.), provienen de lo que se llama población. población: colección de toda la posible información y observaciones que caracterizan a un fenómeno. Lo que sea que se haya definido como población, es puramente arbitraria; depende de los límites del problema a investigar. En la práctica es bastante difícil realizar estudios de una población en su conjunto, en lugar de analizar cada dato de la población se analiza una parte de ellos. Muestra: subconjunto representativo seleccionado de una población.
METODOLOGÍAS ESTADÍSTICAS METODOLOGÍA ESTADÍSTICA SIMPLE. Sólo afecta a una o dos variables. Métodos descriptivos: Estadística descriptiva. Ofrece una visión superficial de las características.
Frecuencias,
Tablas de contingencia o
Exploración. Métodos explicativos: Estadística inferencial. Ofrece una visión profunda de las características del fenómeno.
- ANOVA, - T-test y - Medias.
METODOLOGÍA ESTADÍSTICA MÚLTIPLE O COMPLEJA. Afecta a una multiplicidad de variables: Métodos multivariantes. Métodos jerárquicos: Estadística que divide las variables en dependientes (VD) e independientes (VI).
- Análisis de regresión múltiple. Métodos no jerárquicos: Estadística que no divide a las variables en dos, sino que todas ellas tienen idéntico status.
- Análisis cluster, - Análisis factorial o - Escalamiento.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 22
ANÁLISIS DESCRIPTIVO BIVARIANTE. VD Métrica y VI No métrica: Explore (examine).
o Frecuencias, Histograma, Estadísticas. o Tests (Normalidad y Homocedasticidad). o Gráficas de cajas (Boxplot).
VD Métrica y VI Temporal (fecha): Graphs-sequence (tsplot).
Análisis de series temporales (ARIMA) VD Métrica y VI Métrica: Grafico de dispersión (Scatterplot). VD Métrica y VI Métrica: Análisis de correlación (Correlate). VD No métrica y VI No métrica: Análisis o tabla de asociación ode contingencia. Tablas cruzadas o de la Chi-Cuadrada (Crosstabs).
Tablas de frecuencias por celdas (frecuencias relativas (%) y absolutas).
Estadísticos que miden la fuerza de la asociación. Pueden ser de varios tipos:
Pearsonianos o simétricos (tienen valores entre 0 y 1).
Direccionales o RPE (tienen valores entre -1 y 1). VD Métrica y VI No métrica: Análisis de la varianza simple (t-test de muestras independientes.
T-test realiza una comparación simple de medias.
Contrasta las H0 de igualdad de varianzas (homocedasticidad) y de igualdad de medias.
VD Métrica y VI No métrica: Análisis de correlación (t-test de muestras dependientes). VD Métrica y VI No métrica: Comparación de medias (Means). VD Métrica y VI No métrica: Comparación de varianzas (ANOVA de una vía – Oneway).
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 23
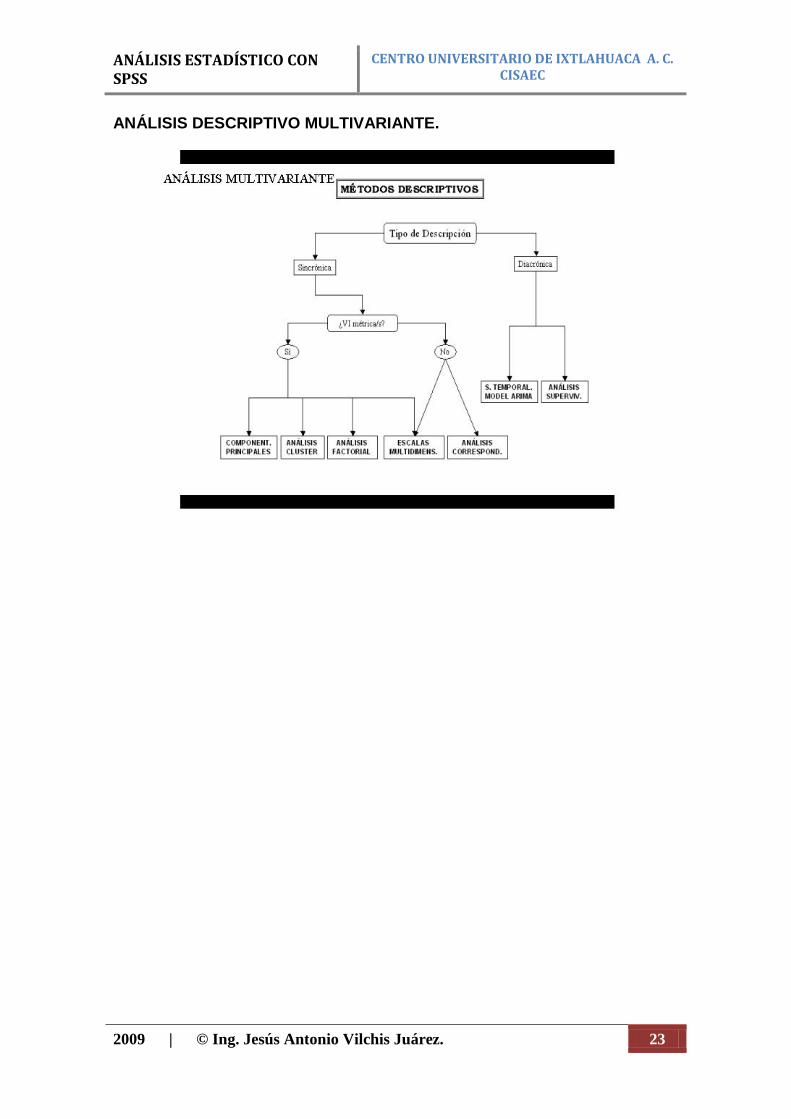
ANÁLISIS DESCRIPTIVO MULTIVARIANTE.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 24
INICIO DE SPSS
Para iniciar SPSS: ► Elija en el menú Inicio de Windows (figura 9): Programas SPSS para Windows SPSS para Windows
Figura 9. Ventana para iniciar SPSS 15.0 para Windows.
Al iniciar el programa se abre automáticamente el asistente de inicio (figura 10), el cual plantea la pregunta ¿Qué desea hacer? Y abarca 6 posibilidades:
Ejecutar tutorial.
Introducir datos.
Ejecutar una consulta creada anterior mente.
Crear una nueva consulta mediante el asistente de datos.
Abrir una fuente de datos existente.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 25
Figura 10. Asistente de inicio.
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 26
Abrir otro tipo de archivo.
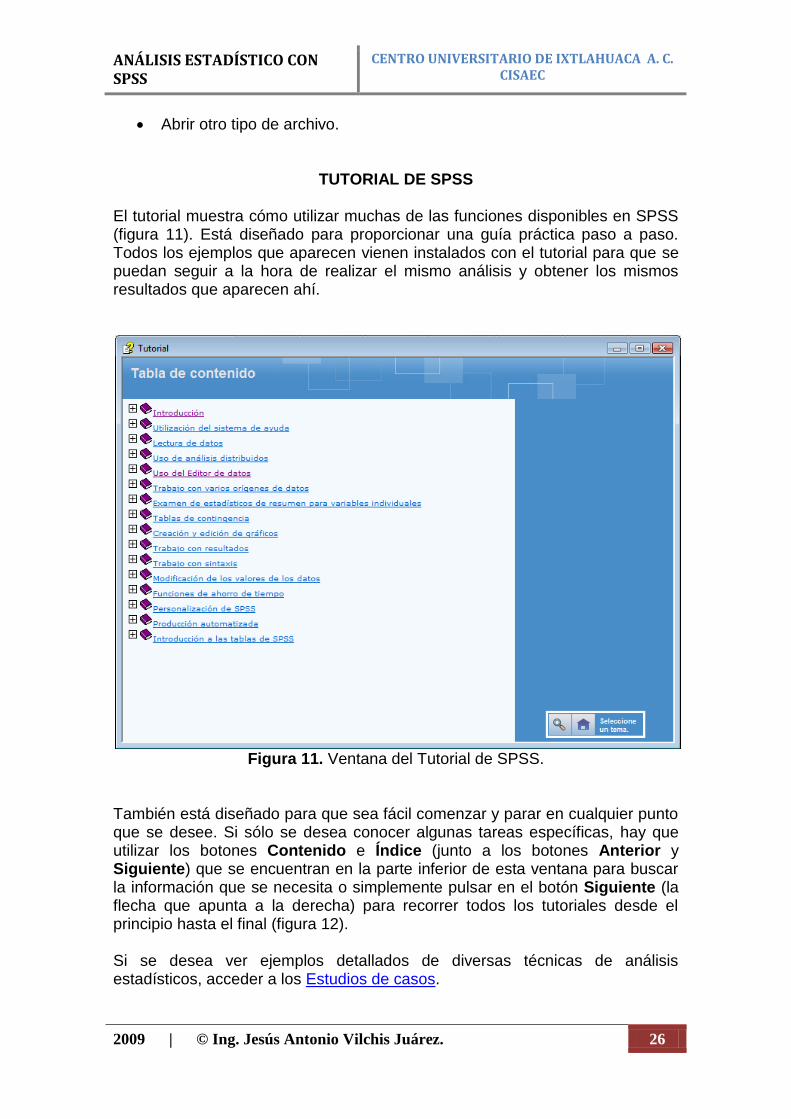
TUTORIAL DE SPSS El tutorial muestra cómo utilizar muchas de las funciones disponibles en SPSS (figura 11). Está diseñado para proporcionar una guía práctica paso a paso. Todos los ejemplos que aparecen vienen instalados con el tutorial para que se puedan seguir a la hora de realizar el mismo análisis y obtener los mismos resultados que aparecen ahí.
Figura 11. Ventana del Tutorial de SPSS.
También está diseñado para que sea fácil comenzar y parar en cualquier punto que se desee. Si sólo se desea conocer algunas tareas específicas, hay que utilizar los botones Contenido e Índice (junto a los botones Anterior y Siguiente) que se encuentran en la parte inferior de esta ventana para buscar la información que se necesita o simplemente pulsar en el botón Siguiente (la flecha que apunta a la derecha) para recorrer todos los tutoriales desde el principio hasta el final (figura 12). Si se desea ver ejemplos detallados de diversas técnicas de análisis estadísticos, acceder a los Estudios de casos.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 27
Figura 12. Botones para seleccionar un tema del tutorial de SPSS.
USO DEL EDITOR DE DATOS
En el Editor de datos se muestra el contenido del archivo de datos activo (figura 13). La información incluida en el Editor de datos consta de variables y casos.
En la Vista de datos, las columnas representan las variables y las filas representan los casos (observaciones).
En la Vista de variables, cada fila es una variable y cada columna es un atributo asociado a dicha variable.
Las variables se utilizan para representar los diferentes tipos de datos que haya recopilado. Una analogía común es la de una encuesta. La respuesta a cada pregunta de una encuesta equivale a una variable. Las variables son de distintos tipos, incluyendo números, cadenas, moneda y fechas. INTRODUCCIÓN DE DATOS NUMÉRICOS Los datos se pueden introducir en el Editor de datos, lo que puede resultar útil para archivos de datos pequeños o para realizar tareas de edición menores en archivos de datos más grandes.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 28
Figura 13. Editor de datos SPSS.
VENTANA EDITOR DE DATOS. Esta es la ventana principal del paquete; en ella encontramos las herramientas fundamentales del programa, además esta ventana es la única que nos permite observar la información (Datos y Variables), en su forma original (desagrupada), para tener una idea más clara debemos conocer algunos conceptos fundamentales. Antes de conocer las partes del editor de datos es necesario conocer cómo está diseñada la estructura de los datos en SPSS (tabla 1).
Tabla 1. Estructura de los datos.
VARIABLE 1 VARIABLE 2
CASO 1 Observaciones Observaciones
CASO 2 Observaciones Observaciones
Las columnas representan las variables o preguntas y las filas contienen las observaciones, mediciones o respuestas. Cada caso contiene las respuestas de un individuo a la totalidad de las preguntas o variables. PARTES DE LA VENTANA. El editor de datos de divide en 5 partes:
o Barra de menús.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 29
Como cualquier programa basado en ambiente Windows, el editor de datos del SPSS posee una barra de menús desplegables, dentro de los cuales podemos encontrar diferentes aplicaciones, procedimientos o procesos. En SPSS se cuenta con 10 diferentes menús desplegables como lo son: Archivo, Edición, Ver, Datos, Transformar, Analizar, Gráficos, Utilidades, Ventana y Ayuda (?).
o Barra de herramientas. En esta barra se encuentran los procedimientos más comúnmente utilizados, se puede personalizar el contenido de esta barra mediante la opción menú Ver… Barra de herramientas (figura 14). Al hacer clic nos abre un nuevo cuadro de diálogo llamado mostrar barra de herramientas (figura 15), en el cual encontraremos la opción personalizar en la parte inferior derecha; al hacer clic en ella, se abre un nuevo cuadro llamado Personalizar barra de herramientas (figura 16a), en el cual encontraremos cada uno de los procesos, procedimientos o elementos que posee el programa.
Figura 14. Menú Ver….
Por defecto la barra posee las funciones: (1) Abrir archivo, (2) Guardar archivo, (3) Imprimir Como podemos observar, estos 3 iconos son comunes en casi todos los programas para Windows, por lo cual no entraremos en detalle de ellos. (4) Recuperar cuadro de diálogo
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 30
Figura 15. Mostrar barra de herramientas.
Figura 16a. Personalizar barra de herramientas.
Este icono nos permite acceder de forma rápida a los últimos procedimientos que hayamos efectuado en SPSS, es decir, nos muestra los diferentes cuadros de diálogo (ventanas) a que hayamos ejecutado (entrado) con anterioridad como frecuencias, gráficos, tablas, etc. Lo que hace es abrirlo nuevamente. (5) Deshacer, (6) rehacer
1 2
3 4 5 6
7 8
9
10 11
0
12
13
0
14

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 31
Estepar de iconos también son comunes en la mayoría de los programas para Windows. Se activan después de realizar alguna operación en el paquete. (7) Ir a caso Como su nombre lo indica, nos permite ir a un caso específico, es decir, ir a la posición donde se ubica dicho caso. (8) Variables Cuando seleccionamos este icono se abre un nuevo cuadro de diálogo (figura 17), en el cual nos muestra toda la información de cada una de las variables (el nombre, la etiqueta, si hay o no valores perdidos, el nivel de medida, los valores y las etiquetas de cada valor).
Figura 17. Variables.
La forma de utilizarlo es haciendo clic sobre la variable que deseemos en la lista. (9) Buscar Este icono nos permite ubicar un valor dentro de una variable, es decir, nos permite encontrar un número o una combinación de caracteres dentro de los registros. Dado que generalmente se utilizan números para representar una categoría (hombre = 0 y mujer = 1), y las bases de datos poseen múltiples variables, sería ilógico esperar que la búsqueda se realice en todo el archivo, es por este motivo que al activar el icono aparece en la parte superior del cuadro de diálogo (figura 18) la frase “Buscar datos en la variable *****” (***** = nombre de la variable). La forma de seleccionar una variable es hacer clic sobre ella en el editor de datos, con lo cual el nombre de la variable en la frase cambiará por el de la seleccionada. Podemos observar en el cuadro de diálogo Buscar, una pequeña casilla en

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 32
Figura 18. Buscar datos en variable….
la parte inferior izquierda la cual nos da la posibilidad de pedirle que la búsqueda sea lo más exacta posible; esta opción sólo se utiliza en variables alfanuméricas. Por último tenemos el botón Buscar siguiente el cual nos permite pasar de un caso o registro encontrado al siguiente. (10) Insertar caso Como su nombre lo indica nos permite ingresar un nuevo caso, es decir, las respuestas de un nuevo individuo. Hago énfasis en las respuestas, ya que generalmente se trabaja con encuestas, pero también pueden ser observaciones si se trata de un experimento. (11) Insertar variable Nos permite ingresar una nueva variable o pregunta, no necesariamente tiene que ser respondida por todos los individuos. (12) Segmentar archivo Este icono nos permite dividir nuestra base en distintos grupos de acuerdo a la variable que utilicemos para la segmentación, al hacer clic sobre el icono se abre un nuevo cuadro de diálogo (figura 19), el cual nos brinda 3 posibilidades:
Analizar todos los casos, no crear los grupos: Esta opción nos permite trabajar con todos los casos de la base y sacar resultados (estadísticos), con todos los casos u observaciones.
Comparar los grupos: Esta opción nos permite comparar los resultados de cada uno de los grupos.
Organizar los resultados por grupos: Esta opción nos permite ver de forma organizada los resultados (gráficos, tablas, estadísticos) por cada uno de los grupos. Esta opción es bastante útil si nosotros deseamos hacer un nálisis separado de la muestra por algún tipo de ―rango‖, como por ejemplo el género, o la región, o la fecha, etc..

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 33
Figura 19. Segmentar archivo.
La forma de utilizarlo es seleccionar una de las dos últimas opciones e ingresar la variable o las variables que deseamos utilizar como rango y luego darle aceptar, después de esto cada procedimiento (tablas, gráficos o estadísticos) que le pidamos al programa nos lo mostrará de acuerdo a la segmentación. (13) Ponderar Ponderar es dar un peso o valor diferente a cada uno de los casos, es decir, darle mayor importancia a unos valores que a otros, esto se hace con el fin de poder sacar algún resultado representativo de la población y no de la muestra. (14) Seleccionar casos Selecciona sólo aquellos casos que cumplan una condición o también podemos pedirle al programa que tome un fragmento de los casos ya sea de forma arbitraria o no. (15) Etiquetas de valor (figura 16b) Esta opción nos permite observar los valores de los datos o la categoría a la que corresponde, es decir, cuando está activada vemos en el editor de datos las palabras de cada uno de los rangos de las variables y por el contrario, cuando está desactivada, vemos los números que les corresponde dentro de cada variable, es útil para hacerse una idea de los datos. (16) Usar conjuntos (figura 16b) Este icono nos permite generar o utilizar conjuntos de variables, es útil cuando trabajamos con preguntas de respuesta múltiple o tenemos variables que podemos agrupar para hacer un análisis específico.
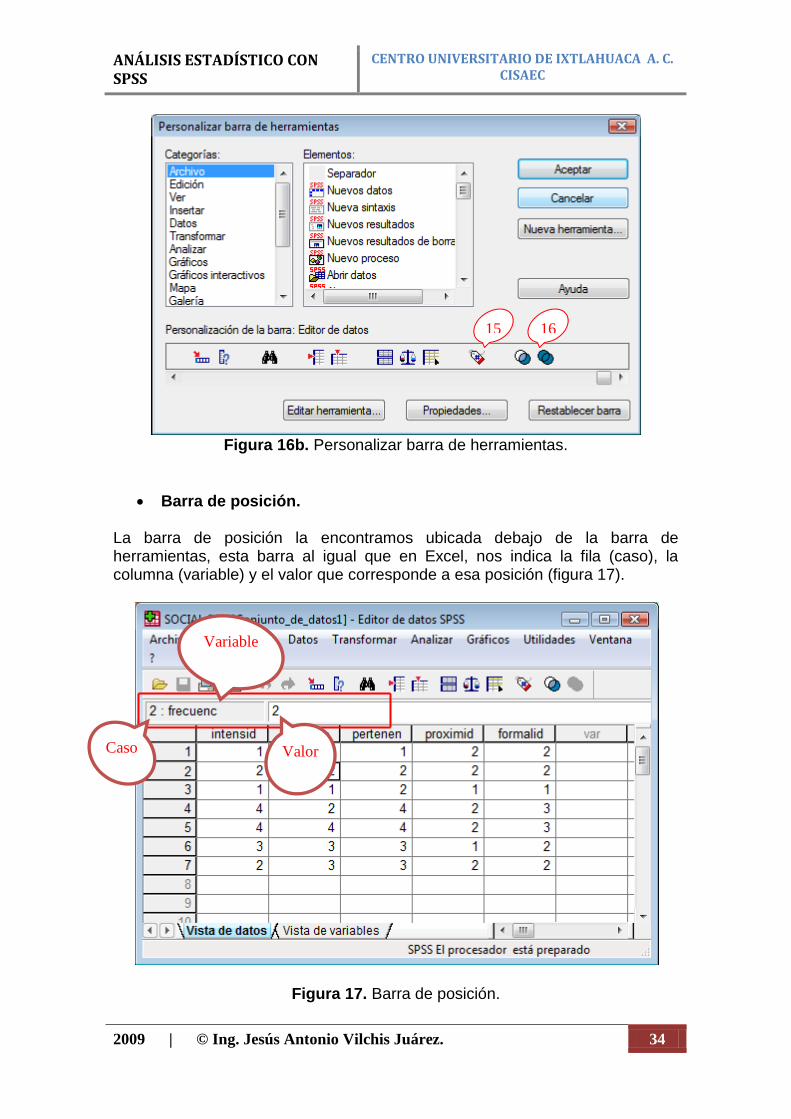
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 34
Figura 16b. Personalizar barra de herramientas.
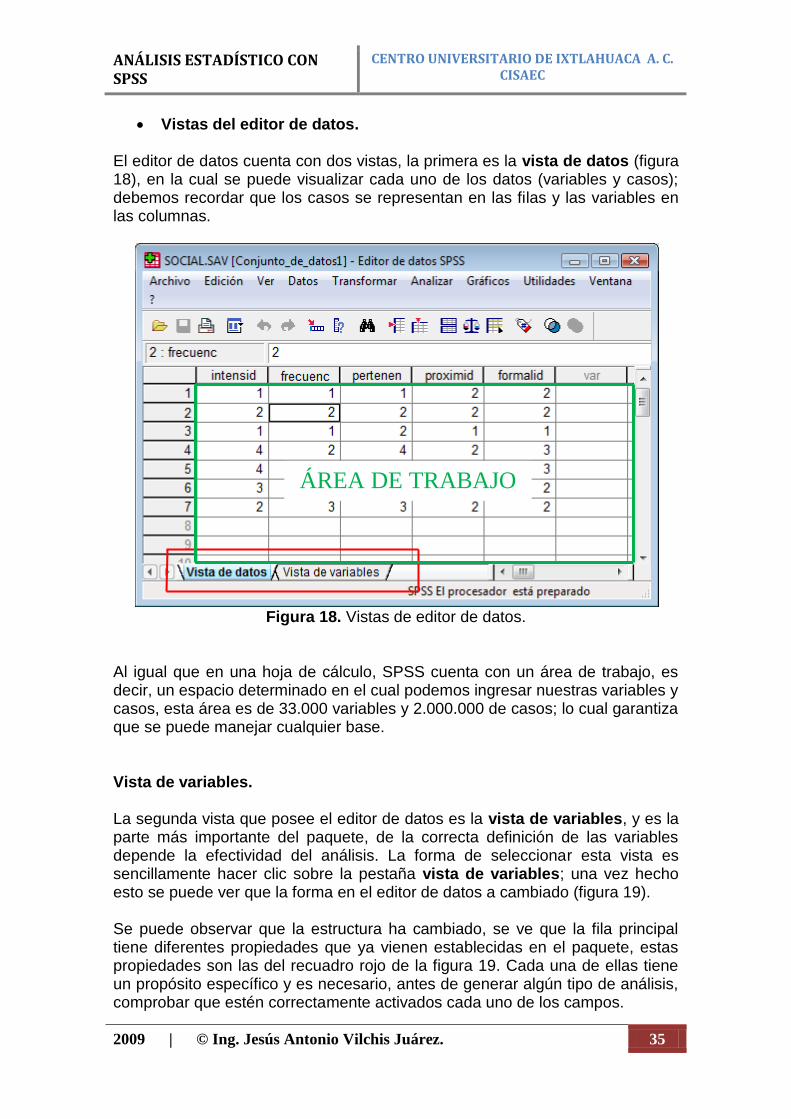
Barra de posición. La barra de posición la encontramos ubicada debajo de la barra de herramientas, esta barra al igual que en Excel, nos indica la fila (caso), la columna (variable) y el valor que corresponde a esa posición (figura 17).
Figura 17. Barra de posición.
16 15
Caso
Variable
Valor
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 35
Vistas del editor de datos. El editor de datos cuenta con dos vistas, la primera es la vista de datos (figura 18), en la cual se puede visualizar cada uno de los datos (variables y casos); debemos recordar que los casos se representan en las filas y las variables en las columnas.
Figura 18. Vistas de editor de datos.
Al igual que en una hoja de cálculo, SPSS cuenta con un área de trabajo, es decir, un espacio determinado en el cual podemos ingresar nuestras variables y casos, esta área es de 33.000 variables y 2.000.000 de casos; lo cual garantiza que se puede manejar cualquier base. Vista de variables. La segunda vista que posee el editor de datos es la vista de variables, y es la parte más importante del paquete, de la correcta definición de las variables depende la efectividad del análisis. La forma de seleccionar esta vista es sencillamente hacer clic sobre la pestaña vista de variables; una vez hecho esto se puede ver que la forma en el editor de datos a cambiado (figura 19). Se puede observar que la estructura ha cambiado, se ve que la fila principal tiene diferentes propiedades que ya vienen establecidas en el paquete, estas propiedades son las del recuadro rojo de la figura 19. Cada una de ellas tiene un propósito específico y es necesario, antes de generar algún tipo de análisis, comprobar que estén correctamente activados cada uno de los campos.
ÁREA DE TRABAJO

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 36
Figura 19. Vista de variables.
También se puede notar que ahora las filas corresponden a cada una de las variables de la base o archivo. Por lo tanto la estructura de la vista de variables es como se muestra en la tabla 2.
Tabla 2. Estructura de la Vista de variables.
Propiedades Propiedades
Variable 1 Definición Definición
Variable 2 Definición Definición
Es importante hacer notar que en esta vista hay una gran diferencia con la vista de datos (figura 20), esto es debido a que en la vista de variables se definen las características de las variables, es decir, sus propiedades y no se van a modificar los datos; lo único que se realiza es ingresar información importante de las variables, la cual será utilizada en el análisis.
Vista de datos Vista de variables
Registros
Variables
columnas
Variables
Definición
columnas
Filas Filas
Figura 20. Comparación de las estructuras de las vistas.
Una vez aclaradas las diferencias estructurales de las vistas, podemos continuar. Ahora conoceremos cada una de las propiedades de las vistas, las cuales son:

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 37
Nombre. El nombre de la variable es la forma de identificarla, cada variable debe
tener un nombre único y sus características son:
Puede ser alfanumérica, es decir letras y números.
El primer carácter debe ser siempre una letra.
No se puede utilizar palabras clave (reservadas) como AND, OR y NOT.
No se pueden utilizar caracteres específicos (+, -, *, /, !, ―, etc.). Tipo. El tipo de la variable especifica la forma de los datos de cada variable, es decir, identifica el tipo de caracteres que encontraremos en los registros. Es aconsejable trabajar las variables de forma numérica, ya que el análisis estadístico es una ciencia matemática y para su correcto funcionamiento es necesario realizar las operaciones con números. En algunos casos no es posible tener los datos de forma numérica, para estos casos el paquete nos permite trabajarlos como una cadena de caracteres. La forma de activarlo, es haciendo clic en la casilla tipo correspondiente a la variable que estamos editando; con lo cual la activaremos. En ese momento podemos ver un pequeño botón con unos pontos suspensivos, haciendo clic sobre él activaremos el cuadro de diálogo tipo de variable (figura 21). Los tipos que maneja SPSS son:
Figura 21. Tipo de variable.
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 38
Numérico: una variable numérica cuyos valores son números y se muestran de forma estándar, es decir, asume la notación por defecto de Windows para la separación decimal (enteros (,) decimales) ―1000,00‖; es el tipo más usado. Coma: una variable numérica cuyos valores se muestran con comas que delimitan cada tres posiciones y con el punto como delimitador decimal ―1,000,00‖. Punto: una variable numérica cuyos valores se muestran con puntos que delimitan cada tres posiciones y con la coma como delimitador decimal ―1.000,00‖. Notación científica: una variable numérica cuyos valores son demasiado grandes o pequeños, por lo cual se utiliza un exponente con signo que representa una potencia en base diez. Por ejemplo:
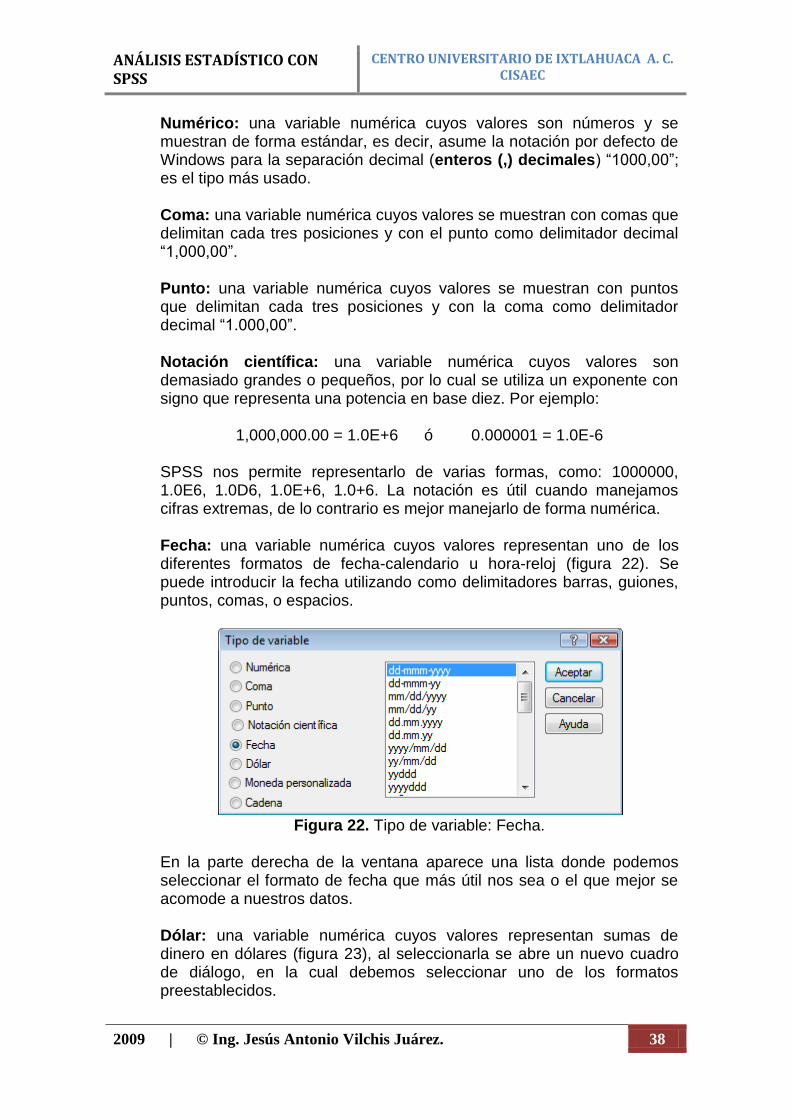
1,000,000.00 = 1.0E+6 ó 0.000001 = 1.0E-6 SPSS nos permite representarlo de varias formas, como: 1000000, 1.0E6, 1.0D6, 1.0E+6, 1.0+6. La notación es útil cuando manejamos cifras extremas, de lo contrario es mejor manejarlo de forma numérica. Fecha: una variable numérica cuyos valores representan uno de los diferentes formatos de fecha-calendario u hora-reloj (figura 22). Se puede introducir la fecha utilizando como delimitadores barras, guiones, puntos, comas, o espacios.
Figura 22. Tipo de variable: Fecha.
En la parte derecha de la ventana aparece una lista donde podemos seleccionar el formato de fecha que más útil nos sea o el que mejor se acomode a nuestros datos. Dólar: una variable numérica cuyos valores representan sumas de dinero en dólares (figura 23), al seleccionarla se abre un nuevo cuadro de diálogo, en la cual debemos seleccionar uno de los formatos preestablecidos.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 39
Figura 23. Tipo de variable: Dólar.
Moneda personalizada: una variable numérica cuyos valores representan sumas de dinero, al seleccionarla se abre una nueva ventana en la cual debemos seleccionar uno de los formatos preestablecidos (figura 24).
Figura 24. Tipo de variable: Moneda personalizada.
La diferencia con el tipo dólar, es que nos permite trabajar con 5 tipos de moneda diferentes; al seleccionar alguno, el programa desconocerá el origen de la moneda, sólo tendrá en cuenta que es un tipo de moneda diferente al dólar. Cadena: variable cuyos valores no son numéricos y por ello, no se utilizan en los cálculos. Pueden contener cualquier tipo de caracteres siempre que no exceda la longitud máxima de 255; las mayúsculas y las minúsculas se consideran diferentes, ya que trabaja bajo el código ASCII. También se conoce como variable alfanumérica. Anchura. Determina el máximo de dígitos que podemos esperar en una variable, este ancho incluye los dígitos enteros y los decimales. Anchura 5=xxx.xx ó x,xxx.x ó xx,xxx donde x representa un número aleatorio. No se debe cometer el error de pensar que una vez establecida la anchura ya no se podrá encontrar una cifra con mayor cantidad de números; ya que esta opción es para darle una idea al investigador de

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 40
las cifras que encontrará cuando le pida al paquete información de las variables, es decir, no restringe la cantidad de números sino que es un parámetro informativo, el cual le brinda a la persona que opere el programa una idea de los rangos máximos que puede tomar esta variable, pero no impide sobrepasarlo. Decimales. Determina el máximo de dígitos decimales que se tendrán, las cifras que superen la longitud serán aproximadas hacia arriba; si superan el valor 5, al contrario serán aproximadas hacia abajo, es decir: En 1.07X, si X≤5 entonces se aproxima a 0, es decir 1.07 En 1.07X, si X>5 entonces se aproxima a 10, es decir 1.08 Estas dos columnas (Anchura y Decimales) pueden ser editadas directamente desde la ventana de Tipo de variable (figura 25) ya que esta ventana nos da la posibilidad de definirlas.
Figura 25. Tipo de variable: Anchura y Decimales.
Hay que notar que cuando seleccionamos Tipos de variables, como Fecha, etas opciones se desactivan ya que el formato de la fecha está predefinido y no se puede alterar, la única opción que se tiene es escoger otro formato de fecha. Etiqueta. SPSS nos brinda la posibilidad de utilizar una etiqueta en la cual podemos describir la variable mediante la utilización de un máximo de 255 caracteres. El uso de la etiqueta es bastante útil para facilitar la interpretación de los resultados (tablas o gráficos), para las personas que no han participado en la generación de los procedimientos y desconocen el significado del nombre de la variable. El uso de la etiqueta es opcional, el programa en caso de no existir una etiqueta utiliza el nombre de la variable para generar los resultados. Podemos darnos cuenta de las etiquetas manteniendo el cursor sobre el nombre de la variable en la vista de datos.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 41
En la figura 26, podemos observar claramente la diferencia que existe al utilizar las etiquetas y las etiquetas de valor en los resultados.
Estado civil
Con etiquetas
Frecuencia Porcentaje
Válidos Soltero
Casado
Total
3224
3176
6400
50.4
49.6
100.0
ECIVIL
Sin etiquetas
Frecuencia Porcentaje
Válidos 0
1
Total
3224
3176
6400
50.4
49.6
100.0
Figura 26. Resultado de la variable ECIVIL.
Perdidos. Los valores perdidos son razones por las cuales no obtenemos una respuesta coherente de algún entrevistado, es decir, es una razón que me indica la causa para la que el entrevistado no me aporta información. Dentro de los valores perdidos podemos encontrar:
No sabe
No responde o se niega a responder
No aplica o sencillamente la pregunta no lo afecta. Ej.: preguntarle a una persona soltera la edad a la que se casó por primera vez, si no se ha casado nunca esta pregunta no le afecta.
Se debe tener claro que los valores perdidos son razones y no errores, generalmente se tiende a confundir un valor perdido con un valor que no esta dentro de nuestro rango. Ejemplo: En la variable género (sexo), se tienen los valores 1=mujer y 2=hombre, después de revisar el archivo nos damos cuenta que tenemos en algunos registros el valor 3; generalmente cometemos el error de pensar que este es un valor perdido, pero no lo es, este tipo de valores se deben considerar como errores ya sea de digitación o de captura y la forma de corregirlos es ir hasta la fuente (entrevista) y determinar a qué grupo pertenecía el individuo. Si no se puede determinar el grupo y los valores son muy pocos, es recomendable prescindir de estos casos. SPSS maneja dos tipos de valores perdidos, el primero es perdido por el sistema, el cual se identifica por la ausencia total de datos, es decir
Etiquetas
Etiquetas
de valor

