深層学習の基礎と 導入⎬向けて ⏳モ⏷ラ ⏤ド ⏨ー 2018 年 3 月 20 日 ァ火ア 早稲田大学

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

深層学習の基礎と導入 向けて
モ ラ ド ー
2018年 3月 20日 火
早稲田大学

自己紹介
• 2015年 7月 BarcelonaTech 博士号 取得
• 2015年 8月 2017年 3月 早稲田大学 研究院助教
• 2017年 4月 同大学 研究院講師
• 2018年 4月 科学技術振興機構 さ 専任研究者
1

目次
1. 深層学習 歴史2. 深層学習 基礎
• モデル• デー• 学習
3. 必要 環境• ハッ ド• フレームワー
4. 例 : ラフ ッ 線画化5. 例 :白黒写真 色付
ε
!
2

深層学習の歴史

深層学習の歴史
• 1957 Perceptron
• 1980 Neocognitron• 1986 Backpropagation• 1998 LeNet• 2012 AlexNet• 2014 GoogleNet / VGG• 2016 AlphaGo• …
Mark I Perceptron機
3

深層学習の歴史
• 1957 Perceptron• 1980 Neocognitron
• 1986 Backpropagation• 1998 LeNet• 2012 AlexNet• 2014 GoogleNet / VGG• 2016 AlphaGo• …
Fukushima, K. Neocognitron: a selforganizing neural network model for a
mechanism of pattern recognitionunafected by shift in position.
Biological cybernetics, 1980.
3

深層学習の歴史
• 1957 Perceptron• 1980 Neocognitron• 1986 Backpropagation
• 1998 LeNet• 2012 AlexNet• 2014 GoogleNet / VGG• 2016 AlphaGo• …
Rumelhart et al. LearningRepresentations by Back-Propagating
Errors. Nature, 1986.
3

深層学習の歴史
• 1957 Perceptron• 1980 Neocognitron• 1986 Backpropagation• 1998 LeNet
• 2012 AlexNet• 2014 GoogleNet / VGG• 2016 AlphaGo• …
LeCun et al. Gradient-based learningapplied to document recognition.Proceedings of the IEEE, 1998.
3
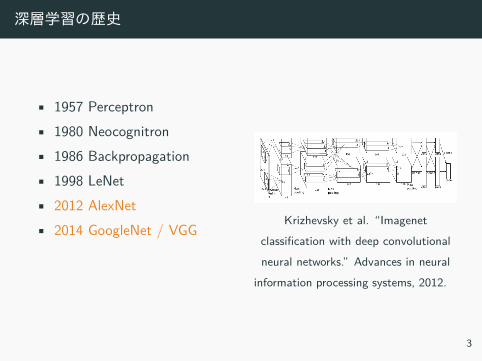
深層学習の歴史
• 1957 Perceptron• 1980 Neocognitron• 1986 Backpropagation• 1998 LeNet• 2012 AlexNet• 2014 GoogleNet / VGG
• 2016 AlphaGo• …
Krizhevsky et al. Imagenetclassiication with deep convolutionalneural networks. Advances in neural
information processing systems, 2012.
3

深層学習の歴史
• 1957 Perceptron• 1980 Neocognitron• 1986 Backpropagation• 1998 LeNet• 2012 AlexNet• 2014 GoogleNet / VGG• 2016 AlphaGo• …
Silver et al. Mastering the game of Gowith deep neural networks and tree
search. Nature, 2016.
3

深層学習の歴史
• 深層学習 現代 人工ニューラルネッ ト ワー• 深層学習?
• 様々 問題 対応• 圧倒的 性能
• 今色々使え ?• GPU 計算効率• 大規模 デー ッ ト
Jia Deng (2016). ILSVRC2016 object localisation: introduction, results. 3

深層学習の歴史
• 深層学習 現代 人工ニューラルネッ ト ワー• 深層学習?
• 様々 問題 対応• 圧倒的 性能
• 今色々使え ?• GPU 計算効率• 大規模 デー ッ ト
Jia Deng (2016). ILSVRC2016 object localisation: introduction, results. 3

深層学習の基礎

教師あ 学習
顔 顔ではない
訓練データ
"顔"
または"顔ではない"
4
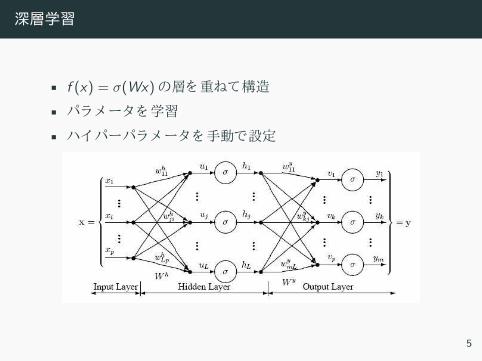
深層学習
• f (x) = σ(Wx) 層 重 構造
• パラメー 学習
• ハ パーパラメー 手動 設定
5

従来の機械学習
• 手動 決 特徴 入力
• 機械学習モデル 特徴 出力 変換 学習
• 特徴 精度 制限
特徴抽出 機械学習入力 出力
• 深層学習 特徴抽出 機械学習モデル 一緒 学習
• ヒューリ テ ッ 避 、 デー 依存
深層学習入力 出力
6

従来の機械学習
• 手動 決 特徴 入力
• 機械学習モデル 特徴 出力 変換 学習
• 特徴 精度 制限
特徴抽出 機械学習入力 出力
• 深層学習 特徴抽出 機械学習モデル 一緒 学習
• ヒューリ テ ッ 避 、 デー 依存
深層学習入力 出力
6

深層学習のよく あ 問題
• デー 集
• 量、 室、 ノ テー ョ ン…
• モデル構造 決
• CNN、 深さ、 レ ヤ 種類…
• モデル 学習
• 学習週報、 学習率、 バッ …
入 正
7
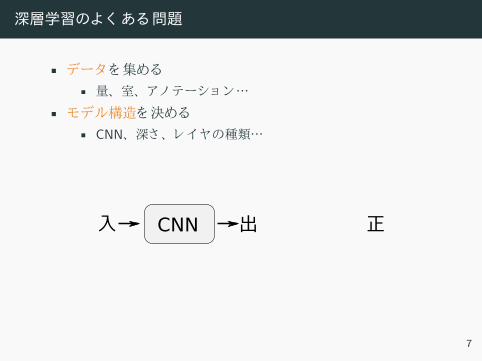
深層学習のよく あ 問題
• デー 集
• 量、 室、 ノ テー ョ ン…
• モデル構造 決
• CNN、 深さ、 レ ヤ 種類…
• モデル 学習
• 学習週報、 学習率、 バッ …
入 正出CNN
7

深層学習のよく あ 問題
• デー 集
• 量、 室、 ノ テー ョ ン…
• モデル構造 決
• CNN、 深さ、 レ ヤ 種類…
• モデル 学習
• 学習週報、 学習率、 バッ …
ロス逆習
入 正出CNN
7

深層学習のよく あ 問題
• デー 集
• 量、 室、 ノ テー ョ ン…
• モデル構造 決
• CNN、 深さ、 レ ヤ 種類…
• モデル 学習
• 学習週報、 学習率、 バッ …
ハ パーパラメー さ 決 い い い!
7
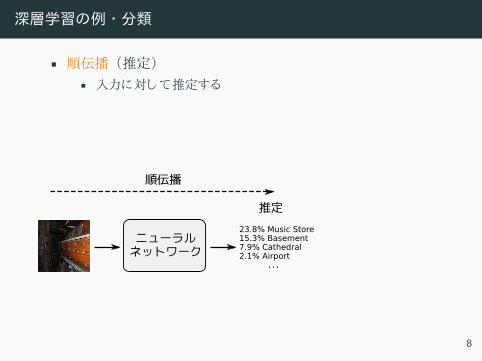
深層学習の例 ・分類
• 順伝播 推定
• 入力 対 推定
• 逆伝播 学習
• 誤差関数 モデル 出力 正解デー 比較• 誤差関数 最終化 う モデル パラメー 更新
ニューラルネットワーク
23.8% Music Store15.3% Basement7.9% Cathedral2.1% Airport ...
推定
順伝播
8

深層学習の例 ・分類
• 順伝播 推定
• 入力 対 推定
• 逆伝播 学習
• 誤差関数 モデル 出力 正解デー 比較• 誤差関数 最終化 う モデル パラメー 更新
ニューラルネットワーク
23.8% Music Store15.3% Basement7.9% Cathedral2.1% Airport ...
推定
順伝播
0.0% Music Store100% Basement0.0% Cathedral0.0% Airport ...
誤差
正解
逆伝播
8

深層学習の基礎 ・ モデル

人工ニューラルネッ ト ワー
• レ ヤ 重 構造
• レ ヤ 線形変換 非線形活性化関数
• 行列書 ベ ト ル計算 表現
...
ビアス
前層
ニューロン
重み(学習するもの)
非線形活性化関数
9

人工ニューラルネッ ト ワー
• レ ヤ 重 構造
• レ ヤ 線形変換 非線形活性化関数
• 行列書 ベ ト ル計算 表現
... ...
行列
ベクトル
9
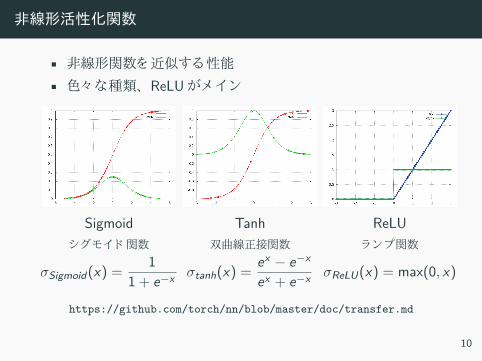
非線形活性化関数
• 非線形関数 近似 性能
• 色々 種類、 ReLU メ ン
Sigmoid Tanh ReLUモ ド 関数 双曲線正接関数 ランプ関数
σSigmoid(x) =1
1 + e−x σtanh(x) =ex − e−x
ex + e−x σReLU(x) = max(0, x)
https://github.com/torch/nn/blob/master/doc/transfer.md
10
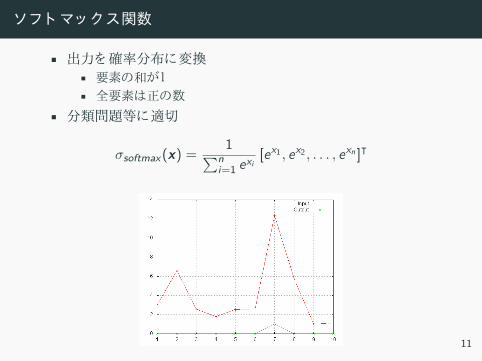
ソフト マッ ス関数
• 出力 確率分布 変換• 要素 和• 全要素 正 数
• 分類問題等 適切
σsoftmax(x) =1
∑ni=1 exi
[ex1 , ex2 , . . . , exn ]⊺
11

畳 込 ニューラルネッ ト ワー
• 視覚野 対応 う 形 配置
• 空間的 フ ル 共有 モデル パラメー 減少
• プーリ ン 畳 込 層 計算効率
INPUT 32x32
Convolutions SubsamplingConvolutions
C1: feature maps 6@28x28
Subsampling
S2: f. maps6@14x14
S4: f. maps 16@5x5
C5: layer120
C3: f. maps 16@10x10
F6: layer 84
Full connection
Full connection
Gaussian connections
OUTPUT 10
LeNet-5 [LeCun+ 1998]
12

プーリン 層
• 解像度 圧縮
• 小さい移動 不変性
マッ 平均 Lp
y = maxx∈P
x y =1|P |
∑
x∈Px y =
(
1|P |
∑
x∈Pxp)
1p
13

畳 込 層
• レ ヤ い フ ル 使用
• ハ パーパラメー : ーネル、 パッデ ン 、 ト ラ ド
• 重 ーネル 表現
• パッデ ン 解像度 不変化• ト ラ ド 解像度 変化
14

畳 込 層
• レ ヤ い フ ル 使用
• ハ パーパラメー : ーネル、 パッデ ン 、 ト ラ ド
• 重 ーネル 表現• パッデ ン 解像度 不変化
• ト ラ ド 解像度 変化
出力
入力
14

畳 込 層
• レ ヤ い フ ル 使用
• ハ パーパラメー : ーネル、 パッデ ン 、 ト ラ ド
• 重 ーネル 表現• パッデ ン 解像度 不変化• ト ラ ド 解像度 変化
出力
入力
14

畳 込 層 ・解像度変換
ト ラ ド 数 三種類 畳 込 レ ヤー
1. Convolution• ーネル 3× 3, パデ ン 1× 1, ト ラ ド
2. Downsampling Convolution• ーネル 3× 3, パデ ン 1× 1, ト ラ ド
3. Upsampling Convolution• ーネル 3× 3, パデ ン 1× 1, ト ラ ド 1/2
Down-convolution
Flat-convolution
Up-convolution
stride
stride
stride
15

CNNレ ヤ ついて
• 畳 込 層
• 空間配置 保護• パラメー 少 い• 解像度変換可
• プーリ ン レ ヤ
• 小さい移動 不変性• ト ラ ド あ 畳 込 層 う いい
• 全結合層
• 入力 固定• パラメー 多い• 画像 出力 不必要
16
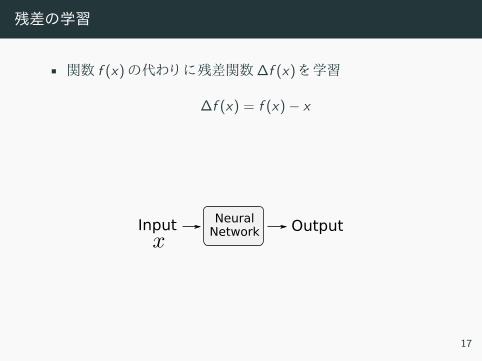
残差の学習
• 関数 f (x) 代わ 残差関数∆f (x) 学習
∆f (x) = f (x)− x
• 仮定 :出力 入力 類似
• 重 0 恒等写像
• ILSVRC2015 画像分類コンペテ ョ ン優勝
NeuralNetworkInput Output
17

残差の学習
• 関数 f (x) 代わ 残差関数∆f (x) 学習
∆f (x) = f (x)− x
• 仮定 :出力 入力 類似
• 重 0 恒等写像
• ILSVRC2015 画像分類コンペテ ョ ン優勝
NeuralNetworkInput Output
17