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 42
casillas vacías; y la segunda es datos perdidos definidos por el usuario. Sea cual sea el tipo de valor perdido, se deben definir, ya que si no se hace, SPSS realizará los cálculos contando con estos valores lo cual afectará severamente los resultados. La forma de definirlos es activando la casilla correspondiente a perdidos, una vez activa observaremos de nuevo el botón en la parte derecha, al hacer clic sobre él, se abrirá la ventana de valores perdidos la cual nos da tres posibilidades(figura 27):
Figura 27. Ventana: Valores perdidos.
No hay valores perdidos.
Valores perdidos discretos: son un máximo de tres valores perdidos que tendremos en nuestra variable, pueden tomar los valores que deseemos. Se recomienda que exista una distancia considerable entre los valores representativos y los perdidos con el fin de facilitar su identificación.
Rango más un valor perdido discreto opcional: Se utiliza cuando tenemos varios parámetros de valores perdidos los cuales se encuentran dentro de un rango y no hay valores representativos de grupos dentro de ellos, además me da la opción de ingresar un valor discreto adicional.
Columnas y alineación. Estos dos parámetros son netamente de formato, es decir, de presentación y veremos sus efectos únicamente en la vista de datos, la primera (columna) nos indica el ancho de la columna y la segunda la alineación dentro de la celda. La columna, al igual que en una hoja de cálculo, podemos alterarla de forma directa en la vista de datos colocando el cursor al lado de la columna hasta que aparezca el indicador, hacemos clic y lo sostenemos arrastrando hasta obtener el ancho deseado. Medida. Es el parámetro más importante de las variables, de su definición depende el tipo de análisis que se puede realizar, dentro de la

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 43
estadística se han catalogado cuatro diferentes escalas de medida, pero para SPSS estas escalas se resumen en tres:
Nomial: son variables numéricas cuyos valores indican una categoría de pertenencia, sin tener un orden dentro de sus categorías. Un ejemplo de variable nominal puede ser el género, la raza, el estado civil, etc. Ordinal: Son variables numéricas cuyos valores indican una categoría de pertenencia y poseen un orden lógico dentro de sus categorías. Un ejemplo de variable ordinal puede ser el nivel de ingresos, categoría del vehículo, nivel educativo, etc. Escala: Son variables numéricas cuyos valores representan una magnitud y no una categoría. Un ejemplo de variable de escala puede ser la edad, años estudiados, la distancia en metros, la altura, el sueldo, etc.
Valores. Los valores o Etiquetas de valor nos permiten generar una leyenda que facilite la interpretación de los valores de una variable, ya sea en los resultados o en la vista de datos. Debido a que se utilizan números para representar cada categoría es necesario crear una pequeña leyenda que nos permita ver en letras la categoría a la que corresponde cada número. Las etiquetas de valor no pueden exceder los 60 caracteres y se utilizan si:
La variable es categórica, es decir Nominal u Ordinal.
Se tienen valores perdidos por el usuario.
Para ingresar se debe activar la celda correspondiente, hacer clic sobre el botón, con lo cual se abre la ventana Etiquetas de valor (figura 28), en esta ventana se encuentran tres celdas:
Figura 28. Ventana: Etiquetas de valor.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 44
La primera corresponde al valor o número, en ella se deb digitar el número al se desea dar la etiqueta, la segunda celda es la etiqueta de valor, en ella se digita la categoría a la que corresponde ese valor (máximo 60 caracteres) y la tercera celda corresponde a las etiquetas añadidas, es decir, las categorías que ya hemos ingresado. Si se desea cambiar una etiqueta que ya se haya añadido, la forma de hacerlo es seleccionándola en la celda (hacer clic sobre ella), editar ya sea el número o la etiqueta y dar cambiar. Si por el contrario se desea eliminarla se selecciona y se hace clic en eliminar.
Área del procesador. Nos indica el estado del procesador, posee diversos estados de acuerdo del proceso que este realizando, es bastante útil cuando se le pide un proceso al paquete y poseemos varios registros; en algunos casos la base es tan extensa que puede tardar bastante tiempo la ejecución del resultado, en estos casos generalmente se tiende a pensar que el programa se bloqueó, antes de determinarlo es importante saber cuál es el estado del procesador. Además, cuando la licencia caduca, en esta área se encuentra el mensaje: el procesador no está disponible. OPCIONES DE LA BARRA DE MENÚ PRINCIPAL. A continuación se explica la finalidad de las distintas opciones que aparecen en la barra de menú del programa (parte superior de la pantalla). La mayoría de las aplicaciones Windows presentan este tipo de menús desplegables, que facilitan la tarea con el programa. La opción Archivo de la barra de menú principal presenta las siguientes subopciones (figura 29):
Nuevo. Abre nuevo archivo de datos, sintaxis, resultados o proceso.
Abrir. Abrir archivo existente de datos, sintaxis, resultados o de proceso.
Abrir base de datos. Crear, editar y ejecutar consultas a bases de datos.
Leer datos de texto. Abrir archivos de texto.
Guardar. Guardar el archivo actual.
Guardar como. Guardar el archivo actual con otro nombre.
Mostrar información de datos. Mostrar el archivo de datos posibles.
Hacer caché de datos. Crear memoria para los datos que se introduzcan.
Imprimir. Imprimir la tarea actual.
Presentación preliminar. Ver en pantalla completa la tarea actual.
Cambiar servidor. Cambiar el servidor al que estamos conectados.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 45
Detener procesador. Interrumpir el procesamiento de SPSS.
Figura 29. Subopciones de la opción Archivo.
Datos usados recientemente. Ver los datos usados recientemente
Archivos usados recientemente. Ver los archivos usados recientemente.
Salir. Salir de SPSS. La opción Edición de la barra de menú principal presenta las siguientes subopciones (figura 30):
Deshacer. Deshacer la última acción.
Rehacer.Rehacer la última acción deshecha.
Cortar. Cortar la selección para almacenarla en el portapapeles.
Copiar. Copiar la selección para almacenarla en el portapapeles.
Pegar. Pegar el contenido del portapapeles en la ubicación actual del cursor.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 46
Pegar variables. Pegar la variable del portapapeles en la ubicación del cursor.
Figura 30. Subopciones de la opción Edición.
Eliminar. Borrar la selección.
Buscar. Buscar los datos que se especifiquen.
Opciones. Opciones de tablas, gráficos. Procesos, etc. La opción Ver de la barra de menú principal presenta las siguientes subopciones (figura 31):
Figura 31. Subopciones de la opción Ver.
Barra de estado. Activa y desactiva la barra de estado.
Barra de herramientas. Activa y desactiva la barra de herramientas.
Fuentes. Permite cambiar estilos y tamaños para las fuentes.
Cuadrícula. Activa y desactiva la cuadrícula del editor de datos.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 47
Etiquetas de valor. Permite situar etiquetas de valor en las variables.
La opción Datos de la barra de menú principal presenta las siguientes subopciones (figura 32):
Figura 32. Subopciones de la opción Datos.
Definir fechas. Permite la definición de valores fecha.
Ordenar casos. Permite ordenar casos según criterios a definir.
Transponer. Transpone filas por columnas en el editor.
Fundir archivos. Permite mezclar archivos por casos o por variables.
Agregar. Permite agregar variables a un archivo.
Diseño ortogonal. Permite diseñar y mostrar diseños factoriales ortogonales.
Segmentar archivo. Permite segmentar archivos según ciertos criterios.
Seleccionar casos. Permite elegir casos.
Ponderar casos. Permite la ponderación de casos. La opción Transformar de la barra de menú principal presenta las siguientes subopciones (figura 33):
Calcular. Realizar cálculos.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 48
Recodificar. Recodificar los valores de una variable.
Asignar rangos a casos. Ordenar a medida.
Figura 33. Subopciones de la opción Transformar.
- Recodificación automática. Recodificación rápida. - Crear serie temporal. Crear una variable tipo serie de tiempo. - Reemplazar valores perdidos. Reemplazar valores missing.
La opción Analizar de la barra de menú principal presenta las siguientes subopciones (figura 34):
- Informes. Cubos OLAP, resúmenes de casos e informes de estadísticos.
- Estadísticos descriptivos. Estadísticos, frecuencias y tablas de contingencia.
- Tablas personalizadas. Tablas de frecuencias y otros tipos de tablas.
- Comparar medias. ANOVA, prueba T, etc. - Modelo lineal general. Modelos univariantes y multivariantes. - Correlaciones. Correlaciones parciales, bivariadas y distancias. - Regresión. Regresión lineal, no lineal, curvilínea, logística,
ordinal, Probit, etc. - Loglineal. Modelos logarítmicos lineales. - Clasificar. Análisis discriminante y de conglomerados. - Reducción de datos. Análisis de correspondencias, factorial y
escalamiento óptimo. - Escalas. Escalamiento multidimensional y análisis de la fiabilidad. - Pruebas no paramétricas. Chi-cuadrado, binomial, rachas y K-S.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 49
Figura 34. Subopciones de la opción Analizar.
- Series temporales. Modelos ARIMA, autorregresión, suavizado y
descomposición estacional. - Supervivencia. Tablas de mortalidad, Kaplan-Meier y regresión
de Cox. - Respuesta múltiple. Definir conjuntos, frecuencias y tablas de
contingencia. La opción Gráficos de la barra de menú principal (figura 35) presenta las clásicas subopciones de construcción de gráficos de líneas, secuencias, barras, dispersión, áreas, gráficos de Pareto, gráficos de control de procesos, gráficos de dispersión, histogramas de frecuencias, gráficos de normalidad, diagramas de caja y bigotes, curvas de correlación, barras de error, gráficos de series temporales, etc. La opción Utilidades de la barra de menú principal (figura 36) permite trabajar con variables, conjuntos, procesos, menús, etc. La opción Ventana permite manejar ventanas (maximizar, minimizar, etc.). La opción Ayuda (figura 37) presenta ayuda en línea por temas, un asesor estadístico, una guía exhaustiva de sintaxis de SPSS y un tutorial.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 50
Figura 35. Subopciones de la opción Gráficos.
Figura 36. Subopciones de la opción Utilidades.
Figura 37. Subopciones de la opción Ayuda.
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 51
AYUDA EN SPSS 15.0. Se puede conseguir ayuda desde cualquier ventana con el menú de Ayuda (?) (figura 38). La opción Temas del menú de Ayuda (figura 39) abre la pestaña Contenido (figura 40) de la Ayuda. La pestaña Contenido está ordenada por temas, como un índice de contenido. Pulse dos veces en los elementos que contengan un icono de libro para expandir o contraer el contenido (figura 41). Pulse en un elemento para acceder a ese tema de ayuda (figura 42). Todos los temas incluyen un cuadro de diálogo con una Demostración del tema de ayuda (figura 43). Esta ventana también permite acceder directamente a un tutorial sobre ese tema.
Figura 38. Opción Ayuda en la barra de menú general de SPSS.
Figura 39. Opción Temas del menú de Ayuda.
Figura 40. Pestaña Contenido de la Ayuda.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 52
Figura 41. Expansión de contenido de la ayuda.
Figura 42. Tema de ayuda.
Figura 43. Cuadro de diálogo del tema de ayuda.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 53
Utilice la pestaña Índice para buscar por temas. La pestaña Índice está ordenada por orden alfabético (figura 44), como el índice de un libro. En la pestaña Índice se utiliza un método incremental para realizar las búsquedas (figura 45). Escriba los caracteres que precise para encontrar el tema (figura 46). En la pestaña Buscar (figura 47) se pueden realizar búsquedas de texto en índice. Para utilizar la búsqueda de texto debe seleccionar un tema de la base de datos con todas las palabras del sistema de ayuda. La búsqueda de texto en índice sólo se recomienda como último recurso si no logra encontrar lo que busca con las pestañas Índice y Contenido.
Figura 44. Pestaña Índice de la ayuda en SPSS 15.0.
Figura 45. Búsqueda incremental en el índice de la ayuda.
La mayoría de los cuadros de diálogo disponen de un botón de Ayuda que permite acceder directamente al tema de ayuda correspondiente (figura 48). El tema de ayuda ofrece información general sobre el cuadro de diálogo (figura 49). El botón Pantalla ofrece instrucciones paso a paso sobre el tema del cuadro de diálogo (figura 50). En la ventana de lado derecha del cuadro de diálogo, se encuentran Temas relacionados que proporciona enlaces a los

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 54
temas relacionados, incluyendo los relativos a cuadros de diálogo secundarios con funciones adicionales (figura 51).
Figura 46. Búsqueda de tema en el índice de ayuda.
Figura 47. Pestaña Buscar y búsqueda de texto.
Figura 48. Botón de ayuda de un cuadro de diálogo.
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 55
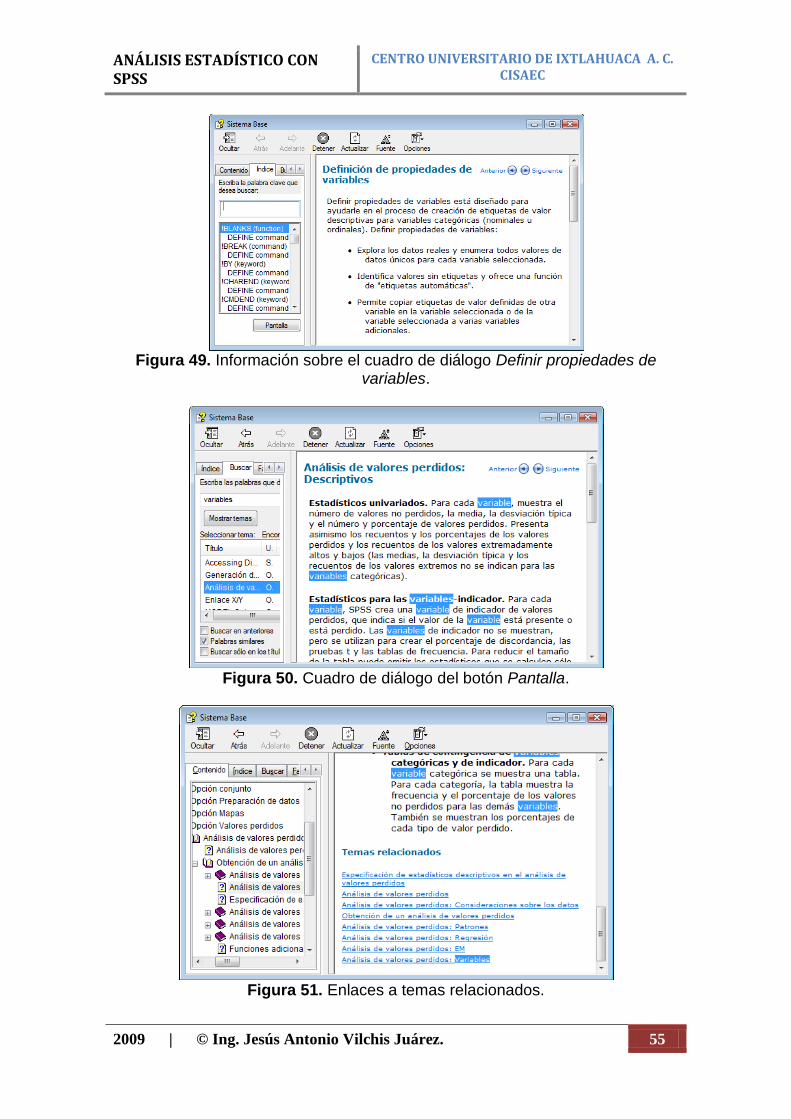
Figura 49. Información sobre el cuadro de diálogo Definir propiedades de
variables.
Figura 50. Cuadro de diálogo del botón Pantalla.
Figura 51. Enlaces a temas relacionados.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 56
INTRODUCCIÓN A LA ESTADÍSTICA APLICADA La estadística nos ayuda a corroborar hipótesis dando un soporte matemático a observaciones realizadas. La estadística es la ciencia de la probabilidad y por ello no es correcto realizar afirmaciones categóricas o negaciones rotundas, sino que estas afirmaciones o rechazos hay que enmarcarlos siempre en un nivel de significación, que no es más que encuadrarlo dentro de un margen de error que nosotros mismos nos estamos fijando (generalmente entre el 1-5%). Lo primero que debe considerarse al realizar un experimento que posteriormente llevará un tratamiento estadístico es: Plantear la hipótesis de trabajo que se quiere demostrar. Definir bien las variables a estudiar. Cómo recoger y recopilar los datos (TIPOS DE MUESTREO). 1. Elección del método estadístico más apropiado para demostrar la
hipótesis de trabajo de la mejor manera posible. Es conveniente resaltar que el fin de los muestreos es extraer una muestra lo suficientemente representativa de una población para que las conclusiones muestrales obtenidas puedan extrapolarse a nivel poblacional, de ahí que sea de suma importancia la minuciosa elección y preparación en la recolección de datos. TIPOS DE MUESTREO • Estratificado: Las muestras se toman por capas o estratos de condiciones homogéneas. Es un muestreo muy utilizado en Ecología. Estos muestreos sirven para confirmar algún tipo de distribución.
- Al azar. - Contagiosa.
• Regular (Sistemático): Se basa en la obtención al azar de una primera unidad a partir de la cual se seleccionan las siguientes mediante algún criterio fijo repetido periódicamente. • Aleatorio simple: Se basa en la toma al azar y de manera independiente de una muestra. Es eficaz para zonas homogéneas. TIPOS DE VARIABLES
VARIABLES CUANTITATIVAS VARIABLES CUALITATIVAS
Se trata de variables medibles (altura, peso,...). Pueden tomar valores enteros o con decimales.
Son variables de cualidad. Los datos que se toman son el número de individuos que presentan dicha cualidad (frecuencias de aparición) y por tanto números enteros.
TRATAMIENTOS ESTADÍSTICOS ☺ TRATAMIENTOS ESTADÍSTICOS ☻

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 57
☺ ☻
χ2 de Pearson: Se denominan ―test de bondad de ajuste‖, y buscan un modelo matemático (teórico) sobre una distribución real. t de Student: Se trata de un contraste para 1 o 2 muestras. Es un test en el que se comparan las medias muestrales (m1=m2) o bien si la muestra es representativa o no. ANOVA (Analisys of variance): En este test se contrastan más de dos muestras (m1=m2=m3). Se aplica para estudios en los que se comparan medias. CORRELACIÓN / Regresión: Se aplican en estudios en los que se quieren relacionar variables, o bien para ajustar un comportamiento poblacional a un modelo matemático con fines predictivos.
χ2 de Pearson: En variables cualitativas se usa como un test de homogeneidad o de independencia. Se trata de un estudio de proporciones (probabilidades de encontrar una cualidad).
ESTUDIO DE HOMOGENEIDAD (DEPENDENCIA O INDEPENDENCIA) INTRODUCCIÓN A LA HOMOGENEIDAD Ejemplo 1 Tomamos una muestra de una determinada especie vegetal en el cauce de un arroyo que, por su situación, presenta una ladera en un sitio A y otra en otro sitio B. Los resultados sobre 100 observaciones realizadas aparecen resumidos en la tabla de frecuencias observadas. ¿Existe alguna preferencia de la especie por alguna de las dos situaciones?.
Observadas Sitio A Sitio B Totales
Presencia (+) 20 (a) 10 (b) 30 (T+)
Ausencia (-) 20 (c) 50 (d) 70 (T-)
Totales 40 (TA) 60 (TB) N = 100
El estudio se realiza basándose en una variable cualitativa, ya que se está estudiando la cualidad de presencia en el sitio A o en el sitio B, y la muestra no es más que un recuento de individuos que presentan la variable a estudiar.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 58
Por tanto, lo que se pretende estudiar es si esta especie se distribuye de forma homogénea tanto en A como en B, o lo que es lo mismo si su presencia es independiente de la ladera del cauce del arroyo en la que estemos. Para este tipo de estudios se usa el test χ2 de Pearson, aunque no hay que confundir esta aplicación con la bondad de ajuste que se usa en variables cuantitativas. 1. Lo primero que hay que realizar es una tabla de frecuencias esperadas a
partir de la tabla de frecuencias observadas. Esta tabla es necesaria si queremos utilizar la fórmula general del estadístico χ2 de Pearson, aunque no se usa para el test si utilizamos la fórmula simplificada para tablas de contingencia de 2x2 (ver la tabla siguiente). La tabla de frecuencias esperadas nos ayuda a saber como sería la presencia teórica y ver si existe una gran diferencia con lo observado.
Observadas Sitio A Sitio B Totales
Presencia (+) 12 18 30
Ausencia (-) 28 42 70
Totales 40 60 N = 100
2. En segundo lugar, se deben plantear las hipótesis de trabajo que queramos
corroborar con el estudio. H0 = homogeneidad o independencia. (dependiendo de los casos). H1 = dependencia o no homogeneidad.
3. En tercer lugar, se debe obtener el χ2 cal. usando los datos de la tabla de
contingencia de las frecuencias observadas mediante la siguiente fórmula (únicamente válida para tablas de contingencia de 2x2 → g.l. = ( filas −1) ⋅ (columnas −1) ):
4. Por último, se debe comparar el estadístico χ2 cal. con el χ2 teórico para los
niveles de significación escogidos, generalmente α=0.01 y α=0.05.
Como criterio de decisión:
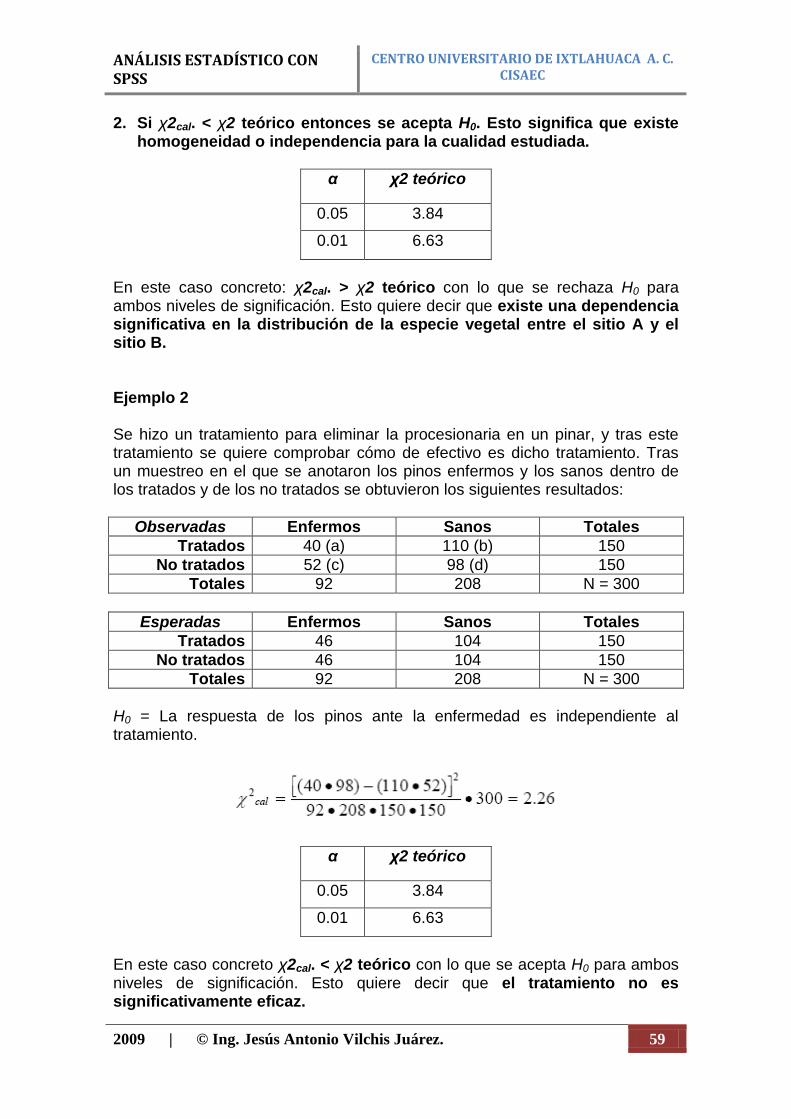
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 59
2. Si χ2cal. < χ2 teórico entonces se acepta H0. Esto significa que existe homogeneidad o independencia para la cualidad estudiada.
α χ2 teórico
0.05 3.84
0.01 6.63
En este caso concreto: χ2cal. > χ2 teórico con lo que se rechaza H0 para ambos niveles de significación. Esto quiere decir que existe una dependencia significativa en la distribución de la especie vegetal entre el sitio A y el sitio B. Ejemplo 2 Se hizo un tratamiento para eliminar la procesionaria en un pinar, y tras este tratamiento se quiere comprobar cómo de efectivo es dicho tratamiento. Tras un muestreo en el que se anotaron los pinos enfermos y los sanos dentro de los tratados y de los no tratados se obtuvieron los siguientes resultados:
Observadas Enfermos Sanos Totales
Tratados 40 (a) 110 (b) 150
No tratados 52 (c) 98 (d) 150
Totales 92 208 N = 300
Esperadas Enfermos Sanos Totales
Tratados 46 104 150
No tratados 46 104 150
Totales 92 208 N = 300
H0 = La respuesta de los pinos ante la enfermedad es independiente al tratamiento.
α χ2 teórico
0.05 3.84
0.01 6.63
En este caso concreto χ2cal. < χ2 teórico con lo que se acepta H0 para ambos niveles de significación. Esto quiere decir que el tratamiento no es significativamente eficaz.
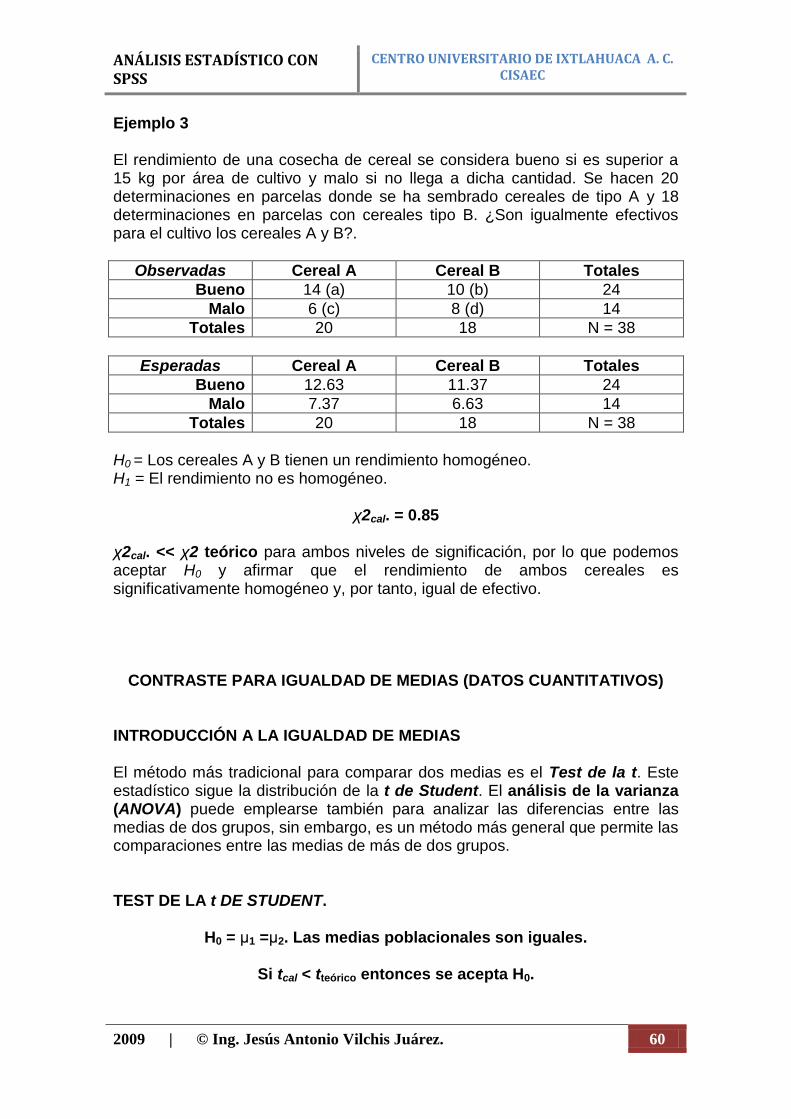
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 60
Ejemplo 3 El rendimiento de una cosecha de cereal se considera bueno si es superior a 15 kg por área de cultivo y malo si no llega a dicha cantidad. Se hacen 20 determinaciones en parcelas donde se ha sembrado cereales de tipo A y 18 determinaciones en parcelas con cereales tipo B. ¿Son igualmente efectivos para el cultivo los cereales A y B?.
Observadas Cereal A Cereal B Totales
Bueno 14 (a) 10 (b) 24
Malo 6 (c) 8 (d) 14
Totales 20 18 N = 38
Esperadas Cereal A Cereal B Totales
Bueno 12.63 11.37 24
Malo 7.37 6.63 14
Totales 20 18 N = 38
H0 = Los cereales A y B tienen un rendimiento homogéneo. H1 = El rendimiento no es homogéneo.
χ2cal. = 0.85 χ2cal. << χ2 teórico para ambos niveles de significación, por lo que podemos aceptar H0 y afirmar que el rendimiento de ambos cereales es significativamente homogéneo y, por tanto, igual de efectivo.
CONTRASTE PARA IGUALDAD DE MEDIAS (DATOS CUANTITATIVOS) INTRODUCCIÓN A LA IGUALDAD DE MEDIAS El método más tradicional para comparar dos medias es el Test de la t. Este estadístico sigue la distribución de la t de Student. El análisis de la varianza (ANOVA) puede emplearse también para analizar las diferencias entre las medias de dos grupos, sin embargo, es un método más general que permite las comparaciones entre las medias de más de dos grupos. TEST DE LA t DE STUDENT.
H0 = μ1 =μ2. Las medias poblacionales son iguales.
Si tcal < tteórico entonces se acepta H0.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 61
Ejemplo 1 Una especie vegetal que aparece en Jiquipilco y Jocotitlán aparenta crecer de manera distinta en ambas ubicaciones. Para ello tomamos muestras de la altura de dicha planta en centímetros. Los resultados obtenidos para Jiquipilco y Jocotitlán aparecen en la tabla siguiente.
Altura en Jiquipilco (cm) 39 36 35 37 40 39 40 38 35 39
Altura en Jocotitlán (cm) 43 45 42 35 37 38 33 38 41 43
1. Calcular las medias (m) y las cuasivarianzas (S2) de ambos grupos
separados por la variable ambiental.
Jocotitlán: m1 = 39.5 s2
1 = 13.65 S21 = 15.16
Jiquipilco: m2 = 37.8 S2
2 = 3.73
2. Comprobar que las varianzas poblacionales (δ2) son iguales. Esta comprobación se realiza mediante el test F de Fisher-Snedecor.
H0 = δ21 = δ2
2. Las varianzas poblacionales son iguales.
Si Fobs < Fteórico entonces se acepta H0.
En nuestro caso Fobs = 4.06 < Fteórico (para α = 0.01) = 5.06, por lo que se acepta H0 y las varianzas poblacionales son significativamente iguales.
3. Calcular el valor de tcal. En este punto, dependiendo de si las varianzas poblacionales son iguales o no, y de si el tamaño muestral (n1+n2) es grande (>30) o pequeño, se aplican diferentes fórmulas para realizar el Test de t.
a. (n1+n2) > 30
En este caso no es necesario comprobar si δ2
1 = δ22 ya que aunque δ2
1 ≠ δ2
2 se utiliza la misma fórmula como solución aproximada. b. (n1+n2) < 30
• δ21 = δ2
2

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 62
• Si n1 = n2 entonces
• Si n1 ≠ n2 entonces
siendo n1 + n2 – 2 = grados de libertad.
En este caso, el tamaño muestral es < 30 , las varianzas poblacionales son iguales y n1 = n2 luego:
4. Comparar tcal con tteórico para los niveles de significación designados y comprobar si las medias poblacionales (μ) son iguales (aceptación de H0).
g.l.
α
tteórico
18
0.01
2.878
0.05
2.101
En este caso, tcal = 1.24 es menor que tteórico para ambos niveles de significación, por lo que se puede aceptar H0 y decir que estadísticamente la especie vegetal parece crecer de igual forma en Jocotitlán y en Jiquipilco.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 63
Ejemplo 2 Un laboratorio de antropología física realizó un estudio sobre nutrición sometiendo a estudio dos dietas diferentes indicadas para el sobrepeso. Así se tomaron datos sobre la reducción de peso en individuos que siguieron la dieta A, y en individuos que siguieron la dieta B. A partir de los datos obtenidos se pretende comprobar si ambas dietas son significativamente iguales en su efectividad o no.
Dieta Ind. Muestreados
(n)
Media de pérdida de
peso
Varianza muestral (s2)
Cuasivarianza (S2)
A 25 4.3 1.96 2.04
B 25 3.6 1.21 1.26
H0 = μA = μB . La media en la pérdida de peso en las poblaciones que siguieron las distintas dietas es la misma. 1. Comprobar que las varianzas poblacionales son iguales. Esto se hace con
el test F de Fisher-Snedecor. H0 = δ2
1 = δ22. Las varianzas poblacionales son iguales.
Si Fobs < Fteórico entonces se acepta H0.
que es menor que Fteórico = 2.27
Se cumple que las varianzas poblacionales son significativamente iguales.
2. Calcular el valor de tcal. En este caso (n1+n2 ) > 30
g.l.
α tteórico
48
0.01 2.57
0.05 1.64

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 64
No se cumple H0 para ambos niveles de significación, por lo que no se puede deducir si la diferencia en las dietas es significativa o no.
Este tipo de solución suele darse cuando los datos no están bien tomados o son insuficientes. Por tanto lo más lógico sería repetir las mediciones, y si estas volvieran a salir iguales, entonces habría que aumentar el tamaño de muestra (generalmente al doble) y volver a tratar los datos estadísticamente.
ANÁLISIS DE LA VARIANZA (ANOVA).
Este test sirve para comparar las medias de más de dos muestras. Se usa para clasificar muestras en función de una variable cuantitativa (altura, peso, ...). Para poder realizar este test han de cumplirse varias premisas: 1. Las muestras deben ser recogidas al azar y provenir de poblaciones con
distribución normal.
2. Las varianzas poblacionales han de ser homogéneas (iguales). Esto se comprueba mediante el test de la Fmáxima que no tiene nada que ver con el estadístico F de Fisher-Snedecor.
H0 = δ2
1 = δ22 = δ2
3 = .... = δ2n
Si Fmáx < Fcrítica entonces se cumple H0 para los α dados.
El test ANOVA se realiza mediante la F de Fisher-Snedecor, y la hipótesis nula que se contrasta es que las muestras procedan de la misma población, por lo que las medias poblacionales extraídas de dichas muestras han de ser iguales.
H0 = μ1 = μ2 = μ3 = .. .= μn H1 = alguna de las medias poblacionales es distinta.
3. Si Fcal < Fteórico, entonces se acepta H0 para los niveles de significación
(α) dados. EJEMPLO 1 Se tomaron muestras en tres regiones de una provincia sobre la altura que alcanzaban los ejemplares de una especie determinada de planta, en zonas abandonadas y no abandonadas por el pastoreo de cabras y ovejas. Se

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 65
pretende determinar si el comportamiento es el mismo. Los resultados del muestreo aparecen reflejados en la tabla siguiente:
Región Ind. muestreados (ni)
Altura media en metros (mi)
Cuasivarianza (S2)
I 104 4.99 4.19
II 102 4.63 5.75
III 69 4.53 5.15
a) Plantear las hipótesis de contraste.
Para este caso concreto serían H0 = Las plantas de las tres regiones se comportan de igual forma, por lo que sus medias poblacionales son iguales. H0 = μ1 = μ2 = μ3
b) Comprobar si las varianzas poblacionales son iguales (homogéneas).
H0 = δ2
1 = δ22 = δ2
3
Si Fmáx < Fcrítica entonces se cumple H0 para los α dados.
α (p) Fmáx crítica
0.05 6.6
0.01 9.9
Como Fmáx = 1.37 < Fmáx crítica para ambos niveles de significación, entonces se acepta la hipótesis nula.
En el caso de que las varianzas poblacionales no fueran iguales, se podría continuar realizando el contraste ANOVA aunque aclarando que el contraste no va a ser significativo por no cumplirse la segunda premisa.
c) Rellenar las tablas resumen con el fín de poder calcular Fcal. En este apartado, dependiendo de cómo se den los datos en el problema, hay que completar 1 o 2 tablas. Si no se dan las medias ya calculadas hay que rellenar dos tablas.
GRUPOS Σxi 𝒙 i Σx2i s2
i ni
I
II
III

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 66
TOTALES Φ 𝑥 𝑇𝑂𝑇𝐴𝐿 =
Φ
𝑁
Θ 𝑠𝑇𝑜𝑡𝑎𝑙
2 =Θ
𝑵− 𝑥 𝑇𝑂𝑇𝐴𝐿
2 N
Con los resultados de esta tabla se completa el cuadro siguiente.
Fuente de
variación
Suma de cuadrados Grados de libertad
Cuadrado medio
Fcal.
ENTRE GRUPOS
(𝑥 𝑖 − 𝑥 𝑇) = 𝑁𝑇 ∙ 𝑆𝑇2
A
Nº de grupos - 1
𝛼 = 𝐴 𝑔. 𝑙
𝐹𝑐𝑎𝑙 . =𝛼
𝛽
DENTRO GRUPOS
∑ 𝑥𝑖 − 𝑥 𝑖 = ∑(𝑛𝑖 ∙ 𝑠𝑖2)
B**
Nº indTot – Nº grupos
𝛽 = 𝐵 𝑔. 𝑙
(**). Si usamos cuasivarianza muestral (S2) en la fórmula habría que poner (ni – 1). Siendo:
En el caso concreto de este problema, sí nos dan calculadas las medias, por lo que sólo es necesario rellenar el Cuadro 2.
Σ( ni −1)• S2
i = 103 • 4.19 +101• 5.75 + 68 • 5.15 = 1403.32
Cuadro 2.
Fuente de
variación
Suma de cuadrados
Grados de libertad
Cuadrado medio Fcal.
ENTRE GRUPOS
275 X 0.039 = 10.776
A
3 – 1 = 2
𝛼 = 10.776 2 =5.39
𝐹𝑐𝑎𝑙 . = 2.088
DENTRO GRUPOS
1403.32
B
275 – 3 = 272
𝛽 = 1403.32 272 = 5.16
d) Comparar Fcal con Fteórica y ver si se cumple la hipótesis nula.
α (p) Fteórica
0.05 2.99

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 67
0.01 4.60
Fcal < Fteórica por lo que se cumple H0, y las medias poblacionales son significativamente iguales.
EJEMPLO 2 Se sospecha que las aguas de un lago están contaminadas por los compuestos fosforados procedentes de una industria. Para tratar de verificar esta sospecha, se midieron los niveles de fósforo en distintos puntos del lago, obteniéndose los siguientes valores:
Lago 1: 7.1 8.5 6.2 7.3 7.9 Después, se midieron los niveles de fósforo en otros tres lagos, que no estaban contaminados, obteniéndose:
Lago 2: 7.2 6.5 5.9 7.8 Lago 3: 5.6 7.1 6.3 6.7 6.5 Lago 4: 7.2 6.6 6.3 7.4
Los valores obtenidos en lago bajo se sospecha que parecen ser algo superiores a los obtenidos en los otros tres. ¿Es suficientemente importante esta diferencia como para poder concluir que el nivel de fósforo en el lago 1 es diferente que el que tienen los demás, y por tanto está contaminado?
GRUPOS Σxi 𝒙 i Σx2i s2
i ni
Lago 1 37 7.4 276.8 0.60 5
Lago 2 27.4 6.85 189.74 0.5125 4
Lago 3 32.2 6.44 208.6 0.2464 5
Lago 4 27.5 6.875 189.85 0.1969 4
TOTALES 124.1 𝑥 𝑇 = 6.894
864.99 𝑠𝑇𝑜𝑡𝑎𝑙2 = 0.522 18
3. Comprobar si las varianzas poblacionales son iguales (homogéneas).
H0 = δ2
1 = δ22 = δ2
3 = δ24
Como Fmáx < Fcrítica entonces se cumple H0 para los α dados.
α (p) Fmáx crítica
0.05 6.6
0.01 9.9

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 68
Fuente
de variación
Suma de cuadrados
Grados de libertad
Cuadrado medio Fcal.
ENTRE GRUPOS
0.1295 X 18 = 2.332
A
4 – 1 = 3
𝛼 = 0.7773
𝐹𝑐𝑎𝑙 . = 1.539
DENTRO GRUPOS
7.0696
B
18 – 4 = 14
𝛽 = 0.5050
α (p) Fteórica
0.05 3.344
0.01 5.564
Fcal < Fteórica por lo que se cumple H0, y las medias poblacionales son significativamente iguales para los niveles de significación dados, es decir, no hay suficiente evidencia estadística para concluir que el primer lago tiene un nivel de contaminación diferente al que tienen el resto.
CORRELACIÓN / REGRESIÓN. INTRODUCCIÓN A LA CORRELACIÓN / REGRESIÓN La correlación, como su nombre indica, es una medida del grado de relación (lineal) entre dos variables. La regresión es un modelo estadístico que sirve para predecir un comportamiento real de una población mediante un modelo matemático (ecuación). Antes de fabricar un modelo matemático, es necesario saber si existe una correlación entre variables, ya que si son incorreladas no tiene mucho sentido tratar de ajustar su relación mediante una recta o una curva.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 69
EJEMPLO 1 Se ha medido la superficie en (dm)2 ocupada por Poa bulbosa (x) y especies anuales (y) en 5 cuadros de muestreo de 10 (dm)2 para comprobar si se asocian o no. Los resultados obtenidos aparecen en la siguiente tabla:
Nº Poa bulbosa (x) 9 2 2 1 6
Nº plantas anuales (y) 1 7 8 10 4
1. Calcular el coeficiente de correlación (r).
Tabla 1. Resumen de valores de ambas variables.
Nº de cuadro
xi yi xy x2 y2
1 9 1 9 81 1
2 2 7 14 4 49
3 2 8 16 4 64
4 1 10 10 1 100
5 6 4 24 36 16
Total 20 30 73 126 230
H0 = no hay correlación a nivel poblacional entre las dos variables (variables incorreladas). ρ = 0. H1 = existe correlación entre las variables (ρ ≠ 0).