残差の学習
• 関数 f (x) 代わ 残差関数∆f (x) 学習
∆f (x) = f (x)− x
• 仮定 :出力 入力 類似
• 重 0 恒等写像
• ILSVRC2015 画像分類コンペテ ョ ン優勝
He et al. Deep Residual Learning for Image Recognition. CVPR, 2016.
17
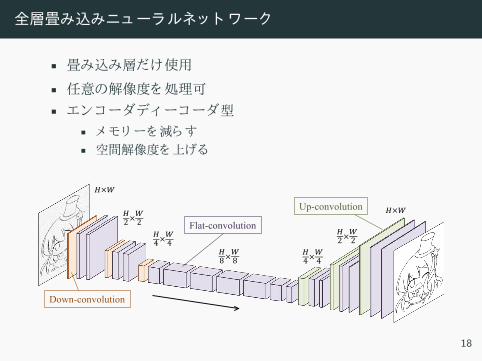
全層畳 込 ニューラルネッ ト ワー
• 畳 込 層 使用
• 任意 解像度 処理可
• ンコー デ ーコー 型• メモリ ー 減• 空間解像度 上
Flat-convolution
Up-convolution
2×2
4×4
8×8
4×4
2×2
×
×
Down-convolution
18
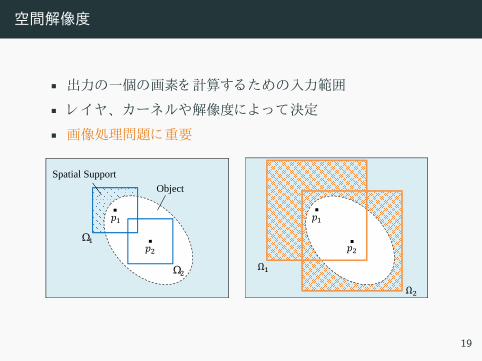
空間解像度
• 出力 一個 画素 計算 入力範囲
• レ ヤ、 ーネルや解像度 決定
• 画像処理問題 重要
Object
Ω
Ω
Spatial Support
Ω Ω19

モデルの容量 ついて
• 覚え 能力
• モデル パラメー 決定
• 普段 100万以上
• 学習難度 関係
• 使用メモリ や計算時間 増加
少モデル(少 いレ ヤや ャンネル)
• 小容量
• 学習 簡単
• 訓練デー 少いい
大モデル(多いレ ヤや ャンネル)
• 大容量
• 学習 困難
• 大規模デー 必要
20

モデルの容量 ついて
• 覚え 能力
• モデル パラメー 決定
• 普段 100万以上
• 学習難度 関係
• 使用メモリ や計算時間 増加
少モデル(少 いレ ヤや ャンネル)
• 小容量
• 学習 簡単
• 訓練デー 少いい
大モデル(多いレ ヤや ャンネル)
• 大容量
• 学習 困難
• 大規模デー 必要
20

デ ープラーニン の基礎 ・データ
デ ープラーニン 向いてい 問題 ついて
• デー 重要
• デ ープラーニン 万能 い
• 問題 選ぶ 大事
• 適切 問題 い
• 入力 出力 決 い 、 情報処理 問題• 正解 一 問題 人間• デー 集
21

デ ープラーニン 向いてい 問題 ついて
• デー 重要
• デ ープラーニン 万能 い
• 問題 選ぶ 大事
• 適切 問題 い
• 入力 出力 決 い 、 情報処理 問題• 正解 一 問題 人間• デー 集
21

向いてい 問題 ・画像分類
• 画像分類• 入力 :画像• 出力 : ラ 確率
• デ ープラーニン 代表的 問題• 入力 出力 決 い• 大規模 デー あ ImageNet
Krizhevsky et al. ImageNet Classiication with Deep Convolutional Neural Networks. NIPS, 2012.
22
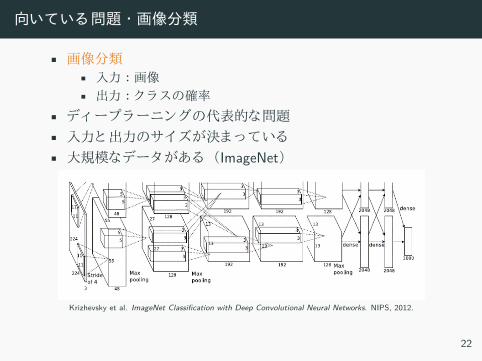
向いてい 問題 ・画像分類
• 画像分類• 入力 :画像• 出力 : ラ 確率
• デ ープラーニン 代表的 問題• 入力 出力 決 い• 大規模 デー あ ImageNet
Krizhevsky et al. ImageNet Classiication with Deep Convolutional Neural Networks. NIPS, 2012.
22

向いてい 問題 ・領域分割
• 領域分割• 入力 :画像• 出力 :画像 各領域 ラ 確率
• デー 作成 難 い• ラ 数 少 い• ImageNet 学習済 モデル 利用可
Chen et al. The Role of Context for Object Detection and Semantic Segmentation in the Wild. CVPR, 2014.
23
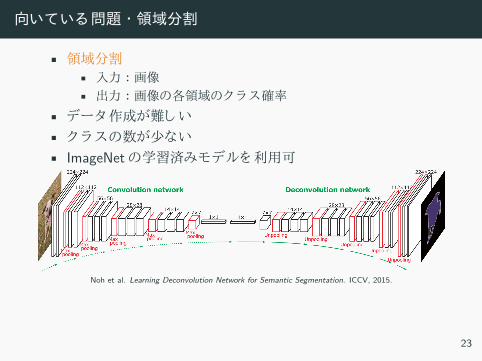
向いてい 問題 ・領域分割
• 領域分割• 入力 :画像• 出力 :画像 各領域 ラ 確率
• デー 作成 難 い• ラ 数 少 い• ImageNet 学習済 モデル 利用可
Noh et al. Learning Deconvolution Network for Semantic Segmentation. ICCV, 2015.
23
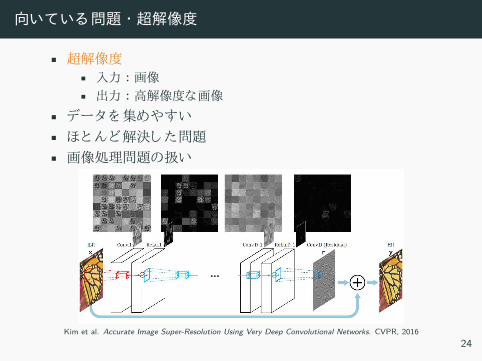
向いてい 問題 ・超解像度
• 超解像度• 入力 :画像• 出力 :高解像度 画像
• デー 集 や い• 解決 問題• 画像処理問題 扱い
Kim et al. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. CVPR, 201624

向いてい い問題 ・画像補完
• 画像補完• 入力 :画像+ マ• 出力 :画像
• 画像 作 出 苦手• 高解像度 苦手• 決 形 出力 苦手
N. Komodakis and G. Tziritas. Image completion using eicient belief propagation via priority scheduling anddynamic pruning. IEEE Trans. Image Processing, 2007.
25

向いてい い問題 ・画像補完
• 画像補完• 入力 :画像+ マ• 出力 :画像
• 画像 作 出 苦手• 高解像度 苦手• 決 形 出力 苦手
Pathak et al. Context Encoders: Feature Learning by Inpainting. CVPR, 2016.
25

向いてい い問題 ・画像補完
• 画像補完• 入力 :画像+ マ• 出力 :画像
• 画像 作 出 苦手• 高解像度 苦手• 決 形 出力 苦手
Iizuka et al. Globally and Locally Consistant Image Completion. SIGGRAPH, 2017.
25

向いてい い問題 ・画像生成
• 画像生成• 入力 : ラン ムノ• 出力 :画像
• 教師 学習 苦手• 出力 固定• 解像度 低い
Salimans et al. Improved Techniques for Training GANs. NIPS, 2016.26

向いてい い問題 ・画像生成
• 画像生成• 入力 : ラン ムノ• 出力 :画像
• 教師 学習 苦手• 出力 固定• 解像度 低い
Salimans et al. Improved Techniques for Training GANs. NIPS, 2016.26

デ ープラーニン 向いてい 問題の とめ
向い い 問題
• デー 多い
• 正解デー 決 い
• 入力 出力 固定さ い
• 学習済 モデル 利用
向い い い問題
• デー 少 い
• 教師 学習
• 入力 出力 固定さ いい
• ユー ー 編集
• 高解像度
27

データ ついて
• 必要?
• 情報 流 い 考え い• ラ ラベル 情報 少 い → 100万枚以上使用• 領域分割ラベル 情報 多い → 1万枚未満
• 品質 大事
• デー 増加
• 反転、 回転、 明度、 コント ラ ト 、 ーリ ン …
Cat
vs
28

データ ついて
• 必要?
• 情報 流 い 考え い• ラ ラベル 情報 少 い → 100万枚以上使用• 領域分割ラベル 情報 多い → 1万枚未満
• 品質 大事
• デー 増加
• 反転、 回転、 明度、 コント ラ ト 、 ーリ ン …
CatCat
Lin et al. Microsoft COCO: Common Objects in Context. arXiv, 2014.
28

データ ついて
• 必要?
• 情報 流 い 考え い• ラ ラベル 情報 少 い → 100万枚以上使用• 領域分割ラベル 情報 多い → 1万枚未満
• 品質 大事
• デー 増加
• 反転、 回転、 明度、 コント ラ ト 、 ーリ ン …
28

データ収集 ついて
• 公開デー ッ ト (ImageNet, Places2, …)• 著作権問題• 相応 いデー ッ ト 存在
• 公開デー (Flickr, Twitter, …)• 著作権問題• ラベル い
• 自分 デー 集
• 時間 金• 正確 ラベル 難 い• 多量 デー 必要
デー 自体 価値 あ ! ! !
29

データ収集 ついて
• 公開デー ッ ト (ImageNet, Places2, …)• 著作権問題• 相応 いデー ッ ト 存在
• 公開デー (Flickr, Twitter, …)• 著作権問題• ラベル い
• 自分 デー 集
• 時間 金• 正確 ラベル 難 い• 多量 デー 必要
デー 自体 価値 あ ! ! !
29

深層学習の基礎 ・学習

学習の基礎
1. デー ッ ト 訓練用 検証用 テ ト 用 分1.1 訓練用デー モデル 重 学習さ1.2 検証用デー ハ パパラメー 決1.3 テ ト 用デー 最後 評価 !
2. デー ッ ト ラン ム 順番
3. バッ 学習さ3.1 小さ 不安定3.2 大 遅 さ 精度 さ3.3 問題 違う 分類〜128、 領域分割〜8
4. 誤差逆伝播法 ロ 関数 最小化
5. 二点 問題点5.1 ン ーフ ッテ ン5.2 ーバーフ ッテ ン 過学習
30

学習の基礎
1. デー ッ ト 訓練用 検証用 テ ト 用 分1.1 訓練用デー モデル 重 学習さ1.2 検証用デー ハ パパラメー 決1.3 テ ト 用デー 最後 評価 !
2. デー ッ ト ラン ム 順番
3. バッ 学習さ3.1 小さ 不安定3.2 大 遅 さ 精度 さ3.3 問題 違う 分類〜128、 領域分割〜8
4. 誤差逆伝播法 ロ 関数 最小化
5. 二点 問題点5.1 ン ーフ ッテ ン5.2 ーバーフ ッテ ン 過学習
30

学習の基礎
1. デー ッ ト 訓練用 検証用 テ ト 用 分1.1 訓練用デー モデル 重 学習さ1.2 検証用デー ハ パパラメー 決1.3 テ ト 用デー 最後 評価 !
2. デー ッ ト ラン ム 順番
3. バッ 学習さ3.1 小さ 不安定3.2 大 遅 さ 精度 さ3.3 問題 違う 分類〜128、 領域分割〜8
4. 誤差逆伝播法 ロ 関数 最小化
5. 二点 問題点5.1 ン ーフ ッテ ン5.2 ーバーフ ッテ ン 過学習
30

誤差逆伝播法
• パラメー 更新 : w ij ← w i
j − λ ∂L∂w i
j
• 誤差 出力 入力 逆伝播さ
∂L∂w i
j=
∂L∂xn
∂xn
∂xn−1 . . .∂x i
∂w ij
ニューラルネットワーク
23.8% Music Store15.3% Basement7.9% Cathedral2.1% Airport ...
推定
順伝播
0.0% Music Store100% Basement0.0% Cathedral0.0% Airport ...
誤差
正解
逆伝播
31

誤差関数
• 平均二乗誤差 (Mean Squared Error MSE)• y : モデル 出力• y∗: 正解
L(y , y∗) =1n
n∑
i=1(yi − y∗
i )2
• 負 対数尤度 (Negative Log-Likelihood NLL)• y : モデル 出力 対数尤度• l : 正解ラベル
L(y , l) = −yl
32
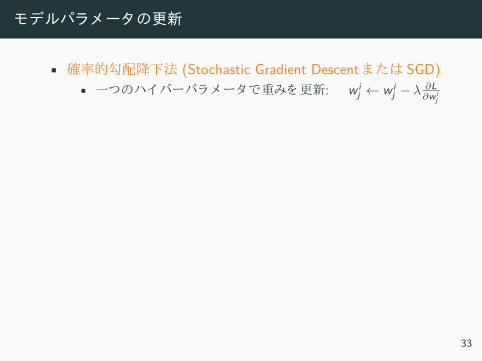
モデルパラメータの更新
• 確率的勾配降下法 (Stochastic Gradient Descent SGD)• 一 ハ パーパラメー 重 更新: w i
j ← w ij − λ ∂L
∂w ij
• 慣性 (Momentum)• w i
j w ij vt vt vt 1
Lw i
j
• Adagrad• 重 更新率 異
• RMSprop• Adagrad 最新版
• Adam• 慣性やバ 調整
• Adadelta• ラーニン レート 自動設定
33