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 70
Se acepta H0 si │rcal│< rteórico · (rteórico realmente una tteórica de Student).
α rteórica
0.05 0.878
0.01 0.959
Se rechaza H0 y, por tanto, existe suficiente evidencia estadística de que existe correlación entre variables y de que dicha correlación es negativa.
2. Ajustar las variables a una regresión. Aunque las regresiones pueden ser lineales (y = Bx + A), logarítmicas, etc...., en este tipo de aplicaciones la regresión a la que se ajustan las variables correlacionadas es una recta. Se pueden obtener dos rectas diferentes según se tome a la variable x o a la variable y como independiente.
• Recta de y sobre x (y/x):
• Recta de x sobre y (x/y):
En este caso, vamos a calcular la recta (y/x) utilizando los datos que aparecen reflejados en la tabla 1:
𝑦 − 6 =−9.4
9.2∙ (𝑥 − 4), y despejando queda: 𝑦 = −1.02𝑥 + 10.08
- Estime el número de plantas anuales que aparecerían si
encontráramos 5 individuos de Poa bulbosa.
𝑦 = −1.02 ∙ 5 + 10.08 = 4.98 ≈ 5 plantas anuales.
- Estime el número de plantas anuales que aparecerían si encontráramos 2 individuos de Poa bulbosa.
¡¡¡OJO!!!, Esta pregunta tiene trampa, ya que podemos pensar que la respuesta puede obtenerse del cuadro de datos que nos dan como enunciado, y no es así. La respuesta ha de hallarse sustituyendo en la recta de regresión obtenida.
𝑦 = −1.02 ∙ 2 + 10.08 = 8.04 ≈ 8
3. Calcular la absorción de la varianza. Al error absoluto que se está cometiendo en el muestreo se le denomina coeficiente de determinación(r2), que no es más que la cantidad de varianza entre los dos grupos. La absorción de la varianza es el coeficiente de determinación expresado en tanto por ciento (%).

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 71
𝑟2 = (𝑐𝑜𝑒𝑓. 𝑐𝑜𝑟𝑟𝑒𝑙𝑎𝑐𝑖ó𝑛)2 = (−0.98)2 = 0.96
⟹ 96% 𝑎𝑏𝑠𝑜𝑟𝑐𝑖ó𝑛 𝑑𝑒 𝑙𝑎 𝑣𝑎𝑟𝑖𝑎𝑛𝑧𝑎
4. Representar gráficamente si fuera necesario. Sustituyendo valores en las rectas de regresión, pueden representarse ambas rectas. Si se representan ambas rectas sobre la misma gráfica, se puede tener una idea visual del grado de correlación entre las variables. Dicho grado viene determinado por el ángulo (α) que se forma entre las dos rectas, de modo que cuanto menor sea el ángulo, mayor será la correlación entre variables.
TIPOS DE DISTRIBUCIÓN ESPACIAL.
INTRODUCCIÓN A LA DISTRIBUCIÓN ESPACIAL La distribución espacial puede ser estudiada a muchas escalas, desde la escala global o planetaria, a la local. Existen tres tipos posibles de patrones de distribución espacial (Pattern): 4. Distribución aleatoria. Los organismos se distribuyen al azar, y por tanto,
la presencia de un individuo no aumenta ni disminuye la probabilidad de encontrar otro. Este patrón se ajusta a distribuciones como Binomial, Poisson y Normal.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 72
5. Distribución contagiosa. Los organismos se distribuyen de tal forma que la presencia de un individuo aumenta la probabilidad de encontrar otro. Este tipo de distribución es la más corriente en la naturaleza, y puede estar propiciada por diversas causas: Morfológicas, Ambientales, etc.
6. Distribución regular. Los organismos se distribuyen de tal forma que la
presencia de un individuo disminuye la probabilidad de encontrar otro. Con este tipo de estudio se pretende comprobar la distribución que sigue una determinada población problema. La distribución puede observarse a diferentes escalas, y en ocasiones el tipo de distribución cambia dependiendo de la escala escogida. En este tipo de estudios se trabaja con una única variable. Para comprobar qué tipo de distribución sigue la población sometida a estudio, es necesario calcular el índice de dispersión (I.D.). Lo que realmente se pretende observar con el índice de dispersión es
cómo están relacionados los individuos y cuál es su nivel de concentración.
Además de calcular el I.D. debemos comprobarlo estadísticamente mediante una t de Student, donde:
H0 = No hay evidencia estadística de que la distribución sea tal y como
indica el Índice de dispersión. Se cumple H0 si │tcal│ > tteórica
En caso de no existir suficientes evidencias estadísticas para aceptar que la distribución sea contagiosa o regular, es conveniente comprobar si es aleatoria (aunque el I.D. no lo indicara) y a qué distribución pertenece (binomial, Poisson, o Normal).
1. Si la muestra es grande o la variable es continua (altura) hay que ajustar a una distribución Normal.
2. Si la muestra es pequeña o la variable es discreta (números enteros), hay que ajustar a una Binomial, o a una Poisson.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 73
EJEMPLO 1 En el cuadro siguiente se ha anotado la cobertura de una especie vegetal muestreada en un transecto, agrupándose las coberturas en diferentes clases. Comprobar qué distribución espacial sigue la citada especie.
CLASES (grupos) 0 1 2 3
Frec. Observadas (oi) 8 12 3 3
Probabilidades de clase** (p) 0.223 0.335 0.251 0.125
Frec. Esperadas (ei)=p x N 5.98 8.71 6.526 3.25 N = 26
** Las probabilidades de clase son valores tomados de las tablas de la distribución escogida. En este caso están sacados de una distribución de Poisson con λ = 1.5 y κ = 0, 1, 2, 3. Si las frecuencias esperadas (ei) se parecen a las frecuencias observadas (oi) entonces intuitivamente se cumplirá la distribución de la que se han obtenido los valores de p. Para comprobar de forma estadística lo que intuitivamente podemos aventurar observando el cuadro, se usa un Test de Bondad de Ajuste mediante un estimador que es χ2 de Pearson.
H0 = La distribución se ajusta a la distribución esperada.
Se cumple H0 si χ2cal < χ2teórica para los niveles de significación dados.
Los grados de libertad (g.l.) para las distribuciones de Poisson y Binomial son de k-2, y para una distribución Normal son k-3, siendo k = nº de grupos.
g.l.
α χ2teórico
2
0.01
9.21
0.05
5.99
Como χ2cal < χ2teórico para ambos niveles de significación, se acepta la H0, lo que implica que existe suficiente evidencia estadística para decir que la distribución de la muestra se ajusta a la distribución esperada, en este caso una distribución de Poisson.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 74
CONSTRUCCIÓN Y ANÁLISIS UNIVARIANTE DE DATOS
TIPOS DE ANÁLISIS DE DATOS (UNI – BI- MULTIVARIANTE) Los análisis de datos pueden ser: 1. Univariantes, si afecta a una sola variable 2. Bivariantes, si afecta a un par de variables 3. Multivariantes, si afecta a un grupo de variables
TABLA DE DISTRIBUCIÓN DE FRECUENCIAS Una tabla de distribución de frecuencias es una representación organizada de los datos, que permite organizar dichos datos de manera que sirvan para apoyar la toma de decisiones. PASOS PARA LA CONSTRUCCIÓN DE UNA TABLA DE FRECUENCIAS Para describir el procedimiento de construcción de la tabla de distribución de frecuencias, tomemos el siguiente ejemplo. A continuación, se presenta un fichero de datos que representa las edades de 30 alumnos de una clase de spinning. Vamos a construir la tabla de distribución de frecuencias para estos 30 alumnos.
Tabla 1 – Tabla de Distribución de Frecuencias
32 38 26 29 32 41 28 31 45 36
45 35 40 30 31 40 37 33 28 30
30 41 39 38 33 35 31 36 37 32
Se va construir una tabla de distribución de frecuencias siguiendo los siguientes pasos: 1. Cálculo del rango 2. Designación del número de clases 3. Cálculo de la amplitud 4. Cálculo de los límites de clase 5. Cálculo de los límites reales de clase 6. Encontrando la marca de clase 7. Contabilización y Frecuencia Absoluta 8. Frecuencia Relativa 9. Frecuencias Absolutas y Relativas Acumuladas 10. Histograma y Polígono de Frecuencias

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 75
Cálculo del Rango de una Variable El rango es la diferencia entre el valor de mayor magnitud y el de menor magnitud. Del fichero de datos en bruto, se busca el valor de mayor magnitud (abreviado, VM) y el de menor magnitud (abreviado, Vm). Con ellos se calcula el rango, con arreglo a la siguiente fórmula:
Rango = VM –Vm
Del conjunto de datos en bruto, se busca el valor de mayor magnitud (VM) y el de menor magnitud (Vm). Con ellos se calcula el rango, con arreglo a la fórmula:
Rango = VM -Vm = 45 - 26 = 19
Designación del Número de Clases Una vez calculado el rango, se designa el número de clases de la tabla de distribución, de acuerdo con el siguiente método:
Método de Designación del Número de Clases
n: número de casos de la muestra
K: número de intervalos o de clases recomendables para la tabla de distribución
n < 50 5 a 7
50 ≤ n < 100 6 a 10
100 ≤ n <250 7 a 12
n ≥ 250 10 a 20
Una vez calculado el rango, se designa el número de clases, a través del método siguiente:
donde: • n: número de casos de la muestra • K: número de intervalos o de clases recomendables para la tabla
de distribución.
Utilizando este método, podremos observar que n = 30 es menor que 50 y se nos recomienda, de acuerdo a la tabla, que tomemos de 5 a 7 clases, por lo tanto K = 5 sería una buena asignación.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 76
Cálculo de la Amplitud del Intervalo La amplitud se calcula redondeando el cociente del rango entre el número de clases (R/K) a la unidad más pequeña (u) inmediata superior en la que se encuentran los datos brutos.
Fórmula para el Cálculo de la Amplitud Amplitud = R/K
donde R es el rango y K el número de clases.
Como los datos de nuestro ejemplo están en enteros, la unidad más pequeña es un entero u = 1, de tal manera que la amplitud será la siguiente:
R/K = 19/5 = 3.8
Este valor, al redondearlo al entero inmediato superior, será igual a 4. Es decir, respuesta:
Amplitud : A = 4. Cálculo de los Límites de Clase
Límites de la Primera Clase
Para construir los límites de clase (límite inferior Li y límite superior Ls), se coloca como límite inferior de la primera clase al valor más pequeño de los datos brutos, 26 para nuestro ejemplo, y cuatro enteros (puesto que la unidad más pequeña es un entero) más adelante, incluyendo el 26, tendremos el límite superior de la primera clase, 26 + 3 = 29 ( se suman solo tres enteros porque el 26 ya está incluido).
Clase Límite inferior y Superior (Li – Ls) (Intervalos de clase)
Amplitud Valores
1 26 - 29 4 26, 27, 28, 29
Límites de la Primera Clase
Límites de la Segunda Clase
Para calcular el límite inferior de la segunda clase, hay que agregarle un entero al límite superior de la primera clase, esto es 29 + 1 = 30 (Li=30). El límite superior es 4 enteros más adelante, incluyendo al 30; esto es 29 + 4 = 33 (Ls=33).
Clase Límite Inferior y Superior (Li – Ls) (Intervalos de clase)
Amplitud Valores
2 30 - 33 4 30, 31, 32 y 33
Límites de la Segunda Clase

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 77
Límites de la Tercera Clase Para calcular el límite inferior de la tercera clase, hay que agregarle un entero al límite superior de la segunda clase, esto es 33 + 1 = 34 (Li=34). El límite superior es 4 enteros adelante, incluyendo al 34; esto es, 33 + 4 = 37 (Ls=37).
Clase Límite Inferior y Superior (Li – Ls) (Intervalos de clase)
Amplitud Valores
3 34 - 37 4 34, 35, 36 y 37
Límites de la Tercera Clase
Límites de la Cuarta Clase Para calcular el límite inferior de la cuarta clase, hay que agregarle un entero al límite superior de la tercera clase, esto es 33 + 1 = 34. El límite superior es 4 enteros adelante, incluyendo al 34, esto es 29 + 4 = 33.
Clase Límite Inferior y Superior (Li – Ls) (Intervalos de clase)
Amplitud Valores
4 38 - 41 4 38, 39, 40 y 41
Límites de la Cuarta Clase
Límites de la Quinta Clase Para calcular el límite inferior de la quinta clase, hay que agregarle un entero al límite superior de la cuarta clase, esto es 33 + 1 = 34. El límite superior es 4 enteros adelante, incluyendo al 34, esto es 29 + 4 = 33.
Clase Límite Inferior y Superior (Li – Ls) (Intervalos de clase)
Amplitud Valores
5 42 - 45 4 42, 43, 44 y 45
Límites de la Quinta Clase
Límites de Todas las Clases
Clase Li - Ls Amplitud (A) Valores incluidos en este rango
1 26 – 29 4 26, 27, 28, 29
2 30 – 33 4 30, 31, 32 y 33
3 34 – 37 4 34, 35, 36 y 37
4 38 – 41 4 38, 39, 40 y 41
5 42 - 45 4 42, 43, 44 y 45
Límites de Todas las Clases Para calcular el límite inferior de la segunda clase, hay que agregarle un entero al límite superior de la primera clase, esto es 29 + 1 = 30. El límite superior es 4

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 78
enteros adelante, incluyendo al 30, esto es 29 + 4 = 33. Este proceso se repite iterativamente hasta completar la clase número 5.
Clases Li - Ls Amplitud (A)
1 26 – 29 4 (26, 27, 28, 29)
2 30 – 33 4 (30, 31, 32 y 33)
3 34 – 37 4 (34, 35, 36 y 37)
4 38 – 41 4 (38, 39, 40 y 41)
5 42 - 45 4 (42, 43, 44 y 45)
Cálculo de los Límites de Clase Cálculo de los Límites Reales de Clase Enseguida, se calculan los límites reales de clase, llamados también fronteras de clase. Estos se calculan a partir de los límites de clase, restándole media unidad (u/2) a los límites inferiores de clase y sumándole la misma cantidad a los límites superiores. u/2 = 1/2 = 0.5.
Clases Li - Ls Lri – Lrs
1 26 – 29 25.5 – 29.5
2 30 – 33 29.5 – 33.5
3 34 – 37 33.5 – 37.5
4 38 – 41 37.5 – 42.5
5 42 - 45 41.5 – 45.5
Cálculo de los Límites Reales de Clase Cálculo de la Marca de Clase o Punto Medio del Intervalo Para calcular la marca de clase o punto medio del intervalo de la tabla, vamos a promediar, para cada clase, el límite inferior y superior de clase o en su defecto los límites reales. Para la primera clase, la marca de clase o punto medio del intervalo será:
X1 = (26 + 29)/2 = (25.5 + 29.5)/2 = 27.5. Para la segunda clase, se procede de la misma forma o simplemente se le suma la amplitud a la primera marca de clase:
X2 = X1 + 4 = 27.5 + 4 = 31.5 Para la tercera clase, se procede de la misma forma o simplemente se le suma la amplitud a la segunda marca de clase:
X3 = X2 + 4 = 31.5 + 4 = 35.5
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 79
Para la cuarta clase, se procede de la misma forma o simplemente se le suma la amplitud a la tercera marca de clase:
X4 = X3 + 4 = 35.5 + 4 = 39.5 Para la quinta clase, se procede de la misma forma o simplemente se le suma la amplitud a la cuarta marca de clase:
X5 = X4 + 4 = 39.5 + 4 = 43.5
Clases Li - Ls Lri – Lrs Xi
1 26 – 29 25.5 – 29.5 27.5
2 30 – 33 29.5 – 33.5 31.5
3 34 – 37 33.5 – 37.5 35.5
4 38 – 41 37.5 – 42.5 39.5
5 42 - 45 41.5 – 45.5 43.5
Cálculo de la Marca de Clase o Punto Medio del Intervalo
Cálculo de los Límites Reales de Clase Enseguida, se calculan los límites reales de clase, llamados también fronteras de clase. Los límites reales de clase se calculan a partir de los límites de clase, restándole media unidad (es decir, u/2 = 0,5) a los límites inferiores de clase (Lis – u/2) y sumándole la misma cantidad a los límites superiores (Lss + u/2)
Clases Li - Ls Lri – Lrs
1 26 – 29 25.5 – 29.5
2 30 – 33 29.5 – 33.5
3 34 – 37 33.5 – 37.5
4 38 – 41 37.5 – 42.5
5 42 - 45 41.5 – 45.5
Cálculo de los Límites Reales de Clase
Cálculo de la Marca de Clase o Punto Medio del Intervalo Para calcular la marca de clase o punto medio del intervalo de la tabla, vamos a promediar, para cada clase, el límite inferior y superior de clase o en su defecto los límites reales. Para la clase uno, X1 = (26 + 29)/2 = (25.5 + 29.5)/2 = 27.5. Para las siguientes clases, se procede de la misma forma o simplemente se le suma la amplitud a la marca de clase anterior, por ejemplo, X2 = X1 + 4 = 27.5 + 4 = 31.5, y así sucesivamente.
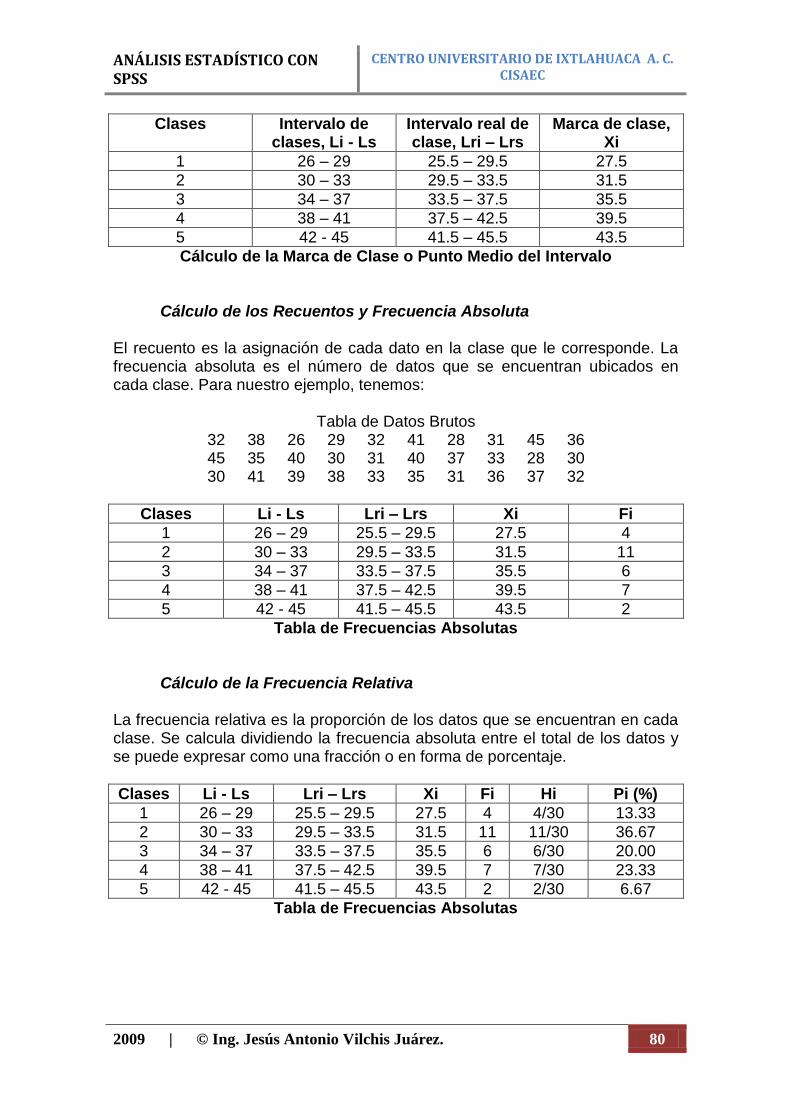
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 80
Clases Intervalo de clases, Li - Ls
Intervalo real de clase, Lri – Lrs
Marca de clase, Xi
1 26 – 29 25.5 – 29.5 27.5
2 30 – 33 29.5 – 33.5 31.5
3 34 – 37 33.5 – 37.5 35.5
4 38 – 41 37.5 – 42.5 39.5
5 42 - 45 41.5 – 45.5 43.5
Cálculo de la Marca de Clase o Punto Medio del Intervalo
Cálculo de los Recuentos y Frecuencia Absoluta El recuento es la asignación de cada dato en la clase que le corresponde. La frecuencia absoluta es el número de datos que se encuentran ubicados en cada clase. Para nuestro ejemplo, tenemos:
Tabla de Datos Brutos 32 38 26 29 32 41 28 31 45 36 45 35 40 30 31 40 37 33 28 30 30 41 39 38 33 35 31 36 37 32
Clases Li - Ls Lri – Lrs Xi Fi
1 26 – 29 25.5 – 29.5 27.5 4
2 30 – 33 29.5 – 33.5 31.5 11
3 34 – 37 33.5 – 37.5 35.5 6
4 38 – 41 37.5 – 42.5 39.5 7
5 42 - 45 41.5 – 45.5 43.5 2
Tabla de Frecuencias Absolutas
Cálculo de la Frecuencia Relativa La frecuencia relativa es la proporción de los datos que se encuentran en cada clase. Se calcula dividiendo la frecuencia absoluta entre el total de los datos y se puede expresar como una fracción o en forma de porcentaje.
Clases Li - Ls Lri – Lrs Xi Fi Hi Pi (%)
1 26 – 29 25.5 – 29.5 27.5 4 4/30 13.33
2 30 – 33 29.5 – 33.5 31.5 11 11/30 36.67
3 34 – 37 33.5 – 37.5 35.5 6 6/30 20.00
4 38 – 41 37.5 – 42.5 39.5 7 7/30 23.33
5 42 - 45 41.5 – 45.5 43.5 2 2/30 6.67
Tabla de Frecuencias Absolutas

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 81
Cálculo de las Frecuencias Absolutas Acumuladas y Relativas Acumuladas
Para agregar a la tabla de distribución de frecuencias las frecuencias acumuladas, tanto absolutas como relativas, hay que generar la columna menor que (<). La nomenclatura de las frecuencias absolutas acumuladas es Fi y la de las frecuencias relativas acumuladas, Hi.
Frecuencias absolutas
Frecuencias absolutas
acumuladas
Frecuencias relativas
Frecuencias relativas
acumuladas
Fi
Fi
hi
Hi
La columna menor que (<) está formada por todos los límites reales de clase y quedaría así:
< Clases Li - Ls Lri – Lrs Xi Fi hi 25.5
1 26 – 29 25.5 – 29.5 27.5 4 13.33 % 29.5 2 30 – 33 29.5 – 33.5 31.5 11 36.67 % 33.5 3 34 – 37 33.5 – 37.5 35.5 6 20.00 % 37.5 4 38 – 41 37.5 – 42.5 39.5 7 23.33 % 41.5 5 42 - 45 41.5 – 45.5 43.5 2 6.67 % 45.5
El cuadro anterior, ordenado, quedaría de la siguiente manera:
<
Clases Li - Ls Lri – Lrs Xi fi Fi hi Hi
25.5
1 26 – 29 25.5 – 29.5 27.5 29.5 4 4 13.33 % 13.33 %
2 30 – 33 29.5 – 33.5 31.5 33.5 11 15 36.67 % 50.00 %
3 34 – 37 33.5 – 37.5 35.5 37.5 6 21 20.00 % 70.00 %
4 38 – 41 37.5 – 42.5 39.5 41.5 7 28 23.33 % 93.33 %
5 42 - 45 41.5 – 45.5 43.5 45.5 2 30 6.67 % 100.00 %
Cálculo de Frecuencias Absolutas Acumuladas y Relativas Acumuladas Para generar la frecuencia absoluta acumulada, debemos de formularnos la siguiente pregunta: ¿Cuántos datos son menores que los limites reales?. Por ejemplo: ¿Cuántos datos son menores que 25.5? La respuesta es ninguno, ya que todos son mayores que esa cantidad. ¿Cuántos datos son menores que 29.5? La respuesta es 4.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 82
A la pregunta, ¿cuántos datos son menores que 33.5?, la respuesta es 4 + 11 = 15, y así sucesivamente, hasta terminar con la columna menor que (<).
< Fi Clases Li - Ls Lri – Lrs Xi Fi hi 25.5 0
1 26 – 29 25.5 – 29.5 27.5 4 13.33 % 29.5 4 2 30 – 33 29.5 – 33.5 31.5 11 36.67 % 33.5 15 3 34 – 37 33.5 – 37.5 35.5 6 20.00 % 37.5 21 4 38 – 41 37.5 – 42.5 39.5 7 23.33 % 41.5 28 5 42 - 45 41.5 – 45.5 43.5 2 6.67 % 45.5 30
El cuadro anterior, ordenado, quedaría de la siguiente manera:
<
Clases Li - Ls Lri – Lrs Xi fi Fi hi Hi
25.5 0 0 0 0
1 26 – 29 25.5 – 29.5 27.5 29.5 4 4 13.33 % 13.33 %
2 30 – 33 29.5 – 33.5 31.5 33.5 11 15 36.67 % 50.00 %
3 34 – 37 33.5 – 37.5 35.5 37.5 6 21 20.00 % 70.00 %
4 38 – 41 37.5 – 42.5 39.5 41.5 7 28 23.33 % 93.33 %
5 42 - 45 41.5 – 45.5 43.5 45.5 2 30 6.67 % 100.00 %
Recálculo de Frecuencias Absolutas y Relativas Acumuladas Análogamente, para generar la frecuencia relativa acumulada, nos debemos de preguntar ¿qué porcentaje de los datos es menor que los limites reales?. Por ejemplo: ¿Qué porcentaje de los datos es menor que 25.5? La respuesta es ninguno, ya que todos son mayores que esa cantidad. ¿Qué porcentaje de los datos es menor que 29.5? La respuesta es 13.33%. A la pregunta, ¿qué porcentaje de los datos es menor que 33.5? La respuesta es 13.33 + 36.67 = 50%, y así sucesivamente hasta terminar con la columna menor que (<).
< Fi
Clases Li - Ls Lri – Lrs Xi Fi hi 25.5 0
1 26 – 29 25.5 – 29.5 27.5 4 13.33 % 29.5 4
2 30 – 33 29.5 – 33.5 31.5 11 36.67 % 33.5 15
3 34 – 37 33.5 – 37.5 35.5 6 20.00 % 37.5 21
4 38 – 41 37.5 – 42.5 39.5 7 23.33 % 41.5 28
5 42 - 45 41.5 – 45.5 43.5 2 6.67 % 45.5 30
Frecuencias Absolutas Acumuladas y Relativas Acumuladas Para concluir, en términos de campos (lo que se llama en Estadística, variables) y de frecuencias de variables, tendríamos:

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 83
Xi Fi
27.5 4
31.5 11
35.5 6
39.5 7
43.5 2
Variables y Frecuencias de Variables Utilizando este método, observamos que n = 30 es menor que 50 y, de acuerdo con la tabla, se nos recomienda, tomar de 5 a 7 clases: Por tanto, K = 5 clases sería una buena asignación. Recuento y Frecuencia Absoluta El recuento es la asignación de cada dato en la clase que le corresponde. La frecuencia absoluta es el número de datos que se encuentran ubicados en cada clase. Para nuestro ejemplo, tenemos:
Tabla de Frecuencias Absolutas
Clases Li - Ls Lri – Lrs Xi Fi
1 26 – 29 25.5 – 29.5 27.5 4
2 30 – 33 29.5 – 33.5 31.5 11
3 34 – 37 33.5 – 37.5 35.5 6
4 38 – 41 37.5 – 42.5 39.5 7
5 42 - 45 41.5 – 45.5 43.5 2
Frecuencia Relativa del Intervalo La frecuencia relativa es la proporción de los datos que se encuentran en cada clase. Se calcula dividiendo la frecuencia absoluta entre el total de los datos y se puede expresar como una fracción o en forma de porcentaje.
Tabla de Frecuencias Relativas
Clases Li - Ls Lri – Lrs Xi Fi hi
1 26 – 29 25.5 – 29.5 27.5 4 4/30 = 13.33 %
2 30 – 33 29.5 – 33.5 31.5 11 11/30 = 36.67 %
3 34 – 37 33.5 – 37.5 35.5 6 6/30 = 20.00 %
4 38 – 41 37.5 – 42.5 39.5 7 7/30 = 23.33 %
5 42 - 45 41.5 – 45.5 43.5 2 2/30 = 6.67 %
Frecuencias Absolutas Acumuladas y Relativas Acumuladas Para agregar a la tabla de distribución de frecuencias las frecuencias acumuladas, tanto absolutas como relativas, hay que generar la columna menor que (<).

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 84
La columna menor que (<) está formada por todos los límites reales de clase y quedaría de la siguiente manera: Tabla de Frecuencias Absolutas Acumuladas y Relativas Acumuladas (I)
<
Clases Li - Ls Lri – Lrs Xi Fi hi 25.5
1 26 – 29 25.5 – 29.5 27.5 4 13.33 % 29.5
2 30 – 33 29.5 – 33.5 31.5 11 36.67 % 33.5
3 34 – 37 33.5 – 37.5 35.5 6 20.00 % 37.5
4 38 – 41 37.5 – 42.5 39.5 7 23.33 % 41.5
5 42 - 45 41.5 – 45.5 43.5 2 6.67 % 45.5
Para generar la frecuencia absoluta acumulada nos debemos de preguntar ¿cuántos datos son menores que los limites reales? Por ejemplo: ¿Cuántos datos son menores que 25.5? La respuesta es ninguno, ya que todos son mayores que esa cantidad. ¿Cuántos datos son menores que 29.5? La respuesta es 4. A la pregunta, ¿cuántos datos son menores que 33.5?, la respuesta es 4 + 11 = 15, y así sucesivamente, hasta terminar con la columna menor que (<).
Tabla de Frecuencias Absolutas y Relativas Acumuladas (II)
< Fi
Clases Li - Ls Lri – Lrs Xi Fi hi 25.5 0
1 26 – 29 25.5 – 29.5 27.5 4 13.33 % 29.5 4
2 30 – 33 29.5 – 33.5 31.5 11 36.67 % 33.5 15
3 34 – 37 33.5 – 37.5 35.5 6 20.00 % 37.5 21
4 38 – 41 37.5 – 42.5 39.5 7 23.33 % 41.5 28
5 42 - 45 41.5 – 45.5 43.5 2 6.67 % 45.5 30
Para generar la frecuencia relativa acumulada, nos debemos de preguntar ¿qué porcentaje de los datos es menor que los limites reales? Por ejemplo: ¿Qué porcentaje de los datos es menor que 25.5? La respuesta es ninguno, ya que todos son mayores que esa cantidad. ¿Qué porcentaje de los datos es menor que 29.5? La respuesta es 13.33%. A la pregunta, ¿qué porcentaje de los datos es menor que 33.5? La respuesta es 13.33 + 36.67 = 50%, y así sucesivamente hasta terminar con la columna menor que (<).