モデルパラメータの更新
• 確率的勾配降下法 (Stochastic Gradient Descent SGD)• 一 ハ パーパラメー 重 更新: w i
j ← w ij − λ ∂L
∂w ij
• 慣性 (Momentum)• w i
j ← w ij − vt vt = γvt−1 + λ ∂L
∂w ij
• Adagrad• 重 更新率 異
• RMSprop• Adagrad 最新版
• Adam• 慣性やバ 調整
• Adadelta• ラーニン レート 自動設定
33
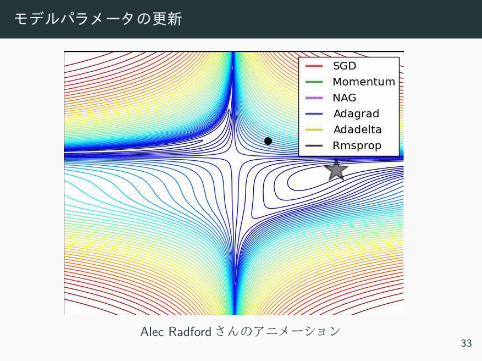
モデルパラメータの更新
Alec Radford さ ニメー ョ ン33
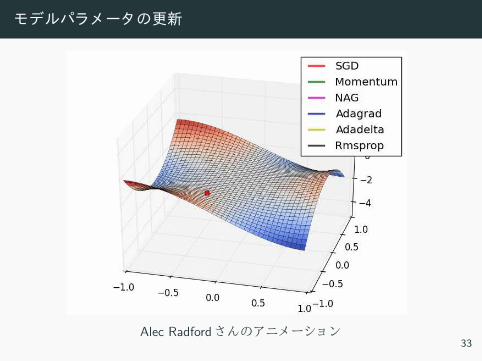
モデルパラメータの更新
Alec Radford さ ニメー ョ ン33
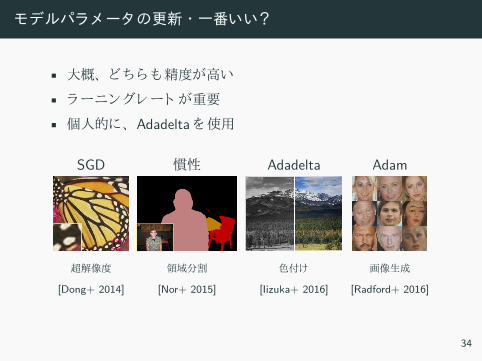
モデルパラメータの更新 ・一番いい?
• 大概、 精度 高い
• ラーニン レート 重要
• 個人的 、 Adadelta 使用
SGD 慣性 Adadelta Adam
超解像度 領域分割 色付 画像生成
[Dong+ 2014] [Nor+ 2015] [Iizuka+ 2016] [Radford+ 2016]
34

汎化能力Generalizing Training
• Dropout [Srivastava et al. 2014]• 学習 間 ノ ード ラン ム ロ• モデル 特定 ノ ード 依存 い
• バッ 正規化 (Batch Normalization) [Iofe and Szegedy 2015]• 各層 出力 N (0, 1) 正規化• モデル中 使用
• デー 増加• 反転• 小さい回転• ロップ
35

学習の問題点
• 学習 間 ロ 監視
• 低いロ 必 一番いいモデル い! ! !• 検証用デー 精度 使 う
• ン ーフ ッテ ン• モデル 重 足 い• 解決方法 :重 増や
• ーバーフ ッテ ン• デー 足 汎化性能 さ• 解決方法 : dropout、 デー 増加…
イテレーション
モデル1
訓練用データのロス
36

学習の問題点
• 学習 間 ロ 監視• 低いロ 必 一番いいモデル い! ! !
• 検証用デー 精度 使 う• ン ーフ ッテ ン
• モデル 重 足 い• 解決方法 :重 増や
• ーバーフ ッテ ン• デー 足 汎化性能 さ• 解決方法 : dropout、 デー 増加…
イテレーション
モデル1
訓練用データのロス訓練用データのロス
モデル2
36

学習の問題点
• 学習 間 ロ 監視• 低いロ 必 一番いいモデル い! ! !• 検証用デー 精度 使 う
• ン ーフ ッテ ン• モデル 重 足 い• 解決方法 :重 増や
• ーバーフ ッテ ン• デー 足 汎化性能 さ• 解決方法 : dropout、 デー 増加…
イテレーション
モデル1
訓練用データのロス
モデル1
検証用データの精度訓練用データのロス
モデル2
検証用データの精度モデル2
36
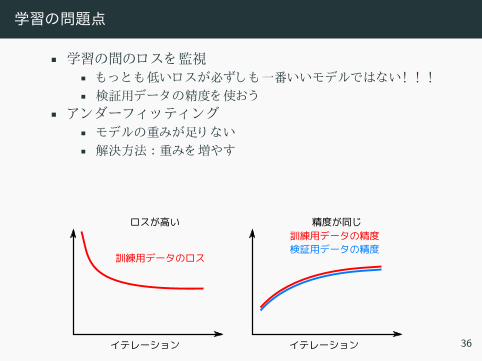
学習の問題点
• 学習 間 ロ 監視• 低いロ 必 一番いいモデル い! ! !• 検証用デー 精度 使 う
• ン ーフ ッテ ン• モデル 重 足 い• 解決方法 :重 増や
• ーバーフ ッテ ン• デー 足 汎化性能 さ• 解決方法 : dropout、 デー 増加…
イテレーション
訓練用データのロス
ロスが高い
イテレーション
検証用データの精度訓練用データの精度
精度が同じ
36

学習の問題点
• 学習 間 ロ 監視• 低いロ 必 一番いいモデル い! ! !• 検証用デー 精度 使 う
• ン ーフ ッテ ン• モデル 重 足 い• 解決方法 :重 増や
• ーバーフ ッテ ン• デー 足 汎化性能 さ• 解決方法 : dropout、 デー 増加…
イテレーション
訓練用データのロス
ロスが低い
イテレーション
検証用データの精度訓練用データの精度
精度が大分違う
36

学習済 のフ ルタ
• 低レベル :角、 縁、 色…
• 中レベル : テ ャ…
• 高レベル :犬 顔、 鳥 足…
Layer 1 Layer 2 Layer 3 Layer 4
Low-Level Mid-Level High-Level
Visualizing and Understanding Convolutional Networks [Zeiler and Fergus 2014]
37
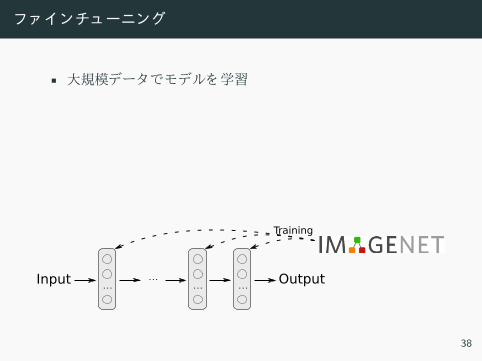
フ ンチューニン
• 大規模デー モデル 学習
• 最終層 新 い層 入 替え
• 新 いデー 学習 続
• 小さいデー ッ ト 性能向上
• 覚え 忘 さ い う 小さい学習率
• 最終層 学習率 大 い
... ......Input Output
Training
38
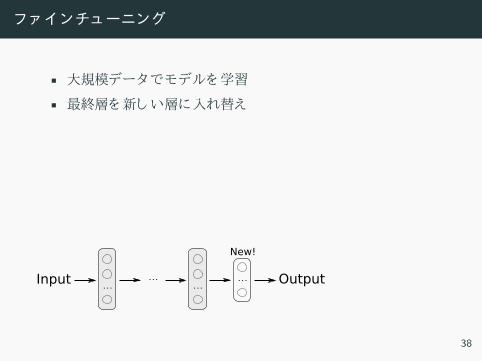
フ ンチューニン
• 大規模デー モデル 学習
• 最終層 新 い層 入 替え
• 新 いデー 学習 続
• 小さいデー ッ ト 性能向上
• 覚え 忘 さ い う 小さい学習率
• 最終層 学習率 大 い
......Input Output
New!
38
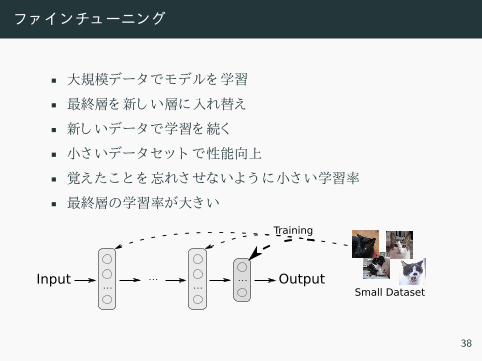
フ ンチューニン
• 大規模デー モデル 学習
• 最終層 新 い層 入 替え
• 新 いデー 学習 続
• 小さいデー ッ ト 性能向上
• 覚え 忘 さ い う 小さい学習率
• 最終層 学習率 大 い
...
...
...Input Output
Small Dataset
Training
38