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 85
Tabla de Frecuencias Absolutas y Relativas Acumuladas (III)
< Fi Hi
Clases Li - Ls Lri – Lrs Xi Fi hi 25.5 0 0
1 26 – 29 25.5 – 29.5 27.5 4 13.33 % 29.5 4 13.33 %
2 30 – 33 29.5 – 33.5 31.5 11 36.67 % 33.5 15 50.00 %
3 34 – 37 33.5 – 37.5 35.5 6 20.00 % 37.5 21 70.00 %
4 38 – 41 37.5 – 42.5 39.5 7 23.33 % 41.5 28 93.33 %
5 42 - 45 41.5 – 45.5 43.5 2 6.67 % 45.5 30 100.00 %
Histograma y Polígono de Frecuencias El histograma es una gráfica de barras construida sobre una gráfica cartesiana, en donde cada clase se levanta por medio de una barra sobre sus límites reales de clase. La altura de cada barra es la frecuencia absoluta o relativa de cada clase. El polígono de frecuencias se forma uniendo los puntos formados por la intersección de la marca de clase o punto medio, con la frecuencia absoluta o con la relativa. Para poder cerrar el polígono, hay que comenzar con la marca de clase anterior a la primera clase, y terminar con la marca de clase posterior a la última, ya que estas clases ficticias tienen una frecuencia nula. A continuación, se va a proceder a la creación de un Histograma y un Polígono de Frecuencias.
Editor de Datos con los datos.
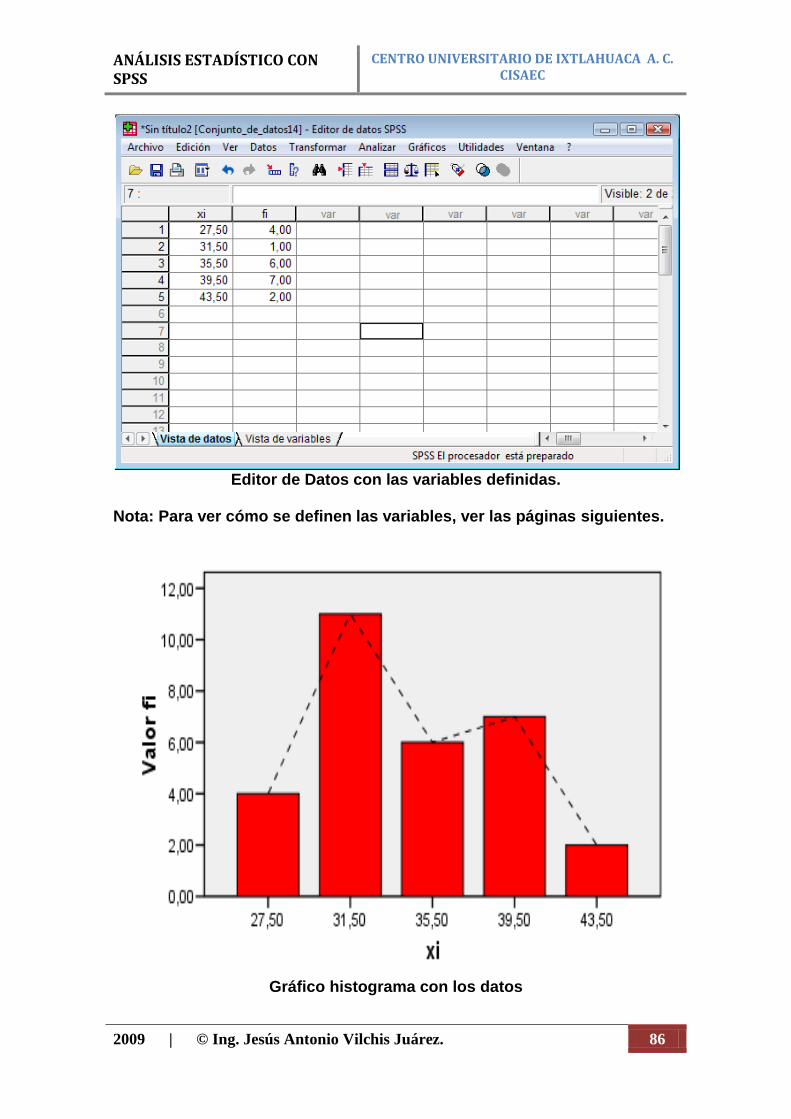
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 86
Editor de Datos con las variables definidas.
Nota: Para ver cómo se definen las variables, ver las páginas siguientes.
Gráfico histograma con los datos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 87
Creación de un Fichero de Datos con SPSS Una vez recogida la información relativa a las edades de los alumnos del ejemplo anterior, y arrancado el programa SPSS: Seleccionar en la barra de menú: Archivo/Nuevo/Datos. Hacer doble clic sobre la cabecera de la primera columna.
Aparece la ventana de Vista de variables. Escribir " edad " en el cuadro Nombre de Variable.
Se abrirá el cuadro de diálogo ―Definir Variable”.
Ventana Vista de variables.
Hacer doble clic sobre la cabecera de la columna Tipo. Dejar seleccionada la opción predeterminada Numérico. Escribir el valor "2" en el cuadro Anchura1. Este ancho representa el
número de caracteres de la variable edad: 2 (ya que no se espera que ningún alumno tenga por encima de los 99 años, en cuyo caso ya se necesitarían 3 dígitos). Esto significa que la variable edad tendrá 2 dígitos, es decir, podrá tomar valores de 0 a 99.
1 Existe otro ancho en el subcomando ―Formato de Columna‖, que permite especificar el ancho de la columna de una variable en el ―Editor de Datos‖.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 88
Escribir el valor "0" en el cuadro Decimales (Lugares Decimales2). El cuadro Decimales (Cifras Decimales), permite especificar el número de cifras decimales de la variable edad: 0 (ya que no se le pregunta a los alumnos edad en años cumplidos) que ningún profesor tenga un número de años fraccionario, en cuyo caso se necesitaría especificar decimales).
Ficha Vista de variables
En Etiqueta escribir una palabra o frase para identificar de qué variable
se trata: Edad del alumno de spinning. Aparece el cuadro de diálogo Definir Etiquetas.
Cuadro de Diálogo Definir etiquetas
2 Es lógico, pues no se contemplan cifras decimales en los datos del estudio.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 89
En el cuadro "Valores " (Etiquetas de los valores de la variable) tan sólo escribir el valor que definirá los valores perdidos (99). Por ello: Escribir el valor 99 en el cuadro Valor. Escribir la etiqueta Ns/Nc en el cuadro Etiqueta.
Cuadro de Diálogo Etiquetas de valor
Pulsar Añadir. Por último, pulsar el botón Aceptar.
Cuadro de Diálogo Etiquetas de valor

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 90
Hacer clic en la celda Perdidos (Valores Perdidos3). Seleccionar la opción Valores perdidos discretos. Escribir el valor "99" en el primer cuadro habilitado4.
Ficha Definir valores perdidos
Ficha Vista de variables
En la celda de Columnas (Ancho de Columna) especificar "8" que es la
opción mejor y más usual. Hacer clic en la celda Alineación que permite especificar la alineación
de la variable sobre la columna y dejar activada la opción por defecto ‗derecha‟.
En Medida dejar activada la opción por defecto: ‗Escala‟. De esta forma hemos terminado de definir la estructura de la variable ‗edad‟.
3 Los valores perdidos representan valores codificados, pero sin respuesta o ausentes.
4 El valor 9, la opción más usada para valores perdidos, designa la respuesta "NS/NC" (no sabe/no
contesta). Si el ancho de la variable fuera uno, se utilizaría 9. Si fuera dos, 99; etc.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 91
Procedimientos de Exploración Estadística Para la exploración estadística de una base de datos existe una multiplicidad de procedimientos. Cada uno de ellos aborda esta tarea desde su propio enfoque. En SPSS, los procedimientos de exploración estadística están concentrados en un bloque aparte, llamado Analizar. Los más importantes procedimientos de exploración estadística de SPSS son los siguientes: Análisis Descriptivo de una Base Datos (DESCRIPTIVOS), cuya
principal contribución es permitir la estandarización de variables, esto es, la transformación de variables mediante una tipificación, con el fin de facilitar su comparación, siendo completamente anecdótico su papel en el análisis descriptivo.
Análisis Descriptivo de una Tabla de Frecuencias (FREQUENCIAS), cuya mayor importancia es dar una rápida pincelada de las características de una variable, que incluye una representación gráfica de las variables.
Exploración Estadística de una Base Datos (EXPLORAR) que, a las
facilidades del procedimiento FREQUENCIAS, añade las ventajas de los contrastes de la normalidad y la homocedasticidad, además de poseer eficaces representaciones gráficas, como gráficas de cajas y de linealidad.
Análisis de la Asociación entre 2 Variables (TABLAS DE
CONTINGENCIA), que crea una tabla de contingencia y posibilita el cálculo de estadísticos que cuantifican la fuerza de la asociación entre variables.
Frecuencias (Frequencies)
El procedimiento Frecuencias genera estadísticos y gráficos que son útiles para la descripción de variables. Es útil como una primera visión de los datos. Se pueden organizar los distintos valores en orden ascendente o descendente, u ordenar las categorías por sus frecuencias. Aplicación del Procedimiento FRECUENCIAS Seleccionar en la barra de menú: Archivo / Abrir. Localizar el fichero de datos „HEALTH.SPINNING.sav' y abrirlo. Seleccionar en la barra de menú: Analizar / Estadísticos decriptivos /
Frecuencias.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 92
Llamada del Procedimiento Frecuencias
Aparece el cuadro de diálogo Frecuencias.
Cuadro de Diálogo Frecuencias
Variable(s). Muestra la(s) variable(s) seleccionadas para el análisis. Seleccionar las variables „estatura‟ y 'pulsaciones' en la lista de
variables fuente. Pulsar el botón, para introducirlas en la lista Variable(s).
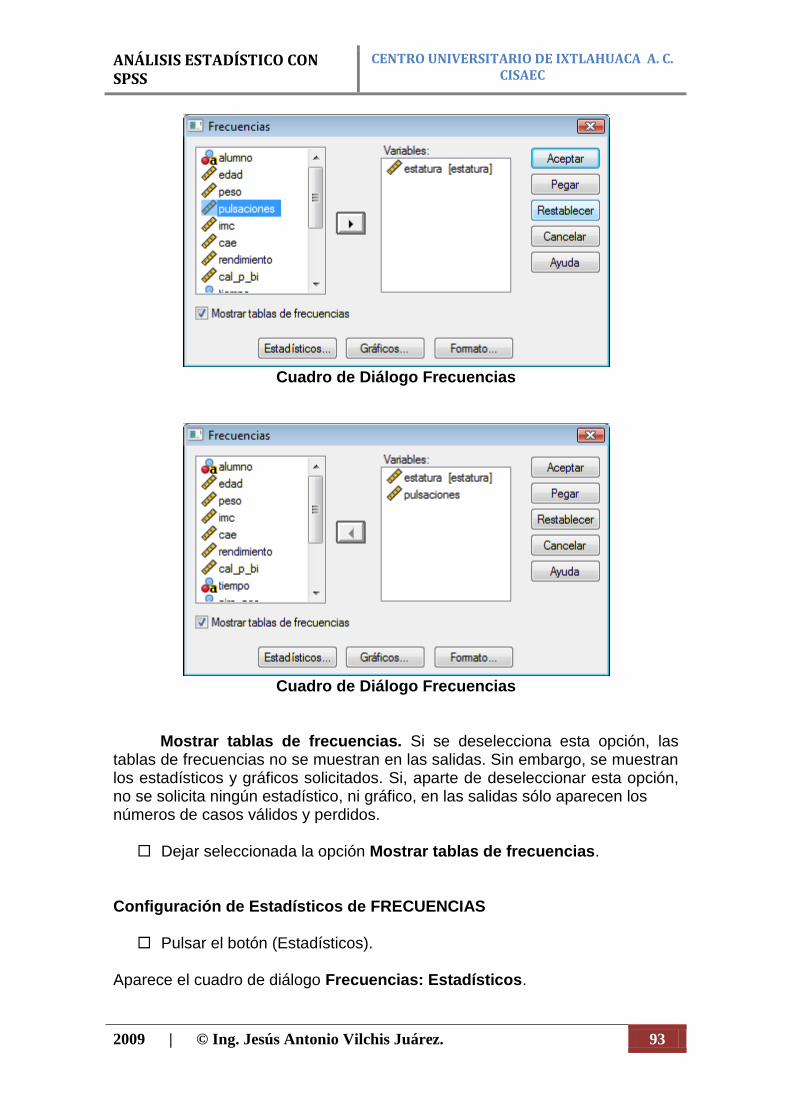
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 93
Cuadro de Diálogo Frecuencias
Cuadro de Diálogo Frecuencias
Mostrar tablas de frecuencias. Si se deselecciona esta opción, las tablas de frecuencias no se muestran en las salidas. Sin embargo, se muestran los estadísticos y gráficos solicitados. Si, aparte de deseleccionar esta opción, no se solicita ningún estadístico, ni gráfico, en las salidas sólo aparecen los números de casos válidos y perdidos. Dejar seleccionada la opción Mostrar tablas de frecuencias.
Configuración de Estadísticos de FRECUENCIAS Pulsar el botón (Estadísticos).
Aparece el cuadro de diálogo Frecuencias: Estadísticos.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 94
Cuadro de Diálogo Frecuencias: Estadísticos
Valores de Percentiles. Representan los valores de una variable cuantitativa que dividen los datos ordenados en grupos de forma que cierto porcentaje esté por encima y otro esté por debajo, sumando ambos porcentajes el 100%.
Cuartiles. Dividen las observaciones en 4 grupos de igual
tamaño, con puntos de corte correspondientes a los percentiles 25, 50 y 75.
Puntos de corte para 10 grupos iguales. Permite dividir los casos en varios grupos iguales. SPSS admite entre 2 y 100 grupos iguales; proponiendo, por defecto, 10 grupos.
Percentiles. Permite introducir tantos puntos de corte como se desee y, además, admite grupos desiguales, por ejemplo: 10, 25, 50, 60.
Seleccionar la opción Puntos de corte para 10 grupos iguales y dejar el número de puntos de corte predeterminado (10).
Dispersión. Estadísticos que miden la variación o dispersión en los datos.
Desviación típica. Medida de dispersión alrededor de la media. Es igual a la raíz cuadrada de la varianza y se expresa en las mismas unidades de medida que las observaciones. En una distribución normal, el 68% de los casos caen dentro de una desviación típica alrededor de la media y el 95%, dentro de dos desviaciones típicas.
Varianza. Medida de dispersión alrededor de la media. Es igual a la suma de los cuadrados de las desviaciones respecto de la media

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 95
dividida por el número de casos menos uno. La unidad de medida de la varianza es el cuadro de la unidad de la variable.
Rango. Diferencia entre el valor más grande (máximo) y el más pequeño (mínimo) de una variable numérica.
Mínimo. El valor más pequeño de una variable numérica. Máximo. El valor más grande de una variable numérica. Error típico de la media. Medida de cuanto puede variar el valor de
la media de una muestra a otra, seleccionada de la misma distribución. Se utiliza para una comparación poco precisa de la media observado y un valor hipotético.
Seleccionar las seis opciones del cuadro Dispersión.
Tendencia Central. Estadísticos que describen la localización de
distribución. Media. La media aritmética: la suma de los valores divida por el
número de casos. La medida de tendencia central más característica, muy influenciada por valores atípicos.
Mediana. Medida de tendencia central insensible a la influencia de valores atípicos. El valor por debajo y por encima del cual cae la mitad del los casos (percentil 50). Cuando el número de casos es par, la mediana se calcula como el promedio de los dos casos centrales cuando estos se ordenan en orden ascendente o descendente.
Moda. El valor más frecuente. Si varios valores son los más frecuentes, cada uno de ellos es una moda. El procedimiento FRECUENCIAS utiliza la más pequeña de estas modas.
Suma. La suma o el total de los valores de todos los casos con valores no perdidos.
Seleccionar las cuatro opciones del cuadro Tendencia Central.
Los valores son puntos medios de grupos. Calcula los valores
percentiles y la mediana suponiendo que los datos han sido agrupados y que los valores de los datos son los puntos medios de los grupos originales.
Seleccionar la opción Los valores son puntos medios de grupos.
Distribución. Los coeficientes de asimetría y curtosis son estadísticos que
miden la forma y la simetría de la distribución. Estos estadísticos se muestran con sus errores típicos.
Asimetría. Una medida de asimetría de la distribución. La distribución
normal es simétrica y tiene asimetría igual a 0. Una distribución con un significativo valor positivo de asimetría tiene una gran asimetría a la derecha. Una distribución con un significativo valor negativo de asimetría tiene una gran asimetría a la izquierda.
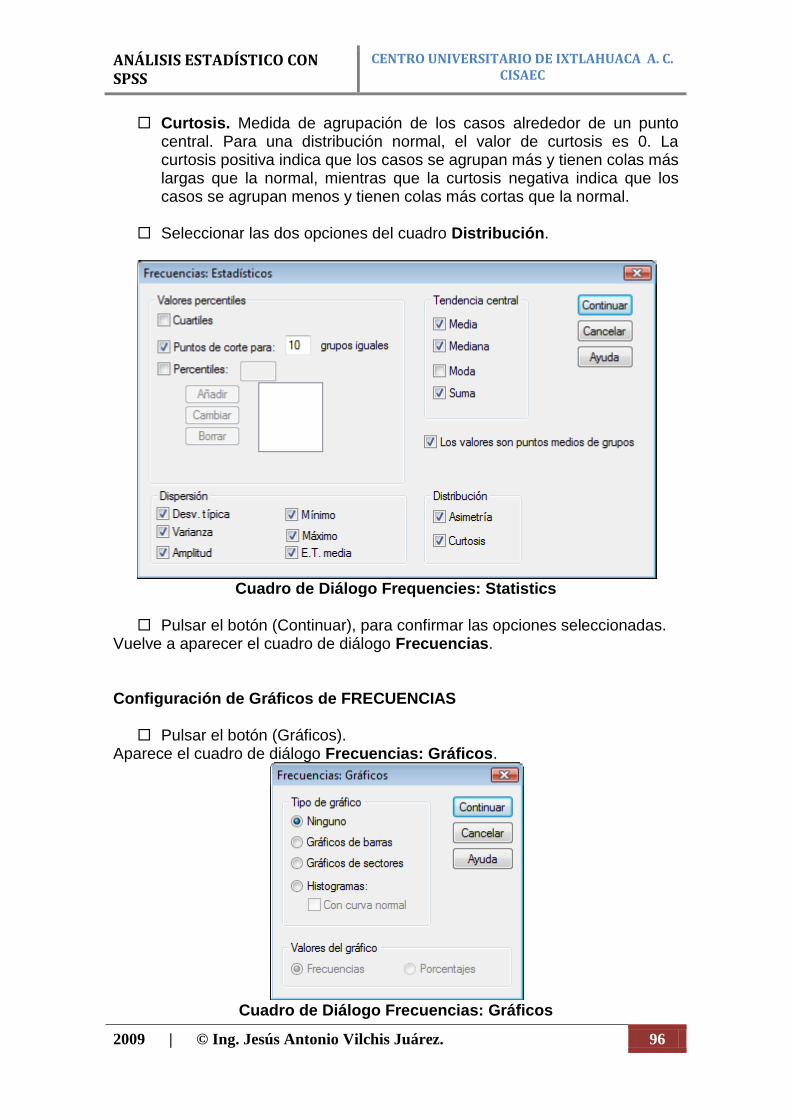
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 96
Curtosis. Medida de agrupación de los casos alrededor de un punto central. Para una distribución normal, el valor de curtosis es 0. La curtosis positiva indica que los casos se agrupan más y tienen colas más largas que la normal, mientras que la curtosis negativa indica que los casos se agrupan menos y tienen colas más cortas que la normal.
Seleccionar las dos opciones del cuadro Distribución.
Cuadro de Diálogo Frequencies: Statistics
Pulsar el botón (Continuar), para confirmar las opciones seleccionadas.
Vuelve a aparecer el cuadro de diálogo Frecuencias. Configuración de Gráficos de FRECUENCIAS Pulsar el botón (Gráficos).
Aparece el cuadro de diálogo Frecuencias: Gráficos.
Cuadro de Diálogo Frecuencias: Gráficos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 97
Tipo de Gráfico. Permite solicitar el tipo de gráfico. Ninguno. No presentar ningún gráfico. Gráficos de barras. Mide la frecuencia para cada valor distinto o
categoría como una barra separada, permitiendo una comparación visual de las categorías.
Gráficos de sectores. Muestra la contribución de las partes al todo. Cada trozo del mismo corresponde a un grupo definido por una sola VI.
Histogramas. Un histograma también tiene barras, pero se representan a lo largo de una escala de intervalo. La altura de cada barra es la frecuencia de los valores de una variable cuantitativa, situados dentro de este intervalo. Un histograma muestra la forma, el centro y la dispersión de la distribución. Con curva normal. Sobrepone la curva normal al histograma,
para ayudar a juzgar visualmente si los datos se distribuyen normalmente.
Seleccionar la opción Histogramas.
Al hacerlo, se habilita la opción adjunta Con curva normal. Seleccionar la opción Con curva normal.
Valores de Gráfico. Para los diagramas de barras, el eje de escalas puede
ser etiquetado según las frecuencias o porcentajes de frecuencias. Frecuencias. Etiqueta el eje vertical de gráfico de barras con
frecuencias. Porcentajes). Etiqueta el eje vertical de gráfico de barras con
porcentajes. Dejar la opción por defecto - Frecuencias.
Cuadro de Diálogo Frecuencias: Graficos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 98
Pulsar el botón (Continuar), para confirmar las opciones seleccionadas. Vuelve a aparecer el cuadro de diálogo Frecuencias. Configuración de Formato de Presentación de FRECUENCIAS Pulsar el botón (Formato).
Aparece el cuadro de diálogo Frecuencias: Formato.
Cuadro de Diálogo Frecuencias: Formato
Ordenar por. La tabla de frecuencias puede ordenarse según los
valores reales de los datos o según la frecuencia de ocurrencia de dichos valores, y en orden ascendente o descendente. Sin embargo, si se solicita un histograma o percentiles, SPSS asume que la variable es cuantitativa y muestra sus valores en orden ascendente.
Valores ascendentes. Ordena la tabla de frecuencias según el
orden ascendente de los valores reales de los datos. Valores descendentes. Ordena la tabla de frecuencias según el
orden descendente de los valores reales de los datos. Frecuencias ascendentes. Ordena la tabla de frecuencias según
el orden ascendente de las frecuencias de los valores de los datos.
Frecuencias descendentes. Ordena la tabla de frecuencias según el orden descendente de las frecuencias de los valores de los datos.
Dejar la opción por defecto - Valores ascendentes.
Suprimir tablas con más de 10 categorías). Permite no visualizar
tablas con más categorías que las especificadas (por defecto, 10). Esta opción es útil cuando una variable tiene muchas categorías y no interesa verla en las salidas.
Seleccionar la opción Suprimir tablas con más de 10 categorías.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 99
Cuadro de Diálogo "Frecuencias: Formato"
Pulsar el botón (Continuar), para confirmar las opciones seleccionadas.
Vuelve a aparecer el cuadro de diálogo Frecuencias. Ejecución del Procedimiento FRECUENCIAS
Cuadro de Diálogo Frecuencias
Pulsar el botón (Aceptar), para ejecutar el procedimiento.
Interpretación de las Salidas de FREQUENCIES El histograma de la variable „estatura‟ nos da idea de un comportamiento que asemeja en gran medida a la normal. La variable „pulsaciones‟ tiene un comportamiento lo mas ajustado posible a la curva normal. Esto quiere decir que el grupo de alumnos de la clase de spinning tiene un comportamiento homogéneo en esta variable. La variable ‗estatura‟ tiene una asimetría modesta, frente a una casi despreciable asimetría de la variable ‗pulsaciones‟. Así también la curtosis de ambas variables es baja. Estamos frente a variables que presentan comportamientos homogéneos. (Ver Anexo al final de este apartado)
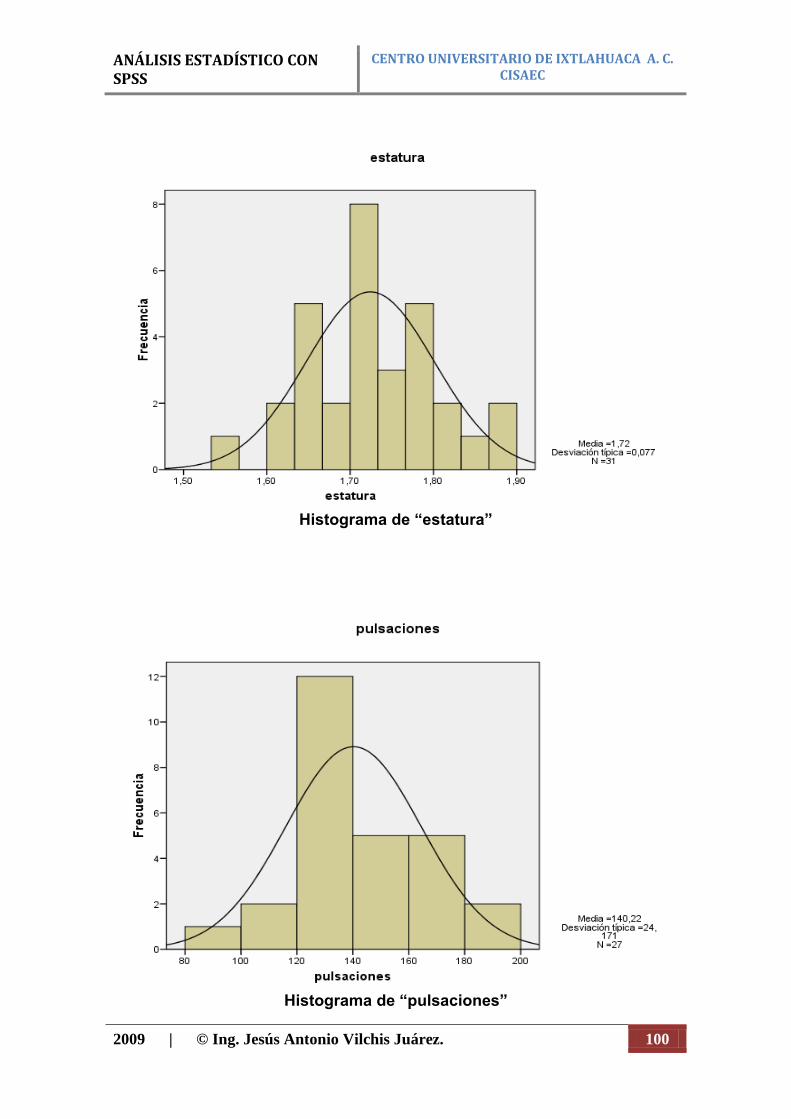
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 100
Histograma de “estatura”
Histograma de “pulsaciones”

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 101
Tabla de estadísticos Estadísticos
estatura pulsaciones
N Válidos 31 27 Perdidos 0 4 Media 1,7242 140,22 Error típ. de la media ,01383 4,652 Mediana 1,7220a 136,00a Moda 1,65b 120b Desv. típ. ,07698 24,171 Varianza ,006 584,256 Asimetría ,099 -,055 Error típ. de asimetría ,421 ,448 Curtosis ,101 -,170 Error típ. de curtosis ,821 ,872 Rango ,34 98 Mínimo 1,55 90 Máximo 1,89 188 Suma 53,45 3786 Percentiles 10 1,6348c 105,60c 20 1,6548 122,88 30 1,6880 129,47 40 1,7051 134,60 50 1,7220 136,00 60 1,7373 144,70 70 1,7660 153,60 80 1,7853 161,60 90 1,8300 173,80
a Calculado a partir de los datos agrupados. b Existen varias modas. Se mostrará el menor de los valores. c Los percentiles se calcularán a partir de los datos agrupados.
Descriptivos El procedimiento Descriptivos muestra estadísticos univariados de resumen para varias variables en una sola tabla y calcula valores estandarizados (puntuaciones Z). Aplicación de DESCRIPTIVOS Seleccionar en la barra de menú: Archivo/Abrir. Localizar el fichero de datos „HEALTH.SPINNING.sav' y abrirlo. Seleccionar en la barra de menú: Analizar / Estadísticos descriptivos /
Descriptivos.
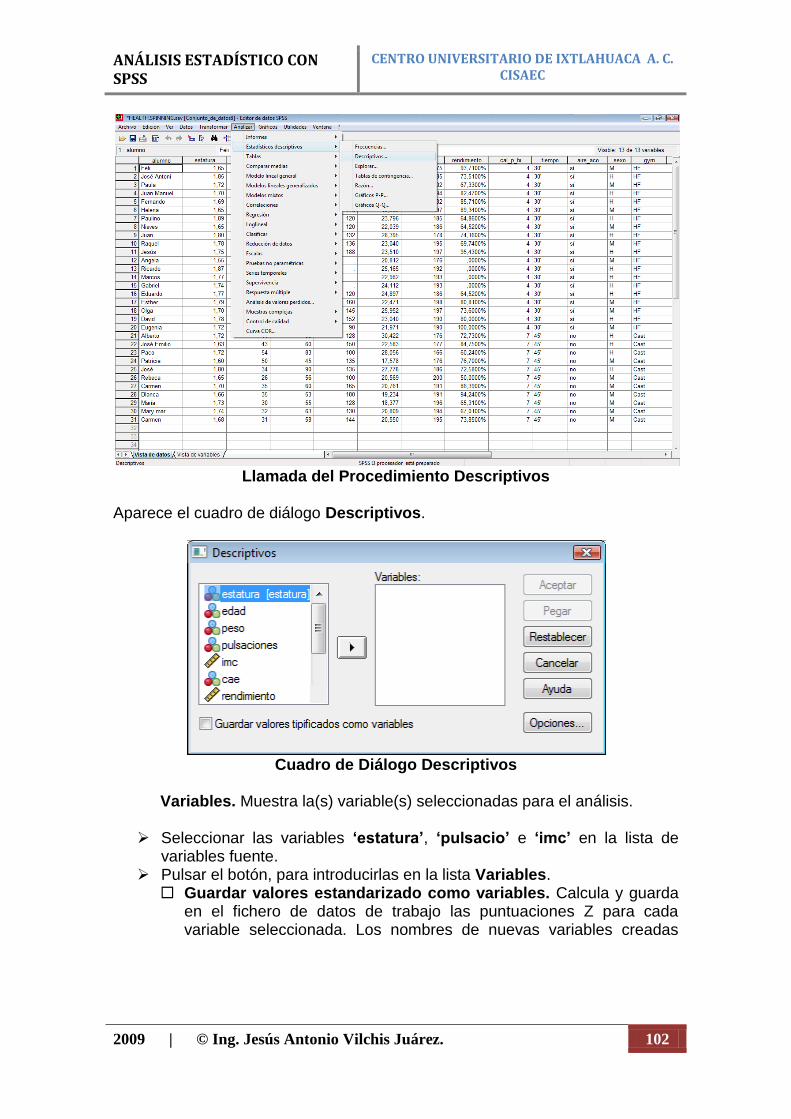
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 102
Llamada del Procedimiento Descriptivos
Aparece el cuadro de diálogo Descriptivos.
Cuadro de Diálogo Descriptivos
Variables. Muestra la(s) variable(s) seleccionadas para el análisis.
Seleccionar las variables „estatura‟, „pulsacio‟ e „imc‟ en la lista de
variables fuente. Pulsar el botón, para introducirlas en la lista Variables. Guardar valores estandarizado como variables. Calcula y guarda
en el fichero de datos de trabajo las puntuaciones Z para cada variable seleccionada. Los nombres de nuevas variables creadas

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 103
tienen el prefijo "z" y los siete primeros caracteres del nombre de la variable original5.
Seleccionar la opción Guardar valores tipificados como variables.
Cuadro de Diálogo Descriptivos
Configuración de Opciones de DESCRIPTIVOS Pulsar el botón (Opciones).
Aparece el cuadro de diálogo Descriptivos: Opciones.
Cuadro de Diálogo Descriptivos: Opciones
5 Las variables tipificadas Z se calculan dividiendo el resultado de restar a cada variable su valor medio
entre la desviación típica de dicha variable. Las variables tipificadas son unos valores normalizados que, situados en la curva normal, pueden ser usados como estadísticos de la dispersión. De hecho, el intervalo de confianza del 95% está comprendido entre las puntuaciones tipificadas -2 y + 2.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 104
Media. La media aritmética: la suma de los valores dividida por el número de casos. La medida de tendencia central más característica, muy influenciada por valores atípicos.
Suma. La suma o el total de los valores de todos los casos con valores no perdidos.
Seleccionar la opción Suma.
Dispersión. Estadísticos que miden la variación o dispersión en los datos.
Desviación típica. Medida de dispersión alrededor de la media. Es igual
a la raíz cuadrada de la varianza y se expresa en las mismas unidades de medida que las observaciones. En una distribución normal, el 68% de los casos caen dentro de 1 desviación típica alrededor de la media y el 95%, dentro de 2 desviaciones típicas. Varianza. Medida de dispersión alrededor de la media. Es igual a la
suma de los cuadrados de las desviaciones respecto de la media dividida por el número de casos menos uno. La unidad de medida de la varianza es el cuadro de la unidad de la variable.
Rango. Diferencia entre el valor más grande (máximo) y el más pequeño (mínimo) de una variable numérica.
Mínimo. El valor más pequeño de una variable numérica. Máximo. El valor más grande de una variable numérica. Error típico de la media). Medida de cuanto puede variar el valor de la
media de una muestra a otra, seleccionada de la misma distribución. Se utiliza para una comparación poco precisa de la media observado y un valor hipotético.
Seleccionar las cuatro opciones no seleccionadas del cuadro
Dispersión.
Distribución. Los coeficientes de asimetría y curtosis son estadísticos que miden la forma y la simetría de la distribución. Estos estadísticos se muestran con sus errores típicos.
Asimetría. Una medida de asimetría de la distribución. La distribución
normal es simétrica y tiene "asimetría" igual a 0. Una distribución con un significativo valor positivo de "asimetría" tiene una gran asimetría a la derecha. Una distribución con un significativo valor negativo de "asimetría" tiene una gran asimetría a la izquierda.
Curtosis. Una medida de hasta que punto se agrupan las observaciones alrededor de un punto central. Para una distribución normal, el valor del estadístico Curtosis es 0. Curtosis positiva indica que las observaciones se agrupan más y tienen colas más largas que las de la distribución normal. Curtosis negativa indica que las observaciones se agrupan menos y tienen colas más cortas que la distribución normal.
Seleccionar las dos opciones del cuadro Distribución.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 105
Orden de Visualización. Define el orden de visualización de variables. Lista de variables). Deja las variables en el orden en el que han sido
seleccionadas. Alfabético. Clasifica las variables en orden alfabético. Medias ascendentes. Clasifica las variables en orden ascendente de la
media. Medias descendentes. Clasifica las variables en orden descendente de
la media. Dejar la opción por defecto - Medias ascendentes.
Cuadro de Diálogo "Descriptivos: Opciones"
Pulsar el botón (Continuar), para confirmar las opciones seleccionadas.
Vuelve a aparecer el cuadro de diálogo Descriptivos. Ejecución del Procedimiento DESCRIPTIVOS
Cuadro de Diálogo Descriptivos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 106
Pulsar el botón (Aceptar), para ejecutar el procedimiento. Interpretación de las Salidas de un Ejemplo con DESCRIPTIVES Se ofrece una tabla de los estadísticos descriptivos solicitados.
Tabla de Estadísticos Descriptivos Estadísticos descriptivos
estatura imc pulsaciones N válido (según lista)
N Estadístico 31 31 27 27
Rango Estadístico ,34 30,422 98
Mínimo Estadístico 1,55 ,000 90
Máximo Estadístico 1,89 30,422 188
Suma Estadístico 53,45 686,353 3786
Media Estadístico 1,7242 22,14042 140,22
Error típico ,01383 ,921670 4,652
Desv. típ. Estadístico ,07698 5,131639 24,171
Varianza Estadístico ,006 26,334 584,256
Asimetría Estadístico ,099 -2,578 -,055
Error típico ,421 ,421 ,448
Curtosis Estadístico ,101 11,364 -,170
Error típico ,821 ,821 ,872
El Error Típico de Estimación de la Media (ETE), también llamado Error Estándar (Std Error, SE) cuantifica el sesgo de una estimación de un parámetro poblacional: la media poblacional, en este caso. El ETE se calcula dividiendo la desviación típica entre la raíz cuadrada del resultado de restar 1 al tamaño muestral:
El coeficiente de Asimetría (As) es un estadístico que alude a la forma de una distribución y mide el alejamiento de la media de la mediana. Se calcula con la fórmula siguiente:
As oscila entre los valores: -3 (máxima asimetría negativa) y +3 (máxima asimetría positiva), indicando el valor 0 la nula asimetría (esto es, simetría perfecta).

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 107
El coeficiente de apuntamiento o curtosis, K, expresa el grado de concentración de los datos en torno al valor central. Se calcula con la fórmula:
K oscila entre los valores: -3 (máximo apuntamiento negativo, forma platicúrtica) y +3 (máximo apuntamiento positivo, forma leptocúrtica), indicando el valor 0 un apuntamiento nulo o una distribución mesocúrtica. Los estadísticos curtosis y Asimetría tienen, en este ejemplo, valores próximos a 0, lo que supone que esas variables están próximas a la distribución normal. Esta aseveración está apoyada por los valores de los estadísticos de tendencia central y de la dispersión. Se muestra a continuación una vista del fichero de datos de trabajo con las puntuaciones típicas de las variables solicitadas.
Tabla de Estadísticos Descriptivos
Volviendo a aplicar el procedimiento DESCRIPTIVOS, pero esta vez a las puntuaciones Z calculadas: 'zestatura', 'zpulsaciones' y 'zimc', y sin guardar las nuevas puntuaciones Z, se obtiene la siguiente tabla:

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 108
Tabla de Estadísticos Descriptivos Estadísticos descriptivos
Puntua(imc) Puntua: estatura Puntua(pulsaciones) N válido (según lista)
N Estadístico 31 31 27 27
Rango Estadístico 5,92832 4,41701 4,05438
Mínimo Estadístico -4,31449 -2,26299 -2,07775
Máximo Estadístico 1,61383 2,15403 1,97662
Suma Estadístico ,00000 ,00000 ,00000
Media Estadístico ,0000000 ,0000000 ,0000000
Error típico ,17960530 ,17960530 ,19245009
Desv. típ. Estadístico 1,00000000 1,00000000 1,00000000
Varianza Estadístico 1,000 1,000 1,000
Asimetría Estadístico -2,578 ,099 -,055
Error típico ,421 ,421 ,448
Curtosis Estadístico 11,364 ,101 -,170
Error típico ,821 ,821 ,872
Podemos ver cómo las variables „zpulsacio‟ y „zestatura‟, tienen poca desviación respecto de la normal, con una baja „asimetría‟ de 0.119 y 0.442 respectivamente. Sin embargo la variable „zimc‟ (índice de masa corporal) se comporta de modo muy heterogéneo, tiene una alta dispersión, con una „asimetría‟ de –2.43. Al contar con estadísticos estandarizados, hemos podido comparar si el comportamiento de estas variables se asemeja a una normal. Es decir si tienen valores más o menos concentrados alrededor de la media.
Anexo: Medidas Estadísticas: Concepto y Características de una Medida Estadística: El Estadístico Yule ha definido algunas propiedades deseables para una medida estadística:
Debe definirse de manera objetiva: dos observadores distintos deben llegar al mismo resultado numérico.
Usar todas las observaciones y no algunas de ellas solamente, de manera que si varia alguna observación la medida considerada debe reflejar esta variación.
Tener un significado concreto: la interpretación debe ser inmediata y sencilla.
Ser sencilla de calcular.
Prestarse fácilmente al cálculo algebraico: Lo que permitirá demostraciones más elegantes.
Ser poco sensible a las fluctuaciones muestrales. Esta condición es imprescindible en la Estadística Matemática y en la Teoría de Sondeos.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 109
Anexo: Tipos de Medida: 1. Medidas de Centralización: Que sirven para determinar los valores centrales
o medios de la distribución. 2. Medidas de Dispersión: Nos van a dar una idea sobre la representatividad de
las medidas centrales, a mayor dispersión menor representatividad. 3. Medidas de Localización: Útiles para encontrar determinados valores
importantes, para una "clasificación" de los elementos de la muestra o población.
4. Medidas de la Curtosis: Sirven para ver si la distribución tiene el mismo apuntamiento por encima y por debajo de los valores centrales.
5. Medidas de la Simetría: Sirven para ver si la distribución tiene el mismo comportamiento por encima y por debajo de los valores centrales.
Medida de Tendencia Central o de Centralización (Promedios)
Medida de Tendencia Central o de Centralización (Promedios): Un único valor que resume un conjunto de datos. Señala el centro de valores.
No hay una sola medida de tendencia central, sino que se consideran cinco:
1. la media aritmética, 2. la media ponderada, 3. la mediana, 4. la moda 5. y la media geométrica.
Vamos a estudiar en este apartado los distintos tipos de medias. Media (Aritmética) La media aritmética de una variable se define como la suma ponderada de los valores de la variable por sus frecuencias relativas y lo denotaremos por y se calcula mediante la expresión:
donde:
xi representa el valor de la variable o en su caso la marca de clase.
Media de la Población La Media de la población:

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 110
A partir de datos en vivo, los que no han sido agrupados en una distribución de frecuencias o en una representación de tallo y hoja, la media de una población es:
Suma de todos los valores de la población Σ X Media de una población = μ Número de valores en la población N
donde:
μ representa la media de población N nº total de elementos en la población X cualquier valor en particular Σ sumatoria
La media de una población es un parámetro (una característica medible de una población) , así como la amplitud de variación (la diferencia entre el valor más grande y el más pequeño en un conjunto de datos).
Media de una Muestra Media de una muestra: Para datos en vivo, no agrupados la media es:
Suma de todos los valores de una muestra Σ X Media de una muestra = X Número de valores en la muestra n
Donde n es el número total de valores de la muestra. La media de una muestra, o cualquier otra medida basada en datos muestrales, se denomina dato estadístico (una característica de una muestra).
Propiedades de la Media Aritmética: Propiedades: 1. Todo conjunto de datos de nivel de intervalo y de nivel de razón tiene un
valor medio. 2. Al evaluar la media se incluyen todos los valores. 3. Un conjunto de datos sólo tiene una media. Esta es un valor único. 4. La media es una medida muy útil para comparar dos o más poblaciones. 5. La media es la única medida de ubicación donde la suma de las
desviaciones de cada valor es con respecto a la media, siempre será cero LAS DESVIACIONES RESPECTO DE LA MEDIA SUMAN CERO
Σ ( X – X ) = 0 6. La media podría no ser un promedio adecuado para representar datos. La
media se ve afectada de modo notable por valores extraordinariamente grandes o pequeños.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 111
7. No se puede determinar la media de datos de extremo abierto (Ej: U$S 100.000 y mayor).
Media Ponderada: Media ponderada: Es un caso especial de la media aritmética. Se presenta cuando hay varias observaciones del mismo valor que pueden ocurrir si los datos se han agrupado en una distribución de frecuencias. Para determinar la media ponderada multiplicamos cada observación por el número de veces que aparece.
w1X1 + w2X2 + w3X3 +...+ wnXn Σ (wX) Media ponderada = Xw w1 + w2 + w3 +...+ wn Σw
Mediana: La mediana es el valor central de la variable, es decir, supuesta la muestra ordenada en orden creciente o decreciente, el valor que divide en dos partes la muestra. Para calcular la mediana debemos tener en cuenta si la variable es discreta o continua. Cálculo de la mediana en el caso discreto: Tendremos en cuenta el tamaño de la muestra.
Si N es Impar, hay un término central, el término
que será el valor de la mediana.
Si N es Par, hay dos términos centrales, la mediana
será la media de esos dos valores.
Para datos que contienen 1 o 2 valores sumamente grandes o muy pequeños, la media aritmética puede no ser representativa. El punto central puede describirse mejor utilizando una medida de tendencia central denominada mediana.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 112
Mediana: Punto medio de los valores después de ordenarlos de menor a mayor, o de mayor a menor. Se tiene que 50% de las observaciones se encuentran por arriba de la mediana y 50% por debajo de ella.
Propiedades de la Mediana Las propiedades de la mediana son:
1. Es única, sólo existe una mediana para un conjunto de datos. 2. No se ve afectada por valores muy grandes o muy pequeños. 3. Puede calcularse para una distribución de frecuencias con una clase de
extremo abierto, si la medina no se encuentra en una clase de tal extremo.
4. Puede obtenerse para datos de nivel de razón, de intervalo y ordinal (excepto para el nominal).
Veamos un ejemplo.
N Impar N par
1, 4, 6, 7, 8, 9, 12, 16, 20, 24, 25, 27, 30. N=13
1, 4, 6, 7, 8, 9, 12, 16, 20, 24, 25, 27. N=13
Término Central el 7º, 12 Términos Centrales el 6º y 7º, 9 y 12
Me = (9+12) / 2 = 10,5 Me = 12
Cálculo de la mediana en caso de que la variable esté dividida en intervalos (sea continua, por ejemplo, Salario < 12.000 $, de 12.000 a 15.000, y > 15.000 $): Si la variable es continua, la tabla vendrá en intervalos, por lo que se calcula de la siguiente forma (nos vamos a apoyar en un gráfico de un histograma de frecuencias acumuladas):

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 113
De donde la mediana vale: donde ai es la amplitud del intervalo.
Veámoslo por medio de un ejemplo. Supongamos los pesos de un grupo de 50 personas se distribuyen de la siguiente forma:
Li-1 Li ni Ni Como el tamaño de la muestra es N=50, buscamos el intervalo en el que la Frecuencia acumulada es mayor que 50/2=25, que en este caso es el 3º y aplicamos la fórmula anterior. Luego la Mediana será
45 55 6 6
𝑴𝒆 = 𝟔𝟓 +𝟓𝟎
𝟐 − 𝟏𝟔
𝟑𝟓 − 𝟏𝟔∙ 𝟏𝟎 = 𝟔𝟗, 𝟕𝟒
55 65 10 16
65 75 19 35
75 85 11 46
85 95 4 50
Moda: La Moda: La moda es el valor de la variable que tenga mayor frecuencia absoluta, la que más se repite, es la única medida de centralización que tiene sentido estudiar en una variable cualitativa, pues no precisa la realización de ningún cálculo. Por su propia definición, la moda no es única, pues puede haber dos o más valores de la variable que tengan la misma frecuencia siendo esta máxima. En cuyo caso tendremos una distribución bimodal o polimodal según el caso. Por lo tanto, el cálculo de la moda en distribuciones discretas o cualitativas no precisa de una explicación mayor; sin embargo, debemos detenernos un poco en el cálculo de la moda para distribuciones cuantitativas continuas. Puede determinarse para todos los niveles de datos: nominal, ordinal, de intervalo y de razón. No se ve afectada por valores muy altos o muy bajos. Al igual que la mediana, puede utilizarse como medida de tendencia central para distribuciones con clases de extremo abierto.
Desventajas de la moda:
1. Para muchos conjuntos de datos no hay valor modal porque ningún valor aparece más de una vez.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 114
2. Para algunos conjuntos de datos hay más de una moda (bimodal = que tiene dos modas).
Apoyándonos en el gráfico, podemos llegar a la determinación de la expresión para la Moda que es:
Otros autores dan una expresión aproximada para la moda que viene dada por la siguiente expresión:
Veamos su cálculo mediante un ejemplo. Para ello, usaremos los datos del apartado anterior. Supongamos los pesos de un grupo de 50 personas se distribuyen de la siguiente forma:
Li-1 Li ni Ni
𝑀𝑜 = 65 +19 − 10
19 − 10 + (19 − 11)∙ 10 = 70,29
Utilizando la fórmula aproximada
𝑀𝑜 = 65 +11
10 + 11∙ 10 = 70,24
45 55 6 6
55 65 10 16
65 75 19 35
75 85 11 46
85 95 4 50
Media geométrica: Útil para encontrar el promedio de porcentajes, razones, índices o tasas de crecimiento. Se utiliza ampliamente en los negocios y la economía porque frecuentemente interesa encontrar el cambio porcentual en ventas, sueldos o cifras económicas, como el Producto Nacional Bruto. Siempre será menor o igual a (nunca mayor que) la media aritmética. Todos los valores de datos deben ser positivos.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 115
La media geométrica de N observaciones es la raíz de índice N del producto de todas las observaciones. La representaremos por G.
Medidas de Forma (Curtosis o Apuntamiento) Medidas de Simetría: Las medidas de la asimetría, al igual que la curtosis, van a ser medidas de la forma de la distribución, es frecuente que los valores de una distribución tiendan a ser similares a ambos lados de las medidas de centralización. La simetría es importante para saber si los valores de la variable se concentran en una determinada zona del recorrido de la variable.
As < 0 Asimetría Negativa o por la Izquierda
As = 0 Simétrica
Cont. Cont. Cont.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 116
As > 0 Asimetría Positiva o por la Derecha
Para medir la asimetría se puede realizar atendiendo básicamente a dos criterios:
Comparando la Media y la Moda.
Comparando los valores de la variable con la media.
Comparando la Media y la Moda: Si, Comparando la Media y la Moda, la diferencia resulta positiva, diremos que hay asimetría positiva o a la derecha. En en el caso de que sea negativa, diremos que hay asimetría negativa o a la izquierda. No obstante, esta medida es poco operativa al no ser una medida relativa, ya que esta influida por la unidad en que se mida la variable, por lo que se define el coeficiente de Asimetría como:
Esta medida es muy fácil de calcular, pero menos precisa que el coeficiente de asimetría de Pearson. El coeficiente de asimetría de Pearson, se basa en la comparación con la media de todos los valores de la variable, así que es una medida que se basará en las diferencias, como vimos en el caso de la dispersión si medimos la media de esas desviaciones sería nula, si las elevamos al cuadrado, serían siempre positivas por lo que tampoco servirían, por lo tanto precisamos elevar esas diferencias al cubo. Para evitar el problema de la unidad, y hacer que sea una medida escalar y por lo tanto relativa, dividimos por el cubo de su desviación típica. Con lo que resulta la siguiente expresión:

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 117
Medidas de Dispersión: Las Medidas de Dispersión nos van a dar una idea sobre la representatividad de las medidas centrales, a mayor dispersión menor representatividad. Hasta el momento, hemos estudiado los valores centrales de la distribución, pero también es importante conocer si los valores en general están cerca o alejados de estos valores centrales, es por lo que surge la necesidad de estudiar medidas de dispersión.
Rango Es la primera medida que vamos a estudiar, se define como la diferencia existente entre el valor mayor y el menor de la distribución. Lo denotaremos como R. Realmente no es una medida muy significativa en la mayoría de los casos, pero indudablemente es muy fácil de calcular. Hemos estudiado varias medidas de centralización, por lo que podemos hablar de desviación con respecto a cualquiera de ellas, sin embargo, la mas utilizada es con respecto a la media.
Concepto de desviación Es la diferencia que se observa entre el valor de la variable y la media aritmética. La denotaremos por di. No es una medida, son muchas medidas, pues cada valor de la variable lleva asociada su correspondiente desviación, por lo que precisaremos una medida que resuma dicha información. La primera solución puede ser calcular la media de todas las desviaciones, es decir, si consideramos como muestra la de todas las desviaciones y calculamos su media. Pero esta solución es mala pues como veremos siempre va a ser 0. Luego por lo tanto esta primera idea no es valida, pues las desviaciones positivas se contrarrestan con las negativas. Para resolver este problema, tenemos dos caminos:
Tomar el valor absoluto de las desviaciones. Desviación media.
Elevar al cuadrado las desviaciones. Varianza.
Desviación Media Es la media de los valores absolutos de las desviaciones, y la denotaremos por dm.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 118
Varianza Es la media de los cuadrados de las desviaciones, y la denotaremos por
o también por
Aunque también es posible calcularla como:
Este estadístico tiene el inconveniente de ser poco significativo, pues se mide en el cuadrado de la unidad de la variable, por ejemplo, si la variable viene dada en cm. La varianza vendrá en cm2.
Desviación Típica Es la raíz cuadrada de la varianza, se denota por Sx.
Este estadístico se mide en la misma unidad que la variable por lo que se puede interpretar mejor. Otros dos estadísticos importantes son la cuasivarianza y la cuasidesviación típica, que, como veremos cuando estudiemos el tema de estimación estadística, son los estimadores de la varianza y desviación típica poblacionales respectivamente.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 119
Cuasi-Varianza Es una medida de dispersión, cuya única diferencia con la varianza es que dividimos por N-1, la representaremos por
O y la calcularemos de la siguiente forma:
Cuasi-Desviación típica La raíz cuadrada de la cuasivarianza y la denotaremos por SN—1.
Todas estas medidas de dispersión vienen influidas por la unidad en la que se mide la variable, esto implica que si cambiamos de unidad de medida, los valores de estos estadísticos se vean a su vez modificados. Además, no permite comparar por ejemplo, en un grupo de alumnos si los pesos o las alturas presentan mas dispersión. Pues no es posible comparar unidades de distinto tipo. Precisamos por lo tanto, una medida "escalar", es decir, que no lleve asociado ninguna unidad de medida.
Coeficiente de Variación Es un estadístico de dispersión que tiene la ventaja de que no lleva asociada ninguna unidad, por lo que nos permitirá decir entre dos muestras, cual es la que presenta mayor dispersión. La denotaremos por C.V.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 120
Ejemplo Veamos, por último, un ejemplo de cómo se calculan todas estas medidas.
𝑪.𝑽. =𝟏𝟏, 𝟎𝟐𝟗
𝟔𝟗, 𝟒∙ 𝟏𝟎𝟎 = 𝟏𝟓,𝟖𝟗𝟐%
Medidas de Localización: Cuartiles, Deciles y Percentiles. Las Medidas de Localización son Útiles para encontrar determinados valores importantes, para una "clasificación" de los elementos de la muestra o población. Las medidas de localización dividen la distribución en partes iguales, sirven para clasificar a un individuo o elemento dentro de una determinada población o muestra. Así en Psicología los resultados de los test o pruebas que realizan a un determinado individuo, sirve para clasificar a dicho sujeto en una determinada categoría en función de la 53-1-u- puntuación obtenida. Tenemos las siguientes Medidas de Localización:
Cuartiles.
Deciles.
Percentiles.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 121
Cuartiles Medida de localización que divide la población o muestra en cuatro partes iguales.
Q1= Valor de la variable que deja a la izquierda el 25% de la distribución.
Q2= Valor de la variable que deja a la izquierda el 50% de la distribución = mediana.
Q3= Valor de la variable que deja a la izquierda el 75% de la distribución.
Al igual que ocurre con el cálculo de la mediana, el cálculo de estos estadísticos, depende del tipo de variable.
1. Caso I: Variable cuantitativa discreta: En este caso, tendremos que observar el tamaño de la muestra: N y para calcular Q1 o Q3 procederemos como si tuviésemos que calcular la mediana de la correspondiente mitad de la muestra.
2. Caso II: Variable cuantitativa continua: En este caso, el cálculo es más simple:, sea la distribución que sigue:
[Li-2 -- Li-1) ni-1 Ni-1
[Li-1 -- Li) ni Ni
Intervalo donde se encuentra el cuartil correspondiente: Siendo el intervalo inferior donde se encuentra el Cuartil correspondiente:
Cuartil 1: Y
Cuartil 3:
Deciles Medida de localización que divide la población o muestra en 10 partes iguales No tiene mucho sentido calcularlas para variables cualitativas discretas. Por lo que lo vamos a ver sólo para las variables continuas. dk = Decil k-ésimo es aquel valor de la variable que deja a su izquierda el k·10 % de la distribución.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 122
[Li-2 -- Li-1) ni-1 Ni-1
[Li-1 -- Li) ni Ni
Intervalo donde se encuentra el Decil correspondiente:
k = 1 .. 9
Percentiles: Medida de localización que divide la población o muestra en 100 partes iguales No tiene mucho sentido calcularlas para variables cualitativas discretas. Por lo que lo vamos a ver sólo para las variables continuas. pk = Percentil k-ésimo es aquel valor de la variable que deja a su izquierda el k % de la distribución. [Li-2 -- Li-1)
[Li-2 -- Li-1) ni-1 Ni-1
[Li-1 -- Li) ni Ni
Intervalo donde se encuentra el Percentil correspondiente:
k=1 .. 99
EJEMPLO: Como se puede observar, la forma de calcular estas medidas es muy similar a la del cálculo de la mediana. Veamos el cálculo de algunas de estas medidas en el ejemplo que estamos estudiando. Vamos a calcular Q1,Q3, d3, y p45
Li-1 Li ni Ni
45 55 6 6
55 65 10 16
65 75 19 35
75 85 11 46
85 95 4 50

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 123
Cálculo de Q1: Buscamos en la columna de las frecuencias Acumuladas el valor que supere al 25% de N=50, corresponde al 2º intervalo.(50/4=12.5)
𝑸𝟏 = 𝟓𝟓 +𝟓𝟎
𝟒 − 𝟔
𝟏𝟔 − 𝟔∙ 𝟏𝟎 = 𝟔𝟏, 𝟓
Análogamente, calculemos Q3: Buscamos ahora en la misma columna el correspondiente al 75 % de N que en este caso es el 4º intervalo (3.50/4=37.5)
𝑸𝟑 = 𝟕𝟓 +𝟑 ∙ 𝟓𝟎 𝟒 − 𝟑𝟓
𝟒𝟔 − 𝟑𝟓∙ 𝟏𝟎 = 𝟕𝟕, 𝟐𝟕
Veamos ahora el decil 3º. (corresponde al 30% 3 · 50 / 10 = 15) sería el 2º intervalo.
𝒅𝟑 = 𝟓𝟓 +𝟑 ∙ 𝟓𝟎 𝟏𝟎 − 𝟔
𝟏𝟔 − 𝟔∙ 𝟏𝟎 = 𝟔𝟒
Por último, veamos el percentil 45 (45·50/100 = 22.5) Corresponde al intervalo 3º.
𝒑𝟒𝟓 = 𝟔𝟓 +𝟒𝟓 ∙ 𝟓𝟎 𝟏𝟎𝟎 − 𝟏𝟔
𝟑𝟓 − 𝟏𝟔∙ 𝟏𝟎 = 𝟔𝟖, 𝟒𝟐𝟏
Algunas medidas de Dispersión asociadas Una vez estudiadas las medidas de localización surgen dos nuevas medidas de dispersión, que son: Recorrido intercuartílico:
Semirecorrido intercuartílico:
Recorrido interdecílico:
Recorrido intercentilico:
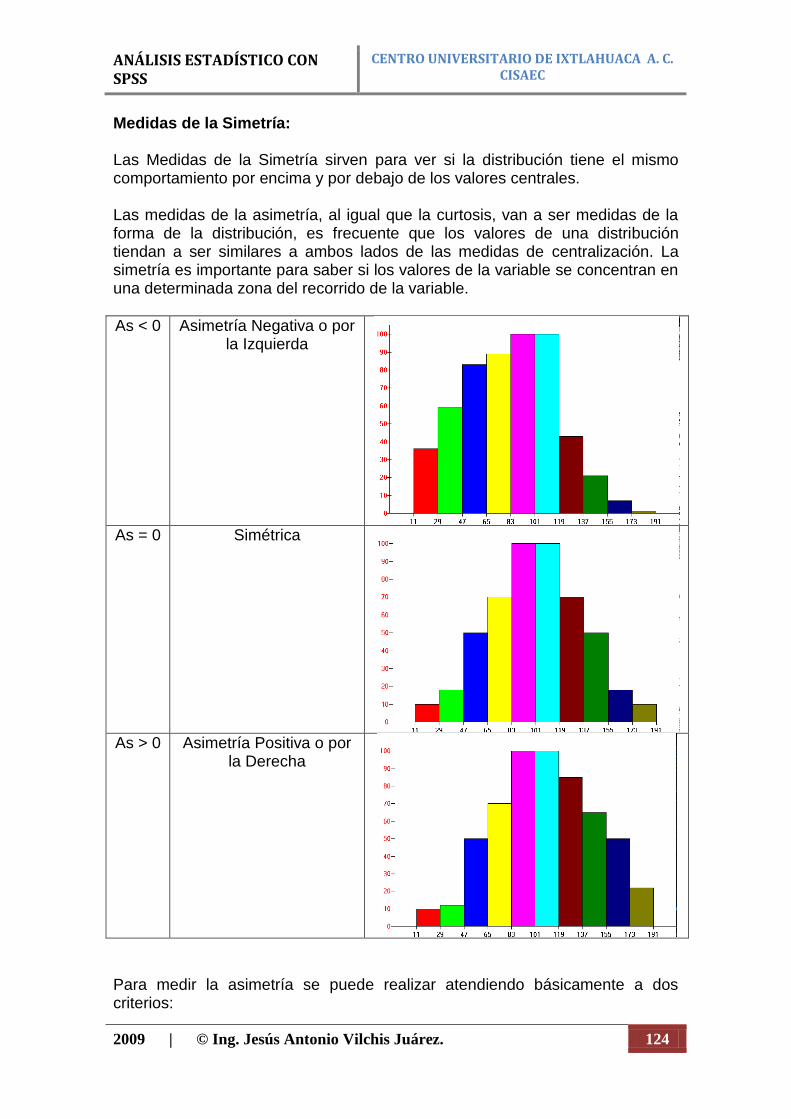
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 124
Medidas de la Simetría: Las Medidas de la Simetría sirven para ver si la distribución tiene el mismo comportamiento por encima y por debajo de los valores centrales. Las medidas de la asimetría, al igual que la curtosis, van a ser medidas de la forma de la distribución, es frecuente que los valores de una distribución tiendan a ser similares a ambos lados de las medidas de centralización. La simetría es importante para saber si los valores de la variable se concentran en una determinada zona del recorrido de la variable.
As < 0 Asimetría Negativa o por la Izquierda
As = 0 Simétrica
As > 0 Asimetría Positiva o por
la Derecha
Para medir la asimetría se puede realizar atendiendo básicamente a dos criterios:

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 125
Comparando la Media y la Moda.
Comparando los valores de la variable con la media.
Comparando la Media y la Moda: Si la diferencia
es positiva, diremos que hay asimetría positiva o a la derecha, en el caso de que sea negativa diremos que hay asimetría negativa o a la izquierda. No obstante, esta medida es poco operativa al no ser una medida relativa, ya que esta influida por la unidad en que se mida la variable, por lo que se define el coeficiente de Asimetría como:
Esta medida es muy fácil de calcular, pero menos precisa que el coeficiente de asimetría de Pearson. El coeficiente de asimetría de Pearson, se basa en la comparación con la media de todos los valores de la variable, así que es una medida que se basará en las diferencias, como vimos en el caso de la dispersión si medimos la media de esas desviaciones sería nula, si las elevamos al cuadrado, serían siempre positivas por lo que tampoco servirían, por lo tanto precisamos elevar esas diferencias al cubo. Para evitar el problema de la unidad, y hacer que sea una medida escalar y por lo tanto relativa, dividimos por el cubo de su desviación típica. Con lo que resulta la siguiente expresión:

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 126
Medidas de la Curtosis o Apuntamiento: La curtosis (k) es una medida del apuntamiento, que nos indicará si la distribución es muy apuntada o poco apuntada.
K < 0 Curtosis Negativa Leptocúrtica
K = 0 Curtosis Nula
K > 0 Curtosis Positiva

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 127
Como podemos observar, el coeficiente de curtosis nos mide el grado de apuntamiento de la distribución. Este coeficiente lo vamos a denotar por K y se calcula según la siguiente expresión:
Veamos, por último, el cálculo de estos dos últimos coeficientes en el ejemplo que estamos estudiando.
final de capítulo: Construcción y Análisis Univariante de Datos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 128
Estudio Bivariante - Correlación y Asociación Utilidad de Una Base de Datos para la Empresa Una base de datos es una espada de doble filo:
Por un lado, es una herramienta fundamental para la defensa de los intereses de la Empresa.
Pero, por otro, si esta arma no estuviese adecuadamente "preparada", puede ser un "boomerang", cuyos efectos pueden llegar a volverse contra nosotros. Por ejemplo, si una base de datos no estuviese preparada para darnos el servicio que de ella se espera, y tuviese errores, puede ser absolutamente funesta para nuestros intereses.
Por ello, es completamente necesario que se lleve a cabo una adecuada exploración de la base de datos, con el fin de poder detectar posibles anomalías o irregularidades en la misma que pudieran alterar el buen comportamiento o rendimiento de la base de datos. Se supone que la Estadística descansa fundamentalmente sobre la suposición de que la distribución de los valores de una variable se asemeja de modo razonable a la de la distribución normal, esto es, que la curva de valores de la variable se parece a una curva campaniforme, gaussiana. Asimismo, se supone que los valores de una variable se distribuyen de modo aleatorio, es decir, que no siguen ningún patrón predeterminado. Esto no siempre es cierto, ya que en ocasiones hay individuos que reaccionan de forma extraña, atípica o inesperada a un factor dado. Estos valores atípicos provocan problemas que pueden llegar a ser graves. Por otro lado, no siempre se consigue una respuesta válida a nuestras preguntas. En tales casos, se dice que estamos ante un caso con valor perdido. Otro problema grave que puede ocurrir en una distribución es la falta de homogeneidad entre la dispersión de los grupos de valores respecto de una determinada variable de agrupación. Este problema, llamado heterogeneidad de las varianzas, (o heterocedasticidad) se da cuando los grupos de valores de una misma variable no pueden ser considerados como procedentes de la misma distribución. Esquema de los Estudios Estadísticos En este caso, se va a aplicar este diseño de investigación a un deporte llamado spinning.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 129
Podemos realizar estudios estadísticos de los datos de los sujetos que practican spinning a través de los siguientes procedimientos estadísticos (en este caso, se va seguir este estricto orden): 1. Estudio Bivariante: Variable Pulsaciones (por ej.) y Edad (por ej.) como
variables continuas, es decir, métricas.
CORRELACIONES
2. Estudio Bivariante: Variable Pulsaciones (por ej.) e IMC (por ej.) como variables continuas, es decir, métricas.
CORRELACIONES
3. Estudio Bivariante: Variable Pulsaciones (por ej.) y Peso (por ej.) como
variables continuas, es decir, métricas.
CORRELACIONES 4. Estudio Bivariante: Variable Pulsaciones (por ej.) y Estatura (por ej.)
como variables continuas, es decir, métricas.
CORRELACIONES 5. Estudio Bivariante: Variable Pulsaciones (por ej.) como variable
continua, es decir, métrica, y Sexo (por ej.) como categórica.
CORRELACIONES 6. Exploración del Fichero: Variable Pulsaciones (por ej.), Edad, Estatura
(por ej.) como variables dependientes (que serán continuas, es decir, métricas), frente a Sexo (por ej.) como variable independiente (que será categórica).
EXPLORAR, CON ESTADISTICOS, GRAFICOS CON PRUEBAS DE NORMALIDAD
7. Análisis de la Asociación (Crosstabs): Variable Pulsaciones (por ej.),
Edad, Estatura (por ej.) como variables dependientes (que serán continuas, es decir, métricas), frente a Sexo (por ej.) como variable independiente (que será categórica).
Estudio Bivariante con Variables MÉTRICAS Pulsaciones y Edad En este caso, se va a realizar un estudio Bivariante, con la variable pulsaciones (por ej.) y la variable edad (por ej.) como variables continuas, es decir, métricas.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 130
Ejemplo. para analizar el procedimiento Correlaciones Bivariadas se utiliza el fichero de datos „HEALTH.FITNESS.sav‟. Es un fichero de datos que pretende conocer cuáles son los factores determinantes del rendimiento de un grupo de alumnos que practica Spinning (aero-bici).
Obtención de Correlaciones Bivariadas
�Seleccionar en la barra de menú: Archivo/Abrir �Localizar el fichero de datos „HEALTH.FITNESS.sav‟ Seleccionar en la barra de menú: Analizar/Correlaciones/Bivariadas
�
Llamada del Procedimiento Bivariate
Aparece el cuadro de diálogo Correlaciones Bivariadas.
Llamada del Procedimiento Bivariate

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 131
Las especificaciones mínimas son dos o más variables numéricas continuas. Las variables numéricas del fichero de datos aparecen en la lista de variables fuente. Se debe seleccionar dos o más variables para el análisis. Para obtener los coeficientes de correlación de Pearson por defecto, utilizando los tests de significación de dos colas, pulsar en el botón "ACEPTAR". Si todos los casos tienen un valor perdido para una o ambas de un par de variables dadas, o si todos tienen el mismo valor para una variable, no se puede calcular el coeficiente mencionado y se muestra en su lugar un punto en el Editor de Datos. Se muestra el cuadro de diálogo Correlaciones Bivariadas, Bivariante.
Llamada del Procedimiento Bivariante
Seleccionar las variables continuas „edad‟ y „pulsacio‟ de la lista de
variables fuente. Pulsar el botón para trasladarlas a la lista de variables destino.
Coeficientes de correlación. Al menos, se debe seleccionar un tipo de coeficiente de correlación. Para variables cuantitativas distribuidas normalmente, se debe elegir el coeficiente de correlación de Pearson. Si los datos no están distribuidos normalmente, o tienen categorías ordenadas, elegir los estadísticos Tau-b de Kendall o Spearman, que miden la asociación entre los órdenes de los rangos. Todos estos coeficientes de correlación oscilan en valor desde –1 (una relación negativa perfecta entre las variables) y +1 (una relación positiva perfecta). Un valor de 0 indica la inexistencia de relación lineal. Cuando se interpreten los resultados, se debe ser cuidadoso en no extraer ninguna conclusión de causa y efecto debido a una correlación significativa. Además, el valor 0 del coeficiente de correlación no indica la inexistencia de