デ ープラーニン の基礎 ・ とめ

とめ
• デー
• 学習始 前 解析• デー 増加
• モデル
• バッ 正規化• 最初 解像度減
• 学習
• 過学習 気• 検証用デー 使用• 解像度 下 い
• 学習
• ーバーフ ッテ ン 気• 学習中ロ や検証用デー 精度 監視
39

必要 環境 ・ハッ ド

ハッ ド ついて
• 基本的 Nvidia GPU マ ン
• GPU あ あ いい
• 分散コンピューテ ン• ハ パーパラメー ・ ューニン
• GPU 選択肢
1. ラ ド コンピューテ ン2. Nvidia Tesla ーバー用3. Nvidia GeForce 民生用
• 現在値段 不安
40
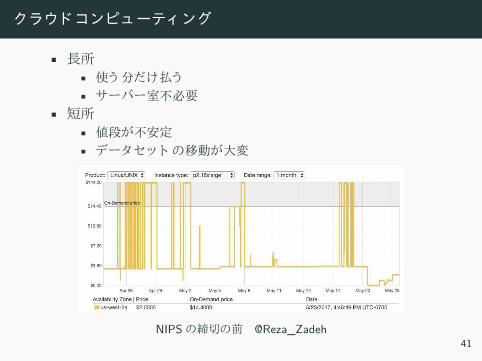
ラ ド コンピューテ ン
• 長所• 使う分 払う• ーバー室不必要
• 短所• 値段 不安定• デー ッ ト 移動 大変
NIPS 締切 前 @Reza_Zadeh41

サーバー設置
• 電源工事 必要 ーバー一台 200V/30A• ーバー室 重要点
• ラッ 型• 無停電電源装置• 温度管理• ネッ ト 速度 NAS等
• ーバー 重要点
• デー ッ ト 読 込 専用 SSD• デー 増加等 CPU• RAM 速度
42

サーバー設置
• 電源工事 必要 ーバー一台 200V/30A• ーバー室 重要点
• ラッ 型• 無停電電源装置• 温度管理• ネッ ト 速度 NAS等
• ーバー 重要点
• デー ッ ト 読 込 専用 SSD• デー 増加等 CPU• RAM 速度
42
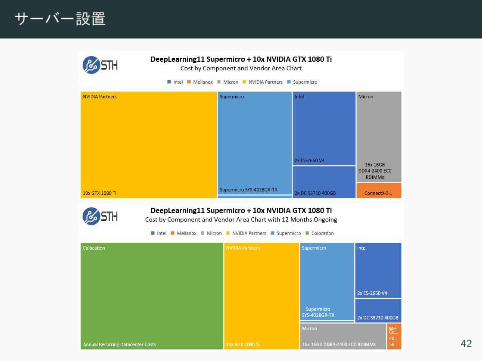
サーバー設置
42

Tesla対GeForce
注意 : Nvidia ラ ン デー ン ー Tesla 使用可
• Tesla• V100、 P100、 K80、 …+ 高性能+ 低発熱量- 値段 高い- 不必要機能 FP64
• GeForce• 1080、 Titan X、 …+ 安い 約 割- 高発熱量- 壊 や い
43

必要 環境 ・ フレームワー

基本環境
• 基本的全部 Linux Ubuntu LTS等• 線型代数学ラ ブラリ : OpenBlas / Intel MKL• Nvidia 深層学習ラ ブラリ CUDNN• Python 環境 : Anaconda、 Docker、 …• 深層学習フレームワー
44

深層学習フレームワー その
• Cafe• C言語 python 可• 硬い 、 速 効率的• Cafe2 置 換え
• PyTorch / Chainer• Python言語• 動的 ラフ 定義• 研究 焦点 当
• Tensorlow• Python言語• 静的 動的 ラフ• 生産 焦点 当
45

深層学習フレームワー その
• Cafe• C言語 python 可• 硬い 、 速 効率的• Cafe2 置 換え
• PyTorch / Chainer• Python言語• 動的 ラフ 定義• 研究 焦点 当
• Tensorlow• Python言語• 静的 動的 ラフ• 生産 焦点 当
45

深層学習フレームワー その
• Cafe• C言語 python 可• 硬い 、 速 効率的• Cafe2 置 換え
• PyTorch / Chainer• Python言語• 動的 ラフ 定義• 研究 焦点 当
• Tensorlow• Python言語• 静的 動的 ラフ• 生産 焦点 当
45
深層学習フレームワー その
• Cafe2• C++言語• PyTorch 補足
• Torch• Lua言語• ラ ブラリ 少 い• PyTorch 置 換え
• さ あ !
46

深層学習フレームワー その
• Cafe2• C++言語• PyTorch 補足
• Torch• Lua言語• ラ ブラリ 少 い• PyTorch 置 換え
• さ あ !
46

深層学習フレームワー その
• Cafe2• C++言語• PyTorch 補足
• Torch• Lua言語• ラ ブラリ 少 い• PyTorch 置 換え
• さ あ !
46

ONNX: Open Neural Network Exchange
• モデル フ ーマッ ト
• 複数 フレームワー 対応
• python モデル 学習 、 C++ ンド ロ ド 等 デプロ
• 全部 レ ヤ 対応 い い
学習
モデル モデル
デプロイ
47

例 :データの重要性 自動線画化

ラフス ッ チの線画化
48

ラフス ッ チの線画化
入力 : ラフ ッ 出力 :線画
49

ラフス ッ チの線画化
ラフ ッ 線画 ラフ ッ 線画
50
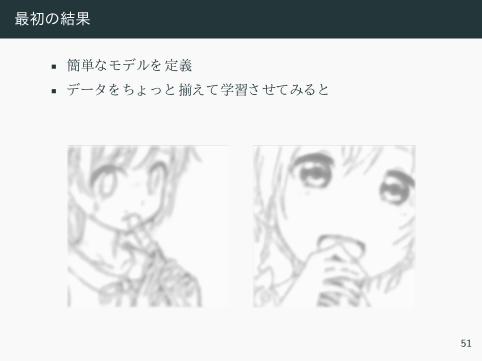
最初の結果
• 簡単 モデル 定義
• デー 揃え 学習さ
• ラフ ッ 正解デー 合わ
51