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 132
relación, sino sólo la inexistencia de relación lineal, lo que no impide que haya algún otro tipo de relación. El cuadro Coeficientes de correlación permite elegir una o más de los siguientes opciones:
Correlación de Pearson. Medida de asociación lineal entre dos variables. Los valores del coeficiente de correlación oscilan de -1 a 1. El valor absoluto del coeficiente de correlación indica el grado de la relación lineal entre las variables, con los valores absolutos grandes, indicando las relaciones más fuertes. El signo del coeficiente indica la dirección de la relación. Esta es la configuración por defecto de este comando. Muestra una matriz cuadrado de correlaciones. La correlación de una variable consigo misma es siempre 1'0000 y se la puede encontrar en la diagonal de la matriz. Cada variable aparece dos veces en la matriz con coeficientes idénticos, y los triángulos superior e inferior de la matriz son imágenes espejo.
Tau-b de Kendall. Medida no paramétrica de asociación para
variables ordinales, cuyos valores posibles oscilan de -1 a 1. El valor absoluto de tau-b indica la fuerza de la relación entre las variables, con los valores absolutos mayores indicando las relaciones más fuertes. Tau b puede obtenerse sólo un valor de -1 o +1 para tablas cuadradas. El signo del coeficiente indica la dirección de la relación. Este coeficiente muestra un coeficiente de órdenes de rangos. Muestra la correlación de cada variable con todas las demás variables en una matriz triangular con valores en su parte inferior. No se muestran la correlación de una variable consigo misma (la diagonal) y los coeficientes redundantes.
Correlación de Spearman6. El coeficiente de Correlación de
Spearman es una versión no paramétrica del coeficiente de correlación de Pearson. Este estadístico es adecuado para los datos ordinales, o los de intervalo, que no satisfagan el supuesto de normalidad. La correlación de Spearman se basa en los rangos de los datos en lugar de los valores reales. Los valores del coeficiente oscilan de -1 a +1. El valor absoluto de la r de Spearman indica la fuerza de la relación entre las variables, con los valores absolutos mayores indicando relaciones más fuertes. El signo del coeficiente indica la dirección de la relación.
� Seleccionar del Cuadro Coeficientes de Correlación los tres
coeficientes de correlación. Tests de significación. Al realizar la prueba del procedimiento "Correlaciones Bivariadas" se debe elegir siempre una significación. La significación de una prueba estadística se compara con el valor 0'05. Si el valor de la significación
6 Al final de esta sección se presenta un ejemplo de cálculo del estadístico ρ (rho) de Spearman.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 133
de la prueba es menor que este valor, se considera que la prueba es significativa y se rechaza la hipótesis nula de la ausencia de correlación entre las variables intervinientes. El procedimiento "Correlaciones Bivariadas" permite elegir uno o más de los siguientes:
Bilateral. Este test es apropiado cuando no es posible determinar el sentido de la relación de antemano, como sucede frecuentemente en el caso del análisis exploratorio de datos. Es la opción por defecto.
Unilateral. Este test es apropiado cuando el sentido de la relación
entre las dos variables puede especificarse antes del análisis.
En el cuadro Prueba de significación, dejar la opción por defecto
„Bilateral‟
Llamada del Procedimiento Bivariate
Resaltar las correlaciones significativas. Los coeficientes de correlación significativos al nivel del 0'05 son identificados con un solo asterisco, los significativos al nivel de 0'01 son identificados con dos asteriscos. Esta opción aparece seleccionada por defecto. � Dejar esta opción activada. Pulsar el botón „Opciones‟ para llamar al cuadro de diálogo
correspondiente. � En el cuadro de diálogo "Opciones..." se definen los estadísticos a visualizar y el método de tratamiento de los valores perdidos.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 134
Stadísticos. Para las correlaciones de Pearson se pueden elegir las siguientes opciones:
Medias y desviaciones estándar. Mostrado para cada variable. Muestra la media, la desviación típica y el número de casos no perdidos para cada variable. El número de casos con valores perdidos no se muestra. Los valores perdidos se manejan sobre una base variable-por-variable, independientemente de la configuración de los valores perdidos.
Desviaciones de productos cruzados y covarianzas. Mostrado
para cada par de variables. El producto cruzado de las desviaciones es igual a la suma de los productos de las variables corregidas por la media. Este es el numerador del coeficiente de correlación de Pearson. La covarianza es una medida no estandarizada de la relación entre dos variables, igual a la desviación de los productos cruzados dividida por (N-1).
Seleccionar los dos estadísticos disponibles; es decir, pulsar en las dos
casillas del cuadro "Estadísticos" del Cuadro de Diálogo "Correlaciones bivariadas: Opciones".
� Valores perdidos. Se puede elegir una de las siguientes alternativas:
Excluir casos según pareja. Se excluye del análisis los casos con valores perdidos para una o ambas de un par de variables. Como cada coeficiente se basa en todos los casos que tengan códigos válidos para cualquier caso particular de variables, se utiliza en todos los cálculos la máxima información disponible. Esto puede resultar en un conjunto de coeficientes basados en un número variable de casos.
Excluir casos según lista. Excluye del análisis los casos con
valores perdidos para cualquier variable de la lista de variables.
Llamada del Procedimiento Bivariante/Opciones
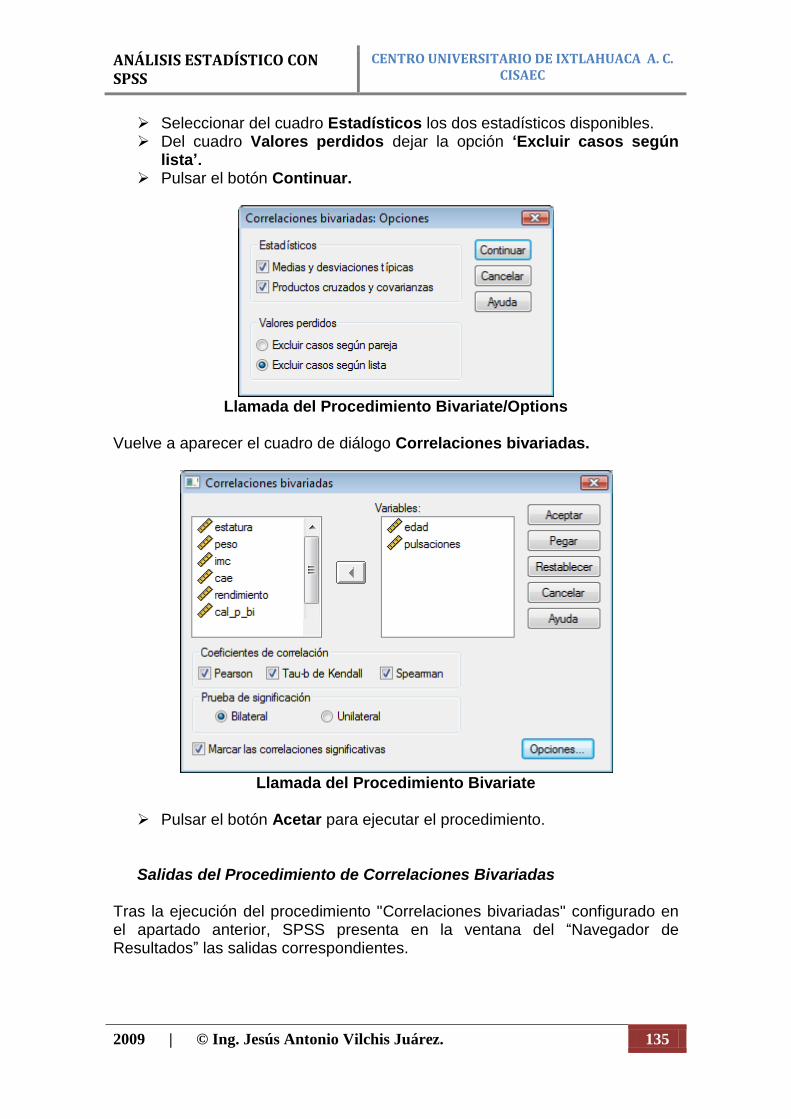
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 135
Seleccionar del cuadro Estadísticos los dos estadísticos disponibles. Del cuadro Valores perdidos dejar la opción „Excluir casos según
lista‟. Pulsar el botón Continuar.
Llamada del Procedimiento Bivariate/Options
Vuelve a aparecer el cuadro de diálogo Correlaciones bivariadas.
Llamada del Procedimiento Bivariate
Pulsar el botón Acetar para ejecutar el procedimiento.
Salidas del Procedimiento de Correlaciones Bivariadas Tras la ejecución del procedimiento "Correlaciones bivariadas" configurado en el apartado anterior, SPSS presenta en la ventana del ―Navegador de Resultados‖ las salidas correspondientes.
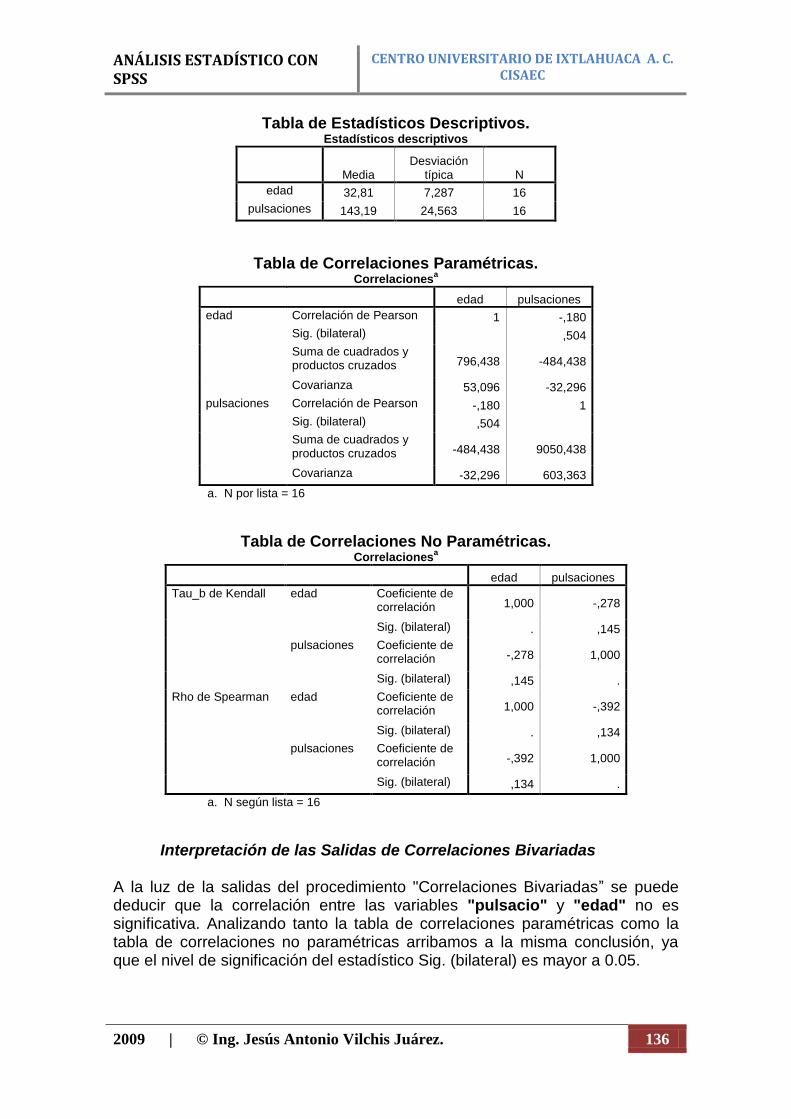
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 136
Tabla de Estadísticos Descriptivos. Estadísticos descriptivos
Media Desviación
típica N
edad 32,81 7,287 16
pulsaciones 143,19 24,563 16
Tabla de Correlaciones Paramétricas.
Correlacionesa
edad pulsaciones
edad Correlación de Pearson 1 -,180
Sig. (bilateral) ,504
Suma de cuadrados y productos cruzados 796,438 -484,438
Covarianza 53,096 -32,296
pulsaciones Correlación de Pearson -,180 1
Sig. (bilateral) ,504
Suma de cuadrados y productos cruzados -484,438 9050,438
Covarianza -32,296 603,363
a. N por lista = 16
Tabla de Correlaciones No Paramétricas.
Correlacionesa
edad pulsaciones
Tau_b de Kendall edad Coeficiente de correlación 1,000 -,278
Sig. (bilateral) . ,145
pulsaciones Coeficiente de correlación -,278 1,000
Sig. (bilateral) ,145 .
Rho de Spearman edad Coeficiente de correlación 1,000 -,392
Sig. (bilateral) . ,134
pulsaciones Coeficiente de correlación -,392 1,000
Sig. (bilateral) ,134 .
a. N según lista = 16
Interpretación de las Salidas de Correlaciones Bivariadas
A la luz de la salidas del procedimiento "Correlaciones Bivariadas‖ se puede deducir que la correlación entre las variables "pulsacio" y "edad" no es significativa. Analizando tanto la tabla de correlaciones paramétricas como la tabla de correlaciones no paramétricas arribamos a la misma conclusión, ya que el nivel de significación del estadístico Sig. (bilateral) es mayor a 0.05.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 137
Estudio Bivariante: Variables Continuas. Ej. Variables Pulsaciones e IMC. Ejemplo. Seguiremos analizando el fichero de datos „HEALTH.FITNESS.sav‟.
Obtención de Correlaciones Bivariadas Seleccionar en la barra de menú: Analizar/Correlaciones/Bivariadas
�
Llamada del Procedimiento Bivariante
Aparece el cuadro de diálogo Correlaciones Bivariadas
Llamada del Procedimiento Bivariate

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 138
Se muestra el cuadro de diálogo Correlaciones bivariadas.
Llamada del Procedimiento Bivariate
� Seleccionar las variables continuas „pulsacio‟ e „imc‟ de la lista de
variables fuente. Pulsar el botón para trasladarlas a la lista de variables destino. Seleccionar del Cuadro Coeficientes de correlación los tres
coeficientes de correlación. En el cuadro Prueba de significación dejar la opción por defecto
„Bilateral‟ Se muestra el cuadro de diálogo Correlaciones bivariadas.
Llamada del Procedimiento Bivariante

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 139
Resaltar las correlaciones significativas. Dejar esta opción activada. Pulsar el botón „Opciones‟ para llamar el cuadro de diálogo
correspondiente. � En el cuadro de diálogo "Opciones..." se definen los estadísticos a visualizar y el método de tratamiento de los valores perdidos. Seleccionar los dos estadísticos disponibles; es decir, pulsar en las dos
casillas del cuadro "Estadísticos" del Cuadro de Diálogo "Correlaciones bivariadas: Opciones".
�
Llamada del Procedimiento Bivariate/Options
Seleccionar del cuadro Estadísticos los dos estadísticos disponibles. Del cuadro Valores perdidos dejar la opción „Excluir casos según
lista‟. Pulsar el botón Continuar.
Llamada del Procedimiento Bivariante/Opciones
Vuelve a aparecer el cuadro de diálogo Correlaciones bivariadas
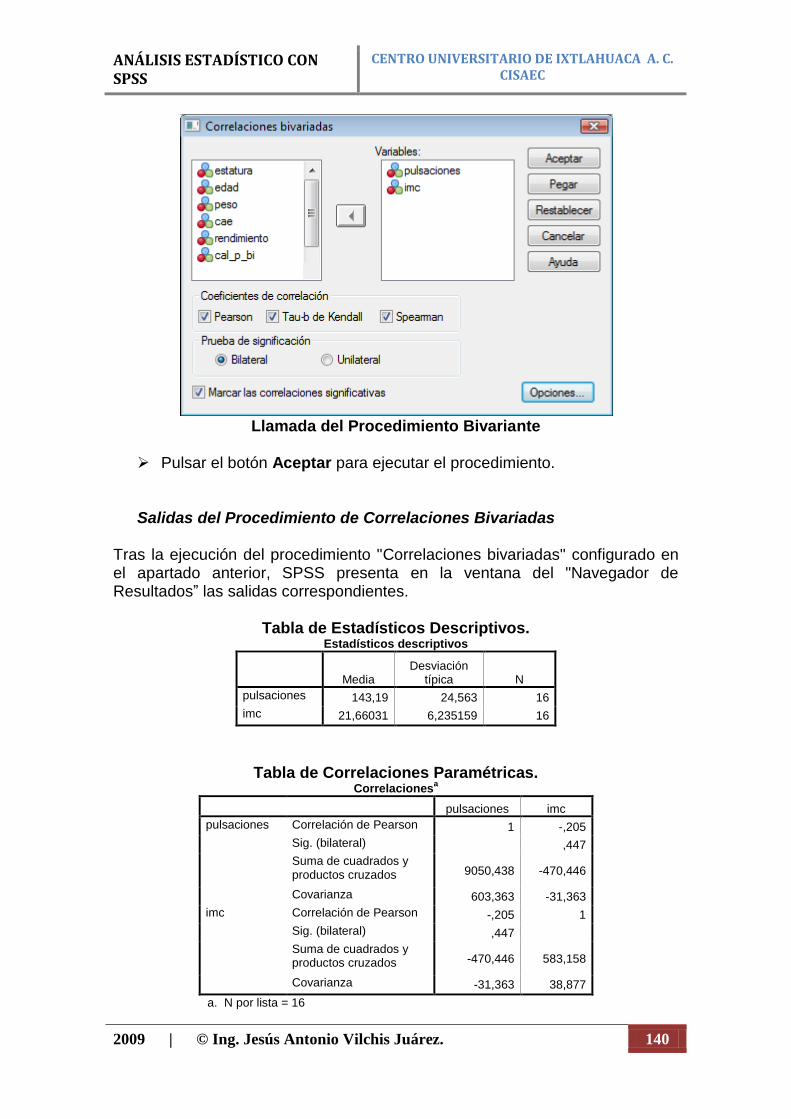
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 140
Llamada del Procedimiento Bivariante
Pulsar el botón Aceptar para ejecutar el procedimiento.
Salidas del Procedimiento de Correlaciones Bivariadas Tras la ejecución del procedimiento "Correlaciones bivariadas" configurado en el apartado anterior, SPSS presenta en la ventana del "Navegador de Resultados‖ las salidas correspondientes.
Tabla de Estadísticos Descriptivos. Estadísticos descriptivos
Media Desviación
típica N
pulsaciones 143,19 24,563 16
imc 21,66031 6,235159 16
Tabla de Correlaciones Paramétricas. Correlaciones
a
pulsaciones imc
pulsaciones Correlación de Pearson 1 -,205
Sig. (bilateral) ,447
Suma de cuadrados y productos cruzados 9050,438 -470,446
Covarianza 603,363 -31,363
imc Correlación de Pearson -,205 1
Sig. (bilateral) ,447
Suma de cuadrados y productos cruzados -470,446 583,158
Covarianza -31,363 38,877
a. N por lista = 16

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 141
Tabla de Correlaciones No Paramétricas.
Correlacionesa
pulsaciones imc
Tau_b de Kendall pulsaciones Coeficiente de correlación 1,000 -,172
Sig. (bilateral) . ,363
imc Coeficiente de correlación -,172 1,000
Sig. (bilateral) ,363 .
Rho de Spearman pulsaciones Coeficiente de correlación 1,000 -,256
Sig. (bilateral) . ,338
imc Coeficiente de correlación -,256 1,000
Sig. (bilateral) ,338 .
a. N según lista = 16
Interpretación de las Salidas de Correlaciones Bivariadas
Concluimos que la correlación existente entre las variables "pulsacio" e "imc" carece de significación estadística (sig >0.05).Tanto la tabla de correlaciones paramétricas como la tabla de correlaciones no paramétricas nos muestran la ausencia de significación entre las correlaciones de estas variables. Estudio Bivariante: Variables Continuas: Ej. Variables Pulsaciones y Peso. Ejemplo. Seguiremos analizando el fichero de datos „HEALTH.FITNESS.sav‟.
Obtención de Correlaciones Bivariadas Seleccionar en la barra de menú: Analizar/Correlaciones/Bivariadas
�
Llamada del Procedimiento Bivariante

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 142
Aparece el cuadro de diálogo Correlaciones Bivariadas.
Llamada del Procedimiento Bivariate
Se muestra el cuadro de diálogo Correlaciones bivariadas. Seleccionar las variables continuas „pulsacio‟ y „peso‟ de la lista de
variables fuente. Pulsar el botón para trasladarlas a la lista de variables destino. Seleccionar del Cuadro Coeficientes de correlación los tres
coeficientes de correlación. En el cuadro Prueba de significación dejar la opción por defecto
„Bilateral‟ Se muestra el cuadro de diálogo Bivariate Correlations.
Llamada del Procedimiento Bivariante

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 143
Resaltar las correlaciones significativas Dejar esta opción activada. Pulsar el botón „Opciones‟ para llamar el cuadro de diálogo
correspondiente. � En el cuadro de diálogo "Opciones..." se definen los estadísticos a visualizar y el método de tratamiento de los valores perdidos.
Llamada del procedimiento Bivariante/Opciones
Seleccionar los dos estadísticos disponibles; es decir, pulsar en las dos
casillas del cuadro "Estadísticos" del Cuadro de Diálogo "Correlaciones bivariadas: Opciones".
Del cuadro Valores perdidos dejar la opción „Excluir casos según lista‟.
Llamada del Procedimiento Bivariante/Opciones
Pulsar el botón Continuar.
Vuelve a aparecer el cuadro de diálogo Correlaciones bivariadas.
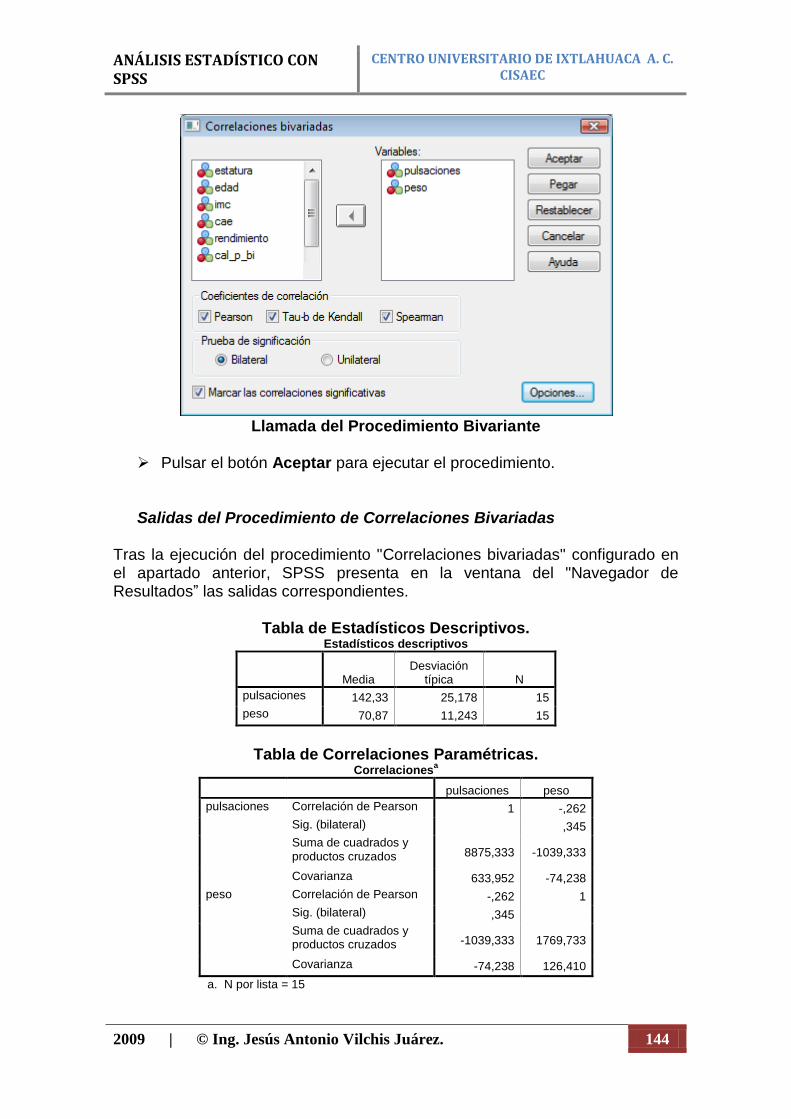
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 144
Llamada del Procedimiento Bivariante
Pulsar el botón Aceptar para ejecutar el procedimiento.
Salidas del Procedimiento de Correlaciones Bivariadas Tras la ejecución del procedimiento "Correlaciones bivariadas" configurado en el apartado anterior, SPSS presenta en la ventana del "Navegador de Resultados‖ las salidas correspondientes.
Tabla de Estadísticos Descriptivos. Estadísticos descriptivos
Media Desviación
típica N
pulsaciones 142,33 25,178 15
peso 70,87 11,243 15
Tabla de Correlaciones Paramétricas.
Correlacionesa
pulsaciones peso
pulsaciones Correlación de Pearson 1 -,262
Sig. (bilateral) ,345
Suma de cuadrados y productos cruzados 8875,333 -1039,333
Covarianza 633,952 -74,238
peso Correlación de Pearson -,262 1
Sig. (bilateral) ,345
Suma de cuadrados y productos cruzados -1039,333 1769,733
Covarianza -74,238 126,410
a. N por lista = 15
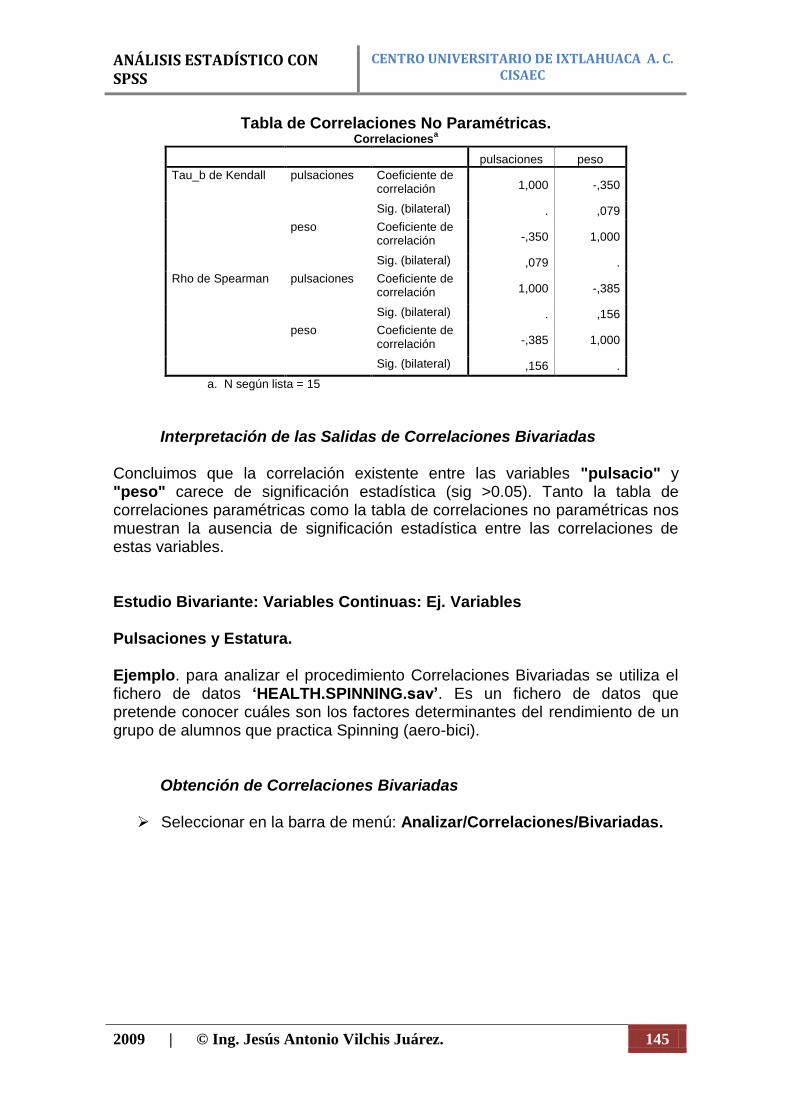
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 145
Tabla de Correlaciones No Paramétricas. Correlaciones
a
pulsaciones peso
Tau_b de Kendall pulsaciones Coeficiente de correlación 1,000 -,350
Sig. (bilateral) . ,079
peso Coeficiente de correlación -,350 1,000
Sig. (bilateral) ,079 .
Rho de Spearman pulsaciones Coeficiente de correlación 1,000 -,385
Sig. (bilateral) . ,156
peso Coeficiente de correlación -,385 1,000
Sig. (bilateral) ,156 .
a. N según lista = 15
Interpretación de las Salidas de Correlaciones Bivariadas Concluimos que la correlación existente entre las variables "pulsacio" y "peso" carece de significación estadística (sig >0.05). Tanto la tabla de correlaciones paramétricas como la tabla de correlaciones no paramétricas nos muestran la ausencia de significación estadística entre las correlaciones de estas variables. Estudio Bivariante: Variables Continuas: Ej. Variables Pulsaciones y Estatura. Ejemplo. para analizar el procedimiento Correlaciones Bivariadas se utiliza el fichero de datos „HEALTH.SPINNING.sav‟. Es un fichero de datos que pretende conocer cuáles son los factores determinantes del rendimiento de un grupo de alumnos que practica Spinning (aero-bici).
Obtención de Correlaciones Bivariadas Seleccionar en la barra de menú: Analizar/Correlaciones/Bivariadas.
�
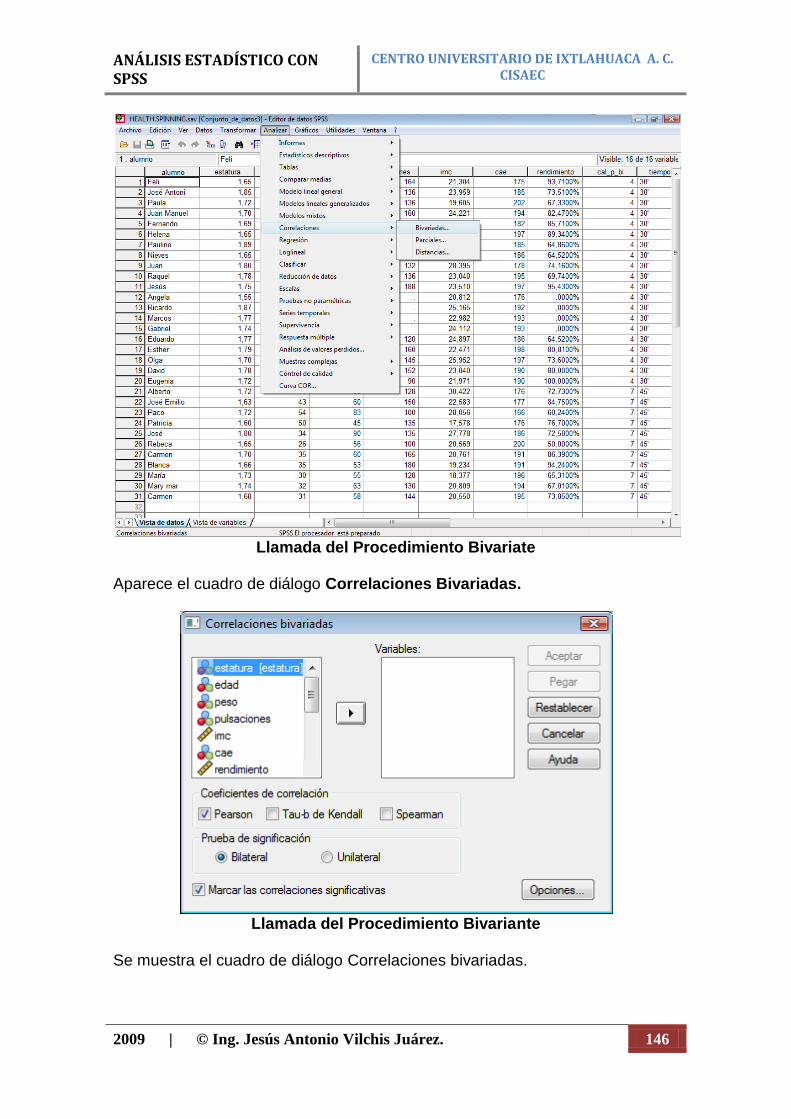
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 146
Llamada del Procedimiento Bivariate
Aparece el cuadro de diálogo Correlaciones Bivariadas.
Llamada del Procedimiento Bivariante
Se muestra el cuadro de diálogo Correlaciones bivariadas.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 147
Seleccionar las variables continuas „estatura‟ y „pulsacio‟ de la lista de variables fuente.
Pulsar el botón para trasladarlas a la lista de variables destino.
Llamada del procedimiento bivariante.
Seleccionar del Cuadro Coeficientes de correlación los tres
coeficientes de correlación. En el cuadro prueba de significación dejar la opción por defecto
„bilateral‟ Se muestra el cuadro de diálogo Bivariate Correlations.
Llamada del procedimiento Bivariante.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 148
Resaltar las correlaciones significativas. Dejar esta opción activada. Pulsar el botón „Opciones‟ para llamar el cuadro de diálogo
correspondiente. � En el cuadro de diálogo "Opciones..." se definen los estadísticos a visualizar y el método de tratamiento de los valores perdidos. Seleccionar los dos estadísticos disponibles; es decir, pulsar en las dos
casillas del cuadro "Estadísticos" del Cuadro de Diálogo "Correlaciones bivariadas: Opciones".
� Llamada del Procedimiento Bivariante/Opciones
Seleccionar del cuadro Estadísticos los dos estadísticos disponibles. Del cuadro Valores perdidos dejar la opción „Excluir casos según
lista‟. Pulsar el botón Continuar.
Vuelve a aparecer el cuadro de diálogo Bivariate Correlations
Llamada del Procedimiento Bivariante

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 149
Pulsar el botón Aceptar para ejecutar el procedimiento.
Salidas del Procedimiento de Correlaciones Bivariadas Tras la ejecución del procedimiento "Correlaciones bivariadas" configurado en el apartado anterior, SPSS presenta en la ventana del "Navegador de Resultados‖ las salidas correspondientes.
Tabla de Estadísticos Descriptivos. Estadísticos descriptivos
Media Desviación
típica N
estatura 1,7230 ,06899 27
pulsaciones 140,22 24,171 27
Tabla de Correlaciones Paramétricas
Correlacionesa
estatura pulsaciones
estatura Correlación de Pearson 1 -,169
Sig. (bilateral) ,400
Suma de cuadrados y productos cruzados ,124 -7,318
Covarianza ,005 -,281
pulsaciones Correlación de Pearson -,169 1
Sig. (bilateral) ,400
Suma de cuadrados y productos cruzados -7,318 15190,667
Covarianza -,281 584,256
a N por lista = 27
Tabla de Correlaciones No Paramétricas
Correlacionesa
estatura pulsaciones
Tau_b de Kendall estatura Coeficiente de correlación 1,000 -,130
Sig. (bilateral) . ,355
pulsaciones Coeficiente de correlación -,130 1,000
Sig. (bilateral) ,355 .
Rho de Spearman estatura Coeficiente de correlación 1,000 -,198
Sig. (bilateral) . ,322
pulsaciones Coeficiente de correlación -,198 1,000
Sig. (bilateral) ,322 .
a N según lista = 27

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 150
Interpretación de las Salidas de Correlaciones Bivariadas Concluimos que la correlación existente entre las variables "pulsacio" y "estatura" carece de significación estadística (sig >0.05).Tanto la tabla de correlaciones paramétricas como la tabla de correlaciones no paramétricas nos muestran la ausencia de significación estadística entre las correlaciones de estas variables. Estudio Bivariante: V. Continuas: Rendimiento y Pulsaciones Ejemplo. Seguiremos analizando el fichero de datos „HEALTH.SPINNING.sav‟. Seleccionar en la barra de menú: Analizar/Correlaciones/Bivariadas.
�
Llamada del Procedimiento Bivariante
Aparece el cuadro de diálogo Correlaciones Bivariadas. Se muestra el cuadro de diálogo Bivariate Correlations

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 151
Llamada del Procedimiento Bivariante
Seleccionar las variables continuas „pulsacio‟ y „rendimie‟ de la lista de
variables fuente. Pulsar el botón para trasladarlas a la lista de variables destino.
Llamada del Procedimiento Bivariante
Seleccionar del Cuadro Coeficientes de correlación los tres
coeficientes de correlación. En el cuadro prueba de significación dejar la opción por defecto
„Bilateral‟ Pulsar el botón „Opciones‟ para llamar el cuadro de diálogo
correspondiente.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 152
Llamada del Procedimiento Bivariante/Opciones
En el cuadro de diálogo "Options..." se definen los estadísticos a
visualizar y el método de tratamiento de los valores perdidos. Seleccionar del cuadro Estadísticos los dos estadísticos disponibles. Del cuadro Valores perdidos dejar la opción „Excluir casos según
lista‟.
Llamada del Procedimiento Bivariante/Opciones
Pulsar el botón Continuar. Vuelve a aparecer el cuadro de diálogo Correlaciones bivariadas.
Llamada del Procedimiento Bivariante

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 153
Pulsar el botón Aceptar para ejecutar el procedimiento.
Salidas del Procedimiento de Correlaciones Bivariadas
Tras la ejecución del procedimiento "Correlaciones bivariadas" configurado en el apartado anterior, SPSS presenta en la ventana del "Navegador de Resultados‖ las salidas correspondientes.
Tabla de Estadísticos Descriptivos. Estadísticos descriptivos
Media Desviación
típica N
pulsaciones 140,22 24,171 27
rendimiento 76,426296%
12,0847479% 27
Tabla de Correlaciones Paramétricas.
Correlacionesa
pulsaciones rendimiento
pulsaciones Correlación de Pearson 1 ,636**
Sig. (bilateral) ,000
Suma de cuadrados y productos cruzados 15190,667 4828,392
Covarianza 584,256 185,707
rendimiento Correlación de Pearson ,636** 1
Sig. (bilateral) ,000
Suma de cuadrados y productos cruzados 4828,392 3797,069
Covarianza 185,707 146,041
** La correlación es significativa al nivel 0,01 (bilateral). a N por lista = 27
Tabla de Correlaciones No Paramétricas.
Correlacionesa
pulsaciones rendimiento
Tau_b de Kendall pulsaciones Coeficiente de correlación 1,000 ,692**
Sig. (bilateral) . ,000
rendimiento Coeficiente de correlación ,692** 1,000
Sig. (bilateral) ,000 .
Rho de Spearman pulsaciones Coeficiente de correlación 1,000 ,733**
Sig. (bilateral) . ,000
rendimiento Coeficiente de correlación ,733** 1,000
Sig. (bilateral) ,000 .
** La correlación es significativa al nivel 0,01 (bilateral). a N según lista = 27

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 154
Interpretación de las Salidas de Correlaciones Bivariadas Si observamos las salidas del procedimiento ‗Correlaciones bivariadas‘ se deduce que la correlación entre las variables "pulsacio" y "rendimi" es bastante elevada (0.961). Sin embargo, cuando analizamos la tabla de correlaciones no paramétricas, la correlación si bien ha disminuido levemente aún sigue siendo alta, siendo 0.848 en el estadístico ‗tau-b de Kendall‘, y 0.952 en el estadístico ‗rho de Spearman‘. Todas las correlaciones son significativas al nivel del 0.01. Exploración de las Variables del Análisis de Grupos La Exploración de las Variables del Análisis de Grupos es una fase necesaria previo al análisis de grupos, por tanto, del valor de una variable métrica (continua) frente a los valores representados por los grupos de una variable cualitativa. A la primera de ellas la llamaremos variable dependiente; a la segunda, variable independiente o factor. En este ejemplo, se contempla el análisis de las Variables Pulsaciones, Edad, Estatura (por ejemplo) como variables dependiente (continuas, es decir, métricas), frente a Sexo (por ejemplo) como variable independiente (categórica). EXPLORAR, con las opciones ESTADÍSTICOS y GRÁFICA DE NORMALIDAD CON PRUEBAS
Exploración de las Variables del Análisis de Grupos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 155
Exploración de las Variables del Análisis de Grupos
Exploración de las Variables del Análisis de Grupos
Salidas de la Exploración de las Variables del Análisis de Grupos Tras la ejecución del procedimiento "Analizar/Estadísticos descriptivos/Explorar" configurado en el apartado anterior, SPSS presenta en la ventana del " Navegador de Resultados‖ las salidas correspondientes.
Resumen del procesamiento de los casos
sexo
Casos
Válidos Perdidos Total
N Porcentaje N Porcentaje N Porcentaje
rendimiento H 15 100,0% 0 ,0% 15 100,0%
M 16 100,0% 0 ,0% 16 100,0%
Exploración de las Variables del Análisis de Grupos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 156
Descriptivos
sexo Estadístico Error típ.
rendimiento H Media 60,730667%
8,4439854%
Intervalo de confianza para la media al 95%
Límite inferior 42,620119%
Límite superior 78,841214%
Media recortada al 5% 62,176852%
Mediana 72,730000%
Varianza 1069,513
Desv. típ. 32,7034150%
Mínimo ,0000%
Máximo 95,4300%
Rango 95,4300%
Amplitud intercuartil 22,2300%
Asimetría -1,356 ,580
Curtosis ,404 1,121
M Media 72,034375%
5,8394785%
Intervalo de confianza para la media al 95%
Límite inferior 59,587821%
Límite superior 84,480929%
Media recortada al 5% 74,482639%
Mediana 73,725000%
Varianza 545,592
Desv. típ. 23,3579140%
Mínimo ,0000%
Máximo 100,0000%
Rango 100,0000%
Amplitud intercuartil 22,8675%
Asimetría -1,994 ,564
Curtosis 5,791 1,091
Exploración de las Variables del Análisis de Grupos Pruebas de normalidad
sexo
Kolmogorov-Smirnova Shapiro-Wilk
Estadístico gl Sig. Estadístico gl Sig.
rendimiento H ,294 15 ,001 ,747 15 ,001
M ,249 16 ,009 ,816 16 ,004
a Corrección de la significación de Lilliefors
Exploración de las Variables del Análisis de Grupos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 157
Prueba de homogeneidad de la varianza
Estadístico de
Levene gl1 gl2 Sig.
rendimiento Basándose en la media 1,832 1 29 ,186
Basándose en la mediana. ,543 1 29 ,467
Basándose en la mediana y con gl corregido
,543 1 24,674 ,468
Basándose en la media recortada 1,523 1 29 ,227
Exploración de las Variables del Análisis de Grupos
Rendimiento (Gráfico de tallo y hojas) rendimiento Stem-and-Leaf Plot for
sexo= H
Frequency Stem & Leaf
3,00 Extremes (=<0)
3,00 6 . 044
4,00 7 . 2234
4,00 8 . 0245
1,00 9 . 5
Stem width: 10,0000
Each leaf: 1 case(s)
Rendimiento (Gráfico de tallo y hojas) rendimiento Stem-and-Leaf Plot for
sexo= M
Frequency Stem & Leaf
1,00 Extremes (=<0)
1,00 5 . 0
5,00 6 . 45779
3,00 7 . 336
3,00 8 . 069
2,00 9 . 34
1,00 10 . 0
Stem width: 10,0000
Each leaf: 1 case(s)

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 158
Exploración de las Variables del Análisis de Grupos
Exploración de las Variables del Análisis de Grupos
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 159
Exploración de las Variables del Análisis de Grupos
Exploración de las Variables del Análisis de Grupos
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 160
Exploración de las Variables del Análisis de Grupos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 161
Interpretación de las Salidas de la Exploración del Análisis de Grupos Si observamos las Salidas de la Exploración del Análisis de Grupos, se deduce que las mujeres muestran un mayor rendimiento que los hombres….. Análisis de la Asociación de Variables (Cualitativas): Crosstabs7 La Exploración de las Variables del Análisis de Grupos es una fase necesaria previo al análisis de grupos, por Análisis de la Asociación de Variables (Cualitativas). En este ejemplo, con los datos de 1.HEALTH.SPINNING.sav, se contempla el análisis de la Variable peso (como variable de fila), frente a la variable rendimient (como variable de columna). Se utilizarán las variables de capa gym y sexo. Obsérvese que todas y cada una de las variables es categórica.
Análisis de la Asociación de Variables (Cualitativas): Crosstabs.
7 Ver capítulo siguiente de este mismo documento.
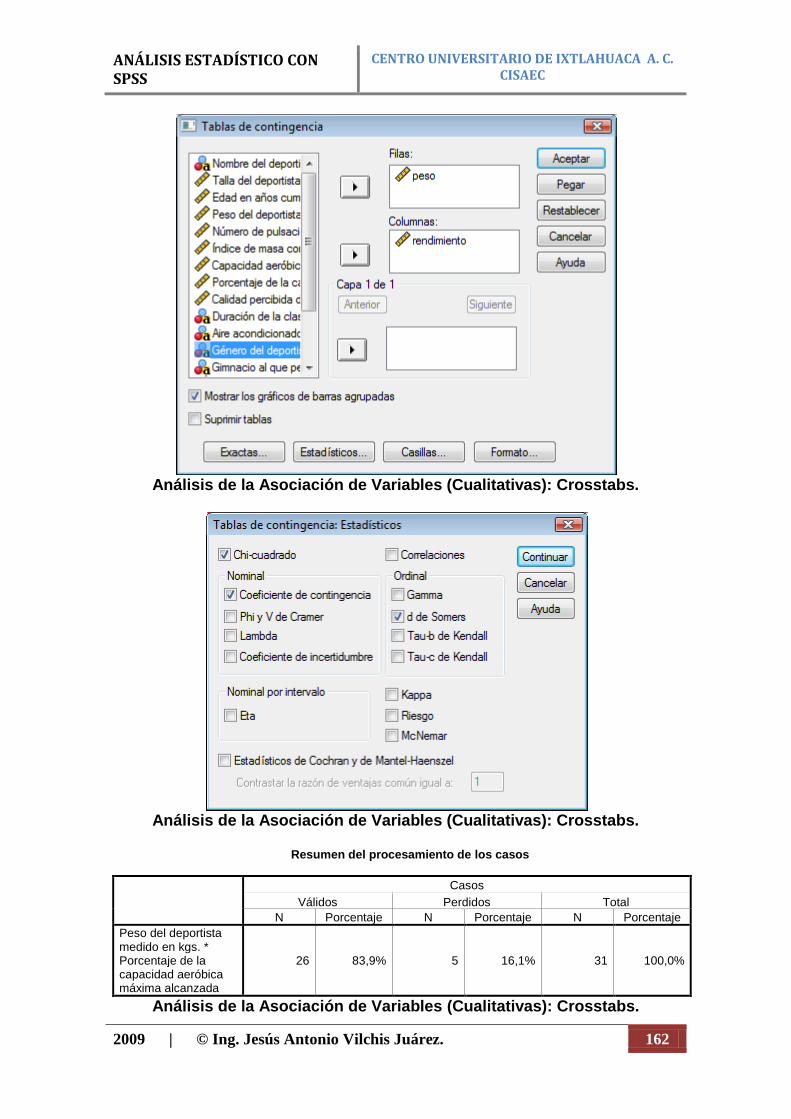
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 162
Análisis de la Asociación de Variables (Cualitativas): Crosstabs.
Análisis de la Asociación de Variables (Cualitativas): Crosstabs.
Resumen del procesamiento de los casos
Casos
Válidos Perdidos Total
N Porcentaje N Porcentaje N Porcentaje
Peso del deportista medido en kgs. * Porcentaje de la capacidad aeróbica máxima alcanzada
26 83,9% 5 16,1% 31 100,0%
Análisis de la Asociación de Variables (Cualitativas): Crosstabs.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 163
Tabla de contingencia Peso del deportista medido en kgs. * Porcentaje de la capacidad aeróbica máxima alcanzada
Recuento
Porcentaje de la capacidad aeróbica máxima alcanzada
Total bajo (50,0 a
65,0)% medio (65,1 a
75,0)% alto (75,1 a
100,0)%
Peso del deportista medido en kgs.
normal (45 a75) 2 7 10 19
sobrepeso (76 a 85) 3 1 0 4
obesidad (86 a 95) 0 3 0 3
Total 5 11 10 26
Análisis de la Asociación de Variables (Cualitativas): Crosstabs.
Pruebas de chi-cuadrado
Valor gl Sig. asintótica
(bilateral)
Chi-cuadrado de Pearson 14,256a 4 ,007
Razón de verosimilitudes 14,201 4 ,007 Asociación lineal por lineal 3,551 1 ,060
N de casos válidos 26
a 7 casillas (77,8%) tienen una frecuencia esperada inferior a 5. La frecuencia mínima esperada es ,58.
Análisis de la Asociación de Variables (Cualitativas): Medidas direccionales
Valor Error típ.
asint.a
T aproximad
b
Sig. aproximada
Ordinal por ordinal
d de Somers
Simétrica -,411 ,105 -3,415 ,001
Peso del deportista medido en kgs. dependiente
-,344 ,099 -3,415 ,001
Porcentaje de la capacidad aeróbica máxima alcanzada dependiente
-,510 ,139 -3,415 ,001
a Asumiendo la hipótesis alternativa. b Empleando el error típico asintótico basado en la hipótesis nula.
Análisis de la Asociación de Variables (Cualitativas): Crosstabs.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 164
Análisis de la Asociación de Variables (Cualitativas): Crosstabs.
Análisis de la Asociación de Variables (Cualitativas): Crosstabs.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 165
Análisis de la Asociación de Variables (Cualitativas): Crosstabs.
Salidas del Análisis de la Asociación de Variables (Cualitativas) Tras la ejecución del procedimiento " Crosstabs", SPSS presenta en la ventana del "Navegador de Resultados‖ las salidas correspondientes. Resumen del procesamiento de los casos
Casos
Válidos Perdidos Total
N Porcentaje N Porcentaje N Porcentaje
Peso del deportista medido en kgs. * Porcentaje de la capacidad aeróbica máxima alcanzada * Gimnacio al que pertenece el deportista
26 83,9% 5 16,1% 31 100,0%
Peso del deportista medido en kgs. * Porcentaje de la capacidad aeróbica máxima alcanzada * Género del deportista
26 83,9% 5 16,1% 31 100,0%
Análisis de la Asociación de Variables (Cualitativas)
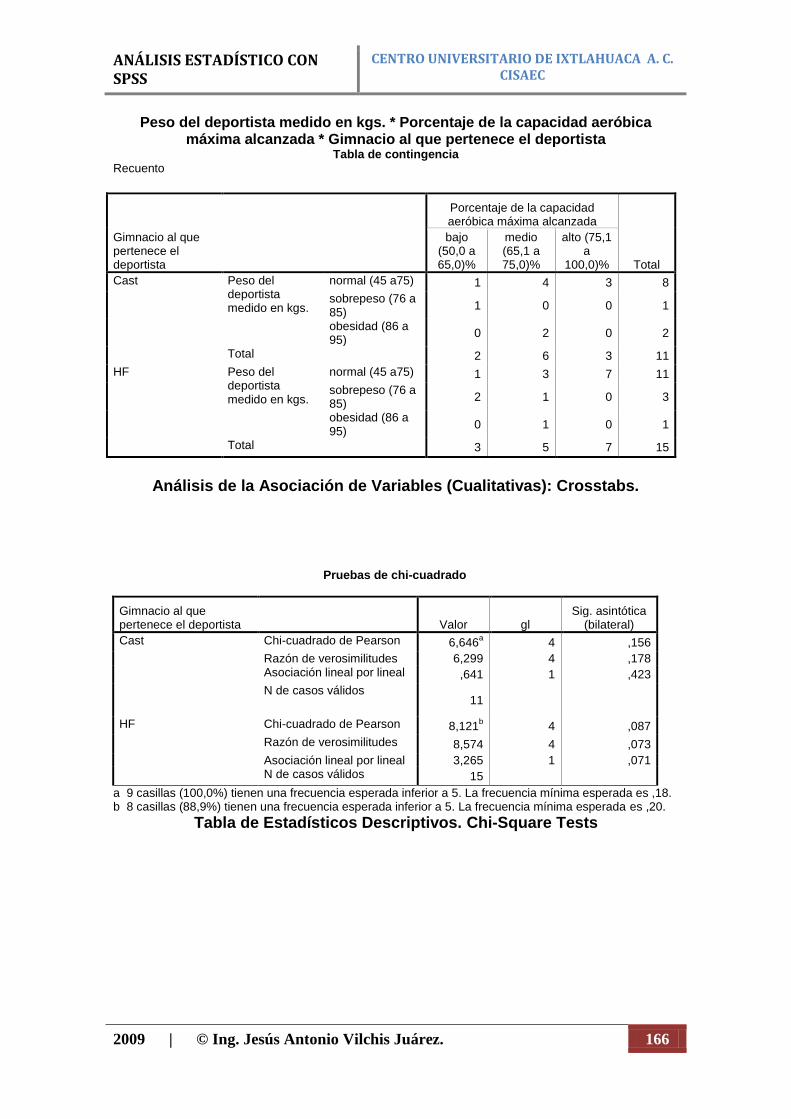
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 166
Peso del deportista medido en kgs. * Porcentaje de la capacidad aeróbica máxima alcanzada * Gimnacio al que pertenece el deportista
Tabla de contingencia
Recuento
Análisis de la Asociación de Variables (Cualitativas): Crosstabs.
Pruebas de chi-cuadrado
Gimnacio al que pertenece el deportista Valor gl
Sig. asintótica (bilateral)
Cast Chi-cuadrado de Pearson 6,646a 4 ,156
Razón de verosimilitudes 6,299 4 ,178 Asociación lineal por lineal ,641 1 ,423
N de casos válidos 11
HF Chi-cuadrado de Pearson 8,121b 4 ,087
Razón de verosimilitudes 8,574 4 ,073
Asociación lineal por lineal 3,265 1 ,071 N de casos válidos 15
a 9 casillas (100,0%) tienen una frecuencia esperada inferior a 5. La frecuencia mínima esperada es ,18. b 8 casillas (88,9%) tienen una frecuencia esperada inferior a 5. La frecuencia mínima esperada es ,20.
Tabla de Estadísticos Descriptivos. Chi-Square Tests
Gimnacio al que pertenece el deportista
Porcentaje de la capacidad aeróbica máxima alcanzada
Total
bajo (50,0 a 65,0)%
medio (65,1 a 75,0)%
alto (75,1 a
100,0)%
Cast Peso del deportista medido en kgs.
normal (45 a75) 1 4 3 8
sobrepeso (76 a 85)
1 0 0 1
obesidad (86 a 95)
0 2 0 2
Total 2 6 3 11
HF Peso del deportista medido en kgs.
normal (45 a75) 1 3 7 11
sobrepeso (76 a 85)
2 1 0 3
obesidad (86 a 95)
0 1 0 1
Total 3 5 7 15
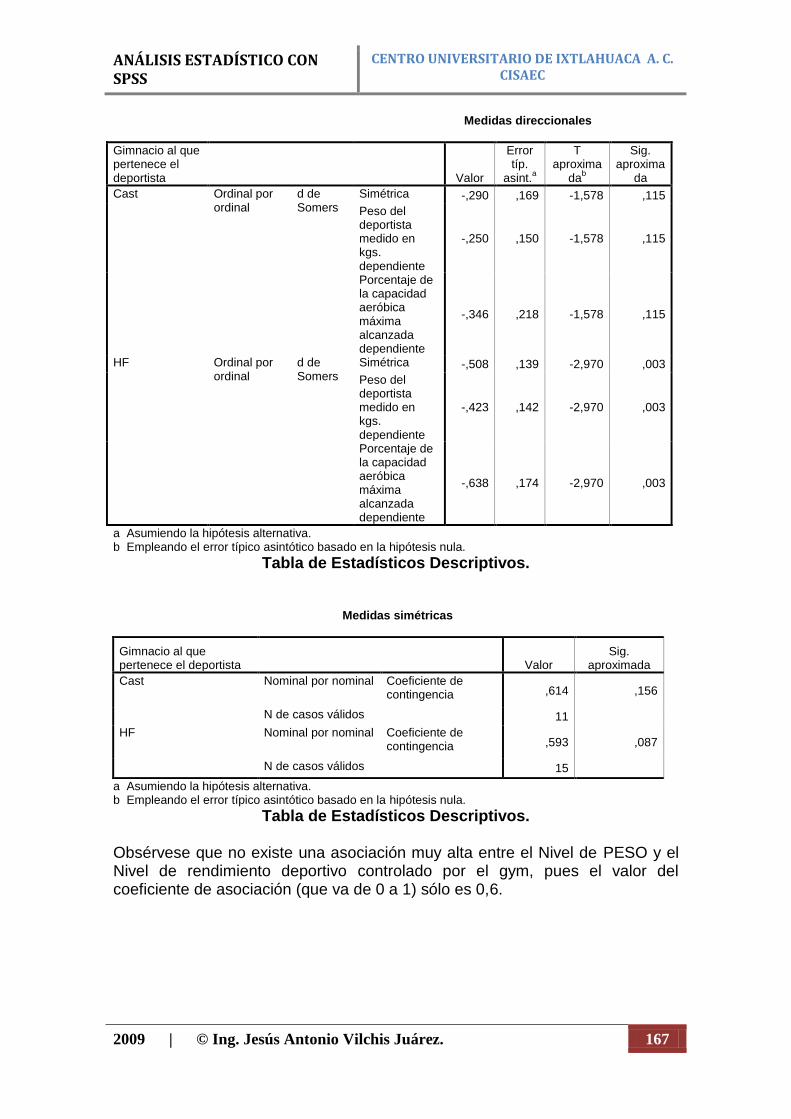
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 167
Medidas direccionales
Gimnacio al que pertenece el deportista Valor
Error típ.
asint.a
T aproxima
dab
Sig. aproxima
da
Cast Ordinal por ordinal
d de Somers
Simétrica -,290 ,169 -1,578 ,115
Peso del deportista medido en kgs. dependiente
-,250 ,150 -1,578 ,115
Porcentaje de la capacidad aeróbica máxima alcanzada dependiente
-,346 ,218 -1,578 ,115
HF Ordinal por ordinal
d de Somers
Simétrica -,508 ,139 -2,970 ,003
Peso del deportista medido en kgs. dependiente
-,423 ,142 -2,970 ,003
Porcentaje de la capacidad aeróbica máxima alcanzada dependiente
-,638 ,174 -2,970 ,003
a Asumiendo la hipótesis alternativa. b Empleando el error típico asintótico basado en la hipótesis nula.
Tabla de Estadísticos Descriptivos. Medidas simétricas
Gimnacio al que pertenece el deportista Valor
Sig. aproximada
Cast Nominal por nominal Coeficiente de contingencia ,614 ,156
N de casos válidos 11
HF Nominal por nominal Coeficiente de contingencia ,593 ,087
N de casos válidos 15
a Asumiendo la hipótesis alternativa. b Empleando el error típico asintótico basado en la hipótesis nula.
Tabla de Estadísticos Descriptivos. Obsérvese que no existe una asociación muy alta entre el Nivel de PESO y el Nivel de rendimiento deportivo controlado por el gym, pues el valor del coeficiente de asociación (que va de 0 a 1) sólo es 0,6.
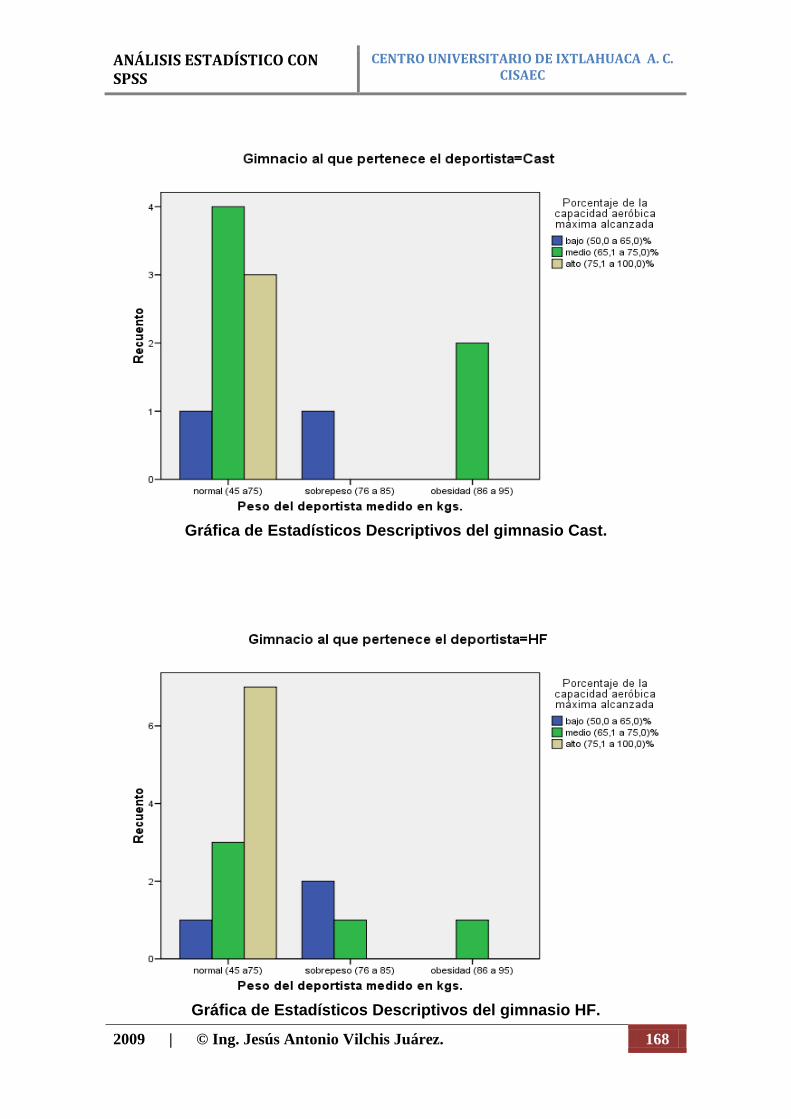
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 168
Gráfica de Estadísticos Descriptivos del gimnasio Cast.
Gráfica de Estadísticos Descriptivos del gimnasio HF.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 169
Peso del deportista medido en kgs. * Porcentaje de la capacidad aeróbica máxima alcanzada * Género del deportista
Tabla de contingencia
Recuento
Género del deportista
Porcentaje de la capacidad aeróbica máxima alcanzada
Total
bajo (50,0 a 65,0)%
medio (65,1 a 75,0)%
alto (75,1 a
100,0)%
H Peso del deportista medido en kgs.
normal (45 a75) 0 0 4 4
sobrepeso (76 a 85)
3 1 0 4
obesidad (86 a 95)
0 3 0 3
Total 3 4 4 11
M Peso del deportista medido en kgs.
normal (45 a75) 2 7 6 15
Total 2 7 6 15
Tabla de Estadísticos Descriptivos. Crosstab Pruebas de chi-cuadrado
Género del deportista Valor gl Sig. asintótica
(bilateral)
H Chi-cuadrado de Pearson 17,188a 4 ,002
Razón de verosimilitudes 19,483 4 ,001 Asociación lineal por lineal 3,201 1 ,074
N de casos válidos 11
M Chi-cuadrado de Pearson .b
N de casos válidos 15
a 9 casillas (100,0%) tienen una frecuencia esperada inferior a 5. La frecuencia mínima esperada es ,82. b No se calculará ningún estadístico porque Peso del deportista medido en kgs. es una constante.
Tabla de Estadísticos Descriptivos. Chi-Square Tests
Medidas direccionales
Género del deportista Valor
Error típ.
asint.a
T aproxima
dab
Sig. aproxim
ada
H Ordinal por ordinal
d de Somers
Simétrica -,475 ,242 -2,040 ,041
Peso del deportista medido en kgs. dependiente
-,475 ,243 -2,040 ,041
Porcentaje de la capacidad aeróbica máxima alcanzada dependiente
-,475 ,243 -2,040 ,041
M Ordinal por ordinal
d de Somers
Simétrica .c
a Asumiendo la hipótesis alternativa. b Empleando el error típico asintótico basado en la hipótesis nula. c No se calculará ningún estadístico porque Peso del deportista medido en kgs. es una constante.
Tabla de Estadísticos Descriptivos.
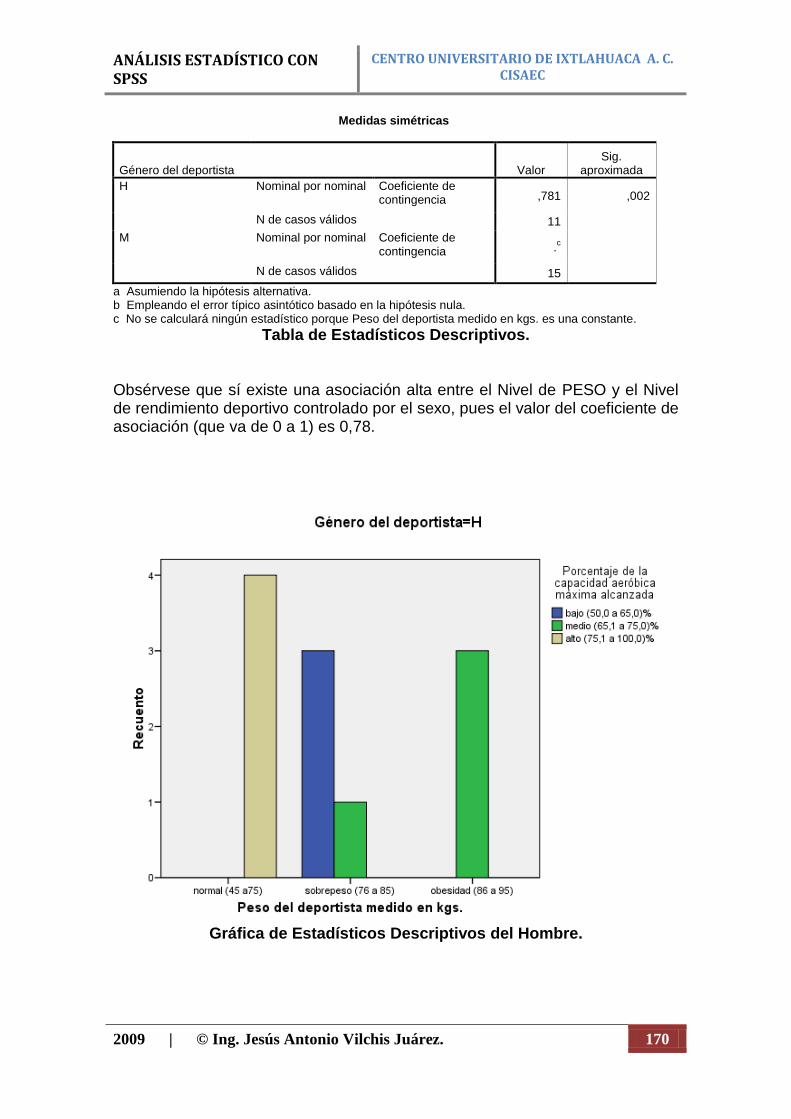
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 170
Medidas simétricas
Género del deportista Valor Sig.
aproximada
H Nominal por nominal Coeficiente de contingencia ,781 ,002
N de casos válidos 11
M Nominal por nominal Coeficiente de contingencia .
c
N de casos válidos 15
a Asumiendo la hipótesis alternativa. b Empleando el error típico asintótico basado en la hipótesis nula. c No se calculará ningún estadístico porque Peso del deportista medido en kgs. es una constante.
Tabla de Estadísticos Descriptivos. Obsérvese que sí existe una asociación alta entre el Nivel de PESO y el Nivel de rendimiento deportivo controlado por el sexo, pues el valor del coeficiente de asociación (que va de 0 a 1) es 0,78.
Gráfica de Estadísticos Descriptivos del Hombre.
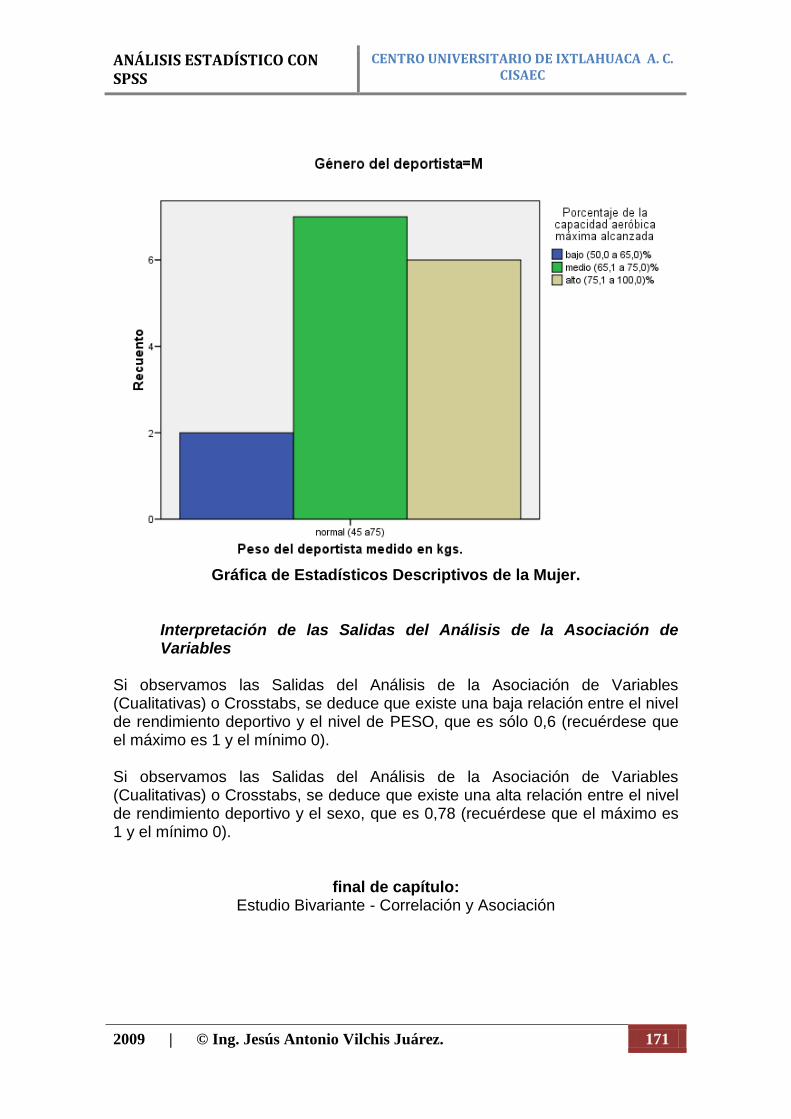
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 171
Gráfica de Estadísticos Descriptivos de la Mujer.
Interpretación de las Salidas del Análisis de la Asociación de Variables
Si observamos las Salidas del Análisis de la Asociación de Variables (Cualitativas) o Crosstabs, se deduce que existe una baja relación entre el nivel de rendimiento deportivo y el nivel de PESO, que es sólo 0,6 (recuérdese que el máximo es 1 y el mínimo 0). Si observamos las Salidas del Análisis de la Asociación de Variables (Cualitativas) o Crosstabs, se deduce que existe una alta relación entre el nivel de rendimiento deportivo y el sexo, que es 0,78 (recuérdese que el máximo es 1 y el mínimo 0).
final de capítulo: Estudio Bivariante - Correlación y Asociación

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 172
Análisis de Asociación c/ Tablas de Contingencia Definición de Tabla de Contingencia o de Asociación La Tabla de Contingencia o de Asociación es una técnica estadística que describe dos o más variables en forma simultánea y da como resultado tablas que reflejan la distribución conjunta de ellas con un número limitado de categorías o valores distintivos. Las categorías de una variable se clasifican en forma cruzada con las categorías de una o más variables, es decir, que la distribución de frecuencias de una variable se subdivide de acuerdo con los valores o categorías de las otras variables.
Tipología de Datos Todos los datos (variables) deberán ser cualitativos (categóricos, es decir, nominales u ordinales).
Características
Fácil interpretación y comprensión de los datos.
Pueden proporcionar mayores conocimientos sobre un fenómeno complejo que un solo análisis multivariante.
Tipos de Tabulación Cruzada
Dos Variables (Tabulación Cruzada Bivariada) Una actuará como VD y la otra como VI. Regla General: Calcular los porcentajes en dirección de la VI, en toda la VD. Es decir:
Tabulación Cruzada Bivariada O sea, debemos calcular los porcentajes de modo que los 100% queden en el
total de columnas(de la VI).
Tres Variables Interviene una tercera variable que explique la ausencia o no de asociación inicial entre las dos variables primeras (VD y VI). La inclusión de esta tercera variable puede ratificar la asociación entre las dos variables iniciales, cambiarla o descubrir nuevas asociaciones. …..

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 173
Ejemplo de Análisis Estadístico Fases en el Ejemplo de Análisis Estadístico
a) Apertura de los ficheros de datos de SPINNING b) Apertura de los ficheros de datos de SPINNING en SPSS c) Almacenamiento de fichero de datos SPINNING d) Almacenamiento de fichero de datos HELATH.FITNES e) Fusión de los ficheros de datos HEALTH.FITNES y SPINNING f) Recodificación de variables g) Definición de las variables recodificadas h) Eliminación de casos perdidos i) Análisis de la regresión lineal
Apertura de los Ficheros de Datos del Análisis El fichero de datos que se muestra se llama „spinning‟ y está en formato de Microsoft Excel. Este estudio pretende conocer cuáles son los factores determinantes al momento de evaluar el rendimiento deportivo de los alumnos asistentes a una clase de spinning. Este fichero contiene las siguientes variables: Alumno: nombre del deportista Estatura: talla del deportista medida en metros. Edad: edad en años cumplidos del deportista. Peso: peso del deportista medido en Kgs. Pulsaciones: número de pulsaciones que alcanza el deportista en un
minuto. IMC (índice de masa corporal): índice que relaciona el peso y la estatura
del deportista. IMC = (Peso/Estatura2)
CAE (capacidad aeróbica máxima): índice que expresa la cantidad máxima de pulsaciones que el deportista puede alcanzar en un minuto haciendo máximo esfuerzo. Su valor se determina en función del sexo y de la edad.
CAEmujeres: 226-Edad CAEhombres: 220-Edad
Rendimiento: porcentaje de la capacidad aeróbica máxima alcanzada por el deportista en un minuto, luego de realizados los sprints.
Cal_p_bi (calidad percibida de la bicicleta): calificación asignada a la bicicleta del 1 al 10 según el estado en que se encontraba.
Aire_aco (aire acondicionado): presencia de aire acondicionado en la sala de práctica de Spinning.
Sexo: género del deportista. Gym: gimnasio al que pertenece el deportista.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 174
En la figura 1, se muestra en pantalla el fichero „SPINNING.xls‟, correspondiente a un gimnasio de la Capital con información de 12 alumnos a los que se les ha medido las variables descriptas en el párrafo anterior, para establecer los factores determinantes del rendimiento deportivo a lo largo de una clase de spinning.
Figura 1 – Base de Datos SPINNING.
En la figura 2, se muestra otro fichero llamado „HEALTH.FITNESS.xls‟, con información de 20 alumnos correspondientes a otro gimnasio de la Capital, a los cuáles se les ha medido las mismas características del grupo anterior para estudiar los factores determinantes del rendimiento deportivo a lo largo de una clase de spinning. Apertura de los Ficheros de Datos de Spinning en SPSS Si queremos analizar estadísticamente en SPSS los datos de los respectivos gimnasios, tendremos que exportar la información contenida en dichos ficheros desde Microsoft Excel a SPSS. Para ello: Seleccionar en la barra de menú Archivo / Abrir / Datos
Se muestra el cuadro de diálogo Abrir datos (figura 3).

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 175
Figura 2 – Base de Datos HEALTH.FITNESS.
Figura 3 – Base de Datos SPINNING (spss)

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 176
Seleccionar en la barra de menú: Archivo/Abrir Archivo Localizar en la pestaña Tipo de archivos la opción Excel (*.xls) (figura
4).
Figura 4 – Base de Datos SPINNING (spss)
Aparece el cuadro de diálogo Apertura de la Fuente de Datos de Excel (figura 5). Activar la opción Leer los nombres de las variables de la primera fila. � Pulsar el botón Aceptar.
Se muestra la ventana Vista de variables con información del fichero „SPINNING‟ que teníamos en formato de Microsoft Excel (figura 6).