最初の結果
• 簡単 モデル 定義
• デー 揃え 学習さ
• ラフ ッ 正解デー 合わ
51

逆方向データ制作
• デー 品質 重要
• ラフ 線画化 合わ い 通常 デー 作成
• 線画 ラフ化 ぴ 逆方向デー 作成
通常 デー 作成 逆方向デー 作成
52
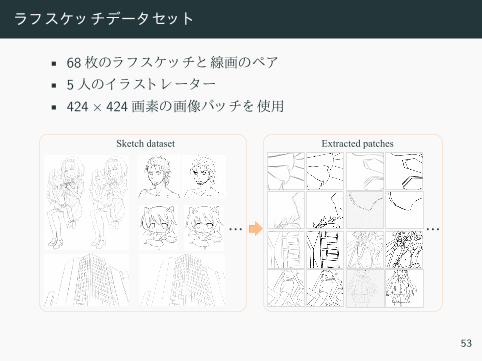
ラフス ッ チデータセッ ト
• 68枚 ラフ ッ 線画 ペ
• 5人 ラ ト レー ー
• 424× 424画素 画像パッ 使用
・・・
Extracted patchesSketch dataset
・・・
53

データ拡大
• 68枚 デー ッ ト 足 い
• 訓練デー 画像 ーリ ン
• 学習 間 ラン ム 回転 反転
• 入力画像 さ 加工 : ト ーン調整、 ぶ 、 ノ
入力 ト ーン調整 ぶ ノ
54

全層畳 込 ニューラルネッ ト ワー
ト ラ ド 数 三種類 畳 込 レ ヤー
1. Flat-convolution1.1 ーネル 3× 3, パデ ン 1× 1, ト ラ ド
2. Down-convolution2.1 ーネル 3× 3, パデ ン 1× 1, ト ラ ド
3. Up-convolution3.1 ーネル 4× 4, パデ ン 1× 1, ト ラ ド 1/2
Down-convolution
Flat-convolution
Up-convolution
stride
stride
stride
55

モデル
• 23層• 出力 解像度 入力 同
• ンコー ー ・ デ ーコー ー型
• メモリ ー 減• 空間解像度 上
Flat-convolution
Up-convolution
2×2
4×4
8×8
4×4
2×2
×
×
Down-convolution
56

学習
• 全層ラン ム 重 学習• 損失関数 重 平均二乗誤差 使用• バッ 正規化 [Iofe and Szegedy 2015] 必要• ADADELTA [Zeiler 2012] 最小化
入力 出力 正解
57
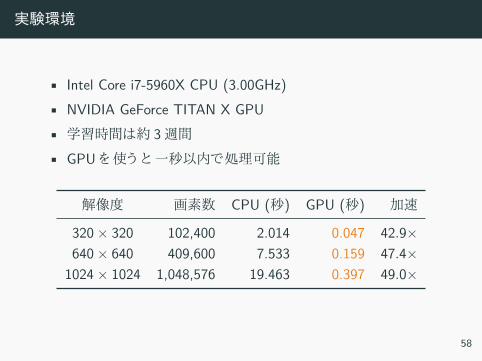
実験環境
• Intel Core i7-5960X CPU (3.00GHz)• NVIDIA GeForce TITAN X GPU• 学習時間 約 3週間• GPU 使う 一秒以内 処理可能
解像度 画素数 CPU (秒) GPU (秒) 加速
320× 320 102,400 2.014 0.047 42.9×640× 640 409,600 7.533 0.159 47.4×
1024× 1024 1,048,576 19.463 0.397 49.0×
58
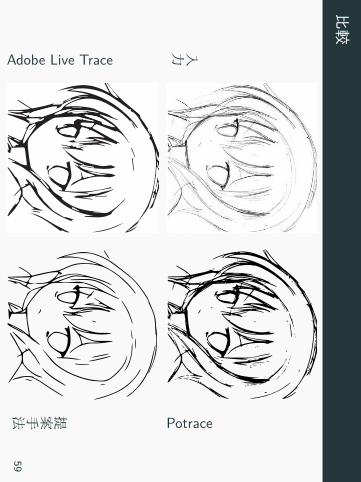
比較
入力
Potrace
Adobe Live Trace
提案手法59
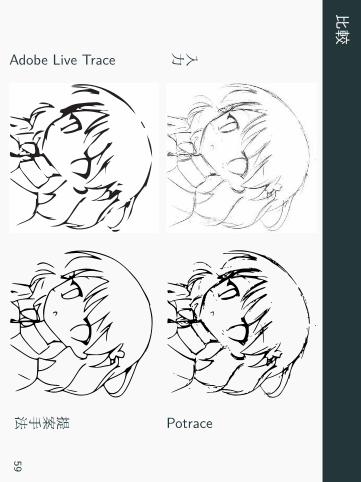
比較
入力
Potrace
Adobe Live Trace
提案手法59

結果
60

結果
60

例 : モデルの重要性 自動色付け
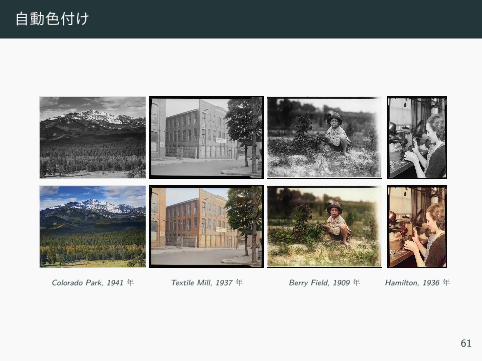
自動色付け
Colorado Park, 1941 年 Textile Mill, 1937 年 Berry Field, 1909 年 Hamilton, 1936 年
61

データ ついて
• 簡単 作
• 現代 ラー写真 白黒
• MIT Placesデー ッ ト 使用 [Zhou et al. 2014]
Abbey Airport terminal Aquarium Baseball field
Dining room Forest road Gas station Gift shop
⋯
⋯
62

問題の難度
• パッ 見 空 天井 区別 い• モデル 改良 必要
正解デー 普通 CNN63

問題の難度
• パッ 見 空 天井 区別 い• モデル 改良 必要
?
正解デー 普通 CNN63
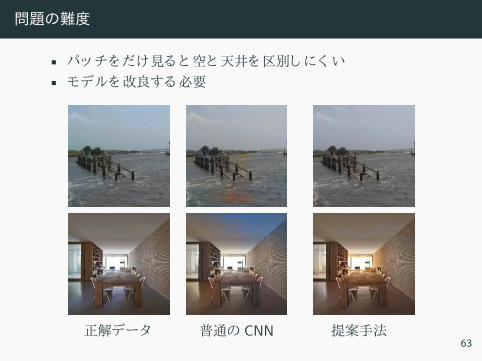
問題の難度
• パッ 見 空 天井 区別 い• モデル 改良 必要
正解デー 普通 CNN 提案手法63
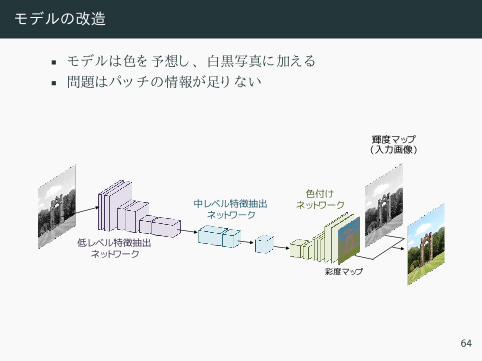
モデルの改造
• モデル 色 予想 、 白黒写真 加え• 問題 パッ 情報 足 い
• 解決方法 :大域特徴 利用• 提案 統合レ ヤ パッ 大域特徴 結合
彩度マップ
中レベル特徴抽出ネットワーク
色付けネットワーク
輝度マップ(入力画像)
低レベル特徴抽出ネットワーク
64