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 177
Figura 5 – Base de Datos SPINNING (spss)
Figura 6 – Base de Datos SPINNING (spss)
Si hacemos clic en la ficha Vista de datos podremos ver la estructura de los datos exportados (figura 7). Ahora tendremos que asignar en el campo etiquetas, de la Vista de variables, las etiquetas a cada una de las variables (figura 8).
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 178
Figura 7 – Base de Datos SPINNING (spss)
Figura 8 – Base de Datos SPINNING (spss)
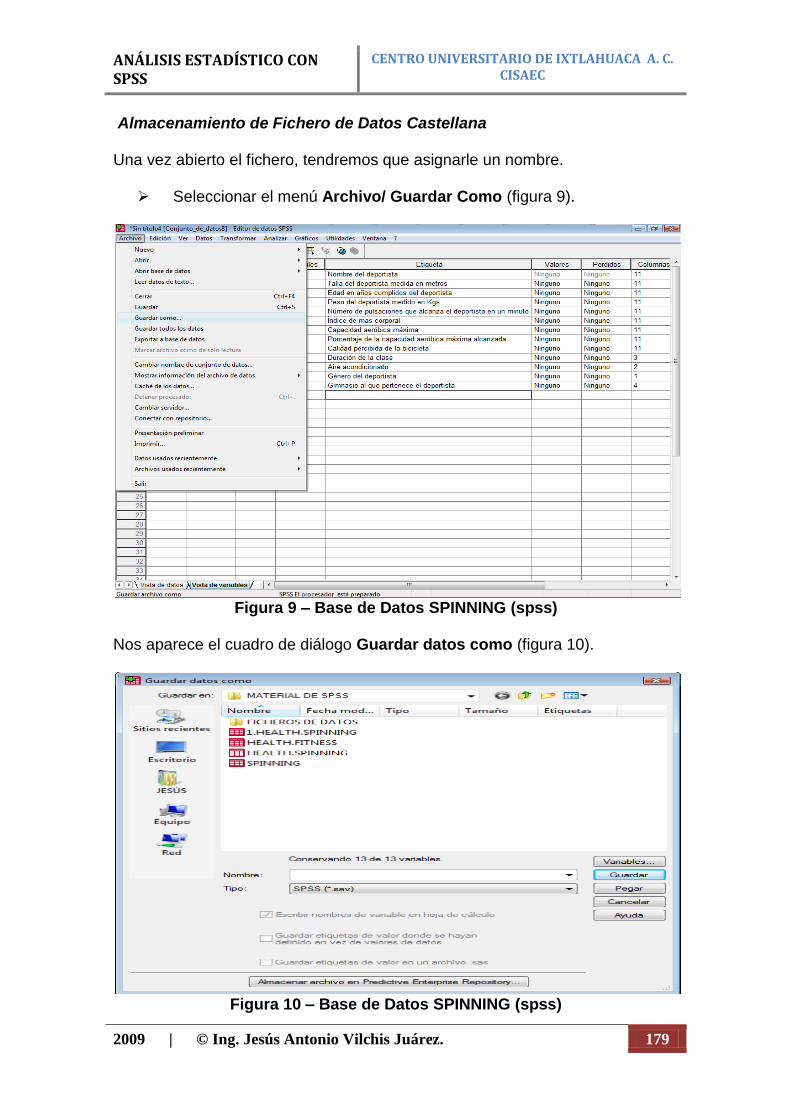
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 179
Almacenamiento de Fichero de Datos Castellana Una vez abierto el fichero, tendremos que asignarle un nombre. �Seleccionar el menú Archivo/ Guardar Como (figura 9).
Figura 9 – Base de Datos SPINNING (spss)
Nos aparece el cuadro de diálogo Guardar datos como (figura 10).
Figura 10 – Base de Datos SPINNING (spss)

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 180
Asignar el nombre „SPINNING‟. Pulsar el botón Guardar.
Ahora ya está guardada la base de datos de trabajo (figura 11).
Figura 11 – Base de Datos SPINNING (spss)
Almacenamiento de Fichero de Datos Health Fitness Del mismo modo que hemos abierto el fichero „SPINNING.xls‟, procederemos a exportar los datos contenidos en el fichero ‗HEALTH.FITNES.xls‟. Seleccionar en la barra de menú: Archivo/ Abrir/ Datos (figura 12).
Figura 12 – Base de Datos HEALTH.FITNES (spss)

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 181
Aparece en pantalla el cuadro de diálogo Abrir datos (figura 13).
Figura 13 – Base de Datos HEALTH.FITNES (spss)
Localizar en la pestaña Tipo de archivos, la opción Excel (*.xls) Seleccionar el fichero „HEALTH.FITNES‟. Pulsar el botón Abrir.
Aparece nuevamente el cuadro de diálogo Apertura de origen de datos de Excel (figura 14).
Figura 14 – Base de Datos HEALTH.FITNES (spss)

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 182
Activar la opción Leer nombre de variables de la primera fila de datos.
Pulsar el botón Aceptar
Una vez abierto el fichero „HEALTH.FITNES‟ en SPSS, se muestra la ventana Vista de variables con la información del fichero que teníamos en formato de Microsoft Excel (figura 15).
Figura 15 – Base de Datos HEALTH.FITNES desde „Vista de variables‟
Si hacemos clic en la ficha Vista de datos, veremos cómo SPSS ha considerado la estructura de los datos del fichero de datos exportado (figura 16). Ahora, tendremos que asignar en el campo etiquetas las etiquetas para cada una de las variables (figura 17). Una vez abierto el fichero, tendremos que asignarle un nombre. Asignar el nombre „HEALTH.FITNES‟.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 183
Figura 16 – Base de Datos HEALTH.FITNES desde „Vista de datos‟
Figura 17 – Base de Datos HEALTH.FITNES (spss)
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 184
Fusión de los Ficheros de Datos HEALTH.FITNES y SPINNING Ahora, nos interesa fusionar estos dos archivos exportados para poder comparar el rendimiento deportivo de los alumnos que asisten a estos gimnasios. Estando abierto en SPSS el fichero ‗HEALTH.FITNES.sav‟, procederemos a agregar, dentro de este mismo archivo, los casos correspondientes al fichero ‗SPINNING.sav‟. Seleccionar en el menú Datos/ Fundir Archivos/ Añadir Casos (figura
18). �
Figura 18 – Ventana con el menú Datos/Fundir archivos/Añadir casos...
Se muestra el cuadro de diálogo Add Cases: Read File (figura 19). Seleccionar el fichero de datos „SPINNING‟ que deseamos forme parte
del archivo actual (HELATH.FITNES). � Pulsar el botón Abrir.
Se muestra un cuadro de diálogo Añadir casos desde... (figura 20)

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 185
Figura 19 – Fusión de Ficheros HEALTH.FITNES y SPINNING
Figura 20 – Fusión de Ficheros HEALTH.FITNES y SPINNING

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 186
En la parte derecha de dicho cuadro Variables en el Nuevo Fichero de Datos podemos apreciar las variables que forman parte del fichero fundido. Pulsar el botón Aceptar (figura 21).
Figura 21 – Fusión de Ficheros HEALTH.FITNES y SPINNING
Vemos que el fichero anterior contenía 21 registros procedentes del fichero HEALTH.FITNES.sav y que tras la fusión con el fichero SPINNING, tenemos 32 casos. Seleccionar en la barra de menú: Archivo/ Guardar Cómo. (Figura 22)
Se muestra el cuadro de diálogo : Guardar datos como (figura 23). En el cuadro Nombre de archivo llamaremos HEALTH.SPINNING al
fichero fundido. Pulsar el botón Guardar.
Aparece, por último, el fichero nombrado como ‗HEALTH.SPINNING.sav‟. (Figura 24)
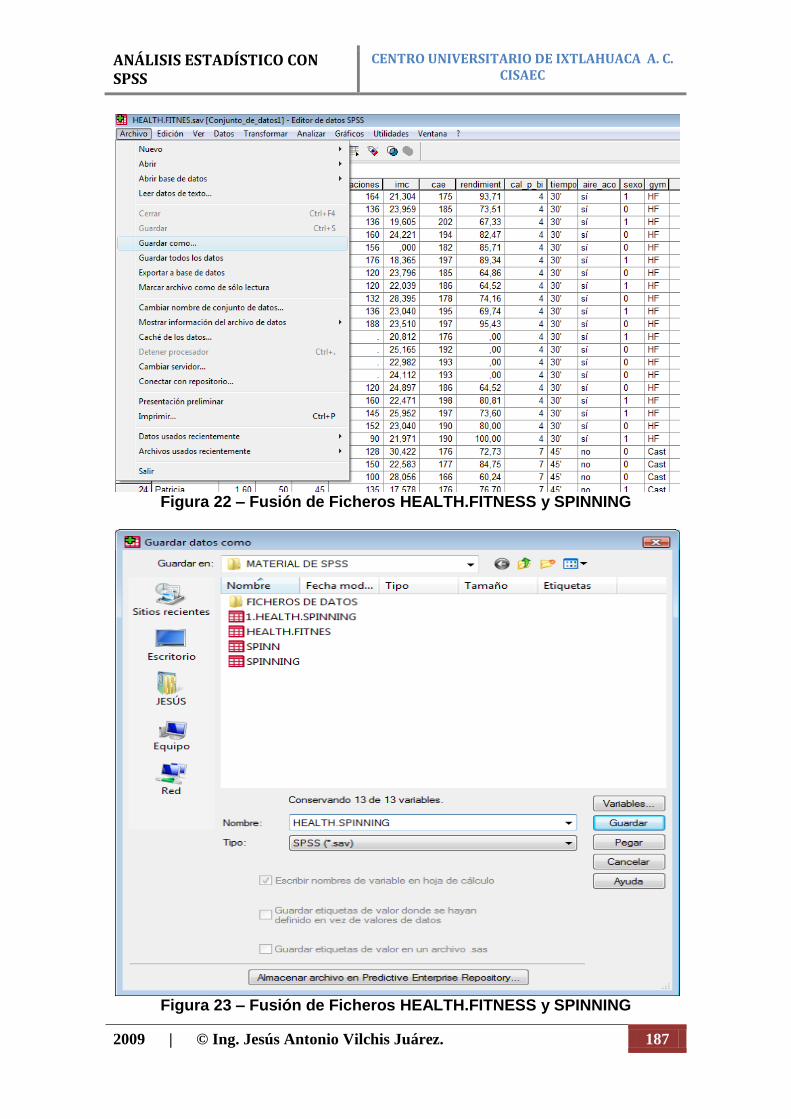
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 187
Figura 22 – Fusión de Ficheros HEALTH.FITNESS y SPINNING
Figura 23 – Fusión de Ficheros HEALTH.FITNESS y SPINNING

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 188
Figura 24 – Fusión de Ficheros HEALTH.FITNESS y SPINNING
Recodificación de Variables Ahora tenemos algunas dificultades para efectuar las comparaciones entre los diferentes grupos de alumnos y realizar el Análisis de la Regresión Lineal (ARL). Nos encontramos con variables de tipo Texto, que necesitamos convertir en numéricas; para aplicar el procedimiento de ARL. Utilizaremos el Procedimiento de Recodificación de Variables. Pero como nos interesa de momento, seguir contando con los valores originales de dichas variables, usaremos el procedimiento Recodificar en Diferentes Variables. Seguidamente, veremos cómo se transforma una variable de tipo Texto a una de tipo Numérica. Seleccionar en la barra de menú: Transformar/ Recodificar/ En
Diferentes Variables. (Figura 25) � Nos aparece el cuadro de diálogo Recodificar en distintas variables. (Figura 26) Seleccionar de la lista de variables fuente, la variable ‗tiempo‘. Hacer doble clic para trasladarla a la lista de Variables destino Var.de
entrada – Var.de resultado. En el cuadro Nombre especificar time, que será el nombre de la nueva
variable (figura 27). Pulsar el botón Cambiar. (Figura 28)

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 189
Figura 25 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 26 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 27 – Recodificación Fichero „HEALTH.SPINNING.sav‟
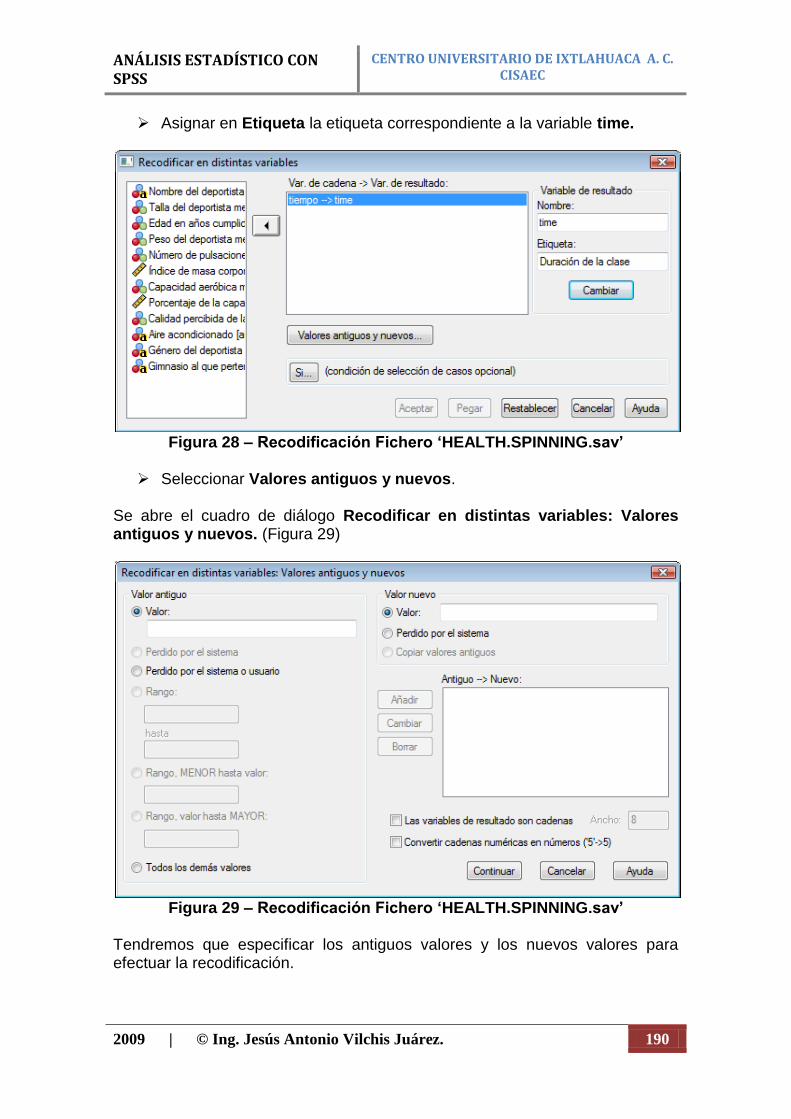
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 190
Asignar en Etiqueta la etiqueta correspondiente a la variable time.
Figura 28 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Seleccionar Valores antiguos y nuevos.
Se abre el cuadro de diálogo Recodificar en distintas variables: Valores antiguos y nuevos. (Figura 29)
Figura 29 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Tendremos que especificar los antiguos valores y los nuevos valores para efectuar la recodificación.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 191
En el sector de Valor Antiguo, hacer clic en la opción Valor y escribir 30‘.
En Nuevo Valor, especificar en el cuadro Valor el valor 1. Pulsar el botón Añadir. (Figura 30)
Figura 30 – Recodificación Fichero „HEALTH.SPINNING.sav‟
En el cuadro Valor Antiguo, hacer clic en la opción Valor y escribir 45‘. En el cuadro Nuevo Valor, especificar en el cuadro Valor el valor 2. Pulsar el botón Añadir. (Figura 31)
Figura 31 – Recodificación Fichero „HEALTH.SPINNING.sav‟
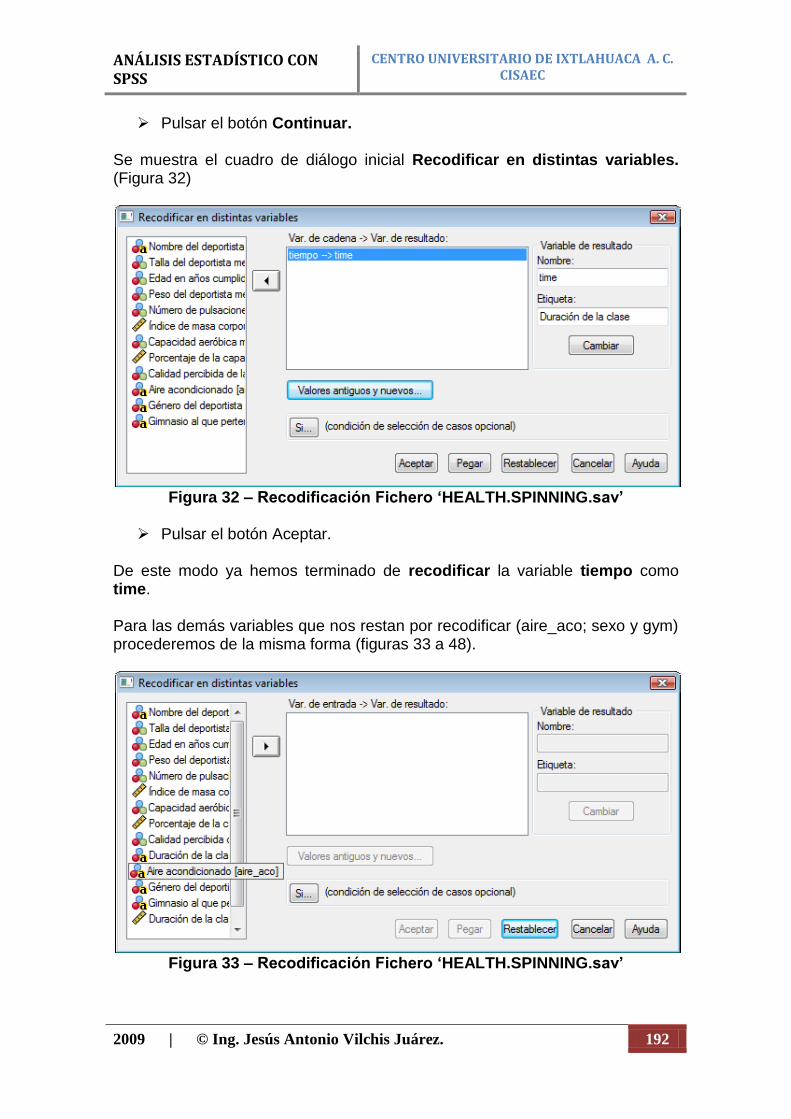
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 192
Pulsar el botón Continuar. Se muestra el cuadro de diálogo inicial Recodificar en distintas variables. (Figura 32)
Figura 32 – Recodificación Fichero „HEALTH.SPINNING.sav‟
� Pulsar el botón Aceptar.
De este modo ya hemos terminado de recodificar la variable tiempo como time. Para las demás variables que nos restan por recodificar (aire_aco; sexo y gym) procederemos de la misma forma (figuras 33 a 48).
Figura 33 – Recodificación Fichero „HEALTH.SPINNING.sav‟

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 193
Figura 34 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 35 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 36 – Recodificación Fichero „HEALTH.SPINNING.sav‟

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 194
Figura 37 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 38 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 39 – Recodificación Fichero „HEALTH.SPINNING.sav‟

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 195
Figura 40 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 41 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 42 – Recodificación Fichero „HEALTH.SPINNING.sav‟

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 196
Figura 43 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 44 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 45 – Recodificación Fichero „HEALTH.SPINNING.sav‟

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 197
Figura 46 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 47 – Recodificación Fichero „HEALTH.SPINNING.sav‟
Figura 48 – Recodificación Fichero „HEALTH.SPINNING.sav‟

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 198
Definición de las Variables Recodificadas Aparecen en la ficha Vista de datos las nuevas variables (time, aire, sexo_al, gyms) con sus respectivos valores (figura 49).
Figura 49 – Definición de las Variables Recodificadas en „Vista de datos‟
� Hacer clic en la ficha Vista de Variables. (Figura 50)
Figura 50 – Definición de las Variables Recodificadas. Variable „time”.
Escribir en el campo Etiqueta las etiquetas de las nuevas variables:
time: duración de la clase aire: aire acondicionado sexo_al: sexo del alumno gyms: gimnasios

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 199
Una vez especificadas las etiquetas, definimos los valores de las variables recodificadas.
Valores de la variable time (figura 51):
Figura 51 – Definición de las Variables Recodificadas. Variable „time”.
� En el cuadro Valor especificar 1. Hacer clic en el cuadro Etiqueta y especificar 30‘. Pulsar el botón Añadir. En el cuadro Valor especificar 2. Hacer clic en el cuadro Etiqueta y especificar 45‘. Pulsar el botón Añadir. (Figura 52)
Figura 52 – Definición de las Variables Recodificadas. Variable „time”.
�

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 200
Pulsar el botón Aceptar.
Valores de la variable aire (figura 53): En el cuadro Valor especificar 0. Hacer clic en el cuadro Etiqueta y especificar ‗No‘. Pulsar el botón Añadir. En el cuadro Valor especificar 1. Hacer clic en el cuadro Etiqueta y especificar ‗Sí‘. Pulsar el botón Añadir. (Figura 53)
Figura 53 – Definición de las Variables Recodificadas. Variable „aire‟.
�Pulsar el botón Aceptar.
Valores de la variable sexo_al (figura 54):
En el cuadro Valor especificar 0. Hacer clic en el cuadro Etiqueta y especificar ‗H‘. Pulsar el botón Añadir. En el cuadro Valor especificar 1. Hacer clic en el cuadro Etiqueta y especificar ‗F‘. Pulsar el botón Añadir. (Figura 54)
Figura 54 – Definición de las Variables Recodificadas. Variable „sexo_al‟.
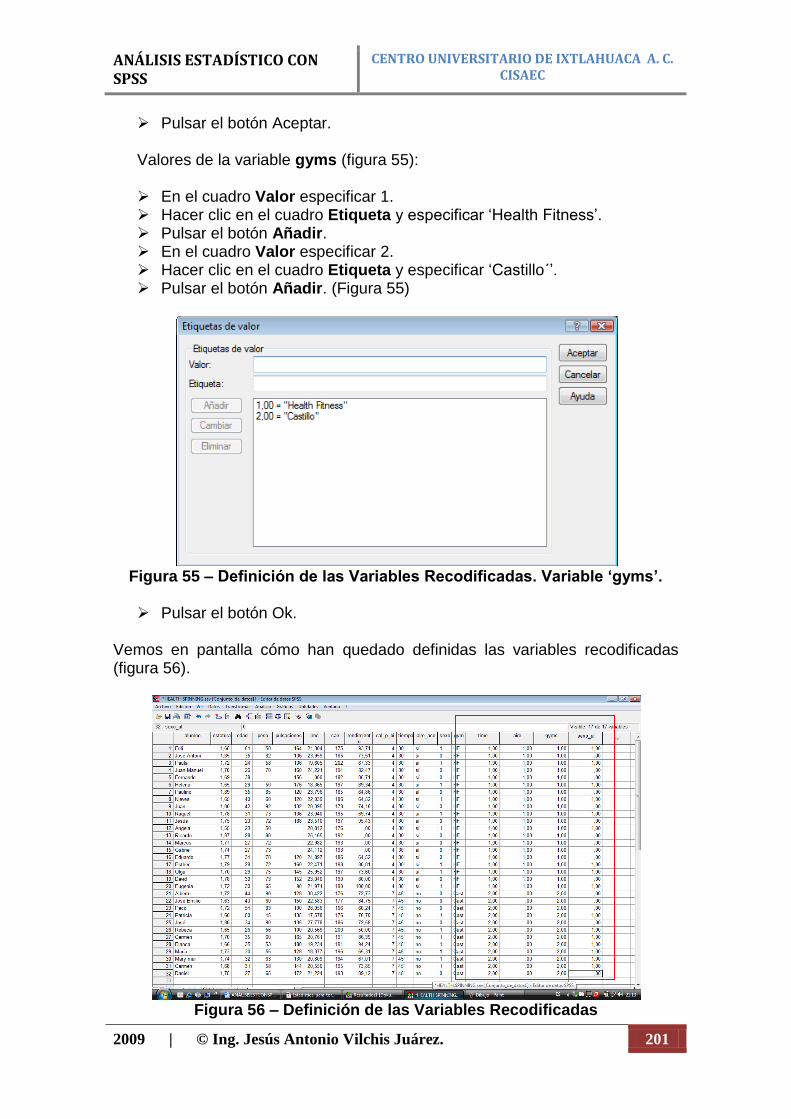
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 201
Pulsar el botón Aceptar.
Valores de la variable gyms (figura 55): En el cuadro Valor especificar 1. Hacer clic en el cuadro Etiqueta y especificar ‗Health Fitness‘. Pulsar el botón Añadir. En el cuadro Valor especificar 2. Hacer clic en el cuadro Etiqueta y especificar ‗Castillo´‘. Pulsar el botón Añadir. (Figura 55)
Figura 55 – Definición de las Variables Recodificadas. Variable „gyms‟.
Pulsar el botón Ok.
Vemos en pantalla cómo han quedado definidas las variables recodificadas (figura 56).
Figura 56 – Definición de las Variables Recodificadas

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 202
Para visualizar las etiquetas de los valores de las variables, pulsar el botón Value Label de la barra de herramientas (figura 57).
Figura 57 – Definición de las Variables Recodificadas
Eliminación de Casos Perdidos Sin embargo, aún nos quedan casos de alumnos que no tienen registro de pulsaciones (celdas vacías), que será preciso eliminar para evitar que en el Análisis de la Regresión Lineal (ARL), se alteren los resultados. Seleccionar el menú Datos/ Seleccionar casos (figura 58).
Figura 58 – Eliminación de casos perdidos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 203
Se muestra el cuadro de diálogo ―Seleccionar casos” (figura 59).
Figura 59 – Eliminación de casos perdidos
Seleccionar la variable rendimiento de la lista de variables fuente
Dentro del cuadro Seleccionar, seleccionar la opción Si se satisface la
condición. (Figura 60)
Figura 60 – Eliminación de casos perdidos

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 204
Pulsar el botón Si... Aparece el siguiente cuadro de diálogo Seleccionar casos: Si. (Figura 61)
Figura 61 – Eliminación de casos perdidos
Seleccionar la variable rendimiento de la lista de variables fuente.
Hacer doble clic sobre la variable rendimiento para llevarla al cuadro de
las reglas de selección. Pulsar el operando (no es igual) a 0. (Figura 62)
Figura 62 – Eliminación de casos perdidos
Pulsar el botón Continue.
Aparece otra vez el cuadro de diálogo inicial Seleccionar casos (figura 63).

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 205
Figura 63 – Eliminación de casos perdidos
Puede visualizarse al lado derecho del botón Si... la regla de selección que hemos expresado. En el cuadro Resultado: Elegir la opción Decantar casos no seleccionados, para que los casos
que no satisfagan la condición sean eliminados de la base de datos. � Vista de la base de datos sin casos perdidos en la variable rendimiento (figura 64).
Figura 64 – Eliminación de casos perdidos
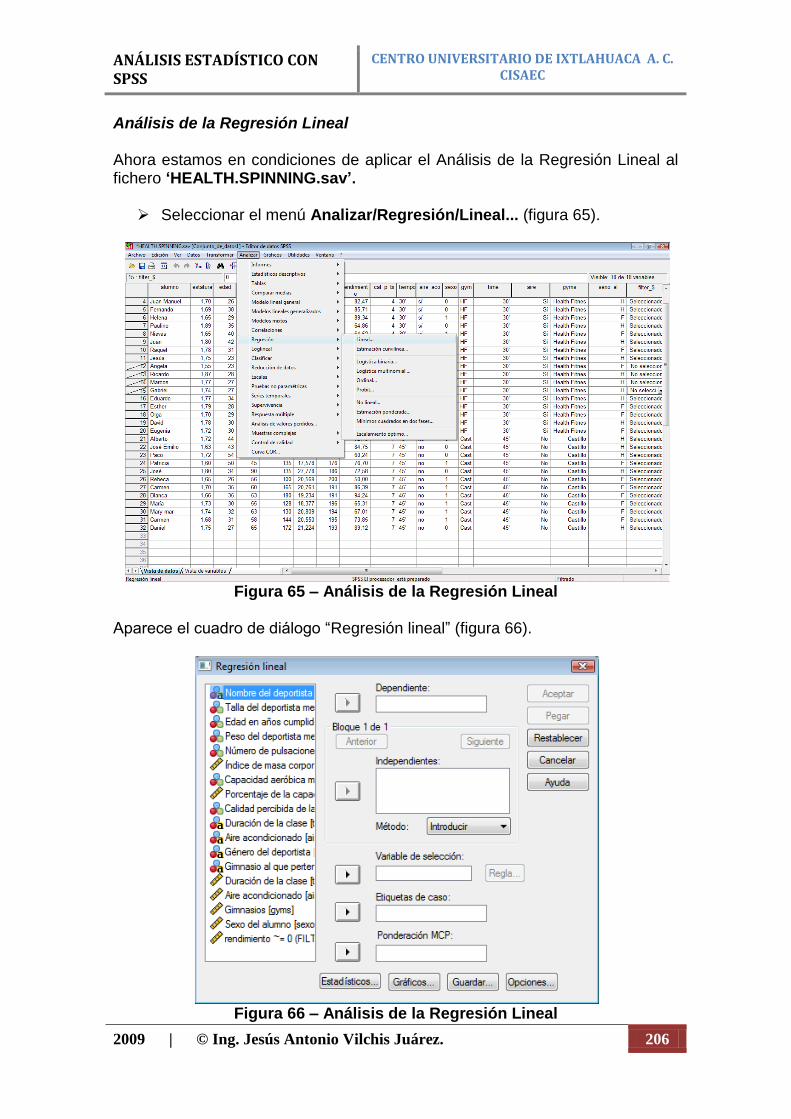
ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 206
Análisis de la Regresión Lineal Ahora estamos en condiciones de aplicar el Análisis de la Regresión Lineal al fichero „HEALTH.SPINNING.sav‟. Seleccionar el menú Analizar/Regresión/Lineal... (figura 65).
Figura 65 – Análisis de la Regresión Lineal
Aparece el cuadro de diálogo ―Regresión lineal‖ (figura 66).
Figura 66 – Análisis de la Regresión Lineal

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 207
Seleccionar la variable rendimiento (VD). Pulsar el botón para introducirla en el cuadro Dependiente. Seleccionar de la lista de variables fuente las variables independientes
(VI). Pulsar el botón para introducirlas en el cuadro Independientes Seleccionar en la pestaña Método, el método Pasos suc.. Seleccionar la variable alumno. Pulsar el botón para introducirla en el cuadro Etiquetas de caso. (Figura
67)
Figura 67 – Análisis de la Regresión Lineal
Pulsar el botón Estadísticos….
Aparece el cuadro de diálogo Regresión lineal: Estadísticos. (figura 68)
Figura 68 – Análisis de la Regresión Lineal

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 208
En el cuadro de diálogo Estadísticos activamos las opciones señaladas. Pulsar el botón Continuar. Pulsar el botón Gráficos.
Aparece el cuadro de diálogo Regresión lineal: Gráficos. (Figura 69)
Figura 69 – Análisis de la Regresión Lineal
Activar las opciones que figuran en pantalla. Pulsar el botón Continuar. Pulsar el botón Guardar.
Aparece el cuadro de diálogo Linear Regresión: Guardar. (Figura 70)
Figura 70 – Análisis de la Regresión Lineal

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 209
Activar las opciones que figuran en pantalla. Pulsar el botón Continuar.
En las salidas de la Regresión podemos apreciar en primer lugar las correlaciones existentes entre pares de variables. La única variable que mantiene una alta correlación con la variable rendimiento (VD) es la variable pulsaciones, que muestra una Correlación de Pearson igual a 100%. (Figura 71) A continuación se muestra una tabla donde figuran las dos variables que han sido introducidas en el modelo por el método Pasos suc.. (Figura 72) La primera variable introducida en el modelo (pulsaciones), contribuye a predecir en un 41.9% el rendimiento de los alumnos. Todas estas pruebas son significativas, ya que el valor de F es menor que 0.05. (Figura 73) El estadístico Durbin-Watson Mide la Auto correlación Serial (influencia de los valores residuales). Si este valor fuese 2,0, no existiría Autocorrelación Serial. En este caso, Durbin-Watson tiene un valor muy alto y positivo, es decir, existe una excesiva tendencia a que los rendimientos sean altos. (Figura 74) El análisis de la varianza del modelo, constata lo dicho anteriormente cuando introducimos en primer lugar la variable pulsaciones y luego agregamos la variable capacidad aeróbica máxima. Las variaciones de la VD son suficientemente explicadas por el modelo, porque el estadístico F tiene una significación menor a 0.05. Se aprecia en la tabla 75 que los valores de rendimiento mínimos y máximos predichos son muy diferentes entre sí. Tienen una alta variabilidad. En la figura 76 se aprecian los residuales estandarizados de la regresión están muy estirados, lo que evidencia enormes diferencias en los valores de la VD. El gráfico de normalidad (figura 77) contrasta la H0 de la normalidad de los residuales estandarizados de la regresión. Cuanto más alejados estén los residuales estandarizados de la recta de la regresión, peor será el ajuste de los valores a la condición de normalidad. Existen algunos valores que se alejan bastante de la recta de regresión, evidenciando una falta de adecuación al modelo.

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 210
Correlaciones
Figura 71 – Análisis de la Regresión Lineal
Porcentaje de la
capacidad aeróbica máxima
alcanzada
Talla del deportist
a medida
en metros
Edad en años
cumplidos del
deportista
Peso del deportist
a medido en Kgs.
Número de
pulsaciones que
alcanza el deportista
en un minuto
Capacidad
aeróbica máxima
Calidad percibida
de la bicicleta
Correlación de Pearson
Porcentaje de la capacidad aeróbica máxima alcanzada
1,000 -,188 -,077 -,233 ,647 ,031 -,160
Talla del deportista medida en metros
-,188 1,000 -,250 ,757 -,135 ,061 -,355
Edad en años cumplidos del deportista
-,077 -,250 1,000 ,113 -,246 -,942 ,262
Peso del deportista medido en Kgs.
-,233 ,757 ,113 1,000 -,254 -,334 -,234
Número de pulsaciones que alcanza el deportista en un minuto
,647 -,135 -,246 -,254 1,000 ,273 -,070
Capacidad aeróbica máxima
,031 ,061 -,942 -,334 ,273 1,000 -,200
Calidad percibida de la bicicleta
-,160 -,355 ,262 -,234 -,070 -,200 1,000
Sig. (unilateral) Porcentaje de la capacidad aeróbica máxima alcanzada
. ,173 ,351 ,121 ,000 ,440 ,213
Talla del deportista medida en metros
,173 . ,104 ,000 ,251 ,382 ,034
Edad en años cumplidos del deportista
,351 ,104 . ,287 ,108 ,000 ,093
Peso del deportista medido en Kgs.
,121 ,000 ,287 . ,100 ,044 ,120
Número de pulsaciones que alcanza el deportista en un minuto
,000 ,251 ,108 ,100 . ,084 ,365
Capacidad aeróbica máxima
,440 ,382 ,000 ,044 ,084 . ,159
Calidad percibida de la bicicleta
,213 ,034 ,093 ,120 ,365 ,159 .
N Porcentaje de la capacidad aeróbica máxima alcanzada
27 27 27 27 27 27 27
Talla del deportista medida en metros
27 27 27 27 27 27 27
Edad en años cumplidos del deportista
27 27 27 27 27 27 27
Peso del deportista medido en Kgs.
27 27 27 27 27 27 27
Número de pulsaciones que alcanza el deportista en un minuto
27 27 27 27 27 27 27
Capacidad aeróbica máxima
27 27 27 27 27 27 27
Calidad percibida de la bicicleta
27 27 27 27 27 27 27

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 211
Variables introducidas/eliminadasa
Modelo Variables introducidas Variables eliminadas Método
1
Número de pulsaciones que alcanza el deportista en un minuto
.
Por pasos (criterio: Prob. de F para entrar <= ,050, Prob. de F para salir >= ,100).
a Variable dependiente: Porcentaje de la capacidad aeróbica máxima alcanzada
Figura 72 – Análisis de la Regresión Lineal
Resumen del modelob
Modelo
1
R ,647a
R cuadrado ,419
R cuadrado corregida ,395
Error típ. de la estimación 9,48838
Estadísticos de cambio Cambio en R cuadrado ,419
Cambio en F 18,004
gl1 1
gl2 25
Sig. del cambio en F ,000
Durbin-Watson 1,950
a Variables predictoras: (Constante), Número de pulsaciones que alcanza el deportista en un minuto b Variable dependiente: Porcentaje de la capacidad aeróbica máxima alcanzada
Figura 73 – Análisis de la Regresión Lineal
ANOVAb
Modelo Suma de
cuadrados gl Media
cuadrática F Sig.
1 Regresión 1620,847 1 1620,847 18,004 ,000a
Residual 2250,735 25 90,029
Total 3871,582 26
a Variables predictoras: (Constante), Número de pulsaciones que alcanza el deportista en un minuto b Variable dependiente: Porcentaje de la capacidad aeróbica máxima alcanzada
Figura 74 – Análisis de la Varianza (ANOVA)

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 212
Estadísticos sobre los residuosa
Mínimo Máximo Media Desviación típ. N
Valor pronosticado 60,3498 91,5980 76,7255 7,80184 28
Valor pronosticado tip. -2,052 1,906 ,022 ,988 28
Error típico del valor pronosticado 1,842 4,233 2,471 ,712 28
Valor pronosticado corregido 50,4987 90,7756 76,4541 8,40597 28
Residuo bruto -13,53842 39,65017 ,15412 9,16655 28
Residuo tip. -1,427 4,179 ,016 ,966 28
Residuo estud. -1,540 4,669 ,029 1,058 28
Residuo eliminado -15,77043 49,50130 ,42552 11,02193 28
Residuo eliminado estud. -1,586 12,789 ,319 2,503 28
Dist. de Mahalanobis ,017 4,211 ,941 1,187 28
Distancia de Cook ,000 2,708 ,111 ,510 28
Valor de influencia centrado ,001 ,162 ,036 ,046 28
a Variable dependiente: Porcentaje de la capacidad aeróbica máxima alcanzada
Figura 75 – Valores Residuales.
Figura 76 – Análisis de la Regresión Lineal

ANÁLISIS ESTADÍSTICO CON SPSS
CENTRO UNIVERSITARIO DE IXTLAHUACA A. C. CISAEC
2009 | © Ing. Jesús Antonio Vilchis Juárez. 213
Figura 77 – Análisis de la Regresión Lineal
final de capítulo: Ejemplo de Análisis Estadístico Completo
Related Documents