モデルの改造
• モデル 色 予想 、 白黒写真 加え• 問題 パッ 情報 足 い• 解決方法 :大域特徴 利用• 提案 統合レ ヤ パッ 大域特徴 結合
彩度マップ
中レベル特徴抽出ネットワーク
色付けネットワーク
輝度マップ(入力画像)
低レベル特徴抽出ネットワーク
大域特徴抽出ネットワーク
統合レイヤ
64
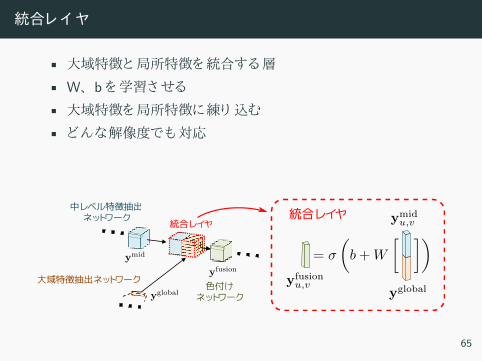
統合レ ヤ
• 大域特徴 局所特徴 統合 層
• W、 b 学習さ
• 大域特徴 局所特徴 練 込
• 解像度 対応
大域特徴抽出ネットワーク
統合レイヤ...
...
...
色付けネットワーク
中レベル特徴抽出ネットワーク 統合レイヤ
65
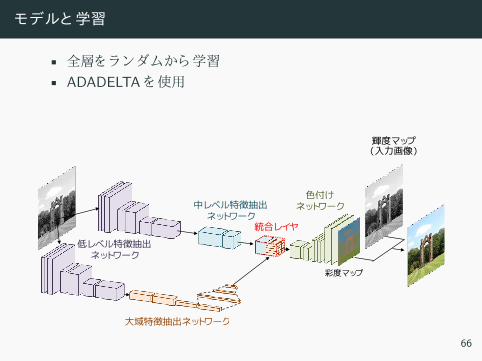
モデルと学習
• 全層 ラン ム 学習• ADADELTA 使用
• ロ 使用• MSE ロ 色付 学習さ• 分類誤差 大域特徴 学習 支援
彩度マップ
中レベル特徴抽出ネットワーク
色付けネットワーク
輝度マップ(入力画像)
低レベル特徴抽出ネットワーク
大域特徴抽出ネットワーク
統合レイヤ
66
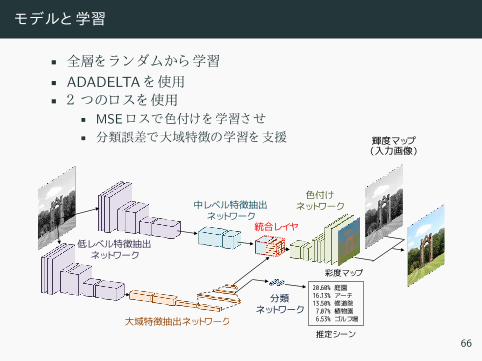
モデルと学習
• 全層 ラン ム 学習• ADADELTA 使用• ロ 使用
• MSE ロ 色付 学習さ• 分類誤差 大域特徴 学習 支援
彩度マップ
中レベル特徴抽出ネットワーク
色付けネットワーク
輝度マップ(入力画像)
低レベル特徴抽出ネットワーク
大域特徴抽出ネットワーク
統合レイヤ
20.60% 庭園16.13% アーチ13.50% 修道院7.07% 植物園6.53% ゴルフ場
推定シーン
分類ネットワーク
66

結果
67
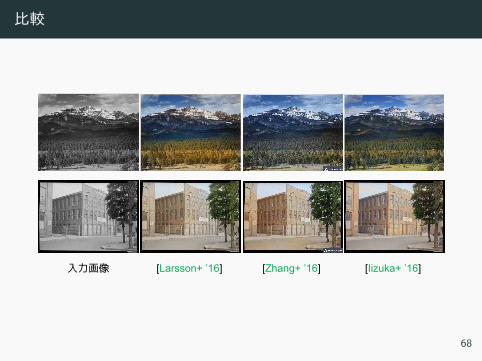
比較
入力画像 [Larsson+ ’16] [Zhang+ ’16] [Iizuka+ ’16]
68
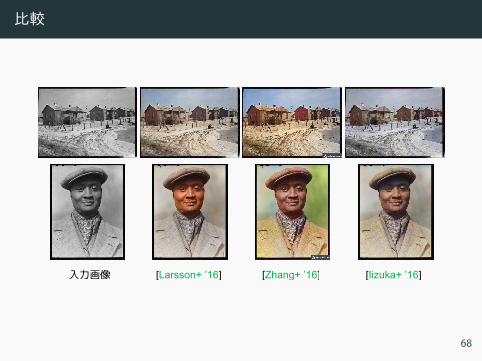
比較
入力画像 [Larsson+ ’16] [Zhang+ ’16] [Iizuka+ ’16]
68

比較
入力画像 [Larsson+ ’16]
[Zhang+ ’16] [Iizuka+ ’16]68

とめ
• 自動線画化• モデル 簡単• デー 作成 難 い
Flat-convolution
Up-convolution
2×2
4×4
8×8
4×4
2×2
×
×
Down-convolution
• 自動色付• 大規模 デー• 普通 モデル あ う い い
彩度マップ
中レベル特徴抽出ネットワーク
色付けネットワーク
輝度マップ(入力画像)
低レベル特徴抽出ネットワーク
大域特徴抽出ネットワーク
統合レイヤ
20.60% 庭園16.13% アーチ13.50% 修道院7.07% 植物園6.53% ゴルフ場
推定シーン
分類ネットワーク
69
おわ
• 理論 経験 大事
• い 考え い い い
• デー 調• モデル 構想• 学習 実装
• デ ープラーニン 機械学習 民主化
• い う
• 研究ペー 恐 い
• い い 試 経験積 う
70

おわ
• 理論 経験 大事
• い 考え い い い
• デー 調• モデル 構想• 学習 実装
• デ ープラーニン 機械学習 民主化
• い う
• 研究ペー 恐 い
• い い 試 経験積 う
70

おわ
• 理論 経験 大事
• い 考え い い い
• デー 調• モデル 構想• 学習 実装
• デ ープラーニン 機械学習 民主化
• い う
• 研究ペー 恐 い
• い い 試 経験積 う
70

補助資料
• モ ラ ド ー http://hi.cs.waseda.ac.jp/˜esimo/• 自動線画化 試 http://hi.cs.waseda.ac.jp:8081/• 自動色付 試 http://hi.cs.waseda.ac.jp:8082/
Related Documents











![ディープラーニング(深層学習)Deep Learning 深層学習[1]は,狭い意味では,層の数が多い(深い) ニューラルネットワーク(neural network)をモデルとし](https://static.cupdf.com/doc/110x72/5ea530d50a2c6709a9411599/fffffffici-deep-learning-c1ioecioeoeii.jpg)